Leverage WordPress Functions to Reduce HTML in your Posts
There is a debate on whether HTML classes belong in your content. As in, classes that are strictly related to the presentation of that content. Sometimes the use of these classes is unavoidable. A callout paragraph, a pull quote, a carousel in the middle of a post… you’ll need classes to style and add functionality to these things.
While you sometimes need them, the less you write them into the actual post content, in my opinion, the better.
Why avoid writing HTML with classes in content?
The main reason is that these HTML classes are fragile as they’re tied to your current theme. On the next redesign there’s a chance these classes will change or require different structure. Or at least, over time, certain classes will be forgotten, new classes will emerge, duplicate classes will happen, and it will get messy.
Changing HTML in templates is easy, as one template is responsible for lots of pages. But changing HTML inside content is hard. They are individual things, sometimes in the hundreds and thousands, that may need to be updated manually one post a time.
But I need those HTML classes!
No worries, WordPress is flexible enough to allow us to generate HTML and insert it into the right spot.
Your content remains pure. No more fragile HTML. Remaining pure, you can easily transform and adapt your post content to your presentational needs.
All these transformations can happen with code. Next time you update the design you’ll update the transformation function to generate the right HTML. Just like templates, you make the updates in one place and it affects all the content at once.
No more updating posts manually.
Strategies for adapting content
Among all the tools offered by WordPress, we’re going to use:
- Shortcodes
the_contentfilter
I’ll quickly explain how the two above work and provide some real word examples of things you can do with them.
Shortcodes
Shortcodes allow you to define a macro that expands to something of your choice. They’re basically a sort of HTML tag that wraps content and accept attributes. For example, you could put this in post content:
[my-shortcode foo="bar"]Hello, World![/my-shortcode]Then write code to have it transform into:
<aside data-foo="bar"><h3>Hello, World!</h3></aside>And then have the power the change that output anytime.
WordPress has extensive documentation for Shortcodes, but I’ll provide a simple example.
function css_tricks_example_shortcode( $attrs, $content = null ) {
extract( shortcode_atts( array(
'twitter' => ''
), $attrs ) );
$twitterURL = 'https://twitter.com/' . $twitter;
return <<<HTML
<p>This post has been written by $content. Follow him on Twitter</p>
HTML;
}
add_shortcode( 'author', 'css_tricks_example_shortcode' );This is a contrived example, but if you include the code above in your `functions.php` file, you can create a post with the following content:
[author twitter="MisterJack"]Alessandro Vendruscolo[/author]that will render this HTML:
<p>This post has been written by Alessandro Vendruscolo. Follow him on <a href="https://twitter.com/MisterJack">Twitter</a></p>Filters
WordPress has many filters available. A filter is a function that has the opportunity to transform something before it’s returned to the entity that requested it. Filters are mainly used by plugins, and are what make WordPress so customizable.
The filter we’re going to use is the_content, which has a page in WordPress’ codex.
The following is a basic example of how to use it.
function css_tricks_example_the_content( $content ) {
global $post;
$title = get_the_title( $post );
$site = get_bloginfo( 'name' );
$author = get_the_author( $post );
return $content . '<p>The post ' . $title . ' on ' . $site . ' is by ' . $author . '.</p>';
}
add_filter( 'the_content', 'css_tricks_example_the_content' );This will add text to the end of a post, which can be useful for RSS scrapers.
Getting more out of the_content
The documentation for the the_content filter provides similar examples to the one above, so let’s do something different. We’ll get to some real world practical examples after we look at the tech involved.
Say you already write pure posts and transform them on the client side with JavaScript. This is a pretty common scenario. Say you write in markdown and do triple-backtick code blocks. Those convert to HTML like…
<pre><code lang="js">
</code></pre>But say your syntax highlighting library requires the code blocks like this:
<pre><code class="language-javascript">
</code></pre>You might be doing something like…
$("code.js")
.removeClass("js")
.addClass("language-javascript");
// then do other languages
// then run syntax highlighterThat works, but it requires a bunch of DOM effort on every single page load. It would be better to fix that HTML before it even comes to the browser. We’ll cover the solution to this in the examples below.
Combined with an HTML (technically, XML) parser such as libxml, we can move DOM transformations back to the server, relieving the browser. Reducing the amount of JavaScript required on the front end is definitely a good goal.
libxml has bindings for PHP that are usually available in standard installations. You have to make sure that your server has PHP > 5.4 and libxml > 2.6. You can check that by inspecting the output of phpinfo() or use the command line:
php -v
php -i | grep libxmlIf your server doesn’t fulfill these requirements you should ask your system administrator to update the required packages.
Parsing a post
The filter we added will receive the raw HTML of the post and return the transformed content.
We’re going to use the DOMDocument class to load and transform the HTML. We’ll use the loadHTML instance method to parse the post and the saveHTML to serialize the transformed document back to a string.
There’s a little catch: this class will automatically add the definition and will also automatically wrap the content in and tags. This is because libxml was designed to be used to parse full pages, not just a part of it, as we’re doing.
One potential solution is to set some flags when loading the HTML, but this isn’t perfect too. When loading the HTML libxml expects to find a single root element, but posts could have more than one root element (usually, you have many paragraphs). In that case, libxml will throw some errors.
The better solution I came up with is to subclass DOMDocument and override the saveHTML function to strip those html and body tags. When loading the HTML I don’t set the LIBXML_HTML_NOIMPLIED flag, so it doesn’t throw any error.
It’s not ideal, but it gets the job done.
class MSDOMDocument extends DOMDocument {
public function saveHTML ( $node = null ) {
$string = parent::saveHTML( $node );
return str_replace( array( '<html><body>', '</body></html>' ), '', $string );
}
}Now we need to use MSDOMDocument instead of DOMDocument in our filter functions. If you’re going to create more than one filter, I advise you to parse the post just once and pass the MSDOMDocument instance around. When all transformations are done we’ll get back the HTML string.
function css_tricks_example_the_content( $content ) {
// First encode all characters to their HTML entities
$encoded = mb_convert_encoding( $content, 'HTML-ENTITIES', 'UTF-8' );
// Load the content, suppressing warnings (libxml complains about not having
// a root element (we have many paragraphs)
$html = new MSDOMDocument();
$ok = @$html->loadHTML( $encoded, LIBXML_HTML_NODEFDTD | LIBXML_NOBLANKS );
// If it didn't parse the HTML correctly, do not proceed. Return the original, untransformed, post
if ( !$ok ) {
return $content;
}
// Pass the document to all filters
css_tricks_content_filter_1( $html );
css_tricks_content_filter_2( $html );
// Filtering is done. Serialize the transformed post
return $html->saveHTML();
}
add_filter( 'the_content', 'css_tricks_example_the_content' );Content Altering Examples
We’ve learned that we can use shortcodes and libxml to reduce the amount of HTML we directly have to insert in the post. It can be a little hard to understand what results we can get, so let’s go through some real world examples.
Many of the following examples come from the production version of MacStories. Other examples are Chris’ ideas, which could be easily added to CSS Tricks one day (or are already in use).
Pull quotes
Your site could have pull quotes. The desired HTML could be something like:
<p>lorem ipsum dolor…</p>
<div class='pull-quote-wrapper'>
<blockquote class='pull-quote-content'>This is the content of the pull quote</blockquote>
<span class='pull-quote-author'>Author</span>
</div>
<p>lorem ipsum and the rest of the post</p>To achieve something like this, I’d suggest a shortcode:
function css_tricks_pull_quote_shortcode( $attrs, $content = null ) {
extract( shortcode_atts( array(
'author' => ''
), $attrs ) );
$authorHTML = $author !== '' ? "<span class='pull-quote-author'>$author</span>" : '';
return <<<HTML
<div class='pull-quote-wrapper'>
<blockquote class='pull-quote-content'>$content</blockquote>
$authorHTML
</div>
HTML;
}
add_shortcode( 'pullquote', 'css_tricks_pull_quote_shortcode' );In your post you would then do this
lorem ipsum dolor…
[pullquote author="Mr. Awesome"]This is the content of the pull quote[/pullquote]
lorem ipsum and the rest of the postThe author is optional and the function that handles that omits it from the HTML altogether if it is not set.
There are many advantages to this:
- If you need a different HTML or different HTML classes you can update the output from the function in one place.
- If you want to scrap pull quotes entirely, you can start returning an empty string from the function.
- If you want to add a feature (e.g. click to tweet) you update the output from the function.
Twitter/Instagram embeds
One of the greatest features of WordPress is, in my opinion, automatic embedding. Say you want to insert external content in your post: chances are you might get the job done just by inserting the URL on its own line. No more hunting for the correct embed code. And most importantly, you don’t have to keep that up to date.
This is called oEmbed, and the list of supported providers is available here and here.
WordPress has a hook to customize such embeds. If you want to wrap the embedded content in a div you can do something like this:
function macstories_wrap_embeds ( $return, $url, $attr ) {
return <<<HTML
<div class='media-wrapper'>$return</div>
HTML;
}
add_filter( 'embed_handler_html', 'macstories_wrap_embeds', 10, 3 );
function macstories_wrap_oembeds ( $cache, $url, $attr, $id ) {
return <<<HTML
<div class='media-wrapper'>$cache</div>
HTML;
}
add_filter( 'embed_oembed_html', 'macstories_wrap_oembeds', 10, 4 );Syntax highlighting
You can process your code blocks on the server to add line numbers to every line. With that you should be able to just insert the code in pre and code blocks.
This is achieved using the_content filter and libxml:
- Search for all code blocks
- Get all lines by splitting on newlines
- Wrap each line in a
span - Apply CSS
The handler also changes the classes (as explained in the earlier example) as required by the syntax highlighter.
function css_tricks_code_blocks_add_line_numbers( $html ) {
// Iterating a nodelist while manipulating it is not a good thing, because
// the nodelist dynamically updates itself. Get all code elements and put
// only the ones that are direct children of pre element in an array
$codeBlocks = array();
$nodes = $html->getElementsByTagName( 'code' );
foreach ( $nodes as $node ) {
if ( $node->parentNode->nodeName == 'pre' ) {
$codeBlocks[] = $node;
}
}
foreach ( $codeBlocks as $code ) {
// Fix HTML classes
$lang = $code->getAttribute( 'lang' );
$code->removeAttribute( 'lang' );
if ( $lang === 'js' ) {
$code->setAttribute( 'class', 'language-javascript' );
}
// Probably add some more `else if` blocks...
// Get the actual code snippet
$snippet = $code->textContent;
// Split in lines
$lines = explode("n", $snippet);
// Remove all code
$code->nodeValue = '';
// Each line must be wrapped in its own element. Encode entities to be
// sure that libxml doesn't complain
foreach ( $lines as $line ) {
$wrapper = $html->createElement('span');
$wrapper->setAttribute( 'class', 'code-line' );
// Create a text node, to have full escaping support
$textNode = $html->createTextNode( $line . "n" );
// Add the text to span
$wrapper->appendChild( $textNode );
// Add the span to code
$code->appendChild( $wrapper );
}
// Jetpack adds a newline at the end of the code block. Remove that
if ( $code->lastChild->textContent == '' ) {
$code->removeChild( $code->lastChild );
}
}
}You can use CSS counters to generate the numbers:
.code-line {
display: block;
counter-increment: line-number;
&::before {
content: counter(line-number);
display: inline-block;
width: 30px;
margin-right: 10px;
}
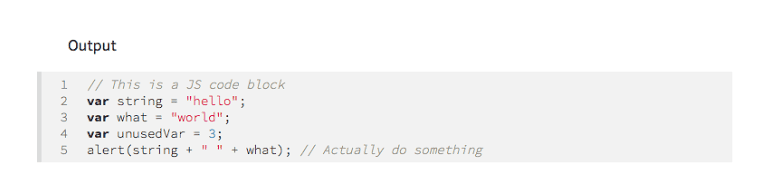
}A real world example, from MacStories, is we can write Markdown like this:
```js
// This is a JS code block
var string = "hello";
var what = "world";
var unusedVar = 3;
alert(string + " " + what); // Actually do something
```Which processes into HTML, then is sent through that filter, ending up like this:
<pre><code class='javascript'><span class='code-line'>// This is a JS code block</span>
<span class='code-line'>var string = "hello";</span>
<span class='code-line'>var what = "world";</span>
<span class='code-line'>var unusedVar = 3;</span>
<span class='code-line'>alert(string + " " + what); // Actually do something</span></code></pre>Which renders like this, with our syntax highlighter:
Rewriting URLs
When we switched to HTTPS at MacStories we faced an issue with mixed content warnings. Old posts linked to images hosted on Rackspace using the HTTP protocol. Whoops.
Fortunately Rackspace also serves content over HTTPS, but the URL is slightly different.
We decided to add a filter to change those URLs. Editors will link images using the HTTPS URL, but this filter can work around HTTP URLs inserted by mistake. Goodbye mixed content warnings.
This is achieved by adding a the_content filter and running a regular expression substitution.
function macstories_rackspace_http_to_https( $content ) {
return preg_replace(
'/http://([A-z0-9]+-[A-z0-9]+.)r[0-9]{1,2}(.cf1.rackcdn.com/)/i',
'https://$1ssl$2',
$content
);
}You can do something similar to CDN-ify image links: if your image URLs have a well defined pattern (so that you don’t change an URL of something that’s not an image) use a similar approach. Otherwise it’s better if you parse the HTML to change just the src attribute of the images.
Adding IDs to headings
Having the id attribute set on all headings allows you to link to a specific section (e.g. when you have a Table of Contents or want to share a link scrolled to the correct section).
If you write in HTML, you can add them manually. But that’s tedious. If you write in Markdown you have to make sure that your Markdown processor adds them (Jetpack does not). In any case, authoring them adds redundancy to your content.
You can automate the process using libxml in a the_content filter:
- Search for all headings
- Generate the slug
- Set that slug as
idattribute
The filter is this:
function css_tricks_add_id_to_headings( $html ) {
// Store all headings of the post in an array
$tagNames = array( 'h1', 'h2', 'h3', 'h4', 'h5', 'h6' );
$headings = array();
$headingContents = array();
foreach ( $tagNames as $tagName ) {
$nodes = $html->getElementsByTagName( $tagName );
foreach ( $nodes as $node ) {
$headings[] = $node;
$headingContents[ $node->textContent ] = 0;
}
}
foreach ( $headings as $heading ) {
$title = $heading->textContent;
if ( $title === '' ) {
continue;
}
$count = ++$headingContents[ $title ];
$suffix = $count > 1 ? "-$count" : '';
$slug = sanitize_title( $title );
$heading->setAttribute( 'id', $slug . $suffix );
}
}This filter also prevents the generation of duplicated ids.
Removing wrapping paragraphs
If automatic embedding is my favorite feature of WordPress, automatic paragraph wrapping is the thing I hate the most. This issue is well known.
Using RegEx to remove them works, but isn’t well suited for working with HTML tags. We can use libxml to remove the wrapping paragraph from images and other elements, such as picture, video, audio, and iframe.
function css_tricks_content_remove_wrapping_p( $html ) {
// Iterating a nodelist while manipulating it is not a good thing, because
// the nodelist dynamically updates itself. Get all things that must be
// unwrapped and put them in an array.
$tagNames = array( 'img', 'picture', 'video', 'audio', 'iframe' );
$mediaElements = array();
foreach ( $tagNames as $tagName ) {
$nodes = $html->getElementsByTagName( $tagName );
foreach ( $nodes as $node ) {
$mediaElements[] = $node;
}
}
foreach ( $mediaElements as $element ) {
// Get a reference to the parent paragraph that may have been added by
// WordPress. It might be the direct parent node or the grandparent
// (LOL) in case of links
$paragraph = null;
// Get a reference to the image itself or to the link containing the
// image, so we can later remove the wrapping paragraph
$theElement = null;
if ( $element->parentNode->nodeName == 'p' ) {
$paragraph = $element->parentNode;
$theElement = $element;
} else if ( $element->parentNode->nodeName == 'a' &&
$element->parentNode->parentNode->nodeName == 'p' ) {
$paragraph = $element->parentNode->parentNode;
$theElement = $element->parentNode;
}
// Make sure the wrapping paragraph only contains this child
if ( $paragraph && $paragraph->textContent == '' ) {
$paragraph->parentNode->replaceChild( $theElement, $paragraph );
}
}
}Adding rel=noopener
Recently we became aware of security issue regarding links opening in a new tab.
Adding the rel=noopener attribute will fix the issue, but that’s not something editors should have to remember to do. It also doesn’t play nice with Markdown, because you’d have to write links in plain HTML.
libxml can help us:
function css_tricks_rel_noopener( $html ) {
$nodes = $html->getElementsByTagName( 'a' );
foreach ( $nodes as $node ) {
$node->setAttribute( 'rel', 'noopener' );
}
}Considerations
I’ve been using the techniques explained above since the launch of MacStories 4 and haven’t had any major issues. Writers can focus solely on writing great content. All presentation related transformations/generations are documented in code and can easily be ported over the new version or updated to the new design. It’s a big win. I won’t have to create a `legacy-theme.css` file to style or fix old (and poor) decisions.
With content filters, you can pretty much do whatever you want. With shortcodes, you’ll need to be careful not to create overly-specialized shortcodes that look like the old raw HTML you had in the past. For example
[bad-shortcode align="left" color="blue" font="georgia"]…[/bad-shortcode]Some of these attributes may not make sense in the future, so it’s up to you to decide on attributes that seem well-suited and abstracted enough to live forever. Still, even a bad shortcode is better than no content abstraction at all.
In the end: do what you think is best and think twice before implementing. Always ask yourself “will I need this when the next design goes live?”
Leverage WordPress Functions to Reduce HTML in your Posts is a post from CSS-Tricks
