Designers, developers, site owners… lend me your eyeballs for a bit. There’s something rotten in the state of pre-made website themes. Alright, I’ve offended The Bard quite enough. But you get my point, right? Themes have gotten a bad rap for a variety of reasons: they can have bloated code, content must be designed to fit in them rather than designing them to fit the content, et cetera.
But they’ve also gotten really good. Many are made to be modular, so you only use and load the code you need. People have gotten a lot better at coding things to load fast, and there’s a theme for nearly every conceivable need. So maybe it’s not as optimized as it could be, if you’re not getting Amazon levels of traffic, regular hosting should be fine, right? And again, there’s a theme for every conceivable need! It’s just so convenient.
Wrong, wrong, wrong, (mostly) wrong.
Let me tell you a little story. A long, long time ago in February of 2018, I had an idea. Well, really I had a few ideas of things I desperately wanted to write about, but no one was paying me to do it. And honestly, keeping up a blog on the topics I had in mind wouldn’t be all that feasible. I like my projects to have a beginning, middle, end, and perhaps most importantly, a deadline.
So I thought, hey, why not make some niche/authority sites on these topics so dear to my heart? There’s no reason niche sites have to be predatory glorified ads with terrible aesthetics and UX. I could make them better. And I could just leave them up when I was done, with minimal updates. And hell, I don’t even need to design them! A wiki or knowledge base theme for WordPress or some other CMS would do quite nicely for my purposes.
I found plenty of themes…I very nearly dropped money on
And so I went theme hunting. I found plenty of themes in the categories I had in mind, including some absolutely beautiful premium themes I very nearly dropped money on. That would have been a terrible waste of my cash.
It’s because, you see, each and every one of these themes depended on JavaScript for their most basic functions: displaying any content at all, navigation, and search. (Now I told myself I wasn’t going to get back into this particular crusade. I told myself I could stop writing about how completely depending on JavaScript is a terrible idea. I wasn’t going to do this anymore, darnit!)
But people are getting ripped off, and I can’t stand for that. If you’re selling a theme that depends on JavaScript to work at all, you’re selling a site that is going to break under certain conditions. Whether it’s a slow connection, a plugin incompatibility, some ad network gone rogue, or a random browser hiccup, it’s going to break. If you allow a web product that’s intended for daily use to be that fragile, that’s an accessibility issue, and it’s a rip-off.
It’s one thing to build a JavaScript-dependent site for a client who knows the risks and chooses to take them. It is quite another to sell templates like that, especially without any warning. These things are only sometimes implemented by professional designers or developers who want to save time. They are very often implemented by beginners who are just learning a bit of HTML even as they use your theme.
More than that, these were wiki and knowledge base themes. Those are the kinds of sites people go to when they need help. Customer support and educational sites should be the least likely to break, period. This is a case where both the customer and the user are being let down in a big way.
People will always want flashy stuff, fine. We can’t help that fancy animation grabs the eye, and I don’t blame theme designers for using it as a selling point. But you owe it to your customers to implement fall-backs for every JavaScript element that might break. You owe it to them to at least make your basic layout, navigation, and any forms work under just about any condition. Ancient browsers notwithstanding.
you owe it to your customers to implement fall-backs for every JavaScript element that might break
In my mind, a lack of progressive enhancement, or at least graceful degradation, is the single biggest accessibility nightmare to plague the wonderful world of pre-made sites and themes. Customers are buying these things without knowing exactly what they’re doing, and it’s bound to end in misery. And here I thought bad planning was the biggest problem for theme-based sites.
Yes, implementing fall-backs for everything is difficult, but that’s why you charge money for these things. If they were all that easy to make, they could all be free, right? No, I don’t expect you to code your themes for every version of IE, and yes I realize that most premium themes come with support of some kind or another.
Theme authors just need to recognize that when JavaScript breaks, it most often only breaks for some of the end users, and only some of the time. But those end users could have turned into paying customers for the people who bought the themes, and now they probably won’t. And that’s on us designers and developers, no one else.
Well, now I have to go design my own wiki/knowledge-base style theme (probably for Grav CMS, at this point), because somebody needs to do it right, and it might as well be me. To quote Taylor Swift, “Look what you made me do.”
Building technology and software has become a very responsible job. People trust the products we create, and they can have a significant impact on their lives, too. Considering this, we not only need to think about inclusive solutions, but also stand up and advocate for ethics, reliability, and security. It’s a position that gives us power.
Eric Meyer published an article elaborating the problems which an HTTPS-only web is bringing along. In it, he reveals that developing countries suffer a lot from this development as they often have bad internet connections and, due to the encryption, they now experience more website errors than before. Ben Werdmüller jumped in and published the article “Stop building for San Francisco” in which he points out one of the biggest problems we have as developers: We use privileged hardware and infrastructure. We build experiences using the latest iPhones, Macbooks with Gigabit or fast 4G connections but never consider that most people we’re building for use devices and infrastructures that are far from being that well-equipped. Making the web more secure is a great idea, beyond question, but we should also keep in mind the consequences that the latest tech and our design decisions might have for others.
Developers have been asking a lot about Safari’s Intelligent Tracking Prevention (ITP) and how to debug websites with it enabled. Now the WebKit team shares the ITP Debug Mode which gives you a lot more flexibility and tools to track down issues.
The latest version of Chrome (68) brings a new “not secure” notification when visiting HTTP pages. Be aware of this and upgrade your sites accordingly. Also new in Chrome 68 are the new Page Lifecycle API, a great new API for page events, as well as the Payment Handler API. HTTP cache is now ignored when requesting updates to a service worker, bringing Chrome in line with the spec and other browsers. Apart from that, the cursor values grab and grabbing are now unprefixed in the new version — finally.
General
If you’re building for Open Source, you need to decide which license your project should use. Now there’s a new option, the Just World License. It’s for developers who “agree in general with the principles of open source software but are uncomfortable with their software being used as part of efforts to destroy lives, our environment and our future”.
Ethics for Design is a project where twelve designers and researchers from eight European cities discuss the, sometimes harmful, impact of design on our societies and what designers can do to work for the good of all and not just a few.
Tooling
Prashant Palikhe wrote a long story about the art of debugging with Chrome’s Developer Tools, which I can highly recommend as it’s a very complete reference to get to know the developer tools of a browser. If you use another browser, that’s not a big problem as most tools are quite similar.
WebP is an image format with a couple of nice features and likely one of the best-known new formats besides the common JPEG/PNG ones. However, creating WebP images can still be a challenge, so Jeremy Wagner wrote a guide on how to convert images to WebP.
Many of us are addicted to communication tools like Slack. The folks from Wildbit decided to shut down Slack for a week — with a significant effect on how they work. An interesting case study about how we tend to get too comfortable with a useful tool and don’t use it as we should anymore. From time to time, it’s important to reset our minds.
Dennis Reimann published the first stable version of UIEngine, a workbench for UI-driven development.
Security
A new Observer is around: The ReportingObserver API lets you know when your site uses a deprecated API or runs into a browser intervention. So far, it’s available in Chrome 69. You could easily use this to send errors that previously were only available in the Console to your backend or error handling service.
Web Performance
Do you remember QUIC (Quick UDP Internet Connections)? The protocol engineered by Google that they use internally and that is shaping up quite well for larger use? While the IETF is currently standardizing the format towards the end of the year, Cloudflare engineers now share their experience from testing it.
A QUIC handshake only takes a single round-trip between client and server to complete, whereas TCP and TLS usually need two. (Image source)
Dave Rupert shares the A11Y Nutrition Cards, a project that attempts to digest and simplify the accessibility expectations when it comes to component authoring.
One year after they introduced their Progressive Web App, Zack Argyle from the Pinterest engineering team takes a look back. It’s important to note why they decided to build a PWA: “Our mobile web experience for people in low-bandwidth environments and limited data plans was not good”. But the results for them are amazing to see.
Philip Walton introduces the new Page Lifecycle API which helps us determine page states in the browser more easily via events, such as the page being in the background (not visible), active, frozen or even terminated.
Addy Osmani researched the cost of JavaScript in 2018 and now shares evidence that every byte of JavaScript is still the most expensive resource we can send to mobile phones because it can delay interactivity significantly. This is a problem especially for not so capable phones that are widely used outside the tech industry.
What’s the real cost of JavaScript? One of the findings from Addy Osmani’s research: It takes a low-end 2018 phone 32 seconds longer than an iPhone 8 to process JavaScript for CNN.com. (Image source)
Paris Marx wrote about why he thinks digital nomads are not the future. He argues that location independence is only possible because of communication infrastructures built with public funds and that it’s not fair to abuse them.
It’s not the first time a company is testing a 4-day workweek. However, it’s great to see how the concept can be established successfully and with benefits for both — the employees and the work done.
Jeremy Nagel makes us think about the impact of our open-source code: As developers we tend to believe that making our code freely available is an amazing move but we forget that we make it available to bad players as well — to coal miners, to pollution-contributing companies, to those who use people to get rich while mistreating them, to those who rip you off indirectly. It’s not that you can’t do anything about it; you have to be aware of these issues and apply a better license or add a dedicated statement to your code.
India has a big plastic waste problem. Since a couple of months, a couple of fishers don’t ignore the plastic problem anymore but collect all the waste in their nets instead, and bring it back to the shore where it’s used to build roads. A great idea of making use of trash efficiently.
Refs make it possible to access DOM nodes directly within React. This comes in handy in situations where, just as one example, you want to change the child of a component. Let’s say you want to change the value of an element, but without using props or re-rendering the whole component.
That’s the sort of thing refs are good for and what we’ll be digging into in this post.
How to create a ref
createRef() is a new API that shipped with React 16.3. You can create a ref by calling React.createRef() and attaching a React element to it using the ref attribute on the element.
class Example extends React.Component {
constructor(props) {
super(props)
// Create the ref
this.exampleRef = React.createRef()
}
render() {
return (
<div>
// Call the ref with the `ref` attribute
<input type="text" ref={this.exampleRef} />
</div>
)
}
}
We can “refer” to the node of the ref created in the render method with access to the current attribute of the ref. From the example above, that would be this.exampleRef.current.
class App extends React.Component {
constructor(props) {
super(props)
// Create the ref
this.textInput = React.createRef();
this.state = {
value: ''
}
}
// Set the state for the ref
handleSubmit = e => {
e.preventDefault();
this.setState({ value: this.textInput.current.value})
};
render() {
return (
<div>
<h1>React Ref - createRef</h1>
// This is what will update
<h3>Value: {this.state.value}</h3>
<form onSubmit={this.handleSubmit}>
// Call the ref on <input> so we can use it to update the <h3> value
<input type="text" ref={this.textInput} />
<button>Submit</button>
</form>
</div>
);
}
}
How a conversation between a child component and an element containing the ref might go down.
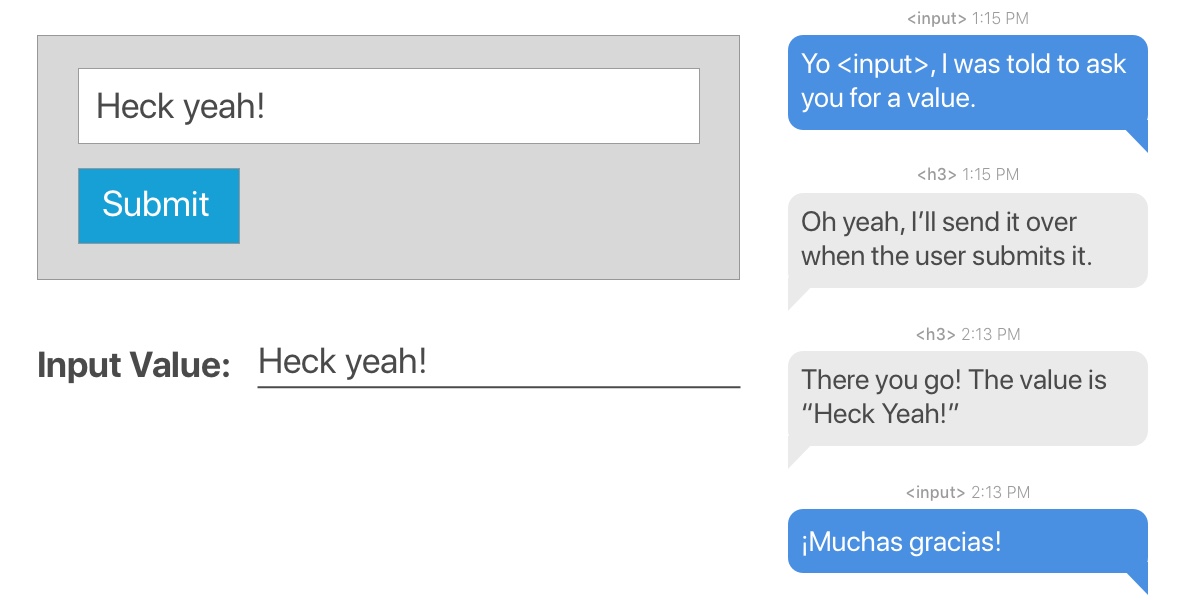
This is a component that renders some text, an input field and a button. The ref is created in the constructor and then attached to the input element when it renders. When the button is clicked, the value submitted from the input element (which has the ref attached) is used to update the state of the text (contained in an H3 tag). We make use of this.textInput.current.value to access the value and the new state is then rendered to the screen.
Passing a callback function to ref
React allows you to create a ref by passing a callback function to the ref attribute of a component. Here is how it looks:
When you make use of callback like we did above, React will call the ref callback with the DOM node when the component mounts, when the component un-mounts, it will call it with null.
It is also possible to pass ref from a parent component to a child component using callbacks.
In the App component, we want to obtain the text that is entered in the input field (which is in the child component) so we can render it. The ref is created using a callback like we did in the first example of this section. The key lies in how we access the DOM of the input element in the Input component from the App component. If you look closely, we access it using this.inputElement. So, when updating the state of value in the App component, we get the text that was entered in the input field using this.inputElement.value.
The ref attribute as a string
This is the old way of creating a ref and it will likely be removed in a future release because of some issues associated with it. The React team advises against using it, going so far as to label it as “legacy” in the documentation. We’re including it here anyway because there’s a chance you could come across it in a codebase.
The component is initialized and we start with a default state value set to an empty string (value=''). The component renders the text and form, as usual and, like before, the H3 text updates its state when the form is submitted with the contents entered in the input field.
We created a ref by setting the ref prop of the input field to textInput. That gives us access to the value of the input in the handleSubmit() method using this.refs.textInput.value.
Forwarding a ref from one component to another
**Ref forwarding is the technique of passing a ref from a component to a child component by making use of the React.forwardRef() method.
We’ve created the ref in this example with inputRef, which we want to pass to the child component as a ref attribute that we can use to update the state of our text.
We all know that form validation is super difficult but something React is well-suited for. You know, things like making sure a form cannot be submitted with an empty input value. Or requiring a password with at least six characters. Refs can come in handy for these types of situations.
class App extends React.Component {
constructor(props) {
super(props);
this.username = React.createRef();
this.password = React.createRef();
this.state = {
errors: []
};
}
handleSubmit = (event) => {
event.preventDefault();
const username = this.username.current.value;
const password = this.password.current.value;
const errors = this.handleValidation(username, password);
if (errors.length > 0) {
this.setState({ errors });
return;
}
// Submit data
};
handleValidation = (username, password) => {
const errors = [];
// Require username to have a value on submit
if (username.length === 0) {
errors.push("Username cannot be empty");
}
// Require at least six characters for the password
if (password.length < 6) {
errors.push("Password should be at least 6 characters long");
}
// If those conditions are met, then return error messaging
return errors;
};
render() {
const { errors } = this.state;
return (
<div>
<h1>React Ref Example</h1>
<form onSubmit={this.handleSubmit}>
// If requirements are not met, then display errors
{errors.map(error => <p key={error}>{error}</p>)}
<div>
<label>Username:</label>
// Input for username containing the ref
<input type="text" ref={this.username} />
</div>
<div>
<label>Password:</label>
// Input for password containing the ref
<input type="text" ref={this.password} />
</div>
<div>
<button>Submit</button>
</div>
</form>
</div>
);
}
}
We used the createRef() to create refs for the inputs which we then passed as parameters to the validation method. We populate the errors array when either of the input has an error, which we then display to the user.
That’s a ref… er, a wrap!
Hopefully this walkthrough gives you a good understanding of how powerful refs can be. They’re an excellent way to update part of a component without the need to re-render the entire thing. That’s convenient for writing leaner code and getting better performance.
At the same time, it’s worth heeding the advice of the React docs themselves and avoid using ref too much:
Your first inclination may be to use refs to “make things happen” in your app. If this is the case, take a moment and think more critically about where state should be owned in the component hierarchy. Often, it becomes clear that the proper place to “own” that state is at a higher level in the hierarchy.
Out series of articles Agency of the Week becomes more and more diverse with each featured design studio. We enjoy, embrace, and explore diversity as an important part of any design-related process. Dox Design is an unusual studio, and today, we are making them known by all the animal lovers out there!
When you own a relatively new pet company, it comes with many challenges. We ourselves know how hard any start might be, but when you’re determined, there’s no turning back. A good time management, great services provided, and amazing marketing, you can make it to the tops in no-time. Now, believe or not, your website, your business card, and your brand’s identity are the best marketers ever. It doesn’t matter how much money you invest in publicity, sponsored posts, and ads, as long as your business’s image is repulsive.
OK, maybe I exaggerated a little bit. It only takes a few small flaws of your website, and your potential clients will find another dog hairdresser. But do not fear! Dox Design specializes in your type of passion, and promises to create “compelling designs for pet businesses.” Dox Design understands that any design goes beyond a pretty picture of a cat with a bow, and focuses on how your client can best relate to your services. Nobody said that creating an emotional bound with your clients is a piece of cake. Dox Design does it with so much talent, that it doesn’t look like rocket science, either.
If you don’t believe be, I invite you to take a look at some of the studios pieces of work.
Even if you are a medicine related company, you don’t want to scare your clients off with cruel images. When the animal feels happy, the owner feels happy. Also, pay close attention to the colors you choose.
Another great example that proves that design and emotion go hand in hand.
Beans & Bones
Clean design means more than overwhelming design. Allow your clients to “breath,” don’t suffocate them with information.
The Michigan-based design studio proves with every fulfilled mission that they are a trust-worthy, dedicated, and amazingly talented team.
Whether it is a beautifully crafted logo or a well thought-out website, we put your customer at the core of what we do. Every color we choose, every screen flow we map out has a rhyme and a reason. We get it, and our designs will help your customers get it too.
We at Webdesignledger have been closely following Dox Design’s work and came to the conclusion that they are one of the top studios for pet companies that need to become a brand. Don’t hesitate to contact them and meet the amazing designers Kaila Piepkow and Jordan Piepkow.
Hoping that this blog post has reached the right people, we invite other unusual design studios to write us at webdesignledger.blog@gmail.com, for a feature on our blog. Also, visit us daily for more snippets of inspiration, resource, and creativity.
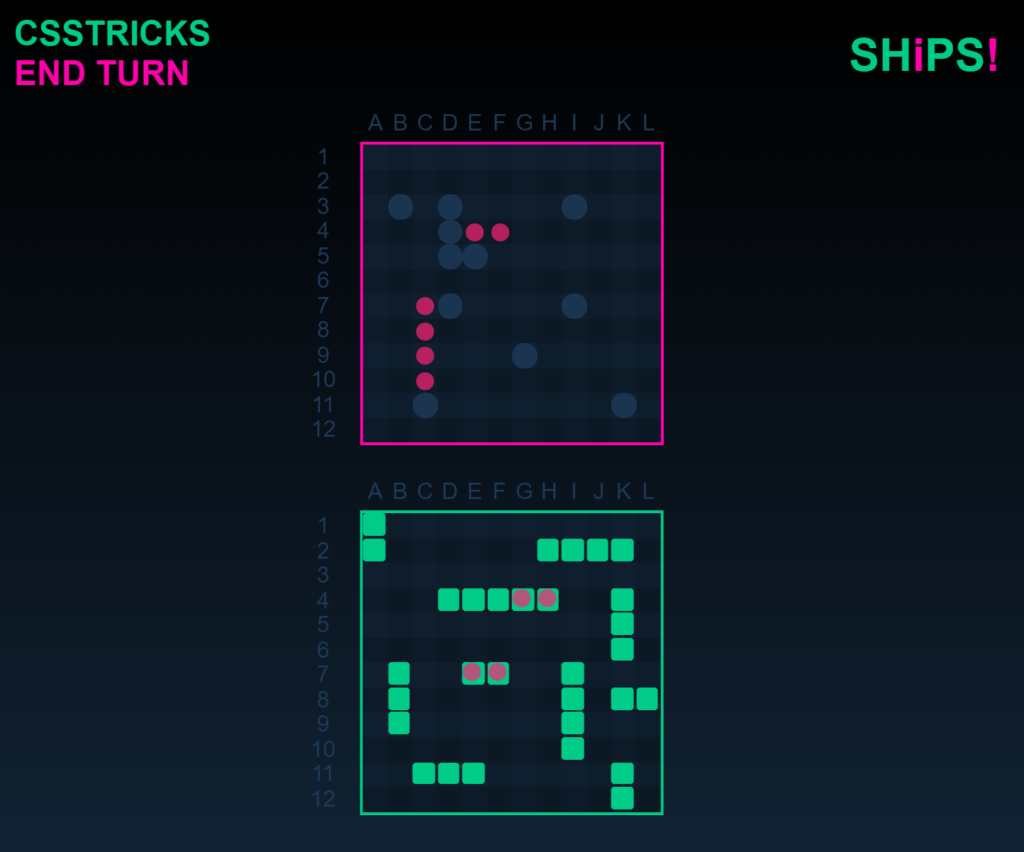
This is an experiment to see how far into an interactive experience I can get using only CSS. What better project to attempt than a game? Battleship seemed like a good challenge and a step up from the CSS games I’ve seen so far because it has the complexity of multiple areas that have to interact with two players.
I could tell right away there was going to be a lot of repetitive HTML and very long CSS selectors coming, so I set up Pug to compile HTML and Less to compile CSS. This is what all the code from here on is going to be written in.
Interactive elements in CSS
In order to get the game mechanics working, we need some interactive elements. We’re going to walk through each one.
HTML checkboxes and :checked
Battleship involves a lot of checking to see whether a field contains a ship or not, so we’re going to use a boatload of checkboxes.
To style checkboxes, we would first need to reset them using appearance: none; which is only poorly supported right now and needs browser prefixes. The better solution here is to add helper elements. tags can’t have children, including pseudo elements (even though Chrome will render them anyway), so we need to work around that using the adjacent sibling selector.
If you use a for the helper element, you will also extend the click area of the checkbox onto the helper, allowing you to position it more freely. Also, you can use multiple labels for the same checkbox. Multiple checkboxes for the same label are not supported, however, since you would have to assign the same ID for each checkbox.
Targets
We’re making a local multiplayer game, so we need to hide one player’s battlefield from the other and we need a pause mode allowing for a player to switch without glancing at the other player’s ships. A start screen explaining the rules would also be nice.
HTML already gives us the option to link to a given ID in the document. Using :target we can select the element that we just jumped to. That allows us to create an Single Page Application-like behavior in a completely static document (and without even breaking the back button).
- var screens = ['screen1', 'screen2', 'screen3'];
body
nav
each screen in screens
a(href='#' + screen)
each screen in screens
.screen(id=screen)
p #{screen}
Rendering elements inactive is usually done by using pointer-events: none; The cool thing about pointer-events is that you can reverse it on the child elements. That will leave only the selected child clickable, but the parent stays click-through. This will come in handy later in combination with checkbox helper elements.
The same goes for visibility: hidden; While display: none; and opacity: 0; make the element and all it’s children disappear, visibility can be reversed.
Note that a hidden visibility also disables any pointer events, unlike opacity: 0;, but stays in the document flow, unlike display: none;.
.foo {
display: none; // invisible and unclickable
.bar {
display: block; // invisible and unclickable
}
}
.foo {
visibility: hidden; // invisible and unclickable
.bar {
visibility: visible; // visible and clickable
}
}
.foo {
opacity: 0;
pointer-evens: none; // invisible and unclickable
.bar {
opacity: 1;
pointer-events: all; // still invisible, but clickable
}
}
CSS Rule
Reversible opacity
Reversible pointer events
display: none;
?
?
visibility: hidden;
?
?
opacity: 0; pointer-events: none;
?
?
OK, now that we’ve established the strategy for our interactive elements, let’s turn to the setup of the game itself.
Setting up
We have some global static variables and the size of our battlefields to define before we actually start:
The grid size is the size of the battlefield: 12×12 fields in this case. Next, we define some z-indexes and colors.
Here’s the Pug skeleton:
doctype html
head
title Ships!
link(rel="stylesheet", href="style.css")
meta(charset="UTF-8")
meta(name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no")
meta(name="theme-color" content="#000000")
body
Everything HTML from this point on will be in the body.
Implementing the states
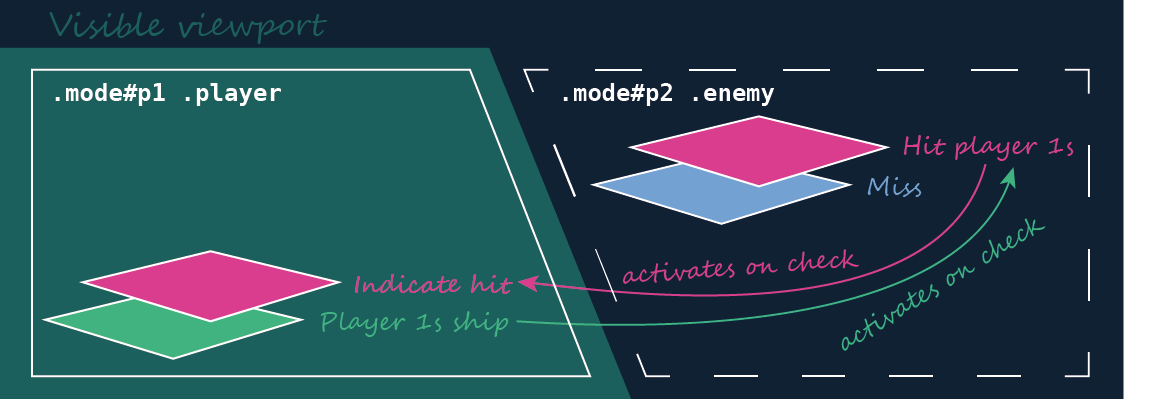
We need to build the states for Player 1, Player 2, pause, and a start screen. We’ll do this like it was explained above with target selectors. Here’s a little sketch of what we’re trying to achieve:
We have a few modes, each in its own container with an ID. Only one mode is to be displayed in the viewport—the others are hidden via display: none;, except for player modes. If one player is active, the other needs to be outside of the viewport, but still have pointer events so the players can interact with each other.
.mode#pause
each party in ['p1', 'p2']
.mode(id=party)
.mode#start
.status
each party in ['p1', 'p2']
a.player-link.switch(href='#' + party)
a.status-link.playpause(href='#pause') End Turn
h1
Ships!
The .status div contains the main navigation. Its entries will change depending on the active mode, so in order to select it properly, we’ll need put it after our .mode elements. The same goes for the
, so it ends up at the end of the document (don’t tell the SEO people).
The .mode div never has pointer events and always is fully transparent (read: inactive), except for the start screen, which is enabled by default and the currently targeted screen. I don’t simply set it to display: none; because I still need it to be in the document flow. Hiding the visibility won’t work because I need to activate pointer events individually later on, when hitting enemy ships.
I need #p1 and #p2 to be next to each other because that’s what’s going to enable the interaction between one players hits and the other players ships.
Implementing the battlefields
We need two sets of two battlefields for a total of four battlefields. Each set contains one battlefield for the current player and another for the opposite player. One set is going to be in #p1 and the other one in #p2. Only one of the players will be in the viewport, but both retain their pointer events and their flow in the document. Here’s a little sketch:
Now we need lots of HTML. Each player needs two battlefields, which need to have 12×12 fields. That’s 576 fields in total, so we’re going to loop around a bit.
The fields are going to have their own class declaring their position in the grid. Also, fields in the first row or line get a position indicator, so you get to say something cool like “Fire at C6.”
The battlefield itself is going to be set in a CSS grid, with its template and measurements coming from the variables we set before. We’ll position them absolutely within our .mode divs and switch the enemy position with the player. In the actual board game, you have your own ships on the bottom as well. Note that we need to escape the calc on the top value, or Less will try to calculate it for you and fail.
We want the tiles of the battlefield to be a nice checkerboard pattern. I wrote a mixin to calculate the colors, and since I like my mixins separated from the rest, this is going into a components.less file.
When we call it with .checkerboard(@gridSize);, it will iterate through every second line of the grid and set background colors for odd and even instances of the current element. We can color the remaining fields with an ordinary :odd and :even.
Next, we place the indicators outside of the battlefields.
Let’s get to the tricky part and place some ships. Those need to be clickable and interactive, so they’re going to be checkboxes. Actually, we need two checkboxes for one ship: miss and hit.
Miss is the bottom one. If nothing else is on that field, your shot hits the water and triggers a miss-animation. The exception is when a player clicks on their own battlefield. In that case, the ship animation plays.
When an own ships spawns, it activates a new checkbox. This one is called hit. It’s placed at the exact same coordinates as its corresponding ship, but in the other players attack field and above the checkbox helper for the miss. If a hit is activated, it displays a hit animation on the current player’s attack field as well as well as on the opponent’s own ship.
This is why we need to position our battlefields absolutely next to each other. We need them aligned at all times in order to let them interact with each other.
First, we’re going to set some styles that apply to both checkboxes. We still need the pointer events, but want to visually hide the checkbox and work with helper elements instead.
Those two events are basically the same. If you hit the sea in your own battlefield, you create a ship. If you hit the sea in the enemy battlefield, you trigger a miss. That happens by calling the respective class from our components.less file within a pseudo element of the helper class. We use pseudo elements here because we need to place two objects in one helper later on.
If you spawn a ship, you shouldn’t be able to un-spawn it, so we make it lose its pointer events after being checked. However, the next hit-checkbox gains it pointer events, enabling the enemy to hit spawned ships.
That new hit checkbox is positioned absolutely on top of the other player’s attack field. For Player 1 that means by 50vw to the right and by the grid height + 50px margin to the top. It has no pointer events by default, they are going to be overwritten by those set in .ship:check ~ .hit, so only ships that are actually set, can be hit.
To display a hit event, we need two pseudo elements: one that confirms the hit on the attack field; and one that shows the victim where they have been hit. :checked + .check-helper::after calls a .hit-obj from components.less onto the attacker’s field and the corresponding ::before pseudo element gets translated back to the victim’s own battlefield.
Since the display of hit events isn’t scoped to the active player, we need to remove all unnecessary instances manually using display: none;.
While we did style our miss, ship and hit objects, there’s nothing to be seen yet. That’s because we are still missing the animations making those objects visible. Those are simple keyframe animations that I put into a new Less file called animations.less.
This isn’t really necessary for functionality, but it’s a nice little extra. Instead of being called “Player 1” and “Player 2,” you can enter your own name. We do this by adding two to .status, one for each player. They have placeholders in case the players don’t want to enter their names and want to skip to the game right away.
.status
input(type="text" placeholder="1st Player").player-name#name1
input(type="text" placeholder="2nd Player").player-name#name2
each party in ['p1', 'p2']
a.player-link.switch(href='#' + party)
a.status-link.playpause(href='#pause') End Turn
Because we put them into .status, we can display them on every screen. On the start screen, we leave them as normal input fields, for the players to enter their names. We style their placeholders to look like the actual text input, so it doesn’t really matter if players enter their names or not.
On the other screens, we remove their typical input field styles as well as their pointer events, making they appear as normal, non-changeable text. .status also contains empty links to select players. We style those links to have actual measurements and display the name inputs without pointer events above them. Clicking a name triggers the link now, targeting the corresponding mode.
Some notes on the Internet Explorer and Edge: Microsoft browsers haven’t implemented the ::placeholder pseudo element. While they do support :-ms-input-placeholder for IE and ::-ms-input-placeholder, as well as the webkit-prefix for Edge, those prefixes only work if ::placeholder is not set. As far as I played around with placeholders, I only managed to style them properly in either the Microsoft browsers, or all the other ones. If someone else has a workaround, please share it!
Putting it all together
What we have so far is a functional, but not very handsome game. I use the start screen to clarify some basic rules. Since we don’t have a hard-coded win condition and nothing to prevent players to place their ships wildly all over the place, I created a “Play fair” note that encourages the good ol’ honor system.
.mode#start
.battlefield.enemy
ol
li
span You are this color.
li
span Your enemy is
span this
span color
li
span You may place your ships as follows:
ul
li 1 x 5 blocks
li 2 x 4 blocks
li 3 x 3 blocks
li 4 x 2 blocks
I’m not going into the detail of how I went about getting things exactly to my liking since most of that is very basic CSS. You can go through the end result to pick them out.
When we finally connect all the pieces, we get this:
HTML and CSS may not be programming languages, but they are mighty tools in their own domain. We can manage states with pseudo classes and manipulate the DOM with pseudo elements.
While most of us use :hover and :focus all the time, :checked goes by largely unnoticed, only for styling actual checkboxes and radio buttons at best. Checkboxes are handy little tools that can help us to get rid of unnecessary JavaScript in our more simple front end features. I wouldn’t hesitate to build dropdown or off-canvas menus in pure CSS in real life projects, as long as the requirements don’t get too complicated.
I’d be a bit more cautious when using the :target selector. Since it uses the URL hash value, it’s only usable for a global value. I think I’d use it for, say, highlighting the current paragraph on a content page, but not for reusable elements like a slider or an accordion menu. It can also quickly get messy on larger projects, especially when other parts of it start controlling the hash value.
Building the game was a learning experience for me, dealing with pseudo selectors interacting with each other and playing around with lots of pointer events. If I had to build it again, I’d surely choose another path, which is a good outcome for me. I definitely don’t see it as a production-ready or even clean solution, and those super specific selectors are a nightmare to maintain, but it has some good parts in it that I can transition to real life projects.
Most importantly though, it was a fun thing to do.
What a great technological analogy by Mandy Michael. A reminder that TypeScript…
makes use of static typing so, for example, you can give your variables a type when you write your code and then TypeScript checks the types at compile time and will throw an error if the variable is given a value of a different type.
In other words, you have a variable age that you declare to be a number, the value for age has to stay a number otherwise TypeScript will yell at you. That type checking is a valuable thing that helps thwart bugs and keep code robust.
This is the same with HTML. If you use the
everywhere, you aren’t making the most of language. Because of this it’s important that you actively choose what the right element is and don’t just use the default
.
And hey, if you’re into TypeScript, it’s notable it just went 3.0.
My pal Lindsay Grizzard wrote about creating a CSS system that works across an organization and all of the things to keep in mind when starting a new project:
Getting other developers and designers to use the standardized rules is essential. When starting a project, get developers onboard with your CSS, JS and even HTML conventions from the start. Meet early and often to discuss every library, framework, mental model, and gem you are interested in using and take feedback seriously. Simply put, if they absolutely hate BEM and refuse to write it, don’t use BEM. You can explore working around this with linters, but forcing people to use a naming convention they hate isn’t going to make your job any easier. Hopefully, you will be able to convince them why the extra underscores are useful, but finding a middle ground where everyone will participate in some type of system is the priority.
I totally agree and the important point I noted here is that all of this work is a collaborative process and compromise is vital when making a system of styles that are scalable and cohesive. In my experience, at least, it’s real easy to walk into a room with all the rules written down and new guidelines ready to be enforced, but that never works out in the end.
Ethan Marcotte riffed on Lindsay’s post in an article called Weft and described why that’s not always a successful approach:
Broad strokes here, but I feel our industry tends to invert Lindsay’s model: we often start by identifying a technical solution to a problem, before understanding its broader context. Put another way, I think we often focus on designing or building an element, without researching the other elements it should connect to—without understanding the system it lives in.
The Logo and the Brand are simply inseparable. A strong logo is as essential for branding as a strong branding is essential for a logo. But there’s one piece that unifies the two: the brand identity. When it comes to creating a successful business, its identity is the foundation that holds everything together.
Brands can be seen as the emotional and intellectual protection of a company. Clients associate their opinion regarding a product or service based on its brand. Here’s where the name of the company, the logo, and its identity plays a major role.
The identity of a business includes all the visual aspects that contribute to making it unique. These include color schemes, packaging, fonts, products, and most important, logos.
The logos are symbols that tell apart any type of organization. We are talking about visual clues that can trigger the emotional responses mentioned earlier. Essentially, the logo’s design represents the brand’s foundation and it is crucial for the visual identity. Some of the best logo designs can make a company world-wide known.
The Siren Design
Let’s think of the undeniable success of the Starbucks’s two-legged mermaid. Chosen initially due to the companies origins, the name Starbuck comes from Moby Dick, and the home city Seattle is built around the harbor. The siren’s logo evolved together with the brand, which became a global reference with over 20,000 store around the world. Its estimated value is 77,87 billion dollars.
After the most recent rebranding process from 2011, the creative team from Starbucks doesn’t feel like the name of the company or the word “coffee” should be on the logo. For this company worth billions, the siren is enough.
She is not a real person, but we kind of think of her as one. She’s the biggest symbol of our brand, really, other than our partners (employees). She’s the face of it,” said Steve Murray, a creative director in the Starbucks Global Creative Studio.
Web design
Starbucks is an amazing example for what a logo with a universal character can do to achieve the success of a global brand. But don’t forget that the logo makes up only a small part of the identity of a company. The market is flooded with businesses nowadays; in order to have a voice in this “chaos,” the companies need to make their brands renown digitally. This begins with incorporating logos in web design.
We live in an era of information that comes in abundantly – a raw truth that is less likely to change any time soon. As a result, transmitting information quickly and clearly is crucial factor in the sustainability of a business on the digital market. Therefore, the digital branding depends on utilizing powerful images that identify, but not explain. These images bring up memories and experiences in the mind of the client in no-time. The images need to be interactive, and are able to bring a brand to life on the screen. The logos are images.
Adding the logos to web design becomes a major party of the global branding. The well created logos have the power to assure a trust and loyalty feeling in relation to the company. Take Apple, Coca-Cola, and Microsoft for example. These giants have a well constructed action plan regarding the integration of the logo in webdesign. Actually, most of the times, their logos act as turn on/off buttons for the website. Not only do they use their logos to stimulate trust in their products, but they also stimulate similar feelings online.
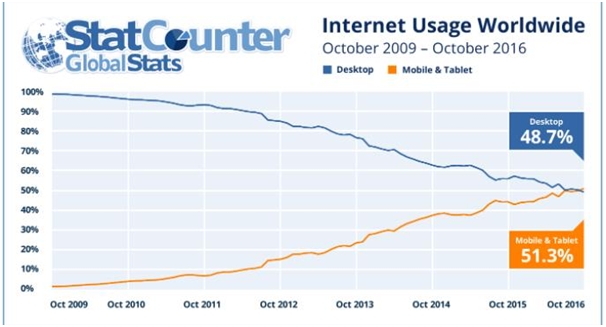
We certainly are a digital society. But we also are part of a mobile era. In 2016, the usage of Mobile Data has surpassed internet usage on desktop for the first time in history. Ever since, the usage of mobile data has been increasing steadfastly.
But what determines such dramatic usage of mobile gadgets? Interactivity. The more the digital media continues to grow, the more the requests and the consumers’ need raise. The consumers want interactive experiences that engage them and make the information come to life on their screens.
Let’s review: the efficient logos identify the brand, but do not explain them. The logo is simply the “touch face” that triggers memories in relation to the brand.
Conclusion
How can we conclude all of these? We are part of an economy that constantly changes and evolves. Without efficient web and mobile platforms, any business is inevitably lost and forgotten. The truth is that establishing a firm presence online is essential for your brand. But an online presence and a successful brand requires a solid foundation, a visual identity/ The first step in setting this identity is the make of an well-designed logo.
We hope all this information opened your eyes towards the importance of a good-looking, powerful logo. We welcome any quality design-related content on our blog. If you are interested in having your work featured here, email us at webdesignledger.blog@gmail.com
CSS scroll snapping allows you to lock the viewport to certain elements or locations after a user has finished scrolling. It’s great for building interactions like this one:
Browser support for CSS scroll snapping has improved significantly since it was introduced in 2016, with Google Chrome (69+), Firefox, Edge, and Safari all supporting some version of it.
This browser support data is from Caniuse, which has more detail. A number indicates that browser supports the feature at that version and up.
Desktop
Chrome
Opera
Firefox
IE
Edge
Safari
69
No
63
11*
18*
11
Mobile / Tablet
iOS Safari
Opera Mobile
Opera Mini
Android
Android Chrome
Android Firefox
11.0-11.2
No
No
No
No
60
Scroll snapping is used by setting the scroll-snap-type property on a container element and the scroll-snap-align property on elements inside it. When the container element is scrolled, it will snap to the child elements you’ve defined. In its most basic form, it looks like this:
This method is pretty limited. Since it only allows evenly-spaced snap points, you can’t really build an interface that snaps to different-sized elements. If elements change their shape across different screen sizes, you’re also bound to run into issues.
At the time of this writing, Firefox, Internet Explorer, and Edge support the older version of the spec, while Chrome (69+) and Safari support the newer, element-based method.
You can use both methods alongside each other (if your layout allows it) to support both groups of browsers:
I’d argue a more flexible option is to use the element-based syntax exclusively and loading a polyfill to support browsers that don’t yet support it. This is the method I’m using in the examples below.
Unfortunately the polyfill doesn’t come with a browser bundle, so it’s a bit tricky to use if you’re not using a build process. The easiest way around this I’ve found is to link to the script on bundle.run and initializing it using cssScrollSnapPolyfill() once the DOM is loaded. It’s also worth pointing out that this polyfill only supports the element-based syntax, not the repeat-method.
Parent container properties
As with any property, it’s a good idea to get familiar with the values they accept. Scroll snap properties are applied to both parent and child elements, with specific values for each. Sort of the same way flexbox and grid do, where the parent becomes a “flex” or “grid” container. In this case, the parent becomes a snap container, if you will.
Here are the properties and values for the parent container and how they work.
scroll-snap-type “mandatory” vs. “proximity”
The mandatory value means the browser has to snap to a snap point whenever the user stops scrolling. The proximity property is less strict—it means the browser may snap to a snap point if it seems appropriate. In my experience this tends to kick in when you stop scrolling within a few hundred pixels of a snap point.
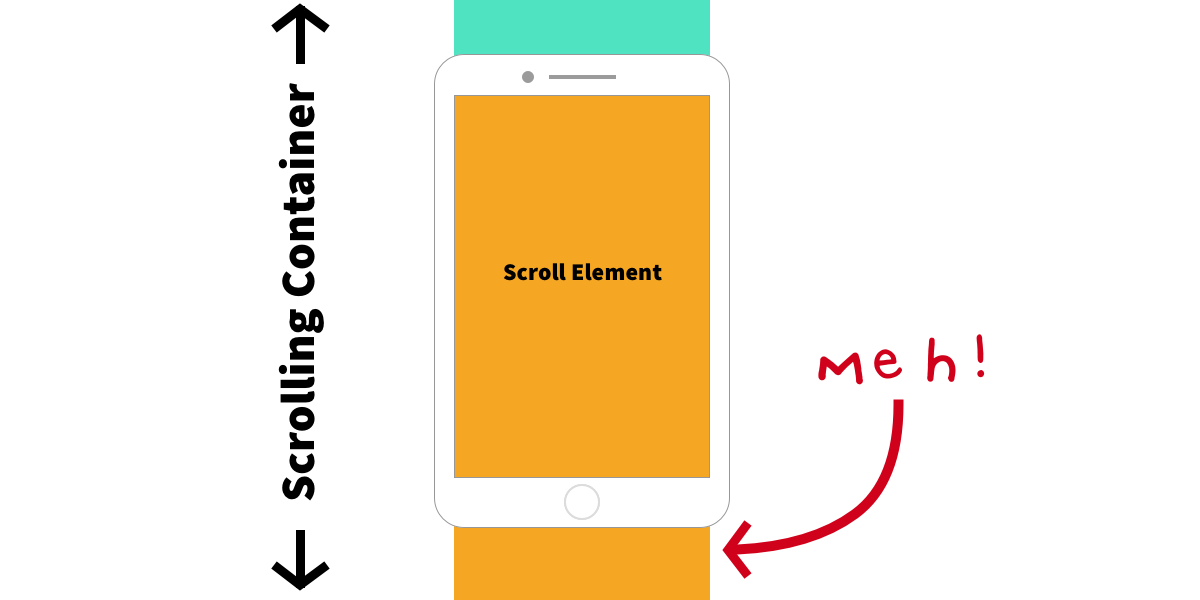
In my own work, I’ve found that mandatory makes for a more consistent user experience, but it can also be dangerous, as the spec points out. Picture a scenario where an element inside a scrolling container is taller than the viewport:
If that container is set to scroll-snap-type: mandatory, it will always snap either to the top of the element or the top of the one below, making the middle part of the tall element impossible to scroll to.
scroll-padding
By default content will snap to the very edges of the container. You can change that by setting the scroll-padding property on the container. It follows the same syntax as the regular padding property.
This can be useful if your layout has elements that could get in the way of the content, like a fixed header.
Properties on the children
Now let’s move on over to the properties for child elements.
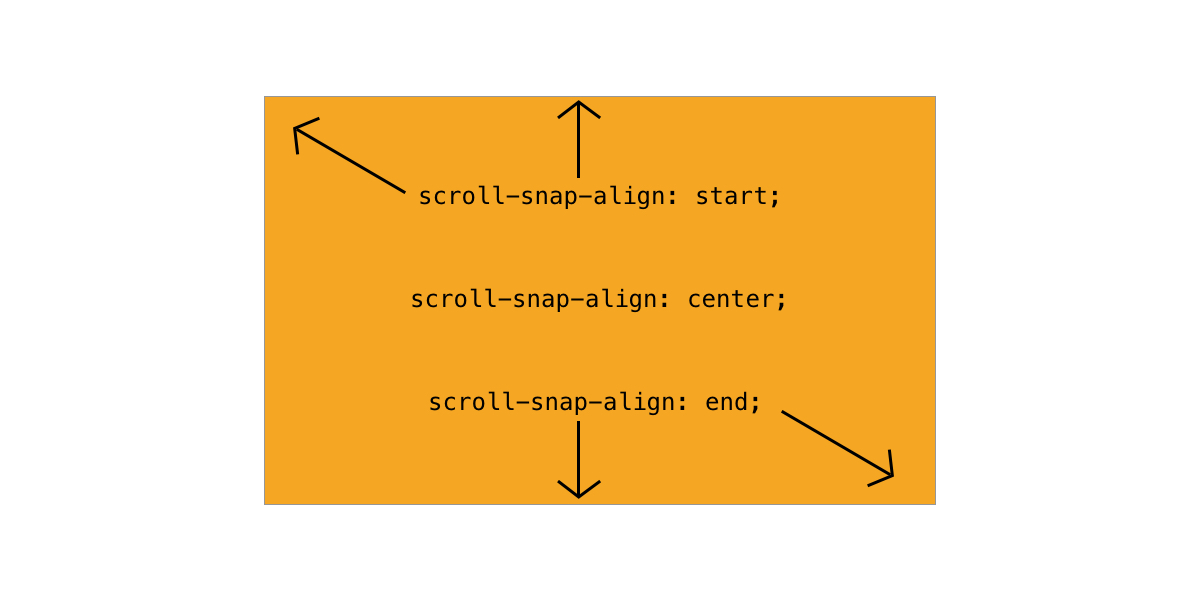
scroll-snap-align
This lets you specify which part of the element is supposed to snap to the container. It has three possible values: start, center, and end.
These are relative to the scroll direction. If you’re scrolling vertically, start refers to the top edge of the element. If you’re scrolling horizontally, it refers to the left edge. center and end follow the same principle. You can set a different values for each scroll direction separated by a space.
scroll-snap-stop “normal” vs. “always”
By default, scroll snapping only kicks in when the user stops scrolling, meaning they can skip over several snap points before coming to a stop.
You can change this by setting scroll-snap-stop: always on any child element. This forces the scroll container to stop on that element before the user can continue to scroll.
At the time of this writing no browser supports scroll-snap-stop natively, though there is a tracking bug for Chrome.
Let’s look at some examples of scroll snap in use.
Example 1: Vertical list
To make a vertical list snap to each list element only takes a few lines of CSS. First, we tell the container to snap along its vertical axis:
.container {
scroll-snap-type: y mandatory;
}
Then, we define the snap points. Here, we’re specifying that the top of each list element is going to be a snap point:
To make a horizontal slider, we tell the container to snap along its x-axis. We’re also using scroll-padding to make sure the child elements snap to the center of the container.
.container {
scroll-snap-type: x mandatory;
scroll-padding: 50%;
}
Then, we tell the container which points to snap to. To center the gallery, we define the center point of each element as a snap point.
Messing with scrolling is risky business. Since it’s such a fundamental part of interacting with the web, changing it in any way can feel jarring—the term scrolljacking used to get thrown around to describe that sort of experience.
The great thing about CSS-based scroll snapping is that you’re not taking direct control over the scroll position. Instead you’re just giving the browser a list of positions to snap in a way that is appropriate to the platform, input method, and user preferences. This means a scrolling interface you build is going to feel just like the native interface (i.e using the same animations, etc.) on whatever platform it’s viewed on.
To me, this is the key advantage of CSS scroll snapping over JavaScript libraries that offer similar functionality.
This works fairly well in my experience, especially on mobile. Maybe this is because scroll snapping is already part of the native UI on mobile platforms. (Picture the home screens on iOS and Android—they’re essentially horizontal sliders with snap points.) The interaction on Chrome on Android is particularly nice because it feels like regular scrolling, but the viewport always happens to come to a stop at a snap point:
There’s definitely some fancy maths going on to make this happen. Thanks to CSS scroll snapping, we’re getting it for free.
Of course, we shouldn’t start throwing snap points onto everything. Things like article pages do just fine without them. But I think they can be a nice enhancement in the right situation—image galleries, slideshows seem like good candidates, but maybe there’s potential beyond that.
Conclusion
If done thoughtfully, scroll snapping can be a useful design tool. CSS snap points allow you to hook into the browser’s native scrolling interaction, so your interface feel seamless and smooth. With a JavaScript API potentially on the horizon, these are going to become even more powerful. Still, a light touch is probably the way to go.
Scroll bouncing (also sometimes referred to as scroll ‘rubber-banding’, or ‘elastic scrolling’) is often used to refer to the effect you see when you scroll to the very top of a page or HTML element, or to the bottom of a page or element, on a device using a touchscreen or a trackpad, and empty space can be seen for a moment before the element or page springs back and aligns itself back to its top/bottom (when you release your touch/fingers). You can see a similar effect happen in CSS scroll-snapping between elements.
However, this article focuses on scroll bouncing when you scroll to the very top or very bottom of a web page. In other words, when the scrollport has reached its scroll boundary.
Collecting Data, The Powerful Way
Did you know that CSS can be used for collecting statistics? Indeed, there’s even a CSS-only approach for tracking UI interactions using Google Analytics. Read article ?
A good understanding of scroll bouncing is very useful as it will help you to decide how you build your websites and how you want the page to scroll.
Scroll bouncing is undesirable if you don’t want to see fixed elements on a page move. Some examples include: when you want a header or footer to be fixed in a certain position, or if you want any other element such as a menu to be fixed, or if you want the page to scroll-snap at certain positions on scroll and you do not want any additional scrolling to occur at the very top or bottom of the page which will confuse visitors to your website. This article will propose some solutions to the problems faced when dealing with scroll bouncing at the very top or bottom of a web page.
My First Encounter With The Effect
I first noticed this effect when I was updating a website that I built a long time ago. You can view the website here. The footer at the bottom of the page was supposed to be fixed in its position at the bottom of the page and not move at all. At the same time, you were supposed to be able to scroll up and down through the main contents of the page. Ideally, it would work like this:
Scroll bouncing in Firefox on macOS. (Large preview)
It currently works this way in Firefox or on any browser on a device without a touchscreen or trackpad. However, at that time, I was using Chrome on a MacBook. I was scrolling to the bottom of the page using a trackpad when I discovered that my website was not working correctly. You can see what happened here:
Oh no! This was not what was supposed to happen! I had set the footer’s position to be at the bottom of the page by setting its CSS position property to have a value of fixed. This is also a good time to revisit what position: fixed; is. According to the CSS 2.1 Specification, when a “box” (in this case, the dark blue footer) is fixed, it is “fixed with respect to the viewport and does not move when scrolled.” What this means is that the footer was not supposed to move when you scroll up and down the page. This was what worried me when I saw what was happening on Chrome.
To make this article more complete, I’ll show you how the page scrolls on both Mobile Edge, Mobile Safari and Desktop Safari below. This is different to what happens in scrolling on Firefox and Chrome. I hope this gives you a better understanding of how the exact same code currently works in different ways. It is currently a challenge to develop scrolling that works in the same way across different web browsers.
Scroll bouncing in Safari on macOS. A similar effect can be seen for Edge and Safari on iOS. (Large preview)
Searching For A Solution
One of my first thoughts was that there would be an easy and a quick way to fix this issue on all browsers. What this means is that I thought that I could find a solution that would take a few lines of CSS code and that no JavaScript would be involved. Therefore, one of the first things I did, was to try to achieve this. The browsers I used for testing included Chrome, Firefox and Safari on macOS and Windows 10, and Edge and Safari on iOS. The versions of these browsers were the latest at the time of writing this article (2018).
HTML And CSS Only Solutions
Absolute And Relative Positioning
One of the first things I tried, was to use absolute and relative positioning to position the footer because I was used to building footers like this. The idea would be to set my web page to 100% height so that the footer is always at the bottom of the page with a fixed height, whilst the content takes up 100% minus the height of the footer and you can scroll through that. Alternatively, you can set a padding-bottom instead of using calc and set the body-container height to 100% so that the contents of the application do not overlap with the footer. The CSS code looked something like this:
This solution works in almost the same way as the original solution (which was just position: fixed;). One advantage of this solution compared to that is that the scroll is not for the entire page, but for just the contents of the page without the footer. The biggest problem with this method is that on Mobile Safari, both the footer and the contents of the application move at the same time. This makes this approach very problematic when scrolling quickly:
Absolute and Relative Positioning.
Another effect that I did not want was difficult to notice at first, and I only realized that it was happening after trying out more solutions. This was that it was slightly slower to scroll through the contents of my application. Because we are setting our scroll container’s height to 100% of itself, this hinders flick/momentum-based scrolling on iOS. If that 100% height is shorter (for example, when a 100% height of 2000px becomes a 100% height of 900px), the momentum-based scrolling gets worse. Flick/momentum-based scrolling happens when you flick on the surface of a touchscreen with your fingers and the page scrolls by itself. In my case, I wanted momentum-based scrolling to occur so that users could scroll quickly, so I stayed away from solutions that set a height of 100%.
Other Attempts
One of the solutions suggested on the web, and that I tried to use on my code, is shown below as an example.
This code works on Chrome and Firefox on macOS the same way as the previous solution. An advantage of this method is that scroll is not restricted to 100% height, so momentum-based scrolling works properly. On Safari, however, the footer disappears:
On iOS Safari, the footer becomes shorter, and there is an extra transparent (or white) gap at the bottom. Also, the ability to scroll through the page is lost after you scroll to the very bottom. You can see the white gap below the footer here:
Shorter Footer on iOS Safari.
One interesting line of code you might see a lot is: -webkit-overflow-scrolling: touch;. The idea behind this is that it allows momentum-based scrolling for a given element. This property is described as “non-standard” and as “not on a standard track” in MDN documentation. It shows up as an “Invalid property value” under inspection in Firefox and Chrome, and it doesn’t appear as a property on Desktop Safari. I didn’t use this CSS property in the end.
To show another example of a solution you may encounter and a different outcome I found, I also tried the code below:
This actually works well across the different desktop browsers, momentum-based scrolling still works, and the footer is fixed at the bottom and does not move on desktop web browsers. Perhaps the most problematic part of this solution (and what makes it unique) is that, on iOS Safari the footer always shakes and distorts very slightly and you can see the content below it whenever you scroll.
Solutions With JavaScript
After trying out some initial solutions using just HTML and CSS, I gave some JavaScript solutions a try. I would like to add that this is something that I do not recommend you to do and would be better to avoid doing. From my experience, there are usually more elegant and concise solutions using just HTML and CSS. However, I had already spent a lot of time trying out the other solutions, I thought that it wouldn’t hurt to quickly see if there were some alternative solutions that used JavaScript.
Touch Events
One approach of solving the issue of scroll bouncing is by preventing the touchmove or touchstart events on the window or document. The idea behind this is that the touch events on the overall window are prevented, whilst the touch events on the content you want to scroll through are allowed. An example of code like this is shown below:
// Prevents window from moving on touch on older browsers.
window.addEventListener('touchmove', function (event) {
event.preventDefault()
}, false)
// Allows content to move on touch.
document.querySelector('.body-container').addEventListener('touchmove', function (event) {
event.stopPropagation()
}, false)
I tried many variations of this code to try to get the scroll to work properly. Preventing touchmove on the window made no difference. Using document made no difference. I also tried to use both touchstart and touchmove to control the scrolling, but these two methods also made no difference. I learned that you can no longer call event.preventDefault() this way for performance reasons. You have to set the passive option to false in the event listener:
// Prevents window from moving on touch on newer browsers.
window.addEventListener('touchmove', function (event) {
event.preventDefault()
}, {passive: false})
Libraries
You may come across a library called “iNoBounce” that was built to “stop your iOS webapp from bouncing around when scrolling.” One thing to note when using this library right now to solve the problem I’ve described in this article is that it needs you to use -webkit-overflow-scrolling. Another thing to note is that the more concise solution I ended up with (which is described later) does a similar thing as it on iOS. You can test this yourself by looking at the examples in its GitHub Repository, and comparing that to the solution I ended up with.
Overscroll Behavior
After trying out all of these solutions, I found out about the CSS property overscroll-behavior. The overscroll-behavior CSS property was implemented in Chrome 63 on December 2017, and in Firefox 59 on March 2018. This property, as described in MDN documentation, “allows you to control the browser’s scroll overflow behavior — what happens when the boundary of a scrolling area is reached.” This was the solution that I ended up using.
All I had to do was set overscroll-behavior to none in the body of my website and I could leave the footer’s position as fixed. Even though momentum-based scrolling applied to the whole page, rather than the contents without the footer, this solution was good enough for me and fulfilled all of my requirements at that point in time, and my footer no longer bounced unexpectedly on Chrome. It is perhaps useful to note that Edge has this property flagged as under development now. overscroll-behavior can be seen as an enhancement if browsers do not support it yet.
Conclusion
If you don’t want your fixed headers or footers to bounce around on your web pages, you can now use the overscroll-behavior CSS property.
Despite the fact that this solution works differently in different browsers (bouncing of the page content still happens on Safari and Edge, whereas on Firefox and Chrome it doesn’t), it will keep the header or footer fixed when you scroll to the very top or bottom of a website. It is a concise solution and on all the browsers tested, momentum-based scrolling still works, so you can scroll through a lot of page content very quickly. If you are building a fixed header or footer on your web page, you can begin to use this solution.