An Extensive Guide To Progressive Web Applications

An Extensive Guide To Progressive Web Applications
Ankita Masand2018-11-27T14:00:29+01:002018-11-27T14:10:54+00:00
It was my dad’s birthday, and I wanted to order a chocolate cake and a shirt for him. I headed over to Google to search for chocolate cakes and clicked on the first link in the search results. There was a blank screen for a few seconds; I didn’t understand what was happening. After a few seconds of staring patiently, my mobile screen filled with delicious-looking cakes. As soon as I clicked on one of them to check its details, I got an ugly fat popup, asking me to install an Android application so that I could get a silky smooth experience while ordering a cake.
That was disappointing. My conscience didn’t allow me to click on the “Install” button. All I wanted to do was order a small cake and be on my way.
I clicked on the cross icon at the very right of the popup to get out of it as soon as I could. But then the installation popup sat at the bottom of the screen, occupying one-fourth of the space. And with the flaky UI, scrolling down was a challenge. I somehow managed to order a Dutch cake.
After this terrible experience, my next challenge was to order a shirt for my dad. As before, I search Google for shirts. I clicked on the first link, and in a blink, the entire content was right in front of me. Scrolling was smooth. No installation banner. I felt as if I was browsing a native application. There was a moment when my terrible internet connection gave up, but I was still able to see the content instead of a dinosaur game. Even with my janky internet, I managed to order a shirt and jeans for my dad. Most surprising of all, I was getting notifications about my order.
I would call this a silky smooth experience. These people were doing something right. Every website should do it for their users. It’s called a progressive web app.
As Alex Russell states in one of his blog posts:
“It happens on the web from time to time that powerful technologies come to exist without the benefit of marketing departments or slick packaging. They linger and grow at the peripheries, becoming old-hat to a tiny group while remaining nearly invisible to everyone else. Until someone names them.”
A Silky Smooth Experience On The Web, Sometimes Known As A Progressive Web Application
Progressive web applications (PWAs) are more of a methodology that involves a combination of technologies to make powerful web applications. With an improved user experience, people will spend more time on websites and see more advertisements. They tend to buy more, and with notification updates, they are more likely to visit often. The Financial Times abandoned its native apps in 2011 and built a web app using the best technologies available at the time. Now, the product has grown into a full-fledged PWA.
But why, after all this time, would you build a web app when a native app does the job well enough?
Let’s look into some of the metrics shared in Google IO 17.
Five billion devices are connected to the web, making the web the biggest platform in the history of computing. On the mobile web, 11.4 million monthly unique visitors go to the top 1000 web properties, and 4 million go to the top thousand apps. The mobile web garners around four times as many users as native applications. But this number drops sharply when it comes to engagement.
A user spends an average of 188.6 minutes in native apps and only 9.3 minutes on the mobile web. Native applications leverage the power of operating systems to send push notifications to give users important updates. They deliver a better user experience and boot more quickly than websites in a browser. Instead of typing a URL in the web browser, users just have to tap an app’s icon on the home screen.
Most visitors on the web are unlikely to come back, so developers came up with the workaround of showing them banners to install native applications, in an attempt to keep them deeply engaged. But then, users would have to go through the tiresome procedure of installing the binary of a native application. Forcing users to install an application is annoying and reduces further the chance that they will install it in the first place. The opportunity for the web is clear.
Recommended reading: Native And PWA: Choices, Not Challengers!
If web applications come with a rich user experience, push notifications, offline support and instant loading, they can conquer the world. This is what a progressive web application does.
A PWA delivers a rich user experience because it has several strengths:
-
Fast
The UI is not flaky. Scrolling is smooth. And the app responds quickly to user interaction. -
Reliable
A normal website forces users to wait, doing nothing, while it is busy making rides to the server. A PWA, meanwhile, loads data instantaneously from the cache. A PWA works seamlessly, even on a 2G connection. Every network request to fetch an asset or piece of data goes through a service worker (more on that later), which first verifies whether the response for a particular request is already in the cache. When users get real content almost instantly, even on a poor connection, they trust the app more and view it as more reliable. -
Engaging
A PWA can earn a place on the user’s home screen. It offers a native app-like experience by providing a full-screen work area. It makes use of push notifications to keep users engaged.
Now that we know what PWAs bring to the table, let’s get into the details of what gives PWAs an edge over native applications. PWAs are built with technologies such as service workers, web app manifests, push notifications and IndexedDB/local data structure for caching. Let’s look into each in detail.
Service Workers
A service worker is a JavaScript file that runs in the background without interfering with the user’s interactions. All GET requests to the server go through a service worker. It acts like a client-side proxy. By intercepting network requests, it takes complete control over the response being sent back to the client. A PWA loads instantly because service workers eliminate the dependency on the network by responding with data from the cache.
A service worker can only intercept a network request that is in its scope. For example, a root-scoped service worker can intercept all of the fetch requests coming from a web page. A service worker operates as an event-driven system. It goes into a dormant state when it is not needed, thereby conserving memory. To use a service worker in a web application, we first have to register it on the page with JavaScript.
(function main () {
/* navigator is a WEB API that allows scripts to register themselves and carry out their activities. */
if ('serviceWorker' in navigator) {
console.log('Service Worker is supported in your browser')
/* register method takes in the path of service worker file and returns a promises, which returns the registration object */
navigator.serviceWorker.register('./service-worker.js').then (registration => {
console.log('Service Worker is registered!')
})
} else {
console.log('Service Worker is not supported in your browser')
}
})()
We first check whether the browser supports service workers. To register a service worker in a web application, we provide its URL as a parameter to the register function, available in navigator.serviceWorker (navigator is a web API that allows scripts to register themselves and carry out their activities). A service worker is registered only once. Registration does not happen on every page load. The browser downloads the service worker file (./service-worker.js) only if there is a byte difference between the existing activated service worker and the newer one or if its URL has changed.
The above service worker will intercept all requests coming from the root (/). To limit the scope of a service worker, we would pass an optional parameter with one of the keys as the scope.
if ('serviceWorker' in navigator) {
/* register method takes in an optional second parameter as an object. To restrict the scope of a service worker, the scope should be provided.
scope: '/books' will intercept requests with '/books' in the url. */
navigator.serviceWorker.register('./service-worker.js', { scope: '/books' }).then(registration => {
console.log('Service Worker for scope /books is registered', registration)
})
}
The service worker above will intercept requests that have /books in the URL. For example, it will not intercept request with /products, but it could very well intercept requests with /books/products.
As mentioned, a service worker operates as an event-driven system. It listens for events (install, activate, fetch, push) and accordingly calls the respective event handler. Some of these events are a part of the life cycle of a service worker, which goes through these events in sequence to get activated.
Installation
Once a service worker has been registered successfully, an installation event is fired. This is a good place to do the initialization work, like setting up the cache or creating object stores in IndexedDB. (IndexedDB will make more sense to you once we get into its details. For now, we can just say that it’s a key-value pair structure.)
self.addEventListener('install', (event) => {
let CACHE_NAME = 'xyz-cache'
let urlsToCache = [
'/',
'/styles/main.css',
'/scripts/bundle.js'
]
event.waitUntil(
/* open method available on caches, takes in the name of cache as the first parameter. It returns a promise that resolves to the instance of cache
All the URLS above can be added to cache using the addAll method. */
caches.open(CACHE_NAME)
.then (cache => cache.addAll(urlsToCache))
)
})
Here, we’re caching some of the files so that the next load is instant. self refers to the service worker instance. event.waitUntil makes the service worker wait until all of the code inside it has finished execution.
Activation
Once a service worker has been installed, it cannot yet listen for fetch requests. Rather, an activate event is fired. If no active service worker is operating on the website in the same scope, then the installed service worker gets activated immediately. However, if a website already has an active service worker, then the activation of a new service worker is delayed until all of the tabs operating on the old service worker are closed. This makes sense because the old service worker might be using the instance of the cache that is now modified in the newer one. So, the activation step is a good place to get rid of old caches.
self.addEventListener('activate', (event) => {
let cacheWhitelist = ['products-v2'] // products-v2 is the name of the new cache
event.waitUntil(
caches.keys().then (cacheNames => {
return Promise.all(
cacheNames.map( cacheName => {
/* Deleting all the caches except the ones that are in cacheWhitelist array */
if (cacheWhitelist.indexOf(cacheName) === -1) {
return caches.delete(cacheName)
}
})
)
})
)
})
In the code above, we’re deleting the old cache. If the name of a cache doesn’t match with the cacheWhitelist, then it is deleted. To skip the waiting phase and immediately activate the service worker, we use skip.waiting().
self.addEventListener('activate', (event) => {
self.skipWaiting()
// The usual stuff
})
Once service worker is activated, it can listen for fetch requests and push events.
Fetch Event Handler
Whenever a web page fires a fetch request for a resource over the network, the fetch event from the service worker gets called. The fetch event handler first looks for the requested resource in the cache. If it is present in the cache, then it returns the response with the cached resource. Otherwise, it initiates a fetch request to the server, and when the server sends back the response with the requested resource, it puts it to the cache for subsequent requests.
/* Fetch event handler for responding to GET requests with the cached assets */
self.addEventListener('fetch', (event) => {
event.respondWith(
caches.open('products-v2')
.then (cache => {
/* Checking if the request is already present in the cache. If it is present, sending it directly to the client */
return cache.match(event.request).then (response => {
if (response) {
console.log('Cache hit! Fetching response from cache', event.request.url)
return response
}
/* If the request is not present in the cache, we fetch it from the server and then put it in cache for subsequent requests. */
fetch(event.request).then (response => {
cache.put(event.request, response.clone())
return response
})
})
})
)
})
event.respondWith lets the service worker send a customized response to the client.
Offline-first is now a thing. For any non-critical request, we must serve the response from the cache, instead of making a ride to the server. If any asset is not present in the cache, we get it from the server and then cache it for subsequent requests.
Service workers only work on HTTPS websites because they have the power to manipulate the response of any fetch request. Someone with malicious intent might tamper the response for a request on an HTTP website. So, hosting a PWA on HTTPS is mandatory. Service workers do not interrupt the normal functioning of the DOM. They cannot communicate directly with the web page. To send any message to a web page, it makes use of post messages.
Web Push Notifications
Let’s suppose you’re busy playing a game on your mobile, and a notification pops up telling you of a 30% discount on your favorite brand. Without any further ado, you click on the notification and shop your breath out. Getting live updates on, say, a cricket or football match or getting important emails and reminders as notifications is a big deal when it comes to engaging users with a product. This feature was only available in native applications until PWA came along. A PWA makes use of web push notifications to compete with this powerful feature that native apps provide out of the box. A user would still receive a web push notification even if the PWA is not open in any of the browser tabs and even if the browser is not open.
A web application has to ask permission of the user to send them push notifications.

Once the user confirms by clicking the “Allow” button, a unique subscription token is generated by the browser. This token is unique for this device. The format of the subscription token generated by Chrome is as follows:
{
"endpoint": "https://fcm.googleapis.com/fcm/send/c7Veb8VpyM0:APA91bGnMFx8GIxf__UVy6vJ-n9i728CUJSR1UHBPAKOCE_SrwgyP2N8jL4MBXf8NxIqW6NCCBg01u8c5fcY0kIZvxpDjSBA75sVz64OocQ-DisAWoW7PpTge3SwvQAx5zl_45aAXuvS",
"expirationTime": null,
"keys": {
"p256dh": "BJsj63kz8RPZe8Lv1uu-6VSzT12RjxtWyWCzfa18RZ0-8sc5j80pmSF1YXAj0HnnrkyIimRgLo8ohhkzNA7lX4w",
"auth": "TJXqKozSJxcWvtQasEUZpQ"
}
}
The endpoint contained in the token above will be unique for every subscription. On an average website, thousands of users would agree to receive push notifications, and for each of them, this endpoint would be unique. So, with the help of this endpoint, the application is able to target these users in the future by sending them push notifications. The expirationTime is the amount of time that the subscription is valid for a particular device. If the expirationTime is 20 days, it means that the push subscription of the user will expire after 20 days and the user won’t be able to receive push notifications on the older subscription. In this case, the browser will generate a new subscription token for that device. The auth and p256dh keys are used for encryption.
Now, to send push notifications to these thousands of users in the future, we first have to save their respective subscription tokens. It’s the job of the application server (the back-end server, maybe a Node.js script) to send push notifications to these users. This might sound as simple as making a POST request to the endpoint URL with the notification data in the request payload. However, it should be noted that if a user is not online when a push notification intended for them is triggered by the server, they should still get that notification once they come back online. The server would have to take care of such scenarios, along with sending thousands of requests to the users. A server keeping track of the user’s connection sounds complicated. So, something in the middle would be responsible for routing web push notifications from the server to the client. This is called a push service, and every browser has its own implementation of a push service. The browser has to tell the following information to the push service in order to send any notification:
- The time to live
This is how long a message should be queued, in case it is not delivered to the user. Once this time has elapsed, the message will be removed from the queue. - Urgency of the message
This is so that the push service preserves the user’s battery by sending only high-priority messages.
The push service routes the messages to the client. Because push has to be received by the client even if its respective web application is not open in the browser, push events have to be listened to by something that continuously monitors in the background. You guessed it: That’s the job of the service worker. The service worker listens for push events and does the job of showing notifications to the user.
So, now we know that the browser, push service, service worker and application server work in harmony to send push notifications to the user. Let’s look into the implementation details.
Web Push Client
Asking permission of the user is a one-time thing. If a user has already granted permission to receive push notifications, we shouldn’t ask again. The permission value is saved in Notification.permission.
/* Notification.permission can have one of these three values: default, granted or denied. */
if (Notification.permission === 'default') {
/* The Notification.requestPermission() method shows a notification permission prompt to the user. It returns a promise that resolves to the value of permission*/
Notification.requestPermission().then (result => {
if (result === 'denied') {
console.log('Permission denied')
return
}
if (result === 'granted') {
console.log('Permission granted')
/* This means the user has clicked the Allow button. We're to get the subscription token generated by the browser and store it in our database.
The subscription token can be fetched using the getSubscription method available on pushManager of the serviceWorkerRegistration object. If subscription is not available, we subscribe using the subscribe method available on pushManager. The subscribe method takes in an object.
*/
serviceWorkerRegistration.pushManager.getSubscription()
.then (subscription => {
if (!subscription) {
const applicationServerKey = ''
serviceWorkerRegistration.pushManager.subscribe({
userVisibleOnly: true, // All push notifications from server should be displayed to the user
applicationServerKey // VAPID Public key
})
} else {
saveSubscriptionInDB(subscription, userId) // A method to save subscription token in the database
}
})
}
})
}
In the subscribe method above, we’re passing userVisibleOnly and applicationServerKey to generate a subscription token. The userVisibleOnly property should always be true because it tells the browser that any push notification sent by the server will be shown to the client. To understand the purpose of applicationServerKey, let’s consider a scenario.
If some person gets ahold of your thousands of subscription tokens, they could very well send notifications to the endpoints contained in these subscriptions. There is no way for the endpoint to be linked to your unique identity. To provide a unique identity to the subscription tokens generated on your web application, we make use of the VAPID protocol. With VAPID, the application server voluntarily identifies itself to the push service while sending push notifications. We generate two keys like so:
const webpush = require('web-push')
const vapidKeys = webpush.generateVAPIDKeys()
web-push is an npm module. vapidKeys will have one public key and one private key. The application server key used above is the public key.
Web Push Server
The job of the web push server (application server) is straightforward. It sends a notification payload to the subscription tokens.
const options = {
TTL: 24*60*60, //TTL is the time to live, the time that the notification will be queued in the push service
vapidDetails: {
subject: 'email@example.com',
publicKey: '',
privateKey: ''
}
}
const data = {
title: 'Update',
body: 'Notification sent by the server'
}
webpush.sendNotification(subscription, data, options)
It uses the sendNotification method from the web push library.
Service Workers
The service worker shows the notification to the user as such:
self.addEventListener('push', (event) => {
let options = {
body: event.data.body,
icon: 'images/example.png',
}
event.waitUntil(
/* The showNotification method is available on the registration object of the service worker.
The first parameter to showNotification method is the title of notification, and the second parameter is an object */
self.registration.showNotification(event.data.title, options)
)
})
Till now, we’ve seen how a service worker makes use of the cache to store requests and makes a PWA fast and reliable, and we’ve seen how web push notifications keep users engaged.
To store a bunch of data on the client side for offline support, we need a giant data structure. Let’s look into the Financial Times PWA. You’ve got to witness the power of this data structure for yourself. Load the URL in your browser, and then switch off your internet connection. Reload the page. Gah! Is it still working? It is. (Like I said, offline is the new black.) Data is not coming from the wires. It is being served from the house. Head over to the “Applications” tab of Chrome Developer Tools. Under “Storage”, you’ll find “IndexedDB”.

Check out the “Articles” object store, and expand any of the items to see the magic for yourself. The Financial Times has stored this data for offline support. This data structure that lets us store a massive amount of data is called IndexedDB. IndexedDB is a JavaScript-based object-oriented database for storing structured data. We can create different object stores in this database for various purposes. For example, as we can see in the image above that “Resources”, “ArticleImages” and “Articles” are called as object stores. Each record in an object store is uniquely identified with a key. IndexedDB can even be used to store files and blobs.
Let’s try to understand IndexedDB by creating a database for storing books.
let openIdbRequest = window.indexedDB.open('booksdb', 1)
If the database booksdb doesn’t already exist, the code above will create a booksdb database. The second parameter to the open method is the version of the database. Specifying a version takes care of the schema-related changes that might happen in future. For example, booksdb now has only one table, but when the application grows, we intend to add two more tables to it. To make sure our database is in sync with the updated schema, we’ll specify a higher version than the previous one.
Calling the open method doesn’t open the database right away. It’s an asynchronous request that returns an IDBOpenDBRequest object. This object has success and error properties; we’ll have to write appropriate handlers for these properties to manage the state of our connection.
let dbInstance
openIdbRequest.onsuccess = (event) => {
dbInstance = event.target.result
console.log('booksdb is opened successfully')
}
openIdbRequest.onerror = (event) => {
console.log('There was an error in opening booksdb database')
}
openIdbRequest.onupgradeneeded = (event) => {
let db = event.target.result
let objectstore = db.createObjectStore('books', { keyPath: 'id' })
}
To manage the creation or modification of object stores (object stores are analogous to SQL-based tables — they have a key-value structure), the onupgradeneeded method is called on the openIdbRequest object. The onupgradeneeded method will be invoked whenever the version changes. In the code snippet above, we’re creating a books object store with unique key as the ID.
Let’s say that, after deploying this piece of code, we have to create one more object store, called as users. So, now the version of our database will be 2.
let openIdbRequest = window.indexedDB.open('booksdb', 2) // New Version - 2
/* Success and error event handlers remain the same.
The onupgradeneeded method gets called when the version of the database changes. */
openIdbRequest.onupgradeneeded = (event) => {
let db = event.target.result
if (!db.objectStoreNames.contains('books')) {
let objectstore = db.createObjectStore('books', { keyPath: 'id' })
}
let oldVersion = event.oldVersion
let newVersion = event.newVersion
/* The users tables should be added for version 2. If the existing version is 1, it will be upgraded to 2, and the users object store will be created. */
if (oldVersion === 1) {
db.createObjectStore('users', { keyPath: 'id' })
}
}
We’ve cached dbInstance in the success event handler of the open request. To retrieve or add data in IndexedDB, we’ll make use of dbInstance. Lets add some book records in our books object store.
let transaction = dbInstance.transaction('books')
let objectstore = dbInstance.objectstore('books')
let bookRecord = {
id: '1',
name: 'The Alchemist',
author: 'Paulo Coelho'
}
let addBookRequest = objectstore.add(bookRecord)
addBookRequest.onsuccess = (event) => {
console.log('Book record added successfully')
}
addBookRequest.onerror = (event) => {
console.log('There was an error in adding book record')
}
We make use of transactions, especially while writing records on object stores. A transaction is simply a wrapper around an operation to ensure data integrity. If any of the actions in a transaction fails, then no action is performed on the database.
Let’s modify a book record with the put method:
let modifyBookRequest = objectstore.put(bookRecord) // put method takes in an object as the parameter
modifyBookRequest.onsuccess = (event) => {
console.log('Book record updated successfully')
}
Let’s retrieve a book record with the get method:
let transaction = dbInstance.transaction('books')
let objectstore = dbInstance.objectstore('books')
/* get method takes in the id of the record */
let getBookRequest = objectstore.get(1)
getBookRequest.onsuccess = (event) => {
/* event.target.result contains the matched record */
console.log('Book record', event.target.result)
}
getBookRequest.onerror = (event) => {
console.log('Error while retrieving the book record.')
}
Adding Icon On Home Screen
Now that there is hardly any distinction between a PWA and a native application, it makes sense to offer a prime position to the PWA. If your website fulfills the basic criteria of a PWA (hosted on HTTPS, integrates with service workers and has a manifest.json) and after the user has spent some time on the web page, the browser will invoke a prompt at the bottom, asking the user to add the app to their home screen, as shown below:
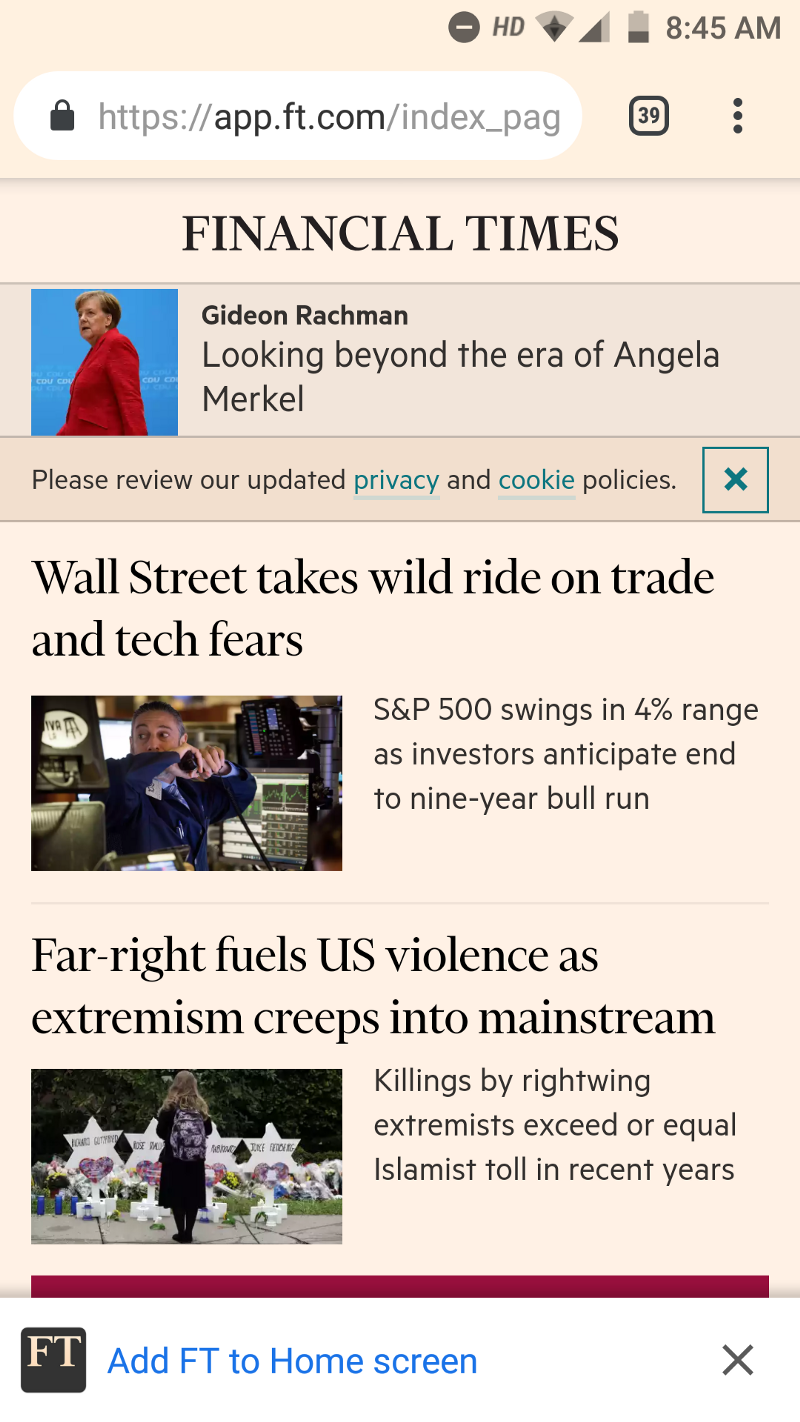
When a user clicks on “Add FT to Home screen”, the PWA gets to set its foot on the home screen, as well as in the app drawer. When a user searches for any application on their phone, any PWAs that match the search query will be listed. They will also be seen in the system settings, which makes it easy for users to manage them. In this sense, a PWA behaves like a native application.
PWAs make use of manifest.json to provide this feature. Let’s look into a simple manifest.json file.
{
"name": "Demo PWA",
"short_name": "Demo",
"start_url": "/?standalone",
"background_color": "#9F0C3F",
"theme_color": "#fff1e0",
"display": "standalone",
"icons": [{
"src": "/lib/img/icons/xxhdpi.png?v2",
"sizes": "192x192"
}]
}
The short_name appears on the user’s home screen and in the system settings. The name appears in the chrome prompt and on the splash screen. The splash screen is what the user sees when the app is getting ready to launch. The start_url is the main screen of your app. It’s what users get when they tap an icon on the home screen. The background_color is used on the splash screen. The theme_color sets the color of the toolbar. The standalone value for display mode says that the app is to be operated in full-screen mode (hiding the browser’s toolbar). When a user installs a PWA, its size is merely in kilobytes, rather than the megabytes of native applications.
Service workers, web push notifications, IndexedDB, and the home screen position make up for offline support, reliability, and engagement. It should be noted that a service worker doesn’t come to life and start doing its work on the very first load. The first load will still be slow until all of the static assets and other resources have been cached. We can implement some strategies to optimize the first load.
Bundling Assets
All of the resources, including the HTML, style sheets, images and JavaScript, are to be fetched from the server. The more files, the more HTTPS requests needed to fetch them. We can use bundlers like WebPack to bundle our static assets, hence reducing the number of HTTP requests to the server. WebPack does a great job of further optimizing the bundle by using techniques such as code-splitting (i.e. bundling only those files that are required for the current page load, instead of bundling all of them together) and tree shaking (i.e. removing duplicate dependencies or dependencies that are imported but not used in the code).
Reducing Round Trips
One of the main reasons for slowness on the web is network latency. The time it takes for a byte to travel from A to B varies with the network connection. For example, a particular round trip over Wi-Fi takes 50 milliseconds and 500 milliseconds on a 3G connection, but 2500 milliseconds on a 2G connection. These requests are sent using the HTTP protocol, which means that while a particular connection is being used for a request, it cannot be used for any other requests until the response of the previous request is served. A website can make six asynchronous HTTP requests at a time because six connections are available to a website to make HTTP requests. An average website makes roughly 100 requests; so, with a maximum of six connections available, a user might end up spending around 833 milliseconds in a single round trip. (The calculation is 833 milliseconds – 100?6 = 1666. We have to divide 1666 by 2 because we’re calculating the time spend on a round trip.) With HTTP2 in place, the turnaround time is drastically reduced. HTTP2 doesn’t block the connection head, so multiple requests can be sent simultaneously.
Most HTTP responses contain last-modified and etag headers. The last-modified header is the date when the file was last modified, and an etag is a unique value based on the contents of the file. It will only be changed when the contents of a file are changed. Both of these headers can be used to avoid downloading the file again if a cached version is already locally available. If the browser has a version of this file locally available, it can add any of these two headers in the request as such:

The server can check whether the contents of the file have changed. If the contents of the file have not changed, then it responds with a status code of 304 (not modified).

This indicates to the browser to use the locally available cached version of the file. By doing all of this, we’ve prevented the file from being downloaded.
Faster responses are in now place, but our job is not done yet. We still have to parse the HTML, load the style sheets and make the web page interactive. It makes sense to show some empty boxes with a loader to the user, instead of a blank screen. While the HTML document is getting parsed, when it comes across , it will make a synchronous HTTP request to the server to fetch asset.js, and the whole parsing process will be paused until the response comes back. Imagine having a dozen of synchronous static asset references. These could very well be managed just by making use of the async keyword in script references, like . With the introduction of the async keyword here, the browser will make an asynchronous request to fetch asset.js without hindering the parsing of the HTML. If a script file is required at a later stage, we can defer the downloading of that file until the entire HTML has been parsed. A script file can be deferred by using the defer keyword, like .
Conclusion
We’ve learned a lot of many new things that make for a cool web application. Here’s a summary of all of the things we’ve explored in this article:
- Service workers make good use of the cache to speed up the loading of assets.
- Web push notifications work under the hood.
- We use IndexedDB to store a massive amount of data.
- Some of the optimizations for instant first load, like using HTTP2 and adding headers like
Etag,last-modifiedandIf-None-Match, prevent the downloading of valid cached assets.
That’s all, folks!
