There’s an interesting distinction that Jeremy Keith defines between prototype code and production code in this post and I’ve been thinking about it all week:
…every so often, we use the materials of front-end development—HTML, CSS, and JavaScript—to produce something that isn’t intended for production. I’m talking about prototyping.
What’s interesting is that—when it comes to prototyping—our usual front-end priorities can and should go out the window. The priority now is speed. If that means sacrificing semantics or performance, then so be it. If I’m building a prototype and I find myself thinking “now, what’s the right class name for this component?”, then I know I’m in the wrong mindset. That question might be valid for production code, but it’s a waste of time for prototypes.
I love the way that Jeremy phrases all of this and how he describes that these two environments require entirely separate mindsets. When prototyping, for instance, we can probably overlook optimizing for accessibility or performance and even let our CSS standards slip in order to get something in the browser and test it as quickly as possible.
Earlier this year, I echoed some of the same thoughts when I wrote a little bit about prototyping in the browser:
I reckon that the first time a designer and/or front-end developer writes code, it should never be in a production environment. Having the leeway and freedom to go crazy with the code in a safe environment focuses your attention on the design and making it compatible with a browser’s constraints. After this, you can think about grooming the code from a hot, steaming heap of garbage into lovely, squeaky-clean, production-ready poetry. Translating the static mockups into an interactive prototype is the first step, but it’s vital to have a next step to enforce your code standards.
I came across this amazing Dribbble shot by Jakub Reis a while back. It caught my eye and I knew that I just had to try recreating it in code. At that moment, I didn’t know how. I tried out a bunch of different things, and about a year later, I finally managed to make this demo.
I learned a couple of things along the way, so let me take you on a little journey of what I did to make this because you may learn a thing or two as well.
And other small animations with some minor CSS transitions
I know, it looks a lot — but we can do this!
Step 2: Take the original demo apart frame-by-frame
I needed to extract as much info as I could out of the original GIF to have a good understanding of the animation, so I split it up into single frames. There actually are a lot of services that can do this for us. I used one at ezgif.com but it could have just as easily been something else. Either way, this enables us to get details such as the colors, sizes, and proportions of all the different elements we need to create.
Oh, and we still need to turn the fingerprint into an SVG. Again, there are plenty of apps that will help us here. I used Adobe Illustrator to trace the fingerprint with the pen tool to get this set of paths:
We’ll go through the same process with the line chart that appears towards the end of the animation, so might as well keep that vector editor open. ?
Step 3: Implement the animations
I’ll explain how the animations work in the final pen, but you can also find some of the unsuccessful approaches I took along the way in the end of the article.
I’ll focus on the important parts here and you can refer to the demos for the full code.
Filling the fingerprint
Let’s create the HTML structure of the phone screen and the fingerprint.
<div class="demo">
<div class="demo__screen demo__screen--clickable">
<svg class="demo__fprint" viewBox="0 0 180 320">
<!-- removes-forwards and removes-backwards classes will be helpful later on -->
<path class="demo__fprint-path demo__fprint-path--removes-backwards demo__fprint-path--pinkish" d="M46.1,214.3c0,0-4.7-15.6,4.1-33.3"/>
<path class="demo__fprint-path demo__fprint-path--removes-backwards demo__fprint-path--purplish" d="M53.5,176.8c0,0,18.2-30.3,57.5-13.7"/>
<path class="demo__fprint-path demo__fprint-path--removes-forwards demo__fprint-path--pinkish" d="M115.8,166.5c0,0,19.1,8.7,19.6,38.4"/>
<!-- ... and about 20 more paths like this -->
</svg>
The styles are quite simple so far. Note that I am using Sass throughout the demo — I find that it helps keep the work clean and helps with some of the heavier lifting we need to do.
// I use a $scale variable to quickly change the scaling of the whole pen, so I can focus on the animation and decide on the size later on.
$scale: 1.65;
$purplish-color: #8742cc;
$pinkish-color: #a94a8c;
$bg-color: #372546;
// The main container
.demo {
background: linear-gradient(45deg, lighten($pinkish-color, 10%), lighten($purplish-color, 10%));
min-height: 100vh;
display: flex;
justify-content: center;
align-items: center;
font-size: 0;
user-select: none;
overflow: hidden;
position: relative;
// The screen that holds the login component
&__screen {
position: relative;
background-color: $bg-color;
overflow: hidden;
flex-shrink: 0;
&--clickable {
cursor: pointer;
-webkit-tap-highlight-color: transparent;
}
}
// Styles the fingerprint SVG paths
&__fprint-path {
stroke-width: 2.5px;
stroke-linecap: round;
fill: none;
stroke: white;
visibility: hidden;
transition: opacity 0.5s ease;
&--pinkish {
stroke: $pinkish-color;
}
&--purplish {
stroke: $purplish-color;
}
}
// Sizes positions the fingerprint SVG
&__fprint {
width: 180px * $scale;
height: 320px * $scale;
position: relative;
top: 20px * $scale;
overflow: visible;
// This is going to serve as background to show "unfilled" paths. we're gonna remove it at the moment where the filling animation is over
background-image: url('https://kiyutink.github.io/svg/fprintBackground.svg');
background-size: cover;
&--no-bg {
background-image: none;
}
}
}
The general idea is this: Create an instance of this class for each path that we have in the fingerprint, and modify them in every frame. The paths will start with an offset ratio of -1 (fully invisible) and then will increase the offset ratio (which we’ll refer to as “offset” from here on) by a constant value each frame until they get to 0 (fully visible). The filling animation will be over at this point.
If you’ve never animated anything with this frame-by-frame approach, here’s a very simple demo to help understand how this works:
We should also handle the case where the user stops tapping or pressing the mouse button. In this case, we will animate in the opposite direction (subtracting a constant value from the offset each frame until it gets to -1 again).
Let’s create the function that calculates the offset increment for every frame — this’ll be useful later on.
function getPropertyIncrement(startValue, endValue, transitionDuration) {
// We animate at 60 fps
const TICK_TIME = 1000 / 60;
const ticksToComplete = transitionDuration / TICK_TIME;
return (endValue - startValue) / ticksToComplete;
}
Now it’s time to animate! We will keep the fingerprint paths in a single array:
let fprintPaths = [];
// We create an instance of Path for every existing path.
// We don't want the paths to be visible at first and then
// disappear after the JavaScript runs, so we set them to
// be invisible in CSS. That way we can offset them first
// and then make them visible.
for (let i = 0; i < $(fprintPathSelector).length; i++) {
fprintPaths.push(new Path(fprintPathSelector, i));
fprintPaths[i].offset(-1).makeVisible();
}
We will go through that array for each frame in the animation, animating the paths one by one:
let fprintTick = getPropertyIncrement(0, 1, TIME_TO_FILL_FPRINT);
function fprintFrame(timestamp) {
// We don't want to paint if less than 1000 / 65 ms elapsed
// since the last frame (because there are faster screens
// out there and we want the animation to look the same on
// all devices). We use 65 instead of 60 because, even on
// 60 Hz screens, `requestAnimationFrame` can sometimes be called
// a little sooner, which can result in a skipped frame.
if (timestamp - lastRafCallTimestamp >= 1000 / 65) {
lastRafCallTimestamp = timestamp;
curFprintPathsOffset += fprintTick * fprintProgressionDirection;
offsetAllFprintPaths(curFprintPathsOffset);
}
// Schedule the next frame if the animation isn't over
if (curFprintPathsOffset >= -1 && curFprintPathsOffset <= 0) {
isFprintAnimationInProgress = true;
window.requestAnimationFrame(fprintFrame);
}
// The animation is over. We can schedule next animation steps
else if (curFprintPathsOffset > 0) {
curFprintPathsOffset = 0;
offsetAllFprintPaths(curFprintPathsOffset);
isFprintAnimationInProgress = false;
isFprintAnimationOver = true;
// Remove the background with grey paths
$fprint.addClass('demo__fprint--no-bg');
// Schedule the next animation step - transforming one of the paths into a string
// (this function is not implemented at this step yet, but we'll do that soon)
startElasticAnimation();
// Schedule the fingerprint removal (removeFprint function will be implemented in the next section)
window.requestAnimationFrame(removeFprint);
}
// The fingerprint is back to the original state (the user has stopped holding the mouse down)
else if (curFprintPathsOffset < -1) {
curFprintPathsOffset = -1;
offsetAllFprintPaths(curFprintPathsOffset);
isFprintAnimationInProgress = false;
}
}
And we’ll attach some event listeners to the demo:
$screen.on('mousedown touchstart', function() {
fprintProgressionDirection = 1;
// If the animation is already in progress,
// we don't schedule the next frame since it's
// already scheduled in the `fprintFrame`. Also,
// we obviously don't schedule it if the animation
// is already over. That's why we have two separate
// flags for these conditions.
if (!isFprintAnimationInProgress && !isFprintAnimationOver)
window.requestAnimationFrame(fprintFrame);
})
// On `mouseup` / `touchend` we flip the animation direction
$(document).on('mouseup touchend', function() {
fprintProgressionDirection = -1;
if (!isFprintAnimationInProgress && !isFprintAnimationOver)
window.requestAnimationFrame(fprintFrame);
})
…and now we should be done with the first step! Here’s how our work looks at this step:
This part is pretty similar to the first one, only now we have to account for the fact that some of the paths remove in one direction and the rest of them in the other. That’s why we added the --removes-forwards modifier earlier.
First, we’ll have two additional arrays: one for the paths that are removed forwards and another one for the ones that are removed backwards:
const fprintPathsFirstHalf = [];
const fprintPathsSecondHalf = [];
for (let i = 0; i < $(fprintPathSelector).length; i++) {
// ...
if (fprintPaths[i].removesForwards)
fprintPathsSecondHalf.push(fprintPaths[i]);
else
fprintPathsFirstHalf.push(fprintPaths[i]);
}
…and we’ll write a function that offsets them in the right direction:
function offsetFprintPathsByHalves(ratio) {
fprintPathsFirstHalf.forEach(path => path.offset(ratio));
fprintPathsSecondHalf.forEach(path => path.offset(-ratio));
}
We’re also going to need a function that draws the frames:
function removeFprintFrame(timestamp) {
// Drop the frame if we're faster than 65 fps
if (timestamp - lastRafCallTimestamp >= 1000 / 65) {
curFprintPathsOffset += fprintTick * fprintProgressionDirection;
offsetFprintPathsByHalves(curFprintPathsOffset);
lastRafCallTimestamp = timestamp;
}
// Schedule the next frame if the animation isn't over
if (curFprintPathsOffset >= -1)
window.requestAnimationFrame(removeFprintFrame);
else {
// Due to the floating point errors, the final offset might be
// slightly less than -1, so if it exceeds that, we'll just
// assign -1 to it and animate one more frame
curFprintPathsOffset = -1;
offsetAllFprintPaths(curFprintPathsOffset);
}
}
function removeFprint() {
fprintProgressionDirection = -1;
window.requestAnimationFrame(removeFprintFrame);
}
Now all that’s left is to call removeFprint when we’re done filling the fingerprint:
function fprintFrame(timestamp) {
// ...
else if (curFprintPathsOffset > 0) {
// ...
window.requestAnimationFrame(removeFprint);
}
// ...
}
You can see that, as the fingerprint is almost removed, some of its paths are longer than they were in the beginning. I moved them into separate paths that start animating at the right moment. I could incorporate them into the existing paths, but it would be much harder and at 60fps would make next-to-no difference.
Let’s create them:
<path class="demo__ending-path demo__ending-path--pinkish" d="M48.4,220c-5.8,4.2-6.9,11.5-7.6,18.1c-0.8,6.7-0.9,14.9-9.9,12.4c-9.1-2.5-14.7-5.4-19.9-13.4c-3.4-5.2-0.4-12.3,2.3-17.2c3.2-5.9,6.8-13,14.5-11.6c3.5,0.6,7.7,3.4,4.5,7.1"/>
<!-- and 5 more paths like this -->
For this, I used some simple straightforward CSS animations. I chose the timing functions to emulate the gravity. You can play around with the timing functions here or here.
Let’s create a div:
<div class="demo__bullet"></div>
…and apply some styles to it:
&__bullet {
position: absolute;
width: 4px * $scale;
height: 4px * $scale;
background-color: white;
border-radius: 50%;
top: 210px * $scale;
left: 88px * $scale;
opacity: 0;
transition: all 0.7s cubic-bezier(0.455, 0.030, 0.515, 0.955);
will-change: transform, opacity;
// This will be applied after the bullet has descended, to create a transparent "aura" around it
&--with-aura {
box-shadow: 0 0 0 3px * $scale rgba(255, 255, 255, 0.3);
}
// This will be applied to make the bullet go up
&--elevated {
transform: translate3d(0, -250px * $scale, 0);
opacity: 1;
}
// This will be applied to make the bullet go down
&--descended {
transform: translate3d(0, 30px * $scale, 0);
opacity: 1;
transition: all 0.6s cubic-bezier(0.285, 0.210, 0.605, 0.910);
}
}
Then we tie it together by adding and removing classes based on a user’s interactions:
This is a fun animation. First, we’ll create a couple of new divs that contain the particles that explode:
<div class="demo__logo-particles">
<div class="demo__logo-particle"></div>
<!-- and several more of these -->
</div>
<div class="demo__money-particles">
<div class="demo__money-particle"></div>
<!-- and several more of these -->
</div>
The two explosions are practically the same with the exception of a few parameters. That’s where SCSS mixins will come in handy. We can write the function once and use it on our divs.
@mixin particlesContainer($top) {
position: absolute;
width: 2px * $scale;
height: 2px * $scale;
left: 89px * $scale;
top: $top * $scale;
// We'll hide the whole container to not show the particles initially
opacity: 0;
&--visible {
opacity: 1;
}
}
// The $sweep parameter shows how far from the center (horizontally) the initial positions of the particles can be
@mixin particle($sweep, $time) {
width: 1.5px * $scale;
height: 1.5px * $scale;
border-radius: 50%;
background-color: white;
opacity: 1;
transition: all $time ease;
position: absolute;
will-change: transform;
// Phones can't handle the particles very well :(
@media (max-width: 400px) {
display: none;
}
@for $i from 1 through 30 {
&:nth-child(#{$i}) {
left: (random($sweep) - $sweep / 2) * $scale + px;
@if random(100) > 50 {
background-color: $purplish-color;
}
@else {
background-color: $pinkish-color;
}
}
&--exploded:nth-child(#{$i}) {
transform: translate3d((random(110) - 55) * $scale + px, random(35) * $scale + px, 0);
opacity: 0;
}
}
}
Note the comment in the code that the particles don’t perform particularly well on less powerful devices such as phones. Perhaps there’s another approach here that would solve this if anyone has ideas and wants to chime in.
Alright, let’s put the mixins to use on the elements:
Every digit will have a few random numbers that we’ll scroll through:
<div class="demo__money">
<div class="demo__money-currency">$</div>
<!-- every digit will be a div like this one -->
<div class="demo__money-digit">
1
2
3
4
5
6
7
8
1
</div>
// ...
</div>
We will put different transition times on all of the digits so that the animations are staggered. We can use a SCSS loop for that:
&__money-digit {
// ...
// we start from 2 because the first child is the currency sign :)
@for $i from 2 through 6 {
&:nth-child(#{$i}) {
transition: transform 0.1s * $i + 0.2s ease;
transition-delay: 0.3s;
transform: translate3d(0, -26px * $scale * 8, 0);
}
&--visible:nth-child(#{$i}) {
transform: none;
}
}
}
All that’s left is to add the CSS classes at the right time:
The rest of the animations are fairly simple and involve light CSS transitions, so I won’t get into them to keep things brief. You can see all of the final code in the completed demo.
In my early attempts I tried using CSS transitions for all of the animation work. I found it virtually impossible to control the progress and direction of the animation, so shortly I abandoned that idea and waited a month or so before starting again. In reality, if I knew back then that the Web Animations API was a thing, I would have tried to make use of it.
I tried making the explosion with Canvas for better performance (using this article as a reference), but I found it difficult to control the frame rate with two separate requestAnimationFrame chains. If you know how to do that, then maybe you can tell me in the comments (or write an article for CSS-Tricks ?).
After I got a first working prototype, I was really unhappy with its performance. I was hitting around 40-50fps on a PC, not to mention phones at all. I spent a lot of time optimizing the code and this article was a lot of help.
You can see that the graph has a gradient. I did that by declaring a gradient directly in the SVG defs block:
The whole process from start to finish — discovering the Dribbble shot and finishing the work — took me about a year. I was taking month-long breaks here and there either because I didn’t know how to approach a particular aspect or I simply didn’t have enough free time to work on it. The entire process was a really valuable experience and I learned a lot of new things along the way.
That being said, the biggest lesson to take away from this is that there’s no need to shy away from taking on an ambitious task, or feel discouraged if you don’t know how to approach it at first. The web is a big place and there is plenty of space to figure things out as you go along.
The least important skills for a front-end developer to have are technical ones.
The nuances of JavaScript. How to use a particular library, framework, or build tool. How the cascade in CSS works. Semantic HTML. Fizz-buzz.
Chris takes that a little farther than I would. I do think that with an understanding of HTML, CSS, and JavaScript, the deeper the better, and that it is an ingredient in making a good front-end developer. But I also agree it’s much more than that. In fact, with solid foundational skills and really good soft skills (e.g. you’re great at facilitating a brainstorming meeting), you could and should get a job before they even look at your language skills.
(This is a sponsored post.) In today’s highly competitive market, it’s vital to move fast. After all, we all know how the famous saying goes: “Time is money.” The faster your product team moves when creating a product, the higher the chance it’ll succeed in the market. If you are a project manager, you need a tool that helps you get the most out of each of your team member’s time.
Though creative teams typically work on new and innovative products, many still use legacy tools to manage their work. Spreadsheets are one of the most common tools in the project manager’s toolbox. While this might be adequate for a team of two or three members, as a team grows, managing the team’s time becomes a demanding job.
Whenever project managers try to manage their team using spreadsheets alone, they usually face the following problems:
1. Lack Of Glanceability
Understanding what’s really happening on a project takes a lot of work. It’s hard to visually grasp who’s busy and who’s not. As a result, some team members might end up overloaded, while others will have too little to do. You also won’t get a clear breakdown of how much time is being devoted to particular work and particular clients, which is crucial not just for billing purposes but also to inform your agency’s future decisions, like who to hire next.
2. Hard To Report To Stakeholders
With spreadsheets as the home of project management, translating data about people and time into tangible insights is a challenge. Data visualization is also virtually impossible with the limited range of chart-building functions that spreadsheet tools provide. As a result, reporting with spreadsheets becomes a time-consuming task. The more people and activities a project has, the more of a project manager’s time will be consumed by reporting.
3. Spreadsheets Manage Tasks, Not People
Managing projects with individual spreadsheets is a disaster waiting to happen. Though a single spreadsheet may give a clear breakdown of a single project, it has no way of indicating overload and underload for particular team members across all projects.
4. Lack Of High-Level Overview Of A Project
It’s well known in the industry that many designers suffer from tunnel vision: Without the big picture of a project in mind, their focus turns to solving ongoing tasks. But the problem of tunnel vision isn’t limited to designers; it also exists in project management.
When a project manager uses a tool like a spreadsheet, it is usually hard (or even impossible) to create a high-level overview of a project. Even when the project manager invests a lot of time in creating this overview, the picture becomes outdated as soon as the company’s direction shifts.
5. The Risk Of Outdated Information
Product development moves quickly, making it a struggle for project managers to continually monitor and introduce all required changes into the spreadsheet. Not only is this time-consuming, but it’s also not much fun — and, as a result, often doesn’t get done.
How Technology Makes Our Life Better: Introducing Float
The purpose of technology has always been to reduce mechanical work in order to focus on innovation. In a creative or product agency, the ultimate goal is to automate as much of the product design and human management process as possible, so that the team can focus on the deep work of creativity and execution.
With this in mind, let’s explore Float, a resource management app for creative agencies. Float makes it easier to understand who’s working on what, becoming a single source of truth for your entire team.
Helping Product Managers Overcome The Challenges Of Time And People Management
Float facilitates team collaboration and makes work more effective. Here’s how:
1. Visual Team Planner: See Team And Tasks At A Glance
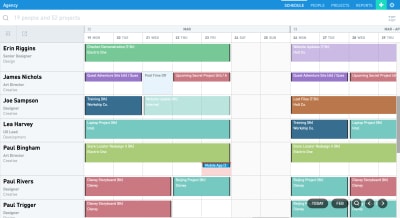
Float allows you to plan tasks visually using the “Schedule” tab. In this view, you can allocate and update project assignments. A drag-and-drop interface makes scheduling your team simple.
Here’s an example of the Schedule View:
The schedule is not only a bird’s-eye view of who’s working on what and when, but also a dynamic canvas. Click on any empty space to create a task. Each task can be easily modified, extended or split. (Large preview)
But that’s not all. You can do more:
Prioritize tasks
You can do this by simply moving them on top of others.
Duplicate tasks
Simply press “Shift” and drag a selected task to a new location.
Extend a task
If someone on your team needs extra time to finish a task, you can extend the time in one click using the visual interface.
Split a task
When it becomes evident that someone on your team needs help with a task, it’s easy to split the task into parts and assign each part to another member.
2. Built-In Reporting And Statistics
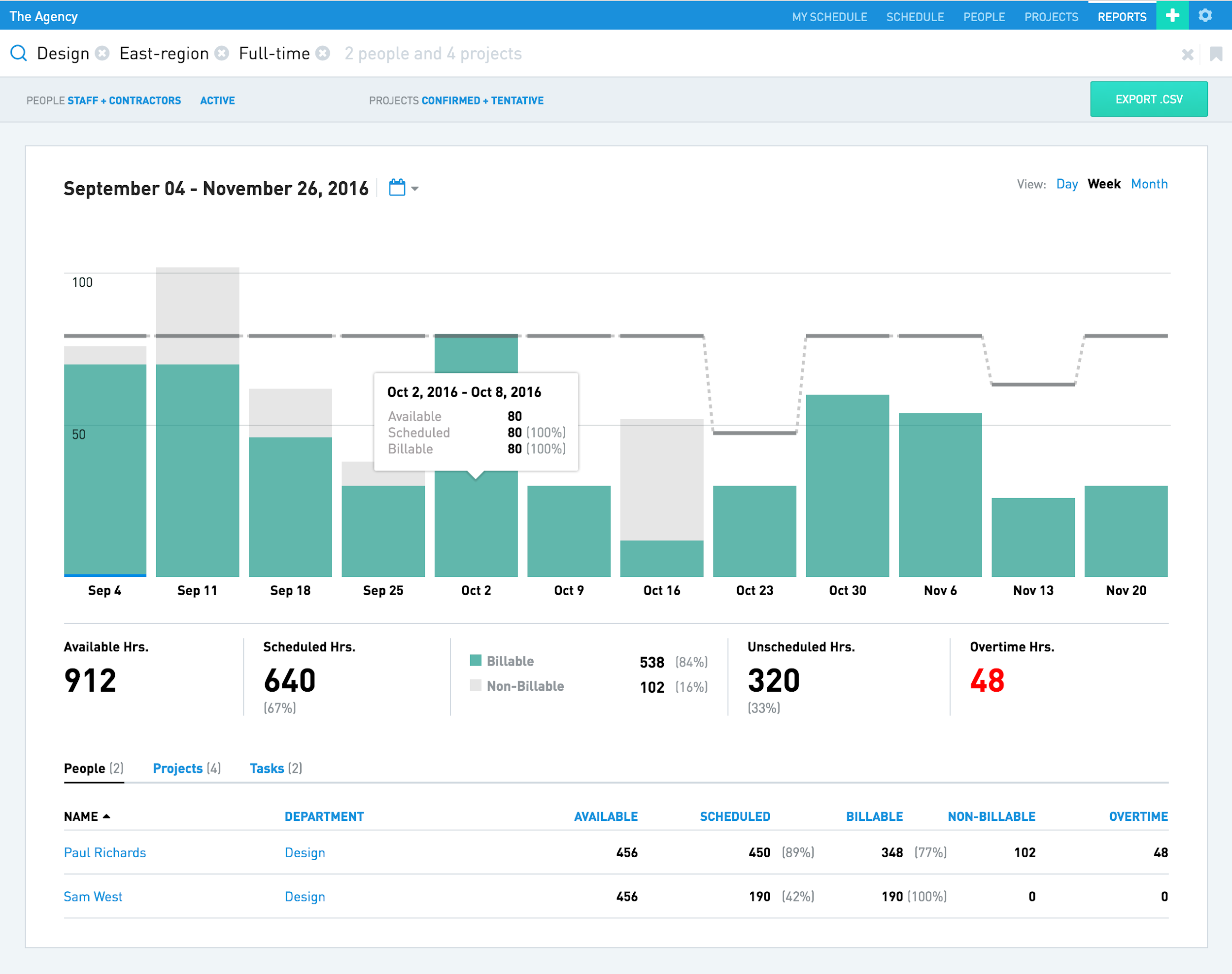
Float’s built-in reporting and statistics feature (“utilization” reports) can save project managers hours of manual work at the end of the week, month or quarter.
Float helps you keep track of all of a project’s hours. (Large preview)
It’s relatively easy to customize the format of the report. You can:
Choose the roles of team members (employees, contractors, all) in “People”;
Choose the type of tasks (tentative, confirmed, completed) in “Task”.
It’s vital to mention that Float allows you to define different roles for team members. For example, if someone works part-time, you can define this in the “Profile” settings and specify that their work is part-time only. This feature also comes handy when you need to calculate a budget.
You can email team members their individual hours for the week.
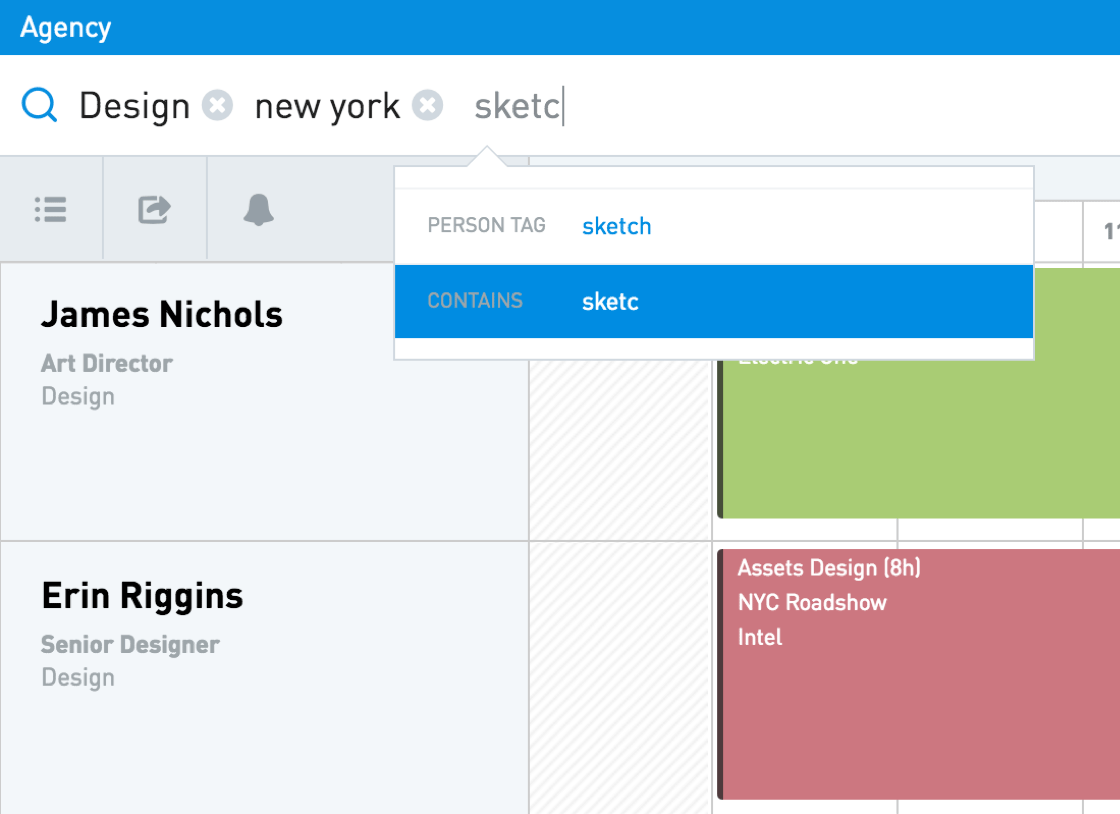
3. Search And Filter: All The Information You Need, At Your Fingertips
All of your team’s information sits in one place. You don’t need to use different spreadsheets for different projects; to add a new project, simply click on “Projects” and add a new object.
You can also use the filtering tools to highlight specific projects. A simple way to see relevant tasks at a glance is to filter by tags, leaving only particular types of projects (for example, projects that have contractors).
4. Getting A High-Level Overview Of All Your Projects
With Float, you’ll always have a record of what happened and when.
– Set milestones in a project’s settings, and keep an eye on upcoming milestones in your Activity Feed.
With Float, you can set milestones for your project. (Large preview)
Drill down into a user or a team and review their schedule. When you see that someone is overscheduled (red will tell you that), you can move other team members to that activity and regroup them.
Float helps you keep track of all of a project’s hours. (Large preview)
You can view by day, week or month, making it easy to zoom out and see a big picture of your project.
Zoom in for a detailed day view, or zoom out to view a monthly forecast. (Large preview)
5. Reducing The Risk Of Outdated Information
You don’t need to switch between multiple tools to find out everything you need to know. This means your information will be up to date (it’s much easier to manage your project using a single tool, rather than many).
Float can be easily connected to all the services you use.
“Schedule”, “People” and “Projects Tools” work together to create context. (Large preview)
Conclusion
If your team’s project management leaves a lot to be desired, Float is a no-brainer. Float makes it easy to see everything you need to know about your team’s projects in a single place, giving project managers the information and functionality they need to handle the fast-paced world of digital design and development. Get started with Float today!
SEO is a complex matter and one that web designers and developers might feel is best left to copywriters and search professionals to handle. That makes sense since many common SEO hacks revolve around the manipulation of content and the tagging of it for search.
Here’s the thing though: there are certain choices you make as a web designer that ultimately affect the search-friendliness of your website. Which means you should be involved in the diagnosis and repair of a website’s SEO mistakes.
Repairing SEO Mistakes with Web Design
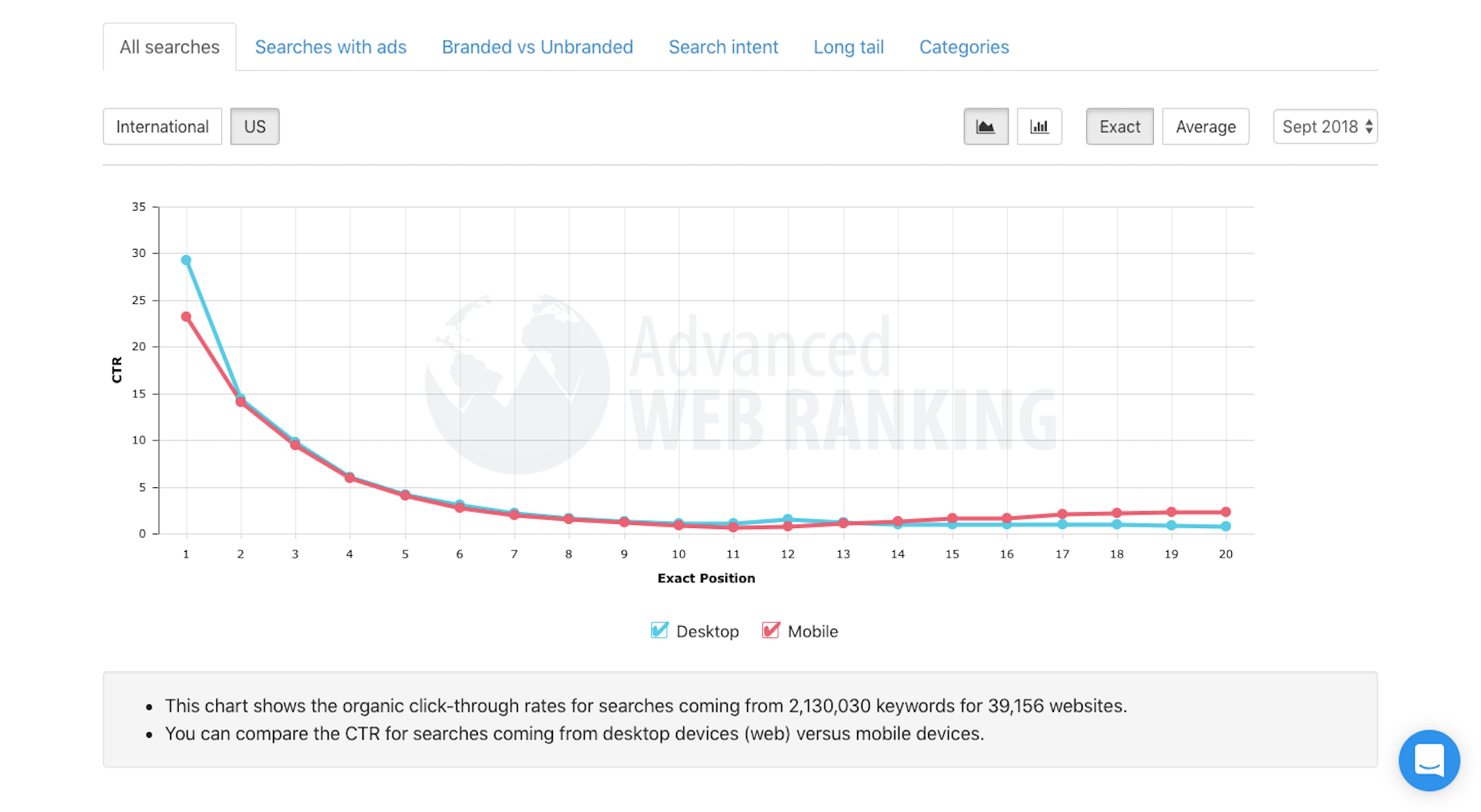
A click-through rate (CTR) tracking study from Advanced Web Ranking reported the following data, from as recent as September 2018:
What this shows is the likelihood of users clicking on an organic link based on its position in search
As you can see, Google is already stacking the odds against your website by filling its prime real estate with paid listings. That said, the data above is proof that search users are willing to sift through paid promotions to get to the genuinely good website recommendations. The only thing is…
How do you repair a website’s SEO mistakes so it can get to the top of search?
Mistake #1: Non-Responsive Elements
We’re operating in a mobile-first world which means websites have to be designed primarily for that experience. That doesn’t mean leaving desktop users out in the cold, but it does mean dotting your i’s and crossing your t’s to ensure that every element fits within the truncated space of a mobile screen.
Open your mobile device and walk through every page of your website. Does everything fit between the two edges of your phone? Are the buttons correctly sized and placed? Are images displayed in full and without distortion?
If not, then start here.
Mistake #2: Usability Issues
If we’re talking about usability issues that are severe enough to cause a high percentage of bounces—which communicates to Google that your website isn’t worth ranking—start by looking at the navigation.
As you can see, the navigation is clearly laid out in a horizontal row. Labels are clear and all pages are present—there’s nothing confusing or hidden. In addition, the header provides users with other information they’d instantly want from a website of this nature.
Since users’ eyes tend to track in a Z-pattern (starting in the top-left and working their way across), your navigation is the first thing visitors see and realistically might be to blame for a lackluster performance in search.
Mistake #3: Low Readability
Although visual content enhances comprehension as well as memorability of what’s on a web page, your visitors eventually need to read the words on it. When that becomes a struggle, websites suffer from short times-on-page and high bounce rates.
Look, you know that your visitors don’t have much of a patience for anything these days. The least you could do is make the reading experience easy for them.
Has your website’s content violated any of these rules?
Typefaces are black (or nearly black) on a white background.
Fonts are in the serif or sans serif families (i.e. be careful with decorative fonts).
The smallest font size should be 16 pixels or larger.
Lines are between 50 and 60 characters.
Paragraphs contain no more than 3 or 4 lines.
Images or lists break up large chunks of content (like I’m doing here).
Headers enables readers (and search bots) to more quickly decipher what a page is about.
WebDesignerDepot does a great job of adhering to these principles, so if you’re looking for inspiration on how to make content readable, start here.
Mistake #4: Bad Pop-Ups
Everyone hates an ill-timed, irrelevant, or pushy pop-up. Google has even gone so far as to penalize mobile websites that utilize what it deems to be bad and intrusive pop-ups.
So, here’s what I’m going to say:
Utilize the least amount of space possible for your pop-ups.
Yotel has a fantastic example of this on its desktop website:
And, if pop-ups need to appear on mobile, relegate them to a top or bottom banner. It keeps your promotional message out of the way.
Mistake #5: Overweight Images
Google rewards websites that are fast—and we’re talking load times under three seconds. While there are a number of things developers can do to get loading speeds under control, designers should look at images to improve performance and SEO.
Specifically, look at file size.
There is only so much room an image can occupy on a website, especially in this age of mobile-first. So, why use a file that’s 12MB when it’s only going to show up as a thumbnail in the site’s news feed?
I’m not saying you should stop using oversized high-resolution images.
Just be sure to resize and run them through a compression software like TinyPNG to ensure you’re not overloading your web server.
Mistake #6: Text Inside Images
There are two reasons why text inside images is a bad idea for SEO. The first has to do with readability.
Think about what happens when text is laid atop an image. If there’s a distinct contrast between the two, readability should be fine. But what if text is placed over an otherwise mundane part of an image on desktop? On mobile, it shrinks down and may end up appearing over a busier and more distracting part of the photo.
Then there’s how the text is added. If text is pasted into an image file, search bots won’t be able to detect it. If your copywriters wrote that particular string of text with a search keyword embedded in it, you’ve just removed it from Google’s view.
Instead, you should work with your content management system to add text using custom fields meant to go on top of images.
In my opinion, it’s best to stay away from text on images unless you can ensure uncompromized readability and that Google bots can read it. Culture Trip shows how this can be done:
It also has links lower on the page where the text is removed from the photo altogether (which I think looks even better):
Mistake #7: Lack of Trust Marks
The last mistake has to do with security. This is something Google cares about greatly, but a lot of it falls to a web developer to implement.
To do your part, find opportunities to include trust marks to boost the confidence of visitors as they travel around your website. Uncommon Goods includes a number of these at the bottom of the site:
Trust marks may differ based on your website’s business type, but they do exist. Anti-malware software. SSL certificate. Secure payment gateway. These are the kinds of symbols that put your visitors’ minds at ease and allow them to stay longer and convert.
Wrap-Up
Now that you know some of the more common SEO mistakes caused by web design, be sure to account for them in your workflow going forward. You’d be amazed what improved performance, security, and usability will do for a website’s ranking!
There is lots of speculation in that thread, but Bruce has a pretty clear answer:
AFAIK, tells the browser to get something and insert it here – eg , “. Stylesheets aren’t ‘inserted’, they are related to the current doc, but typically style more than 1 page. declares a block of rules for this page only
I sort of get that. The location in the document matters with src, but not with — that relates to the entire document instead. I guess the crack in that reasoning is that the order of stylesheets does matter for order-specificity, but I take the point.
The W3C chimed to confirm that logic:
was completely obvious at the time, with for external resources that apply to the whole document (copyright, parent document, alternative formats, translations, style sheets); was never discussed. (1/2)
Can you hear that? That’s the sweet sound of jingle bells followed by the explosion of fireworks. The combination of these two sounds can only mean one thing: 2019 is right around the corner. That might sound a little scary, but I can assure you that this article contains nothing but good vibes and happy thoughts.
As a designer, you’re probably pretty aware that you should be keeping up with trends, right? I certainly hope so. But, that doesn’t mean that you can’t put a little personal flare on those trends. For the purpose of this article, and because the title already says typography trends for 2019, we’re going to discuss… you guessed it: typography trends for 2019. This list is in no particular order. It will contain new trends and a few classics that you totally need to stick with. Fasten your seatbelts, explorers, we’re diving straight in.
We’re going to start this list off with a style of font that will most likely be a trend for many years to come. Handwritten fonts are great because they allow you to put your own touch on your brand, and they bring with them a sense of detail that other fonts can’t. Granted, a handwritten font may not look so great on the side of a corporate office building, but they certainly are a great way to reach out to your audience on a more personal level.
Vintage fonts are also a timeless classic that deserves a spot of any typography trends lists ever. The reason people are so drawn to vintage fonts is very similar to the reason they’re so drawn to handwritten fonts. The difference here is that the audience is most likely already familiar with the font, as it is vintage. Instead of making new connections using a handwritten touch, you renew old connections by going vintage.
Watercolor fonts have risen in popularity almost side-by-side with handwritten fonts because they go so well together. Watercolors have recently existed mainly in the background of a few web pages. But now, people are starting to use them in the spotlight. Watercolor fonts are a great way to portray calm, cool, and collected vibes. They take away from the seriousness of business and add to the homely feel.
Serifs again are nothing new. In fact, they’re probably one of the oldest typography trends we can dig up. They are, however, a trend that’s making a comeback. Serifs can vary depending on how extra you want to be, but they’re another great way to put a little more flare on your work.
Big and small font types… together?
Yes, it’s true. A lot of people are instantly attracted to things that match or at least are the same size. The idea behind using both big and small fonts together isn’t exactly a new thing, but it has made great headway over the years. Because the letters in the font don’t match up, it can grab someone’s attention quicker than a buy-one-get-one sale at Old Navy. plus, it’s a creative way to put emphasis on a particular part of your brand or logo.
In addition to the variation in size, the mix-match of different font types has become a design phenomenon. I mean, why stick to just one font if you’ve found a few that you like? If done correctly, you’ll be able to mix a number of different fonts together and create your own personal masterpiece. Just try not to be too overwhelming.
For too long black and white fonts have haunted our screens! Okay, maybe that’s a little dramatic, but sometimes we just need a little color. Color fonts have been popular on and off for forever, and they’re starting to make a massive comeback. Color fonts allow us to be that much more creative with our projects. They can say as little or as much as you want them to about the letters that they’re highlighting. They’re the perfect way to snag someone’s attention in a crowd full of black and white.
Cutouts and overlays
Everyone wants to add layers to their designs, and it’s for good reason. People don’t want to sit and stare at a flat-looking, boring, underwhelming webpage. They want to be wowed and wanting more. Cutouts and overlays are a great way to give that 3-dimensional effect without having to wear the glasses that hurt your eyes after 30 minutes. They give you yet another layer to be creative with, and thus attracting more attention.
While handwritten fonts and different sized lettering are cool, perfectly straight lines and rounded corners will always be one of the typography trends, too. Don’t get me wrong, though, geometric fonts leave plenty of room to be creative. Geometric fonts have grown exponentially over the past year or two, and I don’t see them slowing down anytime soon.
Customize everything
If you have the extra cash to shell out, customizing your brand is a great way to set your own trends. I’m not talking about just logotypes here, I literally mean customize everything. What better way to give people a new experience than to create one custom for your brand? You’re a designer, challenge yourself!
Bring in the New Year right
Again, these typography trends aren’t in any particular order, but they are all super duper sweet. Trends are made every day. While some of us choose to follow those trends, others create their own path for us to follow in the future. The #1 rule of design is to be yourself and create your best work. Design something that you’re proud of, and show it off to the word.
If you’ve been writing JavaScript for some time now, it’s almost certain you’ve written some scripts dealing with the Document Object Model (DOM). DOM scripting takes advantage of the fact that a web page opens up a set of APIs (or interfaces) so you can manipulate and otherwise deal with elements on a page.
But there’s another object model you might want to become more familiar with: The CSS Object Model (CSSOM). Likely you’ve already used it but didn’t necessarily realize it.
In this guide, I’m going to go through many of the most important features of the CSSOM, starting with stuff that’s more commonly known, then moving on to some more obscure, but practical, features.
The CSS Object Model is a set of APIs allowing the manipulation of CSS from JavaScript. It is much like the DOM, but for the CSS rather than the HTML. It allows users to read and modify CSS style dynamically.
MDN’s info is based on the official W3C CSSOM specification. That W3C document is a somewhat decent way to get familiar with what’s possible with the CSSOM, but it’s a complete disaster for anyone looking for some practical coding examples that put the CSSOM APIs into action.
MDN is much better, but still largely lacking in certain areas. So for this post, I’ve tried to do my best to create useful code examples and demos of these interfaces in use, so you can see the possibilities and mess around with the live code.
As mentioned, the post starts with stuff that’s already familiar to most front-end developers. These common features are usually lumped in with DOM scripting, but they are technically part of the larger group of interfaces available via the CSSOM (though they do cross over into the DOM as well).
Inline Styles via element.style
The most basic way you can manipulate or access CSS properties and values using JavaScript is via the style object, or property, which is available on all HTML elements. Here’s an example:
document.body.style.background = 'lightblue';
Most of you have probably seen or used that syntax before. I can add to or change the CSS for any object on the page using that same format: element.style.propertyName.
In that example, I’m changing the value of the background property to lightblue. Of course, background is shorthand. What if I want to change the background-color property? For any hyphenated property, just convert the property name to camel case:
In most cases, a single-word property would be accessed in this way by the single equivalent word in lowercase, while hyphenated properties are represented in camel case. The one exception to this is when using the float property. Because float is a reserved word in JavaScript, you need to use cssFloat (or styleFloat if you’re supporting IE8 and earlier). This is similar to the HTML for attribute being referenced as htmlFor when using something like getAttribute().
Here’s a demo that uses the style property to allow the user to change the background color of the current page:
So that’s an easy way to define a CSS property and value using JavaScript. But there’s one huge caveat to using the style property in this way: This will only apply to inline styles on the element.
This becomes clear when you use the style property to read CSS:
In the example above, I’m defining an inline style on the element, then I’m logging that same style to the console. That’s fine. But if I try to read another property on that element, it will return nothing — unless I’ve previously defined an inline style for that element in my CSS or elsewhere in my JavaScript. For example:
console.log(document.body.style.color);
// Returns nothing if inline style doesn't exist
This would return nothing even if there was an external stylesheet that defined the color property on the element, as in the following CodePen:
Using element.style is the simplest and most common way to add styles to elements via JavaScript. But as you can see, this clearly has some significant limitations, so let’s look at some more useful techniques for reading and manipulating styles with JavaScript.
Getting Computed Styles
You can read the computed CSS value for any CSS property on an element by using the window.getComputedStyle() method:
Well, that’s an interesting result. In a way, window.getComputedStyle() is the style property’s overly-benevolent twin. While the style property gives you far too little information about the actual styles on an element, window.getComputedStyle() can sometimes give you too much.
In the example above, the background property of the element was defined using a single value. But the getComputedStyle() method returns all values contained in background shorthand. The ones not explicitly defined in the CSS will return the initial (or default) values for those properties.
This means, for any shorthand property, window.getComputedStyle() will return all the initial values, even if none of them is defined in the CSS:
Similarly, for properties like width and height, it will reveal the computed dimensions of the element, regardless of whether those values were specifically defined anywhere in the CSS, as the following interactive demo shows:
Try resizing the parent element in the above demo to see the results. This is somewhat comparable to reading the value of window.innerWidth, except this is the computed CSS for the specified property on the specified element and not just a general window or viewport measurement.
There are a few different ways to access properties using window.getComputedStyle(). I’ve already demonstrated one way, which uses dot-notation to add the camel-cased property name to the end of the method. You can see three different ways to do it in the following code:
// dot notation, same as above
window.getComputedStyle(el).backgroundColor;
// square bracket notation
window.getComputedStyle(el)['background-color'];
// using getPropertyValue()
window.getComputedStyle(el).getPropertyValue('background-color');
The first line uses the same format as in the previous demo. The second line is using square bracket notation, a common JavaScript alternative to dot notation. This format is not recommended and code linters will warn about it. The third example uses the getPropertyValue() method.
The first example requires the use of camel casing (although in this case both float and cssFloat would work) while the next two access the property via the same syntax as that used in CSS (with hyphens, often called “kebab case”).
Here’s the same demo as the previous, but this time using getPropertyValue() to access the widths of the two elements:
One little-known tidbit about window.getComputedStyle() is the fact that it allows you to retrieve style information on pseudo-elements. You’ll often see a window.getComputedStyle() declaration like this:
Notice the second argument, null, passed into the method. Firefox prior to version 4 required a second argument, which is why you might see it used in legacy code or by those accustomed to including it. But it’s not required in any browser currently in use.
That second optional parameter is what allows me to specify that I’m accessing the computed CSS of a pseudo-element. Consider the following CSS:
Here I’m adding a ::before pseudo-element inside the .box element. With the following JavaScript, I can access the computed styles for that pseudo-element:
let box = document.querySelector('.box');
window.getComputedStyle(box, '::before').width;
// "50px"
The above works in the latest Firefox, but not in Chrome or Edge (I’ve filed a bug report for Chrome).
It should also be noted that browsers have different results when trying to access styles for a non-existent (but valid) pseudo-element compared to a pseudo-element that the browser doesn’t support at all (like a made up ::banana pseudo-element). You can try this out in various browsers using the following demo:
As a side point to this section, there is a Firefox-only method called getDefaultComputedStyle() that is not part of the spec and likely never will be.
The CSSStyleDeclaration API
Earlier when I showed you how to access properties via the style object or using getComputedStyle(), in both cases those techniques were exposing the CSSStyleDeclaration interface.
In other words, both of the following lines will return a CSSStyleDeclaration object on the document’s body element:
In the following screenshot you can see what the console produces for each of these lines:
In the case of getComputedStyle(), the values are read-only. In the case of element.style, getting and setting the values is possible but, as mentioned earlier, these will only affect the document’s inline styles.
setProperty(), getPropertyValue(), and item()
Once you’ve exposed a CSSStyleDeclaration object in one of the above ways, you have access to a number of useful methods to read or manipulate the values. Again, the values are read-only in the case of getComputedStyle(), but when used via the style property, some methods are available for both getting and setting.
In this example, I’m using three different methods of the style object:
The setProperty() method. This takes two arguments, each a string: The property (in regular CSS notation) and the value you wish to assign to the property.
The getPropertyValue() method. This takes a single argument: The property whose value you want to obtain. This method was used in a previous example using getComputedStyle(), which, as mentioned, likewise exposes a CSSStyleDeclaration object.
The item() method. This takes a single argument, which is a positive integer representing the index of the property you want to access. The return value is the property name at that index.
Keep in mind that in my simple example above, there are only two styles added to the element’s inline CSS. This means that if I were to access item(2), the return value would be an empty string. I’d get the same result if I used getPropertyValue() to access a property that isn’t set in that element’s inline styles.
Using removeProperty()
In addition to the three methods mentioned above, there are two others exposed on a CSSStyleDeclaration object. In the following code and demo, I’m using the removeProperty() method:
In this case, after I set font-size using setProperty(), I log the property name to ensure it’s there. The demo then includes a button that, when clicked, will remove the property using removeProperty().
In the case of setProperty() and removeProperty(), the property name that you pass in is hyphenated (the same format as in your stylesheet), rather than camel-cased. This might seem confusing at first, but the value passed in is a string in this example, so it makes sense.
Getting and Setting a Property’s Priority
Finally, here’s an interesting feature that I discovered while researching this article: The getPropertyPriority() method, demonstrated with the code and CodePen below:
In the first line of that code, you can see I’m using the setProperty() method, as I did before. However, notice I’ve included a third argument. The third argument is an optional string that defines whether you want the property to have the !important keyword attached to it.
After I set the property with !important, I use the getPropertyPriority() method to check that property’s priority. If you want the property to not have importance, you can omit the third argument, use the keyword undefined, or include the third argument as an empty string.
And I should emphasize here that these methods would work in conjunction with any inline styles already placed directly in the HTML on an element’s style attribute.
So if I had the following HTML:
<div class="box" style="border: solid 1px red !important;">
I could use any of the methods discussed in this section to read or otherwise manipulate that style. And it should be noted here that since I used a shorthand property for this inline style and set it to !important, all of the longhand properties that make up that shorthand will return a priority of important when using getPropertyPriority(). See the code and demo below:
// These all return "important"
box.style.getPropertyPriority('border'));
box.style.getPropertyPriority('border-top-width'));
box.style.getPropertyPriority('border-bottom-width'));
box.style.getPropertyPriority('border-color'));
box.style.getPropertyPriority('border-style'));
In the demo, even though I explicitly set only the border property in the style attribute, all the associated longhand properties that make up border will also return a value of important.
The CSSStyleSheet Interface
So far, much of what I’ve considered deals with inline styles (which often aren’t that useful) and computed styles (which are useful, but are often too specific).
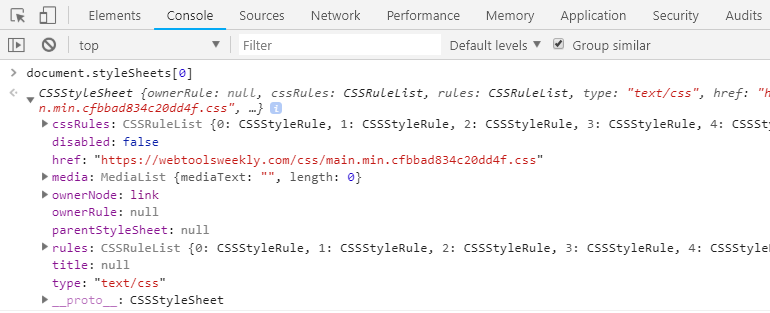
A much more useful API that allows you to retrieve a stylesheet that has readable and writable values, and not just for inline styles, is the CSSStyleSheet API. The simplest way to access information from a document’s stylesheets is using the styleSheets property of the current document. This exposes the CSSStyleSheet interface.
For example, the line below uses the length property to see how many stylesheets the current document has:
document.styleSheets.length; // 1
I can reference any of the document’s stylesheets using zero-based indexing:
document.styleSheets[0];
If I log that stylesheet to my console, I can view the methods and properties available:
The one that will prove useful is the cssRules property. This property provides a list of all CSS rules (including declaration blocks, at-rules, media rules, etc.) contained in that stylesheet. In the following sections, I’ll detail how to utilize this API to manipulate and read styles from an external stylesheet.
Working with a Stylesheet Object
For the purpose of simplicity, let’s work with a sample stylesheet that has only a handful of rules in it. This will allow me to demonstrate how to use the CSSOM to access the different parts of a stylesheet in a similar way to accessing elements via DOM scripting.
There’s a number of different things I can attempt with this example stylesheet and I’ll demonstrate a few of those here. First, I’m going to loop through all the style rules in the stylesheet and log the selector text for each one:
let myRules = document.styleSheets[0].cssRules,
p = document.querySelector('p');
for (i of myRules) {
if (i.type === 1) {
p.innerHTML += `<code>${i.selectorText}</code><br>`;
}
}
A couple of things to take note of in the above code and demo. First, I cache a reference to the cssRules object for my stylesheet. Then I loop over all the rules in that object, checking to see what type each one is.
In this case, I want rules that are type 1, which represents the STYLE_RULE constant. Other constants include IMPORT_RULE (3), MEDIA_RULE (4), KEYFRAMES_RULE (7), etc. You can view a full table of these constants in this MDN article.
When I confirm that a rule is a style rule, I print the selectorText property for each of those style rules. This will produce the following lines for the specified stylesheet:
*
body
main
.component
a:hover
code
The selectorText property is a string representation of the selector used on that rule. This is a writable property, so if I want I can change the selector for a specific rule inside my original for loop with the following code:
if (i.selectorText === 'a:hover') {
i.selectorText = 'a:hover, a:active';
}
In this example, I’m looking for a selector that defines :hover styles on my links and expanding the selector to apply the same styles to elements in the :active state. Alternatively, I could use some kind of string method or even a regular expression to look for all instances of :hover, and then do something from there. But this should be enough to demonstrate how it works.
Accessing @media Rules with the CSSOM
You’ll notice my stylesheet also includes a media query rule and a keyframes at-rule block. Both of those were skipped when I searched for style rules (type 1). Let’s now find all @media rules:
let myRules = document.styleSheets[0].cssRules,
p = document.querySelector('.output');
for (i of myRules) {
if (i.type === 4) {
for (j of i.cssRules) {
p.innerHTML += `<code>${j.selectorText}</code><br>`;
}
}
}
Based on the given stylesheet, the above will produce:
As you can see, after I loop through all the rules to see if any @media rules exist (type 4), I then loop through the cssRules object for each media rule (in this case, there’s only one) and log the selector text for each rule inside that media rule.
So the interface that’s exposed on a @media rule is similar to the interface exposed on a stylesheet. The @media rule, however, also includes a conditionText property, as shown in the following snippet and demo:
let myRules = document.styleSheets[0].cssRules,
p = document.querySelector('.output');
for (i of myRules) {
if (i.type === 4) {
p.innerHTML += `<code>${i.conditionText}</code><br>`;
// (max-width: 800px)
}
}
This code loops through all media query rules and logs the text that determines when that rule is applicable (i.e. the condition). There’s also a mediaText property that returns the same value. According to the spec, you can get or set either of these.
Accessing @keyframes Rules with the CSSOM
Now that I’ve demonstrated how to read information from a @media rule, let’s consider how to access a @keyframes rule. Here’s some code to get started:
let myRules = document.styleSheets[0].cssRules,
p = document.querySelector('.output');
for (i of myRules) {
if (i.type === 7) {
for (j of i.cssRules) {
p.innerHTML += `<code>${j.keyText}</code><br>`;
}
}
}
In this example, I’m looking for rules that have a type of 7 (i.e. @keyframes rules). When one is found, I loop through all of that rule’s cssRules and log the keyText property for each. The log in this case will be:
"0%"
"20%"
"100%"
You’ll notice my original CSS uses from and to as the first and last keyframes, but the keyText property computes these to 0% and 100%. The value of keyText can also be set. In my example stylesheet, I could hard code it like this:
// Read the current value (0%)
document.styleSheets[0].cssRules[6].cssRules[0].keyText;
// Change the value to 10%
document.styleSheets[0].cssRules[6].cssRules[0].keyText = '10%'
// Read the new value (10%)
document.styleSheets[0].cssRules[6].cssRules[0].keyText;
Using this, we can dynamically alter an animation’s keyframes in the flow of a web app or possibly in response to a user action.
Another property available when accessing a @keyframes rule is name:
let myRules = document.styleSheets[0].cssRules,
p = document.querySelector('.output');
for (i of myRules) {
if (i.type === 7) {
p.innerHTML += `<code>${i.name}</code><br>`;
}
}
Recall that in the CSS, the @keyframes rule looks like this:
@keyframes exampleAnimation {
from {
color: blue;
}
20% {
color: orange;
}
to {
color: green;
}
}
Thus, the name property allows me to read the custom name chosen for that @keyframes rule. This is the same name that would be used in the animation-name property when enabling the animation on a specific element.
One final thing I’ll mention here is the ability to grab specific styles that are inside a single keyframe. Here’s some example code with a demo:
let myRules = document.styleSheets[0].cssRules,
p = document.querySelector('.output');
for (i of myRules) {
if (i.type === 7) {
for (j of i.cssRules) {
p.innerHTML += `<code>${j.style.color}</code><br>`;
}
}
}
In this example, after I find the @keyframes rule, I loop through each of the rules in the keyframe (e.g. the “from” rule, the “20%” rule, etc). Then, within each of those rules, I access an individual style property. In this case, since I know color is the only property defined for each, I’m merely logging out the color values.
The main takeaway in this instance is the use of the style property, or object. Earlier I showed how this property can be used to access inline styles. But in this case, I’m using it to access the individual properties inside of a single keyframe.
You can probably see how this opens up some possibilities. This allows you to modify an individual keyframe’s properties on the fly, which could happen as a result of some user action or something else taking place in an app or possibly a web-based game.
Adding and Removing CSS Declarations
The CSSStyleSheet interface has access to two methods that allow you to add or remove an entire rule from a stylesheet. The methods are: insertRule() and deleteRule(). Let’s see both of them in action manipulating our example stylesheet:
In this case, I’m logging the length of the cssRules property (showing that the stylesheet originally has 8 rules in it), then I add the following CSS as an individual rule using the insertRule() method:
article {
line-height: 1.5;
font-size: 1.5em;
}
I log the length of the cssRules property again to confirm that the rule was added.
The insertRule() method takes a string as the first parameter (which is mandatory), comprising the full style rule that you want to insert (including selector, curly braces, etc). If you’re inserting an at-rule, then the full at-rule, including the individual rules nested inside the at-rule can be included in this string.
The second argument is optional. This is an integer that represents the position, or index, where you want the rule inserted. If this isn’t included, it defaults to 0 (meaning the rule will be inserted at the beginning of the rules collection). If the index happens to be larger than the length of the rules object, it will throw an error.
In this case, the method accepts a single argument that represents the index of the rule I want to remove.
With either method, because of zero-based indexing, the selected index passed in as an argument has to be less than the length of the cssRules object, otherwise it will throw an error.
Revisiting the CSSStyleDeclaration API
Earlier I explained how to access individual properties and values declared as inline styles. This was done via element.style, exposing the CSSStyleDeclaration interface.
The CSSStyleDeclaration API, however, can also be exposed on an individual style rule as a subset of the CSSStyleSheet API. I already alluded to this when I showed you how to access properties inside a @keyframes rule. To understand how this works, compare the following two code snippets:
The first example is a set of inline styles that can be accessed as follows:
document.querySelector('div').style
This exposes the CSSStyleDeclaration API, which is what allows me to do stuff like element.style.color, element.style.width, etc.
But I can expose the exact same API on an individual style rule in an external stylesheet. This means I’m combining my use of the style property with the CSSStyleSheet interface.
So the CSS in the second example above, which uses the exact same styles as the inline version, can be accessed like this:
document.styleSheets[0].cssRules[0].style
This opens up a single CSSStyleDeclaration object on the one style rule in the stylesheet. If there were multiple style rules, each could be accessed using cssRules[1], cssRules[2], cssRules[3], and so on.
So within an external stylesheet, inside of a single style rule that is of type 1, I have access to all the methods and properties mentioned earlier. This includes setProperty(), getPropertyValue(), item(), removeProperty(), and getPropertyPriority(). In addition to this, those same features are available on an individual style rule inside of a @keyframes or @media rule.
Here’s a code snippet and demo that demonstrates how these methods would be used on an individual style rule in our sample stylesheet:
// Grab the style rules for the body and main elements
let myBodyRule = document.styleSheets[0].cssRules[1].style,
myMainRule = document.styleSheets[0].cssRules[2].style;
// Set the bg color on the body
myBodyRule.setProperty('background-color', 'peachpuff');
// Get the font size of the body
myBodyRule.getPropertyValue('font-size');
// Get the 5th item in the body's style rule
myBodyRule.item(5);
// Log the current length of the body style rule (8)
myBodyRule.length;
// Remove the line height
myBodyRule.removeProperty('line-height');
// log the length again (7)
myBodyRule.length;
// Check priority of font-family (empty string)
myBodyRule.getPropertyPriority('font-family');
// Check priority of margin in the "main" style rule (!important)
myMainRule.getPropertyPriority('margin');
After everything I’ve considered in this article, it would seem odd that I’d have to break the news that it’s possible that one day the CSSOM as we know it will be mostly obsolete.
That’s because of something called the CSS Typed OM which is part of the Houdini Project. Although some people have noted that the new Typed OM is more verbose compared to the current CSSOM, the benefits, as outlined in this article by Eric Bidelman, include:
Fewer bugs
Arithmetic operations and unit conversion
Better performance
Error handling
CSS property names are always strings
For full details on those features and a glimpse into the syntax, be sure to check out the full article.
As of this writing, CSS Typed OM is supported only in Chrome. You can see the progress of browser support in this document.
Final Words
Manipulating stylesheets via JavaScript certainly isn’t something you’re going to do in every project. And some of the complex interactions made possible with the methods and properties I’ve introduced here have some very specific use cases.
If you’ve built some kind of tool that uses any of these APIs I’d love to hear about it. My research has only scratched the surface of what’s possible, but I’d love to see how any of this can be used in real-world examples.
I’ve put all the demos from this article into a CodePen collection, so you can feel free to mess around with those as you like.
I think it’s kinda cool to see Google dropping repos of interesting web components. It demonstrates the possibilities of cool new web features and allows them to ship them in a way that’s compatible with entirely web standards.
Here’s one:
I wanted to give it a try, so I linked up their example two-up-min.js script in a Pen and used the element by itself to see how it works. They expose the component’s styling with custom properties, which I’d say is a darn nice use case for those.
<p data-height="455" data-theme-id="1" data-slug-hash="YRowgW" data-default-tab="html,result" data-user="chriscoyier" data-pen-title="”>See the Pen <two-up&rt; by Chris Coyier (@chriscoyier) on CodePen.
In this article, we’ll take a look at the challenges involved in building real-time applications and how emerging tooling is addressing them with elegant solutions that are easy to reason about. To do this, we’ll build a real-time polling app (like a Twitter poll with real-time overall stats) just by using Postgres, GraphQL, React and no backend code!
The primary focus will be on setting up the backend (deploying the ready-to-use tools, schema modeling), and aspects of frontend integration with GraphQL and less on UI/UX of the frontend (some knowledge of ReactJS will help). The tutorial section will take a paint-by-numbers approach, so we’ll just clone a GitHub repo for the schema modeling, and the UI and tweak it, instead of building the entire app from scratch.
All Things GraphQL
Do you know everything you need to know about GraphQL? If you have your doubts, Eric Baer has you covered with a detailed guide on its origins, its drawbacks and the basics of how to work with it. Read article ?
Before you continue reading this article, I’d like to mention that a working knowledge of the following technologies (or substitutes) are beneficial:
ReactJS This can be replaced with any frontend framework, Android or IOS by following the client library documentation.
Postgres You can work with other databases but with different tools, the principles outlined in this post will still apply.
You can also adapt this tutorial context for other real-time apps very easily.
A demonstration of the features in the polling app that we’ll be building. (Large preview)
As illustrated by the accompanying GraphQL payload at the bottom, there are three major features that we need to implement:
Fetch the poll question and a list of options (top left).
Allow a user to vote for a given poll question (the “Vote” button).
Fetch results of the poll in real-time and display them in a bar graph (top right; we can gloss over the feature to fetch a list of currently online users as it’s an exact replica of this use case).
Challenges With Building Real-Time Apps
Building real-time apps (especially as a frontend developer or someone who’s recently made a transition to becoming a fullstack developer), is a hard engineering problem to solve.
This is generally how contemporary real-time apps work (in the context of our example app):
The frontend updates a database with some information; A user’s vote is sent to the backend, i.e. poll/option and user information (user_id, option_id).
The first update triggers another service that aggregates the poll data to render an output that is relayed back to the app in real-time (every time a new vote is cast by anyone; if this done efficiently, only the updated poll’s data is processed and only those clients that have subscribed to this poll are updated):
Vote data is first processed by an register_vote service (assume that some validation happens here) that triggers a poll_results service.
Real-time aggregated poll data is relayed by the poll_results service to the frontend for displaying overall statistics.
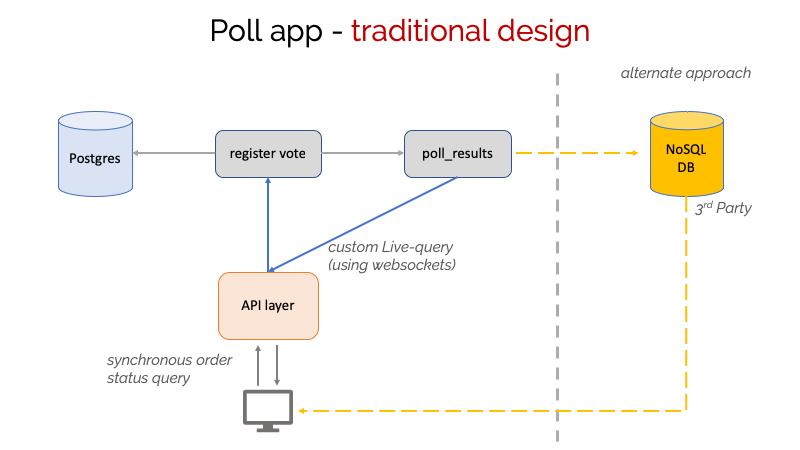
A poll app designed traditionally
This model is derived from a traditional API-building approach, and consequently has similar problems:
Any of the sequential steps could go wrong, leaving the UX hanging and affecting other independent operations.
Requires a lot of effort on the API layer as it’s a single point of contact for the frontend app, that interacts with multiple services. It also needs to implement a websockets-based real-time API — there is no universal standard for this and therefore sees limited support for automation in tools.
The frontend app is required to add the necessary plumbing to consume the real-time API and may also have to solve the data consistency problem typically seen in real-time apps (less important in our chosen example, but critical in ordering messages in a real-time chat app).
Many implementations resort to using additional non-relational databases on the server-side (Firebase, etc.) for easy real-time API support.
Let’s take a look at how GraphQL and associated tooling address these challenges.
What Is GraphQL?
GraphQL is a specification for a query language for APIs, and a server-side runtime for executing queries. This specification was developed by Facebook to accelerate app development and provide a standardized, database-agnostic data access format. Any specification-compliant GraphQL server must support the following:
Queries for reads A request type for requesting nested data from a data source (which can be either one or a combination of a database, a REST API or another GraphQL schema/server).
Mutations for writes A request type for writing/relaying data into the aforementioned data sources.
Subscriptions for live-queries A request type for clients to subscribe to real-time updates.
GraphQL also uses a typed schema. The ecosystem has plenty of tools that help you identify errors at dev/compile time which results in fewer runtime bugs.
Here’s why GraphQL is great for real-time apps:
Live-queries (subscriptions) are an implicit part of the GraphQL specification. Any GraphQL system has to have native real-time API capabilities.
A standard spec for real-time queries has consolidated community efforts around client-side tooling, resulting in a very intuitive way of integrating with GraphQL APIs.
GraphQL and a combination of open-source tooling for database events and serverless/cloud functions offer a great substrate for building cloud-native applications with asynchronous business logic and real-time features that are easy to build and manage. This new paradigm also results in great user and developer experience.
In the rest of this article, I will use open-source tools to build an app based on this architecture diagram:
A poll app designed with GraphQL
Building A Real-Time Poll/Voting App
With that introduction to GraphQL, let’s get back to building the polling app as described in the first section.
The three features (or stories highlighted) have been chosen to demonstrate the different GraphQL requests types that our app will make:
Query Fetch the poll question and its options.
Mutation Let a user cast a vote.
Subscription Display a real-time dashboard for poll results.
GraphQL request types in the poll app (Large preview)
Prerequisites
A Heroku account (use the free tier, no credit card required) To deploy a GraphQL backend (see next point below) and a Postgres instance.
Hasura GraphQL Engine (free, open-source)/>A ready-to-use GraphQL server on Postgres.
Apollo Client (free, open-source SDK) For easily integrating clients apps with a GraphQL server.
npm (free, open-source package manager) To run our React app.
Deploying The Database And A GraphQL Backend
We will deploy an instance each of Postgres and GraphQL Engine on Heroku’s free tier. We can use a nifty Heroku button to do this with a single click.
Heroku button
Note:You can also follow this link or search for documentation Hasura GraphQL deployment for Heroku (or other platforms).
Deploying Postgres and GraphQL Engine to Heroku’s free tier (Large preview)
You will not need any additional configuration, and you can just click on the “Deploy app” button. Once the deployment is complete, make a note of the app URL:
<app-name>.herokuapp.com
For example, in the screenshot above, it would be:
hge-realtime-app-tutorial.herokuapp.com
What we’ve done so far is deploy an instance of Postgres (as an add-on in Heroku parlance) and an instance of GraphQL Engine that is configured to use this Postgres instance. As a result of doing so, we now have a ready-to-use GraphQL API but, since we don’t have any tables or data in our database, this is not useful yet. So, let’s address this immediately.
Modeling the database schema
The following schema diagram captures a simple relational database schema for our poll app:
As you can see, the schema is a simple, normalized one that leverages foreign-key constraints. It is these constraints that are interpreted by the GraphQL Engine as 1:1 or 1:many relationships (e.g. poll:options is a 1: many relationship since each poll will have more than 1 option that are linked by the foreign key constraint between the id column of the poll table and the poll_id column in the option table). Related data can be modelled as a graph and can thus power a GraphQL API. This is precisely what the GraphQL Engine does.
Based on the above, we’ll have to create the following tables and constraints to model our schema:
Poll A table to capture the poll question.
Option Options for each poll.
Vote To record a user’s vote.
Foreign-key constraint between the following fields (table : column):
option : poll_id ? poll : id
vote : poll_id ? poll : id
vote : created_by_user_id ? user : id
Now that we have our schema design, let’s implement it in our Postgres database. To instantly bring this schema up, here’s what we’ll do:
$ git clone clone https://github.com/hasura/graphql-engine
$ cd graphql-engine/community/examples/realtime-poll
Go to hasura/ and edit config.yaml:
endpoint: https://<app-name>.herokuapp.com
Apply the migrations using the CLI, from inside the project directory (that you just downloaded by cloning):
$ hasura migrate apply
That’s it for the backend. You can now open the GraphQL Engine console and check that all the tables are present (the console is available at https://.herokuapp.com/console).
Note:You could also have used the console to implement the schema by creating individual tables and then adding constraints using a UI. Using the built-in support for migrations in GraphQL Engine is just a convenient option that was available because our sample repo has migrations for bringing up the required tables and configuring relationships/constraints (this is also highly recommended regardless of whether you are building a hobby project or a production-ready app).
Integrating The Frontend React App With The GraphQL Backend
The frontend in this tutorial is a simple app that shows poll question, the option to vote and the aggregated poll results in one place. As I mentioned earlier, we’ll first focus on running this app so you get the instant gratification of using our recently deployed GraphQL API , see how the GraphQL concepts we looked at earlier in this article power the different use-cases of such an app, and then explore how the GraphQL integration works under the hood.
NOTE:If you are new to ReactJS, you may want to check out some of these articles. We won’t be getting into the details of the React part of the app, and instead, will focus more on the GraphQL aspects of the app. You can refer to the source code in the repo for any details of how the React app has been built.
Configuring The Frontend App
In the repo cloned in the previous section, edit HASURA_GRAPHQL_ENGINE_HOSTNAME in the src/apollo.js file (inside the /community/examples/realtime-poll folder) and set it to the Heroku app URL from above:
You should be able to play around with the app now. Go ahead and vote as many times as you want, you’ll notice the results changing in real time. In fact, if you set up another instance of this UI and point it to the same backend, you’ll be able to see results aggregated across all the instances.
So, how does this app use GraphQL? Read on.
Behind The Scenes: GraphQL
In this section, we’ll explore the GraphQL features powering the app, followed by a demonstration of the ease of integration in the next one.
The Poll Component And The Aggregated Results Graph
The poll component on the top left that fetches a poll with all of its options and captures a user’s vote in the database. Both of these operations are done using the GraphQL API. For fetching a poll’s details, we make a query (remember this from the GraphQL introduction?):
query {
poll {
id
question
options {
id
text
}
}
}
Using the Mutation component from react-apollo, we can wire up the mutation to a HTML form such that the mutation is executed using variables optionId and userId when the form is submitted:
To show the poll results, we need to derive the count of votes per option from the data in vote table. We can create a Postgres View and track it using GraphQL Engine to make this derived data available over GraphQL.
CREATE VIEW poll_results AS
SELECT poll.id AS poll_id, o.option_id, count(*) AS votes
FROM (( SELECT vote.option_id, option.poll_id, option.text
FROM ( vote
LEFT JOIN
public.option ON ((option.id = vote.option_id)))) o
LEFT JOIN poll ON ((poll.id = o.poll_id)))
GROUP BY poll.question, o.option_id, poll.id;
The poll_results view joins data from vote and poll tables to provide an aggregate count of number of votes per each option.
Using GraphQL Subscriptions over this view, react-google-charts and the subscription component from react-apollo, we can wire up a reactive chart which updates in realtime when a new vote happens from any client.
subscription getResult($pollId: uuid!) {
poll_results(where: {poll_id: {_eq: $pollId}}) {
option {
id
text
}
votes
}
}
GraphQL API Integration
As I mentioned earlier, I used Apollo Client, an open-source SDK to integrate a ReactJS app with the GraphQL backend. Apollo Client is analogous to any HTTP client library like requests for python, the standard http module for JavaScript, and so on. It encapsulates the details of making an HTTP request (in this case POST requests). It uses the configuration (specified in src/apollo.js) to make query/mutation/subscription requests (specified in src/GraphQL.jsx with the option to use variables that can be dynamically substituted in the JavaScript code of your REACT app) to a GraphQL endpoint. It also leverages the typed schema behind the GraphQL endpoint to provide compile/dev time validation for the aforementioned requests. Let’s see just how easy it is for a client app to make a live-query (subscription) request to the GraphQL API.
Configuring The SDK
The Apollo Client SDK needs to be pointed at a GraphQL server, so it can automatically handle the boilerplate code typically needed for such an integration. So, this is exactly what we did when we modified src/apollo.js when setting up the frontend app.
Making A GraphQL Subscription Request (Live-Query)
Define the subscription we looked at in the previous section in the src/GraphQL.jsx file:
One thing to note here is that the above subscription could also have been a query. Merely replacing one keyword for another gives us a “live-query”, and that’s all it takes for the Apollo Client SDK to hook this real-time API with your app. Every time there’s a new dataset from our live-query, the SDK triggers a re-render of our chart with this updated data (using the renderChart(data) call). That’s it. It really is that simple!
Final Thoughts
In three simple steps (creating a GraphQL backend, modeling the app schema, and integrating the frontend with the GraphQL API), you can quickly wire-up a fully-functional real-time app, without getting mired in unnecessary details such as setting up a websocket connection. That right there is the power of community tooling backing an abstraction like GraphQL.
If you’ve found this interesting and want to explore GraphQL further for your next side project or production app, here are some factors you may want to use for building your GraphQL toolchain:
Performance & Scalability GraphQL is meant to be consumed directly by frontend apps (it’s no better than an ORM in the backend; real productivity benefits come from doing this). So your tooling needs to be smart about efficiently using database connections and should be able scale effortlessly.
Security It follows from above that a mature role-based access-control system is needed to authorize access to data.
Automation If you are new to the GraphQL ecosystem, handwriting a GraphQL schema and implementing a GraphQL server may seem like daunting tasks. Maximize the automation from your tooling so you can focus on the important stuff like building user-centric frontend features.
Architecture/>As trivial as the above efforts seem like, a production-grade app’s backend architecture may involve advanced GraphQL concepts like schema-stitching, etc. Moreover, the ability to easily generate/consume real-time APIs opens up the possibility of building asynchronous, reactive apps that are resilient and inherently scalable. Therefore, it’s critical to evaluate how GraphQL tooling can streamline your architecture.
Related Resources
You can check out a live version of the app over here.