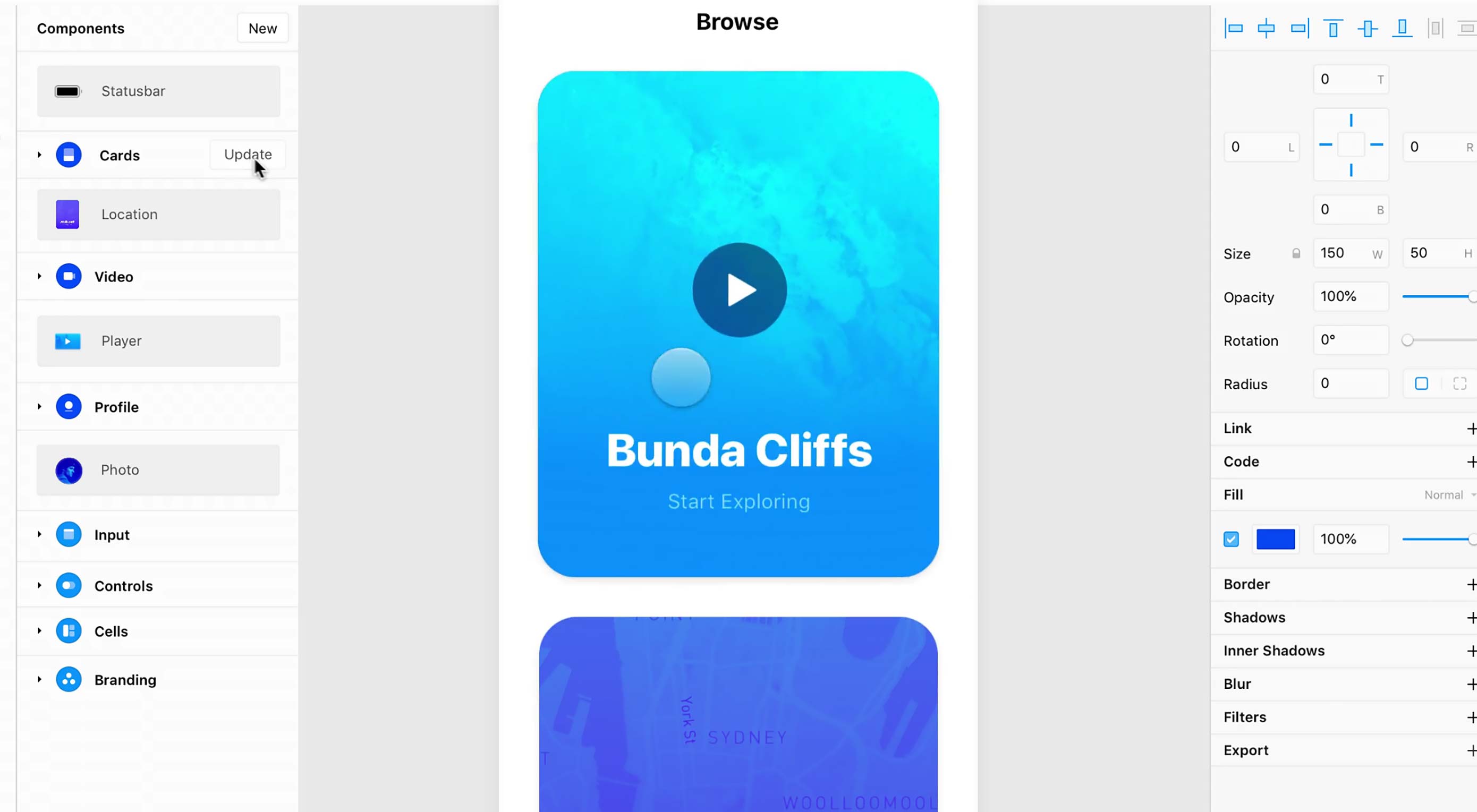
Typography is a fundamental part of design, it enables the designer to create a variety of moods and effects by using various font styles.
There are thousands of different styles available, so the task of finding the correct one to suit your project can often appear very difficult.
There are numerous tools online that offer assistance in selecting the correct font pairings. Here’s one we built ourselves. Using this handy font combination tool we have compiled a list of 19 contemporary font pairings for 2019. All of these fonts can be downloaded for free from Google Fonts.
1. Playfair Display with Source Sans Pro
This would have to be our top font combination for 2019. With it’s more traditional style, Playfair Display is both elegant and unique; it was designed by Claus Eggers Sorense, and can be paired with a variety of simple fonts, however, we think that Source Sans Pro is a perfect match, its thin lines and simple text make it a perfect combination for the more stylish Playfair Display.
Mount Barker By Callum Jackson
2. Merriweather with Oswald
A very versatile font, Merriweather can be adjusted both width and height, which always makes for a popular style. A sans-serif font, like Oswald, with its simple lines, assists in highlighting the detailed serif of Merriweather.
Remarkable Rocks by Ben Goode
3. Montserrat with Merriweather
Streamlined, simple fonts are always top of the list, because they work well in just about any design style. Montserrat was designed by Julieta Ulanovsky, and can be highlighted with a serif font such as Merriweather.
Uraidla By Ben Goode
4. Raleway with Lato
A stylish font that gives a modern twist, Raleway, can be complimented with another sans-serif font, like Lato. It has thin, simple lines and does not detract away from the more interesting shapes of Raleway.
Dolphin Beach by Ben Goode
5. Elsie with Roboto
A lovely feminine font, originally designed to celebrate the world of women. Elsie, is an adorable font style, with its gentle serifs and flowing lettering. With such an interesting font, a subtle font needs to be paired with it, like for example Roboto, because it doesn’t detract from the seed font.
Two Hands Wines by South Australian Tourism Commission
6. Dancing Script with Josefin Sans
A very memorable font that creates a feeling of movement and intrigue, Dancing Script should be paired with a sans-serif font like Josefin Sans. This font is also very elegant and it’s very thin lettering brings the perfect balance between the two font styles.
Pennington Bay By Isaac Forman
7. Abril Fatface with Roboto
What a fabulous font style, Abril Fatface, has combined the use of serifs with beautiful simplicity. It’s bold and ambitious and really jumps out of the page, because it’s such a wow font, a very subtle light weight font is best paired with it.
Bunyeroo Valley By Ben Goode
8. Corben with Nobile
There’s something about this font that makes me think of bubbles and happy days. The unique use of rounded serifs, really makes this font different from others. A simple, slim font, like Nobile, makes the detail of Corben even more fascinating.
Wilpena Pound Resort – Old Wilpena Station By Tourism Australia
9. Spirax with Open Sans
This style of font lends itself to being used for a storybook or some fairytale movie, and was designed by Branda Gallo. It creates such interesting aspects with its unique swirls, that turn this otherwise simple font into one of mystery and complexity. It is beautifully paired with Open Sans, because it’s very simple.
Vivonne Bay By Raphael Alu
10. Wendy One with Lato
Designed by Alejandro Inler, Wendy One, is a very bold, fun font style, that gives a youthful feeling. A bold font such as this should be paired with something thin and streamlined like Lato.
Flinders Ranges By Jake Wundersitz
11. Baloo with Montserrat
Round and thick, Baloo was designed by Ek Type, and is a versatile font style, because it can be used in many different font weights and heights. Such a bold font like this, should be paired with a very simple style like Montserrat.
Grazing Land near Baroota Reservoir By Isaac Forman/Serio
12. Cherry Cream Soda with Josefin Sans
Happy times and good memories, Cherry Cream Soda makes you feel like you’ve stepped back in time to the 1950’s. It was designed by Font Diner, and is a fun and creative font. Due to its interesting design, it should be paired with a gentle font style, like Josefin Sans, as its subtle lines compliment the bold, unique text.
Para Wirra By Ben Goode
13. Amaranth with Open Sans
A font of many surprises, at first glance you think it’s a simple font, but take another look and you realize the slight curves that make this font something different. It can be used for many different design styles, because of its versatility in weight and size, and is best paired with a font like Open Sans.
Kati Thanda-Lake Eyre National Park – Wrightsair Scenic Flight by South Australian Tourism Commission
14. Palanquin with Roboto
A gentle, and extremely usable font, Palanquin was designed by Pria Ravichandran, and can be used in many different design styles. It looks amazing bold or thin, and has many different options for pairing fonts, however we think that Roboto is perfect, because it too is a very simple font.
Steingarten, Rowland Flat by Olivia Reynolds
15. Sansita with Open Sans
Created by Omnibus-Type, this font remind me of summer days and eating mexican food. With its twist on the serif it creates such an interesting font style, that needs a light weight, gentle font to compliment it, like Open Sans.
The Lane Vineyard
16. Waiting for the Sunrise with Rock Salt
Designed by Kimberly Geswein, a beautiful handwritten font, inspired by the writing style of a high school student. Waiting for the Sunrise, would be a perfect choice for a fun, youthful website, and can be used with another handwritten font like Rock Salt.
Cape Willoughby Lighthouse by Ben Goode
17. Eczar with Work Sans
Designed by Valibhav Singh, this font is one of excitement and intrigue. The features of Eczar are designed to intensify as it increases in weight. With all the details of this font, it should be paired with a gentle sans-serif font like Work Sans.
Skye Lookout By Callum Jackson
18. Catamaran with Montserrat
A stylish, simple font that can be used in many different weights and sizes. The slight angles on the stems of the letters, create a unique, interesting feature to this font. It should be paired with a thin font, like Montserrat.
Dolphin Beach by Ben Goode
19. Fascinate with Open Sans
Based on the styles of the Art Deco era, this font is sure to create interest, with its unique lines within the type.
Due to its interesting features, it should be complemented with a simple sans-serif font like Open Sans.
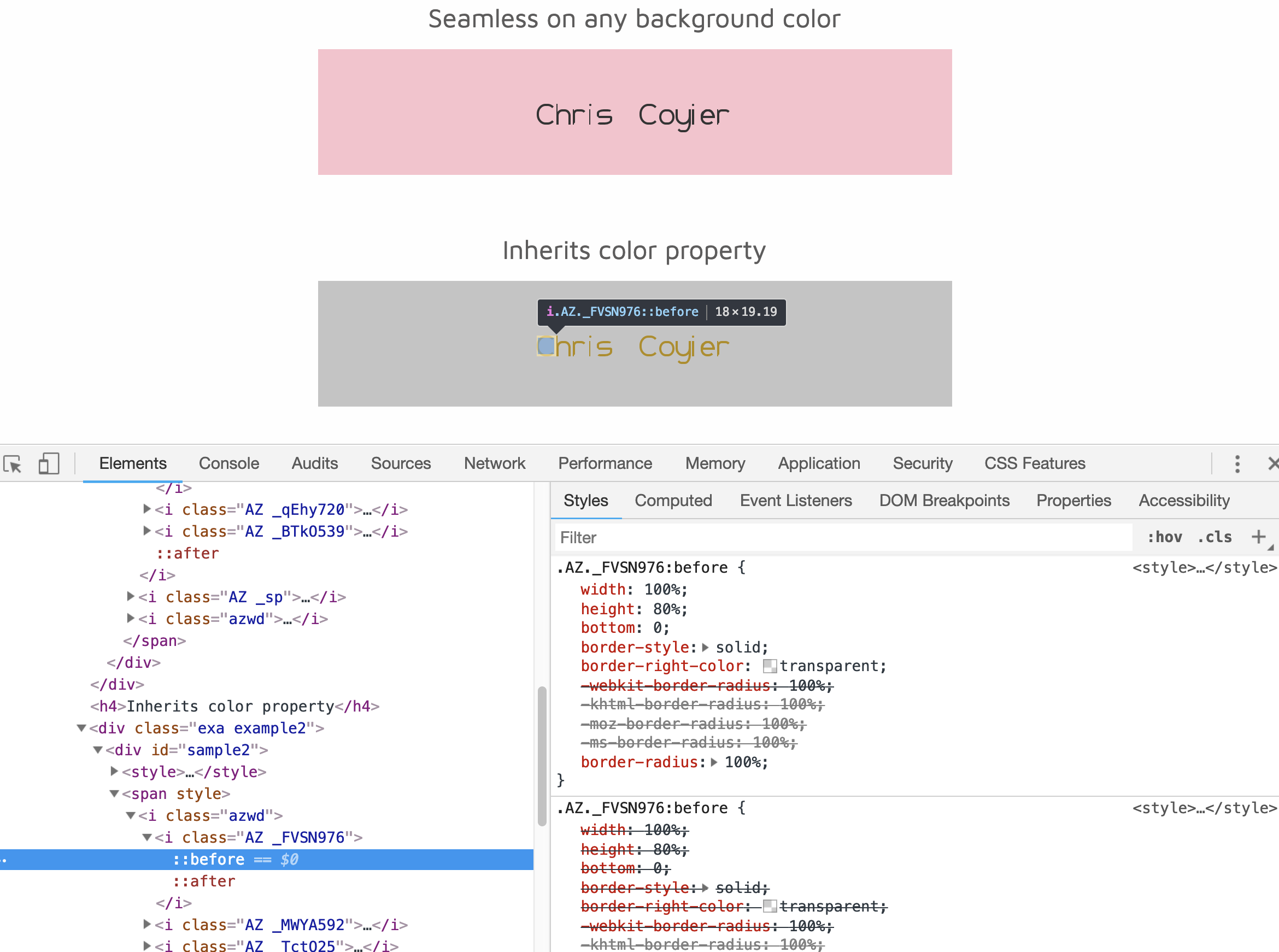
There have been some interesting, boundary-pushing typography-related experiments lately. I was trying to think of a joke like “somethings in the descenders” but I just can’t find something that will stand on its own leg without being easy to counter.
at the top with the full word in it, while those empty elements do the actual drawing of the glyphs. I wouldn’t call it entirely accessible, as I’d argue part of accessibility is stuff like find-on-page with highlighting and selectable text. But this is obviously an artistic experiment and your implementation could go any number of ways. I’d love to see an attempt at setting transparent SVG over the top of it that is sized the same so that the text is selectable.
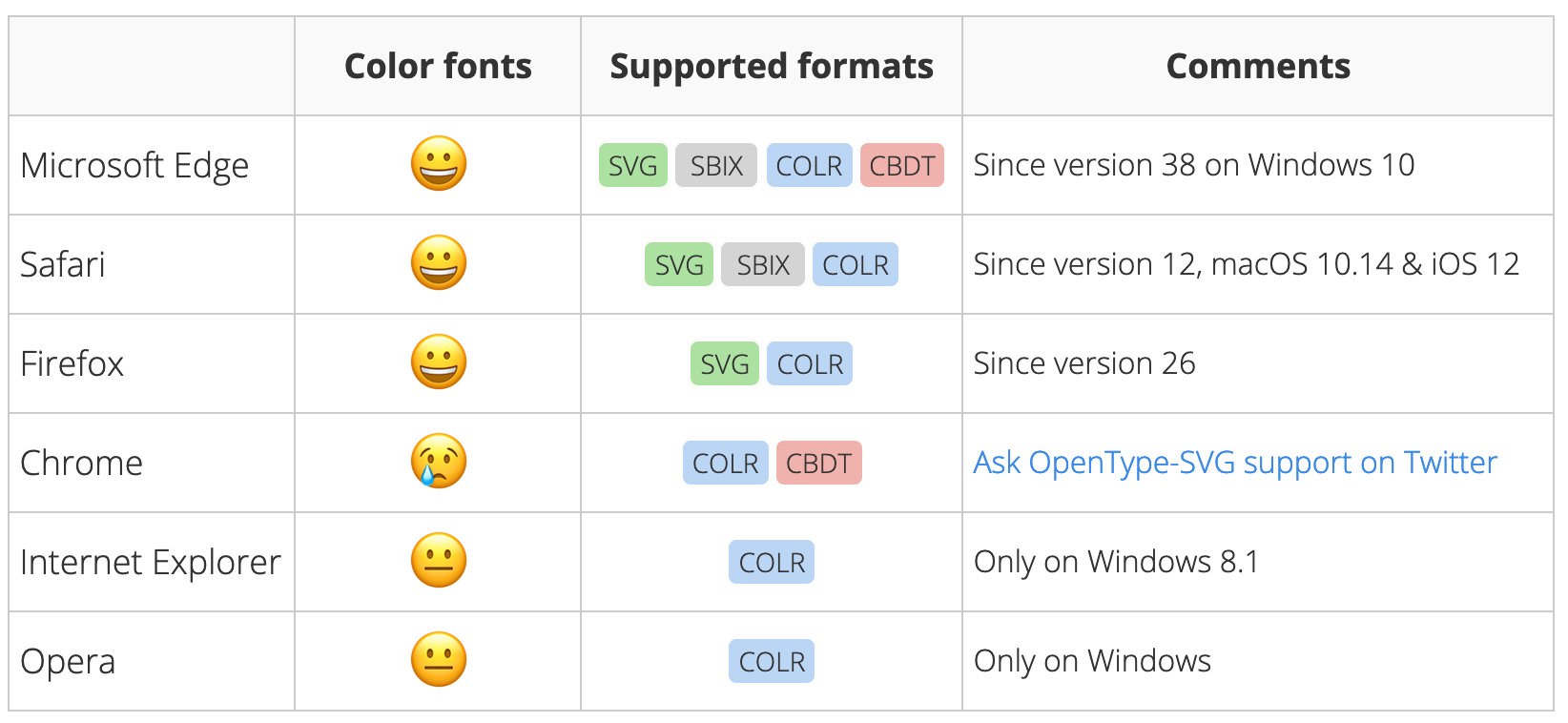
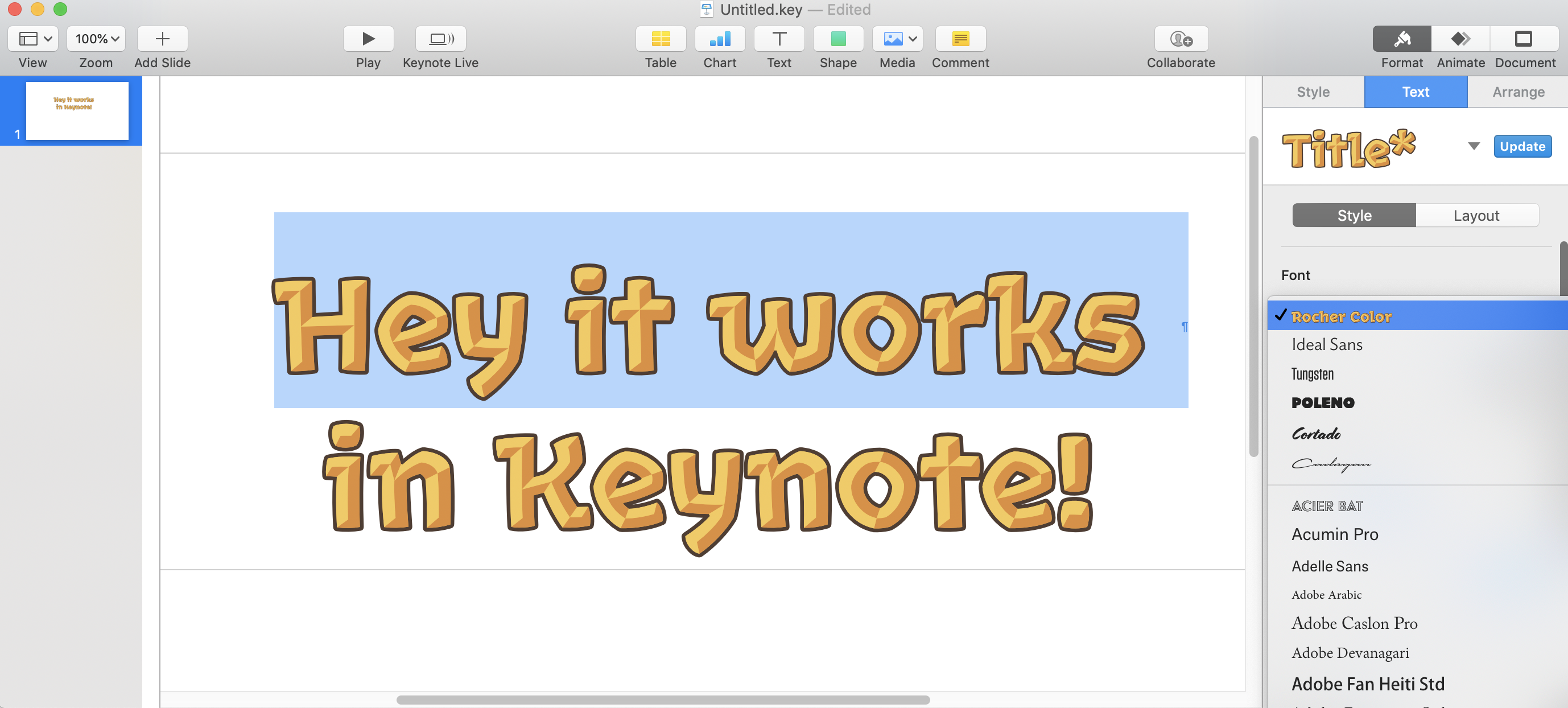
Harbor Type recently put out Rocher Color, a free color font. Yes, color font. That’s a thing. And Rocher Color is actually a color font and a variable font.
Support seems kinda decent to me, but it’s complicated because there are a bunch of different kinds all with different support across browsers.
The other story is that they are, well, kinda humongous, size-wise. The woff2 file is probably the most relevant here as it’s such a modern feature anyway. The download from the site (RocherColorGX.woff2) clocks in at 178KB. Not something you’d just toss on a page for a single headline probably, considering it’s not just weight with fonts — but you’re also always fighting the FOUT/FOIT battle.
I think to justify using a beefy color font like this you’d…
Use it quite a bit around the site for dynamic headlines
Customize the colors to be perfect for you (ahead of time)
Make use of the fancy variable font features like the bevel and shadow adjustments (on the fly)
If you don’t see yourself doing those things, you might be better off using with these shapes all expanded out to paths. You could still use this font to make the SVG, assuming your design tool supports this kind of font. You won’t get text wrapping or anything, but the file size and loading speed will be much faster. Or you could even use a graphic format like PNG/WebP, and there’s no terrible shame in that if you still use a semantic element for the headline (visually hidden, of course). You won’t get find-on-page highlighting or select-ability, but might be an OK trade-off for a one-off.
Kenneth Ormandy has rounded up some more interesting typographic experiments in CSS. In his post, he mentions Diana Smith’s Pure CSS Font, which builds itself from empty elements and all kinds of fancy CSS trickery to draw the shapes.
The point of this project is right in the header:
For private, SEO-hidden, CAPTCHA-friendly unselectable text. Deter plagiarism and spambots!
Hidden for assistive technology too, so careful there, but it seems to me this project is more about exploring possibilities. After all, it’s the letters that power Diana’s remarkable CSS paintings like Zigaro.
Don’t miss Kenneth’s post, as he links to lots more fascinating examples of people being typographers with very unconventional tools. Kenneth takes a crack himself with this fascinating little experiment, using a button there to expose the tricks within:
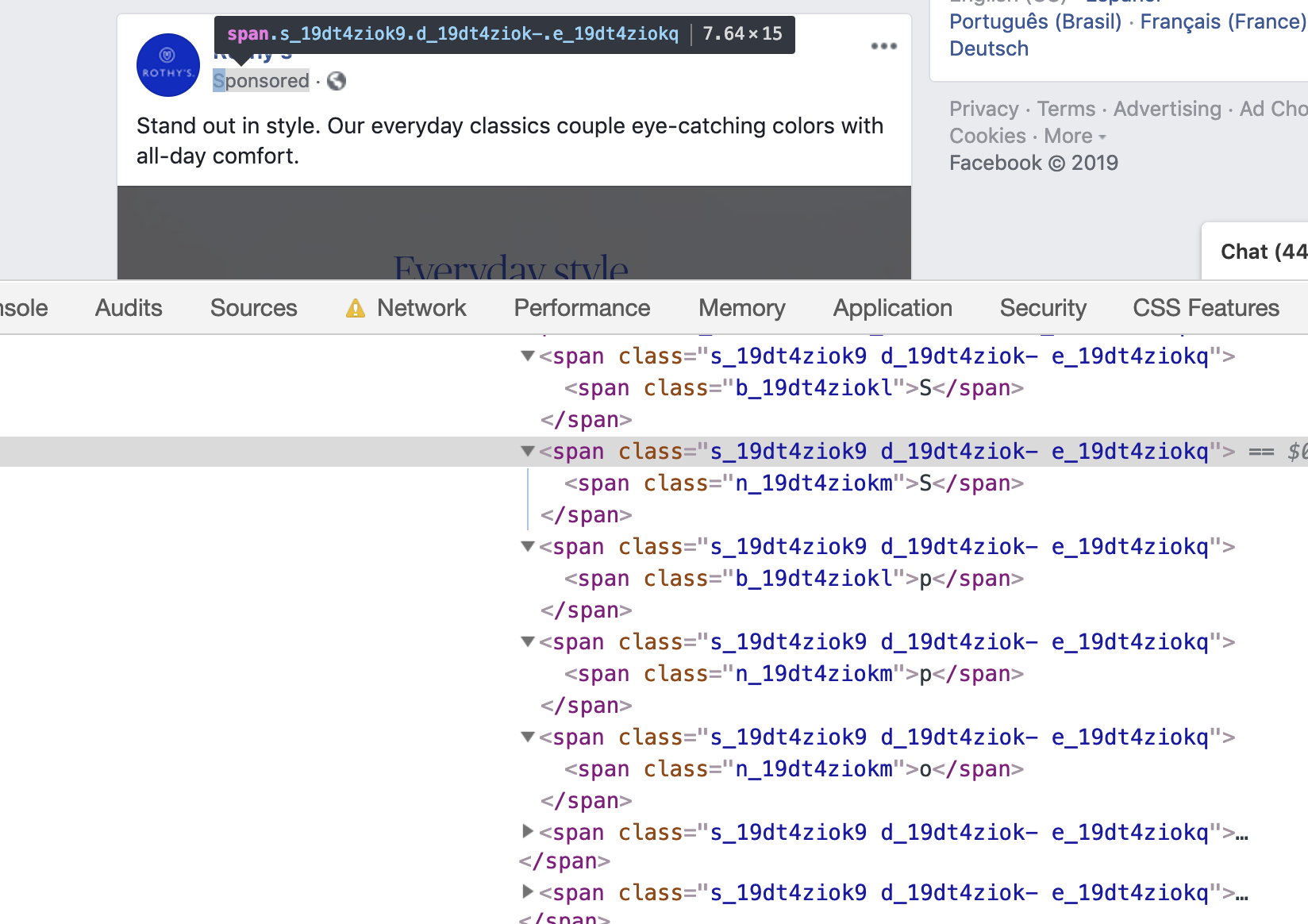
“Why do I need a 4Ghz quadcore to run facebook?” This is why. A single word split up into 11 HTML DOM elements to avoid adblockers. pic.twitter.com/Zv4RfInrL0
I popped over to Facebook to verify that and what I saw was a different and even more nested mess:
They are trying to fight your ad blocker browser extension. Of course they are. I’m sure at their scale not doing this means losing millions of dollars. But I wonder if it’s really losing money when you factor in losing trust, and potentially losing people on the platform entirely.
It just feels so rude, doesn’t it? Like a user specifically installs technology onto their computer in order to exert some control over what they allow onto their computers and into their eyeballs. And they are saying, “No, we do not respect that choice. We are going to fight your technology with our technology and force feed this stuff onto your computer and your eyeballs.” Doesn’t sit right.
I’m not unaware that ad blockers have ad adverse effect on the ability for websites to make money. That’s quite literally how I make money. But I don’t want to do it fighting and at the expense of breaking trust. I want to do it gracefully while building trust.
Anyway.
I wonder what writing HTML to help ad blockers would look like instead:
This span-based lettering stuff makes me think of libraries like Splitting.js and Lettering.js that break up text into individual s for styling reasons.
Turns out that doesn’t affect on-page search (i.e. if you search for “dog,” you’ll find dog), but it does affect some screen readers in that they will treat each letter distinctly, which can result in pretty awful audio output, like pauses between letters where you wouldn’t expect or want them.
Have you seen Diana Smith’s CSS drawings? Stunning. These far transcend the CSS drawings that sort of crudely replicate a flat SVG scene, like I might attempt. We were lucky enough for her to post some of her CSS drawing techniques here last year.
Well, Diana has also listed the top five CSS properties she uses to get these masterpieces done, and they are surprising in their plainness:
border-radius
box-shadow
transform
gradients
overflow
…but of course, layered in trickery!
… for custom rounded elements that are meant to mimic organic objects like faces, it is imperative that you become intimately familiar with all eight available parameters in the border-radius property.
Diana shows her famous Francine drawing with each of the most used properties turned off:
Without border-radiusWithout transform
Be sure to check out this VICE interview she did as well. She covers gems like the fact that Francine was inspired by American Dad (lol) and that the cross-browser fallbacks are both a fascinating and interesting mess.
You’ve probably heard of Node.js as being an “asynchronous JavaScript runtime built on Chrome’s V8 JavaScript engine”, and that it “uses an event-driven, non-blocking I/O model that makes it lightweight and efficient”. But for some, that is not the greatest of explanations.
What is Node in the first place? What exactly does it mean for Node to be “asynchronous”, and how does that differ from “synchronous”? What is the meaning “event-driven” and “non-blocking” anyway, and how does Node fit into the bigger picture of applications, Internet networks, and servers?
We’ll attempt to answer all of these questions and more throughout this series as we take an in-depth look at the inner workings of Node, learn about the HyperText Transfer Protocol, APIs, and JSON, and build our very own Bookshelf API utilizing MongoDB, Express, Lodash, Mocha, and Handlebars.
What Is Node.js
Node is only an environment, or runtime, within which to run normal JavaScript (with minor differences) outside of the browser. We can use it to build desktop applications (with frameworks like Electron), write web or app servers, and more.
Blocking/Non-Blocking And Synchronous/Asynchronous
Suppose we are making a database call to retrieve properties about a user. That call is going to take time, and if the request is “blocking”, then that means it will block the execution of our program until the call is complete. In this case, we made a “synchronous” request since it ended up blocking the thread.
So, a synchronous operation blocks a process or thread until that operation is complete, leaving the thread in a “wait state”. An asynchronous operation, on the other hand, is non-blocking. It permits execution of the thread to proceed regardless of the time it takes for the operation to complete or the result it completes with, and no part of the thread falls into a wait state at any point.
Let’s look at another example of a synchronous call that blocks a thread. Suppose we are building an application that compares the results of two Weather APIs to find their percent difference in temperature. In a blocking manner, we make a call to Weather API One and wait for the result. Once we get a result, we call Weather API Two and wait for its result. Don’t worry at this point if you are not familiar with APIs. We’ll be covering them in an upcoming section. For now, just think of an API as the medium through which two computers may communicate with one another.
Time progression of synchronous blocking operations (Large preview)
Allow me to note, it’s important to recognize that not all synchronous calls are necessarily blocking. If a synchronous operation can manage to complete without blocking the thread or causing a wait state, it was non-blocking. Most of the time, synchronous calls will be blocking, and the time they take to complete will depend on a variety of factors, such as the speed of the API’s servers, the end user’s internet connection download speed, etc.
In the case of the image above, we had to wait quite a while to retrieve the first results from API One. Thereafter, we had to wait equally as long to get a response from API Two. While waiting for both responses, the user would notice our application hang — the UI would literally lock up — and that would be bad for User Experience.
In the case of a non-blocking call, we’d have something like this:
Time progression of asynchronous non-blocking operations (Large preview)
You can clearly see how much faster we concluded execution. Rather than wait on API One and then wait on API Two, we could wait for both of them to complete at the same time and achieve our results almost 50% faster. Notice, once we called API One and started waiting for its response, we also called API Two and began waiting for its response at the same time as One.
At this point, before moving into more concrete and tangible examples, it is important to mention that, for ease, the term “Synchronous” is generally shortened to “Sync”, and the term “Asynchronous” is generally shortened to “Async”. You will see this notation used in method/function names.
Callback Functions
You might be wondering, “if we can handle a call asynchronously, how do we know when that call is finished and we have a response?” Generally, we pass in as an argument to our async method a callback function, and that method will “call back” that function at a later time with a response. I’m using ES5 functions here, but we’ll update to ES6 standards later.
function asyncAddFunction(a, b, callback) {
callback(a + b); //This callback is the one passed in to the function call below.
}
asyncAddFunction(2, 4, function(sum) {
//Here we have the sum, 2 + 4 = 6.
});
Such a function is called a “Higher-Order Function” since it takes a function (our callback) as an argument. Alternatively, a callback function might take in an error object and a response object as arguments, and present them when the async function is complete. We’ll see this later with Express. When we called asyncAddFunction(...), you’ll notice we supplied a callback function for the callback parameter from the method definition. This function is an anonymous function (it does not have a name) and is written using the Expression Syntax. The method definition, on the other hand, is a function statement. It’s not anonymous because it actually has a name (that being “asyncAddFunction”).
Some may note confusion since, in the method definition, we do supply a name, that being “callback”. However, the anonymous function passed in as the third parameter to asyncAddFunction(...) does not know about the name, and so it remains anonymous. We also can’t execute that function at a later point by name, we’d have to go through the async calling function again to fire it.
As an example of a synchronous call, we can use the Node.js readFileSync(...) method. Again, we’ll be moving to ES6+ later.
var fs = require('fs');
var data = fs.readFileSync('/example.txt'); // The thread will be blocked here until complete.
If we were doing this asynchronously, we’d pass in a callback function which would fire when the async operation was complete.
var fs = require('fs');
var data = fs.readFile('/example.txt', function(err, data) { //Move on, this will fire when ready.
if(err) return console.log('Error: ', err);
console.log('Data: ', data); // Assume var data is defined above.
});
// Keep executing below, don't wait on the data.
If you have never seen return used in that manner before, we are just saying to stop function execution so we don’t print the data object if the error object is defined. We could also have just wrapped the log statement in an else clause.
Like our asyncAddFunction(...), the code behind the fs.readFile(...) function would be something along the lines of:
function readFile(path, callback) {
// Behind the scenes code to read a file stream.
// The data variable is defined up here.
callback(undefined, data); //Or, callback(err, undefined);
}
Allow us to look at one last implementation of an async function call. This will help to solidify the idea of callback functions being fired at a later point in time, and it will help us to understand the execution of a typical Node.js program.
setTimeout(function {
// ...
}, 1000);
The setTimeout(...) method takes a callback function for the first parameter which will be fired after the number of milliseconds specified as the second argument has occurred.
Let’s look at a more complex example:
console.log('Initiated program.');
setTimeout(function {
console.log('3000 ms (3 sec) have passed.');
}, 3000);
setTimeout(function {
console.log('0 ms (0 sec) have passed.');
}, 0);
setTimeout(function {
console.log('1000 ms (1 sec) has passed.');
}, 1000);
console.log('Terminated program');
The output we receive is:
Initiated program.
Terminated program.
0 ms (0 sec) have passed.
1000 ms (1 sec) has passed.
3000 ms (3 sec) have passed.
You can see that the first log statement runs as expected. Instantaneously, the last log statement prints to the screen, for that happens before 0 seconds have surpassed after the second setTimeout(...). Immediately thereafter, the second, third, and first setTimeout(...) methods execute.
If Node.js was not non-blocking, we’d see the first log statement, wait 3 seconds to see the next, instantaneously see the third (the 0-second setTimeout(...), and then have to wait one more second to see the last two log statements. The non-blocking nature of Node makes all timers start counting down from the moment the program is executed, rather than the order in which they are typed. You may want to look into Node APIs, the Callstack, and the Event Loop for more information about how Node works under the hood.
It is important to note that just because you see a callback function does not necessarily mean there is an asynchronous call in the code. We called the asyncAddFunction(…) method above “async” because we are assuming the operation takes time to complete — such as making a call to a server. In reality, the process of adding two numbers is not async, and so that would actually be an example of using a callback function in a fashion that does not actually block the thread.
Promises Over Callbacks
Callbacks can quickly become messy in JavaScript, especially multiple nested callbacks. We are familiar with passing a callback as an argument to a function, but Promises allow us to tack, or attach, a callback to an object returned from a function. This would allow us to handle multiple async calls in a more elegant manner.
As an example, suppose we are making an API call, and our function, not so uniquely named ‘makeAPICall(...)‘, takes a URL and a callback.
Our function, makeAPICall(...), would be defined as
function makeAPICall(path, callback) {
// Attempt to make API call to path argument.
// ...
callback(undefined, res); // Or, callback(err, undefined); depending upon the API's response.
}
If we wanted to make another API call using the response from the first, we would have to nest both callbacks. Suppose I need to inject the userName property from the res1 object into the path of the second API call. We would have:
Note: The ES6+ method to inject the res1.userName property rather than string concatenation would be to use “Template Strings”. That way, rather than encapsulate our string in quotes (‘, or “), we would use backticks (), located beneath the Escape key on your keyboard. Then, we would use the notation ${} to embed any JS expression inside the brackets. In the end, our earlier path would be: /newExample/${res.UserName}, wrapped in backticks.
It is clear to see that this method of nesting callbacks can quickly become quite inelegant, so-called the “JavaScript Pyramid of Doom”. Jumping in, if we were using promises rather than callbacks, we could refactor our code from the first example as such:
The first argument to the then() function is our success callback, and the second argument is our failure callback. Alternatively, we could lose the second argument to .then(), and call .catch() instead. Arguments to .then() are optional, and calling .catch() would be equivalent to .then(successCallback, null).
It is important to note that we can’t just tack a .then() call on to any function and expect it to work. The function we are calling has to actually return a promise, a promise that will fire the .then() when that async operation is complete. In this case, makeAPICall(...) will do it’s thing, firing either the then() block or the catch() block when completed.
To make makeAPICall(...) return a Promise, we assign a function to a variable, where that function is the Promise constructor. Promises can be either fulfilled or rejected, where fulfilled means that the action relating to the promise completed successfully, and rejected meaning the opposite. Once the promise is either fulfilled or rejected, we say it has settled, and while waiting for it to settle, perhaps during an async call, we say that the promise is pending.
The Promise constructor takes in one callback function as an argument, which receives two parameters — resolve and reject, which we will call at a later point in time to fire either the success callback in .then(), or the .then() failure callback, or .catch(), if provided.
Here is an example of what this looks like:
var examplePromise = new Promise(function(resolve, reject) {
// Do whatever we are going to do and then make the appropiate call below:
resolve('Happy!'); // — Everything worked.
reject('Sad!'); // — We noticed that something went wrong.
}):
Then, we can use:
examplePromise.then(/* Both callback functions in here */);
// Or, the success callback in .then() and the failure callback in .catch().
Notice, however, that examplePromise can’t take any arguments. That kind of defeats the purpose, so we can return a promise instead.
function makeAPICall(path) {
return new Promise(function(resolve, reject) {
// Make our async API call here.
if (/* All is good */) return resolve(res); //res is the response, would be defined above.
else return reject(err); //err is error, would be defined above.
});
}
Promises really shine to improve the structure, and subsequently, elegance, of our code with the concept of “Promise Chaining”. This would allow us to return a new Promise inside a .then() clause, so we could attach a second .then() thereafter, which would fire the appropriate callback from the second promise.
Refactoring our multi API URL call above with Promises, we get:
makeAPICall('/example').then(function(res) { // First response callback. Fires on success to '/example' call.
return makeAPICall(`/newExample/${res.UserName}`); // Returning new call allows for Promise Chaining.
}, function(err) { // First failure callback. Fires if there is a failure calling with '/example'.
console.log('Error:', err);
}).then(function(res) { // Second response callback. Fires on success to returned '/newExample/...' call.
console.log(res);
}, function(err) { // Second failure callback. Fire if there is a failure calling with '/newExample/...'
console.log('Error:', err);
});
Notice that we first call makeAPICall('/example'). That returns a promise, and so we attach a .then(). Inside that then(), we return a new call to makeAPICall(...), which, in and of itself, as seen earlier, returns a promise, permitting us chain on a new .then() after the first.
Like above, we can restructure this for readability, and remove the failure callbacks for a generic catch() all clause. Then, we can follow the DRY Principle (Don’t Repeat Yourself), and only have to implement error handling once.
makeAPICall('/example')
.then(function(res) { // Like earlier, fires with success and response from '/example'.
return makeAPICall(`/newExample/${res.UserName}`); // Returning here lets us chain on a new .then().
})
.then(function(res) { // Like earlier, fires with success and response from '/newExample'.
console.log(res);
})
.catch(function(err) { // Generic catch all method. Fires if there is an err with either earlier call.
console.log('Error: ', err);
});
Note that the success and failure callbacks in .then() only fire for the status of the individual Promise that .then() corresponds to. The catch block, however, will catch any errors that fire in any of the .then()s.
ES6 Const vs. Let
Throughout all of our examples, we have been employing ES5 functions and the old var keyword. While millions of lines of code still run today employing those ES5 methods, it is useful to update to current ES6+ standards, and we’ll refactor some of our code above. Let’s start with const and let.
You might be used to declaring a variable with the var keyword:
var pi = 3.14;
With ES6+ standards, we could make that either
let pi = 3.14;
or
const pi = 3.14;
where const means “constant” — a value that cannot be reassigned to later. (Except for object properties — we’ll cover that soon. Also, variables declared const are not immutable, only the reference to the variable is.)
In old JavaScript, block scopes, such as those in if, while, {}. for, etc. did not affect var in any way, and this is quite different to more statically typed languages like Java or C++. That is, the scope of var is the entire enclosing function — and that could be global (if placed outside a function), or local (if placed within a function). To demonstrate this, see the following example:
function myFunction() {
var num = 5;
console.log(num); // 5
console.log('--');
for(var i = 0; i
Output:
5
---
0
1 2 3 ... 7 8 9
---
9
10
The important thing to notice here is that defining a new var num inside the for scope directly affected the var num outside and above the for. This is because var‘s scope is always that of the enclosing function, and not a block.
Again, by default, var i inside for() defaults to myFunction‘s scope, and so we can access i outside the loop and get 10.
In terms of assigning values to variables, let is equivalent to var, it’s just that let has block scoping, and so the anomalies that occurred with var above will not happen.
function myFunction() {
let num = 5;
console.log(num); // 5
for(let i = 0; i
Looking at the const keyword, you can see that we attain an error if we try to reassign to it:
const c = 299792458; // Fact: The constant "c" is the speed of light in a vacuum in meters per second.
c = 10; // TypeError: Assignment to constant variable.
Things become interesting when we assign a const variable to an object:
const myObject = {
name: 'Jane Doe'
};
// This is illegal: TypeError: Assignment to constant variable.
myObject = {
name: 'John Doe'
};
// This is legal. console.log(myObject.name) -> John Doe
myObject.name = 'John Doe';
As you can see, only the reference in memory to the object assigned to a const object is immutable, not the value its self.
ES6 Arrow Functions
You might be used to creating a function like this:
function printHelloWorld() {
console.log('Hello, World!');
}
Suppose we have a simple function that returns the square of a number:
const squareNumber = (x) => {
return x * x;
}
squareNumber(5); // We can call an arrow function like an ES5 functions. Returns 25.
You can see that, just like with ES5 functions, we can take in arguments with parentheses, we can use normal return statements, and we can call the function just like any other.
It’s important to note that, while parentheses are required if our function takes no arguments (like with printHelloWorld() above), we can drop the parentheses if it only takes one, so our earlier squareNumber() method definition can be rewritten as:
const squareNumber = x => { // Notice we have dropped the parentheses for we only take in one argument.
return x * x;
}
Whether you choose to encapsulate a single argument in parentheses or not is a matter of personal taste, and you will likely see developers use both methods.
Finally, if we only want to implicitly return one expression, as with squareNumber(...) above, we can put the return statement in line with the method signature:
const squareNumber = x => x * x;
That is,
const test = (a, b, c) => expression
is the same as
const test = (a, b, c) => { return expression }
Note, when using the above shorthand to implicitly return an object, things become obscure. What stops JavaScript from believing the brackets within which we are required to encapsulate our object is not our function body? To get around this, we wrap the object’s brackets in parentheses. This explicitly lets JavaScript know that we are indeed returning an object, and we are not just defining a body.
const test = () => ({ pi: 3.14 }); // Spaces between brackets are a formality to make the code look cleaner.
To help solidify the concept of ES6 functions, we’ll refactor some of our earlier code allowing us to compare the differences between both notations.
asyncAddFunction(...), from above, could be refactored from:
function asyncAddFunction(a, b, callback){
callback(a + b);
}
const aysncAddFunction = (a, b, callback) => callback(a + b); // This will return callback(a + b).
When calling the function, we could pass an arrow function in for the callback:
asyncAddFunction(10, 12, sum => { // No parentheses because we only take one argument.
console.log(sum);
}
It is clear to see how this method improves code readability. To show you just one case, we can take our old ES5 Promise based example above, and refactor it to use arrow functions.
Now, there are some caveats with arrow functions. For one, they do not bind a this keyword. Suppose I have the following object:
const Person = {
name: 'John Doe',
greeting: () => {
console.log(`Hi. My name is ${this.name}.`);
}
}
You might expect a call to Person.greeting() will return “Hi. My name is John Doe.” Instead, we get: “Hi. My name is undefined.” That is because arrow functions do not have a this, and so attempting to use this inside an arrow function defaults to the this of the enclosing scope, and the enclosing scope of the Person object is window, in the browser, or module.exports in Node.
To prove this, if we use the same object again, but set the name property of the global this to something like ‘Jane Doe’, then this.name in the arrow function returns ‘Jane Doe’, because the global this is within the enclosing scope, or is the parent of the Person object.
this.name = 'Jane Doe';
const Person = {
name: 'John Doe',
greeting: () => {
console.log(`Hi. My name is ${this.name}.`);
}
}
Person.greeting(); // Hi. My name is Jane Doe
This is known as ‘Lexical Scoping’, and we can get around it by using the so-called ‘Short Syntax’, which is where we lose the colon and the arrow as to refactor our object as such:
const Person = {
name: 'John Doe',
greeting() {
console.log(`Hi. My name is ${this.name}.`);
}
}
Person.greeting() //Hi. My name is John Doe.
ES6 Classes
While JavaScript never supported classes, you could always emulate them with objects like the above. EcmaScript 6 provides support for classes using the class and new keywords:
class Person {
constructor(name) {
this.name = name;
}
greeting() {
console.log(`Hi. My name is ${this.name}.`);
}
}
const person = new Person(‘John');
person.greeting(); // Hi. My name is John.
The constructor function gets called automatically when using the new keyword, into which we can pass arguments to initially set up the object. This should be familiar to any reader who has experience with more statically typed object-oriented programming languages like Java, C++, and C#.
Without going into too much detail about OOP concepts, another such paradigm is “inheritance”, which is to allow one class to inherit from another. A class called Car, for example, will be very general — containing such methods as “stop”, “start”, etc., as all cars need. A sub-set of the class called SportsCar, then, might inherit fundamental operations from Car and override anything it needs custom. We could denote such a class as follows:
class Car {
constructor(licensePlateNumber) {
this.licensePlateNumber = licensePlateNumber;
}
start() {}
stop() {}
getLicensePlate() {
return this.licensePlateNumber;
}
// …
}
class SportsCar extends Car {
constructor(engineRevCount, licensePlateNumber) {
super(licensePlateNumber); // Pass licensePlateNumber up to the parent class.
this.engineRevCount = engineRevCount;
}
start() {
super.start();
}
stop() {
super.stop();
}
getLicensePlate() {
return super.getLicensePlate();
}
getEngineRevCount() {
return this.engineRevCount;
}
}
You can clearly see that the super keyword allows us to access properties and methods from the parent, or super, class.
JavaScript Events
An Event is an action that occurs to which you have the ability to respond. Suppose you are building a login form for your application. When the user presses the “submit” button, you can react to that event via an “event handler” in your code — typically a function. When this function is defined as the event handler, we say we are “registering an event handler”. The event handler for the submit button click will likely check the formatting of the input provided by the user, sanitize it to prevent such attacks as SQL Injections or Cross Site Scripting (please be aware that no code on the client-side can ever be considered safe. Always sanitize data on the server — never trust anything from the browser), and then check to see if that username and password combination exits within a database to authenticate a user and serve them a token.
Since this is an article about Node, we’ll focus on the Node Event Model.
We can use the events module from Node to emit and react to specific events. Any object that emits an event is an instance of the EventEmitter class.
We can emit an event by calling the emit() method and we listen for that event via the on() method, both of which are exposed through the EventEmitter class.
const EventEmitter = require('events');
const myEmitter = new EventEmitter();
With myEmitter now an instance of the EventEmitter class, we can access emit() and on():
const EventEmitter = require('events');
const myEmitter = new EventEmitter();
myEmitter.on('someEvent', () => {
console.log('The "someEvent" event was fired (emitted)');
});
myEmitter.emit('someEvent'); // This will call the callback function above.
The second parameter to myEmitter.on() is the callback function that will fire when the event is emitted — this is the event handler. The first parameter is the name of the event, which can be anything we like, although the camelCase naming convention is recommended.
Additionally, the event handler can take any number of arguments, which are passed down when the event is emitted:
const EventEmitter = require('events');
const myEmitter = new EventEmitter();
myEmitter.on('someEvent', (data) => {
console.log(`The "someEvent" event was fired (emitted) with data: ${data}`);
});
myEmitter.emit('someEvent', 'This is the data payload');
By using inheritance, we can expose the emit() and on() methods from ‘EventEmitter’ to any class. This is done by creating a Node.js class, and using the extends reserved keyword to inherit the properties available on EventEmitter:
const EventEmitter = require('events');
class MyEmitter extends EventEmitter {
// This is my class. I can emit events from a MyEmitter object.
}
Suppose we are building a vehicle collision notification program that receives data from gyroscopes, accelerometers, and pressure gauges on the car’s hull. When a vehicle collides with an object, those external sensors will detect the crash, executing the collide(...) function and passing to it the aggregated sensor data as a nice JavaScript Object. This function will emit a collision event, notifying the vendor of the crash.
This is a convoluted example for we could just put the code within the event handler inside the collide function of the class, but it demonstrates how the Node Event Model functions nonetheless. Note that some tutorials will show the util.inherits() method of permitting an object to emit events. That has been deprecated in favor of ES6 Classes and extends.
The Node Package Manager
When programming with Node and JavaScript, it’ll be quite common to hear about npm. Npm is a package manager which does just that — permits the downloading of third-party packages that solve common problems in JavaScript. Other solutions, such as Yarn, Npx, Grunt, and Bower exist as well, but in this section, we’ll focus only on npm and how you can install dependencies for your application through a simple Command Line Interface (CLI) using it.
Let’s start simple, with just npm. Visit the NpmJS homepage to view all of the packages available from NPM. When you start a new project that will depend on NPM Packages, you’ll have to run npm init through the terminal in your project’s root directory. You will be asked a series of questions which will be used to create a package.json file. This file stores all of your dependencies — modules that your application depends on to function, scripts — pre-defined terminal commands to run tests, build the project, start the development server, etc., and more.
To install a package, simply run npm install [package-name] --save. The save flag will ensure the package and its version is logged in the package.json file. Since npm version 5, dependencies are saved by default, so --save may be omitted. You will also notice a new node_modules folder, containing the code for that package you just installed. This can also be shortened to just npm i [package-name]. As a helpful note, the node_modules folder should never be included in a GitHub repository due to its size. Whenever you clone a repo from GitHub (or any other version management system), be sure to run the command npm install to go out and fetch all the packages defined in the package.json file, creating the node_modules directory automatically. You can also install a package at a specific version: npm i [package-name]@1.10.1 --save, for example.
Removing a package is similar to installing one: npm remove [package-name].
You can also install a package globally. This package will be available across all projects, not just the one your working on. You do this with the -g flag after npm i [package-name]. This is commonly used for CLIs, such as Google Firebase and Heroku. Despite the ease this method presents, it is generally considered bad practice to install packages globally, for they are not saved in the package.json file, and if another developer attempts to use your project, they won’t attain all the required dependencies from npm install.
APIs & JSON
APIs are a very common paradigm in programming, and even if you are just starting out in your career as a developer, APIs and their usage, especially in web and mobile development, will likely come up more often than not.
An API is an Application Programming Interface, and it is basically a method by which two decoupled systems may communicate with each other. In more technical terms, an API permits a system or computer program (usually a server) to receive requests and send appropriate responses (to a client, also known as a host).
Suppose you are building a weather application. You need a way to geocode a user’s address into a latitude and longitude, and then a way to attain the current or forecasted weather at that particular location.
As a developer, you want to focus on building your app and monetizing it, not putting the infrastructure in place to geocode addresses or placing weather stations in every city.
Luckily for you, companies like Google and OpenWeatherMap have already put that infrastructure in place, you just need a way to talk to it — that is where the API comes in. While, as of now, we have developed a very abstract and ambiguous definition of the API, bear with me. We’ll be getting to tangible examples soon.
Now, it costs money for companies to develop, maintain, and secure that aforementioned infrastructure, and so it is common for corporations to sell you access to their API. This is done with that is known as an API key, a unique alphanumeric identifier associating you, the developer, with the API. Every time you ask the API to send you data, you pass along your API key. The server can then authenticate you and keep track of how many API calls you are making, and you will be charged appropriately. The API key also permits Rate-Limiting or API Call Throttling (a method of throttling the number of API calls in a certain timeframe as to not overwhelm the server, preventing DOS attacks — Denial of Service). Most companies, however, will provide a free quota, giving you, as an example, 25,000 free API calls a day before charging you.
Up to this point, we have established that an API is a method by which two computer programs can communicate with each other. If a server is storing data, such as a website, and your browser makes a request to download the code for that site, that was the API in action.
Let us look at a more tangible example, and then we’ll look at a more real-world, technical one. Suppose you are eating out at a restaurant for dinner. You are equivalent to the client, sitting at the table, and the chef in the back is equivalent to the server.
Since you will never directly talk to the chef, there is no way for him/her to receive your request (for what order you would like to make) or for him/her to provide you with your meal once you order it. We need someone in the middle. In this case, it’s the waiter, analogous to the API. The API provides a medium with which you (the client) may talk to the server (the chef), as well as a set of rules for how that communication should be made (the menu — one meal is allowed two sides, etc.)
Now, how do you actually talk to the API (the waiter)? You might speak English, but the chef might speak Spanish. Is the waiter expected to know both languages to translate? What if a third person comes in who only speaks Mandarin? What then? Well, all clients and servers have to agree to speak a common language, and in computer programming, that language is JSON, pronounced JAY-sun, and it stands for JavaScript Object Notation.
At this point, we don’t quite know what JSON looks like. It’s not a computer programming language, it’s just, well, a language, like English or Spanish, that everyone (everyone being computers) understands on a guaranteed basis. It’s guaranteed because it’s a standard, notably RFC 8259, the JavaScript Object Notation (JSON) Data Interchange Format by the Internet Engineering Task Force (IETF).
Even without formal knowledge of what JSON actually is and what it looks like (we’ll see in an upcoming article in this series), we can go ahead introduce a technical example operating on the Internet today that employs APIs and JSON. APIs and JSON are not just something you can choose to use, it’s not equivalent to one out of a thousand JavaScript frameworks you can pick to do the same thing. It is THE standard for data exchange on the web.
Suppose you are building a travel website that compares prices for aircraft, rental car, and hotel ticket prices. Let us walk through, step-by-step, on a high level, how we would build such an application. Of course, we need our User Interface, the front-end, but that is out of scope for this article.
We want to provide our users with the lowest price booking method. Well, that means we need to somehow attain all possible booking prices, and then compare all of the elements in that set (perhaps we store them in an array) to find the smallest element (known as the infimum in mathematics.)
How will we get this data? Well, suppose all of the booking sites have a database full of prices. Those sites will provide an API, which exposes the data in those databases for use by you. You will call each API for each site to attain all possible booking prices, store them in your own array, find the lowest or minimum element of that array, and then provide the price and booking link to your user. We’ll ask the API to query its database for the price in JSON, and it will respond with said price in JSON to us. We can then use, or parse, that accordingly. We have to parse it because APIs will return JSON as a string, not the actual JavaScript data type of JSON. This might not make sense now, and that’s okay. We’ll be covering it more in a future article.
Also, note that just because something is called an API does not necessarily mean it operates on the web and sends and receives JSON. The Java API, for example, is just the list of classes, packages, and interfaces that are part of the Java Development Kit (JDK), providing programming functionality to the programmer.
Okay. We know we can talk to a program running on a server by way of an Application Programming Interface, and we know that the common language with which we do this is known as JSON. But in the web development and networking world, everything has a protocol. What do we actually do to make an API call, and what does that look like code-wise? That’s where HTTP Requests enter the picture, the HyperText Transfer Protocol, defining how messages are formatted and transmitted across the Internet. Once we have an understanding of HTTP (and HTTP verbs, you’ll see that in the next section), we can look into actual JavaScript frameworks and methods (like fetch()) offered by the JavaScript API (similar to the Java API), that actually allow us to make API calls.
HTTP And HTTP Requests
HTTP is the HyperText Transfer Protocol. It is the underlying protocol that determines how messages are formatted as they are transmitted and received across the web. Let’s think about what happens when, for example, you attempt to load the home page of Smashing Magazine in your web browser.
You type the website URL (Uniform Resource Locator) in the URL bar, where the DNS server (Domain Name Server, out of scope for this article) resolves the URL into the appropriate IP Address. The browser makes a request, called a GET Request, to the Web Server to, well, GET the underlying HTML behind the site. The Web Server will respond with a message such as “OK”, and then will go ahead and send the HTML down to the browser where it will be parsed and rendered accordingly.
There are a few things to note here. First, the GET Request, and then the “OK” response. Suppose you have a specific database, and you want to write an API to expose that database to your users. Suppose the database contains books the user wants to read (as it will in a future article in this series). Then there are four fundamental operations your user may want to perform on this database, that is, Create a record, Read a record, Update a record, or Delete a record, known collectively as CRUD operations.
Let’s look at the Read operation for a moment. Without incorrectly assimilating or conflating the notion of a web server and a database, that Read operation is very similar to your web browser attempting to get the site from the server, just as to read a record is to get the record from the database.
This is known as an HTTP Request. You are making a request to some server somewhere to get some data, and, as such, the request is appropriately named “GET”, capitalization being a standard way to denote such requests.
What about the Create portion of CRUD? Well, when talking about HTTP Requests, that is known as a POST request. Just as you might post a message on a social media platform, you might also post a new record to a database.
CRUD’s Update allows us to use either a PUT or PATCH Request in order to update a resource. HTTP’s PUT will either create a new record or will update/replace the old one.
Let’s look at this a bit more in detail, and then we’ll get to PATCH.
An API generally works by making HTTP requests to specific routes in a URL. Suppose we are making an API to talk to a DB containing a user’s booklist. Then we might be able to view those books at the URL .../books. A POST requests to .../books will create a new book with whatever properties you define (think id, title, ISBN, author, publishing data, etc.) at the .../books route. It doesn’t matter what the underlying data structure is that stores all the books at .../books right now. We just care that the API exposes that endpoint (accessed through the route) to manipulate data. The prior sentence was key: A POST request creates a new book at the ...books/ route. The difference between PUT and POST, then, is that PUT will create a new book (as with POST) if no such book exists, or, it will replace an existing book if the book already exists within that aforementioned data structure.
Suppose each book has the following properties: id, title, ISBN, author, hasRead (boolean).
Then to add a new book, as seen earlier, we would make a POST request to .../books. If we wanted to completely update or replace a book, we would make a PUT request to .../books/id where id is the ID of the book we want to replace.
While PUT completely replaces an existing book, PATCH updates something having to do with a specific book, perhaps modifying the hasRead boolean property we defined above — so we’d make a PATCH request to …/books/id sending along the new data.
It can be difficult to see the meaning of this right now, for thus far, we’ve established everything in theory but haven’t seen any tangible code that actually makes an HTTP request. We shall, however, get to that soon, covering GET in this article, ad the rest in a future article.
There is one last fundamental CRUD operation and it’s called Delete. As you would expect, the name of such an HTTP Request is “DELETE”, and it works much the same as PATCH, requiring the book’s ID be provided in a route.
We have learned thus far, then, that routes are specific URLs to which you make an HTTP Request, and that endpoints are functions the API provides, doing something to the data it exposes. That is, the endpoint is a programming language function located on the other end of the route, and it performs whatever HTTP Request you specified. We also learned that there exist such terms as POST, GET, PUT, PATCH, DELETE, and more (known as HTTP verbs) that actually specify what requests you are making to the API. Like JSON, these HTTP Request Methods are Internet standards as defined by the Internet Engineering Task Force (IETF), most notably, RFC 7231, Section Four: Request Methods, and RFC 5789, Section Two: Patch Method, where RFC is an acronym for Request for Comments.
So, we might make a GET request to the URL .../books/id where the ID passed in is known as a parameter. We could make a POST, PUT, or PATCH request to .../books to create a resource or to .../books/id to modify/replace/update a resource. And we can also make a DELETE request to .../books/id to delete a specific book.
A full list of HTTP Request Methods can be found here.
It is also important to note that after making an HTTP Request, we’ll receive a response. The specific response is determined by how we build the API, but you should always receive a status code. Earlier, we said that when your web browser requests the HTML from the web server, it’ll respond with “OK”. That is known as an HTTP Status Code, more specifically, HTTP 200 OK. The status code just specifies how the operation or action specified in the endpoint (remember, that’s our function that does all the work) completed. HTTP Status Codes are sent back by the server, and there are probably many you are familiar with, such as 404 Not Found (the resource or file could not be found, this would be like making a GET request to .../books/id where no such ID exists.)
A complete list of HTTP Status Codes can be found here.
MongoDB
MongoDB is a non-relational, NoSQL database similar to the Firebase Real-time Database. You will talk to the database via a Node package such as the MongoDB Native Driver or Mongoose.
In MongoDB, data is stored in JSON, which is quite different from relational databases such as MySQL, PostgreSQL, or SQLite. Both are called databases, with SQL Tables called Collections, SQL Table Rows called Documents, and SQL Table Columns called Fields.
We will use the MongoDB Database in an upcoming article in this series when we create our very first Bookshelf API. The fundamental CRUD Operations listed above can be performed on a MongoDB Database.
It’s recommended that you read through the MongoDB Docs to learn how to create a live database on an Atlas Cluster and make CRUD Operations to it with the MongoDB Native Driver. In the next article of this series, we will learn how to set up a local database and a cloud production database.
Building A Command Line Node Application
When building out an application, you will see many authors dump their entire code base at the beginning of the article, and then attempt to explain each line thereafter. In this text, I’ll take a different approach. I’ll explain my code line-by-line, building the app as we go. I won’t worry about modularity or performance, I won’t split the codebase into separate files, and I won’t follow the DRY Principle or attempt to make the code reusable. When just learning, it is useful to make things as simple as possible, and so that is the approach I will take here.
Let us be clear about what we are building. We won’t be concerned with user input, and so we won’t make use of packages like Yargs. We also won’t be building our own API. That will come in a later article in this series when we make use of the Express Web Application Framework. I take this approach as to not conflate Node.js with the power of Express and APIs since most tutorials do. Rather, I’ll provide one method (of many) by which to call and receive data from an external API which utilizes a third-party JavaScript library. The API we’ll be calling is a Weather API, which we’ll access from Node and dump its output to the terminal, perhaps with some formatting, known as “pretty-printing”. I’ll cover the entire process, including how to set up the API and attain API Key, the steps of which provide the correct results as of January 2019.
We’ll be using the OpenWeatherMap API for this project, so to get started, navigate to the OpenWeatherMap sign-up page and create an account with the form. Once logged in, find the API Keys menu item on the dashboard page (located over here). If you just created an account, you’ll have to pick a name for your API Key and hit “Generate”. It could take at least 2 hours for your new API Key to be functional and associated with your account.
Before we start building out the application, we’ll visit the API Documentation to learn how to format our API Key. In this project, we’ll be specifying a zip code and a country code to attain the weather information at that location.
From the docs, we can see that the method by which we do this is to provide the following URL:
For now, copy that URL into a new tab in your web browser, replacing the {YOUR_API_KEY} placeholder with the API Key you obtained earlier when you registered for an account.
The text you can see is actually JSON — the agreed upon language of the web as discussed earlier.
To inspect this further, hit Ctrl + Shift + I in Google Chrome to open the Chrome Developer tools, and then navigate to the Network tab. At present, there should be no data here.
The empty Google Chrome Developer Tools(Large preview)
To actually monitor network data, reload the page, and watch the tab be populated with useful information. Click the first link as depicted in the image below.
The populated Google Chrome Developer Tools (Large preview)
Once you click on that link, we can actually view HTTP specific information, such as the headers. Headers are sent in the response from the API (you can also, in some cases, send your own headers to the API, or you can even create your own custom headers (often prefixed with x-) to send back when building your own API), and just contain extra information that either the client or server may need.
In this case, you can see that we made an HTTP GET Request to the API, and it responded with an HTTP Status 200 OK. You can also see that the data sent back was in JSON, as listed under the “Response Headers” section.
Headers in the response from the API (Large preview)
If you hit the preview tab, you can actually view the JSON as a JavaScript Object. The text version you can see in your browser is a string, for JSON is always transmitted and received across the web as a string. That’s why we have to parse the JSON in our code, to get it into a more readable format — in this case (and in pretty much every case) — a JavaScript Object.
You can also use the Google Chrome Extension “JSON View” to do this automatically.
To start building out our application, I’ll open a terminal and make a new root directory and then cd into it. Once inside, I’ll create a new app.js file, run npm init to generate a package.json file with the default settings, and then open Visual Studio Code.
Thereafter, I’ll download Axios, verify it has been added to my package.json file, and note that the node_modules folder has been created successfully.
In the browser, you can see that we made a GET Request by hand by manually typing the proper URL into the URL Bar. Axios is what will allow me to do that inside of Node.
Starting now, all of the following code will be located inside of the app.js file, each snippet placed one after the other.
The first thing I’ll do is require the Axios package we installed earlier with
const axios = require('axios');
We now have access to Axios, and can make relevant HTTP Requests, via the axios constant.
Generally, our API calls will be dynamic — in this case, we might want to inject different zip codes and country codes into our URL. So, I’ll be creating constant variables for each part of the URL, and then put them together with ES6 Template Strings. First, we have the part of our URL that will never change as well as our API Key:
I’ll also assign our zip code and country code. Since we are not expecting user input and are rather hard coding the data, I’ll make these constant as well, although, in many cases, it will be more useful to use let.
All that is left to do is to actually use axios to make a GET Request to that URL. For that, we’ll use the get(url) method provided by axios.
axios.get(ENTIRE_API_URL)
axios.get(...) actually returns a Promise, and the success callback function will take in a response argument which will allow us to access the response from the API — the same thing you saw in the browser. I’ll also add a .catch() clause to catch any errors.
If we now run this code with node app.js in the terminal, you will be able to see the full response we get back. However, suppose you just want to see the temperature for that zip code — then most of that data in the response is not useful to you. Axios actually returns the response from the API in the data object, which is a property of the response. That means the response from the server is actually located at response.data, so let’s print that instead in the callback function: console.log(response.data).
Now, we said that web servers always deal with JSON as a string, and that is true. You might notice, however, that response.data is already an object (evident by running console.log(typeof response.data)) — we didn’t have to parse it with JSON.parse(). That is because Axios already takes care of this for us behind the scenes.
The output in the terminal from running console.log(response.data) can be formatted — “pretty-printed” — by running console.log(JSON.stringify(response.data, undefined, 2)). JSON.stringify() converts a JSON object into a string, and take in the object, a filter, and the number of characters by which to indent by when printing. You can see the response this provides:
Now, it is clear to see that the temperature we are looking for is located on the main property of the response.data object, so we can access it by calling response.data.main.temp. Let’s look at out application’s code up to now:
The temperature we get back is actually in Kelvin, which is a temperature scale generally used in Physics, Chemistry, and Thermodynamics due to the fact that it provides an “absolute zero” point, which is the temperature at which all thermal motion of all inner particles cease. We just need to convert this to Fahrenheit or Celcius with the formulas below:
F = K * 9/5 — 459.67 C = K — 273.15
Let’s update our success callback to print the new data with this conversion. We’ll also add in a proper sentence for the purposes of User Experience:
axios.get(ENTIRE_API_URL)
.then(response => {
// Getting the current temperature and the city from the response object.
const kelvinTemperature = response.data.main.temp;
const cityName = response.data.name;
const countryName = response.data.sys.country;
// Making K to F and K to C conversions.
const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67;
const celciusTemperature = kelvinTemperature — 273.15;
// Building the final message.
const message = (
`Right now, in
${cityName}, ${countryName} the current temperature is
${fahrenheitTemperature.toFixed(2)} deg F or
${celciusTemperature.toFixed(2)} deg C.`.replace(/s+/g, ' ')
);
console.log(message);
})
.catch(error => console.log('Error', error));
The parentheses around the message variable are not required, they just look nice — similar to when working with JSX in React. The backslashes stop the template string from formatting a new line, and the replace() String prototype method gets rid of white space using Regular Expressions (RegEx). The toFixed() Number prototype methods rounds a float to a specific number of decimal places — in this case, two.
With that, our final app.js looks as follows:
const axios = require('axios');
// API specific settings.
const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip=';
const API_KEY = 'Your API Key Here';
const LOCATION_ZIP_CODE = '90001';
const COUNTRY_CODE = 'us';
const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`;
axios.get(ENTIRE_API_URL)
.then(response => {
// Getting the current temperature and the city from the response object.
const kelvinTemperature = response.data.main.temp;
const cityName = response.data.name;
const countryName = response.data.sys.country;
// Making K to F and K to C conversions.
const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67;
const celciusTemperature = kelvinTemperature — 273.15;
// Building the final message.
const message = (
`Right now, in
${cityName}, ${countryName} the current temperature is
${fahrenheitTemperature.toFixed(2)} deg F or
${celciusTemperature.toFixed(2)} deg C.`.replace(/s+/g, ' ')
);
console.log(message);
})
.catch(error => console.log('Error', error));
Conclusion
We have learned a lot about how Node works in this article, from the differences between synchronous and asynchronous requests, to callback functions, to new ES6 features, events, package managers, APIs, JSON, and the HyperText Transfer Protocol, Non-Relational Databases, and we even built our own command line application utilizing most of that new found knowledge.
In future articles in this series, we’ll take an in-depth look at the Call Stack, the Event Loop, and Node APIs, we’ll talk about Cross-Origin Resource Sharing (CORS), and we’ll build a Full Stack Bookshelf API utilizing databases, endpoints, user authentication, tokens, server-side template rendering, and more.
From here, start building your own Node applications, read the Node documentation, go out and find interesting APIs or Node Modules and implement them yourself. The world is your oyster and you have at your fingertips access to the largest network of knowledge on the planet — the Internet. Use it to your advantage.
The holy grail of web design used to be a three-column layout where every column had equal height. Now, the holy grail is making it so anyone can design a website or app. Visual design apps abound, one of the big names in the Mac community right now is Framer X.
Framer X isn’t staying on only the Mac platform, though. The team has big plans, and it involves more than making it easier to push pixels. They reached out to WDD to see if we wanted to get a sneak peek of what’s coming next, and since I am one of the resident app nerds, I had the pleasure of interviewing them.
WDD: Tell us about yourselves.
Framer: So Jorn and I (Koen) worked at our first company, Sofa, together in 2009. Things really took off after we won a few Apple Design Awards, when we got a call from Mark Zuckerberg. The rest is history, as they say — our company and team were acquired by Facebook in 2011, where we ended up doubling their product design team.
We spent two years there helping launch some major product features but eventually moved back to Amsterdam and co-founded Framer in 2013. It’s been both challenging and extremely rewarding to stick to our guns and build this company in the Netherlands, even raising our Series B last year.
WDD: I’m a Windows user, so I have to ask: when is Framer X coming to Windows?
Framer: It’s in the works! We have a team working hard on this and it’s part of our plan to open up Framer X to a wider audience. I can’t give you definitive dates but you can expect something in 2019. And until then, you can sign up for the waitlist here.
WDD: What inspired you to build Framer? What’s the origin story?
Framer: When we were working at Facebook, we found ourselves pitching these innovative product ideas using traditional presentation slides. It was really frustrating to try and convey responsive, interactive design ideas to board members through static imagery – it’s just counter-intuitive.
As design has evolved, so has our thinking around tooling
Unfortunately, that’s just how things were done at the time, as interactive design was still relatively new and static images were the norm. Which is why, shortly after leaving Facebook, we co-founded Framer to focus on helping everyone better express digital product ideas.
As design has evolved, so has our thinking around tooling. While Framer Classic captured a large share of the very best designers in the world, it was only accessible to a small subset of all designers, as it used code to express ideas.
So we launched a whole new product, Framer X, which opens up interactive design to everyone, regardless of coding ability and offers interfaces for everyday design tasks like wireframing, visual design and interactive work.
WDD: What other design apps most inspired your feature choices and design?
Framer: I’ve always been very inspired by Unity – especially how accessible it is. In a sense, we are building an interactive IDE for product design that anyone can use, much like Unity has done for the gaming industry.
WDD: Your software is big on sharing and centralizing libraries of design assets, and by extension, design systems. How do you, as designers, balance the benefits of design systems (consistency and speed) with the desire for experimentation most designers feel at some point?
Framer: It is definitely a tricky balance. As a company, we have a big maker culture, with a huge emphasis on shipping. A lot of of this is because we genuinely love solving hard product problems, but just as much because our community has come to expect this of us.
As we’ve grown, we’ve come to see the value of adding some structure to this process, including creating our own React-based design system, Fraction. Everyone is still very much empowered to try and test — we even have an R&D team and leave time on Fridays for more experimental projects.
WDD: Out of all the features currently on Framer X, which are you most proud of?
Framer: We’re most proud of the features that make our app so collaborative. For example, Framer X contains a built-in store where users can publish components that can do practically anything, from media players to advanced interactive controls to entire design systems.
This means that new users can instantly leverage the work of advanced users, which provides immediate value to all users and offers incredible network effects. Our community has always been at the core of our product, and the store allows us to bring that into our product in a meaningful way.
WDD: Which feature do you most wish you’d done better with on the first try?
Framer: Interactive design is always evolving, so of course our platform is as well. Framer X’s Interactive tools — Link, Page, and Scroll — have undergone the most changes, thanks in part to the feedback we got from our beta users.
Everything that used to require lines of code in Framer Classic can now be created using the canvas tools we have. I’m not sure we would do anything differently, but hindsight being 20/20, perhaps we could have done some things sooner.
WDD: You can export elements as CSS and SVG code in Framer X. Any plans to support CSS Grid for layout?
Framer: We are planning to launch a grid tool in 2019! Stay tuned.
WDD: Where do you see Framer going in 2019?
Framer: We’re going to bring Framer X to Windows and the Web to give more people access to our interactive design tool. We’ll still be focused on making it the best tool for interactive design and with that, the best place for your team to build out your design systems.
My belief is that people are way more creative than they think and with the right platform, anyone can design. So I’d love to head toward a direction where Framer X becomes accessible enough to appeal even to people who use Powerpoint.
Thanks to Jorn and Koen for taking the time to answer our questions.
Over the years, there has been a dramatic change in the expectations of people who purchase online; thus, impacting user experience principles followed by businesses drastically.
When the concept of the online market was in the beginning stage, no one knew what exactly to expect from these online merchants. However, today, customers are well-informed and trained as well in terms of accepting sellers.
With customers becoming smarter, search engines have improved their algorithms to display information on the basis of what users require. As a result, everything related to internet business has evolved to make experienced customer-centric.
Coming to your business, irrespective of what consumers are expecting, it’s important to adapt as per the trends so as to provide fantastic user experience to the target audience. Owing to this, combining the principle of user experience (UX) and strategies of search engine optimization (SEO) can provide better results.
So, let’s understand more about why, being a business owner or an SEO expert, you should be bothering about UX principles and the ways you can implement to learn how to set up a business website.
Basic User Experience Principles:
One of the primary problems here can be that UX analysis doesn’t come as a part of the skill set of SEO. However, UX is also much more than just concentrating on website visitors. So, if you wish to get the best out of what you have to offer, understanding these basic principles can give you a better start.
1- Analytics Data & Account:
Most of the times, when it comes to SEO, people leave analytics behind. And, that may bring you down affectedly. Whether it’s for better user experience or SEO ranking, having reliable and accurate data is something you must not miss upon.
You must understand that qualitative analytics data is an essential aspect of user experience. And then, you’d also require correct tools to meet the analytics requirements. If you don’t have a significant analytics system, you may receive data from all directions and sources. This isn’t going to help you but add more to your confusion.
Therefore, ensure that you have centralized data, integrated into only one system. Once done, it’s recommended to audit the website analytics to ensure that the data you’re acquiring can be used to achieve different goals. The audit can also help discover and fix several other issues, like self-referrals, 404 errors, events tracking, cross-domain, property settings, and much more.
2- Effective Analytics Metrics & Engagement:
Another one of the vital user experience principles is to track the engagement and analytics metrics. For this, you’d have to emphasize three essential parameters:
Exit Rate
Bounce Rate
Time on Page
By providing adequate user experience, your goal should be to enhance these metrics to such an extent that they provide sufficient engagement level. With people spending less time on your website or bouncing back from your pages, all Google assesses is how visitors are leaving your site and finding better alternatives. That’s what Google is going to factor while deciding the rank of your site.
Therefore, as an SEO expert and business owner, your job is to understand the reason behind the high bounce rate along with other decreasing metrics and how you can improve it.
3- Qualitative & Effective Data:
While quantitative data, collected from analytics tools is essential, you must not overlook the worth of qualitative data at any cost. When talking about the latter, it’s necessary to understand how customers are engaging with your brand. Therefore, concentrating upon their feedback can help you to a great extent by reducing website errors, catering to pain points of potential customers, and increasing engagement – all of which is good for SEO.
To execute this step successfully, begin asking your customers their feedback on your products or services. For this, what you can do is come up with polls and surveys to let the potential customers answer transparently. With their response, you’ll be able to get an insight into their minds. In this way, figuring out what’s wrong and how to fix it will help you efficiently.
4- Consistency:
When talking about important user experience principles for SEO, it’s difficult to miss consistency. There are several reasons that make consistency important. To begin with, it decreases learning, meaning that your customers wouldn’t have to brainstorm upon every new representation of the products that you post if they’re already well-acknowledged with your brand.
With this process, you’ll be able to get a quick and faster response from your customers. When it comes to analytics data, consistency represents lower exit rates and bounce rates.
Best Practices for UX & SEO:
In reality, you don’t have to be an expert in UX designing to match the paces with such an experience that would complement the SEO efforts as well. However, before you dive into learning some best practices, you must keep in mind that not every technique may fulfill your goals and you may have to keep experimenting, depending upon your potential customers and the industry.
Having said that, let’s understand specific tips and best practices that may help you gain satisfactory results.
Keyword Research:
For almost every business owner and SEO expert, the primary starting point would be keyword research. To tell you the fact, this activity impacts practically every aspect of your website, right from the content to the message you want to communicate with the audience.
When you begin with this activity, you’re going to get familiar with a completely different world that exists only for keywords. Hence, you’ll have to be very particular about how you conduct this research and the kind of keywords that you choose so that you can rank higher as well as provide a better experience to your visitors.
Attracting More Clicks:
When you optimize your website, the ranking isn’t the only objective you should be following. However, one of the primary things is to get more clicks and visitors to your site. Having said that, the higher the rank you have, the more chances you get to obtain more clicks.
However, there are no compulsions and restrictions that you should follow to stand equally with your competitors when you can easily outpace them. It’s entirely possible to gain more clicks to the website in comparison with others who are ranking above you.
This can only be done by ensuring that your website catches the attention of people. It can be mainly through attractive language that would encourage them to click and visit your site. If you’re using bland language, it’s going to fetch you nothing but lousy click-through rate.
So, make sure your meta descriptions, title tags, URLs, breadcrumbs, and other similar elements have been curated well-enough.
Keep It Going:
Once you’ve achieved the target of click-through rates, understand that your job isn’t done yet. There would be a lot more to do. One thing that you must always remember is that your visitors will always be in a hurry. They wouldn’t take a lot of time just to figure out what your brand is what you’re offering.
In fact, if they won’t find what they’re looking for on your landing page, they’ll leave quickly. This means you must make sure that you’ve done everything correctly. Your visitors found something worthwhile when clicking on your site. Hence, you’d have to maintain that worth.
Don’t let them lose their interest. If they do, you’re going to lose them. So, make sure you properly optimize the following elements on the site:
Site ID
Navigation
Header Tags
Content Optimization
CTA
Wrapping Up:
Now that you’ve understood the user experience principles and how you can integrate SEO in it, now is the time to enhance your website by keeping the customer journey in mind. From the technology to your customers, everything is evolving; therefore, you must align your business with them to get more benefits.
Every year in December, Pantone, a color categorizing company, nominates their color of the year. Typically speaking, these colors are meant to represent something significant going on in the world. But the Pantone color of the year 2019 has stirred up quite a controversy.
Let’s start by mentioning last year’s color: ultraviolet. This wild shade of purple was chosen because it stands for originality, ingenuity, and visionary thinking.
Now, fast forward to Pantone color of the year 2019, they’ve decided on a lush red called living coral.
As I mentioned before, these colors are chosen to represent something significant. According to Melbourne based design agency Jack and Huei, this “living coral” glosses over the fact that corals are dying at an alarming rate all over the world.
Being from Australia, Jack Railton-Woodstock and Huei Yin Wong, owners of Jank and Huei are greatly concerned. You see, Australia’s waters are home to some of the most beautiful and endangered coral species on the Earth.
The unofficial Pantone color of the year
In protest to the official choice from Pantone, Jack and Huei have taken it upon themselves to create a new color of the year.
During their search for a more appropriate color, the duo came across Pantone sample #F0F6F7. This is a very pale, washed out blue that perfectly matches the dead stems of the coral being affected.
The process of coral dying is called bleaching. As the coral begins to die, it’s exposed skeleton loses all color, and becomes nothing more than a glorified stone.
In light of this color, and the name of the process, Jack and Huei decided to call the unofficial Pantone color of the year “Bleached coral” instead.
This is an issue we care about deeply and we think the creative industry has an opportunity to bring this global issue from the depths of the ocean to the surface of our screens. – Jack and Huei
Pantone’s reaction
As of right now, Pantone has yet to have any sort of reaction to this sort of protest. Most likely, they won’t have much to say.
But, the good news is that artists and designers just like Jack and Huei are using their talents and skills to bring more awareness to issues just like this one.
It’s the responsibility of all of us, creative or otherwise, to find creative solutions to big problems, and right now there aren’t many problems facing humanity that are bigger than climate change. – Jack and Huei
What’s next?
Jack and Huei’s plans are to continue their efforts well into 2020. They’ve begun to brand their newly proposed color using Pantone’s style in order to help bring in more awareness.
“Somber, yet uncomplicated, PANTONE P 115-1 U Bleached Coral harkens back to a simpler time. The subtly inoffensive hue offers a harsh reminder for how quickly things change, with a comforting, greyscale undertone that reinforces the inevitability of time.
Representing the fusion of modern life with the natural world, while straddling the fine line between hope and despair, PANTONE Bleached Coral asks the age-old question – where did it all go wrong?”
These are powerful words that bring a powerful message with them. Hopefully, the efforts of Jack and Huei, as well as others around the world will begin a new age for our planet. One where we value the natural beauty and wonders that we’re surrounded by each and every day. One where all life is valued and fought to be protected, instead of ignored. One where we can look at the issues we face, and overcome them together. We only have one Earth, it’s about time we started to treat it with respect.
5
Critical Elements that Can Make or Break Your Design
At first glance, designing a one-page
website would seem to be intuitively easy. Especially, when compared to
building a multi-pager. Designing one page takes one-third the effort of
designing three pages – right?
In reality, designing a single-pager is
generally much more difficult. The challenge you face is having to get all the
necessary information on a single page. At the same time, you need to make sure
the page is both visually appealing and user-friendly.
This guide for designing one-page websites
is centered around 5 critical elements. Depending on how well you take them
into account they can make or break your design.
As we outline each of these critical
elements, we’ll provide examples. They will illustrate their importance – 15
examples in all.
#1
The GOAL: Identify & Understand the Goal of Your Website & Work Toward
It
You might not understand perfectly what you
expect your website to accomplish. Then, there’s little sense in proceeding
with its design. It needs to have a single goal. Your design needs to take the
user on a journey that reaches that goal and responds accordingly.
Is the goal to promote or sell something?
Is it to invite a visitor to view your
portfolio?
Do you intend to announce an event or a
series of events?
Once you’ve identified the goal, you’re
almost halfway there. You still need to take into account what you need to do.
You need to avoid chasing visitors away from the page before they hit the CTA
button.
Some users are sensitive to page load speed
(more than a few are oversensitive!). So, you might choose to avoid special
effects (like parallax) that tend to reduce page load speeds.
You don’t need a detailed technical dissertation
to promote an app when a cool visual presentation will do the trick.
#2 TEXT: Keep It to the Minimum & Make It Easy
to Read
A one-pager
featuring clunky blocks of text or reads like a book is going to engage
visitors for a second. Sometimes, even less before they head elsewhere. Keep
text brief and in nicely-spaced sections. Strip the information down to its
bare essence.
Rely on bold
headlines, brief paragraphs, and bullet lists to make your point.
Here are several examples worth bookmarking
for future reference:
When a vehicle has the stature of a Mercedes,
high quality images accompanied by a minimal amount of text is often
sufficient.
#3 VISUALS: Identify the Right Patterns & Use Negative
Space Wisely
Knowing how most people will scan a page is
helpful. People tend to read text in an F pattern and scan an image in a Z
pattern. Keep this in mind when you mix elements. You want the natural flow of
the information to be directed toward your goal. Wise use of white space can be
helpful.
Not a particularly exciting subject for a
one pager is it? This ingenious use of slides, white space, and animations
actually succeeds in making a nasal drops one-pager exciting.
#4 NAVIGATION: Make It Easy to Navigate & Entertaining
to Scroll
When
you have a long-form one-page website you have to pay close attention to how
you manage navigation. Depending on your approach, you can keep visitors locked
in or chase them off the page.
Alternative navigation is the key here.
Horizontal sticky menu or a sidebar menu are examples. Your goal should be to
enable users to jump to where they want to go with a single click, as opposed
to scrolling. Auto-scroll links enable visitors to watch the page do the
scrolling. This is yet another approach.
These folks really want to help you
navigate their site quickly by provided a menu on the top and one on the left.
#5 CALL TO ACTION: Identify the Correct CTA & Don’t
Hesitate to Use It
What’s nice about
a one-pager is its aim is to get people to take a single action. This normally
would involve using a single CTA button. You also might be selling several
products or services, however. Then, you may want to place a CTA button at the
end of every major section.
This site doesn’t fool around with its use
of CTA buttons. They’re used judiciously however; and with a proper choice of
colors and text sizes.
Wrapping
It Up
Now you know the 5 critical one-page
website elements. It’s simply a matter of practicing with them until their use
becomes habitual.
They may seem simple at first. Once you
start mixing them in a one-pager and attempt to do so with consistency you’ll
find it can be quite a challenge.
The good news is there’s a shortcut. Try
using pre-built websites that have already incorporated these critical
elements.
A good pre-built website resource is Be Theme It has an impressive library of more than 60 one-pagers, and 400+
pre-built websites of all kinds. Simply choose a pre-built website and
customize it to fit your needs.
I love the idea of programmatically generated images. That power is close at hand these days for us front-end developers, thanks to the concept of headless browsers. Take Puppeteer, the library for controlling headless Chrome. Generating images from URLs is their default use case:
That ought to get the ol’ mind grape going. What if we had URLs on our site that — with the power of our HTML and CSS skills — created perfect little designs for sharing using dynamic data… then turned them into images and used them for our meta tags?
Since the design part is entirely an HTML/CSS adventure, I’m sure you could imagine a setup where the URL passed in parameters that did things like set copy and typography, colors, sizes, etc. Zeit built exactly that!
Kind of amazing that you can spin up an entire browser in a cloud function! Netlify also offers cloud functions, and when I mentioned this to Phil Hawksworth, he told me he was already doing this for his blog!
So on a blog post like this one, an image like this is automatically generated: