There’s been a lot of talk recently about whether or not you need a degree to be in tech (spoiler: you don’t). But please don’t take this to mean you don’t need any kind of education to be in tech, because by not getting a degree, you’re opting to replace the imposed learning structure of an academy with learning on your own.
Academic background or not, technical education doesn’t stop once you get a job. On the contrary: nothing in tech stays in one place, and the single most valuable skill you can possess to remain employable over time is learning how to learn.
Identifying holes
You’re all ready to go, ready to challenge yourself, learn what you can, and grow. But where do you start? Sometimes people rely on a more formal education simply because someone is there, guiding your path.
When you’re learning on your own, this part can sometimes be tough — you don’t know what you don’t know. If you’re starting from scratch, learning web development or computer science, here are some resources that might help:
There are also times when you know what you need to learn, but you have to level up. In this case, I have some strategies on how to organize yourself in the next section.
Possible strategies
You absolutely do not to be as formal in your approach to learning as I am. I used to be a college professor, and so I still organize my own learning as though I’m teaching. I even still use a paper planner designed for teachers. I’ll show you how I do it in case it’s helpful. A few years back I taught myself ES2015/ES6, so I’ll use that as an example. Structure like this is good for some and not good for others, so do what works for you.
If there’s an API I’m trying to learn, I’ll go to the main documentation page (if there is one), and list each of the things I’m trying to learn. Then I’ll divide the sections into what I think are manageable chunks, and spread the sections over my schedule, usually shooting for about a half hour a day. I do this with the understanding that some days I won’t find the time, and others, I’ll dig in for longer. Typically I aim for at least 2.5 hours of learning a week, because that pace seems reasonable to me.
The list of ES2015 features I used when I was learning
Then I take all of those features, write them out, and estimate how much time I’ll need for each one. Here’s an example where I wrote out all the things I needed to learn. The yellow numbers on the side are my time estimates in half hour units.
You can also do this with course materials from an online workshop, writing down the sections and breaking them into chunks to go over every day. I really enjoy Frontend Masters for long form learning like this, as well as Egghead and courses by Wes Bos.
At this point, I’ll break those pieces down and schedule them. The teacher planner allows me to divide my days into the different themes I’m focusing on and put a little in each day. You can see in the first screenshot that I was learning a bit, mentoring a bit, and writing and building what I was learning each day. This kind of input/output really helped me solidify the concepts as I was digging into ES2015/ES6.
I try not to schedule too far out because I’m bound to drop something here and there, or I might dive further one day than I was planning to. I keep the schedules flexible enough to adjust for these inevitable inconsistencies. This also allows me to not get too demotivated. If I feel I’m off-track, the next week is another opportunity to get back on.
Again, you don’t have to be as formal as I am, and there are so many ways to be effective. Find what works for you. I would make a small suggestion that you’re taking a look at the table of contents for those API docs now and again, mostly because then you’re aware of any gaps in your knowledge that you’re not filling.
Setting aside time
Setting aside time can be challenging with all of our busy schedules, but it’s critical. If you look at your week, how much time do you have? Learning won’t happen unless you purposefully devote time for it. It needn’t be a ton of time. If you’re a more habit-driven kind of person, you can set up a daily schedule. If you’re the kind of person who learns better head down and you have an existing job, then you might have to give up some Sunday afternoons, or possibly some time after work now and again. Most of us need a bit of both. ??
If you’re socially motivated, you might want to find a study buddy. Is there someone at work who has similar goals? Maybe going to coding meetups can help keep you on track. Emma Wedekind also builds Coding Coach, where you can have guided mentorship sessions.
Practice
At the end of the day, it’s going to come down to practice. If you read about Cognitive Load Theory (I highly recommend the book Cognitive Load Theory if you want to learn about this), you’ll see that the old “practice makes perfect” adage has some bite to it.
Information Processing Model (how we learn) – Richard Atkinson and Richard Shiffrin’s cognitive load theory, 1968.
I also really like this quote from Zed Shaw’s Learn Python the Hard Way.
Do Not Copy-Paste
You must type each of these exercises in, manually. If you copy and paste, you might as well just not even do them. The point of these exercises is to train your hands, your brain, and your mind in how to read, write, and see code. If you copy-paste, you are cheating yourself out of the effectiveness of the lessons.
I also love this quote from Art and Fear, and bring it up frequently as it’s been a guiding light for me:
The ceramics teacher announced on opening day that he was dividing the class into two groups. All those on the left side of the studio, he said, would be graded solely on the quantity of work they produced, all those on the right solely on its quality. His procedure was simple: on the final day of class he would bring in his bathroom scales and weigh the work of the “quantity” group: fifty pounds of pots rated an “A”, forty pounds a “B”, and so on. Those being graded on “quality”, however, needed to produce only one pot —albeit a perfect one —to get an “A”. Well, came grading time and a curious fact emerged: the works of highest quality were all produced by the group being graded for quantity. It seems that while the “quantity” group was busily churning out piles of work—and learning from their mistakes —the “quality” group had sat theorizing about perfection, and in the end had little more to show for their efforts than grandiose theories and a pile of dead clay.
Learning modalities
Truly there are many different learning modalities, and combining them can even be helpful. Sometimes I will sit and practice refactoring code from other languages into JavaScript (this is a pretty old project now), or reverse engineer things to learn. I like reverse engineering because people tend to problem-solve in different ways. This allows me to peek inside other people’s heads and see how they approach things. I even have a private collection on CodePen where I collect other people’s work that I think can benefit me and my learning.
Personally, I think there’s nothing more motivating than building. You can actually learn a metric ton just by building things.
Storytime: Many years ago, I was at a conference with a few people who worked on the SVG spec, including the inventor of SVG himself. I was completely unknown at the time, but had been churning out tons of SVG animations that were wildly unpopular for a few years. We got on the subject of a certain behavior that was in the spec. I mentioned, that yes, it should work that way but unfortunately Firefox had x behavior and Chrome had y.
No one in the group knew this, and it was the first time I realized that all those silly playful things I was building were actually educating me; that I knew practical, real-life edge cases even though I hadn’t sought them out in a formal manner. I was so excited! I didn’t plan to become an SVG expert — it snuck up on me as I enjoyed myself, building things to relieve stress and play.
This is good news! You can learn so much by creating things you think are fun. I like to learn for a bit, and then practice what I learned by making something, just to make sure I solidify the concepts.
You may find you learn the most by teaching. If you do have a person you can mentor, it can actually benefit you, too. Writing technical posts or helping with documentation can help you learn something concretely as well.
Cognitive Load Theory
The book I cited earlier, Cognitive Load Theory, has this great section breaking down learning modalities and what they require. A central theme to the book is discussing moving information from a source into our own minds, and that there are certain capabilities and limitations affected by design characteristics of the learning structure and our own cognition.
Intrinsic load is created by the difficulty of the materials.
Extraneous load is created by the design characteristics of the type of education and materials.
Germane load is the amount of invested mental effort.
The chart below explores effects of different ways that we learn, and what the primary cognitive load would be of the three listed above.
This kind of meta-understanding of what it takes to learn might be helpful to you in that you might find you have less cognitive load in one learning modality versus another. You may also find that you can cut yourself some slack when one topic with more germane load takes you longer to understand than another that’s mostly memorization.
Know that learning styles do affect our ability to comprehend things, and reducing barriers for yourself is key. Do you keep studying at a cafe where there’s a lot of noise and distraction? Consider that your lack of focus might have more to do with the setting than your ability to process the materials.
One more note on this: learning is hard, and it’s humbling. It’s exciting too, but please don’t feel alone if you struggle, or if you need to repeat something multiple times to really get it. Even after taking care of cognitive leaks, expanding knowledge is not necessarily easy, but does pay off in dividends.
Lifelong learners
By choosing to be a developer, you are choosing to learn. This is amazing. Our field not only values our knowledge, but we can stave off boredom because it doesn’t stagnate. My suggestion is to consider these tips a buffet table. There’s so much you can do, so many tools you can use. You don’t need to learn everything and no one knows absolutely everything. It can feel overwhelming, but try to view it less like a race to the finish and more like a continuous journey.
Remember: no one was born knowing any of this. Even the experts you know started at zero. There’s nothing stopping you from becoming their peer if that’s your goal. Or simply learning enough to get the job done if that’s what you need.
There is a 15-year history of CSS resets. In fact, a “reset” isn’t really the right word. Tantek Çelik’s take in 2004 was called “undohtml.css” and it wasn’t until a few years later when Eric Meyer called his version a reset, that the word became the default term. When Normalize came around, it called itself a reset alternative, which felt right, because it wasn’t trying to obliterate all styles, but instead bring the base styles that browsers provide in their User Agent Stylesheet in line with each other.
We’ve taken a romp through this history before in Reboot, Resets, and Reasoning. Every single take on this — let’s call them “base” stylesheets — has a bit of a different angle. How much does it try to preserve the UA defaults? How opinionated does it get? How far back does it consider for browser support?
Along comes CSS Remedy (they say it’s not ready for usage), with yet another different spin:
Sets CSS properties or values to what they would be if the CSSWG were creating the CSS today, from scratch, and didn’t have to worry about backwards compatibility.
Fascinating to think about.
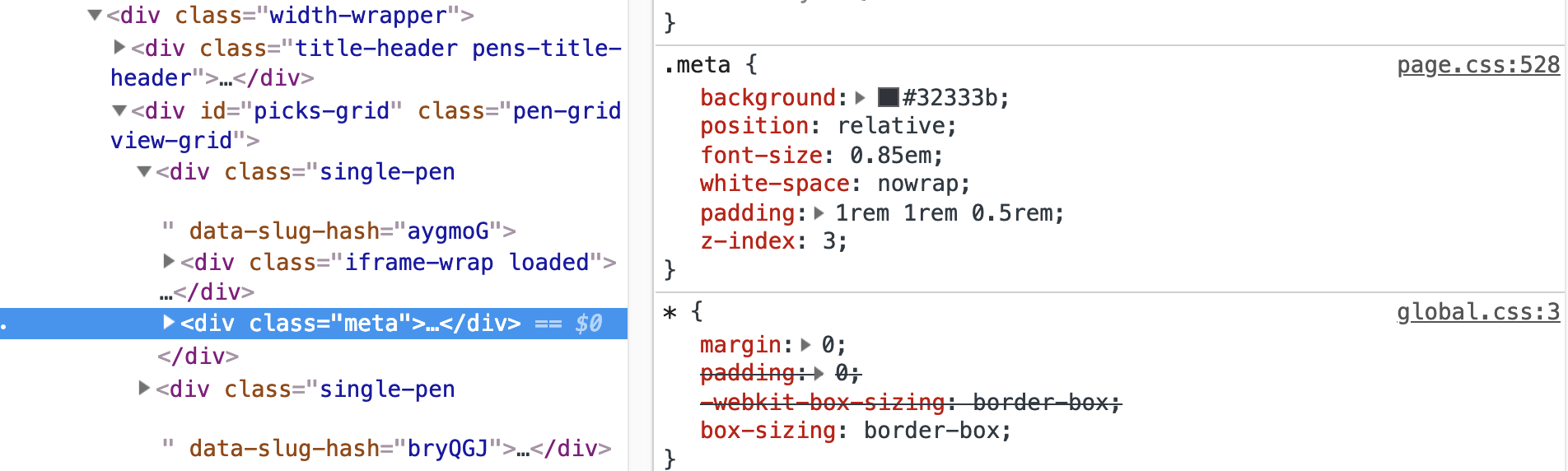
CSS Remedy re-draws the line for what is opinionated and what isn’t. I’d say that something like * { box-sizing: border-box; } is a fairly strong opinion for a base stylesheet to have. No UA stylesheet does this, so it’s applying a blanket rule everywhere just because it’s desirable. It’s definitely desirable! It’s just opinionated.
But not having border-box be the default is considered a CSS mistake. So if CSS Remedy is what a UA stylesheet would be if we were starting from scratch, border-box isn’t opinionated; it’s the new default.
Sadly, we probably can never have a fresh UA stylesheet in browsers, because the danger of breaking sites is so high. If Firefox shipped some new modernized UA stylesheet that was tastefully done and appears to be nice, but only until you browse around the billion websites that weren’t built to handle the new CSS being applied to them, them people would blame Firefox — and not incorrectly. Gracefully handling legacy code is a massive strength of the web and something that holds us back. It’s more the former than the latter, though.
It’s been fun watching Jen think through and gather thoughts on stuff like this though:
I agree! That little space below images has confounded an absolute ton of people. It’s easy enough to fix, but it being the fault of vertical-align is a bit silly and a great candidate for fixing in what would be a new UA stylesheet.
I tossed the in-progress version into the comparison tool:
WordPress is getting modernized. The recent inclusion of JavaScript-based Gutenberg as part of the core has added modern capabilities for building sites on the frontend, and the upcoming bump of PHP’s minimum version, from the current 5.2.4 to 5.6 in April 2019 and 7.0 in December 2019, will make available a myriad of new features to build powerful sites.
In my previous article on Smashing in which I identified the PHP features newly available to WordPress, I argued that the time is ripe to make components the basic unit for building functionalities in WordPress. On one side, Gutenberg already makes the block (which is a high-level component) the basic unit to build the webpage on the frontend; on the other side, by bumping up the required minimum version of PHP, the WordPress backend has access to the whole collection of PHP’s Object-Oriented Programming features (such as classes and objects, interfaces, traits and namespaces), which are all part of the toolset to think/code in components.
So, why components? What’s so great about them? A “component” is not an implementation (such as a React component), but instead, it’s a concept: It represents the act of encapsulating properties inside objects, and grouping objects together into a package which solves a specific problem. Components can be implemented for both the frontend (like those coded through JavaScript libraries such as React or Vue, or CSS component libraries such as Bootstrap) and the backend.
We can use already-created components and customize them for our projects, so we will boost our productivity by not having to reinvent the wheel each single time, and because of their focus on solving a specific issue and being naturally decoupled from the application, they can be tested and bug-fixed very easily, thus making the application more maintainable in the long term.
The concept of components can be employed for different uses, so we need to make sure we are talking about the same use case. In a previous article, I described how to componentize a website; the goal was to transform the webpage into a series of components, wrapping each other from a single topmost component all the way down to the most basic components (to render the layout). In that case, the use case for the component is for rendering — similar to a React component but coded in the backend. In this article, though, the use case for components is importing and managing functionality into the application.
Introduction To Composer And Packagist
To import and manage own and third-party components into our PHP projects, we can rely on the PHP-dependency manager Composer which by default retrieves packages from the PHP package repository Packagist (where a package is essentially a directory containing PHP code). With their ease of use and exceptional features, Composer + Packagist have become key tools for establishing the foundations of PHP-based applications.
Composer allows to declare the libraries the project depends on and it will manage (install/update) them. It works recursively: libraries depended-upon by dependencies will be imported to the project and managed too. Composer has a mechanism to resolve conflicts: If two different libraries depend on a different version of a same library, Composer will try to find a version that is compatible with both requirements, or raise an error if not possible.
To use Composer, the project simply needs a composer.json file in its root folder. This file defines the dependencies of the project (each for a specific version constraint based on semantic versioning) and may contain other metadata as well. For instance, the following composer.json file makes a project require nesbot/carbon, a library providing an extension for DateTime, for the latest patch of its version 2.12:
{
"require": {
"nesbot/carbon": "2.12.*"
}
}
We can edit this file manually, or it can be created/updated through commands. For the case above, we simply open a terminal window, head to the project’s root directory, and type:
composer require "nesbot/carbon"
This command will search for the required library in Packagist (which is found here) and add its latest version as a dependency on the existing composer.json file. (If this file doesn’t yet exist, it will first create it.) Then, we can import the dependencies into the project, which are by default added under the vendor/ folder, by simply executing:
composer install
Whenever a dependency is updated, for instance nesbot/carbon released version 2.12.1 and the currently installed one is 2.12.0, then Composer will take care of importing the corresponding library by executing:
composer update
If we are using Git, we only have to specify the vendor/ folder on the .gitignore file to not commit the project dependencies under version control, making it a breeze to keep our project’s code thoroughly decoupled from external libraries.
Composer offers plenty of additional features, which are properly described in the documentation. However, already in its most basic use, Composer gives developers unlimited power for managing the project’s dependencies.
Introduction To WPackagist
Similar to Packagist, WPackagist is a PHP package repository. However, it comes with one particularity: It contains all the themes and plugins hosted on the WordPress plugin and theme directories, making them available to be managed through Composer.
To use WPackagist, our composer.json file must include the following information:
Then, any theme and plugin can be imported to the project by using "wpackagist-theme" and "wpackagist-plugin" respectively as the vendor name, and the slug of the theme or plugin under the WordPress directory (such as "akismet" in https://wordpress.org/plugins/akismet/) as the package name. Because themes do not have a trunk version, then the theme’s version constraint is recommended to be “*”:
Packages available in WPackagist have been given the type “wordpress-plugin” or “wordpress-theme”. As a consequence, after running composer update, instead of installing the corresponding themes and plugins under the default folder vendor/, these will be installed where WordPress expects them: under folders wp-content/themes/ and wp-content/plugins/ respectively.
Possibilities And Limitations Of Using WordPress And Composer Together
In this concern, WordPress is outperformed by newer frameworks which could incorporate Composer as part of their architecture. For instance, Laravel underwent a major rewriting in 2013 to establish Composer as an application-level package manager. As a consequence, WordPress’ core still does not include the composer.json file required to manage WordPress as a Composer dependency.
Knowing that WordPress can’t be natively managed through Composer, let’s explore the ways such support can be added, and what roadblocks we encounter in each case.
Manage dependencies when developing a theme or a plugin;
Manage themes and plugins on a site;
Manage the site completely (including its themes, plugins and WordPress’ core).
And there are two basic situations concerning who will have access to the software (a theme or plugin, or the site):
The developer can have absolute control of how the software will be updated, e.g. by managing the site for the client, or providing training on how to do it;
The developer doesn’t have absolute control of the admin user experience, e.g. by releasing themes or plugins through the WordPress directory, which will be used by an unknown party.
From the combination of these variables, we will have more or less freedom in how deep we can integrate WordPress and Composer together.
From a philosophical aspect concerning the objective and target group of each tool, while Composer empowers developers, WordPress focuses primarily on the needs of the end users first, and only then on the needs of the developers. This situation is not self-contradictory: For instance, a developer can create and launch the website using Composer, and then hand the site over to the end user who (from that moment on) will use the standard procedures for installing themes and plugins — bypassing Composer. However, then the site and its composer.json file fall out of sync, and the project can’t be managed reliably through Composer any longer: Manually deleting all plugins from the wp-content/plugins/ folder and executing composer update will not re-download those plugins added by the end user.
The alternative to keeping the project in sync would be to ask the user to install themes and plugins through Composer. However, this approach goes against WordPress’ philosophy: Asking the end user to execute a command such as composer install to install the dependencies from a theme or plugin adds friction, and WordPress can’t expect every user to be able to execute this task, as simple as it may be. So this approach can’t be the default; instead, it can be used only if we have absolute control of the user experience under wp-admin/, such as when building a site for our own client and providing training on how to update the site.
The default approach, which handles the case when the party using the software is unknown, is to release themes and plugins with all of their dependencies bundled in. This implies that the dependencies must also be uploaded to WordPress’ plugin and theme subversion repositories, defeating the purpose of Composer. Following this approach, developers are still able to use Composer for development, however, not for releasing the software.
This approach is not failsafe either: If two different plugins bundle different versions of a same library which are incompatible with each other, and these two plugins are installed on the same site, it could cause the site to malfunction. A solution to this issue is to modify the dependencies’ namespace to some custom namespace, which ensures that different versions of the same library, by having different namespaces, are treated as different libraries. This can be achieved through a custom script or through Mozart, a library which composes all dependencies as a package inside a WordPress plugin.
For managing the site completely, Composer must install WordPress under a subdirectory as to be able to install and update WordPress’ core without affecting other libraries, hence the setup must consider WordPress as a site’s dependency and not the site itself. (Composer doesn’t take a stance: This decision is for the practical purpose of being able to use the tool; from a theoretical perspective, we can still consider WordPress to be the site.) Because WordPress can be installed in a subdirectory, this doesn’t represent a technical issue. However, WordPress is by default installed on the root folder, and installing it in a subdirectory involves a conscious decision taken by the user.
To make it easier to completely manage WordPress with Composer, several projects have taken the stance of installing WordPress in a subfolder and providing an opinionated composer.json file with a setup that works well: core contributor John P. Bloch provides a mirror of WordPress’ core, and Roots provides a WordPress boilerplate called Bedrock. I will describe how to use each of these two projects in the sections below.
Managing The Whole WordPress Site Through John P. Bloch’s Mirror Of WordPress Core
I have followed Andrey “Rarst” Savchenko’s recipe for creating the whole site’s Composer package, which makes use of John P. Bloch’s mirror of WordPress’ core. Following, I will reproduce his method, adding some extra information and mentioning the gotchas I found along the way.
First, create a composer.json file with the following content in the root folder of your project:
Through this configuration, Composer will install WordPress 5.1 under folder "wp", and dependencies will be installed under folder "content/vendor". Then head to the project’s root folder in terminal and execute the following command for Composer to do its magic and install all dependencies, including WordPress:
composer install --prefer-dist
Let’s next add a couple of plugins and the theme, for which we must also add WPackagist as a repository, and let’s configure these to be installed under "content/plugins" and "content/themes" respectively. Because these are not the default locations expected by WordPress, we will later on need to tell WordPress where to find them through constant WP_CONTENT_DIR.
Note: WordPress’ core includes by default a few themes and plugins under folders"wp/wp-content/themes"and"wp/wp-content/plugins", however, these will not be accessed.
Add the following content to composer.json, in addition to the previous one:
Hallelujah! The theme and plugins have been installed! Since all dependencies are distributed across folders wp, content/vendors, content/plugins and content/themes, we can easily ignore these when committing our project under version control through Git. For this, create a .gitignore file with this content:
Note: We could also directly ignore foldercontent/, which will already ignore all media files undercontent/uploads/and files generated by plugins, which most likely must not go under version control.
There are a few things left to do before we can access the site. First, duplicate the wp/wp-config-sample.php file into wp-config.php (and add a line with wp-config.php to the .gitignore file to avoid committing it, since this file contains environment information), and edit it with the usual information required by WordPress (database information and secret keys and salts). Then, add the following lines at the top of wp-config.php, which will load Composer’s autoloader and will set constant WP_CONTENT_DIR to folder content/:
// Load Composer's autoloader
require_once (__DIR__.'/content/vendor/autoload.php');
// Move the location of the content dir
define('WP_CONTENT_DIR', dirname(__FILE__).'/content');
By default, WordPress sets constant WP_CONSTANT_URL with value get_option('siteurl').'/wp-content'. Because we have changed the content directory from the default "wp-content" to "content", we must also set the new value for WP_CONSTANT_URL. To do this, we can’t reference function get_option since it hasn’t been defined yet, so we must either hardcode the domain or, possibly better, we can retrieve it from $_SERVER like this:
We can now access the site on the browser under domain.com/wp/, and proceed to install WordPress. Once the installation is complete, we log into the Dashboard and activate the theme and plugins.
Finally, because WordPress was installed under subdirectory wp, the URL will contain path “/wp” when accessing the site. Let’s remove that (not for the admin side though, which by being accessed under /wp/wp-admin/ adds an extra level of security to the site).
The documentation proposes two methods to do this: with or without URL change. I followed both of them, and found the without URL change a bit unsatisfying because it requires specifying the domain in the .htaccess file, thus mixing application code and configuration information together. Hence, I’ll describe the method with URL change.
First, head to “General Settings” which you’ll find under domain.com/wp/wp-admin/options-general.php and remove the “/wp” bit from the “Site Address (URL)” value and save. After doing so, the site will be momentarily broken: browsing the homepage will list the contents of the directory, and browsing a blog post will return a 404. However, don’t panic, this will be fixed in the next step.
Next, we copy the index.php file to the root folder, and edit this new file, adding “wp/” to the path of the required file, like this:
/** Loads the WordPress Environment and Template */
require( dirname( __FILE__ ) . '/wp/wp-blog-header.php' );
We are done! We can now access our site in the browser under domain.com:
WordPress site successfully installed through Composer (Large preview)
Even though it has downloaded the whole WordPress core codebase and several libraries, our project itself involves only six files from which only five need to be committed to Git:
.gitignore
composer.json
composer.lock
This file is generated automatically by Composer, containing the versions of all installed dependencies.
index.php
This file is created manually.
.htaccess
This file is automatically created by WordPress, so we could avoid committing it, however, we may soon customize it for the application, in which case it requires committing.
The remaining sixth file is wp-config.php which must not be committed since it contains environment information.
Not bad!
The process went pretty smoothly, however, it could be improved if the following issues are dealt better:
Some application code is not committed under version control.
Since it contains environment information, the wp-config.php file must not be committed to Git, instead requiring to maintain a different version of this file for each environment. However, we also added a line of code to load Composer’s autoloader in this file, which will need to be replicated for all versions of this file across all environments.
The installation process is not fully automated.
After installing the dependencies through Composer, we must still install WordPress through its standard procedure, log-in to the Dashboard and change the site URL to not contain “wp/”. Hence, the installation process is slightly fragmented, involving both a script and a human operator.
Let’s see next how Bedrock fares for the same task.
Managing The Whole WordPress Site Through Bedrock
Bedrock is a WordPress boilerplate with an improved folder structure, which looks like this:
The people behind Roots chose this folder structure in order to make WordPress embrace the Twelve Factor App, and they elaborate how this is accomplished through a series of blog posts. This folder structure can be considered an improvement over the standard WordPress one on the following accounts:
It adds support for Composer by moving WordPress’ core out of the root folder and into folder web/wp;
It enhances security, because the configuration files containing the database information are not stored within folder web, which is set as the web server’s document root (the security threat is that, if the web server goes down, there would be no protection to block access to the configuration files);
The folder wp-content has been renamed as “app”, which is a more standard name since it is used by other frameworks such as Symfony and Rails, and to better reflect the contents of this folder.
Bedrock also introduces different config files for different environments (development, staging, production), and it cleanly decouples the configuration information from code through library PHP dotenv, which loads environment variables from a .env file which looks like this:
DB_NAME=database_name
DB_USER=database_user
DB_PASSWORD=database_password
# Optionally, you can use a data source name (DSN)
# When using a DSN, you can remove the DB_NAME, DB_USER, DB_PASSWORD, and DB_HOST variables
# DATABASE_URL=mysql://database_user:database_password@database_host:database_port/database_name
# Optional variables
# DB_HOST=localhost
# DB_PREFIX=wp_
WP_ENV=development
WP_HOME=http://example.com
WP_SITEURL=${WP_HOME}/wp
# Generate your keys here: https://roots.io/salts.html
AUTH_KEY='generateme'
SECURE_AUTH_KEY='generateme'
LOGGED_IN_KEY='generateme'
NONCE_KEY='generateme'
AUTH_SALT='generateme'
SECURE_AUTH_SALT='generateme'
LOGGED_IN_SALT='generateme'
NONCE_SALT='generateme'
Let’s proceed to install Bedrock, following their instructions. First create a project like this:
composer create-project "roots/bedrock"
This command will bootstrap the Bedrock project into a new folder “bedrock”, setting up the folder structure, installing all the initial dependencies, and creating an .env file in the root folder which must contain the site’s configuration. We must then edit the .env file to add the database configuration and secret keys and salts, as would normally be required in wp-config.php file, and also to indicate which is the environment (development, staging, production) and the site’s domain.
Next, we can already add themes and plugins. Bedrock comes with themes twentyten to twentynineteen shipped by default under folder web/wp/wp-content/themes, but when adding more themes through Composer these are installed under web/app/themes. This is not a problem, because WordPress can register more than one directory to store themes through function register_theme_directory.
Bedrock includes the WPackagist information in the composer.json file, so we can already install themes and plugins from this repository. To do so, simply step on the root folder of the project and execute the composer require command for each theme and plugin to install (this command already installs the dependency, so there is no need to execute composer update):
The last step is to configure the web server, setting the document root to the full path for the web folder. After this is done, heading to domain.com in the browser we are happily greeted by WordPress installation screen. Once the installation is complete, we can access the WordPress admin under domain.com/wp/wp-admin and activate the installed theme and plugins, and the site is accessible under domain.com. Success!
Installing Bedrock was pretty smooth. In addition, Bedrock does a better job at not mixing the application code with environment information in the same file, so the issue concerning application code not being committed under version control that we got with the previous method doesn’t happen here.
Conclusion
With the launch of Gutenberg and the upcoming bumping up of PHP’s minimum required version, WordPress has entered an era of modernization which provides a wonderful opportunity to rethink how we build WordPress sites to make the most out of newer tools and technologies. Composer, Packagist, and WPackagist are such tools which can help us produce better WordPress code, with an emphasis on reusable components to produce modular applications which are easy to test and bugfix.
First released in 2012, Composer is not precisely what we would call “new” software, however, it has not been incorporated to WordPress’ core due to a few incompatibilities between WordPress’ architecture and Composer’s requirements. This issue has been an ongoing source of frustration for many members of the WordPress development community, who assert that the integration of Composer into WordPress will enhance creating and releasing software for WordPress. Fortunately, we don’t need to wait until this issue is resolved since several actors took the matter into their own hands to provide a solution.
In this article, we reviewed two projects which provide an integration between WordPress and Composer: manually setting our composer.json file depending on John P. Bloch’s mirror of WordPress’ core, and Bedrock by Roots. We saw how these two alternatives, which offer a different amount of freedom to shape the project’s folder structure, and which are more or less smooth during the installation process, can succeed at fulfilling our requirement of completely managing a WordPress site, including the installation of the core, themes, and plugins.
If you have any experience using WordPress and Composer together, either through any of the described two projects or any other one, I would love to see your opinion in the comments below.
I would like to thank Andrey “Rarst” Savchenko, who reviewed this article and provided invaluable feedback.
The WordPress community officially has Gutenberg fever. While there has been some grumbling (and not without some cause), the blocky little editor that could, has gone mainstream. People have been building, writing, collating, and generally just adapting to the changes, and I’m here to show you some of what they’ve done… Enjoy!
Plugins
As is usual, the WordPress community has gone wild, and has already developed loads of plugins for the new editor; we can’t possibly list them all. Besides, so many of them add pretty much the same new blocks, or very similar blocks, so I’ve decided to list only the ones that caught my eye.
For more complete lists, see the “Authority Sites and Directories” section below.
Block Gallery
A photo gallery plugin that does what it says, and doesn’t come with a thousand other blocks. What more could you ask for?
And based on custom conditional logic you might set up yourself.
Coblocks
There are already lots of plugins that aim to turn Gutenberg into a full-on page builder, but Coblocks is the one I currently have my eye on. Sure, they’ve got plenty of layout options and features, but they’re mostly kept light and simple as opposed to overly animated. They seem largely style-agnostic as well.
They don’t use JavaScript on the front end when they don’t have to, and they provide quite good controls for custom typography. Overall, I’m quite impressed.
While this one not the only plugin that provides a map block, it’s one of the few that only provides a map block. Again, does what it says, and doesn’t bloat the menus. I’ll be a fan of these single-purpose block plugins until there aren’t quite so many of those “ultimate block collection” plugins.
Gutenberg Manager
The Gutenberg Manager plugin allows you to enable or disable Gutenberg for posts, pages, or custom post types as you see fit. Basically this allows you to use another plugin in its place for some content types (such as a proper page builder plugin), without disabling Gutenberg completely.
Those looking for flexibility in their content editing experience will want to grab this one.
Jetpack
Yes, thatJetpack. As of November 27th, 2018, Jetpack features a few blocks of its own, including a Markdown-enabling block, payment buttons, maps, and a full-fledged contact form.
It should be noted that some of the blocks, like many Jetpack features, require being on the Jetpack premium plan.
WooCommerce Blocks
Made by Automattic themselves, WooCommerce Blocks provides Gutenberg integration for (you guessed it!) WooCommerce. There are blocks for product grids, featured products, hand-picked products, best-selling products, hand-picked products, and much more.
Combine it with your favorite layout plugins for Gutenberg for the best effect, and you’ve got yet one more way to turn WordPress into a hand-crafted store.
Tutorials and Guides
Gutenberg wasn’t even properly out yet when people started writing tutorials and guides. People from all over the industry wanted to be ahead of the curve, and we’re all reaping the benefits. Here are some of the best I’ve found so far:
Styling the Gutenberg Columns Block – An older tutorial from CSS-Tricks that deals with one specific block, but can be used as a starting point for customizing all block-related styles.
Working with Editor Styles in Gutenberg – Lastly, we have a tutorial on adding custom styles to the editor so that what the users sees in the back end is more or less what they get on the other end.
Authority Sites and Directories
Gutenberg Hub
Gutenberg Hub aims to be the one-stop shop for all things blocky in WordPress. They’ve got massive lists of themes and plugins, their own tutorials, and even a section for Gutenberg news. Whether you just want to learn how to get started, or go full on obsessive about a content editor (there is no shame in that), this is probably the place to start.
WP Gutenberg
WP Gutenberg is a resource hub that focuses heavily on a listing style of content, and forgoes editorial. They have tons of plugins and Gutenberg-supporting themes listed, more than we could reasonably put in an article here on WDD.
The only problem is that at the time of this writing, the site is a bit bugged. Clicking on any listing will take you to a 404 page, so you might just have to copy/paste titles into Google to find the resources listed.
I’ll make the joke for you. It’s buggy like Gutenberg. See? it wasn’t that funny.
Every week users submit a lot of interesting stuff on our sister site Webdesigner News, highlighting great content from around the web that can be of interest to web designers.
The best way to keep track of all the great stories and news being posted is simply to check out the Webdesigner News site, however, in case you missed some here’s a quick and useful compilation of the most popular designer news that we curated from the past week.
Note that this is only a very small selection of the links that were posted, so don’t miss out and subscribe to our newsletter and follow the site daily for all the news.
28 Epic Memes for Graphic Designers
Zest Icons
When is a Button not a Button?
A Comprehensive (and Honest) List of UX Clichés
5 “hacks” to Drastically Improve your Designs
Forghetti — Forget your Passwords. Forever.
The Underlying Principles of Branding and Design in Email
How to Create a SaaS Landing Page that Converts
Site Design: Adtrak Agency
An Interview with Stanley Wood, Head of UX at Volvo
Logo Psychology: How to Design Logos that Inspire Trust
Why Designers Should Understand Code
UI Design: How Golden Ratio Works in User Interfaces
The Dribbble Experiment
Color Spaces
Absurd Design – Free Surrealist Illustrations for Landing Pages
Mint, a New HTTP Library for Elixir
How a Good UX Designer Can Save a Startup
Here are the Winners of Apple’s ‘Shot on iPhone’ Photo Contest
20+ Best Free Photoshop Actions 2019
Six Tips for Better Web Typography
5 Essential Design Tools for 2019
Amino: Live CSS Editor for Chrome
Site Design: Nicky Tesla
11 Must-Watch Conference Talks that will Inspire You for 2019
Want more? No problem! Keep track of top design news from around the web with Webdesigner News.
At the start of 2018, as I was starting to go a bit deeper into CSS gradient masking in order to create interesting visuals one would think are impossible otherwise with just a single element and a tiny bit of CSS, I learned about a property that had previously been completely unknown to me: mask-composite.
As this is not a widely used property, I couldn’t find any comprehensive resources on this topic. So, as I began to use it more and learn more about it (some may remember I’ve mentioned it before in a couple of otherarticles), I decided to create such a resource myself and thus this article was born! Here, I’m covering how mask-composite works, why it’s useful, what values it can take, what each of them does, where we are in terms of support and what alternatives we have in non-supporting browsers.
What mask compositing does
Compositing allows us to combine different mask layers into a single one using various compositing operations. Combine them how? Well, pixel by pixel! Let’s consider two mask layers. We take each pair of corresponding pixels, apply a certain compositing operation (we’ll discuss each possible operation in detail a bit later) on their channels and get a third pixel for the resulting layer.
How compositing two layers works at a pixel level.
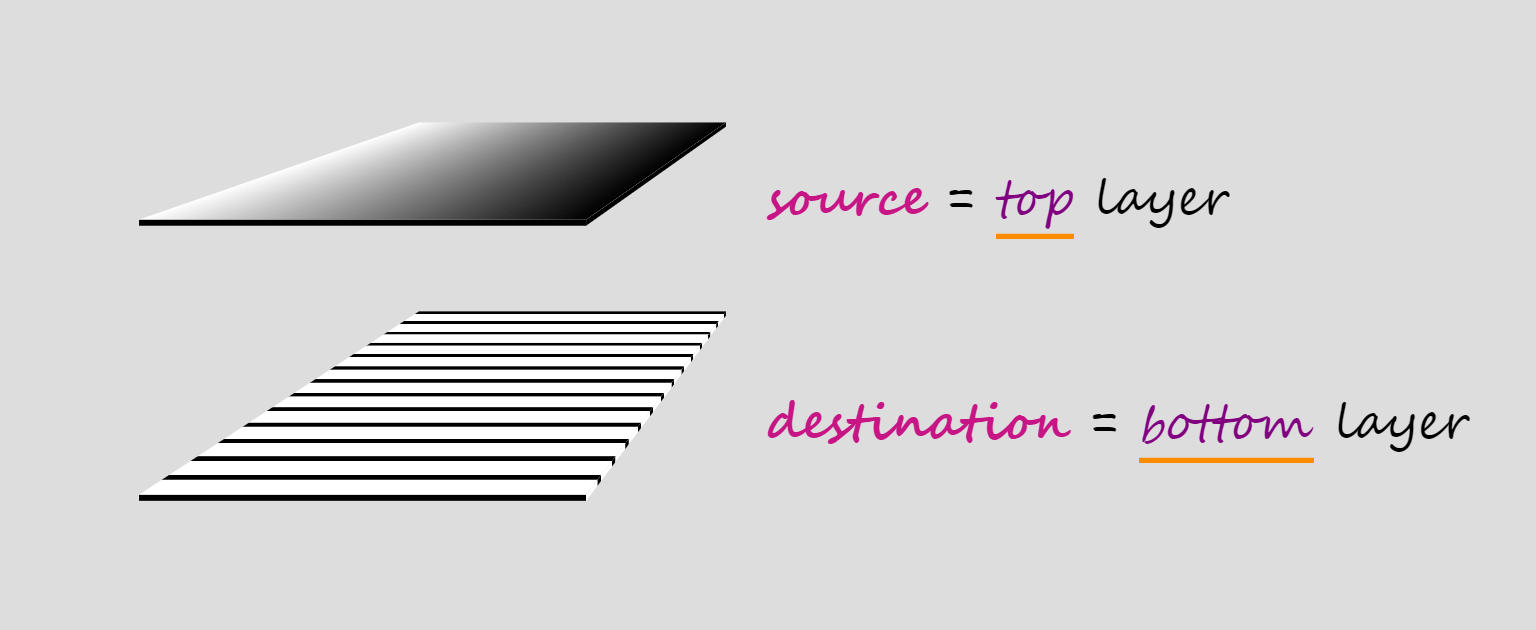
When compositing two layers, the layer on top is called the source, while the layer underneath is called the destination, which doesn’t really make much sense to me because source sounds like an input and destination sounds like an output, but, in this case, they’re both inputs and the output is the layer we get as a result of the compositing operation.
Compositing terminology.
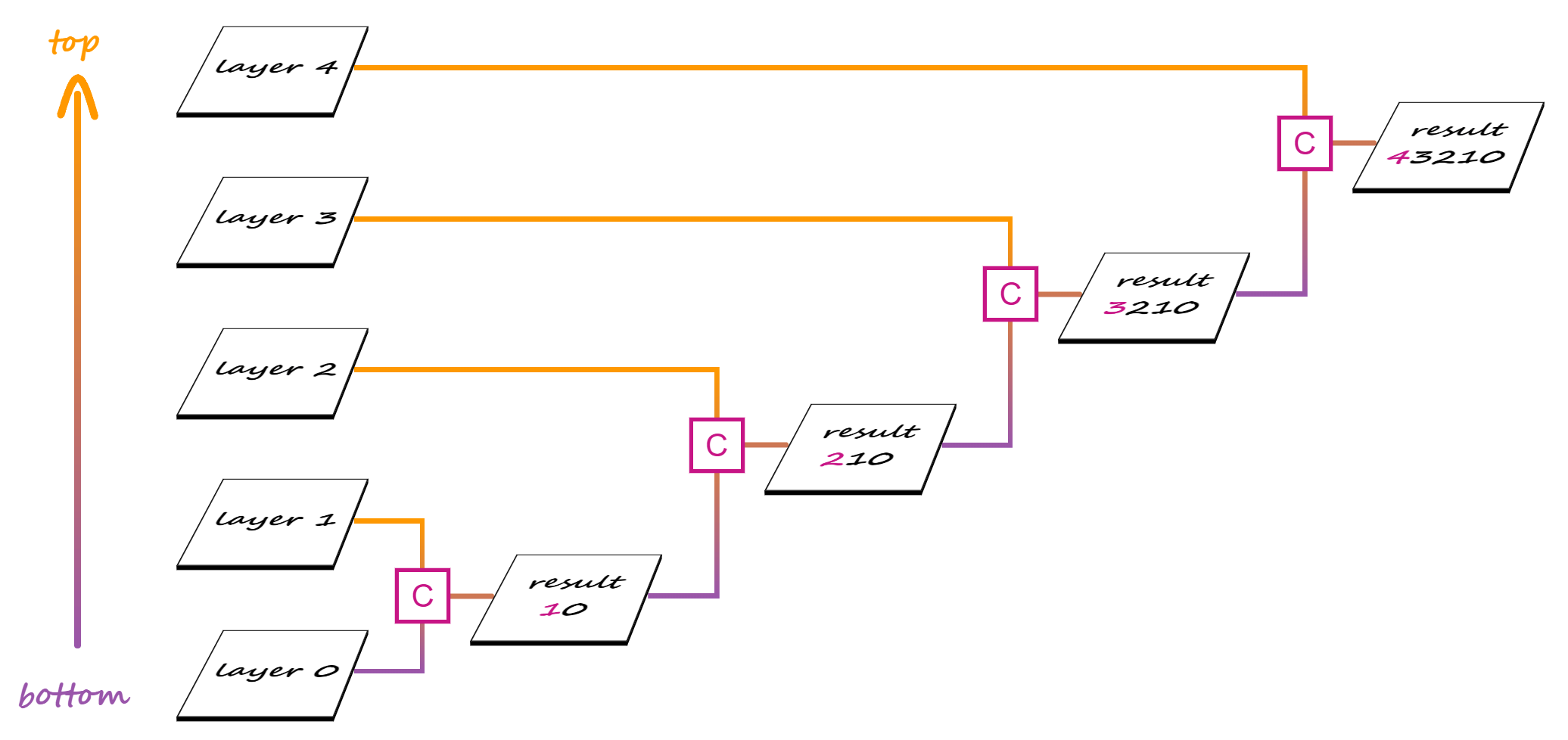
When we have more than two layers, compositing is done in stages, starting from the bottom.
In a first stage, the second layer from the bottom is our source and the first layer from the bottom is our destination. These two layers get composited and the result becomes the destination for the second stage, where the third layer from the bottom is the source. Compositing the third layer with the result of compositing the first two gives us the destination for the third stage, where the fourth layer from the bottom is the source.
Compositing multiple layers.
And so on, until we get to the final stage, where the topmost layer is composited with the result of compositing all the layers beneath.
Why mask compositing is useful
Both CSS and SVG masks have their limitations, their advantages and disadvantages. We can go around the limitations of SVG masks by using CSS masks, but, due to CSS masks working differently from SVG masks, taking the CSS route leaves us unable to achieve certain results without compositing.
In order to better understand all of this, let’s consider the following image of a pawesome Siberian tiger cub:
The image we want to have masked on our page.
And let’s say we want to get the following masking effect on it:
Desired result.
This particular mask keeps the rhombic shapes visible, while the lines separating them get masked and we can see through the image to the element behind.
We also want this masking effect to be flexible. We don’t want to be tied to the image’s dimensions or aspect ratio and we want to be able to easily switch (just by changing a % value to a px one) in between a mask that scales with the image and one that doesn’t.
In order to do this, we first need to understand how SVG and CSS masks each work and what we can and cannot do with them.
SVG masking
SVG masks are luminance masks by default. This means that the pixels of the masked element corresponding to the whitemask pixels are fully opaque, the pixels of the masked element corresponding to blackmask pixels are fully transparent and the pixels of the masked element corresponding to mask pixels somewhere in between black and white in terms of luminance (grey, pink, lime) are semitransparent.
The formula used to get the luminance out of a given RGB value is: .2126·R + .7152·G + .0722·B
For our particular example, this means we need to make the rhombic areas white and the lines separating them black, creating the pattern that can be seen below:
Black and white rhombic pattern used as an SVG mask.
In order to get the pattern above, we start with a white SVG rectangle element rect. Then, one might think we need to draw lots of black lines… but we don’t! Instead, we only add a path made up of the two diagonals of this rectangle and ensure its stroke is black.
To create the first diagonal (top left to bottom right), we use a “move to” (M) command to the top left corner, followed by a “line to” (L) command to the bottom right corner.
To create the second diagonal (top right to bottom left), we use a “move to” (M) command to the top right corner, followed by a “line to” (L) command to the bottom left corner.
… but that’s about to change! We increase the thickness (stroke-width) of the black diagonal lines and make them dashed with the gaps between the dashes (7%) bigger than the dashes themselves (1%).
If we keep increasing the thickness (stroke-width) of our black diagonal lines to a value like 150%, then they end up covering the entire rectangle and giving us the pattern we’ve been after!
The above should work. But sadly, things are not perfect in practice. At this point, we only get the expected result in Firefox (live demo). Even worse, not getting the desired masked pattern in Chrome doesn’t mean our element stays as it is unmasked – applying this mask makes it disappear altogether! Of course, since Chrome needs the -webkit- prefix for the mask property (when used on HTML elements), not adding the prefix means that it doesn’t even try to apply the mask on our element.
The most straightforward workaround for img elements is to turn them into SVG image elements.
This gives us the result we’ve been after, but if we want to mask another HTML element, not an img one, things get a bit more complicated as we’d need to include it inside the SVG with foreignObject.
Even worse, with this solution, we’re hardcoding dimensions and this always feels yucky.
Of course, we can make the mask ridiculously large so that it’s unlikely there may be an image it couldn’t cover. But that feels just as bad as hardcoding dimensions.
We can also try tackling the hardcoding issue by switching the maskContentUnits to objectBoundingBox:
But we’re still hardcoding the dimensions in the viewBox and, while their actual values don’t really matter, their aspect ratio does. Furthermore, our masking pattern is now created within a 1x1 square and then stretched to cover the masked element.
Shape stretching means shape distortion, which is why is why our rhombic shapes don’t look as they did before anymore.
However, in order to get one particular rhombic pattern, with certain angles for our rhombic shapes, we need to know the image’s aspect ratio.
Sigh. Let’s just drop it and see what we can do with CSS.
CSS masking
CSS masks are alpha masks by default. This means that the pixels of the masked element corresponding to the fully opaque mask pixels are fully opaque, the pixels of the masked element corresponding to the fully transparentmask pixels are fully transparent and the pixels of the masked element corresponding to semitransparent mask pixels are semitransparent. Basically, each and every pixel of the masked element gets the alpha channel of the corresponding mask pixel.
For our particular case, this means making the rhombic areas opaque and the lines separating them transparent, so let’s how can we do that with CSS gradients!
In order to get the pattern with white rhombic areas and black separating lines, we can layer two repeating linear gradients:
This is the pattern that does the job if we have a luminancemask.
But in the case of an alphamask, it’s not the black pixels that give us full transparency, but the transparent ones. And it’s not the white pixels that give us full opacity, but the fully opaque ones – red, black, white… they all do the job! I personally tend to use red or tan as this means only three letters to type and the fewer letters to type, the fewer opportunities for awful typos that can take half an hour to debug.
So the first idea is to apply the same technique to get opaque rhombic areas and transparent separating lines. But in doing so, we run into a problem: the opaque parts of the second gradient layer cover parts of the first layer we’d like to still keep transparent and the other way around.
So what we’re getting is pretty far from opaque rhombic areas and transparent separating lines.
My initial idea was to use the pattern with white rhombic areas and black separating lines, combined with setting mask-mode to luminance to solve the problem by making the CSS mask work like an SVG one.
This property is only supported by Firefox, though there is the non-standard mask-source-type for WebKit browsers. And sadly, support is not even the biggest issue as neither the standard Firefox way, nor the non-standard WebKit way give us the result we’re after (live demo).
Fortunately, mask-composite is here to help! So let’s see what values this property can take and what effect they each have.
mask-composite values and what they do
First, we decide upon two gradient layers for our mask and the image we want masked.
The two gradient mask layers we use to illustrate how each value of this property works are as follows:
These two layers can be seen as background gradients in the Pen below (note that the body has a hashed background so that the transparent and semitransparent gradient areas are more obvious):
The layer on top (--l1) is the source, while the bottom layer (--l0) is the destination.
We apply the mask on this image of a gorgeous Amur leopard.
The image we apply the mask on.
Alright, now that we got that out of the way, let’s see what effect each mask-composite value has!
add
This is the initial value, which gives us the same effect as not specifying mask-composite at all. What happens in this case is that the gradients are added one on top of the other and the resulting mask is applied.
Note that, in the case of semitransparent mask layers, the alphas are not simply added, in spite of the value name. Instead, the following formula is used, where ?? is the alpha of the pixel in the source (top) layer and ?? is the alpha of the corresponding pixel in the destination (bottom) layer:
α₁ + α₀ – α₁·α₀
Wherever at least onemask layer is fully opaque (its alpha is 1), the resulting mask is fully opaque and the corresponding pixels of the masked element are shown fully opaque (with an alpha of 1).
If the source (top) layer is fully opaque, then ?? is 1, and replacing in the formula above, we have:
1 + α₀ - 1·α₀ = 1 + α₀ - α₀ = 1
If the destination (bottom) layer is fully opaque, then ?? is 1, and we have:
α₁ + 1 – α₁·1 = α₁ + 1 – α₁ = 1
Wherever bothmask layers are fully transparent (their alphas are 0), the resulting mask is fully transparent and the corresponding pixels of the masked element are therefore fully transparent (with an alpha of 0) as well.
0 + 0 – 0·0 = 0 + 0 + 0 = 0
Below, we can see what this means for the mask layers we’re using – what the layer we get as a result of compositing looks like and the final result that applying it on our Amur leopard image produces.
What using mask-composite: add for two given layers does.
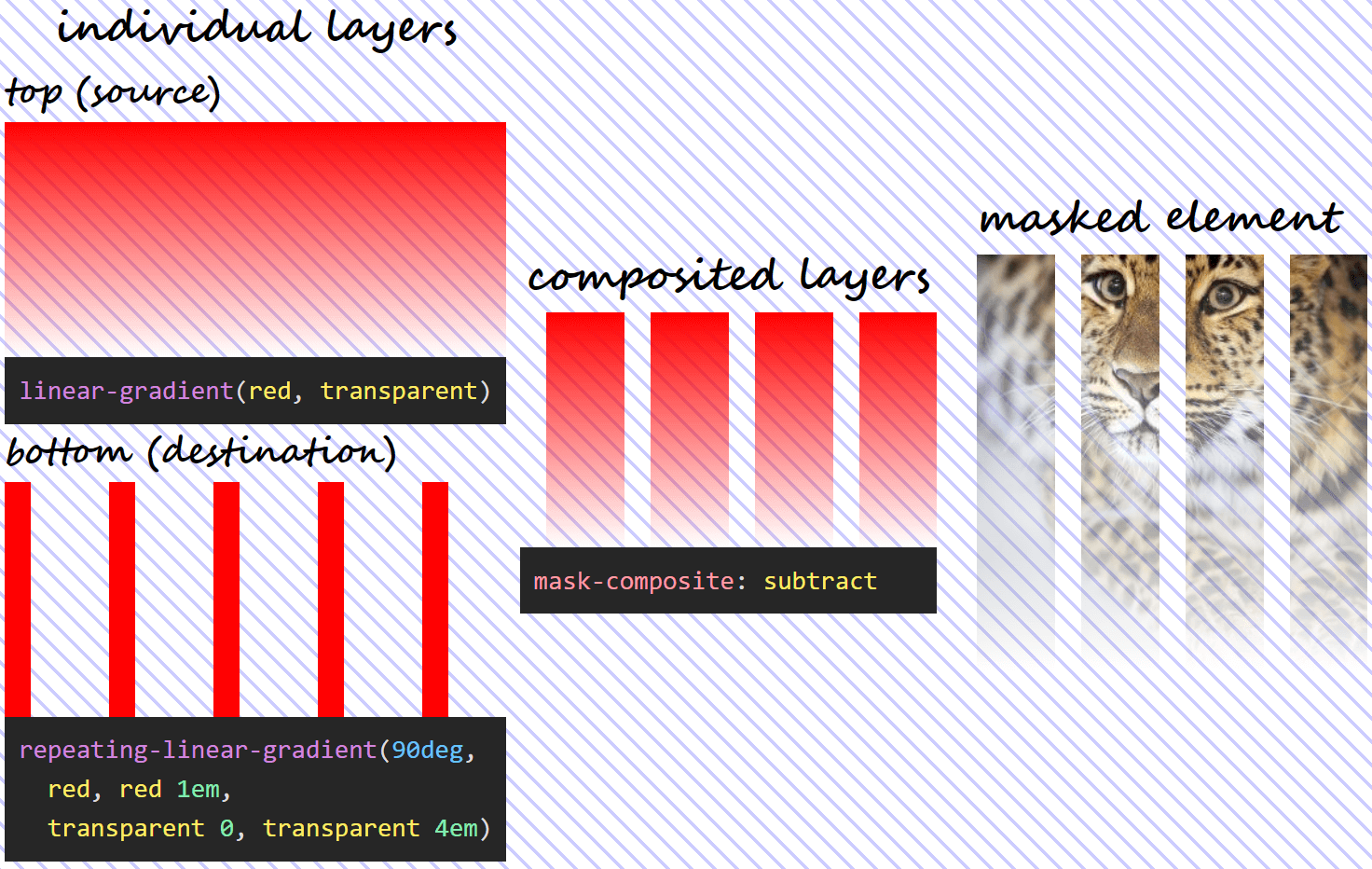
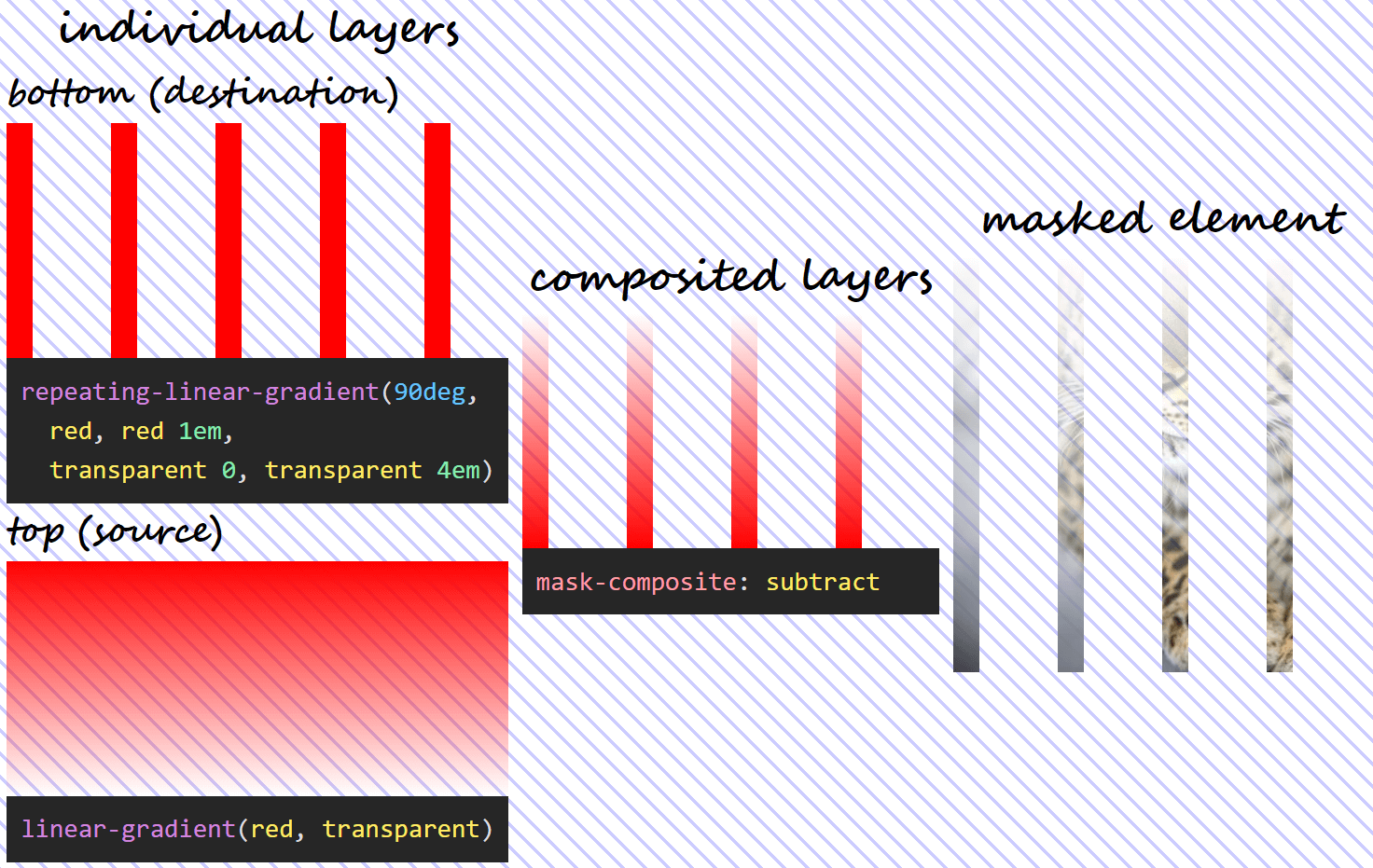
subtract
The name refers to “subtracting” the destination (layer below) out of the source (layer above). Again, this does not refer to simply capped subtraction, but uses the following formula:
α₁·(1 – α₀)
The above formula means that, since anything multiplied with 0 gives us 0, wherever the source (top) layer is fully transparent or wherever the destination (bottom) layer is fully opaque, the resulting mask is also fully transparent and the corresponding pixels of the masked element are also fully transparent.
If the source (top) layer is fully transparent, replacing its alpha with 0 in our formula gives us:
0·(1 – α₀) = 0
If the destination (bottom) layer is fully opaque, replacing its alpha with 1 in our formula gives us:
α₁·(1 – 1) = α₁·0 = 0
This means using the previously defined mask and setting mask-composite: subtract, we get the following:
What using mask-composite: subtract for two given layers does.
Note that, in this case, the formula isn’t symmetrical, so, unless ?? and ?? are equal, we don’t get the same thing if we swap the two mask layers (??·(1 – ??) isn’t the same as ??·(1 – ??)). This means we have a different visual result if we swap the order of the two layers!
Using mask-composite: subtract when the two given layers have been swapped.
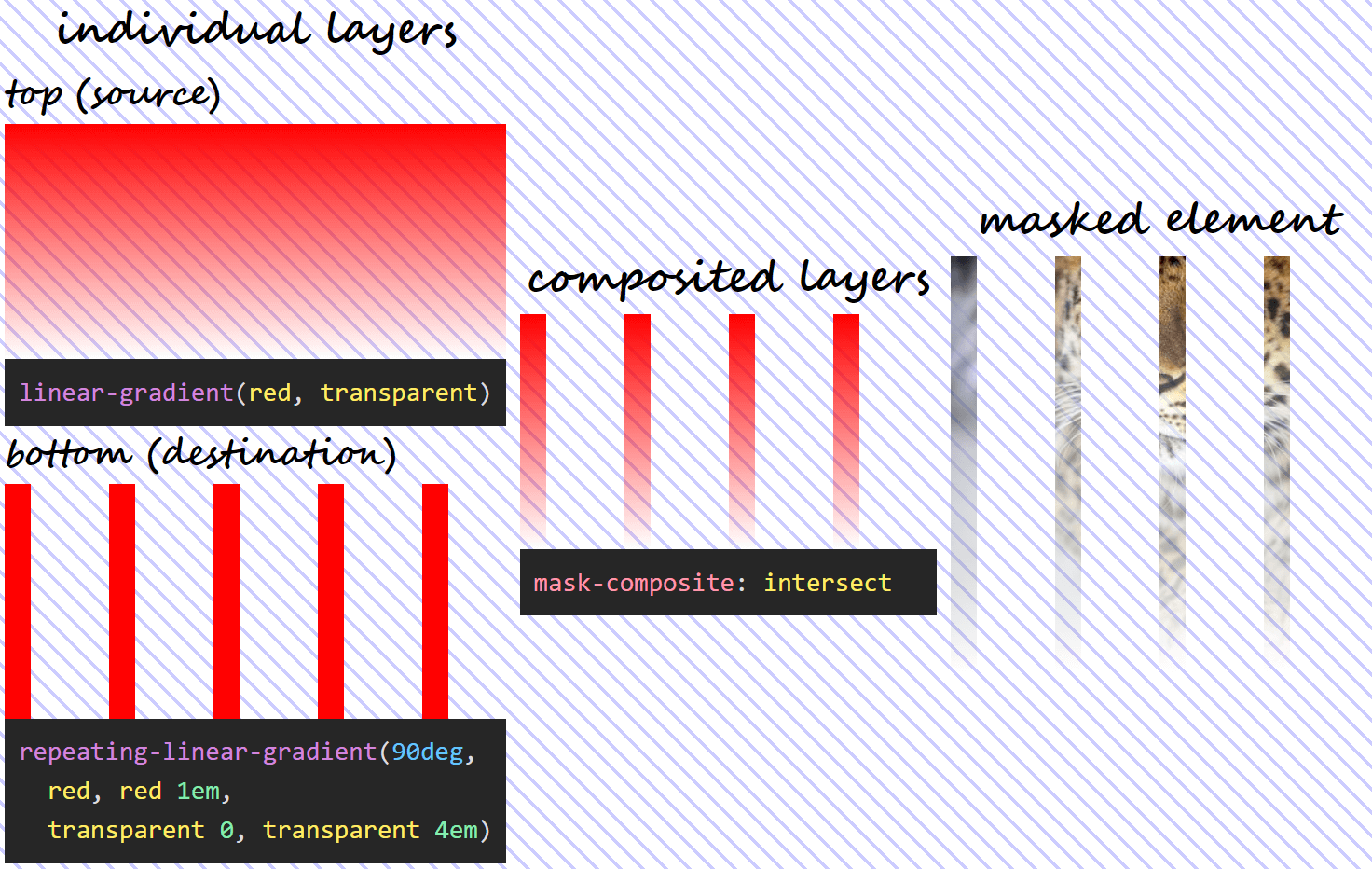
intersect
In this case, we only see the pixels of the masked element from where the two mask layers intersect. The formula used is the product between the alphas of the two layers:
α₁·α₀
What results from the formula above is that, wherever eithermask layer is fully transparent (its alpha is 0), the resulting mask is also fully transparent and so are the corresponding pixels of the masked element.
If the source (top) layer is fully transparent, replacing its alpha with 0 in our formula gives us:
0·α₀ = 0
If the destination (bottom) layer is fully transparent, replacing its alpha with 0 in our formula gives us:
α₁·0 = 0
Also, wherever bothmask layers are fully opaque (their alphas are 1), the resulting mask is fully opaque and so are the corresponding pixels of the masked element. This because, if the alphas of the two layers are both 1, we have:
1·1 = 1
In the particular case of our mask, setting mask-composite: intersect means we have:
What using mask-composite: intersect for two given layers does.
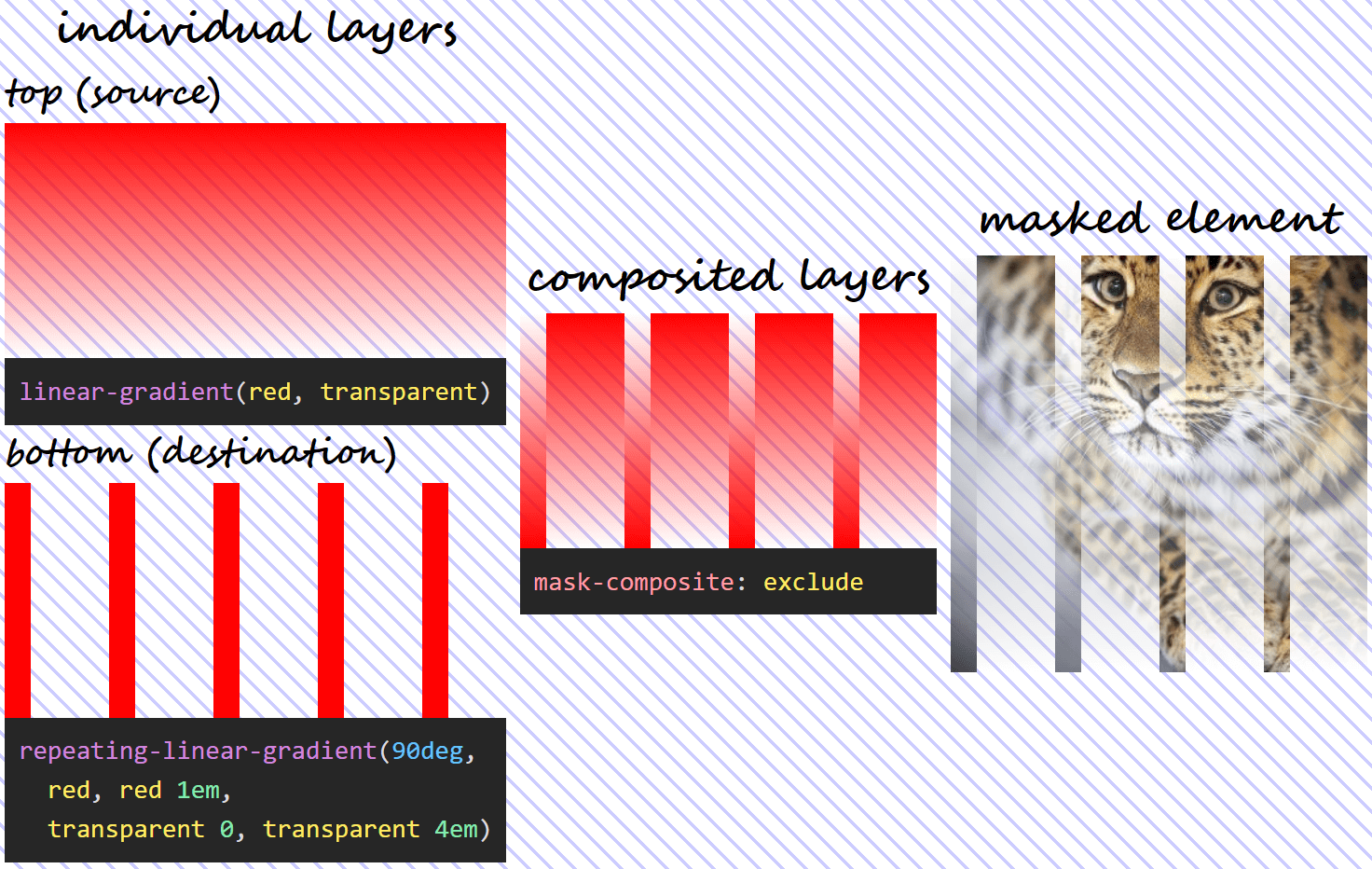
exclude
In this case, each layer is basically excluded from the other, with the formula being:
α₁·(1 – α₀) + α₀·(1 – α₁)
In practice, this formula means that, wherever bothmask layers are fully transparent (their alphas are 0) or fully opaque (their alphas are 1), the resulting mask is fully transparent and the corresponding pixels of the masked element are fully transparent as well.
If both mask layers are fully transparent, our replacing their alphas with 0 in our formula results in:
0·(1 – 0) + 0·(1 – 0) = 0·1 + 0·1 = 0 + 0 = 0
If both mask layers are fully opaque, our replacing their alphas with 1 in our formula results in:
1·(1 – 1) + 1·(1 – 1) = 1·0 + 1·0 = 0 + 0 = 0
It also means that, wherever one layer is fully transparent (its alpha is 0), while the other one is fully opaque (its alpha is 1), then the resulting mask is fully opaque and so are the corresponding pixels of the masked element.
If the source (top) layer is fully transparent, while the destination (bottom) layer is fully opaque, replacing ?? with 0 and ?? with 1 gives us:
0·(1 – 1) + 1·(1 – 0) = 0·0 + 1·1 = 0 + 1 = 1
If the source (top) layer is fully opaque, while the destination (bottom) layer is fully transparent, replacing ?? with 1 and ?? with 0 gives us:
1·(1 – 0) + 0·(1 – 1) = 1·1 + 0·0 = 1 + 0 = 1
With our mask, setting mask-composite: exclude means we have:
What using mask-composite: exclude for two given layers does.
Applying this to our use case
We go back to the two gradients we attempted to get the rhombic pattern with:
--l1: repeating-linear-gradient(-60deg,
transparent 0, transparent 5px,
tan 0, tan 35px);
--l0: repeating-linear-gradient(60deg,
transparent 0, transparent 5px,
tan 0, tan 35px)
If we make the completely opaque (tan in this case) parts semitransparent (let’s say rgba(tan, .5)), the visual result gives us an indication of how compositing could help here:
The rhombic areas we’re after are formed at the intersection between the semitransparent strips. This means using mask-composite: intersect should do the trick!
$sw: 5px;
--l1: repeating-linear-gradient(-60deg,
transparent 0, transparent #{$sw},
tan 0, tan #{7*$sw});
--l0: repeating-linear-gradient(60deg,
transparent 0, transparent #{$sw},
tan 0, tan #{7*$sw});
mask: var(--l1) intersect, var(--l0)
Note that we can even include the compositing operation in the shorthand! Which is something I really love, because the fewer chances of wasting at least ten minutes not understanding why masj-composite, msdk-composite, nask-composite, mask-comoisite and the likes don’t work, the better!
Not only does this give us the desired result, but, if now that we’ve stored the transparent strip width into a variable, changing this value to a % value (let’s say $sw: .05%) makes the mask scale with the image!
If the transparent strip width is a px value, then both the rhombic shapes and the separating lines stay the same size as the image scales up and down with the viewport.
Masked image at two different viewport widths when the transparent separating lines in between the rhombic shapes have a px-valued width.
If the transparent strip width is a % value, then both the rhombic shapes and the separating lines are relative in size to the image and therefore scale up and down with it.
Masked image at two different viewport widths when the transparent separating lines in between the rhombic shapes have a %-valued width.
Too good to be true? What’s the support for this?
The bad news is that mask-composite is only supported by Firefox at the moment. The good news is we have an alternative for WebKit browsers, so we can extend the support.
Extending support
WebKit browsers support (and have supported for a long, long time) a non-standard version of this property, -webkit-mask-composite which needs different values to work. These equivalent values are:
source-over for add
source-out for subtract
source-in for intersect
xor for exclude
So, in order to have a cross-browser version, all we need to is add the WebKit version as well, right?
Well, sadly, things are not that simple.
First off, we cannot use this value in the -webkit-mask shorthand, the following does not work:
-webkit-mask: var(--l1) source-in, var(--l0)
And if we take the compositing operation out of the shorthand and write the longhand after it, as seen below:
And if you think that’s weird, check this: using any of the other three operations add/ source-over, subtract/ source-out, exclude/ xor, we get the expected result in WebKit browsers as well as in Firefox. It’s only the source-in value that breaks things in WebKit browsers!
Why is this particular value breaking things in WebKit?
When I first came across this, I spent a few good minutes trying to find a typo in source-in, then copy pasted it from a reference, then from a second one in case the first reference got it wrong, then from a third… and then I finally had another idea!
It appears as if, in the case of the non-standard WebKit alternative, we also have compositing applied between the layer at the bottom and a layer of nothing (considered completely transparent) below it.
For the other three operations, this makes absolutely no difference. Indeed, adding, subtracting or excluding nothing doesn’t change anything. If we are to take the formulas for these three operations and replace ?? with 0, we always get ??:
However, intersection with nothing is a different story. Intersection with nothing is nothing! This is something that’s also illustrated by replacing ?? with 0 in the formula for the intersect/ source-in operation:
α₁·0 = 0
The alpha of the resulting layer is 0 in this case, so no wonder our image gets completely masked out!
So the first fix that came to mind was to use another operation (doesn’t really matter which of the other three, I picked xor because it has fewer letters and it can be fully selected by double clicking) for compositing the layer at the bottom with this layer of nothing below it:
Note that we need to add the non-standard WebKit version before the standard one so that when WebKit browsers finally implement the standard version as well, this overrides the non-standard one.
Well, that’s about it! I hope you’ve enjoyed this article and learned something new from it.
A couple more demos
Before closing, here are two more demos showcasing why mask-composite is cool.
The first demo shows a bunch of 1 element umbrellas. Each “bite” is created with a radial-gradient() that we exclude from the full circular shape. Chrome has a little rendering issue, but the result looks perfect in Firefox.
1 element umbrellas using mask-composite (live demo).
The second demo shows three 1 element loaders (though only the second two use mask-composite). Note that the animation only works in Chrome here as it needs Houdini.
1 element loaders using mask-composite (live demo).
How about you – what other use cases can you think of?
I reckon that a lot of our uses of Sass maps can be replaced with CSS Custom properties – but hear me out for a sec.
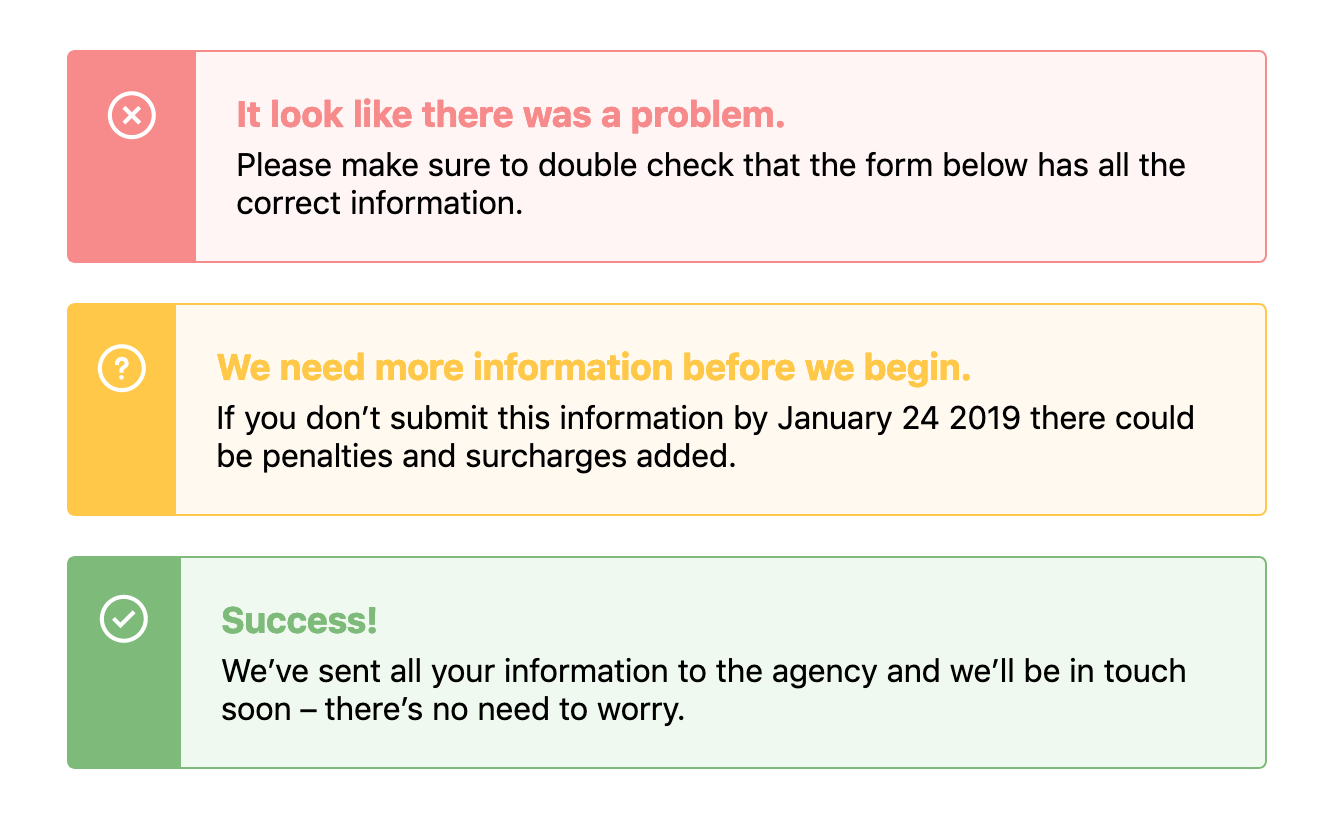
When designing components we often need to use the same structure of a component but change its background or text color based on a theme. For example, in an alert, we might need a warning style, an error style, and a success style – each of which might be slightly different, like this:
There’s a few ways we could tackle building this with CSS, and if you were asking me a couple of years ago, I would’ve tried to solve this problem with Sass maps. First, I would have started with the base alert styles but then I’d make a map that would hold all the data:
Pretty complicated, huh? This would output classes such as .alert-error, .alert-success and .alert-warning, each of which would have a bunch of CSS within them that overrides the default alert styles.
This would leave us with something that looks like this demo:
However! I’ve always found that using Sass maps and looping over all this data can become unwieldy and extraordinarily difficult to read. In recent projects, I’ve stumbled into fantastically complicated uses of maps and slowly closed the file as if I’d stumbled into a crime scene.
How do we keep the code easy and legible? Well, I think that CSS Custom Properties makes these kinds of loops much easier to read and therefore easier to edit and refactor in the future.
Let’s take the example above and refactor it so that it uses CSS Custom Properties instead. First we’ll set out core styles for the .alert component like so:
As we create those base styles, we can setup variables in our .alert class like this:
.alert {
--theme: #ccc;
--darkTheme: #777;
--icon: '';
background: var(--theme);
border: 1px solid var(--darkTheme);
/* other styles go here */
&:before {
background-image: var(--icon);
}
}
We can do a lot more with CSS Custom Properties than changing an interface to a dark mode or theme. I didn’t know until I tried that it’s possible to set an image in a custom property like that – I simply assumed it was for hex values.
Anyway! From there, we can style each custom .alert class like .alert-warning by overriding these properties in .alert:
However! I think there’s an enormous improvement here that’s been made in terms of legibility. It’s much easier to look at this code and to understand it right off the bat. With the Sass loop it almost seems like we are trying to do a lot of clever things in one place – namely, nest classes within other classes and create the class names themselves. Not to mention we then have to go back and forth between the original Sass map and our styles.
With CSS Custom Properties, all the styles are contained within the original .alert.
There you have it! I think there’s not much to mention here besides the fact that CSS Custom Properties can make code more legible and maintainable in the future. And I reckon that’s something we should all be a little excited about.
Although there is one last thing: we should probably be aware of browser support whilst working with Custom Properties although it’s pretty good across the board.
It’s a valid question. A “source map” is a special file that connects a minified/uglified version of an asset (CSS or JavaScript) to the original authored version. Say you’ve got a filed called _header.scss that gets imported into global.scss which is compiled to global.css. That final CSS file is what gets loaded in the browser, so for example, when you inspect an element in DevTools, it might tell you that the
While it is important to have a well-tested API, solid test coverage is a must for any React application. Tests increase confidence in the code and helps prevent shipping bugs to users.
That’s why we’re going to focus on testing in this post, specifically for React applications. By the end, you’ll be up and running with tests using Jest and Enzyme.
No worries if those names mean nothing to you because that’s where we’re headed right now!
Installing the test dependencies
Jest is a unit testing framework that makes testing React applications pretty darn easy because it works seamlessly with React (because, well, the Facebook team made it, though it is compatible with other JavaScript frameworks). It serves as a test runner that includes an entire library of predefined tests with the ability to mock functions as well.
Enzyme is designed to test components and it’s a great way to write assertions (or scenarios) that simulate actions that confirm the front-end UI is working correctly. In other words, it seeks out components on the front end, interacts with them, and raises a flag if any of the components aren’t working the way it’s told they should.
So, Jest and Enzyme are distinct tools, but they complement each other well.
For our purposes, we will spin up a new React project using create-react-app because it comes with Jest configured right out of the box.
yarn create react-app my-app
We still need to install enzyme and enzyme-adapter-react-16 (that number should be based on whichever version of React version you’re using).
yarn add enzyme enzyme-adapter-react-16 --dev
OK, that creates our project and gets us both Jest and Enzyme in our project in two commands. Next, we need to create a setup file for our tests. We’ll call this file setupTests.js and place it in the src folder of the project.
Here’s what should be in that file:
import { configure } from 'enzyme';
import Adapter from 'enzyme-adapter-react-16';
configure({ adapter: new Adapter() });
This brings in Enzyme and sets up the adapter for running our tests.
To make things easier on us, we are going to write tests for a React application I have already built. Grab a copy of the app over on GitHub.
Taking snapshots of tests
Snapshot testing is used to keep track of changes in the app UI. If you’re wonder whether we’re dealing with literal images of the UI, the answer is no, but snapshots are super useful because they capture the code of a component at a moment in time so we can compare the component in one state versus any other possible states it might take.
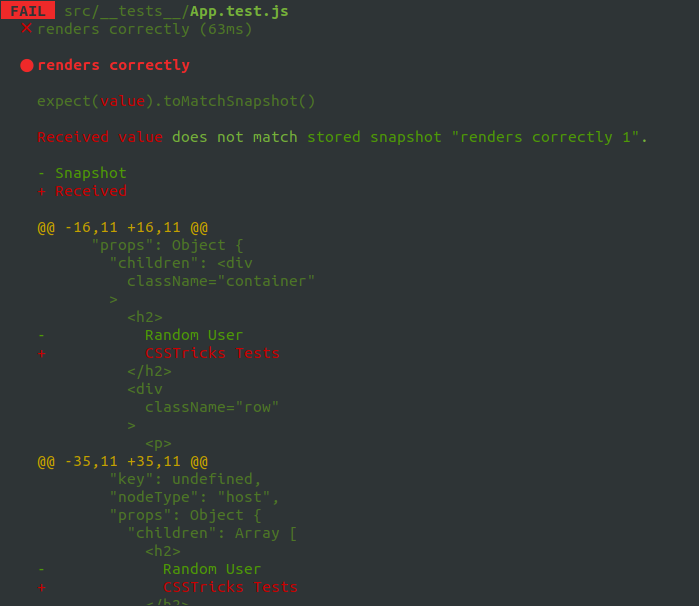
The first time a test runs, a snapshot of the component code is composed and saved in a new __snapshots__ folder in the src directory. On test runs, the current UI is compared to the existing. Here’s a snapshot of a successful test of the sample project’s App component.
Every new snapshot that gets generated when the test suite runs will be saved in the __tests__ folder. What’s great about that Jest will check to see if the component matches is then on subsequent times when we run the test, Jest will check to see if the component matches the snapshot on subsequent tests. Here’s how that files looks.
Let’s create a conditions where the test fails. We’ll change the
tag of our component from
Random User
to
CSSTricks Tests
and here’s what we get in the command line when the tests run:
If we want our change to pass the test, we either change the heading to what it was before, or we can update the snapshot file. Jest even provides instructions for how to update the snapshot right from the command line so there’s no need to update the snapshot manually:
Inspect your code changes or press `u` to update them.
So, that’s what we’ll do in this case. We press u to update the snapshot, the test passes, and we move on.
Did you catch the shallow method in our test snapshot? That’s from the Enzyme package and instructs the test to run a single component and nothing else — not even any child components that might be inside it. It’s a nice clean way to isolate code and get better information when debugging and is especially great for simple, non-interactive components.
In addition to shallow, we also have render for snapshot testing. What’s the difference, you ask? While shallow excludes child components when testing a component, render includes them while rendering to static HTML.
There is one more method in the mix to be aware of: mount. This is the most engaging type of test in the bunch because it fully renders components (like shallow and render) and their children (like render) but puts them in the DOM, which means it can fully test any component that interacts with the DOM API as well as any props that are passed to and from it. It’s a comprehensive test for interactivity. It’s also worth noting that, since it does a full mount, we’ll want to make a call to .unmount on the component after the test runs so it doesn’t conflict with other tests.
Testing Component’s Lifecycle Methods
Lifecycle methods are hooks provided by React, which get called at different stages of a component’s lifespan. These methods come in handy when handling things like API calls.
Since they are often used in React components, you can have your test suite cover them to ensure all things work as expected.
We do the fetching of data from the API when the component mounts. We can check if the lifecycle method gets called by making use of jest, which makes it possible for us to mock lifecycle methods used in React applications.
We attach spy to the component’s prototype, and the spy on the componentDidMount() lifecycle method of the component. Next, we assert that the lifecycle method is called once by checking for the call length.
Testing component props
How can you be sure that props from one component are being passed to another? We have a test confirm it, of course! The Enzyme API allows us to create a “mock” function so tests can simulate props being passed between components.
Let’s say we are passing user props from the main App component into a Profile component. In other words, we want the App to inform the Profile with details about user information to render a profile for that user.
Mock functions look a lot like other tests in that they’re wrapped around the components. However, we’re using an additional describe layer that takes the component being tested, then allows us to proceed by telling the test the expected props and values that we expect to be passed.
This particular example contains two tests. In the first test, we pass the user props to the mounted Profile component. Then, we check to see if we can find a
element that corresponds to what we have in the Profile component.
In the second test, we want to check if the props we passed to the mounted component equals the mock props we created above. Note that even though we are destructing the props in the Profile component, it does not affect the test.
Mock API calls
There’s a part in the project we’ve been using where an API call is made to fetch a list of users. And guess what? We can test that API call, too!
The slightly tricky thing about testing API calls is that we don’t actually want to hit the API. Some APIs have call limits or even costs for making making calls, so we want to avoid that. Thankfully, we can use Jest to mock axios requests. See this post for a more thorough walkthrough of using axios to make API calls.
First, we’ll create a new folder called __mock__ in the same directory where our __tests__ folder lives. This is where our mock request files will be created when the tests run.
We want to check and see that the GET request is made. We’ll import axios for that:
import axios from 'axios';
Just below the import statements, we need Jest to replace axios with our mock, so we add this:
jest.mock('axios')
The Jest API has a spyOn() method that takes an accessType? argument that can be used to check whether we are able to “get” data from an API call. We use jest.spyOn() to call the spied method, which we implemented in our __mock__ file, and it can be used with the shallow, render and mount tests we covered earlier.
it('fetches a list of users', () => {
const getSpy = jest.spyOn(axios, 'get')
const wrapper = shallow(
<App />
)
expect(getSpy).toBeCalled()
})
We passed the test!
That’s a primer into the world of testing in a React application. Hopefully you now see the value that testing adds to a project and how relatively easy it can be to implement, thanks to the heavy lifting done by the joint powers of Jest and Enzyme.
2016 was only three years ago, but that’s almost a whole other era in web development terms. The JavaScript landscape was in turmoil, with up-and-comer React — as well as a little-known framework called Vue — fighting to dethrone Angular.
Like many other developers, I felt lost. I needed some clarity, and I figured the best way to get it was simply to ask fellow coders what they used, and more importantly, what they enjoyed using. The result was the first ever edition of the now annual State of JavaScript survey.
The State of JavaScript 2018
Things have stabilized in the JavaScript world since then. Turns out you can’t really go wrong with any one of the big three frameworks, and even less mainstream options, like Ember, have managed to build up passionate communities and show no sign of going anywhere.
But while all our attention was fixated on JavaScript, trouble was brewing in CSS land. For years, my impression of CSS’s evolution was slow, incremental progress. Back then, I was pretty sure border-radius support represented the crowning, final achievement of web browser technology.
But all of a sudden, things started picking up. Flexbox came out, representing the first new and widely adopted layout method in over a decade. And Grid came shortly after that, sweeping away years of hacky grid frameworks into the gutter of bad CSS practices.
Something even crazier happened: now that the JavaScript people had stopped creating a new framework every two weeks, they decided to use all their extra free time trying to make CSS even better! And thus CSS-in-JS was born.
And now it’s 2019, and the Flexbox Cheatsheet tab I’ve kept open for the past two years has now been joined by a Grid Cheatsheet, because no matter how many times I use them, I still need to double-check the syntax. And despite writing a popular introduction to CSS-in-JS, I still lazily default to familiar Sass for new projects, promising myself that I’ll “do things properly” the next time.
All this to say that I feel just as lost and confused about CSS in 2019 as I did about JavaScript in 2016. It’s high time CSS got a survey of its own.
Starting from scratch
Coming up with the idea for a CSS survey was easy, but deciding on the questions themselves was far from straightforward. Like I said, I didn’t feel confident in my own CSS knowledge, and simply asking about Sass vs. Less for the 37th time felt like a missed opportunity…
Thankfully, the CSS Gods decided to smile down upon me: while attending the DotJS conference in France I discovered that, not only did fellow speaker Florian Rivoal live in Kyoto, Japan, just like me; but that he was a member of the CSS Working Group! In other words, one of the people who knows the most about CSS on the planet was living a few train stops away from me!
Florian was a huge help in coming up with the overall structure and content of the survey. And he also helped me realize how little I really knew about CSS.
Kyoto, Japan: a hotbed of CSS activity (Photo by Jisu Han)
You don’t know CSS
I’m not only talking about obscure CSS properties here, or even new up-and-coming ones, but about how CSS itself is developed. For example, did you know that the development of the CSS Grid spec was sponsored by Bloomberg, because they needed a way to port the layout of their famous terminal to the web?
Did you ever stop to wonder what top: 30px is supposed to mean on a circular screen, such as the one on a smartwatch? Or did you know that some people are laying out entire printed books in CSS, effectively replacing software like InDesign?
Talking with Florian really expanded my mind to how broad and interesting CSS truly is, and convinced me doing the survey was worth it.
Myself, personally, I’ve always enjoyed being a generalist in the sense that I happily hop from one side of the great divide to another whenever I feel like it. At the same time, I’m also wholly convinced that the world needs specialists like Florian; people who dedicate their lives to championing and improving a single aspect of the web.
Devaluing the work the work of generalists is not only unfair, but it’s also counter-productive — after all, HTML and CSS are the foundation on which all modern JavaScript frameworks are built; and on the other hand, new patterns and approaches pioneered by CSS-in-JS libraries will hopefully find their way back into vanilla CSS sooner or later.
Thankfully, I feel like a minority of developers hold those views, and those who do generally hold them do so out of ignorance for what the “other side” really stands for more than any well-informed opinion.
So that’s where the survey comes in: I’m not saying I can fill up the divide, but maybe I can throw a couple walkways across, or distribute some jetpacks — you know, whatever works. ?
If that sounds good, then the first step is — you guessed it — taking the survey!

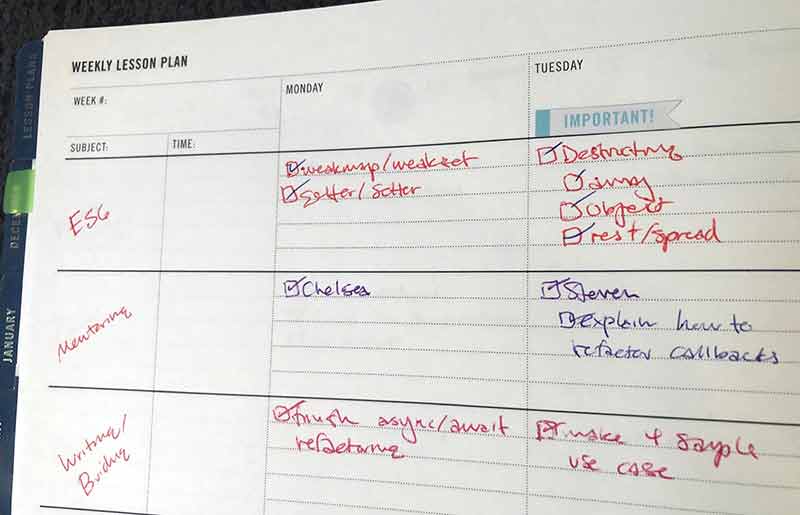

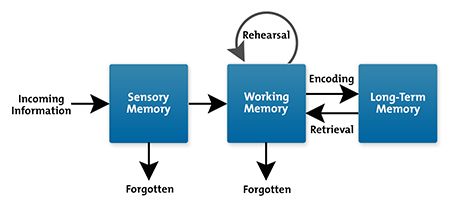
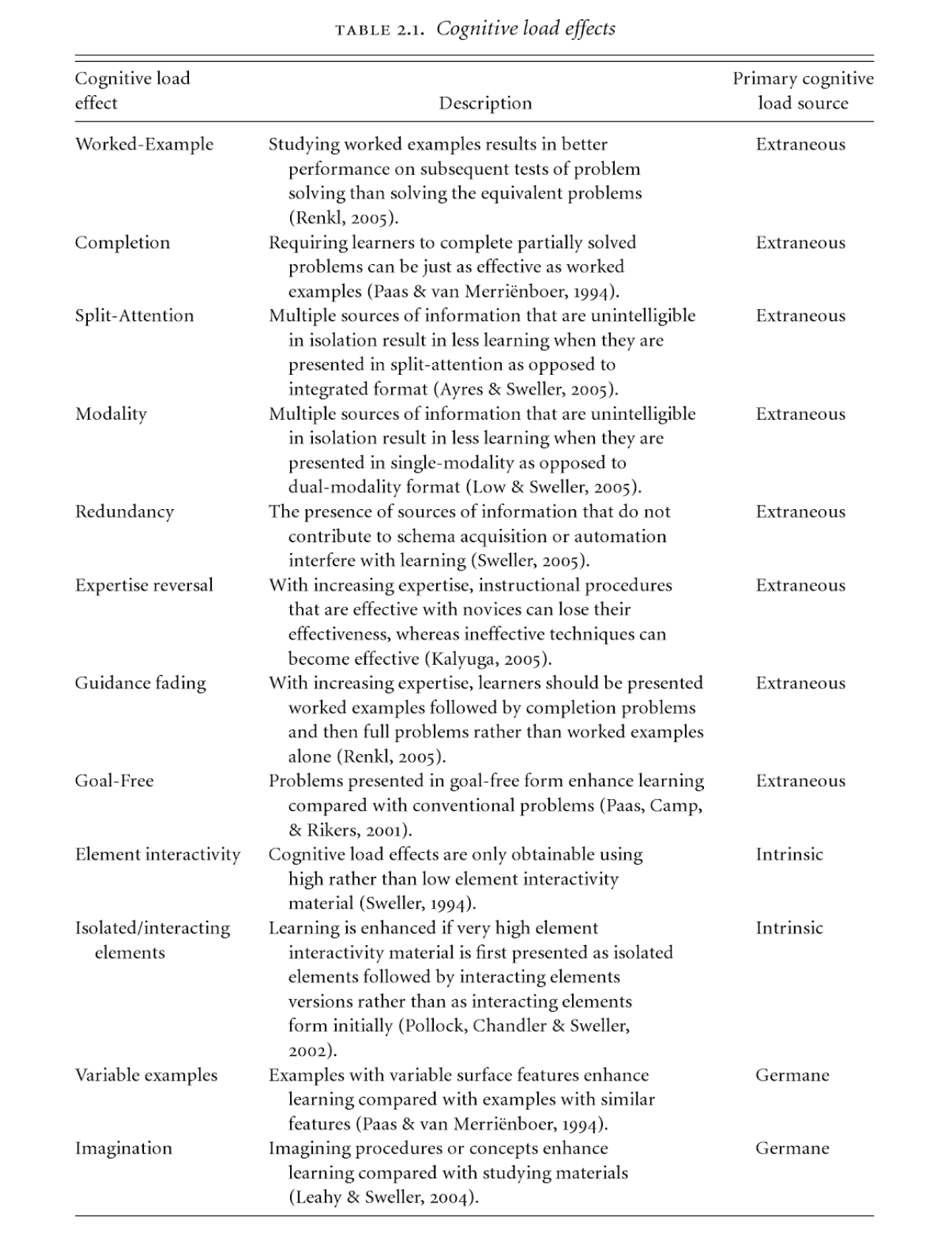




 — Forget your Passwords. Forever.
— Forget your Passwords. Forever.