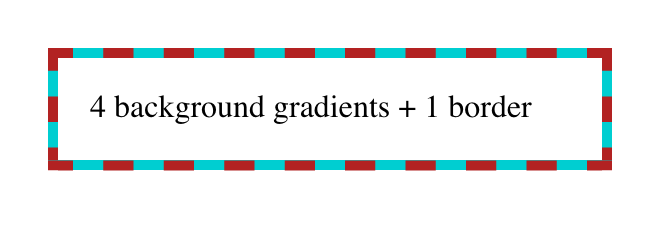Earlier this month Eric Bailey wrote about the current state of accessibility on the web and why it felt like fighting an uphill battle:
As someone with a good deal of interest in the digital accessibility space, I follow WebAIM‘s work closely. Their survey results are priceless insights into how disabled people actually use the web, so when the organization speaks with authority on a subject, I listen.
WebAIM’s accessibility analysis of the top 1,000,000 homepages was released to the public on February 27, 2019. I’ve had a few days to process it, and frankly, it’s left me feeling pretty depressed. In a sea of already demoralizing findings, probably the most notable one is that pages containing ARIA—a specialized language intended to aid accessibility—are actually more likely to have accessibility issues.
Following up from that post, Ethan Marcotte jotted down his thoughts on the matter and about who has the responsibility to fix these issues in the long run:
Organizations like WebAIM have, alongside countless other non-profits and accessibility advocates, been showing us how we could make the web live up to its promise as a truly universal medium, one that could be accessed by anyone, anywhere, regardless of ability or need. And we failed.
I say we quite deliberately. This is on us: on you, and on me. And, look, I realize it may sting to read that. Hell, my work is constantly done under deadline, the way I work seems to change every year month, and it can feel hard to find the time to learn more about accessibility. And maybe you feel the same way. But the fact remains that we’ve created a web that’s actively excluding people, and at a vast, terrible scale. We need to meditate on that.
I suppose the lesson I’m taking from this is, well, we need to much, much more than meditating. I agree with Marcy Sutton: accessibility is a civil right, full stop. Improving the state of accessibility on the web is work we have to support. The alternative isn’t an option. Leaving the web in its current state isn’t fair. It isn’t just.
I entirely agree with Ethan here – we all have a responsibility to make the web a better place for everyone and especially when it comes to accessibility where the bar is so very low for us now. This isn’t to say that I know best, because there’s been plenty of times when I’ve dropped the ball when I’m designing something for the web.
What can we do to tackle the widespread issue surrounding web accessibility?
Well, as Eric mentions in his post, it’s first and foremost a problem of education and he points to Firefox and their great accessibility inspector as a tool to help us see and understand accessibility principles in action:
This inspector is not meant as an evaluation tool. It is an inspection tool. So it will not give you hints about low contrast ratios, or other things that would tell you whether your site is WCAG compliant. It helps you inspect your code, helps you understand how your web site is translated into objects for assistive technologies.
Chris also wrote up some of his thoughts a short while ago, including other accessibility testing tools and checklists that can help us get started making more accessible experiences. The important thing to note here is that these tools need to be embedded within our process for web design if they’re going to solve these issues.
We can’t simply blame our tools.
I know the current state of web accessbility is pretty bad and that there’s an enormous amount of work to do for us all, but to be honest, I can’t help but feel a little optimistic. For the first time in my career, I’ve had designers and engineers alike approach me excitedly about accessibility. Each year, there are tons of workshops, articles, meetups, and talks (and I particularly like this talk by Laura Carvajal) on the matter meaning there’s a growing source of referential content that can teach us to be better.
And I can’t help but think that all of these conversations are a good sign – but now it’s up to us to do the work.
In the last article, we got our hands dirty with Web Components by creating an HTML template that is in the document but not rendered until we need it.
Next up, we’re going to continue our quest to create a custom element version of the dialog component below which currently only uses HTMLTemplateElement:
Creating a Custom Element from Scratch (This post)
Encapsulating Style and Structure with Shadow DOM (Coming soon!)
Advanced Tooling for Web Components (Coming soon!)
Creating a custom element
The bread and butter of Web Components are custom elements. The customElements API gives us a path to define custom HTML tags that can be used in any document that contains the defining class.
Think of it like a React or Angular component (e.g. ), but without the React or Angular dependency. Native custom elements look like this: . More importantly, think of it as a standard element that can be used in your React, Angular, Vue, [insert-framework-you’re-interested-in-this-week] applications without much fuss.
Essentially, a custom element consists of two pieces: a tag name and a class that extends the built-in HTMLElement class. The most basic version of our custom element would look like this:
Note: throughout a custom element, the this value is a reference to the custom element instance.
In the example above, we defined a new standards-compliant HTML element, . It doesn’t do much… yet. For now, using the tag in any HTML document will create a new element with an
tag reading “Hello, World!”
We are definitely going to want something more robust, and we’re in luck. In the last article, we looked at creating a template for our dialog and, since we will have access to that template, let’s utilize it in our custom element. We added a script tag in that example to do some dialog magic. let’s remove that for now since we’ll be moving our logic from the HTML template to inside the custom element class.
Now, our custom element () is defined and the browser is instructed to render the content contained in the HTML template where the custom element is called.
Our next step is to move our logic into our component class.
Custom element lifecycle methods
Like React or Angular, custom elements have lifecycle methods. You’ve already been passively introduced to connectedCallback, which is called when our element gets added to the DOM.
The connectedCallback is separate from the element’s constructor. Whereas the constructor is used to set up the bare bones of the element, the connectedCallback is typically used for adding content to the element, setting up event listeners or otherwise initializing the component.
In fact, the constructor can’t be used to modify or manipulate the element’s attributes by design. If we were to create a new instance of our dialog using document.createElement, the constructor would be called. A consumer of the element would expect a simple node with no attributes or content inserted.
The createElement function has no options for configuring the element that will be returned. It stands to reason, then, that the constructor shouldn’t have the ability to modify the element that it creates. That leaves us with the connectedCallback as the place to modify our element.
With standard built-in elements, the element’s state is typically reflected by what attributes are present on the element and the values of those attributes. For our example, we’re going to look at exactly one attribute: [open]. In order to do this, we’ll need to watch for changes to that attribute and we’ll need attributeChangedCallback to do that. This second lifecycle method is called whenever one of the element constructor’s observedAttributes are updated.
That might sound intimidating, but the syntax is pretty simple:
In our case above, we only care if the attribute is set or not, we don’t care about a value (this is similar to the HTML5 required attribute on inputs). When this attribute is updated, we update the element’s open property. A property exists on a JavaScript object whereas an attribute exists on an HTMLElement, this lifecycle method helps us keep the two in sync.
We wrap the updater inside the attributeChangedCallback inside a conditional checking to see if the new value and old value are equal. We do this to prevent an infinite loop inside our program because later we are going to create a property getter and setter that will keep the property and attributes in sync by setting the element’s attribute when the element’s property gets updated. The attributeChangedCallback does the inverse: updates the property when the attribute changes.
Now, an author can consume our component and the presence of the open attribute will dictate whether or not the dialog will be open by default. To make that a bit more dynamic, we can add custom getters and setters to our element’s open property:
Our getter and setter will keep the open attribute (on the HTML element) and property (on the DOM object) values in sync. Adding the open attribute will set element.open to true and setting element.open to true will add the open attribute. We do this to make sure that our element’s state is reflected by its properties. This isn’t technically required, but is considered a best practice for authoring custom elements.
This does inevitably lead to a bit of boilerplate, but creating an abstract class that keeps the these in sync is a fairly trivial task by looping over the observed attribute list and using Object.defineProperty.
Now that we know whether or not our dialog is open, let’s add some logic to actually do the showing and hiding:
There’s a lot going on here, but let’s walk through it. The first thing we do is grab our wrapper and toggle the .open class based on isOpen. To keep our element accessible, we need to toggle the aria-hidden attribute as well.
If the dialog is open, then we want to save a reference to the previously-focused element. This is to account for accessibility standards. We also add a keydown listener to the document called watchEscape that we have bound to the element’s this in the constructor in a pattern similar to how React handles method calls in class components.
We do this not only to ensure the proper binding for this.close, but also because Function.prototype.bind returns an instance of the function with the bound call site. By saving a reference to the newly-bound method in the constructor, we’re able to then remove the event when the dialog is disconnected (more on that in a moment). We finish up by focusing on our element and setting setting the focus on the proper element in our shadow root.
We also create a nice little utility method for closing our dialog that dispatches a custom event alerting some listener that the dialog has been closed.
If the element is closed (i.e. !open), we check to make sure the this._wasFocused property is defined and has a focus method and call that to return the user’s focus back to the regular DOM. Then we remove our event listener to avoid any memory leaks.
Speaking of cleaning up after ourselves, that takes us to yet another lifecycle method: disconnectedCallback. The disconnectedCallback is the inverse of the connectedCallback in that the method is called once the element is removed from the DOM and allows us to clean up any event listeners or MutationObservers attached to our element.
It just so happens we have a few more event listeners to wire up:
Now we have a well-functioning, mostly accessible dialog element. There are a few bits of polish we can do, like capturing focus on the element, but that’s outside the scope of what we’re trying to learn here.
There is one more lifecycle method that doesn’t apply to our element, the adoptedCallback, which fires when the element is adopted into another part of the DOM.
In the following example, you will now see that our template element is being consumed by a standard element.
The we have created so far is a typical custom element in that it includes markup and behavior that gets inserted into the document when the element is included. However, not all elements need to render visually. In the React ecosystem, components are often used to manage application state or some other major functionality, like in react-redux.
Let’s imagine for a moment that our component is part of a series of dialogs in a workflow. As one dialog is closed, the next one should open. We could make a wrapper component that listens for our dialog-closed event and progresses through the workflow.
This element doesn’t have any presentational logic, but serves as a controller for application state. With a little effort, we could recreate a Redux-like state management system using nothing but a custom element that could manage an entire application’s state in the same one that React’s Redux wrapper does.
That’s a deeper look at custom elements
Now we have a pretty good understanding of custom elements and our dialog is starting to come together. But it still has some problems.
Notice that we’ve had to add some CSS to restyle the dialog button because our element’s styles are interfering with the rest of the page. While we could utilize naming strategies (like BEM) to ensure our styles won’t create conflicts with other components, there is a more friendly way of isolating styles. Spoiler! It’s shadow DOM and that’s what we’re going to look at in the next part of this series on Web Components.
Another thing we need to do is define a new template for every component or find some way to switch templates for our dialog. As it stands, there can only be one dialog type per page because the template that it uses must always be present. So either we need some way to inject dynamic content or a way to swap templates.
In the next article, we will look at ways to increase the usability of the element we just created by incorporating style and content encapsulation using the shadow DOM.
And so our journey continues. In this final part of my series on how to build an endless runner VR game, I’ll show you how you can synchronize the game state between two devices which will move you one step closer to building a multiplayer game. I’ll specifically introduce MirrorVR which is responsible for handling the mediating server in client-to-client communication.
Note: This game can be played with or without a VR headset. You can view a demo of the final product at ergo-3.glitch.me.
A Glitch project completed from part 2 of this tutorial. You can start from the part 2 finished product by navigating to https://glitch.com/edit/#!/ergo-2 and clicking “Remix to edit”;
A virtual reality headset (optional, recommended). (I use Google Cardboard, which is offered at $15 a piece.)
Step 1: Display Score
The game as-is functions at a bare minimum, where the player is given a challenge: avoid the obstacles. However, outside of object collisions, the game does not provide feedback to the player regarding progress in the game. To remedy this, you will implement the score display in this step. The score will be large text object placed in our virtual reality world, as opposed to an interface glued to the user’s field of view.
In virtual reality generally, the user interface is best integrated into the world rather than stuck to the user’s head.
This adds a text entity to the virtual reality scene. The text is not currently visible, because its value is set to empty. However, you will now populate the text entity dynamically, using JavaScript. Navigate to assets/ergo.js. After the collisions section, add a score section, and define a number of global variables:
score: the current game score.
countedTrees: IDs of all trees that are included in the score. (This is because collision tests may trigger multiple times for the same tree.)
scoreDisplay: reference to the DOM object, corresponding to a text object in the virtual reality world.
/*********
* SCORE *
*********/
var score;
var countedTrees;
var scoreDisplay;
Next, define a setup function to initialize our global variables. In the same vein, define a teardown function.
...
var scoreDisplay;
function setupScore() {
score = 0;
countedTrees = new Set();
scoreDisplay = document.getElementById('score');
}
function teardownScore() {
scoreDisplay.setAttribute('value', '');
}
In the Game section, update gameOver, startGame, and window.onload to include score setup and teardown.
/********
* GAME *
********/
function gameOver() {
...
teardownScore();
}
function startGame() {
...
setupScore();
addTreesRandomlyLoop();
}
window.onload = function() {
setupScore();
...
}
Define a function that increments the score for a particular tree. This function will check against countedTrees to ensure that the tree is not double counted.
function addScoreForTree(tree_id) {
if (countedTrees.has(tree_id)) return;
score += 1;
countedTrees.add(tree_id);
}
Additionally, add a utility to update the score display using the global variable.
function updateScoreDisplay() {
scoreDisplay.setAttribute('value', score);
}
Update the collision testing accordingly in order to invoke this score-incrementing function whenever an obstacle has passed the player. Still in assets/ergo.js, navigate to the collisions section. Add the following check and update.
This concludes the score display. Next, we will add proper start and Game Over menus, so that the player can replay the game as desired.
Step 2: Add Start Menu
Now that the user can keep track of the progress, you will add finishing touches to complete the game experience. In this step, you will add a Start menu and a Game Over menu, letting the user start and restart games.
Let’s begin with the Start menu where the player clicks a “Start” button to begin the game. For the second half of this step, you will add a Game Over menu, with a “Restart” button:
Navigate to index.html in your editor. Then, find the Mixins section. Here, append the title mixin, which defines styles for particularly large text. We use the same font as before, align text to the center, and define a size appropriate for the type of text. (Note below that anchor is where a text object is anchored to its position.)
With all text styles defined, you will now define the in-world text objects. Add a new Menus section beneath the Score section, with an empty container for the Start menu:
Navigate to your JavaScript file, assets/ergo.js. Create a new Menus section before the Game section. Additionally, define three empty functions: setupAllMenus, hideAllMenus, and showGameOverMenu.
/********
* MENU *
********/
function setupAllMenus() {
}
function hideAllMenus() {
}
function showGameOverMenu() {
}
/********
* GAME *
********/
Next, update the Game section in three places. In gameOver, show the Game Over menu:
function gameOver() {
...
showGameOverMenu();
}
```
In `startGame`, hide all menus:
```
function startGame() {
...
hideAllMenus();
}
Next, in window.onload, remove the direct invocation to startGame and instead call setupAllMenus. Update your listener to match the following:
Navigate back to the Menu section. Save references to various DOM objects:
/********
* MENU *
********/
var menuStart;
var menuGameOver;
var menuContainer;
var isGameRunning = false;
var startButton;
var restartButton;
function setupAllMenus() {
menuStart = document.getElementById('start-menu');
menuGameOver = document.getElementById('game-over');
menuContainer = document.getElementById('menu-container');
startButton = document.getElementById('start-button');
restartButton = document.getElementById('restart-button');
}
Next, bind both the “Start” and “Restart” buttons to startGame:
function setupAllMenus() {
...
startButton.addEventListener('click', startGame);
restartButton.addEventListener('click', startGame);
}
Define showStartMenu and invoke it from setupAllMenus:
function setupAllMenus() {
...
showStartMenu();
}
function hideAllMenus() {
}
function showGameOverMenu() {
}
function showStartMenu() {
}
To populate the three empty functions, you will need a few helper functions. Define the following two functions, which accepts a DOM element representing an A-Frame VR entity and shows or hides it. Define both functions above showAllMenus:
...
var restartButton;
function hideEntity(el) {
el.setAttribute('visible', false);
}
function showEntity(el) {
el.setAttribute('visible', true);
}
function showAllMenus() {
...
First populate hideAllMenus. You will remove the objects from sight, then remove click listeners for both menus:
function hideAllMenus() {
hideEntity(menuContainer);
startButton.classList.remove('clickable');
restartButton.classList.remove('clickable');
}
Second, populate showGameOverMenu. Here, restore the container for both menus, as well as the Game Over menu and the ‘Restart’ button’s click listener. However, remove the ‘Start’ button’s click listener, and hide the ‘Start’ menu.
function showGameOverMenu() {
showEntity(menuContainer);
hideEntity(menuStart);
showEntity(menuGameOver);
startButton.classList.remove('clickable');
restartButton.classList.add('clickable');
}
Third, populate showStartMenu. Here, reverse all changes that the showGameOverMenu effected.
function showStartMenu() {
showEntity(menuContainer);
hideEntity(menuGameOver);
showEntity(menuStart);
startButton.classList.add('clickable');
restartButton.classList.remove('clickable');
}
Double-check that your code matches the corresponding source files. Then, navigate to your preview, and you will observe the following behavior:
Congratulations! You now have a fully functioning game with a proper start and proper end. However, we have one more step left in this tutorial: We need to synchronize the game state between different player devices. This will move us one step closer towards multiplayer games.
Step 3: Synchronizing Game State With MirrorVR
In a previous tutorial, you learned how to send real-time information across sockets, to facilitate one-way communication between a server and a client. In this step, you will build on top of a fully-fledged product of that tutorial, MirrorVR, which handles the mediating server in client-to-client communication.
Navigate to index.html. Here, we will load MirrorVR and add a component to the camera, indicating that it should mirror a mobile device’s view where applicable. Import the socket.io dependency and MirrorVR 0.2.3.
Next, add a component, camera-listener, to the camera:
<a-camera camera-listener ...>
Navigate to assets/ergo.js. In this step, the mobile device will send commands, and the desktop device will only mirror the mobile device.
To facilitate this, you need a utility to distinguish between desktop and mobile devices. At the end of your file, add a mobileCheck function after shuffle:
/**
* Checks for mobile and tablet platforms.
*/
function mobileCheck() {
var check = false;
(function(a){if(/(android|bbd+|meego).+mobile|avantgo|bada/|blackberry|blazer|compal|elaine|fennec|hiptop|iemobile|ip(hone|od)|iris|kindle|lge |maemo|midp|mmp|mobile.+firefox|netfront|opera m(ob|in)i|palm( os)?|phone|p(ixi|re)/|plucker|pocket|psp|series(4|6)0|symbian|treo|up.(browser|link)|vodafone|wap|windows ce|xda|xiino|android|ipad|playbook|silk/i.test(a)||/1207|6310|6590|3gso|4thp|50[1-6]i|770s|802s|a wa|abac|ac(er|oo|s-)|ai(ko|rn)|al(av|ca|co)|amoi|an(ex|ny|yw)|aptu|ar(ch|go)|as(te|us)|attw|au(di|-m|r |s )|avan|be(ck|ll|nq)|bi(lb|rd)|bl(ac|az)|br(e|v)w|bumb|bw-(n|u)|c55/|capi|ccwa|cdm-|cell|chtm|cldc|cmd-|co(mp|nd)|craw|da(it|ll|ng)|dbte|dc-s|devi|dica|dmob|do(c|p)o|ds(12|-d)|el(49|ai)|em(l2|ul)|er(ic|k0)|esl8|ez([4-7]0|os|wa|ze)|fetc|fly(-|_)|g1 u|g560|gene|gf-5|g-mo|go(.w|od)|gr(ad|un)|haie|hcit|hd-(m|p|t)|hei-|hi(pt|ta)|hp( i|ip)|hs-c|ht(c(-| |_|a|g|p|s|t)|tp)|hu(aw|tc)|i-(20|go|ma)|i230|iac( |-|/)|ibro|idea|ig01|ikom|im1k|inno|ipaq|iris|ja(t|v)a|jbro|jemu|jigs|kddi|keji|kgt( |/)|klon|kpt |kwc-|kyo(c|k)|le(no|xi)|lg( g|/(k|l|u)|50|54|-[a-w])|libw|lynx|m1-w|m3ga|m50/|ma(te|ui|xo)|mc(01|21|ca)|m-cr|me(rc|ri)|mi(o8|oa|ts)|mmef|mo(01|02|bi|de|do|t(-| |o|v)|zz)|mt(50|p1|v )|mwbp|mywa|n10[0-2]|n20[2-3]|n30(0|2)|n50(0|2|5)|n7(0(0|1)|10)|ne((c|m)-|on|tf|wf|wg|wt)|nok(6|i)|nzph|o2im|op(ti|wv)|oran|owg1|p800|pan(a|d|t)|pdxg|pg(13|-([1-8]|c))|phil|pire|pl(ay|uc)|pn-2|po(ck|rt|se)|prox|psio|pt-g|qa-a|qc(07|12|21|32|60|-[2-7]|i-)|qtek|r380|r600|raks|rim9|ro(ve|zo)|s55/|sa(ge|ma|mm|ms|ny|va)|sc(01|h-|oo|p-)|sdk/|se(c(-|0|1)|47|mc|nd|ri)|sgh-|shar|sie(-|m)|sk-0|sl(45|id)|sm(al|ar|b3|it|t5)|so(ft|ny)|sp(01|h-|v-|v )|sy(01|mb)|t2(18|50)|t6(00|10|18)|ta(gt|lk)|tcl-|tdg-|tel(i|m)|tim-|t-mo|to(pl|sh)|ts(70|m-|m3|m5)|tx-9|up(.b|g1|si)|utst|v400|v750|veri|vi(rg|te)|vk(40|5[0-3]|-v)|vm40|voda|vulc|vx(52|53|60|61|70|80|81|83|85|98)|w3c(-| )|webc|whit|wi(g |nc|nw)|wmlb|wonu|x700|yas-|your|zeto|zte-/i.test(a.substr(0,4))) check = true;})(navigator.userAgent||navigator.vendor||window.opera);
return check;
};
First, we will synchronize the game start. In startGame, of the Game section, add a mirrorVR notification at the end.
function startGame() {
...
if (mobileCheck()) {
mirrorVR.notify('startGame', {})
}
}
The mobile client now sends notifications about a game starting. You will now implement the desktop’s response.
In the window load listener, invoke a setupMirrorVR function:
Define a new section above the Game section for the MirrorVR setup:
/************
* MirrorVR *
************/
function setupMirrorVR() {
mirrorVR.init();
}
Next, add keyword arguments to the initialization function for mirrorVR. Specifically, we will define the handler for game start notifications. We will additionally specify a room ID; this ensures that anyone loading your application is immediately synchronized.
Repeat the same synchronization process for Game Over. In gameOver in the Game section, add a check for mobile devices and send a notification accordingly:
function gameOver() {
...
if (mobileCheck()) {
mirrorVR.notify('gameOver', {});
}
}
Navigate to the MirrorVR section and update the keyword arguments with a gameOver listener:
Next, repeat the same synchronization process for the addition of trees. Navigate to addTreesRandomly in the Trees section. Keep track of which lanes receive new trees. Then, directly before the return directive, and send a notification accordingly:
function addTreesRandomly(...) {
...
var numberOfTreesAdded ...
var position_indices = [];
trees.forEach(function (tree) {
if (...) {
...
position_indices.push(tree.position_index);
}
});
if (mobileCheck()) {
mirrorVR.notify('addTrees', position_indices);
}
return ...
}
Navigate to the MirrorVR section, and update the keyword arguments to mirrorVR.init with a new listener for trees:
Double-check that your code matches the appropriate source code files for this step. Then, navigate to your desktop preview. Additionally, open up the same URL on your mobile device. As soon as your mobile device loads the webpage, your desktop should immediately start mirroring the mobile device’s game.
Here is a demo. Notice that the desktop cursor is not moving, indicating the mobile device is controlling the desktop preview.
Final result of the endless runner game with MirrorVR game state synchronization (Large preview)
This concludes your augmented project with mirrorVR.
This third step introduced a few basic game state synchronization steps; to make this more robust, you could add more sanity checks and more points of synchronization.
Conclusion
In this tutorial, you added finishing touches to your endless runner game and implemented real-time synchronization of a desktop client with a mobile client, effectively mirroring the mobile device’s screen on your desktop. This concludes the series on building an endless runner game in virtual reality. Along with A-Frame VR techniques, you’ve picked up 3D modeling, client-to-client communication, and other widely applicable concepts.
Next steps can include:
More Advanced Modeling
This means more realistic 3D models, potentially created in a third-party software and imported. For example, (MagicaVoxel) makes creating voxel art simple, and (Blender) is a complete 3D modeling solution.
More Complexity
More complex games, such as a real-time strategy game, could leverage a third-party engine for increased efficiency. This may mean sidestepping A-Frame and webVR entirely, instead publishing a compiled (Unity3d) game.
Other avenues include multiplayer support and richer graphics. With the conclusion of this tutorial series, you now have a framework to explore further.
It’s the first day of Spring! As you look to clean up other parts of your life (e.g. your home, your refrigerator, your yard) make the cleanup of your web design business a priority as well.
If you’re anything like me, you set aside time later in the week or month, promising yourself that you’ll finally take care of “business stuff”. And if you’re also like me, you often have to postpone those business maintenance tasks because new paid work opportunities come in. (Or you’re just exhausted and want a break from looking at your screen.)
But there’s no time like the present, so if you can spare it, give yourself at least one day off from work to tackle this spring cleaning checklist. Not only will it give you time to zero in on the areas that often go neglected in your business, but you’ll come out of it feeling refreshed and ready to get back to work.
1. Clean Your Workspace
There are some people that thrive in organized chaos. However, if your workspace is piled high with stuff you don’t need, stuff that distracts you, or stuff that’s literally getting in your way as you try to work on your computer, you need to clean your physical workspace.
When you’re done, think about doing something new for your workspace, something that makes you feel excited about sitting down to work. A new piece of artwork over your desk? A book about web design you’ve been meaning to read? A postcard from a client thanking you for a job well done? Then, put it somewhere that you’ll see it every day.
This is what I’ve done with my own workspace:
2. Declutter the Desktop
It doesn’t matter how many folders you put on your desktop to keep things organized. Image files, templates, PDFs, workflow documentation — these loose documents and folders sitting on your desktop are a distraction. Worse, if you don’t move them off of it, you’re putting your business at risk for data loss (if you’re not otherwise backing it all up).
To keep your desktop clutter-free, give your files and folders a new home — one that’s in a secure, cloud-based organizational system. Google Drive and Dropbox are free to start with and easy to use.
3. Review Your Folders
If you’re still storing files on your computer (and not just your desktop), now is the time to migrate them to your cloud storage. Then, once you have all files in a centralized location (which is also great for security and collaboration purposes), work on refining your folder structure:
Delete old client files and folders;
Delete old business documentation or update it so that it’s reflective of what you do now;
Check for files containing the same information. Remove the duplicates;
Review and rename folders for improved clarity and organization;
Review your bookmarks. Delete ones you don’t use. Update incorrect links. Organize links based on how frequently they’re used. And create a file structure to organize it all.
Here’s an example of what I’ve done to my own bookmarks bar to improve my workflow:
4. Check on the State of Your Website
You’re in the business of designing websites for others, but when was the last time you took care of your own?
Start with a site health check:
Is all of the software updated? If not, back your site up and run those updates now;
How about security, your security plugin should have a scanner, run it and make sure all is well;
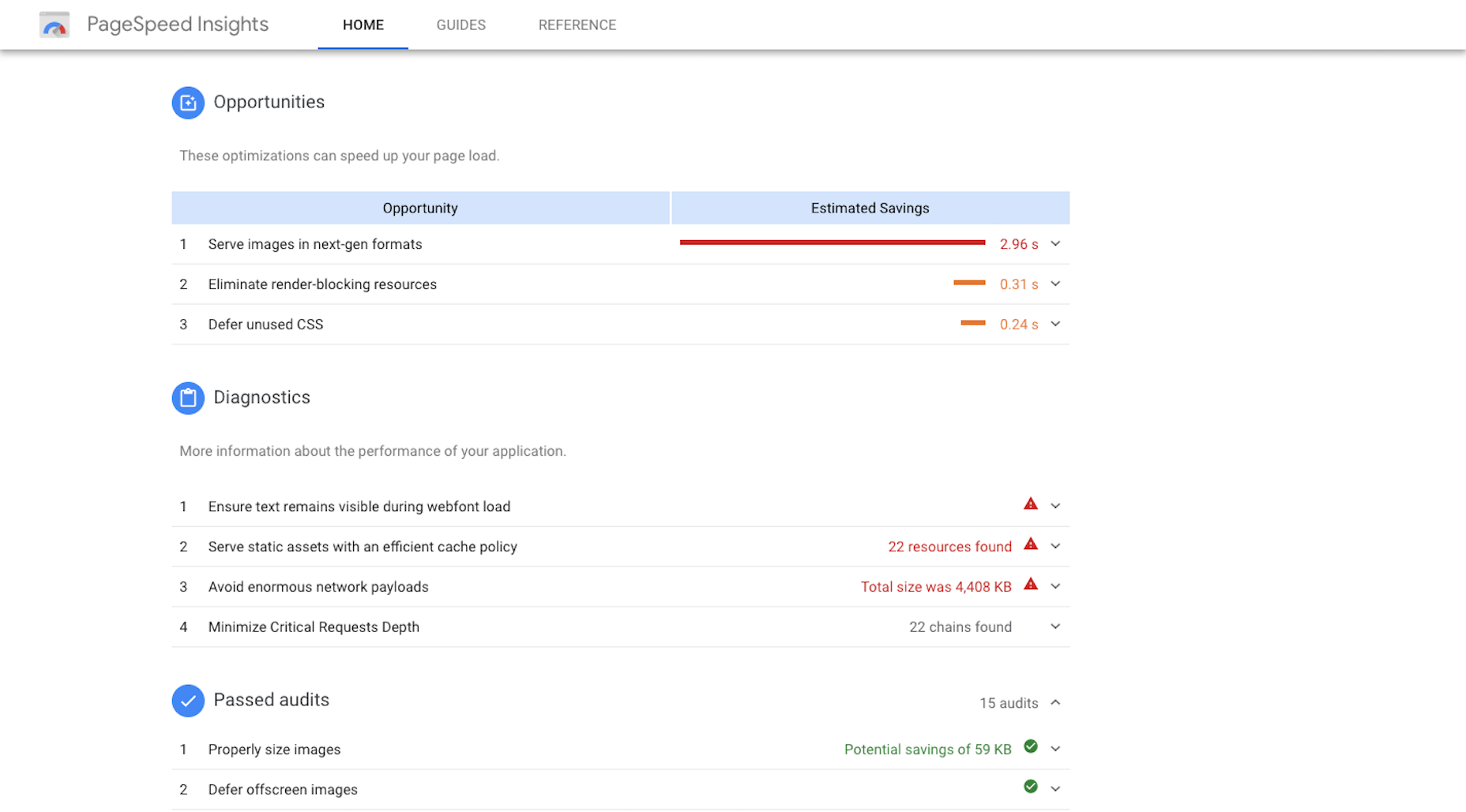
Does the site load as quickly as it could? If you’re unsure, run it through PageSpeed Insights to see if Google suggests any fixes.
Then, check on the content of your website:
Hold old is the design, if it’s over a year old, it at least needs some upgrades;
How old is the information about your business, if anything has changed, take care of it now;
Is any of the content or images no longer relevant, remove them if that’s the case;
How about your links, do all internal links still work, do external links point to recent and relevant sources.
Finally, spend some time updating your portfolio. Even if it’s only been a few months, you may have new samples or testimonials to show off. Don’t let outdated website samples reflect poorly on what you can do.
5. Freshen up Your Social Presence
WebDesignerDepot recently published a post discussing all the ways social media might be hurting your design business. Run through the checklist to see if you can do any cleanup and salvage your social presence.
6. Create Less Email Work
One of the things you’ll learn if you read the 4-Hour Workweek is that email is a huge time waster. Sure, you need it to communicate with clients, but what percentage of emails in your inbox are actually from clients? And how many of those client emails are actually urgent enough to warrant your attention right now?
What you need to do is create a new system for your email so that it stops distracting you from work. Here are some ways to do that:
Unsubscribe from all unnecessary subscriptions;
Review and update your email folder structure to keep everything well-organized;
Use filters so that client emails immediately drop into their corresponding folders;
Use a tool like Boomerang for Gmail. It turns off email notifications on your phone and computer, so you can stay focused during the workday.
Another thing to look at is your email signature. Here’s an example of how mine currently looks (you can also see the Boomerang “Send Later” buttons in action):
If you had to update any of your business or contact information on your site, the same applies here. Now is also a good opportunity to add links that help keep prospects and clients connected — like social media links, your website link, or a meeting scheduler.
7. Review Software Subscriptions
Finally, take a look at your software subscriptions. Is there anything you’ve signed up for in the past that you’re no longer using? How about tools that used to work really well, but that seem to do nothing but slow you down now?
Automation is crucial for web designers. Just make sure you’re using tools that actually enhance your workflow.
WebDesignerDepot has a fantastic roundup of 30 tools and services that help with this. You obviously won’t need or want to use all of them. However, if you’re trying to figure out if that tool you use now is worth it, this is a great reference to confirm your suspicions or find an alternative option.
Spring Cleaning Bonus
Once you’ve finished spring cleaning your business, it’s time to get back to thinking about revenue generation.
So, why not create a spring cleaning service or promotional offer for clients? It shouldn’t even be that hard to do since you probably provided this service in the past, just under a different name: a website redesign.
Just reach out to clients you haven’t spoken to in a year or so, and pitch them a “Spring Cleaning” website audit and cleanup for a flat fee. You can also do the same with brand new clients whose websites are certainly in need of a good scrub.
Chrome on Android’s Data Saver feature helps by automatically optimizing web pages to make them load faster. When users are facing network or data constraints, Data Saver may reduce data use by up to 90% and load pages two times faster, and by making pages load faster, a larger fraction of pages actually finish loading on slow networks. Now, we are securely extending performance improvements beyond HTTP pages to HTTPS pages and providing direct feedback to the developers who want it.
To show users when a page has been optimized, Chrome now shows in the URL bar that a Lite version of the page is being displayed.
All of this is pretty neat but I think the name Lite Pages is a little confusing as it’s in no way related to AMP and Tim Kadlec makes that clear in his notes about the new feature:
Lite pages are also in no way related to AMP. AMP is a framework you have to build your site in to reap any benefit from. Lite pages are optimizations and interventions that get applied to your current site. Google’s servers are still involved, by as a proxy service forwarding the initial request along. Your URL’s aren’t tampered with in any way.
A quick glance at this seems great! We don’t have to give up ownership of our URLs, like with AMP, and we don’t have to develop with a proprietary technology — we can let Chrome be Chrome and do any performance things that it wants to do without turning anything on or off or adding JavaScript.
But wait! What kind of optimizations does a Lite Page make and how do they affect our sites? So far, it can disable scripts, replace images with placeholders and stop the loading of certain resources, although this is all subject to change in the future, I guess.
The optimizations only take effect when the loading experience for users is particularly bad, as the announcement blog post states:
…they are applied when the network’s effective connection type is “2G” or “slow-2G,” or when Chrome estimates the page load will take more than 5 seconds to reach first contentful paint given current network conditions and device capabilities.
It’s probably important to remember that the reason why Google is doing this isn’t to break our designs or mess with our websites — they’re doing this because there are serious performance concerns with the web, and those concerns aren’t limited to developing nations.
Have you seen Local by Flywheel? It’s a native app for helping set up local WordPress developer environments. I absolutely love it and use it to do all my local WordPress development work. It brings a lovingly designed GUI to highly technical tasks in a way that I think works very well. Plus it just works, which wins all the awards with me. Need to spin up a new site locally? Click a few buttons. Working on your site? All your sites are right there and you can flip them on with the flick of a toggle.
Local by Flywheel is useful no matter where your WordPress production site is hosted. But it really shines when paired with Flywheel itself, which is fabulous WordPress hosting that has all the same graceful combination of power and ease as Local does.
Just recently, we moved ShopTalkShow.com over to Local and it couldn’t have been easier.
Running locally.
Setting up a new local site (which you would do even if it’s a long-standing site and you’re just getting it set up on Flywheel) is just a few clicks. That’s one of the most satisfying parts. You know all kinds of complex things are happening behind the scenes, like containers being spun up, proper software being installed, etc, but you don’t have to worry about any of it.
(Local is free, by the way.)
The Cross-platform-ness is nice.
I work on ShopTalk with Dave Rupert, who’s on Windows. Not a problem. Local works on Windows also, so Dave can spin up site in the exact same way I can.
Setting up Flywheel hosting is just as clean and easy as Local is.
If you’ve used Local, you’ll recognize the clean font, colors, and design when using the Flywheel website to get your hosting set up. Just a few clicks and I had that going:
Things that are known to be a pain the butt are painless on Local, like making sure SSL (HTTPS) is active and a CDN is helping with assets.
You get a subdomain to start, so you can make sure your site is working perfectly before pointing a production domain at it.
I didn’t just have to put files into place on the new hosting, move the database, and cross my fingers I did it all right when re-pointing the DNS. I could get the site up and running at the subdomain first, make sure it is, then do the DNS part.
But the moving of files and all that… it’s trivial because of Local!
The best part is that shooting a site up to Flywheel from Local is also just a click away.
All the files and the database head right up after you’ve connected Local to Flywheel.
All I did was make sure I had my local site to be a 100% perfect copy of production. All the theme and plugins and stuff were already that way because I was already doing local development, and I pulled the entire database down easily with WP DB Migrate Pro.
I think I went from “I should get around to setting up this site on Flywheel.” do “Well that’s done.” in less than an hour. Now Dave and I both have a local development environment and a path to production.
A little while back, I was in the process of adding focus styles to An Event Apart’s web site. Part of that was applying different focus effects in different areas of the design, like white rings in the header and footer and orange rings in the main text. But in one place, I wanted rings that were more obvious—something like stacking two borders on top of each other, in order to create unusual shapes that would catch the eye.
I toyed with the idea of nesting elements with borders and some negative margins to pull one border on top of another, or nesting a border inside an outline and then using negative margins to keep from throwing off the layout. But none of that felt satisfying.
It turns out there are a number of tricks to create the effect of stacking one border atop another by combining a border with some other CSS effects, or even without actually requiring the use of any borders at all. Let’s explore, shall we?
Outline and box-shadow
If the thing to be multi-bordered is a rectangle—you know, like pretty much all block elements—then mixing an outline and a spread-out hard box shadow may be just the thing.
Let’s start with the box shadow. You’re probably used to box shadows like this:
That gets you a blurred shadow below and to the right of the element. Drop shadows, so last millennium! But there’s room, and support, for a fourth length value in box-shadow that defines a spread distance. This increases the size of the shadow’s shape in all directions by the given length, and then it’s blurred. Assuming there’s a blur, that is.
So if we give a box shadow no offset, no blur, and a bit of spread, it will draw itself all around the element, looking like a solid border without actually being a border.
This box-shadow “border” is being drawn just outside the outer border edge of the element. That’s the same place outlines get drawn around block boxes, so all we have to do now is draw an outline over the shadow. Something like this:
Bingo. A multicolor “border” that, in this case, doesn’t even throw off layout size, because shadows and outlines are drawn after element size is computed. The outline, which sits on top, can use pretty much any outline style, which is the same as the list of border styles. Thus, dotted and double outlines are possibilities. (So are all the other styles, but they don’t have any transparent parts, so the solid shadow could only be seen through translucent colors.)
If you want a three-tone effect in the border, multiple box shadows can be created using a comma-separated list, and then an outline put over top that. For example:
Taking it back to simpler effects, combining a dashed outline over a spread box shadow with a solid border of the same color as the box shadow creates yet another effect:
The extra bonus here is that even though a box shadow is being used, it doesn’t fill in the element’s background, so you can see the backdrop through it. This is how box shadows always behave: they are only drawn outside the outer border edge. The “rest of the shadow,” the part you may assume is always behind the element, doesn’t exist. It’s never drawn. So you get results like this:
An outer box-shadow casts a shadow as if the border-box of the element were opaque. Assuming a spread distance of zero, its perimeter has the exact same size and shape as the border box. The shadow is drawn outside the border edge only: it is clipped inside the border-box of the element.
(Emphasis added.)
Border and box-shadow
Speaking of borders, maybe there’s a way to combine borders and box shadows. After all, box shadows can be more than just drop shadows. They can also be inset. So what if we turned the previous shadow inward, and dropped a border over top of it?
That’s… not what we were after. But this is how inset shadows work: they are drawn inside the outer padding edge (also known as the inner border edge), and clipped beyond that:
An inner box-shadow casts a shadow as if everything outside the padding edge were opaque. Assuming a spread distance of zero, its perimeter has the exact same size and shape as the padding box. The shadow is drawn inside the padding edge only: it is clipped outside the padding box of the element.
(Ibid; emphasis added.)
So we can’t stack a border on top of an inset box-shadow. Maybe we could stack a border on top of something else…?
Border and multiple backgrounds
Inset shadows may be restricted to the outer padding edge, but backgrounds are not. An element’s background will, by default, fill the area out to the outer border edge. Fill an element background with solid color, give it a thick dashed border, and you’ll see the background color between the visible pieces of the border.
So what if we stack some backgrounds on top of each other, and thus draw the solid color we want behind the border? Here’s step one:
We can see, there on the left side, the blue background visible through the transparent parts of the dashed red border. Add three more like that, one for each edge of the element box, and:
In each case, the background gradient runs for five pixels as a solid dark turquoise background, and then has a color stop which transitions instantly to transparent. This lets the “backdrop” show through the element while still giving us a “stacked border.”
One major advantage here is that we aren’t limited to solid linear gradients—we can use any gradient of any complexity, just to spice things up a bit. Take this example, where the dashed border has been made mostly transparent so we can see the four different gradients in their entirety:
.multibg-me {
border: 15px dashed rgba(128,0,0,0.1);
background:
linear-gradient(to top, darkturquoise, red 15px, transparent 15px),
linear-gradient(to right, darkturquoise, red 15px, transparent 15px),
linear-gradient(to bottom, darkturquoise, red 15px, transparent 15px),
linear-gradient(to left, darkturquoise, red 15px, transparent 15px);
background-origin: border-box;
}
If you look at the corners, you’ll see that the background gradients are rectangular, and overlap each other. They don’t meet up neatly, the way border corners do. This can be a problem if your border has transparent parts in the corners, as would be the case with border-style: double.
Also, if you just want a solid color behind the border, this is a fairly clumsy way to stitch together that effect. Surely there must be a better approach?
Border and background clipping
Yes, there is! It involves changing the clipping boxes for two different layers of the element’s background. The first thing that might spring to mind is something like this:
But that does not work, because CSS requires that only the last (and thus lowest) background be set to a value. Any other background layer must be an image.
So we replace that very-light-gray background color with a gradient from that color to that color: this works because gradients are images. In other words:
The light gray “gradient” fills the entire background area, but is clipped to the padding box using background-clip. The dark turquoise fills the entire area and is clipped to the border box, as backgrounds always have been by default. We can alter the gradient colors and direction to anything we like, creating an actual visible gradient or shifting it to all-white or whatever other linear effect we would like.
The downside here is that there’s no way to make that padding-area background transparent such that the element’s backdrop can be seen through the element. If the linear gradient is made transparent, then the whole element background will be filled with dark turquoise. Or, more precisely, we’ll be able to see the dark turquoise that was always there.
In a lot of cases, it won’t matter that the element background isn‘t see-through, but it’s still a frustrating limitation. Isn’t there any way to get the effect of stacked borders without wacky hacks and lost capabilities?
Border images
In fact, what if we could take an image of the stacked border we want to see in the world, slice it up, and use that as the border? Like, say, this image becomes this border?
First, we set a solid border with some width. We could also set a color for fallback purposes, but it’s not really necessary. Then we point to an image URL, define the slice inset(s) at 15 and width of the border to be 15px, and finally the repeat pattern of round.
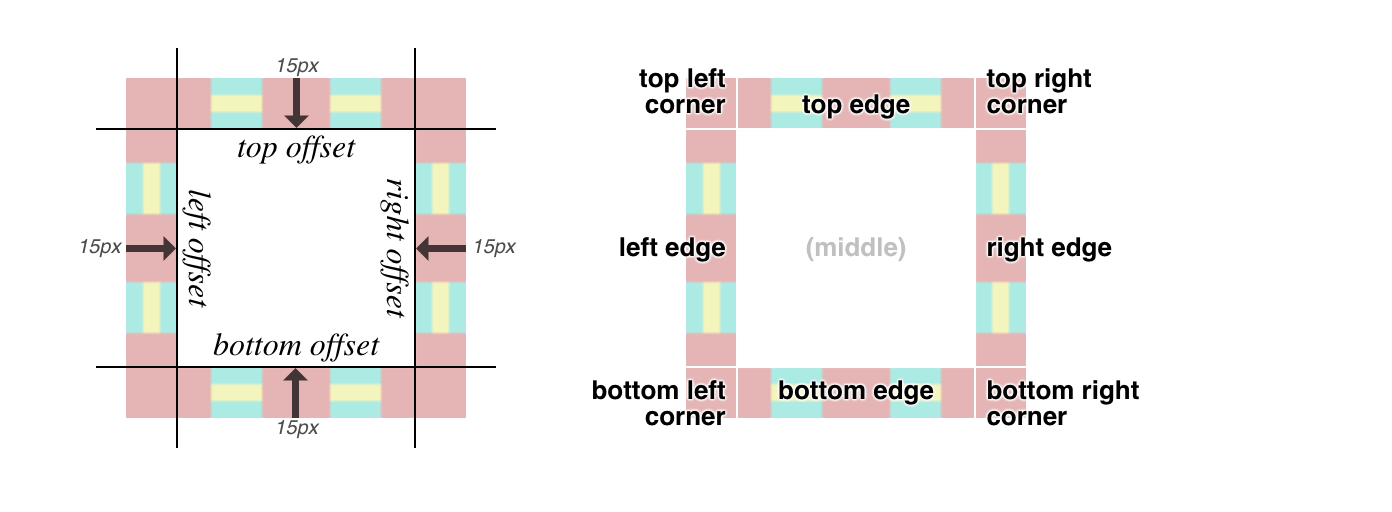
There are more options for border images, which are a little too complex to get into here, but the upshot is that you can take an image, define nine slices of it using offset values, and have those images used to synthesize a complete border around an image. That’s done by defining offsets from the edges of the image itself, which in this case is 15. Since the image is a GIF and thus pixel-based, the offsets are in pixels, so the “slice lines” are set 15 pixels inward from the edges of the image. (In the case of an SVG, the offsets are measured in terms of the SVG’s coordinate system.) It looks like this:
Each slice is assigned to the corner or side of the element box that corresponds to itself; i.e., the bottom right corner slice is placed in the bottom right corner of the element, the top (center) slice is used along the top edge of the element, and so on.
If one of the edge slices is smaller than the edge of the element is long—which almost always happens, and is certainly true here—then the slice is repeated in one of a number of ways. I chose round, which fills in as many repeats as it can and then scales them all up just enough to fill out the edge. So with a 70-pixel-long slice, if the edge is 1,337 pixels long, there will be 19 repetitions of the slice, each of which is scaled to be 70.3 pixels wide. Or, more likely, the browser generates a single image containing 19 repetitions that’s 1,330 pixels wide, and then stretches that image the extra 7 pixels.
You might think the drawback here is browser support, but that turns out not to be the case.
This browser support data is from Caniuse, which has more detail. A number indicates that browser supports the feature at that version and up.
Desktop
Chrome
Opera
Firefox
IE
Edge
Safari
56
43
50
11
12
9.1
Mobile / Tablet
iOS Safari
Opera Mobile
Opera Mini
Android
Android Chrome
Android Firefox
9.3
46
all*
67
71
64
Just watch out for the few bugs (really, implementation limits) that linger around a couple of implementations, and you’ll be fine.
Conclusion
While it might be a rare circumstance where you want to combine multiple “border” effects, or stack them atop each other, it’s good to know that CSS provides a number of ways to get the job done, and that most of them are already widely supported. And who knows? Maybe one day there will be a simple way to achieve these kinds of effects through a single property, instead of by mixing several together. Until then, happy border stacking!
In our last article, we discussed the Web Components specifications (custom elements, shadow DOM, and HTML templates) at a high-level. In this article, and the three to follow, we will put these technologies to the test and examine them in greater detail and see how we can use them in production today. To do this, we will be building a custom modal dialog from the ground up to see how the various technologies fit together.
Creating a Custom Element from Scratch (Coming soon!)
Encapsulating Style and Structure with Shadow DOM (Coming soon!)
Advanced Tooling for Web Components (Coming soon!)
HTML templates
One of the least recognized, but most powerful features of the Web Components specification is the element. In the first article of this series, we defined the template element as, “user-defined templates in HTML that aren’t rendered until called upon.” In other words, a template is HTML that the browser ignores until told to do otherwise.
These templates then can be passed around and reused in a lot of interesting ways. For the purposes of this article, we will look at creating a template for a dialog that will eventually be used in a custom element.
Defining our template
As simple as it might sound, a is an HTML element, so the most basic form of a template with content would be:
<template>
<h1>Hello world</h1>
</template>
Running this in a browser would result in an empty screen as the browser doesn’t render the template element’s contents. This becomes incredibly powerful because it allows us to define content (or a content structure) and save it for later — instead of writing HTML in JavaScript.
In order to use the template, we will need JavaScript
The real magic happens in the document.importNode method. This function will create a copy of the template’s content and prepare it to be inserted into another document (or document fragment). The first argument to the function grabs the template’s content and the second argument tells the browser to do a deep copy of the element’s DOM subtree (i.e. all of its children).
We could have used the template.content directly, but in so doing we would have removed the content from the element and appended to the document’s body later. Any DOM node can only be connected in one location, so subsequent uses of the template’s content would result in an empty document fragment (essentially a null value) because the content had previously been moved. Using document.importNode allows us to reuse instances of the same template content in multiple locations.
That node is then appended into the document.body and rendered for the user. This ultimately allows us to do interesting things, like providing our users (or consumers of our programs) templates for creating content, similar to the following demo, which we covered in the first article:
In this example, we have provided two templates to render the same content — authors and books they’ve written. As the form changes, we choose to render the template associated with that value. Using that same technique will allow us eventually create a custom element that will consume a template to be defined at a later time.
The versatility of template
One of the interesting things about templates is that they can contain any HTML. That includes script and style elements. A very simple example would be a template that appends a button that alerts us when it is clicked.
Once this element is appended to the DOM, we will have a new button with ID #click-me, a global CSS selector targeted to the button’s ID, and a simple event listener that will alert the element’s click event.
For our script, we simply append the content using document.importNode and we have a mostly-contained template of HTML that can be moved around from page to page.
This code will serve as the foundation for our dialog. Breaking it down briefly, we have a global close button, a heading and some content. We have also added in a bit of behavior to visually toggle our dialog (although it isn’t yet accessible). In our next article, we will put custom elements to use and create one of our own that consumes this template in real-time.
This article is part of a series in which I attempt to use the web under various constraints, representing a given demographic of user. I hope to raise the profile of difficulties faced by real people, which are avoidable if we design and develop in a way that is sympathetic to their needs.
But as much as we developers hope for it to go away, it just. Won’t. Die. IE8 continues to show up in browser stats, especially outside of the bubble of the Western world.
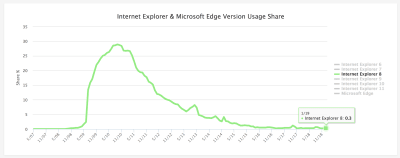
Browser stats have to be taken with a pinch of salt, but current estimates for IE8 usage worldwide are around 0.3% to 0.4% of the desktop market share. The lower end of the estimate comes from w3counter:
From a peak of almost 30% at the end of 2010, W3Counter now believes IE8 accounts for 0.3% of global usage. (Large preview)
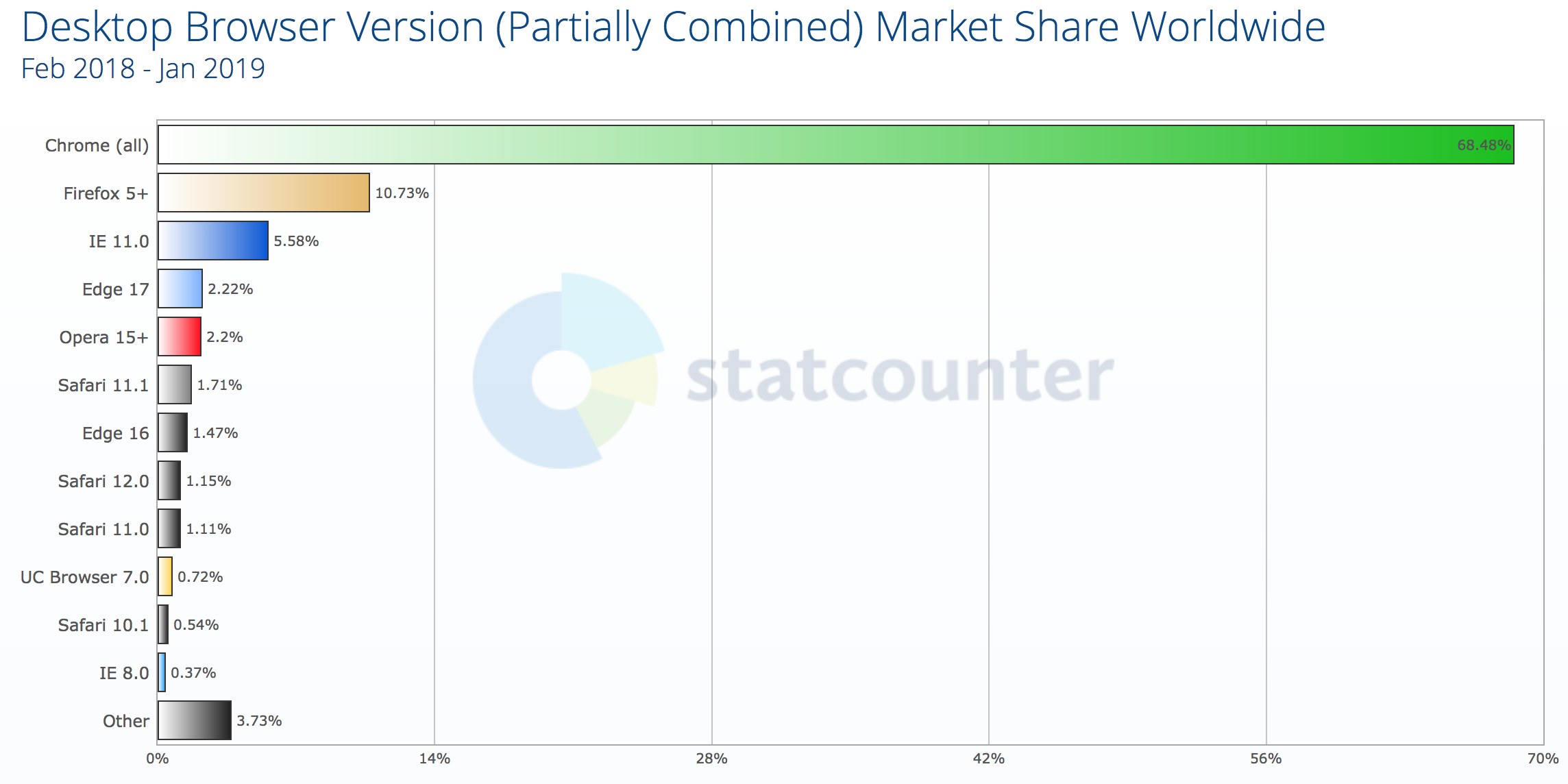
The higher estimate comes from StatCounter (the same data feed used by the “Can I use” usage table). It estimates global IE8 desktop browser proportion to be around 0.37%.
Worldwide usage of IE8 is at 0.37% according to StatCounter. (Large preview)
I suspected we might see higher IE8 usage in certain geographical regions, so drilled into the data by continent.
IE8 Usage By Region
Here is the per-continent IE8 desktop proportion (data from February 2018 — January 2019):
1.
Oceania
0.09%
2.
Europe
0.25%
3.
South America
0.30%
4.
North America
0.35%
5.
Africa
0.48%
6.
Asia
0.50%
Someone in Asia is five times more likely to be using IE8 than someone in Oceania.
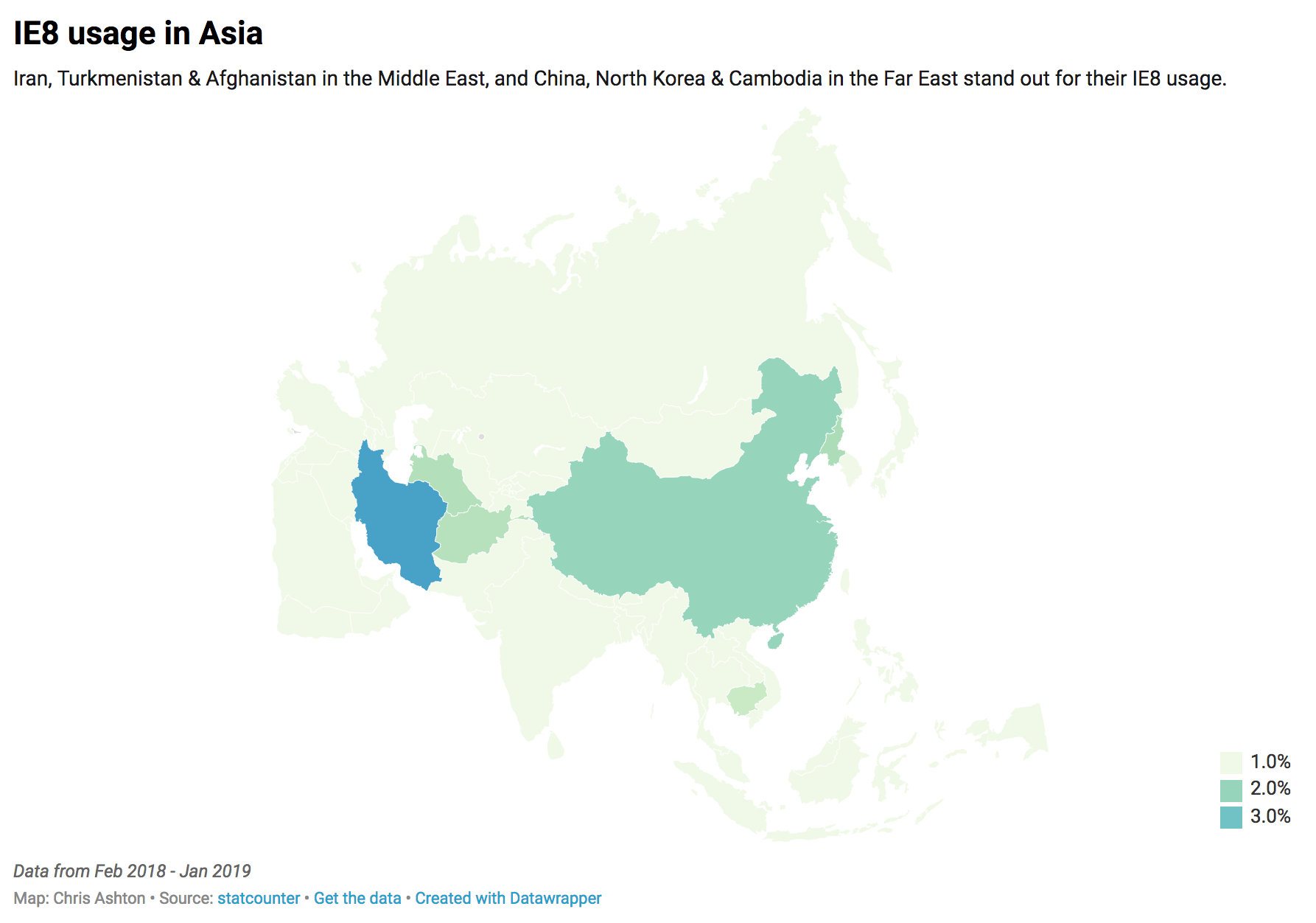
I looked more closely into the Asian stats, noting the proportion of IE8 usage for each country. There’s a very clear top six countries for IE8 usage, after which the figures drop down to be comparable with the world average:
1.
Iran
3.99%
2.
China
1.99%
3.
North Korea
1.38%
4.
Turkmenistan
1.31%
5.
Afghanistan
1.27%
6.
Cambodia
1.05%
7.
Yemen
0.63%
8.
Taiwan
0.62%
9.
Pakistan
0.57%
10.
Bangladesh
0.54%
This data is summarized in the map below:
Iran, Turkmenistan and Afghanistan in the Middle East, and China, North Korea & Cambodia in the Far East stand out for their IE8 usage. (Large preview)
Incredibly, IE8 makes up around 4% of desktop users in Iran — forty times the proportion of IE8 users in Oceania.
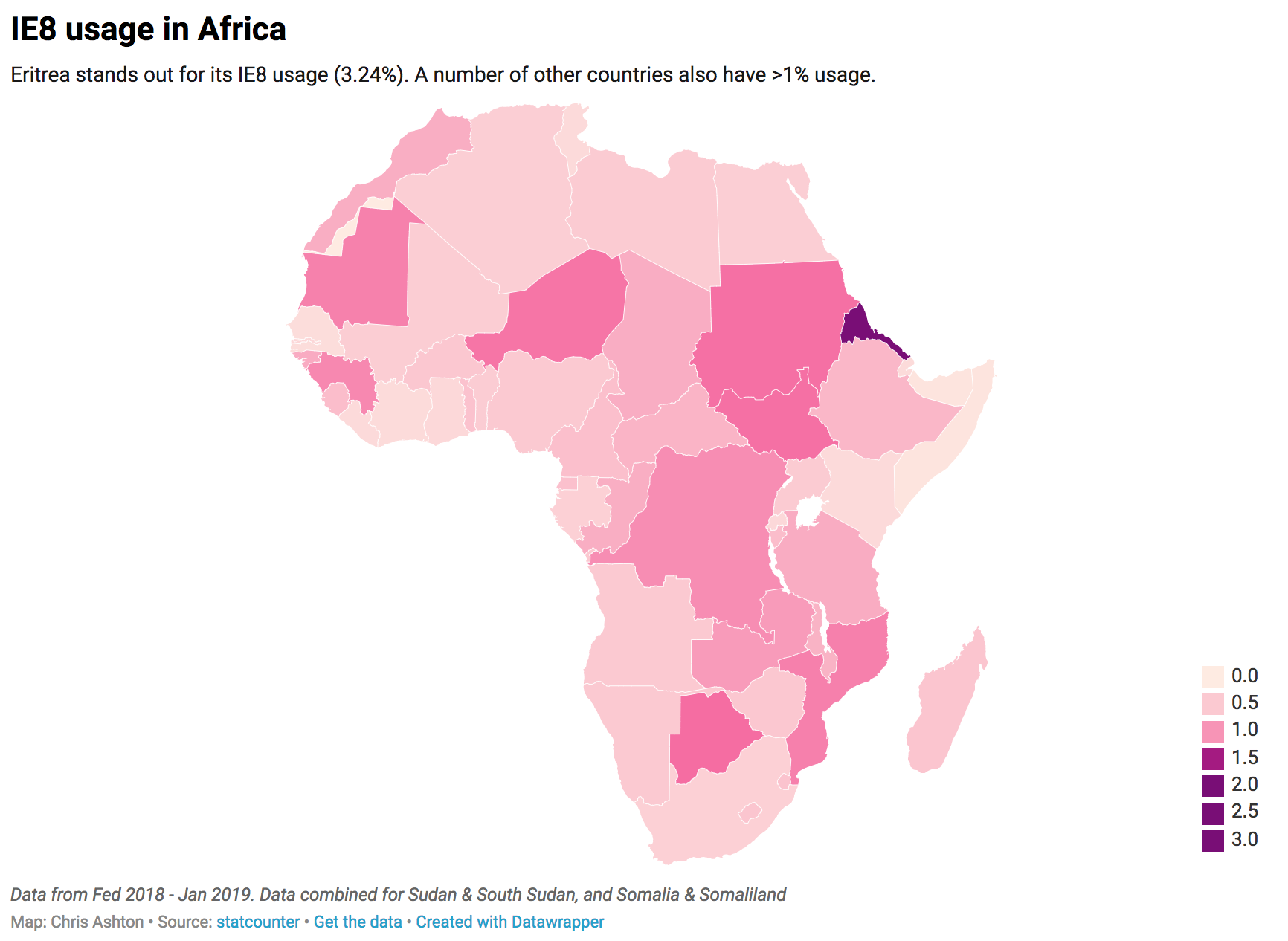
Next, I looked at the country stats for Africa, as it had around the same overall IE8 usage as Asia. There was a clear winner (Eritrea), followed by a number of countries above or around the 1% usage mark:
1.
Eritrea
3.24%
2.
Botswana
1.37%
3.
Sudan & South Sudan
1.33%
4.
Niger
1.29%
5.
Mozambique
1.19%
6.
Mauritania
1.18%
7.
Guinea
1.12%
8.
Democratic Republic of the Congo
1.07%
9.
Zambia
0.94%
This is summarized in the map below:
Eritrea stands out for its IE8 usage (3.24%). A number of other countries also have >1% usage. (Large preview)
Whereas the countries in Asia that have higher-than-normal IE8 usage are roughly batched together geographically, there doesn’t appear to be a pattern in Africa. The only pattern I can see — unless it’s a coincidence — is that a number of the world’s largest IE8 using countries famously censor internet access, and therefore probably don’t encourage or allow updating to more secure browsers.
If your site is aimed at a purely Western audience, you’re unlikely to care much about IE8. If, however, you have a burgeoning Asian or African market — and particularly if you care about users in China, Iran or Eritrea — you might very well care about your website’s IE8 experience. Yes — even in 2019!
Who’s Still Using IE?
So, who are these people? Do they really walk among us?!
Whoever they are, you can bet they’re not using an old browser just to annoy you. Nobody deliberately chooses a worse browsing experience.
Someone might be using an old browser due to the following reasons:
Lack of awareness
They simply aren’t aware that they’re using outdated technology.
Lack of education
They don’t know the upgrade options and alternative browsers open to them.
Lack of planning
Dismissing upgrade prompts because they’re busy, but not having the foresight to upgrade during quieter periods.
Aversion to change
The last time they upgraded their software, they had to learn a new UI. “If it ain’t broke, don’t fix it.”
Aversion to risk
The last time they upgraded, their machine slowed to a crawl, or they lost their favorite feature.
Software limitation
Their OS is too old to let them upgrade, or their admin privileges may be locked down.
Hardware limitation
Newer browsers are generally more demanding of your hard disk space, memory and CPU.
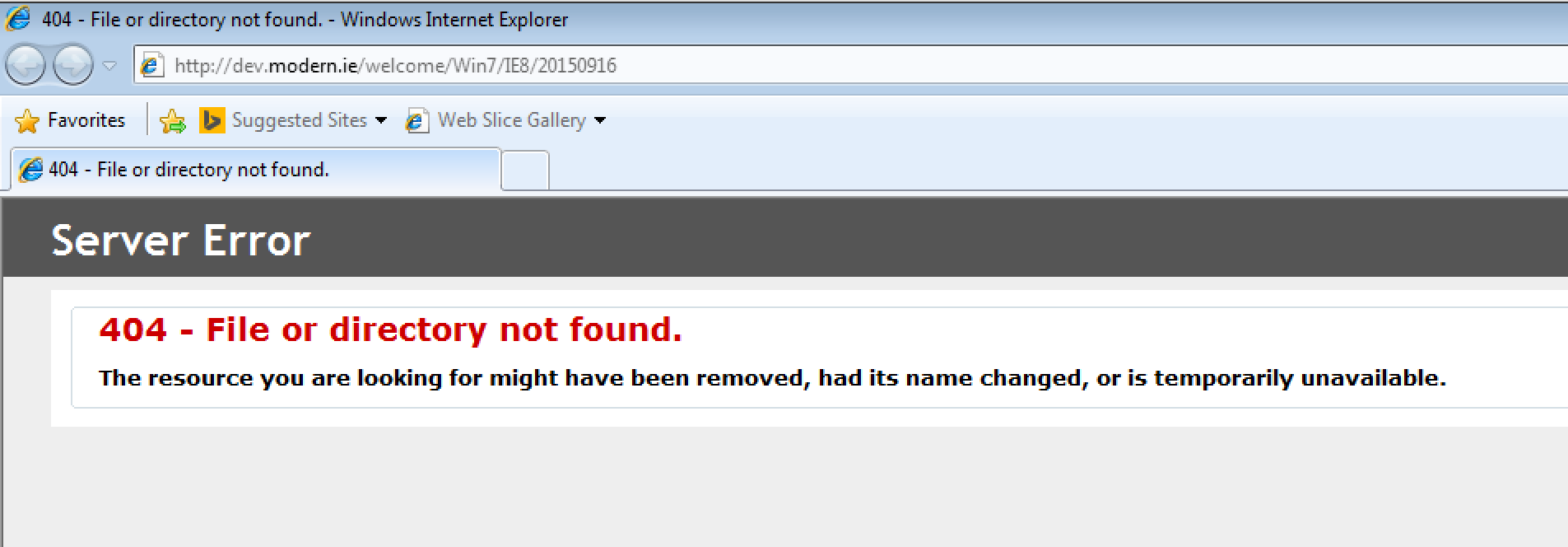
I booted up my IE8 VM, clicked on the Internet Explorer program in anticipation, and this is what I saw:
The first thing I saw was a 404. Great. (Large preview)
Hmm, okay. Looks like the default web page pulled up by IE8 no longer exists. Well, that figures. Microsoft has officially stopped supporting IE8 so why should it make sure the IE8 landing page still works?
I decided to switch to the most widely used site in the world.
Google
The Google homepage renders fine in IE8. (Large preview)
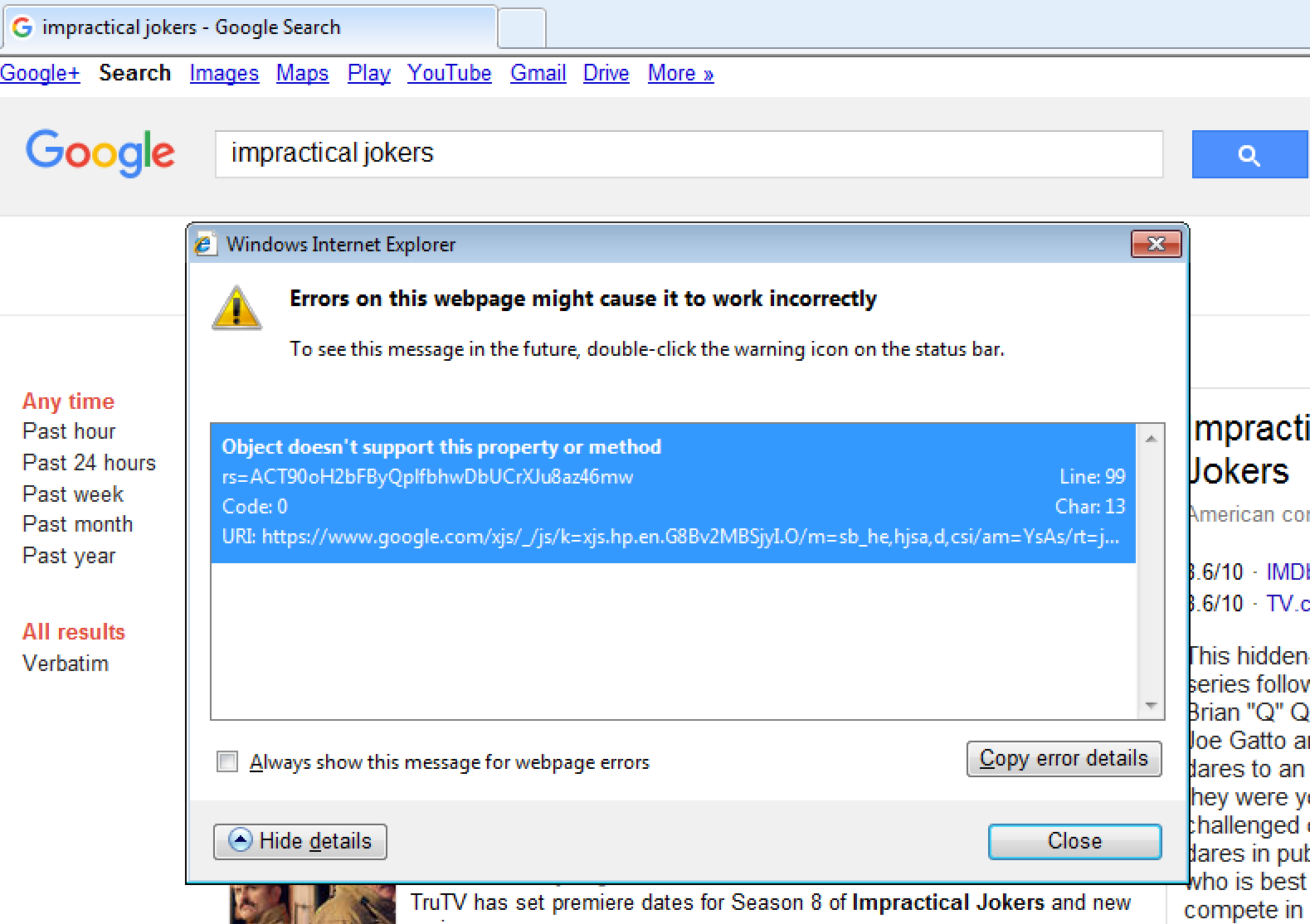
It’s a simple site, therefore difficult to get wrong — but to be fair, it’s looking great! I tried searching for something:
Those who have read my previous articles may notice a recurring theme here. (Large preview)
For reference, here is how the search results look in a modern browser with JavaScript enabled:
Cleaner layout, extra images and meta information, Netflix/Twitter integration. (Large preview)
So, it looks like IE8 gets the no-JS version of Google search. I don’t think this was necessarily a deliberate design decision — it could just be that the JavaScript errored out:
The page tried and failed to run JavaScript. (Large preview)
Still, the end result is fine by me — I got my search results, which is all I wanted.
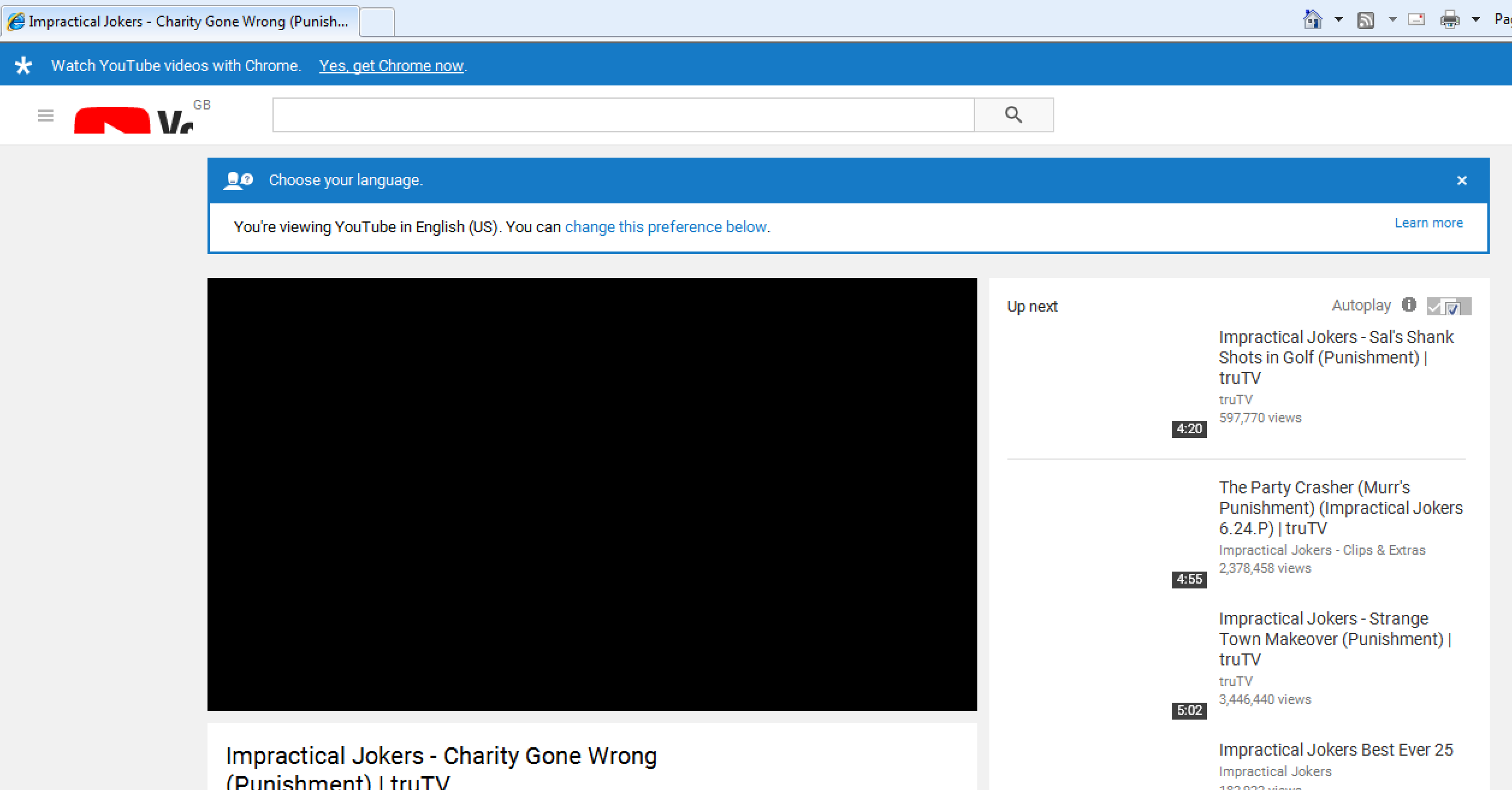
I clicked through to watch a YouTube video.
YouTube
Funky logo, no images for related videos, and unsurprisingly, no video. (Large preview)
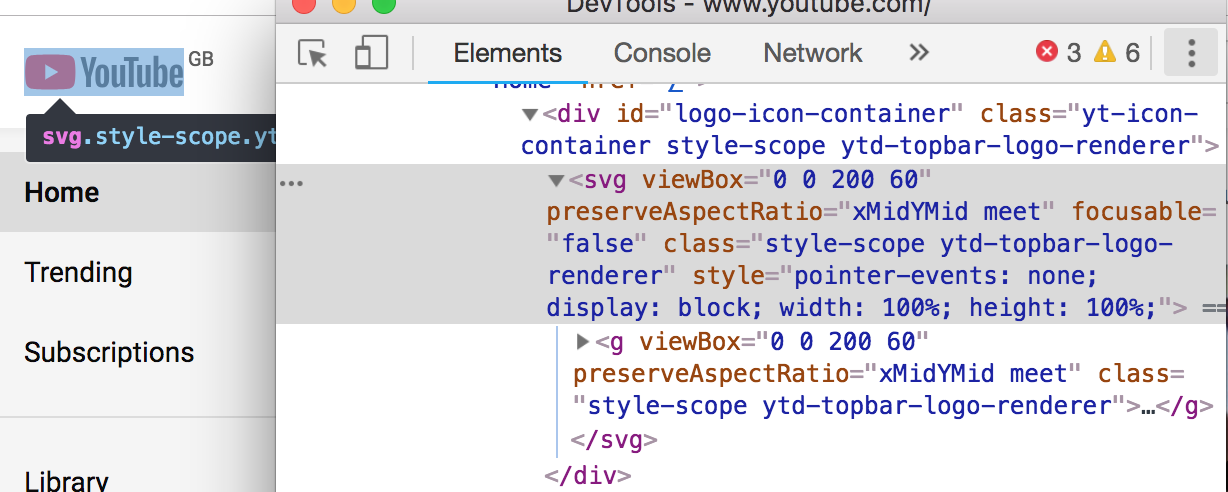
There’s quite a lot broken about this page. All to do with little quirks in IE.
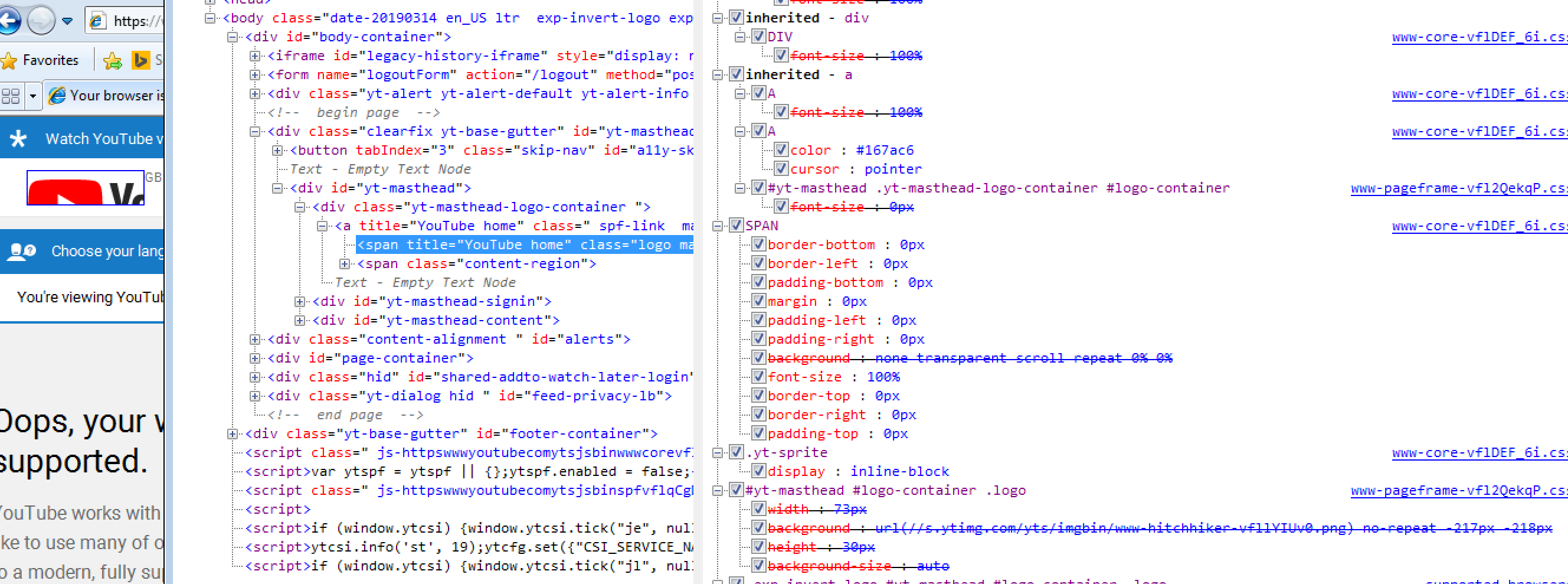
The logo, for instance, is zoomed in and cropped. This is down to IE8 not supporting SVG, and what we’re actually seeing is the fallback option provided by YouTube. They’ve applied a background-image CSS property so that in the event of no SVG support, you’ll get an attempt at displaying the logo. Only they seem to have not set the background-size properly, so it’s a little too far zoomed in.
YouTube set a background-img on the logo span, which pulls in a sprite. (Large preview)
For reference, here is the same page in Chrome (see how Chrome renders an SVG instead):