I had so much fun at An Event Apart Seattle! There is something nice about sitting back and basking in the messages from a variety of such super smart people.
I didn’t take comprehensive notes of each talk, but I did jot down little moments that flickered my brain. I’ll post them here! Blogging is fun! Again, note that these moments weren’t necessarily the main point of the speaker’s presentation or reflective of the whole journey of the topic — they are little micro-memorable moments that stuck out to me.
Jeffrey Zeldman brought up the reading apps Instapaper (still around!) and Readability (not around… but the technology is what seeped into native browser tech). He called them a vanguard (cool word!) meaning they were warning us that our practices were pushing users away. This turned out to be rather true, as they still exist and are now joined by new technologies, like AMP and native reader mode, which are fighting the same problems.
Margot Bloomstein made a point about inconsistency eroding our ability to evaluate and build trust. Certainly applicable to websites, but also to a certain President of the United States.
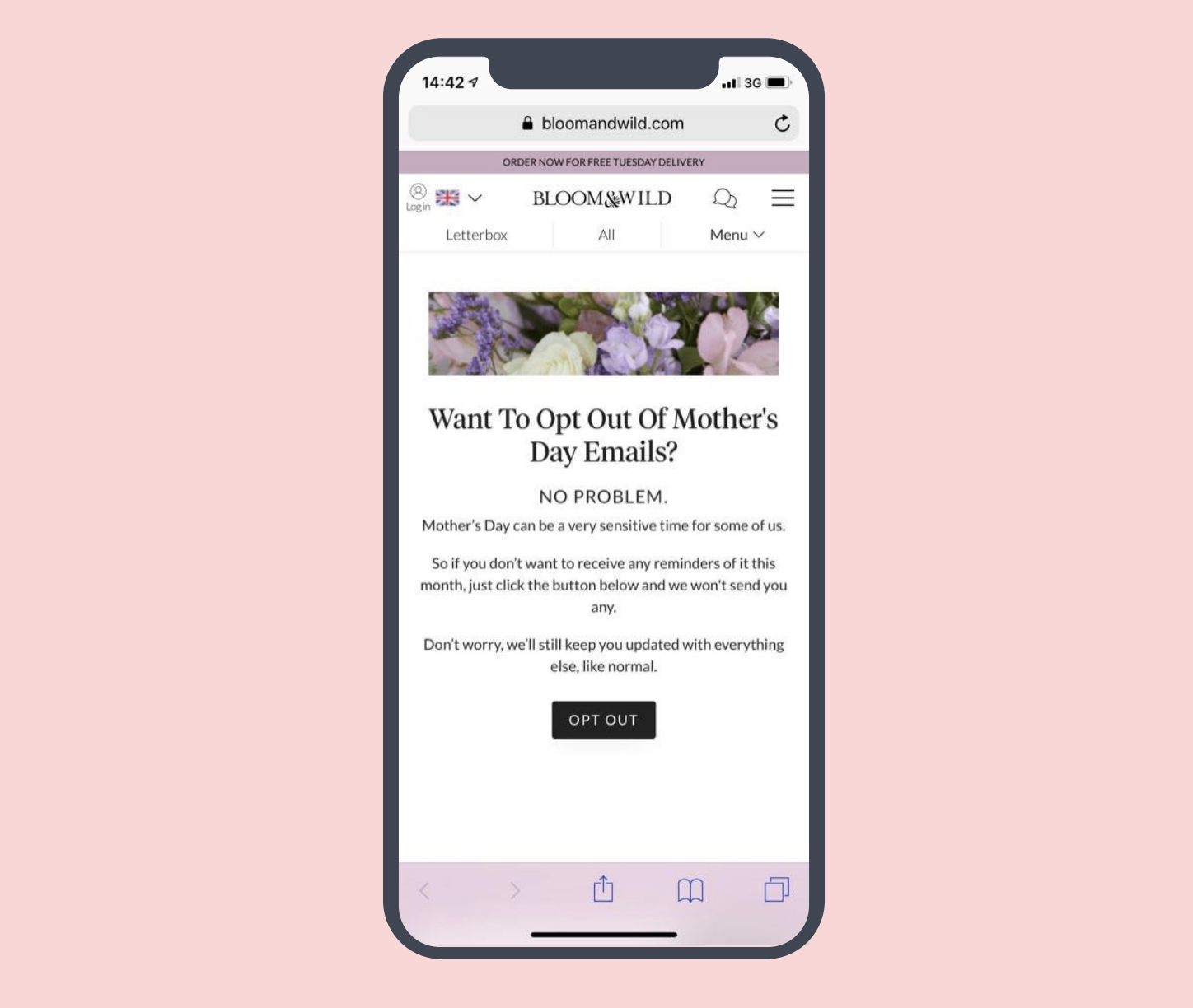
Sarah Parmenter shared a powerful moment where she, through the power of email, reached out to Bloom and Wild, a flower mail delivery service, to tell them a certain type of email they were sending she found to be, however unintentionally, very insensitive. Sarah was going to use this as an example anyway, but the day before, Bloom and Wild actually took her advice and implemented a specialized opt-out system.
This not only made Sarah happy that a company could actually change their systems to be more sensitive to their customers, but it made a whole ton of people happy, as evidenced by an outpouring of positive tweets after it happened. Turns out your customers like it when you, ya know, think of them.
Eric Meyer covered one of the more inexplicable things about pseudo-elements: if you content: url(/icons/icon.png); you literally can’t control the width/height. There are ways around it, notably by using a background image instead, but it is a bit baffling that there is a way to add an image to a page with no possible way to resize it.
Literally, the entire talk was about pseudo-elements, which I found kinda awesome as I did that same thing eight years ago. If you’re looking for some nostalgia (and are OK with some cringe-y moments), here’s the PDF.
Eric also showed a demo that included a really neat effect that looks like a border going from thick to thin to thick again, which isn’t really something easily done on the web. He used a pseudo, but here it is as an
Rachel Andrew had an interesting way of talking about flexbox. To paraphrase:
Flexbox isn’t the layout method you think it is. Flexbox looks at some disparate things and returns some kind of reasonable layout. Now that grid is here it’s a lot more common to use that to be more much explict about what we are doing with layout. Not that flexbox isn’t extremely useful.
Rachel regularly pointed out that we don’t know how tall things are in web design, which is just so, so true. It’s always been true. The earlier we embrace that, the better off we’ll be. So much of our job is dealing with overflow.
Rachel brought up a concept that was new to me, in the sense that it has an official name. The concept is “data loss” through CSS. For example, aligning something a certain way might cause some content to become visually hidden and totally unreachable. Imagine some boxes like this, set in flexbox, with center alignment:
No “data loss” there because we can read everything. But let’s say we have more content in some of them. We can never know heights!
If that element was along the top of a page, for example, no scrollbar will be triggered because it’s opposite the scroll direction. We’d have “data loss” of that text:
We now alignment keywords that help with this. Like, we can still attempt to center, but we can save ourselves by using safe center (unsafe center being the default):
Rachel also mentioned overlapping as a thing that grid does better. Here’s a kinda bad recreation of what she showed:
I was kinda hoping to be able to do that without being as explicit as I am being there, but that’s as close as I came.
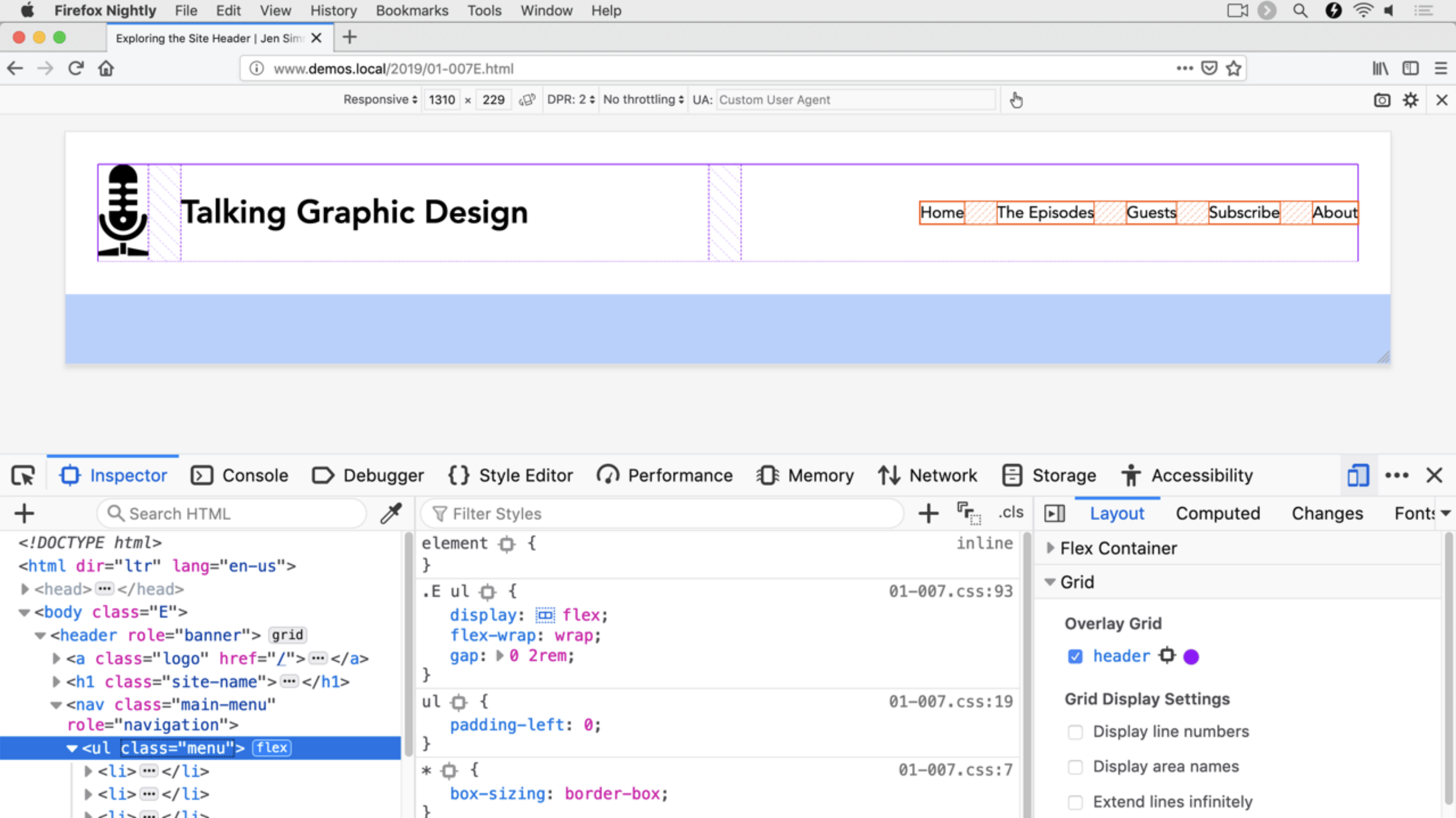
Jen Simmons showed us a ton of different scenarios involving both grid and flexbox. She made a very clear point that a grid item can be a flexbox container (and vice versa).
Perhaps the most memorable part is how honest Jen was about how we arrive at the layouts were shooting for. It’s a ton of playing with the possible values and employing a little trial and error. Happy accidents abound! But there is a lot to know about the different sizing values and placement possibilties of grid, so the more you know the more you can play. While playing, the layout stuff in Firefox DevTools is your best bet.
The idea is that even though brainstorm sessions are supposed to be judgment-free, they never are. Bad ideas are meant to be bad, so the worst you can do is have a good idea. Even better, starting with good ideas is problematic in that it’s easy to get attached to an idea too early, whereas bad ideas allow more freedom to jump through ideation space and land on better ideas.
Scott Jehl mentioned a fascinating idea where you can get the benefits of inlining code and caching files at the same time. That’s useful for stuff we’ve gotten used to seeing inlined, like critical CSS. But you know what else is awesome to inline? SVG icon systems. Scott covered the idea in his talk, but I wanted to see if it I could give it a crack myself.
The idea is that a fresh page visit inlines the icons, but also tosses them in cache. Then other pages can them out of the cache.
Here’s my demo page. It’s not really production-ready. For example, you’d probably want to do another pass where you Ajax for the icons and inject them by replacing the so that everywhere is actually using inline the same way. Plus, a server-side system would be ideal to display them either way depending on whether the cache is present or not.
Jeremy Keith mentioned the incredible prime number shitting bear, which is, as you might suspect, computationally expensive. He mentioned it in the context of web workers, which is essentially JavaScript that runs in a separate thread, so it won’t/can’t slow down the operation of the current page. I see that same idea has crossed other people’s minds.
I’m sad that I didn’t get to see every single talk because I know they were all amazing. There are plenty of upcoming shows with some of the same folks!
(This is a sponsored article.) Over the last few years, there’s been a major shift in terms of the way companies work. As more businesses become location independent, collaboration tools have become the standard way in which teams meet and get work done.
That said, just because we have collaboration apps that integrate our connected business processes and tools, that doesn’t mean the experience always leads to optimum efficiency or productivity. Why? Well, sometimes an unfriendly UI gets in the way.
That’s why, today, I’m going to talk about Block Kit, Slack’s contribution to building a better collaboration UI.
For those of you who have built a custom Slack app (for the app directory or for internal purposes), this will be your introduction to the new design tool. For those of you who haven’t, that’s okay. There are some valuable lessons to take away from this in terms of what makes for an engaging workspace that will improve collaboration.
Developers, Do You Know What Slack Has Been Working On?
Slack has made huge strides since its launch in 2013. What originally began as a messaging app has now blossomed into a powerful collaboration platform.
As of writing this: Slack has over 10 million active users daily — and they live all over the world (over 150 countries, to be exact).
Here’s an example of a Slack channel for Japanese speakers. (Image source: Slack) (Large preview)
It’s not just individuals using Slack either — nearly 585,000 teams of three persons or more collaborate within the platform. 65 of the Fortune 100 companies also happen to be on Slack.
A glimpse into real-time collaboration between Slack users (Image source: Slack) (Large preview)
This is all thanks to the Slack API which has opened the door for developers to create and publish publicly available apps that extend the functionality of Slack workspaces.
The front page of the Slack App Directory. (Image source: Slack) (Large preview)
This way, Slack users don’t have to bounce between their most commonly used business tools. Related processes may take place all from within Slack.
Sometimes, though, what’s available in the Slack App Directory just isn’t enough for what your organization needs internally. You may be able to bridge some of the divides between your business tools with what’s there, but you might also find a reason to build your own custom Slack apps.
Introducing Block Kit From Slack
Here’s the thing: while Slack has succeeded in allowing developers to craft their own apps to enhance collaboration within the platform, how are developers supposed to know how to create a good experience with it?
Until recently, Slack’s API and app directory provided limited flexibility and control. As Brian Elliott, the General Manager of the Platform, explained:
“Today, all apps are forced into a limited set of ways to display rich information. If you’ve looked at and seen and used all of the different apps in Slack, many of them end up with the same layout regardless of which functionality they’re trying to deploy. When in reality what you need is a set of components that let you build rich interactive displays that are easier for people to comprehend, digest and act on.”
Block Kit is a UI framework that enables developers, designers and front-end builders to display their messaging apps through a rich, interactive and intuitive UI. Further, by providing a set of stackable UI elements or blocks, Block Kit now provides developers with more control and flexibility over their app designs and layouts.
Note: If you’d like to see Block Kit in action, join the upcoming Slack session, “Building with Block Kit”, where you’ll get a live product demonstration and see how easy it is to customize the design of your app.
The building components are on the left. Simply click on the one you want to include and watch it get added to the preview of your app in the center.
Want further customization? Check out the text editor on the right. While Block Kit provides pre-made elements that follow best practices for designing messaging apps, you have the ability to make them your own if you prefer.
2. Block Kit Templates
While you can certainly craft a messaging interface from the Builder on your own, I’d suggest exploring the Templates provided as well:
These are just some of the templates Block Kit offers to users. (Image source: Block Kit) (Large preview)
The Slack Team has already seen really useful cases of Slack apps in action. Needless to say, they know what kinds of things your organization might want to leverage for the sake of improved collaboration.
That’s why you’ll find common actions like the following already built out for you:
Reviewing requests for approval;
Taking action on new notifications;
Running polls and monitoring results;
Conducting a search.
Guru is one such tool that’s leveraged Block Kit to improve its Slack app:
Guru provides a database search function within Slack. Results are now quickly retrieved and more clearly displayed on the frontend of Slack.
The Keys To Building A Better Collaboration UI
Now that we’ve seen what’s coming down the line with Block Kit, we need to talk about how it’s going to help you create apps that lead to more productive collaboration.
Blocks
I recently spoke on the subject of Gutenberg and how designers can use it to their advantage. Although the new WordPress editor clearly has its flaws, there’s no questioning why the team at WordPress made the change:
I get that block builders tend to be the preferred tool for web designers and DIY users. Builders allow for visual frontend design and often include abundant customization options.
Some of the pre-made blocks included in Block Kit (Image source: Block Kit) (Large preview)
But Block Kit does much more than that, which means both designers and developers can build custom apps with ease.
Code
The key differentiator between something like a website builder and the Block Kit builder is the coding aspect.
In most cases, designers use page builders so they don’t have to bother with code. They might add some custom CSS classes or add HTML to their text, but that’s generally it. Developers don’t work like that though.
Block Kit includes a panel with pre-written JSON that developers can copy-and-paste into their own Slack app once it’s ready to go. Rather than leave developers to write their own code, Slack provides code that utilizes best practices for speed and design.
A sample of JSON you get when you build your rich messaging experience in the builder. (Image source: Block Kit) (Large preview)
This enables developers to focus on making customizations instead of on having to build their apps from the ground up.
Consistency
When Slack users step inside the platform, they know what to expect. Every interface is the same from workspace to workspace.
However, when an API allows developers to build apps to integrate with those spaces, there’s a risk of introducing elements that just don’t jibe well. When that happens, the unpredictability of the interface can create confusion and hesitation for the end user. Ill-fitting layout choices can also harm the experience.
Block Kit enables developers to build apps with stackable UI components that have been tried and tested. When customizing an experience within an already established platform, it can be difficult to know how far you can take it — or if it’ll even work. Slack has taken those questions out of the equation.
Spacing
This is what the traditional Slack exchange looks like:
An example of Slack users messaging one another (Image source: Slack) (Large preview)
It tends to be a single-column, back-and-forth exchange. And this works perfectly well for Slack channels where collaboration is simple. Employees message about the status of a task. A client uploads a missing asset. The CEO shares a link to a press release mentioning the company. But not all workspaces are that simple.
Block Kit helps you maximize and enhance the space that your app’s features occupy. For instance, Block Kit enables companies like Optimizely to display pertinent information in two-column formats for better readability.
This is indeed a better way to share pertinent details in your team’s Slack app.
Rich Interactions
Another way to elevate your app is by turning the integration into one that’s rich with interactions.
Blocks have been specially developed to enhance the most commonly used elements in Slack collaboration. For example:
Use the Sectional block for better organization.
Use the Text block to customize how messages display.
Use properly sized Image blocks so you can stop worrying about whether or not they’ll display correctly.
Use Context blocks to show bylines or additional context about messages (like author, comments, changes, etc.)
Use Divider blocks to improve the look of the app.
Use Action blocks like menu selection, button selection and calendar dates to bring better features into your app and make them display more intuitively.
Use 2-section blocks for cleaner layouts.
Doodle has a beautiful example of what can be done with rich interactions using Block Kit:
As you can see, users can work together to schedule meetings just as effectively as if they were using a third-party calendar. The only difference is that they can now do all of that within their Slack workspace.
Wrapping Up
Collaboration is an essential part of any organization’s success, and it doesn’t matter if it’s a team of 3 or a team of 300. But there’s a big difference between working together and productivelycollaborating.
Thanks to Slack’s API, developers have created some awesome ways to integrate related processes and tools into the platform. And thanks to Block Kit, those external contributions won’t disrupt the experience if the design of the elements falls short.
With intuitive block-building capabilities, developer-friendly coding options and more, Block Kit is going to help developers bring richer experiences and better collaboration to the Slack platform.
One last thing to mention:
Slack’s Frontiers conference is coming up soon. It’s going to be in San Francisco on April 24 and 25. If you’re planning to attend, note that the Developers track will include a full day’s training on Block Kit, including workshops, new feature demos, tutorials, as well as one-on-one mentoring. If you’re thinking about Block Kit, this is an opportunity you won’t want to miss.
I want you to take a second and think about Twitter, and think about it in terms of scale. Twitter has 326 million users. Collectively, we create ~6,000 tweets every second. Every minute, that’s 360,000 tweets created. That sums up to nearly 200 billion tweets a year. Now, what if the creators of Twitter had been paralyzed by how to scale and they didn’t even begin?
That’s me on every single startup idea I’ve ever had, which is why I love serverless so much: it handles the issues of scaling leaving me to build the next Twitter!
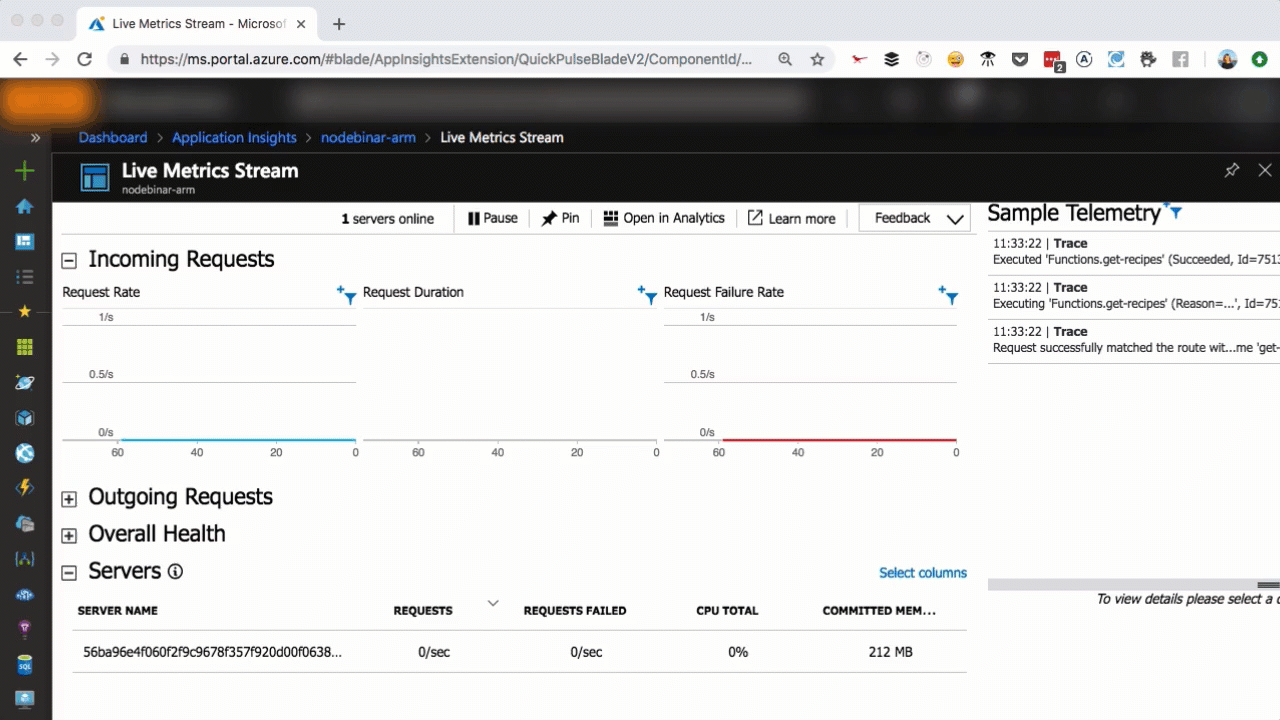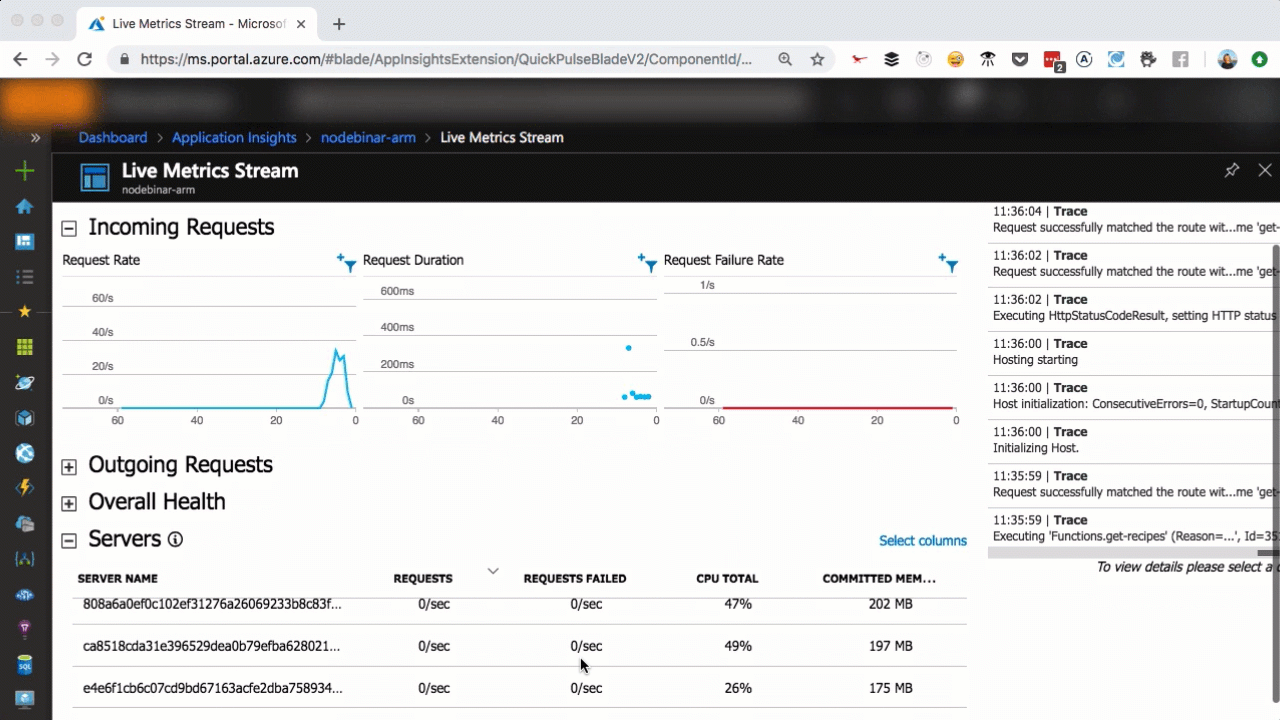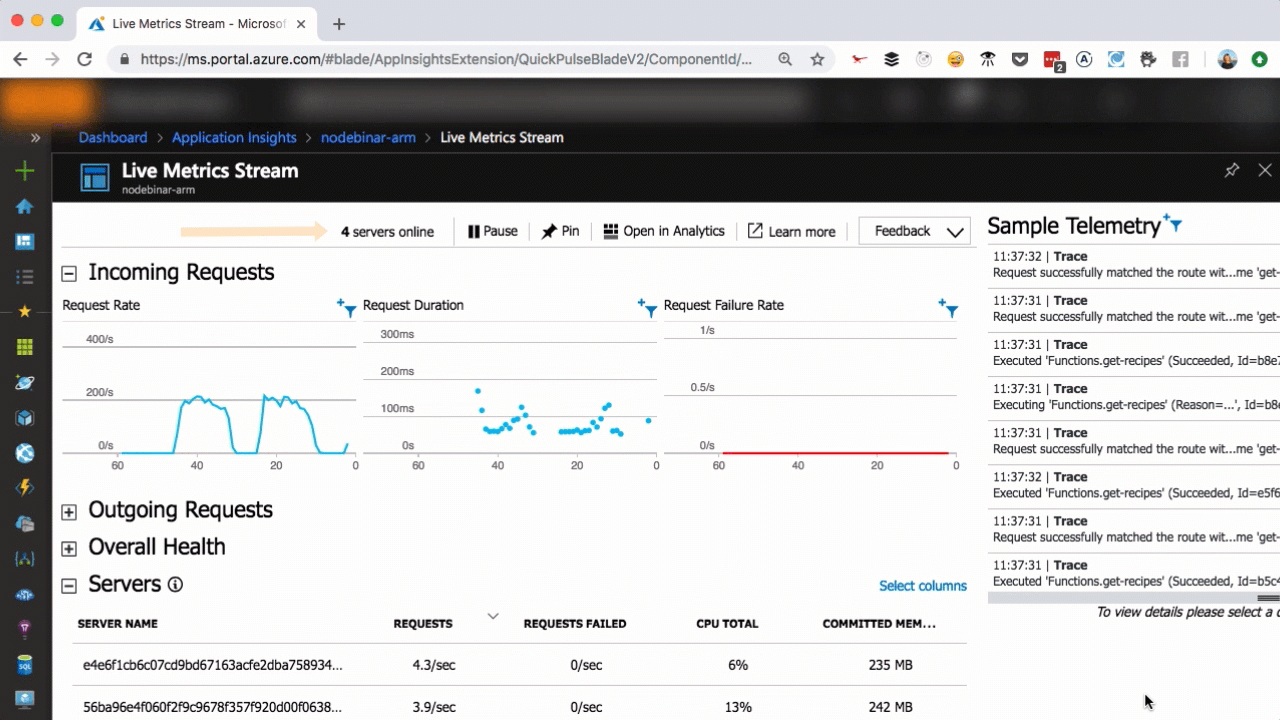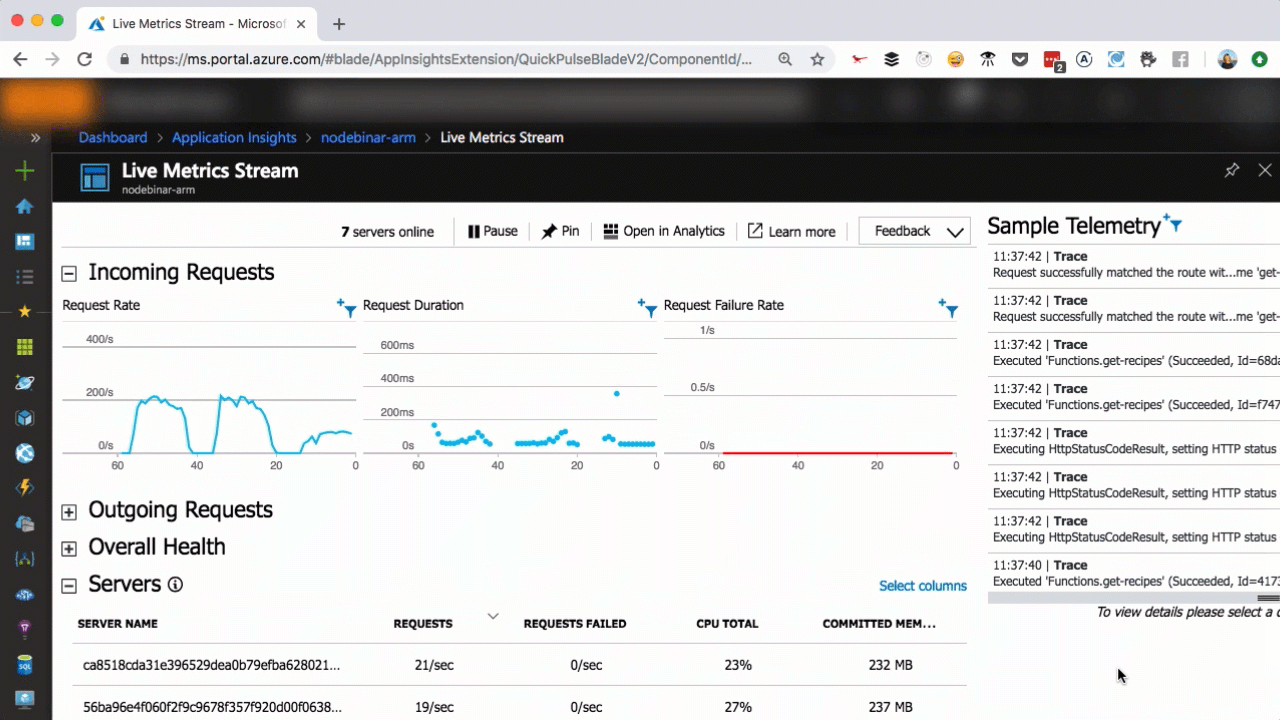
Live metrics with Application Insights
As you can see in the above, we scaled from one to seven servers in a matter of seconds, as more user requests come in. You can scale that easily, too.
So let’s build an API that will scale instantly as more and more users come in and our workload increases. We’re going to do that is by answering the following questions:
With every new technology, we need to figure out what tools are available for us and how we can integrate them into our existing tool set. When getting started with serverless, we have a few options to consider.
First, we can use the good old browser to create, write and test functions. It’s powerful, and it enables us to code wherever we are; all we need is a computer and a browser running. The browser is a good starting point for writing our very first serverless function.
Serverless in the browser
Next, as you get more accustomed to the new concepts and become more productive, you might want to use your local environment to continue with your development. Typically you’ll want support for a few things:
Writing code in your editor of choice
Tools that do the heavy lifting and generate the boilerplate code for you
Run and debug code locally
Support for quickly deploying your code
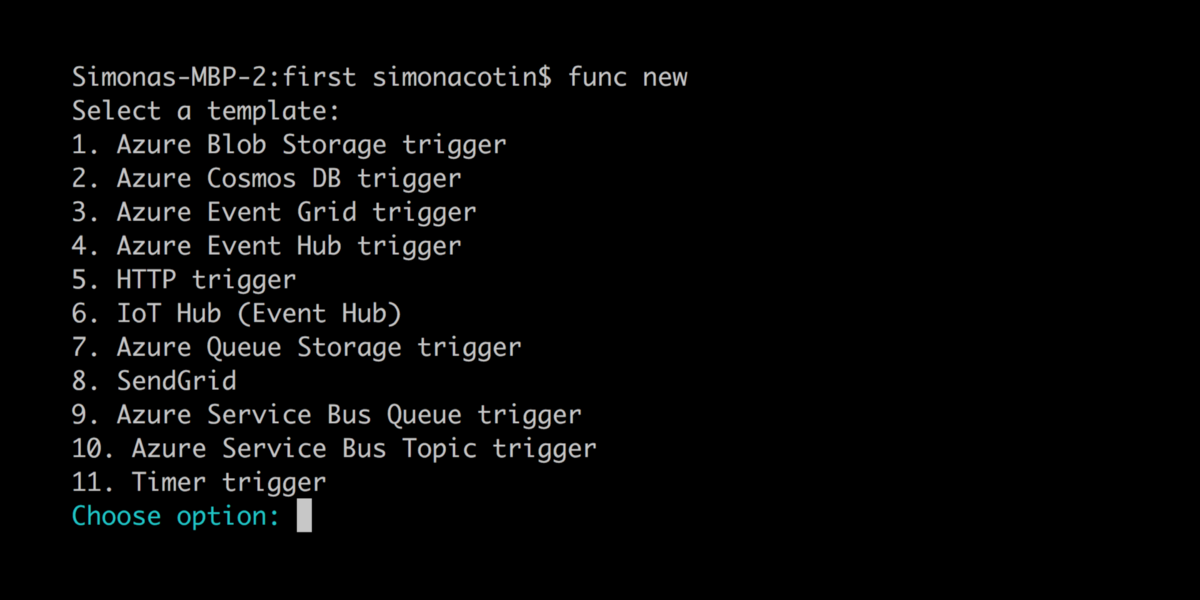
Microsoft is my employer and I’ve mostly built serverless applications using Azure Functions so for the rest of this article I’ll continue using them as an example. With Azure Functions, you’ll have support for all these features when working with the Azure Functions Core Tools which you can install from npm.
npm install -g azure-functions-core-tools
Next, we can initialize a new project and create new functions using the interactive CLI:
func CLI
If your editor of choice happens to be VS Code, then you can use it to write serverless code too. There’s actually a great extension for it.
Once installed, a new icon will be added to the left-hand sidebar?—?this is where we can access all our Azure-related extensions! All related functions can to be grouped under the same project?(also known as a function app). This is like a folder for grouping functions that should scale together and that we want to manage and monitor at the same time. To initialize a new project using VS Code, click on the Azure icon and then the folder icon.
Create new Azure Functions project
This will generate a few files that help us with global settings. Let’s go over those now.
host.json
We can configure global options for all functions in the project directly in the host.json file.
In it, our function app is configured to use the latest version of the serverless runtime?(currently 2.0). We also configure functions to timeout after ten minutes by setting the functionTimeout property to 00:10:00?—?the default value for that is currently five minutes (00:05:00).
In some cases, we might want to control the route prefix for our URLs or even tweak settings, like the number of concurrent requests. Azure Functions even allows us to customize other features like logging, healthMonitor and different types of extensions.
Here’s an example of how I’ve configured the file:
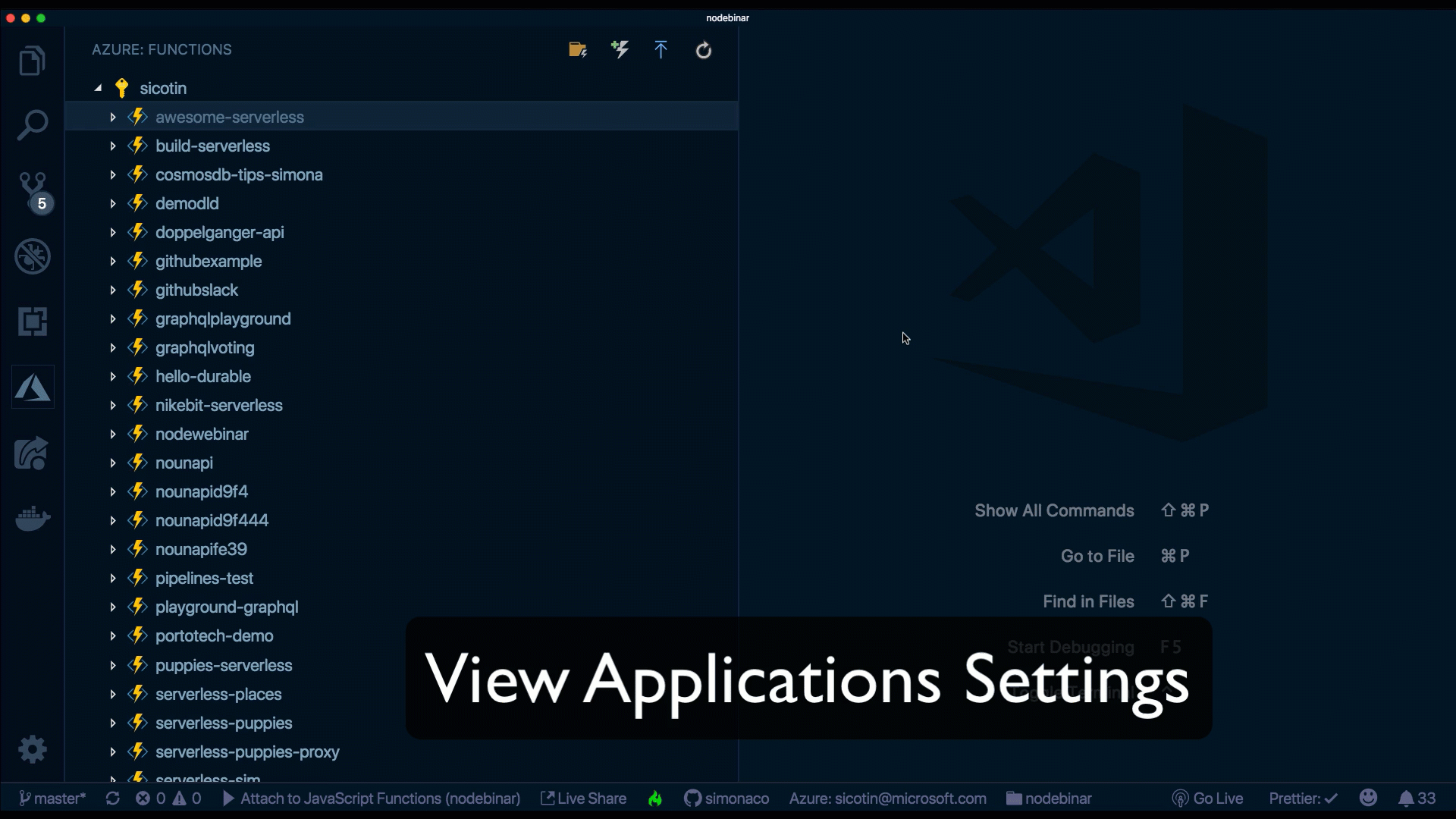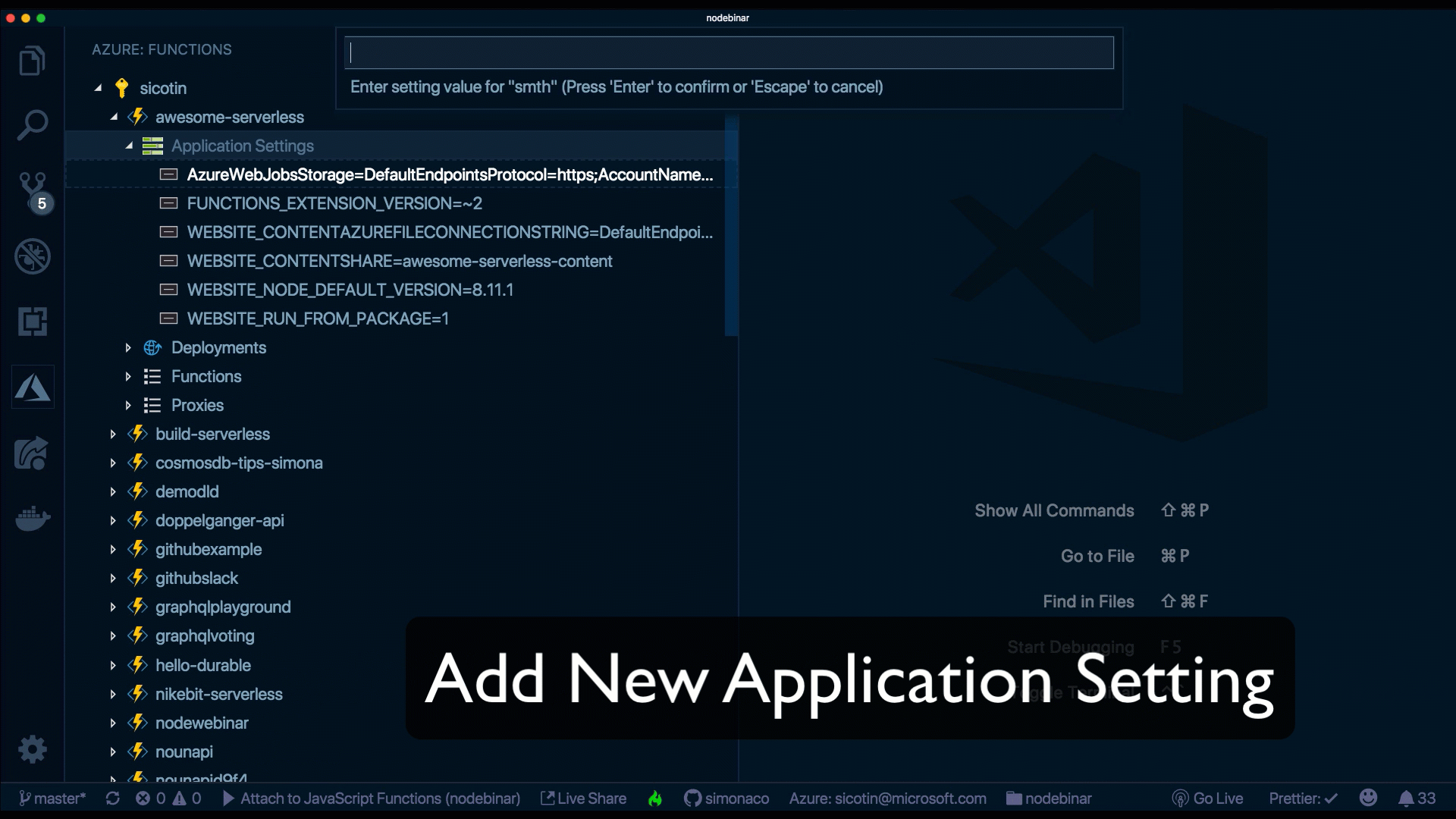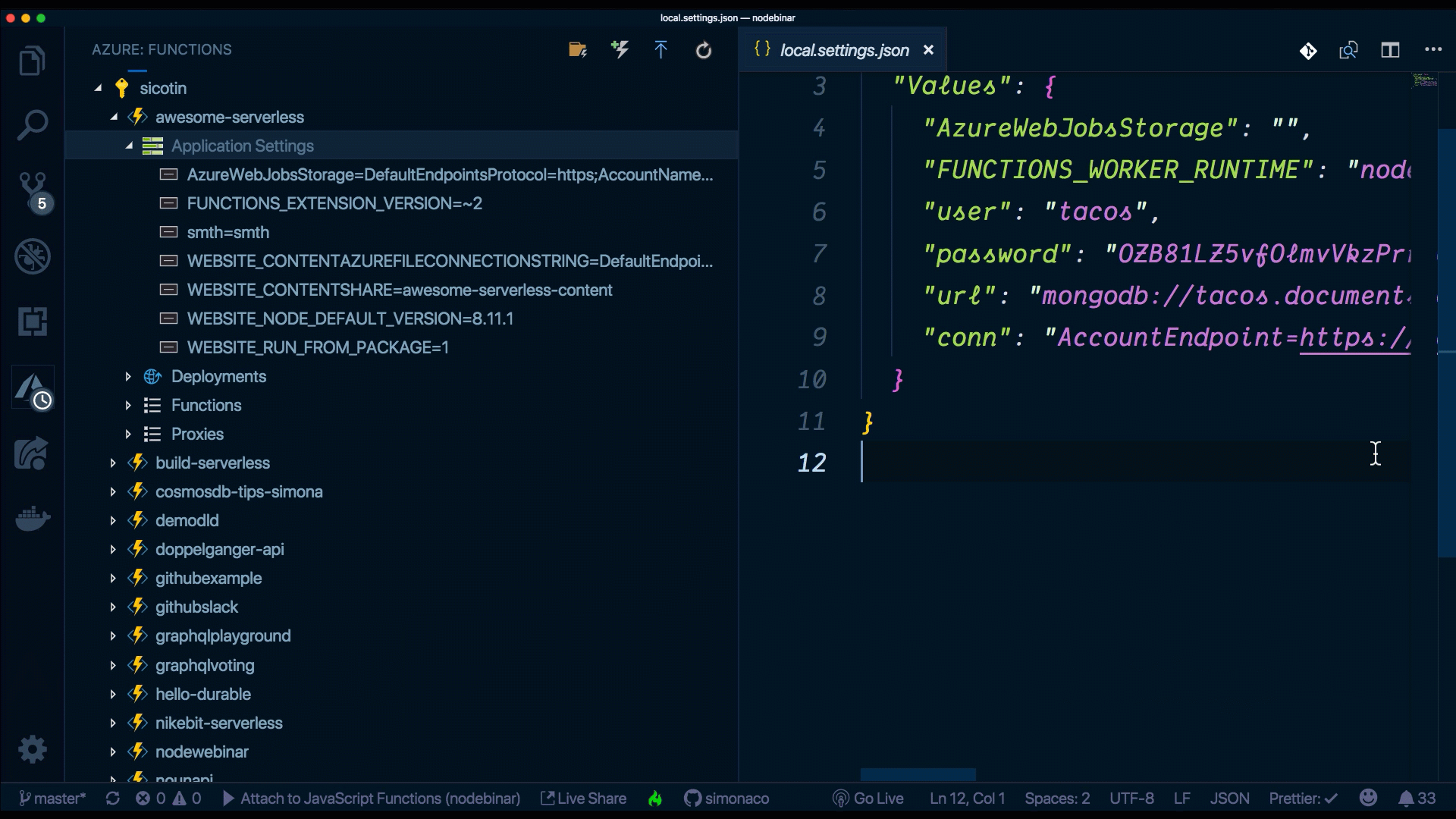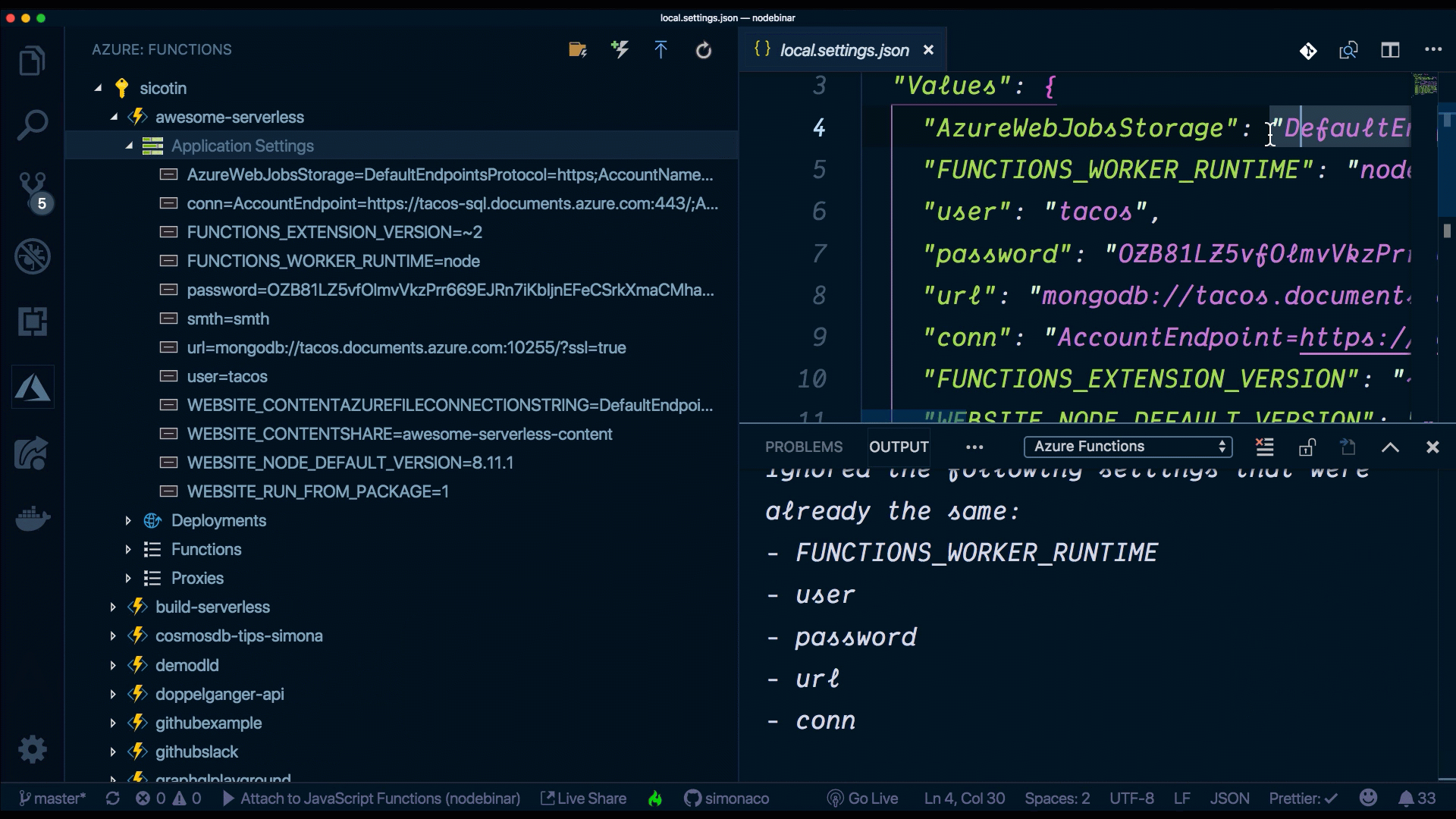
Application settings are global settings for managing runtime, language and version, connection strings, read/write access, and ZIP deployment, among others. Some are settings that are required by the platform, like FUNCTIONS_WORKER_RUNTIME, but we can also define custom settings that we’ll use in our application code, like DB_CONN which we can use to connect to a database instance.
While developing locally, we define these settings in a file named local.settings.json and we access them like any other environment variable.
Again, here’s an example snippet that connects these points:
Azure Functions Proxies are implemented in the proxies.json file, and they enable us to expose multiple function apps under the same API, as well as modify requests and responses. In the code below we’re publishing two different endpoints under the same URL.
Create a new function by clicking the thunder icon in the extension.
Create a new Azure Function
The extension will use predefined templates to generate code, based on the selections we made?—?language, function type, and authorization level.
We use function.json to configure what type of events our function listens to and optionally to bind to specific data sources. Our code runs in response to specific triggers which can be of type HTTP when we react to HTTP requests?—?when we run code in response to a file being uploaded to a storage account. Other commonly used triggers can be of type queue, to process a message uploaded on a queue or time triggers to run code at specified time intervals. Function bindings are used to read and write data to data sources or services like databases or send emails.
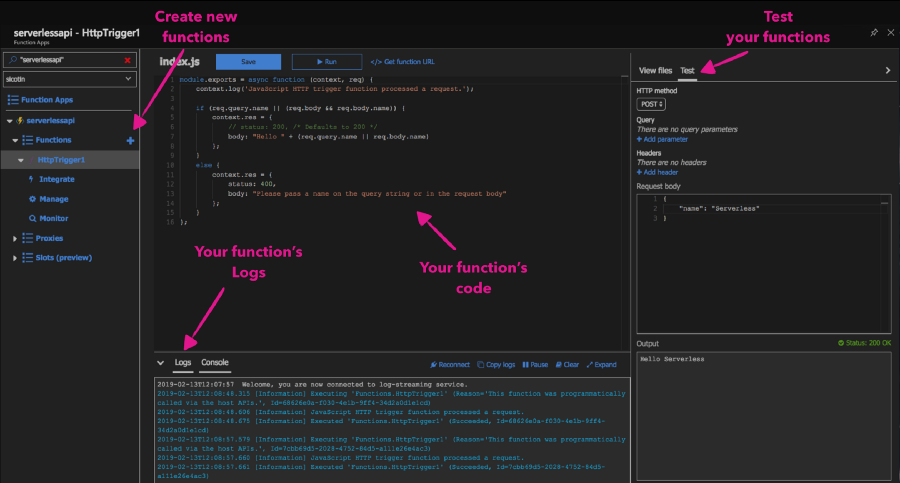
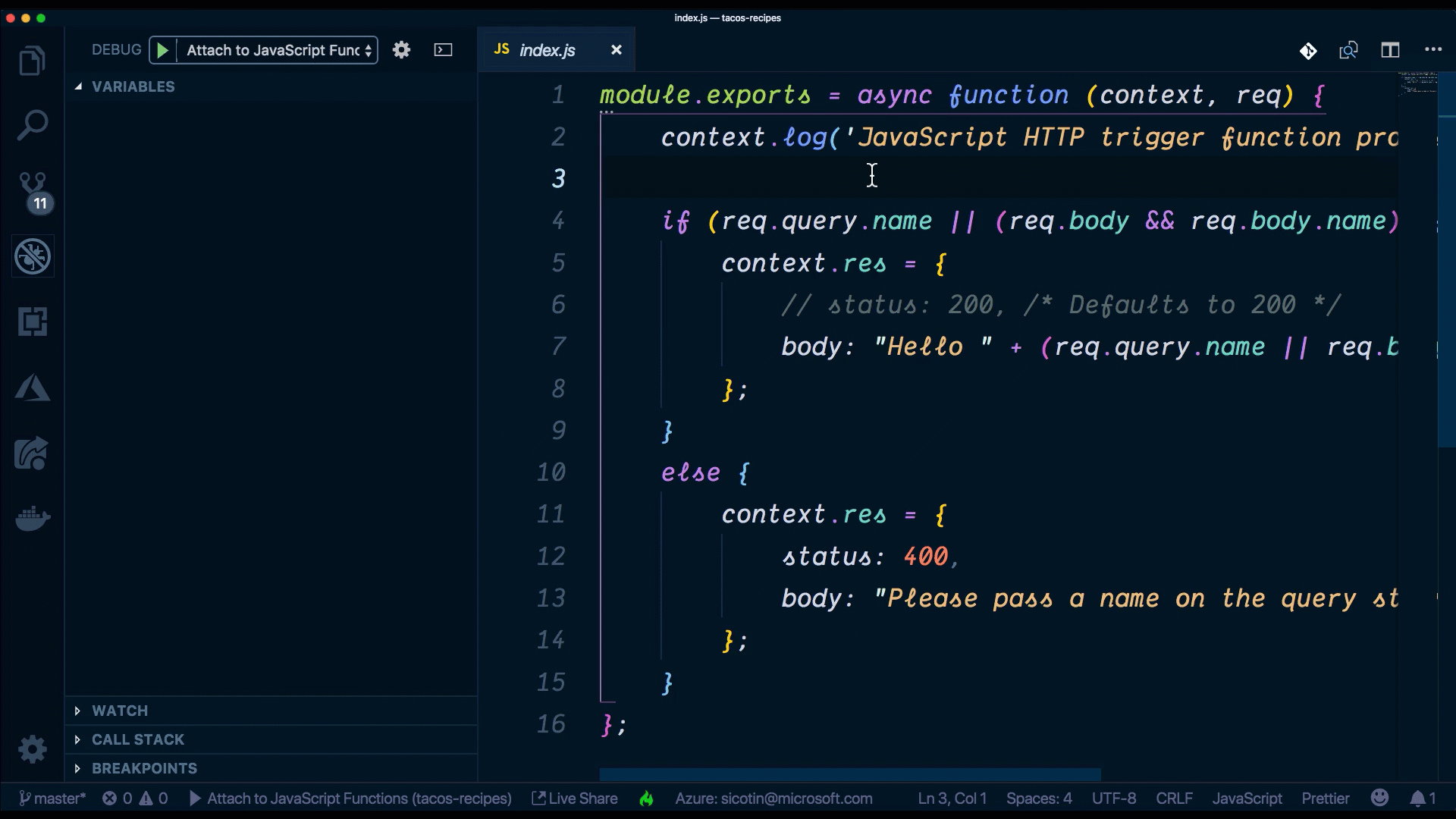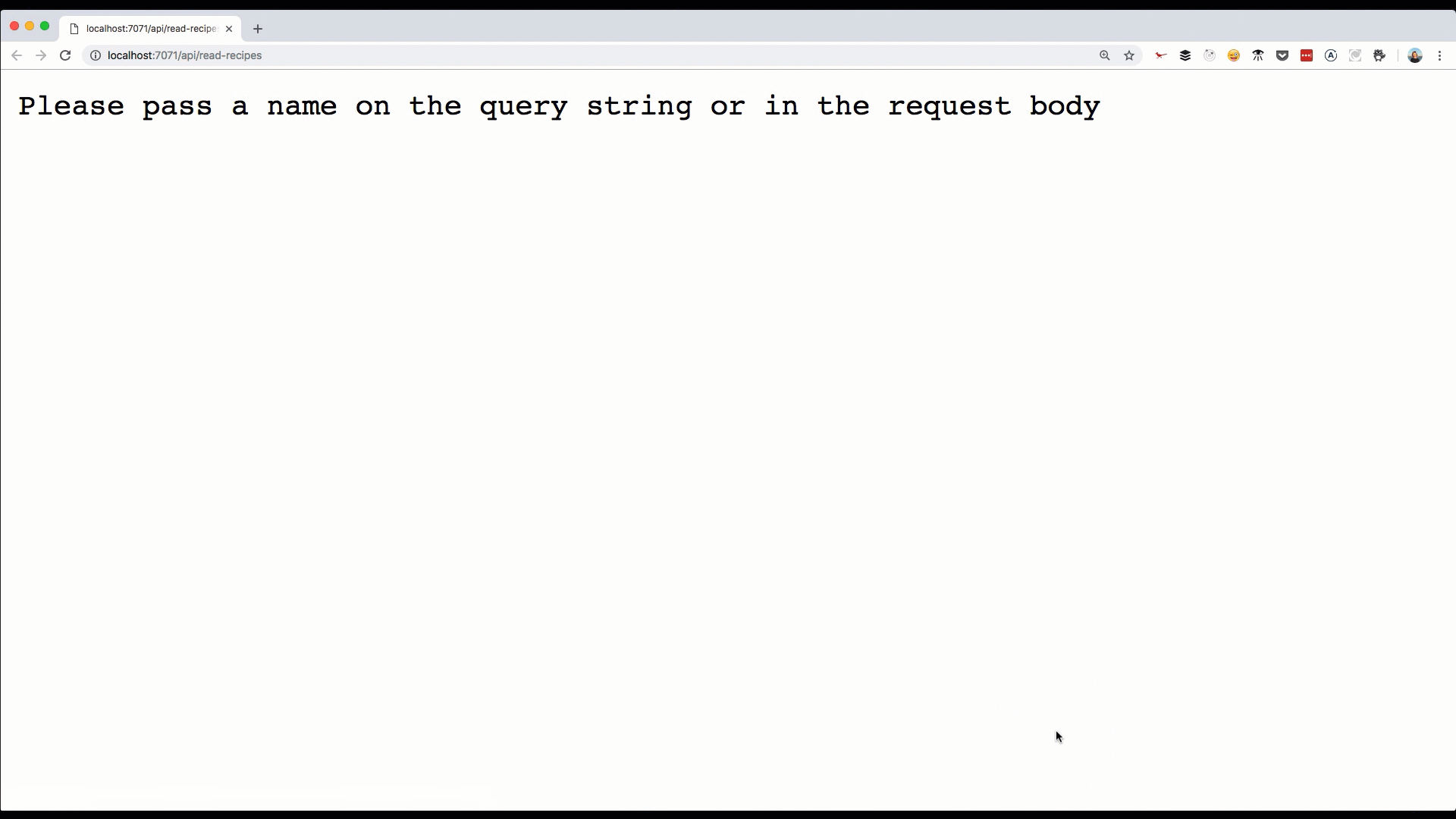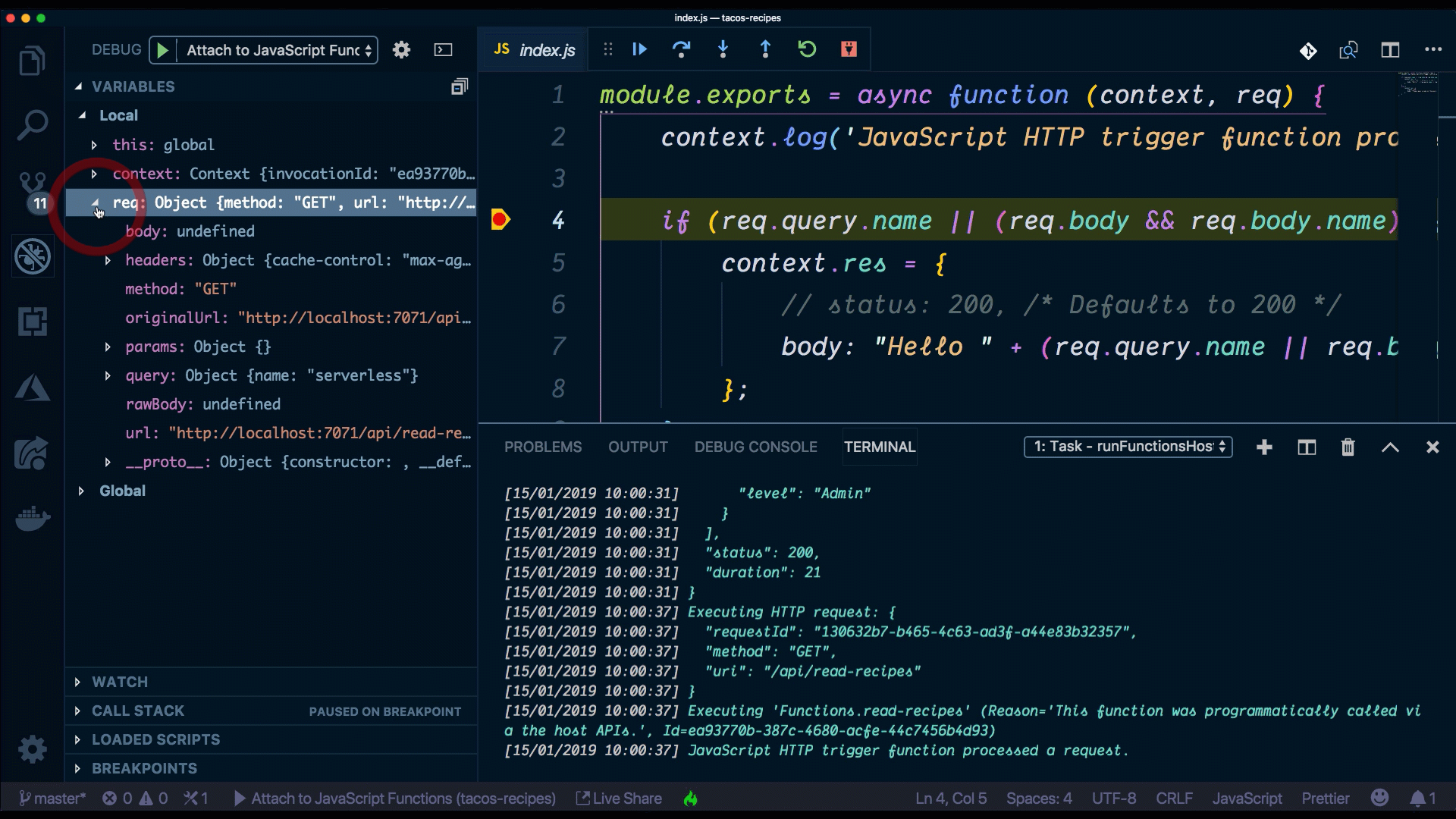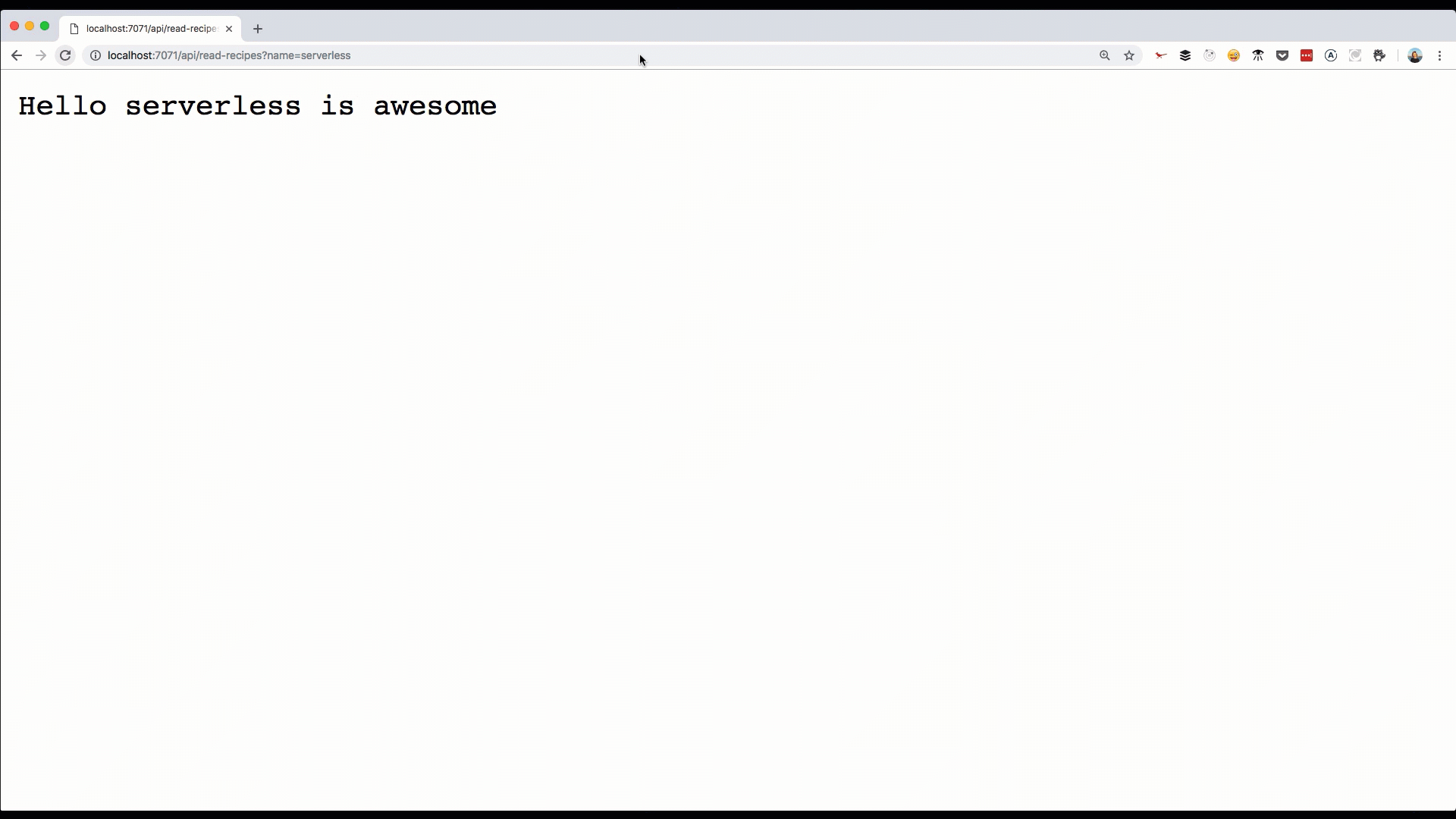
Here, we can see that our function is listening to HTTP requests and we get access to the actual request through the object named req.
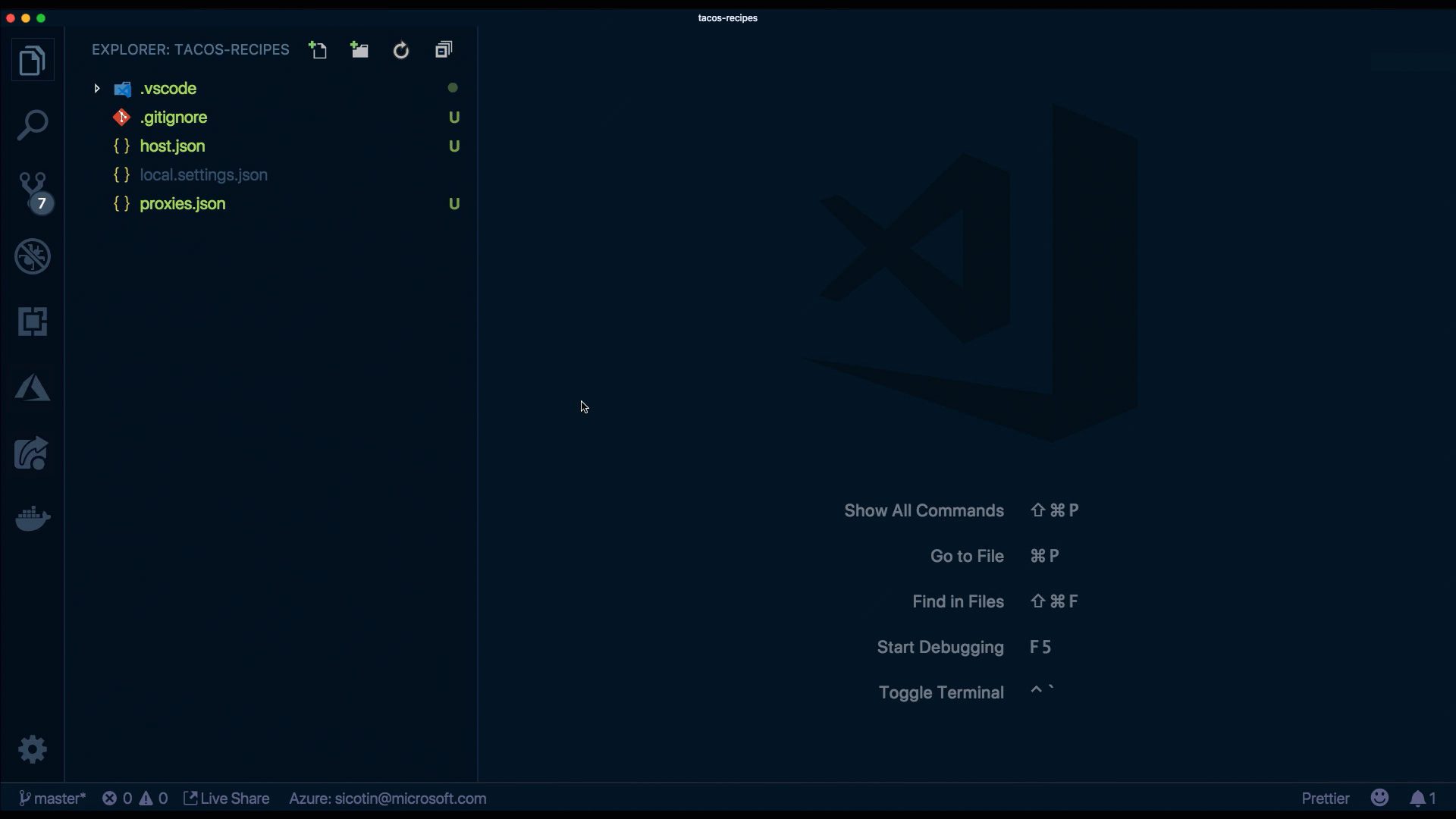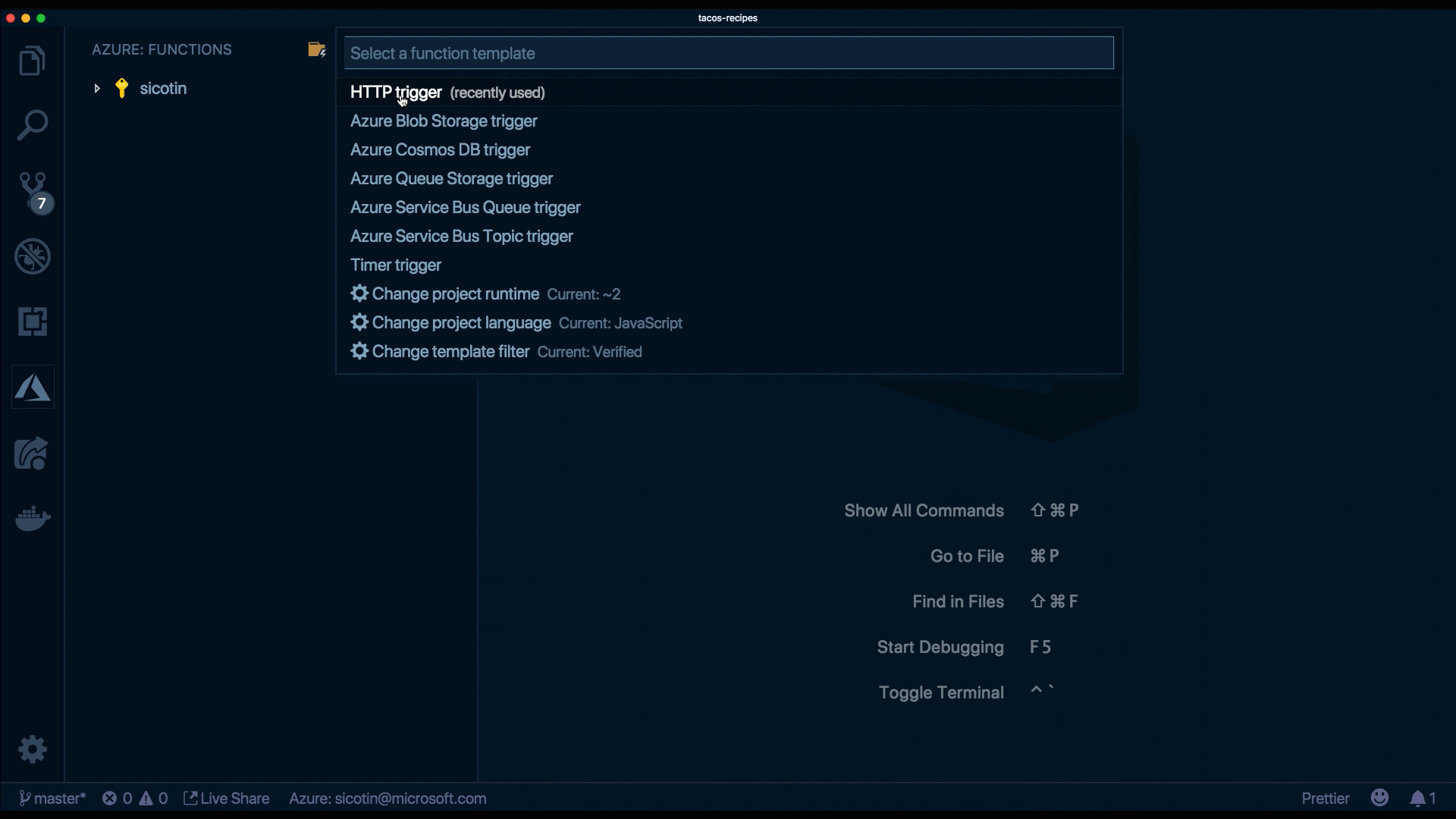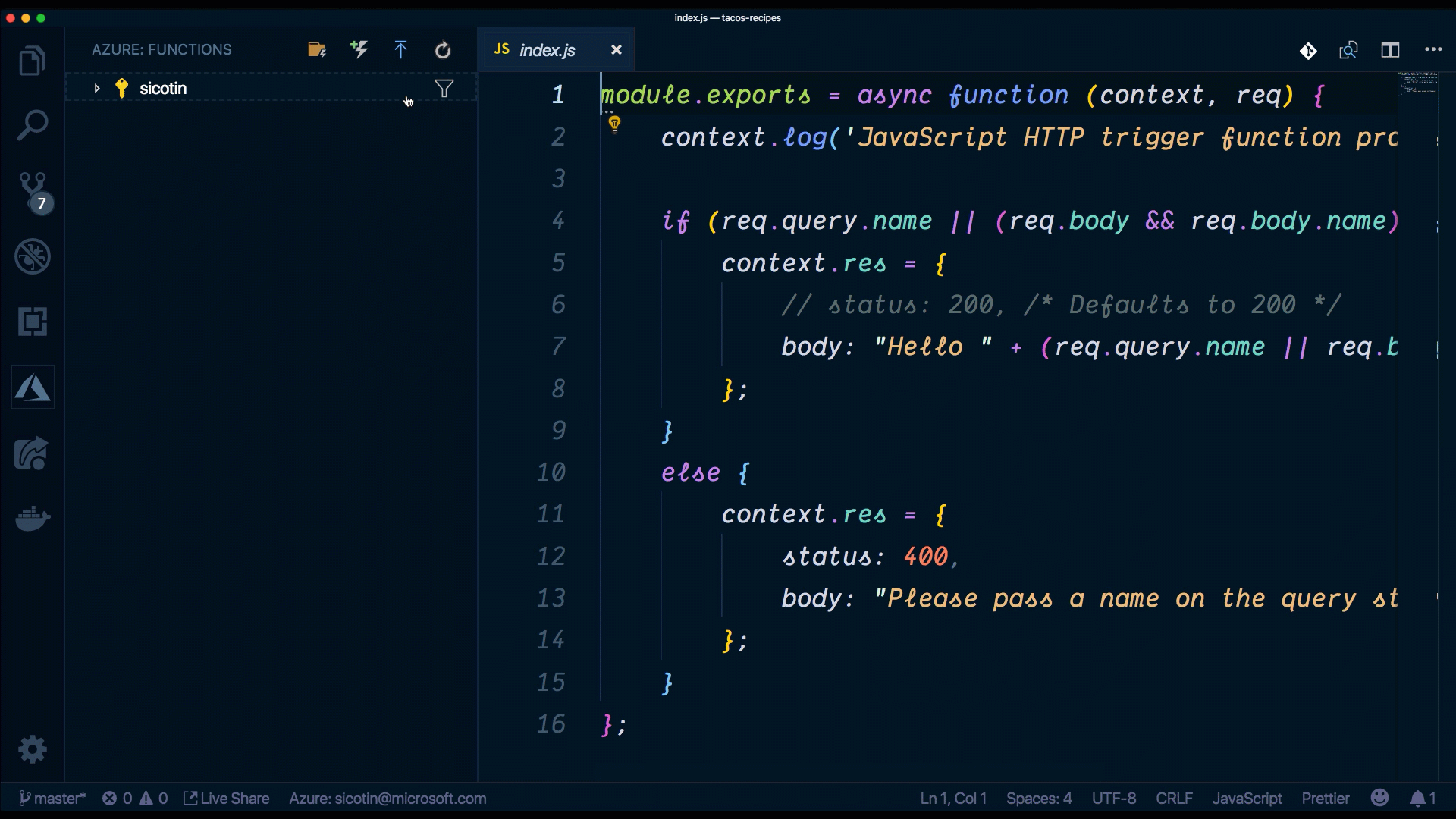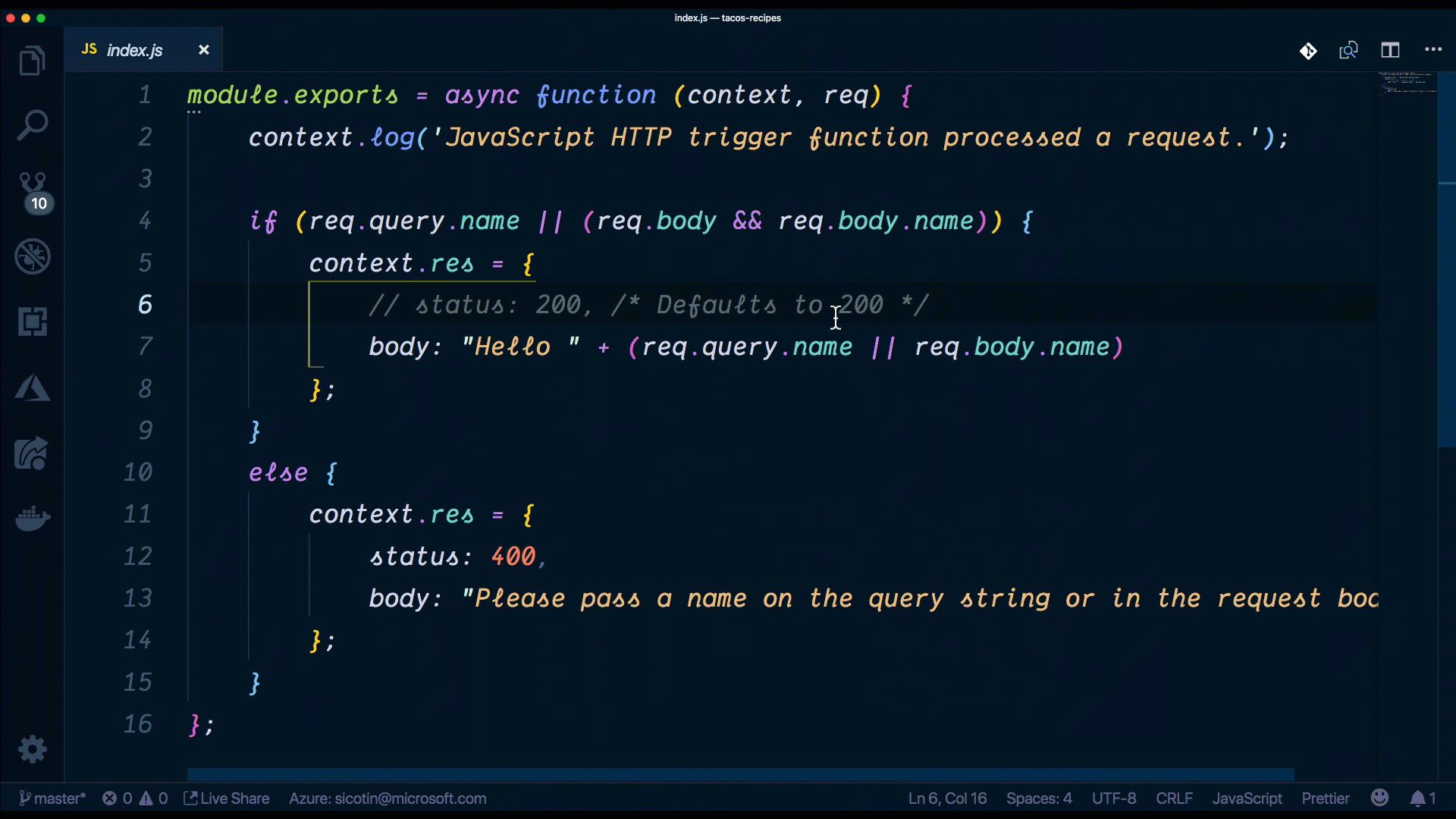
index.js is where we implement the code for our function. We have access to the context object, which we use to communicate to the serverless runtime. We can do things like log information, set the response for our function as well as read and write data from the bindings object. Sometimes, our function app will have multiple functions that depend on the same code (i.e. database connections) and it’s good practice to extract that code into a separate file to reduce code duplication.
//Index.js
module.exports = async function (context, req) {
context.log('JavaScript HTTP trigger function processed a request.');
if (req.query.name || (req.body && req.body.name)) {
context.res = {
// status: 200, /* Defaults to 200 */
body: "Hello " + (req.query.name || req.body.name)
};
}
else {
context.res = {
status: 400,
body: "Please pass a name on the query string or in the request body"
};
}
};
Who’s excited to give this a run?
How do I run and debug Serverless functions locally?
When using VS Code, the Azure Functions extension gives us a lot of the setup that we need to run and debug serverless functions locally. When we created a new project using it, a .vscode folder was automatically created for us, and this is where all the debugging configuration is contained. To debug our new function, we can use the Command Palette (Ctrl+Shift+P) by filtering on Debug: Select and Start Debugging, or typing debug.
Debugging Serverless Functions
One of the reasons why this is possible is because the Azure Functions runtime is open-source and installed locally on our machine when installing the azure-core-tools package.
How do I install dependencies?
Chances are you already know the answer to this, if you’ve worked with Node.js. Like in any other Node.js project, we first need to create a package.json file in the root folder of the project. That can done by running npm init -y?—?the -y will initialize the file with default configuration.
Then we install dependencies using npm as we would normally do in any other project. For this project, let’s go ahead and install the MongoDB package from npm by running:
npm i mongodb
The package will now be available to import in all the functions in the function app.
How do I connect to third-party services?
Serverless functions are quite powerful, enabling us to write custom code that reacts to events. But code on its own doesn’t help much when building complex applications. The real power comes from easy integration with third-party services and tools.
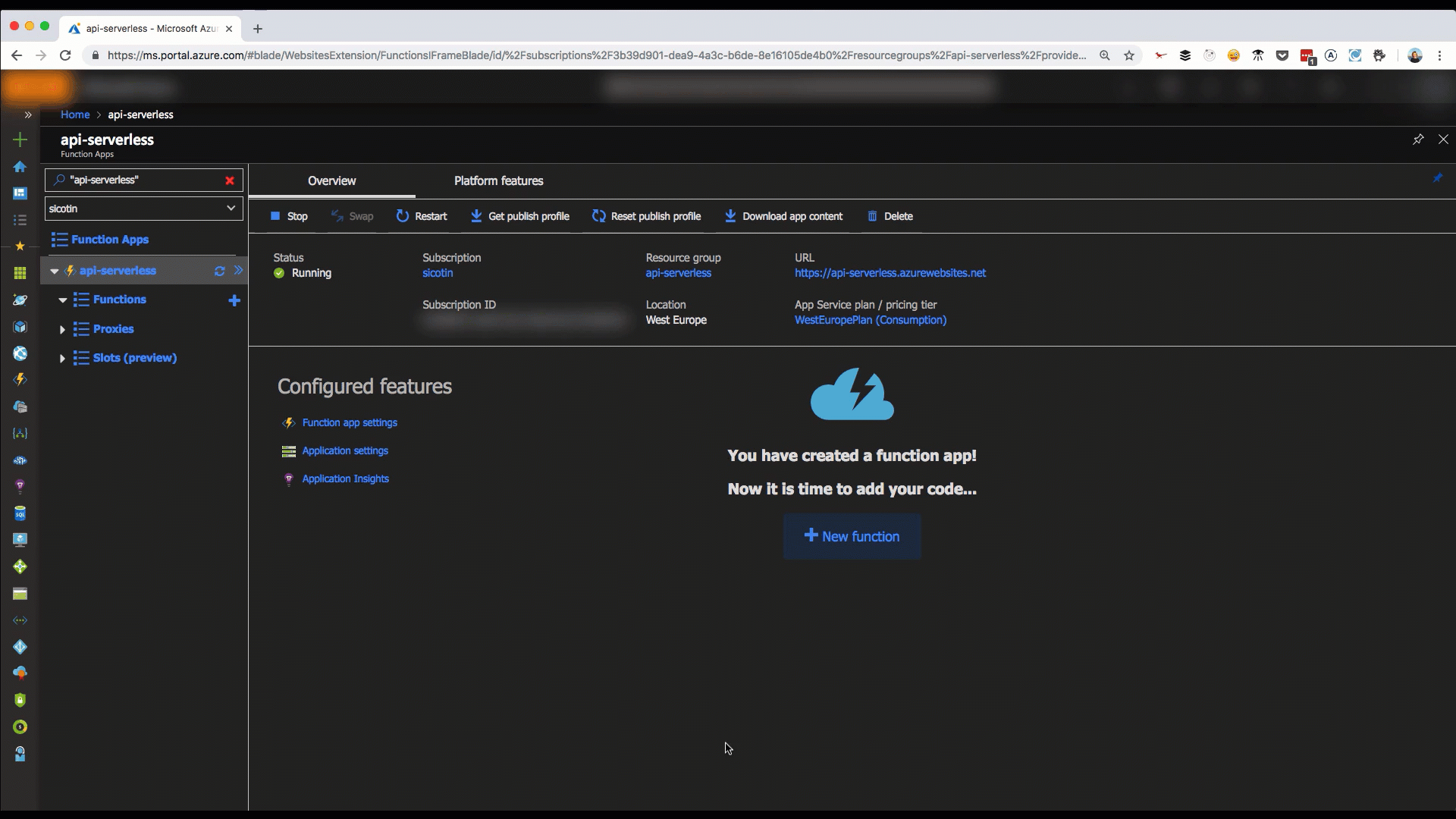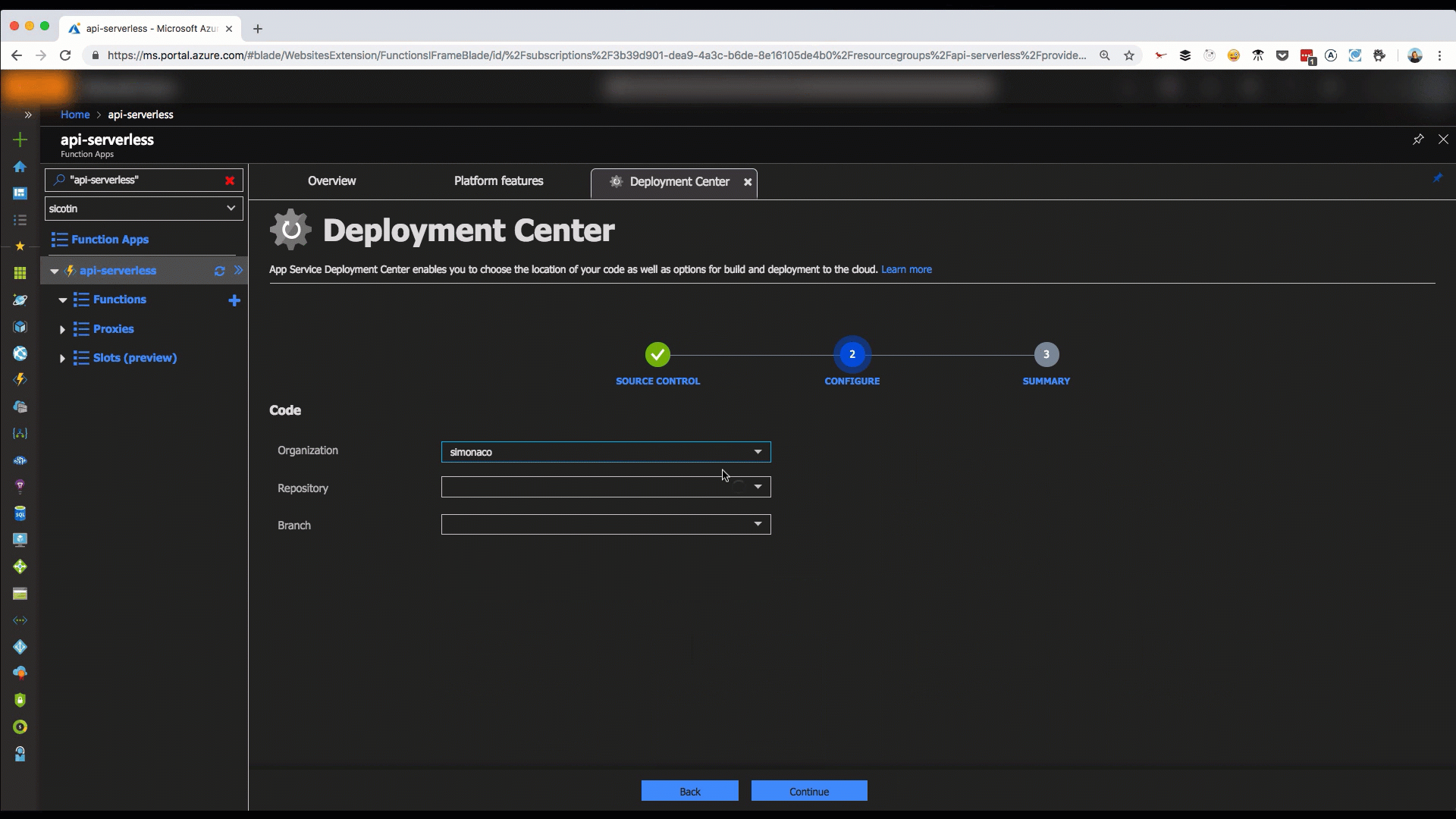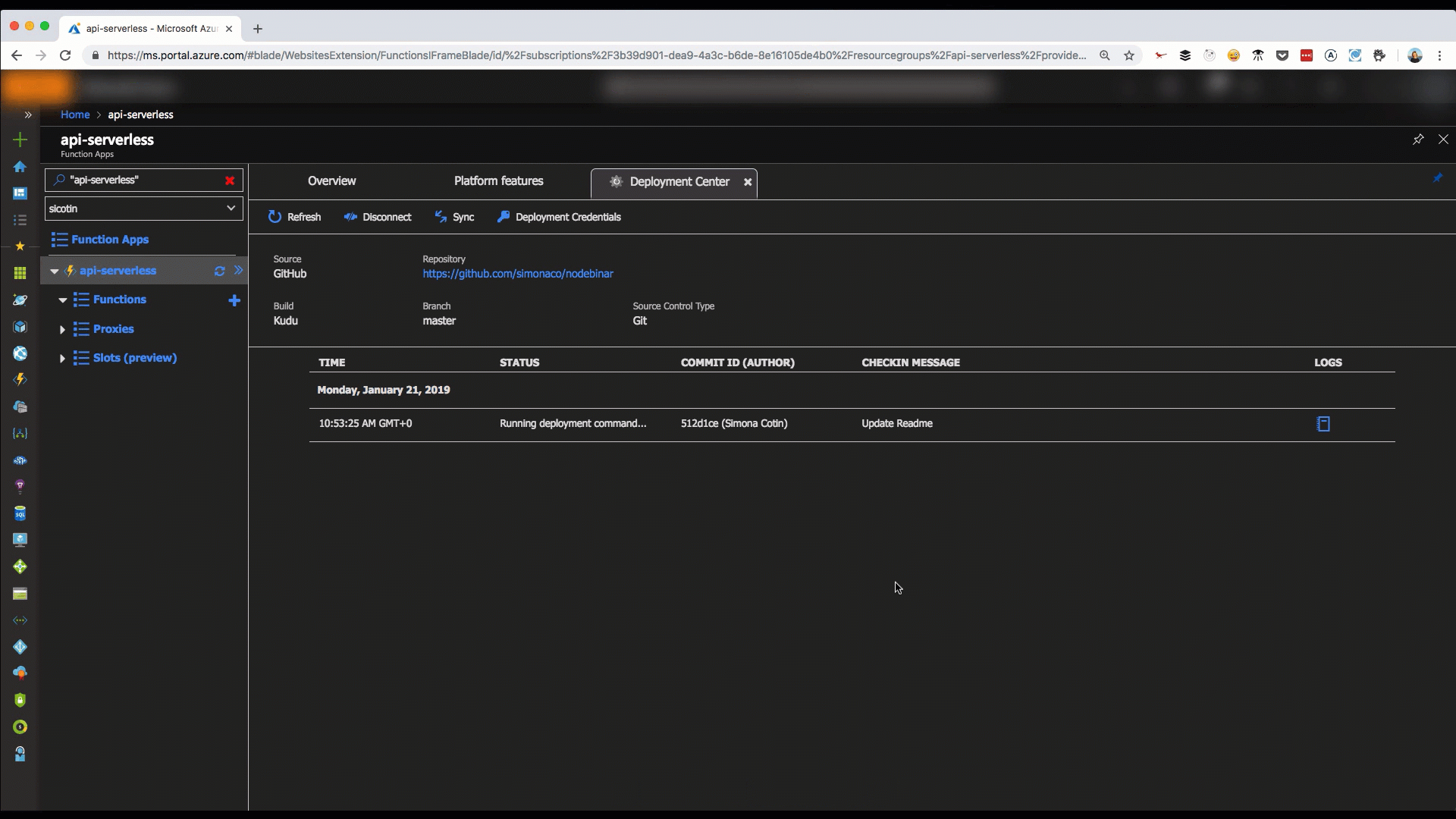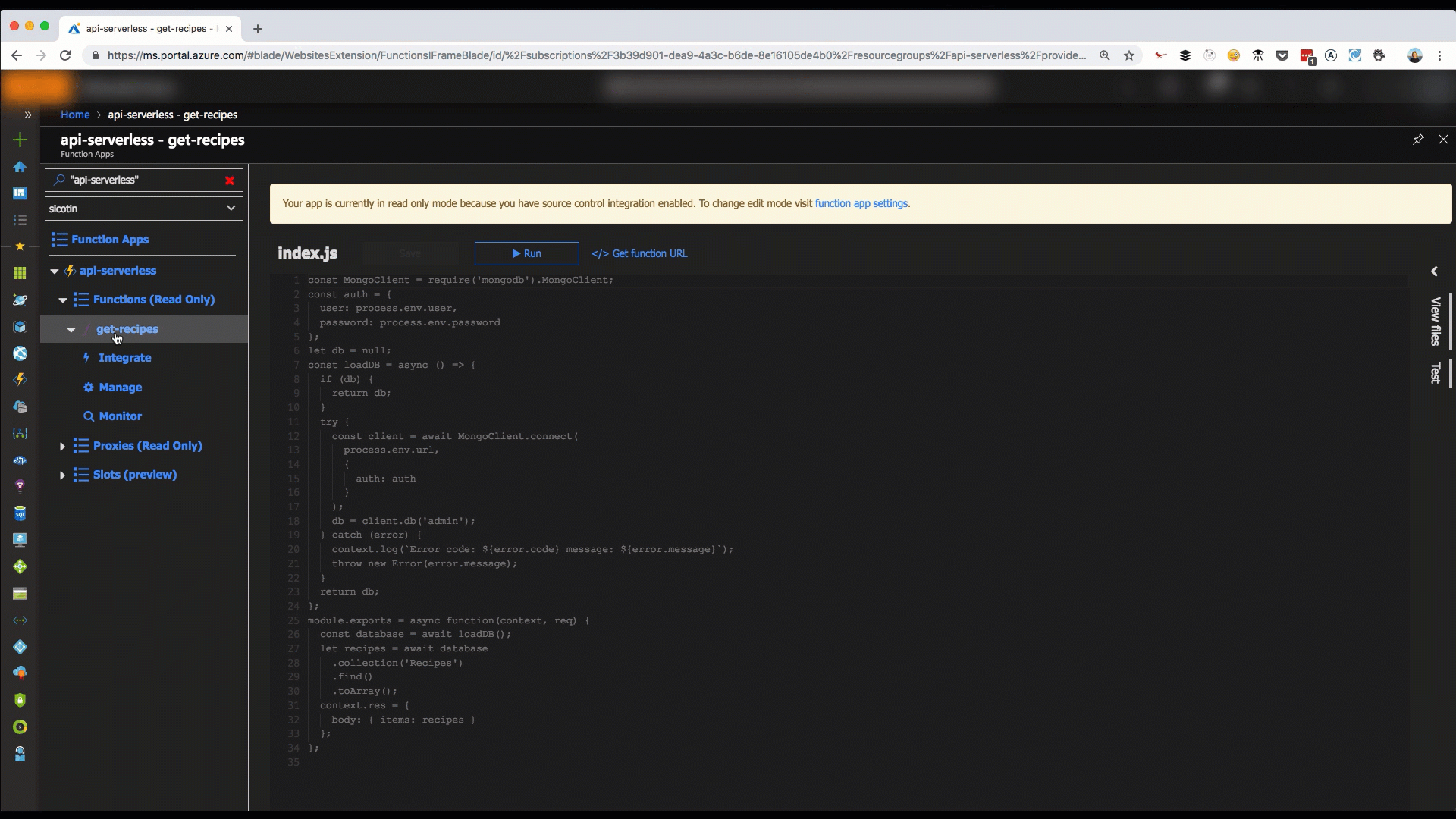
So, how do we connect and read data from a database? Using the MongoDB client, we’ll read data from an Azure Cosmos DB instance I have created in Azure, but you can do this with any other MongoDB database.
//Index.js
const MongoClient = require('mongodb').MongoClient;
// Initialize authentication details required for database connection
const auth = {
user: process.env.user,
password: process.env.password
};
// Initialize global variable to store database connection for reuse in future calls
let db = null;
const loadDB = async () => {
// If database client exists, reuse it
if (db) {
return db;
}
// Otherwise, create new connection
const client = await MongoClient.connect(
process.env.url,
{
auth: auth
}
);
// Select tacos database
db = client.db('tacos');
return db;
};
module.exports = async function(context, req) {
try {
// Get database connection
const database = await loadDB();
// Retrieve all items in the Recipes collection
let recipes = await database
.collection('Recipes')
.find()
.toArray();
// Return a JSON object with the array of recipes
context.res = {
body: { items: recipes }
};
} catch (error) {
context.log(`Error code: ${error.code} message: ${error.message}`);
// Return an error message and Internal Server Error status code
context.res = {
status: 500,
body: { message: 'An error has occurred, please try again later.' }
};
}
};
One thing to note here is that we’re reusing our database connection rather than creating a new one for each subsequent call to our function. This shaves off ~300ms of every subsequent function call. I call that a win!
Where can I save connection strings?
When developing locally, we can store our environment variables, connection strings, and really anything that’s secret into the local.settings.json file, then access it all in the usual manner, using process.env.yourVariableName.
In production, we can configure the application settings on the function’s page in the Azure portal.
However, another neat way to do this is through the VS Code extension. Without leaving your IDE, we can add new settings, delete existing ones or upload/download them to the cloud.
Debugging Serverless Functions
How do I customize the URL path?
With the REST API, there are a couple of best practices around the format of the URL itself. The one I settled on for our Recipes API is:
GET /recipes:?Retrieves a list of recipes
GET /recipes/1:?Retrieves a specific recipe
POST /recipes:?Creates a new recipe
PUT /recipes/1: Updates recipe with ID 1
DELETE /recipes/1: Deletes recipe with ID 1
The URL that is made available by default when creating a new function is of the form http://host:port/api/function-name. To customize the URL path and the method that we listen to, we need to configure them in our function.json file:
Moreover, we can add parameters to our function’s route by using curly braces: route: recipes/{id}. We can then read the ID parameter in our code from the req object:
const recipeId = req.params.id;
How can I deploy to the cloud?
Congratulations, you’ve made it to the last step! ? Time to push this goodness to the cloud. As always, the VS Code extension has your back. All it really takes is a single right-click we’re pretty much done.
Deployment using VS Code
The extension will ZIP up the code with the Node modules and push them all to the cloud.
While this option is great when testing our own code or maybe when working on a small project, it’s easy to overwrite someone else’s changes by accident — or even worse, your own.
Don’t let friends right-click deploy!
?—?every DevOps engineer out there
A much healthier option is setting up on GitHub deployment which can be done in a couple of steps in the Azure portal, via the Deployment Center tab.
Github deployment
Are you ready to make Serverless APIs?
This has been a thorough introduction to the world of Servless APIs. However, there’s much, much more than what we’ve covered here. Serverless enables us to solve problems creatively and at a fraction of the cost we usually pay for using traditional platforms.
Chris has mentioned it in other posts here on CSS-Tricks, but he created this excellent website where you can learn more about serverless and find both ideas and resources for things you can build with it. Definitely check it out and let me know if you have other tips or advice scaling with serverless.
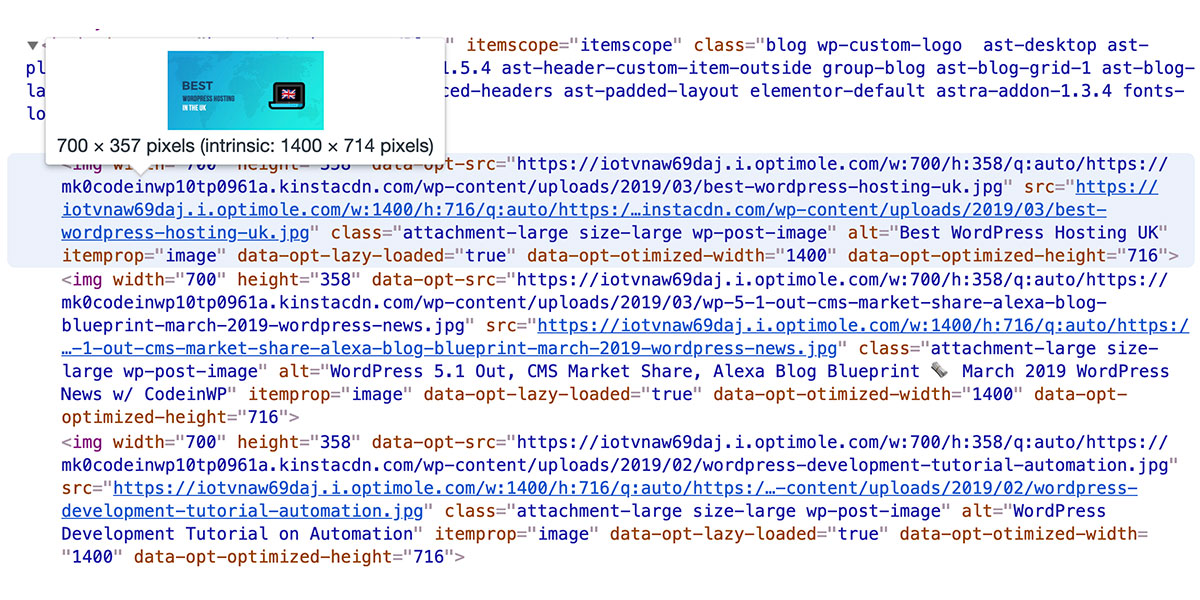
In 2015 there were 24,000 different Android devices, and each of them was capable of downloading images. And this was just the beginning. The mobile era is starting to gather pace with mobile visitors starting to eclipse desktop. One thing is certain, building and running a website in the mobile era requires an entirely different approach to images. You need to consider users on desktops, laptops, tablets, watches, smartphones and then viewport sizes, resolutions, before, finally, getting to browser supported formats.
So, what’s a good image optimization option to help you juggle all of these demands without sacrificing image quality and on-page SEO strategy?
If you’ve ever wondered how many breakpoints a folding screen will have, then you’ll probably like Optimole. It integrates with both the WordPress block editor and page builders to solve a bunch of image optimization problems. It’s an all-in-one service, so you can optimize images and also take advantage of features built to help you improve your page speed.
What’s different about Optimole?
The next step in image optimization is device specificity, so the traditional method of catch and replace image optimization will no longer be the best option for your website. Most image optimizers work in the same way:
Select images for optimization.
Replace images on the page.
Delete the original.
They provide multiple static images for each screen size according to the breakpoints defined in your code. Essentially, you are providing multiple images to try and Optimized? Sure. Optimal? Hardly.
Optimole works like this:
Your images get sucked into the cloud and optimized.
Optimole replaces the standard image URLs with new ones – tailored to the user’s screen.
The images go through a fast CDN to make them load lightning fast.
Here’s why this is better: You will be serving perfectly sized images to every device, faster, in the best format, and without an unnecessary load on your servers.
A quick case study: CodeinWP
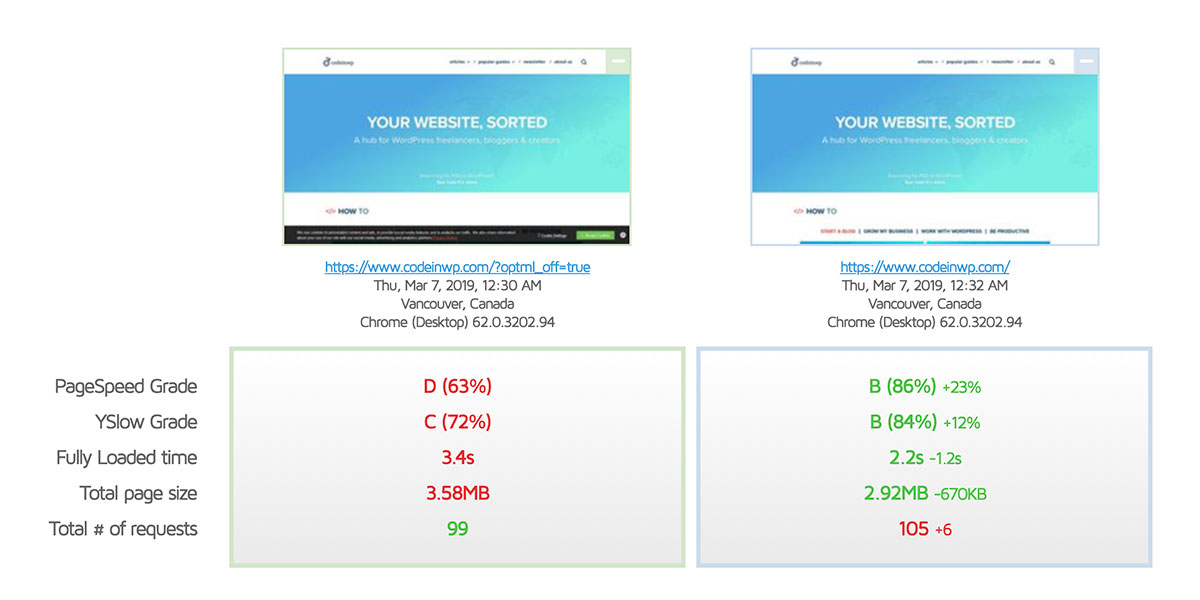
Optimole’s first real test was on CodeinWP as part of a full site redesign. The blog has been around for a while during which time is has emerged as one of the leaders in the WordPress space. Performance wise? Not so much. With over 150,000 monthly visitors, the site needed to provide a better experience for Google and mobile.
Optimole was used as one part of a mobile first strategy. In the early stages, Optimole helped provide a ~0.4s boost in load time for most pages with it enabled. Whereas, on desktop, Optimole is compressing images by ~50% and improving pagespeed grades by 23%. Fully loaded time and the total page size is reduced by ~19%.
Improved PageSpeed and quicker delivery
Along with a device-specific approach, Optimole provides an image by image optimization to ensure each image fits perfectly into the targeted container. Google will love it. These savings in bandwidth are going to help you improve your PageSpeed scores.
It’s not always about the numbers; your website needs to conform to expected behavior even when rendering on mobile. You can avoid content jumping and shifting with any number of tweaks but a container based lazy loading option provides the best user experience. Optimole sends a blurred image at the exact container size, so your visitors never lose their place on the page.
We offer CDNs for both free and premium users. If you’re already using CDN, then we can integrate it from our end. The extra costs involved will be balanced out with a monthly discount.
Picking the perfect image for every device
Everyone loves and but it is time for an automated solution that doesn’t leak bandwidth. With client hints, Optimole provides dynamic image resizing that provides a perfectly sized image for each and every device.
Acting as a proxy service allows Optimole to deliver unique images based on supported formats. Rather than replace an image on the page with a broad appeal, Optimole provides the best image based on the information provided by the browser. This dynamism means WebP and Retina displays are supported for, lucky, users without needing to make any changes.
Optimole can be set to detect slower connections, and deliver an image with a high compression rate to keep the page load time low.
Industrial strength optimization with a simple UI
The clean and simple UI gives you the options you need to make a site; no muss no fuss. You can set the parameters, introduce lazy loading, and test the quality without touching up any of the URLs.
You can reduce the extra CSS you need to make page builder images responsive and compressed. It currently takes time and a few CSS tricks to get all of your Elementor images responsive. For example, the extra thumbnails from galleries and carousels can throw a few curve balls. With Optimole all of these images are picked up from the page, and treated like any other. Automatically.
One of the reasons to avoid changing image optimization strategies is the, frightening, prospect of going through the optimization process again. Optimole is the set-and-forget optimization option that optimizes your images without making changes to the original image. Just install, activate and let Optimole handle the rest.
If you like what you see then you can get a fully functional free plan with all the features. It includes 1GB of image optimization and 5GB of viewing bandwidth. The premium plans start with 10GB of image optimization, and 50GB of viewing bandwidth, plus access to an enhanced CDN including over 130 locations.
If you’re worried about making a big change, then rest assured Optimole can be uninstalled cleanly to leave your site exactly as before.
In 2014, I was a busy, young software engineer working full-time for a tech company in London. On a quest to be hyper efficient, I was always was on the hunt for user-friendly tools that would streamline my workflows and cut back on paper usage, which proved to be a challenge.
I fell right into a market gap when I needed to edit and modify PDFs but none of the tools on the market offered a user-friendly interface with the functionality I needed or wanted.
While plenty of tools were sitting pretty on the throne of page one search results (and sported snazzy marketing campaigns), I still needed a product that prioritized user experience over marketing; a central platform to perform PDF tasks.
All the available options fell flat.
Then I realized that, if I built my own application, I could help everyone from professionals to creatives get their PDF work done online, for free.
So I did.
With a fluency in back-end development, I built the online PDF editor myself. Since I couldn’t afford to quit my day job, I spent nights and weekends programming PDF Pro. Building a product was exciting, yes, but unsurprisingly, it was hard work. Armed with a long list of features and functionalities I wanted the product to have, it was easy for me to focus solely on the complex backend of the software and neglect the front end.
As an engineer, my goal was to build the best online PDF editor available. I thought this meant offering a laundry list of features in order to meet a wide range of use cases. The original design of the product was geared towards communicating all of the tool’s functionalities. For example, after uploading a file, the user was presented with every available option for editing their file. I thought that my product’s breadth of features would impress users and drive sales.
while my company was successful at marketing…we suffered from poor conversion rates
And while my company was successful at marketing the product (as evidenced by the thousands of users who used, and still use, the application every day), we suffered from poor conversion rates.
I felt lost. Wasn’t I offering a more robust application than any of my competitors? What was happening between the time users entered my site and when they bounced? I needed answers.
With the help of an agency, I conducted significant user research to better understand high-level user needs. I also implemented specialized tools, such as Hotjar, that elicited customer feedback and tracked behavior flows so I could understand minute patterns and details.
It became clear: user needs were not being met; a painful, yet valuable, discovery. Even great marketing couldn’t outrun poor UX.
At the genesis of PDF Pro, I focused only on broad goals like ‘increase user acquisition.’ By comparing high-level needs with the nitty gritty feedback, I quickly learned that customers were looking for very specific solutions.
Using these valuable data and insights, I adjusted my approach towards implementing great UX in three critical areas, which resulted in driving significant gains (sometimes north of 100%) for the product’s conversion rate.
Here’s what I needed to understand:
1. Understand the User’s Research Journey & Query Intent
Simply put, query intent refers to the understanding of what problem the user is seeking to solve. And in turn, great UX and optimization should be able to offer solutions that meet that intent.
While customers will frequently search for a ‘PDF editor’, this term means different things to different users. Some users are only focused on converting images to PDFs while others are more interested in electronic signature solutions. To help match query intent, I created a series of mini-products focused on specific needs (e.g. ‘convert PNG to PDF’ or ‘sign a PDF’).
Beyond designing the product around these specific workflows, I also published ‘how-to’ content helping even the most novice users navigate the service and find what they needed, when they needed it.
2. Provide Clear Instructions & Feedback
It’s no secret that humans seek affirmation and direction. People are more likely to experience a boost in confidence when they have clear directions and guidance on what they’re “supposed” to do.
Feeling like you have a guide when you’ve moved to a new city is always comforting; the same goes for the virtual user experience. Clear instructions can offer this level of confidence to users (and help them avoid situations where they feel incompetent).
Provide users with clear instructions and how-to’s through the use of copy, micro-copy, and illustrations. Inversely, there’s nothing worse than taking an action and the action results in…crickets. Never leave your user wondering what went wrong or what to do next. Be sure to include clear feedback when a user “takes a wrong turn” or enters an invalid information.
3. Respect the User’s Time
Few things are as relatable (or more annoying) than waiting for the spinning “rainbow wheel of death” to leave your Macbook’s screen. Or, obsessively refreshing your browser when a page is slow to load. How long do you give your technology to load before you give up hope and jump ship? 2 seconds? 3 seconds?
Site speed matters. In fact, it matters so much that if a website takes longer than three seconds to load, nearly half of all visitors leave. Remedy high bounce rates and low conversions by respecting your user’s time; make sure your site’s images and CSS are properly optimized and keep your scripts below the fold.
As great developers and designers know, the importance of UX and functionality eclipse marketing. Yes, great marketing attracts users but if they can’t figure out how to use your software quickly and easily, they will give up and move on to one of your competitors. So, before you jump feet first into your marketing campaign, take a long, hard look at your user experience and how it satisfies the customers’ needs or helps them achieve their goals. Remember, it’s not about you, it’s about them.
I like this point that Jonathan Snook made on Twitter and I’ve been thinking about it non-stop because it describes something that’s really hard about writing CSS:
I feel like that tweet sounds either very shallow or very deep depending on how you look at it but in reality, I don’t think any system, framework, or library really take this into consideration—especially in the context of maintainability.
In fact, I reckon this is the hardest thing about writing maintainable CSS in a large codebase. It’s an enormous problem in my day-to-day work and I reckon it’s what most technical debt in CSS eventually boils down to.
Let’s imagine we’re styling a checkbox, for example – that checkbox probably has a position on the page, some margins, and maybe other positioning styles, too. And that checkbox might be green but turns blue when you click it.
I think we can distinguish between these two types of styles as layout and appearance.
But writing good CSS requires keeping those two types of styles separated. That way, the checkbox styles can be reused time and time again without having to worry about how those positioning styles (like margin, padding or width) might come back to bite you.
At Gusto, we use Bootstrap’s grid system which is great because we can write HTML like this that explicitly separates these concerns like so:
<div class="row">
<div class="col-6">
<!-- Checkbox goes here -->
</div>
<div class="col-6">
<!-- Another element can be placed here -->
</div>
</div>
Otherwise, you might end up writing styles like this, which will end up with a ton of issues if those checkbox styles are reused in the future:
When I see code like this, my first thought is, “Why is the width 40% – and 40% of what?” All of a sudden, I can see that this checkbox class is now dependent on some other bit of code that I don’t understand.
So I’ve begun to think about all CSS as fitting into one of those two buckets: appearance and layout. That’s important because I believe those two types of styles should almost never be baked into one set of styles or one class. Layout on the page should be one set of styles, and appearance (like what the checkbox actually looks like) should be in another. And whether you do that with HTML or a separate CSS class is up for debate.
The reason why this is an issue is that folks will constantly be trying to overwrite layout styles and that’s when we eventually wind up with a codebase that resembles a spaghetti monster. I think this distinction is super important to writing great CSS that scales properly. What do you think? Add a comment below!
This is a fantastic post by Ahmad Shadeed. It digs into the practical construction of a header on a website — the kind of work that many of us regularly do. It looks like it’s going to be fairly easy to create the header at first, but it starts to get complicated as considerations for screen sizes, edge cases, interactions, and CSS layout possibilities enter the mix. This doesn’t even get into cross-browser concerns, which have been somewhat less of a struggle lately, but is always there.
It’s sometimes hard to explain the interesting and tricky situations that define our work in front-end development, and this article does a good job of showcasing that.
These two illustrations set the scene really well:
That’s not to dunk on designers. I’ve done this to myself plenty of times. Plus, any designer worth their salt thinks about these things right off the bat. The reality is that the implementation weirdness largely falls to the front-end developer and the designer can help when big choices need to be made or the solutions need to be clarified.
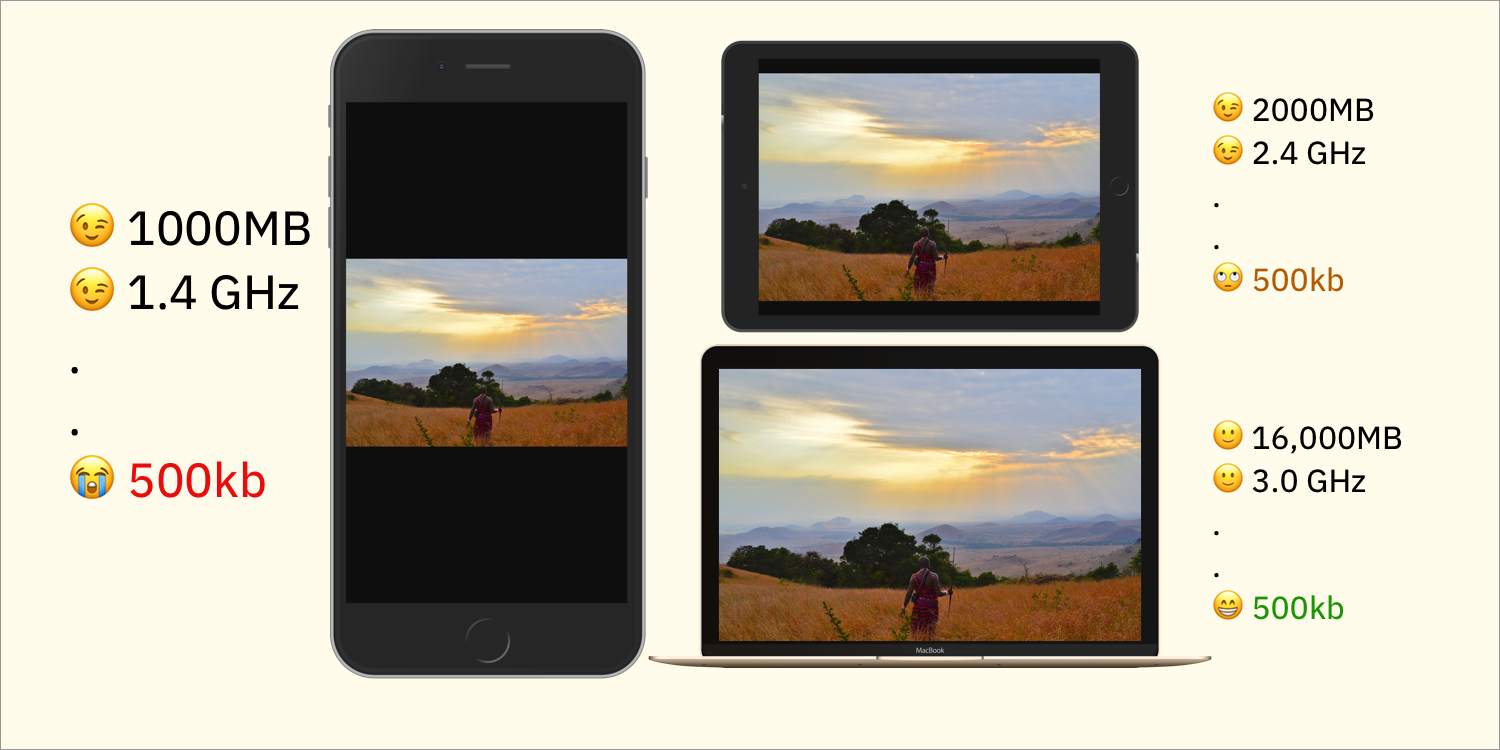
Though that worked for me as a developer, it wasn’t the best for the audience. What happens if the the image in the src attribute is heavy? On high-end developer devices (like mine with 16GB RAM), few or no performance problems occur. But on low-end devices? It’s another story.
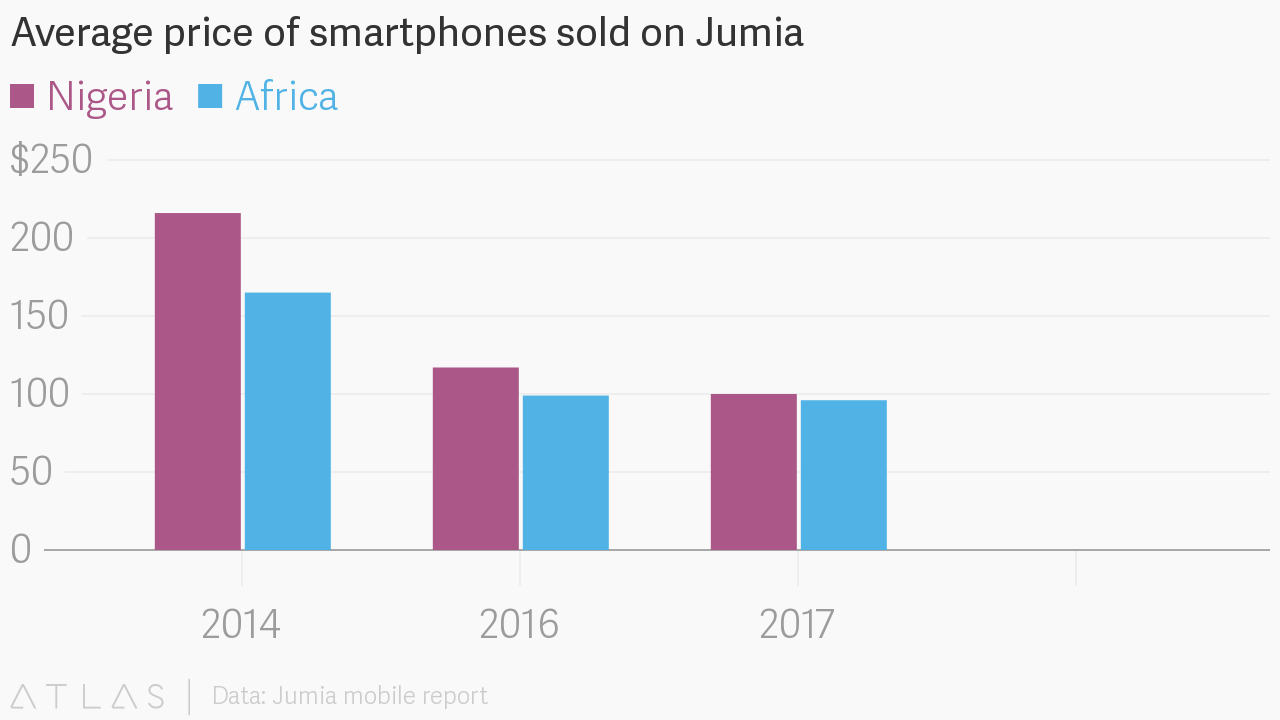
The above illustration isn’t detailed enough. I’m from Nigeria and, if your product works in Africa, then you shouldn’t be looking at that. Look at this graph instead:
Nowadays, the lowest-priced iPhone sells for an average of $300. The average African can’t afford it even though iPhone is a threshold for measuring fast devices.
That’s all the business analysis you need to understand that CSS width doesn’t cut it for responsive images. What would, you ask? Let me first explain what images are about.
Nuances of images
Images are appealing to users but are a painstaking challenge for us developers who must consider the following factors:
Format
Disk size
Render dimension (layout width and height in the browser)
Original dimension (original width and height)
Aspect ratio
So, how do we pick the right parameters and deftly mix and match them to deliver an optimal experience for your audience? The answer, in turn, depends on the answers to these questions:
Are the images created dynamically by the user or statically by a design team?
If the width and height of the image are changed disproportionately, would that affect the quality?
Are all the images rendered at the same width and height? When rendered, must they have a specific aspect ratio or one that’s entirely different?
What must be considered when presenting the images on different viewports?
Jot down your answers. They will not only help you understand your images — their sources, technical requirements and such — but also enable you to make the right choices in delivery.
Provisional strategies for image delivery
Image delivery has evolved from a simple addition of URLs to the src attribute to complex scenarios. Before delving into them, let’s talk about the multiple options for presenting images so that you can devise a strategy on how and when to deliver and render yours.
First, identify the sources of the images. That way, the number of obscure edge cases can be reduced and the images can be handled as efficiently as possible.
In general, images are either:
Dynamic: Dynamic images are uploaded by the audience, having been generated by other events in the system.
Static: A photographer, designer, or you (the developer) create the images for the website.
Let’s dig into strategy for each of this types of images.
Strategy for dynamic images
Static images are fairly easy to work with. On the other hand, dynamic images are tricky and prone to problems. What can be done to mitigate their dynamic nature and make them more predictable like static images? Two things: validation and intelligent cropping.
Validation
Set out a few rules for the audience on what is acceptable and what is not. Nowadays, we can validate all the properties of an image, namely:
Format
Disk size
Dimension
Aspect ratio
Note: An image’s render size is determined during rendering, hence no validation on our part.
After validation, a predictable set of images would emerge, which are easier to consume.
Intelligent Cropping
Another strategy for handling dynamic images is to crop them intelligently to avoid deleting important content and refocus on (or re-center) the primary content. That’s hard to do. However, you can take advantage of the artificial intelligence offered by open-source tools or SaaS companies that specialize in image management. An example is in the upcoming sections.
Once a strategy has been nailed down for dynamic images, create a rule table with all the layout options for the images. Below is an example. It’s even worth looking into analytics to determine the most important devices and viewport sizes.
Browser Viewport
HP Laptop
PS4 Slim
Camera Lens / Aspect Ratio
< 300
100 vw
100 vw
100 vw/1:2
300 – 699
100 vw
100 vw
100 vw/1:1
700 – 999
50 vw
50 vw
50 vw/1:1
> 999
33 vw
33 vw
100 vw/1:2
The bare (sub-optimal) minimum
Now set aside the complexities of responsiveness and just do what we do best — simple HTML markup with maximum-width CSS.
Note: The ellipsis (…) in the image URL specifies the folder, dimension, and cropping strategy, which are too much detail to include, hence the truncation to focus on what matters now. For the complete version, see the CodePen example down below.
This is the shortest CSS example on the Internet that makes images responsive:
/* The parent container */
main {
display: grid;
grid-template-columns: repeat(auto-fill, minmax(300px, 1fr));
}
img {
max-width: 100%;
}
If the images do not have a uniform width and height, replace max-width with object-fit and set the value to cover.
Jo Franchetti’s blog post on common responsive layouts with CSS Grid explains how the value of grid-template-columns makes the entire layout adaptive (responsive).
The above is not what we are looking for, however, because…
the image size and weight are the same on both high-end and low-end devices, and
we might want to be stricter with the image width instead of setting it to 250 and letting it grow.
Well, this section covers “the bare minimum” so that’s it.
Layout variations
The worst thing that can happen to an image layout is mismanagement of expectations. Because images might have varying dimensions (width and height), we must specify how to render the images.
Should we intelligently crop all the images to a uniform dimension? Should we retain the aspect ratio for a viewport and alter the ratio for a different one? The ball is in our court.
In case of images in a grid, such as those in the example above with different aspect ratios, we can apply the technique of art direction to render the images. Art direction can help achieve something like this:
For details on resolution switching and art direction in responsive images, read Jason Grigsby’s series. Another informative reference is Eric Portis’s Responsive Images Guide, parts 1, 2, and 3.
Instead of rendering only one 700px wide image, we render 700px x 700px only if the viewport width exceeds 700px. If the viewport is larger, then the following rendering occurs:
Camera lens images are rendered as a portrait image of 700px in width and 1000px. in height (700px x 1000px).
PS4 Pro images are rendered at 1000px x 1000px.
Art direction
By cropping images to make them responsive, we might inadvertently delete the primary content, like the face of the subject. As mentioned previously, AI open-source tools can help crop intelligently and refocus on the primary objects of images. In addition, Nadav Soferman’s post on smart cropping is a useful start guide.
Strict grid and spanning
The first example on responsive images in this post is a flexible one. At a minimum of 300px width, grid items automagically flow into place according to the viewport width. Terrific.
On the other hand, we might want to apply a stricter rule to the grid items based on the design specifications. In that case, media queries come in handy.
Alternatively, we can leverage the grid-span capability to create grid items of varied widths and lengths:
For an image that is 1000px x 1000px square on a wide viewport, we can span it to take two grid cells on both row and column. The image that changes to a portrait orientation (700px x 1000px) on a wider viewport can take two cells on a row.
Blind optimization is as lame as no optimization. Don’t focus on optimization without predefining the appropriate measurements. And don’t optimize if the optimization is not backed by data.
Nonetheless, ample room exists for optimization in the above examples. We started with the bare minimum, showed you some cool tricks, and now we have a working, responsive grid. The next question to ask is, “If the page contains 20-100 images, how good will the user experience be?”
Here’s the answer: We must ensure that in the case of numerous images for rendering, their size fits the device that renders them. To accomplish that, we need to specify the URLs of several images instead of one. The browser would pick the right (most optimal) one according to the criteria. This technique is called resolution switching in responsive images. See this code example:
Hats off to Jason Grigsby for the clarification in his replies.
Thanks to resolution switching, if the browser is resized, then it downloads the right image for the right viewport; hence small images for small phones (good on CPU and RAM) and larger images for larger viewports.
The above table shows that the browser downloads the same image (blue rectangle) with different disk sizes (red rectangle).
Cloudinary’s open-source and free Responsive Image Breakpoints Generator is extremely useful for adapting website images to multiple screen sizes. However, in many cases, setting srcset and sizes alone would suffice.
Conclusion
This article aims at affording simple yet effective guidelines for setting up responsive images and layouts in light of the many—and potentially confusing—options available. Do familiarize yourself with CSS grid, art direction, and resolution switching and you’ll be a ninja in short order. Keep practicing!
Rachel Andrew says that the CSS Working Group designed an aspect ration unit at a recent meeting. The idea is to find an elegant solution to those times when we want the height of an element to be calculated in response to the width of the element, or vice versa.
Say, for example, we have a grid layout with a row of elements that should maintain a square (1:1) ratio. There are a few existing, but less-than-ideal ways we can go:
Define one explicit dimension. If we define the height of the items in the grid but use an intrinsic value on the template columns (e.g. auto-fill), then we no longer know the width of the element as the container responds to the browser viewport. The elements will grow and squish but never maintain that perfect square.
Define explicit dimensions. Sure, we can tell an element to be 200px wide and 200px tall, but what happens when more content is added to an item than there is space? Now we have an overflow problem.
Use the padding hack. The block-level (top-to-bottom) padding percentage of an element is calculated by the element’s inline width and we can use that to calculate height. But, as Rachel suggests, it’s totally un-intuitive and tough to maintain.
Very cool! But where does the proposal go from here? The aspect-ratio is included in the rough draft of the CSS Sizing 4 specification. Create an issue in the CSSWG GitHub repo if you have ideas or suggestions. Or, as Rachel suggests, comment on her Smashing Magazine post or even write up your own post and send it along. This is a great chance to add your voice to a possible new feature.
In Part 1 of this series, we’ve seen how a virtual reality model with lighting and animation effects can be created. In this part, we will implement the game’s core logic and utilize more advanced A-Frame environment manipulations to build the “game” part of this application. By the end, you will have a functioning virtual reality game with a real challenge.
This tutorial involves a number of steps, including (but not limited to) collision detection and more A-Frame concepts such as mixins.
A Glitch project completed from part 1. (You can continue from the finished product by navigating to https://glitch.com/edit/#!/ergo-1 and clicking “Remix to edit”;
A virtual reality headset (optional, recommended). (I use Google Cardboard, which is offered at $15 a piece.)
Step 1: Designing The Obstacles
In this step, you design the trees that we will use as obstacles. Then, you will add a simple animation that moves the trees towards the player, like the following:
Template trees moving towards player (Large preview)
These trees will serve as templates for obstacles you generate during the game. For the final part of this step, we will then remove these “template trees”.
To start, add a number of different A-Frame mixins. Mixins are commonly-used sets of component properties. In our case, all of our trees will have the same color, height, width, depth etc. In other words, all your trees will look the same and therefore will use a few shared mixins.
Note: In our tutorial, your only assets will be mixins. Visit the A-Frame Mixins page to learn more.
In your editor, navigate to index.html. Right after your sky and before your lights, add a new A-Frame entity to hold your assets:
In your new a-assets entity, start by adding a mixin for your foliage. This mixins defines common properties for the foliage of the template tree. In short, it is a white, flat-shaded pyramid, for a low poly effect.
Next, add the template tree objects that will use these mixins. Still in index.html, scroll down to the platforms section. Right before the player section, add a new tree section, with three empty tree entities:
<a-entity id="tree-container" ...>
<!-- Trees -->
<a-entity id="template-tree-center"></a-entity>
<a-entity id="template-tree-left"></a-entity>
<a-entity id="template-tree-right"></a-entity>
<!-- Player -->
...
Next, reposition, rescale, and add shadows to the tree entities.
Underneath the controls but before the Game section, add a new TREES section. In this section, define a new setupTrees function.
/************
* CONTROLS *
************/
...
/*********
* TREES *
*********/
function setupTrees() {
}
/********
* GAME *
********/
...
In the new setupTrees function, obtain references to the template tree DOM objects, and make the references available globally.
/*********
* TREES *
*********/
var templateTreeLeft;
var templateTreeCenter;
var templateTreeRight;
function setupTrees() {
templateTreeLeft = document.getElementById('template-tree-left');
templateTreeCenter = document.getElementById('template-tree-center');
templateTreeRight = document.getElementById('template-tree-right');
}
Next, define a new removeTree utility. With this utility, you can then remove the template trees from the scene. Underneath the setupTrees function, define your new utility.
function setupTrees() {
...
}
function removeTree(tree) {
tree.parentNode.removeChild(tree);
}
Back in setupTrees, use the new utility to remove the template trees.
function setupTrees() {
...
removeTree(templateTreeLeft);
removeTree(templateTreeRight);
removeTree(templateTreeCenter);
}
Ensure that your tree and game sections match the following:
/*********
* TREES *
*********/
var templateTreeLeft;
var templateTreeCenter;
var templateTreeRight;
function setupTrees() {
templateTreeLeft = document.getElementById('template-tree-left');
templateTreeCenter = document.getElementById('template-tree-center');
templateTreeRight = document.getElementById('template-tree-right');
removeTree(templateTreeLeft);
removeTree(templateTreeRight);
removeTree(templateTreeCenter);
}
function removeTree(tree) {
tree.parentNode.removeChild(tree);
}
/********
* GAME *
********/
setupControls(); // TODO: AFRAME.registerComponent has to occur before window.onload?
window.onload = function() {
setupTrees();
}
Re-open your preview, and your trees should now be absent. The preview should match our game at the start of this tutorial.
In this step, we covered and used A-Frame mixins, which allow us to simplify code by defining common properties. Furthermore, we leveraged A-Frame integration with the DOM to remove objects from the A-Frame VR scene.
In the next step, we will spawn multiple obstacles and design a simple algorithm to distribute trees among different lanes.
Step 2 : Spawning Obstacles
In an endless runner game, our goal is to avoid obstacles flying towards us. In this particular implementation of the game, we use three lanes as is most common.
Unlike most endless runner games, this game will only support movement left and right. This imposes a constraint on our algorithm for spawning obstacles: we can’t have three obstacles in all three lanes, at the same time, flying towards us. If that occurs, the player would have zero chance of survival. As a result, our spawning algorithm needs to accommodate this constraint.
In this step, all of our code edits will be made in assets/ergo.js. The HTML file will remain the same. Navigate to the TREES section of assets/ergo.js.
To start, we will add utilities to spawn trees. Every tree will need a unique ID, which we will naively define to be the number of trees that exist when the tree is spawned. Start by tracking the number of trees in a global variable.
/*********
* TREES *
*********/
...
var numberOfTrees = 0;
function setupTrees() {
...
Next, we will initialize a reference to the tree container DOM element, which our spawn function will add trees to. Still in the TREES section, add a global variable and then make the reference.
...
var treeContainer;
var numberOfTrees ...
function setupTrees() {
...
templateTreeRight = ...
treeContainer = document.getElementById('tree-container');
removeTree(...);
...
}
Using both the number of trees and the tree container, write a new function that spawns trees.
function removeTree(tree) {
...
}
function addTree(el) {
numberOfTrees += 1;
el.id = 'tree-' + numberOfTrees;
treeContainer.appendChild(el);
}
...
For ease-of-use later on, you will create a second function that adds the correct tree to the correct lane. To start, define a new templates array in the TREES section.
var templates;
var treeContainer;
...
function setupTrees() {
...
templates = [templateTreeLeft, templateTreeCenter, templateTreeRight];
removeTree(...);
...
}
Using this templates array, add a utility that spawns trees in a specific lane, given an ID representing left, middle, or right.
function function addTree(el) {
...
}
function addTreeTo(position_index) {
var template = templates[position_index];
addTree(template.cloneNode(true));
}
Navigate to your preview, and open your developer console. In your developer console, invoke the global addTreeTo function.
Now, you will write an algorithm that spawns trees randomly:
Pick a lane randomly (that hasn’t been picked yet, for this timestep);
Spawn a tree with some probability;
If the maximum number of trees has been spawned for this timestep, stop. Otherwise, repeat step 1.
To effect this algorithm, we will instead shuffle the list of templates and process one at a time. Start by defining a new function, addTreesRandomly that accepts a number of different keyword arguments.
function addTreeTo(position_index) {
...
}
/**
* Add any number of trees across different lanes, randomly.
**/
function addTreesRandomly(
{
probTreeLeft = 0.5,
probTreeCenter = 0.5,
probTreeRight = 0.5,
maxNumberTrees = 2
} = {}) {
}
In your new addTreesRandomly function, define a list of template trees, and shuffle the list.
function addTreesRandomly( ... ) {
var trees = [
{probability: probTreeLeft, position_index: 0},
{probability: probTreeCenter, position_index: 1},
{probability: probTreeRight, position_index: 2},
]
shuffle(trees);
}
Scroll down to the bottom of the file, and create a new utilities section, along with a new shuffle utility. This utility will shuffle an array in place.
/********
* GAME *
********/
...
/*************
* UTILITIES *
*************/
/**
* Shuffles array in place.
* @param {Array} a items An array containing the items.
*/
function shuffle(a) {
var j, x, i;
for (i = a.length - 1; i > 0; i--) {
j = Math.floor(Math.random() * (i + 1));
x = a[i];
a[i] = a[j];
a[j] = x;
}
return a;
}
Navigate back to the addTreesRandomly function in your Trees section. Add a new variable numberOfTreesAdded and iterate through the list of trees defined above.
function addTreesRandomly( ... ) {
...
var numberOfTreesAdded = 0;
trees.forEach(function (tree) {
});
}
In the iteration over trees, spawn a tree only with some probability and only if the number of trees added does not exceed 2. Update the for loop as follows.
function addTreesRandomly( ... ) {
...
trees.forEach(function (tree) {
if (Math.random()
To conclude the function, return the number of trees added.
function addTreesRandomly( ... ) {
...
return numberOfTreesAdded;
}
Double check that your addTreesRandomly function matches the following.
/**
* Add any number of trees across different lanes, randomly.
**/
function addTreesRandomly(
{
probTreeLeft = 0.5,
probTreeCenter = 0.5,
probTreeRight = 0.5,
maxNumberTrees = 2
} = {}) {
var trees = [
{probability: probTreeLeft, position_index: 0},
{probability: probTreeCenter, position_index: 1},
{probability: probTreeRight, position_index: 2},
]
shuffle(trees);
var numberOfTreesAdded = 0;
trees.forEach(function (tree) {
if (Math.random()
Finally, to spawn trees automatically, setup a timer that runs triggers tree-spawning at regular intervals. Define the timer globally, and add a new teardown function for this timer.
/*********
* TREES *
*********/
...
var treeTimer;
function setupTrees() {
...
}
function teardownTrees() {
clearInterval(treeTimer);
}
Next, define a new function that initializes the timer and saves the timer in the previously-defined global variable. The below timer is run every half a second.
This concludes the obstacles step. We’ve successfully taken a number of template trees and generated an infinite number of obstacles from the templates. Our spawning algorithm also respects natural constraints in the game to make it playable.
In the next step, let’s add collision testing.
Step 3: Collision Testing
In this section, we’ll implement the collision tests between the obstacles and the player. These collision tests are simpler than collision tests in most other games; however, the player only moves along the x-axis, so whenever a tree crosses the x-axis, check if the tree’s lane is the same as the player’s lane. We will implement this simple check for this game.
Navigate to index.html, down to the TREES section. Here, we will add lane information to each of the trees. For each of the trees, add data-tree-position-index=, as follows. Additionally add class="tree", so that we can easily select all trees down the line:
Navigate to assets/ergo.js and invoke a new setupCollisions function in the GAME section. Additionally, define a new isGameRunning global variable that denotes whether or not an existing game is already running.
/********
* GAME *
********/
var isGameRunning = false;
setupControls();
setupCollision();
window.onload = function() {
...
Define a new COLLISIONS section right after the TREES section but before the Game section. In this section, define the setupCollisions function.
As before, we will register an AFRAME component and use the tick event listener to run code at every timestep. In this case, we will register a component with player and run checks against all trees in that listener:
Next, if there is no game running, do not check if there is a collision.
document.querySelectorAll('.tree').forEach(function(tree) {
if (!isGameRunning) return;
}
Finally (still in the for loop), check if the tree shares the same position at the same time with the player. If so, call a yet-to-be-defined gameOver function:
document.querySelectorAll('.tree').forEach(function(tree) {
...
if (POSITION_Z_LINE_START
Check that your setupCollisions function matches the following:
function setupCollisions() {
AFRAME.registerComponent('player', {
tick: function() {
document.querySelectorAll('.tree').forEach(function(tree) {
position = tree.getAttribute('position');
tree_position_index = tree.getAttribute('data-tree-position-index');
tree_id = tree.getAttribute('id');
if (position.z > POSITION_Z_OUT_OF_SIGHT) {
removeTree(tree);
}
if (!isGameRunning) return;
if (POSITION_Z_LINE_START
This concludes the collision setup. Now, we will add a few niceties to abstract away the startGame and gameOver sequences. Navigate to the GAME section. Update the window.onload block to match the following, replacing addTreesRandomlyLoop with a yet-to-be-defined startGame function.
Beneath the setup function invocations, create a new startGame function. This function will initialize the isGameRunning variable accordingly, and prevent redundant calls.
window.onload = function() {
...
}
function startGame() {
if (isGameRunning) return;
isGameRunning = true;
addTreesRandomlyLoop();
}
Finally, define gameOver, which will alert a “Game Over!” message for now.
function startGame() {
...
}
function gameOver() {
isGameRunning = false;
alert('Game Over!');
teardownTrees();
}
This concludes the collision testing section of the endless runner game.
In this step, we again used A-Frame components and a number of other utilities that we added previously. We additionally re-organized and properly abstracted the game functions; we will subsequently augment these game functions to achieve a more complete game experience.
Conclusion
In part 1, we added VR-headset-friendly controls: Look left to move left, and right to move right. In this second part of the series, I’ve shown you how easy it can be to build a basic, functioning virtual reality game. We added game logic, so that the endless runner matches your expectations: run forever and have an endless series of dangerous obstacles fly at the player. Thus far, you have built a functioning game with keyboard-less support for virtual reality headsets.
Here are additional resources for different VR controls and headsets:
A-Frame for VR Controllers
How A-Frame supports no controllers, 3DoF controllers and 6DoF controllers, in addition to other alternatives for interaction.
In the next part, we will add a few finishing touches and synchronize game states, which move us one step closer to multiplayer games.