As a UX writer, it’s my job to know how to create web copy that convinces readers to take action. That said, it doesn’t matter how engaging of a story I craft for my clients’ web pages or blog posts. If what I’ve written looks terrible on the page, no one will bother to read it.
Here’s the problem though: UX writers are not designers. No matter how many short sentences we write to succinctly communicate a point or jargon-free copy we craft to appeal to a broader audience, poor design choices will negate all of that.
Web designers are the ones that best know how to design for engagement and conversion. As such, you need to be comfortable working with copy as well as you do the visual piece.
1. Don’t Mess with Color
There are a lot of really cool ways to use color and create a memorable look for a website. But typography? That is not the place to mess around with color.
Let me show you something:
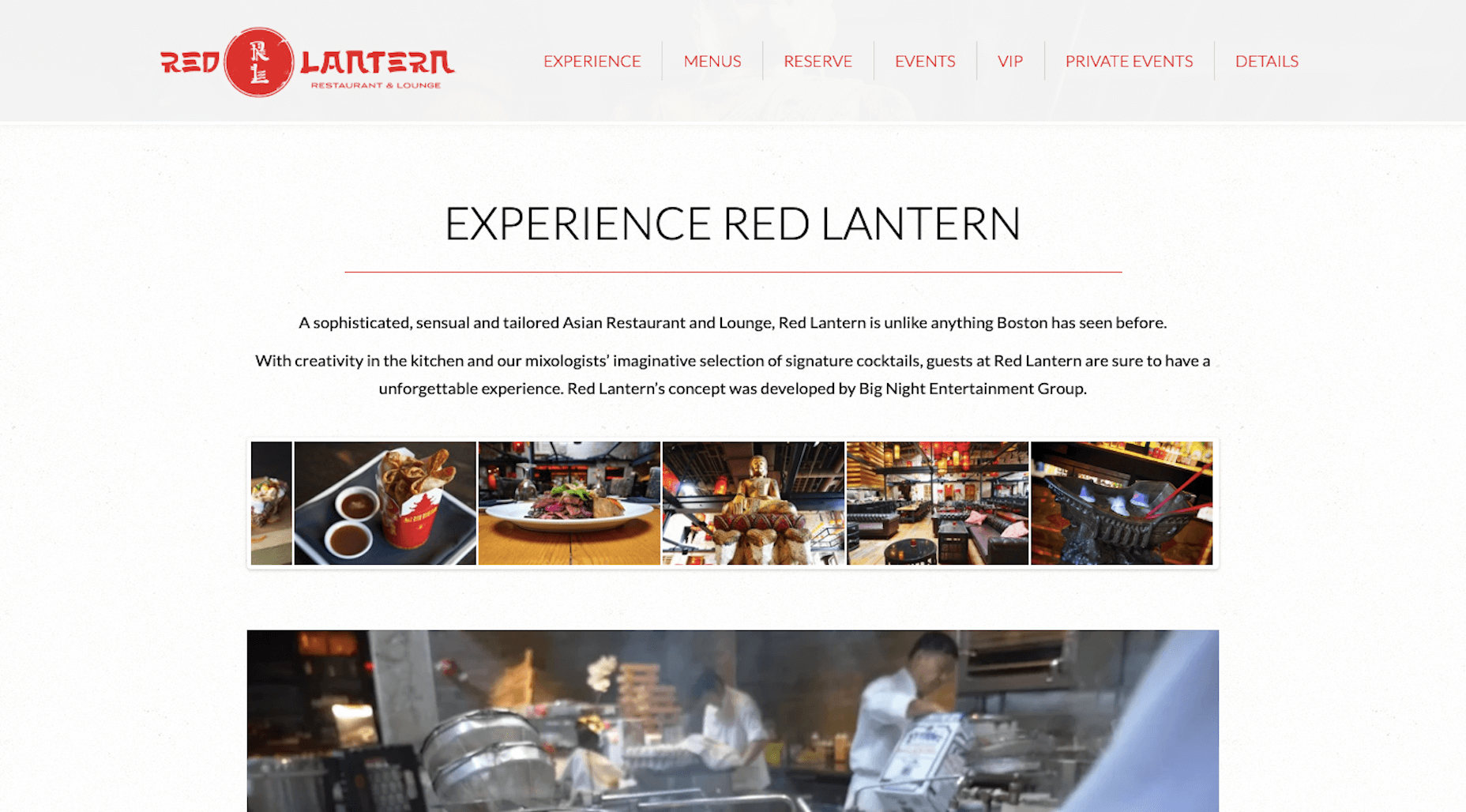
This is the website for the Red Lantern restaurant in Boston:
This website makes great use of wide open spaces to draw attention to the copy on the page. And, while the logo is in a decorative red font, the copy that really matters is black-on-white. Overall, this is a beautifully structured web page and also one that’s easy to read.
There are so many bad choices made with the font on this page.
For starters, it’s far too thin of a font at that size. In addition, the black font on top of the ecru background doesn’t work well either (again, that’s probably due to the skimpiness of the font face). And the hyperlink color against the similarly-colored background is an even worse choice.
I get that the designer wanted to incorporate the brand color into the page, but the background is overkill. A white background, black font, and branded hyperlink color would suffice.
2. Maintain Symmetry
In many cases, there isn’t really a need for symmetry in copywriting. Paragraphs and pages will run as long as they need to be, within reason. However, there is a particular part of a website where symmetry matters a great deal and it’s, unfortunately, something not a lot of writers are mindful of. Worse, there are designers who are too scared to do anything about it.
Here’s what I mean:
This is a block of side-by-side featurettes on the WordStream website:
You’re familiar with this, right? You have a number of features, services, or benefits you want to include on a web page. However, you’d rather not list them out as vertically-aligned plain text. That’s boring and takes up too much space. So, you think, I’ll turn this into a multi-column element with graphics woven in.
In the case of WordStream, you would’ve succeed. Everything is balanced:
It follows the same basic concept. However, the first point runs on way too long. This not only creates a distraction, but it also leads to a lot of unsightly white space.
3. Break up Paragraphs
In general, you never want a paragraph to run longer than five lines on a web page. Anything longer, and it’s safe to say your readers will lose focus. The same happens when you place too many paragraphs one after another.
Your readers need a break.
While the writers should be the ones to determine where a pause should fall within the text, there are other things you can do to break up the monotony of paragraph after paragraph.
There are never more than two paragraphs placed together, before they’re broken up by a creative element. In this case, the history of the company is divided into logical chunks and key milestones get their own dedicated boxes. This looks great.
Usually, I’m all for bulletpoints as they help to break up thick chunks of text. In this case, though, they’re not very well done. For starters, each bulletpoint is too long. Also, the bold font is overwhelming.
To fix this, the designer could go a route similar to Consigli Construction and give each bullet its own dedicated block. Or the designer and writer could work together to strip out the excess. For example, the list could realistically be shortened to:
An assigned primary caregiver;
Personalized care plans;
Sensory-rich spaces and soft places;
Safety, security, and cleanliness practices.
4. Be Space-Conscious with Header Tags
Header tags are an essential part of every page on a website, from the home page to blog posts.
Structurally, they help create a hierarchy of topics, enhancing readers’ ability to scan a page and get an idea of what it’s about without having to read it. In addition, Google bots use header tags to pick up on the key points of a page and rank it according to how well it matches users’ search queries.
That said, you should be careful about how much space your headers take up. As a general rule of thumb, they should be no more than one line.
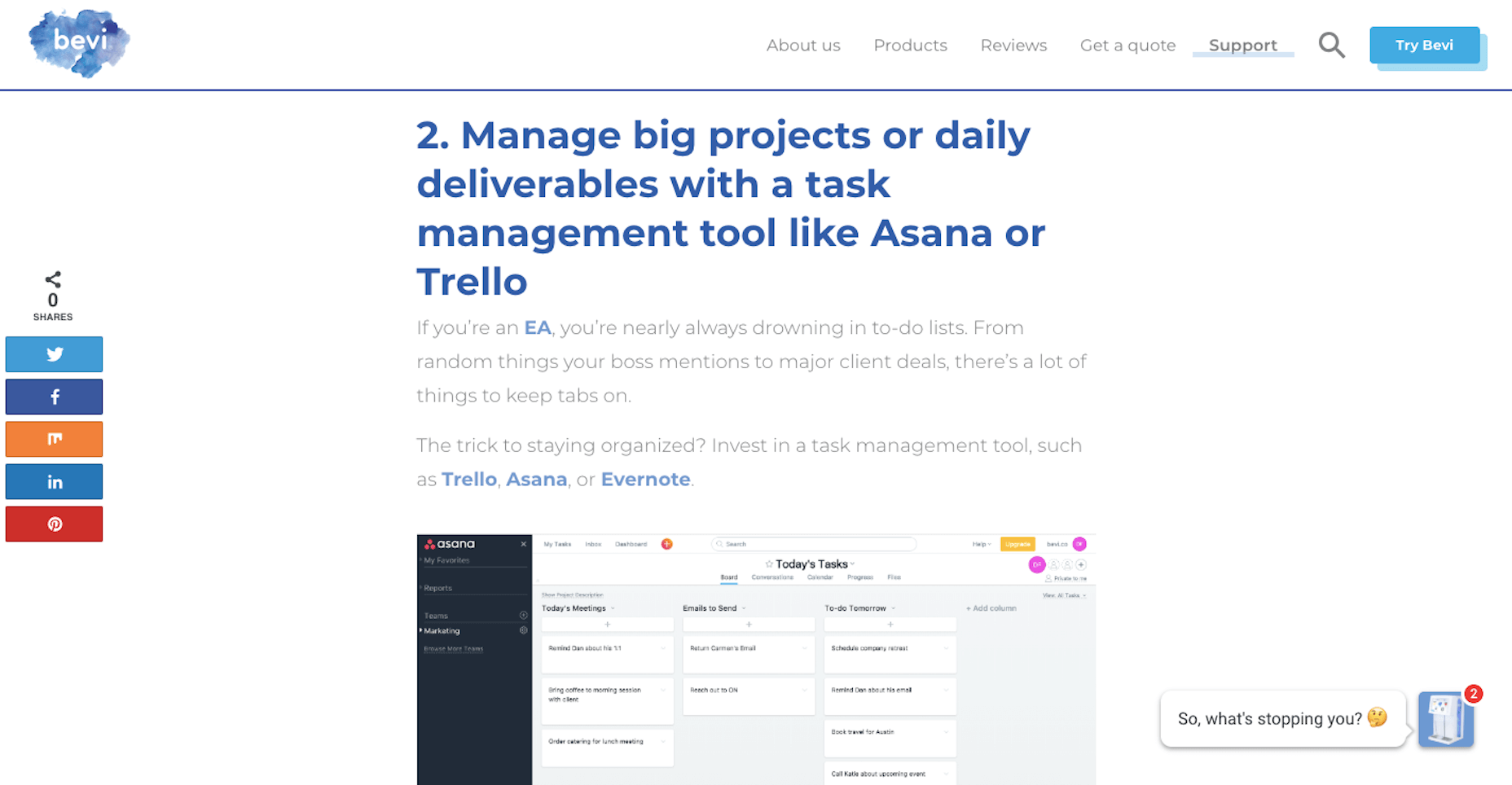
This is a clear example of where header tags become too much.
But it’s not just the size of the header text that’s the problem. It’s the length of the statement itself. Rather than give away what the ensuing text is going to tell the reader, this could simply be left as: “Manage projects and deliverables with a task management tool” or, even better, “Use a task management tool”.
What Web Designers Can Do to Improve Website Copy
While I’d love to say that it’s 100% the UX writer’s responsibility to write copy that converts, there are clear examples of how design can get in the way of that happening. All the more reason why a website should be a collaboration among all parties involved in it.
If you’re ever unsure of how your design choices will affect the quality of the copy, seek out the UX writer’s opinion. Or your project manager’s. Their fresh eyes might be able to catch something that you cannot.
Let’s say you wanted to scroll a web page from top to bottom programmatically. For example, you’re recording a screencast and want a nice full-page scroll. You probably can’t scroll it yourself because it’ll be all uneven and jerky. Native JavaScript can do smooth scrolling. Here’s a tiny snippet that might do the trick for you:
But there is no way to control the speed or easing of that! It’s likely to be way too fast for a screencast. I found a little trick though, originally published by (I think) Jedidiah Hurt.
The trick is to use CSS transforms instead of actual scrolling. This way, both speed and easing can be controlled. Here’s the code that I cleaned up a little:
The idea is to transform a negative top position for the height of the entire document, but subtract the height of what you can see so it doesn’t scroll too far. There is a little magic number in there you may need to adjust to get it just right for you.
Here’s a movie I recorded that way:
It’s still not perrrrrrfectly smooth. I partially blame the FPS of the video, but even with my eyeballs watching it record it wasn’t total butter. If I needed even higher quality, I’d probably restart my computer and have this page open as the only tab and application open, lolz.
It’s entirely too common to make broad-sweeping statements about all websites. Jason Miller:
We often make generalizations about applications we see in the wild, both anecdotal and statistical: “Single-Page Applications are slower than multipage” or “apps with low TTI loaded fast”. However, the extent to which these generalizations hold for the performance and architectural characteristics we care about varies.
Just the other morning, at breakfast an An Event Apart, I sat with a fellow who worked on a university website with a massive amount of pages. Also at the table was someone who worked at a media company with a wide swath of brands, but all largely sites with blog-like content. There was also someone who worked on a developer tool that was heavy on dashboards. We can all care about accessibility, performance, maintainability, etc., but the appropriate technology stacks and delivery processes are quite different both in what we actually do and what we probably should do.
It’s a common stab at solving for these different sites by making two buckets: web sites and web apps. Or dynamic sites and static sites. Or content sites and everything else. Jason builds us more buckets (“holotypes”): Read more…
(This is a sponsored article.) Designers have a strange relationship with trends. On the one hand, when designers follow a crowd, they might feel that they aren’t able to express enough creativity. On the other hand, trends can tell designers a lot about user preferences — what people love, what they hate — and ultimately help designers to create products with better adoption rates.
People are visual creatures, and visual design has a significant impact on the way we understand products. In this article, I want to focus on the most crucial web design trends and illustrate each trend using Be Theme, a responsive multipurpose WordPress theme.
Let’s get started.
1. Digital Illustrations
Digital illustrations have become one of the most important trends in visual design. Relevant illustrations can make your design stand out from a crowd and establish a truly emotional connection with visitors. Illustrations are quite a versatile tool; product designers can use digital illustrations for various purposes: for hero sections, for feature descriptions, or even as a subtle icon in the navigation bar.
Two types of illustrations are popular among digital designers: hand-drawn flat illustrations and three-dimensional ones. Flat hand-drawn ones give an impression of fine craftsmanship, of a hand-made design; it’s relatively easy to see the personal style of the illustrator through their work. Slack, Intercom and Dropbox are just a few companies that use flat hand-drawn illustrations.
Three-dimensional illustrations are quite a new trend. Designers started using them to add more realism, blurring the boundary between the digital and physical worlds.
3D illustrations give users the impression that they can almost reach out and touch objects in the scene. (Image source: themes.muffingroup) (Large preview)
2. Vibrant Colors
There is a reason why so many digital product designers strive to use vibrant colors: Vibrant colors give visual interest to a layout. User attention is a precious resource, and one of the most effective ways to grab attention is by using colors that stand out. Bright colors used for the background can capture the visitor’s attention and contribute to a truly memorable experience.
“Show, don’t tell” is a foundational principle of good product design. Imagery plays a key role in visual design because it helps the designers to deliver the main idea quickly.
For a long time, web designers have had to use static imagery to convey their main idea. But the situation has changed. High-speed connections make it much easier for web designers to turn their home pages into immersive movie-style experiences. Video engages users, and users are more willing to spend time watching clips. Video clips used in a hero section can vary from a few seconds of looped video to full-length preview clips with audio.
Split screen is a relatively simple design technique. All you need to do to create one is divide the screen into two parts (usually 50/50) and use each part to deliver a distinct message. This technique translates well on mobile; two horizontal panels of content can be collapsed into vertical content blocks on small screens. The technique works well when you need to deliver two separate messages, as shown below.
Split screen is an excellent choice for e-commerce websites that offer products for both women and men. (Image source: themes.muffingroup) (Large preview)
It also works well when you have to pair a text message with relevant imagery:
Split screen can be used to connect a text message with relevant imagery. (Image source: themes.muffingroup) (Large preview)
5. Geometric Patterns
Designers can use geometric shapes and patterns endlessly to create beautiful ornaments. This technique works equally well for digital products. Designers can use SVG images and high-resolution PNGs with geometric patterns as backgrounds. Such backgrounds scale well, so you won’t have to worry about how they will look on small and large displays.
Gradients are the multipurpose tool that works in pretty much any type of design. Designers often use gradients to give their work a little more depth. Modern graphic design trends dictate the use of big, bold and colorful gradients, which help designers make a statement.
When it comes to gradients, designers have a lot of creative freedom. They can experiment with various colors and types, using radial gradient, linear gradients, etc. For example, this is what happens when you put a linear one-color gradient overlay on a photo:
The duotone effect was made popular by Spotify, the online music-streaming service. The service was searching for a bold identity for its brand and decided to use duotones in its design.
In the simplest terms, duotones are filters that replace the whites and blacks in a photo with two colors. Duotones can make almost any image match your company’s branding; simply use your brand’s primary color as the duotone filter.
Most designers know that content should always come first in the design process. A design should honor the message that the product’s creators want to deliver to their users. Bold typography helps designers to achieve that. Massive, screen-dominating text puts the written content center stage.
Bold fonts serve a functional purpose — they make it easy to read the text. Consider the following example. This template is an excellent example of how powerful a bold font can be:
Designers can use bold typography to make text the focal point in a graphic. (Image source: themes.muffingroup) (Large preview)
Conclusion
“Should I follow the trends?” As a designer, you have to answer that for yourself. But if you want to see how each trend works for your project, you can do it right now. All of the Be Theme examples listed above can serve as excellent starting points for your creative journey.
GraphQL is becoming increasingly popular. The problem is that if you are a front-end developer, you are only half of the way there. GraphQL is not just a client technology. The server also has to be implemented according to the specification. This means that in order to implement GraphQL into your application, you need to learn not only GraphQL on the front end, but also GraphQL best practices, server-side development, and everything that goes along with it on the back end.
There will come a time when you will also have to deal with issues like scaling your server, complex authorization scenarios, malicious queries, and more issues that require more expertise and even deeper knowledge around what is traditionally categorized as back-end development.
Thankfully, we have an array of managed back-end service providers today that allow front-end developers to only worry about implementing features on the front end without having to deal with all of the traditional back-end work.
Services like Firebase (API) / AWS AppSync (database), Cloudinary (media), Algolia (search) and Auth0 (authentication) allow us to offload our complex infrastructure to a third-party provider and instead focus on delivering value to end users in the form of new features instead.
In this tutorial, we’ll learn how to take advantage of AWS AppSync, a managed GraphQL service, to build a full-stack application without writing a single line of back-end code.
While the framework we’re working in is React, the concepts and API calls we will be using are framework-agnostic and will work the same in Angular, Vue, React Native, Ionic or any other JavaScript framework or application.
We will be building a restaurant review app. In this app, we will be able to create a restaurant, view restaurants, create a review for a restaurant, and view reviews for a restaurant.
The tools and frameworks that we will be using are React, AWS Amplify, and AWS AppSync.
AWS Amplify is a framework that allows us to create and connect to cloud services, like authentication, GraphQL APIs, and Lambda functions, among other things. AWS AppSync is a managed GraphQL service.
We’ll use Amplify to create and connect to an AppSync API, then write the client side React code to interact with the API.
The first thing we’ll do is create a React project and move into the new directory:
npx create-react-app ReactRestaurants
cd ReactRestaurants
Next, we’ll install the dependencies we’ll be using for this project. AWS Amplify is the JavaScript library we’ll be using to connect to the API, and we’ll use Glamor for styling.
yarn add aws-amplify glamor
The next thing we need to do to is install and configure the Amplify CLI:
npm install -g @aws-amplify/cli
amplify configure
Amplify’s configure will walk you through the steps needed to begin creating AWS services in your account. For a walkthrough of how to do this, check out this video.
Now that the app has been created and Amplify is ready to go, we can initialize a new Amplify project.
amplify init
Amplify init will walk you through the steps to initialize a new Amplify project. It will prompt you for your desired project name, environment name, and text editor of choice. The CLI will auto-detect your React environment and select smart defaults for the rest of the options.
Creating the GraphQL API
One we’ve initialized a new Amplify project, we can now add the Restaurant Review GraphQL API. To add a new service, we can run the amplify add command.
amplify add api
This will walk us through the following steps to help us set up the API:
? Please select from one of the below mentioned services GraphQL
? Provide API name bigeats
? Choose an authorization type for the API API key
? Do you have an annotated GraphQL schema? N
? Do you want a guided schema creation? Y
? What best describes your project: Single object with fields
? Do you want to edit the schema now? Y
The CLI should now open a basic schema in the text editor. This is going to be the schema for our GraphQL API.
In this schema, we’re creating two main types: Restaurant and Review. Notice that we have @model and @connection directives in our schema.
These directives are part of the GraphQL Transform tool built into the Amplify CLI. GraphQL Transform will take a base schema decorated with directives and transform our code into a fully functional API that implements the base data model.
If we were spinning up our own GraphQL API, then we’d have to do all of this manually:
Define the schema
Define the operations against the schema (queries, mutations, and subscriptions)
Create the data sources
Write resolvers that map between the schema operations and the data sources.
With the @model directive, the GraphQL Transform tool will scaffold out all schema operations, resolvers, and data sources so all we have to do is define the base schema (step 1). The @connection directive will let us model relationships between the models and scaffold out the appropriate resolvers for the relationships.
In our schema, we use @connection to define a relationship between Restaurant and Reviews. This will create a unique identifier for the restaurant ID for the review in the final generated schema.
Now that we’ve created our base schema, we can create the API in our account.
amplify push
? Are you sure you want to continue? Yes
? Do you want to generate code for your newly created GraphQL API Yes
? Choose the code generation language target javascript
? Enter the file name pattern of graphql queries, mutations and subscriptions src/graphql/**/*.js
? Do you want to generate/update all possible GraphQL operations - queries, mutations and subscriptions Yes
Because we’re creating a GraphQL application, we typically would need to write all of our local GraphQL queries, mutations and subscriptions from scratch. Instead, the CLI will be inspecting our GraphQL schema and then generating all of the definitions for us and saving them locally for us to use.
After this is complete, the back end has been created and we can begin accessing it from our React application.
If you’d like to view your AppSync API in the AWS dashboard, visit https://console.aws.amazon.com/appsync and click on your API. From the dashboard you can view the schema, data sources, and resolvers. You can also perform queries and mutations using the built-in GraphQL editor.
Building the React client
Now that the API is created and we can begin querying for and creating data in our API. There will be three operations we will be using to interact with our API:
Creating a new restaurant
Querying for restaurants and their reviews
Creating a review for a restaurant
Before we start building the app, let’s take a look at how these operations will look and work.
Interacting with the AppSync GraphQL API
When working with a GraphQL API, there are many GraphQL clients available.
We can use any GraphQL client we’d would like to interact with an AppSync GraphQL API, but there are two that are configured specifically to work most easily. These are the Amplify client (what we will use) and the AWS AppSync JS SDK (similar API to Apollo client).
The Amplify client is similar to the fetch API in that it is promise-based and easy to reason about. The Amplify client does not support offline out of the box. The AppSync SDK is more complex but does support offline out of the box.
To call the AppSync API with Amplify, we use the API category. Here’s an example of how to call a query:
import { API, graphqlOperation } from 'aws-amplify'
import * as queries from './graphql/queries'
const data = await API.graphql(graphqlOperation(queries.listRestaurants))
For a mutation, it is very similar. The only difference is we need to pass in a a second argument for the data we are sending in the mutation:
import { API, graphqlOperation } from 'aws-amplify'
import * as mutations from './graphql/mutations'
const restaurant = { name: "Babalu", city: "Jackson" }
const data = await API.graphql(graphqlOperation(
mutations.createRestaurant,
{ input: restaurant }
))
We use the graphql method from the API category to call the operation, wrapping it in graphqlOperation, which parses GraphQL query strings into the standard GraphQL AST.
We’ll be using this API category for all of our GraphQL operation in the app.
The first thing we need to do in our app is configure it to recognize our Amplify credentials. When we created our API, the CLI created a new file called aws-exports.js in our src folder.
This file is created and updated for us by the CLI as we create, update and delete services. This file is what we’ll be using to configure the React application to know about our services.
To configure the app, open up src/index.js and add the following code:
import Amplify from 'aws-amplify'
import config from './aws-exports'
Amplify.configure(config)
Next, we will create the files we will need for our components. In the src directory, create the following files:
Header.js
Restaurant.js
Review.js
CreateRestaurant.js
CreateReview.js
Creating the components
While the styles are referenced in the code snippets below, the style definitions have been omitted to make the snippets less verbose. For style definitions, see the final project repo.
Next, we’ll create the Header component by updating src/Header.js.
Now that our Header is created, we’ll update src/App.js. This file will hold all of the interactions with the API, so it is pretty large. We’ll define the methods and pass them down as props to the components that will call them.
We first create some initial state to hold the restaurants array that we will be fetching from our API. We also create Booleans to control our UI and a selectedRestaurant object.
In componentDidMount, we query for the restaurants and update the state to hold the restaurants retrieved from the API.
In createRestaurant and createReview, we send mutations to the API. Also notice that we provide an optimistic update by updating the state immediately so that the UI gets updated before the response comes back in order to make our UI snappy.
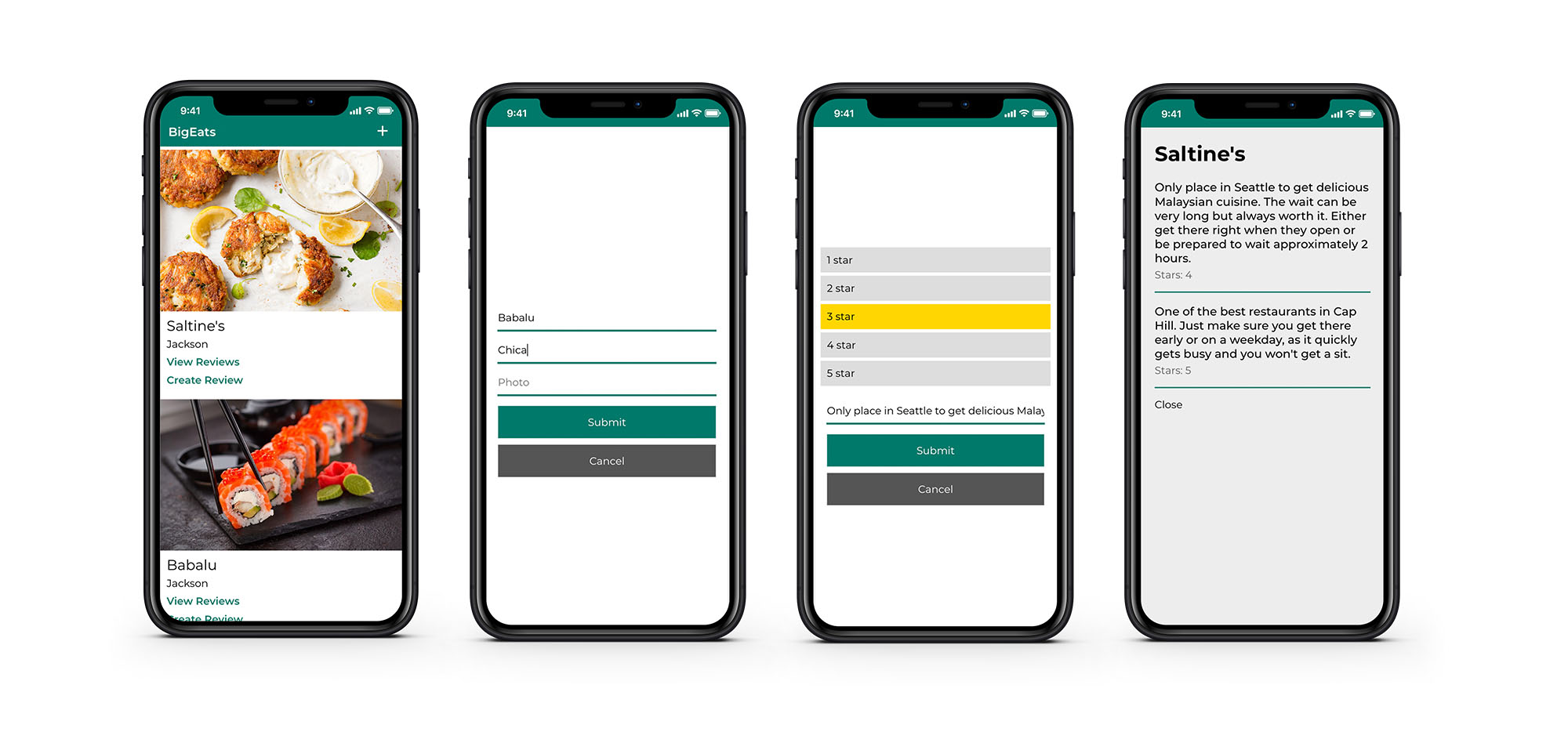
This component is the main view of the app. We map over the list of restaurants and show the restaurant image, its name and location, and links that will open overlays to show reviews and create a new review.
Next, we’ll look at the Reviews component (src/Reviews.js). In this component, we map over the list of reviews for the chosen restaurant.
Next, we’ll take a look at the CreateRestaurant component (src/CreateRestaurant.js). This component holds a form that keeps up with the form state. The createRestaurant class method will call this.props.createRestaurant, passing in the form state.
Next, we’ll take a look at the CreateReview component (src/CreateReview.js). This component holds a form that keeps up with the form state. The createReview class method will call this.props.createReview, passing in the restaurant ID and the form state.
Now that we have built our back-end, configured the app and created our components, we’re ready to test it out:
npm start
Now, navigate to http://localhost:3000. Congratulations, you’ve just built a full-stack serverless GraphQL application!
Conclusion
The next logical step for many applications is to apply additional security features, like authentication, authorization and fine-grained access control. All of these things are baked into the service. To learn more about AWS AppSync security, check out the documentation.
If you’d like to add hosting and a Continuous Integration/Continuous Deployment pipeline for your app, check out the Amplify Console.
This is not a sponsored post. I requested a beta access for this site called Stackbit a while back, got my invite the other day, and thought it was a darn fine idea that’s relevant to us web nerds — particularly those of us who spin up a lot of JAMstack sites.
I’m a big fan of the whole idea of JAMstack sites. Take our new front-end development conferences website as one little example. That site is a custom theme built with 11ty, version controlled on GitHub, hosted on Netlify, and content-managed with Netlify CMS.
Each JAMstack site is a little selection of services (? I’m rebuilding that site to be even more JAMstacky!). I think it’s clever that Stackbit helps make those choices quickly.
Pick a theme, a site generator, a CMS, a repository platform, and a deployment service… and go! Like this:
We’ve all heard of Spotify. Launched back in 2008, the app offers millions of tracks from various legendary and upcoming artists. It allows you to create a playlist, follow other people or choose a playlist based on your mood.
But let’s take the app from another perspective today. Let’s build a two-page server-side rendered web application featuring a “Now Playing on Spotify” component. I’ll walk you through all of the steps of building a client-side application, building and connecting to a server API, as well as connecting to external API services.
Our project will be built using the Node.js and npm ecosystems, Github to store our code, Heroku as our host, Heroku’s Redis for our storage, and Spotify’s web API. The application and internal API will be build entirely using Nuxt’s system. Nuxt is a server-side-rendering framework that runs on Vuejs, Expressjs, Webpack, and Babeljs.
This tutorial is moderately complex, but is broken down into very consumable sections. You’ll find a working demo at cherislistening.heroku.com.
Final result created with Nuxt.js, Redis, and Spotify. (Large preview)
Requirements
This tutorial requires knowledge of HTML, CSS, Javascript (ES6), and how to use command line or terminal. We’ll be working with Node.js and Vuejs; a basic understanding of both will be helpful before starting this tutorial. You’ll also need to have Xcode Tools installed if you are on MacOS.
Planning Our Application We’ll lay out our expected functionality and a visual representation of what we plan to see when we are finished.
Setting Up And Creating Our Project We’ll walk through how to setup an application hosted on Heroku’s server, setup auto-deployment from Github, setup Nuxt using the command line tools, and get our local server running.
Building Our API Layer We’ll learn how to add an API layer to our Nuxt application, how to connect to Redis, and Spotify’s web API.
Client-Side Storage And State Management We’ll look at how we can leverage the built-in Vuex store to keep what’s playing up to date. We’ll set up our initial data connections our API.
Building The Pages And Components We’ll take a brief look into how pages and components differ in Nuxt, and build two pages and a couple of components. We’ll use our data to build our Now Playing app and some animations.
Publishing Our Application We’ll get our app onto GitHub and built on Heroku’s server, authenticate and share with everyone what music we’re listening to.
Planning Our Application
The most important step before we start any new project is to plan our goals. This will help us establish a set of requirements for accomplishing our goals.
How many pages are there?
What do we want on our pages?
Do we want our Spotify “Now Playing” component present on both of our pages?
Do we want a progress bar to show listeners where we are in the song?
How do we want our pages laid out?
These are the types of questions that will help us draft our requirements.
Let’s build out two pages for our application. First, we want a landing page with our “Now Playing” component. Our second page will be our authentication area where we connect our data to Spotify. Our design is going to be very minimalistic, to keep things simple.
For our “Now Playing” component, let’s plan on showing the progress of the track as a bar, the name of the track, the artist’s name, and the album art. We’ll also want to show an alternate state showing the most recent track played, in case we aren’t currently listening to anything.
Since we are dealing with Spotify’s API, we’ll have special tokens for accessing the data from our site. For security purposes, we don’t want to expose these tokens on the browser. We also only want our data, so we’ll want to ensure that we are the only user who can login to Spotify.
The first issue we find in planning is that we have to login to Spotify. This is where our Redis cache storage comes in. Spotify’s API will allow to permanently connect your Spotify account to an application with another special token. Redis is a highly performant in-memory data structure server. Since we are dealing with a token, a simple key:value storage system works well. We want it to be fast so we can retrieve it while our application is still loading.
Heroku has its own Redis cache service built in, so by using Heroku for our server, host, and storage, we can manage everything in one place. With the added benefit of auto-deployment, we can do everything from our console with commands in terminal. Heroku will detect our application language from our push, and will build and deploy it without much configuration.
We’ll need to login and create our app, along with setting up some configuration variables. I named my app “cherislistening”. You can also leave off the -a command and Heroku will give you a randomly generated name. You can always change it later. The url of your app will be http://.herokuapp.com.
Nuxt requires some specific configuration to build and run properly, so we’ll add those now to get them out of the way.
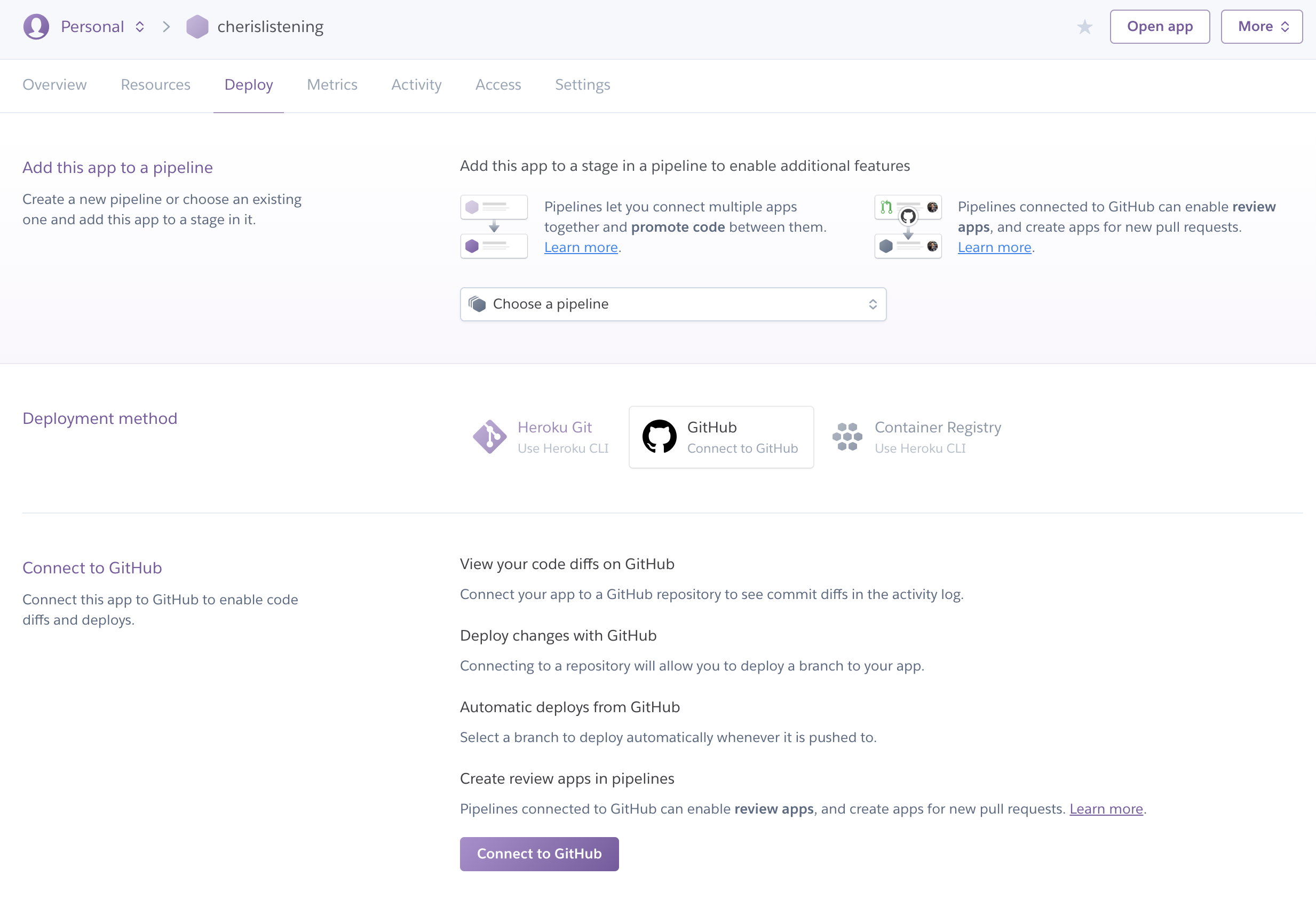
Go to the Heroku dashboard and click into your newly created app. In the ‘Deploy’ tab, connect to your Github account, select the repository you cloned, and enable auto deploys from the Master branch.
Github selected in the Heroku dashboard (Large preview)
Repository selection in Github (Large preview)
Automatic deployment setup with Github (Large preview)
Create Nuxt App
We’ll use npx to create our Nuxt application. Npm is a great ecosystem for managing Node.js packages, but to run a package, we must install it and add it to our package.json file. That isn’t very useful if we want to execute a single package one time, and installing something isn’t really necessary. This makes npx suitable for executing packages that compose file trees, adding boilerplates, and install the packages you need during execution.
$ npx --version
6.4.1
npx is shipped by default in npm 5.2.0+, so it is highly recommended we upgrade npm instead of globally installing npx. If you just installed a fresh version of node.js, you should have current npm and npx.
The Nuxt.js team has created a scaffolding tool which will give your application the basic structure required to run. Make sure you’re in your new project’s folder before running the command.
$ npx create-nuxt-app
npx: installed 407 in 5.865s
> Generating Nuxt.js project in /Users/cstewart/Projects/personal/tutorials/cherislistening
? Project name cherislistening
? Project description A Spotify Now Playing App
? Use a custom server framework none
? Choose features to install Prettier, Axios
? Use a custom UI framework none
? Use a custom test framework none
? Choose rendering mode Universal
? Author name Cher Scarlett
? Choose a package manager npm
npm notice created a lockfile as package-lock.json. You should commit this file.
To get started:
npm run dev
To build and start for production:
npm run build
npm start
npm notice created a lockfile as package-lock.json. You should commit this file.
To get started:
npm run dev
To build & start for production:
npm run build
npm start
Every folder within the scaffolding comes with a README file. This file will give you the basics for how the folder works, and whether or not it’s needed. We will talk about the folders we’ll use as we get to them in the tutorial.
We’ll need to make a change to package.json so that when we deploy to Heroku, our build process will run. In “scripts”, we’ll add "heroku-postbuild": "npm run build". Don’t forget to add a comma after the previous line in the object.
If you run npm run dev, and go to http://localhost:3000 in your browser, you should see the scaffolded app running:
Initial state of Nuxt application after scaffolding (Large preview)
Install Redis
Open a new terminal or command line tab and change directories (cd) into your project’s parent folder. Download redis and run make. If you’re on Windows, you’ll need to check out https://github.com/MicrosoftArchive/redis/releases.
$ cd ../
$ wget http://download.redis.io/releases/redis-5.0.3.tar.gz
$ tar xzf redis-5.0.3.tar.gz
$ cd redis-5.0.3
$ sudo make install
cd src && /Library/Developer/CommandLineTools/usr/bin/make install
That will start our redis server as a background process and we can close this tab. The local redis server will be running at http://127.0.0.1:6379/.
In our tab with our project running, type Ctrl + C to kill the server. We’ll need to install a redis package for node, and provision our Heroku Redis instance.
$ npm install async-redis --save
npm WARN eslint-config-prettier@3.6.0 requires a peer of eslint@>=3.14.1 but none is installed. You must install peer dependencies yourself.
+ async-redis@1.1.5
added 5 packages from 5 contributors and audited 14978 packages in 7.954s
found 0 vulnerabilities
$ heroku addons:create heroku-redis
Creating heroku-redis on ⬢ cherislistening... free
Your add-on should be available in a few minutes.
! WARNING: Data stored in hobby plans on Heroku Redis are not persisted.
redis-metric-84005 is being created in the background. The app will restart when complete...
Use heroku addons:info redis-metric-84005 to check creation progress
Use heroku addons:docs heroku-redis to view documentation
Because we are using a hobby account, we don’t have a backup of our data. If our instance needs rebooted, we’ll need to re-authenticate to get a new key. Our application will also sleep on the free account, so some initial visits will be a little slow, while the app is “waking up”.
Take the Client ID and the Client Secret, which you can find if you click on the green card into your new application’s details, and export them to Heroku as configuration variables. Keep these safe and secret! If you believe your client secret has been exposed, you can get a new one, but you’ll need to update your application’s configuration as well.
Never share your client ID and client secret tokens! (Large preview)
On the top right side of the application dashboard, there is a Settings button. Click that and add in two callback URLs for whitelisting. You’ll need a local callback URL and one for your production server (the Heroku URL we got during setup).
Whitelisted callback URLs in Spotify’s dashboard (Large preview)
Spotify has fantastic developer documentation, including a great reference interface for testing endpoints. We’ll need to get our user ID to save to our configuration variables, so let’s do that with Get Current User’s Profile. Get an auth token from their console, selecting the user-read-private scope. Click “Try It”, and in the right-hand column look for your ID. We’ll use this identifier to make sure no one else can sign into our app.
As we discussed, we will have data we wouldn’t want exposed to the public. Two of these are clientId and clientSecret we were given by Spotify, and another which Heroku exported for us to access our Redis cache on the server. We’ll need to grab those for our local development as well.
We’ll transfer the credentials Heroku returned in our terminal to our new file, .env, and we’ll make our client URL our local server, http://localhost:3000/. We’ll need to make our Redis URL point to our local instance, too, which by default is redis://127.0.0.1:6379. This file will be ignored by git.
In order to access the configuration on our local server, we’ll need to update the nuxt config. We’ll add another item to our modules array: @nuxtjs/dotenv. We’ll also need to import two of the variables we will need available on the client-side of our application. We’ll add an env object following modules.
Nuxt has two separate methods for executing server-side code.
In a single-file component (SFC), you have access to the middleware property, which corresponds with the middleware folder in your scaffolding. The drawback with this middleware for our use-case is that while it will execute server-side when your page is loaded or refreshed, it will execute client-side once your app is mounted, and when you navigate with nuxt’s routes.
The other option is what we’re looking for. We’ll create our own directory and add it as serverMiddleware to our config. Nuxt creates its own express instance, so we can write middleware registered to its stack that will only run on the server. This way, we can protect our private data from exploitation. Let’s add an api folder and index.js to handle our API endpoints.
$ mkdir api
$ touch api/index.js
Next, we’ll need to add our directory to our config so it registers when we start our server. Let’s open up the file nuxt.config.js at the root of our app. This file gives us our HTML , as well as connecting anything to our client at build time. You can read more about the config in the docs.
We’ll add our api directory to our config file,
},
serverMiddleware: ['~/api']
}
nuxt.config.js
While we are developing, our changes will require rebuilds and server reboots. Since we don’t want to have to do this manually, nuxt installs nodemon for us, which is a “hot reload” tool. This just means it will reboot the server and rebuild our app when we save our changes.
Since we’ve added our API as serverMiddleware to Nuxt’s, we’ll need to add our directory to the config. We’ll add watch to our build object, and add the relative path from root.
Now we don’t have to worry about rebooting and restarting our server manually every time we make a change. ?
Let’s start our local development server.
$ npm run dev
Data Flow, Storage, And Security
Before we start writing our API layer, we’ll want to plan how we move data from external sources to our client. We’ve set up a Redis cache server, signed up for Spotify API, and set up a structure that has a client layer and a server layer. The client has pages and a store where we can store and render our data. How do these work together to keep our authentication data safe and drive our Now Playing component?
Any information we want to keep long-term, or for new incoming connections, we’ll want to store on the server. We can’t log into Spotify when other users visit our app, so we’ll need want to ensure that new client connections can bypass authentication by accessing our special service token. We’ll want to keep track of our own Spotify login so that only our own connection is approved by the API, and we’ll want a track ready to show in case we can’t connect to Spotify’s API for some reason.
So, we’ll need to plan on storing our Spotify refresh_token, our Spotify userId, and our lastPlayedTrack in our Redis Cache.
Everything else can safely be stored in our client’s vuex store. The store and the pages (including their components) will pass data back and forth using nuxt’s architecture, and we’ll talk to the Redis cache and Spotify’s API via our own server’s API.
Writing The API
Nuxt comes with the express framework already installed, so we can import it and mount our server application on it. We’ll want to export our handler and our path, so that nuxt can handle our middleware.
We’ll need a few endpoints and functions to handle the services we need:
POST to our Redis Cache
Spotify last played track
Name
Artists
Album Cover Asset URL
Spotify refresh_token
Spotify access_token
Status of Spotify Connection
GET from our Redis Cache
Same as POST
Callback from Spotify
Refresh our Spotify access_token
GET recently played tracks from Spotify
GET currently playing track from Spotify
This may seem like a lot of calls, but we will combine and add small bits of logic where it makes sense as we write.
The Basics Of Writing An Endpoint In Expressjs
We’ll use express’s get() method to define most of our endpoints. If we need to send complex data to our API, we can use the post() method.
But what if we could do both? We can accept multiple methods with all().
Let’s add the first route we’ll need, which is our connection to our Redis Cache. We’ll name it spotify/data. The reason we’re naming it based on spotify rather than redis is because we’re handling information from Spotify, and Redis is simply a service we’re using to handle the data. spotify is more descriptive here, so we know what we’re getting, even if our storage service changes at some point.
Let’s test to make sure everything is working properly. Open a new tab in your terminal or command line, to ensure your nuxt server continues running and run the following cURL command:
As you can see, res.send() returned the message we included in response to our GET request. This is how we will return the data we retrieve from Spotify and Redis to the client, too.
Each one of our endpoints will have the same basic structure as our first one.
Breakdown of an API endpoint function in Expressjs (Large preview)
It will have a path, /spotify/data/, it may have a param, like :key, and on request, express will return a request object, req, and a response object, res. req will have the data we send with to the server, res is waiting to handle what we want to do after we complete any procedures within our function.
Connecting To The Redis Cache
We’ve already seen that we can return data back to our client with res.send(), but we may also want to send a res.status(). When we have an issue reaching Spotify (or our Redis cache), we’ll want to know so we can gracefully handle the error, instead of crashing our server, or crashing the client. We’ll also want to log it, so we can be informed about failures on applications we build and service.
Before we can continue with this endpoint, we’ll need access to our Redis Cache. During setup, we installed async-redis, which will help us easily access our cache from Heroku. We’ll also need to add our dotenv config so we can access our redis URL.
import redis from 'async-redis'
require('dotenv').config()
// Redis
function connectToRedis() {
const redisClient = redis.createClient(process.env.REDIS_URL)
redisClient.on('connect', () => {
console.log('n🎉 Redis client connected 🎉n')
})
redisClient.on('error', err => {
console.error(`n🚨 Redis client could not connect: ${err} 🚨n`)
})
return redisClient
}
api/index.js
By default, redis.createClient() will use host 127.0.0.1 and port 6379, but because our production redis instance is at a different host, we will grab the one we put in our config.
We should add some console commands on the connect and error listeners the redisClient provides us. It’s always good to add logging, especially during development, so if we get stuck and something isn’t working, we’ve got a lot of information to tell us what’s wrong.
We need to handle the following cases in our API layer:
Since we are requesting data from an external resource, we’ll want to use async/await to let our program know that this endpoint contains a function that always returns a promise, and that we’ll need wait for it to be returned before continuing.
In our arguments, we pull out our required, known argument method, and assign the rest (...) of the parameters to the scoped const args.
We make a call to our redis client using bracket notation, allowing us to pass a variable as the method. We again use the spread operator, ... to expand our args Array into a list of arguments with the remaining items. A call to http://localhost:3000/api/spotify/data/test?value=1 would result in a call to the redis client of redisClient['set']('test', 1). Calling redisClient['set']() is exactly the same as calling redisClient.set().
Make a note that we must quit() to close our redis connection each time we open it.
We know that we can get two types of inputs: either a JSON body or a string value. All we really need to do is check if body exists, and we’ll assume it’s JSON and stringify it. Otherwise, we’ll use props.value. If it’s empty, it will be null. We’ll assign whichever we get back from the ternary statement to the const value. Make note that we are not destructuring value from the rest (...) of props because we need to assign body to value if it exists.
The first index of the array we are returning, position 0, will be the method we call on the redis client. We’re making a Boolean check in case something other than null is passed, like undefined. If there is a value, this will return true and our method will be set. If false, get.
Index 1 and index 2 are our key and value, respectively.
The 3rd and 4th positions are used to set an expiration date on the key. This comes in handy for our access_token, which will expire every few minutes to protect the integrity of our application.
As you may have suspected, we don’t want a null or undefined value in our array, so if there is no value, we’ll want to remove it. There are several ways to handle this, but the most readable is to use Array’s method filter(). This creates a new Array, removing any items that don’t match our condition. Using a Boolean() type coercion, we can check for a true or false. A null or undefined argument in our array will be removed, leaving us with an array of arguments we can trust to return back to the caller.
Make note of app.use(express.json()). This gives us access to body on the request object. We’ll also be wrapping our endpoint procedures in try/catch blocks so we don’t wind up with uncaught errors. There are other ways to handle errors, but this is the simplest for our application.
We want to make sure that this endpoint doesn’t return any of the data we’re trying to hide, so after we grab our key by destructuring the request object, we’ll throw an error letting the client know they can’t get those stores. Make note that when we know the structure of an incoming Object’s structure in JavaScript ES6, we can use curly braces to pull out variable names using the Object’s keys.
We’re calling the function named callStorage. Because we may have 3 or 4 arguments, we’re passing in rest parameters using a spread of our args Array. In the call, above, we use ... to expand an Array into our list of arguments of an unknown size, which are built from the function StorageArgs().
res.send({ [key]: reply })
} catch (err) {
console.error(`n🚨 There was an error at /api/spotify/data: ${err} 🚨n`)
res.send(err)
}
})
api/index.js
Now that we have our reply from the redis client, we can send it to the client via the response Object’s method send(). If we POSTed to our cache, we’ll get a 1 back from the server if it’s a new key and 0 if we replaced an existing key. (We’ll want to make a mental note of that for later.) If there’s an error, we’ll catch it, log it, and send it to the client.
We’re ready to call the redis client and begin setting and getting our data.
Mapping an endpoint to a Redis server call (Large preview)
Now let’s send a few test cURLs to our API endpoint in our command line or Terminal:
$ curl --request POST http://localhost:3000/api/spotify/data/test?value=Hello
{"test": 1}
$ curl http://localhost:3000/api/spotify/data/test
{"test": "Hello"}
$ curl --request POST
http://localhost:3000/api/spotify/data/bestSong
--header 'Content-Type: application/json'
--data '{
"name": "Break up with ur gf, I'''m bored",
"artist": "Ariana Grande"
}'
{"bestSong": 1}
$ curl http://localhost:3000/api/spotify/data/bestSong
{"bestSong":"{"name":"Break up with ur gf, I'm bored","artist":"Ariana Grande"}"}
Connecting With Spotify
Our remaining to-do list has shrunk considerably:
Callback from Spotify
Refresh our Spotify access_token
GET recently played track from Spotify
GET currently playing track from Spotify
A callback is a function that must be executed following the completion of a prior function. When we make calls to Spotify’s API, they will “call us back”, and if something isn’t quite right, Spotify’s server will deny us access to the data we requested.
import axios from 'axios'
api/index.js
Our callback will need to do a couple of things. First, it will capture a response from Spotify that will contain a code we need temporarily. Then, we’ll need to make another call to Spotify to get our refresh_token, which you may recognize from our redis storage planning. This token will give us a permanent connection to Spotify’s API as long as we are on the same application logged in as the same user. We’ll also need to check for our userId for a match before we do anything else, to prevent other users from changing our data to their own. Once we confirm we are the logged in user, we can save our refresh_token and access_token to our redis cache. Because we’re making API calls in our callback function, we’ll need to import axios to make requests, which nuxt installed when we scaffolded the app.
Note that JavaScript has a native fetch() method, but it’s very common to see axios used instead, because the syntax is more user-friendly and legible.
One of the benefits to using a function expression instead of an arrow function expression is that you have access to an inherit object called arguments which is mapped by index, you also get access to a contextual this object. While we don’t need access to a lexical this, since we’re only returning the response of our redisClient call, we can omit closures here and implicitly return the response of the call.
We’ll want to write a single function for getting Spotify tokens. The majority of the code for getting our refresh_token and access_token is basically the same, so we can write an axios POST boilerplate, and spread (...) a props Object. Spreading an Object expands its properties into the context parent Object at the root depth, so if we spread { grant_type: 'refresh_token' }, our params Object will be extended to contain the properties of {client_id, client_secret, redirect_url, grant_type }. Again, we forego a return with an arrow function and opt for an implicit return since this function only returns a single response.
Note that we set props in the arguments as an empty Object ({}) by default just in case this function gets called without an argument. This way, nothing should break.
In order to check to see we are the user who logged in via Spotify, we’ll write another implicitly returned arrow function expression and call Spotify’s Get Current User’s Profile method (the one we tested earlier to get our SPOTIFY_USER_ID). We set a const here with the base API URL because we will use it again in our other calls to the library. Should this ever change in the future (like for Version 2), we’ll only have to update it in once.
We now have all of the functions we need to write our callback endpoint. Make note of the fact that this will be a client-facing endpoint.
app.get('/spotify/callback', async ({ query: { code } }, res) => {
try {
const { data } = await getSpotifyToken({
code,
grant_type: 'authorization_code'
})
const { access_token, refresh_token, expires_in } = data
const {
data: { id }
} = await getUserData(access_token)
if (id !== process.env.SPOTIFY_USER_ID)
throw { error: "🤖 You aren't the droid we're looking for. 🤖" }
callStorage(...storageArgs({ key: 'is_connected', value: true }))
callStorage(...storageArgs({ key: 'refresh_token', value: refresh_token }))
callStorage(
...storageArgs({
key: 'access_token',
value: access_token,
expires: expires_in
})
)
const success = { success: '🎉 Welcome Back 🎉' }
res.redirect(`/auth?message=${success}`)
} catch (err) {
console.error(
`n🚨 There was an error at /api/spotify/callback: ${err} 🚨n`
)
res.redirect(`/auth?message=${err}`)
}
api/index.js
Our callback endpoint must match the URL we added to our settings in the Spotify dashboard exactly. We used /api/spotify/callback, so we’ll get at /spotify/callback here. This is another async function, and we need to destructure code from the request object.
We call the function we wrote earlier, getSpotifyToken(), to get our first access_token, our refresh_token, and our first expires_in. We’ll want to save all three of these to our redis cache, using redis’ set method’s built-in key timeout command to expire our access_token in expires_in seconds. This will help us set up a system of refreshing our access_token when we need it. Redis will set the access_token to null after the time to live (TTL) has reached 0 milliseconds.
Now that we have an access_token, we can make sure that the user who connected is us. We call getUserData(), the function we wrote earlier, and destructure the ID to compare to the user ID we saved to our environment configuration. If it’s not a match, we’ll throw an error message.
After we’re sure that our refresh_token is trusted, we can save our tokens to our redis cache. We call callStorage again — once for each token.
Make note that redis does have methods for setting multiple keys, but because we want to expire our access_token, we need to use set().
Since this is a client-facing endpoint, we’ll redirect to a URL and append a success or error message for the client to interpret. We’ll set this path up later on the client side.
We’ll need to retrieve our access_token and refresh it if necessary before we call any other Spotify endpoints. Let’s write an async function to handle that.
We assign a const accessTokenObj to an Object with the value of our redis get('access_token'). If the value is null, we’ll know it’s expired and we need to refresh it. After getting our refresh_token from our cache, and getting a new access_token, we’ll assign our new values to accessTokenObj, set() them in redis, and return the access_token.
Let’s get write our endpoint for getting the currently-playing track. Since we’ll only want recently-played if there’s nothing currently playing, we can write a function for our endpoint to call that handles getting that data if it’s needed.
The endpoint gets the Get the User’s Currently Playing Track endpoint and the async function setLastPlayed() calls the Get Current User’s Recently Played Tracks if nothing is returned from currently-playing. We’ll call our last function postStoredTrack() with whichever one we have, and retrieve it from our cache to send to the client. Note the we cannot omit the else closure because we aren’t returning anything in the if closure.
Vuex: Client-Side Storage And State Management
Now that we have middleware to connect to our services by proxy, we can connect those services to our client-side application. We’ll want our users to have automatic updates when we change songs, pause, rewind, or fast-forward, and we can handle those changes with state management.
State is our application’s way of holding onto information in real-time. It is how our application remembers the data it uses, and any changes to that data. State is really a short way of saying “the state of the system’s data”. The state of a Vue application is held in a user’s browser session, and with certain patterns, we can trigger various events to mutate that state. When the state changes, our application can update without requiring storage or server calls.
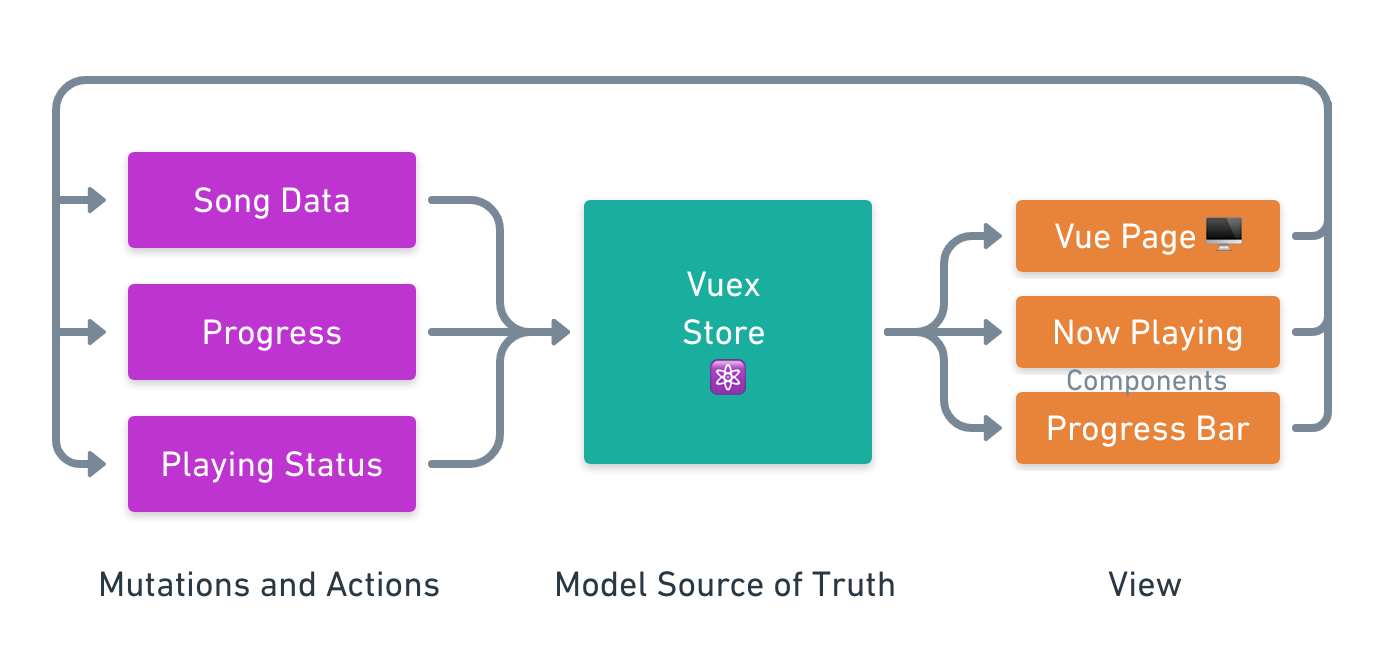
The pattern we’ll use is called a store pattern. This gives us a single source of truth as a user moves about our application (even though we’ll only have two pages for this particular app).
Vue’s component lifecycle adds the necessary one-way bindings we need, and Nuxt comes with Vuex that does all of the heavy lifting when our data changes. We will want our state to be constantly updating, but we won’t to call our API every few milliseconds to keep a progress bar moving. Instead of constantly polling our API, and reaching Spotify’s rate limit, we can lean on Vuex setters to continuously update the state of our bindings.
The data we’ll be dealing with will only be bound one-way. This means that our component and page views can get the data in store, but in order to mutate that data, they will need to call an action in the store.
One way data flow in our application (Large preview)
As you can see, the data only moves one way. When our application starts, we’ll instantiate our models with some default data, then we will hydrate the state in a middleware function expression built into Nuxt’s implementation of Vuex called nuxtServerInit(). After the application is running, we will periodically rehydrate the store by dispatching actions in our pages and components.
Here’s the basic structure we’ll need to activate a store in store/index.js:
// instantiated defaults on state
export const state = () => {
property: null
}
// we don't edit the properties directly, we call a mutation method
export const mutations = {
mutateTheProperty (state, newProperty) {
// we can perform logical state changes to the property here
state.property = newProperty
}
}
// we can dispatch actions to edit a property and return its new state
export const actions = {
updateProperty: ({ commit, state }, newProperty) => {
commit('mutateTheProperty', newProperty)
return state.property // will equal newProperty and trigger subscribers to re-evaluate
}
}
Once you feel comfortable, you can set up more shallow modular stores, which Nuxt implements based on your file structure in store/. We’ll use only the index module.
We’re going to need a few models to instantiate the state when our app starts. Note that this must be a function that returns an Object.
isConnected: tells us if we’re already connected via Spotify.
message: tells us if there’s an error during authentication (we set these up in the API on our callback endpoint).
nowPlaying: the song (track) Object that is currently or recently playing.
recentlyPlayed: the track most recently played.
trackProgress: the amount of the track that has already played (a percentage).
isPlaying: if the nowPlaying track is currently being played.
To update these, we’ll need to add mutations for each model. You can mutate more than one model in a mutation function, but to keep things digestible, we’re going to write a flat mutations object.
We’re not doing much in the way of data massaging for this app, but for progress we’ll need to calculate the percentage ourselves. We’ll return an exact number from 0-100.
nuxtServerInit() will be run when our server starts automatically, and will check if we are connected to Spotify already with a query to our redis data endpoint. If it finds that the redis cache key of is_connected is true, it will call our “now-playing” end point to hydrate nowPlaying with live data from Spotify, or whatever is already in the cache.
Our other actions take our store object and destructure commit() and state with our new data, commit() the data to the store with our mutations, and return the new state to the client.
Building The Pages And Components
Now that we have our API setup to give us data from Spotify and our store, we’re ready to build our pages and components. While we’re only going to make a couple of small pieces in this tutorial for brevity, I encourage liberal creativity.
We’ll need to remove the initial pages that the Nuxt scaffolding added, and then we’ll add our components and pages.
The basic structure of every layout, page, and component in a single file component is the same. In fact, every layout, page, and component in Nuxt is a Vue component.
You can read further usage outside of the scope of this tutorial on Vue’s component registration documentation. We’re just going to do everything in the file and use plain HTML and CSS.
The repository for the demo will contain some components and styles that are not in this tutorial in order to keep things a little less complex.
<template>
// Write plain HTML here, avoid using any logic here
<div></div>
</template>
<script>
// Write plain javascript here, you can import libraries, too
export default {
key: 'value'
}
</script>
<style>
// Write plain global CSS here
div {
display: inline;
}
</style>
Layout
We need to start with the default layout; this is the root of the application, where Vue will be mounted. The layout is a type of view, of which every page extends. This means that the HTML found in the layout will be the basis of all the html in every page we create.
In the template tag, we need a single root container, and is where our application will mount.
Note: In the demo code, I’ve added aand a, and the footer is a functional component because all of the data is static.
In this tutorial, I’ve added a pointed to /auth. creates navigational links for routes within your app. I’ve added a conditional aria-current attribute to nuxt-link. By adding a colon (:) in front of the attribute, I’ve indicated to Vue that the value of the attribute is bound to some data, turning the value into JavaScript that will be interpreted as a string during the component lifecycle, depending on the condition of the expression. In a computed ternary statement, if the user on the route named auth, it will set the aria-current attribute to “page”, giving screen readers context to whether or not the user is on the path the link is pointed to. For more information on Vue’s data-binding, read this documentation.
The script tag can be thought of like a single JavaScript module. You can import other modules, and you export an Object of properties and methods. Above, we set two custom properties: titleShort and authorName. These will be mounted onto this.$options, and down the component tree you can access them through $nuxt.layout. This is useful for information you use at the root level, and in deep-nested children, like for updating the document title, or using our authorName in other contexts.
There are several functions that Vue will look for and run, like head() and computed() in the above example.
head() will modify the of the HTML document. Here I’ll update the document title, and add a link.
The computed() method is for reactive data that needs to be evaluated. Whenever the shape of the data changes, it triggers a re-evaluation and a subsequent re-render of the node it is bound to.
In the CSS, you’ll notice I’m using a non-standard font, but no @import declaration. Since these are rendered on the server, they won’t be able to reach an external resource that isn’t in the build. We can still attach external resources — we just need to do it in a different way. There are workarounds that exist for this, but we just added it to our head(). You can also add it to nuxt.config.js.
The :root selector allows us to set global CSS variables we can use throughout the application. .nuxt-progress selector is for the progress bar that Nuxt adds during build automatically. We can style it here. I’ve just moved it to the bottom of the app and made it transparent and small.
Authentication Page
Now that we have a default layout, we can work on our authentication page. Pages are another kind of view in Nuxt, which render the HTML, CSS, and JavaScript that is needed for specific routes.
Pages and routes are automatically handled for every Vue file inside of the pages directory. You can also add more complex routing.
Everything has led us to this moment! Finally, we get to render some of our API-retrieved data!
is used to add transitions between pages and components mounting and unmounting. This will add conditional class names related to the name, and the mode “in-out” will make our transition happen both on entry and exit. For further usage, check out the documentation.
We get at data in the with double curly braces {{}}. this is implied, so we don’t need to include it in the .
The first thing we need to do is redirect to the authentication server, which will call us back at our callback API proxy, and we setup to redirect us back to /auth, or this file we’re in now. To build the URL, we’ll need to get the environment variables we attached to the context object under the env parameter. This can only be done in pages. To access the context object, we’ll need to add the asyncData() method to our Object.
This function will be run before initializing the component, so make note that you do not have access to a component’s lexical this (which is always in the context of the local $nuxt Object) in this method because it does not exist yet. If there is async data required in a component, you will have to pass it down through props from the parent. There are many keys available in context, but we’ll only need env and query. We’ll return spotifyUrl and query, and they will be automatically merged with the rest of the page’s data.
There are many other lifecycle methods and properties to hook onto, but we’ll really only need mounted() and computed, data(), props, components, methods, and beforeDestroy(). mounted() ensures we have access to the window Object.
In mounted(), we can add our logic to redirect the user (well, us) to login via Spotify. Because our login page is shared with our authentication status page, we’ll check for the message Object we sent back from our callback redirect. If it exists, we will bypass redirecting so we don’t end up in an infinite loop. We’ll also check to see if we’re connected. We can set window.location to our spotifyUrl and it will redirect to the login. After logging in, and grabbing the query Object, we can remove it from our URL so our users don’t see it with window.history.replaceState({}, document.title, window.location.pathname). Let’s commit and dispatch the changes to our state in message and isConnected.
In computed(), we can return our properties from the store and they will be automatically updated on the view when they change.
Note that all properties and methods will have access to the lexical this once the component has been initialized.
Note the scoped attribute added to . This allows us to write shallow selectors that will only affect elements in the scope of this page (or component) by adding unique data attributes to the DOM. For more information read the documentation.
All the selectors starting with fade- are the classes created for our .
Head to http://localhost:3000/auth. If everything’s working, we should be able to login with Spotify by clicking the “Login” button, and be redirected back to see this:
This is the fun part! We’ll be creating the view that users will see when they get to our app, commonly referred to as the root or index. This is just a concise way of indicating it is the home file of its directory, and in our case, the entire application.
We’ll need to import our NowPlaying component (we will write it next), and we’ll want to conditionally load it with a v-if binding based on whether or not we are connected and we have track data to show. Our computed nowPlaying() method will return the nowPlaying Object if it has properties (we instantiated an empty object in the store, so it will always exist), and we’ll dispatch an action that we’re connected. We’re passing the track and isPlaying props since they are required to show the component.
We’ll need to create our components next, otherwise this page won’t build.
Components
In Nuxt, components are partial views. They cannot be rendered on their own, and instead, can only be used to encapsulate parts of a layout or page view that should be abstracted. It’s important to note that certain methods Page views have access to, like asyncData() won’t be ever be called in a component view. Only pages have access to a server-side call while the application is starting.
Knowing when to split a chunk of a layout, page, or even component view can be difficult, but my general rule of thumb is first by the length of the file, and second by complexity. If it becomes cumbersome to understand what is going on in a certain view, it’s time to start abstracting.
We’ll split our landing page in three parts, based on complexity:
Index component: The page we just wrote.
NowPlaying component: The container and track information.
Progress component: The animated track progress indicator.
It’s important we include a link to Spotify, as it is a part of the requirements to use their API free of charge. We’re going to pass the progress and image props to our component.
In addition to our computed() data, we will also have another type of reactive data on the data property. This property returns an Object with reactive properties, but these do not need to be re-evaluated. We will be using them for our timing intervals, so the updates will be come from setInterval().
created() runs when our component is done being initialized, so we’ll call our function getNowPlaying(), and start one of our two interval timers, staleTimer, which will run getNowPlaying() once every 10 seconds. You can make this shorter or longer, but keep in mind that Spotify does have rate limiting, so it shouldn’t be any less than a few seconds to avoid getting undesired API failures.
It’s important we add beforeDestroy() and clear our running intervals as a best practice.
In the methods property, we’ll have three functions: getNowPlaying(), updateProgress(), and timeTrack(). updateProgress() will dispatch progress updates to the store, while getNowPlaying() and timeTrack() will do the heavy lifting of keeping our track object hydrated and the progress bar moving every 10th of a second so we have a constantly moving progress bar.
This is an async function because we’re calling out now-playing endpoint, and we’ll want the function to wait until it has an answer to continue. If the item is not null or undefined, we’ll dispatch an update to the status, clearInterval() of our trackTimer (which may not be running, but that’s OK). If the is_playing is true, we’ll call timeTrack(); if it’s false, we’ll call updateProgress(). Last, we’ll check if our updated track is different than the one in our store. If it is, we’ll dispatch an update to the track in store to rehydrate our data.
timeTrack(now, duration, progress) {
const remainder = duration - progress
const until = now + remainder
this.trackTimer = setInterval(() => {
const newNow = Date.now()
if (newNow
components/NowPlaying.vue
This function takes a current time, duration, and progress in milliseconds and starts running an interval every 100 milliseconds to update the progress. until is the time calculated when the track will be finished playing if it is not paused or scrubbed forwards or backwards. When the interval starts, we grab the current time in milliseconds with JavaScript’s Date Object’s now() method. We’ll compare the current time to see if it is less than until plus a buffer of 2500 milliseconds. The buffer is to allow for Spotify to update the data between tracks.
If we determine the track is theoretically still playing, we’ll calculate a new progress in milliseconds and call out the updateProgress() function. If we determine the track is complete, we’ll update the progress to 100%, clearInterval() and call nowPlaying() to get the next track.
section is a display-type grid that keeps the album art and song metadata in two columns, and then on viewports up to 600px wide (the layout switches to two rows).
Progress
Now let’s build our Progress component. A simple solution is a bar using the width of a
Above, we create two rect SVGs. One has a pattern fill of our image, the other is the progress bar. It’s important that whatever shape you use has a total perimeter of 100. This allows us to use the stroke-dasharray to fill the space based on a percentage. The left value is the length of the stroke, the right value is the space between the strokes. The stroke size getting larger pushes the space out of the frame and eventually is the entire length of the perimeter. We added an animation that fills the progress bar from 0 to its current point when the component is rendered.
Head to localhost:3000 and if we did everything right (and you’re playing a song) we should see something like this:
Log in with Spotify on production and start sharing your jam sessions!
?
Conclusion
Phew! We built a universal, server-side rendered application, wrote an API proxy on our server, connected to a Redis cache, and hosted on our application on Heroku. That’s pretty awesome!
Now that we know how to build an application using Nuxt, and have an understanding of what kind of data we should handle securely on the server, the possibilities for interesting applications are endless!
Build On Your Knowledge
Spotify’s API has a medley of endpoints to add more interesting experiences to the application we built, or for composing entirely new ones! You can fork my repository to explore some other components I’ve coded, or read through the docs and apply what you’ve learned to share more musical ideas!
Behind every successful ecommerce website is an ecommerce platform that makes it possible for the business to manage content, promotions, profiles, shopping carts, orders, inventory and fulfillment.
There are many on the market today to choose from, so it can be difficult to know which one is right for you. And when you consider that what works well for one business may not work well for the next, it only makes the decision that much harder.
If you’re trying to decide which ecommerce platform to use or preparing to switch to another that better fits your needs, use this to help guide the decision-making process.
If you’re selling digital products, you need a system that will make it easy to automate product delivery emails and give you the option to limit the number of times the media you’re offering to buyers can be accessed or downloaded.
If you’re selling physical products, there’s shipping to consider. Does the system make it easy to choose between shipping providers, so you can get the best deal on shipping parcels to buyers without having to pass on a huge shipping expense? Is it easy enough to store information about the size and weight of your inventory, so you can print shipping labels with ease? Does the platform have the capability to surface different content experiences and pricing structures to bulk buyers?
Are You Hosting the Store Yourself?
You have the option to choose between a self-hosted platform – where you source your own server from a hosting company and install the ecommerce platform there – and a hosted platform, where all you do is login to the store’s cloud-based backend and the platform handles hosting and software upkeep. The latter is known as Software-as-a-Service, or SaaS.
This might be the biggest differentiating factor for all of the various types of ecommerce platforms on offer today. If you host the store yourself, you’ll have costs associated with hosting, and you’ll need to be sure your host has a high uptime rate, so you can be sure your website is always up and running. You’ll want to know what will happen to your sales emails if another website on the server gets backlisted. You’ll also want to know what kind of security measures they take to protect your website from hacks, and how frequently they save backups.
If you opt for a hosted platform, you’ll likely pay a monthly fee to the service to help them cover the hosting expense and product updates. Which leads us to the next point – the affordability of the pricing model.
Which Pricing Model Is More Affordable?
This primarily depends on your expected sales volume. Some platforms don’t charge a monthly rate but will instead charge a percentage of each transaction to cover their costs. You’ll have to run some calculations based on your projected average transaction figures and the average number of transactions you can expect to process, to help you determine which price model is the more affordable option for you.
Take for instance a comparison between the Basic Plans offered by BigCommerce and Shopify. BigCommerce is $29.95 a month and does not charge a transaction fee, but you’ll have to pay fees if you use PayPal as a payment processor – those fees go to PayPal, to the tune of 2.9% and 30 cents per transaction. Shopify on the other hand, charges $29/month, plus the same 2.9% and 30 cents per transaction you’d pay PayPal.
Yes, on the surface, this means that BigCommerce and Shopify have similar price tags to merchants. Ultimately, though, there are other costs involved, as each platform has different tools, functionalities and themes that come with basic accounts, while billing more monthly fees to access other features. With self-hosted platforms like Magento or WooCommerce, you’ll pay less for the software license, but more for the hosting – and there are often “hidden” development costs, since installable packages generally don’t have the same self-service accessibility that SaaS solutions have.
Is It Easy to Use, and How Much Control Do You Have?
If the people who are responsible for managing your e-shop’s content, transactions and shipments cannot easily use the platform, you’ll lose money in lost productivity and potential errors. While you always have the option to train your staff on a new platform, it makes sense to use one that is intuitive and won’t require a lot of training. In this case, you can sign up for trials of your top two picks, then let the staff vote on which one is easier to use. Even if it’s the more expensive platform, the difference may pay for itself.
Just keep in mind that you’ll usually get the most control over design if you opt for a self-hosted platform, since you’ll have access to the source code. But that also means you have more responsibility to keep things up and running. And if something breaks, it’ll likely be on you to fix it.
If you don’t have a lot of experience designing for e-commerce, it may make more sense to have most of the design covered for you – but if you want to make sure your shop’s interface fits in visually with the rest of your branding, you may feel differently.
Is It SEO Friendly?
If you don’t have control over various SEO elements, like schema, xml sitemaps, page titles and meta descriptions, then you’ll have a harder time ranking the store in search engines, which is vital to your overall success. Ads are expensive, organic social media doesn’t offer the customer acquisition impact that it once did, and while email marketing is huge, you won’t have much of a subscriber list of people don’t have an easy way to find your website.
You want to aim for as much organic traffic as you can, so optimizing your site for discoverability on Google matters. If a given platform strikes you as being not particularly SEO friendly, there’s really no point in investing in it, regardless of how great a platform seems to be otherwise.
Read Up and Run Experiments
Don’t expect to be able to do 15 minutes of research and emerge on the other side confident that you know which platform you want to use for the tech infrastructure of your online store. It’s not a decision to be taken lightly – it has the potential to have too much influence on your bottom line.
Take your time and do your homework when comparing platforms. Make a list of the platforms you’re considering and why, then compare them side by side to help you narrow it down to a couple you want to try. Only when you try the platforms hands-on will you be able to determine which is best for your business.
Smooth scrolling has gotten a lot easier. If you want it all the time on your page, and you are happy letting the browser deal with the duration for you, it’s a single line of CSS:
html {
scroll-behavior: smooth;
}
I tried this on version 17 of this site, and it was the second most-hated thing, aside from the beefy scrollbar. I haven’t changed the scrollbar. I like it. I’m a big user of scrollbars and making it beefy is extra usable for me and the custom styling is just fun. But I did revert to no smooth scrolling.
As Šime Vidas pointed to in Web Platform News, Wikipedia also tried smooth scrolling:
The recent design for moved paragraphs in mobile diffs called for an animated scroll when clicking from one instance of the paragraph in question to the other. The purpose of this animation is to help the user stay oriented in terms of where the paragraph got moved to.
We initially thought this behavior would benefit Minerva in general (e.g. when using the table of contents to navigate to a page section it would be awesome to animate the scroll), but after trying it out decided to scope this change just to the mobile diffs view for now
I can see not being able to adjust timing being a downside, but that wasn’t what made me ditch smooth scrolling. The thing that seemed to frustrate a ton of people was on-page search. It’s one thing to click a link and get zoomed to some header (that feels sorta good) but it’s another when you’re trying to quickly pop through matches when you do a Find on the page. People found the scrolling between matches slow and frustrating. I agreed.
Surprisingly, even the JavaScript variant of smooth scrolling…
…has no ability to adjust timing. Nor is there a reliable way to detect if the page is actively being searched in order to make UX changes, like turning off smooth scrolling.
Perhaps the largest downside of smooth scrolling is the potential to mismanage focus. Scrolling to an element in JavaScript is fine, so long as you almost move focus to where you are scrolling. Heather Migliorisi covers that in detail here.
While [lots of divs, inline styles, focus management problems] are valid concerns, it should be noted that nothing in React prevents us from building accessible web apps.
True. I’m quite capable (and sadly, guilty) of building inaccessible interfaces with React or without.
I’ve long told people that one way to level up your front-end design and development skills, especially in your early days, is to understand how to change classes. I can write a few lines of JavaScript to add/remove an active class and build a tabbed interface quite quickly. But did I build the HTML in such a way that it’s accessible by default? Did I deal with keyboard events? Did I deal with all the relevant aria-* attributes? I’ll answer for myself here: no. I’ve gotten better about it over time, but sadly my muscle memory for the correct pattern isn’t always there.
I’m optimistic though. For example, React has a blessed tabs solution that is accessible out of the box. I reach for those, and thus my muscle memory for building tabs now results in a more accessible product. And when I to routing/linking with Reach Router, I get accessibility “baked in,” as they say. That’s a powerful thing to get “for free,” again, as they say.