The ECMAScript standard has been updated yet again with the addition of new features in ES2019. Now officially available in node, Chrome, Firefox, and Safari you can also use Babel to compile these features to a different version of JavaScript if you need to support an older browser.
Let’s look at what’s new!
Object.fromEntries
In ES2017, we were introduced to Object.entries. This was a function that translated an object into its array representation. Something like this:
This was a wonderful addition because it allowed objects to make use of the numerous functions built into the Array prototype. Things like map, filter, reduce, etc. Unfortunately, it required a somewhat manual process to turn that result back into an object.
let students = {
amelia: 20,
beatrice: 22,
cece: 20,
deirdre: 19,
eloise: 21
}
// convert to array in order to make use of .filter() function
let overTwentyOne = Object.entries(students).filter(([name, age]) => {
return age >= 21
}) // [ [ 'beatrice', 22 ], [ 'eloise', 21 ] ]
// turn multidimensional array back into an object
let DrinkingAgeStudents = {}
for (let [name, age] of DrinkingAgeStudents) {
DrinkingAgeStudents[name] = age;
}
// { beatrice: 22, eloise: 21 }
Object.fromEntries is designed to remove that loop! It gives you much more concise code that invites you to make use of array prototype methods on objects.
let students = {
amelia: 20,
beatrice: 22,
cece: 20,
deirdre: 19,
eloise: 21
}
// convert to array in order to make use of .filter() function
let overTwentyOne = Object.entries(students).filter(([name, age]) => {
return age >= 21
}) // [ [ 'beatrice', 22 ], [ 'eloise', 21 ] ]
// turn multidimensional array back into an object
let DrinkingAgeStudents = Object.fromEntries(overTwentyOne);
// { beatrice: 22, eloise: 21 }
It is important to note that arrays and objects are different data structures for a reason. There are certain cases in which switching between the two will cause data loss. The example below of array elements that become duplicate object keys is one of them.
let students = [
[ 'amelia', 22 ],
[ 'beatrice', 22 ],
[ 'eloise', 21],
[ 'beatrice', 20 ]
]
let studentObj = Object.fromEntries(students);
// { amelia: 22, beatrice: 20, eloise: 21 }
// dropped first beatrice!
When using these functions make sure to be aware of the potential side effects.
Support for Object.fromEntries
Chrome
Firefox
Safari
Edge
75
67
12.1
No
? We can use your help. Do you have access to testing these and other features in mobile browsers? Leave a comment with your results — we’ll check them out and include them in the article.
Array.prototype.flat
Multi-dimensional arrays are a pretty common data structure to come across, especially when retrieving data. The ability to flatten it is necessary. It was always possible, but not exactly pretty.
Let’s take the following example where our map leaves us with a multi-dimensional array that we want to flatten.
Note that if no argument is given, the default depth is one. This is incredibly important because in our example that would not fully flatten the array.
The justification for this decision is that the function is not greedy by default and requires explicit instructions to operate as such. For an unknown depth with the intention of fully flattening the array the argument of Infinity can be used.
As always, greedy operations should be used judiciously and are likely not a good choice if the depth of the array is truly unknown.
Support for Array.prototype.flat
Chrome
Firefox
Safari
Edge
75
67
12
No
Chrome Android
Firefox Android
iOS Safari
IE Mobile
Samsung Internet
Android Webview
75
67
12.1
No
No
67
Array.prototype.flatMap
With the addition of flat we also got the combined function of Array.prototype.flatMap. We’ve actually already seen an example of where this would be useful above, but let’s look at another one.
What about a situation where we want to insert elements into an array. Prior to the additions of ES2019, what would that look like?
let grades = [78, 62, 80, 64]
let curved = grades.map(grade => [grade, grade + 7])
// [ [ 78, 85 ], [ 62, 69 ], [ 80, 87 ], [ 64, 71 ] ]
let flatMapped = [].concat.apply([], curved) // now flatten, could use flat but that didn't exist before either
// [
// 78, 85, 62, 69,
// 80, 87, 64, 71
// ]
Now that we have Array.prototype.flat we can improve this example slightly.
But still, this is a relatively popular pattern, especially in functional programming. So having it built into the array prototype is great. With flatMap we can do this:
Now, remember that the default argument for Array.prototype.flat is one. And flatMap is the equivalent of combing map and flat with no argument. So flatMap will only flatten one level.
Another nice addition in ES2019 is an alias that makes some string function names more explicit. Previously, String.trimRight and String.trimLeft were available.
let message = " Welcome to CS 101 "
message.trimRight()
// ' Welcome to CS 101'
message.trimLeft()
// 'Welcome to CS 101 '
message.trimRight().trimLeft()
// 'Welcome to CS 101'
These are great functions, but it was also beneficial to give them names that more aligned with their purpose. Removing starting space and ending space.
let message = " Welcome to CS 101 "
message.trimEnd()
// ' Welcome to CS 101'
message.trimStart()
// 'Welcome to CS 101 '
message.trimEnd().trimStart()
// 'Welcome to CS 101'
Support for String.trimStart and String.trimEnd
Chrome
Firefox
Safari
Edge
75
67
12
No
Optional catch binding
Another nice feature in ES2019 is making an argument in try-catch blocks optional. Previously, all catch blocks passed in the exception as a parameter. That meant that it was there even when the code inside the catch block ignored it.
try {
let parsed = JSON.parse(obj)
} catch(e) {
// ignore e, or use
console.log(obj)
}
This is no longer the case. If the exception is not used in the catch block, then nothing needs to be passed in at all.
This is a great option if you already know what the error is and are looking for what data triggered it.
Support for Optional Catch Binding
Chrome
Firefox
Safari
Edge
75
67
12
No
Function.toString() changes
ES2019 also brought changes to the way Function.toString() operates. Previously, it stripped white space entirely.
function greeting() {
const name = 'CSS Tricks'
console.log(`hello from ${name}`)
}
greeting.toString()
//'function greeting() {nconst name = 'CSS Tricks'nconsole.log(`hello from ${name} //`)n}'
Now it reflects the true representation of the function in source code.
function greeting() {
const name = 'CSS Tricks'
console.log(`hello from ${name}`)
}
greeting.toString()
// 'function greeting() {n' +
// " const name = 'CSS Tricks'n" +
// ' console.log(`hello from ${name}`)n' +
// '}'
This is mostly an internal change, but I can’t help but think this might also make the life easier of a blogger or two down the line.
I visited the Fandango website last weekend, hoping to find something that would give me an excuse to spend a couple of hours inside an air-conditioned movie theater. This is what first caught my eye when I got there:
The Fandango home page shows a slider with popular movies and their posters. (Image credit: Fandango) (Large preview)
To be honest, most of these movie posters did absolutely nothing to motivate me to leave the house. Except for The Lion King, which has such a striking color palette, and Once Upon a Time in Hollywood, which does some cool stuff with typography.
Has anyone else ever experienced this before? You’re in the mood to watch a movie and either:
Catch a glimpse of the movie poster you were interested in, only to question whether or not it’s even worth watching?
Catch a glimpse of a movie poster you hadn’t given much thought to, but then changed your plan and saw that one instead?
And we’re not even talking about movie trailers here. We’re talking about what a single poster designed to promote a movie and entice people to watch it can do to your perception of it.
If you think about it, the hero image on a PWA has just as much sway over a first-time visitor.
Do your visitors proceed through the PWA with excitement over what they’re about to find? Or do they do so with apprehension due to disappointment or confusion caused by the first image?
Let’s look at some examples of good and bad movie posters and see what sort of lessons we can use to help you with your PWA hero design:
1. Avoid Stock Photos When You Can
In other parts of a PWA, high-quality stock photos purchased from sites like Getty or iStock may suffice. But your hero image?
I’d say you should be very careful with this, especially if using a stock photo that’s easily recognizable. Even if it’s an attractive photo and aligns perfectly well with the brand’s story, do you really think someone else’s imagery belongs at the top of the PWA?
When Aquaman came out in 2018, they released a series of movie posters to promote it. However, it was this particular poster that caused a huge uproar online:
Essentially, the complaints on Twitter boiled down to the usage of this stock photo from Getty:
Twitter users were in an uproar over the Aquaman movie poster. (Image credit: Twitter) (Large preview)
Now, you can expect there to be arguments whenever any major criticism is made of a superhero movie. With camps clearly divided between Marvel and DC movies, it’s kind of hard not to want to defend your superheroes tooth and nail when someone insults them. Even if it’s because of a stock photo of a shark.
The people against the criticism have a point though. It’s not like the real stars of the movie could be submerged in a body of water with live sharks. Aside from stock photography or CGI, what choice did the poster designers really have?
That said, I think what the real issue is, is that this is a huge movie with a huge studio budget, and the inclusion of a stock photo makes you wonder if they cut corners anywhere else in the film.
The usage of recognizable stock photos in a hero image may send the same sort of signal to visitors if they’re expecting an end-to-end premium experience from the brand behind it.
2. Make It Unique
If you watch as many movies as I do, you’re bound to notice certain trends when it comes to movie posters. This is especially so in the rom-com genre where it almost feels like designers don’t bother to be original or creative.
While this lookalike quality of movie posters can help fans of certain genres instantly identify the kinds of movies they want to watch, it sends another signal to them as well.
If you don’t know who Nicholas Sparks is, he’s the author of over twenty books, most of which have similar plots.
I’m going to let this Vanity Fair movie poster compilation demonstrate my point:
A Vanity Fair article shows off various covers from Nicholas Sparks movies. (Image credit: Vanity Fair) (Large preview)
If you were to talk to someone about one of these movies, it could be summed up as:
“You know the movie… The one with the boy and the girl who don’t really like each other at first, but then they fall madly in love and can’t stand to be apart? Oh yeah and there’s that person who dies in the end.”
That describes about 80% of these stories, which is why it’s not all that surprising that the movie posters for each look so darn similar.
Like I said, a similarly designed poster could work in their favor if they were trying to appeal to a very specific subset of moviegoers. But it doesn’t work that way with PWAs.
Unless you’re building a PWA to directly complement another brand, there’s no reason to design your hero image to look similar to anyone else’s. It’ll only cause confusion when visitors pick up on the similarities. Or they’ll wonder why they’re bothering to look at the PWA, assuming that it’s not just the images that look the same, but the services and products within, too.
If you want your PWA to stand out from the crowd, your hero image should be unique.
3. Zero In On One Thing
One of the problems with making a movie with an all-star cast is that’s it’s impossible to focus on just one person — not just within the plot, but in the movie poster as well.
If I were just stumbling upon this poster for the first time, I wouldn’t know where to start with it.
The title being in the middle helps, but the competing photos are overwhelming. Plus, if you look closely at the top photo, you’ll see that each of the women was individually layered into the picture. Why use a poorly compiled photo beside an actual shot from the movie? It creates a very disjointed experience.
To show you what a difference a singular focus can make, let’s look at the movie poster for E.T. the Extra-Terrestrial:
It’s not as though this film is without a great cast of stars. It’s just that the team who designed this recognized that there’s one real focus at the heart of the movie and it’s the relationship between Elliott (the boy) and E.T. (the alien).
I’d urge you to look for something similar when designing your hero image — even if your clients come to you and say that all of their services are equally important and they want the PWA to demonstrate that they can do all things for everyone. If you try to translate that sort of message into an image, it’s going to fail. So, find your focus.
4. Give The City A Subtle Nod
Movies can take place in any number of settings. Depending on what kind of movie it is, you may even find that the setting almost becomes a character within the story. Let me explain.
Richard Linklater filmed a trilogy of movies with Julie Delpy and Ethan Hawke.
The first movie is called Before Sunrise and takes place when Delpy and Hawke decide to get off a train and walk around the city of Vienna before parting the next morning:
In each of these posters, you can see that the backdrop of the story plays heavily into the design. And that’s because there really is no story without their geographic surroundings.
They’re not just movies about two people talking to one another. It’s about two people getting to know one another as they explore a new city — a city which almost becomes like a third character that the viewer becomes acquainted with throughout the films.
If the company for whom you’re designing has a strong tie to a specific geographic region, see if you can find a way to incorporate it into the hero image somehow. It doesn’t have to be this explicit with the actual cityscape in the background. But there may be other ways to add a special touch that has local visitors thinking, “Hey, that’s where I’m from!” or “I’ve been there!”
5. Be Creative With White Space
You already know that white space is an important part of design, especially when you’re trying to convey a big message above-the-fold on a PWA. So as not to overwhelm visitors, you want to keep things simple. But that doesn’t mean you can’t be creative with how you fill that white space.
Although the space ship does convey a sense of dread, it’s also a really creative way to fill up all of the white space that would otherwise occupy the top of this photo.
Another fun example of playing with white space can be seen in the poster for Scarface:
The Scarface movie poster designers likely used symbolism to create this white space. (Image credit: “Scarface” on IMDB) (Large preview)
At first glance, you might just take this for the striking image that it is. However, knowing that Tony Montana is the head of a drug cartel and has an obscene penchant for snorting coke, the white that consumes him takes on another meaning here.
This one is a bit difficult to give you strict guidance on since this is all about being creative with the space that you have. What I would suggest if you want to go this route, though, is to think of ways to play with symbolism without having to explicitly present them within the photo. If you can play with shadows and light and space to do so, that would have a much greater impact.
6. Be Playful With Typography
For the most part, designers of movie posters tend to be very conservative when it comes to typography. They choose a single color for the font and it’s almost always a big blocky sans serif font.
But why not have a little fun with it? Just as you can imbue the image with creative flourishes, it wouldn’t be such a bad idea to do the same with text so long as the two complement one another.
You’ll find a beautiful example of this in the John Wick poster:
If you were to quickly glance at the image, you might not pick up on the subtleties of the design. But they’re there.
For starters, the barrel of the gun takes the place of the letter “o”. But notice how the rim is tinged in the same color as the rest of the letters? This is what helps it blend so well at first glance.
Then, you have the unhinged look of the letters themselves, where they’re split and slanted through the middle.
For those of you who haven’t seen the film, this is essentially what’s happening to Keanu Reeves’s character. He was once an assassin, but gave it up for love. When his wife dies and the last remnants of her are taken from him, he’s torn. Does he continue the life of a normal man? Or does he give it all up and go on a murderous rampage?
I know that the smart thing to do when designing a hero image is to let the image tell the story, but I think subtle touches to the text can really take it up a notch.
Wrapping Up
So, what have we learned here? Well, there’s certainly a right and wrong way to go about designing a movie poster and PWA. But, more than that, the most important thing to do is to put some real thought into what you want those first few seconds to convey to your viewers.
If you fail to capture what the PWA is about or you do so in a manner that’s boring, unoriginal, vague or cheesy, you’re going to lose their interest almost immediately.
But…
If you can perfectly capture what a brand is all about along with the subtle nuances that make it special, you’ll encourage more visitors to scroll and click with a single image.
I’ve tried a handful of websites based on “tip with micropayments” in the past. They come and go. That’s fine. From a publisher perspective, it’s low-commitment. I’ve never earned a ton, but it was typically enough to be worth it.
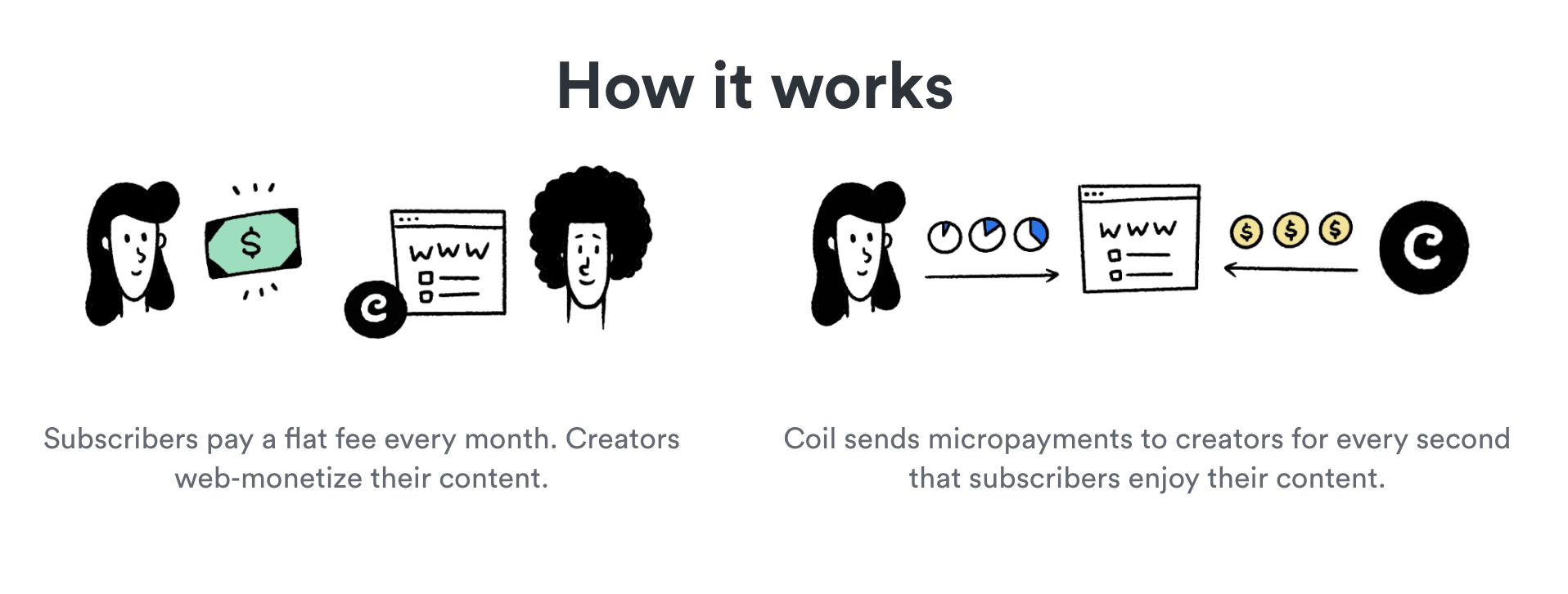
Now Bruce has me trying Coil. It’s compelling to me for a couple reasons:
Coil is nicely designed. It’s the service that readers actually subscribe to and a browser extension (for Chrome and Firefox) that pays publishers.
The money ends up in a Stronghold account1. I don’t know much about those, but it was easy enough to set up and is also nicely designed.
Everything is anonymous. I don’t have access to, know anything about, or store anything from the users who end up supporting the site with these micropayments.
Even though everyone is anonymous, I can still do things for the supporters, like not show ads.
It’s a single tag on your site.
After signing up with Coil and having a Stronghold account, all you really need to do is put a tag in the of your site. Here’s mine:
Readers who have an active Coil subscription and are using the Coil browser extension will start sending micropayments to you, the publisher. Pretty cool.
Non-monetized site.Monetized site (and payments successful)
Cash money
I’ve already made a dollar!
Since everything is anonymous, I didn’t set up any logic to prevent injecting the meta tag if an admin is viewing the site. I bet it’s mostly me paying myself. And Bruce.
The big hope is that this becomes a decent source of revenue once this coerces a web standard and lots of users choose to do it. My guess is it’ll take years to get there if it does indeed become a winning player.
It’s interesting thinking about the global economy as well. A dollar to me isn’t the same as a dollar to everyone around the world. Less money goes a lot further in some parts of the world. This has the potential to unlock an income stream that perhaps things like advertising aren’t as good at accounting for. I hear people who work in advertising talking about “bad geos” which literally means geographic places where advertisers avoid sending ad dollars.
Reward users for being supporters
Like I mentioned, this is completely anonymous. You can’t exactly email people a free eBook or whatever for leaving a donation. But the browser itself can know if the current user is paying you or not.
It’s essentially like… user isn’t paying you:
document.monetization === undefined
User might be paying you, oh wait, hold on a second:
You can do whatever you want with that. Perhaps you can generate a secure download link on the fly if you really wanted to do something like give away an eBook or do some “subscriber only” content or whatever.
Not showing ads to supporters
Ads are generally powered by JavaScript anyway. In the global JavaScript for this site, I literally already have a function called csstricks.getAds(); which kicks off the process. That allows me to wrap that function call in some logic in case there are situations I don’t even wanna bother kicking off the ad process, just like this.
if (showAdsLogic) {
csstricks.getAds();
}
It’s slightly tricky though, as document.monetization.state === 'started' doesn’t just happen instantaneously. Fortunately, an event fires when that value changes:
if (document.monetization) {
document.monetization.addEventListener("monetizationstart", event => {
if (!document.monetization.state === "started") {
getAds();
}
});
} else {
getAds();
}
And it can get a lot fancier: validating sessions, doing different things based on payment amounts, etc. Here’s a setup from their explainer:
if (document.monetization) {
document.monetization.addEventListener("monetizationstart", event => {
// User has an open payment stream
// Connect to backend to validate the session using the request id
const { paymentPointer, requestId } = event.detail;
if (!isValidSession(paymentPointer, requestId)) {
console.error("Invalid requestId for monetization");
showAdvertising();
}
});
document.monetization.addEventListener("monetizationprogress", event => {
// A payment has been received
// Connect to backend to validate the payment
const {
paymentPointer,
requestId,
amount,
assetCode,
assetScale
} = event.detail;
if (
isValidPayment(paymentPointer, requestId, amount, assetCode, assetScale)
) {
// Hide ads for a period based on amount received
suspendAdvertising(amount, assetCode, assetScale);
}
});
// Wait 30 seconds and then show ads if advertising is no longer suspended
setTimeout(maybeShowAdvertising, 30000);
} else {
showAdvertising();
}
I’m finding the monetizationstart event takes a couple of seconds to fire, so it does take a while to figure out if a user is actively monetizing. A couple of seconds is quite a while to wait before starting to fetch ads, so I’m not entirely sure the best approach there. You might want to kick off the ad requests right away, then choose to inject them or not (or hide them or not) based on the results. Depending on how those ads are tracked, that might present false impressions or harm your click-through rate. Your mileage may vary.
How does the web standard stuff factor in?
Here’s the proposal. I can’t pretend to understand it all, but I would think the gist of it is that you wouldn’t need a browser extension at all, because the concept is baked into the browser. And you don’t need Coil either; it would be just one option among others.
1 I’m told more “wallets” are coming soon and that Stronghold won’t be the only option forever. ?
Many developers write about how to maintain a CSS codebase, yet not a lot of them write about how they measure the quality of that codebase. Sure, we have excellent linters like StyleLint and CSSLint, but they only help at preventing mistakes at a micro level. Using a wrong color notation, adding a vendor prefix when you’re already using Autoprefixer, writing a selector in an inconsistent way… that kind of thing.
We’re constantly looking for ways to improve the way we write CSS: OOCSS, BEM, SMACSS, ITCSS, utility-first and more. But where other development communities seem to have progressed from just linters to tools like SonarQube and PHP Mess Detector, the CSS community still lacks tooling for deeper inspection than shallow lint rules. For that reason I have created Project Wallace, a suite of tools for inspecting and enforcing CSS quality.
What is Project Wallace?
At the core, Project Wallace is a group of tools that includes a command line interface, linter, analysis, and reporting
Here’s a quick rundown of those tools.
Command Line Interface
This lets you run CSS analytics on the command line and get statistics for any CSS that you feed it.
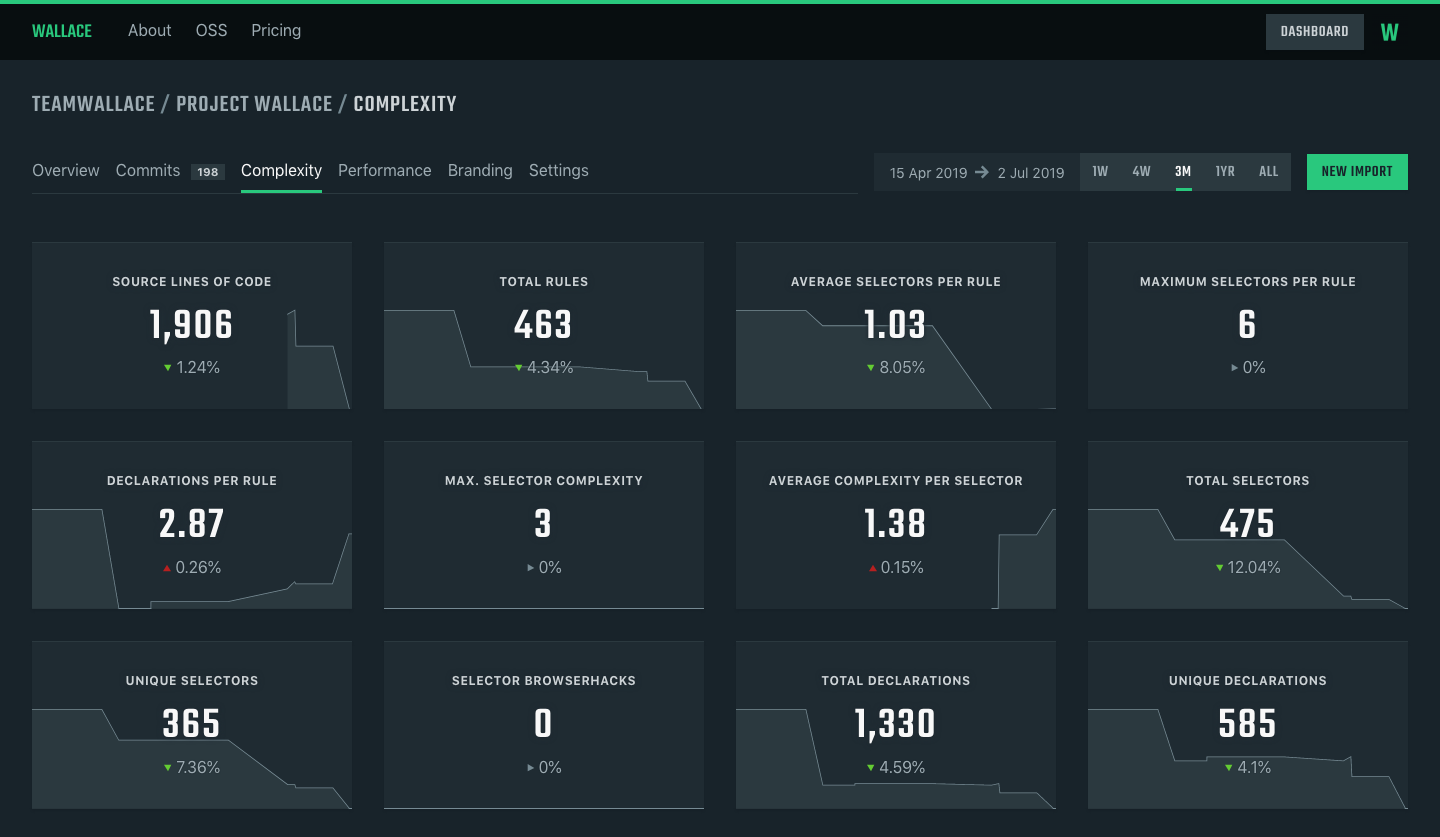
Example output for projectwallace.com
Constyble Linter
This is a linter designed specifically forCSS. Based on the analytics that Wallace generates, you can set thresholds that should not be exceeded. For example, a single CSS rule should not contain more than 10 selectors, or the average selector complexity should not be higher than three.
Analysis
Extract-CSS does exactly what the name says: Extract all the CSS from a webpage, so we can send it over to projectwallace.com for analysis.
Reporting
All analysis from Extract CSS is sent over to projectwallace.com where a dashboard contains all of the reporting of that data. It’s similar to CSS Stats, but it tracks more metrics and stores the results over time and shows them in a dashboard. It also shows the differences between to points in time, and many, many more features.
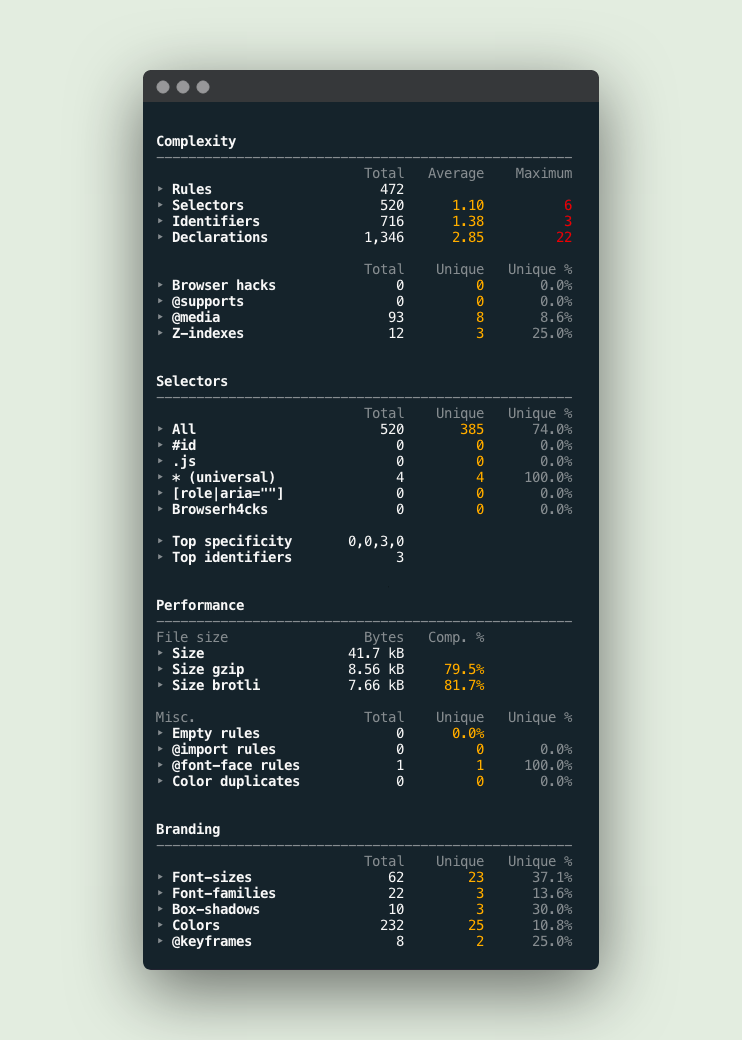
A complexity analysis generated by projectwallace.com
Analyzing CSS complexity
There aren’t many articles about CSS complexity but the one that Harry Roberts (csswizardry) wrote got stuck in my brain. The gist of it is that every CSS selector is basically a bunch of if-statements, which reminded me of taking computer science courses where I had to manually calculate cyclomatic complexity for methods. Harry’s article made perfect sense to me in the sense that we can write a module that calculates the complexity of a CSS selector — not to be confused with specificity, of course, because that’s a whole different can of worms when it comes to complexity.
Basically, complexity in CSS can appear in many forms, but here are the ones that I pay closest attention to when auditing a codebase:
The cyclomatic complexity of CSS selectors
Every part of a selector means another if-statement for the browser. Longer selectors are more complex than shorter ones. They are harder to debug, slower to parse for the browser and harder to override.
.my-selector {} /* 1 identifier */
.my #super [complex^="selector"] > with ~ many :identifiers {} /* 6 identifiers */
Declarations per ruleset (cohesion)
A ruleset with many declarations is more complex than a ruleset with a few declarations. The popularity of functional CSS frameworks like Tailwind and Tachyons is probably due to the relative “simplicity” of the CSS itself.
More code means more complexity. Every line of code that is written needs to be maintained and, as such, is included in the reporting.
Average selectors per rule
A rule usually contains 1 selector, but sometimes there are more. That makes it hard to delete certain parts of the CSS, making it more complex.
All of these metrics can be linted with Constyble, the CSS complexity linter that Project Wallace uses in its stack. After you’ve defined a baseline for your metrics, it’s a matter of installing Constyble and setting up a config file. Here’s an example of a config file that I’ve pulled directly from the Constyble readme file:
{
// Do not exceed 4095 selectors, otherwise IE9 will drop any subsequent rules
"selectors.total": 4095,
// We don't want ID selectors
"selectors.id.total": 0,
// If any other color than these appears, report an error!
"values.colors.unique": ["#fff", "#000"]
}
The cool part is that Constyble runs on your final CSS, so it does its thing only after all of your preprocessed work from Sass, Less, PostCSS or whatever you use. That way, we can do smart checks for the total amount of selectors or average selector complexity — and just like any linter, you can make this part of a build step where your build fails if there are any issues.
Takeaways from using Project Wallace
After using Project Wallace for a while now, I’ve found that it’s great for tracking complexity. But while it is mainly designed to do that, it’s also a great way to find subtle bugs in your CSS that linters may not find because of they’re checking preprocessed code. Here’s a couple of interesting things that I found:
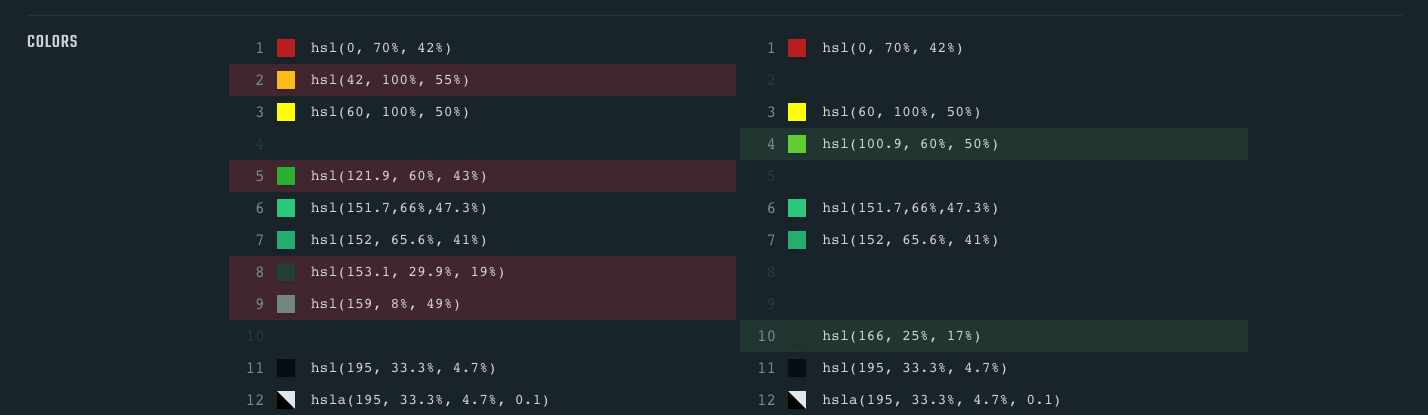
I’ve stopped counting the amount of user stories in our sprints where we had to fix inconsistent colors on a website. Projects that are several years old and people entering and leaving the company: it’s a recipe for getting each and every brand color wrong on a website. Luckily, we implemented Constyble and Project Wallace to get stakeholder buy-in, because we were able to proof that the branding for our customer was spot on for newer projects. Constyble stops us from adding colors that are not in the styleguide. A color graph proving that our color game is spot on. Only a handful of colors and only those that originate from the client’s styleguide or in the codebase.
I have installed Project Wallace webhooks at all the projects that I worked on at one of my former employers. Any time that new CSS is added to a project, it sends the CSS over to projectwallace.com and it’s immediately visible in the projects’ dashboard. This makes it pretty easy to spot when a particular selector of media query was added to the CSS. “Hey, where did that orange go?” An example diff from projectwallace.com.
The CSS-Tricks redesign earlier this year meant a massive drop in complexity and filesize. Redesigns are awesome to analyze. It gives you the opportunity to take a small peek behind the scenes and figure out what and how the authors changed their CSS. Seeing what parts didn’t work for the site and new parts that do might teach you a thing or two about how rapidly CSS is moving forward.
A large international company based in the Netherlands once had more than 4,095 selectors in a single CSS file. I knew that they were growing aggressively in upcoming markets and that they had to support Internet Explorer 8+. IE9 stops reading all CSS after 4,095 selectors and so a good chunk of their CSS wasn’t applied in old IE browsers. I sent them an email and they verified the issue and fixed it right away by splitting the CSS into two files.
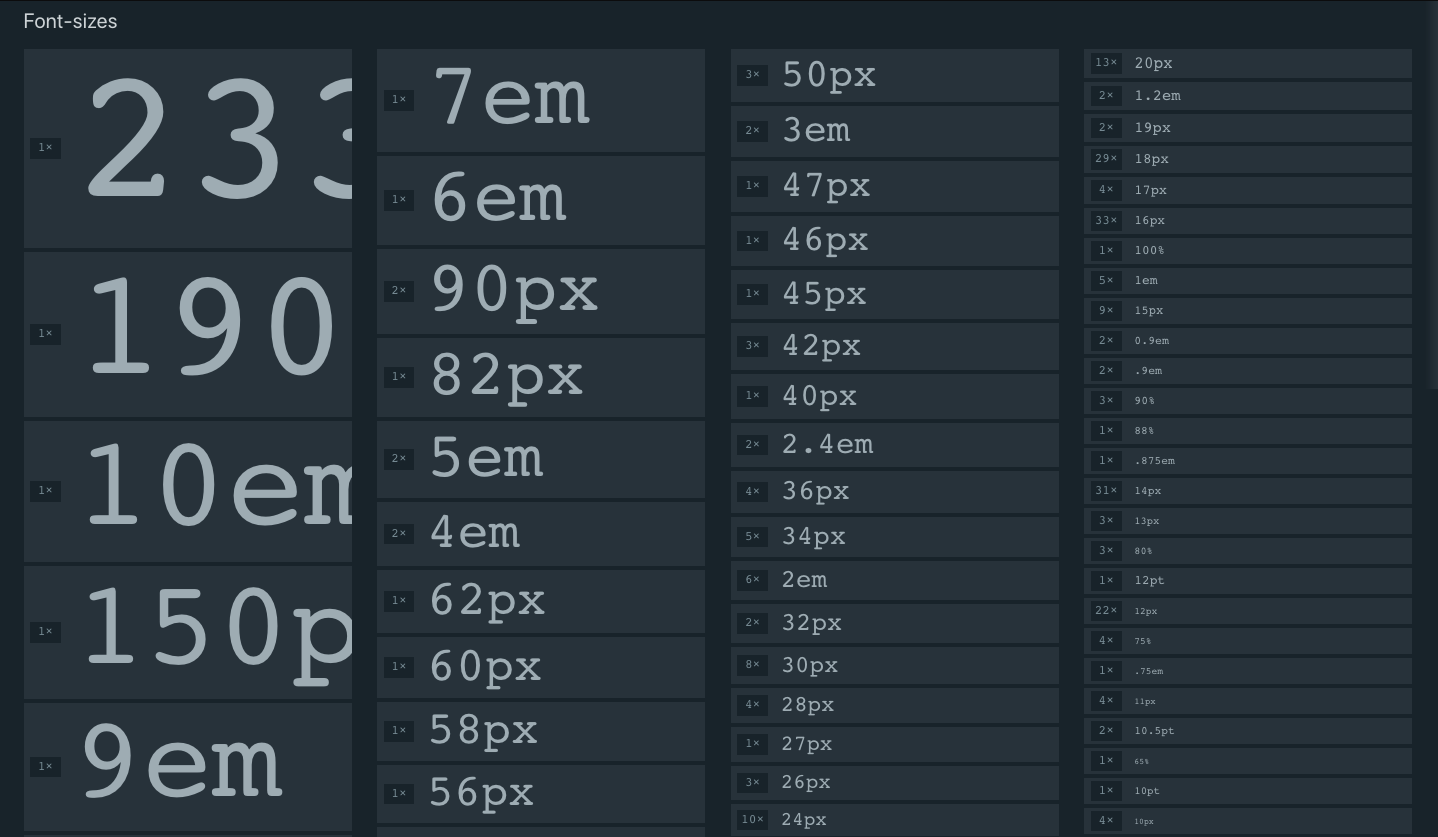
GitLab currently uses more than 70 unique font sizes. I’m pretty sure their typography system is complex, but this seems a little overly ambitious. Maybe it is because of some third party CSS, but that’s hard to tell. A subset of the 70+ unique font-sizes used at GitLab.
When inheriting a project from other developers, I take a look at the CSS analytics just to get a feel about the difficult bits of the project. Did they use !important a lot? Is the average ruleset size comprehensible, or did they throw 20+ declarations at each one of them? What is the average selector length, will they be hard to override? Not having to resort to .complex-selector-override[class][class][class]...[class] would be nice.
A neat trick for checking that your minification works is to let Constyble check that the Lines of Code metric is not larger than 1. CSS minification means that all CSS is put on a single line, so the Lines of Code should be equal to 1!
A thing that kept happening in another project of mine was that the minification broke down. I had no idea, until a Project Wallace diff showed me how a bunch of colors were suddenly written like #aaaaaa instead of #aaa. This isn’t a bad thing necessarily, but it happened for so many colors at the same time, that something had to be out of order. A quick investigation showed me that I made a mistake in the minification.
StackOverflow has four unique ways of writing the color white. This isn’t necessarily a bad thing, but it may be an indication of a broken CSS minifier or inconsistencies in the design system.
Facebook.com has more than 650 unique colors) in their CSS. A broken design system is starting to sound like a possibility for them, too.
A project for a former employer of mine showed input[type=checkbox]:checked+.label input[type=radio]+label:focus:after as the most complex selector. After inspecting carefully, we saw that this selector targets an input nested in another input. That’s not possible to do in HTML, and we figured that we must have forgotten a comma in our CSS. No linter warned us there.
Nesting in CSS preprocessors is cool, but can lead to buggy things, like @media (max-width: 670px) and (max-width: 670px), as I found in Syntax.fm.
This is the tip of the iceberg when it comes to Project Wallace. There is so much more to learn and discover once you start analyzing your CSS. Don’t just look at your own statistics, but also look at what others are doing.
I have used my Constyble configs as a conversation piece with less experienced developers to explain why their build failed on complex chunks of CSS. Talking with other developers about why we’re avoiding or promoting certain ways of writing CSS is helpful in transferring knowledge. And it helps me keep my feet on the ground too. Having to explain something that I’ve been doing for years to a PHP developer who just wanted to help out makes me re-think why I’m doing things the way I do.
My goal is not to tell anyone what is right or what is wrong in CSS, but to create the tools so that you can verify what works for you and your peers. Project Wallace is here to help us make sense of the CSS that we write.
On any given day, walk into your local coffee shop and you’ll likely see someone situated at a table, staring into a computer screen. Without knowing any details, one thing’s for sure, it’s obvious they’re ‘at work’. Many of us have been there at some point in our careers—all we need is a power outlet, internet access, and we’re good to go.
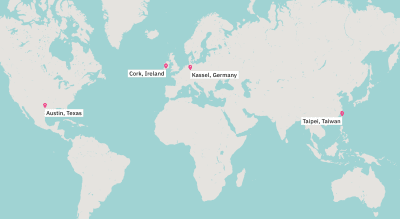
As a software developer for a global company, I have the benefit of collaborating with people from all over the world. Here, from the IBM Design Studio in Austin, Texas, approximately 4,500 miles and at least a fifteen-hour flight separate myself from the nearest developers on our product team. If we consider the furthest members, try 18 hours away by plane, literally on the other side of the planet.
In this current role, I’m a part of a multi-site team where most of the technical people are based out of two primary locations: Cork, Ireland and Kassel, Germany. On this product team, I happen to be the only satellite developer based in Austin, although I do have the benefit of sitting alongside our design team.
Scenarios like these are common nowadays. In 2018, Owl Labs found that 56% of the participating companies in their study adopted or allowed for some form of remote arrangement for its employees. While this organizational approach has revolutionized the way we perform our job functions, it’s also paved the way for new patterns to emerge in the way we interact with each other across the distance.
Our product dev team is spread across the globe. (Large preview)
Connecting With People
I’ve always found that the most fascinating aspect of a distributed team is its people. The ‘diversity of people’, in itself, deserves emphasis. In my view, this mix of skills, knowledge, and perspectives make up the heart of the experience. Being able to integrate with people from various backgrounds is eye-opening. Hearing different accents, discovering new ways to look at problems, and learning about world cultures all within the normal flow of the day is simply refreshing.
At the same time, one of the biggest hurdles for those on remote teams is forming a relationship with your colleagues, that genuine human connection. In a 2018 study by And Co and Remote Year, 30% of the respondents reported lack of community as the number one factor impacting their happiness at work, understandably so. Having virtual colleagues makes it easy to fall into the trap of thinking ‘we all have individual assignments, we only need to interact when our work crosses paths, and all we’re here to do is deliver’.
It’s just not enough.
Throughout my career, almost every project I’ve worked on involved others that were remote in some capacity. In this context, I’ve learned plenty about what it takes to build meaningful partnerships with people across varying distances and multiple time zones. My hope is that the following list of suggestions and ideas can help others out there who are navigating through the challenge of building actual human connections with their teammates.
Problem:Sometimes, remote team members can be mistakenly reduced or perceived as ‘contributors only’. In some cases, people are actually referred to as ‘resources’, literally.
About a year ago, I was on a kick-off call for a project where the client was headquartered in another city. At one point during the virtual meeting, I politely asked one of the client-stakeholders about credentials and ownership of a third-party app that they used. It was a fair question, I was simply gathering requirements. But his response towards me was belittling and unprofessional, making it seem as if I were questioning his knowledge or authority. From then on, it’s been a personal goal of mine to always acknowledge remote colleagues as people, not just resources.
At the very minimum, great collaborations are comprised of individuals who respect and care about one another on a holistic level. Sure, we collectively share the same objectives, but we’re also more than just workers. The very idea of ‘having a genuine connection with people you work with‘, is a proven motivator for many when it comes to job satisfaction. It makes sense because as human beings, we have an innate need to connect with one another—this is especially true on remote teams.
These are some ways to remind us that people are the foundation of your team:
Proactively introduce yourself to as many teammates as possible.
Learn about each other, share cultures, stories, and professional backgrounds.
Be mindful of your audible and legible tone (on calls and chats), keep it friendly and respectful.
2. Building A Continuous Improvement Culture
Problem:As remote team members, we can find ourselves stranded on an island if we don’t ask for help sooner than later.
Oftentimes, we make the mistake of believing that in order to bring value to the team, we must know everything (all the time). This ‘rugged individualist‘ mentality is a one-way ticket to imposter syndrome. The next thing you know, a significant amount of time passes, your progress remains stagnant, and by the time someone extends a hand you’re already underwater. Remember, no one knows everything, and more importantly, teams thrive off of collaboration. We learn together.
The best functioning teams that I’ve been on all had a healthy continuous learning culture. On these teams, failure is okay, especially when our mistakes are transformed into learning opportunities. When working on a remote team, instead of running or hiding from our mistakes, I personally recommend that we fail in “public”. This lets the team know that you hired a human, one who’ll run into stumbling blocks and will inevitably produce errors. By doing so, this gives others the opportunity to either offer assistance, or learn.
Asking for help and admitting mistakes allow you to improve your craft. (Large preview)
You can contribute to the team’s improvement culture in the following ways:
Leverage public channels to show when you’re stuck, this allows the group to help or point you in the right direction.
Share what you’ve learned in public channels, retrospectives, or through documentation.
Spend time listening and scanning for ways to help others.
When you do help your team, remind them that everyone asks for help and how you are all on this journey together.
3. Reading Emotions Across The Distance
Problem:Understanding someone’s emotional state is already difficult when you’re in the same office. When it comes to communicating online, getting a good read on someone’s tone, feelings, or intent, becomes even more challenging.
In person, it’s relatively easier to exercise soft-skills because you’re in the same physical space as your colleagues. From laughter to frustration, there’s an advantage we gain from being co-located when it comes to interpreting how someone is feeling. We can gauge these emotions based off of vocal inflections, facial expressions, and gestures.
However, when we’re far from teammates, we have to be more creative when trying to convey or pick-up on these sentiments. When I breakdown how I communicate with my team throughout the day, about 90% of it occurs in chats; the remaining 10% is split between in conference calls, email, and any other tool that allows for commenting. In each of these modes, we have to clearly convey not only what we say, but what we mean and how we feel.
Using the appropriate emoji can allow others to have a better grasp of how you might feel. (Large preview)
We can improve our team’s collective ability to read and convey emotions in the following ways:
Video calls provide a visual and audible opportunity to pick up on our expressions; turn on the camera and smile at each other.
Instead of just focusing on business objectives, develop the habit of paying particular attention to tone and feelings when communicating with your team.
Use the appropriate emoji to supplement your thoughts or reactions; these fun and effective special characters can help to surface your feelings.
4. A Little Extra Effort Can Bridge The Gap
Problem:The physical mileage between team members and multiple time-zones can cause a strain in our effort to connect with our colleagues.
With Germany being 7 hours ahead and Ireland being 6, I am constantly reminded how the time difference is an issue. On most occasions, when I have questions or run into some sort of blocker anytime after lunch, all of our dev team is offline.
If I worked the typical 9-to-5 schedule, I’d only have about 3 to 4 hours of an overlap with my remote team. It took me a few weeks to fully realize how much the time difference was a factor, but once I did, I decided to flex my schedule.
When I learned that our Ireland team had daily standups at 10:30 AM, (4:30 AM our time), I asked to be invited to those meetings. Most people might think: that’s way too early! But, for a couple of weeks, I joined their call and found it to be incredibly helpful from an alignment and tracking perspective. More importantly, the team understood that I was here to be as helpful as possible and was willing to sacrifice my own conveniences for the sake of the team.
While we can’t do much about the distance, there are a few strategies to potentially improving the overlap:
Find creative ways to extend yourself for the interest of the team; these gestures show good faith and the willingness to make things better for the group.
Be equally accommodating towards others and reciprocate the flexibility your colleagues show towards one another.
Take the most advantage of the overlapping time, ask critical questions, and ensure no one is blocked from making progress.
5. Staying Thankful At The Core
Problem:In our work, we spend almost every minute of every day focusing our attention on solving some sort of problem.
Deeply embedded into my personal culture is an appreciation mindset; practicing gratitude allows me to maintain a fairly good mood throughout the day. I regularly think about how blessed I am to work in the tech industry, helping to solve some of the world’s most challenging problems. I can never take this for granted. Being able to listen to my favorite hip hop playlists, writing code all day, and having access to learning from a wealth of individuals, this is a dream come true. This thankful mentality stays with me no matter what and it’s something I aim to emit when interacting with my team.
It’s not always easy though. In the tech industry, we spend nearly every minute of the day, using our skills and creativity to find our way out of a problem. Sometimes we’re focused on business problems, maybe we’re solving a user pain point, or maybe we’re managing an internal team issue. This repetition, over time, this can take a toll on us, and we could forget why we even chose to do this.
Keeping a positive attitude can help lift team morale and has been known to make you a better collaborator. Even though you may be far from your teammates, your attitude comes through in your work and communications. Here are some pointers to keep in mind when showing appreciation towards your team:
Use company tools to acknowledge a teammate.
Ask teammates how they’d like to be recognized, and thank them accordingly.
Relay positive feedback to a colleague’s lead or manager.
At IBM, we use the Recognition platform to acknowledge our peers. (Large preview)
Remember To Be Human
You see them on various social media platforms, posts or photos of a team retreat where employees step away from their projects for a few days to focus on team-building. Some organizations intentionally design these events into their annual schedules; it’s an excellent way to bridge the gaps and facilitate bonding. Many teams return home from these retreats and experience improved alignment and productivity.
For other organizations, having the ability to meet face-to-face with your remote counterparts isn’t an option. In these cases, we have to make the best of our circumstances by depending on our soft-skills and creativity to help form the alliances we need. I’m confident that by caring for one another as people first, we collectively become better at what we do.
Behind every @username, profile picture, and direct message is a person, one who probably cries and rejoices for the same reasons you might. As technology continues to influence new social behaviors that shape the way we work, it’s important to remember that phenomenal teams are composed of individuals who understand each other and care for one another.
People make products, it’s not the other way around. No matter how far the distance between you and your teammates, I encourage you to make a conscious effort to connect with one another, invest in long-lasting friendships, and last but not least, remember to be human.
Some of the new tools in this month’s roundup are designed for productivity and getting ahead, from a tool that converts text to speech to a font that’s made for the winter holidays. That’s the whole point of new tools – to make our design lives that much easier. Here’s what’s new for designers this month.
Paaatterns
Paaatterns is a collection of vector patterns for backgrounds, fills, and anywhere you want an interesting design element. The patterns here are strong with bright colors and geo shapes. The collection is free to download and comes in multiple formats, including Sketch, Figma, XD, Illustrator as well as SVG and PNG.
Verby
Verby is a free text to speech tool that lets you create and download natural voices as MP3 files. The free version is even available for commercial use. This can be a valuable tool for websites or apps, online learning tools, video broadcasting, audiobook production, or communication accessibility. (There’s also a premium version with even more voice options.)
Dashblock
Dashblock uses a machine-learning model that can turn any website into an API. Go to a page, right-click on the data you want and save a custom API that you can query.
Rooki.design
Rooki.design is a magazine for design students and junior designers. It’s packed with features and resources to help rookies get acclimated into the design industry. Rooki.design is developed and managed by a student designer, Edoardo Rainoldi.
Gradient Magic
Gradient Magic is a huge gallery of CSS gradients in so many colors and styles that you might get lost browsing through all the combinations. Pick a style – standard, angular, stripes, checkered, burst – and color palette to get started. Then you can view and copy CSS for any selection you like.
Dynamic Charts
Dynamic Charts is a GitHub project that allows you to create animated charts and visualize data using React. Charts can use custom callbacks, labels, and allow you to run by command. There’s default styling that makes it easy to use, but you can go crazy with the design to make it your own.
Components AI
Components AI describes itself as an “experimental platform for exploring generative design systems.” It’s a neat concept that allows you to cycle through ideas and tweak designs until they are just right and then save and export for use.
Avant UI
Avant UI is a Bootstrap-based user interface kit that’s packed with sleek elements and animations. Everything is customizable, although the core design might be all you need. The UI kit includes almost every type of component you can imagine, including colors and gradients, buttons, inputs, dropdowns, alerts, tables, thumbnails, carosels, and more.
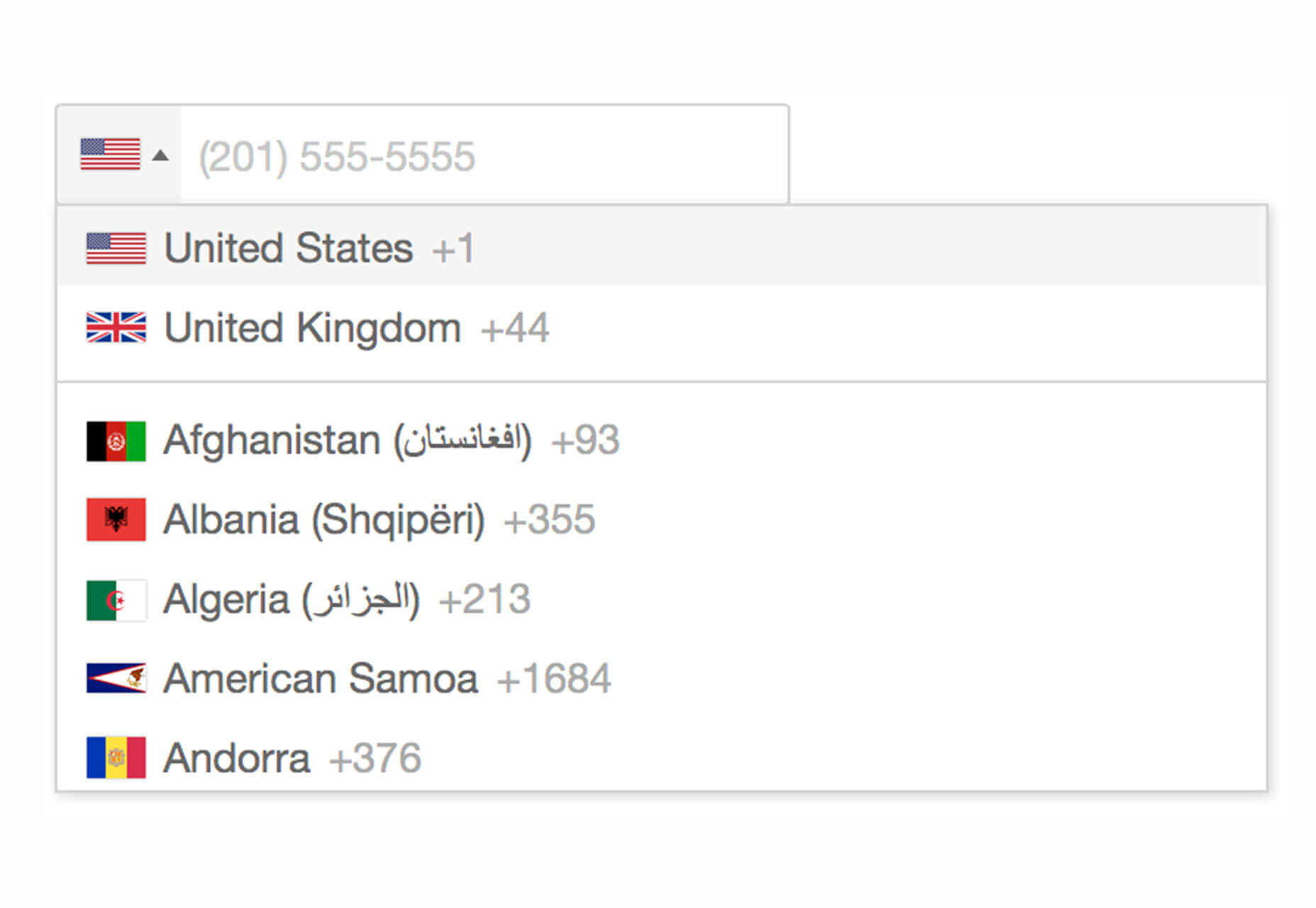
Tutorial: Phone Number Field Design Best Practices
It might be one of the most common fields in online forms, but do you ever stop to think about how phone number inputs work? Nick Babich has an excellent tutorial on how to best design these inputs for usability and efficiency. The tips include not splitting fields, using a country selector, and auto-formatting.
Money Vector Icons
Show me the money (icons)! This vector pack includes 50 icons that show currency, banks, and credit in three designed styles.
Stories Illustrations
Stories is an illustration kit with 11 vectors and characters that can tell a business story. The premium kit comes in AI and SVG format for easy use and manipulation.
Isometric
Isometric is a collection of free icon-style scenes that you can use in digital projects. Each illustration is an a true isometric style and SVG format featuring dozens of different designs.
jExcel v3
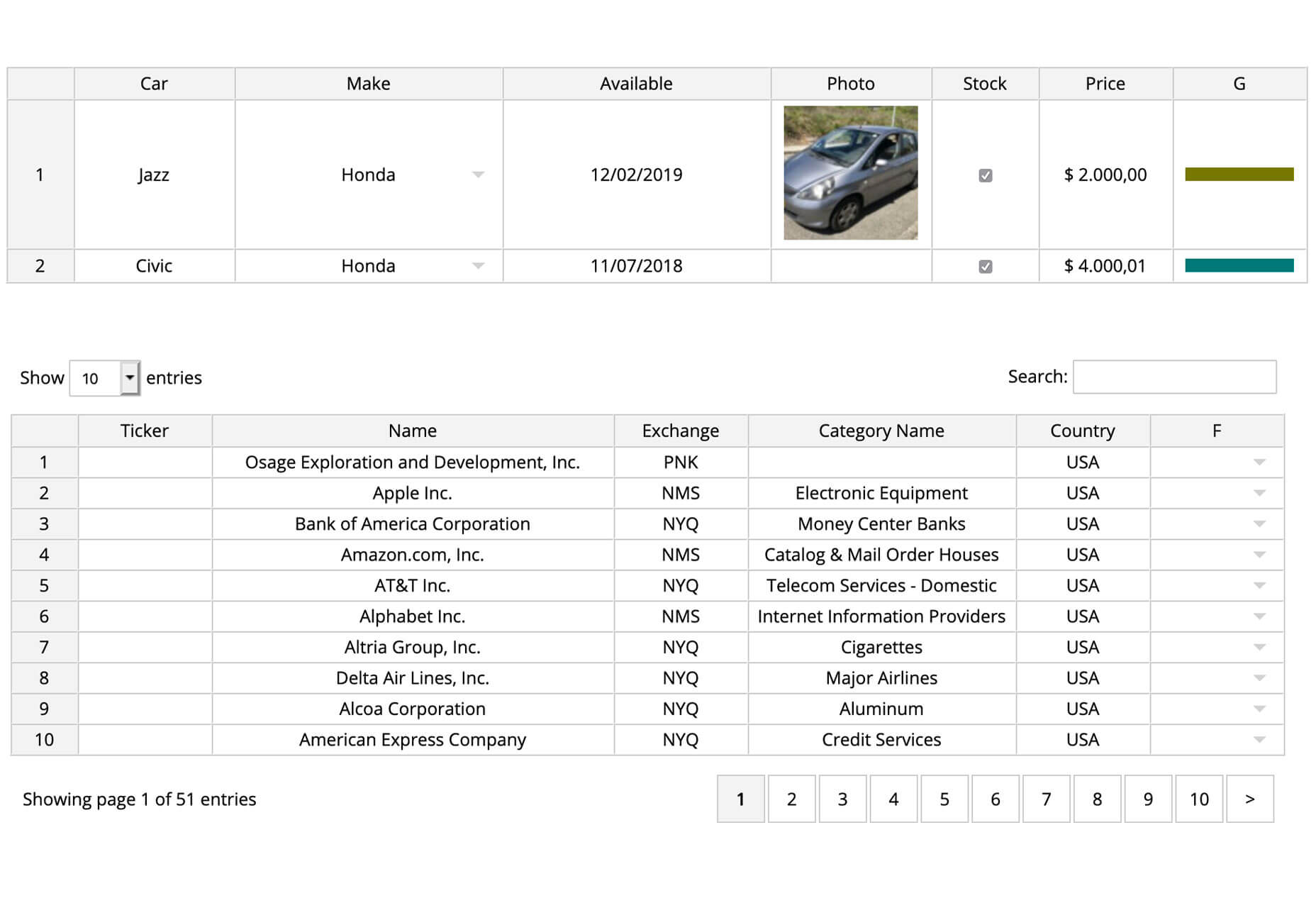
jExcel v3 is a tool to help you build spreadsheets online with columns, rows, and multiple data formats. From the developer: “jExcel is a lightweight vanilla javascript plugin to create amazing web-based interactive tables and spreadsheets compatible with Excel or any other spreadsheet software. You can create an online spreadsheet table from a JS array, JSON, CSV or XSLX files. You can copy from excel and paste straight to your jExcel spreadsheet and vice versa.”
Space Browser
Space Browser lets you organize all those unruly website tabs into smart folders that make it easy to go back to often used websites and track browsing history. You can also share and sync for collaboration with the tool.
Drama
Drama is a Mac app that’s still in beta and designed to help you draw user interfaces, create prototype, and make animations all in one location.
Font Awesome Duotone
Font Awesome now has a duotone option for Pro users. The style includes two-color options for over 1,600 icons.
Cocomat Pro
Cocomat Pro is a delightful grotesque style typeface with nice ligatures and interesting lines. The premium typeface includes a full family of styles and works for a variety of uses for almost all type elements.
Grinched 2.0
It’s never too early to start holiday planning. Save this font for those projects. Grinched 2.0 is a fun character-style typeface with a full character and number set.
Lansdowne Decorative Font
Lansdowne Decorative Font is just what you’d expect from the name. It includes all caps upper- and lowercase letters with tons of glyphs for personality in your typesetting. It has a vintage style that’s a fun option for light text and display use.
Mobstex
Mobstex is an uppercase handwriting style typeface with a light feel. The thin lines are somewhat elegant and provide visual interest.
Oliver
Oliver is a sans serif typeface featuring an uppercase character set in three weights. It could make a nice display option in light, regular, or bold.
It’s no secret anymore that a good social media presence can bring anyone some sweet cash. It’s also no secret that in order to start making money online and become an “influencer,” you have to put a lot of work into your online activity and image. From personalized messages, engaging videos, spontaneous stories, charming photos, to matching backgrounds and fonts, they are all contributing keys to an attractive and followable account. But nothing would matter if the style, the theme, and the design you choose doesn’t match YOU.
If color, glow, bold typography, radical shapes, and retro aesthetics define you, you have to show it to your audience in the purerest forms. How? Let me introduce you to the ultimate social media kits with a retro vibe. Start being your true self online and the followers with flow.
Let’s get started.
1. OMG80s Background Image Pack
The combination of bright colors and radical shapes has always been the ace up the sleeve of many big companies when it came to marketing. Why not use this trend to your own benefit? OMG80s Image Pack not only features eye-catching colors, but the images also come in a square shape, ready for Instagram or Facebook!
2. 80s Synthwave Square Art Pack
Words and images go hand-in-hand when transmitting a message. But words need to have their own personality, too, which can simply be achieved if you use the right font. What looks more like the 80s and sounds more like the 80s than Synthwave? The music genre transcribed into this font masterpiece will wow your followers and fans. Now, the message is just as important. Whether you are the girly, all pink type or the high-fashion guy that prefers quality over anything, use this versatile Art Pack. It will do the job well. Moreover, the files are highly editable and the guide will teach you how to use them.
3. BOLD Social Media Brand Templates
Do you plan on creating your own brand or do you already own a brand? Get your campaign going the right, retro way! Inspired by the Swiss design, this pack of Bold Social Media Brand Templates features bold fonts and overlaying images that create a visual impact. With only a few clicks you can design perfect, captivating Instagram, Facebook, Twitter, and Pinterest posts. The 90 PSD File Design will make your account on any of the mentioned platforms popular in no time.
4. Celebgram Instagram Fashion Pack
Everybody can sell clothes online, but not everybody can do it with style. This particular pack screams glam-retro, and it’s perfect for anyone going for that vibe. The kit comes with 10 Photoshop/Illustrator files, and the templates are optimized for Instagram. You can customize pretty much every aspect of these templates, so let your inner retro-glam shine.
5. Retro 80’s Social Media Template Pack
One of the biggest fashion trends from the 80s and 90s were the colors! Pastels, pinks, blues, and many more lit up the design world back then, and it’s definitely something that needs to be incorporated into any retro-themed social media kit. This particular kit comes with 9 templates in 5 different colors. All of which can be edited in Photoshop.
The 80s were wild, weren’t they? Any time you look back on old pictures, or see movies from that time, they had the strangest patterns on their clothes, in their carpets, and painted on their walls. These abstract patterns are definitely signature 80s retro, and they’re differently the perfect fit for any retro-inspired design. The Flat Memphis Style Instagram Stories Collection takes everything we remember and loved about the 80s and crammed it into 9 templates. Each template has similar style, but they all most cool colors and wild patterns that is unmistakably retro 80s.
7. NEORD Social Media Brand Templates
As we’ve stated before, bold is the theme for the 80s and 90s. At least, what is considered bold to us now. The NEORD kit has lots of bold lines, sharp patterns, and interesting color choices, making it perfect for a retro vibe. Everything is easily editable, and it includes 30 files for Insta, Facebook, and Pinterest. It’s worth the purchase for the uniqueness alone.
8. Stream 10 Duotone Instagram Posts
Some of the best designs out there take inspiration from previous trends, and put a modern twist on it. The Stream 10 Duotone Instagram Posts are a perfect example of reimagined design. These10 Photoshop files take all the vibrant colors from the 80s and 90s and turns them into unique gradients that are sure to light up anyone’s Instagram feed. But, as cool as the colors are, you can certainly edit them if you want to in Photoshop.
9. Colorful Summer Party
Hosting a party soon? Want to shout it out on Instagram? Then you’ve found the perfect retro-inspired stories template to do it. This social media kit comes with 9 vibrant templates that are perfect to share your upcoming house party. Or, maybe you have other ideas for how to use this. No worries. Simply drop it into Photoshop, and change any aspect you’d like.
Start posting
These are just a few of our favorite retro inspired social media kits out there right now. That being said, there are plenty more on the market you can choose from. There is a very clear theme present throughout all of them, but the uniqueness of each one is why they made this list
The key to nailing any retro-themed design is clearly the right choice of colors and imagery. Often times, as we saw in a few examples above, it really only takes a few shapes to pull of the 80s vibe.
We hope you enjoyed this fun little list. If you have any other suggestions and want to share, feel free to let us know in the comments below. Not every occasion allows you to rock a retro design on social media, so make sure you find the perfect one to fit the mood. But, most importantly, have some fun!
Every week users submit a lot of interesting stuff on our sister site Webdesigner News, highlighting great content from around the web that can be of interest to web designers.
The best way to keep track of all the great stories and news being posted is simply to check out the Webdesigner News site, however, in case you missed some here’s a quick and useful compilation of the most popular designer news that we curated from the past week.
Note that this is only a very small selection of the links that were posted, so don’t miss out and subscribe to our newsletter and follow the site daily for all the news.
Instagram and WhatsApp Get a Rebrand
Why is Modern Web Development so Complicated?
Ooops, I Guess We’re Full-stack Developers Now.
What is Brand Identity Design?
Convert any HTML Project to a Custom WordPress Theme
A Beginner’s Guide to Psychology Principles in UX Design
User Interface Design Inspiration
Domino’s Pizza is Locked in a Legal Battle Over the Future of Web Design
7 Best Mailchimp Alternatives of 2019 (with Better Features + Fair Pricing)
The 3 Laws of Locality
77 Things About Uber Design
Trouble – Free Sans Serif Font
Google has a Secret Design Library. Here are 35 of its Best Books
Essential Tools for Modern Graphic Designers
Paaatterns
6 Months Designing with Figma
Results! 200+ Freelance Designer Pricing Survey
5 Key Principles for a User-Friendly Website
Frontend Vs Backend
Was Email a Mistake?
5 Podcasts Every UX Designer Should Listen to
You are not a Brand
SVG Filters: 80s Font Text Effects
How to Write a Better Bio
New Identity for Venmo
Want more? No problem! Keep track of top design news from around the web with Webdesigner News.
There was a fun article in The New York Times the other day describing the fancy way Elizabeth Warren and her staff let people take a selfie with Warren. But… the pictures aren’t actually selfies because they are taken by someone else. The article has his hilarious line of text that wiggles by on a curved line as you scroll down the page.
Let’s look at how they did it.
Movie:
The curved line is drawn in SVG as a , and the is set upon it by a :
The movement trick happens by adjusting the startOffset attribute of the textPath element.
I’m not 100% sure how they did it, but we can do some quick hacky math by watching the scroll position of the page and setting that attribute in a way that makes it move about as fast and far as we want.
const textPath = document.querySelector("#text-path");
const h = document.documentElement,
b = document.body,
st = 'scrollTop',
sh = 'scrollHeight';
document.addEventListener("scroll", e => {
let percent = (h[st]||b[st]) / ((h[sh]||b[sh]) - h.clientHeight) * 100;
textPath.setAttribute("startOffset", (-percent * 40) + 1200)
});
One of my favorite developments in software development has been the advent of serverless. As a developer who has a tendency to get bogged down in the details of deployment and DevOps, it’s refreshing to be given a mode of building web applications that simply abstracts scaling and infrastructure away from me. Serverless has made me better at actually shipping projects!
That being said, if you’re new to serverless, it may be unclear how to translate the things that you already know into a new paradigm. If you’re a front-end developer, you may have no experience with what serverless purports to abstract away from you – so how do you even get started?
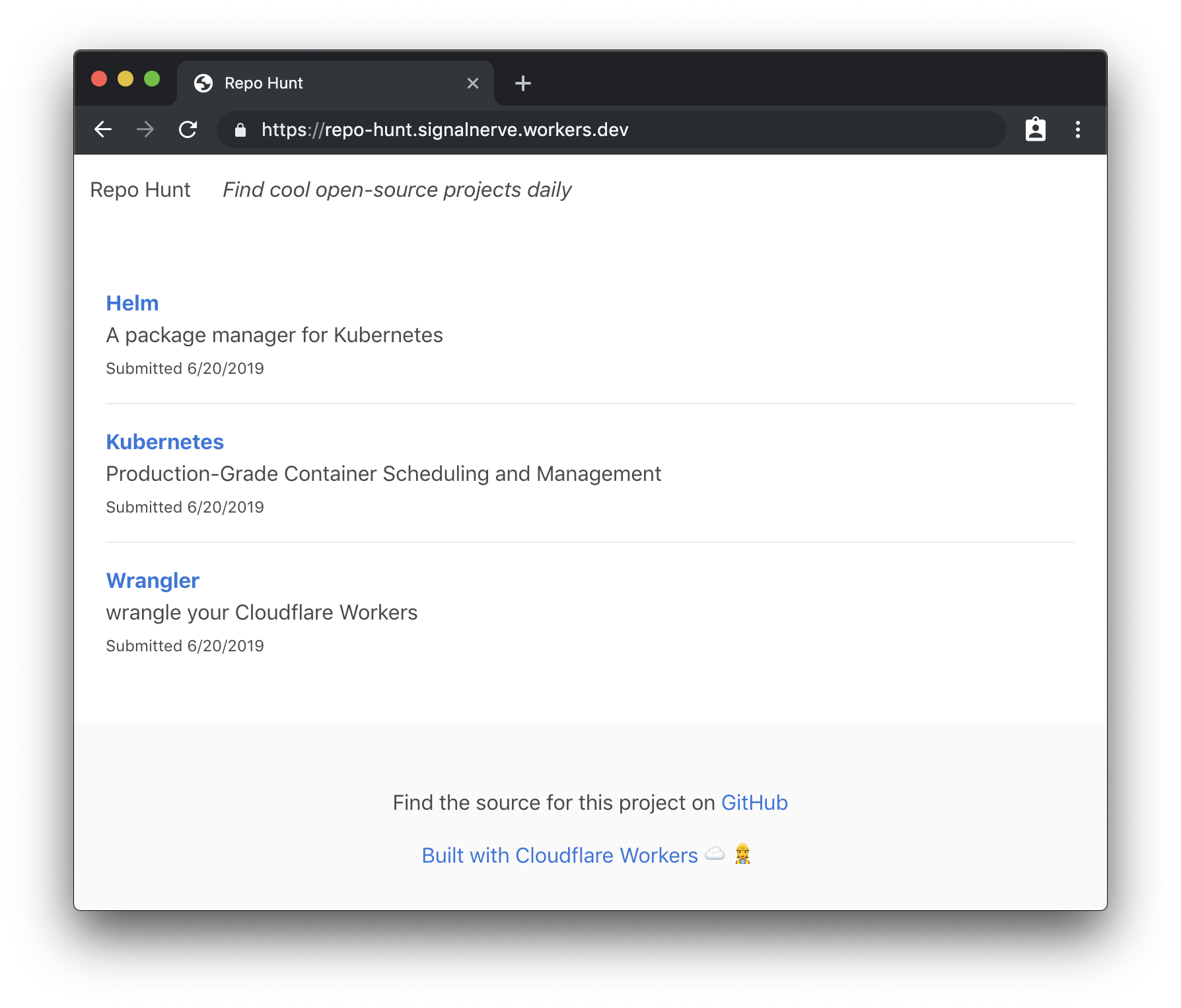
Today, I’ll try to help demystify the practical part of working with serverless by taking a project from idea to production, using Cloudflare Workers. Our project will be a daily leaderboard, called “Repo Hunt” inspired by sites like Product Hunt and Reddit, where users can submit and upvote cool open-source projects from GitHub and GitLab. You can see the final version of the site, published here.
Workers is a serverless application platform built on top of Cloudflare’s network. When you publish a project to Cloudflare Workers, it’s immediately distributed across 180 (and growing) cities around the world, meaning that regardless of where your users are located, your Workers application will be served from a nearby Cloudflare server with extremely low latency. On top of that, the Workers team has gone all-in on developer experience: our newest release, at the beginning of this month, introduced a fully-featured command line tool called Wrangler, which manages building, uploading, and publishing your serverless applications with a few easy-to-learn and powerful commands.
The end result is a platform that allows you to simply write JavaScript and deploy it to a URL – no more worrying about what “Docker” means, or if your application will fall over when it makes it to the front page of Hacker News!
If you’re the type that wants to see the project ahead of time, before hopping into a long tutorial, you’re in luck! The source for this project is available on GitHub. With that, let’s jump in to the command-line and build something rad.
Installing Wrangler and preparing our workspace
Wrangler is the command-line tool for generating, building, and publishing Cloudflare Workers projects. We’ve made it super easy to install, especially if you’ve worked with npm before:
npm install -g @cloudflare/wrangler
Once you’ve installed Wrangler, you can use the generate command to make a new project. Wrangler projects use “templates” which are code repositories built for re-use by developers building with Workers. We maintain a growing list of templates to help you build all kind of projects in Workers: check out our Template Gallery to get started!
In this tutorial, we’ll use the “Router” template, which allows you to build URL-based projects on top of Workers. The generate command takes two arguments: first, the name of your project (I’ll use repo-hunt), and a Git URL. This is my favorite part of the generate command: you can use all kinds of templates by pointing Wrangler at a GitHub URL, so sharing, forking, and collaborating on templates is super easy. Let’s run the generate command now:
wrangler generate repo-hunt https://github.com/cloudflare/worker-template-router
cd repo-hunt
The Router template includes support for building projects with webpack, so you can add npm modules to your project, and use all the JavaScript tooling you know and love. In addition, as you might expect, the template includes a Router class, which allows you to handle routes in your Worker, and tie them to a function. Let’s look at a simple example: setting up an instance of Router, handling a GET request to /, and returning a response to the client:
// index.js
const Router = require('./router')
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
async function handleRequest(request) {
try {
const r = new Router()
r.get('/', () => new Response("Hello, world!"))
const resp = await r.route(request)
return resp
} catch (err) {
return new Response(err)
}
}
All Workers applications begin by listening to the fetch event, which is an incoming request from a client to your application. Inside of that event listener, it’s common practice to call a handleRequest function, which looks at the incoming request and determines how to respond. When handling an incoming fetch event, which indicates an incoming request, a Workers script should always return a Response back to the user: it’s a similar request/response pattern to many web frameworks, like Express, so if you’ve worked with web frameworks before, it should feel quite familiar!
In our example, we’ll make use of a few routes: a “root” route (/), which will render the homepage of our site; a form for submitting new repos, at /post, and a special route for accepting POST requests, when a user submits a repo from the form, at /repo.
Building a route and rendering a template
The first route that we’ll set up is the “root” route, at the path /. This will be where repos submitted by the community will be rendered. For now, let’s get some practice defining a route, and returning plain HTML. This pattern is common enough in Workers applications that it makes sense to understand it first, before we move on to some more interesting bits!
To begin, we’ll update index.js to set up an instance of a Router, handle any GET requests to /, and call the function index, from handlers/index.js (more on that shortly):
// index.js
const Router = require('./router')
const index = require('./handlers/index')
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
function handleRequest(request) {
try {
const r = new Router()
r.get('/', index)
return r.route(request)
} catch (err) {
return new Response(err)
}
}
As with the example index.js in the previous section, our code listens for a fetch event, and responds by calling the handleRequest function. The handleRequest function sets up an instance of Router, which will call the index function on any GET requests to /. With the router setup, we route the incoming request, using r.route, and return it as the response to the client. If anything goes wrong, we simply wrap the content of the function in a try/catch block, and return the err to the client (a note here: in production applications, you may want something more robust here, like logging to an exception monitoring tool).
To continue setting up our route handler, we’ll create a new file, handlers/index.js, which will take the incoming request and return a HTML response to the client:
Our handler function is simple: it returns a new instance of Response with the text “Hello, world!” as well as a headers object that sets the Content-Type header to text/html – this tells the browser to render the incoming response as an HTML document. This means that when a client makes a GET request to the route /, a new HTML response will be constructed with the text “Hello, world!” and returned to the user.
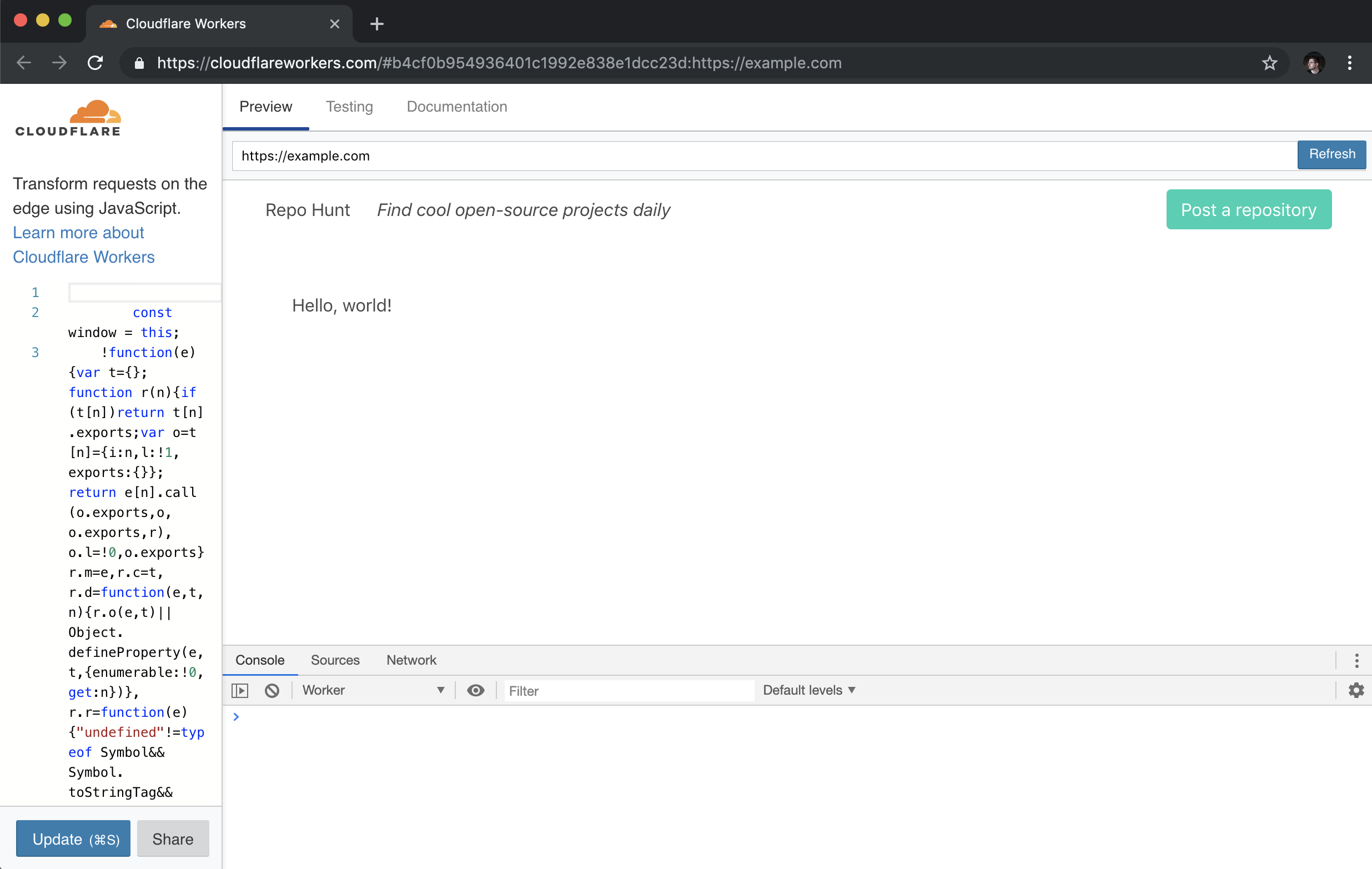
Wrangler has a preview function, perfect for testing the HTML output of our new function. Let’s run it now to ensure that our application works as expected:
wrangler preview
The preview command should open up a new tab in your browser, after building your Workers application and uploading it to our testing playground. In the Preview tab, you should see your rendered HTML response:
With our HTML response appearing in browser, let’s make our handler function a bit more exciting, by returning some nice looking HTML. To do this, we’ll set up a corresponding index “template” for our route handler: when a request comes into the index handler, it will call the template and return an HTML string, to give the client a proper user interface as the response. To start, let’s update handlers/index.js to return a response using our template (and, in addition, set up a try/catch block to catch any errors, and return them as the response):
As you might imagine, we need to set up a corresponding template! We’ll create a new file, templates/index.js, and return an HTML string, using ES6 template strings:
Our template function returns a simple HTML string, which is set to the body of our Response, in handlers/index.js. For our final snippet of templating for our first route, let’s do something slightly more interesting: creating a templates/layout.js file, which will be the base “layout” that all of our templates will render into. This will allow us to set some consistent styling and formatting for all the templates. In templates/layout.js:
This is a big chunk of HTML code, but breaking it down, there’s only a few important things to note: first, this layout variable is a function! A body variable is passed in, intended to be included inside of a div right in the middle of the HTML snippet. In addition, we include the Bulmahttps://bulma.io) CSS frameworkhttps://bulma.io), for a bit of easy styling in our project, and a navigation bar, to tell users *what* this site is, with a link to submit new repositories.
To use our layout template, we’ll import it in templates/index.js, and wrap our HTML string with it:
With that, we can run wrangler preview again, to see our nicely rendered HTML page, with a bit of styling help from Bulma:
Storing and retrieving data with Workers KV
Most web applications aren’t very useful without some sort of data persistence. Workers KV is a key-value store built for use with Workers – think of it as a super-fast and globally distributed Redis. In our application, we’ll use KV to store all of the data for our application: each time a user submits a new repository, it will be stored in KV, and we’ll also generate a daily array of repositories to render on the home page.
A quick note: at the time of writing, usage of Workers KV requires a paid Workers plan. Read more in the “Pricing” section of the Workers docs here.
Inside of a Workers application, you can refer to a pre-defined KV namespace, which we’ll create inside of the Cloudflare UI, and bind to our application once it’s been deployed to the Workers application. In this tutorial, we’ll use a KV namespace called REPO_HUNT, and as part of the deployment process, we’ll make sure to attach it to our application, so that any references in the code to REPO_HUNT will correctly resolve to the KV namespace.
Before we hop into creating data inside of our namespace, let’s look at the basics of working with KV inside of your Workers application. Given a namespace (e.g. REPO_HUNT), we can set a key with a given value, using put:
The API is super simple, which is great for web developers who want to start building applications with the Workers platform, without having to dive into relational databases or any kind of external data service. In our case, we’ll store the data for our application by saving:
A repo object, stored at the key repos:$id, where $id is a generated UUID for a newly submitted repo.
A day array, stored at the key $date (e.g. "6/24/2019"), containing a list of repo IDs, which indicate the submitted repos for that day.
We’ll begin by implementing support for submitting repositories, and making our first writes to our KV namespace by saving the repository data in the object we specified above. Along the way, we’ll create a simple JavaScript class for interfacing with our store – we’ll make use of that class again, when we move on to rendering the homepage, where we’ll retrieve the repository data, build a UI, and finish our example application.
Allowing user-submitted data
No matter what the application is, it seems that web developers always end up having to write forms. In our case, we’ll build a simple form for users to submit repositories.
At the beginning of this tutorial, we set up index.js to handle incoming GET requests to the root route (`/). To support users adding new repositories, we’ll add another route, GET /post, which will render a form template to users. In index.js:
// index.js
// ...
const post = require('./handlers/post')
// ...
function handleRequest(request) {
try {
const r = new Router()
r.get('/', index)
r.get('/post', post)
return r.route(request)
} catch (err) {
return new Response(err)
}
}
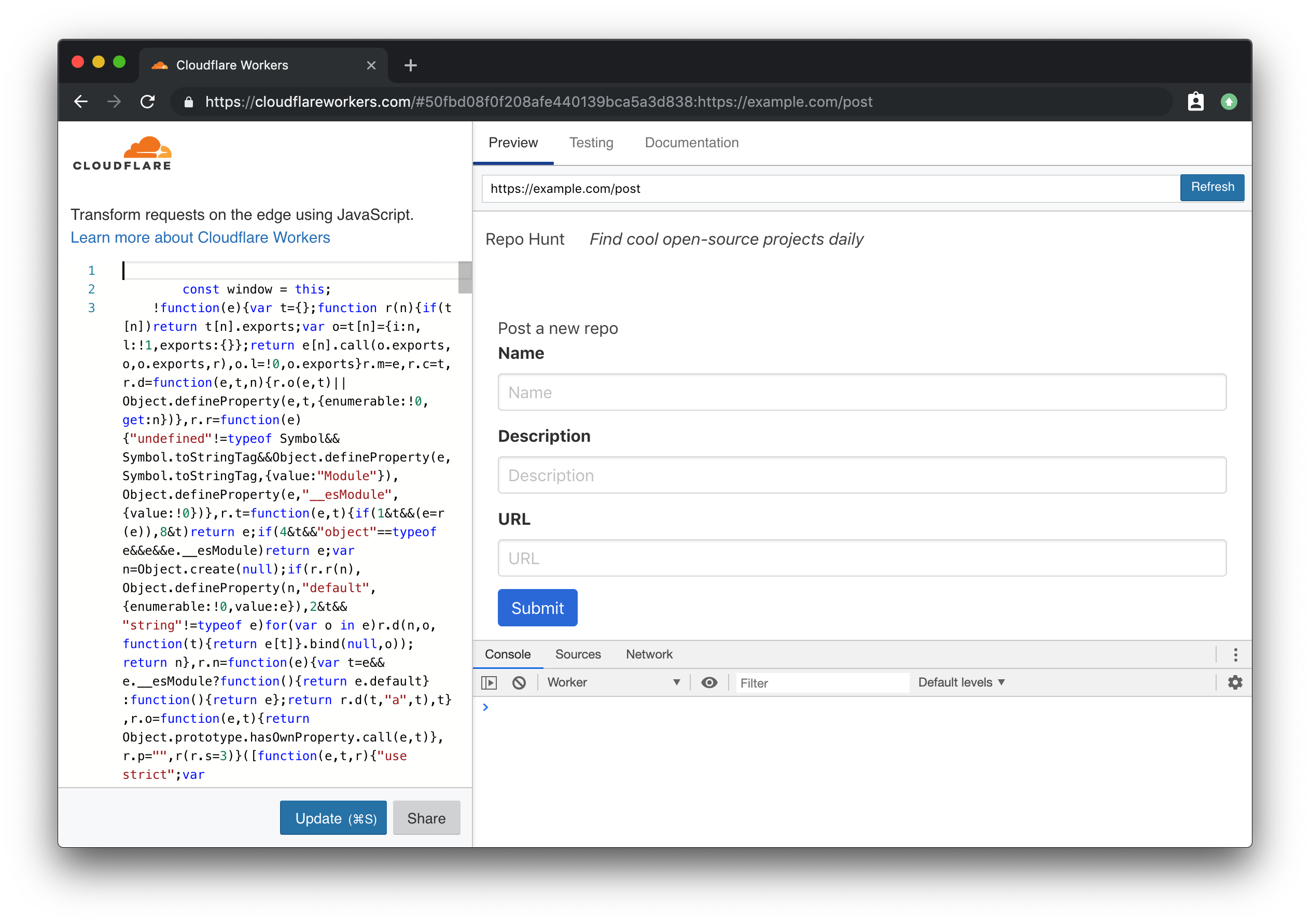
In addition to a new route handler in index.js, we’ll also add handlers/post.js, a new function handler that will render an associated template as an HTML response to the user:
The final piece of the puzzle is the HTML template itself – like our previous template example, we’ll re-use the layout template we’ve built, and wrap a simple three-field form with it, exporting the HTML string from templates/post.js:
Using wrangler preview, we can navigate to the path /post and see our rendered form:
If you look at the definition of the actual form tag in our template, you’ll notice that we’re making a POST request to the path /repo. To receive the form data, and persist it into our KV store, we’ll go through the process of adding another handler. In index.js:
// index.js
// ...
const create = require('./handlers/create')
// ...
function handleRequest(request) {
try {
const r = new Router()
r.get('/', index)
r.get('/post', post)
r.post('/repo', create)
return r.route(request)
} catch (err) {
return new Response(err)
}
}
When a form is sent to an endpoint, it’s sent as a query string. To make our lives easier, we’ll include the qs library in our project, which will allow us to simply parse the incoming query string as a JS object. In the command line, we’ll add qs simply by using npm. While we’re here, let’s also install the node-uuid package, which we’ll use later to generate IDs for new incoming data. To install them both, use npm’s install --save subcommand:
npm install --save qs uuid
With that, we can implement the corresponding handler function for POST /repo. In handlers/create.js:
// handlers/create.js
const qs = require('qs')
const handler = async request => {
try {
const body = await request.text()
if (!body) {
throw new Error('Incorrect data')
}
const data = qs.parse(body)
// TODOs:
// - Create repo
// - Save repo
// - Add to today's repos on the homepage
return new Response('ok', { headers: { Location: '/' }, status: 301 })
} catch (err) {
return new Response(err, { status: 400 })
}
}
module.exports = handler
Our handler function is pretty straightforward — it calls text on the request, waiting for the promise to resolve to get back our query string body. If no body element is provided with the request, the handler throws an error (which returns with a status code of 400, thanks to our try/catch block). Given a valid body, we call parse on the imported qs package, and get some data back. For now, we’ve stubbed out our intentions for the remainder of this code: first, we’ll create a repo, based on the data. We’ll save that repo, and then add it to the array of today’s repos, to be rendered on the home page.
To write our repo data into KV, we’ll build two simple ES6 classes, to do a bit of light validation and define some persistence methods for our data types. While you could just call REPO_HUNT.put directly, if you’re working with large amounts of similar data, it can be nice to do something like new Repo(data).save() – in fact, we’ll implement something almost exactly like this, so that working with a Repo is incredibly easy and consistent.
Let’s define store/repo.js, which will contain a Repo class. With this class, we can instantiate new Repo objects, and using the constructor method, we can pass in data, and validate it, before continuing to use it in our code.
// store/repo.js
const uuid = require('uuid/v4')
class Repo {
constructor({ id, description, name, submitted_at, url }) {
this.id = id || uuid()
this.description = description
if (!name) {
throw new Error(`Missing name in data`)
} else {
this.name = name
}
this.submitted_at = submitted_at || Number(new Date())
try {
const urlObj = new URL(url)
const whitelist = ['github.com', 'gitlab.com']
if (!whitelist.some(valid => valid === urlObj.host)) {
throw new Error('The URL provided is not a repository')
}
} catch (err) {
throw new Error('The URL provided is not valid')
}
this.url = url
}
save() {
return REPO_HUNT.put(`repos:${this.id}`, JSON.stringify(this))
}
}
module.exports = Repo
Even if you aren’t super familiar with the constructor function in an ES6 class, this example should still be fairly easy to understand. When we want to create a new instance of a Repo, we pass the relevant data to constructor as an object, using ES6‘s destructuring assignment to pull each value out into its own key. With those variables, we walk through each of them, assigning this.$key (e.g. this.name, this.description, etc) to the passed-in value.
Many of these values have a “default” value: for instance, if no ID is passed to the constructor, we’ll generate a new one, using our previously-saved uuid package’s v4 variant to generate a new UUID, using uuid(). For submitted_at, we’ll generate a new instance of Date and convert it to a Unix timestamp, and for url, we’ll insure that the URL is both valid *and* is from github.com or gitlab.com to ensure that users are submitting genuine repos.
With that, the save function, which can be called on an instance of Repo, inserts a JSON-stringified version of the Repo instance into KV, setting the key as repos:$id. Back in handlers/create.js, we’ll import the Repo class, and save a new Repo using our previously parsed data:
With that, a new Repo based on incoming form data should actually be persisted into Workers KV! While the repo is being saved, we also want to set up another data model, Day, which contains a simple list of the repositories that were submitted by users for a specific day. Let’s create another file, store/day.js, and flesh it out:
Note that the code for this isn’t even a class — it’s an object with key-value pairs, where the values are functions! We’ll add more to this soon, but the single function we’ve defined, add, loads any existing repos from today’s date (using the function today to generate a date string, used as the key in KV), and adds a new Repo, based on the id argument passed into the function. Back inside of handlers/create.js, we’ll make sure to import and call this new function, so that any new repos are added immediately to today’s list of repos:
Our repo data now persists into KV and it’s added to a listing of the repos submitted by users for today’s date. Let’s move on to the final piece of our tutorial, to take that data, and render it on the homepage.
Rendering data
At this point, we’ve implemented rendering HTML pages in a Workers application, as well as taking incoming data, and persisting it to Workers KV. It shouldn’t surprise you to learn that taking that data from KV, and rendering an HTML page with it, our homepage, is quite similar to everything we’ve done up until now. Recall that the path / is tied to our index handler: in that file, we’ll want to load the repos for today’s date, and pass them into the template, in order to be rendered. There’s a few pieces we need to implement to get that working – to start, let’s look at handlers/index.js:
// handlers/index.js
// ...
const Day = require('../store/day')
const handler = async () => {
try {
let repos = await Day.getRepos()
return new Response(template(repos), { headers })
} catch (err) {
return new Response(`Error! ${err} for ${JSON.stringify(repos)}`)
}
}
// ...
While the general structure of the function handler should stay the same, we’re now ready to put some genuine data into our application. We should import the Day module, and inside of the handler, call await Day.getRepos to get a list of repos back (don’t worry, we’ll implement the corresponding functions soon). With that set of repos, we pass them into our template function, meaning that we’ll be able to actually render them inside of the HTML.
Inside of Day.getRepos, we need to load the list of repo IDs from inside KV, and for each of them, load the corresponding repo data from KV. In store/day.js:
The getRepos function reuses our previously defined todayData function, which returns a list of ids. If that list has *any* IDs, we want to actually retrieve those repositories. Again, we’ll call a function that we haven’t quite defined yet, importing the Repo class and calling Repo.findMany, passing in our list of IDs. As you might imagine, we should hop over to store/repo.js, and implement the accompanying function:
To support finding all the repos for a set of IDs, we define two class-level or static functions, find and findMany which uses Promise.all to call find for each ID in the set, and waits for them all to finish before resolving the promise. The bulk of the logic, inside of find, looks up the repo by its ID (using the previously-defined key, repos:$id), parses the JSON string, and returns a newly instantiated instance of Repo.
Now that we can look up repositories from KV, we should take that data and actually render it in our template. In handlers/index.js, we passed in the repos array to the template function defined in templates/index.js. In that file, we’ll take that repos array, and render chunks of HTML for each repo inside of it:
Breaking this file down, we have two primary functions: template (an updated version of our original exported function), which takes an array of repos, maps through them, calling repoTemplate, to generate an array of HTML strings. If repos is an empty array, the function simply returns a p tag with an empty state. The repoTemplate function uses destructuring assignment to set the variables description, name, submitted_at, and url from inside of the repo object being passed to the function, and renders each of them into fairly simple HTML, leaning on Bulma’s CSS classes to quickly define a media object layout.
And with that, we’re done writing code for our project! After coding a pretty comprehensive full-stack application on top of Workers, we’re on the final step: deploying the application to the Workers platform.
Deploying your site to workers.dev
Every Workers user can claim a free Workers.dev subdomain, after signing up for a Cloudflare account. In Wrangler, we’ve made it super easy to claim and configure your subdomain, using the subdomain subcommand. Each account gets one Workers.dev subdomain, so choose wisely!
wrangler subdomain my-cool-subdomain
With a configured subdomain, we can now deploy our code! The name property in wrangler.toml will indicate the final URL that our application will be deployed to: in my codebase, the name is set to repo-hunt, and my subdomain is signalnerve.workers.dev, so my final URL for my project will be repo-hunt.signalnerve.workers.dev. Let’s deploy the project, using the publish command:
wrangler publish
Before we can view the project in browser, we have one more step to complete: going into the Cloudflare UI, creating a KV namespace, and binding it to our project. To start this process, log into your Cloudflare dashboard, and select the “Workers” tab on the right side of the page.
Inside of the Workers section of your dashboard, find the “KV” menu item, and create a new namespace, matching the namespace you used in your codebase (if you followed the code samples, this will be REPO_HUNT).
In the listing of KV namespaces, copy your namespace ID. Back in our project, we’ll add a `kv-namespaces` key to our `wrangler.toml`, to use our new namespace in the codebase:
# wrangler.toml
[[kv-namespaces]]
binding = "REPO_HUNT"
id = "$yourNamespaceId"
To make sure your project is using the new KV namespace, publish your project one last time:
wrangler publish
With that, your application should be able to successfully read and write from your KV namespace. Opening my project’s URL should show the final version of our project — a full, data-driven application without needing to manage any servers, built entirely on the Workers platform!
What’s next?
In this tutorial, we built a full-stack serverless application on top of the Workers platform, using Wrangler, Cloudflare’s command-line tool for building and deploying Workers applications. There’s a ton of things that you could do to continue to add to this application: for instance, the ability to upvote submissions, or even to allow comments and other kinds of data. If you’d like to see the finished codebase for this project, check out the GitHub repo!
The Workers team maintains a constantly growing list of new templates to begin building projects with – if you want to see what you can build, make sure to check out our Template Gallery. In addition, make sure to check out some of the tutorials in the Workers documentation, such as building a Slack bot, or a QR code generator.
If you went through the whole tutorial (or if you’re building cool things you want to share), I’d love to hear about how it went on Twitter. If you’re interested in serverless and want to keep up with any new tutorials I’m publishing, make sure to join my newsletter and subscribe to my YouTube channel!