Images are the most efficient means to showcase a product or service on a website. They make up for most of the visual content on our website.
But, the more images a webpage has, the more bandwidth it consumes, affecting the page load speed – a raging factor having a significant impact on not just our search ranking, but also on our conversion rates.
Image optimization helps serve the right images and improve the page load time. A faster website has a positive impact on our user experience.
With image optimization becoming a standard practice for websites and apps, finding a service that offers the most competent features with a coherent pricing model, one that integrates seamlessly with the existing infrastructure and business needs, is paramount to any website and its efficiency.
So what are the most common criteria for selecting an image optimization tool?
The importance of image optimization isn’t up for debate, our choice of tool or service for it may just be. And it is a factor we should consider carefully. So where are the challenges?
Inability to integrate with existing infrastructure – Image optimization is very fundamental on modern websites. To implement it, we should not have to make any changes to our existing setup. But unfortunately, a lot of these tools or services can only be used with specific CDNs or are incapable of being integrated with our existing image servers or storage.
Dependency on their image storage – Some tools require us to move our images to their system, making us more dependent on them — an added hassle. And nobody wants to spend their time and effort on a virtually unnecessary step like migrating assets from one platform to another (and may be migrating to some other service in the future, if this one doesn’t work out). Not when it’s not needed. Not if we have hundreds of thousands of images and can never be sure if all the images have been migrated to the new tool or not.
Apart from the above challenges, it is possible that the choice of tool could be expensive or has a complex pricing structure. Or could have only the basic image-related features or not deliver excellent performance across the globe.
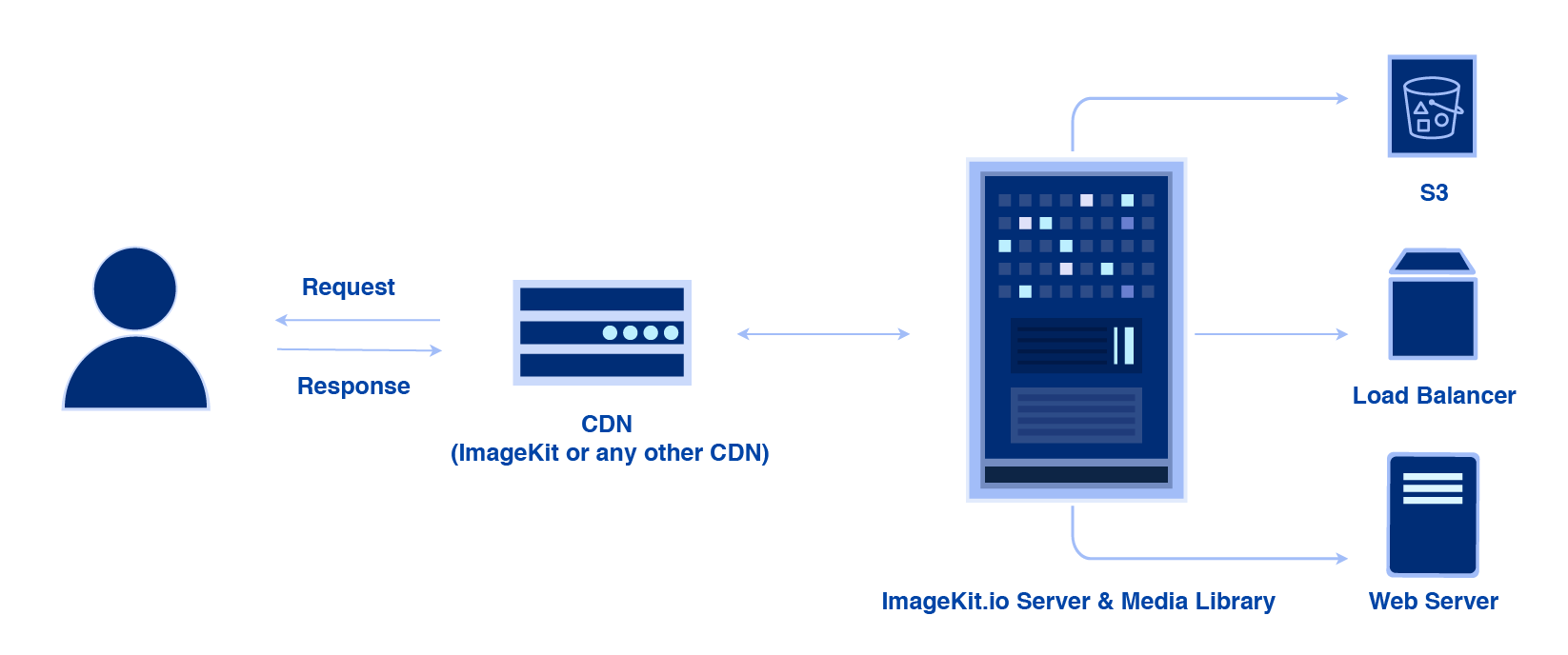
It is the only tool that we will need for image optimization and transformation with minimal effort and almost no changes to our existing infrastructure.
It is a complete image CDN with optimization and transformation capabilities for images on websites and apps. What does that mean?
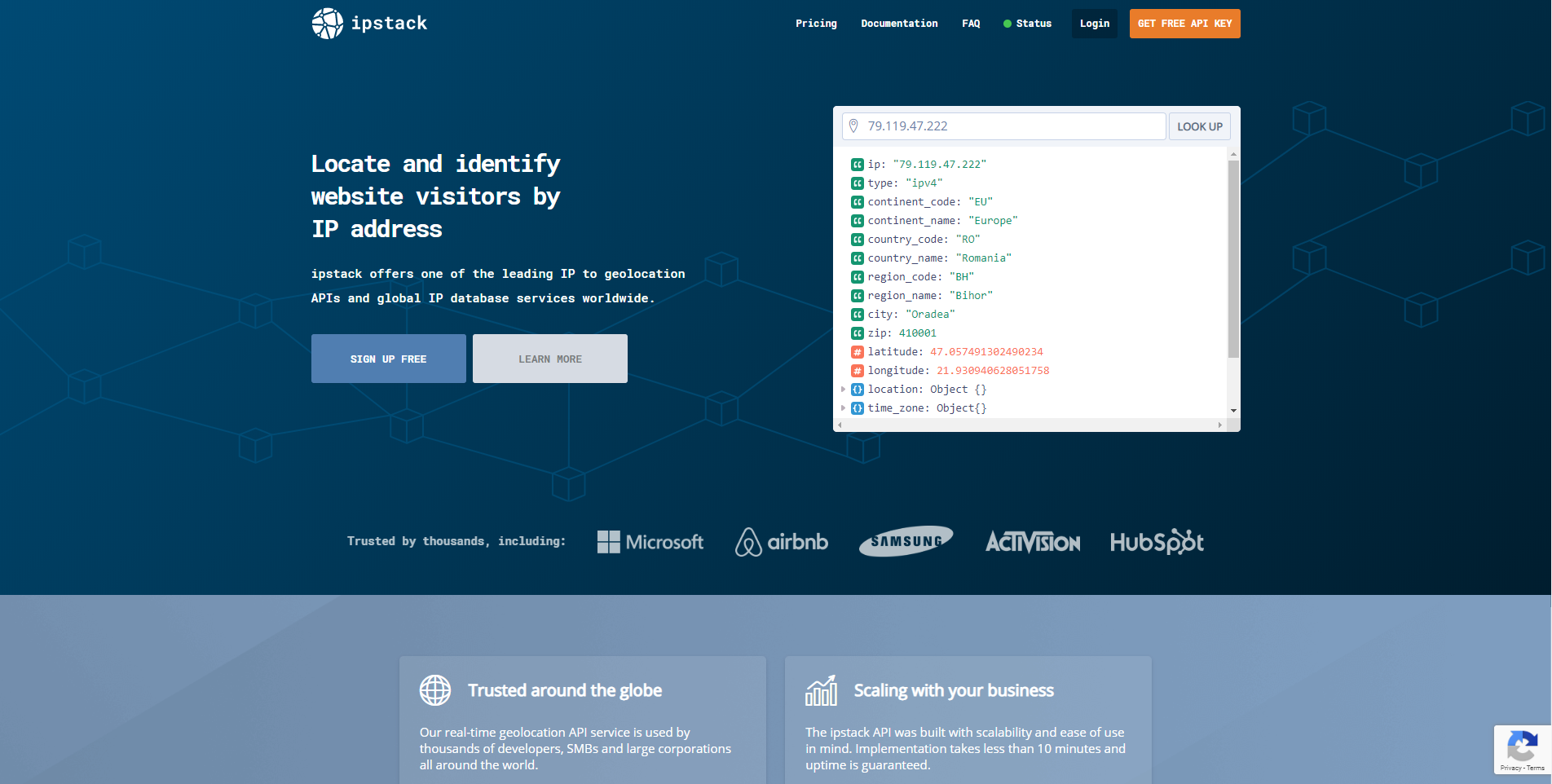
Feed ImageKit.io an original, un-optimized image and fetch it using an ImageKit.io URL, and it shall deliver an optimized, rightly resized image to our user’s devices!
For example:
ImageKit.io resizes the image automatically by simply specifying the size in the image URL.
Here, the width and height of the final image are specified with “w” and “h” parameters in the URL. The output image has dimensions 300×100px, scaled down from an original size of 1000×1000px.
As we know, the right image formats can have a significant impact on our website’s bandwidth consumption.
ImageKit.io automatically uses the correct output image format based on image content, image quality, browser support, and user device capabilities. Also, the above image will be converted and delivered as a WebP for all browsers supporting the WebP image format.
Just turn it on, and we’re good to go!
And not just simple resizing and cropping, ImageKit.io allows for more advanced transformations like smart crop, image and text overlays, image trimming, blurring, contrast and sharpness correction, and many more. It also comes with advanced delivery features like Brotli compression for SVG images and image security. ImageKit.io is the solution to all our image optimization needs. And more.
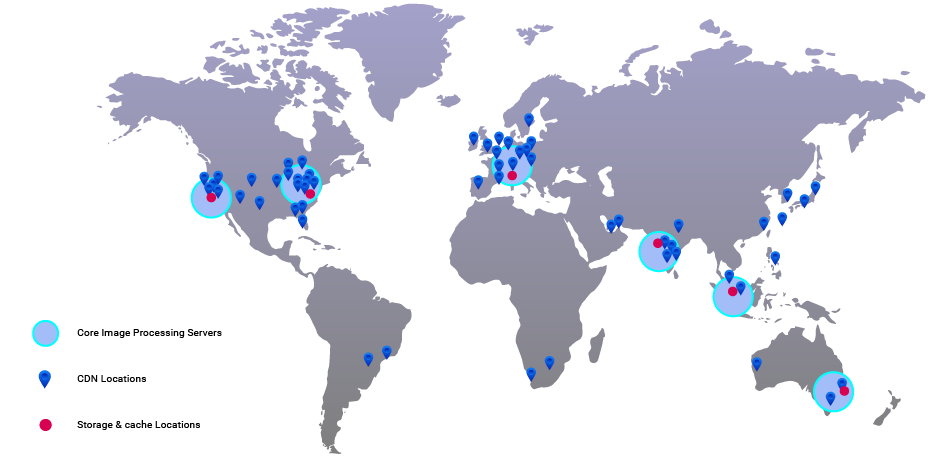
It also comes bundled with a stellar infrastructure — AWS CloudFront CDN, multi-region core processing servers, and a media library with automatic global backups.
Integrations
It isn’t enough to find the most appropriate tool for our website. It should also provide an optimum experience fitting in just right with our existing setup.
ImageKit.io integration with the existing infrastructure
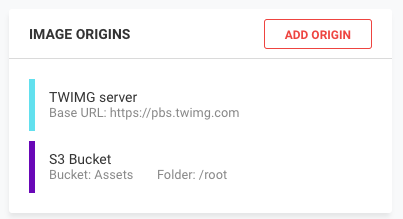
With S3 bucket or other web servers
It is usually a tedious task to integrate any image optimization tool into our infrastructure. For example, for images, we would already have a CMS in place to upload the images. And a server or storage to store all of those images. We would not want to make any significant changes to the existing setup that could potentially disrupt all our team’s processes.
But with ImageKit.io, the whole process from integration to image delivery takes just a few minutes. ImageKit.io allows us to plug our S3 bucket or webserver and start delivering optimized and transformed images instantly. No movement or re-upload of images is required. It takes just a few minutes to get the best optimization results.
We can attach our server or storage using “ADD ORIGIN” in the ImageKit.io dashboard
Such simple integrations with AWS S3 or web servers are not available even with some leading players in the market.
Images fetched through ImageKit.io are automatically optimized and converted to the appropriate format. And we can resize and transform any image by just adding URL parameters.
For example:
Image with width 300px and height is adjusted automatically to preserve aspect ratio:
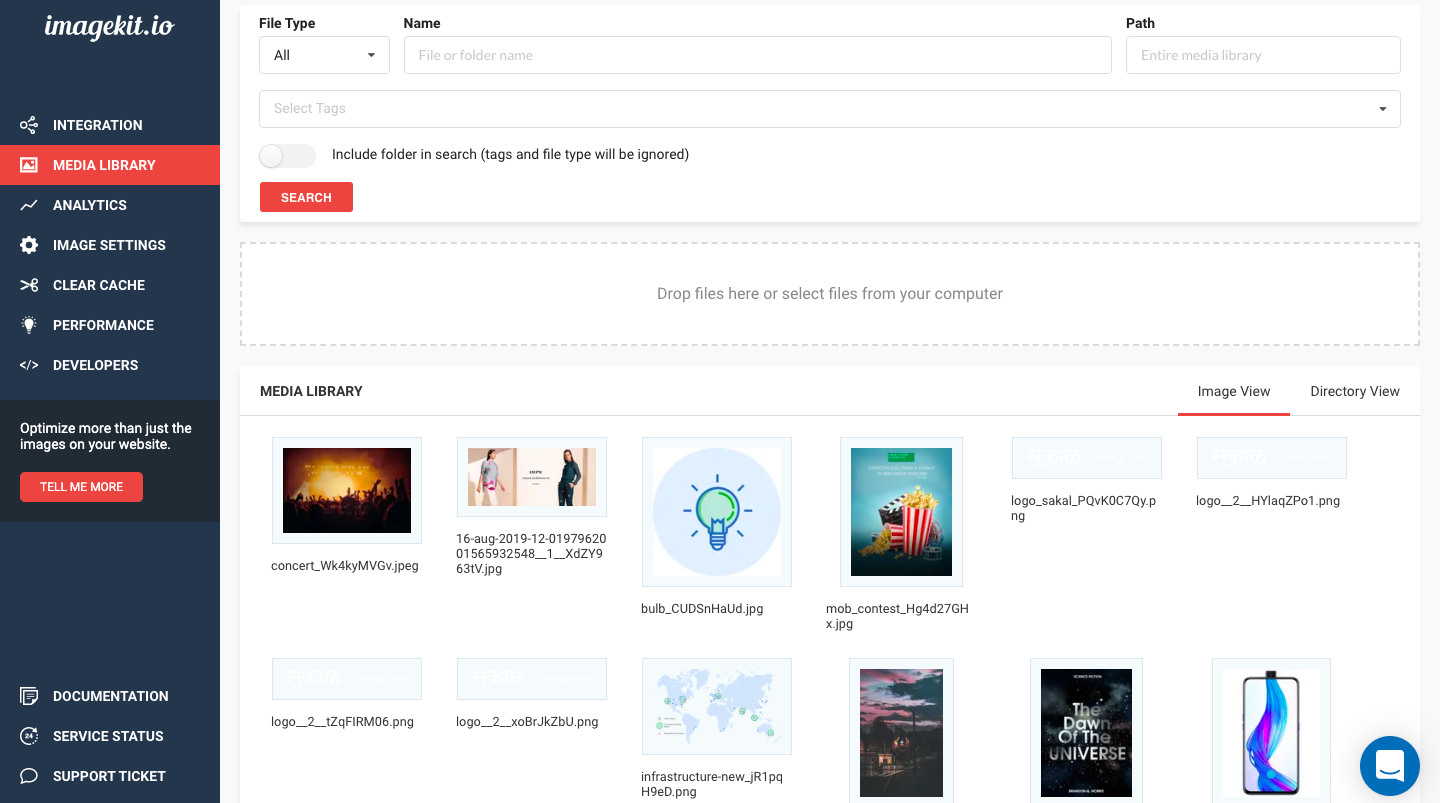
ImageKit.io also provides a media library, a feature missing in many prominent image optimization tools. Media library is a highly available file storage for all ImageKit.io users. It comes with a simple user interface to upload, search, and manage files, images, and folders.
ImageKit.io Media Library
With platforms like Magento and WordPress
Most SMBs use WordPress to build their websites. ImageKit.io proves handy and almost effortless to set up for these websites.
Installing a plugin on WordPress and making some minor changes in the settings from the WP plugin is all we need to do to integrate ImageKit.io with our WordPress website for all essential optimizations. Learn more about it here.
Similarly, we can integrate ImageKit.io with our Magento store. The essential format and quality optimizations do not require any code change and can be set up by making some changes in Settings in the Magento Admin Panel. Learn more about it here.
For advanced use cases like granular image quality control, smart cropping, watermarking, text overlays, and DPR support, ImageKit.io offers a much better solution, with more robust features, more control over the optimizations and more complex transformations, than the ones provided natively by WordPress or Magento. And we can implement them by making some changes in our website’s template files.
With other CDNs
Most businesses use CDNs for their websites, usually under contracts, or running processes other than or in addition to image optimizations on these CDNs, or simply because a particular CDN performs better in a specific region.
Even then, it is possible to use ImageKit.io with our choice of CDN. They support integrations with:
Akamai
Azure
Alibaba Cloud CDN
CloudFlare (if one is on an Enterprise plan in CloudFlare)
CloudFront
Fastly
Google CDN
Zenedge
To ensure correct optimizations and caching on our CDN, their team works closely with their customer’s team to set up the configuration.
Custom domain names
As image optimization has become a norm, services like LetsEncrypt, which make obtaining and deploying an SSL certificate free, have also become standard practice. In such a scenario, enabling a custom domain name should not be charged heavily.
ImageKit.io helps us out here too.
It offers one custom domain name like images.example.com, SSL and HTTP2 enabled, free of charge, with each paid account. Additional domain names are available at a nominal one-time fee of $50. There are no hidden costs after that.
One ImageKit.io account, multiple websites
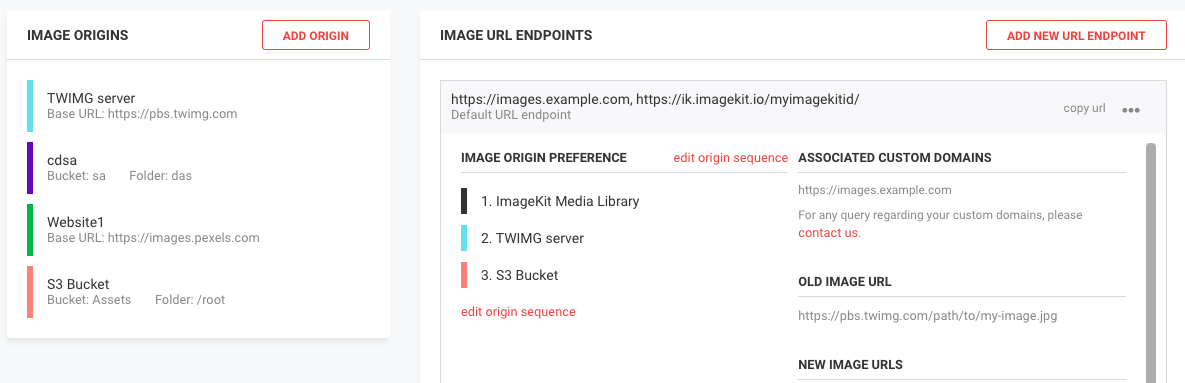
For image optimization needs for multiple websites or agencies handling hundreds of websites, ImageKit.io would prove to be an ideal solution. We’re free to attach as many “origins” (storages or servers) with ImageKit.io. What that means is each website has its storage or image server, which can be mapped to separate URLs within the same ImageKit.io account.
Configure the origin for a new site in the ImageKit.io dashboard and map it against a URL endpoint
The added advantage of using ImageKit.io for multiple websites and apps is their pricing model. When one consolidates the usage across their many business accounts, and if it crosses the 1TB mark, they can reach out to ImageKit.io’s team for a special quote. Learn more about it here.
Multiple server regions
ImageKit.io is a global image CDN, It has a distributed infrastructure and processing regions around the world, in North Virginia (US East), North California (US West), Frankfurt (EU), Mumbai (India), Sydney (Australia) and Singapore, aiming to reduce latency between their servers and our image origins.
Multiple server regions with processing and delivery nodes across the globe
Additionally, ImageKit.io stores the images (transformed as well as original) in their cache after fetching them from our origins. This intermediate caching is done to avoid processing the images again. Doing so not only reduces the load on our origin servers and storage but also reduces data transfer costs from them.
Custom cache time
There are times when a shorter cache time is required. For cases where one or more images are set to change at intervals, while the others remain the same, ImageKit.io offers the option to set up custom cache times in place of the default 180 days preset in ImageKit.io, giving us more control over how our resources are cached.
Custom cache time
This feature is usually not provided by third-party image CDNs or is available to enterprise customers only, but it is available with ImageKit.io on request.
Deliver non-image files through ImageKit.io CDN
ImageKit.io comes integrated with a CDN to store and serve resources. And while the primary use case is to deliver optimized images, it can do the same for the other static assets on our website, like JS, CSS as well as fonts.
There is no point dividing our static resources between two services when one, ImageKit.io, can do the whole job on its own.
It’s worth a mention here that though ImageKit.io provides delivery for non-image assets, it does not process or optimize them.
With ImageKit.io’s pricing model in mind, using their CDN may prove beneficial as it bills only based on one parameter — the total bandwidth consumed.
Cost efficiency
Most image optimization tools charge us for image storage or bill us based on requests or the number of master images or transformations.
ImageKit.io bills its customers on a single parameter, their output bandwidth. With ImageKit.io, we can optimize and transform to our heart’s content, without worrying about the costs they may incur. With our focus no longer on the billing costs, we can now focus on important tasks, like optimizing our images and website.
Usually, when an ImageKit.io account crosses 1TB total bandwidth consumption, that account becomes eligible for special pricing.
One can contact their team for a quote after crossing that threshold.
Final thoughts
Image optimization holds many benefits, but are we doing it right? And are we using the best service in the market for it?
ImageKit.io might prove to be the solution for all image optimization and management needs. But we don’t have to take their word for it. We can know for ourselves by joining the many developers and companies using ImageKit.io to deliver best-in-class image optimizations to their users by signing up for free here.
I believe I speak for everyone when I say that I love to find amazing, high-quality design resources for free.
Sometimes, when you’re in the middle of a design process, you find that you’re about to have to invest more money than you originally intended. You should save money when you can and you should spend money on things that require investment.
That’s why I came up with the ultimate collection of free design resources for you to check out.
Whether it’s free vectors or mockups, or free images and presets you’re looking for, I have it all right here in one incredibly comprehensive list for you, so you don’t have to search all around for your answers. Everything is right here, in one place.
Now, let’s get into it.
Free Stock Images
Photography has been and will always be a key piece of design. Stock photos are no longer what they used to be, luckily. No longer will you be seeing just those awkward group photos of people laughing or two businessmen shaking hands.
No, there are so many stock photo sites for you to choose from with quality work from real photographers. Check out these 10 awesome free stock images websites!
Unsplash
I want to start this list off with a bang. Unsplash is my personal favorite free stock image website. I use it for everything from article writing to making designs. Unsplash has a huge collection of images, consisting of over 110,000 high-quality free stock images. Just type in a keyword and see hundreds of images that can suit your needs. All images are released under Unsplash’s copyright policy.
Stocksnap
Stocksnap has hundreds of new high-quality free stock images added to their library every week. They have stock images to fit just about any occasion you can think of. From website building to brochure making, they having everything you need. You can find any image you need by typing in tag words, and you’ll be presented with hundreds of images that will be perfect for you. All images are free for you to use!
Pexels
Pexels has one of the most beautiful stock images website interfaces I’ve ever seen. Pexels provides tons of high-quality stock images that are free for you to use under their license. With hundreds of thousands of beautiful free images of you to choose from, surely you’ll find what you need here.
Reshot
“Reshot. Uniquely free photos. Handpicked, non-stocky images. Yours to use as you wish”. That’s a pretty self-explanatory and sweet tagline. They work hand-in-hand with amazing professional photographers and give them a great place to display their work and be discovered. Find amazing free stock images on Reshot!
Pixabay
Pixabay has loads of free photos, but not only. They also have art illustrations and vectors. All images, art illustrations vectors, etc are released under Creative Commons CC0.
Life of Pix
Next up, we have Life of Pix. Free high-resolution photography for everyone. Besides having loads of amazing photos to choose from, they also feature a new photographer of the week. Find new photographers whose work you love every week and in turn, have tons of stock photos to choose from!
Foodiesfeed
Foodiesfeed is for the foodie at heart. Which gorgeous, appetizing stock images that look so delicious that you can almost smell them just by looking at them. If you have a food blog or just need some inspiration, check out this awesome stock image site.
Gratisography
Gratisography is for the non-mainstream person. If you’re looking for the complete opposite of the classic boring stock photo, this website is for you. You truly won’t find photos like these anywhere else.
Foca
FOCA is a great stock website if you’re looking for a little more than just some stock images. They have everything from free photos to videos and templates!
Kaboompics
Kaboompics is so aesthetically pleasing, it hurts. The amazing blog pictures are everything. According to their about page, Kaboompics is one of the most popular sources of free images for lifestyle, interior design and specialized bloggers in the world.
Free Vectors
Creating your own vectors can take up so much of your precious time, and that’s why finding perfect vector art or vector icons can be a major time-saver, but finding them for free is like finding treasure. That’s why I picked out my 10 favorite free vector websites. Check ‘em out.
Vexels
Vexels has great free vectors for you to use for personal and commercial use. What I really like about their vectors is that many of them are editable. You can get everything from icons to backgrounds and designs that are ready for print. Give them a try!
Vector Stock
Vector stock has over 300,000 vectors for you to choose from. With such a wide variety of vectors, surely you’ll find something that’ll suit your project and save you loads of time.
The Noun Project
The Noun Project can be summed up in icons, icons, icons! They have over 2 million royalty-free vector icons for you to use. And what’s better? You can edit them. That is insane, people. Don’t sleep on the noun-project. They have all those quality things you’re looking for.
Vector 4 Free
Vector 4 Free has vector art for everyone. Their goal is to share vector art created by professional designers with everyone. They have all sorts of formats, such as .ai format, but also .eps, .pdf, .svg, and even .cdr. All of their vectors are free for personal use, but for commercial use, you have to check each artist’s terms of use, as they all differ.
Freepik
Freepik has over 708,000 free vectors for you to use for personal use and also for commercial use. The styles vary as far as feminine and elegant-looking invitations to vectors that are perfect for backend technology promotion. You’ll find every style you could need here, and you can download everything in .Ai and .EPS formats.
Free Vector
Free Vector is full of fun and colorful cartoonish vectors. They are basically a world full of free vector art that is simply at your fingertips. Type in your keywords in the search bar to find vectors that suit your style, or scroll to the end of the page and find tons of categories to browse through.
Vecteezy
Vecteezy has thousands of gorgeous vector art for you to use. Everything is copyright free, so you never have to worry about that. There are tons of free vectors for you to use, or you can upgrade your account to a pro account and have access to everything at your fingertips.
Flat Icon
Flat Icon is the largest database of free icons that are available in PNG, SVG, EPS, PSD, and BASE 64 formats to date! With a free account, you can access thousands of free icons, or you can upgrade your account and get millions of icons for free.
Pngtree
Pngtree has wonderful vectors for you to choose from, and with a free account, you have access to 2 daily downloads. Get royalty-free PNG images, vectors, backgrounds, templates, and text effects from Pngtree.
Free Mockups
Showing real-life visuals of your work to your client is a vital selling point, and that’s one of the huge reasons that mockups are so crucially important. Here are 10 free amazing mockup websites for you to use for your next project.
Placeit
Placeit is a site where you can visualize all of your designs on products within seconds. Not only can you just upload your images, but you can also make designs on the platform, and create videos. Create your own design, or try out one of their 32,938 smart templates!
Smart Mockups
Smart Mockups is the fastest web-based mockup tool out there right now. It’s user-friendly in the manner that advanced designers and beginners alike can use and understand their product. You can use a free account and create 200 mockups and use basic features, or you can upgrade your account and have access to all mockups and features.
Mockuuups
Mockuuups will generate tour product mockups in literally a second. The tool is easy to use, as it is drag-and-drop based. Download the app to your computer to start using. You can use a free account and still have access to lots of features and mockups, or you can upgrade your account to have access to everything!
Mckups
Mckups has a beautiful, minimalist interface and beautiful, free mockups for you to use. The mockups are hand-crafted by professional designers and are just waiting for you to use them.
The Mockup Club
The Mockup Club is absolutely free and that might just be my favorite part. It’s a one-stop shop with loads of free mockups for you to use to showcase your lovely designs.
Psd Repo
Psd Repo has every mockup imaginable. From key-chains to shorts, to t-shirts, to protein powder packaging, I think I can safely say they have it all. The mockups are made by talented designers who want to share their work with you for free. Download your favorite mockup as a PSD file and get to designing!
Mockups Design
Mockups Design is an easy-to-use website where designers can find professional mockups for free to use in their next design project. From DVDs and CD to letterheads and brochures. They have lots to choose from.
Good Mockups
Good Mockups can be summed up about something like this: High-quality, hand-picked, premium mockups for all to use. They strive to have mockups to fit everyone and every design. With an entire list for you to go through, I believe that they are truly well worth your time.
Mr. Mockup
Last but not least, we have Mr. Mockup. They have a team of professional and creative designers working to mockups for everyone. With a vast experience in designing just about anything, you can count on them to find beautiful mockups for your next design project.
Wrapping up
I hope you guys found this ultimate collection of free design resources helpful! Let us know in the comment section below what sites you’ll be using in the near future, or tellus about a website you know that you think is worth mentioning.
Photos in design can kill it or breathe life into it. You can spend days and weeks on creating a fantastic design but use too generic hero image, and people won’t notice your work at all; they will see a stock-looking picture and leave.
In this article, you will find tips on getting quality photos, not an obvious choice of photo stocks, and some handy tools to ease up your work.
How to Choose Photos for Your Designs
Tip 1. Check if the image was used before.
One of the things you probably don’t want is to find out that the photo you used in your design is also used by a local pharmacy, an internet-marketing course, or a restaurant across the street for their discount ads. And this is a real possibility, especially while using a free photo.
Most likely, you’ve already met Kate somewhere.
This photo of Kate on a pink background is quite popular all over the world, as you can see. The picture was originally taken for Moose Stock Photos and then uploaded to free popular photo stock Unsplash. For sure, it is a great image; otherwise, it wouldn’t be so sought-after, but maybe you would prefer to use a different photo of Kate instead of the one that you can see on a weekly basis in various designs.
So before using an image in your project, google it.
Tip 2. Make sure the photo you want to use is hi-res.
The size of the image depends on where exactly you want to use it. In some stocks, photos with higher resolution cost much more expensive than an image that will be ok for web usage in a blog post. If you are on a budget you can either use free photo stocks, but don’t forget about tip 1, or choose a subscription model that unlike a pay-per-image model will give you access to hi-res pictures. After all, you can cancel the subscription once you got all the images you need.
Tip 3. Select realistic emotions and scenes.
The quality of the photo is not only about good lightning and the absence of blurriness but about what people see. Do they feel fakeness? Do they believe the emotions of models? Everyone knows “Oh salad, you are so funny” memes, and you don’t want to use such a photo unless it is chosen on purpose or to laugh.
To make your design look better, select photos with more realistic emotions and scenarios for your goal. If the company’s call center doesn’t work with stand up comedians maybe you shouldn’t use an image with all models laughing while talking on their phones.
Though emotions on these pictures look natural, the scene, itself might not, especially for a tech support center, for example.
Tip 4. Make your own photos when possible.
When you design a page about the team of the company, it is much better to use the image with real employees. While designing a project about a physical product, you better use real pictures; otherwise, it can harm the sales level even. How can you get your own photos if you are on the budget?
If you have an audience on social media or newsletter subscribers, you can announce a photo contest. Ask users to create photos with the product and award those participants whose photos you like the most.
You can hire several beginner photographers to take photos. Their rates will be lower than the professional ones, some times they can agree to work for free if you credit them when publishing or give them a shout out. This way, you get to choose from plenty of photos and experiment with styles.
Rent a studio and order a light setting, but do images yourself with an iPhone.
Real photos gain more trust in most cases.
Photo Stocks: In Search of Diverse and Quality Photos
This is a list of photo stocks that are not as famous as Shutterstock or Unsplash. Some of these stocks offer more diverse collections than those giants. The list consists of free and paid photo libraries. Rawpixel goal is to reflect today’s society as it really is. The library is quite huge with plenty of categories to choose from. Users can download up to five images per day from the Free Collection and unlimited CC0 free images. Also, Rawpixel offers lifetime licenses for $99 (for personal use) and $499 (for commercial use).
Moose Photos is more than just a free photo stock. First, users can recompose most of the photos for their needs: change models, replace backgrounds including uploading your own, add and remove objects. It helps to diversify the scenes: add a transgender person to office space, create a mix-race family, and so on. Second, photos were shot by one team with the same lighting and angles to make images work together in one design.
The library has filters for body features giving users an option to find a specific looking models. You can use photos for free and set a link to Moose website, or buy a license for $19.90/month.
Nappy offers photos of black and brown people. There are just six categories to choose from. But you can use a search option (beta) to find the image you need faster. Users can download, modify, share, distribute, or use photos in any project for free.
Create Her Stock collects authentic stock photography featuring women of color mostly, though you can find photos of men there as well. There are not many categories in this library. Users can choose from Beauty, Business, Creatives, Desk, Family, Fellas, Hair, Holidays, Lifestyle, Love, Visuals, Wellness, and Miscellaneous collections. The whole stock has 3000+ images currently.
180+ photos are available for free without registration. The price is starting from $10/month for full access. The downside: you can not see the whole collection before buying one of the plans.
The Gender Spectrum Collection is a stock photo library with images of trans and non-binary models. The difference between this and other stocks that these models were captured in scenes that go beyond the clichés; it represents members of these communities as people not necessarily defined by their gender identities, but as people with careers, relationships, and talents. The collection is quite small, though. All photos are free, but you need to credit The Collectionin your captions. And you may not create derivative work from the images or use the images for commercial purposes.
TONL is a photo stock that showcases people of different ethnic backgrounds and sexual orientations doing everyday things: going to the gym, cooking, reading, etc. The basic subscription costs $29 and allows downloading of 15 photos.
Reshot collects photos from talented photographers and gives them away for free (for personal and commercial use). There are no categories on the website, but there is a section with several packs that are available for a tweet, and there is a search option, of course.
Stocksy offers quality photos starting from $15 per image. The higher the resolution, the more you need to pay. The cool thing is you can choose to use the image exclusively from 6 months to 4 years. Lots of photos look quite natural, including models’ emotions.
Haute Stock is a source of Instagram-worthy photos. New images added weekly. If you sign up for their newsletter, you will receive some free photos every month. The plan price starts from $99 for 3 months (unlimited downloads).
Handy Photo Tools to Get Quality Images
FreePhotos.cc is a tool that works as a search engine basically. It uses the APIs from several stock photo providers (Rawpixel, Pexels, Foodiesfeed, and many others) and assembles pictures in one library. Users can download these photos directly from FreePhotos.cc. The tool has its own simple photo editor built-in to the website.
Photo Creator tool is based on Moose photos. Anyone can create a photo they need from scratch choosing from thousands of models, objects and backgrounds (rendered, real-life, or solid colored). Photo Creator library has plenty of funny animals, and moreover 3D meme faces and aliens. So for those who need bizarre or comical images, it can be very handy as well. The tool allows for uploading of custom images and a background removal (only for paid accounts). PhotoCreator is available for free.
Removebg is a free tool for removing a background from the photo automatically. Sometimes you like the main model or an object on the photo but you don’t need the background, and if you don’t want to use tools like PhotoShop this is a way to go. But keep in mind that not all services allow modifications of the photos. Read the terms of use before doing anything with the image.
Conclusion
Choosing photos can be an enjoyable search operation or a nightmare. Hopefully, these tips, photo stocks, and tools will help you to find images you need to compliment your design.
The JAMstack (JavaScript, APIs and Markup) revolution is in full swing. Static sites are secure, fast, reliable and fun to work on. At the heart of the JAMstack are static site generators (SSGs) that store your data as flat files: Markdown, YAML, JSON, HTML, and so on. Sometimes, managing data this way can be overly complicated. Sometimes, we still need a database.
With that in mind, Netlify — a static site host and FaunaDB — a serverless cloud database — collaborated to make combining both systems easier.
Why A Bookmarking Site?
The JAMstack is great for many professional uses, but one of my favorite aspects of this set of technology is its low barrier to entry for personal tools and projects.
There are plenty of good products on the market for most applications I could come up with, but none would be exactly set up for me. None would give me full control over my content. None would come without a cost (monetary or informational).
With that in mind, we can create our own mini-services using JAMstack methods. In this case, we’ll be creating a site to store and publish any interesting articles I come across in my daily technology reading.
I spend a lot of time reading articles that have been shared on Twitter. When I like one, I hit the “heart” icon. Then, within a few days, it’s nearly impossible to find with the influx of new favorites. I want to build something as close to the ease of the “heart,” but that I own and control.
How are we going to do that? I’m glad you asked.
Interested in getting the code? You can grab it on Github or just deploy straight to Netlify from that repository! Take a look at the finished product here.
Our Technologies
Hosting And Serverless Functions: Netlify
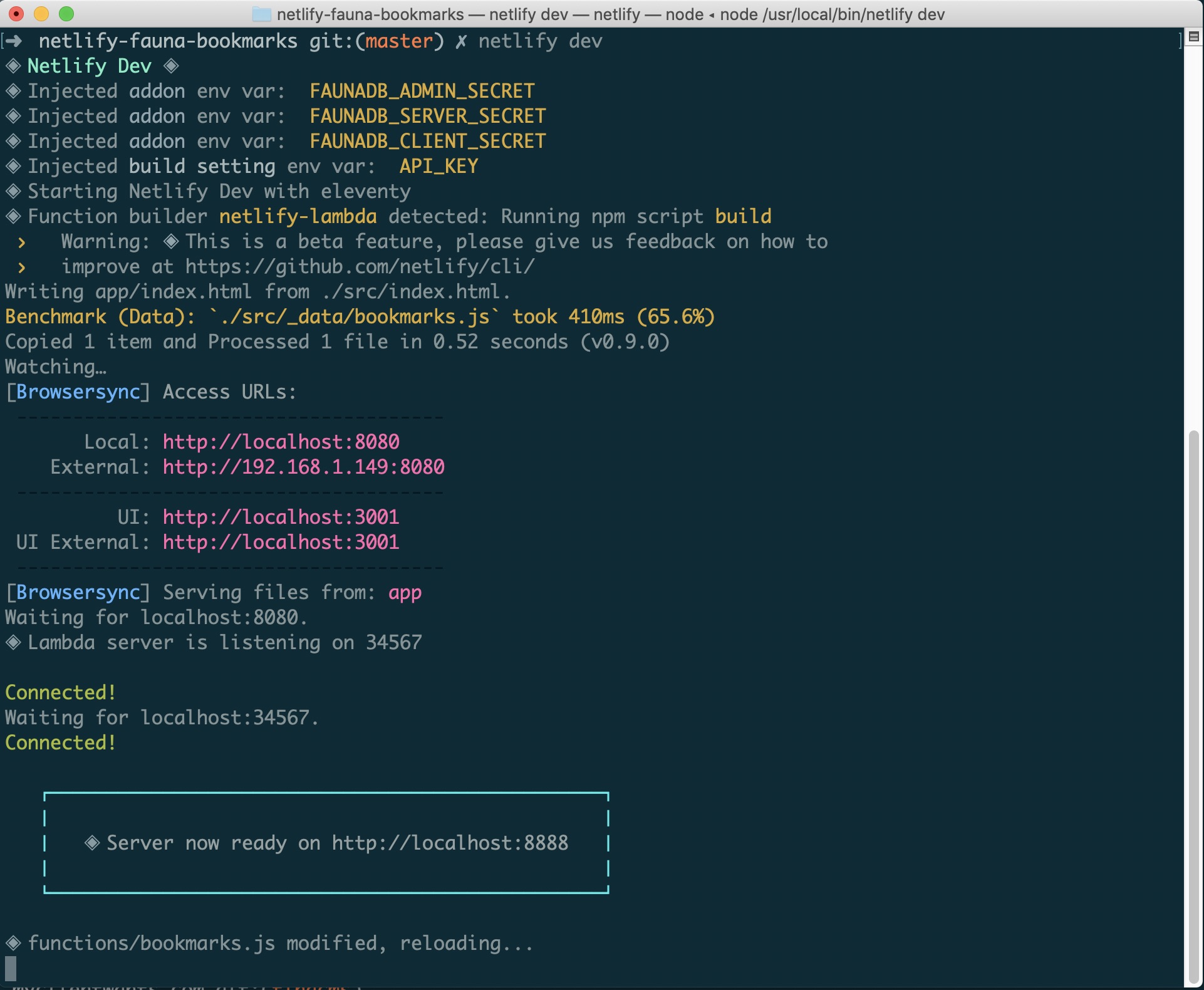
For hosting and serverless functions, we’ll be utilizing Netlify. As an added bonus, with the new collaboration mentioned above, Netlify’s CLI — “Netlify Dev” — will automatically connect to FaunaDB and store our API keys as environment variables.
Database: FaunaDB
FaunaDB is a “serverless” NoSQL database. We’ll be using it to store our bookmarks data.
Static Site Generator: 11ty
I’m a big believer in HTML. Because of this, the tutorial won’t be using front-end JavaScript to render our bookmarks. Instead, we’ll utilize 11ty as a static site generator. 11ty has built-in data functionality that makes fetching data from an API as easy as writing a couple of short JavaScript functions.
iOS Shortcuts
We’ll need an easy way to post data to our database. In this case, we’ll use iOS’s Shortcuts app. This could be converted to an Android or desktop JavaScript bookmarklet, as well.
Setting Up FaunaDB Via Netlify Dev
Whether you have already signed up for FaunaDB or you need to create a new account, the easiest way to set up a link between FaunaDB and Netlify is via Netlify’s CLI: Netlify Dev. You can find full instructions from FaunaDB here or follow along below.
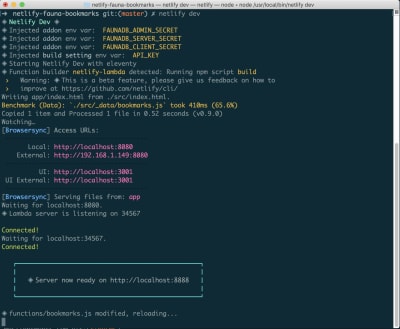
Netlify Dev running in the final project with our environment variable names showing (Large preview)
If you don’t already have this installed, you can run the following command in Terminal:
npm install netlify-cli -g
From within your project directory, run through the following commands:
netlify init // This will connect your project to a Netlify project
netlify addons:create fauna // This will install the FaunaDB "addon"
netlify addons:auth fauna // This command will run you through connecting your account or setting up an account
Once this is all connected, you can run netlify dev in your project. This will run any build scripts we set up, but also connect to the Netlify and FaunaDB services and grab any necessary environment variables. Handy!
Creating Our First Data
From here, we’ll log into FaunaDB and create our first data set. We’ll start by creating a new Database called “bookmarks.” Inside a Database, we have Collections, Documents and Indexes.
A screenshot of the FaunaDB console with data (Large preview)
A Collection is a categorized group of data. Each piece of data takes the form of a Document. A Document is a “single, changeable record within a FaunaDB database,” according to Fauna’s documentation. You can think of Collections as a traditional database table and a Document as a row.
For our application, we need one Collection, which we’ll call “links.” Each document within the “links” Collection will be a simple JSON object with three properties. To start, we’ll add a new Document that we’ll use to build our first data fetch.
{
"url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/",
"pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?",
"description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan."
}
This creates the basis for the information we’ll need to pull from our bookmarks as well as provides us with our first set of data to pull into our template.
If you’re like me, you want to see the fruits of your labor right away. Let’s get something on the page!
Installing 11ty And Pulling Data Into A Template
Since we want the bookmarks to be rendered in HTML and not fetched by the browser, we’ll need something to do the rendering. There are many great ways of doing it, but for ease and power, I love using the 11ty static site generator.
Since 11ty is a JavaScript static site generator, we can install it via NPM.
npm install --save @11ty/eleventy
From that installation, we can run eleventy or eleventy --serve in our project to get up and running.
Netlify Dev will often detect 11ty as a requirement and run the command for us. To have this work – and make sure we’re ready to deploy, we can also create “serve” and “build” commands in our package.json.
Most static site generators have an idea of a “data file” built-in. Usually, these files will be JSON or YAML files that allow you to add extra information to your site.
In 11ty, you can use JSON data files or JavaScript data files. By utilizing a JavaScript file, we can actually make our API calls and return the data directly into a template.
The file will be a JavaScript module. So in order to have anything work, we need to export either our data or a function. In our case, we’ll export a function.
Let’s break that down. We have two functions doing our main work here: mapBookmarks() and getBookmarks().
The getBookmarks() function will go fetch our data from our FaunaDB database and mapBookmarks() will take an array of bookmarks and restructure it to work better for our template.
Let’s dig deeper into getBookmarks().
getBookmarks()
First, we’ll need to install and initialize an instance of the FaunaDB JavaScript driver.
npm install --save faunadb
Now that we’ve installed it, let’s add it to the top of our data file. This code is straight from Fauna’s docs.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries.
const faunadb = require('faunadb'),
q = faunadb.query;
// Once required, we need a new instance with our secret
var adminClient = new faunadb.Client({
secret: process.env.FAUNADB_SERVER_SECRET
});
After that, we can create our function. We’ll start by building our first query using built-in methods on the driver. This first bit of code will return the database references we can use to get full data for all of our bookmarked links. We use the Paginate method, as a helper to manage cursor state should we decide to paginate the data before handing it to 11ty. In our case, we’ll just return all the references.
In this example, I’m assuming you installed and connected FaunaDB via the Netlify Dev CLI. Using this process, you get local environment variables of the FaunaDB secrets. If you didn’t install it this way or aren’t running netlify dev in your project, you’ll need a package like dotenv to create the environment variables. You’ll also need to add your environment variables to your Netlify site configuration to make deploys work later.
adminClient.query(q.Paginate(
q.Match( // Match the reference below
q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index
)
))
.then( response => { ... })
This code will return an array of all of our links in reference form. We can now build a query list to send to our database.
adminClient.query(...)
.then((response) => {
const linkRefs = response.data; // Get just the references for the links from the response
const getAllLinksDataQuery = linkRefs.map((ref) => {
return q.Get(ref) // Return a Get query based on the reference passed in
})
return adminClient.query(getAllLinksDataQuery).then(ret => {
return ret // Return an array of all the links with full data
})
}).catch(...)
From here, we just need to clean up the data returned. That’s where mapBookmarks() comes in!
mapBookmarks()
In this function, we deal with two aspects of the data.
First, we get a free dateTime in FaunaDB. For any data created, there’s a timestamp (ts) property. It’s not formatted in a way that makes Liquid’s default date filter happy, so let’s fix that.
function mapBookmarks(data) {
return data.map(bookmark => {
const dateTime = new Date(bookmark.ts / 1000);
...
})
}
With that out of the way, we can build a new object for our data. In this case, it will have a time property, and we’ll use the Spread operator to destructure our data object to make them all live at one level.
Now, we’ve got well-formatted data that’s ready for our template!
Let’s write a simple template. We’ll loop through our bookmarks and validate that each has a pageTitle and a url so we don’t look silly.
<div class="bookmarks">
{% for link in bookmarks %}
{% if link.url and link.pageTitle %} // confirms there's both title AND url for safety
<div class="bookmark">
<h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2>
<p>Saved on {{ link.time | date: "%b %d, %Y" }}</p>
{% if link.description != "" %}
<p>{{ link.description }}</p>
{% endif %}
</div>
{% endif %}
{% endfor %}
</div>
We’re now ingesting and displaying data from FaunaDB. Let’s take a moment and think about how nice it is that this renders out pure HTML and there’s no need to fetch data on the client side!
But that’s not really enough to make this a useful app for us. Let’s figure out a better way than adding a bookmark in the FaunaDB console.
Enter Netlify Functions
Netlify’s Functions add-on is one of the easier ways to deploy AWS lambda functions. Since there’s no configuration step, it’s perfect for DIY projects where you just want to write the code.
This function will live at a URL in your project that looks like this: https://myproject.com/.netlify/functions/bookmarks assuming the file we create in our functions folder is bookmarks.js.
Basic Flow
Pass a URL as a query parameter to our function URL.
Use the function to load the URL and scrape the page’s title and description if available.
Format the details for FaunaDB.
Push the details to our FaunaDB Collection.
Rebuild the site.
Requirements
We’ve got a few packages we’ll need as we build this out. We’ll use the netlify-lambda CLI to build our functions locally. request-promise is the package we’ll use for making requests. Cheerio.js is the package we’ll use to scrape specific items from our requested page (think jQuery for Node). And finally, we’ll need FaunaDb (which should already be installed.
Warning:There’s an error with Fauna’s NodeJS driver when compiling with Webpack, which Netlify’s Functions use to build. To get around this, we need to define a configuration file for Webpack. You can save the following code to a new — or existing — webpack.config.js.
Once this file exists, when we use the netlify-lambda command, we’ll need to tell it to run from this configuration. This is why our “serve” and “build scripts use the --config value for that command.
Function Housekeeping
In order to keep our main Function file as clean as possible, we’ll create our functions in a separate bookmarks directory and import them into our main Function file.
import { getDetails, saveBookmark } from "./bookmarks/create";
getDetails(url)
The getDetails() function will take a URL, passed in from our exported handler. From there, we’ll reach out to the site at that URL and grab relevant parts of the page to store as data for our bookmark.
We start by requiring the NPM packages we need:
const rp = require('request-promise');
const cheerio = require('cheerio');
Then, we’ll use the request-promise module to return an HTML string for the requested page and pass that into cheerio to give us a very jQuery-esque interface.
From here, we need to get the page title and a meta description. To do that, we’ll use selectors like you would in jQuery.
Note:In this code, we use'head > title'as the selector to get the title of the page. If you don’t specify this, you may end up getting</code> <em>tags inside of all SVGs on the page, which is less than ideal.</em></p>
<div>
<pre><code>const getDetails = async function(url) {
const data = rp(url).then(function(htmlString) {
const $ = cheerio.load(htmlString);
const title = $('head > title').text(); // Get the text inside the tag
const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute
// Return out the data in the structure we expect
return {
pageTitle: title,
description: description
};
});
return data //return to our main function
}</code></pre>
</div>
<p>With data in hand, it’s time to send our bookmark off to our Collection in FaunaDB!</p>
<h4><code>saveBookmark(details)</code></h4>
<p>For our save function, we’ll want to pass the details we acquired from <code>getDetails</code> as well as the URL as a singular object. The Spread operator strikes again!</p>
<pre><code>const savedResponse = await saveBookmark({url, ...details});</code></pre>
<p>In our <code>create.js</code> file, we also need to require and setup our FaunaDB driver. This should look very familiar from our 11ty data file.</p>
<pre><code>const faunadb = require('faunadb'),
q = faunadb.query;
const adminClient = new faunadb.Client({
secret: process.env.FAUNADB_SERVER_SECRET
});
</code></pre>
<p>Once we’ve got that out of the way, we can code.</p>
<div></div>
<p>First, we need to format our details into a data structure that Fauna is expecting for our query. Fauna expects an object with a data property containing the data we wish to store.</p>
<pre><code>const saveBookmark = async function(details) {
const data = {
data: details
};
...
}</code></pre>
<p>Then we’ll open a new query to add to our Collection. In this case, we’ll use our query helper and use the Create method. Create() takes two arguments. First is the Collection in which we want to store our data and the second is the data itself.</p>
<p>After we save, we return either success or failure to our handler.</p>
<div>
<pre><code>const saveBookmark = async function(details) {
const data = {
data: details
};
return adminClient.query(q.Create(q.Collection("links"), data))
.then((response) => {
/* Success! return the response with statusCode 200 */
return {
statusCode: 200,
body: JSON.stringify(response)
}
}).catch((error) => {
/* Error! return the error with statusCode 400 */
return {
statusCode: 400,
body: JSON.stringify(error)
}
})
}</code></pre>
</div>
<p>Let’s take a look at the full Function file.</p>
<div>
<pre><code>import { getDetails, saveBookmark } from "./bookmarks/create";
import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute)
exports.handler = async function(event, context) {
try {
const url = event.queryStringParameters.url; // Grab the URL
const details = await getDetails(url); // Get the details of the page
const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna
if (savedResponse.statusCode === 200) {
// If successful, return success and trigger a Netlify build
await rebuildSite();
return { statusCode: 200, body: savedResponse.body }
} else {
return savedResponse //or else return the error
}
} catch (err) {
return { statusCode: 500, body: `Error: ${err}` };
}
};
</code></pre>
</div>
<h4><code>rebuildSite()</code></h4>
<p>The discerning eye will notice that we have one more function imported into our handler: <code>rebuildSite()</code>. This function will use Netlify’s Deploy Hook functionality to rebuild our site from the new data every time we submit a new — successful — bookmark save.</p>
<p>In your site’s settings in Netlify, you can access your Build & Deploy settings and create a new “Build Hook.” Hooks have a name that appears in the Deploy section and an option for a non-master branch to deploy if you so wish. In our case, we’ll name it “new_link” and deploy our master branch.</p>
<figure><a target="_blank" href="https://cloud.netlifyusercontent.com/assets/344dbf88-fdf9-42bb-adb4-46f01eedd629/58bf7a4f-3248-4227-bb3c-0c2a6ed96d69/bookmarking-application-faunadb-netlify-11ty-netlify-build-hook.png"></p>
<p> <img decoding="async" src="https://res.cloudinary.com/indysigner/image/fetch/f_auto,q_auto/w_400/https://cloud.netlifyusercontent.com/assets/344dbf88-fdf9-42bb-adb4-46f01eedd629/58bf7a4f-3248-4227-bb3c-0c2a6ed96d69/bookmarking-application-faunadb-netlify-11ty-netlify-build-hook.png" alt="A visual reference for the Netlify Admin's build hook setup"></a><figcaption>
A visual reference for the Netlify Admin’s build hook setup (<a target="_blank" href="https://cloud.netlifyusercontent.com/assets/344dbf88-fdf9-42bb-adb4-46f01eedd629/58bf7a4f-3248-4227-bb3c-0c2a6ed96d69/bookmarking-application-faunadb-netlify-11ty-netlify-build-hook.png">Large preview</a>)<br />
</figcaption></figure>
<p>From there, we just need to send a POST request to the URL provided.</p>
<p>We need a way of making requests and since we’ve already installed <code>request-promise</code>, we’ll continue to use that package by requiring it at the top of our file.</p>
<div>
<pre><code>const rp = require('request-promise');
const rebuildSite = async function() {
var options = {
method: 'POST',
uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c',
body: {},
json: true
};
const returned = await rp(options).then(function(res) {
console.log('Successfully hit webhook', res);
}).catch(function(err) {
console.log('Error:', err);
});
return returned
}
</code></pre>
</div>
<figure><figcaption>A demo of the Netlify Function setup and the iOS Shortcut setup combined</figcaption></figure>
<h3>Setting Up An iOS Shortcut</h3>
<p>So, we have a database, a way to display data and a function to add data, but we’re still not very user-friendly.</p>
<p>Netlify provides URLs for our Lambda functions, but they’re not fun to type into a mobile device. We’d also have to pass a URL as a query parameter into it. That’s a LOT of effort. How can we make this as little effort as possible?</p>
<figure><a target="_blank" href="https://cloud.netlifyusercontent.com/assets/344dbf88-fdf9-42bb-adb4-46f01eedd629/d68438f8-23dc-4253-b34c-bce3428ade47/bookmarking-application-faunadb-netlify-11ty-ios-shortcuts-image.png"></p>
<p> <img decoding="async" src="https://res.cloudinary.com/indysigner/image/fetch/f_auto,q_auto/w_400/https://cloud.netlifyusercontent.com/assets/344dbf88-fdf9-42bb-adb4-46f01eedd629/d68438f8-23dc-4253-b34c-bce3428ade47/bookmarking-application-faunadb-netlify-11ty-ios-shortcuts-image.png" alt="A visual reference for the setup for our Shortcut functionality"></a><figcaption>
A visual reference for the setup for our Shortcut functionality (<a target="_blank" href="https://cloud.netlifyusercontent.com/assets/344dbf88-fdf9-42bb-adb4-46f01eedd629/d68438f8-23dc-4253-b34c-bce3428ade47/bookmarking-application-faunadb-netlify-11ty-ios-shortcuts-image.png">Large preview</a>)<br />
</figcaption></figure>
<p>Apple’s Shortcuts app allows the building of custom items to go into your share sheet. Inside these shortcuts, we can send various types of requests of data collected in the share process.</p>
<p>Here’s the step-by-step Shortcut:</p>
<ol>
<li>Accept any items and store that item in a “text” block.</li>
<li>Pass that text into a “Scripting” block to URL encode (just in case).</li>
<li>Pass that string into a URL block with our Netlify Function’s URL and a query parameter of <code>url</code>.</li>
<li>From “Network” use a “Get contents” block to POST to JSON to our URL.</li>
<li>Optional: From “Scripting” “Show” the contents of the last step (to confirm the data we’re sending).</li>
</ol>
<p>To access this from the sharing menu, we open up the settings for this Shortcut and toggle on the “Show in Share Sheet” option.</p>
<p>As of iOS13, these share “Actions” are able to be favorited and moved to a high position in the dialog.</p>
<p>We now have a working “app” for sharing bookmarks across multiple platforms!</p>
<h3>Go The Extra Mile!</h3>
<p>If you’re inspired to try this yourself, there are a lot of other possibilities to add functionality. The joy of the DIY web is that you can make these sorts of applications work for you. Here are a few ideas:</p>
<ol>
<li>Use a faux “API key” for quick authentication, so other users don’t post to your site (mine uses an API key, so don’t try to post to it!).</li>
<li>Add tag functionality to organize bookmarks.</li>
<li>Add an RSS feed for your site so that others can subscribe.</li>
<li>Send out a weekly roundup email programmatically for links that you’ve added.</li>
</ol>
<p>Really, the sky is the limit, so start experimenting!</p>
<div>
<span>(dm, yk)</span>
</div>
</article>
<div class="fixed"></div>
</div>
<div class="under">
<span class="categories">Categories: </span><span><a href="http://www.webmastersgallery.com/category/uncategorized/" rel="category tag">Others</a></span> <span class="tags">Tags: </span><span></span> </div>
</div>
<div class="post" id="post-2689693">
<h2><a class="title" href="http://www.webmastersgallery.com/2019/10/23/why-are-accessible-websites-so-hard-to-build/" rel="bookmark">Why Are Accessible Websites so Hard to Build?</a></h2>
<div class="info">
<span class="date">October 23rd, 2019</span>
<span class="author"><a href="http://www.webmastersgallery.com/author/admin/" title="Posts by admin" rel="author">admin</a></span> <span class="comments"><a href="http://www.webmastersgallery.com/2019/10/23/why-are-accessible-websites-so-hard-to-build/#respond">No comments</a></span>
<div class="fixed"></div>
</div>
<div class="content">
<div class="ftpimagefix" style="float:left"><a target="_blank" href="https://css-tricks.com/why-are-accessible-websites-so-hard-to-build/"><img decoding="async" src="https://css-tricks.com/wp-content/uploads/2019/10/code-accessibility-warning.jpg" alt="An example of how performance and accessibility issues might be flagged in VS Code whilst you type."></a></div>
<p>I was chatting with some front-end folks the other day about why so many companies struggle at making accessible websites. <em>Why are accessible websites so hard to build?</em> We learn about HTML, we make sure things are semantic and — voila! @— we have an accessible website. During the course of conversation, someone mentioned the <a target="_blank" href="https://www.theverge.com/2019/8/1/20750913/dominos-pizza-website-accessible-blind-supreme-court-lawsuit">Domino’s pizza legal case</a>, which is perhaps the most public example of a company being sued because of a lack of accessibility.</p>
<p>Here’s an interesting tidbit from that link:</p>
<blockquote>
<p>According to <em>CNBC</em>, the number of lawsuits over inaccessible websites jumped 58 percent last year over 2017, to more than 2,200.</p>
</blockquote>
<p>Inaccessible websites are not just a consideration for designers and engineers but a serious problem for a company’s legal team as well. Thankfully, it seems more of these cases will be brought to trial and (my personal hope is) this will get folks to care more about semantics and front-end development best practices. Although I’d like to think that companies would do what’s best for the web and make websites that meet <a target="_blank" href="https://css-tricks.com/accessibility-and-web-performance-are-not-features-theyre-the-baseline">the baseline requirements</a> without a legal threat, we absolutely need to make inaccessible websites <em>illegal</em> for folks to really pay attention to this issue.</p>
<p><span></span></p>
<p>However! I also worry about attributing what might simply be a lack of knowledge to malice. I reckon a lot of websites have bad accessibility not because folks don’t care, but because they don’t know there’s an issue in the first place. As my conversation with front-end engineers progressed, I realized that the reason accessibility isn’t tackled seriously probably doesn’t have anything to do with bandwidth, or experience, or money. </p>
<p>I reckon the problem is that the accessibility of a website can be invisibly and silently broken. </p>
<p>Here’s an example: when developing a site, JavaScript errors are probably going to be caught because everything breaks if something goes wrong. And CSS bugs are going to get caught because something will look off. But the accessibility or performance of a website can go from okay to terrible overnight and with no warning whatsoever. Yhe only way to fix these invisibly broken things is to first make them <em>visible</em>.</p>
<p>So, here’s an idea: what if our text editors caught accessibility issues and showed them to us during development? It could look something like this:</p>
<figure></figure>
<p>I’m sure there are a ton of other ways we can make accessibility issues more public and visible. There are tools such as Lighthouse and browser extensions that are already out there, but making accessibility (and even performance, another silent fail) a part of our minute-to-minute workflow ensures that we can’t ignore it. Something like this would encourage us to learn about the problems, give us links to potential solutions, and encourage us all to care for a relatively misunderstood part of front-end development.</p>
<p>The post <a target="_blank" rel="nofollow" href="https://css-tricks.com/why-are-accessible-websites-so-hard-to-build/">Why Are Accessible Websites so Hard to Build?</a> appeared first on <a target="_blank" rel="nofollow" href="https://css-tricks.com/">CSS-Tricks</a>.</p>
<div class="fixed"></div>
</div>
<div class="under">
<span class="categories">Categories: </span><span><a href="http://www.webmastersgallery.com/category/design/" rel="category tag">Designing</a>, <a href="http://www.webmastersgallery.com/category/uncategorized/" rel="category tag">Others</a></span> <span class="tags">Tags: </span><span></span> </div>
</div>
<div class="post" id="post-2689358">
<h2><a class="title" href="http://www.webmastersgallery.com/2019/10/23/what-i-like-about-writing-styles-with-svelte/" rel="bookmark">What I Like About Writing Styles with Svelte</a></h2>
<div class="info">
<span class="date">October 23rd, 2019</span>
<span class="author"><a href="http://www.webmastersgallery.com/author/admin/" title="Posts by admin" rel="author">admin</a></span> <span class="comments"><a href="http://www.webmastersgallery.com/2019/10/23/what-i-like-about-writing-styles-with-svelte/#respond">No comments</a></span>
<div class="fixed"></div>
</div>
<div class="content">
<div class="ftpimagefix" style="float:left"><a target="_blank" href="https://css-tricks.com/what-i-like-about-writing-styles-with-svelte/"><img decoding="async" src="https://css-tricks.com/wp-content/uploads/2019/10/svelte-devtools.png" alt=""></a></div>
<p>There’s been a lot of well-deserved hype around Svelte recently, with the project <a target="_blank" href="https://github.com/sveltejs/svelte">accumulating over 24,000 GitHub stars</a>. Arguably the simplest JavaScript framework out there, Svelte was written by Rich Harris, the developer behind <a target="_blank" href="https://github.com/rollup/rollup">Rollup</a>. There’s a lot to like about Svelte (performance, built-in state management, writing proper markup rather than JSX), but the big draw for me has been its approach to CSS.</p>
<p><span></span></p>
<h3>Single file components</h3>
<p>??</p>
<blockquote>
<p>React does not have an opinion about how styles are defined<br /><small>—React Documentation</small>?</p>
</blockquote>
<p>?</p>
<p>????</p>
<blockquote>
<p>A UI framework that doesn’t have a built-in way to add styles to your components is unfinished.<br /><small>—Rich Harris, creator of Svelte</small></p>
</blockquote>
<p>?</p>
<p>In Svelte, you can write CSS in a stylesheet like you normally would on a typical project. You can also <a target="_blank" href="https://svelte.dev/blog/svelte-css-in-js">use CSS-in-JS solutions</a>, like <a target="_blank" href="https://www.styled-components.com/">styled-components</a> and <a target="_blank" href="https://emotion.sh/docs/introduction">Emotion</a>, if you’d like. It’s become increasingly common to divide code into components, rather than by file type. React, for example, allows for the collocation of a components markup and JavaScript. In Svelte, this is taken one logical step further: the Javascript, markup and styling for a component can all exist together in a single `.svelte`? file. If you’ve ever used single file components in Vue, then Svelte will look familiar.</p>
<pre><code>// button.svelte
<style>
button {
border-radius: 0;
background-color: aqua;
}
</style>
<button>
<slot/>
</button></code></pre>
<h3>Styles are scoped by default</h3>
<p>By default, styles defined within a Svelte file are <em>scoped</em>. Like CSS-in-JS libraries or CSS Modules, Svelte generates unique class names when it compiles to make sure the styles for one element never conflict with styles from another.</p>
<p>That means you can use simple element selectors like <code>div</code> and <code>button</code> in a Svelte component file without needing to work with class names. If we go back to the button styles in our earlier example, we know that a ruleset for <code><button></code> will only be applied to our <code><Button></code> component — not to any other HTML button elements within the page. If you were to have multiple buttons within a component and wanted to style them differently, you’d still need classes. Classes will also be scoped by Svelte. </p>
<p>The classes that Svelte generates look like gibberish because they are based on a hash of the component styles (e.g. <code>svelte-433xyz</code>). This is far easier than a naming convention <a target="_blank" href="https://css-tricks.com/bem-101/">like BEM</a>. Admittedly though, the experience of looking at styles in DevTools is slightly worse as the class names lack meaning.</p>
<figure><figcaption>The markup of a Svelte component in DevTools.</figcaption></figure>
<p>It’s not an either/or situation. You can use Svelte’s scoped styling along with a regular stylesheet. I personally write component specific styles within <code>.svelte</code> files, but make use of utility classes defined in a stylesheet. For global styles to be available across an entire app — CSS custom properties, reusable CSS animations, utility classes, any ‘reset’ styles, or a CSS framework like Bootstrap — I suggest putting them in a stylesheet linked in the head of your HTML document.</p>
<h3>It lets us create global styles</h3>
<p>As we’ve just seen, you can use a regular stylesheet to define global styles. Should you need to define any global styles from within a Svelte component, you can do that too by using <code>:global</code>. This is essentially a way to opt out of scoping when and where you need to.</p>
<p>For example, a modal component may want to toggle a class to style the body element:</p>
<pre><code><style>
:global(.noscroll) {
overflow: hidden;
}
</style></code></pre>
<h3>Unused styles are flagged</h3>
<p>Another benefit of Svelte is that it will alert you about any unused styles during compilation. In other words, it searches for places where styles are defined but never used in the markup. </p>
<h3>Conditional classes are terse and effortless</h3>
<p>If the JavaScript variable name and the class name is the same, the syntax is incredibly terse. In this example, I’m creating modifier props for a full-width button and a ghost button. </p>
<pre><code><script>
export let big = false;
export let ghost = false;
</script>
<style>
.big {
font-size: 20px;
display: block;
width: 100%;
}
.ghost {
background-color: transparent;
border: solid currentColor 2px;
}
</style>
<button class:big class:ghost>
<slot/>
</button></code></pre>
<p>A class of <code>ghost</code> will be applied to the element when a <code>ghost</code> prop is used, and a class of <code>big</code> is applied when a <code>big</code> prop is used. </p>
<pre><code><script>
import Button from './Button.svelte';
</script>
<Button big ghost>Click Me</Button></code></pre>
<p>Svelte doesn’t require class names and prop names to be identical.</p>
<pre><code><script>
export let primary = false;
export let secondary = false;
</script>
<button
class:c-btn--primary={primary}
class:c-btn--secondary={secondary}
class="c-btn">
<slot></slot>
</button></code></pre>
<p>The above button component will always have a <code>c-btn</code> class but will include modifier classes only when the relevant prop is passed in, like this:</p>
<pre><code><Button primary>Click Me</Button></code></pre>
<p>That will generate this markup:</p>
<pre><code><button class="c-btn c-btn--primary">Click Me</button></code></pre>
<p>Any number of arbitrary classes can be passed to a component with a single prop:</p>
<pre><code><script>
let class_name = '';
export { class_name as class };
</script>
<button class="c-btn {class_name}">
<slot />
</button></code></pre>
<p>Then, classes can be used much the same way you would with HTML markup:</p>
<pre><code><Button class="mt40">Click Me</Button></code></pre>
<h3>From BEM to Svelte</h3>
<p>Let’s see how much easier Svelte makes writing styles compared to a standard CSS naming convention. Here’s a simple component coded up using BEM. </p>
<pre><code>.c-card {
border-radius: 3px;
border: solid 2px;
}
.c-card__title {
text-transform: uppercase;
}
.c-card__text {
color: gray;
}
.c-card--featured {
border-color: gold;
}</code></pre>
<p>Using BEM, classes get long and ugly. In Svelte, things are a lot simpler. </p>
<pre><code><style>
div {
border-radius: 3px;
border: solid 2px;
}
h2 {
text-transform: uppercase;
}
p {
color: gray;
}
.featured {
border-color: gold;
}
</style>
<div class:featured>
<h2>{title}</h2>
<p>
<slot />
</p>
</div></code></pre>
<h3>It plays well with preprocessors</h3>
<p>CSS preprocessors feels a lot less necessary when working with Svelte, but they can work perfectly alongside one another by making use of a package called Svelte Preprocess. Support is available for Less, Stylus and PostCSS, but here we’ll look at Sass. The first thing we need to do is to install some dependencies:</p>
<pre><code>npm install -D svelte-preprocess node-sass</code></pre>
<p>Then we need to import autoPreprocess in <code>rollup.config.js</code> at the top of the file. </p>
<pre><code>import autoPreprocess from 'svelte-preprocess';</code></pre>
<p>Next, let’s find the plugins array and add <code>preprocess: autoPreprocess()</code> to Svelte:</p>
<pre><code>export default {
plugins: [
svelte({
preprocess: autoPreprocess(),
...other stuff</code></pre>
<p>Then all we need to do is specify that we’re using Sass when we’re working in a component file, using <code>type="text/scss"</code> or <code>lang="scss"</code> to the style tag. </p>
<pre><code><style type="text/scss">
$pink: rgb(200, 0, 220);
p {
color: black;
span {
color: $pink;
}
}
</style></code></pre>
<h3>Dynamic values without a runtime</h3>
<p>We’ve seen that Svelte comes with most of the benefits of CSS-in-JS out-of-the-box — but without external dependencies! However, there’s one thing that third-party libraries can do that Svelte simply can’t: use JavaScript variables in CSS. </p>
<p>The following code is <strong>not valid and will not work:</strong></p>
<pre><code><script>
export let cols = 4;
</script>
<style>
ul {
display: grid;
width: 100%;
grid-column-gap: 16px;
grid-row-gap: 16px;
grid-template-columns: repeat({cols}, 1fr);
}
</style>
<ul>
<slot />
</ul></code></pre>
<p>We can, however, achieve similar functionality by using CSS variables. </p>
<pre><code><script>
export let cols = 4;
</script>
<style>
ul {
display: grid;
width: 100%;
grid-column-gap: 16px;
grid-row-gap: 16px;
grid-template-columns: repeat(var(--columns), 1fr);
}
</style>
<ul style="--columns:{cols}">
<slot />
</ul></code></pre>
<hr>
<p>I’ve written CSS in all kinds of different ways over the years: Sass, Shadow DOM, CSS-in-JS, BEM, atomic CSS and PostCSS. Svelte offers the most intuitive, approachable and user-friendly styling API. If you want to read more about this topic then check out the aptly titled <a target="_blank" href="https://svelte.dev/blog/the-zen-of-just-writing-css">The Zen of Just Writing CSS</a> by Rich Harris.</p>
<p>The post <a target="_blank" rel="nofollow" href="https://css-tricks.com/what-i-like-about-writing-styles-with-svelte/">What I Like About Writing Styles with Svelte</a> appeared first on <a target="_blank" rel="nofollow" href="https://css-tricks.com/">CSS-Tricks</a>.</p>
<div class="fixed"></div>
</div>
<div class="under">
<span class="categories">Categories: </span><span><a href="http://www.webmastersgallery.com/category/design/" rel="category tag">Designing</a>, <a href="http://www.webmastersgallery.com/category/uncategorized/" rel="category tag">Others</a></span> <span class="tags">Tags: </span><span></span> </div>
</div>
<div class="post" id="post-2691361">
<h2><a class="title" href="http://www.webmastersgallery.com/2019/10/23/writing-a-multiplayer-text-adventure-engine-in-node-js-game-engine-server-design-part-2/" rel="bookmark">Writing A Multiplayer Text Adventure Engine In Node.js: Game Engine Server Design (Part 2)</a></h2>
<div class="info">
<span class="date">October 23rd, 2019</span>
<span class="author"></span> <span class="comments"><a href="http://www.webmastersgallery.com/2019/10/23/writing-a-multiplayer-text-adventure-engine-in-node-js-game-engine-server-design-part-2/#respond">No comments</a></span>
<div class="fixed"></div>
</div>
<div class="content">
<div class="ftpimagefix" style="float:left"><a target="_blank" href="http://feedproxy.google.com/~r/SmashingMagazine/~3/WYtujiJLfKQ/"><img decoding="async" src="https://www.smashingmagazine.com/images/logo/logo--red.png" alt="Smashing Editorial"></a></div>
<p> <title>Writing A Multiplayer Text Adventure Engine In Node.js: Game Engine Server Design (Part 2)
Writing A Multiplayer Text Adventure Engine In Node.js: Game Engine Server Design (Part 2)
After some careful consideration and actual implementation of the module, some of the definitions I made during the design phase had to be changed. This should be a familiar scene for anyone who has ever worked with an eager client who dreams about an ideal product but needs to be restraint by the development team.
Once features have been implemented and tested, your team will start noticing that some characteristics might differ from the original plan, and that’s alright. Simply notify, adjust, and go on. So, without further ado, allow me to first explain what has changed from the original plan.
Battle Mechanics
This is probably the biggest change from the original plan. I know I said I was going to go with a D&D-esque implementation in which each PC and NPC involved would get an initiative value and after that, we would run a turn-based combat. It was a nice idea, but implementing it on a REST-based service is a bit complicated since you can’t initiate the communication from the server side, nor maintain status between calls.
So instead, I will take advantage of the simplified mechanics of REST and use that to simplify our battle mechanics. The implemented version will be player-based instead of party-based, and will allow players to attack NPCs (Non-Player Characters). If their attack succeeds, the NPCs will be killed or else they will attack back by either damaging or killing the player.
Whether an attack succeeds or fails will be determined by the type of weapon used and the weaknesses an NPC might have. So basically, if the monster you’re trying to kill is weak against your weapon, it dies. Otherwise, it’ll be unaffected and — most likely — very angry.
Triggers
If you paid close attention to the JSON game definition from my previous article, you might’ve noticed the trigger’s definition found on scene items. A particular one involved updating the game status (statusUpdate). During implementation, I realized having it working as a toggle provided limited freedom. You see, in the way it was implemented (from an idiomatic point of view), you were able to set a status but unsetting it wasn’t an option. So instead, I’ve replaced this trigger effect with two new ones: addStatus and removeStatus. These will allow you to define exactly when these effects can take place — if at all. I feel this is a lot easier to understand and reason about.
When picking up the item, we’re setting up a status, and when dropping it, we’re removing it. This way, having multiple game-level status indicators is completely possible and easy to manage.
The Implementation
With those updates out of the way, we can start covering the actual implementation. From an architectural point of view, nothing changed; we’re still building a REST API that will contain the main game engine’s logic.
The Tech Stack
For this particular project, the modules I’m going to be using are the following:
We’ll need to generate some unique IDs — this module will help us with that task.
As for other technologies used aside from Node.js, we have MongoDB and Redis. I like to use Mongo due to the lack of schema required. That simple fact allows me to think about my code and the data formats, without having to worry about updating the structure of my tables, schema migrations or conflicting data types.
Regarding Redis, I tend to use it as a support system as much as I can in my projects and this case is no different. I will be using Redis for everything that can be considered volatile information, such as party member numbers, command requests, and other types of data that are small enough and volatile enough to not merit permanent storage.
I’m also going to be using Redis’ key expiration feature to auto manage some aspects of the flow (more on this shortly).
API Definition
Before moving into client-server interaction and data-flow definitions I want to go over the endpoints defined for this API. They aren’t that many, mostly we need to comply with the main features described in Part 1:
Feature
Description
Join a game
A player will be able to join a game by specifying the game’s ID.
Create a new game
A player can also create a new game instance. The engine should return an ID, so that others can use it to join.
Return scene
This feature should return the current scene where the party is located. Basically, it’ll return the description, with all of the associated information (possible actions, objects in it, etc.).
Interact with scene
This is going to be one of the most complex ones, because it will take a command from the client and perform that action — things like move, push, take, look, read, to name just a few.
Check inventory
Although this is a way to interact with the game, it does not directly relate to the scene. So, checking the inventory for each player will be considered a different action.
Register client application
The above actions require a valid client to execute them. This endpoint will verify the client application and return a Client ID that will be used for authentication purposes on subsequent requests.
The above list translates into the following list of endpoints:
Verb
Endpoint
Description
POST
/clients
Client applications will require to get a Client ID key using this endpoint.
POST
/games
New game instances are created using this endpoint by the client applications.
POST
/games/:id
Once the game is created, this endpoint will enable party members to join it and start playing.
GET
/games/:id/:playername
This endpoint will return the current game state for a particular player.
POST
/games/:id/:playername/commands
Finally, with this endpoint, the client application will be able to submit commands (in other words, this endpoint will be used to play).
Let me go into a bit more detail about some of the concepts I described in the previous list.
Client Apps
The client applications will need to register into the system to start using it. All endpoints (except for the first one on the list) are secured and will require a valid application key to be sent with the request. In order to obtain that key, client apps need to simply request one. Once provided, they will last for as long as they are used, or will expire after a month of not being used. This behavior is controlled by storing the key in Redis and setting a one-month long TTL to it.
Game Instance
Creating a new game basically means creating a new instance of a particular game. This new instance will contain a copy of all of the scenes and their content. Any modifications done to the game will only affect the party. This way, many groups can play the same game on their own individual way.
Player’s Game State
This is similar to the previous one, but unique to each player. While the game instance holds the game state for the entire party, the player’s game state holds the current status for one particular player. Mainly, this holds inventory, position, current scene and HP (health points).
Player Commands
Once everything is set up and the client application has registered and joined a game, it can start sending commands. The implemented commands in this version of the engine include: move, look, pickup and attack.
The move command will allow you to traverse the map. You’ll be able to specify the direction you want to move towards and the engine will let you know the result. If you take a quick glimpse at Part 1, you can see the approach I took to handle maps. (In short, the map is represented as a graph, where each node represents a room or scene and is only connected to other nodes that represent adjacent rooms.)
The distance between nodes is also present in the representation and coupled with the standard speed a player has; going from room to room might not be as simple as stating your command, but you’ll also have to traverse the distance. In practice, this means that going from one room to the other might require several move commands). The other interesting aspect of this command comes from the fact that this engine is meant to support multiplayer parties, and the party can’t be split (at least not at this time).
Therefore, the solution for this is similar to a voting system: every party member will send a move command request whenever they want. Once more than half of them have done so, the most requested direction will be used.
look is quite different from move. It allows the player to specify a direction, an item or NPC they want to inspect. The key logic behind this command, comes into consideration when you think about status-dependant descriptions.
For example, let’s say that you enter a new room, but it’s completely dark (you don’t see anything), and you move forward while ignoring it. A few rooms later, you pick up a lit torch from a wall. So now you can go back and re-inspect that dark room. Since you’ve picked up the torch, you now can see inside of it, and be able to interact with any of the items and NPCs you find in there.
This is achieved by maintaining a game wide and player specific set of status attributes and allowing the game creator to specify several descriptions for our status-dependant elements in the JSON file. Every description is then equipped with a default text and a set of conditional ones, depending on the current status. The latter are optional; the only one that is mandatory is the default value.
Additionally, this command has a short-hand version for look at room: look around; that is because players will be trying to inspect a room very often, so providing a short-hand (or alias) command that is easier to type makes a lot of sense.
The pickup command plays a very important role for the gameplay. This command takes care of adding items into the players inventory or their hands (if they’re free). In order to understand where each item is meant to be stored, their definition has a “destination” property that specifies if it is meant for the inventory or the player’s hands. Anything that is successfully picked up from the scene is then removed from it, updating the game instance’s version of the game.
The use command will allow you to affect the environment using items in your inventory. For instance, picking up a key in a room will allow you to use it to open a locked door in another room.
There is a special command, one that is not gameplay-related, but instead a helper command meant to obtain particular information, such as the current game ID or the player’s name. This command is called get, and the players can use it to query the game engine. For example: get gameid.
Finally, the last command implemented for this version of the engine is the attack command. I already covered this one; basically, you’ll have to specify your target and the weapon you’re attacking it with. That way the system will be able to check the target’s weaknesses and determine the output of your attack.
Client-Engine Interaction
In order to understand how to use the above-listed endpoints, let me show you how any would-be-client can interact with our new API.
Step
Description
Register client
First things first, the client application needs to request an API key to be able to access all other endpoints. In order to get that key, it needs to register on our platform. The only parameter to provide is the name of the app, that’s all.
Create a game
After the API key is obtained, the first thing to do (assuming this is a brand new interaction) is to create a brand new game instance. Think about it this way: the JSON file I created in my last post contains the game’s definition, but we need to create an instance of it just for you and your party (think classes and objects, same deal). You can do with that instance whatever you want, and it will not affect other parties.
Join the game
After creating the game, you’ll get a game ID back from the engine. You can then use that game ID to join the instance using your unique username. Unless you join the game, you can’t play, because joining the game will also create a game state instance for you alone. This will be where your inventory, your position and your basic stats are saved in relation to the game you’re playing. You could potentially be playing several games at the same time, and in each one have independent states.
Send commands
In other words: play the game. The final step is to start sending commands. The amount of commands available was already covered, and it can be easily extended (more on this in a bit). Everytime you send a command, the game will return the new game state for your client to update your view accordingly.
Let’s Get Our Hands Dirty
I’ve gone over as much design as I can, in the hopes that that information will help you understand the following part, so let’s get into the nuts and bolts of the game engine.
Note: I will not be showing you the full code in this article since it’s quite big and not all of it is interesting. Instead, I’ll show the more relevant parts and link to the full repository in case you want more details.
The Main File
First things first: this is an Express project and it’s based boilerplate code was generated using Express’ own generator, so the app.js file should be familiar to you. I just want to go over two tweaks I like to do on that code to simplify my work.
First, I add the following snippet to automate the inclusion of new route files:
It’s quite simple really, but it removes the need to manually require each route files you create in the future. By the way, require-dir is a simple module that takes care of auto-requiring every file inside a folder. That’s it.
The other change I like to do is to tweak my error handler just a little bit. I should really start using something more robust, but for the needs at hand, I feel like this gets the work done:
The above code takes care of the different types of error messages we might have to deal with — either full objects, actual error objects thrown by Javascript or simple error messages without any other context. This code will take it all and format it into a standard format.
Handling Commands
This is another one of those aspects of the engine that had to be easy to extend. In a project like this one, it makes total sense to assume new commands will pop up in the future. If there is something you want to avoid, then that would probably be avoid making changes on the base code when trying to add something new three or four months in the future.
No amount of code comments will make the task of modifying code you haven’t touched (or even thought about) in several months easy, so the priority is to avoid as many changes as possible. Lucky for us, there are a few patterns we can implement to solve this. In particular, I used a mixture of the Command and the Factory patterns.
I basically encapsulated the behavior of each command inside a single class which inherits from a BaseCommand class that contains the generic code to all commands. At the same time, I added a CommandParser module that grabs the string sent by the client and returns the actual command to execute.
The parser is very simple since all implemented commands now have the actual command as to their first word (i.e. “move north”, “pick up knife”, and so on) it’s a simple matter of splitting the string and getting the first part:
Note: I’m using the require-dir module once again to simplify the inclusion of any existing and new command classes. I simply add it to the folder and the entire system is able to pick it up and use it.
With that being said, there are many ways this can be improved; for instance, by being able to add synonym support for our commands would be a great feature (so saying “move north”, “go north” or even “walk north” would mean the same). That is something that we could centralize in this class and affect all commands at the same time.
I won’t go into details on any of the commands because, again, that’s too much code to show here, but you can see in the following route code how I managed to generalize that handling of the existing (and any future) commands:
/**
Interaction with a particular scene
*/
router.post('/:id/:playername/:scene', function(req, res, next) {
let command = req.body
command.context = {
gameId: req.params.id,
playername: req.params.playername,
}
let parser = new CommandParser(command)
let commandObj = parser.parse() //return the command instance
if(!commandObj) return next({ //error handling
status: 400,
errorCode: config.get("errorCodes.invalidCommand"),
message: "Unknown command"
})
commandObj.run((err, result) => { //execute the command
if(err) return next(err)
res.json(result)
})
})
All commands only require the run method — anything else is extra and meant for internal use.
I encourage you to go and review the entire source code (even download it and play with it if you like!). In the next part of this series, I’ll show you the actual client implemention and interaction of this API.
Closing Thoughts
I may not have covered a lot of my code here, but I still hope that the article was helpful to show you how I tackle projects — even after the initial design phase. I feel like a lot of people try to start coding as their first response to a new idea and that sometimes can end up discouraging to a developer since there is no real plan set nor any goals to achieve — other than having the final product ready (and that is too big of a milestone to tackle from day 1). So again, my hope with these articles is to share a different way to go about working solo (or as part of a small group) on big projects.
I hope you’ve enjoyed the read! Please feel free to leave a comment below with any type of suggestions or recommendations, I’d love to read what you think and if you’re eager to start testing the API with your own client-side code.
Once in a while, every professional comes across a challenge so great, so ridiculous, that they just can’t help themselves. They just have to go for it. It’s like the story of David and Goliath… if David was just bored and Goliath wasn’t threatening his entire nation. As for me, I’m about to argue for putting sounds on a website, and discuss how to do it right.
Yeah, I know… I’m one of the “Never Ever Autoplay Sounds on Your Site” people. Even so, here we are. And I’m not going to cheat by talking about embedded video, podcasts, or Soundcloud wrappers. I’m also not going to talk about background music or even just ambient background sounds, because all of those are still evil, in my opinion.
Even looking for examples about sites with sound done right is nigh-impossible, because all of the search results are either music-focused examples, or articles about how you should never, ever use sound.
But as much as it rankles me to admit it, there are cases for adding sound to your websites and apps…on occasion…in very specific cases…look, I will not be held responsible for any customers you might lose, okay? This is an intellectual exercise, and it should go without saying that whatever you do, there should be a way to turn it off forever.
The Case for Adding Sound
Notifications and Alerts
Few things let you know that you should be paying attention like a fairly high-pitched noise. Teachers have their fingernails on the chalkboard, phones have their ringtones, and cats and babies use very similarly pitched sounds specifically to drive us mad/get what they need from you. Interface and product designers made use of this principle long before personal computers were even a thing. It’s effective.
I think these are only acceptable for chat conversations, or for notifications that users specifically request. When you’re waiting for information, and you need to pay attention the moment it arrives, an alert sound might well be appreciated.
Examples include everything from Facebook Messenger and Slack, to news aggregators, to dating apps of all kinds.
Success Alerts
One pattern we might use a little more in our web and app design is actually a little bit of sound to tell people things went right. Those of us gamers, at least, often have fond memories of victory music that played every time you won a battle, or completed a level. If you can find a short “success” sound that evokes nostalgia and a dopamine hit instead of just annoying people, you may have a winner.
Accessibility Enhancement
Alert sounds are all well and good, but what about using the power of audio to help people with, say, sight problems? Sure, there are screen readers and such, but if you know that a large portion of your user base have vision problems, you might consider giving them optional audio cues to make things easier.
Think of “clicking” sounds on buttons, a tone that changes pitch when you use click and drag on a slider, a general sense of haptic feedback that might usually be represented by animation. To people with poor vision, sound is a very useful form of skeuomorphism.
Artistic Experiments
And then, of course, we have the sort of thing that might be in the “experimental” section of your portfolio, or on your CodePen profile. Here’s a site full of them: Chrome Music Lab.
General Tips for Implementing Sound
Actually Playing the Sounds
JavaScript is sort of the only way to do it. Sure, you can just embed a sound with HTML5, but that will only provide you with an audio player. If you’re trying to integrate sound into your UI in a more functional way, JS is the only way to do it. I mean, sure, technically we still have Silverlight, but who’s going to go back to using plugins?
If you’ve never intentionally added sound to your own page before, or just aren’t that familiar with JS, here’s how to play a sound on click. Now, that’s all well and good, but what if your users are having trouble finding the buttons to click on them in the first place? You might want to look at this tutorial from CSS-Tricks about how to play sound when someone hovers over an element.
You Still Have to Try Not to Annoy People
Always, always, always give people a way to shut sounds off, for good. The next question is, of course, whether you should have sound on by default. My vote? No… well, in most cases. Again, if you expect to have a lot of visually impaired people on your site, you might consider making sounds play by default, and putting in a big “You can turn these sounds off off, please don’t run away!” notice front and center.
And Lastly…
Sound files can, depending on their quality, hit people real hard, right in the bandwidth. Use a CDN for your bandwidth, and cache the heck out of any sound files for the sake of your users’ bandwidth. Next, have a look at at Aural style sheets, and think real hard about how your site is presented to screen readers.
And would you look at that? I’ve just about convinced myself that sound on the Internet is a good idea. I should probably stop, now.
Each year, loads of development tools come out. It’s becoming harder and harder to decide what tools you actually need and which ones you can live without.
Honestly, it’s probably a personal preference, but it really helps me decide what I need when I have a list of useful tools to look over.
So here we go: the top 8 development tools you absolutely need in 2020.
1. IPstack
IPstack allows you to locate and identify website visitors with an IP address. This is extremely helpful for a lot of reasons, but simply knowing who is coming to your website is one of the most valuable tools anyone can ever ask for.
Built within this tool are 5 different modules that are definitely worth mentioning:
Location module
This module gives you all the information for the visitor’s location. All the way down to the zip code. With this information, you can optimize your ad targeting based on geolocation.
Currency Module
Using the information above, you’ll also get an accurate report on the primary currency being used in the visitor’s region.
Time zone module
The time zone module instantly lets you know the local time of the visitor. No more guessing and counting in your head.
Connection module
Gather valuable information about the ASN and the hostname of the ISP your website visitors are using.
Security module
IPstack will also detect any proxies, crawlers, or tor users. Security is a big deal for many users, and Ipstack makes sure you feel comfortable at all times.
Ipstack is fast and trusted by literally the biggest names in tech. To top it all off, they partner with the largest ISPs around the world, so you can rest assured that the information you’re getting is 100% accurate.
2. VSCode
VSCode is an open-source code editor that makes editing code as easy as pie. The developers of this tool basically took everything that sucked about coding and reinvented it to be easier.
So for example, they use InteliSense, which provides smart completions based on variable types, function definitions, and imported modules.
Possibly the worst thing about coding is debugging. At the very least, it can be quite time-consuming. But not so much with VSCode. You will no longer have to print out a debugging statement. Now, you can simply identify the bug and fix it right from the editor. Attach this to your running apps and debug with breakpoints, call stacks, and an awesome interactive console.
VSCode has built-in Git commands, it’s completely customizable, and it’s completely free. Check it out.
3. Postman
Postman is a collaboration platform for API development, and it has a lot to offer. Essentially, it’s your all-in-one tool for creating APIs. Here’s a list of some of the features you’ll have access to:
API client
Send REST, SOAP, and GraphQL requests super fast.
Automated testing
Automate your manual testing process.
App mock
Run simulated endpoints and predict potential behaviors of the app.
Monitor
After all is said and done, keep an updated report of the performance of the app.
Of course, there are quite a few features that Postman offers. Overall, it’s definitely worth checking out and using. It will make your life so much easier, and the amount you end up paying compared to the value you get out of it is incredible.
4. Docker
Docker is a platform for building, testing, and deploying applications. As simple as that sounds, it has quite a bit to offer. When I say a lot, I really mean a ton. There is a wide variety of development tools ready to go at any time.
Docker has been a developer favorite for a while now, and it’s only getting better. If I added absolutely everything you have to look forward to on the list, we’d be here for a while. My best advice is to go and check it out for yourself to see what you think.
5. Sublime Text
I think Sublime Text said it best when they described themselves as a sophisticated text editor for code, markups, and prose. Even if they didn’t use the Oxford comma in their original description.
In fact, just watching the demo on their main page shows you just how easy it is to fix and create text. Across the board, Sublime is getting great reviews for its ease of use, friendly interface, and for being the best text editor on the market.
You may want to take the time to learn all of the specific commands for making the process even faster, as there are quite a few to memorize. But, all-in-all, you really won’t find a better product for editing text for code.
6. GitHub
Github has been a fan favorite for many years now. Some even consider it to be the best social coding and social sharing platform on the market.
The concept is simple: code together with your team to avoid confusion and delays. It sounds kind of messy, but I can assure you that it works pretty flawlessly. It really streamlines the process of bug fixing as well. Instead of making changes on a local device and then sending off the patches to be approved and implemented, you can simply (if approved by the lead developer) fix it on the spot.
7. Sifter
Sifter is definitely one of the best issue tracking software out there today. Possibly one of the best things about Sifter is how easy it is to learn and use. I would be very confident in suggesting this tool to even beginners.
Sifter brings all the issues it found to one platform. From there, the lead developer can label, attach files (screenshots, Docs, etc.), and assign them to qualified team members in basically minutes. On top of that, Sifter leaves a progression trail so that you can track exactly who did what.
Sifter also integrates really well with Slack, GitHub, and others to make sure that you have absolutely everything you need to make your app perfect.
8. Microsoft Visual Studio
Visual Studio by Microsoft is an IDE that is a great fit for anyone. It uses IntelliSense to autocomplete code and is notorious for the massive amount of languages it can support.
Visual Studio is jam-packed with all sorts of integration, plugins, and shortcuts to make your life easier. And that’s what we all really want, right?
Wrapping up
Now don’t get me wrong, there are thousands of development tools out there to get lost in. This is simply a list of the top 8 development tools you need in 2020. Or the top 8 that you should at least look into.
Regardless of your skill level, I think you’ll find something on this list that will help you out tremendously. Be sure to check out each link and take advantage of those free trials!
WordPress shipped the Block Editor (aka Gutenberg) back in version 5.0 and with it came a snazzy new post preview screen that shows the WordPress logo drawing itself while the preview loads.
That’s what you get when saving a post draft and clicking the “Preview” button in the editor. How’d they make it? I had a tough time viewing source for the page because the preview loads up pretty quickly, but I did see that SVG is being used for the WordPress logo. That’s all I really needed because my mind instantly went back to something Chris wrote in 2014 that uses uses the stroke-dasharray and stroke-dashoffset properties to create the same effect.
I’ve since been able to get my hands on the CSS to confirm that the WordPress drawing is indeed using the same technique, but I’ll share how my mind broke things out while I was trying to reverse-engineer it.
We’re working with a straight-up inlined SVG
The neat thing about the WordPress version is that we’re working with two SVG paths instead of one. That means we have two parts that appear to be drawing at the same time. Here’s the SVG which is inlined in the HTML. We’ve got that “Generating preview” text as well, which can live outside the SVG.
The first path is an ellipse that acts as a border around the second path, which is the shape of the WordPress logo. It’s probably a good idea to give each path a class — especially if this isn’t the only element on the page — but I decided to leave things class-less since this is the only element in the demo. We can select both paths together in CSS or use pseudo-selectors (e.g. path:nth-child(2)) to select them individually in this instance.
There are a few other housekeeping things happening in there. For example, the SVG gets attributes to make it more accessible, such as identifying it as an image, hiding it from screen readers, and preventing it from being focused.
We need to lightly style the SVG
Very, very light styling. We need a stroke since there is no fill color on the paths. Otherwise we’ll be looking at a whole lot of nothing. Well, an invisible shape, but essentially a nothing burger.
That gives us the outline for both paths. The nice thing about the stroke-width property is that it accepts decimal values, so we get to make the lines a little thinner. The drawing sorta looks like it’s drawn in pencil that way.
The width is pretty arbitrary here, but it’s important because the stroke-dasharray and stroke-dashoffset properties we’ll be working with rely on it. If those property values are smaller than the size of the SVG, then the drawing will stop short of completing. If it’s too large, then the speed of the drawing becomes too fast.
Now that we know our width and can see the path strokes, we can set stroke-dasharray and stroke-dashoffset accordingly.
A little larger than the SVG and lots of space between the dashes, which should be just about right. Those values can be adjusted to tailor the animation to your liking.
The rest is merely using Chris’ technique
The drawing is a CSS animation using one keyframe. If we start the stroke-dashoffset at zero, then the paths will be invisible on initial load and grow to the 300 value we set earlier when the animation reaches 100%. Again, we set the offset at 300 so that the stroke dashes and the spaces between them will extend beyond the SVG to cover the entire thing.
All the magic is a mere five lines of code:
@keyframes draw {
0% {
stroke-dashoffset: 0;
}
}
Name the animation whatever you’d like. We can get away with only defining the animation at 0% since 100% is implicit.
Oh! And we’ve gotta attach the animation to the paths, so:
You can definitely tweak those values as well to speed thing up or down. Easing gives the animation that slight pulsing effect where it starts and ends a little slower than the middle of the movement.
I mentioned it earlier, but I was eventually able to snatch the source code from the actual implementation and it’s pretty darn close, using the same principles.