scrapestack: An API for Scraping Sites
(This is a sponsored post.)
Not every site has an API to access data from it. Most don’t, in fact. If you need to pull that data, one approach is to “scrape” it. That is, load the page in web browser (that you automate), find what you are looking for in the DOM, and take it.
You can do this yourself if you want to deal with the cost, maintenance, and technical debt. For example, this is one of the big use-cases for “headless” browsers, like how Puppeteer can spin up and control headless Chrome.
Or, you can use a tool like scrapestack that is a ready-to-use API that not only does the scraping for you, but likely does it better, faster, and with more options than trying to do it yourself.
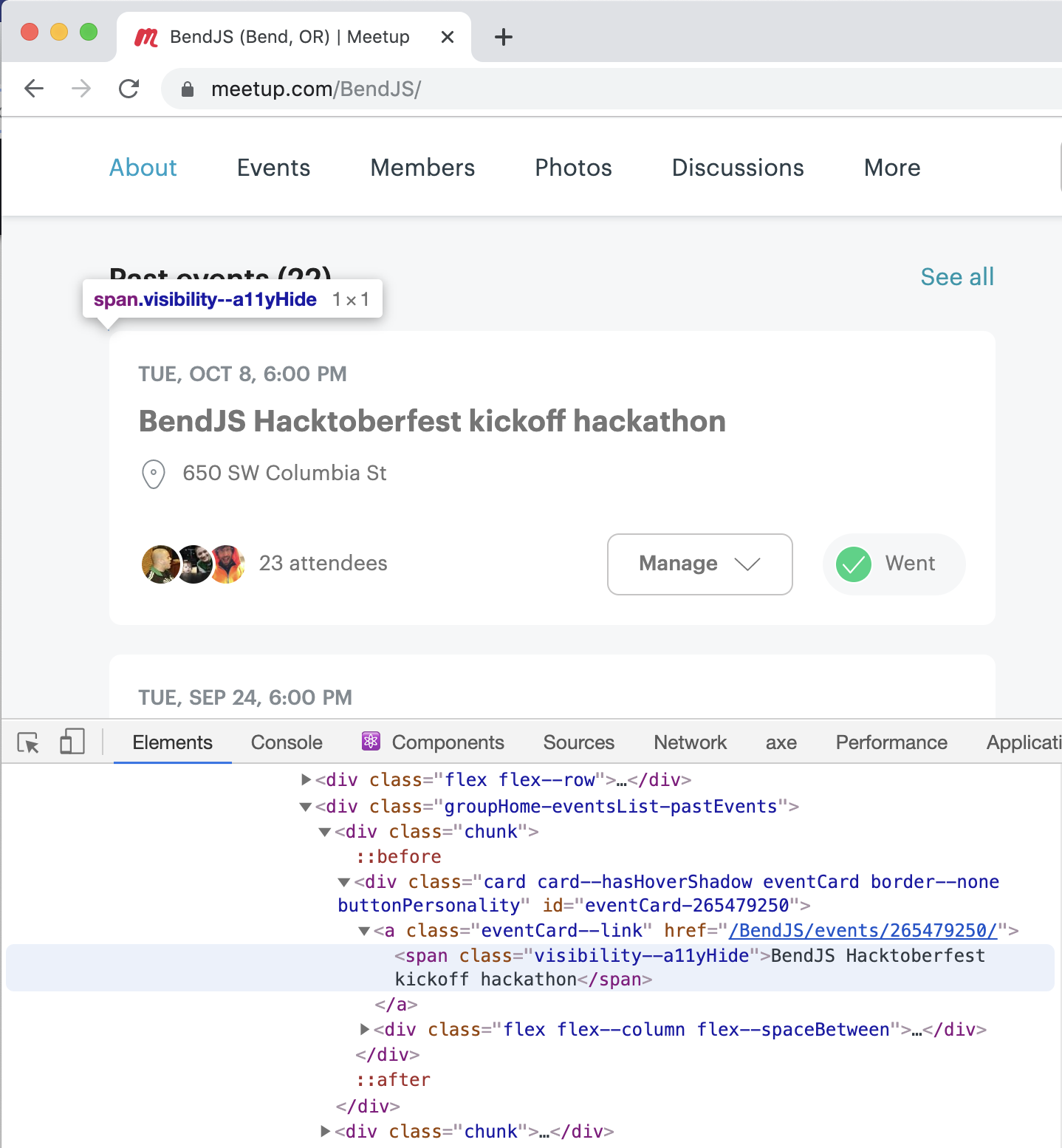
Say my goal is to pull the latest completed meetup from a Meetup.com page. Meetup.com has an API, but it’s pricy and requires OAuth and stuff. All we need is the name and link of a past meetup here, so let’s just yank it off the page.
We can see what we need in the DOM:
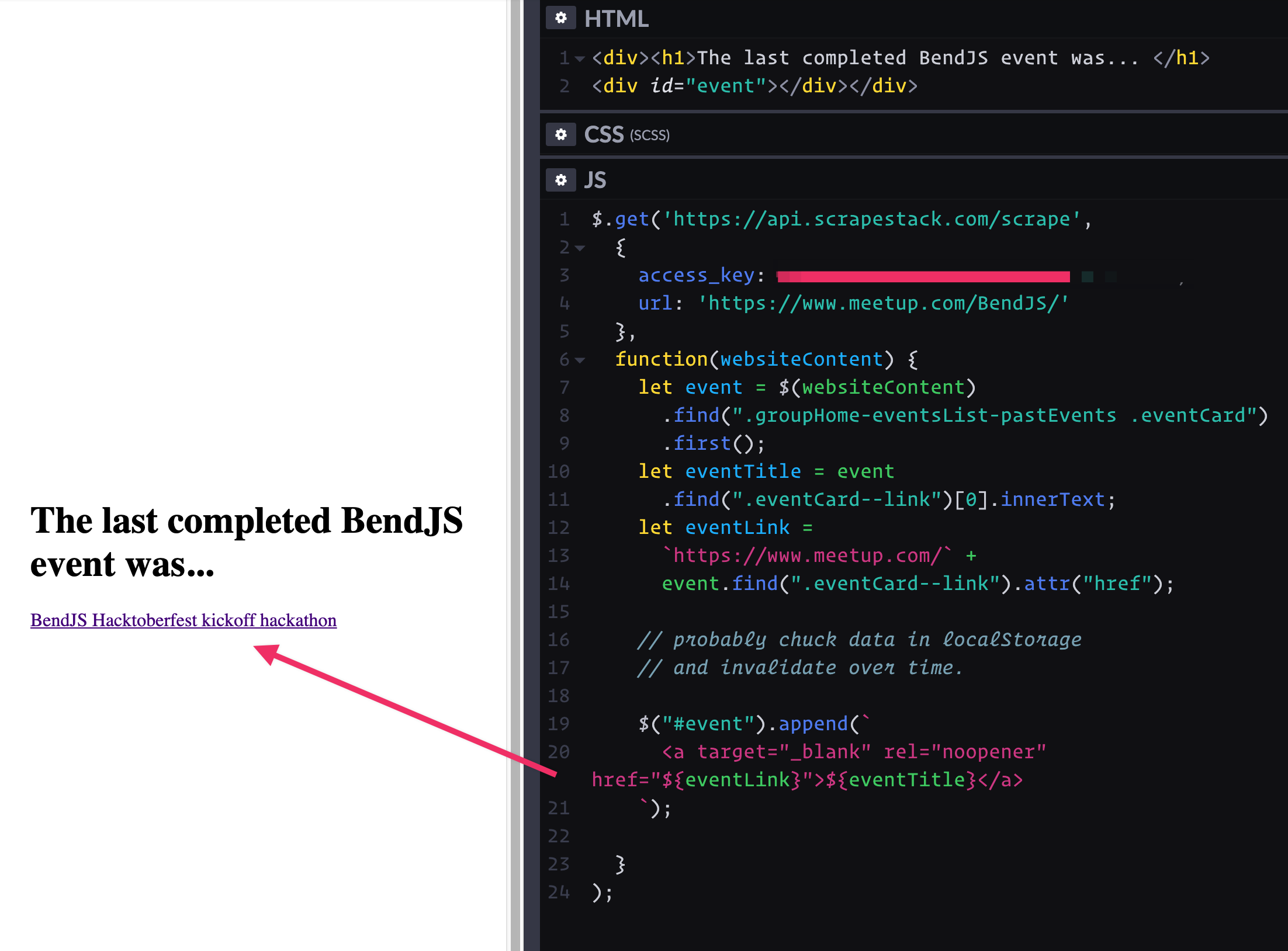
To have a play, let’s scrape it with the scrapestack API client-side with jQuery:
$.get('https://api.scrapestack.com/scrape',
{
access_key: 'MY_API_KEY',
url: 'https://www.meetup.com/BendJS/'
},
function(websiteContent) {
// we have the entire sites HTML here!
}
);Within that callback, I can now also use jQuery to traverse the DOM, snagging the pieces I want, and constructing what I need on our site:
// Get what we want
let event = $(websiteContent)
.find(".groupHome-eventsList-pastEvents .eventCard")
.first();
let eventTitle = event
.find(".eventCard--link")[0].innerText;
let eventLink =
`https://www.meetup.com/` +
event.find(".eventCard--link").attr("href");
// Use it on page
$("#event").append(`
${eventTitle}
`);In real usage, if we were doing it client-side like this, we’d make use of some rudimentary storage so we wouldn’t have to hit the API on every page load, like sticking the result in localStorage and invalidating after a few days or something.
It works!
It’s actually much more likely that we do our scraping server-side. For one thing, that’s the way to protect your API keys, which is your responsibility, and not really possible on a public-facing site if you’re using the API directly client-side.
Myself, I’d probably make a cloud function to do it, so I can stay in JavaScript (Node.js), and have the opportunity to tuck the data in storage somewhere.
I’d say go check out the documentation and see if this isn’t the right answer next time you need to do some scraping. You get 10,000 requests on the free plan to try it out anyway, and it jumps up a ton on any of the paid plans with more features.
Direct Link to Article — Permalink
The post scrapestack: An API for Scraping Sites appeared first on CSS-Tricks.
