Here’s a great thread by Kevin Powell that’s making the rounds. He believes so many folks see CSS as a frustrating and annoying language:
That’s just as unintuitive as JS starting to count at 0, but since you learned that and accept it, it’s fine.
The real issue isn’t with CSS. If you struggle with it, or ever call it unintuitive, it’s probably because you don’t really understand how CSS is meant to work.
Why do people respect JavaScript or other languages enough to learn them inside-out, and yet constantly dunk on CSS? Well, all this reminds me of what Jeremy Keith wrote a while back when he argued that CSS is simple, but not easy:
Unlike a programming language that requires knowledge of loops, variables, and other concepts, CSS is pretty easy to pick up. Maybe it’s because of this that it has gained the reputation of being simple. It is simple in the sense of “not complex”, but that doesn’t mean it’s easy. Mistaking “simple” for “easy” will only lead to heartache.
I think that’s what’s happened with some programmers coming to CSS for the first time. They’ve heard it’s simple, so they assume it’s easy. But then when they try to use it, it doesn’t work. It must be the fault of the language, because they know that they are smart, and this is supposed to be easy. So they blame the language. They say it’s broken. And so they try to “fix” it by making it conform to a more programmatic way of thinking.
There have been time where I’ve sat down with engineers to pair with them about a tricky layout issue and the CSS is treated as being beneath them — as if the language is somehow too unpredictable to warrant learning and mastering. Perhaps this has something to do with the past, where we’ve spent years fighting the way browsers render things differently. But this is mostly a solved problem. I can’t remember the last time I fought against browsers like that.
Instead, I reckon the biggest issue that engineers face — and the reason why they find it all so dang frustrating — is that CSS forces you to face the webishness of the web. Things require fallbacks. You need to take different devices into consideration, and all the different ways of seeing a website: mobile, desktop, no mouse, no keyboard, etc. Sure, you have to deal with that when writing JavaScript, too, but it’s easier to ignore. You can’t ignore your the layout of your site being completely broken on a phone.
Side note: We have a guide to centering in CSS not because CSS is busted and dumb, but because there’s so many variables to the extent that a simple question like, “How do I center text?” is actually much more complicated than it appears. There’s so much context that’s missed.
This reminds me of one of my favorite blog posts of all time, where Brandon Smith argues that CSS is awesome and we should respect the language and learn how it works under the hood:
CSS is hard because its properties interact, often in unexpected ways. Because when you set one of them, you’re never just setting that one thing. That one thing combines and bounces off of and contradicts with a dozen other things, including default things that you never actually set yourself.
One rule of thumb for mitigating this is, never be more explicit than you need to be. Web pages are responsive by default. Writing good CSS means leveraging that fact instead of overriding it. Use percentages or viewport units instead of a media query if possible. Use min-width instead of width where you can. Think in terms of rules, in terms of what you really mean to say, instead of just adding properties until things look right. Try to get a feel for how the browser resolves layout and sizing, and make your changes and additions on top of that judiciously. Work with CSS, instead of against it.
One particular pattern [for loading non-critical CSS] I’ve seen is the preload/polyfill pattern. With this approach, you load any stylesheets as preloads instead, and then use their onload events to change them back to a stylesheet once the browser has them ready.
So you’re trying to make your stylesheet more async, but it causes two big problems:
You’ve kicked up the priority of the downloading higher than any other asset.
You’ve blocked the HTML parser too (because of the polyfill as an inline script).
Firefox does something fancy to avoid problem #2 in this particular case, but it affects every other browser.
I’ve never had good luck with fancy techniques to trick the browser into theoretically better downloading/rendering patterns. I’m kind of a stylesheets in the head, scripts at the end of the body kinda guy, but I know the web is a complicated place. In fact, in a quick peek, I see that Jetpack is inserting an inline script into my , so that would affect my loading too, except they load it with an obfuscated type until later scripts execute and change it, probably to avoid this exact problem.
Anyway, Tim’s advice:
• If you’re using loadCSS with the preload/polyfill pattern, switch to the print stylesheet pattern instead.
• If you have any external stylesheets that you’re loading normally (that is, as a regular stylesheet link), move any and all inline scripts that you can above it in the markup
• Inline your critical CSS for the fastest possible start render times.
Here’s a fun one. How might we create a set of those cool Matryoshka dolls where they nest inside one another… but in CSS?
I toyed with this idea in my head for a little while. Then, I saw a tweet from CSS-Tricks and the article image had the dolls. I took that as a sign! It was time to put fingers to the keyboard.
Our goal here is to make these fun and interactive, where we can click on a doll to open it up and reveal another, smaller doll. Oh, and stick with just CSS for the functionality. And while we’re at it, let’s replace the dolls with our own character, say a CodePen bear. Something like this:
We won’t dwell on making things pretty to start. Let’s get some markup on the page and thrash out the mechanics first.
We can’t have an infinite amount of dolls. When we reach the innermost doll, it’d be nice to be able to reset the dolls without having to do a page refresh. A neat trick for this is to wrap our scene in an HTML form. That way we can use an input and set the type attribute to reset to avoid using any JavaScript.
Next, we need some dolls. Or bears. Or something to start with. The key here will be to use the classic checkbox hack and any associated form labels. As a note, I’m going to use Pug to handle the markup because it supports loops, making things a little easier. But, you can certainly write the HTML by hand. Here’s the start with form fields and labels that set up the checkbox hack.
CodePen Embed Fallback
Try clicking some of the inputs and hitting the Reset input. They all become unchecked. Nice, we’ll use that.
We have some interactivity but nothing is really happening yet. Here’s the plan:
We’ll only show one checkbox at a time
Checking a checkbox should reveal the label for the next checkbox.
When we get to the last checkbox, there our only option should be to reset the form.
The trick will be to make use of the CSS adjacent sibling combinator (+).
When a checkbox is checked, we need to show the label for the next doll, which will be three siblings along in the DOM. How do we make the first label visible? Give it an explicit display: block via inline styles in our markup. Putting this together, we have something along these lines:
CodePen Embed Fallback
Clicking each label reveals the next. Hold on, the last label isn’t shown! That’s correct. And that’s because the last label doesn’t have a checkbox. We need to add a rule that caters to that last label.
Cool. We’re getting somewhere. That’s the basic mechanics. Now things are going to get a little trickier.
Basic styling
So, you might be thinking, “Why aren’t we hiding the checked label?” Good question! But, if we hide it straight away, we won’t have any transition between the current doll and the next. Before we start animating our dolls, let’s create basic boxes that will represent a doll. We can style them up so they mimic the doll outline without the detail.
Clicking one doll instantly reveals the next one and, when we’ve reached the last doll, we can reset the form to start again. That’s what we want here.
The mechanics
We are going to animate the dolls based on a center point. Our animation will consist of many steps:
Slide the current doll out to the left.
Open the doll to reveal the next one.
Move the next doll where the current one started.
Make the current doll fade out.
Assign the next doll as the current doll.
Let’s start by sliding the current doll out to the left. We apply an animation when we click a label. Using the :checked pseudo-selector we can target the current doll. At this point, it’s worth noting that we are going to use CSS variables to control animation speed and behavior. This will make it easier to chain animations on the labels.
Great! Now once we have started, we can’t stop the animation chain from happening.
CodePen Embed Fallback
Next up, we need to crack open the doll to reveal the next one. This is where things get tricky because we are going to need some extra elements, not only to create the effect that the doll is opening up, but also to reveal the next doll inside of it. That’s right: we need to duplicate the inner doll. The trick here is to reveal a “fake” doll that we swap for the real one once we’ve animated it. This also means delaying the reveal of the next label.
Now our markup updates labels so that they contains span elements.
Next is where we can use CSS custom properties to handle changing values. Once the doll has slid over to the left, we can open it. But how do we know how long to delay it from opening until that happens? We can use the --speed custom property we defined earlier to calculate the correct delay.
It looks a little quick if we use the --speed value as it is, so let’s multiply it by two seconds:
Now we need to move the inner “dummy” doll to the new position. This animation is like the open animation in that it consists of three stages. Again, that’s one to move up, one to move right, and one to set down. It’s like the slide animation, too. We are going to use CSS custom properties to determine the distance that the doll moves.
:root {
// Introduce a new variable that defines how high the dummy doll should pop out.
--pop-height: 60;
}
@keyframes move {
0% {
transform: translate(0, 0) translate(0, 0);
}
33.333333333333336% {
transform: translate(0, calc(var(--pop-height) * -1%)) translate(0, 0);
}
66.66666666666667% {
transform: translate(0, calc(var(--pop-height) * -1%)) translate(calc((var(--base-slide) * 1px) + var(--slide-distance) * 1%), 0);
}
100% {
transform: translate(0, calc(var(--pop-height) * -1%)) translate(calc((var(--base-slide) * 1px) + var(--slide-distance) * 1%), calc(var(--pop-height) * 1%));
}
}
Almost there!
CodePen Embed Fallback
The only thing is that the next doll is available as soon as we click a doll. that means we can spam click our way through the set.
Technically, the next doll shouldn’t show until the “fake” one has moved into place. It’s only once the “fake” doll is in place that we can hide it and reveal the real one. That means we going to use zero-second scale animations! That’s right. We can play pretend by delaying two zero-second animations and using animation-fill-mode.
@keyframes appear {
from {
transform: scale(0);
}
}
We actually only need one set of @keyframes. because we can re-use what we have to create the opposite movement with animation-direction: reverse. With that in mind, all our animations get applied something like this:
// The next doll
input:checked + .doll + input + .doll,
// The last doll (doesn't have an input)
input:checked + .doll + .doll {
animation: appear 0s calc(var(--speed) * 5s) both;
display: block;
}
// The current doll
input:checked + .doll,
// The current doll that isn't the first. Specificity prevails
input:checked + .doll + input:checked + .doll {
animation: slideLeft calc(var(--speed) * 1s) forwards;
pointer-events: none;
}
input:checked + .doll .doll__half--top,
input:checked + .doll + input:checked + .doll .doll__half--top {
animation: open calc(var(--speed) * 2s) calc(var(--speed) * 1s) forwards;
}
input:checked + .doll .doll__dummy,
input:checked + .doll + input:checked + .doll .doll__dummy {
animation: move calc(var(--speed) * 2s) calc(var(--speed) * 3s) forwards, appear 0s calc(var(--speed) * 5s) reverse forwards;
}
Note how important the variables are, especially where we are chaining animations. That gets us almost where we need to be.
CodePen Embed Fallback
I can hear it now: “They’re all the same size!” Yep. That’s the missing piece. They need to scale down. The trick here is to adjust the markup again and make use of CSS custom properties yet again.
We just introduced a CSS custom property inline that tells us the index of the doll. We can use this to generate a scale of each half as well as the fake inner doll. The halves will have to scale to match the actual doll size, but the fake inner doll scale will need to match that of the next doll. Tricky!
We can apply these scales inside the containers so that our animations are not affected.
Here’s a demo where the containers have been given a background color to see what’s happening.
CodePen Embed Fallback
We can see that, although the content size changes, they remain the same size. This makes for consistent animation behavior and makes the code easier to maintain.
Finishing touches
Wow, things are looking pretty slick! All we need are some finishing touches and we are done!
The scene starts to look cluttered because we’re stacking the “old” dolls off to the side when a new one is introduced. So let’s slide a doll out of view when the next one is revealed to clean that mess up.
The new slideOut animation fades the doll out while it translates to the left. Perfect. ?
That’s it for the CSS trickery we need to make this effect work. All that’s left style the dolls and the scene.
We have many options to style the dolls. We could use a background image, CSS illustration, SVG, or what have you. We could even throw together some emoji dolls that use random inline hues!
CodePen Embed Fallback
Let’s go with inline SVG.
I’m basically using the same underlying mechanics we’ve already covered. The difference is that I’m also generating inline variables for hue and lightness so the bears sport different shirt colors.
CodePen Embed Fallback
There we have it! Stacking dolls — err, bears — with nothing but HTML and CSS! All the code for all the steps is available in this CodePen collection. Questions or suggestions? Feel free to reach out to me here in the comments.
4 Tips For Dark User Interface Design – What You Need to Know
If you’re considering “coming to the dark side”, then there are 5 things you need to know before you start designing.
So, here we go!
1. Allow People to Use Dark or Regular Mode
The first and most important thing is to give your clients and users the option of using dark or regular mode.
You can’t please everyone 100%, but at least you can give people the option of using whatever mode they like most.
Some people like dark mode, some people like regular mode. I, personally, am one of the few of my friends that will always use regular mode.
I am definitely the outcast of my group when it comes to using dark mode.
I’m literally the only person who will ever use regular mode because all of my co-workers and friends are obsessed with dark mode.
So remember, it’s important to let people choose what they want to use.
2. Don’t Use Pure Black
Dark mode doesn’t mean you have to use the color pure black as your background.
In fact, using a pure black color can actually cause more harm to your eye than using the bright mode.
One of the many reasons people use dark mode is to protect their eyes from all the bright colors, and when you use pure black, it can be hard for people’s eyes to adjust and register everything.
It’s safest to go with the more neutral version of whatever color you’ve chosen as your primary and secondary colors.
It’ll still be beautiful, and it will be less straining on your client’s eyes.
Wouldn’t you hate to lose a client that loves your product, over a poor color choice?
4. Use Depth to Your Advantage
When you decide to create and design a dark mode for your app, it’s very important to use depth to your advantage and create a sense of hierarchy and to put lots of emphasis on important elements in your design.
As you know, in regular or light mode, you can use shadows to express elevation. But that approach won’t work well in dark mode.
Since you can’t see a shadow on a dark color very well, a better approach to this problem would be to use lighter colors to create some depth.
Ninety-five percent of C-suite executives list data management as key to business strategy. Data management allows business leaders to leverage the data they collect from customers and suppliers to propel growth.
Data management is how you extract answers and insights from raw data to meet your information needs. The proliferation of electronic data-collection methods in recent years has created the impression data management is all about technology, but its roots are firmly in accounting, statistics, and planning.
In the 1960s, the Association of Data Processing Service Organizations (ADAPSO) was one of several groups that advocated for data management standards for training and data quality. By the 1970s, the relational database management strategy provided a way to consistently process data and reduce duplicates. Throughout the 1980s, the Data Management Association International (DAMA International) worked to improve education and training in data management.
As computer use became widespread, IT professionals built data warehouses that used relational techniques for offline data analysis. This gave managers powerful new ways to use data for decision-making purposes.
Today, data management shapes corporate strategy and guides decision-makers searching for a competitive edge. Research firm IDC predicts that by 2025 users will be creating 463 billion GB of data per day. That mind-boggling volume is priceless with good data management but just noise without it.
Data management includes storage, data security, data sharing, data governance, data architecture, database management, and records management. Once your data management strategy is in place, you’ll glean important insights by using your data to its full potential.
In this guide, you’ll learn why data management is so important. We’ll begin with an overview of data management techniques you can use to collect and maintain your data, review best practices for data management, and examine the top three data management solutions available.
Why is data management important?
Data is the lifeblood of dynamic organizations. It can help you retain customers and attract new ones, improve your customer service, fine-tune your marketing, and reveal sales trends. But to get the most out of your data, you need to manage it.
There are a lot of advantages to data management:
You’ll be more productive. Data management makes it easier for you and your employees to find, understand, and communicate information to each other and to customers.
You’ll save money. By making you more productive, data management reduces costs. Your employees won’t waste time searching for data or duplicating efforts.
You can react quicker. Data management reveals trends so you can act sooner than your competition.
You’ll mitigate security risks. Think of all the big security breaches that have been in the news. Since data security is an integral part of data management, you’ll lock down your data and avoid ending up in the news for all the wrong reasons.
You’ll be able to make more accurate decisions. Data management ensures that you and your employees are reacting to the most up-to-date data.
Common data management strategies
Formulating a data management strategy seems daunting, but there are well-established best practices and proven strategies to choose from. The two basic data management strategies to consider are offense and defense.
In the offensive data management strategy, you’re engaged in customer-focused activities, like sales and marketing. The goal is to increase revenue, profitability, and customer satisfaction. You’ll use this strategy to conduct data analysis and modeling or integrate different data sources into dashboards.
In the defensive data management strategy, you’re focused on security and compliance. Your goal is to demonstrably comply with regulations protecting customer data and privacy while using analytics to detect and prevent fraud.
A good data management strategy is solid on both offense and defense. There are five additional core components that should be part of your data management strategy:
Identification of data and what it means, how it’s structured, where it came from, or where it’s located
Storage that lets you easily access, share, and process your data
Provisioning that lets you package your data so that it can be reused and shared, and lets you add rules and guidelines for accessing the data
Governance to establish, manage, and communicate the policies and mechanisms in place for using data
Processing that lets you move and combine data stored in different systems to provide a single, unified view
How to develop a data management plan
Begin developing your data management plan by considering your goals. Use aspects of both offensive and defensive strategies, and include the five core components of data management. The details of your plan will depend on your company type as well; an educational institution has different data concerns than a healthcare provider.
Evaluate how you currently manage data and identify any shortcomings in your existing plan. If you don’t have a plan, create a wish list of things you’d like to have: real-time access to data, predictive analytics, and role-based dashboards, for example.
Once you’ve created your list, it’s time to start looking at data management systems. Investing in one will increase productivity by making your data easily accessible and consistent.
Only consider data management systems that will work with your existing software, including CRM systems, marketing databases, and accounting systems, so you can pull information from your key business systems, analyze it, and make more informed decisions.
Carefully consider the security features of these platforms, how easy it is to integrate data from multiple sources, and how easy it will be to access your data. Later in this guide, we’ll dive into the features and benefits of three common data management systems.
If all of this is overwhelming, consider hiring a data manager. A capable manager can track and analyze your data and refine your data management plan, freeing you to focus on your business.
Regardless of which data management strategy you’re tackling first, make sure your data is protected. Privacy and security should be central to your data management plan. This includes security controls for your database; encrypting data in transit and at rest; educating your employees; and establishing data best practices.
Now that you have a head start on data management, you’ll want to know more about enterprise data management. The next section discusses what enterprise data management is, what master data management is, and the tools you can use for it.
What you need to know about enterprise data management
Enterprise data management is how you put your data management strategy into action.
Think of data management as an administrative process that encompasses data acquisition, validation, storage, protection, and processing. Enterprise data management (EDM) is the next level. It’s how your company creates, integrates, disseminates, and manages all the data that flows in and out of your applications and processes.
EDM creates a structure for delivering actionable insights from raw data that’s often disorganized and full of duplicates. EDM encompasses software, hardware, infrastructure, business logic, and company policies. It requires far-reaching collaboration, including every department from frontline sales staff to the back-office team.
Managing data internally across departments is central to EDM. Three top challenges are data organization, data processing, and efficient data entry. You can collect data from customers and prospects with readily available tools from JotForm.
Effective EDM begins with listening to stakeholders to learn what problems they need to solve. Once you have their buy-in, you can determine your platform requirements, establish policies and procedures, and create data definitions and tagging. Take into account stakeholder requirements, workflow, data dependencies, and the organization’s resilience in case of disruption.
EDM requires explicit policies and procedures for change management, data management, security, and data dependencies. You’ll need to standardize the terms and definitions used to classify data, known as metadata, and choose technology to help you do all of this.
The early stages of formulating your EDM strategy is a good time to begin familiarizing yourself with master data management (MDM), which you’ll need to take your capabilities a step further. MDM is how you develop a “single source of truth,” the data that everyone in the organization uses when making business decisions.
What is master data management?
MDM consolidates enterprise data into a single master reference source to provide consistent, accurate, and complete data across the enterprise. Vigilant MDM is a multistep process of data cleansing, data transformation, and data integration.
Integrating your data management software into your business systems, like CRM and accounting, as we discussed in the last chapter, positions you for an effective MDM initiative. Some key MDM processes include
Administering business rules
Aggregating data
Classifying data
Collecting data
Consolidating data
Distributing data
Data governance
Mapping data
Matching data
Normalizing data
As you add more data sources, the MDM system identifies, collects, transforms, and repairs your data. As you set quality standards and taxonomies for your data, your MDM software will take care of the rest. In the end, you get accurate, up-to-date, and consistent data that can be used throughout your organization.
One of the ways companies use MDM is to update customer information. For example, you might have customer data in your CRM, order fulfillment, and accounting systems. If the customer contact information changes in the accounting system, MDM updates all three of these systems so you’re not shipping products to the wrong location or following up on service calls at the wrong phone number.
MDM helps companies comply with regulations, including the Sarbanes-Oxley Act (SOX), the EU General Data Protection Regulation (GDPR), and the Health Insurance Portability and Accountability Act (HIPAA). With master data management, companies can show regulators that they have clean, consistent, and accurate data that meets compliance requirements.
Companies also use MDM to improve the customer experience because it pulls in data from multiple systems, giving them that elusive 360-degree view of the customer. This data is used in customer service, sales, and marketing departments to upsell and cross-sell, send personalized offers, or troubleshoot a problem.
For example, a customer may contact a company about a recent purchase. With the data all in one place, the customer care agent can quickly see what the customer is calling about and provide faster service.
The top master data management tools
There are plenty of tools available for companies that want to embark on MDM. According to research firm Gartner, MDM tools need to include workflow, data modeling, data governance, and support for multiple domains, multiple usage scenarios, and multiple implementation styles.
The leaders in MDM tools are Informatica and Orchestra Networks (which has been acquired by TIBCO). Informatica’s customers give Informatica MDM products above average scores for initial implementation and deployment as well as account management. Orchestra Networks’s single, integrated offering also scored above average with its customers, as the majority of them can integrate data in real time or near real time.
Now that you know more about EDM and MDM, you’re ready to learn about data management techniques.
In the next chapter, you’ll find out about the best ways to manage your data, including how to improve data management. You’ll discover why controlling the point of data entry can help you improve data quality and how controlling backup and replacement of data affects the management process. You’ll also learn how regular maintenance can ensure data quality.
Top data management techniques
Reaping the full benefits of enterprise data management and master data management requires you to implement a data management strategy. Here we explore the top data management techniques for collecting and storing the clean, reliable data essential to making informed business decisions.
Inventory your existing data
Managing your data begins with identifying your existing data assets so you can integrate different databases to achieve a single source of truth.
Many companies store data in multiple locations, for example, in separate databases for each application, along with cloud-based storage apps like Dropbox for easy employee access. Talk to stakeholders in multiple departments to gather this information and begin mapping out where all of your data is currently stored.
Next, you’ll need to create a way to track this data. This can be as simple as a spreadsheet or as complex as using a tool to help you create a full data inventory. Start by including where the data is stored, its purpose, the file type (for example, you may have a bunch of Excel spreadsheets full of customer data), subjects or keywords for the data, and how often it’s updated.
Review your business goals
Top data management techniques take into account what you want to get out of your data and how it lines up with what you want from your business. For example, do you want to create or improve automation and processes, or do you want insight into customer buying habits and patterns? What you do with your data needs to align with your business goals.
Make data security your top priority
Data security is critical to data management. Regulations like Sarbanes-Oxley, the Health Insurance Portability and Accountability Act (HIPAA), and the EU’s General Data Protection Regulation (GDPR) all come with stringent data security standards.
If you handle payment information, you also have to contend with the Payment Card Industry Data Security Standard (PCI DSS). Running afoul of regulations or industry standards can cost your company hundreds of thousands of dollars in fines and damage your reputation.
Encryption is one of the most effective techniques for keeping your data secure. Encrypt your data both when it’s in transit and at rest, with decryption keys stored separately.
In addition, limit who has access to your data by creating role-based user accounts. Make sure employees and partners have access to enough data to do their jobs effectively but not full access to all company data.
Immediately revoke access to data when an employee leaves the company. Require everyone to use strong passwords that include uppercase and lowercase characters, numbers, and special characters.
Make your data accessible
A big part of data management is striking a balance between data security and easy access to the data your team needs to do their jobs. For example, customer service agents need immediate access to customer data. Set up role-based permissions for data so that team members get what they need without compromising the security of your entire data inventory.
Give employees tools so they can quickly find the data they need. For example, a natural language interface allows employees to ask, “What percentage of our sales were awesome widgets?” Other helpful tools allow you to easily add role-based dashboards.
Data management isn’t a “set it and forget it” procedure. Review your data management plan regularly to ensure it still meets your company’s needs. Regular reviews are also crucial for data security, as external threats only get more sophisticated. These top data management techniques can help keep your data accessible, reliable, and secure.
Limit your data entry points
The more data entry points you have, the bigger your risk of duplicate or incorrect data. According to a study by the Journal of the American Medical Informatics Association, the error rate in manually input lab results was 3.7 percent, while the standard in most industries is less than 1 percent.
For instance, your customers may fill out paper forms. Team members then have to manually input these forms into your system. They may not be able to read a customer’s handwriting. Or perhaps your team members take information from customers over the phone, and they mistype the customer’s address. Human error can cause all sorts of data problems, so it’s important to consider where your data is coming from.
The key to accurately inputting data is to streamline data entry points. JotForm allows you to create customized forms, including order forms, feedback forms, and contact forms that dramatically reduce the potential for data entry errors.
Update your data frequently
More than half of surveyed executives report feeling overwhelmed by too much data. They only want what’s relevant to make better decisions, but frenzied data collection has swept up data that’s irrelevant or redundant along with what’s useful.
Removing irrelevant data through “data cleansing” frees up much-needed space and reduces the feeling of being overwhelmed. Data cleansing is a one-off process that involves purging data anomalies and unnecessary data.
In addition to standardizing the entry point for your data, look for tools that can help you validate the accuracy of your data and identify duplicates. List imports and email hygiene tools can help you verify accuracy.
As you cleanse your data, report back to the different departments so that they’re on board with new data accuracy and collection standards. Always back up your existing data before you begin a data cleansing effort, in case something goes wrong.
Control data backup and recovery
It’s extremely important to control data backup and recovery in case the worst happens. Even a minor error can cost you valuable lines of data. There are two ways you can do this: Back up data onsite, which can be costly, or use a cloud-based service. Make sure that whatever you choose will be accessible in the event of an emergency so that you can quickly restore your data and minimize the disruption to your business.
An onsite data backup can be on hard drives or servers stored at your location. As you collect more data, you’ll need to expand your storage space. Cloud-based backups range from consumer-grade options like Carbonite to enterprise-grade services from AWS and Microsoft Azure.
Ensure quality by reviewing and maintaining data
It’s important to review and maintain data to ensure you’re working with quality data sets. Unlike data cleansing, data maintenance is an ongoing process. Regularly review and verify your data to be certain it’s still reliable and usable. Reviewing and maintaining data also makes your database run faster by removing unnecessary files.
Rebuilding your database indexes is an important part of data maintenance. As you delete irrelevant data and verify it, you’ll create index fragmentation, which causes gaps in your data and slows down access to your data.
Use these data management techniques to keep your data clean and usable. In the next section, you’ll learn about data management best practices, including data privacy, storage, and archiving.
Top data management best practices
There are well established best practices for data management that help maximize your results. These best practices deal with data access, documentation, data privacy, data sharing channels, storage, and archiving. Using these best practices will ensure your data is secure, accessible, and usable.
You need trained staff who know how to use standard data management processes. Technology allows you to set access privileges, create data-sharing channels, ensure data privacy, and set up storage and archiving. Here’s what you need to know.
Make data access and data collaboration simple
Everyone on your team needs access to your single source of truth so they can collaborate on solutions with teammates, partners, suppliers, and other relevant third parties. The best practices for data access and data collaboration are to set role-based permissions for different types of employees and partners. Strike a balance between convenience and security that allows individuals access to the data they need, but no more.
Create data documentation users can understand
Data documentation includes data dictionaries, readme files, and embedded metadata. Good data documentation gives users meaning and context so they understand the data and can use it to solve business problems. Your data documentation should explain how to interpret data correctly. The documentation can vary according to the complexity of the data and the needs of your team.
Data documentation needs to be in place before you begin collecting data. A data dictionary is necessary to answer key questions about your data. Check out standards for data documentation as a starting point for your own use cases.
Ensure data privacy
Protecting data requires establishing procedures for handling data correctly, beginning with how data is collected and stored, regulatory compliance, and protocols for how it’s shared with third parties.
Data privacy differs from data security in that it deals with your internal processes versus mitigating external threats. For example, good data security keeps hackers from accessing your data. Data privacy makes sure you have permission to share users’ information with third parties.
Data protection is a key part of data privacy. Your team will need to be trained on best practices for keeping your company data secure. This includes the processes and procedures you use to make sure your data is collected, shared, and used in accordance with your policies and applicable regulations.
Data privacy has always been a serious responsibility but is now a major potential liability as well. Poor data privacy practices risk serious violations of the regulations discussed earlier in this guide. Liability for a major data breach can cost your company millions of dollars.
Have the proper data sharing channels available
A key part of your data management plan is enabling data sharing channels. Data sharing is essentially sharing your data with multiple applications and/or users. Most companies share their information with outside partners and suppliers as well as employees.
The channels you use will vary based on how your users consume data. For example, executives may want to view data on dashboards to see the overall metrics of the business. Customer care agents may want a list of purchases that a customer has made so they can help that customer.
You might use an analytics dashboard to dive into sales metrics or use a CRM system to examine a customer’s service call history. You can make all of this data available by integrating CRM systems and analytics dashboards, as well as other systems that employees and partners may use, with your master database.
Application programming interfaces (APIs) selectively open up data to third parties, such as your suppliers. An API restricts access to only relevant data and systems while shielding the rest of your data. Many APIs are readily available. You don’t necessarily have to program one from scratch.
Choose the right data storage
How you store your data will affect how well you manage your data. When you choose a data storage solution, you can select on-premises servers, a cloud-based solution, or a combination of both, known as hybrid storage. Cloud storage is an affordable way to store massive volumes of data without purchasing expensive servers.
There are also several on-premises storage types available. Direct attached storage, like USB drives and external hard drives, can be connected directly to your computers. Network-attached storage (NAS) is the central server storage model, where everything is kept on servers and shared across the network. Some companies still use offline storage like optical disk (CD or DVD) backups as well.
What you need to keep in mind, regardless of the storage method you choose, is how available your data will be and how secure it is. Look for storage with high uptime (99.999 percent availability), as well as automatic backup and disaster recovery. You’ll also need to know how much it will cost to get more storage, as well as how secure it is. This includes how it’s encrypted, both when it’s being stored and when in transit.
Archive old data to reduce costs
You can archive old data that you need but aren’t currently using to free up space and reduce costs. Typical archived data includes older data that’s still important to the company or data that needs to be kept for compliance reasons, such as spreadsheets, email, and other communications.
Storage meant for data archiving often costs significantly less than storage for active data because you’re not accessing the data multiple times a day and piping it through your applications. It also reduces the amount of data you back up, so your backup storage costs will be lower.
Now that you know more about the top data management techniques, let’s look at data management solutions. The final chapter of this guide discusses the common data management solutions available, what they provide, and how data management tools and applications can aid the overall process.
Top data management solutions
The success of your data management initiative depends on how well you collect, organize, and use your data. To do all well, you need data management software.
Data management platforms collect and manage data from both online and offline sources. Data management software aggregates your data so you can use it. Data management tools and applications connect to your data source via APIs, webhooks, or direct database connections to help you accomplish tasks like creating data visualizations for reports.
Here’s a rundown of how data management platforms, software, and tools and applications help you extract the most value from your data.
What a data management platform provides
A data management platform is a centralized system for collecting and analyzing your data. In its most basic form, it imports data from all of your systems to a single place. In a more complex setup, it includes tools to aggregate data from multiple sources and data analytics tools for discerning trends within that data.
Your data management platform must be able to collect data from multiple sources, including online forms, mobile devices, partner systems, and internal sources. This includes both structured data from spreadsheets and relational databases and unstructured data like social media posts, PDFs, and Word documents. All this data must be integrated and stored so that it’s usable.
Using a data management platform provides you with control over your data for multiple use cases. For example, a data management platform could collect customer data from multiple sources, then analyze and organize it to segment your customers by purchase history.
Data management platforms can be housed onsite. However, cloud-based data management platforms running on AWS, Oracle, and other services, as well as open-source platforms like EDB Postgres are also available.
What data management software provides
Different from a data management platform, data management software is a program like Microsoft MySQL, PostgreSQL, Microsoft Access, or Oracle that handles queries on your data. Use it to create, edit, and maintain your database files and records in the form of structured tables, fields, and columns.
The term “data management software” is used interchangeably with database management software. Both aggregate and secure your data, ensure its integrity, and handle different types of queries.
Some data management software requires a lot of coding knowledge to create databases and add-on applications. The better systems allow you to quickly build databases and begin using applications without any coding knowledge.
Data management software prepares your data for analysis, secures it, and lets you apply policies to identify and manage it. Your data is kept throughout its lifecycle. You can create policies and rules for your data, like what constitutes personal information or how long you retain customer data. You can also automate tasks, like importing data and populating your database fields with it.
The software can help with data quality by standardizing data into fields, eliminating duplicate data, and protecting it against unintentional changes. This, in turn, prepares your data for analytics and reporting, which you’ll do with data management tools and applications.
How data management tools and applications can help
With so many ways to manage your data, you should look into data management tools and applications to import and integrate data, create policies, and run analytics. Some data management platforms and software suites come with these capabilities built in. However, you may want to explore other standalone options that have specific functionality.
Data management tools and applications are particularly helpful for data analysis. Some tools will cleanse your data and perform quality checks beyond what your data management software does. You can then run analytics and use tools with AI and machine learning to glean insights from your data, like forecasting sales for the winter holiday season.
These tools use learning algorithms to pick up on trends that they find in data sets. Data visualization tools can create graphic representations of your data, like pie charts and line graphs, that can be easily (and quickly) consumed by busy executives and employees.
You can also use data management tools to import and export data from your data management platform in different formats, like Excel and CSV. Some tools will let you search for submissions and then delete them, like when you test out new forms on your website. Others will combine data from different forms into a single file.
Data management applications let you access your data on mobile devices. You can build an application that allows customers to book service appointments.
Data management requires technology, and using data management platforms, software, and applications and tools in concert with one another can help you get the most out of your data.
Conclusion
You’ve learned a lot about data management, from why it’s important to the tools you’ll need to make it a reality in your organization. This guide discussed common data management strategies and how to start developing a data management plan. You also learned about enterprise data management, master data management, and the top master data management tools.
Data management techniques, along with data management best practices, are necessary for an effective data management strategy. It’s important to control your data entry point to improve your overall data management, remove irrelevant data, and control the backup and replacement of your data. It’s also important to continually review and conduct maintenance on your data to ensure its quality.
This guide also discussed data management best practices, from making sure all relevant parties can easily access and collaborate on data to the importance of data documentation, data privacy, data sharing, and storage and archiving.
With this knowledge, you can now start implementing a data management strategy. As you continue to collect, store, and analyze data, continually revisit your strategy and toolkit to make sure it still meets your needs and gives you the useful data you require.
Handling digital media assets such as audio and video in your application can be tricky because of the considerations that have to be made server-side (e.g. networking, storage and the asynchronous nature of handling file uploads). However, we can use libraries like Multer and Express.js to simplify our workflow on the backend while using Nuxt.js (Vue framework) to build out the front-end interactions.
Whenever a web client uploads a file to a server, it is generally submitted through a form and encoded as multipart/form-data. Multer is a middleware for Express.js and Node.js that makes it easy to handle this so-called multipart/form-data whenever your users upload files. In this tutorial, I will explain how you can build a music manager app by using Express.js with Multer to upload music and Nuxt.js (Vue framework) for our frontend.
Prerequisites
Familiarity with HTML, CSS, and JavaScript (ES6+);
Node.js, npm and MongoDB installed on your development machine;
VS code or any code editor of your choice;
Basic Knowledge of Express.js.
Building The Back-End Service
Let’s start by creating a directory for our project by navigating into the directory, and issuing npm init -y on your terminal to create a package.json file that manages all the dependencies for our application.
mkdir serverside && cd serverside
npm init -y
Next, install multer, express, and the other dependencies necessary to Bootstrap an Express.js app.
npm install express multer nodemon mongoose cors morgan body-parser --save
Next, create an index.js file:
touch index.js
Then, in the index.js file, we will initialize all the modules, create an Express.js app, and create a server for connecting to browsers:
const express = require("express");
const PORT = process.env.PORT || 4000;
const morgan = require("morgan");
const cors = require("cors");
const bodyParser = require("body-parser");
const mongoose = require("mongoose");
const config = require("./config/db");
const app = express();
//configure database and mongoose
mongoose.set("useCreateIndex", true);
mongoose
.connect(config.database, { useNewUrlParser: true })
.then(() => {
console.log("Database is connected");
})
.catch(err => {
console.log({ database_error: err });
});
// db configuaration ends here
//registering cors
app.use(cors());
//configure body parser
app.use(bodyParser.urlencoded({ extended: false }));
app.use(bodyParser.json());
//configure body-parser ends here
app.use(morgan("dev")); // configire morgan
// define first route
app.get("/", (req, res) => {
res.json("Hola MEVN devs...Assemble");
});
app.listen(PORT, () => {
console.log(`App is running on ${PORT}`);
});
We, first of all, bring in Express.js into the project and then define a port that our application will be running on. Next, we bring in the body-parser, morgan ,mongoose and the cors dependencies.
We then save the express instance in a variable called app. We can use the app instance to configure middleware in our application just as we configured the cors middleware. We also use the app instance to set up the root route that will run in the port we defined.
Let’s now create a /config folder for our database config and multer config:
mkdir config and cd config
touch multer.js && touch db.js
Then open config/db.js and add the following code to configure our database:
Let’s set up a file structure by typing in the following:
mkdir api && cd api
mkdir model && cd model && touch Music.js
cd ..
mkdir controller && cd controller && touch musicController.js
cd ..
mkdir routes && cd routes && touch music.js
In our terminal, we use mkdir to create a new directory, and then cd to move into a directory. So we start by creating a directory called api and then move into the api directory.
The touch command is used to create a new file inside a directory using the terminal, while the cd command is used to move out of a directory.
Now let’s head on over to our api/model/Music.js file to create a music schema. A model is a class with which we construct documents. In this case, each document will be a piece of music with properties and behaviors as declared in our schema:
In the multer.js file, we start by setting up a folder where all the uploaded music files will be uploaded. We need to make this file static by defining that in the index.js file:
app.use('/uploads', express.static('uploads'));
After that, we write a simple validator that will check the file mimetype before uploading. We then define the multer instance by adding the storage location, the limits of each file, and the validator that we created.
Create The Necessary Routes
Now let’s create our routes. Below is the list of endpoints we will be creating.
HTTP POST /music
Add new music
HTTP GET /music
Get all music
HTTP DELETE /music/:blogId
Delete a music
Let’s start by creating the blog route. Head over to api/routes/music.js and write the following code:
Note: Now whenever we make agetrequest to/music. the route calls thegetAllMusicfunction that is located in the ‘controllers’ file.
Let’s move on over to api/controllers/musicController to define the controllers. We start by writing a function to get all the music in our database using the mongoose db.collection.find method which will return all the items in that collection.
After doing that, we write another function that will create a piece of new music in the database. We need to create a new music instance using the new keyword and then define the music object. After doing this, we will use the mongoose save method to add new music to the database.
In order to delete a piece of music, we need to use the mongoose remove method by simply passing the music ID as a parameter in the remove instance. This results to mongoose looking into the music collection that has that particular ID and then removing it from that collection.
let mongoose = require("mongoose");
const Music = require("../model/Music");
exports.getAllMusics = async (req, res) => {
try {
let music = await Music.find();
res.status(200).json(music);
} catch (err) {
res.status(500).json(err);
}
};
exports.addNewMusic = async (req, res) => {
try {
const music = new Music({
title:req.body.title,
artist:req.body.artist,
music:req.file
});
let newMusic = await music.save();
res.status(200).json({ data: newMusic });
} catch (err) {
res.status(500).json({ error: err });
}
};
exports.deleteMusic = async (req, res) => {
try {
const id = req.params.musicId;
let result = await Music.remove({ _id: id });
res.status(200).json(result);
} catch (err) {
res.status(500).json(err);
}
};
Last but not least, in order to test the routes, we need to register the music routes in our index.js file:
const userRoutes = require("./api/user/route/user"); //bring in our user routes
app.use("/user", userRoutes);
Testing The End Points
To test our endpoints, we will be using POSTMAN.
Adding New Music
To test the Add Music functionality, set the method of the request by clicking on the methods drop-down. After doing this, type the URL of the endpoint and then click on the body tab to select how you want to send your data. (In our case, we will be using the form-data method.)
So click on the form-data and set up your model key. As you set it up, give the keys some value as shown in the image below:
Testing Adding new music API in Postman dashboard (Large preview)
After doing this, click on ‘Send’ to make the request.
Listing All Music
To list all of the music in our database, we have to type the endpoint URL in the URL section provided. After doing this, click on the ‘Send’ button to make the request.
Testing Listing API in Postman dashboard (Large preview)
Deleting Music
To delete a piece of music, we need to pass the music id as a parameter.
Testing Delete API Postman dashboard (Large preview)
That’s it!
Building The Frontend
For our frontend, we will be using a Vue framework: Nuxt.js.
“Nuxt is a progressive framework based on Vue.js to create modern web applications. It is based on Vue.js official libraries (vue, vue-router and vuex) and powerful development tools (webpack, Babel and PostCSS).”
To create a new Nuxt.js application, open up your terminal and type in the following (with musicapp as the name of the app we will be building):
$ npx create-nuxt-app musicapp
During the installation process, we will be asked some questions regarding the project setup:
Project name
musicapp
project description
A Simple music manager app
Author name
Package manager
npm
UI framework
Bootstrap vue
custom ui framework
none
Nuxt modules
Axios,pwa (use the spacebar on your keyboard to select items)
Linting tool
Prettier
test framework
None
Rendering Mode
Universal (SSR)
development tool
Jsonconfig.json
After selecting all of this, we have to wait a little while for the project to be set up. Once it’s ready, move into the /project folder and serve the project as follows:
cd musicapp && npm run dev
Open up the project in any code editor of your choice and then open the project in the browser by accessing localhost:3000.
We will be using axios to make an HTTP request to our back-end server. Axios is already installed in our project, so we just have to configure the baseURL– to our backend server.
To do this, open the nuxt.config.js file in the root directory and add the baseURL in the axios object.
axios: {
baseURL:'http://localhost:4000'
},
Building The Music Manager
Setting Up The UI
Let’s start by cleaning up the UI. Open up the pages/index.vue file and remove all of the code in there with the following:
<template>
<div>Hello</div>
</template>
After doing this, you should only be able to see a “Hello” in the browser.
In the root directory, create a /partials folder. Inside the /partials folder, create a navbar.vue file and add the following code:
Note: We will be using the component to navigate through pages in our application. This is just going to be a simple component made up of Bootstrapnavbar. Check out the official Bootstrap documentation for more reference.
Next, let’s define a custom layout for the application. Open the /layouts folder, replace the code in the default.vue file with the code below.
We import the navbar into this layout, meaning that all the pages in our application will have that navbar component in it. (This is going to be the component that all other component in our application will be mounted.)
After this, you should be able to see this in your browser:
Now let’s setup the UI for our manager. To do this, we need to create a /manager folder within the components folder and then add a file into the folder named manager.vue.
Note: This is just a simple Bootstrap template for adding music into our application. The form will define a table template that will list all os the music that can be found in our database.
After defining this component, we need to register it in the /pages folder to initailize routing.
Nuxt.js doesn’t have a ‘router.js’ file like Vue.js. It uses the pages folder for routing. For more details, visit the Nuxt.js website.
To register the component, create a /manager folder within the /pages folder and create an index.vue file. Then, place the following code inside the file:
Let’s continue by creating a function that will fetch all of the music. This function will be registered in the created life cycle hook, so that whenever the component is created, the function will be called.
Let’s start by creating a variable in the vue instance that will hold all of the music:
allmusic = [];
musicLoading: false,
Then, define a getAllMusics function and add the following code:
Remember that table we created earlier? Well, we will need to loop through the response we get back from our backend to list all of the music received back from the database.
Adding Music
To add a new piece of music we need to make an HTTP request to the back-end server with the music details. To do this, let’s start by modifying the form and handling of the file uploads.
On the form, we need to add an event listener that will listen to the form when it is submitted. On the input field, we add a v- model to bind the value to the input field.
We will define a function that will send a request to our back-end service to create any new music that has been added to the list. Also. we need to write a simple validation function that will check for the file type so that the users can only upload files with an extention of .mp3 and .mp4.
It’s important to define a computed property to make sure that our input field isn’t empty. We also need to add a simple validator that will make sure the the file we are trying to upload is actually a music file.
Let’s continue by editing the addMusic function to make a request to our back-end service. But before we do this, let’s first install sweetalert which will provide us with a nice modal window. To do this this, open up your terminal and type in the following:
npm i sweetalert
After installing the package, create a sweetalert.js file in the /plugins folder and add this:
import Vue from 'vue';
import swal from 'sweetalert';
Vue.prototype.$swal = swal;
Then, register the plugin in the nuxt.config.js file inside the plugin instace like this:
plugins: [
{
src: '~/plugins/sweetalert'
}
],
We have now successfully configured sweetalert in our application, so we can move on and edit the addmusic function to this:
addNewMusic() {
let types = /(.|/)(mp3|mp4)$/i
if (
types.test(this.musicDetails.music.type) ||
types.test(this.musicDetails.music.name)
) {
let formData = new FormData()
formData.append('title', this.musicDetails.title)
formData.append('artist', this.musicDetails.artist)
formData.append('music', this.musicDetails.music)
this.addLoading = true
this.$axios
.$post('/music', formData)
.then(response => {
console.log(response)
this.addLoading = false
this.musicDetails = {}
this.getAllMusics() // we will create this function later
swal('Success', 'New Music Added', 'success')
})
.catch(err => {
this.addLoading = false
swal('Error', 'Something Went wrong', 'error')
console.log(err)
})
} else {
swal('Error', 'Invalid file type', 'error')
return !this.isValid
}
},
Let’s write a simple script that will toggle the form, i.e it should only display when we want to add new music.
We can do this by editing the ‘Add Music’ button in the table that displays all of the music that can be found:
<button
class="btn btn-info m-3"
@click="initForm">
{{addState?"Cancel":"Add New Music"}}
</button>
Then, add a state that will hold the state of the form in the data property:
addState: false
After doing this, let’s define the initForm function:
initForm() {
this.addState = !this.addState
},
And then add v-if="addState" to the div that holds the form:
<div class="card" v-if="addState">
Deleting Music
To delete music, we need to call the delete endpoint and pass the music id as a param. Let’s add a click event to the ‘Delete’ button that will trigger the function to delete a function:
The delete function will be making an HTTP request to our back-end service. After getting the music ID from the deleteMusic function parameter, we will add the ID in the URL that we are using to send the request. This specifies the exact piece of music that ought to be removed from the database.
deleteMusic(id) {
swal({
title: 'Are you sure?',
text: 'Once deleted, you will not be able to recover this Music!',
icon: 'warning',
buttons: true,
dangerMode: true
}).then(willDelete => {
if (willDelete) {
this.$axios
.$delete('/music/' + id)
.then(response => {
this.getAllMusics()
swal('Poof! Your Music file has been deleted!', {
icon: 'success'
})
})
.catch(err => {
swal('Error', 'Somethimg went wrong', 'error')
})
} else {
swal('Your Music file is safe!')
}
})
}
With all of this, we have just built our music manager. Now it’s time to build the music player.
Let’s start by creating a new folder in the components folder named /player. Then, create a player.vue file within this folder and add this:
Next, let’s import this component into the index.vue file in the /pages folder. Replace the code in index.vue file to this:
<template>
<div>
<player />
</div>
</template>
<script>
import player from '@/components/player/player'
export default {
components: {
player
}
}
</script>
Let’s configure routing in our navbar component to enable routing between our pages.
To route in a Nuxt.js application, the nuxt-link is used after which you have specified the page for that route to a particular instance. So let’s edit the code in the partials/navbar component to this:
With this, we can navigate through our pages by using the navbar.
Building The Player
Before we begin, we need to extend Webpack to load audio files. Audio files should be processed by file-loader. This loader is already included in the default Webpack configuration, but it is not set up to handle audio files.
To do this, go to the nuxt.config.js file and modify the build object to this:
We don’t want to display the ‘Play’ and ‘Pause’ icons at the same time. Instead, we want a situation that when the song is playing, the ‘Pause’ icon is displayed. Also, when the song is paused, the play icon should be displayed.
To achieve this, we need to set a isPlaying state to the false instance and then use this instance to toggle the icons. After that, we will add a function to our ‘Play’ icon.
isplaying:false
After doing this, modify your ‘Play’ and ‘Pause’ icon to this:
play(song) {
console.log(song)
if (song) {
this.current = song
this.player.src = `http://localhost:4000/${this.current.music.path}`
}
this.player.play()
this.isplaying = true
},
We, first of all, get the current song and pass it into the function parameter. We then define the JavaScript Audio() instance. Next, we check if the song is null: If it isn’t, we set this.current to the song we passed in the parameter, and then we call the Audio player instance. (Also, don’t forget that we have to set the isPlaying state to true when the music is playing.)
Adding The Pause Function
To pause a song, we will use the Audio pause method. We need to add a click event to the pause icon:
This is quite simple to implement. All we have to do is add a click event that will change the song parameter in the play method to the song we just created.
Simply modify the play button on the music list table to this:
This conditional is responsible for replaying all of the songs whenever the last song in the list has been played.
Adding The previous Function
This is actually the opposite of the next function, so let’s add a click event to the previous function:
@click="prev"
Next, we define the previous function:
prev() {
this.index--
if (this.index
Our music player app is now complete!
Conclusion
In this article, we looked at how we can build a music manager with Nuxt.js and Express.js. Along the way, we saw how Multer streamlines the process of handling file uploads and how to use Mongoose to interact without a database. Finally, we used Nuxt.js to build the client app which gives it a fast and snappy feel.
Unlike other frameworks, building an application with Nuxt.js and Express.js is quite easy and fast. The cool part about Nuxt.js is the way it manages your routes and makes you structure your apps better.
You can access more information about Nuxt.js here.
This is not that blog post. I’m saying let’s say you were.
This is not a knock any other blog posts out there about Dark Mode. There are lots of good ones, and I’m a fan of any information-sharing blog post. This is more of a thought exercise on what I think it would take to write a really great blog post on this subject.
You’d explain what Dark Mode is. You wouldn’t dwell on it though, because chances are are people reading a blog post like this already essentially know what it is.
You’d definitely have a nice demo. Probably multiple demos. One that is very basic so the most important lines of code can be easily seen. Perhaps something that swaps out background-color and color. The other demo(s) will deal with more complex and real-world scenarios. What do you do with images and background images? SVG strokes and fills? Buttons? Borders? Shadows? These are rare things that sites have, so anyone looking at designing a Dark Mode UI will come across them.
You’d deal with the fact that Dark Mode is a choice that can happen at the operating system level itself. Fortunately, we can detect that in CSS, so you’ll have to cover how.
JavaScript might need to know about the operating system choice as well. Perhaps because some styling is happening at the JavaScript level, but also because of this next thing.
Dark Mode could (should?) be a choice on the website as well. That servers cases where, on this particular site, a user prefers a choice opposite of what their operating system preference is.
Building a theme toggle isn’t a small job. If your site has authentication, that choice should probably be remembered at the account level. If it doesn’t, the choice should be remembered in some other way. One possibility is localStorage, but that can have problems, like the fact that CSS is generally applied to a page before JavaScript executes, meaning you’re facing a “flash of incorrect theme” situation. You might be needing to deal with cookies so that you can send theme-specific CSS on each page load.
Your blog post would include real-world examples of people already doing this. That way, you can investigate how they’ve done it and evaluate how successful they were. Perhaps you can reach out to them for comment as well.
You’ll be aware of other writing on this subject. That should not dissuade you from writing about the subject yourself, but a blog post that sounds like you’re the first and only person writing about a subject when you clearly aren’t has an awkward tone to it that doesn’t come across well. Not only can you learn from others’ writing, but you can also pull from it and potentially take it further.
Since you’ll be covering browser technology, you’ll be covering the support of that technology across the browser landscape. Are there notable exceptions in support? Is that support coming? Have you researched what browsers themselves are saying about the technology?
There are accessibility implications abound. Dark Mode itself can be considered an accessibility feature, and there are tangential accessibility issues here too, like how the toggle works, how mode changes are announced, and a whole new set of color contrasts to calculate and get right. A blog post is a great opportunity to talk about all that. Have you researched it? Have you talked to any people who have special needs around these features? Any experts? Have you read what accessibility people are saying about Dark Mode?
That was all about Dark Mode, but I bet you could imagine how considering all these points could benefit any blog post covering a technical concept.
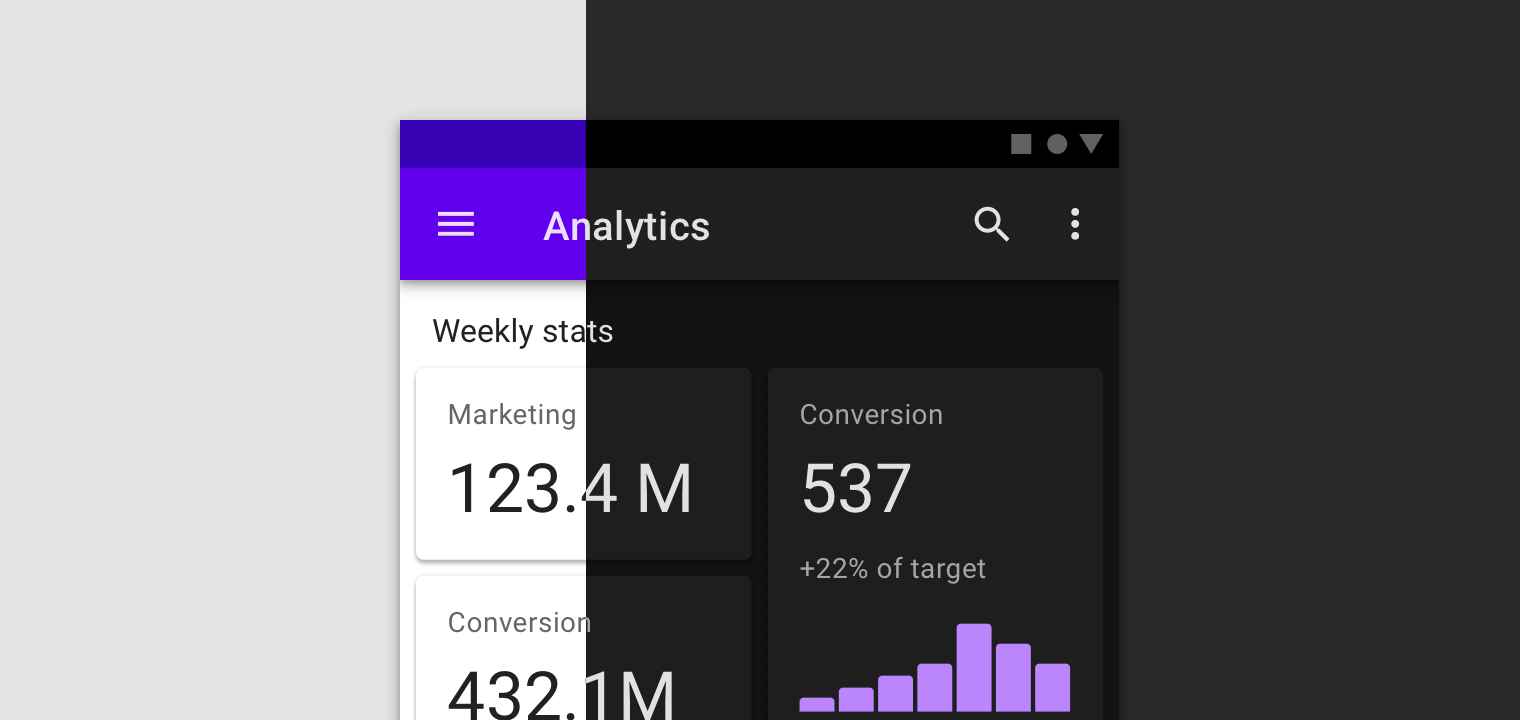
Nice demo from Sebastiano Guerriero. When a fixed-position header moves from overlapping differently-colored backgrounds, the colors flop out to be appropriate for that background. Sebastiano’s technique is very clever, involving multiple copies of the header within each section (where the copies are hidden from screenreaders) which are all positioned on top of each other and then revealed as the new section comes, thanks to each section having a clip-path around it.
A bonafide CSS trick if I’ve ever seen one.
It makes me wish there was an easier way of doing it. Like, what if there was some magical value of mix-blend-mode that would handle it? I got close enough that it gives me hope.
Earlier this year, I came across this demo by Florin Pop, which makes a line go either over or under the letters of a single line heading. I thought this was a cool idea, but there were a few little things about the implementation I felt I could simplify and improve at the same time.
First off, the original demo duplicates the headline text, which I knew could be easily avoided. Then there’s the fact that the length of the line going through the text is a magic number, which is not a very flexible approach. And finally, can’t we get rid of the JavaScript?
So let’s take a look into where I ended up taking this.
HTML structure
Florin puts the text into a heading element and then duplicates this heading, using Splitting.js to replace the text content of the duplicated heading with spans, each containing one letter of the original text.
Already having decided to do this without text duplication, using a library to split the text into characters and then put each into a span feels a bit like overkill, so we’re doing it all with an HTML preprocessor.
- let text = 'We Love to Play';
- let arr = text.split('');
h1(role='image' aria-label=text)
- arr.forEach(letter => {
span.letter #{letter}
- });
Since splitting text into multiple elements may not work nicely with screen readers, we’ve given the whole thing a role of image and an aria-label.
The above code takes care of the positioning and height of the pseudo-element, but what about the width? How do we make it stretch from the left edge of the viewport to the right edge of the heading text?
Line length
Well, since we have a grid layout where the heading is middle-aligned horizontally, this means that the vertical midline of the viewport coincides with that of the heading, splitting both into two equal-width halves:
The middle-aligned heading.
Consequently, the distance between the left edge of the viewport and the right edge of the heading is half the viewport width (50vw) plus half the heading width, which can be expressed as a % value when used in the computation of its pseudo-element’s width.
So the width of our ::after pseudo-element is:
width: calc(50vw + 50%);
Making the line go over and under
So far, the result is just a crimson line crossing some black text:
CodePen Embed Fallback
What we want is for some of the letters to show up on top of the line. In order to get this effect, we give them (or we don’t give them) a class of .over at random. This means slightly altering the Pug code:
- let text = 'We Love to Play';
- let arr = text.split('');
h1(role='image' aria-label=text)
- arr.forEach(letter => {
span.letter(class=Math.random() > .5 ? 'over' : null) #{letter}
- });
We then relatively position the letters with a class of .over and give them a positive z-index.
.over {
position: relative;
z-index: 1;
}
My initial idea involved using translatez(1px) instead of z-index: 1, but then it hit me that using z-index has both better browser support and involves less effort.
The line passes over some letters, but underneath others:
CodePen Embed Fallback
Animate it!
Now that we got over the tricky part, we can also add in an animation to make the line enter in. This means having the crimson line shift to the left (in the negative direction of the x-axis, so the sign will be minus) by its full width (100%) at the beginning, only to then allow it to go back to its normal position.
I opted to have a bit of time to breathe before the start of the animation. This meant adding in the 1s delay which, in turn, meant adding the backwards keyword for the animation-fill-mode, so that the line would stay in the state specified by the 0% keyframe before the start of the animation:
animation: slide 2s ease-out 1s backwards;
CodePen Embed Fallback
A 3D touch
Doing this gave me another idea, which was to make the line go through every single letter, that is, start above the letter, go through it and finish underneath (or the other way around).
This requires real 3D and a few small tweaks.
First off, we set transform-style to preserve-3d on the heading since we want all its children (and pseudo-elements) to a be part of the same 3D assembly, which will make them be ordered and intersect according to how they’re positioned in 3D.
Next, we want to rotate each letter around its y-axis, with the direction of rotation depending on the presence of the randomly assigned class (whose name we change to .rev from “reverse” as “over” isn’t really suggestive of what we’re doing here anymore).
However, before we do this, we need to remember our span elements are still inline ones at this point and setting a transform on an inline element has absolutely no effect.
To get around this issue, we set display: flex on the heading. However, this creates a new issue and that’s the fact that span elements that contain only a space (" ") get squished to zero width.
Inspecting a space only in Firefox DevTools.
A simple fix for this is to set white-space: pre on our .letter spans.
Once we’ve done this, we can rotate our spans by an angle $a… in one direction or the other!
Since rotation around the y-axis squishes our letters horizontally, we can scale them along the x-axis by a factor ($f) that’s the inverse of the cosine of $a.
If you wish to understand the why behind using this particular scaling factor, you can check out this older article where I explain it all in detail.
And that’s it! We now have the 3D result we’ve been after! Do note however that the font used here was chosen so that our result looks good and another font may not work as well.
Here’s a neat idea from Tim Kadlec. He uses the Modheader extension to toggle custom headers in his browser. It also lets him see when images are too big and need to be optimized in some way. This is a great way to catch issues like this in a local environment because browsers will throw an error and won’t display them at all!
As Tim mentions, the trick is with the Feature Policy header with the oversized-images policy, and he toggles it on like this:
Feature-Policy: oversized-images ‘none';
Tim writes:
By default, if you provide the browser an image in a format it supports, it will display it. It even helpful scales those images so they look great, even if you’ve provided a massive file. Because of this, it’s not immediately obvious when you’ve provided an image that is larger than the site needs.
The oversized-images policy tells the browser not to allow any images that are more than some predefined factor of their container size. The recommended default threshold is 2x, but you are able to override that if you would like.
I love this idea of using the browser to do linting work for us! I wonder what other ways we could use the browser to place guard rails around our work to prevent future mistakes…








 [
[