In this post, Sarah Chima walks us through how we can work with browser events, such as clicking, using JavaScript. There’s a ton of great info in here! If JavaScript isn’t your strong suit, I think this is the best explanation of event handling that I’ve read in quite some time.
When an event occurs, the browser creates an event object and passes it as an argument to the event handler. This event object contains details of the event. For instance, you might want to know which button was clicked or which key was pressed or the mouse coordinates when the event occurred. You can get all of these from the event object.
Sarah also links to this really good primer on bubbling and capturing that’s worth checking out, too.
For all the times we asked folks about Smashing, most still seem to believe that we’re some sort of large publishing company situated somewhere in the United States — both of which are wrong. It all started in Freiburg, Germany, and the team consists of folks scattered all over the world — with most of us not working fulltime for Smashing.
That’s right, working remotely is quite familiar to us, and so with the current situation going on with COVID-19 that is making everyone uneasy, we’d like to make the best of things and help our friends who are having to work or lead teams remotely for the first time. Our editor-in-chief, Rachel Andrew, has prepared a nice post to help you stay connected and keep learning while we go through this together.
You may have already heard that SmashingConf SF has been postponed to November due to the unfortunate travel restrictions and many other reasons. It was truly a difficult decision for the team to make, but we believe it is the best way forward — safety and health always come first.
Without further ado, here’s a short update of things going on at Smashing and some super creative work shared from and to the community!
Happy reading — from my computer to yours!
Designing With Ethics In Mind
After months of hard work, the “The Ethical Design Handbook” is finally here — and it’s shipping! The response has already been overwhelmingly positive, and we’re excited to share reviews with you soon. There is still quite a bit of work to do on the web, but our hope is that with this book, you will be equipped with enough tooling to slowly move a company towards a more sustainable and healthy digital footprint!
Of course, you can jump to the table of contents right away, or download a free PDF excerpt to get a first impression of the book — we’re sure you won’t be disappointed! Read our official release post with all the details ?
Always Learning New Things From One Another
We all have busy schedules, but there’s always time to pop in those earplugs and listen to some music or podcasts that make you happy! We’re moving on to our 12th episode of the Smashing Podcast — with folks from different backgrounds and so much to share! You’re always welcome to tune in and share your questions and thoughts with us anytime!
Apart from the heart-breaking news about our postponed SmashingConf SF, our SmashingConfs are known to be friendly, inclusive events where front-end developers and designers come together to attend live sessions and hands-on workshops. From live designing to live debugging, all of our speakers like to go into detail and show useful examples from their own projects on the big screen.
Here are some talks you may like to watch and learn from:
The first SmashingConf took place in Freiburg back in 2012, so there are so many more talks you can watch. See all SmashingConf videos ?
Shining The Spotlight On React, Redux And Electron
Mark your calendars! Next week on March 19, we’ll be hosting a Smashing TV webinar with Cassidy Williams who’ll be explaining how to organize a modern React application and build an Electron application (with React). Join us at 17:00 London time — we’d love to hear your thoughts and experiences you’ve had with React in your projects!
Smashing TV is a series of webinars and live streams packed with practical tips for designers and developers. They’re not just talks, but more like conversations and “here-is-how-I-work”-sessions. Smashing Members can download recordings, and also receive discounts and lots of goodies to make their membership worthwhile. Tell me more ?
Trending Topics On SmashingMag
We publish a new article every day on various topics that are current in the web industry. Here are some that our readers seemed to enjoy the most and have recommended further:
“Why Are We Talking About CSS4?” by Rachel Andrew Around the web and within the CSS Working Group, there has been some discussion about whether we should specify a version of CSS — perhaps naming it CSS4. In this article, Rachel Andrew rounds up some of the pros and cons of doing so, and asks for your feedback on the suggestion.
“Setting Height And Width On Images Is Important Again” by Barry Pollard Thanks to some recent changes in browsers, it’s now well worth setting width and height attributes on your images to prevent layout shifts and improve the experience of your site visitors.
“Setting Up Tailwind CSS In A React Project” by Blessing Krofegha This article introduces Tailwind CSS, a CSS library that gives you all of the building blocks you need to build bespoke designs without opinionated styles. You’ll also learn how to seamlessly set up Tailwind CSS in a React project.
“Introducing Alpine.js: A Tiny JavaScript Framework” by Phil Smith Ever built a website and reached for jQuery, Bootstrap, Vue.js or React to acheive some basic user interaction? Alpine.js is a fraction of the size of these frameworks because it involves no build steps and provides all of the tools you need to build a basic user interface.
“How To Design Mobile Apps For One-Hand Usage” by Maitrik Kataria 90% of the smartphones sold today have >5-inch displays. Bigger screen real estate presents newer challenges and opportunities for app makers and designers. Let’s look at how designing apps for one-handed usage can solve those challenges.
Best Picks From Our Newsletter
We’ll be honest: Every second week, we struggle with keeping the Smashing Newsletter issues at a moderate length — there are just so many talented folks out there working on brilliant projects! So, without wanting to make this monthly update too long either, we’re shining the spotlight on the following projects:
P.S.: A huge thank you to Cosima Mielke for writing and preparing these posts!
Find And Fix Errors In Your Designs
We all know those moments when we are so immersed in a project that we lose the distance we need to be able to catch little inconsistencies: an incorrect border-radius around an image or missing styles or text, for example. If you’re designing in Figma, the free and open-source plugin Design Lint makes finding and fixing errors like these easy so that no bug makes it into production.
A free and open-source plugin for Figma built to help you find and fix errors in your designs.: Design Lint.
Design Lint checks for missing text, fill, stroke, and effects styles, and catches incorrect border-radius values on all your layers. To not interrupt your workflow, the plugin automatically updates as you fix errors. The repo is available on GitHub, so feel free to write specific rules to tailor the plugin to your needs.
Learn CSS Positioning With… Cats!
Could there be a better way to learn CSS positioning as with a bunch of friendly cats? That’s probably what Ahmad Shadeed thought, too, when he created his interactive guide to how CSS positioning works.
Meow! Ahmad Shadeed has prepared a great guide for you to learn everything about CSS positioning!
The guide teaches you to use CSS to position three cartoon cats and their blanket inside a box, and once you’ve grasped the concept, you can start tinkering with the interactive demo that visualizes how the result changes as you edit the values. Now who said learning can’t be fun?
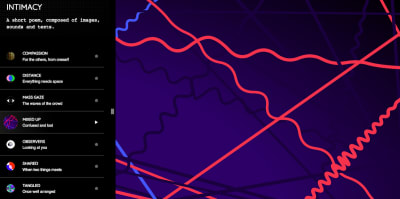
Intimacy, An Interactive Short Poem
An inspiring experiment comes from the French graphic and interaction design student Thibaud Giffon: “Intimacy”. The interactive short poem uses abstract images, sound, and text to explore intimacy from different angles.
The “Mixed Up” musical poem is brought to life (sound ON) by just moving your cursor across the cords. Try it out!
Compassion, distance, confusion, touch — these are four of the eight chapters that make up the poem; and each one of them reflects the topic in its own, unique way: with warm and harmonious waves or circles that melt into each other but also with dissonant strings or colorful bubbles that burst as they make space for themselves. Beautiful!
All Your SVG Icons In One Place
Having one central place to organize all your assets is always a good thing, not only for teams — to keep track of what you have and to quickly find what you’re looking for. The free cross-platform app Iconset is such a place: it helps you collect, customize, share, and manage all your SVG icon sets.
Organizing SVG icons all in one place with Iconset.
To make it easier to find the icon you’re looking for, you can organize your icons in sets or with tags, and, once you’ve found the icon you need, you can drag it directly into your favorite tool. A real timesaver. Iconset supports cloud services like Dropbox or OneDrive so that all your icons are always in sync between team members. The app is available for Mac and Windows.
An Ancient Hero’s WebGL Adventure
A reluctant hero on a quest he never asked for — that’s the story behind the browser-based adventure video game Heraclos. Set in ancient Greece, the young Heraclos stumbles across an amphora that belongs to one of the gods. He is declared to be the chosen one and gets sent off to climb the secret mountain and return the amphora to his owner.
What makes the game so noteworthy is the fun twist in the interaction between the hero and the god (a parody of common heroic stories) but also the technical background: Heraclos was designed in only three months by a group of students at the Gobelins school of images in Paris — with WebGL and Cannon.js. A great example of what’s possible on the web.
An Open-Source Screen Recorder Built With Web Technology
Have you heard of Kap, yet? The open-source screen recorder is one that is definitely worth checking out if you’re frequently doing screen recordings.
Kap, an open-source screen recorder built with web technology.
Built with web technologies, Kap produces high-quality recordings in GIF, MP4, WebM, or APNG formats. You can include audio (even from your microphone), highlight clicks, and trim the recordings. As a bonus goodie, there are also options to share your recorded GIFs on Giphy, deploy them with ZEIT now, or upload them to Streamable. Perfect for technical demos.
Open Peeps, A Free Hand-Drawn Illustration Library
584,688 possible combinations. That’s the number of different characters you could create with Pablo Stanley’s hand-drawn illustration library Open Peeps.
“Open Peeps,” a hand-drawn illustration library created by Pablo Stanley.
Open Peeps lets you mix and match different vector elements to create diverse personalities: combine clothing and hairstyles, change emotion with facial expressions, set the scene with different poses — the possibilities are sheer endless. And if you’re in a hurry, Pablo also prepared some ready-to-download Peeps that you can use right away. Open Peeps is released under a CC0 license, so you are free to use the illustrations in both personal and commercial projects. A great way to add a handmade touch to your design.
How To Make Inputs More Accessible
In 2019, WebAim analyzed the accessibility of the top one million websites, with a shocking conclusion: the percentage of error-free pages was estimated to be under one percent. To make our sites inclusive and usable for people who rely on assistive technology, we need to get the basics of semantic HTML right. With its credo of starting small, sharing, and working together, Oscar Braunert’s article on inclusive inputs is a great starting point to do so.
Starting off with the basics of WAI, ARIA, and WCAG, the article explores how to make inputs more accessible. The tips can be implemented without changing the user interface, and, as Oscar puts it: “If in doubt, just do it. Nobody will notice. Except some of your users. And they will thank you for it.”
An Open-Source Font For Developers
High readability, quick text scanning, no distraction — these are just some of the demands developers have on a typeface. Well, the free and open-source typeface JetBrains Mono meets all of them beautifully.
JetBrains Mono’s typeface forms are simple and free from unnecessary details. Rendered in small sizes, the text looks crisper.
To do so, Jet Brains Mono takes advantage of some small but mighty details: Compared to other monospace fonts, the height of JetBrains Mono is increased while the characters remain standard in width to keep code lines to the length developers expect. To improve readability even further, 138 code-specific ligatures reduce noise so that your eyes need to process less and whitespace becomes more balanced. Clever! JetBrains Mono comes in four weights and supports 145 languages.
The Ultimate Guide To iframes
With a lot of articles advising against them, iframes don’t have the best reputation. JavaScript developer Nada Rifki sees things differently: She suggests not to let their reputation prevent you from relying on iframes. After all, they have many legitimate use cases.
The ultimate guide to iframes written by Nada Rifki.
To help you form your own opinion on this controversial element, Nada wrote an ultimate guide to iframes which explores iframe features and how to use them; tricky situations where iframes might come in handy; last but not least, how you can secure your iframe against potential vulnerabilities. A great opportunity to see things from a different perspective.
A Guide To Console Commands
The capabilities of the developer’s debugging console have evolved significantly in the past years — from a means to report errors to automatically logging information like network requests and security errors or warnings. There’s also a way for a website’s JavaScript to trigger various commands that output to the console for debugging purposes. And while these features are mostly consistent between browsers, there are also some functional differences.
“A Guide to Console Commands” by Travis Almand
If you’re looking for an overview of what console commands are capable of, Travis Almand put together a helpful guide. It covers Firefox and Chrome and examines various commands that can be used in the browser’s console output or with JavaScript. A handy summary.
Smashing Newsletter
Upgrade your inbox and get our editors’ picks 2× a month — delivered right into your inbox. Earlier issues.
YouTube is one of the biggest social media platforms, with over 2 billion monthly active users, second only to Facebook. Additionally, nearly 81% of 15-to-25-year-olds in the US use YouTube, and about 58% of people above the age of 56 years use it too. This makes it a great platform for brands to reach out to their target audiences.
However, building your reputation and subscriber base on YouTube is quite challenging due to the humongous number of videos that are uploaded onto the platform daily.
In fact, nearly 500 hours of videos are uploaded every minute onto YouTube, and this makes it extremely difficult for any new or small business to grow on the platform.
This is where you can take advantage of YouTube influencer marketing. The platform has many micro-influencers who have a highly engaged subscriber base. You can tap into this audience by partnering with them.
What’s more?
Micro-influencers tend to charge lower fees due to their smaller audience sizes, and this can be great for startups and small businesses, which often have budget constraints.
However, creating an influencer marketing campaign for YouTube is no easy task. There are several steps involved and it can be difficult for beginners to navigate them.
So, let’s take a look at how you can partner with YouTube influencers to grow your brand.
How Can You Partner With YouTube Influencers?
Let’s take a closer look at how you can partner with YouTube influencers to grow your brand:
1. Decide on What You Want to Achieve From the Campaign
Just like all other influencer marketing campaigns, when you’re looking to partner with YouTube influencers, you need to set your campaign goals first.
This is essential because you need to have a clear picture of what you want to accomplish. Without it, you’ll be aiming in the dark, and your efforts won’t be aligned towards achieving the goal.
What’s more?
Setting your goals helps you decide on the key performance indicators (KPIs) that you need to track. They enable you to find out how well your campaign is progressing.
Lastly, the goal will help you determine the ideal YouTube influencers for your brand. Each influencer can help you with different goals like growing brand awareness, increasing engagement, driving sales, lead generation, etc. So your goal affects the choice of influencers too.
2. Look for YouTube Influencers
Once you’ve decided on the goal of your YouTube influencer marketing campaign, you need to start looking for relevant YouTube influencers for your brand.
This step is critical because it’s important that you find the right influencers. Remember, influencers are viewed as an extension of your brand, so whatever they do can affect your brand image.
For this, you can search for keywords related to your industry and see who’s posting relevant videos regularly. You can then go through their profiles to find out if it’s worth partnering with them. Don’t just look at the number of views their videos generate but also go through their comments and analyze their quality.
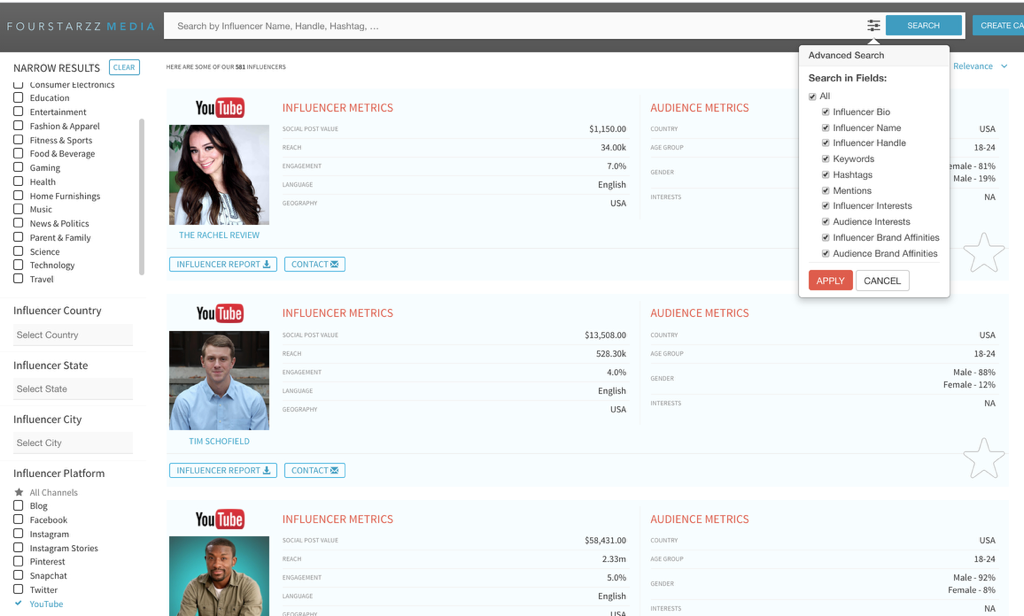
However, a manual search can be quite challenging and you may not be able to find influencers with ease. Additionally, it can be difficult to determine the demographics of their subscriber base. Without this, you won’t know if the influencer’s audience matches yours. In such a situation, an influencer discovery tool like Fourstarzz Media can be helpful.
It’s got over 750K influencers, and you can get detailed reports on each of them, which shows you all the details from their audience demographics to engagement rates.
You can filter the influencers based on their niche, platform, reach, engagement rate, country. Fourstarzz Media also offers advanced search features like hashtag search, name search, audience interests, and more.
Image via Fourstarzz Media
3. Reach Out to the YouTube Influencers
Once you’ve found reliable YouTube influencers, you need to reach out to them with your pitch for a partnership. A great way of doing this is by building a rapport with them first. You don’t want to make the influencers feel like you’re connecting with them just for promoting your brand.
Remember, they are creative people who love to have their work recognized and appreciated. So you should start building a relationship with them before you pitch your idea for a collaboration.
You can begin by commending their work or giving your views on some of the kickstarter video that they’ve created. Once you’ve established a good relationship with them, you can send them an email with your pitch.
4. Draw Up a Contract
Once the YouTube influencers have agreed to work with your brand, you need to draw up a contract for the collaboration. This contract should detail the deliverables from both parties so that there’s no conflict at a later stage. At the same time, it serves as a guideline for both to work together too.
For this, both the brand and the influencers must agree on how the campaign’s success will be evaluated. Being transparent with the influencer can help you win their trust, and this can motivate them to do better for your campaign too.
What’s more?
The contract should elaborate on the type of collaboration and video too. There are a variety of videos that YouTube influencers can make for your brand. These include product reviews, testimonials, Q&A videos, how-to videos, demos, tutorials, and more. This can help you define the campaign better too.
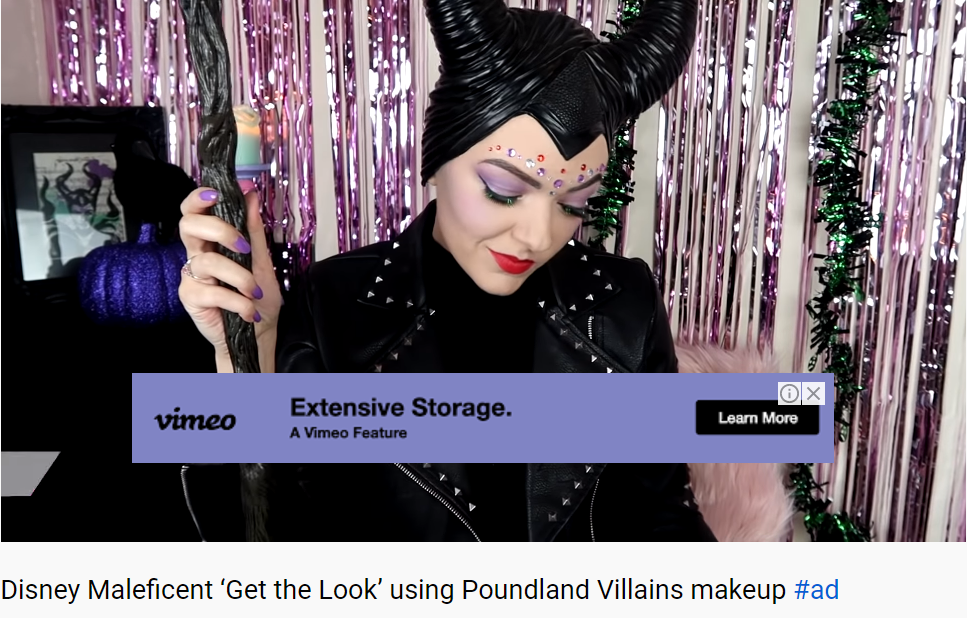
For instance, Sarah Louise Porter is a YouTube influencer who partnered with Poundland to promote their range of makeup items. She created a tutorial video to show her audience how to use the items.
5. Execute the Campaign
Once the contract is signed, you can start the campaign. While you may want to be in control of things to ensure that the video created by the influencer is top-notch, you should refrain from doing being too controlling.
Make sure you give your influencers enough creative freedom. They know exactly what works with their audience and what doesn’t.
So, what should you do?
You can provide a few guidelines to the influencers on how you want the video to be but leave the rest to them. Trust your influencers to come up with high-quality videos related to your brand and products using video creation tools. Once they’ve created the videos, you can discuss changes with them, if any, before uploading it.
6. Measure and Analyze
The last step of a YouTube influencer marketing campaign is that of measuring the progress of your campaign. Based on your campaign goals, track the relevant KPIs.
For this, you need to go through video analytics. This can give you an overall picture of whether your campaign is progressing the way you want or not.
Based on these analytics, you can determine the future course of your campaigns and identify where you’re excelling and where you’re lagging behind. Accordingly, you can modify your approach and optimize your YouTube influencer marketing campaigns.
Final Thoughts
YouTube is one of the biggest social media platforms, and you can leverage it to promote your brand via influencer marketing.
All you need to do is decide on your goals and find the right influencers for your campaign. Once that’s done, you can reach out to them for collaboration.
Make sure you draw up a contract for the campaign and give enough creative freedom to your influencers. Lastly, track the progress of your campaign and analyze it so that you can figure out where you can improve and optimize it.
Do you have any questions about partnering with YouTube influencers? Let us know in the comments.
As a designer, you’ve probably wished you could know exactly what your clients were thinking at one point or another. Maybe it was when they were vaguely describing how they wanted their design to “pop”. Or maybe when they were trying to express exactly why the fifteenth revision still wasn’t quite right. Or maybe it was after they refused to do a customer testimonial despite insisting they loved everything about the final product. Whatever it was, you probably left the interaction feeling you had no idea how to communicate with your clients.
When you consider that 64% of clients cite poor communication as the worst part of working with their designer, it’s clear that the feeling is mutual.
But that’s far from the only issue standing in the way of designers and clients getting along. To get to the bottom of the biggest problems in the client-designer relationship, we surveyed 100 users on their experiences working with designers.
The big question: What’s the worst part of working with a designer?
Who Are These Designers Anyway?
Now you might be looking at that 64% and saying, “No way that includes me; I’m not one of those designers.” But it’s more likely than you’d like to think.
To get some context on who these communication-challenged designers were, we also asked respondents about how they found their designer. Here’s a breakdown of the results:
As you can see online marketplaces are the main source of designers, at 34%, which could explain some of the complaints clients had. Online marketplaces are a notorious gamble for clients, since anyone can create an account, upload a portfolio, and start looking for design jobs.
But, between referrals from friends and family members and friends and family members themselves, personal connections win out as the main source of designers for this survey, accounting for almost 45% of the designers discussed by respondents.
What does this tell us? Two things:
Even with the rise of online marketplaces, like Upwork or Freelancer, referrals and network connections are still the most popular way for designers and clients to find each other;
Just because designers have a personal connection to their clients doesn’t mean they’re going to be able to work together without issue, poor communication isn’t something a personal connection can solve.
The Worst Parts About Working With a Designer
To give customers adequate room to air their designer grievances, we left the response field to this question completely open, allowing them to write as much (or as little) as they wanted. After reviewing the responses, we found that complaints typically fell within one or more of these seven categories.
Or, as we like to call them, the seven deadly designer sins:
Poor communication;
Missed deadlines;
Difficulty trusting the designer;
Limited revisions;
Business needs not taken into account;
Cost;
Not feeling like a priority.
Due to the free-form nature of the responses, many responses fit into multiple categories. Here’s how those issues add up:
At 64%, poor communication is overwhelmingly the biggest complaint clients have about their designer. Now, we’ve brought this figure up before, but when you consider other communication-related complaints clients had, the true number is much worse.
Taking into account adjacent categories like “Business needs not taking into account” (15%), “Difficulty trusting the designer” (15%), and “Not feeling like a priority” (6%), issues that could be resolved with better communication begin to dominate the conversation.
While “Missed deadlines” (17%), “Limited revisions” (15%), and “Cost” (14%) are important for many respondents, focusing on how fast, often, and cheap you can deliver work won’t fix everything.
The biggest problem clients have with designers has little to do with their technical skills—and everything to do with their people skills.
This might almost seem a little too intuitive to be groundbreaking. After all, any designer who’s had a few years in the industry is familiar with the endless email chains over small changes and vague directions clients often give. But even though these complaints have become commonplace, designers can’t afford to ignore them anymore—because of the rise of AI-powered design.
Designers vs. Artificial Intelligence
In the past few years, AI-powered or Computer Assisted Design has been making advances in designing everything golf clubs to websites.
There are some aspects of AI-powered design that human designers won’t be able to outcompete. Things like a lower cost, unlimited revisions, and never missing a deadline aren’t the most practical selling points for a human who has to pay rent and sleep.
But those are only a small part of the complaints clients have.
If you’re a designer looking to compete against an increasing array of AI-powered design options, it’s time to start taking client relations seriously. When you’re competing against AI, your humanity is your selling point.
Becoming a Better Designer (Without Learning Any New Design Skills)
If you need any more convincing before you roll up your sleeves and start improving your communication skills, here’s another response from our survey, this time to the question: What’s the most important thing about working with a designer?
There it is, straight from the client’s mouth: communication is more important than skill when working with designers.
But let’s go back to the worst parts about working with a designer. After analyzing customer answers, we found a few common communication-related issues that designers can easily remedy.
Practicing Better Communication
Complaint: “It is difficult to accurately express one’s thoughts so that they can understand as needed to create a logo that works and meets our needs and desires.”
Solution: When you’re first trying to get an idea of what your client wants, don’t rush. They typically don’t have the same design vocabulary you do, so take your time to explain the ways that you can bring their vision to life. Focus on closing the communication gap early on and keep clients in the loop with regular updates. The more you communicate what you’re doing, the more they’ll feel connected to the final product.
Building Trust
Complaint: “Building the trust to allow the designer to do his thing. Letting someone outside make decisions independently was hard for us and we had to learn to accept outside advice and decisions.”
Solution: For most clients, trust comes down to communication. Can you demonstrate that you understand their needs and goals for this project? Can you show them that you care about producing great work for them?
Demonstrate a deeper connection to your client’s business and how your design fits into their goals. While you might not be on their payroll, you should show the same kind of commitment to the company an employee would have. The more you can invest yourself in a project beyond just collecting your payment, the more likely clients are to trust your judgment when you need to make a difficult design call.
Taking Business Needs Into Account
Complaint: “It felt he was more focused on what would look good on his portfolio rather than what was appropriate for our business needs.”
Solution: We all want to produce work that will look good in our portfolios, but you need to remember you’re designing for your clients—not yourself. Put the effort into understanding the context of a project, what a client is looking to accomplish, any trends in their industry, the audience they want to attract, and the metrics they want to achieve. As AI-powered design becomes more powerful, your capacity to act both as a consultant and a designer for your clients will give you an edge.
Making Every Client Feel Like a Priority
Complaint: “My designer had more than one project on the go so we were not always his priority.”
Solution: You’re likely always going to have a few projects on the go at the same time, but your clients don’t need to know that. When you’re on a call, in a meeting, or even just responding to their emails, give them your full attention. While you won’t be able to be at their beck and call 24/7 (however much they might want you to be), showing attention and enthusiasm during your interactions will help clients to feel like you care about them and their project.
Moving Past Your Design Sins
If you’ve made it to the bottom of this article, it’s fair to say you’re ready to remedy some of your designer sins to better serve your clients. But even if you do everything right, you’re still bound to get a few client complaints—and that’s okay. As much as you can improve your designer-client relations by being more human, it’s also human nature for clients to find something to complain about. As long as you’re continuously working on your communication, you’ll be able to stay one step ahead of other designers—both human and AI.
Are you looking forward to building a website from scratch, and yet you don’t exactly know how? Well, you’ve come to the right place!
It doesn’t matter if you wanted to start a blog or create a website for your business. Setting up a site is much easier than you think.
In this post, we’ll walk you through the nine steps on how to build your first website from scratch:
Register a domain
Before you purchase a domain, you first have to know what a domain is.
Just like your real-life address, your site must have an address online, as well. It should look something like this: www.yourwebsite.com.
Also, before you register, you need to think about all the possibilities your brand represents, as well as what you do. If you want to create a personal website promoting yourself, then you should create a site under your name.
You also have to be creative with your domain name. Whenever you try to get one, make it respectable in all kinds of industries. It should also be related to who you are, and what you do.
Choose a web host provider
There are hundreds, if not thousands, of web hosting providers out there. That’s why choosing the right web hosting provider that will suit your needs can be a difficult decision.
Here are some popular web hosting provider options:
BlueHost
Hostinger
SiteGround
HostGator
GoDaddy
InMotion
FastComet
Wix
Just keep in mind that whatever web host you choose, you’ll find a lot of guides online on how to build a website from scratch using their platform.
Select a website-building approach
There are three primary ways you can build a website. If you’re a beginner, one of the easiest ways to launch a site is to use a website builder. You can check out what other people say about your preferred website builder by typing in something like “Wix review” on Google.
If you’re a bit tech-savvy, then you can utilize a content management system (CMS) like WordPress, Drupal, or Joomla.
Meanwhile, if you’re an expert in coding, then it’s possible to utilize HTML or PHP as you build your site from the ground up.
Just keep in mind that every approach will have its unique sets of advantages, as well as challenges.
Look for some inspiration
The next thing that you need to do is to look for some inspiration.
Inspiration comes from all kinds of things and places. You can browse through platforms like Pinterest to look for your next brilliant idea.
From there, you can start gathering certain elements that you think will work best for your brand. And then try to apply it on your website.
Prepare valuable and engaging content
Now that your site is in shape, the next thing that you need to do is to come up with valuable and engaging content.
It’s also ideal that you gather all the copies and texts that you plan on using before you start building your site. This may involve your site’s tagline for the header, enticing call-to-action, web page content, product descriptions, and more.
It also helps that you update these content regularly to keep Google happy and your readers on their toes. Ideally, showcase your best and most up-to-date work.
The rule here is simple: Always choose quality over quantity.
Develop a sitemap
Your sitemap serves as a blueprint of your website’s architecture. It should include all the pages that you’re planning to create, as well as how they’re interconnected with one another.
Google loves it if there is a healthy ration of inbound and outbound links, as well as internal links. Doing so can have a positive impact on your search engine optimization efforts.
Pick the best fonts for your site
If there’s something that you shouldn’t overlook in the process of creating your site, that should be your fonts.
Typography does have a lot to say, evoking more than just words.
If you’re not experienced in site design, understanding typeface can be a bit of a challenge, especially in picking one that will fit your brand the best.
Think about hierarchy
Your site should be organized as much as possible. Ideally, you want to place your most eye-catching content above the fold ? the visible part of your website that doesn’t require scrolling or clicking.
Also, you have to accept the fact that most readers will just skim through your content. Internet users’ attention spans continuously decreases, so most users will likely pay attention to only two places on your site: Above the fold and below the fold.
All of your most important information should be put there. In the middle, you can place your less crucial content, like videos and images.
Optimize your website for search engines
SEO or search engine optimization is the process where you optimize your site’s pages so that it can rank higher on search results.
The more visible your website is on the search results, the more likely you can drive traffic to your site. And you can turn these traffic into paying and loyal customers.
There are a few ways that you can improve your search rankings. First, you must pick the right domain name, put alt text to your images, as well as create keyword-rich titles and descriptions for your pages.
Over to You
Nowadays, it is imperative for every business to have an online presence. Hence, you’ll need to have a website.
Luckily, you don’t have to spend a hefty amount and hire a web developer in order to have a site. That’s because there are website builders that let you DIY your site.
Hopefully, you can use the points that we’ve made in this article as a guide so that you can build a beautiful and functional site for your business. Good luck!
Brent Jackson says CSS utility libraries failed somewhat:
Eventually, you’ll need to add one-off styles that just aren’t covered by the library you’re using, and there isn’t always a clear way to extend what you’re working with. Without a clear way to handle things like this, developers tend to add inconsistent hacks and append-only styles.
I have a feeling Tailwind people would disagree. I have no particular opinion here, I’m just noting that Tailwind seems to have a more fervent fanbase than those early days of Basscss/Tachyons.
Brent goes on to say that CSS-in-JS solves the same problem, but in a better way:
CSS-in-JS libraries help solve a lot of the same issues Utility-based CSS methodologies were focused on (and more) in a much better way. They connect styles directly to elements without needing to name things or create abstractions in class selectors. They avoid append-only stylesheets with encapsulation and hashed classnames. These libraries work with existing build tools, allowing for code splitting, lazy loading, and dead code elimination with virtually zero effort, and they don’t require additional tools like Sass or PostCSS. Many libraries also include CSS performance optimizations, such as critical CSS, enabled by default so that developers don’t need additional tooling or even need to think about them.
No wonder people have been raving about this.
The one-step-back refers to the fact that CSS-in-JS is more open-ended and doesn’t encourage consistency as much. I’m not sure about that. Seems like if you’re building in a component-based way already, consistency kind of comes along for the ride, even before using design tokens and the like — which a CSS-in-JS approach also encourages.
We have all been looking forward to our SmashingConf in San Francisco, and are so sad to have to announce that the conference is being postponed until 10th–11th November 2020. If you have tickets for the event, you should already have received an email. If not, then please see the detailed information on this page, get in touch with us, and we will help you out. The team is on standby to try and help you as quickly as possible.
As you can imagine, it was a very tough decision for our team to make. We have been working hard to plan this event and were looking very much forward to it for the last few months, however, we believe it is the right decision for the conference and for everyone we hoped to meet there.
We are all faced with a difficult few weeks ahead, but we still need to do our jobs, keep learning, and also stay connected with our friends. We hope that even though we can’t all meet in person, we can help a little bit as we all get through this together.
Topple the Cat agrees that this is the best way forward for the safety and health of you, our dearest Smashing Family! (Read our full statement here.)
Stay Connected
We know that many of you are working from home for the first time to help prevent the spread of COVID-19, and the events and meetups that we all love to attend are being cancelled. We’re working on some ideas for the coming weeks that can be attended virtually — with no need for awkward elbow bumps and footshakes. Our online communities are going to become even more important than usual.
Lot’s of us will be stuck at home for weeks if not months. Let’s help each other. What are your best coping tips? How do you take care of your mental health?
The entire Smashing team are remote, and the conferences are one place that many of us get to meet and spend time in person, so we know how hard it can be to lose those opportunities. The community have been sharing some great resources online, however, for those of you who are new to working from home, we went ahead and asked Twitter for tips and got some great replies — as well as links to resources.
The Smashing Team are all remote, but many of our friends are having to work or lead teams remotely for the first time.
What are your top tips, or useful websites and apps for remote working, or remote team leading?
Some of you might be having to manage a remote team for the first time, with little time to prepare. In “You’ve Found Yourself Leading A Remote Design Team,” Mark Boulton shares some tips from his own experience having led remote teams for many years. On Twitter, Linda Eliasen wrote a thread with all her tips on leading a team remotely. Also, Holloway have released a section from their upcoming guide which covers morale, mental health, and burnout in remote teams.
We have a whole back catalog of video from previous conferences, which you can enjoy from the comfort of your sofa. The talks from last year alone should keep you occupied for a while.
SmashingConf NYC 2019
Watch videos featuring Dan Mall, Brad Frost and Ian Frost, Marcy Sutton, Denys Mishunov, Trine Falbe, Maggie Wachs, Wes Bos, dina Amin, Harry Roberts, Sara Soueidan, Remy Sharp, Scott Jehl, and Miriam Suzanne.
SmashingConf Freiburg 2019
Watch talks from Guillaume Kurkdjian, Joe Leech, Heather Burns, Uri Shaked and Benjamin Gruenbaum, Anna Migas, Val Head, Rémi Parmentier, Sara Soueidan, Robyn Larsen, Benjamin Hersh, and Philip Walton.
SmashingConf Toronto 2019
Listen to talks from Brad Frost, Sarah Drasner, Phil Hawksworth, Jenny Shen, Kristina Podnar, Steven Hoober, Phil Nash, Dan Rose, Diana Mounter, Scott Jehl, and Chris Gannon.
SmashingConf SF 2019
Watch and learn from Jen Simmons, Jason Pamental, Jeremy Wagner, Katie Sylor-Miller, Miriam Suzanne, Chris Coyier, Darin Senneff, Anna Migas, Sara Soueidan, and Brad Frost.
Last But Not Least, Smashing Podcast
If you haven’t found our Smashing Podcast yet, we’re already up to episode 11. Check out the episodes and subscribe here. Of course, we will also be bringing you an article every day here on Smashing Magazine, and perhaps if you find yourself with some extra time, you might like to join our authors and write for us.
Keep In Touch
We are obviously dealing with a fast changing situation, and can only take each day or week as it comes. Take every chance to keep in touch with your friends and peers via phone, text and video chat. Check in on people who might be having a hard time. Your outgoing extrovert friend may be the person who finds the isolation of the next few weeks the hardest. Look after yourselves, each other, and please wash your hands!
We’re all looking for low-hanging fruit to make our sites and apps more accessible. One of the easier things we can do is make sure the colors we use are easy on the eyes. High color contrast is something that benefits everyone. It not only reduces eye strain in general, but is crucial for folks who deal with reduced vision.
So let’s not only use better color combinations in our designs but find a way to make it easier for us to implement high contrasts. There’s one specific strategy we use over at Oomph that lets a Sass function do all the heavy lifting for us. I’ll walk you through how we put that together.
Want to jump right to the code because you already understand everything there is to know about color accessibility? Here you go.
What we mean by “accessible color combinations”
Color contrast is also one of those things we may think we have handled. But there’s more to high color contrasts than eyeballing a design. There are different levels of acceptable criteria that the WCAG has defined as being accessible. It’s actually humbling to crack open the WebAIM Contrast Checker and run a site’s color combinations through it.
My team adheres to WCAG’s Level AA guidelines by default. This means that:
Text that is 24px and larger, or 19px and larger if bold, should have a Color Contrast Ratio (CCR) of 3.0:1.
Text that is smaller than 24px should have a CCR of 4.5:1.
If a site needs to adhere to the enhanced guidelines for Level AAA, the requirements are a little higher:
Text that is 24px and larger, or 19px and larger if bold, should have a CCR of 4.5:1.
Text that is smaller than 24px should have a CCR of 7:1.
Ratios? Huh? Yeah, there’s some math involved here. But the good news is that we don’t need to do it ourselves or even have the same thorough understanding about how they’re calculated the way Stacie Arellano recently shared (which is a must read if you’re into the science of color accessibility).
That’s where Sass comes in. We can leverage it to run difficult mathematical computations that would otherwise fly over many of our heads. But first, I think it’s worth dealing with accessible colors at the design level.
Accessible color palettes start with the designs
That’s correct. The core of the work of creating an accessible color palette starts with the designs. Ideally, any web design ought to consult a tool to verify that any color combinations in use pass the established guidelines — and then tweak the colors that don’t. When our design team does this, they use a tool that we developed internally. It works on a list of colors, testing them over a dark and a light color, as well as providing a way to test other combinations.
ColorCube provides an overview of an entire color palette, showing how each color performs when paired with white, black, and even each other. It even displays results for WCAG Levels AA and AAA next to each result. The tool was designed to throw a lot of information at the user all at once when evaluating a list of colors.
This is the first thing our team does. I’d venture to guess that many brand colors aren’t chosen with accessibility at the forefront. I often find that those colors need to change when they get translated to a web design. Through education, conversation, and visual samples, we get the client to sign off on the new color palette. I’ll admit: that part can be harder than the actual work of implementing accessible colors combinations.
The Color Contrast Audit: A typical design delivery when working with an existing brand’s color palette. Here, we suggest to stop using the brand color Emerald with white, but use an “Alt” version that is slightly darker instead.
The problem that I wanted to solve with automation are the edge cases. You can’t fault a designer for missing some instance where two colors combine in an unintended way — it just happens. And those edge cases will come up, whether it is during the build or even a year later when new colors are added to the system.
Developing for accessibility while keeping true to the intent of a color system
The trick when changing colors to meet accessibility requirements is not changing them so much that they don’t look like the same color anymore. A brand that loves its emerald green color is going to want to maintain the intent of that color — it’s “emerald-ness.” To make it pass for accessibility when it is used as text over a white background, we might have to darken the green and increase its saturation. But we still want the color to “read” the same as the original color.
To achieve this, we use the Hue Saturation Lightness (HSL) color model. HSL gives us the ability to keep the hue as it is but adjust the saturation (i.e. increase or decrease color) and lightness (i.e. add more black or more white). The hue is what makes a green that green, or a blue that blue. It is the “soul” of the color, to get a little mystical about it.
Hue is represented as a color wheel with a value between 0° and 360° — yellow at 60°, green at 120°, cyan at 180°, etc. Saturation is a percentage ranging from 0% (no saturation) to 100% (full saturation). Lightness is also a value that goes from 0% to 100%, where no lightness is at 0%, no black and no white is at 50%, and 100% is all lightness, or very light.
A quick visual of what tweaking a color looks like in our tool:
With HSL, changing the low-contrast green to a higher contrast meant changing the saturation from 63 to 95 and the lightness from 45 to 26 on the left. That’s when the color gets a green check mark in the middle when used with white. The new green still feels like it is in the same family, though, because the Hue remained at 136, which is like the color’s “soul.”
Designers can adjust colors with the tools that we just reviewed, but so far, no Sass that I have found could do it with mathematical magic. There had to be a way.
These are some similar approaches I have seen in the wild:
An idea by Josh Bader uses CSS variables and colors split into their RGB values to calculate whether white or black is the best accessible color to use in a given situation.
I didn’t like these approaches. I didn’t want to fallback to white or black. I wanted colors to be maintained but adjusted to be accessible. Additionally, changing colors to their RGB or HSL components and storing them with CSS variables seemed messy and unsustainable for a large codebase.
I wanted to use a preprocessor like Sass to do this: given two colors, automagically adjust one of them so the pair receives a passing WCAG grade. The rules state a few other things to consider as well — size of the text and whether or not the font is bold. The solution had to take this into account.
In code terms, I wanted to do this:
// Transform this non-passing color pair:
.example {
background-color: #444;
color: #0094c2; // a 2.79 contrast ratio when AA requires 4.5
font-size: 1.25rem;
font-weight: normal;
}
// To this passing color pair:
.example {
background-color: #444;
color: #00c0fc; // a 4.61 contrast ratio
font-size: 1.25rem;
font-weight: normal;
}
A solution that does this would be able to catch and handle those edge cases we mentioned earlier. Maybe the designer accounted for a brand blue to be used over a light blue, but not a light gray. Maybe the red used in error messages needs to be tweaked for this one form that has a one-off background color. Maybe we want to implement a dark mode feature to the UI without having to retest all the colors again. These are the use cases I had in mind going into this.
With formulas can come automation
The W3C has provided the community with formulas that help analyze two colors used together. The formula multiplies the RGB channels of both colors by magic numbers (a visual weight based on how humans perceive these color channels) and then divides them to come up with a ratio from 0.0 (no contrast) to 21.0 (all the contrast, only possible with white and black). While imperfect, this is the formula we use right now:
If L1 is the relative luminance of a first color
And L2 is the relative luminance of a second color, then
- Color Contrast Ratio = (L1 + 0.05) / (L2 + 0.05)
Where
- L = 0.2126 * R + 0.7152 * G + 0.0722 * B
And
- if R sRGB <= 0.03928 then R = R sRGB /12.92 else R = ((R sRGB +0.055)/1.055) ^ 2.4
- if G sRGB <= 0.03928 then G = G sRGB /12.92 else G = ((G sRGB +0.055)/1.055) ^ 2.4
- if B sRGB <= 0.03928 then B = B sRGB /12.92 else B = ((B sRGB +0.055)/1.055) ^ 2.4
And
- R sRGB = R 8bit /255
- G sRGB = G 8bit /255
- B sRGB = B 8bit /255
While the formula looks complex, it’s just math right? Well, not so fast. There is a part at the end of a few lines where the value is multiplied by a decimal power — raised to the power of 2.4. Notice that? Turns out that it’s complex math which most programming languages can accomplish — think Javascript’s math.pow() function — but Sass is not powerful enough to do it.
There’s got to be another way…
Of course there is. It just took some time to find it. ?
My first version used a complex series of math calculations that did the work of decimal powers within the limited confines of what Sass can accomplish. Lots of Googling found folks much smarter than me supplying the functions. Unfortunately, calculating only a handful of color contrast combinations increased Sass build times exponentially. So, that means Sass can do it, but that does not mean it should. In production, build times for a large codebase could increase to several minutes. That’s not acceptable.
After more Googling, I came across a post from someone who was trying to do a similar thing. They also ran into the lack of exponent support in Sass. They wanted to explore “the possibility of using Newtonian approximation for the fractional parts of the exponent.” I totally understand the impulse (not). Instead, they decided to use a “lookup table.” It’s a genius solution. Rather than doing the math from scratch every time, a lookup table provides all the possible answers pre-calculated. The Sass function retrieves the answer from the list and it’s done.
In their words:
The only part [of the Sass that] involves exponentiation is the per-channel color space conversions done as part of the luminance calculation. [T]here are only 256 possible values for each channel. This means that we can easily create a lookup table.
Now we’re cooking. I had found a more performant direction.
Usage example
Using the function should be easy and flexible. Given a set of two colors, adjust the first color so it passes the correct contrast value for the given WCAG level when used with the second color. Optional parameters will also take the font size or boldness into account.
// @function a11y-color(
// $color-to-adjust,
// $color-that-will-stay-the-same,
// $wcag-level: 'AA',
// $font-size: 16,
// $bold: false
// );
// Sass sample usage declaring only what is required
.example {
background-color: #444;
color: a11y-color(#0094c2, #444); // a 2.79 contrast ratio when AA requires 4.5 for small text that is not bold
}
// Compiled CSS results:
.example {
background-color: #444;
color: #00c0fc; // which is a 4.61 contrast ratio
}
I used a function instead of a mixin because I preferred the output of a single value independent from a CSS rule. With a function, the author can determine which color should change.
An example with more parameters in place looks like this:
// Sass
.example-2 {
background-color: a11y-color(#0094c2, #f0f0f0, 'AAA', 1.25rem, true); // a 3.06 contrast ratio when AAA requires 4.5 for text 19px or larger that is also bold
color: #f0f0f0;
font-size: 1.25rem;
font-weight: bold;
}
// Compiled CSS results:
.example-2 {
background-color: #087597; // a 4.6 contrast ratio
color: #f0f0f0;
font-size: 1.25rem;
font-weight: bold;
}
A deeper dive into the heart of the Sass function
To explain the approach, let’s walk through what the final function is doing, line by line. There are lots of helper functions along the way, but the comments and logic in the core function explain the approach:
// Expected:
// $fg as a color that will change
// $bg as a color that will be static and not change
// Optional:
// $level, default 'AA'. 'AAA' also accepted
// $size, default 16. PX expected, EM and REM allowed
// $bold, boolean, default false. Whether or not the font is currently bold
//
@function a11y-color($fg, $bg, $level: 'AA', $size: 16, $bold: false) {
// Helper: make sure the font size value is acceptable
$font-size: validate-font-size($size);
// Helper: With the level, font size, and bold boolean, return the proper target ratio. 3.0, 4.5, or 7.0 results expected
$ratio: get-ratio($level, $font-size, $bold);
// Calculate the first contrast ratio of the given pair
$original-contrast: color-contrast($fg, $bg);
@if $original-contrast >= $ratio {
// If we pass the ratio already, return the original color
@return $fg;
} @else {
// Doesn't pass. Time to get to work
// Should the color be lightened or darkened?
// Helper: Single color input, 'light' or 'dark' as output
$fg-lod: light-or-dark($fg);
$bg-lod: light-or-dark($bg);
// Set a "step" value to lighten or darken a color
// Note: Higher percentage steps means faster compile time, but we might overstep the required threshold too far with something higher than 5%
$step: 2%;
// Run through some cases where we want to darken, or use a negative step value
@if $fg-lod == 'light' and $bg-lod == 'light' {
// Both are light colors, darken the fg (make the step value negative)
$step: - $step;
} @else if $fg-lod == 'dark' and $bg-lod == 'light' {
// bg is light, fg is dark but does not pass, darken more
$step: - $step;
}
// Keeping the rest of the logic here, but our default values do not change, so this logic is not needed
//@else if $fg-lod == 'light' and $bg-lod == 'dark' {
// // bg is dark, fg is light but does not pass, lighten further
// $step: $step;
//} @else if $fg-lod == 'dark' and $bg-lod == 'dark' {
// // Both are dark, so lighten the fg
// $step: $step;
//}
// The magic happens here
// Loop through with a @while statement until the color combination passes our required ratio. Scale the color by our step value until the expression is false
// This might loop 100 times or more depending on the colors
@while color-contrast($fg, $bg) < $ratio {
// Moving the lightness is most effective, but also moving the saturation by a little bit is nice and helps maintain the "power" of the color
$fg: scale-color($fg, $lightness: $step, $saturation: $step/2);
}
@return $fg;
}
}
The final Sass file
Here’s the entire set of functions! Open this in CodePen to edit the color variables at the top of the file and see the adjustments that the Sass makes:
CodePen Embed Fallback
All helper functions are there as well as the 256-line lookup table. Lots of comments should help folks understand what is going on.
When an edge case has been encountered, a version in SassMeister with debug output was helpful while I was developing it to see what might be happening. (I changed the main function to a mixin so I can debug the output.) Feel free to poke around at this as well.
And finally, the functions have been stripped out of CodePen and put into a GitHub repo. Drop issues into the queue if you run into problems.
Cool code! But can I use this in production?
Maybe.
I’d like to say yes, but I’ve been iterating on this thorny problem for a while now. I feel confident in this code but would love more input. Use it on a small project and kick the tires. Let me know how the build time performs. Let me know if you come across edge cases where passing color values are not being supplied. Submit issues to the GutHub repo. Suggest improvements based on other code you’ve seen in the wild.
I’d love to say that I have Automated All the A11y Things, but I also know it needs to be road-tested before it can be called Production Ready™. I’m excited to introduce it to the world. Thanks for reading and I hope to hear how you are using it real soon.
In the previous article, we explained what strong (vs. eventual) consistency is. This article is the second part of a series where we explain how a lack of strong consistency makes it harder to deliver a good end-user experience, can bring serious engineering overhead, and opens you up to exploits. This part is longer since we will explain different database anomalies, go through several example scenarios, and briefly highlight which kind of database suffers from each anomaly.
User experience is the driving factor in the success of any app, and relying on an inconsistent backend can increase the challenge to deliver a good experience. More importantly, building application logic on top of inconsistent data can lead to exploits. One paper calls these kinds of attacks “ACIDrain.” they investigated 12 of the most popular self-hosted e-commerce applications and at least 22 possible critical attacks were identified. One website was a Bitcoin wallet service that had to shut down due to these attacks. When you choose a distributed database that is not 100% ACID, there will be dragons. As explained in one of our previous examples, due to misinterpretations, badly defined terminology, and aggressive marketing, it is very hard for an engineer to determine what guarantees a specific database delivers.
Which dragons? Your app might feature issues such as wrong account balances, unreceived user rewards, trade transactions that executed twice, messages that appear out of order, or application rules that are violated. For a quick introduction why distributed databases are necessary and difficult, please refer to our first article or this excellent video explanation. In short, a distributed database is a database that holds copies of your data in multiple locations for scale, latency, and availability reasons
We’ll go through four of these potential issues (there are more) and illustrate them with examples from game development. Game development is complex and those developers are faced with many problems that closely resemble serious real-life problems. A game has trading systems, messaging systems, awards that require conditions to be fulfilled, etc. Remember how angry (or happy ?) gamers can be if things go wrong or appear to go wrong. In games, user experience is everything, so game developers are often under huge pressure to make sure their systems are fault-tolerant.
Ready? Let’s dive into the first potential issue!
1. Stale reads
Stale reads are reads that return old data, or in other words, data that returns values which are not yet updated according to the latest writes. Many distributed databases, including traditional databases that scale up with replicas (read Part 1 to learn how these work), suffer from stale reads.
Impact on end users
First off, stale reads can affect end users. And it’s not a single impact.
Frustrating experiences and unfair advantages
Imagine a scenario where two users in a game encounter a chest with gold. The first user receives the data from one database server while the second is connected to a second database server. The order of events goes as follows:
User 1 (via database server 1) sees and opens the chest, retrieves the gold.
User 2 (via database server 2) sees a full chest, opens it, and fails.
User 2 still sees a full chest and does not understand why it fails.
Although this seems like a minor problem, the result is a frustrating experience for the second player. Not only did he have a disadvantage, but he will also often see situations in the game where things appear to be there, yet they are not. Next, let’s look at an example where the player takes action on a stale read!
Stale reads leading to duplicated writes
Imagine a situation where a character in the game tries to buy a shield and a sword in a shop. If there are multiple locations that contain the data and there is no intelligent system in place to provide consistency, then one node will contain older data than another. In that case, the user might buy the items (which contacts the first node) and then check his inventory (which contacts the second node), only to see that they are not there. The user will probably be confused and might think that the transaction didn’t go through. What would most people do in that case? Well, they try to buy the item again. Once the second node has caught up, the user has already bought a duplicate, and once the replica catches up, he suddenly sees that he has no money left and two items of each. He is left with the perception that our game is broken.
Example of a user requesting the same transaction twice due to eventual consistency (t1) – A player buys a shield and sword. This buy transaction is committed to the master node. (r1) – The player loads his inventory, but the read hits replica1. Since (t1) is not yet replicated, he does not see his items. (rt1) – The first transaction is replicated, yet too late to have an effect on (r1) (t2) – The player thinks his buy attempt failed and buys the sword and shield again. (rt2) – The second transaction is replicated. (r2) – The player loads his inventory, and now sees he has two shields, two swords, and almost no gold left.
In this case, the user has spent resources which he did not want to spend. If we write an email client on top of such a database, a user might try to send an email, then refresh the browser and not be able to retrieve the email he has just sent, and therefore send it again. Delivering a good user experience and implementing secure transactions such as bank transactions on top of such a system is notoriously hard.
Impact on developers
When coding, you always have to expect that something is not there (yet) and code accordingly. When reads are eventually consistent, writing fault-proof code becomes very challenging and chances are that users will encounter problems in your application. When reads are eventually consistent, these problems will be gone by the time you are able to investigate them. Basically, you end up chasing ghosts. Developers still often choose databases or distribution approaches that are eventually consistent since it often takes time to notice the problems. Then, once the problems in their application arise, they try to be creative and build solutions (1, 2) on top of their traditional database to fix the stale reads. The fact that there are many guides like this and that databases like Cassandra have implemented some consistency features shows that these problems are real and do cause issues in production systems more frequently than you might imagine. Custom solutions on top of a system that is not built for consistency are very complex and brittle. Why would someone go through such a hassle if there are databases that deliver strong consistency out-of-the-box?
Databases that exhibit this anomaly
Traditional databases (PostgreSQL, MySQL, SQL Server, etc..) that use master-read replication typically suffer from stale reads. Many newer distributed databases also started off as eventually consistent, or in other words, without protection against stale reads. This was due to a strong belief in the developer community that this was necessary to scale. The most famous database that started off like this is Cassandra, but Cassandra recognized how their users struggled to deal with this anomaly and have since provided extra measures to avoid this. Older databases or databases which are not designed to provide strong consistency in an efficient way such as Cassandra, CouchDB, and DynamoDB are by default eventually consistent. Other approaches such as Riak are also eventually consistent, but take a different path by implementing a conflict resolution system to reduce the odds of outdated values. However, this does not guarantee that your data is safe since conflict resolution is not fault-proof.
2. Lost writes
In the realm of distributed databases, there is an important choice to make when writes happen at the same time. One option (the safe one) is to make sure that all database nodes can agree on the order of these writes. This is far from trivial since it either requires synchronized clocks, for which specific hardware is necessary, or an intelligent algorithm like Calvin that doesn’t rely on clocks. The second, less safe option is to allow each node to write locally and then decide what to do with the conflicts later on. Databases that choose the second option can lose your writes.
Two database choices, avoid conflicts by ordering transactions or allow conflicts and resolve them.
Impact on end users
Consider two trade transactions in a game where we start with 11 gold pieces and buy two items. First, we buy a sword at 5 gold pieces and then buy a shield at five gold pieces, and both transactions are directed to different nodes of our distributed database. Each node reads the value, which in this case is still 11 for both nodes. Both nodes will decide to write 6 as the result (11- 5) since they are not aware of any replication. Since the second transaction could not see the value of the first write yet, the player ends up buying both the sword and shield for five gold pieces total instead of 10. Good for the user, but not so good for the system! To remedy such behavior, distributed databases have several strategies — some better than others.
Impact of lost writes on users. In this case, the user succeeds in buying two items while paying only once.
Resolution strategies include “last write wins” (LWW) or “longest version history” (LVH) wins. LWW has for a long time been the strategy of Cassandra and is still the default behavior if you do not configure it differently.
If we apply LWW conflict resolution to our previous example, the player will still be left with 6 gold, but will only have bought one item. This is a bad user experience because the application confirmed his purchase of the second item, even though the database doesn’t recognize it as existing in his inventory.
An example of simple conflict resolution. Two transactions on different nodes are changing the amount of gold at the same time. The writes initially go through but when the two nodes communicate, the conflict becomes apparent. The conflict resolution strategy here is to cancel one of the transactions. The user can no longer try to take advantage of the system but occasionally writes will be lost.
Unpredictable security
As you might imagine, it is unsafe to write security rules on top of such a system. Many applications rely on complex security rules in the backend (or directly on the database where possible) to determine whether a user can or cannot access a resource. When these rules are based on stale data that’s updated unreliably, how can we be sure that there is never a breach? Imagine one user of a PaaS application calls his administrator and asks: “Could you make this public group private so that we can repurpose it for internal data?” The admin applies the action and tells him it’s done. However, because the admin and user might be on different nodes, the user might start adding sensitive data to a group that is technically still public.
Impact on developers
When writes are lost, debugging user issues will be a nightmare. Imagine that a user reports that he has lost data in your application, then one day goes by before you get time to respond. How will you try to find out whether the issue was caused by your database or by faulty application logic? In a database that allows tracking data history such as FaunaDB or Datomic, you would be able to travel back in time to see how the data had been manipulated. Neither of these is vulnerable to lost writes though, and databases that do suffer from this anomaly typically don’t have the time-travel feature.
Databases that suffer from lost writes
All databases that use conflict resolution instead of conflict avoidance will lose writes. Cassandra and DynamoDB use last write wins (LWW) as default; MongoDB used to use LWW but has since moved away from it. The master-master distribution approaches in traditional databases such as MySQL offer different conflict resolution strategies. Many distributed databases that were not built for consistency suffer from lost writes. Riak’s simplest conflict resolution is driven by LWW, but they also implement more intelligent systems. But even with intelligent systems, sometimes there’s just no obvious way to resolve a conflict. Riak and CouchDB place the responsibility to choose the correct write with the client or application, allowing them to manually choose which version to keep.
Since distribution is complex and most databases use imperfect algorithms, lost writes are common in many databases when nodes crash or when network partitions arise. Even MongoDB, which does not distribute writes (writes go to one node), can have write conflicts in the rare case that a node goes down immediately after a write.
3. Write skew
Write skew is something that can happen in a type of guarantee that database vendors call snapshot consistency. In snapshot consistency, the transaction reads from a snapshot that was taken at the time the transaction started. Snapshot consistency prevents many anomalies. In fact, many thought it was completely secure until papers (PDF) started to appear proving the opposite. Therefore, it’s not a surprise that developers struggle to understand why certain guarantees are just not good enough.
Before we discuss what doesn’t work in snapshot consistency, let’s first discuss what does. Imagine that we have a battle between a knight and a mage, whose respective life powers consist of four hearts.
When either character gets attacked, the transaction is a function that calculates how many hearts have been removed:
In a trivial situation, the knight’s strike removes three hearts from the mage, and then the mage’s spell removes four hearts from the knight, bringing his own life points back to four. These two transactions would behave correctly in most databases if one transaction runs after the other.
But what if we add a third transaction, an attack from the knight, which runs concurrently with the mage’s spell?
Example of two transactions (Life Leech and the second Powerful Strike) that will determine the outcome of the battle. What would be the outcome in a system that provides snapshot consistency? To know that we have to learn about the ‘first committer wins’ rule.
Is the knight dead, and is the mage alive?
To deal with this confusion, snapshot consistency systems typically implement a rule called “the first committer wins.” A transaction can only conclude if another transaction did not already write to the same row, else it will roll back. In this example, since both transactions tried to write to the same row (the mage’s health), only the Life Leech spell would work and the second strike from the knight would be rolled back. The end result would then be the same as in the previous example: a dead knight and a mage with full hearts.
However, some databases such as MySQL and InnoDB do not consider “the first committer wins” as part of a snapshot isolation. In such cases, we would have a lost write: the mage is now dead, although he should have received the health from the life leech beforethe strike of the knight took effect. (We did mention badly defined terminology and loose interpretations, right?)
Snapshot consistency that includes the “first committer wins” rule does handle some things well, not surprising since it was considered a good solution for a long time. This is still the approach of PostgreSQL, Oracle, and SQL Server, but they all have different names for it. PostgreSQL calls this guarantee “repeatable read,” Oracle calls it “serializable” (which is incorrect according to our definition), and SQL Server calls it “snapshot isolation.” No wonder people get lost in this forest of terminology. Let’s look at examples where it is not behaving as you would expect!
Impact on end users
The next fight will be between two armies, and an army is considered dead if all of the army characters are dead:
isArmyDead(army){
if (<all characters are dead>) { return true }
else { return false }
}
After every attack, the following function determines if a character has died, and then runs the above function to see if the army has died:
First, the character’s hearts are diminished with the damage that was received. Then, we verify whether the army is dead by checking whether each character is out of hearts. Then, if the state of the army has changed, we update the ‘dead’ boolean of army.
Example of write skew, an anomaly that can happen in databases that provide snapshot consistency.
There are three mages that each attack one time resulting in three ‘Life Leech’ transactions. Snapshots are taken at the beginning of the transactions, since all transactions start at the same time, the snapshots are identical. Each transaction has a copy of the data where all knights still have full health.
Let’s take a look at how the first ‘Life Leech’ transaction resolves. In this transaction, mage1 attacks knight1, and the knight loses 4 life points while the attacking mage regains full health. The transaction decides that the army of knights is not dead since it can only see a snapshot where two knights still have full health and one knight is dead. The other two transactions act on another mage and knight but proceed in a similar way. Each of those transactions initially had three live knights in their copy of the data and only saw one knight dying. Therefore, each transaction decides that the army of knights is still alive.
When all transactions are finished, none of the knights are still alive, yet our boolean that indicates whether the army is dead is still set to false. Why? Because at the time the snapshots were taken, none of the knights were dead. So each transaction saw his own knight dying, but had no idea about the other knights in the army. Although this is an anomaly in our system (which is called write skew), the writes went through since they each wrote to a different character and the write to the army never changed. Cool, we now have a ghost army!
Impact on developers
Data quality
What if we want to make sure users have unique names? Our transaction to create a user will check whether a name exists; if it does not, we will write a new user with that name. However, if two users try to sign up with the same name, the snapshot won’t notice anything since the users are written to different rows and therefore do not conflict. We now have two users with the same name in our system.
There are numerous other examples of anomalies that can occur due to write skew. If you are interested, Martin Kleppman’s book “Designing Data-Intensive Applications” describes more.
Code differently to avoid the rollbacks
Now, let’s consider a different approach where an attack is not directed towards a specific character in the army. In this case, the database is responsible for selecting which knight should be attacked first.
If we execute several attacks in parallel as in our previous example, the getFirstHealthyCharacterwill always target the same knight, which would result in multiple transactions that write to the same row. This would be blocked by the “first committer wins” rule, which will roll back the two other attacks. Although it prevents an anomaly, the developer is required to understand these issues and code around them creatively. But wouldn’t it be easier if the database just did this for you out-of-the-box?
Databases that suffer from write skew
Any database that provides snapshot isolation instead of serializability can suffer from write skew. For an overview of databases and their isolation levels, please refer to this article.
4. Out of order writes
To avoid lost writes and stale reads, distributed databases aim for something called “strong consistency.” We mentioned that databases can either choose to agree on a global order (the safe choice) or decide to resolve conflicts (the choice that leads to lost writes). If we decide on a global order, it would mean that although the sword and shield are bought in parallel, the end result should behave as if we bought the sword first and then bought the shield. This is also often called “linearizability” since you can linearize the database manipulations. Linearizability is the gold standard to make sure your data is safe.
Different vendors offer different isolation levels, which you can compare here. A term that comes back often is serializability which is a slightly less strict version of strong consistency (or linearizability). Serializability is already quite strong and covers most anomalies, but still leaves room for one very subtle anomaly due to writes that get reordered. In that case, the database is free to switch that order even after the transaction has been committed. Linearizability in simple terms is serializability plus a guaranteed order. When the database is missing this guaranteed order, your application is vulnerable to out of order writes.
Impact on end users
Reordering of conversations
Conversations can be ordered in a confusing way if someone sends a second message due to a mistake.
Reordering of user actions
If our player has 11 coins and simply buys items in the order of importance while not actively checking the amount of gold coins he has, then the database can reorder these buy orders. If he didn’t have enough money, he could have bought the item of least importance first.
In this case, there was a database check which verified whether we have enough gold. Imagine that we did not have enough money and it would cost us money to let the account go below zero, just like a bank charges you overdraft fees when you go below zero. You might sell an item quickly in order to make sure you have enough money to buy all three items. However, the sale that was meant to increase your balance might be reordered to the end of the transaction list, which would effectively push your balance below zero. If it were a bank, you would likely incur charges you definitely did not deserve.
Unpredictable security
When an invulnerability spell swaps order with an axe attack
After configuring security settings, a user will expect that these settings will apply to all forthcoming actions, but issues can arise when users talk to each other via different channels. Remember the example we discussed where an administrator is on the phone with a user who wants to make a group private and then adds sensitive data to it. Although the time window within which this can happen becomes smaller in databases that offer serializability, this situation can still occur since the administrator’s action might not be completed until after the user’s action. When users communicate through different channels and expect that the database is ordered in real-time, things go wrong.
This anomaly can also happen if a user is redirected to different nodes due to load balancing. In that case, two consecutive manipulations end up on different nodes and might be reordered. If a girl adds her parents to a facebook group with limited viewing rights, and then posts her spring break photos, the images might still end up in her parents’ feeds.
In another example, an automatic trading bot might have settings such as a maximum buy price, a spending limit, and a list of stocks to focus on. If a user changes the list of stocks that the bot should buy, and then the spending limit, he will not be happy if these transactions were reordered and the trading bot has spent the newly allocated budget on the old stocks.
Impact on developers
Exploits
Some exploits depend on the potential reversal of transactions. Imagine that a game player receives a trophy as soon as he owns 1,000 gold, and he really wants that trophy. The game calculates how much money a player has by adding together gold of multiple containers, for example his storage and what he’s carrying (his inventory). If the player quickly swaps money in between his storage and inventory, he can actually cheat the system.
In the illustration below, a second player acts as a partner in crime to make sure that the money transfer between the storage and the inventory happens in different transactions, increasing the chance that these transactions get routed to different nodes. A more serious real world example of this happens with banks that use a third account to transfer money; the bank might miscalculate whether or not someone is eligible for a loan because various transactions have been sent to different nodes and not had enough time to sort themselves out.
Databases that suffer from out of order writes
Any database that does not provide linearizability can suffer from write skew. For an overview of which databases do provide linearizability, please refer to this article. Spoiler: there are not that many.
All anomalies can return when consistency is bounded
One final relaxation of strong consistency to discuss is to only guarantee it within certain bounds. Typical bounds are a datacenter region, a partition, a node, a collection, or a row. If you program on top of a database that imposes these kinds of boundaries to strong consistency, then you need to keep those in mind to avoid accidentally opening Pandora’s Box again.
Below is an example of consistency, but only guaranteed within one collection. The example below contains three collections: one for the players, one for the smithies (i.e., blacksmiths repairing players’ items), and another for the items. Each player and each smithy has a list of ids that point to items in the items collection.
If you want to trade the shield between two players (e.g., from Brecht to Robert), then everything is fine since you remain in one collection and therefore your transaction remains within the boundaries where consistency is guaranteed. However, what if Robert’s sword is in the smithy for repairs and he wants to retrieve it? The transaction then spans two collections, the smithy’s collection and the player’s collection, and the guarantees are forfeited. Such limitations are often found in document databases such as MongoDB. You will then be required to change the way you program to find creative solutions around the limitations. For example, you could encode the location of the item on the item itself.
Of course, real games are complex. You might want to be able to drop items on the floor or place them in a market so that an item can be owned by a player but does not have to be in the player’s inventory. When things become more complex, these workarounds will significantly increase technical depth and change the way you code to stay within the guarantees of the database.
Consistency with limitations often requires you to be aware of the limitations and change the way you code, stepping out of the boundary, and again exposing your application to the aforementioned anomalies.
Conclusion
We have seen different examples of issues that can arise when your database does not behave as you would expect. Although some cases might seem insignificant at first, they all have a significant impact on developer productivity, especially as a system scales. More importantly, they open you up to unpredictable security exploits — which can cause irreparable damage to your application’s reputation.
We discussed a few degrees of consistency, but let’s put them together now that we have seen these examples:
Stale reads
Lost writes
Write skew
Out of order writes
Linearizability
safe
safe
safe
safe
Serializability
safe
safe
safe
unsafe
Snapshot consistency
safe
safe
unsafe
unsafe
Eventual consistency
unsafe
unsafe
unsafe
unsafe
Also remember that each of these correctness guarantees can come with boundaries:
Row-level boundaries
The guarantees delivered by the database are only honored when the transaction reads/writes to one row. Manipulations such as moving items from one player to another can cause issues. HBase is an example database that limits guarantees to one row.
Collection-level boundaries
The guarantees delivered by the database are only honored when the transaction reads/writes to one collection. E.g., trading items between two players stays within a “players” collection, but trading them between a player and an entity from another collection such as a market opens the door to anomalies again. Firebase is an example which limits correctness guarantees to collections.
Shard/Replica/Partition/Session boundaries
As long as a transaction only affect data on one machine or shard, the guarantees hold. This is, of course, less practical in distributed databases. Cassandra has recently started offering serializability features if you configure them, but only within a partition.
Regionboundaries
Some databases almost go all the way and provide guarantees across multiple nodes (shards/replicas), but their guarantees do not hold anymore if your database is distributed across multiple regions. Such an example is Cosmos. Cosmos is a great technology, but they have chosen an approach where consistency guarantees are limited to one region.
Finally, realize that we have only mentioned a few anomalies and consistency guarantees while in fact there are more. For the interested reader, I fondly recommend Martin Kleppman’s Designing Data-Intensive Applications.
We live in a time when we no longer have to care, as long as we choose a strongly consistent database without limitations. Thanks to new approaches such as Calvin (FaunaDB) and Spanner (Google Spanner, FoundationDB), we now have multi-region distributed databases that deliver great latencies and behave as you expect in each scenario. So why would you still risk shooting yourself in the foot and choose a database that does not deliver these guarantees?
In the next article in this series, we will go through the effects on your developer experience. Why is it so hard to convince developers that consistency matters? Spoiler: most people need to experience it before they see the necessity. Think about this though: “If bugs appear, is your app wrong, or is it the data? How can you know?” Once the limitations of your database manifest themselves as bugs or bad user experiences, you need to work around the limitations of the database, which results in inefficient glue code that does not scale. Of course, at that point, you are deeply invested and the realization came too late.
Shopping ads are a sure attention grabber when you are browsing online. Every retailer wants its shopping ads to come up on Google, which is one of the most popular spaces online to host your products and services.
The more your Shopping ads are popular, the better sales you achieve. To obtain visibility for your products online, Google Shopping is the best way. Google Shopping is meant for retailers to promote their products online. Getting your eStore products to Google Shopping is made easier with a Google Product Feed plugin. If you own a WooCommerce store, then take a look at the popular WooCommerce Google Product Feed plugins that take your products on Google Shopping.
Why Google Shopping is important for Retailers?
You have your eStore up and ready for selling. Now you need to strategize your selling. To do the same, you need to focus on making use of targeted selling using technology. This is where Google Shopping comes into the picture. Google shopping serves only relevant ads that will propel the on-page promotion of your store. Shopping ads have outperformed all kinds of marketing strategies in convincing a larger crowd.
How does Google Shopping help retailers for Higher Conversion Rates?
To get your products on Google Shopping, you need a Google Merchant Center account, Google Analytics, and a Google Ads account. With your store products displayed on Google Shopping, it gives you a popularity edge compared to the rest of the competitive ones in the market. The Shopping Ads on Google Shopping contains the image of the product, the URL of the page, the availability of the product and the price. To reach the business goals and to augment their conversion rates, the retailers have been making use of Google Shopping in an optimal way.
To get your products on Google Shopping, you need to create a Google product feed. If you own a WooCommerce store, then you need to either manually create a Google product feed for the Google Merchant Center or automatically generate it with the help of WooCommerce plugins.
Creating a Google Product Feed
Google Merchant Center helps retailers to create Google Product feed with the help of predefined templates in it. There are several ways to input the Google product feed into the Google Merchant Center.
Google Sheets can be downloaded and then the data corresponding to your store can be fed into the Google Sheets. Once the data is filled, the sheet can be uploaded to the Google Merchant Center.
Again this is indeed a tedious job to be done and time-consuming. Once you save time in creating feeds and uploading and doing hassle-free management of your feeds, you can invest in growing your business.
WooCommerce Google Product Feed Plugins
WooCommerce has several plugins that will help you generate feeds in an error-free manner. As Google product feed is the basis of generating ads for Google Shopping, it is important to keep it intact, data-rich and accurate.
There are several WooCommerce Google Product feed generating plugins, which will assist you to automatically generate feeds for your Google Shopping. Let us take a look at the same :
Automatically helps you generate your Google Product feeds from your WooCommerce store in an effortless manner. The plugin is easy to work with and has very simplified navigation to help the retailer navigate across the google product feed creation method swiftly. The plugin is comparatively low priced but worth the investment.
Here are some noteworthy features to look for in the plugin :
Create multiple feeds quickly in various file formats like CSV, TSV and XML.
A timely Refresh schedule can be done with respect to Daily, Weekly and even monthly basis.
Intuitive mapping of Google Attributes and Product Categories with exquisite conditional statements to help to filter of required data that will strengthen the feed generation.
Batch management of generated feed files.
Easy Google Taxonomy matching with products also with a default mapping possibility to ease the process.
Also, the plugin allows to include meta tags that help to add custom tags depending on the business needs.
You can append or prepend any attribute to the existing attribute using the expert attribute mapping solution in the plugin.
Easy to add or upload any product without a unique identifier (GTIN, MPN or brand) using the option which helps to auto set the “identifier_exist” to No.
Get all your products automatically on to Google Shopping using the smooth integration with the plugin. The plugin helps to connect with the Google Merchant Center on the go. Other than the ideal functionality of generating product feeds, the plugin has various other features that make it stand out in the crowd.
Easily helps to create templates and also generate feeds quickly.
Extra fields are available to match the product categories and attributes.
You can also set overrides for your products as well as google attributes.
It is also translation ready.
Supports multiple languages.
You can also choose what needs to display on your Google Shopping.
The plugin allows real-time feed generation to help your products show up in Google Shopping. The plugin can generate feeds not only for Google but also for Bing as well as provide Google Product Reviews data too. Here are some of the major highlights of the plugin:
It helps you map attributes other than the available default ones in WooCommece.
Real-time feeds show the latest updates.
Easily integrates with common WooCommerce extensions
The plugin supports multiple channels for product feed like Facebook Remarketing, Vergelijk.nl, Bing Ads, Pricerunner,Billiger.de. Etc. You can easily provide comparison studies for shopping engines, rule-based mapping, and filtering. The plugin supports generating unlimited feeds. Here are some features that make the plugin popular :
An unlimited number of products and product feeds.
Advanced filters and rules help to set the feeds as per the need.
Quick one-on-one category mapping.
It also helps to support shipping zones or classes to populate shipping costs.
The plugin is the premium version of Woocommerce Google Feed Manager and can support multiple channels like Bing, Connexity, PriceGrabber, Amazon, etc. Here are some features to look out for :
Simple Interface.
Quick and easy editing.
Multi-channel support
Easy to add innovative product categories.
Completely automated product updates to every targeted channel supported.
Conclusion
The above-listed plugins are the popular ones who can help you generate your Google product feeds for the Google Merchant center accurately. Once you get the google product feeds done, you can simply upload it to the Google Merchant Center. With the help of Google Analytics, you can even find out your target audience and concentrate on the marketing strategies to approach the target audience. Ultimately using Google AdSense and Google Analytics with the data from Google Product Feed, you can target the market and sell your products on Google Shopping.