Have you ever clicked on an image on a webpage that opens up a larger version of the image with navigation to view other photos?
Some folks call it a pop-up. Others call it a lightbox. Bootstrap calls it a modal. I mention Bootstrap because I want to use it to make the same sort of thing. So, let’s call it a modal from here on out.
Why Bootstrap? you might ask. Well, a few reasons:
I’m already using Bootstrap on the site where I want this effect, so there’s no additional overhead in terms of loading resources.
I want something where I have complete and easy control over aesthetics. Bootstrap is a clean slate compared to most modal plugins I’ve come across.
The functionality I need is fairly simple. There isn’t much to be gained by coding everything from scratch. I consider the time I save using the Bootstrap framework to be more beneficial than any potential drawbacks.
Here’s where we’ll end up:
CodePen Embed Fallback
Let’s go through that, bit by bit.
Step 1: Create the image gallery grid
Let’s start with the markup for a grid layout of images. We can use Bootstrap’s grid system for that.
Now we need data attributes to make those images interactive. Bootstrap looks at data attributes to figure out which elements should be interactive and what they should do. In this case, we’ll be creating interactions that open the modal component and allow scrolling through the images using the carousel component.
About those data attributes:
We’ll add data-toggle="modal" and data-target="#exampleModal" to the parent element (#gallery). This makes it so clicking anything in the gallery opens the modal. We should also add the data-target value (#exampleModal) as the ID of the modal itself, but we’ll do that once we get to the modal markup.
Let’s add data-target="#carouselExample" and a data-slide-to attribute to each image. We could add those to the image wrappers instead, but we’ll go with the images in this post. Later on, we’ll want to use the data-target value (#carouselExample) as the ID for the carousel, so note that for when we get there. The values for data-slide-to are based on the order of the images.
This is a carousel inside a modal, both of which are standard Bootstrap components. We’re just nesting one inside the other here. Pretty much a straight copy-and-paste job from the Bootstrap documentation.
Here’s some important parts to watch for though:
The modal ID should match the data-target of the gallery element.
The carousel ID should match the data-target of the images in the gallery.
The carousel slides should match the gallery images and must be in the same order.
Here’s the markup for the modal with our attributes in place:
Looks like a lot of code, right? Again, it’s basically straight from the Bootstrap docs, only with our attributes and images.
Step 3: Deal with image sizes
This isn’t necessary, but if the images in the carousel have different dimensions, we can crop them with CSS to keep things consistent. Note that we’re using Sass here.
You may have noticed that the markup uses the same image files in the gallery as we do in the modal. That doesn’t need to be the case. In fact, it’s a better idea to use smaller, more performant versions of the images for the gallery. We’re going to be blowing up the images to their full size version anyway in the modal, so there’s no need to have the best quality up front.
The good thing about Bootstrap’s approach here is that we can use different images in the gallery than we do in the modal. They’re not mutually exclusive where they have to point to the same file.
So, for that, I’d suggest updating the gallery markup with lower-quality images:
<div class="row" id="gallery" data-toggle="modal" data-target="#exampleModal">
<div class="col-12 col-sm-6 col-lg-3">
<img class="w-100" src="/image-1-small.jpg" data-target="#carouselExample" data-slide-to="0">
<!-- and so on... -->
</div>
That’s it!
The site where I’m using this has already themed Bootstrap. That means everything is already styled to spec. That said, even if you haven’t themed Bootstrap you can still easily add custom styles! With this approach (Bootstrap vs. plugins), customization is painless because you have complete control over the markup and Bootstrap styling is relatively sparse.
Burke Holland thinks that to “build applications without thinking about servers” is a pretty good way to describe serverless, but…
Nobody really thinks about servers when they are writing their code. I mean, I doubt any developer has ever thrown up their hands and said “Whoa, whoa, whoa. Wait just a minute. We’re not declaring any variables in this joint until I know what server we’re going to be running this on.”
Instead of just one idea wrap it all up, Burke thinks there are three laws:
Law of Furthest Abstraction (I don’t really care where my code runs, just that it runs.)
The Law of Inherent Scale (I can hammer this code if I need to, or barely use it at all.)
Law of Least Consumption (I only pay for what I use.)
Power BI is rapidly becoming a lot more popular than other BI tools. It is one of the best BI tools as it contains several cutting-edge features. Being a Microsoft product, the tool has already gained a lot of popularity in the market.
Also, it is extremely reliable, of course, because it is a Microsoft product. The data scientists find Power BI as a topnotch solution to churn out meaning from the data. If any company wants to utilize their business data to the fullest, they should definitely use Power BI. Power BI is a cloud-based solution, therefore, it is automatically apt for modern businesses. Power BI contains superb visualization features too, and in this article, we will talk about the visualization of the data through Power BI.
Why is visualization of data important?
In the simplest way possible, visualization can be described as the presentation of the data insights in the most understandable and attractive manner. The huge amount of data that the company gathers has to be analyzed to generate valuable insights. However, the data can only be deemed useful if the insights are visualized properly. The way you represent the data makes all the difference. As, only when the data scientists, the leaders and others are able to understand the message and the meaning of the data, then only they can reap benefits from it.
Why is Power BI regarded as a top tool for business intelligence visualization?
Power BI is not only used for the analysis of the data. Rather, it is even used for the visualizing of the Business Intelligence data. It is one of the most efficient cloud-based tools which allows the data scientists to seamlessly exhibit the insights. The data can be presented in a host of interesting ways. However, the users need to know the right way of presenting the data. Also, it is important for them to have the right tool that allows them to share the data in the best possible manner. Power BI is surely one of the coolest and most apt tools that can be used to represent the data.
Power BI offers much more than just collection and analysis of the data
Organizations require business intelligence tools that not only enable them to collect, study and analyze the information, but that also helps them to represent the outcome of the analysis. Power BI empowers businesses to make useful reports. The data scientists are able to make attractive, engaging, intuitive and impressive reports quickly using Power BI. For example, say the marketing team wishes to know “target audience of which geographical location showed the least interest”, they can see the results using the BI tool. However, they can present the insights in the form of interesting reports, along with other important details. In fact, with the help of Power BI, the marketing teams or the data scientists can even add a lot more add-ons in the reports. The best part about using Power BI is that it allows you to personalize and customize the reports. Therefore, the results automatically become more interactive.
Power of data visualization
Power BI enables you to link to several sources of data. It even allows the users to clean and transform the insights into a data model. This further allows the data scientists and visualizers to clearly represent the data. The data scientists are able to present the data in the most attractive manner, in the form of charts, infographics, graphs etc. Not just that, the tools even allows the people to share the data and the reports with different departments.
Power BI is linked to a wide range of data sources. It makes the reports in the Power BI desktop. Basically, all the reports are move from the Desktop to Power BI service. Afterwards, the reports are then shared with the other users. Also, the reports can be shared via mobile devices. Therefore, users are able to study the reports carefully. Power BI allows the users to explain what the users want to exhibit with the help of further slides as well. Every person who is using Power BI makes personal dashboard. And, the reports created using Power BI can be shared with other users as well.
Power BI makes data visualization a piece of cake
Power BI is a very easy to use the tool. It is not complicated, therefore, the process of data interpretation and visualization is also streamlined and quick. It is a perfect tool for businesses. And, it doesn’t require you to have superb technical skills. All you need to do is have some decent data analysis and presentation skills. That’s it! You will be able to use Power BI to the fullest and derive maximum benefits from it. Even if you don’t have advanced technical skills, you can still easily perform high-level data visualization actions.
Power BI gives the business fantastic visibility of the data and insights. Therefore, the leaders are able to identify the key business insights in real-time. Also, Power BI makes it possible for the users to visualize the data in the best possible manner as it contains several pre-built visualizations. However, you can still customize the reports as per your needs. You can either play with the existing inbuilt visualizations or create your own reports. You can even personalize the reports as per your requirements.
Are you all set to adopt Power BI for business intelligence visualization?
If a business has to grow immensely, they have to make the most of the timely actionable insights. BI allows the companies to process the data from dynamics 365 for finance and operations every source and derive valuable insights. The insights generated have to be visualized for consumption. Power BI is one of the best tools that helps the companies with the visualization of the data and insights. Even the most complex insights or data sets could be represented in an engaging and intuitive manner with the help of Power BI. Therefore, the adoption of Power BI is increasing quite rapidly.
Google’s multi-language input method, known as Google Input Tools is a good example of a web app that uses transliteration to input non-English characters. The basic idea is to have a text box, in which users spell the words of their own language, using English characters. They usually type those words using an English keyboard. The web app converts the typed English keystrokes into characters of their local (non-English) language, and displays those non-English characters in the text box in real-time. Users can copy the text from the text box and paste it into whatever the text field or search bar on another web page or app.
In this article, we’ll see how Google Input Tools behaves on a desktop and a mobile browser and identify its weakness, when running on the Chrome browser on Android. We’ll also compare that with the performance of our alternative JavaScript code snippet, and appreciate how it avoids the issues related to the Chrome mobile browser. You can use this method when you develop your own alternative to Google Input Tools in the future.
Using The Web With Just A Keyboard
Many of us are taught to make sure our sites can be used via keyboard. Why is that, and what is it like in practice? Chris Ashton did an experiment to find out. Read a related article ?
Google Input Tools
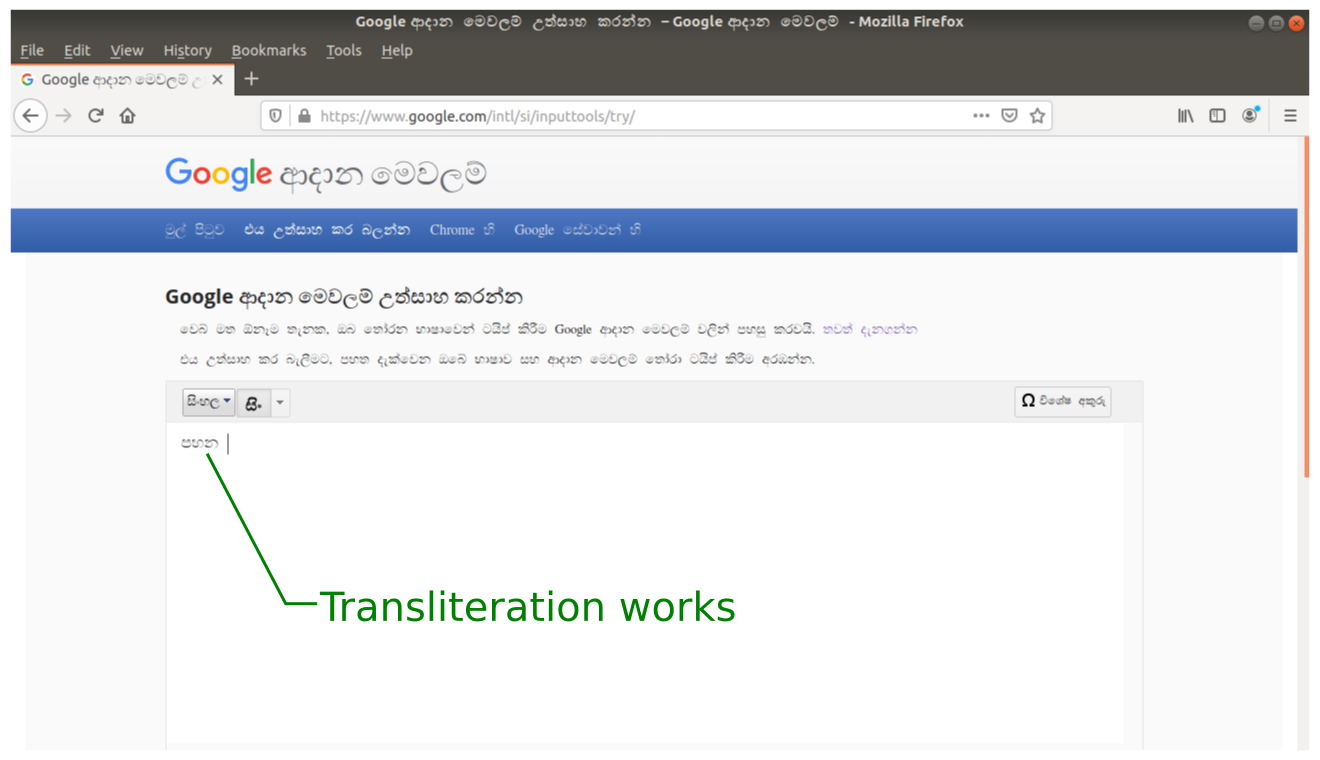
Below you can see how Google Input Tools works on a desktop and a mobile browser. It is obvious that transliteration doesn’t work on Chrome mobile browser (on Android) due to some kind of a bug. You can check for yourself by visiting Google Input Tools on a PC and a mobile device running Android with Chrome browser.
We’ll try it out by typing a very simple word in Sinhala, an official language of the South Asian island, Sri Lanka. We’ll type the Sinhala word “???”, meaning “lamp” in English. The mapping specified by Google Input Tools is “pa” for “?”, “ha” for “?” and “na” for “?”. So, just type “pahana” in the Google Input Tools text box and hit Enter. The mapped Sinhala characters, “???” will appear in the textbox.
Try this on a desktop and an Android mobile device with the Chrome browser. As seen in the images below, it works on the Firefox desktop browser but fails on the Chrome mobile browser.
Transliteration works on Firefox browser on Ubuntu desktop PC. (Large preview)
Transliteration does not work on Chrome browser on Android mobile device. (Large preview)
How did it happen? It works perfectly on a desktop browser, but fails on the Chrome mobile browser running on Android.
Two Possible Methods
Conversion of keystrokes can easily be implemented using JavaScript. If word prediction is also involved, then there’s a need for a back-end database and hence PHP, but the basic functionality can be achieved only with JavaScript.
Two methods could be used to implement this. Here, we’ll limit our example to a very simple input method design, where each non-English character can directly be mapped to a unique single keystroke.
For example, we could map the non-English (Sinhala) character “?” to the English character “p”, or the key “p” on the keyboard.
There are two main steps to achieve this with JavaScript in method 1. First, the default behavior when a key is pressed or held down must be stopped. Then the desired character or characters to be typed must be specified in the KeyPress, KeyDown or KeyUp event capture functions./> The default behavior when a key is pressed or held down, is to type the character associated with that key on the keyboard. For example, when the key “p” is pressed, the English character “p” will be typed in the text box by default. We could prevent this default behavior and replace the default character for any key, with a non-English character of our choice./> In our example, we’ll prevent typing of “p” when the key “p” is pressed and programmatically insert the mapped character “?” instead of character “p”. We can do this for all the mapped characters on the keyboard.
Method 2 (New Method): Listen to the Textbox Input and Modify the Contents in Real-Time, Based on Latest Input
In this method, we are not dealing with any keyboard events. Instead, we’ll keep track of the latest input character in the textbox and replace that character with a non-English character of our choice.
In the background, our script must be listening to the changes in the contents of the textbox. When the key “p” is pressed let “p” be typed. When the script detects that the last typed character is “p”, it must programmatically delete that typed “p” and replace it with “?”. In a similar fashion, any non-English character can be typed by assigning them to an English character through an appropriate mapping.
Whenever an English character is typed by pressing a key on the keyboard, all you have to do is to programmatically delete that typed character and replace it with the non-English character specified in the mapping.
Which Method Does Google Input Tools Use?
From what’s happening in the two different scenarios, it seems that Google Input Tools is using the first method (Method 1), which is also the typical way of implementing such functionality. Now that we’ve invented a new method (Method 2), it’s time for a little bit of experimentation.
Let’s Compare the Two Methods
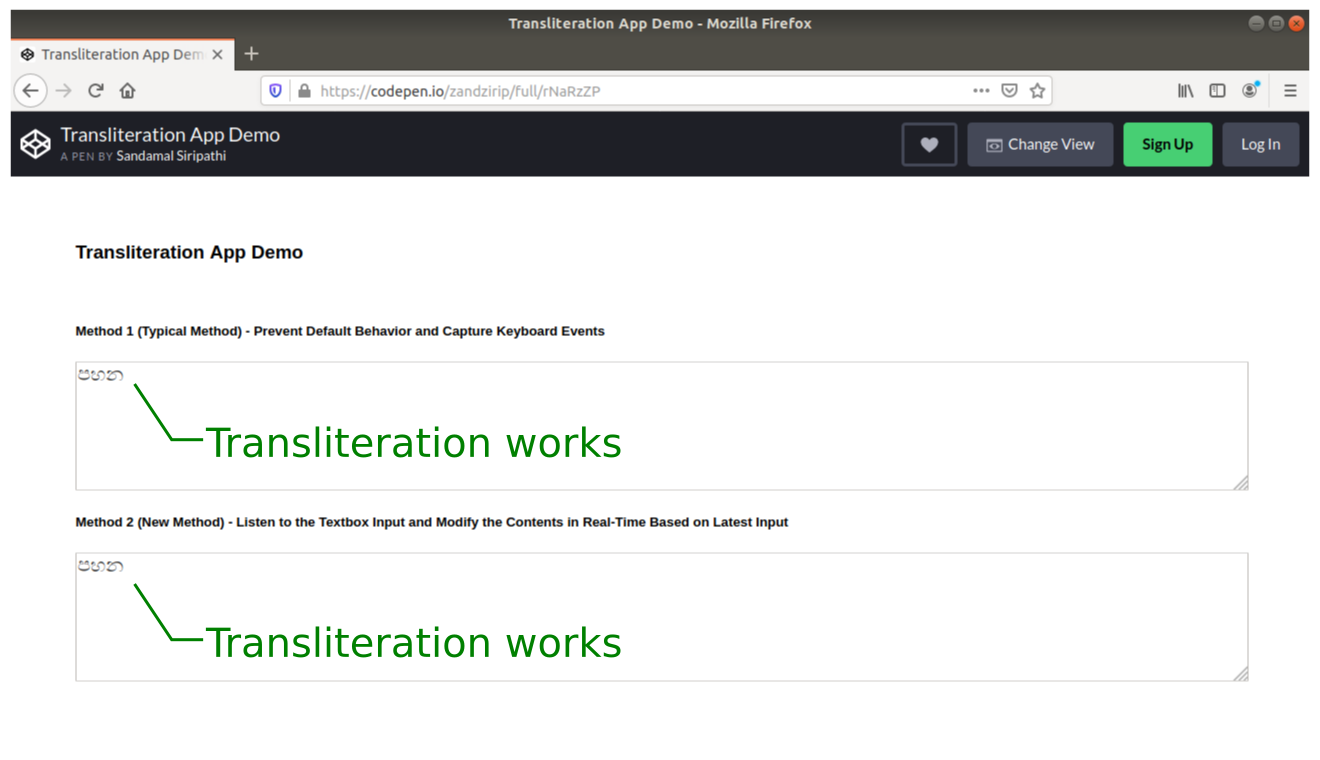
Below you can compare how the two different methods perform on Firefox on a laptop and Chrome mobile browser on an Android mobile device. Unlike Google Input Tools, which uses more than one English character per non-English character, we have already used a one-to-one mapping for simplicity. According to our mapping, “p” equals “?”, “h” equals “?”, and “n” equals “?”. So, just type “phn” to produce the Sinhala word “???”.
Only Method 2 (that’s our new method) can handle both laptop and Chrome mobile browser without any problem. Method 1 (the typical method) fails when it comes to the Chrome mobile browser.
The Firefox browser on Ubuntu desktop PC : Both Method 1 and Method 2 can correctly handle transliteration. (Large preview)
Chrome browser on Android: Method 1 fails to handle transliteration correctly while Method 2 is capable of handling transliteration correctly. (Large preview)
You can also visit my CodePen and verify by yourself.
Fix Another Minor Issue
If you experience some unexpected results when you type using transliteration on your Android mobile, that’s because you have enabled text prediction on your mobile’s soft keyboard. Just disable text prediction, auto suggestions plus auto-capitalization and it should work like magic.
However, SwiftKey (pre-installed on most Huawei phones) doesn’t allow the word prediction to be disabled. So, installing an alternative such as a Gboard keyboard will fix that problem. Disable text prediction plus auto-suggestions and start typing.
This following CodePen example provides you with the complete source code:
See the Pen [Transliteration App Demo](https://codepen.io/smashingmag/pen/eYNGzqW]) by Sandamal Siripathi.
To demonstrate Method 1 and Method 2, I created two text areas named textarea1 and textarea2 in a normal HTML file. Then I added some CSS styling to make them look nice on the web page. Using two JavaScript scripts to change the contents of those two textboxes, I was able to implement the two methods, which I wanted to experiment with.
For Method 1
I devised a method to capture the keydown event and call a function named “whichKey” when the keydown event fires. JavaScript onkeydown event fires whenever a user presses a key on the keyboard. I used that to capture the keyboard event.
Function whichKey handles the core job of preventing default behavior when a key is pressed. It then calls another function named “typeIt1”, which is responsible for typing the actual non-English (Sinhala) characters according to the mapping of our choice. Whenever a key is pressed on the keyboard, the function whichKey passes that pressed key to the function typeIt1, which in turn types the relevant Sinhala character in the text box.
You can refer to the well-commented example on CodePen and see for yourself how that has been achieved:
See the Pen [Transliteration App Demo](https://codepen.io/smashingmag/pen/rNVGMNw]) by Sandamal Siripathi.
Since the bug on Chrome browser on Android, fails to perform the transliteration correctly, it still displays the English characters instead of converting them to Sinhala characters. Yet, it works fine on a desktop browser. So, I suspected the bug was caused by not correctly capturing the keyboard events on the Chrome browser running on Android.
Since fixing the browser bug was clearly beyond my capabilities, I decided to go for a clever trick. What if I could avoid the bug, rather than trying to fix it? With a little more innovative thinking, I was able to come up with a solution.
I switched to a completely new method that doesn’t rely on keyboard event capturing. My idea was to keep track of the changes in the contents of the textbox. When a key is pressed, the contents of this textbox will naturally change. Based on that change, it’s always possible to introduce another change, using JavaScript.
For example, start with an empty textbox. Now, suppose the key “p” was pressed. Then the textbox’s contents will change from blank to “p”. The script running in the background will detect this change and replace “p” with a non-English character of my choice. This choice could be based on some predetermined mapping between English characters on the keyboard and non-English characters of the language, in which we want to type.
To demonstrate this, I added an oninput event to textarea2. I specifically selected oninput instead of onchange, because the latter updates the contents only after the textbox loses focus, while the former updates it immediately on pressing the keys. When the oninput event fires, it will call a function named “typeIt2”, which handles the process of replacing the typed English character with the relevant non-English character.
Again, there’s another example on CodePen that describes all of the necessary information you need to understand how this has been implemented.
See the Pen [Transliteration App Demo](https://codepen.io/smashingmag/pen/rNVGMaz]) by Sandamal Siripathi.
It’s obvious that our new method can successfully avoid the transliteration-related problem on the Chrome browser running on Android. Although we used a one-to-one mapping between English and non-English characters for the sake of simplicity, such a simple mapping might not be always possible. Most of these languages — especially the Asian ones — are full of very complex features and may require more advanced mappings. Sinhala language, for example, has independent vowels, consonants, dependent vowel signs, additional dependent vowel signs, punctuation and various other signs.
Note: For more details about Sinhala Unicode code charts, you can visit the relevant page on The Unicode Consortium. If you are thinking of developing text input apps for non-English languages, I recommend you visit The Unicode Consortium and improve your knowledge about Unicode before actually starting your project. It provides you with full coverage of the subject including the basics, best practices, and in-depth technical details.
If you ever wanted to develop an alternative to Google Input Tools, now you are in a better position to do that.
Whenever a company posts a job opening for a web design employee or freelancer, they typically include a set of hard and soft skills they’re looking for.
Hard skills are design skills that are measurable and well-documented. For instance:
A degree in a web design-related field;
Aptitude with Sketch or Photoshop;
Training in color theory and responsive design.
Your portfolio and résumé serve as proof of hard skills.
Soft skills, on the other hand, are non-design skills that make you a good person to work with, but aren’t as easy to verify. While an employer might list out the qualities they’re looking for, they’re often subjective or vague, like:
Meets deadlines;
Team player;
Goal-driven.
It’s easy to dismiss these kinds of soft skills because they seem arbitrary. Of course I have them, you think.
The truth is, real soft skills not only help you stand out from other web designers, but they affect how successful you’ll be in running your own business.
Let’s take a look at what the most important of these non-design skills are and how they’ll help you go farther in your career.
1. Sales
these kinds of sales skills allow you to build stronger relationships with prospects
It’s easy to equate sales with associates who approach you in stores asking if you need help, or with reps who call you to see how you’re feeling about the free trial of their product. The problem with that particular sales approach is that it often makes one product seem just as good as another: Oh, you didn’t like that style? Let me see if I can get you another.
For you, this isn’t about negotiation or compromise nor can it be a numbers game. When selling yourself as a web designer, what you really need to be skilled in is the following:
Knowing your niche so well that it’s easy to find your target clients;
Knowing what exactly their pain is so you can quickly get the conversation started;
Knowing how to position yourself before them as the solution.
For web designers, these kinds of sales skills allow you to build stronger relationships with prospects so they easily and inevitably become your clients.
That said, one of the sales skills you can borrow from professional sales people is the ability to let rejection roll right off your back. In other words, it’s going to be tough — especially early on — when prospects say, “no, thank you”. It’s natural to want to take it personally. Just keep in mind that once you perfect the right sales approach for your business, this’ll be something you have to deal with less and less.
2. Finance Management
You might be thinking that you’ll just offload your finances to software like QuickBooks or Xero or you’ll hire an accountant once you’re making enough money. But finance management skills go beyond being able to balance your profits and overhead costs.
There are a number of things you need to be able to do properly manage your cash flow. For example:
Research industry rates so you can set competitive prices. Then, be able to negotiate for higher rates with clients.
Confidently talk to prospects about your prices and convey the value of your services in a way that none of it is called into question.
Create business proposals and contracts containing critical details about your prices, fees, payment schedules, etc.
Be able to confront a client who hasn’t paid on time, assess late fees, and take action to track down non-paying clients.
Set and stick to budgets for your business and personal life so you don’t go crazy buying things you don’t need or spending money you don’t have yet.
Master these skills and profitability will never be an issue for you.
3. Project Management
Things are going to get very hectic for you the more clients you add to your roster and the more services you offer.
The easiest way to keep everything in order when you’re bootstrapping your business (i.e. doing it on your own) is to get really good at project and time management.
Here are some things you’ll need to be able to do to dominate this non-design skill:
Create processes — for yourself as well as your client projects;
Document your processes and keep them organized;
Use the right tools and resources to streamline it all;
Predict accurate timelines, set milestones, and deliver by them;
Monitor your time and stay focused.
What’s nice about this skill is that you can use a project management tool and templates to automate a lot of it. The only thing is, you have to first lay the groundwork with a solid process and system of your own.
4. Client Communication and Management
If you start your client relationships off on the right foot during the sale process, this skill will be an easy one to get the hang of since you’ll be working with the ideal client. Even if that isn’t always the case, you can still effectively navigate the sometimes rocky terrain of client relationships, it’ll just require extra patience.
Underpinning all of these skills is confidence
As for how you master client communication and management skills, keep the following in mind:
Take charge from the very get-go. You want to be able to earn their trust, command respect, and keep doubts from appearing at any point. This’ll keep your job free of scope creep, too.
Set boundaries. Let clients know what they can expect from you and when, but never let them overstep their bounds in terms of the limits you’ve set.
Speak their language. Clients don’t understand things like “CSS grid” or “responsive design”. Talk to them with words that make sense.
Be professional in every exchange. There’s no need to let your personal drama become a distraction nor should clients ever know about trouble brewing on other jobs. Stay on point.
Keep calm even when the client isn’t. If that means sitting on a nasty email for a few hours, so be it. It’s best to enter every conversation with a clear head.
Know when it’s time to listen and also be okay accepting fair criticism or feedback.
Underpinning all of these skills is confidence; confidence in what you do and confidence in being able to steer clients and projects in the direction they need to go.
5. Problem-Solving
As a web designer, you’re in the business of solving a very big problem: I need a website for my business, but don’t have the ability or time to do it myself.
That alone is a powerful skill, but we’re focusing on the non-design skills you need right now. So, think of other ways you will need to solve problems for your clients along the way.
For example, during the initial discovery call stage, your client might have a very specific problem like: I need an ecommerce website with 24/7 chatbot support.
you need to be able to think quickly and creatively on your feet
Would you know how to devise a solution for that request on the spot? If not, would you know exactly where to go to figure out how to do it? What’s more, would you be okay telling your client that you’re unsure right now, but promise to get an answer to them in the next day or two?
In other words, you need to be able to think quickly and creatively on your feet.
What about issues or requests that come up later? For instance: The button on the homepage doesn’t work anymore. Help!
Are you resourceful enough to be able to investigate the issue and fix it? If you’re really good at this particular skill, you could monetize it by offering website maintenance services. You’d need to pair vigilance and resourcefulness to make the most of it, but it’s totally possible to do if you’re a problem-solver by nature.
Start Mastering These Non-Design Skills Today
It’s not just your aptitude in web design that’s going to help you land new client after new client. If you want a steady influx of new clients willing to pay you top dollar to design their websites, then you’re going to have to flex these important non-design skills as well.
The first rule of animating on the web: don’t animate width and height. It forces the browser to recalculate a bunch of stuff and it’s slow (or “expensive” as they say). If you can get away with it, animating any transform property is faster (and “cheaper”).
Butttt, transform can be tricky. Check out how complex this menu open/close animation becomes in order to make it really performant. Rik Schennink blogs about another tricky situation: border-radius. When you animate the scale of an element in one direction, you get a squishy effect where the corners don’t maintain their nice radius. The solution? 9-slice scaling:
This method allows you to scale the element and stretch image 2, 4, 6, and 8, while linking 1, 3, 7, and 9 to their respective corners using absolute positioning. This results in corners that aren’t stretched when scaled.
More than ever, new products aim to make an impact on a global scale, and user experience is rapidly becoming the determining factor for whether they are successful or not. These properties of your application can significantly influence the user experience:
Performance & low latency
The application does what you expect
Security
Features and UI
Let’s begin our quest toward the perfect user experience!
1) Performance & Low Latency
Others have said it before; performance is user experience (1, 2). When you have caught the attention of potential visitors, a slight increase in latency can make you lose that attention again.
2) The application does what you expect
What does ‘does what you expect’ even mean? It means that if I change my name in my application to ‘Robert’ and reload the application, my name will be Robert and not Brecht. It seems important that an application delivers these guarantees, right?
Whether the application can deliver on these guarantees depends on the database. When pursuing low latency and performance, we end up in the realm of distributed databases where only a few of the more recent databases deliver these guarantees. In the realm of distributed databases, there might be dragons, unless we choose a strongly (vs. eventually) consistent database. In this series, we’ll go into detail on what this means, which databases provide this feature called strong consistency, and how it can help you build awesomely fast apps with minimal effort.
3) Security
Security does not always seem to impact user experience at first. However, as soon as users notice security flaws, relationships can be damaged beyond repair.
4) Features and UI
Impressive features and great UI have a great impact on the conscious and unconscious mind. Often, people only desire a specific product after they have experienced how it looks and feels.
If a database saves time in setup and configuration, then the rest of our efforts can be focused on delivering impressive features and a great UI. There is good news for you; nowadays, there are databases that deliver on all of the above, do not require configuration or server provisioning, and provide easy to use APIs such as GraphQL out-of-the-box.
What is so different about this new breed of databases? Let’s take a step back and show how the constant search for lower latency and better UX, in combination with advances in database research, eventually led to a new breed of databases that are the ideal building blocks for modern applications.
The Quest for distribution
I. Content delivery networks
As we mentioned before, performance has a significant impact on UX. There are several ways to improve latency, where the most obvious is to optimize your application code. Once your application code is quite optimal, network latency and write/read performance of the database often remain the bottleneck. To achieve our low latency requirement, we need to make sure that our data is as close to the client as possible by distributing the data globally. We can deliver the second requirement (write/read performance) by making multiple machines work together, or in other words, replicating data.
Distribution leads to better performance and consequently to good user experience. We’ve already seen extensive use of a distribution solution that speeds up the delivery of static data; it’s called a Content Delivery Network (CDN). CDNs are highly valued by the Jamstack community to reduce the latency of their applications. They typically use frameworks and tools such as Next.js/Now, Gatsby, and Netlify to preassemble front end React/Angular/Vue code into static websites so that they can serve them from a CDN.
Unfortunately, CDNs aren’t sufficient for every use case, because we can’t rely on statically generated HTML pages for all applications. There are many types of highly dynamic applications where you can’t statically generate everything. For example:
Applications that require real-time updates for instantaneous communication between users (e.g., chat applications, collaborative drawing or writing, games).
Applications that present data in many different forms by filtering, aggregating, sorting, and otherwise manipulating data in so many ways that you can’t generate everything in advance.
II. Distributed databases
In general, a highly dynamic application will require a distributed database to improve performance. Just like a CDN, a distributed database also aims to become a global network instead of a single node. In essence, we want to go from a scenario with a single database node…
…to a scenario where the database becomes a network. When a user connects from a specific continent, he will automatically be redirected to the closest database. This results in lower latencies and happier end users.
If databases were employees waiting by a phone, the database employee would inform you that there is an employee closer by, and forward the call. Luckily, distributed databases automatically route us to the closest database employee, so we never have to bother the database employee on the other continent.
Distributed databases are multi-region, and you always get redirected to the closest node.
Besides latency, distributed databases also provide a second and a third advantage. The second is redundancy, which means that if one of the database locations in the network were completely obliterated by a Godzilla attack, your data would not be lost since other nodes still have duplicates of your data.
Distributed databases provide redundancy which can save your application when things go wrong. Distributed databases divide the load by scaling up automatically when the workload increases.
Last but not least, the third advantage of using a distributed database is scaling. A database that runs on one server can quickly become the bottleneck of your application. In contrast, distributed databases replicate data over multiple servers and can scale up and down automatically according to the demands of the applications. In some advanced distributed databases, this aspect is completely taken care of for you. These databases are known as “serverless”, meaning you don’t even have to configure when the database should scale up and down, and you only pay for the usage of your application, nothing more.
Distributing dynamic data brings us to the realm of distributed databases. As mentioned before, there might be dragons. In contrast to CDNs, the data is highly dynamic; the data can change rapidly and can be filtered and sorted, which brings additional complexities. The database world examined different approaches to achieve this. Early approaches had to make sacrifices to achieve the desired performance and scalability. Let’s see how the quest for distribution evolved.
Traditional databases’ approach to distribution
One logical choice was to build upon traditional databases (MySQL, PostgreSQL, SQL Server) since so much effort has already been invested in them. However, traditional databases were not built to be distributed and therefore took a rather simple approach to distribution. The typical approach to scale reads was to use read replicas. A read replica is just a copy of your data from which you can read but not write. Such a copy (or replica) offloads queries from the node that contains the original data. This mechanism is very simple in that the data is incrementally copied over to the replicas as it comes in.
Due to this relatively simple approach, a replica’s data is always older than the original data. If you read the data from a replica node at a specific point in time, you might get an older value than if you read from the primary node. This is called a “stale read”. Programmers using traditional databases have to be aware of this possibility and program with this limitation in mind. Remember the example we gave at the beginning where we write a value and reread it? When working with traditional database replicas, you can’t expect to read what you write.
You could improve the user experience slightly by optimistically applying the results of writes on the front end before all replicas are aware of the writes. However, a reload of the webpage might return the UI to a previous state if the update did not reach the replica yet. The user would then think that his changes were never saved.
The first generation of distributed databases
In the replication approach of traditional databases, the obvious bottleneck is that writes all go to the same node. The machine can be scaled up, but will inevitably bump into a ceiling. As your app gains popularity and writes increase, the database will no longer be fast enough to accept new data. To scale horizontally for both reads and writes, distributed databases were invented. A distributed database also holds multiple copies of the data, but you can write to each of these copies. Since you update data via each node, all nodes have to communicate with each other and inform others about new data. In other words, it is no longer a one-way direction such as in the traditional system.
However, these kinds of databases can still suffer from the aforementioned stale reads and introduce many other potential issues related to writes. Whether they suffer from these issues depends on what decision they took in terms of availability and consistency.
This first generation of distributed databases was often called the “NoSQL movement”, a name influenced by databases such as MongoDB and Neo4j, which also provided alternative languages to SQL and different modeling strategies (documents or graphs instead of tables). NoSQL databases often did not have typical traditional database features such as constraints and joins. As time passed, this name appeared to be a terrible name since many databases that were considered NoSQL did provide a form of SQL. Multiple interpretations arose that claimed that NoSQL databases:
do not provide SQL as a query language.
do not only provide SQL (NoSQL = Not Only SQL)
do not provide typical traditional features such as joins, constraints, ACID guarantees.
model their data differently (graph, document, or temporal model)
Some of the newer databases that were non-relational yet offered SQL were then called “NewSQL” to avoid confusion.
Wrong interpretations of the CAP theorem
The first generation of databases was strongly inspired by the CAP theorem, which dictates that you can’t have both Consistency and Availability during a network Partition. A network partition is essentially when something happens so that two nodes can no longer talk to each other about new data, and can arise for many reasons (e.g., apparently sharks sometimes munch on Google’s cables). Consistency means that the data in your database is always correct, but not necessarily available to your application. Availability means that your database is always online and that your application is always able to access that data, but does not guarantee that the data is correct or the same in multiple nodes. We generally speak of high availability since there is no such thing as 100% availability. Availability is mentioned in digits of 9 (e.g. 99.9999% availability) since there is always a possibility that a series of events cause downtime.
Visualization of the CAP theorem, a balance between consistency and availability in the event of a network partition. We generally speak of high availability since there is no such thing as 100% availability.
But what happens if there is no network partition? Database vendors took the CAP theorem a bit too generally and either chose to accept potential data loss or to be available, whether there is a network partition or not. While the CAP theorem was a good start, it did not emphasize that it is possible to be highly available and consistent when there is no network partition. Most of the time, there are no network partitions, so it made sense to describe this case by expanding the CAP theorem into the PACELC theorem. The key difference is the three last letters (ELC) which stand for Else Latency Consistency. This theorem dictates that if there is no network partition, the database has to balance Latency and Consistency.
According to the PACELC theorem, increased consistency results in higher latencies (during normal operation).
In simple terms: when there is no network partition, latency goes up when the consistency guarantees go up. However, we’ll see that reality is still even more subtle than this.
How is this related to User Experience?
Let’s look at an example of how giving up consistency can impact user experience. Consider an application that provides you with a friendly interface to compose teams of people; you drag and drop people into different teams.
Once you drag a person into a team, an update is triggered to update that team. If the database does not guarantee that your application can read the result of this update immediately, then the UI has to apply those changes optimistically. In that case, bad things can happen:
The user refreshes the page and does not see his update anymore and thinks that his update is gone. When he refreshes again, it is suddenly back.
The database did not store the update successfully due to a conflict with another update. In this case, the update might be canceled, and the user will never know. He might only notice that his changes are gone the next time he reloads.
This trade-off between consistency and latency has sparked many heated discussions between front-end and back-end developers. The first group wanted a great UX where users receive feedback when they perform actions and can be 100% sure that once they receive this feedback and respond to it, the results of their actions are consistently saved. The second group wanted to build a scalable and performant back end and saw no other way than to sacrifice the aforementioned UX requirements to deliver that.
Both groups had valid points, but there was no golden bullet to satisfy both. When the transactions increased and the database became the bottleneck, their only option was to go for either traditional database replication or a distributed database that sacrificed strong consistency for something called “eventual consistency”. In eventual consistency, an update to the database will eventually be applied on all machines, but there is no guarantee that the next transaction will be able to read the updated value. In other words, if I update my name to “Robert”, there is no guarantee that I will actually receive “Robert” if I query my name immediately after the update.
Consistency Tax
To deal with eventual consistency, developers need to be aware of the limitations of such a database and do a lot of extra work. Programmers often resort to user experience hacks to hide the database limitations, and back ends have to write lots of additional layers of code to accommodate for various failure scenarios. Finding and building creative solutions around these limitations has profoundly impacted the way both front- and back-end developers have done their jobs, significantly increasing technical complexity while still not delivering an ideal user experience.
We can think of this extra work required to ensure data correctness as a “tax” an application developer must pay to deliver good user experiences. That is the tax of using a software system that doesn’t offer consistency guarantees that hold up in todays webscale concurrent environments. We call this the Consistency Tax.
Thankfully, a new generation of databases has evolved that does not require you to pay the Consistency Tax and can scale without sacrificing consistency!
The second generation of distributed databases
A second generation of distributed databases has emerged to provide strong (rather than eventual) consistency. These databases scale well, won’t lose data, and won’t return stale data. In other words, they do what you expect, and it’s no longer required to learn about the limitations or pay the Consistency Tax. If you update a value, the next time you read that value, it always reflects the updated value, and different updates are applied in the same temporal order as they were written. FaunaDB, Spanner, and FoundationDB are the only databases at the time of writing that offer strong consistency without limitations (also called Strict serializability).
The PACELC theorem revisited
The second generation of distributed databases has achieved something that was previously considered impossible; they favor consistency and still deliver low latencies. This became possible due to intelligent synchronization mechanisms such as Calvin, Spanner, and Percolator, which we will discuss in detail in article 4 of this series. While older databases still struggle to deliver high consistency guarantees at lower latencies, databases built on these new intelligent algorithms suffer no such limitations.
Database designs influence the attainable latency at high consistency greatly.
Since these new algorithms allow databases to provide both strong consistency and low latencies, there is usually no good reason to give up consistency (at least in the absence of a network partition). The only time you would do this is if extremely low write latency is the only thing that truly matters, and you are willing to lose data to achieve it.
intelligent algorithms result in strong consistency and relatively low latencies
Are these databases still NoSQL?
It’s no longer trivial to categorize this new generation of distributed databases. Many efforts are still made (1, 2) to explain what NoSQL means, but none of them still make perfect sense since NoSQL and SQL databases are growing towards each other. New distributed databases borrow from different data models (Document, Graph, Relational, Temporal), and some of them provide ACID guarantees or even support SQL. They still have one thing in common with NoSQL: they are built to solve the limitations of traditional databases. One word will never be able to describe how a database behaves. In the future, it would make more sense to describe distributed databases by answering these questions:
Is it strongly consistent?
Does the distribution rely on read-replicas, or is it truly distributed?
What data models does it borrow from?
How expressive is the query language, and what are its limitations?
Conclusion
We explained how applications can now benefit from a new generation of globally distributed databases that can serve dynamic data from the closest location in a CDN-like fashion. We briefly went over the history of distributed databases and saw that it was not a smooth ride. Many first-generation databases were developed, and their consistency choices–which were mainly driven by the CAP theorem–required us to write more code while still diminishing the user experience. Only recently has the database community developed algorithms that allow distributed databases to combine low latency with strong consistency. A new era is upon us, a time when we no longer have to make trade-offs between data access and consistency!
At this point, you probably want to see concrete examples of the potential pitfalls of eventually consistent databases. In the next article of this series, we will cover exactly that. Stay tuned for these upcoming articles:
A fascinating new site called The Markup just launched. Tagline: Big Tech Is Watching You. We’re Watching Big Tech. Great work from Upstatement. The content looks amazing, but of course, around here we’re always interested in the design and tech as well. There is loads to adore, from the clean typography, interesting layout, and bold angled hover states on blocks, to the tasteful dots motif.
The footer is clever as well, in how it appears to slide out from underneath the content as you scroll to the bottom of the page. Let’s make it!
Here’s the trick:
The main content area is at least 100vh tall. Most sites are anyway, but just to be safe.
The main content area has a solid background as well, which covers the footer we’re going to hide behind it.
The footer comes after the main content area in the HTML, so to make sure the main content area sits on top, you’ll need a little relative positioning and z-index.
The footer uses sticky positioning to place itself on the bottom.
That last one is the fanciest trick, and it’s actually fancier than The Markup does it. They use position: fixed; on the footer and a magic numbermargin-bottom on the main content to make it work. No magic numbers needed when going sticky.
CodePen Embed Fallback
The fact that that works so easily without magic numbers is pretty rad. Thanks to Stephen Shaw for the sticky trick! My first crack at this used fixed positioning and magic numbers, but it’s so much more usable without that.
Preethi showed us a super similar technique in 2018. The main different here is using a linear gradient on the body’s background, which is a nice workaround if applying a solid color is somehow limiting to the overall design.
You know what the best thing is about building and running automated browser tests is? It means that the site you’re doing it on really matters. It means you’re trying to take care of that site by making sure it doesn’t break, and it’s worth the time to put guards in place against that breakages. That’s awesome. It means you’re on the right track.
My second favorite thing about automated browser tests is just how much coverage you get for such little code. For example, if you write a script that goes to your homepage, clicks a button, and tests if a change happened, that covers a lot of ground. For one, your website works. It doesn’t error out when it loads. The button is there! The JavaScript ran! If that test passes, a lot of stuff went right. If that fails, you’ve just caught a major problem.
So that’s what we’re talking about here:
Selenium is the tool that automates browsers. Go here! Click this!
Jest is the testing framework that developers love. I expect this to be that, was it? Yes? PASS. No? ERROR.
LambdaTest is the cloud cross-browser testing platform you run it all on.
Are you one of those folks who likes the concept of automated testing but might not know where to start? That’s what we’re going to check out in this post. By stitching together a few resources, we can take the heavy lifting out of cross-browser testing and feel more confident that the code we write isn’t breaking other things.
Serenity Selenium now!
If you’re new to Selenium, you’re in for a treat. It’s an open source suite of automated testing tools that can run tests on different browsers and platforms on virtual machines. And when we say it can run tests, we’re talking about running them all in parallel. We’ll get to that.
It’s able to do that thanks to one of its components, Selenium Grid. The grid is a self-hosted tool that creates a network of testing machines. As in, the browsers and operating systems we want to test automatically. All of those machines provide the environments we want to test and they are able to run simultaneously. So cool.
Jest you wait ’til you see this
Where Selenium is boss at running tests, Jest is the testing framework. Jest tops the charts for developer satisfaction, interest, and awareness. It provides a library that helps you run code, pointing out not only where things fall apart, but the coverage of that code as a way of knowing what code impacts what tests. This is an amazing feature. How many times have you made a change to a codebase and been completely unsure what parts will be affected? That’s what Jest provides: confidence.
Jest is jam-packed with a lot of testing power and its straightforward API makes writing unit tests a relative cinch. It comes from the Facebook team, who developed it as a way to test React applications, but it’s capable of testing more than React. It’s for literally any JavaScript, and as we’ll see, browser tests themselves.
So, let’s make Jest part of our testing stack.
Selenium for machines, Jest for testing code
If we combine the superpowers of Selenium with Jest, we get a pretty slick testing environment. Jest runs the unit tests and Selenium provides and automates the grounds for cross-browser testing. It’s really no more than that!
Let’s hit pause on developing our automated testing stack for a moment to grab Selenium and Jest. They’re going to be pre-requisites for us, so we may as well snag them.
Start by creating a new project and cd-ing into it. If you already have a project, you can cd into that instead.
Once we’re in the project folder, let’s make sure we have Node and npm at the ready.
## Run this or download the package yourself at: https://nodejs.org/brew install node
## Then we'll install the latest version of npm
npm install npm@latest -g
Okey-dokey, now let’s install Jest. If you happen to be running a React project that was created with create-react-app, then you’re in luck — Jest is already included, so you’re good to go!
For the rest of us mortals, we’re going back to the command line:
## Yarn is also supported
npm install --save-dev jest
OK, we have the core dependencies we need to get to work, but there is one more thing to consider…
Scalability!
Yep, scale. If you’re running a large, complex site, then it’s not far-fetched to think that you might need to run thousands of tests. And, while Selenium Grid is a fantastic resources, it is hosted on whatever environment you put it on, meaning you may very well outgrow it and need something more robust.
That’s where LambdaTest comes into play. If you haven’t heard of it, LambdaTest is a cloud-based cross-browser testing tool with 2,000+ real browsers for both manual and Selenium automation testing. Not to mention, it plays well with a lot of other services, from communication tools like Slack and Trello to project management tools like Jira and Asana — and GitHub, Bitbucket, and such. It’s extensible like that.
Here’s an important thing to know: Jest doesn’t support running tests in parallel all by itself, which is really needed when you have a lot of tests and you’re running them on multiple browsers. But on LambdaTest, you can be running concurrent sessions, meaning different Jest scripts can be running on different sessions at thesame time. That’s right, it can run multiple tests together, meaning the time to run tests is cut down dramatically compared to running them sequentially.
Integrating LambdaTest Into the Stack
We’ve already installed Jest. Let’s say Selenium is already set up somewhere. The first thing we need to do is sign up for LambdaTest and grab the account credentials. We’ll need to set them up as environment variables in our project.
LambdaTest has a repo that contains a sample of how to set things up from here. You could clone that as a starting point if you’re just interested in testing things out.
Running tests
The LambdaTest docs use this as a sample test script:
The ‘Capabilities’ object look confusing? It’s actually a lot easier to write this sort of thing using the Selenium Desired Capabilities Generator that the LambdaTest team provides. That sample script defines a set of tests that can be run on a cloud machine that have browser configuration Chrome 72 and operating system Windows 10. You can run the script from the command line, like this:
npm test .single.test.js
The sample script also have an example that you can use to run the tests on your local machine like this:
npm test .local.test.js
Great, but what about test results?
Wouldn’t it be great to have a record of all your tests, which ones are running, logs of when they ran, and what their results were? This is where LambdaTest is tough to beat because it has a UI for all of that through their automation dashboard.
The dashboard provides all of those details and more, including analytics that show how many builds ran on a given day, how much time it took to run them, and which ones passed or failed. Pretty nice to have that nearby. LambdaTest even has super handy documentation for the Selenium Automation API that can be used to extract all this test execution data that you can use for any custom reporting framework that you may have.
Test all the things!
That’s the stack: Selenium for virtual machines, Jest for unit tests, and LambdaTest for automation, hosting and reporting. That’s a lot of coverage from only a few moving pieces.
If you’ve ever used online cross-browser tools, it’s kind of like having that… but running on your own local machine. Or a production environment.
LambdaTest is free to try and worth every minute of the trial.
We all love that satisfying feeling you get when 2 objects just fit perfectly together.
If you’re anything like me, I bet you love watching a good satisfying video that occasionally pops up on my Instagram feed, or seeing the most satisfying logo ever.
One sure-fire way to create and design the perfect, aesthetically-pleasing logo is by creating a symmetrical logo.
What is a symmetrical logo?
A symmetrical is a logo that mirrors itself perfectly from the left side to the right side.
There’s a reason why symmetrical logos work so perfectly together, though.
Actually, there are quite a few reasons why symmetrical logos work so well.
The first reason why symmetrical logos work so well is because our brains automatically and subconsciously love to organize and group the things that it sees in order to make sense of it all. A symmetrical logo makes it easier for the brain to digest and process than, perse, a different type of logo.
Secondly, symmetrical logos create a sense of balance. Having a symmetrical design naturally creates a great sense of balance. Now, whether or not your viewers and clients realize that consciously or not, will always be a mystery.
Thirdly, we all know that symmetrical designs and logos are just aesthetically-pleasing as heck. And who doesn’t love some aesthetically pleasing content? I know I do.
Finally, creating and designing a symmetrical logo could be easier for you. First, you just have to create the perfect half-design, duplicate it, and mirror it, and you’re done! Not to say that that ever actually happens though. We all know designers put (or at least, we try to…) our entire hearts and souls into our designs. If we’re passionate about our project, that is.
20 Symmetrical Logos That Will Have You Shook
There are probably loads more famous symmetrical logo designs out there than you ever realized.
Today, we’re going over 20 symmetrical logos that you can be inspired from in order to create your own.
Let’s do this!
1. McDonald’s
You probably weren’t expecting this one to be our first pick, were you?
Mcdonald’s is a prime example of a symmetrical design, but did you ever consciously realize that?
Also, did you know that the color red is scientifically proven to raise your sense of appetite?
McDonald’s surely had a great design and marketing team on their side.
2. Target
Target. Only my favorite retailer of all time. Besides the fact that they literally have everything you could ever want in one place, they have amazing branding and a symmetrical logo. Also, how cute is that iconic dog you see in all their advertisements?
3. Airbnb
Need a place to stay, anywhere, ever? Airbnb has got you covered. Also, just check out that intricate, symmetrical logo design.
4. Mercedes
Next up we have Mercedes. I know, you never thought about putting them into your list of symmetrical designs, but here we are. This gorgeous and simplistic logo will always be iconic.
5. Adidas
6. Starbucks
8. Chanel
9. Volkswagen
10. Honda
11. Xbox
12. Walmart
13. Audi
14. Toyota
15. Mazda
16. Motorola
17. Snapchat
18. Batman
19. Shell
20. Mitsubishi
We hope you enjoyed looking over all these famous symmetrical logos and felt inspired to create your own.