Dune has been growing in popularity in recent years. Therefore, Dune Art is becoming more popular.
Dune is a science-fiction saga, written by Frank Herbert. Dune, the first book, is cited as the best selling science-fiction novel in history. With Dune, Frank Herbert won the 1966 Huge Award, and the Nebula Award for the Best Novel.
It was adapted into a movie in 1984 and into a mini-series in 2000. There also have been different card, board and video games inspired by Dune.
And it seems like this popularity is going to grow. There is a new movie that is being shot by the director Denis Villeneuve, starring famous actors like Javier Bardem and Jason Mamoa, and Charlotte Rampling. The movie is scheduled to be released in IMAX and 3D on December 18, 2020, by Warner. Bros.
So we don’t need to say there have been many artworks created that are inspired by the Dune franchise.
Here are the ones that we like the most in no particular order, now take your spice melange out and enjoy.
Also, in the 1970s, famous cult film director Alejandro Jodorowsky dreamt about creating a 15-hour film adaptation of Dune. It was going to feature the designs of legendary H.R Giger. The film never got made, but we got to see the dune concept art that was created by H.R Giger. You should definitely watch the documentary “Jodorowsky’s Dune”, created by Frank Pavich, which explores the process.
Some commentary from Zack Bloom on the Cloudflare Blog, looking at requests to CDNJS for versions of jQuery.
What we don’t see is a decline in our old versions which come close to the volume of growth of new versions when they’re released. In fact the release of 3.4.1, as popular as it quickly becomes, doesn’t change the trend of old version deprecation at all.
Sorta makes sense. We make CDNJS easy to use at CodePen, where people can quickly search for, find, and add libraries like jQuery to Pens. I very much doubt most users are rushing back to their old Pens to update versions when a new jQuery comes out.
And upgrading versions is hard and scary on large sites. I saw an Instagram from someone at Etsy (the photo is private) commemorating their upcoming upgrade off of jQuery 1.8.2, which is eight years old!
React cares exactly zero about styling. Think of it as generating the barebones HTML. React will put elements on the page, but everything after that is the job of CSS: how they appear, what they look like, how they’re positioned, and how centered or uncentered they are.
“How to center a div in React” is… not a React problem. It’s a CSS problem. You don’t need “react” in your Google query. Once you figure it out, use React to apply the right CSS class name to your components
How do you center a
in WordPress? How do you center a
in Vue? On one hand, they are broken questions. Those technologies don’t have anything to do with centering things. Centering on the web is something CSS does. On the other hand, higher-level tech is sometimes involved. Maybe there is some Gutenberg thing in WordPress that handles centering on this particular site that you should use for editorial consistency. Maybe there is some styling library being used which means you can’t write regular CSS — you have to write the way the library wants you to write it. Complicated, all this “making websites” stuff.
Tartan is a patterned cloth that’s typically associated with Scotland, particularly their fashionable kilts. On tartanify.com, we gathered over 5,000 tartan patterns (as SVG and PNG files), taking care to filter out any that have explicit usage restrictions.
The idea was cooked up by Sylvain Guizard during our summer holidays in Scotland. At the very beginning, we were thinking of building the pattern library manually in some graphics software, like Adobe Illustrator or Sketch. But that was before we discovered that the number of tartan patterns comes in thousands. We felt overwhelmed and gave up… until I found out that tartans have a specific anatomy and are referenced by simple strings composed of the numbers of threads and color codes.
Tartan anatomy and SVG
Tartan is made with alternating bands of colored threads woven at right angles that are parallel to each other. The vertical and horizontal bands follow the same pattern of colors and widths. The rectangular areas where the horizontal and vertical bands cross give the appearance of new colors by blending the original ones. Moreover, tartans are woven with a specific technique called twill, which results in visible diagonal lines. I tried to recreate the technique with SVG rectangles as threads here:
The horizontalStripes group creates a 280×280 square with horizontal stripes. The verticalStripes group creates the same square, but rotated by 90 degrees. Both squares start at (0,0) coordinates. That means the horizontalStripes are completely covered by the verticalStripes; that is, unless we apply a mask on the upper one.
The mask SVG element defines an alpha mask. By default, the coordinate system used for its x, y, width, and height attributes is the objectBoundingBox. Setting width and height to 1 (or 100%) means that the mask covers the verticalStripes resulting in just the white parts within the mask being full visible.
Can we fill our mask with a pattern? Yes, we can! Let’s reflect the tartan weaving technique using a pattern tile, like this:
In the pattern definition we change the patternUnits from the default objectBoundingBox to userSpaceOnUse so that now, width and height are defined in pixels.
I won’t cover how to convert this string representation into the stripes array but, if you are interested, you can find my method in this Gist.
The SvgTile component takes the tartan array as props and returns an SVG structure.
const SvgTile = ({ tartan }) => {
// We need to calculate the starting position of each stripe and the total size of the tile
const cumulativeSizes = tartan
.map(el => el.size)
.reduce(function(r, a) {
if (r.length > 0) a += r[r.length - 1]
r.push(a)
return r
}, [])
// The tile size
const size = cumulativeSizes[cumulativeSizes.length - 1]
return (
<svg
viewBox={`0 0 ${size} ${size}`}
width={size}
height={size}
x="0"
y="0"
xmlns="http://www.w3.org/2000/svg"
>
<SvgDefs />
<g id="horizontalStripes">
{tartan.map((el, index) => {
return (
<rect
fill={el.fill}
width="100%"
height={el.size}
x="0"
y={cumulativeSizes[index - 1] || 0}
/>
)
})}
</g>
<g id="verticalStripes" mask="url(#grating)">
{tartan.map((el, index) => {
return (
<rect
fill={el.fill}
width={el.size}
height="100%"
x={cumulativeSizes[index - 1] || 0}
y="0"
/>
)
})}
</g>
</svg>
)
}
CodePen Embed Fallback
Using a tartan SVG tile as a background image
On tartanify.com, each individual tartan is used as a background image on a full-screen element. This requires some extra manipulation since we don’t have our tartan pattern tile as an SVG image. We’re also unable to use an inline SVG directly in the background-image property.
Fortunately, encoding the SVG as a background image does work:
Let’s now create an SvgBg component. It takes the tartan array as props and returns a full-screen div with the tartan pattern as background.
We need to convert the SvgTile React object into a string. The ReactDOMServer object allows us to render components to static markup. Its method renderToStaticMarkup is available both in the browser and on the Node server. The latter is important since later we will server render the tartan pages with Gatsby.
Our SVG string contains hex color codes starting with the # symbol. At the same time, # starts a fragment identifier in a URL. It means our code will break unless we escape all of those instances. That’s where the built-in JavaScript encodeURIComponent function comes in handy.
The SvgDownloadLink component takes svgData (the already encoded SVG string) and fileName as props and creates an anchor () element. The download attribute prompts the user to save the linked URL instead of navigating to it. When used with a value, it suggests the name of the destination file.
Converting an SVG tartan tile to a high-res PNG image file
What about users that prefer the PNG image format over SVG? Can we provide them with high resolution PNGs?
The PngDownloadLink component, just like SvgDownloadLink, creates an anchor tag and has the tartanData and fileName as props. In this case however, we also need to provide the tartan tile size since we need to set the canvas dimensions.
In the browser, once the component is ready, we draw the SVG tile on a element. We’ll use the canvas toDataUrl() method that returns the image as a data URI. Finally, we set the date URI as the href attribute of our anchor tag.
Notice that we use double dimensions for the canvas and double scale the ctx. This way, we will output a PNG that’s double the size, which is great for high-resolution usage.
For that demo, I could have skipped React’s useEffect hook and the code would worked fine. Nevertheless, our code is executed both on the server and in the browser, thanks to Gatsby. Before we start creating the canvas, we need to be sure that we are in a browser. We should also make sure the anchor element is ”ready” before we modify its attribute.
Making a static website out of CSV with Gatsby
If you haven’t already heard of Gatsby, it’s a free and open source framework that allows you to pull data from almost anywhere and generate static websites that are powered by React.
Tartanify.com is a Gatsby website coded by myself and designed by Sylvain. At the beginning of the project, all we had was a huge CSV file (seriously, 5,495 rows), a method to convert the palette and threadcount strings into the tartan SVG structure, and an objective to give Gatsby a try.
In order to use a CSV file as the data source, we need two Gatsby plugins: gatsby-transformer-csv and gatsby-source-filesystem. Under the hood, the source plugin reads the files in the /src/data folder (which is where we put the tartans.csv file), then the transformer plugin parses the CSV file into JSON arrays.
Now, let’s see what happens in the gatsby-node.js file. The file is run during the site-building process. That’s where we can use two Gatsby Node APIs: createPages and onCreateNode. onCreateNode is called when a new node is created. We will add two additional fields to a tartan node: its unique slug and a unique name. It is necessary since the CSV file contains a number of tartan variants that are stored under the same name.
// gatsby-node.js
// We add slugs here and use this array to check if a slug is already in use
let slugs = []
// Then, if needed, we append a number
let i = 1
exports.onCreateNode = ({ node, actions }) => {
if (node.internal.type === 'TartansCsv') {
// This transforms any string into slug
let slug = slugify(node.Name)
let uniqueName = node.Name
// If the slug is already in use, we will attach a number to it and the uniqueName
if (slugs.indexOf(slug) !== -1) {
slug += `-${i}`
uniqueName += ` ${i}`
i++
} else {
i = 1
}
slugs.push(slug)
// Adding fields to the node happen here
actions.createNodeField({
name: 'slug',
node,
value: slug,
})
actions.createNodeField({
name: 'Unique_Name',
node,
value: uniqueName,
})
}
}
Next, we create pages for each individual tartan. We want to have access to its siblings so that we can navigate easily. We will query the previous and next edges and add the result to the tartan page context.
We decided to index tartans by letters and create paginated letter pages. These pages list tartans with links to their individual pages. We display a maximum of 60 tartans per page, and the number of pages per letter varies. For example, the letter “a” will have have four pages: tartans/a, tartans/a/2, tartans/a/3 and tartans/a/4. The highest number of pages (15) belongs to “m” due to a high number of traditional names starting with “Mac.”
The tartans/a/4 page should point to tartans/b as its next page and tartans/b should point to tartans/a/4 as its previous page.
We will run a for of loop through the letters array ["a", "b", ... , "z"] and query all tartans that start with a given letter. This can be done with filter and regex operator:
The previousLetterLastIndex variable will be updated at the end of each loop and store the number of pages per letter. The /tartans/b page need to know the number of a pages (4) since its previous link should be tartans/a/4.
The paginateNode function returns an array where initial elements are grouped by pageLength.
const paginateNodes = (array, pageLength) => {
const result = Array()
for (let i = 0; i < Math.ceil(array.length / pageLength); i++) {
result.push(array.slice(i * pageLength, (i + 1) * pageLength))
}
return result
}
Now let’s look into the tartan template. Since Gatsby is a React application, we can use the components that we were building in the first part of this article.
The TartansNavigation component adds next-previous navigation between the index pages.
// ./src/components/tartansnavigation.js
import React from "react"
import {Link} from "gatsby"
const letters = "abcdefghijklmnopqrstuvwxyz".split("")
const TartansNavigation = ({
className,
letter,
index,
last,
previousLetterLastIndex,
}) => {
const first = index === 0
const letterIndex = letters.indexOf(letter)
const previousLetter = letterIndex > 0 ? letters[letterIndex - 1] : ""
const nextLetter =
letterIndex < letters.length - 1 ? letters[letterIndex + 1] : ""
let previousUrl = null, nextUrl = null
// Check if previousUrl exists and create it
if (index === 0 && previousLetter) {
// First page of each new letter except "a"
// If the previous letter had more than one page we need to attach the number
const linkFragment =
previousLetterLastIndex === 1 ? "" : `/${previousLetterLastIndex}`
previousUrl = `/tartans/${previousLetter}${linkFragment}`
} else if (index === 1) {
// The second page for a letter
previousUrl = `/tartans/${letter}`
} else if (index > 1) {
// Third and beyond
previousUrl = `/tartans/${letter}/${index}`
}
// Check if `nextUrl` exists and create it
if (last && nextLetter) {
// Last page of any letter except "z"
nextUrl = `/tartans/${nextLetter}`
} else if (!last) {
nextUrl = `/tartans/${letter}/${(index + 2).toString()}`
}
return (
<nav>
{previousUrl && (
<Link to={previousUrl} aria-label="Go to Previous Page" />
)}
{nextUrl && (
<Link to={nextUrl} aria-label="Go to Next Page" />
)}
</nav>
)
}
export default TartansNavigation
Final thoughts
Let’s stop here. I tried to cover all of the key aspects of this project. You can find all the tartanify.com code on GitHub. The structure of this article reflects my personal journey — understanding the specificity of tartans, translating them into SVG, automating the process, generating image versions, and discovering Gatsby to build a user-friendly website. It was maybe not as fun as our Scottish journey itself ?, but I truly enjoyed it. Once again, a side project proved to be the best way to dig into new technology.
Eventually, I settled on a list of questions I would ask myself for each problem as it arose. I found that asking these questions, in order, helped me make the best decision possible:
1) Is this really a problem? 2) Does the problem need to be solved? 3) Does the problem need to be solved now? 4) Does the problem need to be solved by me? 5) Is there a simpler problem I can solve instead?
We’ve talked about what it takes to be a senior developer before, and I’d say this kind of thinking should be on that list as well.
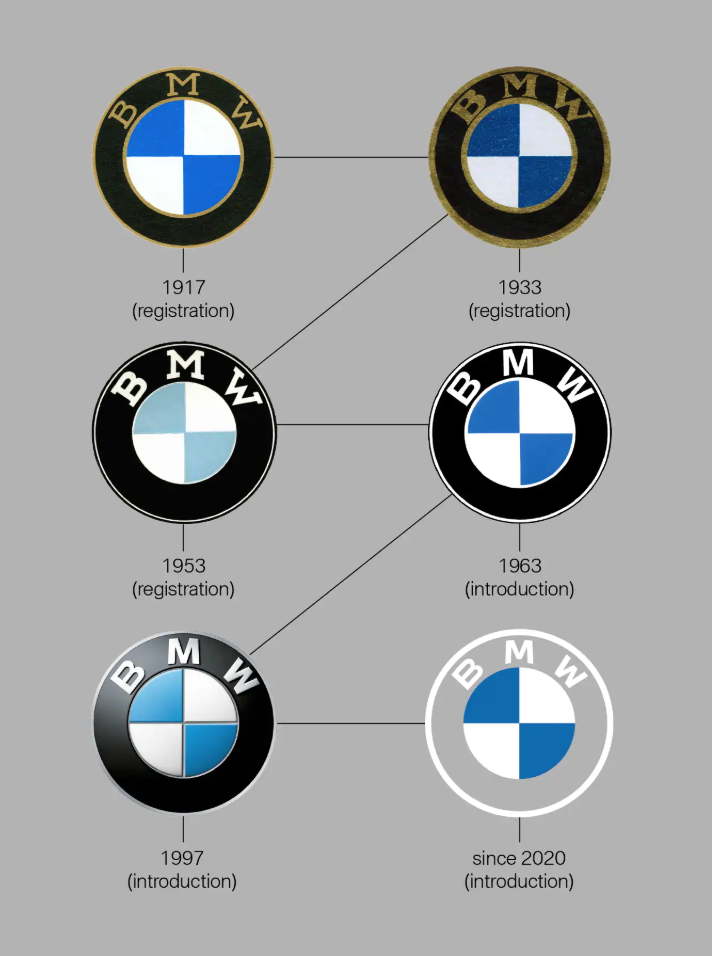
After nearly 100 years, BMW has decided to change up its old logo and give us something new and fresh.
With every new and upcoming generation, BMW loves to switch things up and give us a new logo.
“The new logo and brand design symbolizes the importance and relevance of the brand for mobility and the joy of driving in the future,” Jens Thiemer, Senior Vice President BMW Customer Brand
The logo has seen 6 facelifts in its time, each corresponding to an appropriate design of the era.
The BMW logo that I grew up with (1997-2019) is quite different than the new one of 2020.
To me, it seems BMW really took it back to its roots when they retired their gradients and 3D effects and traded it for a flat design.
The colors are obviously changed from a lighter blue to a dark blue and the font also got the slightest facelift.
The new and improved logo has kept its original shape, but it’s withing the logo that we’re going to see some major differences.
Of course, the bavarian colors of the iconic BMW emblem are still a must and are prevalent in the design.
And the outer ring is now flat, as opposed to what it used to be.
It is with these identity changes and visual changes that BMW wants their clients to view them as more accessible and available to all.
Also, I need to mention that BMW’s subbrands, BMW i and BMW m, will also stand to get new identities.
I personally am a huge fan of the new logo. It’s the perfect combo of modern-yet-vintage-and-a-little-bit-of-luxurious, but we want to know your thoughts on the new BMW logo.
Like most developers, I have a bad tendency to over-complicate my workflow, especially if there’s some new hotness on the horizon. Why use CSS when you can use CSS-in-JS? Why use Grunt when you can use Gulp? Why use Gulp when you can use Webpack? Why use a traditional CMS when you can go headless? Every so often though, the new-hotness makes life simpler.
Recently, the rise of utility based tools like Tailwind CSS have done this for CSS, and now Alpine.js promises something similar for JavaScript.
In this article, we’re going to take a closer look at Alpine.js and how it can replace JQuery or larger JavaScript libraries to build interactive websites. If you regularly build sites that require a sprinkling on Javascript to alter the UI based on some user interaction, then this article is for you.
Throughout the article, I refer to Vue.js, but don’t worry if you have no experience of Vue — that is not required. In fact, part of what makes Alpine.js great is that you barely need to know any JavaScript at all.
Now, let’s get started.
What Is Alpine.js?
According to project author Caleb Porzio:
“Alpine.js offers you the reactive and declarative nature of big frameworks like Vue or React at a much lower cost. You get to keep your DOM, and sprinkle in behavior as you see fit.”
Let’s unpack that a bit.
Let’s consider a basic UI pattern like Tabs. Our ultimate goal is that when a user clicks on a tab, the tab contents displays. If we come from a PHP background, we could easily achieve this server side. But the page refresh on every tab click isn’t very ‘reactive’.
To create a better experience over the years, developers have reached for jQuery and/or Bootstrap. In that situation, we create an event listener on the tab, and when a user clicks, the event fires and we tell the browser what to do.
That works. But this style of coding where we tell the browser exactly what to do (imperative coding) quickly gets us in a mess. Imagine if we wanted to disable the button after it has been clicked, or wanted to change the background color of the page. We’d quickly get into some serious spaghetti code.
Developers have solved this issue by reaching for frameworks like Vue, Angular and React. These frameworks allow us to write cleaner code by utilizing the virtual DOM: a kind of mirror of the UI stored in the browser memory. The result is that when you ‘hide’ a DOM element (like a tab) in one of these frameworks; it doesn’t add a display:none; style attribute, but instead it literally disappears from the ‘real’ DOM.
This allows us to write more declarative code that is cleaner and easier to read. But this is at a cost. Typically, the bundle size of these frameworks is large and for those coming from a jQuery background, the learning curve feels incredibly steep. Especially when all you want to do is toggle tabs! And that is where Alpine.js steps in.
Like Vue and React, Alpine.js allows us to write declarative code but it uses the “real” DOM; amending the contents and attributes of the same nodes that you and I might edit when we crack open a text editor or dev-tools. As a result, you can lose the filesize, wizardry and cognitive-load of larger framework but retain the declarative programming methodology. And you get this with no bundler, no build process and no script tag. Just load 6kb of Alpine.js and you’re away!
Alpine.js
JQuery
Vue.js
React + React DOM
Coding style
Declarative
Imperative
Declarative
Declarative
Requires bundler
No
No
No
Yes
Filesize (GZipped, minified)
6.4kb
30kb
32kb
5kb + 36kb
Dev-Tools
No
No
Yes
Yes
When Should I Reach For Alpine?
For me, Alpine’s strength is in the ease of DOM manipulation. Think of those things you used out of the box with Bootstrap, Alpine.js is great for them. Examples would be:
Showing and hiding DOM nodes under certain conditions,
Binding user input,
Listening for events and altering the UI accordingly,
Appending classes.
You can also use Alpine.js for templating if your data is available in JSON, but let’s save that for another day.
When Should I Look Elsewhere?
If you’re fetching data, or need to carry out additional functions like validation or storing data, you should probably look elsewhere. Larger frameworks also come with dev-tools which can be invaluable when building larger UIs.
From jQuery To Vue To Alpine
Two years ago, Sarah Drasner posted an article on Smashing Magazine, “Replacing jQuery With Vue.js: No Build Step Necessary,” about how Vue could replace jQuery for many projects. That article started me on a journey which led me to use Vue almost every time I build a user interface. Today, we are going to recreate some of her examples with Alpine, which should illustrate its advantages over both jQuery and Vue in certain use cases.
Alpine’s syntax is almost entirely lifted from Vue.js. In total, there are 13 directives. We’ll cover most of them in the following examples.
Getting Started
Like Vue and jQuery, no build process is required. Unlike Vue, Alpine it initializes itself, so there’s no need to create a new instance. Just load Alpine and you’re good to go.
x-model allow us to keep any input element in sync with the values set using x-data. In the following example, we set the name value to an empty string (within the form tag). Using x-model, we bind this value to the input field. By using x-text, we inject the value into the innerText of the paragraph element.
This highlights the key differences with Alpine.js and both jQuery and Vue.js.
Updating the paragraph tag in jQuery would require us to listen for specific events (keyup?), explicitly identify the node we wish to update and the changes we wish to make. Alpine’s syntax on the other hand, just specifies what should happen. This is what is meant by declarative programming.
Updating the paragraph in Vue while simple, would require a new script tag:
new Vue({ el: '#app', data: { name: '' } });
While this might not seem like the end of the world, it highlights the first major gain with Alpine. There is no context-switching. Everything is done right there in the HTML — no need for any additional JavaScript.
Click Events, Boolean Attributes And Toggling Classes
Like with Vue, : serves as a shorthand for x-bind (which binds attributes) and @ is shorthand for x-on (which indicates that Alpine should listen for events).
In the following example, we instantiate a new component using x-data, and set the default value of show to be false. When the button is clicked, we toggle the value of show. When this value is true, we instruct Alpine to append the aria-expanded attribute.
x-bind works differently for classes: we pass in object where the key is the class-name (active in our case) and the value is a boolean expression (show).
This will set a given DOM node to display:none. If you need to remove a DOM element completely, x-if can be used. However, because Alpine.js doesn’t use the Virtual DOM, x-if can only be used on a (tag that wraps the element you wish to hide).
Magic Properties
In addition to the above directives, three Magic Properties provide some additional functionality. All of these will be familiar to anyone working in Vue.js.
$el fetches the root component (the thing with the x-data attribute);
$refs allows you to grab a DOM element;
$nextTick ensures expressions are only executed once Alpine has done its thing;
$event can be used to capture a nature browser event.
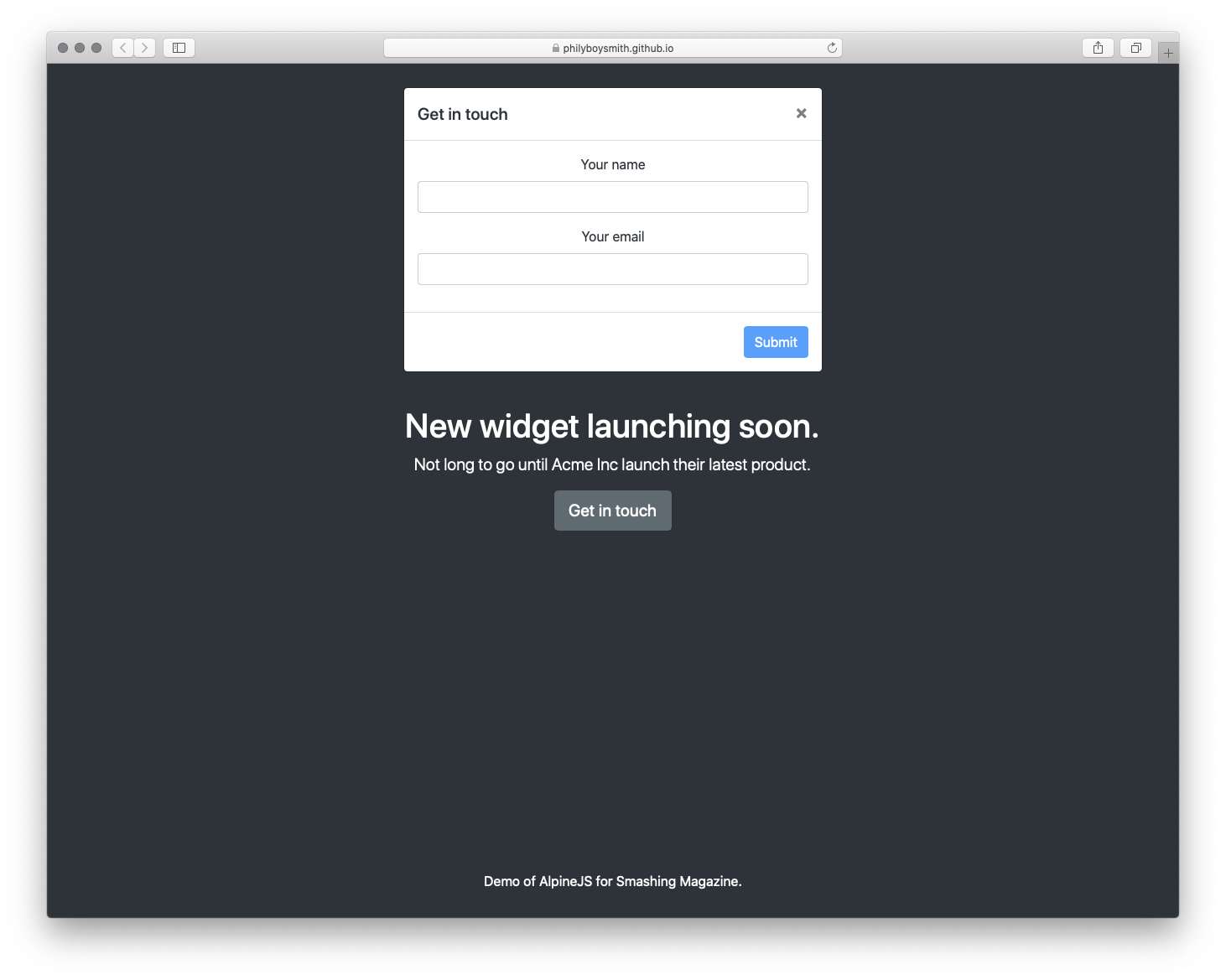
It’s time to build something for the real world. In the interests of brevity I’m going to use Bootstrap for styles, but use Alpine.js for all the JavaScript. The page we’re building is a simple landing page with a contact form displayed inside a modal that submits to some form handler and displays a nice success message. Just the sort of thing a client might ask for and expect pronto!
To make this work, we could add jQuery and Bootstrap.js, but that is quite a bit of overhead for not a lot of functionality. We could probably write it in Vanilla JS, but who wants to do that? Let’s make it work with Alpine.js instead.
When building websites, I’m increasingly trying to ask myself what would be “just enough JavaScript”? When building a sophisticated web application, that might well be React. But when building a marketing site, or something similar, Alpine.js feels like enough. (And even if it’s not, given the similar syntax, switching to Vue.js takes no time at all).
It’s incredibly easy to use (especially if you’ve never used VueJS). It’s tiny (< 6kb gzipped). And it means no more context switching between HTML and JavaScript files.
There are more advanced features that aren’t included in this article and Caleb is constantly adding new features. If you want to find out more, take a look at the official docs on Github.
There has been some discussion recently about whether there should be a CSS4, as in a defined “next version” of CSS. In this article, I take a look at the discussions around this, the pros and cons of creating a feature release for CSS, and the potential problems in deciding what goes into it.
I’m using the term CSS4 as that is how the discussion was started, and not attempting to discuss what the naming should actually be, should this approach be taken forward. Bikeshedding naming is an excellent distraction from the discussion of whether we should do this at all, so I will use CSS4 as a placeholder for the version of CSS we are proposing to define, and CSS5 for the next one along the line.
The Issue
A discussion around whether we should define a CSS4 has been raised in the community, and Jen Simmons then raised a CSS Working Group issue which neatly rounds up some of that existing debate. Outside of the actual issue that we are discussing, it is fantastic to see so many people who are not part of the CSS WG replying on this thread, and I hope that having commented once, people will be happy to come and comment on some of our other issues.
In order to understand why there is no CSS4, we need to look at a little bit of web platform history. The initial versions of CSS were as a single, monolithic specification. These specifications contained every possible CSS property and value. This worked well as there wasn’t a lot of CSS to detail. CSS1 mostly covered features for formatting text documents, additional features and clarifications were added to CSS2 and CSS2.1 however CSS was still a relatively small specification.
CSS3
At the point the CSS Working Group began work on CSS3, it was decided to split the big spec into modules. These modules would each cover part of CSS. Not all of CSS was immediately placed into a new module. Many things remained defined in CSS2.1 as there were no changes or additions to them. For this reason, you will still find links to the CSS2 specification in modern modules, if the thing that is being referenced is still defined in CSS2. However, any new CSS is created in separate modules. This modularization continues today as new CSS is being created. For example, several of the features that make up the Box Alignment specification initially started life in the Flexbox spec. Once it became apparent that they could apply to other layout methods such as Grid Layout, they were moved into a new module to be defined for that other method too.
We stopped referring to new specifications as CSS3 Specifications, partly because it didn’t make a lot of sense. The way that modules are versioned is that the modules which were a progression of CSS2, for example Selectors, became a Level 3 module. Brand new CSS, for example CSS Grid Layout, did not exist at all in CSS2 and so start life as a Level 1 module. Some of those initial modules are now at Level 4 or even Level 5. Therefore, calling all new CSS CSS3 doesn’t map to the level numbers anymore, and is potentially rather confusing.
Specification Maturity Levels
In addition to specification levels, each individual level goes through a staged process from the initial draft to becoming a W3C Recommendation, the steps in the process are referred to as Maturity Levels. A W3C Recommendation is what you might think of as a “web standard”, however many of the things we use daily in our work are defined in specifications that are not at that maturity level yet. You can see the list of specifications and their status on the CSS WG Current Work page.
Explaining The Missing CSS4
Many of us involved with the process saw the confusion about CSS3 or the apparent lack of progress to CSS4 and began to write articles, post videos, and try to help people understand a bit about how the process actually worked. That said, while it was important to share this information so that people teaching CSS would explain it correctly, I am not sure how much this information matters to the average web developer. What level a specification is at, or the internal W3C process of specification maturity, is far less important to a web developer than the issue of what CSS can actually be used in browsers.
Looking through the responses to the issue, and the discussion around the web, there are certainly some potential benefits of having a clear version number for CSS.
As a writer of books and a producer of educational materials, I would probably benefit from CSS version numbers. It’s an excuse to publish an updated book that covers the latest and greatest version of CSS. On the other side of that, it is a way for the purchasers of books and courses to be sure that what they are buying is reasonably up to date – although the publishing date is arguably a better indication of that than anything else.
One thing we did lose by moving away from a version number of all of CSS, was the ability to do something like the Acid Test. The Acid 1 Test tested for support of CSS1, Acid 2 for support of CSS2.1. These tests were reasonably well known and seen as a good benchmark for browser support of web standards. A version 3 test was developed, however, it tested for a range of features and was less tightly tied to the Level 3 CSS Modules than previous tests had been to CSS1 and 2.1. A definite line drawn around a set of features would allow for user agents to declare their level of support for those features.
Some commenters on the issue have mentioned that a version would allow them to push for dropping of older browser versions because they “don’t support CSS4”.
“[…] perhaps CSS4 could help to push their mindset towards a more secure and better web. During pitch meeting, it’s hard to tell them we can’t support IE10 because we want CSS Variables and Grid Layout. Stakeholders do not know and do not care. They just want to support as many browsers as they could (very typical FOMO mindset) and they have the dollars to throw.
However, if we could tell them we can’t support IE10 because it doesn’t have the latest CSS4 technology and throw them the “Are you sure you want your newly created website to be behind your competitors because of that?” question, that might ponder them (of course, on top of the fact that IE10 is completely obsolete and vulnerable).”
There is an argument that defining a version gives developers a clear set of things to learn. In opening the issue on the CSS WG Jen Simmons said,
“I see a lot of resistance to learning the CSS that came after CSS3. People are tired and overwhelmed. They feel like they’ll never learn it all, never catch up, so why try, or why try now? If the CSSWG can draw a line around the never-ending pile of new, and say ‘Here, this. This part is ready. This part is done. This part is what you should take the time to learn. You can do this. It’s not infinite.’ I believe that will help tremendously.”
What Are The Problems Of Versioning CSS?
The first issue is that any collection of “ready for the primetime” CSS, is not as straightforward as selecting a set of specifications. Many specifications are partially implemented, with great support for some properties and none for others. There are features which many web developers would see as mature, sat in specifications still at Working Draft status alongside features which are still being debated and clarified in the Working Group.
If we take Multiple-column Layout as an example. The majority of properties have had widespread browser implementation for many years. However, the column-span property has only recently been implemented in Firefox, and there are a number of features that have recently been clarified, such as column-fill.
We could decide to ignore specifications altogether and look at properties. That isn’t straightforward either due to the fact that we have partial implementations across layout methods. The Box Alignment Properties are an excellent example. These are defined for all layout methods, where the property makes sense in that layout method. However support for Box Alignment is currently only seen in Grid and Flexbox. Therefore is justify-self, which is defined for block-level boxes, absolutely-positioned boxes, and grid items stable? Yes in a Grid context, no in a Block Layout context.
Box Sizing is another area, we have support for the intrinsic sizing valuefit-content() in CSS Grid Layout for track sizing, yet not as a value for width. Then, none of the intrinsic sizing keywords are implemented for flex-basis by browsers other than Firefox.
Finally, if we return to multicol, many of the problems people have with multicol are nothing to do with the properties themselves, but are to do with poor support of fragmentation across browsers. This makes multicol seem to behave badly despite there being excellent support of the various properties. Disentangling all of these dependencies to come up with a set of features is going to be quite a difficult job.
CSS Is Not Just For Web Browsers
As I and one other commenter have mentioned, CSS is not just for web browsers. There are a whole raft of user agents that take CSS and HTML and output printed documents by way of creating a print-ready PDF. They typically have excellent support for the Paged Media specification, fragmentation and so on. However, they often lag behind browsers in terms of implementing newer CSS, for example Grid Layout. How do they fit into CSS4?
People Expect A Feature Release To Include Currently Non-Existent Features
Something interesting that has happened in the discussion on the issue, is that a number of people have commented saying that their expectations of a CSS4 are that it would contain certain features that are not yet part of CSS at all. Joshua Lindquist, in his excellent roundup of the comments notes that,
“When discussing authors that do not keep up with the latest developments, I think this approach will be simple to understand. Everything will feel like it’s brand new to them, even though some of these features, like Grid and Flexbox, have been in browsers for years.
But anyone who does keep up will likely be confused about why there is a ‘new’ specification full of things that are actually old.”
Who Would Decide What Makes The Cut?
Given the fact that the features that would make up CSS4 are not completely straightforward, someone is going to have to make the decision as to what is included.
The CSS Working Group has criteria for stability via the Maturity Levels already discussed. Once a spec has two implementations of each feature it can progress from Candidate Recommendation Status to become a Recommendation. However, as detailed above, it can take some time for that to happen, and while we are waiting for some features in a spec to have implementations, other may have widespread and stable browser support. If we were to say that CSS4 was only those specifications that were at Recommendation Status it would include:
CSS Color Level 3
CSS Namespaces
Selectors Level 3
CSS Level 2 Revision 1
Media Queries
CSS Style Attributes
CSS Fonts Level 3
CSS Writing Modes Level 3
CSS Basic User Interface Level 3
CSS Containment Level 1
So, no Grid, Flexbox, Box Alignment, and many more specifications that most of us are using.
If we are going to define a version of CSS, that is separate to the existing specification levels and maturity that we already have as part of the W3C process, then there needs to be a group with the time and resources to work on this. That group not only needs to define CSS4, but needs to do that as part of developing a framework to make these decisions this time, and for the next n versions of CSS. Otherwise, we will be having this discussion again in another two years, about the fact that no-one has shipped CSS5. I don’t believe the CSS Working Group is the right venue for that, even if only that there is other work that the WG needs to be doing to actually develop and define new CSS. There are already more jobs to be done than we have time to do. In addition, having another consideration when working on specifications will make decisions around each spec harder. Currently, we have situations where parts of a spec are marked as at-risk if their inclusion might prevent the spec from progressing to a Recommendation. It was for this reason that subgrid was bumped to Level 2 of Grid. If we have this additional level of abstraction, which doesn’t really fit into the process, will this just be another thing to consider and thus delay work on specifications?
What Problem Are We Trying To Solve?
In many of the responses to this issue, web developers brought up browser support as being key to what should be included in a CSS4, and I think that the issue we face is less one of CSS versioning and more of web developers being clear as to which collection of features should generally be considered usable in their projects.
“One of the advantages of a CSS4 approach is that it signals two things. First, that there’s a significant bundle of new CSS features that have been developed after CSS3 and which are ready for use and second, that they are ready for use. Not experimental or implemented by Chrome but no one else, but ready for broad adoption.”
The fact that browser support comes up so frequently in this discussion makes me wonder if a better place to be defining this would be somewhere like MDN. MDN is already contributed to by all browser vendors, it already has support data for these features in a way that allows us to see partial implementations of things like Box Alignment. MDN is the documentation for the web platform, so we could sidestep the issue of print implementations, or any other implementations of CSS, scoping the feature set to the web alone.
I remain unconvinced that a CSS4, or whatever we choose to call a version of CSS, will actually make any difference to the perception of CSS outside of a relatively small community. Nor do I think it will help to solve the problems that web developers have in terms of convincing their bosses and clients to upgrade browsers. If Microsoft, who provides the software, is telling companies to upgrade and companies are not upgrading, I fail to see what the carrot of supporting CSS4 will do. And, I’ve been doing this a long time and know that back when we did have versions of CSS, people still didn’t upgrade their browsers. However, I think it will make it easier to talk about a particular chunk of functionality in a less abstract way, but I think that it needs to happen outside of the CSS Working Group and the specification process, and be based on what is usable as opposed to what is well specified.
“However, I must agree with several others that major marketing versions only have meaning in a compatibility situation. If we announce that CSS5 is finally here, it must mean all major browsers have full or near-full support.
Without this compatibility condition met, I think some developers will be cynical, and return to feature or module based thinking, the current status quo.”
I wanted to bring the discussion to Smashing Magazine as I think that many of our readers won’t have noticed this discussion. I’d be interested in what you think. Are there ways in which declaring a version of CSS would help you, that I haven’t mentioned here? Would checking to see what was in this version be something you would do, or would you be more inclined to check Can I Use, or MDN to find out what is supported? Do you think the average web developer cares about this stuff? Let us know in the comments, post to the original issue, or join the new Community Group set up to discuss this.
When the web was young, a 56k connection was fast, CSS was new, and Flash was but a glint in Macromedia’s eye, there was a phrase that graced half of all splash screens: Best viewed in IE6.
You see, back in the early 00s, the web was a lot less competitive. It was perfectly possible to ignore 40% of your users and still turn a profit. In fact, given the expense of maintaining a different codebase for every browser, it was often financially inviable to build for more than a single browser.
front-end code still renders very differently in different browsers
Over the years, the web became far more competitive, and developers serious about building profitable sites looked for ways to code sites for a wider audience; web standards began to emerge.
It’s difficult to envisage how we would have coped with the exponential growth of the mobile web without the backbone of web standards. However, web standards have fed the misconception that browsers display code consistently; The truth is that front-end code still renders very differently in different browsers.
Why Aren’t Browsers Consistent?
Despite near-industry wide commitment to web standards, browsers still render web pages very differently. There are a few reasons for this:
Evolving Web Standards
Releasing a new feature of CSS3, HTML5, and especially ECMAScript takes a long time. From initial proposal to recommendation there are hundreds of revisions and amendments.
The problem is that early-adopters frequently find themselves going to production with an out-dated version of the specification.
Take CSS’s Flexbox, which enjoys excellent support across all major browsers, officially, even IE; Unfortunately Microsoft coded in an older version of the specification and anyone who still needs to support IE will find they need to run backwards compatible code.
Scope for Interpretation
Web standards deliberately leave a lot of scope for interpretation. There are numerous properties that are rendered differently because the specification refers to a default setting, without defining that default.
While is may be frustrating, there’s a solid reason for this flexibility: Compare a select element on macOS’s Safari browser, with the same select on iOS’ Safari browser; Not only is the select styled differently — as it would be on Edge, or Chrome — it’s an entirely different UI element!
Bugs, Legacy Code, and Hacks
Like all coders, the engineers that build browsers aren’t perfect. They work with the same pressures, deadlines, and marketing departments that the rest of us contend with. The result is patchy code that’s often buggy, especially in edge cases.
There’s a classic browser bug that only appears in Chrome: Input fields with placeholder text, rotated 180 degrees on the Y axis, unexpectedly override the backface-visibility property. The reason? Somewhere down the line, someone working on Chrome’s engine (probably in an effort to speed up rendering) chose to toggle visibility instead of detecting the current current state.
Designing for Inconsistency
We’re lucky that the browser wars are far behind us. But for the reasons listed above, developers must embrace the fact that in subtle, but unmistakable ways, browsers are inconsistent.
Naturally, websites don’t need to look the same on every browser and device — one of the reasons that there are multiple browsers is that different users have different preferences — but a site must function, and be familiar (especially across mobile and desktop) however the user chooses to access it.
One way of testing sites is to buy 10–20 computers, and 20–30 mobile devices, install multiple browsers onto each one, and painstakingly test on each one, every time you tweak your code.
The smarter way is to use a cross-browser testing app like Lambdatest.
Designing with Lambdatest
Lambdatest is a SaaS that enables testing on a huge range of devices from the comfort of your development machine. You don’t need any special equipment, just log into the site for a range of different testing options:
Cross Browser Testing
Lambdatest lets you perform live, and interactive testing across over 2000 different browsers installed on numerous devices. These aren’t simulators, they’re real browser instances that you access remotely.
Through an intuitive UI you can navigate through the top browsers on macOS, iOS, Windows, and Android. Compare inconsistencies, and even use the screenshot and video options to record problem areas as buggy.
This manual approach to testing is flexible, and ideal for checking individual components of your build. It’s great for checking that bug-fixes are fully resolved. But for really comprehensive testing a manual test is too labor intensive, for that Lambdatest provides automated testing.
Automated Testing
Where Lambdatest really comes into its own is with automated testing. Automation allows you to test your design against up to 2000+ browser implementations. Simply select your OS and the browsers you want to test on, run the automated screenshot process, and review the results in your dashboard.
For ongoing testing during development you probably only want to compare your target browsers, but for any build milestones it’s worth testing as comprehensively as possible.
Using the restful API you can automate logs, test metadata, and hunt down bugs at world-record pace, saving you time, money, and reputation.
Third-Party Integration
As well as manual testing, and automation, Lambdatest also integrates with a wide range of third-party tools including Jira, GitLab, and Trello. This means you can test your site thoroughly, without ever leaving the safety of your existing workflow.
There are also a Chrome extension, and a WordPress plugin. Both allow you to take a screenshot of your site, on 2000+ browsers, with a single click either in your browser, or in the WordPress admin panel.
Smart Comparison Testing
Perhaps the feature we like the best, is the Smart UI testing feature. What this innovative feature does is automatically detect when something’s gone wrong. It’s great for designers and developers working remotely, who don’t have a colleague’s fresh pair of eyes to borrow to check changes.
Simply pull up one of the screenshots from Lambdatest’s automated testing to use as a baseline, then run the Smart Comparison Testing tool, and it will flag up any notable differences.
It’s a fantastic tool for when you’re rapidly fixing bugs, and need to double-check your fix didn’t break something else. Given that the vast majority of bugs in code are introduced when hacking around browser inconsistencies, it’s always wise to check that the solutions you introduce aren’t bringing with them a host of all-new problems.
Why Choose Lambdatest
The number of different browsers and devices you need to test on, just to cover the more popular brands on the market, is prohibitively expensive for most teams. Not to mention the constant demand to keep updating. Lambdatest eliminates this cost and brings comprehensive testing within reach of every web professional. Without the cross-browser testing that Lambdatest enables, it’s all but impossible to design and build a modern website.
What we love about Lambdatest is that it’s a flexible way to work comprehensive and reliable testing into your existing workflow. There are other apps that allow you to test across different browsers, but they typically force a new way of working on you, Lambdatest doesn’t.
You can try Lambdatest for free by taking advantage of the freemium plan that gives you 6 x 10 minutes of testing, 10 sessions of screenshots, and 10 sessions of responsive tests. Once you’re happy that Lambdatest is right for you and your team, plans start at just $15/month.
[– This is a sponsored post on behalf of Lambdatest –]
MD Anderson failed to encrypt its devices. Three of these devices, a laptop and two thumb drives, were stolen. This seemingly simple breach cost the organization $4.3 million in civil penalties.
Could your practice afford to pay even $50,000 for a single violation? This scenario is more likely than you may realize.
Data privacy is no longer as simple as locking a file cabinet. Technology has made it easier for healthcare data to be stolen, leaked, and misused. This vulnerability is why you and your employees need to understand what HIPAA (the Health Insurance Portability and Accountability Act) is and how you can stay compliant.
Here’s what you need to know to keep patients and your practice safe, including why you need HIPAA-compliant forms.
“HIPAA compliance is a multitiered issue that is made up of three main pillars. These pillars are designed to identify and mitigate risk on an ongoing basis.”
First things first, we need to understand who HIPAA applies to. Put simply, healthcare providers and their partners are bound to HIPAA law, as well as related legislation such as the HITECH Act and the HIPAA Omnibus Rule. The law requires that healthcare providers and their partners take every precaution to keep protected health information (PHI) safe, whether it’s physical or electronic.
Protecting health information wouldn’t be so difficult if healthcare practices could safely collect it, store it, and “throw away the key.” But modern medical, dental, and other healthcare practices don’t have that luxury. After all, protected health information isn’t static. It’s constantly changing.
Staff members frequently retrieve and update protected health information. PHI changes hands between treating physicians, pharmacies, insurance companies, patients, and sometimes a patient’s legal representatives. Office staff also handle printed copies of protected health information.
Every healthcare organization must have clear protocols to keep patient data safe. They also need the necessary technology to comply with HIPAA law and avoid violations.
HIPAA compliance enforcement
As mentioned earlier, HIPAA violations care hefty fines. Who enforces HIPAA? The U.S. Department of Health and Human Services (HHS) has delegated all HIPAA enforcement to their Office for Civil Rights (OCR). With a hefty annual budget of over $32 million, this department gets results. If you’re not complying with HIPAA, they’ll find out and you will face the consequences.
Enforcement by the OCR includes three primary functions:
Investigating complaints filed by individuals
Conducting compliance reviews of those who manage protected health information
Providing education, outreach, and resources on staying compliant
The OCR describes someone who manages protected health information as a “covered entity.” When reading HIPAA laws, you’ll repeatedly see this term. Every mention of a covered entity refers to you and your practice.
An investigation into a covered entity, like your practice, may result in one of three outcomes:
The OCR finds no violations.
The OCR obtains voluntary compliance, corrective action, or other agreement.
The OCR issues a formal finding of violation.
Since the HIPAA Privacy Rule began to be enforced in 2003, the Office for Civil Rights has handled nearly 200,000 complaints with a 96–percent resolution rate. Its success makes the OCR potentially one of the most efficient and effective government entities in the United States.
While government regulations might conjure up dystopian imagery of Big Brother watching over your shoulder, they serve an essential function. In effect, HIPAA enforcement by the Office for Civil Rights has increased the rights of patients in the United States.
What rights does HIPAA grant patients?
You might think that HIPAA is a big list of regulations and fines designed to make your life more difficult. But that’s not HIPAA’s purpose at all. HIPAA is first and foremost designed to protect data and patient rights.
One of these rights is the patient’s right to access their health information. Of course, this means you must have systems in place to verify that the person requesting information is, indeed, the patient or a legal representative.
Patients also have the right to inspect or receive a copy of their medical records. They can request that you send those records to another person. There is no time limit for a patient to request information. As long as you maintain protected health information, which is typically retained for seven years, the patient can request it.
Protected health information goes beyond healthcare basics and includes
Billing information
Claims processing
Enrollment status
Case management, including community services, etc.
Prior authorization documentation
X-rays, lab results, and other test and procedure results
Visit notes
Even a photo of a patient sitting in your waiting room is protected health information because it connects the patient to your practice.
While the covered health information may seem endless, there are some limitations to these requests. For example, HIPAA doesn’t give patients the right to certain types of healthcare data:
Patients can’t request logs of information that may include protected health information but are not part of medical decisions. For example, a person can’t request a log of their calls with a receptionist or customer service department.
Patients don’t have the right to access psychotherapy analysis notes. This exception maintains the integrity of mental health evaluations. However, the patient does have a right to session notes that are kept separately.
Patients don’t have the right to view notes compiled for legal purposes.
To protect themselves, some medical providers try to bar certain individuals from accessing their information. Others make it unnecessarily difficult to do so. But the regulations require that you balance security and accessibility. For example, medical providers can’t impose restrictive policies, such as
Allowing access only through an online portal. Patients without internet service would be unable to gain access.
Requiring everyone to request information in person. Patients who are homebound or live far away would be unable to gain access.
Sending an authorization form by regular mail when there are faster ways of getting permission. Patients may need to wait an unreasonable amount of time to access protected health information.
The rights granted by HIPAA guarantee patients access to their health information. Enforcement by the Office for Civil Rights makes sure that healthcare providers protect their patients’ private data and confidentiality.
What is patient confidentiality, and how does it affect your practice?
The Gale Encyclopedia of Surgery and Medical Tests defines confidentiality as “the right of an individual to have personal, identifiable medical information kept private. Such information should be available only to the physician of record and other health care and insurance personnel as necessary.”
Patients have a right to confidentiality. They rely on you to keep their personal information safe for many reasons. Inappropriate disclosure of protected health information could have negative consequences for your patients.
Public or personal embarrassment Medical information can be embarrassing. From mental health challenges to strange fungi to STDs, many people have information that they don’t want shared with others.
In 2013, a pharmacist at a national pharmacy chain accessed the health records of her husband’s ex-girlfriend, who lived more than 150 miles away. The pharmacist discovered that the ex-girlfriend was taking medication for a sexually transmitted disease. After the pharmacist confronted her husband, he contacted his former girlfriend.
Anyone would feel embarrassed when such private medical information is spread around. Because the patient’s right to confidentiality had been breached, she sued the pharmacy and won.
Job discrimination If employers had access to health information, how would they use it? If they could get this information in a background check, it could influence hiring and firing decisions. This could easily lead to discrimination. Legally, employers can’t ask about pregnancy or health conditions in an interview. Patients are protected because employers can’t access health records.
Family or legal disputes Certain protected health information could affect the outcome of a legal dispute, such as using mental health records in a custody battle.
A nurse at a mid-sized clinic accessed the health information of a driver who was suing her husband for personal injury after a car accident. After viewing the medical records, the nurse gave the information to her husband’s lawyer. She believed the lawyer could use the information to get the lawsuit dropped. However, she violated the driver’s rights.
The nurse now faces up to $250,000 in fines and 10 years in prison for attempting to profit off her access to medical records.
Victim targeting Certain types of patients are especially vulnerable to having their protected health information misused. For example, patients with a diagnosis of early dementia may be targeted by nefarious financial institutions or fraudsters. People who have chronic conditions could become prey to quacks pushing costly fake cures.
One recent scam has seen people using the opioid crisis for personal financial gain. They target individuals addicted to painkillers with expensive cures for opioid addiction. The U.S. Food and Drug Administration is working with the Federal Trade Commission to prevent these individuals from misleading vulnerable consumers and potentially delaying lifesaving addiction treatments.
The threat is very real, and patients deserve to have their health information protected.
Loss of trust One of the most commonly overlooked impacts of breaching HIPAA regulations is loss of trust. New patients may choose to go elsewhere. Existing patients may leave a longtime doctor over safety concerns.
For example, patients may feel violated if staff members discuss patient information while other patients are nearby. If your practice has a data breach, your patients feel less secure.
The issue of trust goes back to the core purpose of HIPAA compliance. HIPAA is about protecting the patient, which isn’t always as straightforward as you might think.
Patient confidentiality laws you need to know about
“HIPAA has helped to streamline administrative healthcare functions, improve efficiency in the healthcare industry, and ensure protected health information is shared securely.”
Directory information rule. If a patient is admitted to a facility or an emergency room, you can relay the patient’s location and general health status to a person who calls and asks about that patient by name. However, it’s unacceptable to share any information with a caller if the patient just has a routine exam.
Treating physician rule. If a person calls your office claiming to be treating your patient, no signed forms are needed. However, you’re only required to share information that you deem relevant to the other physician’s treatment of your patient. That leaves a little bit of a gray area. What exactly is considered relevant is up to your professional judgment.
Social media rule. Many practices are so afraid of HIPAA violations that they overlook how to share health information legally on social media. Using health information, such as real patient experiences, on social media can be a very effective marketing tool for your practice. To use it, you’ll need a signed PHI release form from the patient that includes what information you will use, how you will use it, and for how long.
Business Associate Agreement (BAA) rule. A business associate is any third party that you grant access to protected health information for business purposes. Business associate agreements are legal contracts that define how your business associate maintains HIPAA compliance. If you authorize access to ePHI to anyone outside of your organization, you must have a signed BAA from that person.
Departing doctor rule. Medical professionals who leave a practice may think their patient records go with them. In a multi-physician practice, that’s not always true. Protected health information belongs to the covered entity, the practice. If you choose to transfer the PHI to the departing physician, you’ll need to get a signed records custodian agreement from each patient and a BAA from the departing doctor.
Failure to follow these rules can land your practice in very hot water.
Consider what happened at Michigan State University. Recently, the university faced intense scrutiny and potential fines for not reporting the removal of patient records from a university clinic. Although staff knew the records had been taken, they didn’t notify the patients or get their consent.
Why didn’t they think this was a reportable privacy breach? Because they forgot about the departing doctor rule.
The records were allegedly given to Larry Nassar, who had previously treated all of the patients. As you may recall, Larry Nassar is the physician who was convicted of abusing gymnasts in the USA Gymnastics program while providing them with medical care.
The removal of records without proper authorization was a violation of HIPAA law. If staff had remembered that a departing doctor doesn’t necessarily have a right to patient files, they might have taken the event more seriously.
To report violations promptly, your staff needs to know what actions are considered HIPAA violations.
What actions are considered a HIPAA violation?
What are the most common cases of HIPAA violations that result in penalties? You may be surprised by the answer.
Improper disclosure of protected health information
Delayed breach notification when data breaches occur
Failure to encrypt electronic health information
Failure to obtain a HIPAA-compliant business associate agreement
These violations may seem obvious and easy to avoid, but you may not realize how easy it is to get a BAA-related violation. In fact, many practices don’t realize how many third parties they authorize to access their information just by using a computer in their practice. This includes allowing a computer program, cloud service, or other technology to collect, store, process, analyze, retrieve, or distribute health information.
For example, an orthopedic practice in North Carolina found themselves in the hot seat with the Office for Civil Rights when they hired a vendor to convert their X-rays to digital media. They worked with a reputable company that managed the X-rays in a professional manner. But the practice made one important mistake. They didn’t have the conversion company sign a business associate agreement.
This oversight cost them $750,000 in penalties.
That’s right. Penalties for violating HIPAA law can cost you dearly.
Sanctions of HIPAA violations
If your practice violates HIPAA, you might not only face fines. Certain HIPAA offenses can even lead to time in prison.
Tier 1: $100–$50,000 per violation ($1.5 million per year maximum). You didn’t know that a violation had taken place. Even if you had done your due diligence, you wouldn’t have known. You can’t avoid fines completely, but they could be lower. This tier was added to encourage thorough risk assessment to uncover possible risks.
Tier 2: $1,000–$50,000 per violation ($1.5 million per year maximum). The Office for Civil Rights has reasonable cause to believe that you knew or should have known about the violation if you were doing due diligence.
Tier 3: $10,000–$50,000 per violation ($1.5 million per year maximum). You willfully neglected the rules. Once the violation was discovered in an internal or outside audit, you corrected it within 30 days.
Tier 4: $50,000 per violation ($1.5 million per year maximum). You willfully neglected the rules and made no effort to fix the error within 30 days of finding the violation.
A violation is defined as “a single patient record.” In other words, one very bad mistake could represent hundreds or thousands of violations. Could your practice handle a $50,000 hit? What if 1,000 records were compromised?
Most practices can’t survive these kinds of penalties. That’s why being HIPAA compliant is so important. HIPAA compliance means being proactive so these worst-case scenarios never happen to your practice.
Smaller practices may think they’re virtually invisible compared to huge health systems and will be overlooked. If you think that way, think again. Private practices like yours are the most scrutinized for this very reason. In reality, the OCR often targets small private practices to set an example and show that no one is immune.
A five-physician cardiology group had to pay $100,000 for posting patient appointments on an online booking system that allowed other patients to see the names of patients who had already booked appointments.
A physical therapy provider was charged with failing to reasonably safeguard PHI and impermissibly disclosing PHI without authorization. The provider agreed to a settlement payment of $25,000.
How many records have you turned over to Microsoft, Google, or an even less well-known company without a BAA? Taking a serious look at this could help you uncover and mitigate your risk.
Criminal penalties
The person who directly commits a violation can be held criminally liable under HIPAA rules. Criminal penalties are typically reserved for people who knowingly, and possibly defiantly, commit or attempt to cover up HIPAA violations.
If a person defies HIPAA in order to harm others, make a profit, or obstruct justice, they can expect the long arm of the law to come down hard on them. If someone collaborated with another person to cover up HIPAA violations, they could be charged with aiding and abetting or with conspiracy. In these cases, the Office for Civil Rights turns you over to the Department of Justice for a federal investigation.
That’s serious business.
A conviction would completely destroy your chances of ever working in the medical field again in any capacity. It could even hinder you from getting any form of employment where integrity is important.
Like civil penalties, criminal penalties are also divided into tiers:
The lowest criminal penalty is up to $50,000 and up to a year in prison.
You could face $100,000 and up to 5 years in prison if you conspired to break HIPAA law by lying about your right to access the information.
The criminal penalty goes up to $250,000 and up to 10 years if you access protected health information with the intention to influence a court case, sell it on the black market, or ruin a person’s life by sharing it on social media.
In addition to criminal penalties, any victims may be able to sue you directly for damages.
Think doing hard time is excessive for a HIPAA violation? Consider some notable violations that earned individuals time in prison.
Revenge, interrupted
In 2010, the first-ever prosecution for a HIPAA violation happened after a 2003 incident. A researcher fired from UCLA Medical Center wanted to get back at his former employers. He took advantage of his access to medical records to view information about managerial staff, likely searching for embarrassing medical information.
He also accessed the records of numerous celebrities, including Drew Barrymore, Leonardo DiCaprio, and Tom Hanks. He may have hoped to profit from selling something to the tabloids. Because the system was monitored, the breach was identified before any harm could be done.
He got four months and was fined $2,000. If he had shared any of that information, the penalty would have been much higher.
Almost rich
A 30-year-old man was sentenced to 18 months in prison for collecting protected health information at the Texas hospital where he worked. He intended to sell the information on the black market. Many considered his sentence light. If he had sold any of the data, he could have gotten 10 years.
Addiction and desperation
A respiratory therapist accessed more than 500 patient records over 10 months. Her goal was to obtain intravenous drugs under the pretense that the patients needed them. However, the drugs were shipped to the practice addressed to her. The prosecution argued that she intended to use the drugs to feed her own addiction.
She faces up to one year in prison, and the hospital where she worked could face additional penalties for not catching the violation sooner.
How to identify your risk level
“Conduct an accurate and thorough assessment of the potential risks and vulnerabilities to the confidentiality, integrity, and availability of electronic protected health information held by [your practice].” —U.S. Department of Health and Human Services
It’s up to you to know your risk level by conducting a thorough risk analysis.
Identify PHI and ePHI in your practice
Where is health information being uploaded, stored, or transmitted? Anything that potentially links a patient to your practice is protected health information even if it doesn’t include medical information.
Leave no stone unturned.
Don’t disregard physical PHI just because you have paperless medical records. Protected health information can pop up in unexpected places. For example, one small psychology practice in New Jersey was sending copies of billing information to a collections agency that worked for them. An audit revealed that the bills included procedural and diagnostic codes along with insurance information.
A few codes on a bill may not seem like much, but they’re protected health information. Sharing them without having the proper forms signed is a sanctionable HIPAA violation. Make sure to look everywhere for PHI during your risk assessment.
What external entities have access to your PHI?
External entities include vendors and subcontractors. They can even include basic computer programs like Microsoft Word if someone uses it to type up patient cases.
When using any software to manage protected health information, remember to get a business associate agreement. A verbal agreement isn’t enough. Neither is a statement on a company’s website stating that they’re HIPAA compliant. Always have a signed BAA before using a business associate’s product.
For example, JotForm allows you to create custom, electronic forms that are fully HIPAA compliant. Their forms support secure collection of patient data and signatures online. When they sign a business associate agreement with your practice, they assume full responsibility for keeping that protected health information safe.
What risks does PHI face?
The risks to protected health information come from humans, malware, natural disasters, or even a major power outage.
In 2017, the ransomware aptly named “WannaCry” brought one of the world’s largest healthcare systems to its knees. Hackers used the ransomware to lock down the United Kingdom’s National Health System. They demanded payment in exchange for decrypting patient records. At the same time, several U.S.-based health systems were hit. In most cases, the affected medical centers chose to pay rather than lose their patient records forever.
It was a hard lesson.
HIPAA requires that you make patient records available to patients within a reasonable amount of time. If your patient records are locked down by ransomware, how would you fulfill your HIPAA obligations? Planning for these types of scenarios is part of your risk assessment.
While evaluating your risk levels, you’ll undoubtedly find new risks. You may even uncover some violations. Never push what you find under the rug, and don’t wait to resolve it. Address any risks or violations immediately to avoid more violations and even bigger penalties.
Once you’ve found the risks to HIPAA compliance, train your staff on how to stay HIPAA compliant.
HIPAA training essentials
HIPAA states that training should be provided “as necessary and appropriate for members of the workforce to carry out their functions.”
Do you need to educate your cleanup crew about HIPAA compliance? Not likely. But most employees in your practice will manage patient data in some way. Many of them won’t necessarily be medical professionals. If they previously worked outside of the healthcare field, they may have never even heard of HIPAA before.
Those who need training could be in a variety of departments, including
Billing
Bookkeeping
Insurance authorizations
Office management
Reception
Data entry
Don’t forget your temporary workers. If you hire from a staffing agency, the temporary employee must sign a business associate agreement since they aren’t your employee. If this contract worker will access PHI, you need to give them some HIPAA training.
Communicate the gravity of the law to them. Then, have someone follow up with them to make sure they’re following the rules.
How to conduct HIPAA training
You can obtain online certifications or create your own program. Learn the security rules and share them with your team.
The Health and Human Services website offers information on every aspect of the law. It’s mostly in everyday language, rather than legal jargon, so that it can be understood by the average person. But don’t think you can just send someone to the HHS website and tell them to learn the rules.
Formal training is essential for all employees. Your training should answer questions like
What is HIPAA compliance?
What is PHI?
How am I responsible for protecting PHI?
How do I properly follow procedures?
How do I use technology to safeguard PHI?
What physical safeguards should I take?
What are the penalties for the organization and me if I fail to safeguard PHI?
Stipulate any disciplinary measures for violating HIPAA, and follow through with them. Your practice can’t afford to keep an employee who doesn’t “get it.” When you show how serious you are about HIPAA training and enforcement, your employees will know they can’t be lackadaisical about compliance.
How often should you provide HIPAA training?
HHS requires you to provide training to every new employee or contract worker within a “reasonable time.” That’s a vague timeline. Yet, considering the importance of HIPAA, it should be the first thing a new employee learns. You may have some wiggle room when hiring clinical staff who have worked in the medical industry, but don’t wait too long. You must be able to show that training was completed within a reasonable period of time.
You are then required to retrain employees “periodically.” Again, that’s vague. Most practices interpret this as annually.
Keep in mind that HIPAA does change as new risks arise and technology changes. You should periodically review new guidance from the HHS site. Keep your training program and employees up to date with any changes.
If any of the new guidance has a significant impact on your practice, don’t wait until the next scheduled training to inform staff. Do it immediately.
One new technology that has had a direct impact on HIPAA training is social media. How can your employees use social media and still be HIPAA compliant?
How to be HIPAA compliant on social media
Social media platforms, both personal and professional, play a large role in the life of your employees. Sharing information about everyday matters, including work, is the norm. But employees who share PHI on social media will leave your practice open to steep penalties.
Never discuss a patient even if you don’t use their name. Someone who knows them may put two and two together.
Never discuss health information through social media messaging or comments even if the patient initiates it.
Never share pictures of patients in or around your practice without written consent. Use a medical information release form designed specifically for social media.
Verbal consent isn’t enough. Be sure to get patient consent in writing using the proper form. A release form is useful for social media, but what other HIPAA forms do you need in your practice?
What are the main types of HIPAA forms?
In the medical industry, the maxim “not documented, not done” highlights the importance of keeping accurate medical records. As you can imagine, HIPAA has a number of requirements regarding documentation. Always keep HIPAA-compliant forms pertinent to your practice on hand to use with your patients.
Receipt of privacy agreement form
This form documents that the patient acknowledges receiving a copy of your privacy agreement, which states how you comply with HIPAA to protect patient information. A privacy agreement also explains that a patient has the right to request and receive their medical records.
HIPAA medical release form
You’ll need to complete this form when sharing medical information with someone other than the
Patient
Patient’s legal representative
Treating physician
Health insurance company
Pharmacy
Remember that this information can only be shared on a need-to-know basis to protect the patient’s confidentiality.
You’ll also need a signed release form from the patient when
Sharing PHI with a university for research or educational purposes
Sharing records with the patient’s attorney for a personal injury lawsuit
Transferring records to a departing physician who will continue attending the patient
Using a patient’s personal recovery story as part of a marketing campaign
While the patient must give their consent to share their protected health information, you may need additional forms depending on the circumstances.
Records custodian agreement
A records custodian agreement is the form that a departing physician signs when taking patient records to a new practice. It transfers the responsibility for the storage and use of medical records from the covered entity to the departing provider.
Patient intake form
Patient intake forms gather the basic information that you need to know about new patients. Well-designed electronic patient intake forms can significantly enhance the patient’s experience. They also streamline the intake process.
Patients appreciate being able to easily and securely fill out the encrypted form at home or on their smartphone before their appointment. Plus, your practice benefits by having all of the patient’s information before their next appointment.
By using a patient intake form, you’ll be able to
Understand the reason for their visit
Verify their insurance
Review and update office notes
Better assess appointment length
Medication and prescription refill forms
These electronic “prescription pads” make it easy to send prescriptions to the pharmacy. Electronic prescription forms put an end to deciphering messy handwriting, photocopying, filing paper scripts, waiting on hold for the pharmacist, and asking sick patients to wait at the pharmacy. They speed up the process so prescriptions are ready when the patient arrives.
Additional benefits of this form are updating existing prescriptions electronically and having a permanent copy of the form in the patient’s electronic file.
Payment request form
Over half of bills are now paid online. If you’re only accepting traditional payment methods or mailing out monthly bills, you could be contributing to nonpayment and increased overhead. After all, time and postage aren’t free.
By sending payment request forms to patients through HIPAA-compliant email, you make it easier for patients to pay their bills. You also reduce your administrative workload. Using these forms in conjunction with common payment processors, like PayPal, Stripe, or Square, makes for a powerful combination.
Business associate agreement
The business associate agreement is a written agreement between you and an individual or entity outside your practice. A business associate could include any software and cloud services that are receiving, transmitting, processing, or storing protected health information. If you use a number of third-party apps that integrate with your software, each app must sign a business associate agreement.
When an entity signs a BAA, they acknowledge their responsibility to keep PHI safe. They also confirm that they have systems in place to comply with HIPAA regulations. Without a signed BAA form, your practice is responsible for any mishandling of PHI that happens on the third party’s watch.
As you’ve seen, there are HIPAA-compliant forms for all areas of your business. Now that you know a little about each one, let’s take a closer look at the form that starts your HIPAA responsibility.
The first step in HIPAA compliance: Intake forms
Intake forms are the cornerstone of protected health information in a practice. The vital information that they contain enables you to better treat your patients. But you are also responsible for protecting that information.
In the modern era of HIPAA, paper forms simply pose too great a risk to compliance. Why? Protected health information on papers forms can be easily exposed:
While patients fill out paper forms in waiting rooms, others can look over their shoulders.
Forms may stay on a staff member’s desk for days before being manually entered into a computer system or filed.
Forms may unwittingly be thrown into waste bins rather than shredders.
Forms may wait in a closet to be shredded because, really, who has time to shred papers in a busy practice?
Electronic forms, on the other hand
Cut wait times. Patients can easily fill them out on their home computer or smartphone before their appointment.
Eliminate inefficiencies. If a patient is late to their appointment, you won’t need to wait another 10 minutes for them to complete forms. They’ll already have finished them before arriving. You also won’t have to transfer written information from a handwritten form into a computer.
Reduce booking gaps and overbooking. Patients will be more aware of their appointments and less likely to miss them when they fill out forms in advance. Intake forms can also be reviewed beforehand to better judge how long certain visits may take.
Project a modern image. Many patients judge a practice’s level of care on the intake process. Intake forms shouldn’t be an afterthought. Having a streamlined electronic intake process lets your patients know that your practice is modern, organized, and efficient.
Streamline appointments. Not everyone enjoys filling out forms on the internet, but most patients will appreciate how electronic forms streamline their appointments.
Are flexible. Not everyone has internet access, but that doesn’t mean you can’t or shouldn’t use electronic forms. Allow these patients to fill out their forms on a tablet when they arrive.
Getting electronic signatures and verifying patient information can all be squared away before the patient walks into the waiting room. If using electronic intake forms is as easy as sending an email, why don’t all practices use them? What else should you do to improve the intake process for your patients?
How to improve your patient intake process
Creating the right patient intake process isn’t rocket science, but it does take some planning and the right tools.
Get rid of outdated paper forms. Smart forms, like those from JotForm, make the transition smooth.
Streamline your communication. It’s not the ’90s anymore, so why are so many practices playing phone tag with patients and using appointment reminder cards? Start identifying the steps in your process that waste the most time. Then, look for an automated solution.
Reinforce the patient experience. How many times have you gotten a bad review that had nothing to do with the actual care you provided? The front desk experience is as important as the healthcare you provide. Make sure everyone in your office is up for the challenge. Have reliable systems in place to help them provide exceptional care throughout the patient experience.
How to keep patient intake forms secure
With the barrage of data breaches in the news, many think that electronic equals unsafe. However, when set up correctly electronic records are far more secure than traditional paper records and file cabinets.
Randomized URLs like https://www.jotform.com/uploads/user/63043229924960/353747904850626197432/JotForm-icon.png make it impossible for a hacker to guess at file names. This adds an extra layer of security by making files harder to find in the first place.
An SSL certificate means that all patient data is transmitted securely, fully encrypted, and impossible to hack. JotForm uses the same advanced technology that major banks use to prevent financial information theft.
Unique logins for patient and office staff provide extra security by discouraging account sharing.
Technical safeguards are essential to keeping intake forms and protected health information safe. But without human cooperation, your forms will still be vulnerable. Technology and your team must come together to maintain security throughout the practice.
Consider four ways you can work on the human firewall that will keep patient intake forms and all PHI safe:
Complete a thorough risk assessment. Do you remember what happened in the WannaCry attack? You don’t want to be crying over HIPAA penalties because you failed to do a complete risk assessment. Make this a top priority in becoming HIPAA compliant.
Train your staff on proper security protocol. Employees should always lock their computers when they step away from the desk. They should also create strong passwords that they don’t use anywhere else. And, remind them to never click on suspicious links in emails.
Update software promptly. When your computer sends you an update notification, this often means that a vulnerability has been discovered. The software company has patched it promptly, but you must install that patch. Every hour you wait, you remain vulnerable to a known threat. Updating software is part of managing risks promptly.
Lead by example. Demonstrate that you follow the same rules you’ve put in place for other staff members. All members of your staff must be HIPAA compliant, so leaders need to show that they are dedicated to HIPAA compliance.
Every practice needs an effective patient intake process, but sometimes there are unique situations that call for special attention. Providing massage therapy and attending to infants are two examples of these unique intake situations. Let’s look at both.
How to use massage intake forms
A massage therapy business can use intake forms to gather information just like any other healthcare provider. Beyond that, massage intake forms can help you build a relationship with the patient. They are useful to
Make a great first impression. Massage is a notoriously competitive business, and many clients pay for massages to get pampered. Electronic massage intake forms offer this discerning type of client the seamless experience that leads them to schedule their next appointment.
Get to know your clients. Massage intake forms are a great way to effortlessly start a conversation with a new client. You can learn more about why the patient decided to come in. Then, use what you learn to tailor recommendations for services and packages to the patient.
Market to repeat clients. Massage intake forms are a non-intimidating way to get someone’s email. Once you have them on your mailing list, you can send tips, offers, and other marketing by email. As long as you send marketing emails at a reasonable frequency, stay relevant, and obey all email marketing laws, they’ll usually stay subscribed and visit you more often.
How to use intake forms for infants
A second unique case is using intake forms for infant patients. Infant forms ask very specific questions because the answers to these questions may influence infant care. In general, they ask about things that a parent or guardian may not think to mention, for example
Does the baby eat anything other than breast milk?
Does the child have known food allergies?
Is your child on a special diet?
What does your baby use to drink?
What frightens your child?
In addition to specific questions, an infant form will include a request for parental or guardian consent to treat the child
Because your practice may also have unique needs, you should use HIPAA-compliant forms that can be easily customized. This will be helpful especially when creating more specialized forms, such as baby massage forms. Once you have the various forms you need set up, consider where else you are storing or transmitting electronic PHI. What types of security safeguards do you need to comply with HIPAA online?
What are the HIPAA security safeguards?
These days, electronic protected health information doesn’t just reside in an isolated computer in someone’s office. It’s on the internet. It’s being transferred from one place to another wirelessly. This transfer is a particularly critical point for ePHI because anytime it’s transmitted, it can be intercepted with the right tools.
Think about it. Where are you safest on a typical day? At home, at work, or during your commute? Statistically speaking, you’re much more likely to have an accident in transit between destinations. In the same way, information is most vulnerable when it’s in movement.
So how can you transmit information securely? What is data security, and how can you do it correctly?
Encryption is the answer. A system of encoding information, encryption disguises all the information in another form before transmitting it. When the information has safely reached its destination, it is then converted back to a usable form.
What are the requirements for HIPAA-compliant servers?
Any server your practice uses must be HIPAA compliant. It could be your primary server, a cloud backup, your email provider, or the server that hosts your website. If it will store or transmit protected health information, it must be compliant. And, you guessed it: You need a signed business associate agreement from the organization that runs it.
A HIPAA-compliant server must safeguard the integrity, confidentiality, and accessibility of health information. Be aware that the Department of Health and Human Services doesn’t recognize any organization as a certifying body of HIPAA-compliant servers. So do your homework to confirm that a server is HIPAA compliant. Then, get a BAA signed before using it. These steps are essential to safeguarding your patients and your practice.
For any server to be HIPAA compliant, it must do more than just keep ePHI safe. It should
Provide reports that permit a thorough risk assessment
Create unique logins for each user with associated file access permissions
Log users off automatically after a certain span of inactivity
Track individual users’ activity
Encrypt data during transmission and while at rest
Prevent improper alteration or destruction of files
Offer an emergency access procedure
Let’s look at some of the top HIPAA-compliant software service providers.
Best HIPAA-compliant email providers
Whether you have employee-to-employee communications or send and receive patient forms and updates through email, your email must be a fortress. Otherwise, email easily becomes a weak link in HIPAA compliance.
You have several great options that are both secure and versatile, so it’s easy to integrate them into your existing systems.
Cloud storage offers the flexibility to store large amounts of data without continually having to upgrade your computers. While they excel at convenience, most cloud services only take minimal precautions to keep information safe. They aren’t intended for protected health information, financial information, or other highly sensitive data and could pose a security risk.
However, several companies that offer services to the average consumer also have paid services that are HIPAA compliant. Getting secure storage requires upgrading to these more advanced versions of cloud and file-sharing software. Because they will store protected health information, always get a signed BAA before allowing staff to use any cloud drive.
Box provides seamless integration into existing healthcare systems. Although it’s a newcomer to cloud storage, it’s quickly claiming market share because of its flawless user experience.
Carbonite offers built-in, multilocation backup to ensure that medical records are always accessible, even during a disaster. It is a more costly option, but it has been in the cloud business since 2005 and is one of the most respected brands in the industry.
Dropboxis HITECH- and HIPAA-certified by an independent certification body. It offers up to five accounts for a low monthly price and can be integrated with many helpful third-party applications, like JotForm.
Google Drive easily integrates with Google’s online office suite. It also gives you tiered control to limit PHI access to a need-to-know basis.
Microsoft OneDrive has many options for tracking user behavior. Although it’s more expensive than other compliance options, it offers greater control over who can access sensitive data.
After securing your data, next you should consider which HIPAA-compliant software you’ll need to use in your practice.
Best HIPAA-compliant software
To run a practice in the 21st century, you need a variety of software. From office suites to specialized forms, healthcare providers must use software that offers HIPAA compliance. These software programs include fax services as well.
Google G Suite has been HIPAA-compliant certified by an independent certifying body. In addition, it’s certified as ISO-27017, which expanded data access controls over previous security standards. Because your employees probably already use Google products, this software is very easy to integrate into your office.
Microsoft 365 has obtained HIPAA-compliant certifications from multiple independent organizations. Plus, its software suite includes programs that most people who work in offices already know how to use.
UpDox is a HIPAA-compliant company that built its software specifically for the needs of healthcare practices. It offers advanced features, such as appointment reminder automation. It also has a patient portal so that patients can communicate with medical staff, access test results, and pay bills online.
JotForm provides users with the tools to create, manage, transmit, and store custom HIPAA-compliant forms. This mobile-friendly tool is easy to use and can be embedded in email, websites, and other applications. It allows you to request information and transmit prescriptions to equipment providers and pharmacies electronically. You can effortlessly acquire signatures and accept online payments to provide services and get paid more quickly.
Now that you’re using HIPAA-compliant software, what everyday guidelines should you be following to protect health information in your office?
Best physical safeguards you can take to protect PHI
Software can take security to an extreme degree. But human error can weaken even the toughest security measures. If you have people sharing passwords, staying logged in indefinitely, or setting up the HIPAA safety components incorrectly, software won’t protect you.
Take simple precautions in the office to make all the extra security worthwhile:
Make things easy but secure. If keeping things secure is too hard, people will create workarounds that put health information at risk. User-friendly systems should always be part of keeping patient data safe.
Post HIPAA reminders conspicuously around work areas. Move them around periodically so that people are more likely to see them.
Point monitors away from general access areas. Purchase screen covers that obscure the screen from someone not sitting directly in front of it. It doesn’t take Ocean’s 11-style planning to pull off this kind of data heist. These days, anyone can easily pull out a smartphone and zoom in on computer screens to capture data.
Require employees to use strong passwords and to change their passwords regularly.
Don’t allow people to share passwords.
Force system updates after asking employees to update them voluntarily. An uninstalled update represents a security threat.
Only allow protected health information to be transmitted to or from your practice using encrypted forms.
With the basic safeguards ready, what are the next steps in becoming HIPAA compliant?
Becoming HIPAA compliant: Where to start
Many people want to know the minimum necessary standard so that they can become HIPAA compliant more quickly. That’s really hard to determine because every healthcare practice is different.
Still, everyone has to start somewhere. Perhaps you’ve been trying to comply but don’t know where to begin. You might have discovered things you’ve overlooked while reading this article.
Here are seven steps that you can use as a HIPAA compliance checklist for your practice:
Take an online HIPAA checkup. Using an online HIPAA checkup can help small practices quickly identify gaps and risks in their processes. You can then use this information as a baseline to start from. Planet HIPAA’s online HIPAA Checkup helps you start down the road toward compliance.
Do a thorough risk assessment. How can you be HIPAA compliant if you don’t know where your weaknesses are? Even if you’ve done a risk assessment in the past, you may have new information to add. There may be areas of your PHI management that you hadn’t previously considered.
Review the Health and Human Services website for the most recent guidelines. Sign up for updates from the site. Technology is constantly changing. As it does, HHS updates will keep you updated on best practices. This guidance should be thought of as equally important as the law itself. If the Office for Civil Rights audits you, they will be looking at whether you’re up to date.
Update your training materials at least once a year. Most of the material will stay the same, but incorporate any recent HHS updates into the manual. If you’ve been using the same manual for more than five years, you’re way past due for an update.
Schedule annual HIPAA training for your team. This training isn’t something you want to skimp on, so plan a whole day for it. If everyone can’t be away at once, consider creating a modular online course. Because this type of course is interactive and includes quizzes, it can also improve your staff’s understanding and retention of the material.
Get signed Business Associate Agreements from any third-party providers, partners, or contractors. BAAs are not optional, so have procedures in place to get them signed before you share any protected health information.
Use HIPAA–compliant software to make managing protected health information easy and secure. Your electronic recordkeeping should include data storage solutions and forms that comply with HIPAA requirements.
Why HIPAA-compliant forms are essential to your practice
“Providers need to fill out an average of 20,000 forms every year.”
Due to the considerable amount of recordkeeping required for HIPAA compliance, electronic forms provide many advantages. Unlike written forms, electronic forms are permanent and always legible.
Electronic forms increase the efficiency of your documentation process by eliminating duplicate work. They can ease, or even automate, data collection. They also reduce data entry when interfaced with electronic spreadsheets or medical systems.
When choosing a HIPAA-compliant form service for your practice, remember the importance of electronic security. Your forms must use data encryption to ensure that any stolen or leaked data will be unusable. In addition, the connection between the form and the server must be secure.
Remember that even a small practice has an enormous, and potentially overwhelming, responsibility to be HIPAA compliant. Show your concern for securing protected health information by using HIPAA-compliant forms. Integrate them into your existing recordkeeping system. Use them to centralize and automate PHI management. In this way, you and your team will have to worry about fewer HIPAA protocols. You’ll also demonstrate to the Office for Civil Rights that you have trusted systems in place to protect health information. In the event of an investigation, your obvious concern for HIPAA compliance will work in your favor.