Neumorphism (aka neomorphism) is a relatively new design trend and a term that’s gotten a good amount of buzz lately. It’s aesthetic is marked by minimal and real-looking UI that’s sort of a new take on skeuomorphism — hence the name. It got its name in a UX Collective post from December 2019, and since then, various design and development communities have been actively discussing the trend, usually with differing opinions. Chris poked fun at it on Twitter. Adam Giebl created an online generator for it. Developers, designers, and UX specialists are weighing in on the topic of aesthetics, usability, accessibility, and practicality of this design trend.
Clearly, it’s stricken some sort of chord in the community.
Let’s dip our toes into the neumorphism pool, showcasing the various neumorphic effects that can be created using our language of choice, CSS. We’ll take a look at both the arguments for and against the style and weigh how it can be used in a web interface.
Neumorphism as a user interface
We’ve already established that the defining quality of neumorphism is a blend of minimalism and skeuomorphism. And that’s a good way to look at it. Think about the minimal aesthetic of Material Design and the hyper-realistic look of skeuomorphism. Or, think back to Apple’s design standards circa 2007-12 and compare it to the interfaces it produces today.
Nine years of Apple Calendar! The image on the left is taken from 2011 and exhibits the look and feel of a real, leather-bound journal, said to be inspired by one on Steve Jobs’ personal yacht. The right is the same app as shown today in 2020, bearing a lot less physical inspiration with a look and feel we might describe as “flat” or minimal.
If we think about Apple’s skeuomorphic designs from earlier in the century as one extreme and today’s minimal UI as another, then we might consider neumorphism as something in the middle.
Alexander Plyuto has championed and evolved neomorphic designs on his Dribbble account. (Source)
Neumorphic UI elements look like they’re connected to the background, as if the elements are extruded from the background or inset into the background. They’ve been described by some as “soft UI” because of the way soft shadows are used to create the effect.
Another way to understand neumorphic UI is to compare it to Material Design. Let’s use a regular card component to draw a distinction between the two.
Notice how the Material Design card (left) looks like it floats above the background, while the neumorphic variation(right) appears to be pushed up through the background, like a physical protrusion.
Let’s break down the differences purely from a design standpoint.
Quality
Material Design
Neomorphism
Shadows
Elements have a single or multiple dark shadows around them.
Elements have two shadows: one light and one dark.
Background colors
An element’s background color can be different than the background color of the parent element.
Background colors must be the same (or very similar) as the background color of the parent element.
Edges
Elements can be rounded or squared.
Rounded edges are a defining quality.
Borders
There are no hard rules on borders. Using them can help prevent elements that look like they are floating off the screen.
Elements can have an optional subtle border to improve contrast and make the edges a bit sharper
That should draw a pretty picture of what we’re talking about when we refer to neumorphism. Let’s move on to how it’s implemented in CSS.
Neumorphism and CSS
Creating a neumorphic interface with CSS is seemingly as easy as applying a regular box-shadow property on any element, but it’s more nuanced than that. The distinctiveness of a neumorphic UI comes from using multiple box-shadow and background-color values to achieve different types of effects and variations.
Neumorphic box shadows
Let’s do a quick refresher on the box-shadow property first so we can get a better understanding. Here’s the syntax:
Horizontal offset: A positive value offsets shadow to the right, while a negative value offsets it to the left.
Vertical offset: A positive value offsets shadow upwards, while a negative value offsets it downwards.
Blur Radius: The length of the shadow. The longer the length, the bigger and lighter the shadow becomes. There are no negative values.
Spread Radius: This is another length value, where larger values result in bigger, longer shadows.
Color: This defines the shadow’s color, just as we’d do for the CSS color property.
Inset: The default value (initial) results in a drop shadow. Using the inset value moves the shadow inside the frame of the element, resulting in an inner shadow.
We can apply multiple shadows using comma-separated box-shadow values. Up to four values can be concatenated, one for each side of the box.
box-shadow: 20px 20px 50px #00d2c6,
-30px -30px 60px #00ffff;
The following shows the box-shadow property values for a neumorphic UI element. Individual offset, blur and opacity values can be adjusted to be higher or lower, depending on the size of an element and the intensity of the effect that you’re trying to achieve. For neumorphism, it’s required to keep the shadows soft and low contrast.
CodePen Embed Fallback
As we’ve mentioned before, a core part of neumorphic elements is the use of two shadows: a light shadow and a dark shadow. That’s how we get that sort of “raised” effect and we can create variations by changing the “light source” of the shadows.
Two positive and two negative offset values need to be set. Taking this into account, we get the following four combinations, simply by changing the placement of each shadow.
CodePen Embed Fallback
Let’s use CSS variables to keep the values abstract and better understand the variations.
We can use inset shadows to create yet more variations. Unlike drop shadows that make an element appear to be raised from beneath the background, an inset shadow gives the appearance that the element is being pressed into it.
We can change if the element is extruded from the background or inset into the background by applying the initial (not apply the option at all) or inset, respectively.
Let’s keep our light source as the top left and only toggle the inset option to see the difference.
CodePen Embed Fallback
Background colors
You might have noticed that the box-shadow values change the look of the edges of a neumorphic element. So far, we haven’t changed the background-color because it needs to be transparent or have the same (or similar) color as a background color of an underlying element, such as the element’s parent.
We can use both solid and gradient backgrounds. Using a solid color background on the element can create a flat surface sort of look, when that solid color is the same as the color of the underlying element.
On the other hand, using subtle gradients can change how the surface is perceived. As with the box-shadow property, there is alight and a dark value in a gradient. The gradient angle needs to be adjusted to match the light source. We have the following two variations when using gradients:
Convex surface variation: The surface curves outwards where the gradient’s lighter section is aligned with the shadow’s lighter section, and the gradient’s darker section is aligned to the shadow’s darker section.
Concave surface variation: The surface curves inward where the gradient’s lighter section is aligned to the shadow’s darker section, and the gradient’s darker section is aligned to the shadow’s lighter section.
Let’s see how Neumorphism performs when applied to a simple button. The main characteristic of a neumorphic interface is that it blends with the background and does so by having a similar or same background color as the underlying element. The main purpose of many buttons, especially a primary call-to-action, is to stand out as much as possible, usually with a prominent background color in order to separate it from other elements and other buttons on the page.
The background color constraint in neumorphism takes away that convenience. If the background color of the button matches the background color of what it’s on top of, we lose the ability to make it stand out visually with a unique color.
We can try and adjust text color, add a border below the text, add an icon or some other elements to increase the visual weight to make it stand out, etc. Whatever the case, a solid background color on a neumorphic button seems to stand out more than a gradient. Plus, it can be paired with an inset shadow on the active state to create a nice “pressed” effect.
Even though the solid color on a neumorphic button calls more attention than a gradient background, it still does not beat the way an alternate color makes a button stand out from other elements on the page.
Taking some inspiration from the real-world devices, I’ve created the following examples as an attempt to improve on the neumorphic button and toggle concept. Although the results look somewhat better, the regular button still provides a better UX, has much fewer constraints, is more flexible, is simpler to implement, and does a better job overall.
CodePen Embed Fallback
The first example was inspired by a button on my router that extrudes from the device and has a sticker with an icon on it. I added a similar “sticker” element with a solid color background as well as a slight inset to add more visual weight and make it stand out as closely as possible to the ideal button. The second example was inspired by a car control panel where the button would light up when it’s in an active (pressed) state.
Let’s take a look at some more HTML elements. One of the downsides of neumorphism that has been pointed out is that it shouldn’t be applied to elements that can have various states, like inputs, select elements, progress bars, and others. These states include:
UX and accessibility rules require some elements to look different in each of their respective validation states and user interaction states. Neumorphism constraints and restrictions severely limit the customization options that are required to achieve the different styles for each possible state. Variations will be very subtle and aren’t possibly able to cover every single state.
Everything looks like a button! Notice how the input and button look similar and how the progress bar looks like a scrollbar or a really wide toggle.
It’s hard to see which elements are clickable! Even though this is the simplest possible example that showcases the issue, we could have added extra elements and styles to try and mitigate the issues. But as we’ve seen with the button example, some other types of elements would still perform better in terms of UX and accessibility.
It’s important to notice that Neumorphic elements also take more space (inside padding and outside margin) due to the shadow and rounded corners. A neumorphic effect wouldn’t look so good on a small-sized element simply because the visual effects consume the element.
The ideal element for neumorphism are cards, or any other static container element that doesn’t have states based on user interaction (e.g. hover, active and disabled) or validation (e.g. error, warning, and success).
In his highly critical article on neumorphism, Michal Malewicz (who helped coin “Neumorphism” as a term) suggests adding Neumorphic effects to the cards that already look good without it.
So the only way it works OK is when the card itself has the right structure, and the whole extrusion is unnecessary for hierarchy.
See?
It works well when it can be removed without any loss for the product.
Accessibility and UX
We’ve seen which elements work well with neumorphism, but there are some important rules and restrictions to keep in mind when adding the effect to elements.
First is accessibility. This is a big deal and perhaps the biggest drawback to neumorphism: color contrast.
Neumorphic UI elements rely on multiple shadows that help blend the element into the background it is on. Using subtle contrasts isn’t actually the best fit for an accessible UI. If a contrast checker is scanning your UI, it may very well call you out for not having high enough contrast between the foreground and background because shadows don’t fit into the equation and, even if they did, they’d be too subtle to make much of a difference.
Here are some valid criticisms about the accessibility of a neumorphic design:
Users with color blindness and poor vision would have difficulty using it due to the poor contrast caused by the soft shadows.
Page hierarchy is difficult to perceive when the effect is overused on a page. No particular element stands out due to the background color restrictions.
Users can get confused when the effect is overused on a page. Due to the extrusion effect, it’s difficult to determine which elements users can interact with and which are static.
In order to achieve a good contrast with the shadow, the background color of what a neumorphic element sits on shouldn’t get too close to the edges of RGB extremes (white and black).
Now let’s talk UX for a moment. Even though Neumorphic UI looks aesthetically pleasing, it shouldn’t be a dominant style on a page. If used too often, the UI will have an overwhelmingly plastic effect and the visual hierarchy will be all out of whack. Ae page could easily lose its intended structure when directing users to the most important content or to the main flow.
My personal take is that neumorphism is best used as an enhancement to another style. For example, it could be paired with Material Design in a way that draws distinctions between various component styles. It’s probably best to use it sparsely so that it adds a fresh alternative look to something on the screen — there’s a diminishing return on its use and it’s a good idea to watch out for it.
Here’s an example where neumorphic qualities are used on card elements in combination with Materialize CSS:
CodePen Embed Fallback
See, it can be pretty nice when used as an accent instead of an entire framework.
That’s a wrap
So that was a deep look at neumorphism. We broke down what makes the style distinct from other popular styles, looked at a few ways to re-create the effect in CSS, and examined the implications it has on accessibility and user experience.
In practice, a full-scale neumorphic design system probably cannot be used on a website. It’s simply too restrictive in what colors can be used. Plus, the fact that it results in soft contrasts prevents it from being used on interactive elements, like buttons and toggle elements. Sure, it’s aesthetically-pleasing, modern and unique, but that shouldn’t come at the expense of usability and accessibility. It should be used sparsely, ideally in combination with another design system like Material Design.
Neumorphism is unlikely to replace the current design systems we use today (at least in my humble opinion), but it may find its place in those same design systems as a fresh new alternative to existing cards and static container styles.
That might look a little weird to us folks who are so used to the CSS syntax, where it is font-size (not fontSize), margin-bottom (not marginBottom), and semi-colons (not commas).
That’s not JSX (or React or whatever) being weird — that’s just how styles are in JavaScript. If you wanted to set the font-size from any other JavaScript, you’d have to do:
div.style.fontSize = "16px";
I say that, but other APIs do want you to use the CSS syntax, like:
There are also lots of CSS-in-JS libraries that either require or optionally support setting styles in this object format. I’ve even heard that with libraries that support both the CSS format (via template literals) and the object format (e.g. Emotion), that some people prefer the object syntax over the CSS syntax because it feels more at home in the surrounding JavaScript and is a bit less verbose when doing stuff like logic or injecting variables.
Anyway, the actual reason for the post is this little website I came across that converts the CSS format to the object format. CSS2JS:
Definitely handy if you had a big block of styles to convert.
Table sorting has always been a pretty hard issue to get right. There’s a lot of interactions to keep track of, extensive DOM mutations to do and even intricate sorting algorithms, too. It’s just one of those challenges that are hard to get right. Right?
Instead of pulling in external libraries, let’s try to make stuff ourselves. In this article, we’re going to create a reusable way to sort your tabular data in React. We’ll go through each step in detail, and learn a bunch of useful techniques along the way.
We won’t go through basic React or JavaScript syntax, but you don’t have to be an expert in React to follow along.
Creating A Table With React
First, let’s create a sample table component. It’ll accept an array of products, and output a very basic table, listing out a row per product.
Here, we accept an array of products and loop them out into our table. It’s static and not sortable at the moment, but that’s fine for now.
Sorting The Data
If you’d believe all the whiteboard interviewers, you’d think software development was almost all sorting algorithms. Luckily, we won’t be looking into a quick sort or bubble sort here.
Sorting data in JavaScript is pretty straightforward, thanks to the built-in array function sort(). It’ll sort arrays of numbers and strings without an extra argument:
If you want something a bit more clever, you can pass it a sorting function. This function is given two items in the list as arguments, and will place one in front of the other based on what you decide.
Let’s start by sorting the data we get alphabetically by name.
function ProductTable(props) {
const { products } = props;
let sortedProducts = [...products];
sortedProducts.sort((a, b) => {
if (a.name < b.name) {
return -1;
}
if (a.name > b.name) {
return 1;
}
return 0;
});
return (
<Table>
{/* as before */}
</Table>
);
}
So what’s going on here? First, we create a copy of the products prop, which we can alter and change as we please. We need to do this because the Array.prototype.sort function alters the original array instead of returning a new sorted copy.
Next, we call sortedProducts.sort, and pass it a sorting function. We check if the name property of the first argument a is before the second argument b, and if so, return a negative value. This indicates that a should come before b in the list. If the first argument’s name is after the second argument’s name, we return a positive number, indicating that we should place b before a. If the two are equal (i.e. both have the same name), we return 0 to preserve the order.
Making Our Table Sortable
So now we can make sure the table is sorted by name — but how can we change the sorting order ourselves?
To change what field we sort by, we need to remember the currently sorted field. We’ll do that with the useState hook.
A hook is a special kind of function that lets us “hook” into some of React’s core functionality, like managing state and triggering side effects. This particular hook lets us maintain a piece of internal state in our component, and change it if we want to. This is what we’ll add:
Now, whenever we click a table heading, we update the field we want to sort by. Neat-o!
We’re not doing any actual sorting yet though, so let’s fix that. Remember the sorting algorithm from before? Here it is, just slightly altered to work with any of our field names.
We first make sure we’ve chosen a field to sort by, and if so, we sort the products by that field.
Ascending vs Descending
The next feature we want to see is a way to switch between ascending and descending order. We’ll switch between ascending and descending order by clicking the table heading one more time.
To implement this, we’ll need to introduce a second piece of state — the sort order. We’ll refactor our current sortedField state variable to keep both the field name and its direction. Instead of containing a string, this state variable will contain an object with a key (the field name) and a direction. We’ll rename it to sortConfig to be a bit clearer.
Now we’re starting to look pretty feature-complete, but there’s still one big thing left to do. We need to make sure that we only sort our data when we need to. Currently, we’re sorting all of our data on every render, which will lead to all sorts of performance issues down the line. Instead, let’s use the built-in useMemo hook to memoize all the slow parts!
If you haven’t seen it before, useMemo is a way to cache — or memoize — expensive computations. So given the same input, it doesn’t have to sort the products twice if we re-render our component for some reason. Note that we want to trigger a new sort whenever our products change, or the field or direction we sort by changes.
Wrapping our code in this function will have huge performance implications for our table sorting!
Making It All Reusable
One of the best things about hooks is how easy it is to make logic reusable. You’ll probably be sorting all types of tables throughout your application, and having to reimplement the same stuff all over again sounds like a drag.
React has this feature called custom hooks. They sound fancy, but all they are are regular functions that use other hooks inside of them. Let’s refactor our code to be contained in a custom hook, so we can use it all over the place!
This is pretty much copy and paste from our previous code, with a bit of renaming thrown in. useSortableData accepts the items, and an optional initial sort state. It returns an object with the sorted items, and a function to re-sort the items.
There’s one tiny piece missing — a way to indicate how the table is sorted. In order to indicate that in our design, we need to return the internal state as well — the sortConfig. Let’s return that as well, and use it to generate styles we can apply to our table headings!
As it turns out, creating your own table sorting algorithm wasn’t an impossible feat after all. We found a way to model our state, we wrote a generic sorting function, and we wrote a way to update what our sorting preferences are. We made sure everything was performant and refactored it all into a custom hook. Finally, we provided a way to indicate the sort order to the user.
You can see a demo of the table in this CodeSandbox:
If you’re self-isolating thanks to Covid-19, or simply a fulltime remote worker, keeping in touch with the industry can be tricky; There aren’t any water-coolers to gather around, and your cat is less knowledgeable about CSS than she likes to pretend.
One of the best solutions is web design podcasts. They’re a great way to grow your skills and ideas, while enjoying a fun, informal chat. Web design podcasts are entertaining, insightful, and easy to consume, even when you don’t have a great deal of time or focus to give.
We’ve put together this list of some of the top contenders to inspire you, no matter how long you’re working from home.
1. Resourceful Designer
Resourceful Designer is both a graphic design podcast and a blog, so you can choose to access content in the way that’s most suitable for you. Both tools are designed and managed by designer Mark Des Cotes, who provides endless access to useful tips and resources for professionals.
Intended for passionate designers who want to turn their talents into a paying career, the resourceful designer podcast will help you to grow. It shows you how to deal with deadlines, manage your home office, and find new clients. There are hundreds of episodes to explore, and you can listen in whenever and however you like.
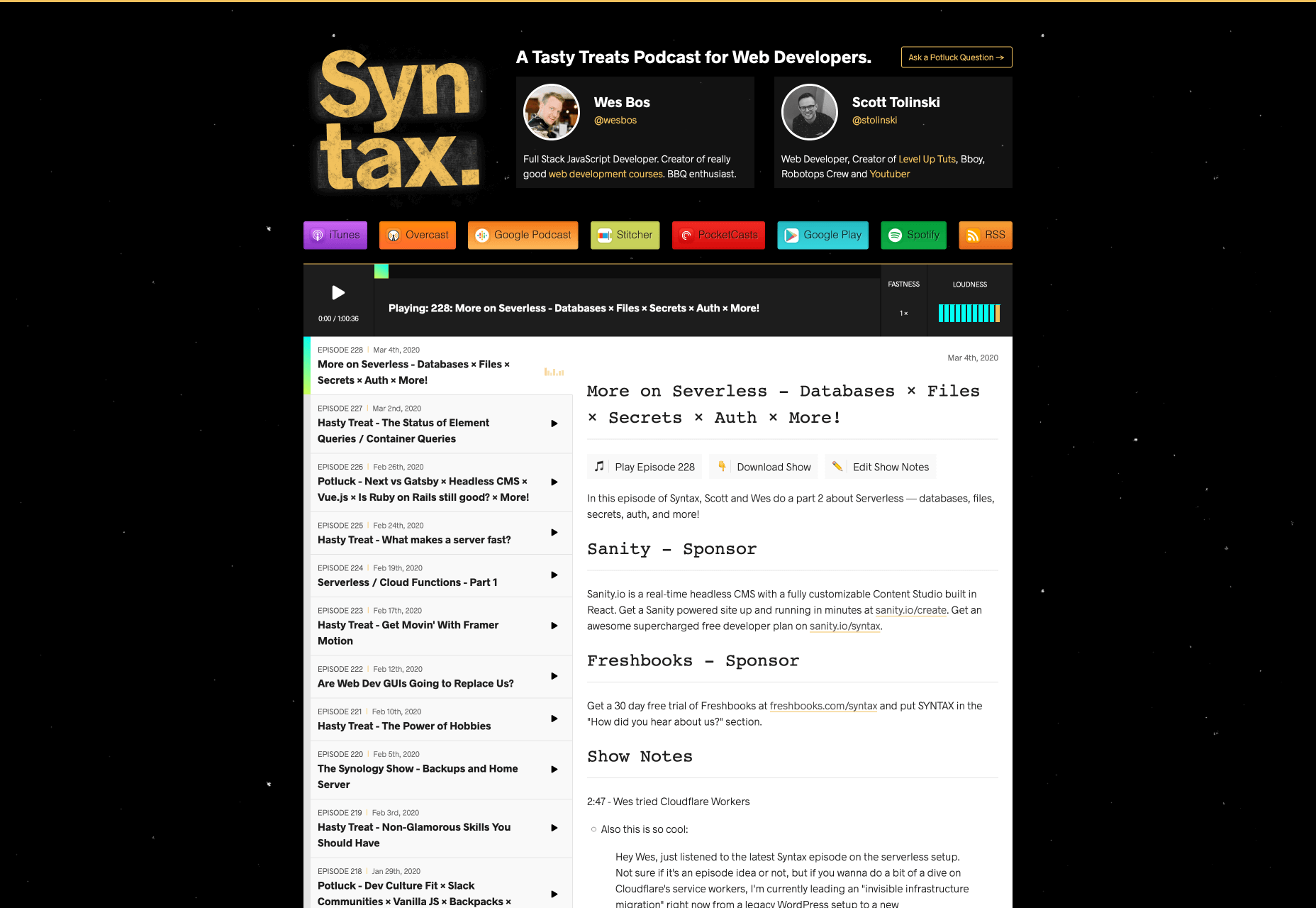
2. Syntax
Syntax is a slightly more specific web design podcast, created for people who want to learn a bit more about web development based on CSS and JavaScript. The podcast, hosted by Scott Tolinski and Wes Bos, provides guidance from dedicated developers and full-stack designers.
If you want to go beyond the basics of web design and explore what’s possible with things like code and frameworks, then Syntax is the solution for you. Both hosts for this site have endless experience with running online courses, and they’re great at breaking down the complicated parts of complex topics, so they’re easier to consume.
3. Motion and Meaning
Another of the best web design podcasts on the market for 2020 is Motion and Meaning. This unique podcast explores the importance of movement and dynamic design in user experience. If you want to play around with more immersive experiences on your websites, but you don’t know how to get started, then you should definitely listen in.
Hosts Val Head and Cennydd Bowles will guide you through digital design concepts like progressive enhancement, web animation tools, and UX choreography. This is a great podcast for anyone who wants to take their design skills to the next level.
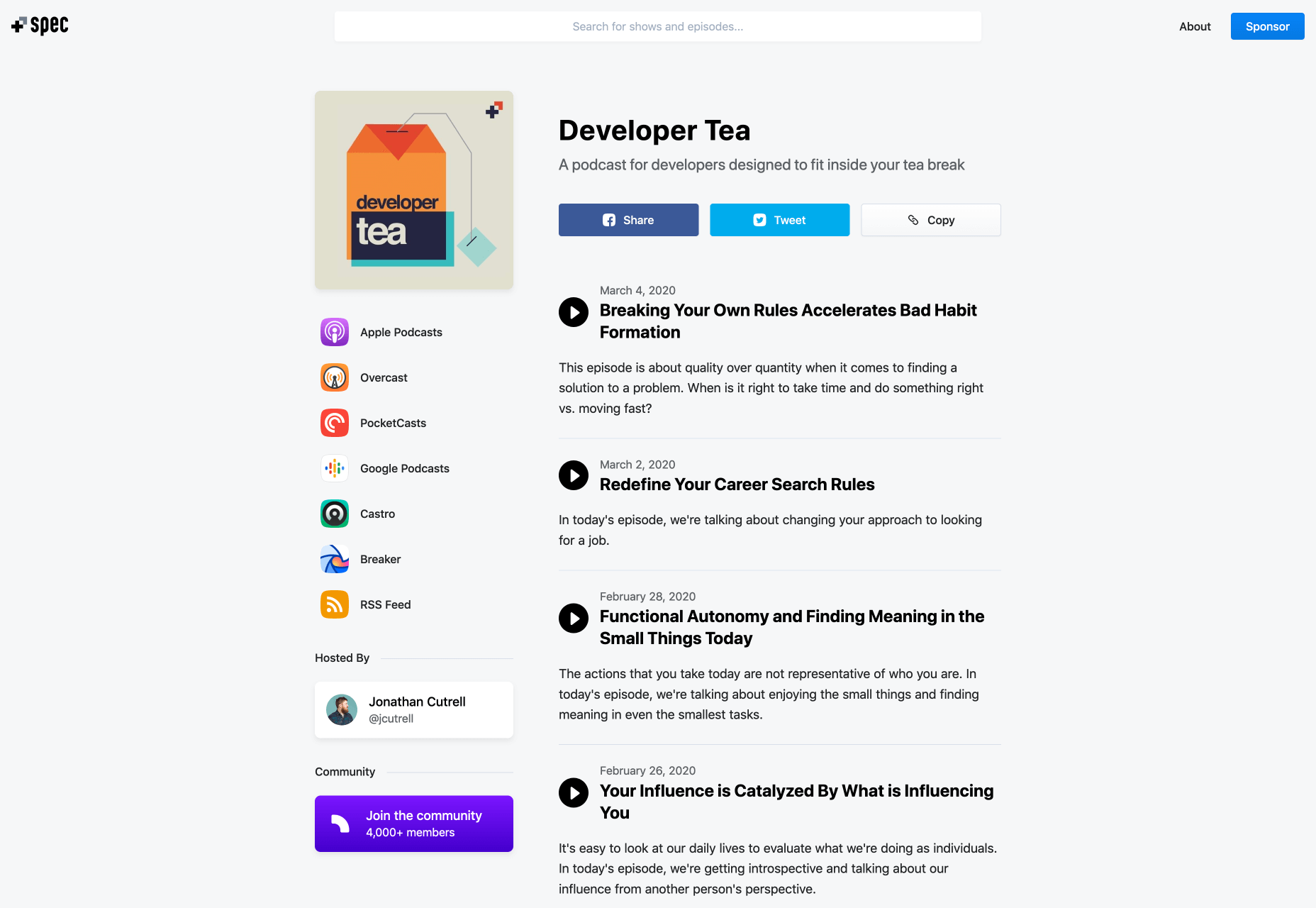
4. Developer Tea
Developer Tea isn’t exactly the most long-form podcast on the market right now, but it’s a great option for designers and developers who want to top up their knowledge as part of their afternoon coffee break. The regular selection of new podcasts will give you insights into things like how to make your work more satisfying, or what you can do to speed up production.
The host, Jonathan Cutrell, is fantastic at delivering thought-provoking ideas, state-of-the-art resources, and tips into a range of topics, from career development, to coding, mindset, habits, and problem-solving too.
5. User Defenders
As user experience continues to stand out as one of the most critical considerations for business leaders today, podcasts that focus on UX are going to be great for 2020. One of the most popular options for this year is User Defenders, a podcast that covers everything you need to know about user experience and its role in digital design.
The host, Jason Ogle chats with amazing UX designers from around the world, each one offering a unique insight into how other professionals can connect with end-users through design. This is a great web design podcast for people who want to learn about all things web development while gaining insights from other professionals.
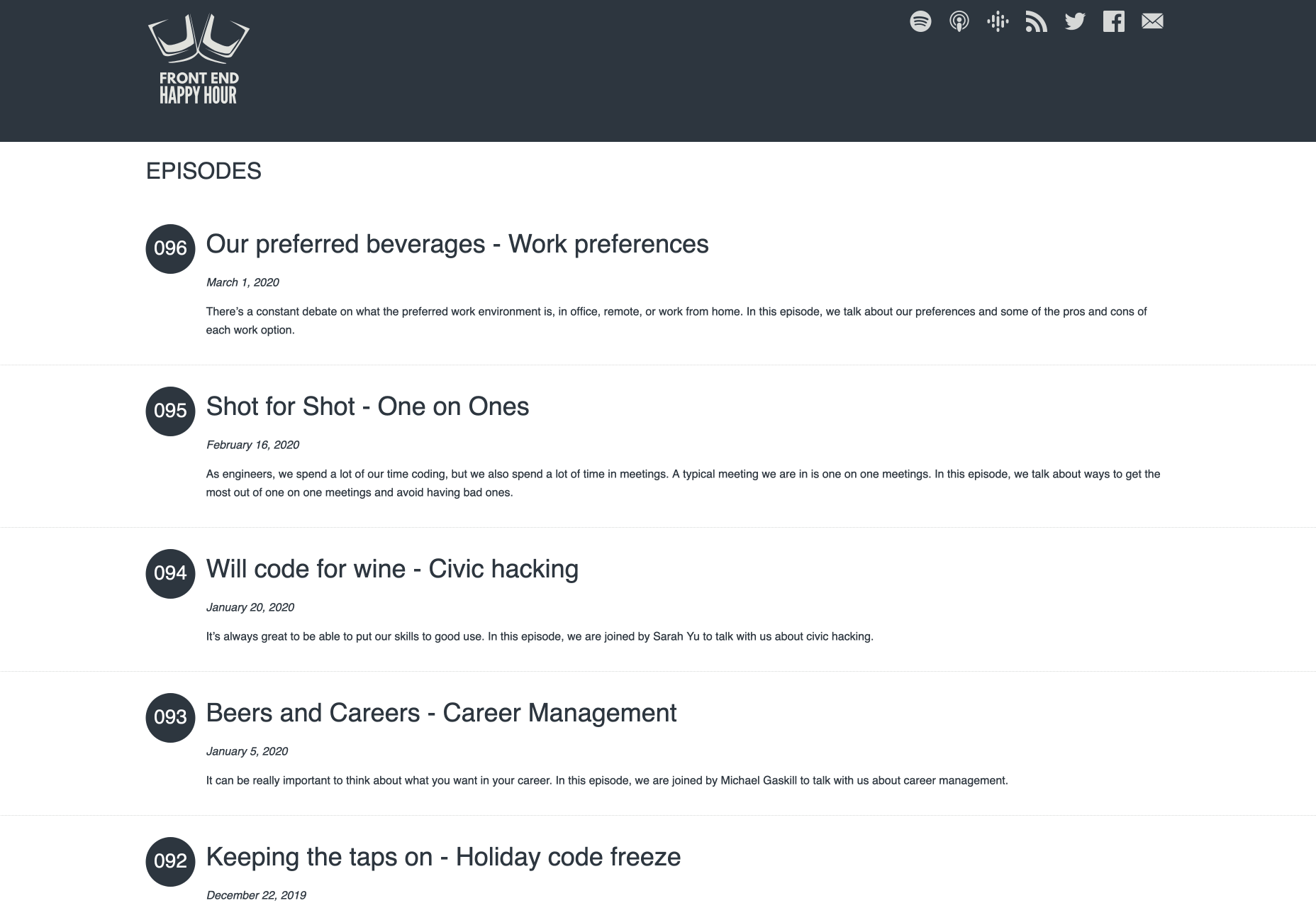
6. Front End Happy Hour
While many of the leading web design podcasts are quite professional and formal, there are a handful that combine professional insights with fun. If you like the idea of discussing web design over a glass of wine, the Front End Happy Hour could be the perfect podcast for you.
Published on a weekly basis, this podcast not only discusses important topics, but also welcomes experts from organizations like LinkedIn, Evernote, Netflix, and many others. It’s a great way to discover how the minds behind some of the world’s biggest websites tick. Additionally, the topics are broken down into a useful and easy-to-consume format.
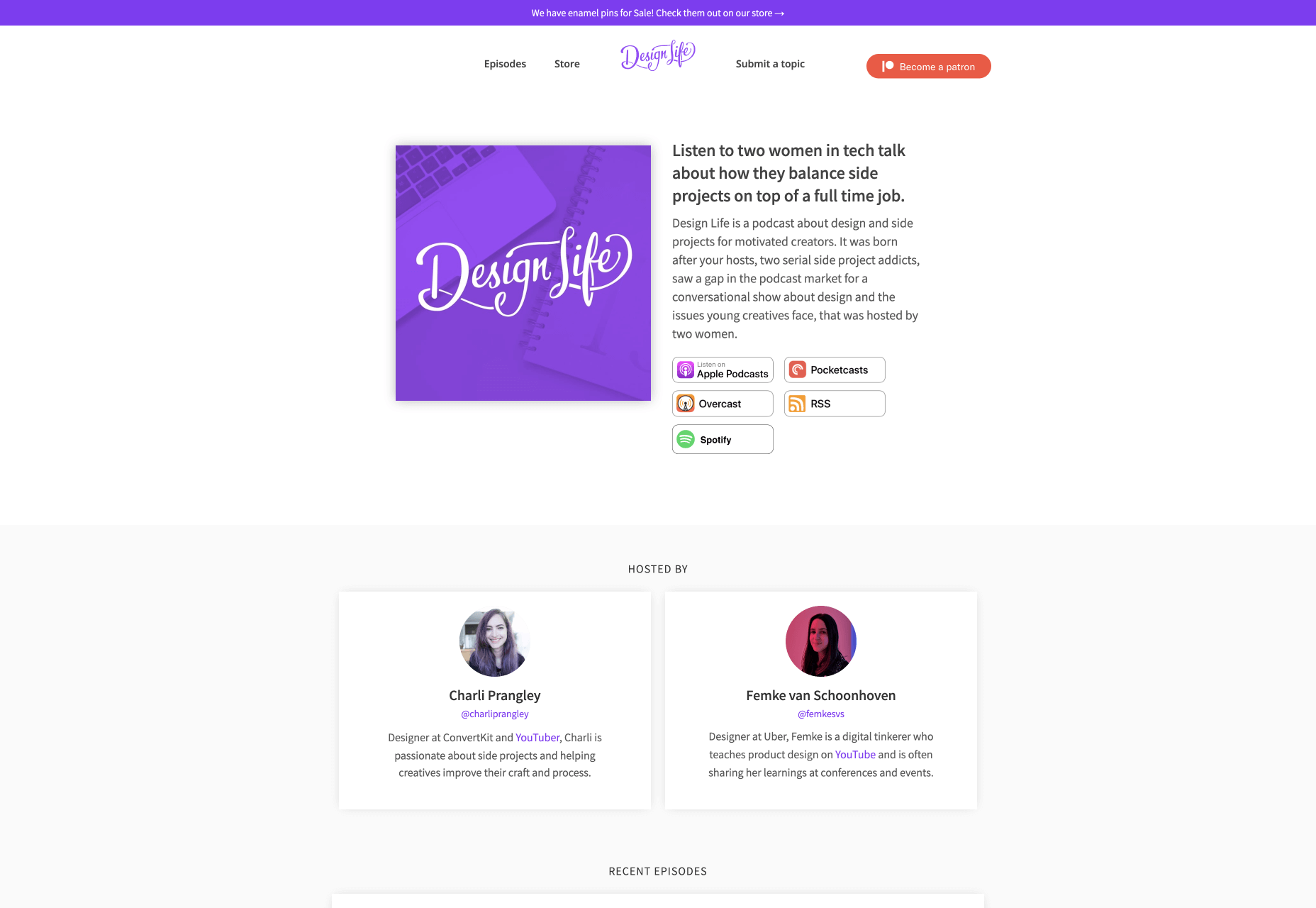
7. Design Life
Being a successful designer is often about keeping up with the latest trends, from the color of the year to new UX strategies. However, when you’re staying up to date, it’s also nice to connect with experts that you can relate to.
Unfortunately for women in the web design world, there aren’t as many inspiring podcasts hosted by women. That’s why Femke van Schoonhoven and Charli Prangley created Design Life. This podcast discusses the ins and outs of being a woman working in tech. There are also insights into the latest industry news, landing clients, and how to create a portfolio.
8. JavaScript Jabber
If JavaScript isn’t something that you enjoy working with, then this isn’t likely to be the best web design podcast for you. However, since about 94.9% of websites use JavaScript, there’s a pretty good chance that you might want to know more about this language. The JavaScript Jabber podcast concentrates on keeping experts up to date on the world of ECMAScript.
Every episode features a new crucial topic and a selection of amazing guests too. You’ll learn about everything from JS communities to building your career. However, you are expected to have a basic knowledge of the language when you tune in.
9. Code Newbie
From a podcast designed for growing professionals, to one that’s all about supporting beginners in the design world. Code Newbie is a podcast that covers unique stories from people who are pursuing their dreams of full-time design and development jobs. Designed for those who need both inspiration and guidance, the website covers a range of different topics.
With this podcast, you’ll discover interviews from front-end developers, programmers, and a bunch of other people who have discovered how to be successful in the world of code. Additionally, the podcast approaches each topic in an easy-to-follow manner, so it’s great for newbies.
10. Adventures in Design
Another excellent web design podcast for those who need a good combination of information and inspiration is Adventures in Design. This podcast, hosted by Mark Brickey, takes the format of a daily talk show for people who want to learn about all aspects of design. The podcast conducts interviews with creatives and well-known designers, as well as offering tons of information for professionals and freelancers.
This particular option has a unique structure, however. You need to pay a monthly or yearly subscription fee to listen in. While most podcasts are free, the AID network can offer something incredibly useful and exciting, if you’re willing to shell out some cash.
11. Design Details
All great designers know that the smallest details can transform user experience instantly. That’s why it’s essential to get deep into the different components of every design. With the Design Details podcast, you’ll have an opportunity to learn more about the small changes that can make a big difference to your development efforts.
The hosts, Brian Lovin and Bryn Jackson, interview some of the world’s most brilliant developers, including those behind apps like Google Search, Stripe, and even the social site, Instagram. Despite some high-profile guests, the show is fun, insightful, and informal – great for those who don’t want anything too deep.
12. Responsive Web Design
Last but not least, we have an oldie-but-goodie. The Responsive Web Design podcast is hosted by Ethan Marcotte and Karen McGrane. The hosts focus on interviews with leaders in the responsive design world and discuss strategies for implementing various designs into websites. The interviews touch on a number of incredible industries and deliver exciting perspectives into design.
Previous guests on this podcast include people from companies like Expedia, Microsoft, and even the Guardian newspaper. The Responsive Web Design podcast has received critical acclaim over the years. Although there hasn’t been a new episode for a while, it’s well worth going back through the 157 episodes for some incredible tips.
Conversational User Interfaces aren’t a new concept. It has widely gained acceptance over the past few years and more and more websites are willing to have conversational user interfaces on their websites. We’re finally at a point where everyone can use it irrespective of their skill level. In this article, we throw light on the advantages and challenges of conversational user interfaces.
For a long time, we’ve visualized interfaces in the form of buttons, lists, drop-down lists, etc. But now we have entered a future composed of not just visual interfaces but conversational interfaces as well. Microsoft has reported that every week, three thousand bots are created using their bot framework.
A well-known advancement enabling conversational user interfaces is Natural Language Processing, a branch of artificial intelligence that deals with analyzing, understanding and generating the languages that humans use naturally to interface with computers in both written and spoken form using human languages.
Have a look at the below video where Google assistant calls a Salon (in the background) to book an appointment for Lisa.
There’s a business side to design and there’s a psychological one. CUIs incorporate both of these. Some well-known examples of conversational interfaces include chatbots and voice assistants. In order for CUIs to be effective, you must follow best practices and core principles involving creating conversational experiences that feel natural and frictionless.
Let’s dive deep into the advantages and challenges of conversational user interfaces.
Advantages of Conversational User Interfaces
Easy To Learn & Use
It is easy for users to learn how to interact with conversational interfaces. The various chat apps and voice assistants have paved the way for the adoption of conversational user interfaces. You can just speak to a device and you will get the information you require.
Non-Procedural Approach Saves Time
The human language is non-procedural. While speaking or chatting, users can provide all the necessary information in one go which is not the case with graphical user interfaces where we have sequential steps. Conversational UI allows users to provide all information in one go thereby saving time. Here’s a sample non-procedural query to a voice assistant – Find flights from San Francisco to Berlin on Tuesday or Thursday next week.
Enable Multitasking
Voice interfaces really excel at hands-free and multitasking situations where the use of our hands is not optimal or simply not possible. With voice user interfaces, one can multitask without significant context switching reducing the risk of accidents. For example, you can be driving and still talking to your voice assistant.
Better Engagement With End-Users
By asking the right questions at appropriate times, we can significantly have better engagement with the users. Live chat applications maximize website conversions. Conversational interfaces are smart, and they help in keeping the customers engaged for prolonged periods. Better engagement results in more leads which eventually leads to higher revenue for the brands. Hence, using conversational interfaces not only increases the revenue of the company but also improves the engagement with its users. Interactive voice systems are a more natural means of interaction than visual interfaces as it removes a visible interface replacing it with voice.
Cross-Platform Integration & Compatibility
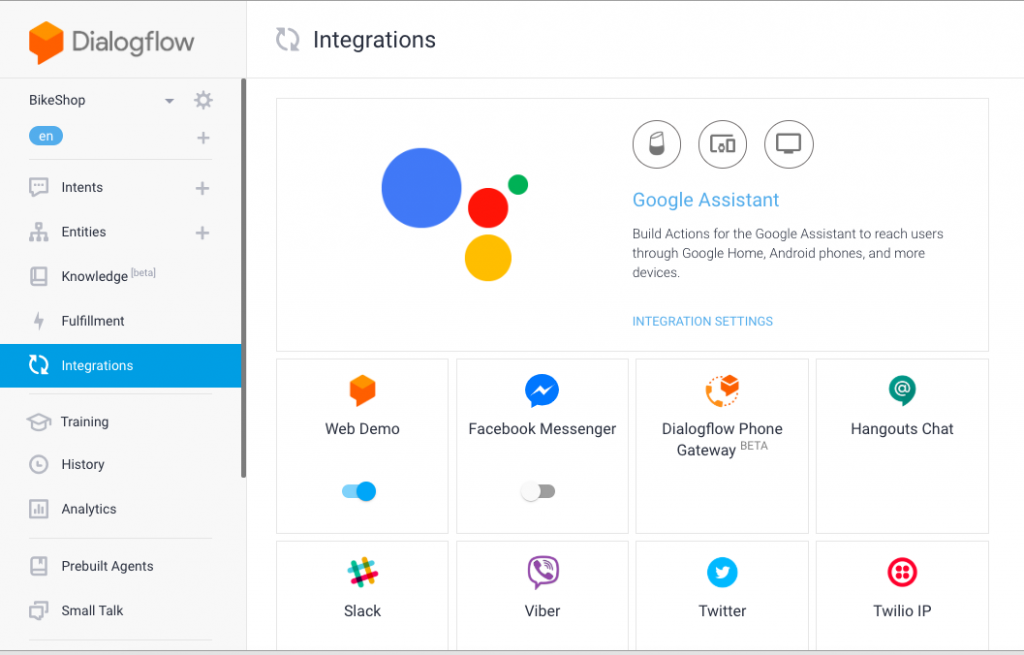
Conversational interfaces allow companies to extend their services to platforms where their customers are: on Facebook Messenger, Slack, Telegram, Skype, and WhatsApp. Users can interact with the same service across various devices: TVs, set-top boxes, virtual assistants, phones, tablets, desktop computers, cars, and even watches. Any platform that supports conversational user interfaces can be integrated with the same chatbot – an extremely cost-effective way for businesses to have a multi-channel presence.
You can use Dialogflow’s cross-platform functionality to seamlessly integrate your conversational interface on leading platforms such as Amazon Alexa, Microsoft Azure’s framework for Crotona or Skype, and more.
Conversational interfaces have the ability to take the customer through the exact journey they are looking for. The progress in natural language processing and machine learning has made it possible to provide tailor-made personalized experiences to users via conversational interfaces in order to establish a deeper personal connection.
Now, we can have targeted questions with clear call-to-action for every interaction making the end-user experience more personalized. We can now deliver the same content or ask the same question to two different users in different ways based on their preferences like gender, tone, accent, and pace. Conversational interfaces can also leverage customer contexts like previous live chat transcripts, purchasing history, and recommended products or services for personalized experiences.
Superior Frictionless User Experience
Everybody knows the importance of user experience these days which largely depends on the interface between the user and the service or product. Traditional user interfaces present many elements like side panels, buttons, and menus – which usually turns the focus away from what they are looking for. Conversational Interfaces make the human-computer interaction more efficient thereby providing users with a superior experience. Having interfaces that don’t require their end-users to spend valuable time learning it creates an effortless and frictionless experience for them.
With voice user interfaces, users don’t need to install multiple apps or create separate accounts for services they use. Why download an app for booking a flight or ordering food when a single chat or voice interface can do it?
Conversational interfaces can be useful for multi-step complex operations. For example: returning a product or claiming a refund. In such cases, the system will collect all required information and create appropriate requests with less friction via a simple conversation.
Challenges Involving Conversational User Interfaces
Conversational UI is fairly new. Here are a few challenges involving conversational user interfaces that prevent it from reaching its full potential
High Expectation from Users
Users expect a lot from chatbots and voice assistants. Users expect conversational interfaces to exactly know what they want, the solutions to their problems, and more. Some even want them to be their companion and sort out their life problems. According to the Uncanny Valley theory, the more the conversation sounds human, the more unrealistic user expectations may become.
We must understand that a conversational interface is still a bot (at the end of the day). The companies must explicitly state that their bot is what it is – and not a human. The companies should also mention that their bot may not have answers to all user queries and if that’s the case – the user must interact with their customer support.
Low Discoverability & Understanding of System Scope
According to Don Norman’s “How to design everyday things”, discoverability and understanding are the two basic characteristics of good design. If a web page has 3 buttons, it probably means that it can do 3 things and you probably know what those are. Chatbots lack both these characteristics. Users are not sure about the capabilities of the chatbot. This leads to the users having unrealistic expectations from the chatbots. Chatbots must try to overcome this challenge by literally telling users what their capabilities are.
Inefficient For Complex Processes
According to research by Nielson Norman Group, chatbots and voice assistants work well only for limited and simple queries having fairly simple and short answers. CUIs only work well when the users know what to ask and how. When the user needs to compare multiple options (consider the case of flight or hotel booking), using CUIs does not really help. Designing complex processes in a conversation format makes them inefficient and frustrating for the users. Buttons, menus, etc now appear in chatbots making them fully-fledged apps.
Technology Is Expensive
While natural language processing and machine learning have been around the corner for some time now, the technology is still expensive and is yet to become fully “human-proof”. According to a solutions engineer from Salesforce – one needs to consider 50k$-100k$ to build an NLP-based voice assistant along with training the system for 3-6 months with human agents which incurs additional costs.
Machine Learning Model Training
Machine learning is not required for every conversational interface but if you want to provide personalized experiences, it is essential to set the right patterns. The bot must be trained to recognize the input and deliver relevant output. Moreover, the bot must adapt to a particular user profile to increase the personalization and relevancy of outputs. In order to overcome this challenge, time and effort are required but once you have passed that stage – it’s all good.
Configuring The NLP
In order for the bot to not show “Sorry, I didn’t understand that” response, there should be a coherent system that processes inputs. It includes cleaning up of the input (removal of punctuation and stop words, and word tokenization), word stemming, and a decision-making component that integrates with outside services to commit requested actions.
Non-Implicit Contextual Conversations
Conversational interfaces do not have a mind of their own. CUIs need implicit context in order to process your requests. Users directly need to mention the tasks that need to be done. If you tell your travel agent that your birthday is on the 15th of next month, they will implicitly understand that vacation needs to be booked & they will come up with their research. Even though you didn’t explicitly ask your travel agent to plan and book the vacation, they implicitly understood.
Security & Privacy
Are chatbots and voice assistants really secure? Is your privacy at risk? Do you know that the various chatbot and voice-bot platforms are owned by the leading corporates and all our data and information are their assets? These big corporations “listen to us” outside of the web/app environment. In one particular case, Amazon’s Alexa recorded a private conversation and sent it to a random contact. Such cases really hamper the trust between the users and CUIs.
Third-Party Integrations
No doubt that CUIs support cross-platform integration and are compatible with multiple devices, the challenge is to integrate with third-party services like the ones used for integrating with the companies’ customer data.
Conclusion
We briefly touched upon conversational user interfaces, their advantages, and the challenges involving them. CUIs are easy to learn and use, enable multitasking, follow a non-procedural approach to save time, facilitate better engagement with end-users, provide tailor-made personalized frictionless experiences.
On the other hand, CUIs have low discoverability and understanding of system scope, the technology is expensive and inefficient for complex processes, users expect a lot from chatbots and voice assistants, requires a lot of time and effort for creating personalized experiences, need implicit context to process your request, difficult to integrate with third-party services, and there are concerns over security and user privacy.
This post is about understanding how Suspense works, what it does, and seeing how it can integrate into a real web app. We’ll look at how to integrate routing and data loading with Suspense in React. For routing, I’ll be using vanilla JavaScript, and I’ll be using my own micro-graphql-react GraphQL library for data.
If you’re wondering about React Router, it seems great, but I’ve never had the chance to use it. My own side project has a simple enough routing story that I always just did it by hand. Besides, using vanilla JavaScript will give us a better look at how Suspense works.
A little background
Let’s talk about Suspense itself. Kingsley Silas provides a thorough overview of it, but the first thing to note is that it’s still an experimental API. That means — and React’s docs say the same — not to lean on it yet for production-ready work. There’s always a chance it will change between now and when it’s fully complete, so please bear that in mind.
That said, Suspense is all about maintaining a consistent UI in the face of asynchronous dependencies, such as lazily loaded React components, GraphQL data, etc. Suspense provides low-level API’s that allow you to easily maintain your UI while your app is managing these things.
But what does “consistent” mean in this case? It means not rendering a UI that’s partially complete. It means, if there are three data sources on the page, and one of them has completed, we don’t want to render that updated piece of state, with a spinner next to the now-outdated other two pieces of state.
What we do want to do is indicate to the user that data are loading, while continuing to show either the old UI, or an alternative UI which indicates we’re waiting on data; Suspense supports either, which I’ll get into.
What exactly Suspense does
This is all less complicated than it may seem. Traditionally in React, you’d set state, and your UI would update. Life was simple. But it also led to the sorts of inconsistencies described above. What Suspense adds is the ability to have a component notify React at render time that it’s waiting for asynchronous data; this is called suspending, and it can happen anywhere in a component’s tree, as many times as needed, until the tree is ready. When a component suspends, React will decline to render the pending state update until all suspended dependencies have been satisfied.
So what happens when a component suspends? React will look up the tree, find the first component, and render its fallback. I’ll be providing plenty of examples, but for now, know that you can provide this:
<Suspense fallback={<Loading />}>
…and the component will render if any child components of are suspended.
But what if we already have a valid, consistent UI, and the user loads new data, causing a component to suspend? This would cause the entire existing UI to un-render, and the fallback to show. That’d still be consistent, but hardly a good UX. We’d prefer the old UI stay on the screen while the new data are loading.
To support this, React provides a second API, useTransition, which effectively makes a state change in memory. In other words, it allows you to set state in memory while keeping your existing UI on screen; React will literally keep a second copy of your component tree rendered in memory, and set state on that tree. Components may suspend, but only in memory, so your existing UI will continue to show on the screen. When the state change is complete, and all suspensions have resolved, the in-memory state change will render onto the screen. Obviously you want to provide feedback to your user while this is happening, so useTransition provides a pending boolean, which you can use to display some sort of inline “loading” notification while suspensions are being resolved in memory.
When you think about it, you probably don’t want your existing UI to show indefinitely while your loading is pending. If the user tries to do something, and a long period of time elapses before it’s finished, you should probably consider the existing UI outdated and invalid. At this point, you probably will want your component tree to suspend, and your fallback to display.
To accomplish this, useTransition takes a timeoutMs value. This indicates the amount of time you’re willing to let the in-memory state change run, before you suspend.
Here, startTransition is a function. When you want to run a state change “in memory,” you call startTransition, and pass a lambda expression that does your state change.
You can call startTransition wherever you want. You can pass it to child components, etc. When you call it, any state change you perform will happen in memory. If a suspension happens, isPending will become true, which you can use to display some sort of inline loading indicator.
That’s it. That’s what Suspense does.
The rest of this post will get into some actual code to leverage these features.
Example: Navigation
To tie navigation into Suspense, you’ll be happy to know that React provides a primitive to do this: React.lazy. It’s a function that takes a lambda expression that returns a Promise, which resolves to a React component. The result of this function call becomes your lazily loaded component. It sounds complicated, but it looks like this:
SettingsComponent is now a React component that, when rendered (but not before), will call the function we passed in, which will call import() and load the JavaScript module located at ./modules/settings/settings.
The key piece is this: while that import() is in flight, the component rendering SettingsComponent will suspend. It seems we have all the pieces in hand, so let’s put them together and build some Suspense-based navigation.
Navigation helpers
But first, for context, I’ll briefly cover how navigation state is managed in this app, so the Suspense code will make more sense.
I’ll be using my booklist app. It’s just a side project of mine I mainly keep around to mess around with bleeding-edge web technology. It was written by me alone, so expect parts of it to be a bit unrefined (especially the design).
The app is small, with about eight different modules a user can browse to, without any deeper navigation. Any search state a module might use is stored in the URL’s query string. With this in mind, there are a few methods which scrape the current module name, and search state from the URL. This code uses the query-string and history packages from npm, and looks somewhat like this (some details have been removed for simplicity, like authentication).
import createHistory from "history/createBrowserHistory";
import queryString from "query-string";
export const history = createHistory();
export function getCurrentUrlState() {
let location = history.location;
let parsed = queryString.parse(location.search);
return {
pathname: location.pathname,
searchState: parsed
};
}
export function getCurrentModuleFromUrl() {
let location = history.location;
return location.pathname.replace(///g, "").toLowerCase();
}
I have an appSettings reducer that holds the current module and searchState values for the app, and uses these methods to sync with the URL when needed.
The pieces of a Suspense-based navigation
Let’s get started with some Suspense work. First, let’s create the lazy-loaded components for our modules.
Now we need a method that chooses the right component based on the current module. If we were using React Router, we’d have some nice components. Since we’re rolling this manually, a switch will do.
export const getModuleComponent = moduleToLoad => {
if (moduleToLoad == null) {
return null;
}
switch (moduleToLoad.toLowerCase()) {
case "activate":
return ActivateComponent;
case "authenticate":
return AuthenticateComponent;
case "books":
return BooksComponent;
case "home":
return HomeComponent;
case "scan":
return ScanComponent;
case "subjects":
return SubjectsComponent;
case "settings":
return SettingsComponent;
case "admin":
return AdminComponent;
}
return HomeComponent;
};
The whole thing put together
With all the boring setup out of the way, let’s see what the entire app root looks like. There’s a lot of code here, but I promise, relatively few of these lines pertain to Suspense, and I’ll cover all of it.
First, we have two different calls to useTransition. We’ll use one for routing to a new module, and the other for updating search state for the current module. Why the difference? Well, when a module’s search state is updating, that module will likely want to display an inline loading indicator. That updating state is held by the moduleUpdatePending variable, which you’ll see I put on context for the active module to grab, and use as needed:
The appStatePacket is the result of the app state reducer I discussed above (but did not show). It contains various pieces of application state which rarely change (color theme, offline status, current module, etc).
let appStatePacket = useAppState();
A little later, I grab whichever component happens to be active, based on the current module name. Initially this will be null.
let Component = getModuleComponent(appState.module);
The first call to useEffect will tell our appSettings reducer to sync with the URL at startup.
Since this is the initial module the web app navigates to, I wrap it in startTransitionNewModule to indicate that a fresh module is loading. While it might be tempting to have the appSettings reducer have the initial module name as its initial state, doing this prevents us from calling our startTransitionNewModule callback, which means our Suspense boundary would render the fallback immediately, instead of after the timeout.
The next call to useEffect sets up a history subscription. No matter what, when the url changes we tell our app settings to sync against the URL. The only difference is which startTransition that same call is wrapped in.
If we’re browsing to a new module, we call startTransitionNewModule. If we’re loading a component that hasn’t been loaded already, React.lazy will suspend, and the pending indicator visible only to the app’s root will set, which will show a loading spinner at the top of the app while the lazy component is fetched and loaded. Because of how useTransition works, the current screen will continue to show for three seconds. If that time expires and the component is still not ready, our UI will suspend, and the fallback will render, which will show the component:
If the update causes a suspension, the pending indicator we’re putting on context will be triggered. The active component can detect that and show whatever inline loading indicator it wants. As before, if the suspension takes longer than three seconds, the same Suspense boundary from before will be triggered… unless, as we’ll see later, there’s a Suspense boundary lower in the tree.
One important thing to note is that these three-second timeouts apply not only to the component loading, but also being ready to display. If the component loads in two seconds, and, when rendering in memory (since we’re inside of a startTransition call) suspends, the useTransition will continue to wait for up to one more second before Suspending.
In writing this blog post, I used Chrome’s slow network modes to help force loading to be slow, to test my Suspense boundaries. The settings are in the Network tab of Chrome’s dev tools.
Let’s open our app to the settings module. This will be called:
dispatch({ type: URL_SYNC });
Our appSettings reducer will sync with the URL, then set module to “settings.” This will happen inside of startTransitionNewModule so that, when the lazy-loaded component attempts to render, it’ll suspend. Since we’re inside startTransitionNewModule, the isNewModulePending will switch over to true, and the component will render.
If the component is still not ready to render within three seconds, the in-memory version of our component tree will switch over, suspend, and our Suspense boundary will render the component.When it’s done, the settings module will show.
So what happens when we browse somewhere new? Basically the same thing as before, except this call:
dispatch({ type: URL_SYNC });
…will come from the second instance of useEffect. Let’s browse to the books module and see what happens. First, the inline spinner shows as expected:
If the three-second timeout elapses, our Suspense boundary will render its fallback:And, eventually, our books module loads:
Searching and updating
Let’s stay within the books module, and update the URL search string to kick off a new search. Recall from before that we were detecting the same module in that second useEffect call and using a dedicated useTransition call for it. From there, we were putting the pending indicator on context for whichever module was active for us to grab and use.
Let’s see some code to actually use that. There’s not really much Suspense-related code here. I’m grabbing the value from context, and if true, rendering an inline spinner on top of my existing results. Recall that this happens when a useTransition call has begun, and the app is suspended in memory. While that’s happening, we continue to show the existing UI, but with this loading indicator.
Let’s set a search term and see what happens. First, the inline spinner displays.
Then, if the useTransition timeout expires, we’ll get the Suspense boundary’s fallback. The books module defines its own Suspense boundary in order to provide a more fine-tuned loading indicator, which looks like this:
This is a key point. When making Suspense boundary fallbacks, try not to throw up any sort of spinner and “loading” message. That made sense for our top-level navigation because there’s not much else to do. But when you’re in a specific part of your application, try to make your fallback re-use many of the same components with some sort of loading indicator where the data would be — but with everything else disabled.
This is what the relevant components look like for my books module:
Before we move on, I’d like to point out one thing from the earlier screenshots. Look at the inline spinner that displays while the search is pending, then look at the screen when that search suspended, and next, the finished results:
Notice how there’s a “C++” label to the right of the search pane, with an option to remove it from the search query? Or rather, notice how that label is only on the second two screenshots? The moment the URL updates, the application state governing that label is updated; however, that state does not initially display. Initially, the state update suspends in memory (since we used useTransition), and the prior UI continues to show.
Then the fallback renders. The fallback renders a disabled version of that same search bar, which does show the current search state (by choice). We’ve now removed our prior UI (since by now it’s quite old, and stale) and are waiting on the search shown in the disabled menu bar.
This is the sort of consistency Suspense gives you, for free.
You can spend your time crafting nice application states, and React does the leg work of surmising whether things are ready, without you needing to juggle promises.
Nested Suspense boundaries
Let’s suppose our top-level navigation takes a while to load our books component to the extent that our “Still loading, sorry” spinner from the Suspense boundary renders. From there, the books component loads and the new Suspense boundary inside the books component renders. But, then, as rendering continues, our book search query fires, and suspends. What will happen? Will the top-level Suspense boundary continue to show, until everything is ready, or will the lower-down Suspense boundary in books take over?
The answer is the latter. As new Suspense boundaries render lower in the tree, their fallback will replace the fallback of whatever antecedent Suspense fallback was already showing. There’s currently an unstable API to override this, but if you’re doing a good job of crafting your fallbacks, this is probably the behavior you want. You don’t want “Still loading, sorry” to just keep showing. Rather, as soon as the books component is ready, you absolutely want to display that shell with the more targeted waiting message.
Now, what if our books module loads and starts to render while the startTransition spinner is still showing and then suspends? In other words, imagine that our startTransition has a timeout of three seconds, the books component renders, the nested Suspense boundary is in the component tree after one second, and the search query suspends. Will the remaining two seconds elapse before that new nested Suspense boundary renders the fallback, or will the fallback show immediately? The answer, perhaps surprisingly, is that the new Suspense fallback will show immediately by default. That’s because it’s best to show a new, valid UI as quickly as possible, so the user can see that things are happening, and progressing.
How data fits in
Navigation is fine, but how does data loading fit into all of this?
It fits in completely and transparently. Data loading triggers suspensions just like navigation with React.lazy, and it hooks into all the same useTransition and Suspense boundaries. This is what’s so amazing about Suspense: all your async dependencies seamlessly work in this same system. Managing these various async requests manually to ensure consistency was a nightmare before Suspense, which is precisely why nobody did it. Web apps were notorious for cascading spinners that stopped at unpredictable times, producing inconsistent UIs that were only partially finished.
OK, but how do we actually tie data loading into this? Data loading in Suspense is paradoxically both more complex, and also simple.
I’ll explain.
If you’re waiting on data, you’ll throw a promise in the component that reads (or attempts to read) the data. The promise should be consistent based on the data request. So, four repeated requests for that same “C++” search query should throw the same, identical promise. This implies some sort of caching layer to manage all this. You’ll likely not write this yourself. Instead, you’ll just hope, and wait for the data library you use to update itself to support Suspense.
This is already done in my micro-graphql-react library. Instead of using the useQuery hook, you’ll use the useSuspenseQuery hook, which has an identical API, but throws a consistent promise when you’re waiting on data.
Wait, what about preloading?!
Has your brain turned to mush reading other things on Suspense that talked about waterfalls, fetch-on-render, preloading, etc? Don’t worry about it. Here’s what it all means.
Let’s say you lazy load the books component, which renders and then requests some data, which causes a new Suspense. The network request for the component and the network request for the data will happen one after the other—in a waterfall fashion.
But here’s the key part: the application state that led to whatever initial query that ran when the component loaded was already available when you started loading the component (which, in this case, is the URL). So why not “start” the query as soon as you know you’ll need it? As soon as you browse to /books, why not fire off the current search query right then and there, so it’s already in flight when the component loads.
The micro-graphql-react module does indeed have a preload method, and I urge you to use it. Preloading data is a nice performance optimization, but it has nothing to do with Suspense. Classic React apps could (and should) preload data as soon as they know they’ll need it. Vue apps should preload data as soon as they know they’ll need it. Svelte apps should… you get the point.
Preloading data is orthogonal to Suspense, which is something you can do with literally any framework. It’s also something we all should have been doing already, even though nobody else was.
But seriously, how do you preload?
That’s up to you. At the very least, the logic to run the current search absolutely needs to be completely separated into its own, standalone module. You should literally make sure this preload function is in a file by itself. Don’t rely on webpack to treeshake; you’ll likely face abject sadness the next time you audit your bundles.
You have a preload() method in its own bundle, so call it. Call it when you know you’re about to navigate to that module. I assume React Router has some sort of API to run code on a navigation change. For the vanilla routing code above, I call the method in that routing switch from before. I had omitted it for brevity, but the books entry actually looks like this:
switch (moduleToLoad.toLowerCase()) {
case "activate":
return ActivateComponent;
case "authenticate":
return AuthenticateComponent;
case "books":
// preload!!!
booksPreload();
return BooksComponent;
That’s it. Here’s a live demo to play around with:
To modify the Suspense timeout value, which defaults to 3000ms, navigate to Settings, and check out the misc tab. Just be sure to refresh the page after modifying it.
Wrapping up
I’ve seldom been as excited for anything in the web dev ecosystem as I am for Suspense. It’s an incredibly ambitious system for managing one of the trickiest problems in web development: asynchrony.
There are very few scenarios in which an eventually consistent database is preferable over a strongly consistent database. Further, in a multi-region application scenario where scaling is necessary, choosing either an undistributed database or an eventually consistent database is even more questionable. So what motivates engineers to ignore strongly consistent distributed databases? We have seen many reasons, but wrong assumptions drive most of them.
“The CAP theorem says it’s impossible”
As we explained in Part 1 of this series (insert link), the CAP theorem is widely accepted yet often misinterpreted. When many people misinterpret a well-known theorem, it leaves a mark. In this case, many engineers still believe that eventual consistency is a necessary evil.
“Building a strongly consistent distributed database is too hard/impossible”
It is slowly sinking in that consistency should not be sacrificed, yet many databases still put consistency second. Why is that? Some popular databases offer options that deliver higher consistency, but only at the cost of potentially very high latencies. Their sales messaging might even claim that delivering consistency at low latencies in a multi-region distributed database is incredibly hard or even impossible, and the developer audience has salient memories of experiencing very poor latencies in databases that were not built for consistency. Combined, they jointly fortify the misconception that strong consistency in a distributed database with relatively low latencies is impossible.
“Premature optimization is the root of all evil”
Many engineers build according to the “Premature optimization is the root of all evil” (Donald Knuth) principle, but that statement is only meant to apply to small inefficiencies. Building your startup on a strongly consistent distributed scalable database might seem like a premature optimization, because initially, your application doesn’t require scale and might not require distribution. However, we are not talking about small inefficiencies here. The requirement to scale or distribute might arise overnight when your application becomes popular. At that point, your users have a terrible experience, and you are looking at a substantial challenge to change your infrastructure and code.
“It’s hard to program against a distributed database”
This used to have some truth to it since distributed databases were new, and many came with severe limitations. They did not allow joins, only allowed key-value storage, or required you to query your data according to predefined sharding keys, which you couldn’t change any more. Today, we have distributed databases that have flexible models and provide the flexibility you are used to with traditional databases. This point is very related to the previous point, which ignores that nowadays, starting to programming against a strongly consistent distributed database is just as easy and probably easier in the long run compared to a traditional database. If it’s just as easy, then why not optimize from the start?
Working with an eventually consistent database is like…
Distributed databases are often created by people who have experienced problems with eventual consistency. For example, FaunaDB was built by former Twitter engineers after having experienced how difficult it is to build a scalable system on top of the eventually consistent databases that were popular around that time, such as Cassandra. These problems typically manifest when a new company starts to scale, hence many younger engineers have never experienced them first hand.
Sometimes painful things can teach us lessons that we didn’t think we needed to know.
— Amy Poehler
Discussing the dangers of eventual consistency typically leads to the “it works for me” argument from engineers who simply haven’t experienced any issues yet. Since that often takes months (or years, if you are lucky), let’s look at an analogy.
…riding a bike with loose wheels.
A while ago, my best friend was about to miss an appointment, so I lent him my bike. I was happy that I helped out, he was happy, and everything went well. That happiness quickly turned into pain when he tried to jump the bike onto a side-walk. You see… I had tinkered with the bike earlier that day and had forgotten to tighten the front wheel. He came back with a huge purple bruise.
The bike example is very similar to working with a database that is not strongly consistent. Everything will go well until you try to lift the bike’s wheel (or in other words, until your company lifts off and starts scaling up).
At the moment your application needs to scale up, you typically do so by replicating services. Once the database becomes the bottleneck, you replicate your traditional database or move to a distributed database. Sadly, at that point, features in your application might break when you start replicating your database. Until now, you hadn’t noticed these problems since the database ran on a single node. At that point, two things might happen:
Situation 1, build around it/fix it: the developers soon realize that the database they are ‘riding’ is unreliable for the features they have built or are trying to build. Their choices come down to canceling the features, simplifying the features, or changing the database.
Situation 2, fail epically: the developers were not well informed by the vendor (I was a lousy bike vendor to my friend) about the risks, and now lack the information to understand the very subtle implications of what’s happening. This is not necessarily due to a lack of capability of the engineer. Poorly defined standards and optimistic marketing do a great job of obfuscating different databases’ consistency guarantees.
The developers who end up in the first situation are often already experienced in dealing with eventually consistent systems. They will now either accept that they can’t deliver on some features, or will build a complex and hard-to-maintain layer on top of the database to get what they need. In essence, they attempt to develop a strongly consistent database on top of an eventually consistent one. That’s a shame since other people have designed distributed databases from the ground up that will not only be more efficient, but don’t require maintenance from your development team!
…riding an invisible bike with loose wheels.
The developers who end up in the second situation are riding a partly invisible bike. They do not realize that the wheel is loose, do not see the wheel detach, and once they look up after falling, they still see a completely intact bike.
At the moment things go wrong, the complexity to resolve these bugs is high for several reasons:
Determine whether it’s an eventual consistency bug. The issue might be either an application bug, or a bug caused by misunderstanding the guarantees of the underlying database. To know for sure, we need to investigate the application logic, and in case the application logic is sound in a non-distributed environment, the engineer has to have the instinct to evaluate whether this situation might arise due to eventual consistency.
The cause has disappeared. Second, since the database eventually becomes consistent, the cause of the problem has probably disappeared (the wheel is magically reattached to the bike, and all you see is an impeccable bike).
Fix it! Once the problem is determined, you can either find a way around it, attempt to build a layer on top of the database (hello latency and other potential bugs), remove the features, or change the database. The last option is sometimes perceived as easy. However, even the most subtle differences between databases make this a very challenging endeavor. At the moment your application is lifting off, you already have your hands full. This is not the moment you want to be swapping databases!
…riding an invisible bike with loose wheels and a group of people standing on your shoulders.
The invisible bike example is still too forgiving. In reality, others are probably depending on your application. So basically, you are riding an invisible bike while others (your clients) are standing on your shoulders.
Not only will you fall, but they will fall with you and land on top of you–heavily and painfully. You might not even survive the fall at that point; in other words, your company might not survive the storm of negative feedback from your clients.
The moral of the story? If you had chosen a strongly (vs.eventually) consistent database from the beginning, you would not have to consider going through a complex and resource-intensive project like migrating your database at a point when your clients are already frustrated.
Conclusion
Choosing an eventually consistent database for scaling was justified a few years back when there was simply no other choice. However, we now have modern databases that can scale efficiently without sacrificing data consistency or performance. . Moreover, these modern databases also include several other awesome features that go beyond consistency, such as ease of use, serverless pricing models, built-in authentication, temporality, native GraphQL, and more. With a modern database, you can scale without opening Pandora’s box!
And, if after reading this series of articles, you still choose not to use a strongly consistent distributed database, please at least make sure to tighten your wheels (in other words, read and understand different databases’ consistency guarantees).
If you’re a teacher, you’ve likely heard about all the ways technology can support you in the classroom. Whether it’s tablets and smart boards or the internet and social media, technology influences the modern classroom in too many ways to count. But most teachers don’t get a manual that shows them how to effectively use and implement this kind of technology in the classroom.
This guide will help you understand how technology can empower you and your students. We’ll explore how digital tools can help teachers and students succeed, and how you can use that tech in a safe, professional way. Learning how technology is shaping the world of learning will help you see how it fits into your specific needs and your goals as an educator.
This guide will cover
The benefits of technology in the classroom. Learn how technology improves tasks like attendance-taking and standards-based lesson planning while preparing students for the future.
How to use technology in the classroom. Discover the power of devices for more engaging, interactive lessons for students of all ages.
Technology grants. How to find, apply for, and obtain grants for using technology in the classroom.
Assistive technology in the classroom. See how technology can expand access to learning for special-needs students.
Using technology for differentiated instruction. Leverage classroom data to create personalized learning experiences for each student.
The pros and cons of classroom technology. What are the main arguments against using classroom tech, and what benefits outweigh these challenges?
The current state of classroom technology. Find out how technology has shaped contemporary education — and where we’re headed.
Technology can be overwhelming, but it doesn’t have to be. We’ll show you how to get started with the right tools for you and your students.
Benefits of technology in the classroom
There are a multitude of tools, devices, and apps specifically designed to help teachers do what they do best. Most teachers who use technology in the classroom will agree: It makes their lives easier.
Unsurprisingly, one of the fastest-growing education trends is the increasing use of laptops, tablets, and other mobile devices for learning, says Steelcase. Smartphones in particular are becoming an increasingly common tool in the classroom, and more students expect to have essential information available on mobile.
6 ways classroom technology helps teachers
It’s clear that both teachers and students are taking advantage of all that technology has to offer. But how exactly can technology support teachers?
Automating everyday tasks. One of the greatest benefits of using technology in the classroom is that it saves time.
A number of apps are designed to help teachers take attendance so the task doesn’t take time out of their day. Students can mark their names on a tablet when they enter the door, even if the teacher is busy preparing for class.
Other tasks can be eliminated completely: Photocopying and stapling is no longer necessary when students can access their assignments online.
Simplified grading. Grading is a breeze with online tools that instantly interpret test answers on a mass scale. Many apps give teachers status reports so they can gain a bird’s-eye view of each student’s progress. These reports also pinpoint areas of improvement, allowing teachers to identify learning struggles earlier in the year. In addition to making grading easier for teachers, technology helps students get the help and attention they need.
Online lesson planning and storage. The internet is full of inspiration and ideas from other teachers. Instead of creating a new lesson plan from scratch every day, teachers can repurpose and reuse great ideas from other educators.
Storing and sharing lessons in the cloud lets teachers access lessons anytime, from anywhere. Digital lesson planning also allows teachers to quickly access and apply their own lessons from past years — no filing cabinets required.
Fast feedback and workflows. Teachers can use Google Drive and other cloud applications for faster editing and grading. When students submit their work online, teachers can easily access it without having to juggle papers. This creates a more meaningful revision workflow between teachers and students because teachers can see exactly what students changed. The cloud enables students to collaborate with each other on assignments and projects too.
Meeting state standards. More lesson planning tools are equipped with Common Core standards, making it easier to check all the boxes for standardized tests. Teachers can also find lesson plan ideas and templates that meet specific standards for grades and states on the internet and in lesson planning apps.
School safety. An unexpected benefit of classroom technology is school safety. Teachers and administrators have the power to lock all school doors and send emergency announcements at the click of a button.
Teachers can also use automated email and text alerts to communicate with a large number of parents in an instant. And information about weather delays and school closings can be sent out quickly and efficiently with technology.
Preparing children for the future
There’s no denying that we’re moving toward a technology-driven society. Knowing how to use technology — everything from digital menus to self-driving cars — prepares students for the future. Technology skills learned early can support the growth of students both in their careers and personal lives.
Career preparedness. Internet skills are essential for success in higher education. College students will have to use a variety of apps beyond word processing. They’ll also use tablets and share digital information. Students can explore potential careers online and through career workshops. Finding inspirational professionals on social media can help students network and connect with mentors.
Digital citizenship. Learning to present yourself on the internet is an increasingly important skill. When students grasp digital citizenship at an early age, they’re more likely to present themselves accurately and safely. This increases students’ professional opportunities because it ensures they won’t be dismissed outright as a result of inappropriate online content.
Another part of digital citizenship is learning how to stay safe by using tools like password managers and multifactor authentication, plus learning to identify scams.
Life skills. Searching for jobs, writing cover letters, and sending emails are all crucial skills for twenty-first century success. Students who know how to express themselves well online are much better equipped for a competitive job market. Learning to create a basic website or implement a social media strategy also makes students more desirable candidates in a competitive job market.
Supporting collaboration and connection
Technology enables students to connect with people in the classroom and around the globe. Learning how to use digital tools to collaborate on projects prepares students for nearly any career.
Connecting to students in other parts of the world fosters cultural learning and teaches students how to work with people who are different from them. While the internet can sometimes be an ugly place full of hate, it offers an immense sense of community and support when used wisely.
Classroom websites. Students of any age can benefit from classroom websites. They often foster connections between students and create a place for them to collaborate on group projects.
They also benefit students by creating a shared sense of belonging and community. Websites, which are usually filled with student work, classroom updates, and assignments, mimic what it’s like to be part of an online forum or group. Students can gain experience designing and editing the site as well as uploading files to the site.
Global citizens. Technology connects students to other classrooms in different countries across the globe. Learning how other students live promotes cultural understanding and reduces fear of those who are different. It also helps students develop interests in travel, other cultures, and different career paths.
Historical context. Theinternet connects students to archives from around the world. Students can learn about their world through images, videos, and text archives. The internet can also illuminate the past: Accessing historical archives makes history lessons more relevant and tangible.
How do you actually use technology in the classroom?
Whether it’s gamification, online quizzes, or group collaboration, there are a near-infinite number of ways to use technology in the classroom.
The most effective educational technology applications use digital tools to meet specific learning objectives. Here are some of the most common ways teachers can enhance everyday lessons through strategies and lesson plans involving technology.
Passive vs active learning
Technology can be used for two different types of learning: active and passive. Both are important, so let’s explore how technology plays a role in each.
Active learning. Active learning engages the student through activities and discussions that reinforce concepts, says Classcraft. The benefit of active learning is that it helps students draw connections to real life. In turn, this gives them a better understanding of their place in the world and facilitates important skills such as analysis, evaluation, and collaboration.
Active learning may also improve student attention while fostering meaningful discussions and divergent learning, in which there is more than one correct answer to a question. Many educators think of active learning as activities and lessons that don’t involve digital tools. However, online games and tools that foster real-time collaboration can facilitate active learning.
Passive learning. With passive learning, students are responsible for absorbing and retaining information at their own pace. Passive learning fosters skills such as reading, analyzing, listening, and writing.
This method primarily relies on convergent learning, meaning there’s a single answer to the question at hand. Traditional tests and quizzes evaluate students’ understanding of concepts learned through passive methods.
Passive learning lessons give teachers a stronger grasp of how class time is spent and what’s learned each day. They also offer a standardized presentation of learning material, which some students may benefit from. Reading something on a tablet, viewing an educational video, or watching an online lesson are all ways that technology can facilitate passive learning.
Gamification
One of the greatest benefits of technology in the classroom is that it can be used to foster fun, engaging learning through games. Games use the processes that students already know from video and computer games to create fun lessons that promote active learning. Almost any lesson can be turned into a game.
Points and badges. There are myriad classroom apps that allow students to earn points or badges instead of grades. In fact, points can be accumulated throughout a unit to determine a grade once the project or lesson is finished. Badges can symbolize different levels of mastery and can include small rewards or titles, like “reading rockstar” or “algebra expert,” to help students feel proud of their accomplishments.
Progress visualization. Instructional video games or gamified lesson plans can also help students visualize their progress. As they earn points with every success, students can begin to clearly see the roadmap toward a long-term learning goal. This may make them more excited about working hard and staying focused. Seeing other students’ roadmaps promotes healthy competition and creates a culture of collaboration, community, and respect.
Instant feedback
Online tools facilitate a meaningful exchange between students and teachers. When students can easily see teacher feedback, they internalize changes privately and safely. Teachers can use feedback from students to shape a learning program that’s optimized for the specific needs of their class. This is possible through the use of the following:
The cloud. Cloud-based tools allow educators to view student work, and make comments and suggestions for improvement, from anywhere. Students can see these edits instantly and make quick changes to their work. This is helpful both for individual and group work.
Online polls and quizzes. The use of online polls and quizzes ensures that students gain instant feedback on their work. Teachers can also poll students on specific aspects of a lesson to gauge how well they understood it. Digital quizzes provide teachers with analytics so they can identify areas where multiple students are struggling.
Distance learning. Even if you teach in a traditional classroom environment, you may still benefit from the ability to record and share lessons with students. If you have a snow day, for example, a recorded lesson can keep students from falling behind in the curriculum. A student who has to miss school due to a medical or family emergency can also stay up to date through such recordings.
Flipped learning. Digital tools give teachers the opportunity to test a flipped classroom model, which can optimize class time to answer questions and facilitate discussion. As certified educator Elizabeth Trach points out, a flipped classroom allows students to explore new concepts in their own way, at their own pace, which provides more differentiation in learning.
Integrating technology in the classroom
Choosing the right technology for your classroom can be overwhelming. But as we mentioned before, getting clear on your learning objectives can help you determine which tools will be best.
Device-to-student ratios. Not all schools have the luxury of a one-to-one device ratio in the classroom. If you can’t offer a device to each student, how can you use them strategically so that each student has an equal chance to learn from them?
One idea is to use devices to offset high teacher-to-student ratios, says Emily Levitt, vice president of education at Sylvan Learning. In environments where there are many more students than teachers, digital tools help provide personalized instruction for every student. Personalized digital applications can ensure that, while teachers are meeting privately with other students, the rest of the class is using devices to work on their specific areas of improvement.
If you do have a one-to-one device ratio in your school, it’s still important to consider how devices will support learning. Having access to technology doesn’t mean devices should be used in every single lesson. In fact, being strategic about device use makes technology more effective.
Setting healthy boundaries. Whether you have one device in your classroom or 100, you’ll need to set healthy boundaries around use. Technology should only be used when it can enhance learning and make lessons more engaging and effective.
You may choose to use technology only in the morning, for example. Or you may have one day a week where technology isn’t a basis for any lesson plan. Regardless of technology’s prevalence in our daily lives, educators should strive to strike a balance between manual and digital activities.
Technology for different age groups
Technology is used differently in the classroom depending on what grade you’re teaching. For example, elementary school teachers tend to use technology to keep students engaged in and excited about what they’re learning. In contrast, middle-school or high-school students may use technology as a means of connecting to the outside world and learning career skills.
Technology in the elementary classroom. Tablets are a great way to provide each elementary student with equal access to learning material. If a student is falling behind, the teacher can quickly see who is struggling and what the problem is.
Elementary teachers also use technology to give young students more ownership over their learning. Gamification, for example, often allows students to make an avatar for themselves and control how they collaborate and participate.
Many teachers also use technology to involve parents and families in the learning process. Teachers can provide parents with access to project reports, grades, and classroom calendars to demonstrate what students are learning — and what they may need to work on at home.
Technology in the middle-school and high-school classroom. As with elementary students, middle and high schoolers benefit from the engaging nature of technology. However, more advanced learners may also profit from using tech tools to digitally collaborate with other students.
Digital study guides and test prep quizzes can help students prepare for standardized tests. Online databases allow students to explore history and find primary sources for research projects. This can facilitate discussion about how to find reputable sources online, which also ties into important conversations about how to keep data safe and private.
Moreover, middle- and high-school students benefit from the real-world exchanges offered by the internet. Whether communicating with a classroom abroad or watching video clips from another country, devices connect today’s students to new people and places to foster cultural exchange and understanding.
Grants for technology in the classroom
Budget constraints are one of the main obstacles preventing teachers from implementing technology in their classrooms. Whether it’s switching to a smartboard or buying some Chromebooks, even small device adoptions can feel unattainable without proper funding.
This is problematic because learning how to use technology is essential for student success. Being unable to access the right hardware and software can limit a student’s personal, academic, and professional growth.
Fortunately, there are many grants available. Local, state, federal, and nonprofit grants can all help teachers acquire educational devices and pursue technology-driven projects. Here’s what you need to know about finding and applying for grants that can improve access to technology and promote learning equity for students of all backgrounds.
What do you need an educational technology grant for?
Educational technology grants can fund the purchase of specific hardware and software needed to fulfill a learning objective. Grants are often given to schools or teachers pursuing a certain initiative, such as improving device equity in a low-income school or teaching STEM skills.
Grants can be applied to small-scale projects that further a certain unit or lesson in a classroom. They can also be on a larger scale, advancing technology access across an entire school or district. If you feel that technology would give your students more opportunities to learn, chances are you could benefit from a grant. The next step is understanding where such funding could be applied and how it could make a difference for your class.
Evaluate technology access at your school. Before you make any major requests or send any applications, it’s important to assess the technology currently available at your school. Consider resources like computer labs, personal student devices, and internet access.
What educational technology is already furthering learning at your school? Where are there opportunities to expand access? Give grant donors a clear picture of what the students at your school are working with. This will make it easier to for you to articulate how their funds can complement existing resources.
Clarify your project. It’s important to have a clear focus when applying for a grant. This makes the impact of technology access more measurable over time. When you know what goal the technology is meant to help achieve, you can better quantify the impacts of those devices.
Getting clear on your goal early can also make the application process easier. Most grant applications will ask for details about how you’ll use the technology. The more specific you can be, the more likely a grant will be awarded.
Many donors, especially those in the private sector, will also want to see how their funding made an impact. Keep tabs on student growth before, during, and after the grant money was applied. When you can clearly articulate how the grant advanced student learning, you boost the chances of your classroom or school receiving a grant again in the future.
Applying for classroom technology grants
When writing a grant proposal, it’s best to keep your options open to numerous funding sources. Your list of potential resources should span both public and private donors. Each of the entities you apply to will have different requirements, notes Gregory Firn, Ed.D., a former school administrator and current executive at RoboKind.
“The way grants are structured, the amounts available, the specific deadlines, the time it takes to be notified of an award after application, and the number of people on grant application review committees vary widely, which is why it’s important to explore many different sources and to apply to multiple agencies.”
Grants tend to have specific requirements about who is granted funds and why. Not every available grant is going to work for your classroom, your students, and/or your school. Diversifying your grant applications can increase the chances that you’ll find the right funding fit for your project.
Keep it simple. It’s easy to get caught up in jargon when talking about technology. Don’t fall into the trap that so many teachers do when writing grants.
You’re talking to people who care about advancing education equity. Use data and details to illustrate how your students can benefit from technology, but don’t be afraid to use emotion and storytelling to explain why your students deserve the grant. Strike this balance, and your grant application will be both well-rounded and relatable.
State measurable, actionable goals. Clarifying your project’s goals and intentions early on will make your grant application more powerful. Break down your goals into measurable learning outcomes within the proposal, but remember to keep it simple.
What technology do you need to meet your goals? How long will it take to execute these projects? What will success look like for your classroom? The reviewers will likely be looking at hundreds of applications, and keeping things direct will help your application stand out.
Ask for help. Your district likely offers many resources for helping write your grant application. There may be other teachers in your school who have successfully applied for a grant in the past. Similarly, administrators at your school may have insight into funding sources or proposal writing tips. You may also have a district grants coordinator, whose sole job it is to help teachers like you secure essential grant funding.
Finding state and federal grant resources
You may investigate government-sponsored programs, such as The Every Student Succeeds Act (ESSA), which helps each state create its own plan for improving access to technology, among other initiatives. Depending on your state, there may be ESSA funds available for expanding technology access in your classroom.
New ESSA changes have expanded the availability of technology funds, which can be used for “purchasing devices, equipment, and software applications in order to address readiness shortfalls.” ESSA also grants funds to provide educators with professional learning tools, implement school-wide technology instruction, execute blended learning projects, and expand technology access to students in rural environments.
You can find state funding sources by looking at your state’s education website too. For example, The New York State Department of Education offers a list of funding resources for schools and districts across the state. The Office of Educational Technology also has information and resources to support the advancement of technology in the classroom. The U.S. Department of Energy provides grants to classrooms pursuing STEM initiatives as well.
Foundations, associations, and unions. In addition to looking at state and federal grants, it’s a good idea to explore national and private foundations, associations, and unions. For example, the Corning Foundation provides technology grants to teachers with a specific plan for learning advancement in STEAM. The Captain Planet Foundation provides technology grants to projects with a sustainability focus.
Technology companies. Many international technology companies have educational foundations specifically designed to help low-income schools obtain devices. The Toshiba America Foundation provides K–12 teachers with grants to put toward classroom materials. The Verizon Foundation provides schools with technologies that support educational STEM projects. Another corporate source is the Oracle Foundation, which seeks to close the technology gender gap by providing technology access to young girls.
Assistive technology in the classroom
The number of American students enrolled in special education programs has risen 30 percent in the past 10 years, according to the National Education Association. And nearly every classroom across the country has students with special needs.
This rise is in part due to increasing awareness and understanding of the many types of learning challenges that exist. Instead of focusing just on students with visual or auditory impairments, for example, schools and teachers now better recognize the signs of dyslexia, dysgraphia, ADHD, and intellectual disabilities.
Modern research and technology have made us more adept at understanding learning challenges and supporting students living with disabilities. That has led to more personalized education programs to suit the varying needs of these students.
Assistive technology already plays a pivotal role in expanding learning opportunities. Text-to-speech tools, for example, can help students with visual impairments and dyslexia, as well as those with ADHD. Understanding the many opportunities for using assistive technology allows educators to create equitable learning environments for all students.
Personalizing learning with assistive technology
Assistive technology in the classroom takes into account the fact that students learn in different ways. It allows all students in a classroom to work at their own pace using tools that support their specific needs. This is especially beneficial in schools with larger class sizes, where it can be harder to cater to each student in a personalized and meaningful way.
Assistive technology also empowers teachers with a deeper understanding of each student’s needs. This is because many assistive technology tools offer data on how each student is performing. Such data arms teachers with greater insight into which students need special attention in specific areas. It also tells teachers which topics might be challenging for all students — and where a classroom-wide review could support everyone.
Some teachers may think that adding technology will complicate lesson planning and increase their workloads. However, integrating technology into the classroom doesn’t have to involve any extra planning. Special education teacher Morgan Tigert explains that she doesn’t offer an alternative curriculum for special-needs students in her class. Instead, she creates one curriculum and provides students many different options for learning the same information.
Using this model, teachers can create one lesson plan designed to be taught across a variety of assistive technologies and mediums. Tigert’s approach allows students to work at their own pace and demonstrate aptitude in their own way. Special-needs students in this classroom model may feel more included when using assistive technology, as everyone is using individual tools. This may reduce the stigma on students who use assistive technology in a classroom where others don’t. It can also provide all students with more agency over the learning process, which can boost motivation, reliability, and self-advocacy.
Since students in the classroom are all learning the same material, albeit in different ways, they can collaborate during meaningful discussions. This ensures that special-needs students of all levels have the opportunity to learn real-world communication and teamwork skills.
In this way, assistive technology can promote learning equity, unlike traditional special-needs teaching. Different students in those more traditional special-needs classrooms are presented with varying levels of material, which can actually widen the achievement gap.
Assistive technology for special needs
From simple timers to complex voice recognition tools, there are a variety of assistive technologies available to the modern classroom. Different tools, apps, and devices can support nearly all learning challenges and abilities. Here’s an overview of the most common assistive technology in the classroom.
Assistive technology tools don’t have to be advanced or complicated to make a difference in student learning. For example, audio players and recorders can record what’s taught in class so that students can replay the files at home when they do homework. Timers are a visual aid that can help students who struggle with time management and self-pacing.
Large-display and talking calculators can help students who have visual or auditory impairments with their math assignments. Students with dyscalculia may also benefit from talking calculators, which help them perform equations and read numbers correctly.
Digital assignments can also be helpful for students with challenges like dyslexia. Electronic worksheets can guide students through the proper alignment of words, equations, and numbers. Similarly, audiobooks can help students follow along with written textbooks both in class and after school. An audio version of the day’s lesson allows students to replay the lecture so that they don’t lose or forget information.
Advanced assistive technology tools
More advanced technologies can also support students with visual, auditory, and motor skill challenges. The benefit of advanced technology tools is that many of them can be incorporated with laptops and tablets, meaning all students can learn from the same devices, yet in different ways.
Text-to-speech (TTS) tools support students with blindness, dyslexia, ADHD, autism, and other issues that cause visual or concentration impairment. These can be integrated with a Braille translator. Text-to-speech tools scan textbooks, assignments, and other materials, then read the text aloud to the student.
This shows students not only what material is presented, but also how to properly pace their words and how to pronounce them correctly. This can be especially helpful in subjects where new vocabulary and concepts are presented.
Screen readers are another TTS tool that teachers can incorporate into lessons that use e-readers, tablets, and laptops. A screen reader can be hooked up to headphones for a student in a large class so that it doesn’t disrupt or distract other students.
Speech-to-text assistive tools. In contrast with text-to-speech tools, speech-to-text tools can help students transform spoken words into written text. Also called dictation technology, these tools are ideal for students who struggle with writing challenges such as dyslexia, dysgraphia, poor penmanship, or poor spelling.
Students with attention issues like ADHD and ADD may also benefit from speech-to-text tools, as they can help them record their thoughts more efficiently. Students can use these tools to write, edit, and revise their work using just their voice. These tools can also be used to record the teacher so that lessons can be transcribed into notes for the student to review later.
Alternative keyboards. Alternative keyboards assist students with a variety of learning challenges. For example, some keyboards have extra-large buttons and colors, making it easier for those with visual impairments to see each key.
Students with dyslexia might also benefit from a keyboard that reads from A to Z, rather than the standard QWERTY keyboard. These keyboards can be connected to the laptops or tablets that other students are using so that everyone can view and complete the same work at once.
Onscreen keyboards can also help students with limited physical ability because they can be used with alternative microphones and switches, as well as eye gazes.
FM listening systems. Frequency modulation (FM) systems help students with impaired hearing better understand the teacher. FM tools require that the teacher wear a microphone, which directs information either through classroom-wide speakers or directly into students’ earphones. They reduce background noise so students with auditory impairments, attention deficits, language processing issues, and autism can better hear what the teacher is saying.
Virtual and augmented reality. Virtual reality is an emerging education tool that holds a lot of promise for special-needs students. For example, mixed reality headsets can support students who struggle with reading by walking them through a text step-by-step, adding highlights and notes along the way.
Teachers can also join students in virtual reality scenarios to walk students through specific instructions or lessons. Mixed reality headsets can provide students with a more personalized learning experience, even in a large class where other students are progressing at a different pace.
Apps and software for assistive technology. Many apps and software tools bring the functionality of assistive technology straight to your student’s device. The following are few common assistive technology apps:
Voice4U is an interactive communication app that helps English language learners and students with autism express their feelings.
Dragon is a speech-to-text app that brings dictation to any device, without an additional tool.
Notability helps students with motor skill and processing challenges take more effective notes.
ClaroRead is a robust text-to-speech tool that helps students with visual and attention impairments in reading, writing, studying, and test-taking.
Co:Writer helps students write not only through speech recognition and translation, but also through intuitive word prediction.
How classroom technology enables differentiated instruction
Differentiated instruction can be an intimidating concept for many teachers. When there are already so many units to plan and papers to grade, creating a personalized plan for each student sounds like a big job.
Contrary to popular belief, differentiated instruction doesn’t require that you create a unique plan for each student. Rather, a differentiated instruction strategy helps you understand each student’s unique learning style. It helps teachers cater to these strengths to make teaching and learning easier and more efficient.
For example, differentiated instruction might mean organizing your class into groups based on students’ interests or skills. It could also mean giving each student access to a device, then using their recent history to tailor their course of study.
Technology offers an infinite number of possibilities when it comes to learning personalization. With the right strategies, technology can differentiate instruction and improve learning outcomes — all while making life easier for the teacher.
What is differentiated instruction?
Students enter the school system with a wide range of learning styles, skills, and knowledge levels. Usually, as students advance through each grade, these differences deepen due to minimal differentiation in instruction.
Imagine two students who are equally capable of mastering a lesson, but only one of them receives instruction in their preferred learning style throughout the year. The other student will likely fall behind because they don’t have an opportunity to learn according to their skill set. This widening achievement gap is perhaps the biggest reason why differentiated instruction is a growing trend.
Casting a wide net when teaching to different learning styles helps meet each student’s needs more effectively. For teachers, this means greater flexibility around how students learn and how they demonstrate knowledge. It also ensures that students aren’t left behind just because they have a different learning style.
Understanding the fundamentals of differentiated learning can ensure you personalize lesson plans effectively, without feeling overwhelmed.
Leveraging personalized learning strategies
There are many ways to differentiate learning in the classroom. When you’re first getting started with differentiated instruction, it can be helpful to learn the basic strategies that other teachers follow for success. These include creating student groups, curating content, and leveraging student performance data.
Create dynamic student groups. To improve lesson planning for differentiated instruction, plan to separate students into different groups. You may start the year with two groups, then differentiate further as you get to know students’ strengths. Each group can have one or two captains, students who have demonstrated mastery of the material. These captains can support the other students who need further help with a lesson.
Another idea is to break students up into pairs. Students should only be paired if they demonstrate a similar skill level. Students can also be grouped or paired by interest, preparedness, or choice.
Regardless of how you create groups, be sure to rotate them often. This ensures students have continual opportunities to learn and grow alongside students with different learning styles. You can also switch back and forth between larger groups and pairs to ensure no two students get too accustomed to working together.
Curate content, tools, and resources. When getting started with differentiated instruction in the classroom, you’ll want to give students a variety of learning options. Gathering a list of content, tools, and resources ensures you always have a reliable library of content available.
The internet connects teachers to an endless number of online tools and resources. Since it can be daunting to sort through all the content available online, consider a website that aggregates educational content.
For example, Epic! is an educational digital library for children under 12. Teachers can use Epic! to search for books, learning videos, and quizzes based on age range and content type.
Another tool for finding and curating content resources is Edcite. Their online library contains assignments crafted by other English language arts teachers. This free teaching tool also makes it easy to change or pivot lesson plans based on where students are at the moment.
Tap into student data. One of the greatest benefits of differentiated instruction is that it gives teachers insight into student comprehension. It shows not only where students may be struggling, but also what tools and techniques will help them best.
To better help students succeed, teachers need to expand the possibilities of how a single lesson can be learned. Then, they can leverage tools that provide data on student progress and learning outcomes.
There are a number of tools that can evaluate learning aptitudes across different projects. Edji, for example, is a reading tool that tracks student progress within a given text and provides them with prompts based on their skill level. Since all student interactions with the app are monitored, teachers can glean insights, such as how long students read, when they were engaged in a text, and what passage was most engaging.
Allow students to choose their own methods of assessment. The next step in differentiated education is giving students more say in how they demonstrate aptitude. This is beneficial because it ensures students are learning and presenting knowledge to the best of their ability with the tools and resources available. It recognizes the unique needs of each student and prevents them from falling behind or getting bored. Plus, students are much more motivated and engaged in assessment projects when they have a voice in their own learning.
Instead of assigning everyone a unit test, for example, you can give students options. Technology can help facilitate each one of these assessments.
Students who feel more comfortable using a keyboard to type out their thoughts can stick with an essay. Other students may prefer to give a presentation and use video to record it. Whether students make a video, create an art project, or record an audio presentation, technology allows teachers to assess student comprehension.
Another idea is to provide students with surveys to see which methods of learning and knowledge demonstration they enjoy most. Try asking
What projects they’ve enjoyed in the past
What projects they might want to try
What you can do as a teacher to provide these opportunities
Surveys are great because they let you solicit student opinions anonymously, which helps many students open up and share opinions they otherwise might not.
Modern, adaptable learning environments
Flexibility is another core benefit of differentiated instruction.
Teachers in traditional classroom environments create one lesson plan with the same assignments and projects for each student. This doesn’t allow much room for flexibility. If one student is struggling and asking questions, the rest of the class is brought down to that level. Likewise, if a student is excelling and moving forward, they may finish early and get bored because there isn’t enough content to support their needs.
The goal of differentiated technology is to cater to each unique skill level. Closing this gap early helps students realize what their learning styles are and where they excel — something that can serve them throughout their schooling.
Flipped classroom models
Flipped classroom models encourage both differentiated learning and flexibility. A flipped classroom is when teachers film themselves lecturing (or providing another instructional method), and students learn at home. Classroom time is spent discussing what students learned from the video lesson, answering questions, and engaging in collaborative group work.
Two of the most common teacher tools for flipped classroom models are
Hippo Video. Teachers can use Hippo Video to record lessons, explainer videos, screencasts, or interviews. Students can then engage with this content at their own pace. Teachers can also use this tool to give feedback on student work. The addition of facial cues and voice intonation can help certain students better understand their feedback.
Edpuzzle. With Edpuzzle, teachers can create their own video or upload one from a library of educational content that includes resources like YouTube and Khan Academy. They can then incorporate the videos into at-home assignments. Teachers can see viewing data for each student and add assessment questions to gauge understanding.
A flipped classroom transforms how classroom time is used by creating more flexibility around what students do in class. It provides opportunity for differentiated instruction, as some students can advance to supplemental texts and materials while others can review lessons.
Throughout this personalized learning process, the teacher is there to support and oversee students as they progress. This also redefines homework entirely. Instead of asking students to demonstrate aptitude at home on their own, flipped classroom models provide a safe and supportive atmosphere at school for questions, collaboration, and advancement.
The pros and cons of technology in the classroom
From making learning more accessible to advancing personalized instruction, it’s clear that technology has many benefits for the classroom. But these pros don’t come without their cons, and technology can be just as challenging as it is beneficial.
For example, teachers, parents, and community members who oppose technology in the classroom may feel that it’s too distracting. And students may use tools in unethical ways to cheat or bully other students.
Many parents are also concerned that technology use may contribute to additional screen time in a world where students are already bombarded by cell phones, televisions, and tablets.
While tech does have the ability to boost equality among students, it can also widen equality gaps between students of different socioeconomic levels. Another common complaint against technology in the classroom is that it can lead to hyperactivity and attention disorders, which is one of the leading learning challenges students face today.
These arguments against technology in the classroom are both important and valid. However, it’s also true that most innovations in the world come with both benefits and drawbacks. Diving into technology without information isn’t a good idea, just as avoiding technology can cause your students to fall behind. Understanding the many pros and cons of technology in the classroom can help ensure that you know how to deploy these tools correctly.
To help you make more informed choices when using technology in the classroom, here’s a breakdown of how digital tools benefit students and how they can be a detriment.
Personalized education vs unequal learning
As discussed earlier, technology can support individualized instruction for students at varying skill levels. This is especially true for classrooms with students of different abilities.
Students who are already further along can use technology to access higher-level instruction, while students who need extra support can get it when and how they need it. Best of all, teachers can use technology to see where students are in the learning process and how they’re progressing. This offers more insight into each student’s learning journey, which allows for individualized instruction that wouldn’t otherwise be possible.
If students in a classroom work at many different levels, this can pose challenges. This could make it hard for students to collaborate on group work. If one student is much further ahead than another student in the unit, their group collaboration time may be spent educating and answering questions rather than collaborating.
Since communication and collaboration are essential skills for students to develop, this could put the development of these traits at risk. It may also make it hard for teachers to provide equal support to each student, as more resources may be spent on the students who need additional help.
Future preparation vs widening the achievement gap
It’s true that technology prepares students for the future in an increasingly digital world. Students who learn how to type, research, and use social media will be much more equipped to succeed both personally and professionally than those who don’t learn these skills.
And students who are comfortable using technology are more likely to excel in high school, which can help them be more prepared for a university setting. Teachers who make technology an everyday aspect of the classroom ensure that their students are ready and equipped to succeed in the world.
While access to technology helps certain students advance, lack of access can make students fall behind. Students in low-income schools may not have the same opportunities as students in high-income schools.
More privileged students may have a one-to-one device ratio in the classroom, while less privileged students may have just one computer to share. Expense is the greatest barrier to accessibility in technology, and some people feel that this cost is widening the achievement gap in more ways than one.
Expanding worldview vs a tool for cheating
Teachers often appreciate the many ways technology can expand students’ worldviews. From Google Maps to virtual museum exhibits to primary source films, technology connects students to other places and times in ways that wouldn’t otherwise be possible.
Students can access any information they want — which may not always be a good thing. Many parents worry that increased technology use in schools will enable students to cheat. If students use technology to cheat now (and get away with it), it could cause them to create unethical habits for the future. This can become a serious problem in college, where getting caught cheating can be grounds for expulsion.
Teachers and students worried about cheating should consider creating a standard of ethics for technology use. This can help educate students about what’s allowed and what isn’t. Creating clear ramifications for plagiarism and cheating can also prevent students from using technology to cheat on tests and assignments. These ethical codes can also outline rules for online communication and interactions, which can prevent cyberbullying and other harmful online behavior.
Beneficial tool vs unnecessary distraction
One of the leading arguments against technology in the classroom is that it’s distracting and deters from learning. If students have become intelligent citizens without technology in schools for decades, why do we need the tools now?
The truth is, today’s students are accustomed to using screens in every aspect of their lives, so using technology in the classroom is often easy for both teachers and students. Since most children already know how to use tablets and computers, there isn’t a steep learning curve.
It makes sense for students to learn these tools in the classroom, as they’ll likely use them in the future. Students need to be exposed to technology early on in order to succeed at work and life.
Beyond being familiar with technology, students need to learn how to perform important functions like writing, researching, communicating, and creating an online identity. These skills can’t be developed by simply using a laptop once in awhile. They need to be incorporated into specific lesson plans designed to help students become technology literate.
On the other hand, the technology used in schools can be distracting. The downside of technology literate students is that they know how to use digital tools for fun and games. When your classroom is full of students on devices, it can be challenging to keep tabs on everyone. This can exacerbate distractions and, in turn, widen achievement gaps among students.
Setting healthy boundaries
Today’s children already have more attention deficit disorders than in the past. This could be linked to overstimulation caused by screens. Setting boundaries for technology can limit screen time to a certain number of minutes or hours per day. Teachers can also take time to instill these boundaries, helping students create healthy relationships with technology for the rest of their lives.
In addition, setting healthy boundaries for technology use in the classroom can ensure that students aren’t constantly checking social media or falling down a research rabbit hole. Technology should be used at the teacher’s discretion. When it can enhance and improve learning, it should be included. But not all lessons will be more engaging and memorable by simply adding a computer.
Teachers can also do their part to limit screen time in the classroom. Many people oppose classroom technology because it can lead to behavioral disruptions, sleep disorders, and social challenges. It’s too early to determine the long-term effects of this kind of technology on young children, but many people would rather take the safe route and impose healthy limits on these tools.
Whether you’re totally new to technology or you’re hoping to create healthier boundaries for screens, it’s important to be clear on the most prominent benefits and drawbacks of using technology in the classroom.
Technology in the classroom: The current situation
Technology has played an increasingly important role in the classroom since formal education began in the United States. Whether it was chalkboards and paper or computers and the internet, each invention has brought new opportunities for learning. Understanding how technology has evolved sheds light not only on where we are in today’s classroom, but where educational technology can take us in the future.
The history and evolution of technology in the classroom
From the schoolhouse to the computer lab, school environments have changed drastically over the past three centuries. Technology has been perhaps the biggest driver of educational transformation, changing the way students interpret information and demonstrate their knowledge.
Here’s a look back at how technology has changed education over the years.
1700s: Students often didn’t have access to paper and textbooks. Instead, they used what were called hornbooks — wooden paddles with lessons printed on them. Most lessons revolved around the Bible, and students were instructed to read passages and memorize verses. Students were also taught basic math, reading, writing, and poetry. Girls and boys were taught separate lessons; boys studied more advanced subjects, while girls were taught to take care of the home.
1800s: By the 1800s, pencils and paper were more popular in classrooms, as were textbooks and printed works of literature and poetry. The chalkboard was invented in Scotland during this century. Originally made from natural black or grey slate, it gave teachers a way of sharing information with a larger range of students. The slide rule was also invented during this century, enabling students to perform basic and complex math problems in a more organized format. The end of the century saw the invention of magic lanterns, which used lanterns and oil lamps to give presentations.
1920s–1950s: Filmstrip projectors were invented in the 1920s, taking the place of magic lanterns. These projectors allowed teachers to show multiple images on a large scale. Filmstrips were usually accompanied by prerecorded audio. This coincides with the increasing role of radio and recorded audio in the classroom, which added to the teacher’s toolkit.
“Audio cues let teachers know when to advance to the next image; later models performed this function automatically,” says educator Laura Gray. Filmstrip projectors were used until the 1980s, when videocassettes became more popular and eliminated the need for projectors. Ballpoint pens also became an important tool during this time, and students began recording their own homework on paper and in notebooks.
1960s–1980s: Overhead projectors were an important invention in the ’60s. Projectors allowed teachers to demonstrate workflows in real time. This supported visual learners, especially with math and science problems. In this sense, the overhead projector was one of the first technologies that offered differentiated instruction and made lessons more accessible to students with different learning styles.
Educational videos also became more popular during the ’70s and ’80s, helping to present material in a more dynamic and compelling way that captured students’ attention. Scantrons were another major invention of this period. They enabled more efficient and accurate test-taking and better evaluation of results. The computer began to find its way into classrooms, but it was still emerging as a personal technology and not universally accessible by teachers, students, and schools due to the high price.
1990s–2000: The 1990s saw two of the biggest technology changes in history: the rise of personal computers and the invention of the World Wide Web. During this time, typing became an important skill for all students, and more lessons incorporated computers and the internet. Word processing tools also became a major part of assignments, and typed and printed lessons were growing in popularity.
Computers enabled teachers to access, create, and print their own worksheets, and students were also empowered to create and print assignments from home. With more access to information than ever before, students had more opportunities to research information on the internet.
2000–2010: This was the decade when specific websites were incorporated into the classroom. Cloud storage allowed students to complete and share documents online, and YouTube became a destination for educational video content. Most classrooms in the United States had multiple computers available, either in the classroom or in a school computer lab.
Tools like Moodle allowed teachers to create and share lessons with students. The open-source nature of this tool also introduced the idea of teachers being able to share lesson plans with other teachers from around the world. This expanded teacher knowledge and promoted the sharing of lessons across states and countries. Clickers also became popular during this time, allowing students a more interactive way to answer questions.
2010–present: So far, this has been the most explosive decade of classroom technology transformation. The tablet is, in itself, a major transformation, with the development of apps bringing personalized education and gamification to everyday classroom learning. Digital whiteboards also created a more interactive experience that allowed students to immerse more deeply in subjects like math, English, and science. Mobile phones are also important pieces of classroom technology.
As more students began to acquire their own digital devices, including smartphones, laptops, and tablets, lessons and learning tools became accessible at all times, from anywhere. This is also the decade when social media became a major learning tool. Learning to ethically use social media and create a digital presence online became a core part of learning to navigate the digital environment.
Technology in the classroom statistics
Technology has come far from the days of Scantrons and projectors. But how exactly has technology changed? What relationship do today’s students have with technology? Classroom technology statistics offer insight into what technology means for today’s students.
How do teachers use technology in the classroom?
Larry Bernstein at EdTech magazine, citing a survey by Cambridge International, says many students today rely on a variety of tech tools:
48 percent of students say they use desktop computers in the classroom.
42 percent say they use smartphones.
33 percent say the use interactive whiteboards.
20 percent say they use tablets.
What is the state of technology access and disparity in the United States?
A study by MidAmerica Nazarene University shows that 86 percent of classrooms have Wi-Fi, and 62 percent of students use their own technology tools in the classroom. In fact, nearly three-quarters of teachers say they use a laptop or a tablet every day in the classroom.
The main reason teachers don’t have more technology in the classroom is a lack of funding.
How do teachers feel about technology?
The MidAmerica Nazarene University survey found that 66 percent of teachers think technology makes students more productive. That said, most teachers say access to cell phones can cause distractions. In fact, 93 percent of classrooms have some kind of policy about limiting the use of smartphones and the internet.
What does the future hold for technology in the classroom?
Moving forward, technology will continue to transform the ways students learn. For example, augmented reality is poised to elevate the learning experience by helping students see the world in new ways. For instance, Google Cardboard and AR experiences designed for education will help students learn in a way that feels more personalized and private.
Apps continue to change how students communicate with teachers as well. They facilitate a flipped classroom model, for example, which encourages more one-on-one teacher and student time in the classroom. This kind of tech also allows students to access lessons remotely.
The power of technology in the classroom
We live in a world that is inextricably connected to technology. The way we find information, share our lives, and connect with others is becoming increasingly digital. Likewise, more classrooms rely on technology to deliver personalized experiences that engage students and elevate learning. Tech tools give teachers the ability to differentiate instruction, which caters to different learning types and supports students with special needs and learning challenges.
Technology also holds the power to transform not only what we learn but how. Teachers can bring immersive, global experiences to their students. Whether you’re a parent, a teacher, or an administrator, it’s crucial to understand how technology is used in the classroom today.
It takes a long time for a new CSS feature or improvement to progress from an initial draft to a fully-supported and stable CSS feature that developers can use. JavaScript-based polyfills can be used as a substitute for the lack of browser support in order to use new CSS features before they’re officially implemented. But they are flawed in most cases. For example, scrollsnap-polyfill is one of several polyfills that can be used to fix browser support inconsistencies for the CSS Scroll Snap specification. But even that solution has some limitations, bugs and inconsistencies.
The potential downside to using polyfills is that they can have a negative impact on performance and are difficult to implement properly. This downside is related to the browser’s DOM and CSSOM. Browser creates a DOM (Document Object Model) from HTML markup and, similarly, it created CSSOM (CSS Object Model) from CSS markup. These two object trees are independent of one another. JavaScript works on DOM and has very limited access to CSSOM.
JavaScript Polyfill solutions run only after the initial render cycle has been completed, i.e. when both DOM and CSSOM have been created and the document has finished loading. After Polyfill makes changes to styles in the DOM (by inlining them), it causes the render process to run again and the whole page re-renders. Negative performance impact gets even more apparent if they rely on the requestAnimationFrame method or depend on user interactions like scroll events.
Another obstacle in web development is various constraints imposed by the CSS standards. For example, there are only a limited number of CSS properties that can be natively animated. CSS knows how to natively animate colors, but doesn’t know how to animate gradients. There has always been a need to innovate and create impressive web experiences by pushing the boundaries despite the tech limitations. That is why developers often tend to gravitate towards using less-than-ideal workarounds or JavaScript to implement more advanced styling and effects that are currently not supported by CSS such as masonry layout, advanced 3D effects, advanced animation, fluid typography, animated gradients, styled select elements, etc.
It seems impossible for CSS specifications to keep up with the various feature demands from the industry such as more control over animations, improved text truncation, better styling option for input and select elements, more display options, more filter options, etc.
What could be the potential solution? Give developers a native way of extending CSS using various APIs. In this article, we are going to take a look at how frontend developers can do that using Houdini APIs, JavaScript, and CSS. In each section, we’re going to examine each API individually, check its browser support and current specification status, and see how they can be implemented today using Progressive enhancement.
What Is Houdini?
Houdini, an umbrella term for the collection of browser APIs, aims to bring significant improvements to the web development process and the development of CSS standards in general. Developers will be able to extend the CSS with new features using JavaScript, hook into CSS rendering engine and tell the browser how to apply CSS during a render process. This will result in significantly better performance and stability than using regular polyfills.
Houdini specification consists of two API groups – high-level APIs and low-level APIs.
High-level APIs are closely related to the browser’s rendering process (style ? layout ? paint ? composite). This includes:
Paint API
An extension point for the browser’s paint rendering step where visual properties (color, background, border, etc.) are determined.
Layout API
An extension point for the browser’s layout rendering step where element dimensions, position, and alignment are determined.
Animation API
An extension point for browser’s composite rendering step where layers are drawn to the screen and animated.
Low-Level APIs form a foundation for high-level APIs. This includes:
Typed Object Model API
Custom Properties & Values API
Font Metrics API
Worklets
Some Houdini APIs are already available for use in some browsers with other APIs to follow suit when they’re ready for release.
The Future Of CSS
Unlike regular CSS feature specifications that have been introduced thus far, Houdini stands out by allowing developers to extend the CSS in a more native way. Does this mean that CSS specifications will stop evolving and no new official implementations of CSS features will be released? Well, that is not the case. Houdini’s goal is to aid the CSS feature development process by allowing developers to create working prototypes that can be easily standardized.
Additionally, developers will be able to share the open-source CSS Worklets more easily and with less need for browser-specific bugfixes.
Typed Object Model API
Before Houdini was introduced, the only way for JavaScript to interact with CSS was by parsing CSS represented as string values and modifying them. Parsing and overriding styles manually can be difficult and error-prone due to the value type needing to be changed back and forth and value unit needing to be manually appended when assigning a new value.
Typed Object Model (Typed OM) API adds more semantic meaning to CSS values by exposing them as typed JavaScript objects. It significantly improves the related code and makes it more performant, stable and maintainable. CSS values are represented by the CSSUnitValue interface which consists of a value and a unit property.
{
value: 20,
unit: "px"
}
This new interface can be used with the following new properties:
computedStyleMap(): for parsing computed (non-inline) styles. This is a method of selected element that needs to be invoked before parsing or using other methods.
attributeStyleMap: for parsing and modifying inline styles. This is a property that is available on a selected element.
// Get computed styles from stylesheet (initial value)
selectedElement.computedStyleMap().get("font-size"); // { value: 20, unit: "px"}
// Set inline styles
selectedElement.attributeStyleMap.set("font-size", CSS.em(2)); // Sets inline style
selectedElement.attributeStyleMap.set("color", "blue"); // Sets inline style
// Computed style remains the same (initial value)
selectedElement.computedStyleMap().get("font-size"); // { value: 20, unit: "px"}
// Get new inline style
selectedElement.attributeStyleMap.get("font-size"); // { value: 2, unit: "em"}
Notice how specific CSS types are being used when setting a new numeric value. By using this syntax, many potential type-related issues can be avoided and the resulting code is more reliable and bug-free.
The get and set methods are only a small subset of all available methods defined by the Typed OM API. Some of them include:
clear: removes all inline styles
delete: removes a specified CSS property and its value from inline styles
has: returns a boolean if a specified CSS property is set
append: adds an additional value to a property that supports multiple values
The CSS Properties And Values API allows developers to extend CSS variables by adding a type, initial value and define inheritance. Developers can define CSS custom properties by registering them using the registerProperty method which tells the browsers how to transition it and handle fallback in case of an error.
This method accepts an input argument that is an object with the following properties:
name: the name of the custom property
syntax: tells the browser how to parse a custom property. These are pre-defined values like , , , , , etc.
inherits: tells the browser whether the custom property inherits its parent’s value.
initialValue: tells the initial value that is used until it’s overridden and this is used as a fallback in case of an error.
In the following example, the type custom property is being set. This custom property is going to be used in gradient transition. You might be thinking that current CSS doesn’t support transitions for background gradients and you would be correct. Notice how the custom property itself is being used in transition, instead of a background property that would be used for regular background-color transitions.
Browser doesn’t know how to handle gradient transition, but it knows how to handle color transitions because the custom property is specified as type. On a browser that supports Houdini, a gradient transition will happen when the element is being hovered on. Gradient position percentage can also be replaced with CSS custom property (registered as type) and added to a transition in the same way as in the example.
If registerProperty is removed and a regular CSS custom property is registered in a :root selector, the gradient transition won’t work. It’s required that registerProperty is used so the browser knows that it should treat it as color.
In the future implementation of this API, it would be possible to register a custom property directly in CSS.
This simple example showcases gradient color and position transition on hover event using registered CSS custom properties for color and position respectively. Complete source code is available on the example repository.
Animated gradient color and position using Custom Properties & Values API. Delay for each property added for effect in CSS transition property. (Large preview)
Feature Detection
if (CSS.registerProperty) {
/* ... */
}
W3C Specification Status
Working Draft: published for review by the community
The Font Metrics API is still in a very early stage of development, so its specification may change in the future. In its current draft, Font Metrics API will provide methods for measuring dimensions of text elements that are being rendered on screen in order to allow developers to affect how text elements are being rendered on screen. These values are either difficult or impossible to measure with current features, so this API will allow developers to create text and font-related CSS features more easily. Multi-line dynamic text truncation is an example of one of those features.
Before moving onto the other APIs, it’s important to explain the Worklets concept. Worklets are scripts that run during render and are independent of the main JavaScript environment. They are an extension point for rendering engines. They are designed for parallelism (with 2 or more instances) and thread-agnostic, have reduced access to the global scope and are called by the rendering engine when needed. Worklets can be run only on HTTPS (on production environment) or on localhost (for development purposes).
Houdini introduces following Worklets to extend the browser render engine:
Paint Worklet – Paint API
Animation Worklet – Animation API
Layout Worklet – Layout API
Paint API
The Paint API allows developers to use JavaScript functions to draw directly into an element’s background, border, or content using 2D Rendering Context, which is a subset of the HTML5 Canvas API. Paint API uses Paint Worklet to draw an image that dynamically responds to changes in CSS (changes in CSS variables, for example). Anyone familiar with Canvas API will feel right at home with Houdini’s Paint API.
There are several steps required in defining a Paint Worklet:
Write and register a Paint Worklet using the registerPaint function
Call the Worklet in HTML file or main JavaScript file using CSS.paintWorklet.addModule function
Use the paint() function in CSS with a Worklet name and optional input arguments.
Let’s take a look at the registerPaint function which is used to register a Paint Worklet and define its functionality.
registerPaint("paintWorketExample", class {
static get inputProperties() { return ["--myVariable"]; }
static get inputArguments() { return ["<color>"]; }
static get contextOptions() { return {alpha: true}; }
paint(ctx, size, properties, args) {
/* ... */
}
});
The registerPaint function consists of several parts:
inputProperties:
An array of CSS custom properties that the Worklet will keep track of. This array represents dependencies of a paint worklet.
inputArguments:
An array of input arguments that can be passed from paint function from inside the CSS.
contextOptions: allow or disallow opacity for colors. If set to false, all colors will be displayed with full opacity.
paint: the main function that provides the following arguments:
ctx: 2D drawing context, almost identical to Canvas API’s 2D drawing context.
size: an object containing the width and height of the element. Values are determined by the layout rendering process. Canvas size is the same as the actual size of the element.
properties: input variables defined in inputProperties
args: an array of input arguments passed in paint function in CSS
After the Worklet has been registered, it needs to be invoked in the HTML file by simply providing a path to the file.
After the Worklet has been called, it can be used inside CSS using the paint function. This function accepts the Worklet’s registered name as a first input argument and each input argument that follows it is a custom argument that can be passed to a Worklet (defined inside Worklet’s inputArguments ). From that point, the browser determines when to call the Worklet and which user actions and CSS custom properties value change to respond to.
.exampleElement {
/* paintWorkletExample - name of the worklet
blue - argument passed to a Worklet */
background-image: paint(paintWorketExample, blue);
}
Example
The following example showcases Paint API and general Worklet reusability and modularity. It’s using the ripple Worklet directly from Google Chrome Labs repository and runs on a different element with different styles. Complete source code is available on the example repository.
Ripple effect example (uses Ripple Worklet by Google Chrome Labs) (Large preview)
Feature detection
if ("paintWorklet" in CSS) {
/* ... */
}
@supports(background:paint(paintWorketExample)){
/* ... */
}
The Animation API extends web animations with options to listen to various events (scroll, hover, click, etc.) and improves performance by running animations on their own dedicated thread using an Animation Worklet. It allows for user action to control the flow of animation that runs in a performant, non-blocking way.
Like any Worklet, Animation Worklet needs to be registered first.
constructor: called when a new instance is created. Used for general setup.
animate: the main function that contains the animation logic. Provides the following input arguments:
currentTime: the current time value from the defined timeline
effect: an array of effects that this animation uses
After the Animation Worklet has been registered, it needs to be included in the main JavaScript file, animation (element, keyframes, options) needs to be defined and animation is instantiated with the selected timeline. Timeline concepts and web animation basics will be explained in the next section.
/* Include Animation Worklet */
await CSS.animationWorklet.addModule("path/to/worklet/file.js");;
/* Select element that's going to be animated */
const elementExample = document.getElementById("elementExample");
/* Define animation (effect) */
const effectExample = new KeyframeEffect(
elementExample, /* Selected element that's going to be animated */
[ /* ... */ ], /* Animation keyframes */
{ /* ... */ }, /* Animation options - duration, delay, iterations, etc. */
);
/* Create new WorkletAnimation instance and run it */
new WorkletAnimation(
"animationWorkletExample" /* Worklet name */
effectExample, /* Animation (effect) timeline */
document.timeline, /* Input timeline */
{}, /* Options passed to constructor */
).play(); /* Play animation */
Timeline Mapping
Web animation is based on timelines and mapping of the current time to a timeline of an effect’s local time. For example, let’s take a look at a repeating linear animation with 3 keyframes (start, middle, last) that runs 1 second after a page is loaded (delay) and with a 4-second duration.
Effect timeline from the example would look like this (with the 4-second duration with no delay):
Effect timeline (4s duration)
Keyframe
0ms
First keyframe – animation starts
2000ms
Middle keyframe – animation in progress
4000ms
Last keyframe – animation ends or resets to first keyframe
In order to better understand effect.localTime, by setting its value to 3000ms (taking into account 1000ms delay), resulting animation is going to be locked to a middle keyframe in effect timeline (1000ms delay + 2000ms for a middle keyframe). The same effect is going to happen by setting the value to 7000ms and 11000ms because the animation repeats in 4000ms interval (animation duration).
No animation happens when having a constant effect.localTime value because animation is locked in a specific keyframe. In order to properly animate an element, its effect.localTime needs to be dynamic. It’s required for the value to be a function that depends on the currentTime input argument or some other variable.
The following code shows a functional representation of 1:1 (linear function) mapping of a timeline to effect local time.
animate(currentTime, effect) {
effect.localTime = currentTime; // y = x linear function
}
Timeline (document.timeline)
Mapped effect local time
Keyframe
startTime + 0ms (elapsed time)
startTime + 0ms
First
startTime + 1000ms (elapsed time)
startTime + 1000ms (delay) + 0ms
First
startTime + 3000ms (elapsed time)
startTime + 1000ms (delay) + 2000ms
Middle
startTime + 5000ms (elapsed time)
startTime + 1000ms (delay) + 4000ms
Last / First
startTime + 7000ms (elapsed time)
startTime + 1000ms (delay) + 6000ms
Middle
startTime + 9000ms (elapsed time)
startTime + 1000ms (delay) + 8000ms
Last / First
Timeline isn’t restricted to 1:1 mapping to effect’s local time. Animation API allows developers to manipulate the timeline mapping in animate function by using standard JavaScript functions to create complex timelines. Animation also doesn’t have to behave the same in each iteration (if animation is repeated).
Animation doesn’t have to depend on the document’s timeline which only starts counting milliseconds from the moment it’s loaded. User actions like scroll events can be used as a timeline for animation by using a ScrollTimeline object. For example, an animation can start when a user has scrolled to 200 pixels and can end when a user has scrolled to 800 pixels on a screen.
const scrollTimelineExample = new ScrollTimeline({
scrollSource: scrollElement, /* DOM element whose scrolling action is being tracked */
orientation: "vertical", /* Scroll direction */
startScrollOffset: "200px", /* Beginning of the scroll timeline */
endScrollOffset: "800px", /* Ending of the scroll timeline */
timeRange: 1200, /* Time duration to be mapped to scroll values*/
fill: "forwards" /* Animation fill mode */
});
...
The animation will automatically adapt to user scroll speed and remain smooth and responsive. Since Animation Worklets are running off the main thread and are connected to a browser’s rending engine, animation that depends on user scroll can run smoothly and be very performant.
Example
The following example showcases how a non-linear timeline implementation. It uses modified Gaussian function and applies translation and rotation animation with the same timeline. Complete source code is available on the example repository.
Animation created with Animation API which is using modified Gaussian function time mapping (Large preview)
The Layout API allows developers to extend the browser’s layout rendering process by defining new layout modes that can be used in display CSS property. Layout API introduces new concepts, is very complex and offers a lot of options for developing custom layout algorithms.
Similarly to other Worklets, the layout Worklet needs to be registered and defined first.
inputProperties:
An array of CSS custom properties that the Worklet will keep track of that belongs to a Parent Layout element, i.e. the element that calls this layout. This array represents dependencies of a Layout Worklet.
childrenInputProperties:
An array of CSS custom properties that the Worklet will keep track of that belong to child elements of a Parent Layout element, i.e. the children of the elements that set this layout.
layoutOptions: defines the following layout properties:
childDisplay: can have a pre-defined value of block or normal. Determines if the boxes will be displayed as blocks or inline.
sizing: can have a pre-defined value of block-like or manual. It tells the browser to either pre-calculate the size or not to pre-calculate (unless a size is explicitly set), respectively.
intrinsicSizes: defines how a box or its content fits into a layout context.
children: child elements of a Parent Layout element, i.e. the children of the element that call this layout.
edges: Layout Edges of a box
styleMap: typed OM styles of a box
layout: the main function that performs a layout.
children: child elements of a Parent Layout element, i.e. the children of the element that call this layout.
edges: Layout Edges of a box
constraints: constraints of a Parent Layout
styleMap: typed OM styles of a box
breakToken: break token used to resume a layout in case of pagination or printing.
Like in the case of a Paint API, the browser rendering engine determines when the paint Worklet is being called. It only needs to be added to an HTML or main JavaScript file.
This element is called a Parent Layout that is enclosed with Layout Edges which consists of paddings, borders and scroll bars. Parent Layout consists of child elements which are called Current Layouts. Current Layouts are the actual target elements whose layout can be customized using the Layout API. For example, when using display: flex; on an element, its children are being repositioned to form the flex layout. This is similar to what is being done with the Layout API.
Each Current Layout consists of Child Layout which is a layout algorithm for the LayoutChild (element, ::before and ::after pseudo-elements) and LayoutChild is a CSS generated box that only contains style data (no layout data). LayoutChild elements are automatically created by browser rendering engine on style step. Layout Child can generate a Fragment which actually performs layout render actions.
Example
Similarly to the Paint API example, this example is importing a masonry layout Worklet directly from Google Chrome Labs repository, but in this example, it’s used with image content instead of text. Complete source code is available on the example repository.
Masonry layout example (uses Masonry Worklet by Google Chrome Labs (Large preview)
Even though CSS Houdini doesn’t have optimal browser support yet, it can be used today with progressive enhancement in mind. If you are unfamiliar with Progressive enhancement, it would be worth to check out this handy article which explains it really well. If you decide on implementing Houdini in your project today, there are few things to keep in mind:
Use feature detection to prevent errors.
Each Houdini API and Worklet offers a simple way of checking if it’s available in the browser. Use feature detection to apply Houdini enhancements only to browsers that support it and avoid errors.
Use it for presentation and visual enhancement only.
Users that are browsing a website on a browser that doesn’t yet support Houdini should have access to the content and core functionality of the website. User experience and the content presentation shouldn’t depend on Houdini features and should have a reliable fallback.
Make use of a standard CSS fallback.
For example, regular CSS Custom Properties can be used as a fallback for styles defined using Custom Properties & Values API.
Focus on developing a performant and reliable website user experience first and then use Houdini features for decorative purposes as a progressive enhancement.
Conclusion
Houdini APIs will finally enable developers to keep the JavaScript code used for style manipulation and decoration closer to the browser’s rendering pipeline, resulting in better performance and stability. By allowing developers to hook into the browser rendering process, they will be able to develop various CSS polyfills that can be easily shared, implemented and, potentially, added to CSS specification itself. Houdini will also make developers and designers less constrained by the CSS limitations when working on styling, layouts, and animations, resulting in new delightful web experiences.
CSS Houdini features can be added to projects today, but strictly with progressive enhancement in mind. This will enable browsers that do not support Houdini features to render the website without errors and offer optimal user experience.
It’s going to be exciting to watch what the developer community will come up with as Houdini gains traction and better browser support. Here are some awesome examples of Houdini API experiments from the community:
If I need a quick background pattern to spruce something up, I often think of the CSS3 Patterns Gallery. Some of those are pretty intense but remember they are easily editable because they are just CSS. That means you could take these bold zags and chill them out.
CodePen Embed Fallback
My usual go-to through is Hero Patterns. They are also editable, but they already start from a pretty chill place, which is usually what I’m looking for from a pattern. They also happen to provide ones we’ve baked into the Assets Panel on CodePen for extra-easy access.
If you’re into SVG-based patterns (and who isn’t?) SVG Backgrounds has some extra clever ones. Looks like it’s gotten a nice design refresh lately, too, where the editable options are intuitive and the code is easy to copy. If you are a DIY type, remember SVG literally has a element you can harness.
I’ve seen some new fun pattern sites lately though! One is the exceptionally deep Tartanify which has over 5,000 Scottish tartan patterns. Paulina Hetman even wrote about it for us.
Beautiful Dingbats has a very nice pattern generator as well that seems pretty newish. It’s got very fun controls to play with and easy output.
One that is really mind-blowing is Mazeletter. It’s a collection of nine fonts that are made to be infinitely tiling, so you essentially have unlimited pattern possibilities you can make from characters.
Just to end with a classic here… you can’t go wrong with a little noise.