When React 16.8 was released officially in early February 2019, it shipped with an additional API that lets you use state and other features in React without writing a class. This additional API is called Hooks and they’re becoming popular in the React ecosystem, from open-sourced projects to being used in production applications.
React Hooks are completely opt-in which means that rewriting existing code is unecessary, they do not contain any breaking changes, and they’re available for use with the release of React 16.8. Some curious developers have been making use of the Hooks API even before it was released officially, but back then it was not stable and was only an experimental feature. Now it is stable and recommended for React developers to use.
Note: We won’t be talking about React or JavaScript in general. A good knowledge of ReactJS and JavaScript will come in handy as you work through this tutorial.
What Are React Hooks?
React Hooks are in-built functions that allow React developers to use state and lifecycle methods inside functional components, they also work together with existing code, so they can easily be adopted into a codebase. The way Hooks were pitched to the public was that they allow developers to use state in functional components but under the hood, Hooks are much more powerful than that. They allow React Developers to enjoy the following benefits:
Improved code reuse;
Better code composition;
Better defaults;
Sharing non-visual logic with the use of custom hooks;
Flexibility in moving up and down the components tree.
With React Hooks, developers get the power to use functional components for almost everything they need to do from just rendering UI to also handling state and also logic — which is pretty neat.
Reusing stateful logic between components is difficult.
With Hooks, you can reuse logic between your components without changing their architecture or structure.
Complex components can be difficult to understand.
When components become larger and carry out many operations, it becomes difficult to understand in the long run. Hooks solve this by allowing you separate a particular single component into various smaller functions based upon what pieces of this separated component are related (such as setting up a subscription or fetching data), rather than having to force a split based on lifecycle methods.
Classes are quite confusing.
Classes are a hindrance to learning React properly; you would need to understand how this in JavaScript works which differs from other languages. React Hooks solves this problem by allowing developers to use the best of React features without having to use classes.
The Rules Of Hooks
There are two main rules that are strictly to be adhered to as stated by the React core team in which they outlined in the hooks proposal documentation.
Make sure to not use Hooks inside loops, conditions, or nested functions;
Only use Hooks from inside React Functions.
Basic React Hooks
There are 10 in-built hooks that was shipped with React 16.8 but the basic (commonly used) hooks include:
These are the 4 basic hooks that are commonly used by React developers that have adopted React Hooks into their codebases.
useState()
The useState() hook allows React developers to update, handle and manipulate state inside functional components without needing to convert it to a class component. Let’s use the code snippet below is a simple Age counter component and we will use it to explain the power and syntax of the useState() hook.
function App() {
const [age, setAge] = useState(19);
const handleClick = () => setAge(age + 1)
return
<div>
I am {age} Years Old
<div>
<button onClick={handleClick}>Increase my age! </button>
</div>
</div>
}
If you’ve noticed, our component looks pretty simple, concise and it’s now a functional component and also does not have the level of complexity that a class component would have.
The useState() hook receives an initial state as an argument and then returns, by making use of array destructuring in JavaScript, the two variables in the array can be named what. The first variable is the actual state, while the second variable is a function that is meant for updating the state by providing a new state.
This is how our component should look when it is rendered in our React application. By clicking on the “Increase my Age” button, the state of the age will change and the component would work just like a class component with state.
useEffect()
The useEffect() hook accepts a function that would contain effectual code. In functional components, effects like mutations, subscriptions, timers, logging, and other effects are not allowed to be placed inside a functional component because doing so would lead to a lot of inconsistencies when the UI is rendered and also confusing bugs.
In using the useEffect() hook, the effectual function passed into it will execute right after the render has been displayed on the screen. Effects are basically peeked into the imperative way of building UIs that is quite different from React’s functional way.
By default, effects are executed mainly after the render has been completed, but you have the option to also fire them when certain values change.
The useEffect() hook mostly into play for side-effects that are usually used for interactions with the Browser/DOM API or external API-like data fetching or subscriptions. Also, if you are already familiar with how React lifecycle methods work, you can also think of useEffect() hook as component mounting, updating and unmounting — all combined in one function. It lets us replicate the lifecycle methods in functional components.
We will use the code snippets below to explain the most basic way that we can by using the useEffect() hook.
Just like we discussed in the previous section on how to use the useState() hook to handle state inside functional components, we used it in our code snippet to set the state for our app that renders my full name.
Step 2: Call The useEffect Hook
import React, {useState, useEffect} from 'react';
function App() {
//Define State
const [name, setName] = useState({firstName: 'name', surname: 'surname'});
const [title, setTitle] = useState('BIO');
//Call the use effect hook
useEffect(() => {
setName({name: 'Shedrack', surname: 'Akintayo'})
}, [])//pass in an empty array as a second argument
return(
<div>
<h1>Title: {title}</h1>
<h3>Name: {name.firstName}</h3>
<h3>Surname: {name.surame}</h3>
</div>
);
};
export default App
We have now imported the useEffect hook and also made use of the useEffect() function to set the state of our the name and surname property which is pretty neat and concise.
You may have noticed the useEffect hook in the second argument which is an empty array; this is because it contains a call to the setFullName which does not have a list of dependencies. Passing the second argument will prevent an infinite chain of updates (componentDidUpdate()) and it’ll also allow our useEffect() hook to act as a componentDidMount lifecycle method and render once without re-rendering on every change in the tree.
The useContext() hook accepts a context object, i.e the value that is returned from React.createContext, and then it returns the current context value for that context.
This hook gives functional components easy access to your React app context. Before the useContext hook was introduced you would need to set up a contextType or a to access your global state passed down from some provider in a class component.
Basically, the useContext hook works with the React Context API which is a way to share data deeply throughout your app without the need to manually pass your app props down through various levels. Now, the useContext() makes using Context a little easier.
The code snippets below will show how the Context API works and how the useContext Hook makes it better.
The Normal Way To Use The Context API
import React from "react";
import ReactDOM from "react-dom";
const NumberContext = React.createContext();
function App() {
return (
<NumberContext.Provider value={45}>
<div>
<Display />
</div>
</NumberContext.Provider>
);
}
function Display() {
return (
<NumberContext.Consumer>
{value => <div>The answer to the question is {value}.</div>}
</NumberContext.Consumer>
);
}
ReactDOM.render(<App />, document.querySelector("#root"));
Let’s now break down the code snippet and explain each concept.
Below, we are creating a context called NumberContext. It is meant to return an object with two values: { Provider, Consumer }.
const NumberContext = React.createContext();
Then we use the Provider value that was returned from the NumberContext we created to make a particular value available to all the children.
With that, we can use the Consumer value that was returned from the NumberContext we created to get the value we made available to all children. If you have noticed, this component did not get any props.
function Display() {
return (
<NumberContext.Consumer>
{value => <div>The answer to the question is {value}.</div>}
</NumberContext.Consumer>
);
}
ReactDOM.render(<App />, document.querySelector("#root"));
Note how we were able to get the value from the App component into the Display component by wrapping our content in a NumberContext.Consumer and using the render props method to retrieve the value and render it.
Everything works well and the render props method we used is a really good pattern for handling dynamic data, but in the long run, it does introduce some unnecessary nesting and confusion if you’re not used to it.
Using The useContext Method
To explain the useContext method we will rewrite the Display component using the useContext hook.
// import useContext (or we could write React.useContext)
import React, { useContext } from 'react';
// old code goes here
function Display() {
const value = useContext(NumberContext);
return <div>The answer is {value}.</div>;
}
That’s all we need to do in order to display our value. Pretty neat, right? You call the useContext() hook and pass in the context object we created and we grab the value from it.
Note:Don’t forget that the argument that is passed to the useContext hook must be the context object itself and any component calling the useContext will always re-render when the context value changes.
useReducer()
The useReducer hook is used for handling complex states and transitions in state. It takes in a reducer function and also an initial state input; then, it returns the current state and also a dispatch function as output by the means of array destructuring.
The code below is the proper syntax for using the useReducer hook.
It is sort of an alternative to the useState hook; it is usually preferable to useState when you have complex state logic that has to do with multiple sub-values or when the next state is dependent on the previous one.
Other React Hooks Available
useCallback
This hook returns a callback function that is memoized and that only changes if one dependency in the dependency tree changes.
useMemo
This hook returns a memoized value, you can pass in a “create” function and also an array of dependencies. The value it returns will only use the memoized value again if one of the dependencies in the dependency tree changes.
useRef
This hook returns a mutable ref object whose .current property is initialized to the passed argument (initialValue). The returned object will be available for the full lifetime of the component.
useImperativeHandle
This hook is used for customizing the instance value that is made available for parent components when using refs in React.
useLayoutEffect
This hook similar to the useEffect hook, however, it fires synchronously after all DOM mutations. It also renders in the same way as componentDidUpdate and componentDidMount.
useDebugValue
This hook can be used to display a label for custom hooks in the React Dev Tools. It is very useful for debugging with the React Dev Tools.
Custom React Hooks
A “custom Hook” is a JavaScript function whose names are prefixed with the word use and can be used to call other Hooks. It also lets you to extract component logic into reusable functions; they are normal JavaScript functions that can make use of other Hooks inside of it, and also contain a common stateful logic that can be made use of within multiple components.
The code snippets below demonstrate an example of a custom React Hook for implementing infinite scroll (by Paulo Levy):
This custom Hook accepts two arguments which are start and pace. The start argument is the starting number of elements to be rendered while the pace argument is the subsequent number of elements that are to be rendered. By default, the start and pace arguments are set to 30 and 10 respectively which means you can actually call the Hook without any arguments and those default values will be used instead.
So in order to use this Hook within a React app, we would use it with an online API that returns ‘fake’ data:
The code above will render a list of fake data (userID and title) that make use of the infinite scroll hook to display the initial number of data on the screen.
Conclusion
I hope you enjoyed working through this tutorial. You could always read more on React Hooks from the references below.
If you have any questions, you can leave them in the comments section and I’ll be happy to answer every single one!
Foldable phones are starting to be a thing. Early days, for sure, but some are already shipping, and they definitely have web browsers on them. Stands to reason that, as web designers, we are going to want to know where that fold is so we can design screens that fit onto the top half and bottom half… or left half and right half¹.
Looks like that’s going to make its way to us in the form of env() constants, just like all that notch stuff.
Interesting how there is no fold-right, isn’t it? And aren’t we trying to stay away from directional terms like that and use logical properties? Why not fold-inline-start?
It’ll be interesting to see how that sentence ages. Just watch the first really popular foldable phone will have three segments.
I would normally be a #2 kinda guy — slice off the top and bottom a bit, make sure there is ample padding, and call it a day. But Nils almost has me convinced this fancy math is better.
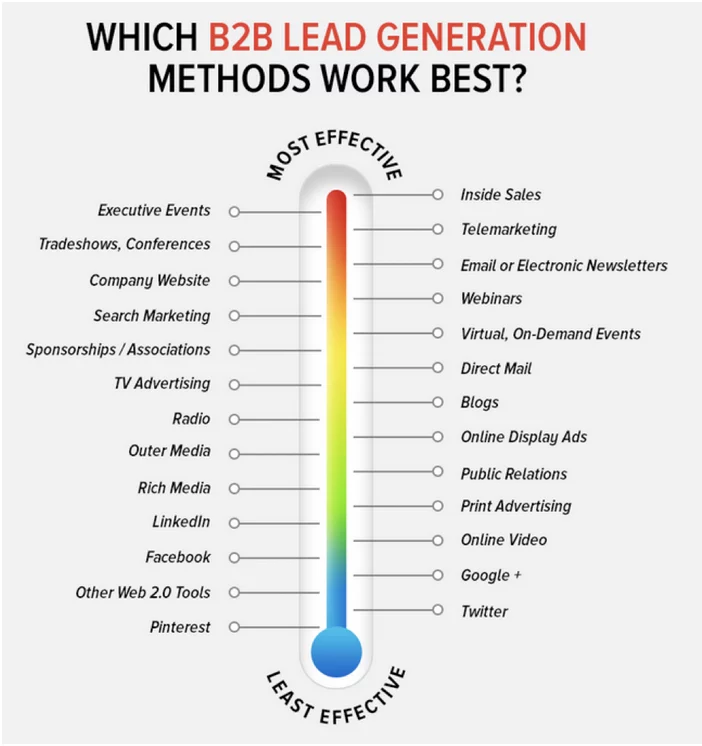
When it comes to B2B lead generation, what impacts the most?
Many B2B business houses tend to spend a lot of time, pouring water into leaky buckets. Rather than fixing the bucket i.e. the marketing funnel, they pour more water i.e. traffic into the bucket to keep it to the brim. This tendency leads to inflated acquisition costs and below-average results in terms of generating leads.
Landing pages are most crucial, particularly- the forms. Forms separate your leads from non-leads. Structures on your website indicate on your conversion rates and overall lead generation results.
Let’s say around 1000 people visit your landing page, maybe about 1% tends to convert. The fundamental reason is that most people tend to procrastinate, some feel that they will convert late, and some tend to find a different alternative. So what is to be done now? An urgency arises, in such a situation to turn at the moment. Here comes the main gameplay of optimizing your website for conversion. It is an ongoing process. There is always a next step you can take to bring in more leads and make that 1% go up the chart.
You must be feeling a dire need to optimize your website for lead generation. Questions might arise in your mind like how do I improve my landing page? What strategies should I follow? How to get more website leads?
Exclusively for you, we are covering website lead generation best practices that will help experienced business owners to take the next step in optimizing their website for lead generation and conversion, Let’s begin!
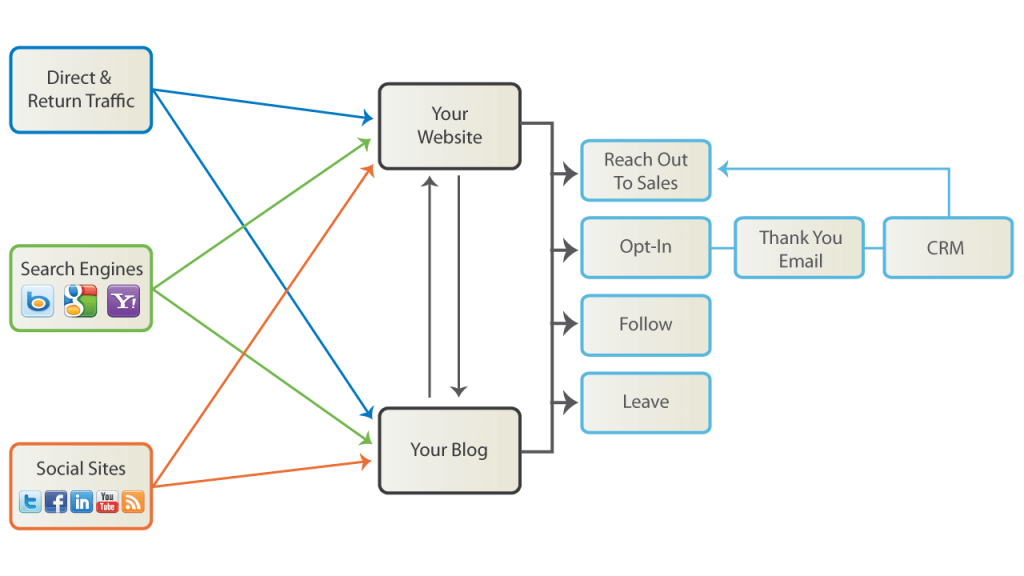
A website is one of the most potent tools most business owners possess when it comes to generating leads.
All potential new leads should be brought back to your website aka remarketing
It is evident that when a person visits your website’s homepage, it needs more than some kind of action in order to convert and become a lead. If each step is not transparent, it becomes hard for visitors to convert.
A clear path needs to be set for visitors to follow through the website to convert from just leads to buyers. The more, the merrier is the motto. It means that the website must draw more traffic and every page of your website has to correspond to the ideal customer journey that you want visitors and leads to follow.
Every website and growth agency lead generation efforts start and end with that path, implying that every web page you create has to serve as a specific stepping stone toward conversion.
Every step should build a bridge towards the next step.
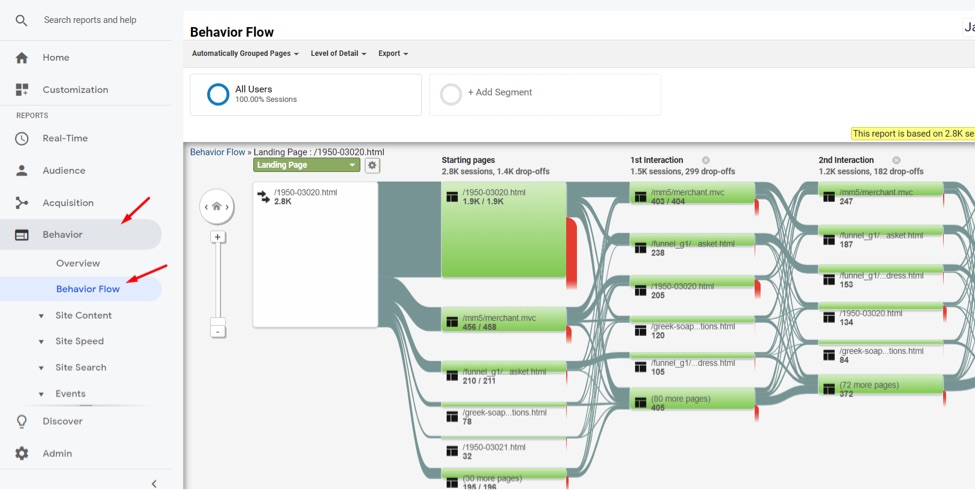
One of the ways to approach this outlook can be using Google Analytics Behavior Flow and filter for website visitors who become your best leads and best customers. It indicates which pages target audience visited along the way and help you identify where in the journey potential leads who did not convert fall off.
Google Analytics Behavior Flow
Build One Landing Page for One Persona (Buyer)
One of the biggest mistakes that most B2B business houses make with their website is that they use the same content to attract different segments of their customer base. If you create a landing page designed to convert all of your buyer personas, chances are, it will not be so effective since every buyer has a different opinion, mindset and preference.
It is therefore needed to create multiple landing pages –
“one for each of your buyer personas“
Let’s say you create a landing page exclusive that addresses the pain points of your audience, and another landing page for your visitors who visits due to interest, create one landing page for end-users focusing on your product and a separate landing page for their managers, so on and so forth.
Breaking out separate landing pages in that way, can get even more target audience and is effective to bring in “quality leads“
Send a Consistent Message All Over Your Digital Presence
The message you are sending to your target audience, if inconsistent, creates a mismatch in their expectations. If your website does not do what it promises its target audience, then it leads to
High exit rate of the visitors
Lower conversion rate
Poor user experience
Issues like High exit rate, high bounce rates, and low session durations can also negative effect.
According to Google, “the experience you offer affects your Ad Rank and therefore your CPC and position in the ad auction.”
The solution to these problems is to ensure everything that leads visitors to a given page of your website sends the same message and sets the same expectations.
Example –
Your advertisement copy – paid social media ads, display PPC ads, Google Ads, etc.
Your SEO, meta title and meta description
Social media posts
Get Your Capture Form Right
If you want to convert website visitors into leads, then you need to have some kind of capture form included in your website design. That is “Basic Marketing 101“.
To generate better-qualified leads, you will need to take it a step further and optimize your capture form for not only your unique audience but also for your business.
The best method is to offer something your audience deems valuable in exchange for their information. Basic -” helps them solve a problem” like a 30-minute consultant call or a quick chat.
Balance the type and amount of information you gather (like phone numbers and other contact information) with that perceived value. The more value your visitors expect to get from you, the more information they will be willing to hand over.
Conversion optimization activities, optimizing your form’s Call To Action and submit buttons also falls under this best practice along with a combination of placement, web design, and A/B testing.
Use Retargeting to Capture (Who Didn’t Convert)
No matter how consistent and compelling your website might be, there will always be visitors who fit the persona of your best leads but still do not convert – the worst part of digital marketing. It does not imply that those potential customers disappear and they cannot be converted. This is where “Remarketing “ makes its marks.
The biggest disadvantage of retargeting advertisements only target one individual, and most of the times that do not work for B2B businesses. You need to find tools that will allow you to target retargeting advertisements to an entire business/organisation. For this, it is recommended to use website visitor identification software along with some retargeting tools that focus on B2B.
Conclusion
Majority of website visits end without conversion, but there is always something more you can do to get more qualified companies to convert into leads. With the best practices above, you can take it to the next step and start generating more and more qualified website leads and increase your business profitability. Experiment with them to see exactly what works for you. Test the methods that convert the most, test the lead magnets that will convert best. Keep testing until you find what works best for your target audience and this helps you acquire more leads, make more sales. Tell us what do you feel?
Search engine optimization (SEO) is essential for almost every kind of website, but its finer points remain something of a specialty. Even today SEO is often treated as something that can be tacked on after the fact. It can up to a point, but it really shouldn’t be. Search engines get smarter every day and there are ways for websites to be smarter too.
The foundations of SEO are the same as they’ve always been: great content clearly labeled will win the day sooner or later — regardless of how many people try to game the system. The thing is, those labels are far more sophisticated than they used to be. Meta titles, image alt text, and backlinks are important, but in 2020, they’re also fairly primitive. There is another tier of metadata that only a fraction of sites are currently using: structured data.
All search engines share the same purpose: to organize the web’s content and deliver the most relevant, useful results possible to search queries. How they achieve this has changed enormously since the days of Lycos and Ask Jeeves. Google alone uses more than 200 ranking factors, and those are just the ones we know about.
SEO is a huge field nowadays, and I put it to you that structured data is a really, really important factor to understand and implement in the coming years. It doesn’t just improve your chances of ranking highly for relevant queries. More importantly, it helps make your websites better — opening it up to all sorts of useful web experiences.
Structured data is a way of labeling content on web pages. Using vocabulary from Schema.org, it removes much of the ambiguity from SEO. Instead of trusting the likes of Google, Bing, Baidu, and DuckDuckGo to work out what your content is about, you tell them. It’s the difference between a search engine guessing what a page is about and knowing for sure.
As Schema.org puts it:
By adding additional tags to the HTML of your web pages — tags that say, “Hey search engine, this information describes this specific movie, or place, or person, or video” — you can help search engines and other applications better understand your content and display it in a useful, relevant way.
Schema.org launched in 2011, a project shared by Google, Microsoft, Yahoo, and Yandex. In other words, it’s a ‘bipartisan’ effort — if you like. The markup transcends any one search engine. In Schema.org’s own words,
“A shared vocabulary makes it easier for webmasters and developers to decide on a schema and get the maximum benefit for their efforts.”
It is in many respects a more expansive cousin of microformats (launched around 2005) which embed semantics and structured data in HTML, mainly for the benefit of search engines and aggregators. Although microformats are currently still supported, the ‘official’ nature of the Schema.org library makes it a safer bet for longevity.
JSON for Linked Data (JSON-LD) has emerged as the dominant underlying standard for structured data, although Microdata and RDFa are also supported and serve the same purpose. Schema.org provides examples for each type depending on what you’re most comfortable with.
As an example, let’s say Joe Bloggs writes a review of Joseph Heller’s 1961 novel Catch-22 and publishes it on his blog. Sadly, Bloggs has poor taste and gives it two out of five stars. For a person looking at the page, this information would be understood unthinkingly, but computer programs would have to connect several dots to reach the same conclusion.
With structured data, the following markup could be added to the page’s code. (This is a JSON-LD approach. Microdata and RDFa can be used to weave the same information into content):
This sets in stone that the page is about Catch-22, a novel by Joseph Heller published on November 10th, 1961. The reviewer has been identified, as has the parameters of the scoring system. Different schemas can be combined (or tiered) to describe different things. For example, through tagging of this sort, you could make clear a page is the event listing for an open-air film screening, and the film in question is The Life Aquatic with Steve Zissou by Wes Anderson.
Ok, wonderful. I can label my website up to its eyeballs and it will look exactly the same, but what are the benefits? To my mind, there are two main benefits to including structured data in websites:
It makes search engine’s jobs much easier. They can index content more accurately, which in turn means they can present it more richly.
It helps web content to be more thorough and useful. Structured data gives you a ‘computer perspective’ on content. Quality content is fabulous. Quality content thoroughly tagged is the stuff of dreams.
You know when you see snazzy search results that include star ratings? That’s structured data. Rich snippets of film reviews? Structured data. When a selection of recipes appear, ingredients, preparation time and all? You guessed it. Dig into the code of any of these pages and you’ll find the markup somewhere. Search engines reward sites using structured data because it tells them exactly what they’re dealing with.
Examine the code on the websites featured above and sure enough, structured data is there. (Large preview)
It’s not just search either, to be clear. That’s a big part of it but it’s not the whole deal. Structured data is primarily about tagging and organizing content. Rich search results are just one way for said content to be used. Google Dataset Search uses Schema.org/Dataset markup, for example.
Below are a handful of examples of structured data being useful:
In many respects, structured data is a branch of the Semantic Web, which strives for a fully machine-readable Internet. It gives you a machine-readable perspective on web content that (when properly implemented) feeds back into richer functionality for people.
As such, just about anyone with a website would benefit from knowing what structured data is and how it works. According to W3Techs, only 29.6% of websites use JSON-LD, and 43.2% don’t use any structured data formats at all. There’s no obligation, of course. Not everyone cares about SEO or being machine-readable. On the flip side, for those who do there’s currently a big opportunity to one-up rival sites.
In the same way that HTML forces you to think about how content is organized, structured data gets you thinking about the substance. It makes you more thorough. Whatever your website is about, if you comb through the relevant schema documentation you’ll almost certainly spot details that you didn’t think to include beforehand.
As humans, it is easy to take for granted the connections between information. Search engines and computer programs are smart, but they’re not that smart. Not yet. Structured data translates content into terms they can understand. This, in turn, allows them to deliver richer experiences.
Weaving structured data into a website isn’t as straightforward as, say, changing a meta title. It’s the data DNA of your web content. If you want to implement it properly, then you need to be willing to get into the weeds — at least a little bit. Below are a few simple steps developers can take to weave structured data into the design process.
Note: I personally subscribe to a holistic approach to design, where design and substance go hand in hand. Juggling a bunch of disciplines is nothing new to web design, this is just another one, and if it’s incorporated well it can strengthen other elements around it. Think of it as an enhancement to your site’s engine. The car may not look all that different but it handles a hell of a lot better.
Start With A Concept
I’ll use myself as an example. For five years, two friends and I have been reviewing an album a week as a hobby (with others stepping in from time to time). Our sneering, insufferable prose is currently housed in a WordPress site, which — under my well-meaning but altogether ignorant care — had grown into a Frankenstein’s monster of plugins.
We are in the process of redesigning the site which (among other things) has entailed bringing structured data into the core design. Here, as with any other project, the first thing to do is establish what your content is about. The better you answer this question, the easier everything that follows will be.
In our case, these are the essentials:
We review music albums;
Each review has three reviewers who each write a summary by choosing up to three favorite tracks and assigning a personal score out of ten;
These three scores are combined into a final score out of 30;
From the three summaries, a passage is chosen to serve as an ‘at-a-glance’ roundup of all our thoughts.
Some of this may sound a bit specific or even a bit arbitrary (because it is), but you’d be surprised how much of it can be woven together using structured data.
Below is a mockup of what the revamped review pages will look like, and the information that can be translated into schema markup:
Even the most sprawling content is packed full of information just waiting to be tagged and structured. (Large preview)
There’s no trick to this process. I know what the content is about, so I know where to look in the documentation. In this case, I go to Schema.org/MusicAlbum and am met with all manner of potential properties, including:
albumReleaseType
byArtist
genre
producer
datePublished
recordedAt
There are dozens; some exclusive to MusicAlbum, others falling under the larger umbrella of CreativeWork. Digging deeper into the documentation, I find that the markup can connect to MusicBrainz, a music metadata encyclopedia. The same process unfolds when I go to the Review documentation.
From that one simple page, the following information can be gleaned and organized:
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "Review",
"reviewBody": "Whereas My Love is Cool was guilty of trying too hard no such thing can be said of Visions. The riffs roar and the melodies soar, with the band playing beautifully to Ellie Rowsell's strengths.",
"datePublished": "October 4, 2017",
"author": [{
"@type": "Person",
"name": "André Dack"
},
{
"@type": "Person",
"name": "Frederick O'Brien"
},
{
"@type": "Person",
"name": "Marcus Lawrence"
}],
"itemReviewed": {
"@type": "MusicAlbum",
"@id": "https://musicbrainz.org/release-group/7f231c61-20b2-49d6-ac66-1cacc4cc775f",
"byArtist": {
"@type": "MusicGroup",
"name": "Wolf Alice",
"@id": "https://musicbrainz.org/artist/3547f34a-db02-4ab7-b4a0-380e1ef951a9"
},
"image": "https://lesoreillescurieuses.files.wordpress.com/2017/10/a1320370042_10.jpg",
"albumProductionType": "http://schema.org/StudioAlbum",
"albumReleaseType": "http://schema.org/AlbumRelease",
"name": "Visions of a Life",
"numTracks": "12",
"datePublished": "September 29, 2017"
},
"reviewRating": {
"@type": "Rating",
"ratingValue": 27,
"worstRating": 0,
"bestRating": 30
}
}
</script>
And honestly, I may yet add a lot more. Initially, I found the things that are already part of a review page’s structures (i.e. artist, album name, overall score) but then new questions began to present themselves. What could be clearer? What could I add?
This should obviously be counterbalanced by questions of what’s unnecessary. Just because you can do something doesn’t mean that you should. There is such a thing as ‘too much information’. Still, sometimes a bit more detail can really take a page up a notch.
Familiarize Yourself With Schema
There’s no way around it; the best way to get the ball rolling is to immerse yourself in the documentation. There are tools that implement it for you (more on those below), but you’ll get more out of the markup if you have a proper sense of how it works.
Trawl through the Schema.org documentation. Whoever you are and whatever your website’s for, the odds are that there are plenty of relevant schemas. The site is very good with examples, so it needn’t remain theoretical.
The step beyond that, of course, is to find rich search results you would like to emulate, visiting the page, and using browser dev tools to look at what they’re doing. They are often excellent examples of websites that know their content inside out. You can also feed code snippets or URLs into Google’s Structured Data Markup Helper, which then generates appropriate schema.
Tools like Google”s Structured Data Markup Helper are excellent for getting to grips with how structured data works. (Large preview)
The fundamentals are actually very simple. Once you get your head around them, it’s the breadth of options that take time to explore and play around with. You don’t want to be that person who gets to the end of a design process, looks into schema options, and starts second-guessing everything that’s been done.
Ask The Right Questions
Now that you’re armed with your wealth of structured data knowledge, you’re better positioned to lay the foundations for a strong website. Structured data rides a fairly unique line. In the immediate sense, it exists ‘under the hood’ and is there for the benefit of computers. At the same time, it can enable richer experiences for the user.
Therefore, it pays to look at structured data from both a technical and user perspective. How can structured data help my website be better understood? What other resources, online databases, or hardware (e.g. smart speakers) might be interested in what you’re doing? What options appear in the documentation that I hadn’t accounted for? Do I want to add them?
It is especially important to identify recurring types of content. It’s safe to say a blog can expect lots of blog posts over time, so incorporating structured data into post templates will yield the most results. The example I gave above is all well and good on its own, but there’s no reason why the markup process can’t be automated. That’s the plan for us.
Consider also the ways that people might find your content. If there are opportunities to, say, highlight a snippet of copy for use in voice search, do it. It’s that, or leave it to search engines to work it out for themselves. No-one knows your content better than you do, so make use of that understanding with descriptive markup.
You don’t need to guess how content will be understood with structured data. With tools like Google’s Rich Results Tester, you can see exactly how it gives content form and meaning that might otherwise have been overlooked.
You’ll find no greater advocate of great content than me. The SEO industry loses its collective mind whenever Google rolls out a major search update. The response to the hysteria is always the same: make quality content. To that I add: mark it up properly.
Familiarize yourself with the documentation and be clear on what your site is about. Every piece of information you tag makes it that much easier for it to be indexed and shared with the right people.
Whether you’re a Google devotee or a DuckDuckGo convert, the spirit remains the same. It’s not about ranking so much as it is about making websites as good as possible. Accommodating structured data will make other aspects of your website better.
You don’t need to trust tech to understand what your content is about — you can tell it. From reviews to recipes to audio search, developers can add a whole new level of sophistication to their content.
The heart and soul of optimizing a website for search have never changed: produce great content and make it as clear as possible what it is and why it’s useful. Structured data is another tool for that purpose, so use it.
Businesses wanting to speak to customers by phone must find ways to combat the adverse effects of robocalls, so people will engage with them over the phone.
Research by Clutch, a B2B research firm, shows that 79% of people are uncomfortable providing personal information over the phone to any number, not just a robocall.
Robocalls are making people distrust the phone as a legitimate communication channel.
Phone calls provide a human touch that helps businesses build relationships with their customers, though. Voice conversations can deliver a level of accuracy and speed that other channels can’t achieve.
In this article, we show you three steps businesses can take to encourage customers to speak with them on the phone.
Use the information in this article to combat the negative influence of robocalls and get your customers to pick up the phone and engage in conversation.
Scammers try to trick people into giving away personal information, and some robocalls go so far as to threaten people with phrases such as “you’ll be taken into custody by the local cops.”
Robocalls increasingly dominate people’s phones and have left many unwilling to answer calls from anyone other than their closest friends. This leaves businesses that rely on the phone to communicate with customers in a lurch.
More than one-fourth of people can’t distinguish between robocalls and real callers at the beginning of a call, according to Clutch, increasing the likelihood of people ignoring your business calls.
The FCC recently announced steps to block robocalls, but businesses should be aware that these steps won’t entirely solve their problems.
It’s not clear if the anti-robocall will stop international callers, plus the smart scammers will find workarounds, according to CBS correspondent Nick Thompson.
Robocall scammers “threaten the way consumers view and use their telephones” and “are undermining our entire phone system,” according to Rep. Frank Pallone during a July hearing that approved the Stopping Bad Robocalls Act.
Despite the challenges, there are steps businesses can take to greatly increase the chances of their phone calls getting answered.
1. Confirm Your Identity
Test your business phone’s outgoing calls to ensure your caller ID is showing up correctly. Your caller ID should show the name of your business, not a sequence of numbers, so customers can immediately recognize you.
Take care not to place calls from personal phones or alternative business numbers that show up as something other than your primary caller ID.
Vanity numbers, such as 1-800-FLOWERS, make it easier for customers to recognize your call and remember your phone number.
Vanity numbers may be an excellent option for businesses that make frequent phone calls because they increase the likelihood of people picking up the phone.
Businesses should confirm their identity by ensuring their caller ID shows properly, and consider obtaining a vanity number to help customers recognize who’s calling.
2. Send a Text Before Calling
Sending a text before placing a phone call is another great way to let customers know that your incoming call is authentic.
A well-timed text notifies customers of your identity and increases the likelihood that they’ll accept your call.
Nearly one-fourth of people (26%) aren’t sure whether they can distinguish a robocall from a real human when they answer the phone. Sending a text assures customers that your call is genuine.
3. Remain Open to Alternate Communication Channels
Phone conversations aren’t the only option for voice conversations that help you build a personal connection with customers.
Apple’s Facetime, Facebook video calls, and Skype-like digital apps allow you to place video calls and have face-to-face conversations with people.
If customers request that you contact them using a video calling app, or another alternative service, be flexible to their new ideas and consider giving it a try.
You can take a proactive approach to alternate communication channels by polling your customers to learn what tools they use for conversation.
Build Trust Over Time
When customers do answer your phone calls, takes steps to continue building the trust needed to get your phone calls answered in the future.
Immediately let the customer know who you are and why you’re calling.
Avoid using the phone for sales calls and, instead, send promotional messages by email or physical mail.
Don’t ask for personal information, such as credit card numbers, by phone.
Avoid automated phone communication and use services such as a virtual assistant to ensure you have the proper resources to engage with all phone calls.
Providing customers with a sense of security during your phone calls helps ensure their willingness to speak with you again in the future.
Robocalls Affect the Way Businesses Communicate
Robocalls impact the way most businesses are able to communicate with customers in 2019.
Implementing the suggestions outlined in this article can help get your calls answered so you can continue building friendly and trusting business relationships.
Scheduled is the key word there — that’s a fairly new thing! When a push notification is scheduled (i.e. “Take your pill” or “You’ve got a flight in 3 hours”) that means it can be shown to the user even if they’ve gone offline. That’s an improvement from the past where push notification required the user being online.
So how do scheduled push notifications work? There are four key parts we’re going to look at:
Registering a Service Worker
Adding and removing scheduled push notifications
Enhancing push notifications with action buttons
Handling push notifications in the Service Worker
First, a little background
Push notifications are a great way to inform site users that something important has happened and that they might want to open our (web) app again. With the Notifications API — in combination with the Push API and the HTTP Web Push Protocol — the web became an easy way to send a push notification from a server to an application and display it on a device.
You may have already seen this sort of thing evolve. For example, how often do you see some sort of alert to accept notifications from a website? While browser vendors are already working on solutions to make that less annoying (both Firefox and Chrome have outlined plans), Chrome 80 just started an origin trial for the new Notification Trigger API, which lets us create notifications triggered by different events rather than a server push alone. For now, however, time-based triggers are the only supported events we have. But other events, like geolocation-based triggers, are already planned.
Scheduling an event in JavaScript is pretty easy, but there is one problem. In our push notification scenario, we can’t be sure the application is running at the exact moment we want to show the notification. This means that we can’t just schedule it on an application layer. Instead, we’ll need to do it on a Service Worker level. That’s where the new API comes into play.
The Notification Trigger API is in an early feedback phase. You need to enable the #enable-experimental-web-platform-features flag in Chrome or you should register your application for an origin trial.
Also, the Service Worker API requires a secure connection over HTTPS. So, if you try it out on your machine, you’ll need to ensure that it’s served over HTTPS.
Setting things up
I created a very basic setup. We have one application.js file, one index.html file, and one service-worker.js file, as well as a couple of image assets.
First, we need to register a Service Worker. For now, it will do nothing but log that the registration was successful.
// service-worker.js
// listen to the install event
self.addEventListener('install', event => console.log('ServiceWorker installed'));
<!-- index.html -->
<script>
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/service-worker.js');
}
</script>
Setting up the push notification
Inside our application, we need to ask for the user’s permission to show notifications. From there, we’ll get our Service Worker registration and register a new notification for this scope. So far, nothing new.
The cool part is the new showTrigger property. This lets us define the conditions for displaying a notification. For now, we want to add a new TimestampTrigger, which accepts a timestamp. And since everything happens directly on the device, it also works offline.
// application.js
document.querySelector('#notification-button').onclick = async () => {
const reg = await navigator.serviceWorker.getRegistration();
Notification.requestPermission().then(permission => {
if (permission !== 'granted') {
alert('you need to allow push notifications');
} else {
const timestamp = new Date().getTime() + 5 * 1000; // now plus 5000ms
reg.showNotification(
'Demo Push Notification',
{
tag: timestamp, // a unique ID
body: 'Hello World', // content of the push notification
showTrigger: new TimestampTrigger(timestamp), // set the time for the push notification
data: {
url: window.location.href, // pass the current url to the notification
},
badge: './assets/badge.png',
icon: './assets/icon.png',
}
);
}
});
};
Handling the notification
Right now, the notification should show up at the specified timestamp. But now we need a way to interact with it, and that’s where we need the Service Worker notificationclick and notificationclose events.
Both events listen to the relevant interactions and both can use the full potential of the Service Worker. For example, we could open a new window:
That’s a pretty straightforward example. But with the power of the Service Worker, we can do a lot more. Let’s check if the required window is already open and only open a new one if it isn’t.
// service-worker.js
self.addEventListener('notificationclick', event => {
event.waitUntil(self.clients.matchAll().then(clients => {
if (clients.length){ // check if at least one tab is already open
clients[0].focus();
} else {
self.clients.openWindow('/');
}
}));
});
Notification actions
Another great way to facilitate interaction with users is to add predefined actions to the notifications. We could, for example, let them choose if they want to dismiss the notification or open the app.
// application.js
reg.showNotification(
'Demo Push Notification',
{
tag: timestamp, // a unique ID
body: 'Hello World', // content of the push notification
showTrigger: new TimestampTrigger(timestamp), // set the time for the push notification
data: {
url: window.location.href, // pass the current url to the notification
},
badge: './assets/badge.png',
icon: './assets/icon.png',
actions: [
{
action: 'open',
title: 'Open app'
},
{
action: 'close',
title: 'Close notification',
}
]
}
);
Now we use those notifications inside the Service Worker.
It’s also possible to cancel pending notifications. In this case, we need to get all pending notifications from the Service Worker and then close them before they are sent to the device.
The last step is to set up the communication between the app and the Service Worker using the postMessage method on the Service Worker clients. Let’s say we want to notify the tab that’s already active that a push notification click happened.
// service-worker.js
self.addEventListener('notificationclick', event => {
event.waitUntil(self.clients.matchAll().then(clients => {
if(clients.length){ // check if at least one tab is already open
clients[0].focus();
clients[0].postMessage('Push notification clicked!');
} else {
self.clients.openWindow('/');
}
}));
});
The Notification API is a very powerful feature to enhance the mobile experience of web applications. Thanks to the arrival of the Notification Trigger API, it just got a very important improvement. The API is still under development, so now is the perfect time to play around with it and give feedback to the developers.
If you are working with Vue or React, I’d recommend you take a look at my own Progressive Web App demo. It includes a documented example using the Notification Trigger API for both frameworks that looks like this:
This report made a big splash last year. It’s a large chunk of research that shows just how terribly the web does with accessibility. It’s been updated this year and (drumroll…) we got a little worse. I’ll use their blockquote:
The number of errors increased 2.1% between February 2019 and February 2020.
From the choir:
Over the last year websites got **checks notes** LESS accessible?!?1 Jesus, my dudes. https://t.co/zvwb2wQxsH
I wonder if Chrome (at least) could be more aggressive about this — running an a11y test in the background after load and printing legit console errors on findings. People get v uppity about those, I’ve noticed ?. /cc @slightlylate
Last year I wrote about @webaim‘s analysis of one million home pages, and how it painted an *incredibly* bleak picture of the web’s accessibility: https://t.co/yLG9poTSMf
#Accessibility The WebAIM report is out and it’s apparently getting worse. Seriously, it’s about time we start making the web more accessible, people rely now more than even on a lot of online services for security, health, information, etc. https://t.co/7n0zxtUuyZ
Web accessibility is getting statistically worse. This is going to keep happening – and we’re going to keep being surprised about it – until we get honest about ableism. These cold, hard numbers are a human problem. https://t.co/gplKhUKQLy
Part of me thinks: it’s time for browsers to step up and auto-fix the things they can. But I also think that’s dangerous territory. AMP is a browser vendor’s version of “enough is enough” with poor web performance and I’m not loving how that’s turned out to date. That said, evangelism doesn’t seem to be working.
You can fix your site though. My favorite tool is axe.
We will take a Test-Driven Development (TDD) approach and the set up Continuous Integration (CI) job to automatically run our tests on Travis CI and AppVeyor, complete with code quality and coverage reporting. We will learn about controllers, models (with PostgreSQL), error handling, and asynchronous Express middleware. Finally, we’ll complete the CI/CD pipeline by configuring automatic deploy on Heroku.
It sounds like a lot, but this tutorial is aimed at beginners who are ready to try their hands on a back-end project with some level of complexity, and who may still be confused as to how all the pieces fit together in a real project.
It is robust without being overwhelming and is broken down into sections that you can complete in a reasonable length of time.
Getting Started
The first step is to create a new directory for the project and start a new node project. Node is required to continue with this tutorial. If you don’t have it installed, head over to the official website, download, and install it before continuing.
I will be using yarn as my package manager for this project. There are installation instructions for your specific operating system here. Feel free to use npm if you like.
Open your terminal, create a new directory, and start a Node.js project.
# create a new directory
mkdir express-api-template
# change to the newly-created directory
cd express-api-template
# initialize a new Node.js project
npm init
Answer the questions that follow to generate a package.json file. This file holds information about your project. Example of such information includes what dependencies it uses, the command to start the project, and so on.
You may now open the project folder in your editor of choice. I use visual studio code. It’s a free IDE with tons of plugins to make your life easier, and it’s available for all major platforms. You can download it from the official website.
Create the following files in the project folder:
README.md
.editorconfig
Here’s a description of what .editorconfig does from the EditorConfig website. (You probably don’t need it if you’re working solo, but it does no harm, so I’ll leave it here.)
“EditorConfig helps maintain consistent coding styles for multiple developers working on the same project across various editors and IDEs.”
The [*] means that we want to apply the rules that come under it to every file in the project. We want an indent size of two spaces and UTF-8 character set. We also want to trim trailing white space and insert a final empty line in our file.
Open README.md and add the project name as a first-level element.
# Express API template
Let’s add version control right away.
# initialize the project folder as a git repository
git init
Create a .gitignore file and enter the following lines:
I consider this to be a good point to commit my changes and push them to GitHub.
Starting A New Express Project
Express is a Node.js framework for building web applications. According to the official website, it is a
Fast, unopinionated, minimalist web framework for Node.js.
There are other great web application frameworks for Node.js, but Express is very popular, with over 47k GitHub stars at the time of this writing.
In this article, we will not be having a lot of discussions about all the parts that make up Express. For that discussion, I recommend you check out Jamie’s series. The first part is here, and the second part is here.
Install Express and start a new Express project. It’s possible to manually set up an Express server from scratch but to make our life easier we’ll use the express-generator to set up the app skeleton.
# install the express generator globally
yarn global add express-generator
# install express
yarn add express
# generate the express project in the current folder
express -f
The -f flag forces Express to create the project in the current directory.
We’ll now perform some house-cleaning operations.
Delete the file index/users.js.
Delete the folders public/ and views/.
Rename the file bin/www to bin/www.js.
Uninstall jade with the command yarn remove jade.
Create a new folder named src/ and move the following inside it:
1. app.js file
2. bin/ folder
3. routes/ folder inside.
Open up package.json and update the start script to look like below.
"start": "node ./src/bin/www"
At this point, your project folder structure looks like below. You can see how VS Code highlights the file changes that have taken place.
The code generated by express-generator is in ES5, but in this article, we will be writing all our code in ES6 syntax. So, let’s convert our existing code to ES6.
Replace the content of routes/index.js with the below code:
import express from 'express';
const indexRouter = express.Router();
indexRouter.get('/', (req, res) =>
res.status(200).json({ message: 'Welcome to Express API template' })
);
export default indexRouter;
It is the same code as we saw above, but with the import statement and an arrow function in the / route handler.
Replace the content of src/app.js with the below code:
import logger from 'morgan';
import express from 'express';
import cookieParser from 'cookie-parser';
import indexRouter from './routes/index';
const app = express();
app.use(logger('dev'));
app.use(express.json());
app.use(express.urlencoded({ extended: true }));
app.use(cookieParser());
app.use('/v1', indexRouter);
export default app;
Let’s now take a look at the content of src/bin/www.js. We will build it incrementally. Delete the content of src/bin/www.js and paste in the below code block.
#!/usr/bin/env node
/**
* Module dependencies.
*/
import debug from 'debug';
import http from 'http';
import app from '../app';
/**
* Normalize a port into a number, string, or false.
*/
const normalizePort = val => {
const port = parseInt(val, 10);
if (Number.isNaN(port)) {
// named pipe
return val;
}
if (port >= 0) {
// port number
return port;
}
return false;
};
/**
* Get port from environment and store in Express.
*/
const port = normalizePort(process.env.PORT || '3000');
app.set('port', port);
/**
* Create HTTP server.
*/
const server = http.createServer(app);
// next code block goes here
This code checks if a custom port is specified in the environment variables. If none is set the default port value of 3000 is set on the app instance, after being normalized to either a string or a number by normalizePort. The server is then created from the http module, with app as the callback function.
The #!/usr/bin/env node line is optional since we would specify node when we want to execute this file. But make sure it is on line 1 of src/bin/www.js file or remove it completely.
Let’s take a look at the error handling function. Copy and paste this code block after the line where the server is created.
/**
* Event listener for HTTP server "error" event.
*/
const onError = error => {
if (error.syscall !== 'listen') {
throw error;
}
const bind = typeof port === 'string' ? `Pipe ${port}` : `Port ${port}`;
// handle specific listen errors with friendly messages
switch (error.code) {
case 'EACCES':
alert(`${bind} requires elevated privileges`);
process.exit(1);
break;
case 'EADDRINUSE':
alert(`${bind} is already in use`);
process.exit(1);
break;
default:
throw error;
}
};
/**
* Event listener for HTTP server "listening" event.
*/
const onListening = () => {
const addr = server.address();
const bind = typeof addr === 'string' ? `pipe ${addr}` : `port ${addr.port}`;
debug(`Listening on ${bind}`);
};
/**
* Listen on provided port, on all network interfaces.
*/
server.listen(port);
server.on('error', onError);
server.on('listening', onListening);
The onError function listens for errors in the http server and displays appropriate error messages. The onListening function simply outputs the port the server is listening on to the console. Finally, the server listens for incoming requests at the specified address and port.
At this point, all our existing code is in ES6 syntax. Stop your server (use Ctrl + C) and run yarn start. You’ll get an error SyntaxError: Invalid or unexpected token. This happens because Node (at the time of writing) doesn’t support some of the syntax we’ve used in our code.
We’ll now fix that in the following section.
Configuring Development Dependencies: babel, nodemon, eslint, And prettier
It’s time to set up most of the scripts we’re going to need at this phase of the project.
Install the required libraries with the below commands. You can just copy everything and paste it in your terminal. The comment lines will be skipped.
This installs all the listed babel scripts as development dependencies. Check your package.json file and you should see a devDependencies section. All the installed scripts will be listed there.
The babel scripts we’re using are explained below:
@babel/cli
A required install for using babel. It allows the use of Babel from the terminal and is available as ./node_modules/.bin/babel.
@babel/core
Core Babel functionality. This is a required installation.
@babel/node
This works exactly like the Node.js CLI, with the added benefit of compiling with babel presets and plugins. This is required for use with nodemon.
@babel/plugin-transform-runtime
This helps to avoid duplication in the compiled output.
@babel/preset-env
A collection of plugins that are responsible for carrying out code transformations.
@babel/register
This compiles files on the fly and is specified as a requirement during tests.
@babel/runtime
This works in conjunction with @babel/plugin-transform-runtime.
Create a file named .babelrc at the root of your project and add the following code:
The watch key tells nodemon which files and folders to watch for changes. So, whenever any of these files changes, nodemon restarts the server. The ignore key tells it the files not to watch for changes.
Now update the scripts section of your package.json file to look like the following:
# build the content of the src folder
"prestart": "babel ./src --out-dir build"
# start server from the build folder
"start": "node ./build/bin/www"
# start server in development mode
"startdev": "nodemon --exec babel-node ./src/bin/www"
prestart scripts builds the content of the src/ folder and puts it in the build/ folder. When you issue the yarn start command, this script runs first before the start script.
start script now serves the content of the build/ folder instead of the src/ folder we were serving previously. This is the script you’ll use when serving the file in production. In fact, services like Heroku automatically run this script when you deploy.
yarn startdev is used to start the server during development. From now on we will be using this script as we develop the app. Notice that we’re now using babel-node to run the app instead of regular node. The --exec flag forces babel-node to serve the src/ folder. For the start script, we use node since the files in the build/ folder have been compiled to ES5.
Run yarn startdev and visit http://localhost:3000/v1. Your server should be up and running again.
The final step in this section is to configure ESLint and prettier. ESLint helps with enforcing syntax rules while prettier helps for formatting our code properly for readability.
Add both of them with the command below. You should run this on a separate terminal while observing the terminal where our server is running. You should see the server restarting. This is because we’re monitoring package.json file for changes.
This file mostly defines some rules against which eslint will check our code. You can see that we’re extending the style rules used by Airbnb.
In the "rules" section, we define whether eslint should show a warning or an error when it encounters certain violations. For instance, it shows a warning message on our terminal for any indentation that does not use 2 spaces. A value of [0] turns off a rule, which means that we won’t get a warning or an error if we violate that rule.
Create a file named .prettierrc and add the code below:
We’re setting a tab width of 2 and enforcing the use of single quotes throughout our application. Do check the prettier guide for more styling options.
Now add the following scripts to your package.json:
# add these one after the other
"lint": "./node_modules/.bin/eslint ./src"
"pretty": "prettier --write '**/*.{js,json}' '!node_modules/**'"
"postpretty": "yarn lint --fix"
Run yarn lint. You should see a number of errors and warnings in the console.
The pretty command prettifies our code. The postpretty command is run immediately after. It runs the lint command with the --fix flag appended. This flag tells ESLint to automatically fix common linting issues. In this way, I mostly run the yarn pretty command without bothering about the lint command.
Run yarn pretty. You should see that we have only two warnings about the presence of alert in the bin/www.js file.
Here’s what our project structure looks like at this point.
Settings And Environment Variables In Our .env File
In nearly every project, you’ll need somewhere to store settings that will be used throughout your app e.g. an AWS secret key. We store such settings as environment variables. This keeps them away from prying eyes, and we can use them within our application as needed.
I like having a settings.js file with which I read all my environment variables. Then, I can refer to the settings file from anywhere within my app. You’re at liberty to name this file whatever you want, but there’s some kind of consensus about naming such files settings.js or config.js.
For our environment variables, we’ll keep them in a .env file and read them into our settings file from there.
Create the .env file at the root of your project and enter the below line:
TEST_ENV_VARIABLE="Environment variable is coming across"
To be able to read environment variables into our project, there’s a nice library, dotenv that reads our .env file and gives us access to the environment variables defined inside. Let’s install it.
# install dotenv
yarn add dotenv
Add the .env file to the list of files being watched by nodemon.
Now, create the settings.js file inside the src/ folder and add the below code:
import dotenv from 'dotenv';
dotenv.config();
export const testEnvironmentVariable = process.env.TEST_ENV_VARIABLE;
We import the dotenv package and call its config method. We then export the testEnvironmentVariable which we set in our .env file.
Open src/routes/index.js and replace the code with the one below.
The only change we’ve made here is that we import testEnvironmentVariable from our settings file and use is as the return message for a request from the / route.
It’s time to incorporate testing into our app. One of the things that give the developer confidence in their code is tests. I’m sure you’ve seen countless articles on the web preaching Test-Driven Development (TDD). It cannot be emphasized enough that your code needs some measure of testing. TDD is very easy to follow when you’re working with Express.js.
In our tests, we will make calls to our API endpoints and check to see if what is returned is what we expect.
Each of these libraries has its own role to play in our tests.
mocha
test runner
chai
used to make assertions
nyc
collect test coverage report
sinon-chai
extends chai’s assertions
supertest
used to make HTTP calls to our API endpoints
coveralls
for uploading test coverage to coveralls.io
Create a new test/ folder at the root of your project. Create two files inside this folder:
test/setup.js
test/index.test.js
Mocha will find the test/ folder automatically.
Open up test/setup.js and paste the below code. This is just a helper file that helps us organize all the imports we need in our test files.
import supertest from 'supertest';
import chai from 'chai';
import sinonChai from 'sinon-chai';
import app from '../src/app';
chai.use(sinonChai);
export const { expect } = chai;
export const server = supertest.agent(app);
export const BASE_URL = '/v1';
This is like a settings file, but for our tests. This way we don’t have to initialize everything inside each of our test files. So we import the necessary packages and export what we initialized — which we can then import in the files that need them.
Open up index.test.js and paste the following test code.
import { expect, server, BASE_URL } from './setup';
describe('Index page test', () => {
it('gets base url', done => {
server
.get(`${BASE_URL}/`)
.expect(200)
.end((err, res) => {
expect(res.status).to.equal(200);
expect(res.body.message).to.equal(
'Environment variable is coming across.'
);
done();
});
});
});
Here we make a request to get the base endpoint, which is / and assert that the res.body object has a message key with a value of Environment variable is coming across.
If you’re not familiar with the describe, it pattern, I encourage you to take a quick look at Mocha’s “Getting Started” doc.
Add the test command to the scripts section of package.json.
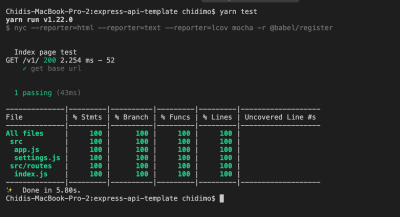
This script executes our test with nyc and generates three kinds of coverage report: an HTML report, outputted to the coverage/ folder; a text report outputted to the terminal and an lcov report outputted to the .nyc_output/ folder.
Now run yarn test. You should see a text report in your terminal just like the one in the below photo.
Look inside .gitignore and you’ll see that we’re already ignoring both. I encourage you to open up coverage/index.html in a browser and view the test report for each file.
This is a good point to commit your changes.
The corresponding branch in my repo is 04-first-test.
Continuous Integration(CD) And Badges: Travis, Coveralls, Code Climate, AppVeyor
It’s now time to configure continuous integration and deployment (CI/CD) tools. We will configure common services such as travis-ci, coveralls, AppVeyor, and codeclimate and add badges to our README file.
Let’s get started.
Travis CI
Travis CI is a tool that runs our tests automatically each time we push a commit to GitHub (and recently, Bitbucket) and each time we create a pull request. This is mostly useful when making pull requests by showing us if the our new code has broken any of our tests.
Visit travis-ci.com or travis-ci.org and create an account if you don’t have one. You have to sign up with your GitHub account.
Hover over the dropdown arrow next to your profile picture and click on settings.
Under Repositories tab click Manage repositories on Github to be redirected to Github.
On the GitHub page, scroll down to Repository access and click the checkbox next to Only select repositories.
Click the Select repositories dropdown and find the express-api-template repo. Click it to add it to the list of repositories you want to add to travis-ci.
Click Approve and install and wait to be redirected back to travis-ci.
At the top of the repo page, close to the repo name, click on the build unknown icon. From the Status Image modal, select markdown from the format dropdown.
Copy the resulting code and paste it in your README.md file.
On the project page, click on More options > Settings. Under Environment Variables section, add the TEST_ENV_VARIABLE env variable. When entering its value, be sure to have it within double quotes like this "Environment variable is coming across."
Create .travis.yml file at the root of your project and paste in the below code (We’ll set the value of CC_TEST_REPORTER_ID in the Code Climate section).
First, we tell Travis to run our test with Node.js, then set the CC_TEST_REPORTER_ID global environment variable (we’ll get to this in the Code Climate section). In the matrix section, we tell Travis to run our tests with Node.js v12. We also want to cache the node_modules/ directory so it doesn’t have to be regenerated every time.
We install our dependencies using the yarn command which is a shorthand for yarn install. The before_script and after_script commands are used to upload coverage results to codeclimate. We’ll configure codeclimate shortly. After yarn test runs successfully, we want to also run yarn coverage which will upload our coverage report to coveralls.io.
Coveralls
Coveralls uploads test coverage data for easy visualization. We can view the test coverage on our local machine from the coverage folder, but Coveralls makes it available outside our local machine.
Visit coveralls.io and either sign in or sign up with your Github account.
Hover over the left-hand side of the screen to reveal the navigation menu. Click on ADD REPOS.
Search for the express-api-template repo and turn on coverage using the toggle button on the left-hand side. If you can’t find it, click on SYNC REPOS on the upper right-hand corner and try again. Note that your repo has to be public, unless you have a PRO account.
Click details to go to the repo details page.
Create the .coveralls.yml file at the root of your project and enter the below code. To get the repo_token, click on the repo details. You will find it easily on that page. You could just do a browser search for repo_token.
This command uploads the coverage report in the .nyc_output folder to coveralls.io. Turn on your Internet connection and run:
yarn coverage
This should upload the existing coverage report to coveralls. Refresh the repo page on coveralls to see the full report.
On the details page, scroll down to find the BADGE YOUR REPO section. Click on the EMBED dropdown and copy the markdown code and paste it into your README file.
Code Climate
Code Climate is a tool that helps us measure code quality. It shows us maintenance metrics by checking our code against some defined patterns. It detects things such as unnecessary repetition and deeply nested for loops. It also collects test coverage data just like coveralls.io.
Visit codeclimate.com and click on ‘Sign up with GitHub’. Log in if you already have an account.
Once in your dashboard, click on Add a repository.
Find the express-api-template repo from the list and click on Add Repo.
Wait for the build to complete and redirect to the repo dashboard.
Under Codebase Summary, click on Test Coverage. Under the Test coverage menu, copy the TEST REPORTER ID and paste it in your .travis.yml as the value of CC_TEST_REPORTER_ID.
Still on the same page, on the left-hand navigation, under EXTRAS, click on Badges. Copy the maintainability and test coverage badges in markdown format and paste them into your README.md file.
It’s important to note that there are two ways of configuring maintainability checks. There are the default settings that are applied to every repo, but if you like, you could provide a .codeclimate.yml file at the root of your project. I’ll be using the default settings, which you can find under the Maintainability tab of the repo settings page. I encourage you to take a look at least. If you still want to configure your own settings, this guide will give you all the information you need.
AppVeyor
AppVeyor and Travis CI are both automated test runners. The main difference is that travis-ci runs tests in a Linux environment while AppVeyor runs tests in a Windows environment. This section is included to show how to get started with AppVeyor.
From the repo list, find the express-api-template repo. Hover over it and click ADD.
Click on the Settings tab. Click on Environment on the left navigation. Add TEST_ENV_VARIABLE and its value. Click ‘Save’ at the bottom of the page.
Create the appveyor.yml file at the root of your project and paste in the below code.
environment:
matrix:
- nodejs_version: "12"
install:
- yarn
test_script:
- yarn test
build: off
This code instructs AppVeyor to run our tests using Node.js v12. We then install our project dependencies with the yarn command. test_script specifies the command to run our test. The last line tells AppVeyor not to create a build folder.
Click on the Settings tab. On the left-hand navigation, click on badges. Copy the markdown code and paste it in your README.md file.
Commit your code and push to GitHub. If you have done everything as instructed all tests should pass and you should see your shiny new badges as shown below. Check again that you have set the environment variables on Travis and AppVeyor.
Currently, we’re handling the GET request to the root URL, /v1, inside the src/routes/index.js. This works as expected and there is nothing wrong with it. However, as your application grows, you want to keep things tidy. You want concerns to be separated — you want a clear separation between the code that handles the request and the code that generates the response that will be sent back to the client. To achieve this, we write controllers. Controllers are simply functions that handle requests coming through a particular URL.
To get started, create a controllers/ folder inside the src/ folder. Inside controllers create two files: index.js and home.js. We would export our functions from within index.js. You could name home.js anything you want, but typically you want to name controllers after what they control. For example, you might have a file usersController.js to hold every function related to users in your app.
Open src/controllers/home.js and enter the code below:
You will notice that we only moved the function that handles the request for the / route.
Open src/controllers/index.js and enter the below code.
// export everything from home.js
export * from './home';
We export everything from the home.js file. This allows us shorten our import statements to import { indexPage } from '../controllers';
Open src/routes/index.js and replace the code there with the one below:
import express from 'express';
import { indexPage } from '../controllers';
const indexRouter = express.Router();
indexRouter.get('/', indexPage);
export default indexRouter;
The only change here is that we’ve provided a function to handle the request to the / route.
You just successfully wrote your first controller. From here it’s a matter of adding more files and functions as needed.
Go ahead and play with the app by adding a few more routes and controllers. You could add a route and a controller for the about page. Remember to update your test, though.
Run yarn test to confirm that we’ve not broken anything. Does your test pass? That’s cool.
Connecting The PostgreSQL Database And Writing A Model
Our controller currently returns hard-coded text messages. In a real-world app, we often need to store and retrieve information from a database. In this section, we will connect our app to a PostgreSQL database.
We’re going to implement the storage and retrieval of simple text messages using a database. We have two options for setting a database: we could provision one from a cloud server, or we could set up our own locally.
I would recommend you provision a database from a cloud server. ElephantSQL has a free plan that gives 20MB of free storage which is sufficient for this tutorial. Visit the site and click on Get a managed database today. Create an account (if you don’t have one) and follow the instructions to create a free plan. Take note of the URL on the database details page. We’ll be needing it soon.
ElephantSQL turtle plan details page (Large preview)
If you would rather set up a database locally, you should visit the PostgreSQL and PgAdmin sites for further instructions.
Once we have a database set up, we need to find a way to allow our Express app to communicate with our database. Node.js by default doesn’t support reading and writing to PostgreSQL database, so we’ll be using an excellent library, appropriately named, node-postgres.
node-postgres executes SQL queries in node and returns the result as an object, from which we can grab items from the rows key.
Open your .env file and add the CONNECTION_STRING variable. This is the connection string we’ll be using to establish a connection to our database. The general form of the connection string is shown below.
If you’re using elephantSQL you should copy the URL from the database details page.
Inside your /src folder, create a new folder called models/. Inside this folder, create two files:
pool.js
model.js
Open pools.js and paste the following code:
import { Pool } from 'pg';
import dotenv from 'dotenv';
import { connectionString } from '../settings';
dotenv.config();
export const pool = new Pool({ connectionString });
First, we import the Pool and dotenv from the pg and dotenv packages, and then import the settings we created for our postgres database before initializing dotenv. We establish a connection to our database with the Pool object. In node-postgres, every query is executed by a client. A Pool is a collection of clients for communicating with the database.
To create the connection, the pool constructor takes a config object. You can read more about all the possible configurations here. It also accepts a single connection string, which I will use here.
Open model.js and paste the following code:
import { pool } from './pool';
class Model {
constructor(table) {
this.pool = pool;
this.table = table;
this.pool.on('error', (err, client) => `Error, ${err}, on idle client${client}`);
}
async select(columns, clause) {
let query = `SELECT ${columns} FROM ${this.table}`;
if (clause) query += clause;
return this.pool.query(query);
}
}
export default Model;
We create a model class whose constructor accepts the database table we wish to operate on. We’ll be using a single pool for all our models.
We then create a select method which we will use to retrieve items from our database. This method accepts the columns we want to retrieve and a clause, such as a WHERE clause. It returns the result of the query, which is a Promise. Remember we said earlier that every query is executed by a client, but here we execute the query with pool. This is because, when we use pool.query, node-postgres executes the query using the first available idle client.
The query you write is entirely up to you, provided it is a valid SQL statement that can be executed by a Postgres engine.
The next step is to actually create an API endpoint to utilize our newly connected database. Before we do that, I’d like us to create some utility functions. The goal is for us to have a way to perform common database operations from the command line.
Create a folder, utils/ inside the src/ folder. Create three files inside this folder:
queries.js
queryFunctions.js
runQuery.js
We’re going to create functions to create a table in our database, insert seed data in the table, and to delete the table.
Open up queries.js and paste the following code:
export const createMessageTable = `
DROP TABLE IF EXISTS messages;
CREATE TABLE IF NOT EXISTS messages (
id SERIAL PRIMARY KEY,
name VARCHAR DEFAULT '',
message VARCHAR NOT NULL
)
`;
export const insertMessages = `
INSERT INTO messages(name, message)
VALUES ('chidimo', 'first message'),
('orji', 'second message')
`;
export const dropMessagesTable = 'DROP TABLE messages';
In this file, we define three SQL query strings. The first query deletes and recreates the messages table. The second query inserts two rows into the messages table. Feel free to add more items here. The last query drops/deletes the messages table.
Open queryFunctions.js and paste the following code:
Here, we create functions to execute the queries we defined earlier. Note that the executeQueryArray function executes an array of queries and waits for each one to complete inside the loop. (Don’t do such a thing in production code though). Then, we only resolve the promise once we have executed the last query in the list. The reason for using an array is that the number of such queries will grow as the number of tables in our database grows.
This is where we execute the functions to create the table and insert the messages in the table. Let’s add a command in the scripts section of our package.json to execute this file.
"runQuery": "babel-node ./src/utils/runQuery"
Now run:
yarn runQuery
If you inspect your database, you will see that the messages table has been created and that the messages were inserted into the table.
If you’re using ElephantSQL, on the database details page, click on BROWSER from the left navigation menu. Select the messages table and click Execute. You should see the messages from the queries.js file.
Let’s create a controller and route to display the messages from our database.
Create a new controller file src/controllers/messages.js and paste the following code:
import Model from '../models/model';
const messagesModel = new Model('messages');
export const messagesPage = async (req, res) => {
try {
const data = await messagesModel.select('name, message');
res.status(200).json({ messages: data.rows });
} catch (err) {
res.status(200).json({ messages: err.stack });
}
};
We import our Model class and create a new instance of that model. This represents the messages table in our database. We then use the select method of the model to query our database. The data (name and message) we get is sent as JSON in the response.
We define the messagesPage controller as an async function. Since node-postgres queries return a promise, we await the result of that query. If we encounter an error during the query we catch it and display the stack to the user. You should decide how choose to handle the error.
Add the get messages endpoint to src/routes/index.js and update the import line.
# update the import line
import { indexPage, messagesPage } from '../controllers';
# add the get messages endpoint
indexRouter.get('/messages', messagesPage)
Now, let’s update our test file. When doing TDD, you usually write your tests before implementing the code that makes the test pass. I’m taking the opposite approach here because we’re still working on setting up the database.
Create a new file, hooks.js in the test/ folder and enter the below code:
When our test starts, Mocha finds this file and executes it before running any test file. It executes the before hook to create the database and insert some items into it. The test files then run after that. Once the test is finished, Mocha runs the after hook in which we drop the database. This ensures that each time we run our tests, we do so with clean and new records in our database.
Create a new test file test/messages.test.js and add the below code:
Note: I hope everything works fine on your end, but in case you should be having trouble for some reason, you can always check my code in the repo!
Now, let’s see how we can add a message to our database. For this step, we’ll need a way to send POST requests to our URL. I’ll be using Postman to send POST requests.
Let’s go the TDD route and update our test to reflect what we expect to achieve.
Open test/message.test.js and add the below test case:
This test makes a POST request to the /v1/messages endpoint and we expect an array to be returned. We also check for the id, name, and message properties on the array.
Run your tests to see that this case fails. Let’s now fix it.
To send post requests, we use the post method of the server. We also send the name and message we want to insert. We expect the response to be an array, with a property id and the other info that makes up the query. The id is proof that a record has been inserted into the database.
Open src/models/model.js and add the insert method:
We destructure the request body to get the name and message. Then we use the values to form an SQL query string which we then execute with the insertWithReturn method of our model.
Add the below POST endpoint to /src/routes/index.js and update your import line.
import { indexPage, messagesPage, addMessage } from '../controllers';
indexRouter.post('/messages', addMessage);
Run your tests to see if they pass.
Open Postman and send a POST request to the messages endpoint. If you’ve just run your test, remember to run yarn query to recreate the messages table.
GET request showing newly added message. (Large preview)
Commit your changes and push to GitHub. Your tests should pass on both Travis and AppVeyor. Your test coverage will drop by a few points, but that’s okay.
The corresponding branch on my repo is 08-post-to-db.
Middleware
Our discussion of Express won’t be complete without talking about middleware. The Express documentation describes a middlewares as:
“[…] functions that have access to the request object (req), the response object (res), and the next middleware function in the application’s request-response cycle. The next middleware function is commonly denoted by a variable named next.”
We’re going to write a simple middleware that modifies the request body. Our middleware will append the word SAYS: to the incoming message before it is saved in the database.
Before we start, let’s modify our test to reflect what we want to achieve.
Open up test/messages.test.js and modify the last expect line in the posts message test case:
it('posts messages', done => {
...
expect(m).to.have.property('message', `SAYS: ${data.message}`); # update this line
...
});
We’re asserting that the SAYS: string has been appended to the message. Run your tests to make sure this test case fails.
Now, let’s write the code to make the test pass.
Create a new middleware/ folder inside src/ folder. Create two files inside this folder:
Here, we append the string SAYS: to the message in the request body. After doing that, we must call the next() function to pass execution to the next function in the request-response chain. Every middleware has to call the next function to pass execution to the next middleware in the request-response cycle.
Enter the below code in index.js:
# export everything from the middleware file
export * from './middleware';
This exports the middleware we have in the /middleware.js file. For now, we only have the modifyMessage middleware.
Open src/routes/index.js and add the middleware to the post message request-response chain.
import { modifyMessage } from '../middleware';
indexRouter.post('/messages', modifyMessage, addMessage);
We can see that the modifyMessage function comes before the addMessage function. We invoke the addMessage function by calling next in the modifyMessage middleware. As an experiment, comment out the next() line in the modifyMessage middle and watch the request hang.
Open Postman and create a new message. You should see the appended string.
The corresponding branch in my repo is 09-middleware.
Error Handling And Asynchronous Middleware
Errors are inevitable in any application. The task before the developer is how to deal with errors as gracefully as possible.
In Express:
“Error Handling refers to how Express catches and processes errors that occur both synchronously and asynchronously.
If we were only writing synchronous functions, we might not have to worry so much about error handling as Express already does an excellent job of handling those. According to the docs:
“Errors that occur in synchronous code inside route handlers and middleware require no extra work.”
But once we start writing asynchronous router handlers and middleware, then we have to do some error handling.
Our modifyMessage middleware is a synchronous function. If an error occurs in that function, Express will handle it just fine. Let’s see how we deal with errors in asynchronous middleware.
Let’s say, before creating a message, we want to get a picture from the Lorem Picsum API using this URL https://picsum.photos/id/0/info. This is an asynchronous operation that could either succeed or fail, and that presents a case for us to deal with.
Start by installing Axios.
# install axios
yarn add axios
Open src/middleware/middleware.js and add the below function:
In this async function, we await a call to an API (we don’t actually need the returned data) and afterward call the next function in the request chain. If the request fails, we catch the error and pass it on to next. Once Express sees this error, it skips all other middleware in the chain. If we didn’t call next(err), the request will hang. If we only called next() without err, the request will proceed as if nothing happened and the error will not be caught.
Import this function and add it to the middleware chain of the post messages route:
This is our error handler. According to the Express error handling doc:
“[…] error-handling functions have four arguments instead of three: (err, req, res, next).”
Note that this error handler must come last, after every app.use() call. Once we encounter an error, we return the stack trace with a status code of 400. You could do whatever you like with the error. You might want to log it or send it somewhere.
To start the app, it needs to be compiled down to ES5 using babel in the prestart step because babel only exists in our development dependencies. We have to set NPM_CONFIG_PRODUCTION to false in order to be able to install those as well.
To confirm everything is set correctly, run the command below. You could also visit the settings tab on the app page and click on Reveal Config Vars.
# check configuration variables
heroku config
Now run git push heroku.
To open the app, run:
# open /v1 route
heroku open /v1
# open /v1/messages route
heroku open /v1/messages
If like me, you’re using the same PostgresSQL database for both development and production, you may find that each time you run your tests, the database is deleted. To recreate it, you could run either one of the following commands:
# run script locally
yarn runQuery
# run script with heroku
heroku run yarn runQuery
Continuous Deployment (CD) With Travis
Let’s now add Continuous Deployment (CD) to complete the CI/CD flow. We will be deploying from Travis after every successful test run.
The first step is to install Travis CI. (You can find the installation instructions over here.) After successfully installing the Travis CI, login by running the below command. (Note that this should be done in your project repository.)
# login to travis
travis login --pro
# use this if you're using two factor authentication
travis login --pro --github-token enter-github-token-here
If your project is hosted on travis-ci.org, remove the --pro flag. To get a GitHub token, visit the developer settings page of your account and generate one. This only applies if your account is secured with 2FA.
Open your .travis.yml and add a deploy section:
deploy:
provider: heroku
app:
master: app-name
Here, we specify that we want to deploy to Heroku. The app sub-section specifies that we want to deploy the master branch of our repo to the app-name app on Heroku. It’s possible to deploy different branches to different apps. You can read more about the available options here.
Run the below command to encrypt your Heroku API key and add it to the deploy section:
# encrypt heroku API key and add to .travis.yml
travis encrypt $(heroku auth:token) --add deploy.api_key --pro
This will add the below sub-section to the deploy section.
Now commit your changes and push to GitHub while monitoring your logs. You will see the build triggered as soon as the Travis test is done. In this way, if we have a failing test, the changes would never be deployed. Likewise, if the build failed, the whole test run would fail. This completes the CI/CD flow.
If you’ve made it this far, I say, “Thumbs up!” In this tutorial, we successfully set up a new Express project. We went ahead to configure development dependencies as well as Continuous Integration (CI). We then wrote asynchronous functions to handle requests to our API endpoints — completed with tests. We then looked briefly at error handling. Finally, we deployed our project to Heroku and configured Continuous Deployment.
You now have a template for your next back-end project. We’ve only done enough to get you started, but you should keep learning to keep going. Be sure to check out the Express.js docs as well. If you would rather use MongoDB instead of PostgreSQL, I have a template here that does exactly that. You can check it out for the setup. It has only a few points of difference.
Thirty years after the historic passage of the Americans with Disabilities Act, the landmark legislation that transformed the US’s workplaces and common spaces for the better, so much of our lives have moved out of the physical world and into the digital one. The urgency of equality — and the need to ensure that web design and development consider digital accessibility and the user experience of those with disabilities — is at an all-time high.
Nearly one in five Americans has some form of disability. Globally, the number is higher than 1 billion. Although equal access to community spaces — both in the physical and virtual world — is a clear human right, for millions of Americans, the web is broken. It’s a place packed with frustrating stumbling blocks and disorienting design, and it’s in dire need of a UX overhaul.
This is evidenced in the WebAIM Million study conducted last year. The Center for Persons with Disabilities at Utah State University conducted an evaluation of the top million webpages focusing on the automatically detectable issues. Not surprisingly, the results are dire. The study found an average of nearly 60 accessibility errors on each of the site’s homepages, which was virtually the same amount of errors detected when the same evaluations were run, six months prior. The WebAIM Alexa 100 study didn’t fare much better. Across the top 100 homepages of the most trafficked websites, the study found an average of approximately 56 errors per page (including highly pervasive color contrast errors).
This all amounts to an incredible number of digital access barriers. It’s no wonder plaintiffs are filing lawsuits in record numbers. Over the past two years, alone, there have been nearly 5,000 ADA Title III website accessibility lawsuits filed in federal court. There’s still a lot of work to be done.
No matter where you are in your accessibility journey, here are some common mistakes to avoid, as well as some of the often-overlooked accessibility considerations that will have a meaningful impact for your site visitors.
Test With People
If you’re creating inclusive websites, it’s crucial that you expand your user pool of testers to include individuals with disabilities or, at a minimum, subject matter experts versed in the many nuances of navigating the digital world with assistive technologies (AT), such as screen readers.
At best, automated testing tools can only detect about one third of the potential issues
One of the most common misperceptions about accessibility is that, if you use an automated testing tool, you can find out everything that is wrong with your site.
At best, automated testing tools can only detect about one third of the potential issues. Even in the case of the WebAIM Million study, the number of issues uncovered only consisted of automatically detectable issues. It’s safe to assume, the number of issues that actually exist on the web pages evaluated in the study are largely understated. Accessibility testing might seem simple on the surface, but usability testing leveraging assistive technologies is complex and multi-faceted. Motor, visual, cognitive and auditory impairments can all impact user experience, as can the specific AT and browser combination being used. To gain a true understanding of how usable your site is with these tools, you can’t just rely on automated testing.
If All You Plan To Do Is Implement A Toolbar, Think Again
Doing something is certainly better than doing nothing, and we should all applaud anyone that is taking steps to improve the accessibility of their digital assets. But if you think that adding a free accessibility toolbar, alone, is doing enough, you should take note. It’s not.
Toolbar providers that don’t test your site with people or couple their offering with custom, human-informed fixes that correct accessibility violations, do next to nothing to reduce compliance risk. Despite many of the claims they tend to make about their AI and ML technologies achieving full compliance by simply embedding a single code into your website, most overlay solutions do not have a material impact in improving website accessibility compliance. Unfortunately, fully autonomous website accessibility isn’t a thing. Be wary of those making bold, sweeping claims to the contrary. Outsourced accessibility providers will continue to fall short without a broader, more holistic approach.
fully autonomous website accessibility isn’t a thing
Not all toolbar (or “overlay”) solutions are alike, though. A trusted provider will be backed by an expansive customer base of enterprise-grade clients who have vetted the integrity and, perhaps most importantly, the security of the service. At the end of the day, unless they are having a meaningful impact in improving conformance with the Web Content Accessibility Guidelines (WCAG), they aren’t moving the needle toward compliance, which is very much focused on adhering to these internationally recognized standards and, more importantly, removing digital access barriers for individuals with disabilities.
Stay Current With The Latest Standards
Speaking of WCAG, for the last several years, the talk of the town, when it came to website accessibility, has been WCAG 2.0 Level AA Success Criteria. WCAG 2.1 (which incorporates 2.0) was actually released back in 2018. Since the latter half of 2019, plaintiffs and claimants have begun to reference WCAG 2.1 AA. When benchmarking, be sure to reference WCAG 2.1, which includes 12 new level AA testable success criteria, which are heavily focused on cognitive disabilities and requirements for mobile/responsive design.
If you really want to stay ahead of the curve, keep pace with the W3C’s progress on evolving the standards. Check out WCAG 2.2, which will be here before you know it.
Think Different For Those Who Might Think (And Navigate) Differently
A lot of the discussion around digital accessibility tends to lean toward vision and hearing disabilities. The vast majority of lawsuits filed are from blind individuals relying on screen reader compatibility or hearing impaired individuals requiring video captioning. But, the size of these demographics pales in comparison to the number of individuals impacted by cognitive and ambulatory disabilities, the two most prevalent disabilities in the United States.
There are several accommodations designers and developers can take to improve usability for individuals with cognitive and learning disabilities. Reading level aligns with the higher level, AAA, WCAG conformance, but making sure your content isn’t written for a rocket scientist to understand is always a good idea. Something below a lower secondary education level is optimal for lower-literacy users. Breaking up, or chunking, site content into digestible snippets is also proven to improve retention and understanding, especially for those site visitors with shorter attention spans or individuals with Attention Deficit Disorder. Providing options to change fonts and letter and paragraph spacing has proven to offer a similar benefit.
the more accessible your website, the better your search results
For individuals with mobility impairments, optimizing for keyboard navigation has many benefits and it’s easy and fun to test. Harnessing the power of the tab key and putting yourself in the shoes of a user who relies solely on the keyboard to engage and interact with your site should become an essential tool in your accessibility testing arsenal. You’ll quickly understand and become fanatic about keyboard focus indicators, skip navigation links, and if you’ve implemented infinite scroll, you might just pull your hair out. Your users will likely be better off with easy-to-follow triggers, like a “Load more results…” button.
There are a considerable number of additional factors that must be taken into account when striving to ensure a fully accessible website experience. Video transcription and captioning, audio description, color selection, layout, structure, animation and effects are just a few examples. When you start examining your website through the lens of accessibility, you’ll quickly realize that the potential pitfalls are many, but the potential to transform your site — and expand your access as a result — is significant.
Simply put, designing for accessibility is good business. Accessibility is directly proportional to SEO friendliness; the more accessible your website, the better your search results and the wider the net cast around your potential audience. When usability is good, clean and simple, reach and impact are also increased. And no one can argue with the cost-benefit analysis of that.