As a follow-up to Jhey’s recent post on responsive motion paths, Michelle Barker notes that another approach could be to just transform: scale() the whole dang element.
The trade-off there is that you’re scaling both the path and the element on the path at the same time; Jhey’s approach only makes path flexbile and the element stays the same size.
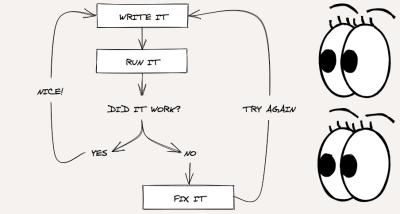
Taking your first steps in programming is like picking up a foreign language. At first, the syntax makes no sense, the vocabulary is unfamiliar, and everything looks and sounds unintelligible. If you’re anything like me when I started, fluency feels impossible.
I promise it isn’t. When I began coding, the learning curve hit me — hard. I spent ten months teaching myself the basics while trying to stave off feelings of self-doubt that I now recognize as imposter syndrome. It wasn’t until I started going to beginner-friendly meetups that I realized how coding collaboratively opens up amazing possibilities. You just need the right community of people to practice with.
For me, that community was Founders and Coders, the free JavaScript bootcamp that helped me to switch my career from copywriting to coding. Even now, less than a year after completing the course, I can hardly believe I’m being paid to develop software.
Collaborative coding is all about tackling problems and discovering solutions together. It encompasses techniques like pair programming, which several tech companies take seriously enough to screen for during their interview processes. It also cultivates useful skills that are tough to learn if all you’re doing is coding alone at home.
Whether you’re just starting out in the tech industry or you have several years of experience under your belt, collaborative coding never stops being useful. In this article, we’ll look at how these evergreen skills equip you for a long and successful career in software development.
Perfect Pairing
My first experience of pair programming was at a meetup for beginners called Coding For Everyone. Here’s how it works: people pair up, often with people they’ve never met, to solve JavaScript challenges together at the same laptop. One person assumes the role of the ‘navigator’ and proposes the code they think should be written. The other person, the ‘driver’, types out their suggestions on the laptop and asks questions whenever something isn’t clear. You continue doing this, swapping roles frequently, until the end of the two-hour session.
In theory, it was simple. In practice, not so much.
I found it quite distracting to have someone I didn’t know watching my screen while I typed, and I was reluctant to hand over control when it was time to swap roles. I found navigating even trickier. When an idea cannot go from your head into the computer without first going through your partner’s hands, every word that you say matters. It demanded a degree of communication from us both that we simply weren’t used to, and I felt sure we’d both learn more if we split up to work separately.
Fortunately, we stuck with it; I went again to the meetup the following week. I’ve since spent hundreds of hours pairing with dozens of developers, and I’ve learned more than I initially thought possible.
Pair programming is an incredibly fast way to learn. The magic of the method — once you get over the initial awkwardness — is that it yields immediate results. Some feedback loops, like bubbles in the stock market, can take hours, days, or even months to produce a correction. Pair programming takes minutes, if not seconds. When you misplace a semicolon, two pairs of eyes can spot the mistake faster than one. Need to search StackOverflow for clues about a rogue error message? You and your partner can each read different threads, halving the time it takes to find an answer.
For even trickier problems, mob programming can be a further step up. This method requires a cross-functional section of a team to gather around the same computer screen and brainstorm solutions in realtime while one person types.
“All the brilliant minds working on the same thing, at the same time, in the same space, on the same computer.”
— Woody Zuill, Agile Coach and Mob Programming Trainer
While it might seem like an inefficient way to work, mob programming advocates such as Woody Zuill say it can actually save time by eliminating the need for individual code reviews because everyone reviews the code in realtime as it’s being written. Productivity aside, I think mobbing is a fantastic way to learn not just about the code, but about how other people approach problems. If pair programming doubles the number of perspectives you’re exposed to, mob programming yields even more insights.
Sometimes, ten heads are better than two. (Large preview)
That’s not to say that pairing — or indeed mobbing — is plain sailing. Something I struggled with initially was putting my ego to one side to ask questions that I thought might sound stupid. In these situations, it’s good to remember that your partner might be having the same thoughts, especially if you’re both just starting out.
If you find yourself pairing with someone more senior, perhaps at work, don’t be afraid to pick their brains and impress them with your inquisitiveness. Even someone who is only a bit further ahead than you might think of things that wouldn’t occur to someone more senior. Some of my favorite pair programmers only have a few months more experience than me, yet they always seem to know exactly which mistakes I’m about to make and how to steer me in the right direction. When these developers say there’s no such thing as a silly question, they really mean it. The best pair programmers speak freely, without the need to appear fantastic or the fear of looking foolish.
Pair programming takes practice, but it’s worth perfecting. Studies show that programmers who pair to solve problems tend to be more confident, productive, and engaged with their work. Whether you’re looking for your next job or you’re onboarding new hires, pairing is caring.
When I started teaching myself JavaScript, my code looked a lot like my bedroom floor: I’d let it get messier and messier until I had no choice but to tidy it. As long as my web browser could understand it, I didn’t care how it looked.
It wasn’t until I started reviewing other people’s code that I realized I needed to show a lot more empathy for the people reviewing mine.
Peer code review — the act of checking each other’s code for mistakes — calls on us to exercise empathy. As the reviewer, it’s important to recognize that someone has gone to considerable effort to write the code that you are about to critique. As such, try to avoid using phrases that might imply judgment or trivialize their work. When you refer to their code, you want to show them the specific functions and lines that you have questions about, and suggest how they might refactor it. Sharing learning resources can also be more helpful than spoon-feeding a solution. Some of the most useful feedback I’ve received from code reviews has come in the form of educational articles, videos, and even podcast recommendations.
Writing good documentation for your code also goes a long way. An act as simple as creating a readme with clear installation instructions shows empathy for anyone who needs to work with your code. GitHub founder Tom Preston-Werner advocates a readme-first approach to development.
“A perfect implementation of the wrong specification is worthless. By the same principle, a beautifully crafted library with no documentation is also damn near worthless. If your software solves the wrong problem or nobody can figure out how to use it, there’s something very bad going on.”
— Tom Preston-Werner, GitHub Founder
I’ve also spoken with tech founders who treat documentation as an essential part of successful onboarding. One CTO said that if a junior developer struggles to reach a level of productivity within six months of joining his team, it points towards the codebase not being well documented enough. It only takes a few seconds to add an explanatory comment to a complex function you’ve written, but it could save the next person who joins your team hours of effort.
From the millions of man-hours that go into making CGI movies to the intense development crunches leading up to big-budget video game releases, towering technical achievements take a mind-boggling amount of effort. The first time I saw my current employer’s codebase, I was floored by the enormity of it all. How on earth did anybody build this?
The answer is that everybody can build a lot more than anybody, given the right collaborative framework. In companies that encourage collaborative coding, the software doesn’t emerge from the efforts of a lone genius. Instead, there are ways of working together that help great teams to do amazing work. Developers at Founders and Coders practice a popular software development methodology known as ‘Agile’, and in my experience, it puts the ‘functional’ in cross-functional development teams.
Entire books have been written about Agile, but here is a summary of the core concepts:
A product development team breaks down large pieces of work into small units called ‘user stories’, prioritizes them, and delivers them in two-week cycles called ‘sprints’.
For as long as the project continues, the cycles repeat, and new product requirements get fed into a backlog of tasks for future sprints.
The team holds daily standup meetings to discuss their progress and address any blockers.
The process is both incremental and iterative: the software is built and delivered in pieces and refined in successive sprints.
As a chronic tinkerer whose solo hobby projects often succumb to ‘feature creep‘, I know how easy it is to waste time building the things that no one ever uses. I love the way that Agile forces you to prioritize user stories so that the entire team can focus on delivering features that your users actually care about. It’s motivating to know that you’re all united around the common goal of building a product or service that will continue to have a life after you finish working on it.
Splitting tasks into small user stories also happens to be a great way to timebox pair programming sessions. No matter how deep in the zone you find yourselves, finishing up work on a key feature is always a nice reminder to step away from your desks and take a break. Agile lends structure to collaborative coding where it could otherwise be lacking.
Meanwhile, daily standups give you the freedom to talk about anything that is holding you back, and sprint retrospectives provide space to share key wins and pinpoint where the team could improve. These ceremonies foster a sense of collaboration and accountability, and help us to learn more together than we could by ourselves.
Putting all of these Agile principles into practice can be challenging, especially when no one in a team is used to this way of working. At Founders and Coders, it takes most students a while to get into the habit of doing daily standups. However, after 18 weeks of project-based practice, you find that your processes and communication skills improve immensely. By the time you take on your first client work, you’ve formed a much clearer mental model of how to approach building a full-stack web app in a team.
The best way to learn Agile is to build interesting projects with other people. Attending hackathons is an excellent way to connect with potential collaborators. Many open-source projects make their kanban project boards public, so you can see which GitHub issues different contributors are working on. Several welcome contributions from beginners, and you can often assign yourself to open issues and begin raising pull requests.
Since most tech companies subscribe to some form of Agile, it’s not uncommon for employers to ask about it in interviews. Any experience you have can set you apart from other applicants who may never have coded collaboratively, let alone with Agile in mind.
In the last several years, remote working tools have advanced to the point that prominent companies like Gatsby and Zapier are now “remote first”. While it remains to be seen whether this will turn into a trend, it’s safe to say that remote development teams are here to stay.
In that spirit, here are some tools that can help you and your team code collaboratively from afar:
Markdown Editors
HackMD The killer feature is that you can turn markdown documents into slideshow presentations with next to no effort. Borrows from the popular reveal.js library.
StackEdit A collaborative online editor with a clean UI and lots of file export options.
Code Editors
CodeSandbox A fantastic collaborative cloud-based code editor that you run in your browser, with no installation needed.
Live Share A neat extension for the popular Microsoft Visual Studio Code editor that supports real time editing and debugging of files inside the same workspace.
Video Conferencing Solutions
Google Hangouts Superb Google Calendar integration makes it a cinch to schedule video calls.
Microsoft Teams Video conferencing software that offers really good call quality (1080p video), and supports up to 250 simultaneous participants.
If you take one thing away from reading this article, I want it to be that team players trump individual contributors. In a field where there seems to be a hot new framework to master every other week, our technical skills age in a way that our soft skills don’t. The upshot is that developers who can work well with other people will always find their abilities are in demand. Collaborative coding isn’t just an effective way to learn; it’s a sought after skill set that anyone can develop with enough practice and patience.
Not so long ago, we wrote about dark mode in CSS and I’ve been thinking about how white text on a black background is pretty much always harder to read than black text on a white background. After thinking about this for a while, I realized that we can fix that problem by making the text thinner in dark mode using variable fonts!
Here’s an example of the problem where I’m using the typeface Yanone Kaffeesatz from Google Fonts. Notice that the section with white text on a black background looks heavier than the section with black text on a white background.
CodePen Embed Fallback
Oddly enough, these two bits of text are actually using the same font-weight value of 400. But to my eye, the white text looks extra bold on a black background.
Stare at this example for a while. This is just how white text looks on a darker background; it’s how our eyes perceive shapes and color. And this might not be a big issue in some cases but reading light text on a dark background is always way more difficult for readers. And if we don’t take care designing text in a dark mode context, then it can feel as if the text is vibrating as we read it.
How do we fix this?
Well, this is where variable fonts come in! We can use a lighter font weight to make the text easier to read whenever dark mode is active:
body {
font-weight: 400;
}
@media (prefers-color-scheme: dark) {
body {
font-weight: 350;
}
}
Here’s how that looks with this new example:
CodePen Embed Fallback
This is better! The two variants now look a lot more balanced to me.
Again, it’s only a small difference, but all great designs consist of micro adjustments like this. And I reckon that, if you’re already using variable fonts and loading all these weights, then you should definitely adjust the text so it’s easier to read.
This effect is definitely easier to spot if we compare the differences between longer paragraphs of text. Here we go, this time in Literata:
CodePen Embed Fallback
Notice that the text on the right feels bolder, but it just isn’t. It’s simply an optical allusion — both examples above have a font-weight of 500.
So to fix this issue we can do the same as the example above:
body {
font-weight: 500;
}
@media (prefers-color-scheme: dark) {
body {
font-weight: 400;
}
}
CodePen Embed Fallback
Again, it’s a slight change but it’s important because at these sizes every typographic improvement we make helps the reading experience.
Oh and here’s a quick Google fonts tip!
Google Fonts lets you can add a font to your website by adding a in the of the document, like this:
That’s using the Rosario typeface and adding a font-weight of 515 — that’s the bit in the code above that says wght@515. Even if this happens to be a variable font, 515 only this font weight that’s downloaded. If we try to do something like this:
body {
font-weight: 400;
}
…nothing will happen! In fact, the font won’t load at all. Instead, we need to declare which range of font-weight values we want by doing the following:
This @300..500 bit in the code above is what tells Google Fonts to download a font file with all the weights between 300 and 500. Alternatively, adding a ; between each weight will then only download weights 300 and 500 – so, for example, you can’t pick weight 301:
It took me a few minutes to figure out what was going wrong and why the font wasn’t loading at all, so hopefully the Google Fonts team can make that a bit clearer with the embed codes in the future. Perhaps there should be an option or a toggle somewhere to select a range or specific weights (or maybe I just didn’t see it).
Either way, I think all this is why variable fonts can be so gosh darn helpful; they allow us to adjust text in ways that we’ve never been able to do before. So, yay for variable fonts!
The Web Content Accessibility Guidelines (WCAG), an organization that defines standards for web content accessibility, does not specify a minimum font size for the web.
But we know there’s such a thing as text that is too small to be legible, just as text that can be too large to consume. So, how can we make sure our font sizes are accessible? What sort of best practices can we rely on to make for an accessible reading experience?
The answer: it’s not up to us. It Depends™. We’ll get into some specific a bit later but, for now, let’s explore the WCAG requirements for fonts.
Sizing, contrast, and 300 alphabets
First, resizing text. We want to provide users with low vision a way to choose how fonts are displayed. Not in a crazy way. More like the ability to increase the size by 200% while maintaining readability and avoiding content collisions and overlaps.
Secondly, there’s contrast. This is why I said “it depends” on what makes an accessible font size. Text has to follow a contrast ratio of at least 4.5:1, with the exception of a large-scale text that should have a contrast ratio of at least 3:1. You can use tools like WebAIM’s Contrast Checker to ensure your text meets the guidelines. Stacy Arrelano’s deep dive on color contrast provides an excellent explanation of how contrast ratios are calculated.
Example of three color contrast measurements and their WCAG test results according to WebAIM’s contrast checker.
There are around 300 alphabets in the world. Some characters are simple and readable in smaller sizes, others are incredibly complex and would lose vital details at the same size. That’s why specs cannot define a font size that meets the specification for contrast ratios.
And when we talk about “text” and “large text” sizes, we’re referring to what the spec calls “the minimum large print size used for those languages and the next larger standard large print size.” To meet AAA criteria using Roman text, for example, “large” is 18 points. Since we live in a world with different screen densities, specs measure sizes in points, not pixels, and in some displays, 18pt is equal to 24px. For other fonts, like CJK (Chinese, Japanese, Korean) or Arabic languages, the actual size in pixel would be different. Here’s the word “Hello” compared next to three other languages:
Hello?????????????
In short, WCAG specifies contrast instead of size.
The WCAG recommended font size for large text has greater contrast than something half the size. Notice how a larger font size lets in more of the background that sits behind the text.
Here is the good news: a browser’s default styles are accessible and we can leverage them to build an accessible font size strategy. Let’s see how.
Think about proportions, not size
The browser first loads its default styles (also known as the “User Agent stylesheet”), then those cascade to the author’s styles (the ones we define), and they both cascade and get overwritten by the user’s styles.
We don’t fully control the font-family property, either. The content might be translated, the custom font family might fail to load, or it might even be changed. For example, OpenDyslexic is a typeface created to increase readability for readers with dyslexia. In some situations, we may even explicitly allow switching between a limited set of fonts.
Therefore, when defining fonts, we have to avoid hindering the ability of a user or a device to change our styles and let go of assumptions: we just don’t know where our content is going to land and we can’t be sure about the exact size, language, or font that’s used to display content.
But there is one thing that we can control: proportions.
By using CSS relative units, we can set our content to be proportional to whatever the environment tells it to be. WCAG recommends using em units to define font size. There are several publications discussing the benefits of using ems and rems and it’s beyond the scope of this article. What I’d say here is to use rems and ems for everything, even for other properties besides font-size (with the exception of borders, where I use pixels).
Avoid setting a base font-size
My recommendation is to avoid setting font-size on the :root, or elements in favor of letting the browser’s default size serve as a baseline from where we can cascade our own styles. Since this default is accessible, the content will also be accessible. The WACAG 2.2 working draft states that:
When using text without specifying the font size, the smallest font size used on major browsers for unspecified text would be a reasonable size to assume for the font.
Of course, there is an exception to the rule. When using an intricate, thin, or super short x-height font, for example, you might consider bumping up the font size base to get the correct contrast. Remember that the spec defines contrast, not size:
Fonts with extraordinarily thin strokes or unusual features and characteristics that reduce the familiarity of their letter forms are harder to read, especially at lower contrast levels.
In the same manner, a user might change the base font size to fit their needs. A person with low vision would want to choose a larger size, while someone with an excellent vision can go smaller to gain real estate on their screens.
It’s all about proportions: we define how much larger or smaller parts of the content should be by leveraging the default base to set the main text size.
:root {
/* Do not set a font-size on a :root, body nor html level */
/* Let your main text size be decided by the browser or the user settings */
}
.small {
font-size: .8rem;
}
.large {
font-size: 2rem;
}
What about headings?
Since headings create a document outline that helps screenreaders navigate a document, we aren’t defining type selectors for heading sizes. Heading order is a WCAG criteria: the heading elements should be organized in descending order without skipping a level, meaning that an h4 should come right after an h3.
Sometimes resetting the font sizing of all headings to 1rem is a good strategy to make the separation of the visual treatment from the meaning mandatory.
How can we work with pixels?
Both rem or em sizing is relative to something else. For example, rem calculates size relative to the element, where em is calculated by the sizing of its own element. It can be confusing, particularly since many of us came up working exclusively in pixels.
So, how can we still think in pixels but implement relative units?
More often than not, a typographical hierarchy is designed in pixels. Since we know about user agent stylesheets and that all major browsers have a default font size of 16px, we can set that size for the main text and calculate the rest proportionately with rem units.
Browser Name
Base Font Size
Chrome v80.0
16px
FireFox v74.0
16px
Safari v13.0.4
16px
Edge v80.0 (Chromium based)
16px
Android (Samsung, Chrome, Firefox)
16px
Safari iOS
16px
Kindle Touch
26px (renders as 16px since it’s a high density screen)
Now let’s explore three methods for using relative sizing in CSS by converting those pixels to rem units.
Method 1: The 62.5% rule
In order to seamlessly convert pixels to rem, we can set the root sizing to 62.5%. That means 1rem equals 10px:
Similar to calc() , we can leverage a preprocessor to create a “pixel-to-rem” function. There are implementations of this in many flavors, including this Sass mixin and styled-components polish.
The bottom line is this: we don’t have control over how content is consumed. Users have personal browser settings, the ability to zoom in and out, and various other ways to customize their reading experience. But we do have best CSS best practices we can use to maintain a good user experience alongside those preferences:
Work with proportions instead of explicit sizes.
Rely on default browser font sizes instead of setting it on the :root, or .
Use rem units to help scale content with a user’s personal preferences.
Avoid making assumptions and let the environment decide how your content is being consumed.
Special thanks to Franco Correa for all the help writing this post.
I still think Coil is cool. I have it installed on CSS-Tricks as a publisher and money trickles in. I have a paid account and I trickle out money to other sites that use it. I wrote about all that last year.
This’ll explode to something huge if we actually get the Web Monetization API stuff. No more browser extensions would be needed, and a real ecosystem could be built around it.
Anselm Hook writes about using Coil (for now) to monetize games on the web, which is a good reminder that this isn’t just for publications — it’s for anything-web. Coil even works for things off your own domain, like your YouTube channel.
In a previous article, we showed how to build a GraphQL API with FaunaDB. We’ve also written a series of articles [1, 2, 3, 4] explaining how traditional databases built for global scalability have to adopt eventual (vs. strong) consistency, and/or make compromises on relations and indexing possibilities. FaunaDB is different since it does not make these compromises. It’s built to scale so it can safely serve your future startup no matter how big it gets, without sacrificing relations and consistent data.
In this article, we’re very excited to start bringing all of this together in a real-world app with highly dynamic data in a serverless fashion using React hooks, FaunaDB, and Cloudinary. We will use the Fauna Query Language (FQL) instead of GraphQL and start with a frontend-only approach that directly accesses the serverless database FaunaDB for data storage, authentication, and authorization.
The golden standard for example applications that feature a specific technology is a todo app–mainly because they are simple. Any database out there can serve a very simple application and shine.
And that is exactly why this app will be different! If we truly want to show howFaunaDB excels for real world applications, then we need to build something more advanced.
Introducing Fwitter
When we started at Twitter, databases were bad. When we left, they were still bad
Evan Weaver
Since FaunaDB was developed by ex-Twitter engineers who experienced these limitations first-hand, a Twitter-like application felt like an appropriately sentimental choice. And, since we are building it with FaunaDB, let’s call this serverless baby ‘Fwitter’.
Below is a short video that shows how it looks, and the full source code is available on GitHub.
When you clone the repo and start digging around, you might notice a plethora of well-commented example queries not covered in this article. That’s because we’ll be using Fwitter as our go-to example application in future articles, and building additional features into it with time.
But, for now, here’s a basic rundown of what we’ll cover here:
We build these features without having to configure operations or set up servers for your database. Since both Cloudinary and FaunaDB are scalable and distributed out-of-the-box, we will never have to worry about setting up servers in multiple regions to achieve low latencies for users in other countries.
Let’s dive in!
Modeling the data
Before we can show how FaunaDB excels at relations, we need to cover the types of relations in our application’s data model. FaunaDB’s data entities are stored in documents, which are then stored in collections–like rows in tables. For example, each user’s details will be represented by a User document stored in a Users collection. And we eventually plan to support both single sign-on and password-based login methods for a single user, each of which will be represented as an Account document in an Accounts collection.
At this point, one user has one account, so it doesn’t matter which entity stores the reference (i.e., the user ID). We could have stored the user ID in either the Account or the User document in a one-to-one relation:
One-to-one
However, since one User will eventually have multiple Accounts (or authentication methods), we’ll have a one-to-many model.
One-to-many
In a one-to-many relation between Users and Accounts, each Account points to only one user, so it makes sense to store the User reference on the Account:
We also have many-to-many relations, like the relations between Fweets and Users, because of the complex ways users interact with each other via likes, comments, and refweets.
Many-to-many
Further, we will use a third collection, Fweetstats, to store information about the interaction between a User and a Fweet.
Fweetstats’ data will help us determine, for example, whether or not to color the icons indicating to the user that he has already liked, commented, or refweeted a Fweet. It also helps us determine what clicking on the heart means: unlike or like.
The final model for the application will look like this:
The application model of the fwitter application
Fweets are the center of the model, because they contain the most important data of the Fweet such as the information about the message, the number of likes, refweets, comments, and the Cloudinary media that was attached. FaunaDB stores this data in a json format that looks like this:
As shown in the model and in this example json, hashtags are stored as a list of references. If we wanted to, we could have stored the complete hashtag json in here, and that is the preferred solution in more limited document-based databases that lack relations. However, that would mean that our hashtags would be duplicated everywhere (as they are in more limited databases) and it would be more difficult to search for hashtags and/or retrieve Fweets for a specific hashtag as shown below.
Note that a Fweet does not contain a link to Comments, but the Comments collection contains a reference to the Fweet. That’s because one Comment belongs to one Fweet, but a Fweet can have many comments–similar to the one-to-many relation between Users and Accounts.
Finally, there is a FollowerStats collection which basically saves information about how much users interact with each other in order to personalize their respective feeds. We won’t cover that much in this article, but you can experiment with the queries in the source code and stay tuned for a future article on advanced indexing.
Hopefully, you’re starting to see why we chose something more complex than a ToDo app. Although Fwitter is nowhere near the complexity of the real Twitter app on which it’s based, it’s already becoming apparent that implementing such an application without relations would be a serious brainbreaker.
Now, if you haven’t already done so from the github repo, it’s finally time to get our project running locally!
Setup the project
To set up the project, go to the FaunaDB dashboard and sign up. Once you are in the dashboard, click on New Database, fill in a name, and click Save. You should now be on the “Overview” page of your new database.
Next, we need a key that we will use in our setup scripts. Click on the Security tab in the left sidebar, then click the New key button.
In the “New key” form, the current database should already be selected. For “Role”, leave it as “Admin”. Optionally, add a key name. Next, click Save and copy the key secret displayed on the next page. It will not be displayed again.
Now that you have your database secret, clone the git repository and follow the readme. We have prepared a few scripts so that you only have to run the following commands to initialize your app, create all collections, and populate your database. The scripts will give you further instructions:
// install node modules
npm install
// run setup, this will create all the resources in your database
// provide the admin key when the script asks for it.
// !!! the setup script will give you another key, this is a key
// with almost no permissions that you need to place in your .env.local as the
// script suggestions
npm run setup
npm run populate
// start the frontend
After the script, your .env.local file should contain the bootstrap key that the script provided you (not the admin key)
You can optionally create an account with Cloudinary and add your cloudname and a public template (there is a default template called ‘ml_default’ which you can make public) to the environment to include images and videos in the fweets.
Without these variables, the include media button will not work, but the rest of the app should run fine:
Creating the front end
For the frontend, we used Create React App to generate an application, then divided the application into pages and components. Pages are top-level components which have their own URLs. The Login and Register pages speak for themselves. Home is the standard feed of Fweets from the authors we follow; this is the page that we see when we log into our account. And the User and Tag pages show the Fweets for a specific user or tag in reverse chronological order.
We use React Router to direct to these pages depending on the URL, as you can see in the src/app.js file.
The only other thing to note in the above snippet is the SessionProvider, which is a React context to store the user’s information upon login. We’ll revisit this in the authentication section. For now, it’s enough to know that this gives us access to the Account (and thus User) information from each component.
Take a quick look at the home page (src/pages/home.js) to see how we use a combination of hooks to manage our data. The bulk of our application’s logic is implemented in FaunaDB queries which live in the src/fauna/queries folder. All calls to the database pass through the query-manager, which in a future article, we’ll refactor into serverless function calls. But for now these calls originate from the frontend and we’ll secure the sensitive parts of it with FaunaDB’s ABAC security rules and User Defined Functions (UDF). Since FaunaDB behaves as a token-secured API, we do not have to worry about a limit on the amount of connections as we would in traditional databases.
The FaunaDB JavaScript driver
Next, take a look at the src/fauna/query-manager.js file to see how we connect FaunaDB to our application using FaunaDB’s JavaScript driver, which is just a node module we pulled with `npm install`. As with any node module, we import it into our application as so:
import faunadb from 'faunadb'
And create a client by providing a token.
this.client = new faunadb.Client({
secret: token || this.bootstrapToken
})
We’ll cover tokens a little more in the Authentication section. For now, let’s create some data!
Creating data
The logic to create a new Fweet document can be found in the src/fauna/queries/fweets.js file. FaunaDB documents are just like JSON, and each Fweet follows the same basic structure:
The Now()function is used to insert the time of the query so that the Fweets in a user’s feed can be sorted chronologically. Note that FaunaDB automatically places timestamps on every database entity for temporal querying. However, the FaunaDB timestamp represents the time the document was last updated, not the time it was created, and the document gets updated every time a Fweet is liked; for our intended sorting order, we need the created time.
Next, we send this data to FaunaDB with the Create() function. By providing Create() with the reference to the Fweets collection using Collection(‘fweets'), we specify where the data needs to go.
const query = Create(Collection('fweets'), data )
We can now wrap this query in a function that takes a message parameter and executes it using client.query()which will send the query to the database. Only when we call client.query() will the query be sent to the database and executed. Before that, we combine as many FQL functions as we want to construct our query.
function createFweet(message, hashtags) {
const data = …
const query = …
return client.query(query)
}
Note that we have used plain old JavaScript variables to compose this query and in essence just called functions. Writing FQL is all about function composition; you construct queries by combining small functions into larger expressions. This functional approach has very strong advantages. It allows us to use native language features such as JavaScript variables to compose queries, while also writing higher-order FQL functions that are protected from injection.
For example, in the query below, we add hashtags to the document with a CreateHashtags() function that we’ve defined elsewhere using FQL.
The way FQL works from within the driver’s host language (in this case, JavaScript) is what makes FQL an eDSL (embedded domain-specific language). Functions like CreateHashtags() behave just like a native FQL function in that they are both just functions that take input. This means that we can easily extend the language with our own functions, like in this open source FQL library from the Fauna community.
It’s also important to notice that we create two entities in two different collections, in one transaction. Thus, if/when things go wrong, there is no risk that the Fweet is created yet the Hashtags are not. In more technical terms, FaunaDB is transactional and consistent whether you run queries over multiple collections or not, a property that is rare in scalable distributed databases.
Next, we need to add the author to the query. First, we can use theIdentity() FQL function to return a reference to the currently logged in document. As discussed previously in the data modeling section, that document is of the type Account and is separated from Users to support SSO in a later phase.
Then, we need to wrap Identity() in a Get() to access the full Account document and not just the reference to it.
Get(Identity())
Finally, we wrap all of that in a Select() to select the data.user field from the account document and add it to the data JSON.
By using functional composition, you can easily combine all your advanced logic in one query that will be executed in one transaction. Check out the file src/fauna/queries/fweets.js to see the final result which takes even more advantage of function composition to add rate-limiting, etc.
Securing your data with UDFs and ABAC roles
The attentive reader will have some thoughts about security by now. We are essentially creating queries in JavaScript and calling these queries from the frontend. What stops a malicious user from altering these queries?
FaunaDB provides two features that allow us to secure our data: Attribute-Based Access Control (ABAC) and User Defined Functions (UDF). With ABAC, we can control which collections or entities that a specific key or token can access by writing Roles.
With UDFs, we can push FQL statements to the database by using the CreateFunction().
Since the query is now saved on the database (just like a stored procedure), the user can no longer manipulate it.
One example of how UDFs can be used to secure a call is that we do not pass in the author of the Fweet. The author of the Fweet is derived from the Identity() function instead, which makes it impossible for a user to write a Fweet on someone’s behalf.
Of course, we still have to define that the user has access to call the UDF. For that, we will use a very simple ABAC role that defines a group of role members and their privileges. This role will be named logged_in_role, its membership will include all of the documents in the Accounts collection, and all of these members will be granted the privilege of calling the create_fweet UDF.
We now know that these privileges are granted to an account, but how do we ‘become’ an Account? By using the FaunaDB Login() function to authenticate our users as explained in the next section.
How to implement authentication in FaunaDB
We just showed a role that gives Accounts the permissions to call the create_fweets function. But how do we “become” an Account?.
First, we create a new Account document, storing credentials alongside any other data associated with the Account (in this case, the email address and the reference to the User).
We use this token in the client to impersonate the Account. Since all Accounts are members of the Account collection, this token fulfills the membership requirement of the logged_in_role and is granted access to call the create_fweet UDF.
To bootstrap this whole process, we have two very important roles.
bootstrap_role: can only call the login and register UDFs
logged_in_role: can call other functions such as create_fweet
The token you received when you ran the setup script is essentially a key created with the bootstrap_role. A client is created with that token in src/fauna/query-manager.js which will only be able to register or login. Once we log in, we use the new token returned from Login() to create a new FaunaDB client which now grants access to other UDF functions such as create_fweet. Logging out means we just revert to the bootstrap token. You can see this process in the src/fauna/query-manager.js, along with more complex role examples in the src/fauna/setup/roles.js file.
How to implement the session in React
Previously, in the “Creating the front end” section, we mentioned the SessionProvider component. In React, providers belong to a React Context which is a concept to facilitate data sharing between different components. This is ideal for data such as user information that you need everywhere in your application. By inserting the SessionProvider in the HTML early on, we made sure that each component would have access to it. Now, the only thing a component has to do to access the user details is import the context and use React’s ‘useContext’ hook.
import SessionContext from '../context/session'
import React, { useContext } from 'react'
// In your component
const sessionContext = useContext(SessionContext)
const { user } = sessionContext.state
But how does the user end up in the context? When we included the SessionProvider, we passed in a value consisting of the current state and a dispatch function.
The state is simply the current state, and the dispatch function is called to modify the context. This dispatch function is actually the core of the context since creating a context only involves calling React.createContext() which will give you access to a Provider and a Consumer.
This is the logic that allows you to change the context. In essence, it receives an action and decides how to modify the context given that action. In my case, the action is simply a type with a string. We use this context to keep user information, which means that we call it on a successful login with:
sessionContext.dispatch({ type: 'login', data: e })
Adding Cloudinary for media
When we created a Fweet, we did not take into account assets yet. FaunaDB is meant to store application data, not image blobs or video data. However, we can easily store the media on Cloudinary and just keep a link in FaunaDB. The following inserts the Cloudinary script (in app.js):
As mentioned earlier, you need to provide a Cloudinary cloud name and template in the environment variables (.env.local file) to use this feature. Creating a Cloudinary account is free and once you have an account you can grab the cloud name from the dashboard.
You have the option to use API keys as well to secure uploads. In this case, we upload straight from the front end so the upload uses a public template. To add a template or modify it to make it public, click on the gear icon in the top menu, go to Upload tab, and click Add upload preset.
You could also edit the ml_default template and just make it public.
Now, we just call widget.open() when our media button is clicked.
This provides us with a small media button that will open the Cloudinary Upload Widget when it’s clicked.
When we create the widget, we can also provide styles and fonts to give it the look and feel of our own application as we did above (in src/components/uploader.js):
Once we have uploaded media to Cloudinary, we receive a bunch of information about the uploaded media, which we then add to the data when we create a Fweet.
We can then simply use the stored id (which Cloudinary refers to as the publicId) with the Cloudinary React library (in src/components/asset.js):
import { Image, Video, Transformation } from 'cloudinary-react'
When you use the id, instead of the direct URL, Cloudinary does a whole range of optimizations to deliver the media in the most optimal format possible. For example when you add a video image as follows:
Cloudinary will automatically scale down the video to a width of 600 pixels and deliver it as a WebM (VP9) to Chrome browsers (482 KB), an MP4 (HEVC) to Safari browsers (520 KB), or an MP4 (H.264) to browsers that support neither format (821 KB). Cloudinary does these optimizations server-side, significantly improving page load time and the overall user experience.
Retrieving data
We have shown how to add data. Now we still need to retrieve data. Getting the data of our Fwitter feed has many challenges. We need to:
Get fweets from people you follow in a specific order (taking time and popularity into account)
Get the author of the fweet to show his profile image and handle
Get the statistics to show how many likes, refweets and comments it has
Get the comments to list those beneath the fweet.
Get info about whether you already liked, refweeted, or commented on this specific fweet.
If it’s a refweet, get the original fweet.
This kind of query fetches data from many different collections and requires advanced indexing/sorting, but let’s start off simple. How do we get the Fweets? We start off by getting a reference to the Fweets collection using the Collection()function.
Collection('fweets')
And we wrap that in the Documents()function to get all of the collection’s document references.
Documents(Collection('fweets'))
We then Paginate over these references.
Paginate(Documents(Collection('fweets')))
Paginate() requires some explanation. Before calling Paginate(), we had a query that returned a hypothetical set of data. Paginate() actually materializes that data into pages of entities that we can read. FaunaDB requires that we use this Paginate() function to protect us from writing inefficient queries that retrieve every document from a collection, because in a database built for massive scale, that collection could contain millions of documents. Without the safeguard of Paginate(), that could get very expensive!
Let’s save this partial query in a plain JavaScript variable references that we can continue to build on.
So far, our query only returns a list of references to our Fweets. To get the actual documents, we do exactly what we would do in JavaScript: map over the list with an anonymous function. In FQL, a Lambda is just an anonymous function.
This might seem verbose if you’re used to declarative query languages like SQL that declare what you want and let the database figure out how to get it. In contrast, FQL declares both what you want and how you want it which makes it more procedural. Since you’re the one defining how you want your data, and not the query engine, the price and performance impact of your query is predictable. You can exactly determine how many reads this query costs without executing it, which is a significant advantage if your database contains a huge amount of data and is pay-as-you-go. So there might be a learning curve, but it’s well worth it in the money and hassle it will save you. And once you learn how FQL works, you will find that queries read just like regular code.
Let’s prepare our query to be extended easily by introducing Let. Let will allow us to bind variables and reuse them immediately in the next variable binding, which allows you to structure your query more elegantly.
const fweets = Map(
references,
Lambda(
['ref'],
Let(
{
fweet: Get(Var('ref'))
},
// Just return the fweet for now
Var('fweet')
)
)
)
Now that we have this structure, getting extra data is easy. So let’s get the author.
Although we did not write a join, we have just joined Users (the author) with the Fweets. We’ll expand on these building blocks even further in a follow up article. Meanwhile, browse src/fauna/queries/fweets.js to view the final query and several more examples.
More in the code base
If you haven’t already, please open the code base for this Fwitter example app. You will find a plethora of well-commented examples we haven’t explored here, but will in future articles. This section touches on a few files we think you should check out.
First, check out the src/fauna/queries/fweets.js file for examples of how to do complex matching and sorting with FaunaDB’s indexes (the indexes are created in src/fauna/setup/fweets.js). We implemented three different access patterns to get Fweets by popularity and time, by handle, and by tag.
Getting Fweets by popularity and time is a particularly interesting access pattern because it actually sorts the Fweets by a sort of decaying popularity based on users’ interactions with each other.
Also, check out src/fauna/queries/search.js, where we’ve implemented autocomplete based on FaunaDB indexes and index bindings to search for authors and tags. Since FaunaDB can index over multiple collections, we can write one index that supports an autocomplete type of search on both Users and Tags.
We’ve implemented these examples because the combination of flexible and powerful indexes with relations is rare for scalable distributed databases. Databases that lack relations and flexible indexes require you to know in advance how your data will be accessed and you will run into problems when your business logic needs to change to accommodate your clients’ evolving use cases.
In FaunaDB, if you did not foresee a specific way that you’d like to access your data, no worries — just add an Index! We have range indexes, term indexes, and composite indexes that can be specified whenever you want without having to code around eventual consistency.
A preview of what’s to come
As mentioned in the introduction, we’re introducing this Fwitter app to demonstrate complex, real-world use cases. That said, a few features are still missing and will be covered in future articles, including streaming, pagination, benchmarks, and a more advanced security model with short-lived tokens, JWT tokens, single sign-on (possibly using a service like Auth0), IP-based rate limiting (with Cloudflare workers), e-mail verification (with a service like SendGrid), and HttpOnly cookies.
The end result will be a stack that relies on services and serverless functions which is very similar to a dynamic JAMstack app, minus the static site generator. Stay tuned for the follow-up articles and make sure to subscribe to the Fauna blog and monitor CSS-Tricks for more FaunaDB-related articles.
Since you are dealing with customers — even if it’s just a few, it is important that you offer them the best possible experience. This is especially important for freelancers and small design agencies with a few clients because they don’t have the luxury of losing clients. In fact, 73% of clients say that having a positive experience is one of the key factors that influence their brand loyalty.
One way to improve your client experience is by having a good customer support/engagement channel. In this article, we’ll list the best tools for customer support/engagement. Let’s get started:
Help Desk Software
Help desk software is a centralized system that makes it easy to keep track of customer complaints, user requests, and efficiently deal with customer-care related queries.
Zendesk
Zendesk comes with all the features you would require from a help desk software. The app provides a flexible ticketing system with advanced reporting and analytics.
For design agencies and freelancers with a few clients, Zendesk offers a feature that allows you to host communities and forums where your clients can share and exchange answers.
It also offers over 100 integrations with other business solutions like CRM, cloud storage, and productivity apps. This is very useful for freelancers and small agencies with a limited budget. Instead of running all these applications separately, you can just integrate them into Zendesk.
Freshdesk
Freshdesk comes with an intuitive and simple UI that makes it easy to work with. It offers different plans to meet the needs of both freelance designers and small design agencies.
For freelancers that work on mobile devices, Freshdesk also comes with a robust mobile app that is available for both Android and iOS users. With the app, you can handle client complaints and take your data anywhere you go.
Freshdesk also allows you to track recurring client complaints. Having a thread of recurring client complaints can be very useful. It is most likely you are doing something wrong since most of your clients are complaining of the same thing. Having this information can help you improve your performance.
Zoho Desk
Zoho Desk is a powerful help desk platform that offers designers multi-channel support capabilities. What this means is that you can engage with your clients on other channels apart from the app itself.
A unique feature that Zoho comes with is a content-aware AI called Zia. This AI provides clients with human-level responses in real-time. If you are not available to handle customer complaints, the AI can assist clients in navigating the right knowledge base for accurate answers and solutions to their queries.
Vision Helpdesk
Vision helpdesk is a robust helpdesk software that centralizes all client communications on one platform.
The platform offers multi-channel support that allows designers to communicate with clients through email, phone and chat, websites, and Facebook.
The platform also allows you to run client satisfaction surveys and reports. If you own a growing design agency, surveys like this are very important. It helps you understand which area of your business to improve.
If you work with a team of designers or freelancers, the software also has its own social media like hub for teams called Blabby.
Social Media Support
Most of your clients are on social media and it is important that you have an efficient system to answer queries and complaints. You need a dedicated social media support tool to efficiently deal with customer queries on social media.
Hootsuite
When it comes to social media management, Hootsuite is one of the best tools available. The biggest advantage of this tool is that it allows you to manage all of your social media accounts in one place. Not only can you share posts and schedule updates with this tool, you can connect with your clients and answer all their requests/complaints on more than thirty social media platforms. The tool also offers easy integration with other third-party apps and business solutions.
Sprout Social
Sprout Social is an all-in-one social media interaction software that helps designers to increase engagement and communicate more efficiently with their clients. Sprout Social comes with three main features that make it essential for design agencies and freelancers: social customer service, social media management, and social media analytics. With this tool, you’re able to collect customer feedback that will help you to serve clients better.
One significant advantage of the tool is the user dashboard. It is well organized into six sections: Messages, Tasks, Feed, Publishing, Discovery, and Reports, that makes it easy to interact with your clients and also share social media posts.
AgoraPulse
AgoraPulse is a social moderation tool that allows designers to manage all their social media channels in one place. The platform is built to help designers communicate and respond to client queries efficiently across all social media platforms. It also allows designers to monitor mentions of themselves or their brand on popular social media networks like Facebook and LinkedIn.
Self-Service Knowledge Base
A self-service knowledge base is a centralized database that contains useful information that clients can go to directly for answers.
Bloomfire
Bloomfire is a powerful knowledge management platform that allows agencies (and freelancers who have the time) to centralize all information and recurring customer queries in an easy-to-use search solution.
The software comes with a QnA module that allows clients to ask and answer the questions that bother them. The best part of the platform is that every information asked or answered on the application is never lost.
Helpjuice
Helpjuice is an all-in-one knowledge base and customer support platform with a great user interface. It comes with tags that can be searched depending on the answer category.
A cool feature the platform comes with is that answers are automatically suggested as a client type in a question.
It also offers advanced analytics to help you see how many times a question was read and if the client found the solution helpful.
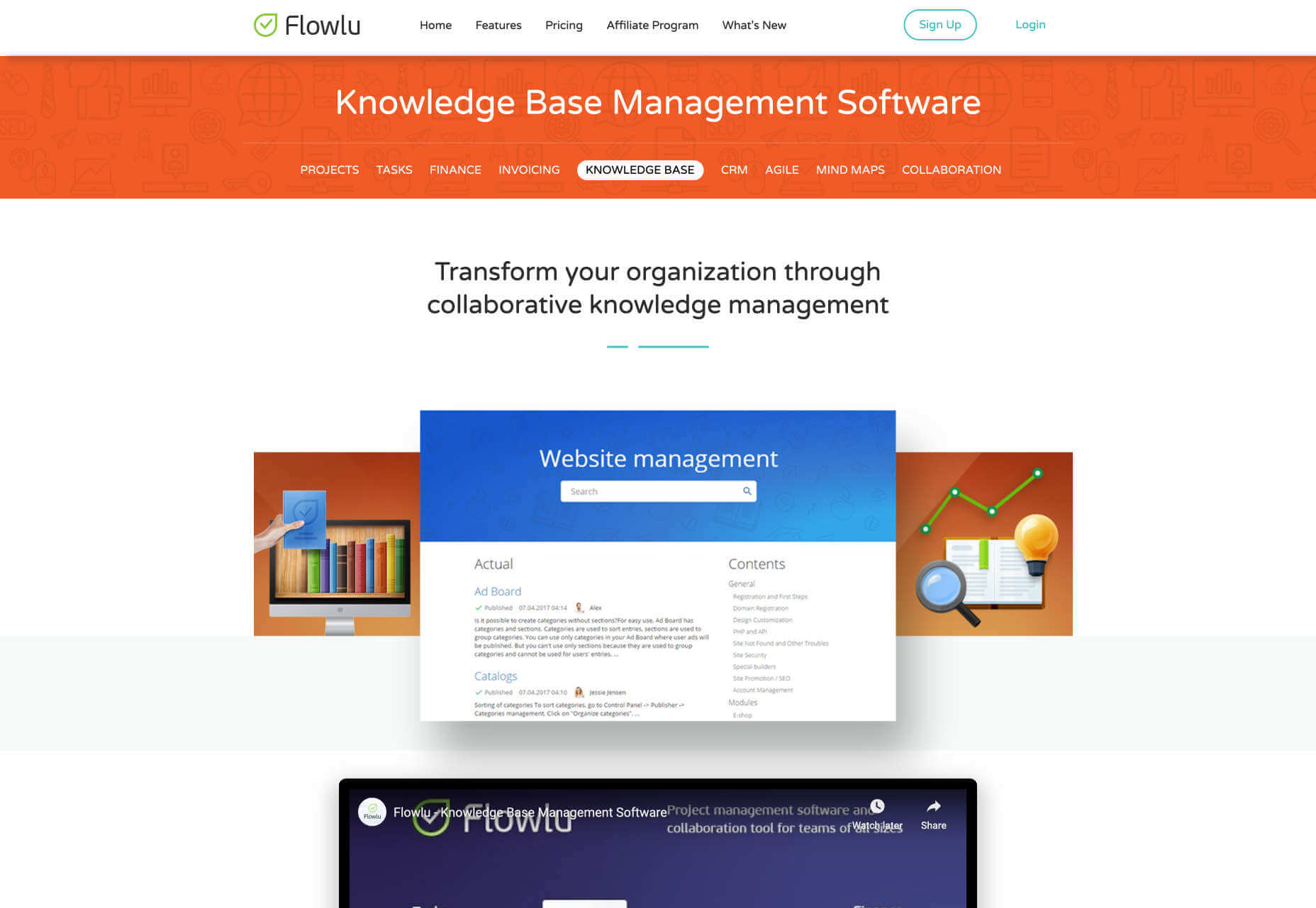
Flowlu
Flowlu is a platform that makes it easy for designers to curate data or information into a consolidated knowledge base for easy access by clients. The platform also features an online financial management system, intuitive collaboration tools, third party integration, and online payment integrations (this feature makes it easy for freelancers to collect payment from their clients).
Real-Time Communication
With real-time communication tools, allows you to respond to client complaints and queries immediately in a live environment.
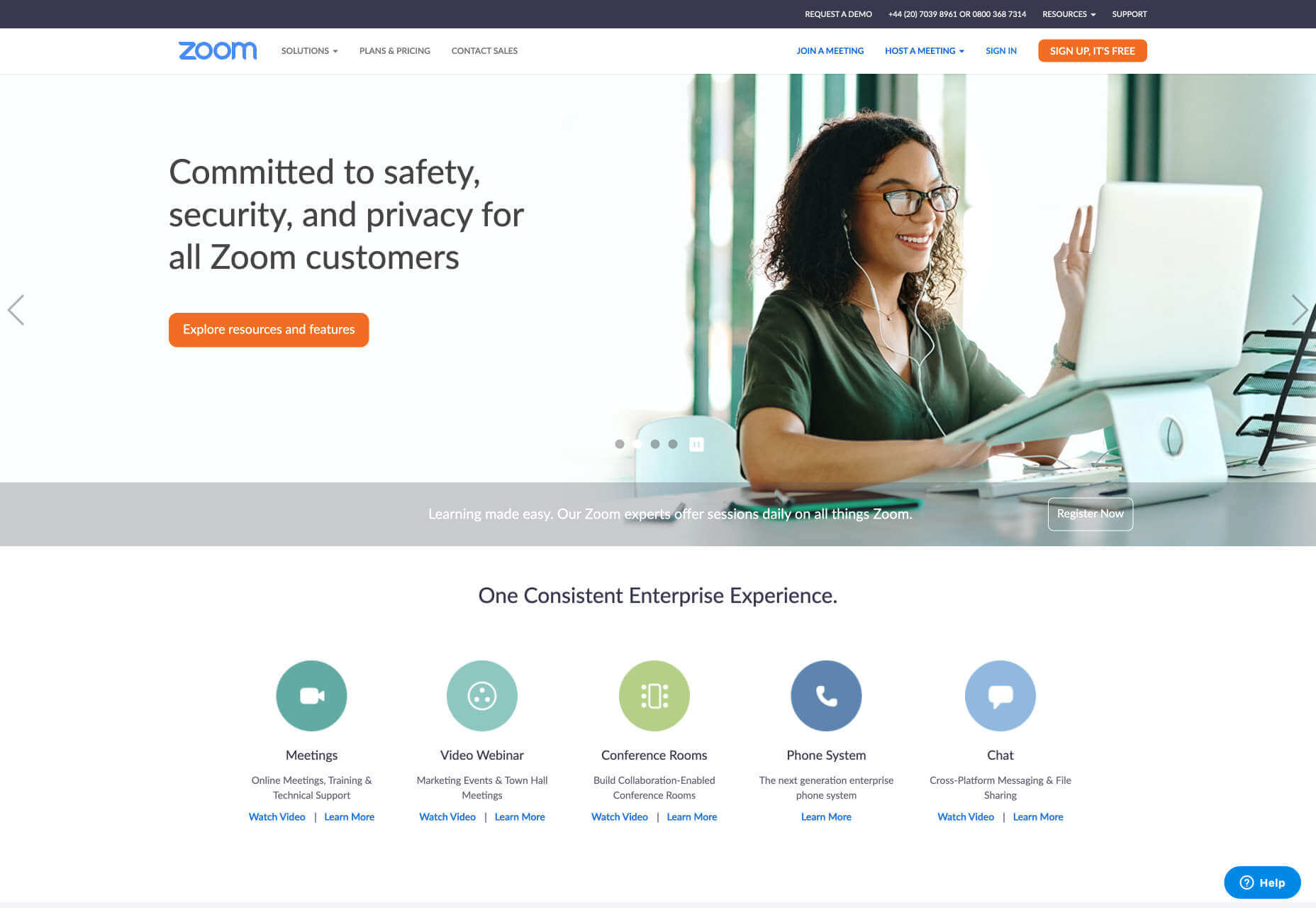
Zoom
Video is a great way to increase engagement with your clients and this is where Zoom comes into play. Zoom is a video conferencing tool that is used to run virtual meetings and conduct video demonstrations for clients. Another useful feature that Zoom comes with is instant sharing of documents, video files, and photos with clients. It supports a dual-screen system and comes with HD video and audio quality.
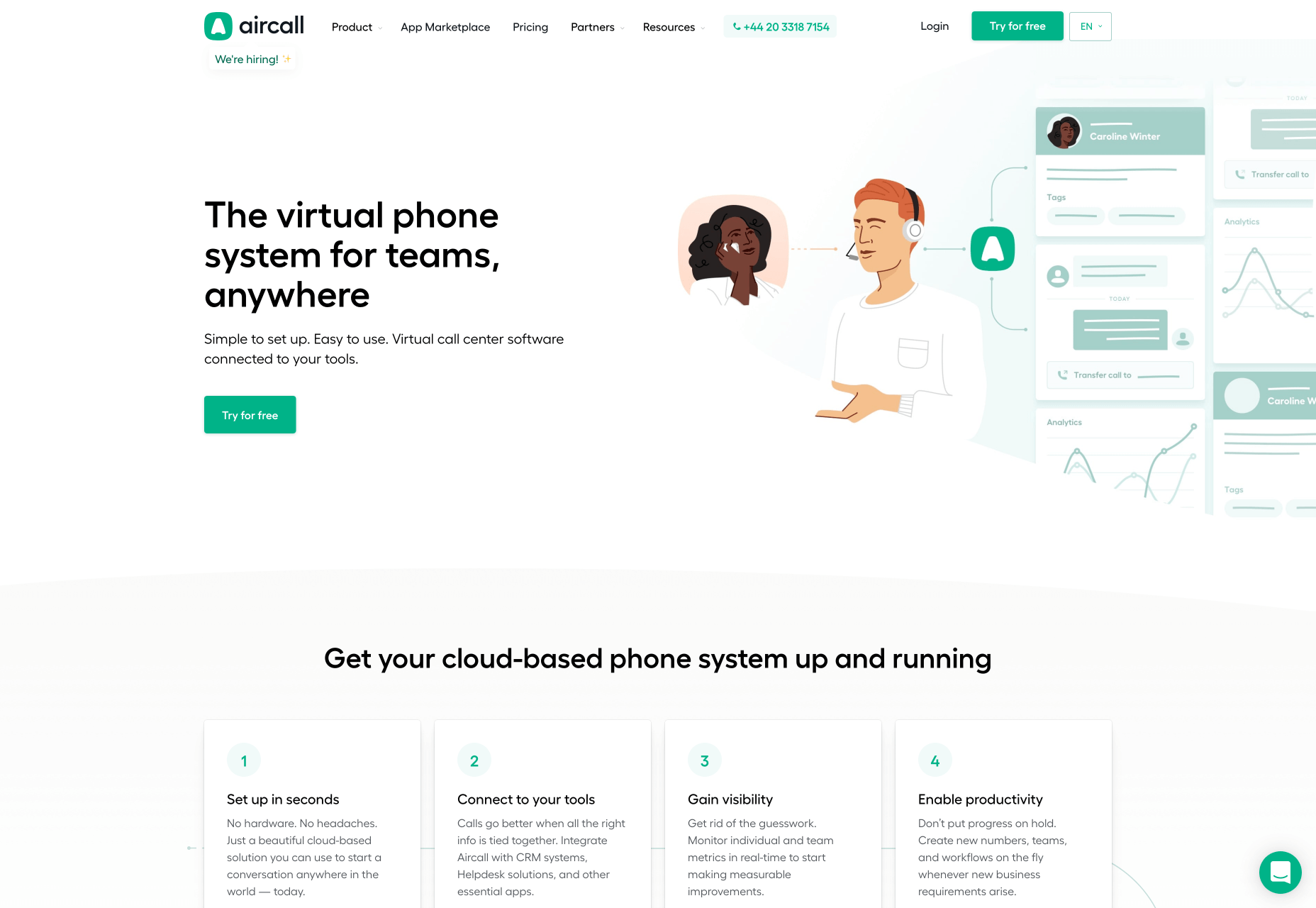
Aircall
Aircall is a modern phone system solution that helps designers to run a call center without the need of physical phone lines. With this tool, you can conduct calls from anywhere in the world and provide services to your clients using its mobile and desktop applications. All you need to do is to install a VoIP system and you can start receiving phone calls from clients right away.
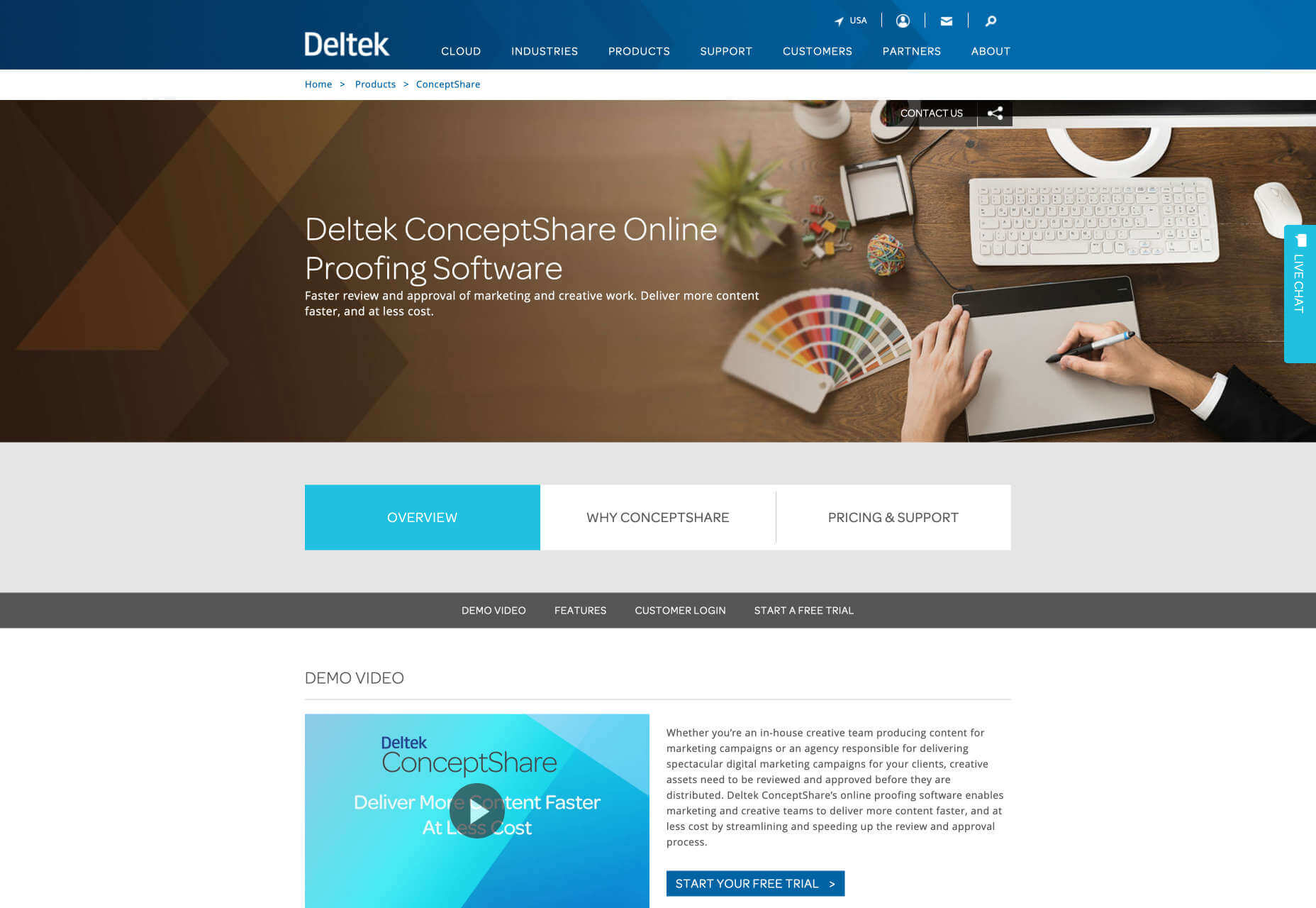
ConceptShare
ConceptShare is a communication platform specifically created for designers and creatives. With ConceptShare, designers can review and approve any upcoming project. It also offers workflow automation which means that you and a client can communicate with each other on the platform without having to send a hundred emails back and forth. Another useful feature it offers designers is online proofing.
Customer Feedback & Satisfaction Surveys
Receiving feedback from clients helps you to serve them better. There are a ton of individuals offering the same services as you. To stand out, you need to give your clients the best user experience possible.
UserVoice
UserVoice is a management software that helps designers to collect feedback from their customers. It comes with iOS and Android SDKs which allow you to use the software directly on your phone. UserVoice aims to help businesses improve customer experience by enhancing customer service.
Client Heartbeat
Client Heartbeat is a tool that allows you to analyze customer satisfaction by sending out surveys via email. You can schedule the surveys to go out at different times — like every three to six months. The software makes use of a proprietary algorithm that helps you to determine the best questions to include in your survey depending on your industry.
Helio
Helio is one of the easiest ways for designers to receive feedback on their projects. The platform allows designers to get feedback easily during every stage of the design process. Designers can easily upload images, PowerPoint, and PDFs to the platform. From sketches to fully coded pages, or wireframes, Helio allows designers to share notes with clients, receive feedback, and stay organized.
zipBoard
zipBoard is a platform that allows designers and developers to collaborate and share feedback on designs. The platform features a project management solution and a visual feedback tool. zipBoard allows users to leave replies and attach files to feedback comments. The platform also integrates with third-party solutions like Slack.
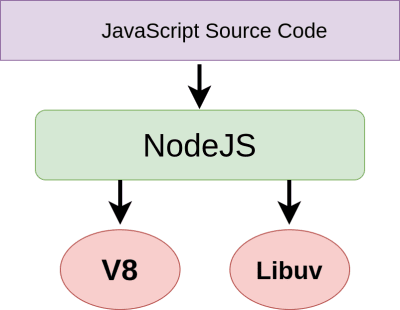
Since the introduction of Node.js by Ryan Dahl at the European JSConf on 8 November 2009, it has seen wide usage across the tech industry. Companies such as Netflix, Uber, and LinkedIn give credibility to the claim that Node.js can withstand a high amount of traffic and concurrency.
Armed with basic knowledge, beginner and intermediate developers of Node.js struggle with many things: “It’s just a runtime!” “It has event loops!” “Node.js is single-threaded like JavaScript!”
While some of these claims are true, we will dig deeper into the Node.js runtime, understanding how it runs JavaScript, seeing whether it actually is single-threaded, and, finally, better understanding the interconnection between its core dependencies, V8 and libuv.
Prerequisites
Basic knowledge of JavaScript
Familiarity with Node.js semantics (require, fs)
What Is Node.js?
It might be tempting to assume what many people have believed about Node.js, the most common definition of it being that it’s a runtime for the JavaScript language. To consider this, we should understand what led to this conclusion.
Node.js is often described as a combination of C++ and JavaScript. The C++ part consists of bindings running low-level code that make it possible to access hardware connected to the computer. The JavaScript part takes JavaScript as its source code and runs it in a popular interpreter of the language, named the V8 engine.
With this understanding, we could describe Node.js as a unique tool that combines JavaScript and C++ to run programs outside of the browser environment.
But could we actually call it a runtime? To determine that, let’s define what a runtime is.
In one of his answers on StackOverflow, DJNA defines a runtime environment as “everything you need to execute a program, but no tools to change it”. According to this definition, we can confidently say that everything that is happening while we run our code (in any language whatsoever) is running in a runtime environment.
Other languages have their own runtime environment. For Java, it is the Java Runtime Environment (JRE). For .NET, it is the Common Language Runtime (CLR). For Erlang, it is BEAM.
Nevertheless, some of these runtimes have other languages that depend on them. For example, Java has Kotlin, a programming language that compiles to code that a JRE can understand. Erlang has Elixir. And we know there are many variants for .NET development, which all run in the CLR, known as the .NET Framework.
Now we understand that a runtime is an environment provided for a program to be able to execute successfully, and we know that V8 and a host of C++ libraries make it possible for a Node.js application to execute. Node.js itself is the actual runtime that binds everything together to make those libraries an entity, and it understands just one language — JavaScript — regardless of what Node.js is built with.
Internal Structure Of Node.js
When we attempt to run a Node.js program (such as index.js) from our command line using the command node index.js, we are calling the Node.js runtime. This runtime, as mentioned, consists of two independent dependencies, V8 and libuv.
V8 is a project created and maintained by Google. It takes JavaScript source code and runs it outside of the browser environment. When we run a program through a node command, the source code is passed by the Node.js runtime to V8 for execution.
The libuv library contains C++ code that enables low-level access to the operating system. Functionality such as networking, writing to the file system, and concurrency are not shipped by default in V8, which is the part of Node.js that runs our JavaScript code. With its set of libraries, libuv provides these utilities and more in a Node.js environment.
Node.js is the glue that holds the two libraries together, thereby becoming a unique solution. Throughout the execution of a script, Node.js understands which project to pass control to and when.
Interesting APIs For Server-Side Programs
If we study a little history of JavaScript, we would know that it’s meant to add some functionality and interaction to a page in the browser. And in the browser, we would interact with the elements of the document object model (DOM) that make up the page. For this, a set of APIs exists, referred to collectively as the DOM API.
The DOM exists only in the browser; it is what is parsed to render a page, and it is basically written in the markup language known as HTML. Also, the browser exists in a window, hence the window object, which acts as a root for all of the objects on the page in a JavaScript context. This environment is called the browser environment, and it is a runtime environment for JavaScript.
In a Node.js environment, we have nothing like a page, nor a browser — this nullifies our knowledge of the global window object. What we do have is a set of APIs that interact with the operating system to provide additional functionality to a JavaScript program. These APIs for Node.js (fs, path, buffer, events, HTTP, and so on), as we have them, exist only for Node.js, and they are provided by Node.js (itself a runtime) so that we can run programs written for Node.js.
Experiment: How fs.writeFile Creates A New File
If V8 was created to run JavaScript outside of the browser, and if a Node.js environment does not have the same context or environment as a browser, then how would we do something like access the file system or make an HTTP server?
As an example, let’s take a simple Node.js application that writes a file to the file system in the current directory:
As shown, we are trying to write a new file to the file system. This feature is not available in the JavaScript language; it is available only in a Node.js environment. How does this get executed?
To understand this, let’s take a tour of the Node.js code base.
Heading over to the GitHub repository for Node.js, we see two main folders, src and lib. The lib folder has the JavaScript code that provides the nice set of modules that are included by default with every Node.js installation. The src folder contains the C++ libraries for libuv.
If we look in the src folder and go through the fs.js file, we will see that it is full of impressive JavaScript code. On line 1880, we will notice an exports statement. This statement exports everything we can access by importing the fs module, and we can see that it exports a function named writeFile.
Searching for function writeFile( (where the function is defined) leads us to line 1303, where we see that the function is defined with four parameters:
On lines 1315 and 1324, we see that a single function, writeAll, is called after some validation checks. We find this function on line 1278 in the same fs.js file.
It is also interesting to note that this module is attempting to call itself. We see this on line 1280, where it is calling fs.write. Looking for the write function, we will discover a little information.
The write function starts on line 571, and it runs about 42 lines. We see a recurring pattern in this function: the way it calls a function on the binding module, as seen on lines 594 and 612. A function on the binding module is called not only in this function, but in virtually any function that is exported in the fs.js file file. Something must be very special about it.
The binding variable is declared on line 58, at the very top of the file, and a click on that function call reveals some information, with the help of GitHub.
This internalBinding function is found in the module named loaders. The main function of the loaders module is to load all libuv libraries and connect them through the V8 project with Node.js. How it does this is rather magical, but to learn more we can look closely at the writeBuffer function that is called by the fs module.
We should look where this connects with libuv, and where V8 comes in. At the top of the loaders module, some good documentation there states this:
// This file is compiled and run by node.cc before bootstrap/node.js
// was called, therefore the loaders are bootstraped before we start to
// actually bootstrap Node.js. It creates the following objects:
//
// C++ binding loaders:
// - process.binding(): the legacy C++ binding loader, accessible from user land
// because it is an object attached to the global process object.
// These C++ bindings are created using NODE_BUILTIN_MODULE_CONTEXT_AWARE()
// and have their nm_flags set to NM_F_BUILTIN. We do not make any guarantees
// about the stability of these bindings, but still have to take care of
// compatibility issues caused by them from time to time.
// - process._linkedBinding(): intended to be used by embedders to add
// additional C++ bindings in their applications. These C++ bindings
// can be created using NODE_MODULE_CONTEXT_AWARE_CPP() with the flag
// NM_F_LINKED.
// - internalBinding(): the private internal C++ binding loader, inaccessible
// from user land unless through `require('internal/test/binding')`.
// These C++ bindings are created using NODE_MODULE_CONTEXT_AWARE_INTERNAL()
// and have their nm_flags set to NM_F_INTERNAL.
//
// Internal JavaScript module loader:
// - NativeModule: a minimal module system used to load the JavaScript core
// modules found in lib/**/*.js and deps/**/*.js. All core modules are
// compiled into the node binary via node_javascript.cc generated by js2c.py,
// so they can be loaded faster without the cost of I/O. This class makes the
// lib/internal/*, deps/internal/* modules and internalBinding() available by
// default to core modules, and lets the core modules require itself via
// require('internal/bootstrap/loaders') even when this file is not written in
// CommonJS style.
What we learn here is that for every module called from the binding object in the JavaScript section of the Node.js project, there is an equivalent of it in the C++ section, in the src folder.
From our fs tour, we see that the module that does this is located in node_file.cc. Every function that is accessible through the module is defined in the file; for example, we have the writeBuffer on line 2258. The actual definition of that method in the C++ file is on line 1785. Also, the call to the part of libuv that does the actual writing to the file can be found on lines 1809 and 1815, where the libuv function uv_fs_write is called asynchronously.
What Do We Gain From This Understanding?
Just like many other interpreted language runtimes, the runtime of Node.js can be hacked. With greater understanding, we could do things that are impossible with the standard distribution just by looking through the source. We could add libraries to make changes to the way some functions are called. But above all, this understanding is a foundation for further exploration.
Is Node.js Single-Threaded?
Sitting on libuv and V8, Node.js has access to some additional functionalities that a typical JavaScript engine running in the browser does not have.
Any JavaScript that runs in a browser will execute in a single thread. A thread in a program’s execution is just like a black box sitting on top of the CPU in which the program is being executed. In a Node.js context, some code could be executed in as many threads as our machines can carry.
To verify this particular claim, let’s explore a simple code snippet.
const fs = require("fs");
// A little benchmarking
const startTime = Date.now()
fs.writeFile("./test.txt", "test", (err) => {
If (error) {
console.log(err)
}
console.log("1 Done: ", Date.now() — startTime)
});
In the snippet above, we are trying to create a new file on the disk in the current directory. To see how long this could take, we’ve added a little benchmark to monitor the start time of the script, which gives us the duration in milliseconds of the script that is creating the file.
If we run the code above, we will get a result like this:
Time taken to create a single file in Node.js (Large preview)
$ node ./test.js
-> 1 Done: 0.003s
This is very impressive: just 0.003 seconds.
But let’s do something really interesting. First let’s duplicate the code that generates the new file, and update the number in the log statement to reflect their positions:
const fs = require("fs");
// A little benchmarking
const startTime = Date.now()
fs.writeFile("./test1.txt", "test", function (err) {
if (err) {
console.log(err)
}
console.log("1 Done: %ss", (Date.now() — startTime) / 1000)
});
fs.writeFile("./test2.txt", "test", function (err) {
if (err) {
console.log(err)
}
console.log("2 Done: %ss", (Date.now() — startTime) / 1000)
});
fs.writeFile("./test3.txt", "test", function (err) {
if (err) {
console.log(err)
}
console.log("3 Done: %ss", (Date.now() — startTime) / 1000)
});
fs.writeFile("./test4.txt", "test", function (err) {
if (err) {
console.log(err)
}
console.log("4 Done: %ss", (Date.now() — startTime) / 1000)
});
If we attempt to run this code, we will get something that blows our minds. Here is my result:
First, we will notice that the results are not consistent. Secondly, we see that the time has increased. What’s happening?
Low-Level Tasks Get Delegated
Node.js is single-threaded, as we know now. Parts of Node.js are written in JavaScript, and others in C++. Node.js uses the same concepts of the event loop and the call stack that we are familiar with from the browser environment, meaning that the JavaScript parts of Node.js are single-threaded. But the low-level task that requires speaking with an operating system is not single-threaded.
When a call is recognized by Node.js as being intended for libuv, it delegates this task to libuv. In its operation, libuv requires threads for some of its libraries, hence the use of the thread pool in executing Node.js programs when they are needed.
By default, the Node.js thread pool provided by libuv has four threads in it. We could increase or reduce this thread pool by calling process.env.UV_THREADPOOL_SIZE at the top of our script.
It appears that once we invoke the code to create our file, Node.js hits the libuv part of its code, which dedicates a thread for this task. This section in libuv gets some statistical information about the disk before working on the file.
This statistical checking could take a while to complete; hence, the thread is released for some other tasks until the statistical check is completed. When the check is completed, the libuv section occupies any available thread or waits until a thread becomes available for it.
We have only four calls and four threads, so there are enough threads to go around. The only question is how fast each thread will process its task. We will notice that the first code to make it into the thread pool will return its result first, and it blocks all of the other threads while running its code.
Conclusion
We now understand what Node.js is. We know it’s a runtime. We’ve defined what a runtime is. And we’ve dug deep into what makes up the runtime provided by Node.js.
We have come a long way. And from our little tour of the Node.js repository on GitHub, we can explore any API we might be interested in, following the same process we took here. Node.js is open source, so surely we can dive into the source, can’t we?
Even though we have touched on several of the low levels of what happens in the Node.js runtime, we mustn’t assume that we know it all. The resources below point to some information on which we can build our knowledge:
Introduction to Node.js
Being an official website, Node.dev explains what Node.js is, as well as its package managers, and lists web frameworks built on top of it.
“JavaScript & Node.js”, The Node Beginner Book
This book by Manuel Kiessling does a fantastic job of explaining Node.js, after warning that JavaScript in the browser is not the same as the one in Node.js, even though both are written in the same language.
Beginning Node.js
This beginner book goes beyond an explanation of the runtime. It teaches about packages and streams and creating a web server with the Express framework.
LibUV
This is the official documentation of the supporting C++ code of the Node.js runtime.
V8
This is the official documentation of the JavaScript engine that makes it possible to write Node.js with JavaScript.
I did a little thing the other day that I didn’t know was possible until then. I had a project folder open in VS Code like I always do, and I added another different root folder to the window. I always assumed when you had a project open, it was one top level root folder and that’s it, if you needed another folder elsewhere open, you would open that in another window. But nope!
We kind of have a “duo repo” thing going on at CodePen (one is the main Ruby on Rails app, and one is our microservices), and now I can open them both together:
Multiple folders open at once. This means I don’t need to deal with my symlinks anymore.
Now I can search across both projects and basically just pretend like it’s one big project.
When you do that for the first time and then close the VS Code window, it will ask you if you want to save a “Workspace.” Meh, maybe later, I always thought. I knew what it meant, but I was too lazy to deal with it. It’ll make a file, I thought, and I don’t really have a place for files like that. (I’d avoid the repo itself, just because I don’t want to force my system on anyone else.)
Well, I finally got over it and did it. I chucked all my .code-workspace files into a local folder. They are actually quite useful as files, because I can put the files in my Dock and one-click open my Workspace just how I like it.
Custom Workspace icons
Workspace files have special little icons like this:
The icon is a little generic, but I like it. A document with a little tiny VS Code icon below it.
Since I’m putting these in my Dock, I saw that as a cool opportunity to make them into custom icons! That’ll make it super clear for me and a little more delightful to use since I’ll probably reach for them many times a day.
Taking a little inspiration from the original, I snagged the SVG logo and plopped it on the bottom-right of my project logos.
Changing logos on macOS is as simple as “Get Info” on the file, clicking the logo in that panel, then pasting the image.
Now I can keep them in my Dock and open everything with a single click:
Launch terminal commands when opening a project
Now that I have these really handy one-click icons for opening my projects, I thought, “How cool would it be if it kicked off the commands to start the project too!” Apparently, that’s what Tasks are for, and it wasn’t too hard to set up (thanks, Andrew!). Right next to that settings file, at .vscode/tasks.json, is where I have this:
That kicks off the command gulp for me whenever I open this Workspace. I guess you have to run the task once manually (Terminal ? Run Task) so that it has the right permissions, then it works from there on out.
Overrides
I don’t think this is specific to Workspaces necessarily, but I really like how you can have a file like .vscode/settings.json in a project folder to override VS Code settings for a particular project.
For example, here on CSS-Tricks, I have a super basic Sass setup where Gulp preprocesses .scss into .css. That’s all fine, but it’s likely that I’ll search for a selector at some point. I don’t need to see it in .css because I’m not working in vanilla CSS. Like ever. I can put this in that settings file, and know that it’s just for this project, rather than all my projects:
Matthias Ott’s posted his VS Code setup. I find lists like this (I rounded up some recent updates of my own) irresistible, probably because, like y’all, I spend an awful lot of time in VS Code and wanna make sure I’m getting the most out of it.
Things from the list that stood out to me:
I didn’t realize Bracket Pair Colorizer had gone v2 and it’s a separate install.
I din’t realize you needed an extension to honor .editorconfig files.
I wasn’t using anything for PHP, but Matthias listed PHP Intelephense and I’m giving it a whirl. It has fewer users than the non-weirdly named one though? And when I installed that, I saw Format HTML in PHP which I’m also trying because, yes, please! (Even Prettier’s PHP add-on can’t do that.)
Messing with extensions is also a good opportunity to clear out old crap.