Solving Common Cross-Platform Issues When Working With Flutter
Solving Common Cross-Platform Issues When Working With Flutter
Carmine Zaccagnino 2020-06-18T10:30:00+00:00
2020-06-18T13:34:20+00:00
I’ve seen a lot of confusion online regarding Web development with Flutter and, often, it’s sadly for the wrong reasons.
Specifically, people sometimes confuse it with the older Web-based mobile (and desktop) cross-platform frameworks, which basically were just Web pages running within browsers running within a wrapper app.
That was truly cross-platform in the sense that the interfaces were the same anyway because you only had access to the interfaces normally accessible on the Web.
Flutter isn’t that, though: it runs natively on each platform, and it means each app runs just like it would run if it were written in Java/Kotlin or Objective-C/Swift on Android and iOS, pretty much. You need to know that because this implies that you need to take care of the many differences between these very diverse platforms.
In this article, we’re going to see some of those differences and how to overcome them. More specifically, we’re going to talk about storage and UI differences, which are the ones that most often cause confusion to developers when writing Flutter code that they want to be cross-platform.
Example 1: Storage
I recently wrote on my blog about the need for a different approach to storing JWTs in Web apps when compared to mobile apps.
That is because of the different nature of the platforms’ storage options, and the need to know each and their native development tools.
Web
When you write a Web app, the storage options you have are:
- downloading/uploading files to/from disk, which requires user interaction and is therefore only suitable for files meant to be read or created by the user;
- using cookies, which may or may not be accessible from JS (depending on whether or not they’re
httpOnly) and are automatically sent along with requests to a given domain and saved when they come as part of a response; - using JS
localStorageandsessionStorage, accessible by any JS on the website, but only from JS that is part of the pages of that website.
Mobile
The situation when it comes to mobile apps is completely different. The storage options are the following:
- local app documents or cache storage, accessible by that app;
- other local storage paths for user-created/readable files;
NSUserDefaultsandSharedPreferencesrespectively on iOS and Android for key-value storage;Keychainon iOS andKeyStoreon Android for secure storage of, respectively, any data and cryptographic keys.
If you don’t know that, you’re going to make a mess of your implementations because you need to know what storage solution you’re actually using and what the advantages and drawbacks are.
Cross-Platform Solutions: An Initial Approach
Using the Flutter shared_preferences package uses localStorage on the Web, SharedPreferences on Android and NSUserDefaults on iOS. Those have completely different implications for your app, especially if you’re storing sensitive information like session tokens: localStorage can be read by the client, so it’s a problem if you’re vulnerable to XSS. Even though mobile apps aren’t really vulnerable to XSS, SharedPreferences and NSUserDefaults are not secure storage methods because they can be compromised on the client side since they are not secure storage and not encrypted. That’s because they are meant for user preferences, as mentioned here in the case of iOS and here in the Android documentation when talking about the Security library which is designed to provide wrappers to the SharedPreferences specifically to encrypt the data before storing it.
Secure Storage On Mobile
The only secure storage solutions on mobile are Keychain and KeyStore on iOS and Android respectively, whereas there is no secure storage on the Web.
The Keychain and KeyStore are very different in nature, though: Keychain is a generic credentials storage solution, whereas the KeyStore is used to store (and can generate) cryptographic keys, either symmetric keys or public/private keys.
This means that if, for instance, you need to store a session token, on iOS you can let the OS manage the encryption part and just send your token to the Keychain, whereas on Android it’s a bit more of a manual experience because you need to generate (not hard-code, that’s bad) a key, use it to encrypt the token, store the encrypted token in SharedPreferences and store the key in the KeyStore.
There are different approaches to that, as are most things in security, but the simplest is probably to use symmetric encryption, as there is no need for public key cryptography since your app both encrypts and decrypts the token.
Obviously, you don’t need to write mobile platform-specific code that does all of that, as there is a Flutter plugin that does all of that, for instance.
The Lack Of Secure Storage On the Web
That was, actually, the reason that compelled me to write this post. I wrote about using that package to store JWT on mobile apps and people wanted the Web version of that but, as I said, there is no secure storage on the Web. It doesn’t exist.
Does that mean your JWT has to be out in the open?
No, not at all. You can use httpOnly cookies, can’t you? Those aren’t accessible by JS and are sent only to your server. The issue with that is that they’re always sent to your server, even if one of your users clicks on a GET request URL on someone else’s website and that GET request has side effects you or your user won’t like. This actually works for other request types as well, it’s just more complicated. It’s called Cross-Site Request Forgery and you don’t want that. It’s among the web security threats mentioned in Mozilla’s MDN docs, where you can find a more complete explanation.
There are prevention methods. The most common one is having two tokens, actually: one of them getting to the client as an httpOnly cookie, the other as part of the response. The latter has to be stored in localStorage and not in cookies because we don’t want it to be sent automatically to the server.
Solving Both
What if you have both a mobile app and a Web app?
That can be dealt with in one of two ways:
- Use the same backend endpoint, but manually get and send the cookies using the cookie-related HTTP headers;
- Create a separate non-Web backend endpoint that generates different token than either token used by the Web app and then allow for regular JWT authorization if the client is able to provide the mobile-only token.
Running Different Code On Different Platforms
Now, let’s see how we can run different code on different platforms in order to be able to compensate for the differences.
Creating A Flutter Plugin
Especially to solve the problem of storage, one way you can do that is with a plugin package: plugins provide a common Dart interface and can run different code on different platforms, including native platform-specific Kotlin/Java or Swift/Objective-C code. Developing packages and plugins is rather complex, but it’s explained in many places on the Web and elsewhere (for example in Flutter books), including the official Flutter documentation.
For mobile platforms, for instance, there already is a secure storage plugin, and that’s flutter_secure_storage, for which you can find an example of usage here, but that doesn’t work on the Web, for example.
On the other hand, for simple key-value storage that also works on the web, there’s a cross-platform Google-developed first-party plugin package called shared_preferences, which has a Web-specific component called shared_preferences_web which uses NSUserDefaults, SharedPreferences or localStorage depending on the platform.
TargetPlatform on Flutter
After importing package:flutter/foundation.dart, you can compare Theme.of(context).platform to the values:
TargetPlatform.androidTargetPlatform.iOSTargetPlatform.linuxTargetPlatform.windowsTargetPlatform.macOSTargetPlatform.fuchsia
and write your functions so that, for each platform you want to support, they do the appropriate thing. This will come especially useful for the next example of platform difference, and that is differences in how widgets are displayed on different platforms.
For that use case, in particular, there is also a reasonably popular flutter_platform_widgets plugin, which simplifies the development of platform-aware widgets.
Example 2: Differences In How The Same Widget Is Displayed
You can’t just write cross-platform code and pretend a browser, a phone, a computer, and a smartwatch are the same thing — unless you want your Android and iOS app to be a WebView and your desktop app to be built with Electron. There are plenty of reasons not to do that, and it’s not the point of this piece to convince you to use frameworks like Flutter instead that keep your app native, with all the performance and user experience advantages that come with it, while allowing you to write code that is going to be the same for all platforms most of the time.
That requires care and attention, though, and at least a basic knowledge of the platforms you want to support, their actual native APIs, and all of that. React Native users need to pay even more attention to that because that framework uses the built-in OS widgets, so you actually need to pay even more attention to how the app looks by testing it extensively on both platforms, without being able to switch between iOS and Material widget on the fly like it’s possible with Flutter.
What Changes Without Your Request
There are some aspects of the UI of your app that are automatically changed when you switch platforms. This section also mentions what changes between Flutter and React Native in this respect.
Between Android And iOS (Flutter)
Flutter is capable of rendering Material widgets on iOS (and Cupertino (iOS-like) widgets on Android), but what it DOESN’T do is show exactly the same thing on Android and iOS: Material theming especially adapts to the conventions of each platform.
For instance, navigation animations and transitions and default fonts are different, but those don’t impact your app that much.
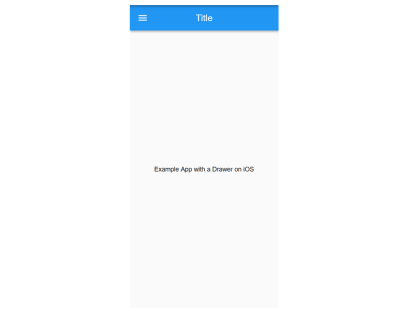
What may affect some of your choices when it comes to aesthetics or UX is the fact that some static elements also change. Specifically, some icons change between the two platforms, app bar titles are in the middle on iOS and on the left on Android (on the left of the available space in case there is a back button or the button to open a Drawer (explained here in the Material Design guidelines and also known as a hamburger menu). Here’s what a Material app with a Drawer looks like on Android:
And what the same, very simple, Material app looks like on iOS:
Between Mobile and Web and With Screen Notches (Flutter)
On the Web there is a bit of a different situation, as mentioned also in this Smashing article about Responsive Web Development with Flutter: in particular, in addition to having to optimize for bigger screens and account for the way people expect to navigate through your site — which is the main focus of that article — you have to worry about the fact that sometimes widgets are placed outside of the browser window. Also, some phones have notches in the top part of their screen or other impediments to the correct viewing of your app because of some sort of obstruction.
Both of these problems can be avoided by wrapping your widgets in a SafeArea widget, which is a particular kind of padding widget which makes sure your widgets fall into a place where they can actually be displayed without anything impeding the users’ ability to see them, be it a hardware or software constraint.
In React Native
React Native requires much more attention and a much deeper knowledge of each platform, in addition to requiring you to run the iOS Simulator as well as the Android Emulator at the very least in order to be able to test your app on both platforms: it’s not the same and it converts its JavaScript UI elements to platform-specific widgets. In other words, your React Native apps will always look like iOS — with Cupertino UI elements as they are sometimes called — and your Android apps will always look like regular Material Design Android apps because it’s using the platform’s widgets.
The difference here is that Flutter renders its widgets with its own low-level rendering engine, which means you can test both app versions on one platform.
Getting Around That Issue
Unless you’re going for something very specific, your app is supposed to look different on different platforms otherwise some of your users will be unhappy.
Just like you shouldn’t simply ship a mobile app to the web (as I wrote in the aforementioned Smashing post), you shouldn’t ship an app full of Cupertino widgets to Android users, for example, because it’s going to be confusing for the most part. On the other hand, having the chance to actually run an app that has widgets that are meant for another platform allows you to test the app and show it to people in both versions without having to use two devices for that necessarily.
The Other Side: Using The Wrong Widgets For The Right Reasons
But that also means that you can do most of your Flutter development on a Linux or Windows workstation without sacrificing the experience of your iOS users, and then just build the app for the other platform and not have to worry about thoroughly testing it.
Next Steps
Cross-platform frameworks are awesome, but they shift responsibility to you, the developer, to understand how each platform works and how to make sure your app adapts and is pleasant to use for your users. Other small things to consider may be, for example, using different descriptions for what might be in essence the same thing if there are different conventions on different platforms.
It’s great to not have to build the two (or more) apps separately using different languages, but you still need to keep in mind you are, in essence, building more than one app and that requires thinking about each of the apps you are building.
Further Resources
- The Flutter Gallery website and Android app, showcasing the use of Flutter widgets typical of different platforms and their platform agnosticism
- Flutter API Documentation on TargetPlatform
- Flutter documentation on the creation of packages and plugins
- Flutter documentation on platform adaptations
- MDN documentation on cookies
(ra, yk, il)