This is a great collection of icons by Corey Ginnivan that’s both free and with no attribution required when you use them. The style is super simple. Each icon looks like older versions of the icons from macOS to me because they’re cute but not too cute.
Also? The icon picker UI is slick and looks something like this today:
Oh and also, as I was looking around Corey’s personal site I noticed this lovely UI effect when you scroll —each card stacks on top of each other:
Today we have a loose coupling between the front end and the back end of web applications. They are usually developed by separate teams, and keeping those teams and the technology in sync is not easy. To solve part of this problem, we can “fake” the API server that the back end tech would normally create and develop as if the API or endpoints already exist.
The most common term used for creating simulated or “faking” a component is mocking. Mocking allows you to simulate the API without (ideally) changing the front end. There are many ways to achieve mocking, and this is what makes it so scary for most people, at least in my opinion.
Let’s cover what a good API mocking should look like and how to implement a mocked API into a new or existing application.
Note, the implementation that I am about to show is framework agnostic — so it can be used with any framework or vanilla JavaScript application.
Mirage: The mocking framework
The mocking approach we are going to use is called Mirage, which is somewhat new. I have tested many mocking frameworks and just recently discovered this one, and it’s been a game changer for me.
Mirage is marketed as a front-end-friendly framework that comes with a modern interface. It works in your browser, client-side, by intercepting XMLHttpRequest and Fetch requests.
We will go through creating a simple application with mocked API and cover some common problems along the way.
Mirage setup
Let’s create one of those standard to-do applications to demonstrate mocking. I will be using Vue as my framework of choice but of course, you can use something else since we’re working with a framework-agnostic approach.
So, go ahead and install Mirage in your project:
# Using npm
npm i miragejs -D
# Using Yarn
yarn add miragejs -D
To start using Mirage, we need to setup a “server” (in quotes, because it’s a fake server). Before we jump into the setup, I will cover the folder structure I found works best.
In a mock directory, open up a new index.js file and define your mock server:
// api/mock/index.js
import { Server } from 'miragejs';
export default function ({ environment = 'development' } = {}) {
return new Server({
environment,
routes() {
// We will add our routes here
},
});
}
The environment argument we’re adding to the function signature is just a convention. We can pass in a different environment as needed.
Now, open your app bootstrap file. In our case, this is he src/main.js file since we are working with Vue. Import your createServer function, and call it in the development environment.
// main.js
import createServer from './mock'
if (process.env.NODE_ENV === 'development') {
createServer();
}
We’re using the process.env.NODE_ENV environment variable here, which is a common global variable. The conditional allows Mirage to be tree-shaken in production, therefore, it won’t affect your production bundle.
That is all we need to set up Mirage! It’s this sort of ease that makes the DX of Mirage so nice.
Our createServer function is defaulting it to development environment for the sake of making this article simple. In most cases, this will default to test since, in most apps, you’ll call createServer once in development mode but many times in test files.
How it works
Before we make our first request, let’s quickly cover how Mirage works.
Mirage is a client-side mocking framework, meaning all the mocking will happen in the browser, which Mirage does using the Pretender library. Pretender will temporarily replace native XMLHttpRequest and Fetch configurations, intercept all requests, and direct them to a little pretend service that the Mirage hooks onto.
If you crack open DevTools and head into the Network tab, you won’t see any Mirage requests. That’s because the request is intercepted and handled by Mirage (via Pretender in the back end). Mirage logs all requests, which we’ll get to in just a bit.
Let’s make requests!
Let’s create a request to an /api/tasks endpoint that will return a list of tasks that we are going to show in our to-do app. Note that I’m using axios to fetch the data. That’s just my personal preference. Again, Mirage works with native XMLHttpRequest, Fetch, and any other library.
The routes() hook is the way we define our route handlers. Using a this.get() method lets us mock GET requests. The first argument of all request functions is the URL we are handling, and the second argument is a function that responds with some data.
As a note, Mirage accepts any HTTP request type, and each type has the same signature:
We will discuss the schema and request parameters of the callback function in a moment.
With this, we have successfully mocked our route and we should see inside our console a successful response from Mirage.
Working with dynamic data
Trying to add a new to-do in our app won’t be possible because our data in the GET response has hardcoded values. Mirage’s solution to this is that they provide a lightweight data layer that acts as a database. Let’s fix what we have so far.
Like the routes() hook, Mirage defines a seeds() hook. It allows us to create initial data for the server. I’m going to move the GET data to the seeds() hook where I will push it to the Mirage database.
I moved our static data from the GET method to seeds() hook, where that data is loaded into a faux database. Now, we need to refactor our GET method to return data from that database. This is actually pretty straightforward — the first argument of the callback function of any route() method is the schema.
We mock this route in Mirage by creating a POST /api/tasks route handler:
this.post('/tasks', (schema, request) => {})
Using the second parameter of the callback function, we can see the sent request.
Inside the requestBody property is the data that we sent. That means it’s now available for us to create a new task.
this.post('/api/tasks', (schema, request) => {
// Take the send data from axios.
const task = JSON.parse(request.requestBody).data
return schema.db.tasks.insert(task)
})
The id of the task will be set by the Mirage’s database by default. Thus, there is no need to keep track of ids and send them with your request — just like a real server.
Dynamic routes? Sure!
The last thing to cover is dynamic routes. They allow us to use a dynamic segment in our URL, which is useful for deleting or updating a single to-do item in our app.
Our delete request should go to /api/tasks/1, /api/tasks/2, and so on. Mirage provides a way for us to define a dynamic segment in the URL, like this:
this.delete('/api/tasks/:id', (schema, request) => {
// Return the ID from URL.
const id = request.params.id;
return schema.db.tasks.remove(id);
})
Using a colon (:) in the URL is how we define a dynamic segment in our URL. After the colon, we specify the name of the segment which, in our case, is called id and maps to the ID of a specific to-do item. We can access the value of the segment via the request.params object, where the property name corresponds to the segment name — request.params.id. Then we use the schema to remove an item with that same ID from the Mirage database.
If you’ve noticed, all of my routes so far are prefixed with api/. Writing this over and over can be cumbersome and you may want to make it easier. Mirage offers the namespace property that can help. Inside the routes hook, we can define the namespace property so we don’t have to write that out each time.
So far, everything we’ve looked at integrates Mirage into a new app. But what about adding Mirage to an existing application? Mirage has you covered so you don’t have to mock your entire API.
The first thing to note is that adding Mirage to an existing application will throw an error if the site makes a request that isn’t handled by Mirage. To avoid this, we can tell Mirage to pass through all unhandled requests.
routes() {
this.get('/tasks', () => { ... })
// Pass through all unhandled requests.
this.passthrough()
}
Now we can develop on top of an existing API with Mirage handling only the missing parts of our API.
Mirage can even change the base URL of which it captures the requests. This is useful because, usually, a server won’t live on localhost:3000 but rather on a custom domain.
routes() {
// Set the base route.
this.urlPrefix = 'https://devenv.ourapp.example';
this.get('/tasks', () => { ... })
}
Now, all of our requests will point to the real API server, but Mirage will intercept them like it did when we set it up with a new app. This means that the transition from Mirage to the real API is pretty darn seamless — delete the route from the mock server and things are good to go.
Wrapping up
Over the course of five years, I have used many mocking frameworks, yet I never truly liked any of the solutions out there. That was until recently, when my team was faced with a need for a mocking solution and I found out about Mirage.
Other solutions, like the commonly used JSON-Server, are external processes that need to run alongside the front end. Furthermore, they are often nothing more than an Express server with utility functions on top. The result is that front-end developers like us need to know about middleware, NodeJS, and how servers work… things many of us probably don’t want to handle. Other attempts, like Mockoon, have a complex interface while lacking much-needed features. There’s another group of frameworks that are only used for testing, like the popular SinonJS. Unfortunately, these frameworks can’t be used to mock the regular behavior.
My team managed to create a functioning server that enables us to write front-end code as if we were working with a real back-end. We did it by writing the front-end codebase without any external processes or servers that are needed to run. This is why I love Mirage. It is really simple to set up, yet powerful enough to handle anything that’s thrown at it. You can use it for basic applications that return a static array to full-blown back-end apps alike — regardless of whether it’s a new or existing app.
There’s a lot more to Mirage beyond the implementations we covered here. A working example of what we covered can be found on GitHub. (Fun fact: Mirage also works with GraphQL!) Mirage has well-written documentation that includes a bunch of step-by-step tutorials, so be sure to check it out.
Pretty neat little website from Joan Perals, inspired by stuff like Lynn’s A Single Div. With multiple hard-stopbackground-image gradients, you don’t need extra HTML elements to draw shapes — you can draw as many shapes as you want on a single element. There is even a stacking order to work with. Drawing with backgrounds is certainly CSS trickery!
The site stores your drawing IDs in localStorage so you’ve got basic CRUD functionality right there. I bet the whole thing is a little hop away from being an offline PWA.
How much stock do you need to carry on hand? The simple answer is enough to keep up with consumer demand. Randomly filling a warehouse with products might help you keep up with demand, but it could eat up capital and warehousing space.
Suppliers can be unreliable, so you have to account for that as well. At times, demand can suddenly increase for unknown reasons, so you have to plan for that contingency. How do you account for all these variables and keep just enough inventory on hand?
You can accomplish this by setting a reorder point — a quantity that triggers the purchase of a specific stock item. You can find that value by using a reorder point formula. This formula will take the variables we just discussed and give you the answer. But this will not be a static number that you set and forget. It will be based on your purchase and sales cycles and will change over time.
How to Calculate a Reorder Point
We will start by studying these variables and see how to put them together to find a reorder point. We will use a fictional company called Vagabond Electronics and calculate the reorder point of their new smart light bulbs.
Average Daily Sales Units
The first number you need is the average daily units you’ve sold of a product. Vagabond has only been in business three months and sold 60 light bulbs in January, 90 in February, and 120 in March for a total of 270 lightbulbs sold in 90 days. The average daily sales for this light bulb is three per day.
This is just the average daily sales for the light bulbs. Each product will be unique. Some items will be more popular than others and will have to be ordered in more volume and frequency. Some items will sell quicker during certain seasons like Christmas, which is another reason why average daily sales have to be recalculated frequently.
Average Delivery Lead Time
Average delivery lead time is the time it takes from ordering a product to having it on your shelves and ready to ship. If you deal with more than one supplier, each will have a different lead-time. Products that need to ship from overseas will take longer to get to your warehouse, which means you will have to reorder more at a time to keep stock at the levels you need. But a supplier that ships express from the same state will allow you to have less in stock because it only takes a few days to replenish your inventory.
Vagabond Electronics has placed three orders for light bulbs in the three months that they have been open. The first order took only four days, the second took five days, and the third took six days. To get our average lead time, you just need to add the days together which gives us 15 and then divide by three. This makes the average delivery lead time five days.
Safety Stock
Safety stock is stock you keep on hand “just in case” something goes wrong and demand outpaces supply. For example, a product goes viral and suddenly you are selling it faster than you can keep it on the shelves, which is great news for your business until you run out of stock and have to deal with backorders and irate customers. Or maybe your supplier’s factory burned to the ground. You can never know exactly what you will have to face in the future of your business, but you can plan for unforeseen events.
You do this with safety stock. You can calculate safety stock in a few different ways. A common formula is:
(maximum daily sales x maximum lead time) – (average daily sales x average lead time)
You will subtract the average scenario from the worst-case scenario, at least when it comes to keeping products on the shelf. You already have three of the numbers we need to apply this formula to get the safety stock value for Vagabond Electronics’ light bulbs. The last number we need is maximum daily sales, which happened in March after they sent out a coupon to past buyers. On that day, they sold eight light bulbs. Now, plug the numbers into the formula and you get:
(8 x 6) – (3 x 5) = 33
So Vagabond Electronics needs 33 light bulbs as safety stock.
Safety stock is also a number that will have to be recalculated with seasonal sales. For example, if the product you are setting safety stock levels for are school lunchboxes, you will want to set your safety stock level based on last year’s school season right before this year’s season starts and then adjust the number back down as sales drop off before summer.
Putting a Reorder Point Formula to Use
Now that you have figured out all the variables you need, plug them into a reorder point formula, and find the reorder point for Vagabond light bulbs. This formula is simple:
(average daily sales units x average delivery lead time) + safety stock = reorder point
So for the light bulbs, we get:
(3 x 5) + 33 = 48
So whenever Vagabond’s stock of light bulbs drops to 48, they need to reorder more. When sales are regular, Vagabond would never have to touch their safety stock. But if a perfect storm hits and they sell the maximum amount they have ever sold for days in a row and their supplier lead time increases, they will have the safety stock they need to cover it.
Using Reorder Point Calculators
Setting reorder points is a critical part of managing your inventory. They help you keep your business running smoothly by ensuring you always have stock on hand for any orders you may have. But reorder points will only work for you if they are accurate, they are recalculated when your sales cycles change, and you are alerted when your stock levels drop to the reorder point.
You can use a spreadsheet to hold your inventory and an online reorder point calculator to set the reorder points, but you may have problems with accuracy and end up with a lot of manual work to do. There are a few ways to calculate safety stock, some more accurate than others depending on your sales cycles. We used a simple version to calculate the safety stock for Vagabond’s light bulbs. Whenever a business moves out of the startup phase, it is time to look at an automated inventory management system to make this process easier and trouble-free. The right inventory management system will not only keep track of your inventory and create a purchase order for you when something needs to be reordered but will also be able to use a more complex and accurate formula to calculate reorder points that will change to keep up with changes in your business.
The right typeface can make or break your website. As designers, we will always be naturally drawn towards the premium fonts such as Circular, DIN, or Maison Neue; Before you know it, your website is racking up a font bill larger than your hosting bill.
We’ve put together a list of open-source fonts that will rival your fancy fonts, and might even persuade you to switch them out. All the fonts listed here are completely open-source, which means they’re free to use on both personal and commercial projects.
Manrope
Manrope has sprung onto the font circuit in style, with a website better than most early startups. It’s a variable font, which means you have a flexible range of font weights to choose from in a single font file. Manrope is a personal favorite of mine, it has every ligature you could want, and is fully multi-lingual. It’s a lovely bit of everything as it states on the website: it is semi-condensed, semi-rounded, semi-geometric, semi-din, semi-grotesque.
Gidole
DIN – the font we all love, the font that looks great at every size, and the font that costs quite a bit, especially with a large amount of traffic. Gidole is here to save the day, it’s an open-source version of our favorite – DIN. It’s extremely close to DIN, but designers with a keen eye will spot very few minor differences. Overall, if you’re looking to use DIN, try Gidole out before going live. (There is also a very passionate community around the font on Github)
Inter
Inter is now extremely popular, but we wanted to include it as it’s become a staple in the open-source font world — excellent releases, constant updates, and great communication. If you’re looking for something a bit fancier than Helvetica and something more stable than San Francisco, then Inter is a great choice. The font has now even landed on Google Fonts, making it even easier to install. As of today: 2500+ Glyphs, Multilingual, 18 Styles, and 33 Features… do we need to say more?
Overpass
Overpass was created by Delvefonts and sponsored by Redhat, it was designed to be an alternative to the popular fonts Interstate and Highway Gothic. It’s recently cropped up on large ecommerce sites and is growing in popularity due to its large style set and ligature library. Did we mention it also has a monospace version? Overpass is available via Google Fonts, KeyCDN, and Font Library.
Public Sans
Public Sans is a project of the United States Government, it’s used widely on their own department websites and is part of their design system. The font is based on the popular open-source font Libre Franklin. Public Sans has great qualities such as multilingual support, a wide range of weights, and tabular figures. The font is also available in variable format but this is currently in the experimental phase of development.
Space Grotesk
Space Grotesk isn’t widely known yet, but this quirky font should be at the forefront of your mind if you’re looking for something “less boring” than good old Helvetica. Space Grotesk has all the goodies you can expect from a commercial font such as multiple stylistic sets, tabular figures, accented characters, and multilingual support.
Alice
Alice is a quirky serif font usually described as eclectic and quaint, old-fashioned — perfect if you’re looking to build a website that needs a bit of sophistication. Unfortunately, it only has one weight, but it is available on Google Fonts.
Urbanist
Urbanist is an open-source variable, geometric sans serif inspired by Modernist typography. Designed from elementary shapes, Urbanist carries intentional neutrality that grants its versatility across a variety of print and digital mediums. If you’re looking to replace the premium Sofia font, then Urbanist is your best bet.
Evolventa
Evolventa is a Cyrillic extension of the open-source URW Gothic L font family. It has a familiar geometric sans-serif design and includes four faces. Evolventa is a small font family, generally used across the web for headlines and bold titles.
Fira Sans
Fira Sans is a huge open source project, brought to you, and opened sourced by the same team that makes Firefox. It’s Firefox’s default browser font and the font they use on their website. The font is optimized for legibility on screens. (And it’s on Google Fonts!)
Hack
Building a development website, or need a great code font to style those pesky code-blocks? Then Hack is the font for you. Super lightweight and numerous symbols and ligatures. The whole font was designed for source code and even has a handy Windows installer.
IBM Plex
IBM needs no introduction. Plex is IBM’s default website font and is widely used around the web in its numerous formats Mono, Sans, Serif, Sans-Serif, and Condensed – it has everything you’d need from a full font-family. The whole font family is multi-lingual, perfect for multi-national website designs. (It’s fully open-source!)
Monoid
Another great coding font, Monoid is a favorite of mine for anything code. The clever thing about Monoid is that it has font-awesome built into it, which they call Monoisome. This means when writing code, you can pop a few icons in there easily. Monoid looks just as great when you’re after highly readable website body text.
Object Sans
Object Sans (formally known as Objectivity) is a beautiful geometric font family that can be used in place of quite a few premium fonts out there. The font brings together the top qualities of both Swiss neo-grotesks and geometric fonts. The font works beautifully as large headings but can be used for body content as well.
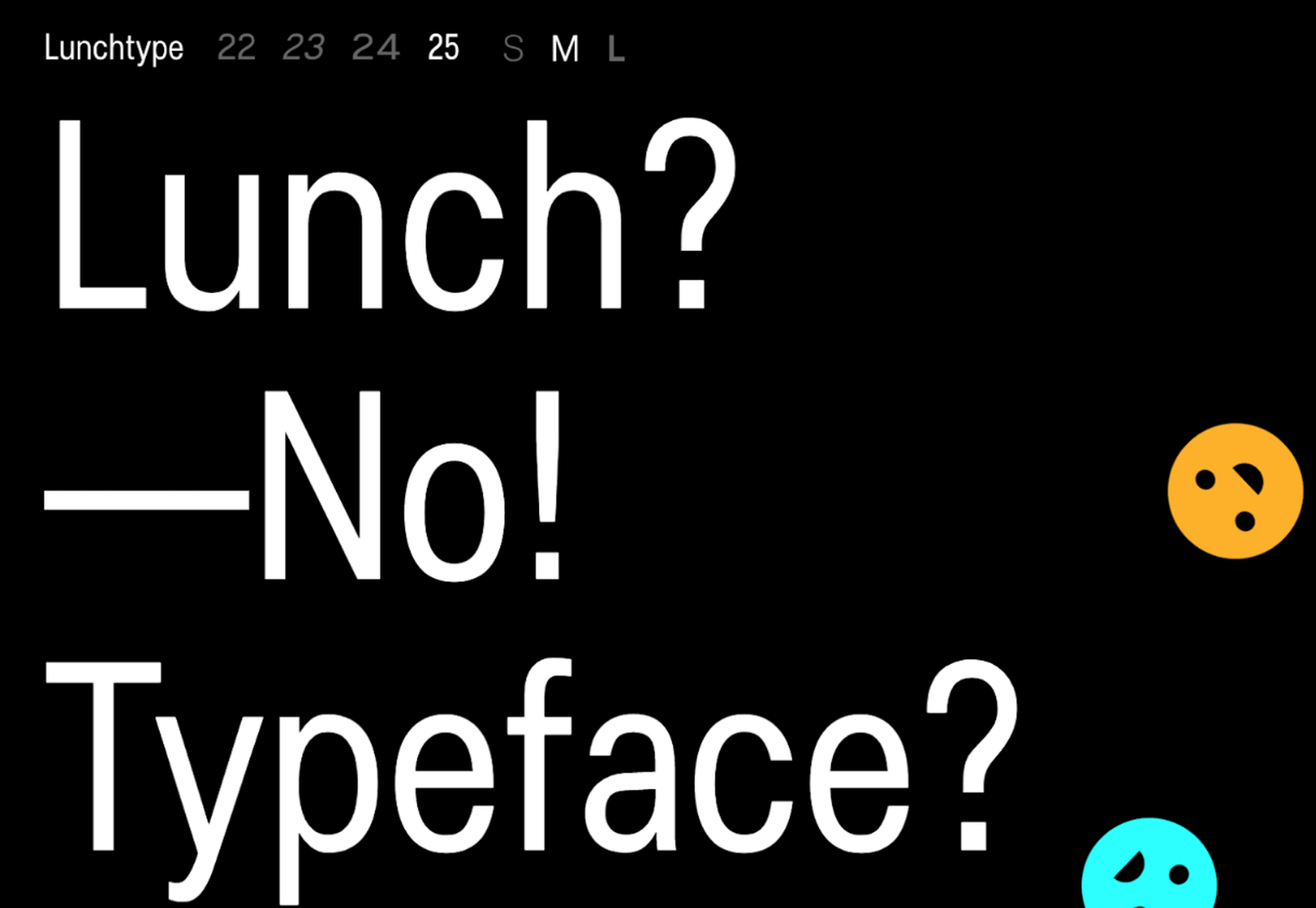
Lunchtype
Lunchtype has a very interesting back-story, originally designed during the creator’s daily lunchtime during a 100-day project. If you’re looking for something a bit “jazzier” than the typical Helvetica for your project, then Lunchtype is a perfect choice. The family comes with numerous weights as well as a condensed version — enough to fill any lunchbox.
Jost
Inspired by the early 1920’s German sans-serif’s, Jost is a firm favorite in the open-source font world. Jost brings a twist to its closest web designer favorite Futura. When you want a change from the typical Futura, then Jost is a great option with its variable weighting as well as multilingual support.
Work Sans
Work Sans is a beautiful grotesk sans with numerous little eccentricities that may delight or annoy some designers. The font has variable weighting, multilingual support and is optimized for on-screen text use but works perfectly well for print also.
Every week users submit a lot of interesting stuff on our sister site Webdesigner News, highlighting great content from around the web that can be of interest to web designers.
The best way to keep track of all the great stories and news being posted is simply to check out the Webdesigner News site, however, in case you missed some here’s a quick and useful compilation of the most popular designer news that we curated from the past week.
16 Impressive SVG Animations
EazyCSS
Qube – A Virtual Office for Remote Workers
Brick.do – Free Notion-Like Tool for Zero-Hassle Website Making
Feather CMS – A Modern CMS on Top of Swift & Vapor
RevKit – Design System UI Kit
ColorFlick – Friendly Color Palette for Dribbble
21 Fabulous UX Design Infographics
Papercups – Open Source Live Customer Chat
Speculative Design Methods & Tools
Logo Process: RosyBee Plants for Bees Logo & Identity
HockeyStack – No-Code Analytics Tool
DeGoogle my Life
THEREMIX – Virtual Theremin
ReAim – ReMarketing Platform
2020 Helped Me – What’s been Good About your 2020?
Digityl Vinyl – Magical Vinyl Record Audio Filters
New Logo for Mars 2020
Getting the Most Out of Variable Fonts on Google Fonts
Adobe XD Vs Sketch Design Tool Showdown
Redesigning Famous Icons Using 3D Neumorphic Designs
How to Generate Extra Income as a Designer
One Task at a Time: The Key to Achieving Deep, Focused Work
How to Get Visitors to a New Website
Meet the YouTuber Who’s Schooling Developers on How Blind People Really Use Tech
Want more? No problem! Keep track of top design news from around the web with Webdesigner News.
Have you ever come across a site where light text is sitting on a light background image? If you have, you’ll know how difficult that is to read. A popular way to avoid that is to use a transparent overlay. But this leads to an important question: Just how transparent should that overlay be? It’s not like we’re always dealing with the same font sizes, weights, and colors, and, of course, different images will result in different contrasts.
Trying to stamp out poor text contrast on background images is a lot like playing Whac-a-Mole. Instead of guessing, we can solve this problem with HTML and a little bit of math.
Like this:
CodePen Embed Fallback
We could say “Problem solved!” and simply end this article here. But where’s the fun in that? What I want to show you is how this tool works so you have a new way to handle this all-too-common problem.
Here’s the plan
First, let’s get specific about our goals. We’ve said we want readable text on top of a background image, but what does “readable” even mean? For our purposes, we’ll use the WCAG definition of AA-level readability, which says text and background colors need enough contrast between them such that that one color is 4.5 times lighter than the other.
Let’s pick a text color, a background image, and an overlay color as a starting point. Given those inputs, we want to find the overlay opacity level that makes the text readable without hiding the image so much that it, too, is difficult to see. To complicate things a bit, we’ll use an image with both dark and light space and make sure the overlay takes that into account.
Our final result will be a value we can apply to the CSS opacity property of the overlay that gives us the right amount of transparency that makes the text 4.5 times lighter than the background.
Optimal overlay opacity: 0.521
To find the optimal overlay opacity we’ll go through four steps:
We’ll put the image in an HTML , which will let us read the colors of each pixel in the image.
We’ll find the pixel in the image that has the least contrast with the text.
Next, we’ll prepare a color-mixing formula we can use to test different opacity levels on top of that pixel’s color.
Finally, we’ll adjust the opacity of our overlay until the text contrast hits the readability goal. And these won’t just be random guesses — we’ll use binary search techniques to make this process quick.
Let’s get started!
Step 1: Read image colors from the canvas
Canvas lets us “read” the colors contained in an image. To do that, we need to “draw” the image onto a element and then use the canvas context (ctx) getImageData() method to produce a list of the image’s colors.
function getImagePixelColorsUsingCanvas(image, canvas) {
// The canvas's context (often abbreviated as ctx) is an object
// that contains a bunch of functions to control your canvas
const ctx = canvas.getContext('2d');
// The width can be anything, so I picked 500 because it's large
// enough to catch details but small enough to keep the
// calculations quick.
canvas.width = 500;
// Make sure the canvas matches proportions of our image
canvas.height = (image.height / image.width) * canvas.width;
// Grab the image and canvas measurements so we can use them in the next step
const sourceImageCoordinates = [0, 0, image.width, image.height];
const destinationCanvasCoordinates = [0, 0, canvas.width, canvas.height];
// Canvas's drawImage() works by mapping our image's measurements onto
// the canvas where we want to draw it
ctx.drawImage(
image,
...sourceImageCoordinates,
...destinationCanvasCoordinates
);
// Remember that getImageData only works for same-origin or
// cross-origin-enabled images.
// https://developer.mozilla.org/en-US/docs/Web/HTML/CORS_enabled_image
const imagePixelColors = ctx.getImageData(...destinationCanvasCoordinates);
return imagePixelColors;
}
The getImageData() method gives us a list of numbers representing the colors in each pixel. Each pixel is represented by four numbers: red, green, blue, and opacity (also called “alpha”). Knowing this, we can loop through the list of pixels and find whatever info we need. This will be useful in the next step.
Step 2: Find the pixel with the least contrast
Before we do this, we need to know how to calculate contrast. We’ll write a function called getContrast() that takes in two colors and spits out a number representing the level of contrast between the two. The higher the number, the better the contrast for legibility.
When I started researching colors for this project, I was expecting to find a simple formula. It turned out there were multiple steps.
To calculate the contrast between two colors, we need to know their luminance levels, which is essentially the brightness (Stacie Arellano does a deep dive on luminance that’s worth checking out.)
Thanks to the W3C, we know the formula for calculating contrast using luminance:
Getting the luminance of a color means we have to convert the color from the regular 8-bit RGB value used on the web (where each color is 0-255) to what’s called linear RGB. The reason we need to do this is that brightness doesn’t increase evenly as colors change. We need to convert our colors into a format where the brightness does vary evenly with color changes. That allows us to properly calculate luminance. Again, the W3C is a help here:
But wait, there’s more! In order to convert 8-bit RGB (0 to 255) to linear RGB, we need to go through what’s called standard RGB (also called sRGB), which is on a scale from 0 to 1.
So the process goes:
8-bit RGB → standard RGB → linear RGB → luminance
And once we have the luminance of both colors we want to compare, we can plug in the luminance values to get the contrast between their respective colors.
// getContrast is the only function we need to interact with directly.
// The rest of the functions are intermediate helper steps.
function getContrast(color1, color2) {
const color1_luminance = getLuminance(color1);
const color2_luminance = getLuminance(color2);
const lighterColorLuminance = Math.max(color1_luminance, color2_luminance);
const darkerColorLuminance = Math.min(color1_luminance, color2_luminance);
const contrast = (lighterColorLuminance + 0.05) / (darkerColorLuminance + 0.05);
return contrast;
}
function getLuminance({r,g,b}) {
return (0.2126 * getLinearRGB(r) + 0.7152 * getLinearRGB(g) + 0.0722 * getLinearRGB(b));
}
function getLinearRGB(primaryColor_8bit) {
// First convert from 8-bit rbg (0-255) to standard RGB (0-1)
const primaryColor_sRGB = convert_8bit_RGB_to_standard_RGB(primaryColor_8bit);
// Then convert from sRGB to linear RGB so we can use it to calculate luminance
const primaryColor_RGB_linear = convert_standard_RGB_to_linear_RGB(primaryColor_sRGB);
return primaryColor_RGB_linear;
}
function convert_8bit_RGB_to_standard_RGB(primaryColor_8bit) {
return primaryColor_8bit / 255;
}
function convert_standard_RGB_to_linear_RGB(primaryColor_sRGB) {
const primaryColor_linear = primaryColor_sRGB < 0.03928 ?
primaryColor_sRGB/12.92 :
Math.pow((primaryColor_sRGB + 0.055) / 1.055, 2.4);
return primaryColor_linear;
}
Now that we can calculate contrast, we’ll need to look at our image from the previous step and loop through each pixel, comparing the contrast between that pixel’s color and the foreground text color. As we loop through the image’s pixels, we’ll keep track of the worst (lowest) contrast so far, and when we reach the end of the loop, we’ll know the worst-contrast color in the image.
function getWorstContrastColorInImage(textColor, imagePixelColors) {
let worstContrastColorInImage;
let worstContrast = Infinity; // This guarantees we won't start too low
for (let i = 0; i < imagePixelColors.data.length; i += 4) {
let pixelColor = {
r: imagePixelColors.data[i],
g: imagePixelColors.data[i + 1],
b: imagePixelColors.data[i + 2],
};
let contrast = getContrast(textColor, pixelColor);
if(contrast < worstContrast) {
worstContrast = contrast;
worstContrastColorInImage = pixelColor;
}
}
return worstContrastColorInImage;
}
Step 3: Prepare a color-mixing formula to test overlay opacity levels
Now that we know the worst-contrast color in our image, the next step is to establish how transparent the overlay should be and see how that changes the contrast with the text.
When I first implemented this, I used a separate canvas to mix colors and read the results. However, thanks to Ana Tudor’s article about transparency, I now know there’s a convenient formula to calculate the resulting color from mixing a base color with a transparent overlay.
For each color channel (red, green, and blue), we’d apply this formula to get the mixed color:
With that, we have all the tools we need to find the optimal overlay opacity!
Step 4: Find the overlay opacity that hits our contrast goal
We can test an overlay’s opacity and see how that affects the contrast between the text and image. We’re going to try a bunch of different opacity levels until we find the contrast that hits our mark where the text is 4.5 times lighter than the background. That may sound crazy, but don’t worry; we’re not going to guess randomly. We’ll use a binary search, which is a process that lets us quickly narrow down the possible set of answers until we get a precise result.
Here’s how a binary search works:
Guess in the middle.
If the guess is too high, we eliminate the top half of the answers. Too low? We eliminate the bottom half instead.
Guess in the middle of that new range.
Repeat this process until we get a value.
I just so happen to have a tool to show how this works:
CodePen Embed Fallback
In this case, we’re trying to guess an opacity value that’s between 0 and 1. So, we’ll guess in the middle, test whether the resulting contrast is too high or too low, eliminate half the options, and guess again. If we limit the binary search to eight guesses, we’ll get a precise answer in a snap.
Before we start searching, we’ll need a way to check if an overlay is even necessary in the first place. There’s no point optimizing an overlay we don’t even need!
Now we can use our binary search to look for the optimal overlay opacity:
function findOptimalOverlayOpacity(textColor, overlayColor, worstContrastColorInImage, desiredContrast) {
// If the contrast is already fine, we don't need the overlay,
// so we can skip the rest.
const isOverlayNecessary = isOverlayNecessary(textColor, worstContrastColorInImage, desiredContrast);
if (!isOverlayNecessary) {
return 0;
}
const opacityGuessRange = {
lowerBound: 0,
midpoint: 0.5,
upperBound: 1,
};
let numberOfGuesses = 0;
const maxGuesses = 8;
// If there's no solution, the opacity guesses will approach 1,
// so we can hold onto this as an upper limit to check for the no-solution case.
const opacityLimit = 0.99;
// This loop repeatedly narrows down our guesses until we get a result
while (numberOfGuesses < maxGuesses) {
numberOfGuesses++;
const currentGuess = opacityGuessRange.midpoint;
const contrastOfGuess = getTextContrastWithImagePlusOverlay({
textColor,
overlayColor,
imagePixelColor: worstContrastColorInImage,
overlayOpacity: currentGuess,
});
const isGuessTooLow = contrastOfGuess < desiredContrast;
const isGuessTooHigh = contrastOfGuess > desiredContrast;
if (isGuessTooLow) {
opacityGuessRange.lowerBound = currentGuess;
}
else if (isGuessTooHigh) {
opacityGuessRange.upperBound = currentGuess;
}
const newMidpoint = ((opacityGuessRange.upperBound - opacityGuessRange.lowerBound) / 2) + opacityGuessRange.lowerBound;
opacityGuessRange.midpoint = newMidpoint;
}
const optimalOpacity = opacityGuessRange.midpoint;
const hasNoSolution = optimalOpacity > opacityLimit;
if (hasNoSolution) {
console.log('No solution'); // Handle the no-solution case however you'd like
return opacityLimit;
}
return optimalOpacity;
}
With our experiment complete, we now know exactly how transparent our overlay needs to be to keep our text readable without hiding the background image too much.
We did it!
Improvements and limitations
The methods we’ve covered only work if the text color and the overlay color have enough contrast to begin with. For example, if you were to choose a text color that’s the same as your overlay, there won’t be an optimal solution unless the image doesn’t need an overlay at all.
In addition, even if the contrast is mathematically acceptable, that doesn’t always guarantee it’ll look great. This is especially true for dark text with a light overlay and a busy background image. Various parts of the image may distract from the text, making it difficult to read even when the contrast is numerically fine. That’s why the popular recommendation is to use light text on a dark background.
We also haven’t taken where the pixels are located into account or how many there are of each color. One drawback of that is that a pixel in the corner could possibly exert too much influence on the result. The benefit, however, is that we don’t have to worry about how the image’s colors are distributed or where the text is because, as long as we’ve handled where the least amount of contrast is, we’re safe everywhere else.
I learned a few things along the way
There are some things I walked away with after this experiment, and I’d like to share them with you:
Getting specific about a goal really helps! We started with a vague goal of wanting readable text on an image, and we ended up with a specific contrast level we could strive for.
It’s so important to be clear about the terms. For example, standard RGB wasn’t what I expected. I learned that what I thought of as “regular” RGB (0 to 255) is formally called 8-bit RGB. Also, I thought the “L” in the equations I researched meant “lightness,” but it actually means “luminance,” which is not to be confused with “luminosity.” Clearing up terms helps how we code as well as how we discuss the end result.
Complex doesn’t mean unsolvable. Problems that sound hard can be broken into smaller, more manageable pieces.
When you walk the path, you spot the shortcuts. For the common case of white text on a black transparent overlay, you’ll never need an opacity over 0.54 to achieve WCAG AA-level readability.
In summary…
You now have a way to make your text readable on a background image without sacrificing too much of the image. If you’ve gotten this far, I hope I’ve been able to give you a general idea of how it all works.
I originally started this project because I saw (and made) too many website banners where the text was tough to read against a background image or the background image was overly obscured by the overlay. I wanted to do something about it, and I wanted to give others a way to do the same. I wrote this article in hopes that you’d come away with a better understanding of readability on the web. I hope you’ve learned some neat canvas tricks too.
If you’ve done something interesting with readability or canvas, I’d love to hear about it in the comments!
You don’t have all that much control over how big or long the dashes or gaps are. And you certainly can’t give the dashes slants, fading, or animation! You can do those things with some trickery though.
Amit Sheen build this really neat Dashed Border Generator:
CodePen Embed Fallback
The trick is using four multiple backgrounds. The background property takes comma-separated values, so by setting four backgrounds (one along the top, right, bottom, and left) and sizing them to look like a border, it unlocks all this control.
…what does that % value mean here? What is it a percentage of? There’ve been so many times when I’ll be using percentages and something weird happens. I typically shrug, change the value to something else and move on with my day.
But Amelia Wattenberger says no! in this remarkable deep dive into how percentages work in CSS and all the peculiar things we need to know about them. And as is par for the course at this point, any post by Amelia has a ton of wonderful demos that perfectly describe how the CSS in any given example works. And this post is no different.
Every website that’s made me oooo and aaahhh lately has been of a special kind; they’re written and designed like essays. There’s an argument, a playfulness in the way that they’re not so much selling me something as they are trying to convince me of the thing. They use words and type and color in a way that makes me sit up and listen.
And I think that framing our work in this way lets us web designers explore exciting new possibilities. Instead of throwing a big carousel on the page and being done with it, thinking about making a website like an essay encourages us to focus on the tough questions. We need an introduction, we need to provide evidence for our statements, we need a conclusion, etc. This way we don’t have to get so caught up in the same old patterns that we’ve tried again and again in our work.
And by treating web design like an essay, we can be weird with the design. We can establish a distinct voice and make it sound like an honest-to-goodness human being wrote it, too.
One example of a website-as-an-essay is the Analogue Pocket site which uses real paragraphs to market their fancy new device.
Another example is the new email app Hey in which the website is nothing but paragraphs — no screenshots, no fancy product information. It’s almost feels like a political manifesto hammered onto a giant wooden door.
Apple’s marketing sites are little essays, too. Take this one section from the iPad Pro all about the LiDAR Scanner. It’s not so much trying to sell you an iPad at this point so much as it is trying to argue the case for LiDAR. And as with all good essays it answers the who, what, why, when, and how.
Another example is Stripe’s recent beautiful redesign. What I love more than the outrageously gorgeous animated gradients is the argument that the website is making. What is Stripe? How can I trust them? How easy is it to get set up? Who, what, why, when, how.
To be my own devil’s advocate for a bit though, we’re all familiar with this line of reasoning: Why care about the writing so much when people don’t read? Folks skim through a website. They don’t persevere with the text, they don’t engage with the writing, and you only have half a millisecond to hit them with something flashy before they leave. They can’t handle complex words or sentences. They can’t grasp complex ideas. So keep those paragraphs short! Remove all text from the page!
The implication here is that users are dumb. They can’t focus and they don’t care. You have to shout at them. And I kinda sorta hate that.
Instead, I think the opposite is true. They’ve seen the same boring websites for years. Everyone is tired of lifeless, humorless copywriting. They’ve seen all the animations, witnessed all the cool fonts, and in the face of all that stuff, they yawn. They yawn because it supports a bad argument, or more precisely, a bad essay; one that doesn’t charm the reader, or give them a reason to care.
So what if we made our websites more like essays and less like billboards that dot the freeways? What would that look like?