If you are a website owner and publish content frequently, you would always be looking for online utilities that can help you out in measuring the quality and originality of content.
To ensure that you publish high-quality content with no grammatical errors, you may go for any of the grammar checkers, but if you are concerned about the originality and don’t want yourself to land with copyright issues, then you need to go for plagiarism checker.
You might have some writers on-board with you. They will be providing you content regularly, but everyone is concerned about the originality, uniqueness, and quality. You would find an extensive range of tools over the web. Some of them are paid while others are free.
However, the search for an impressive tool that provides accurate results must not end. These days, the highly competitive digital market requires everyone to put extra effort into generating quality content that covers new areas with fresh thoughts and ideas.
You need to bring original and quality content to grab the user’s attention towards your website or blog. Therefore, whenever you get content from the writer’s end, make sure to run it through a grammar checker and plagiarism detector.
You should articulate a strategy for content marketing. It must not be limited to following your competitor’s strategy, but instead, ensure to move ahead by introducing advanced ideas. No matter what type of content you produce, always ensure to get it through a plagiarism checker to avoid duplication.
Make Your Website’s Content Duplication Free
Search engines have a stringent policy regarding plagiarized content. Along with Google, not a single search engine’s algorithm allows us to rank duplicate content. The search engines will either de-rank the plagiarized web page or would even get your monetizing account limited. Therefore, always make sure to publish content that is free from piracy.
There are online plagiarism checker that helps the website owners to find duplication in the content, one of my recommended tool can be accessed by visiting the following link: searchenginereports.net
There are many other free plagiarism detectors that can be found over the web easily.
Additionally, apart from search engines, users don’t like to read content that has been replicated from any other source. Your website’s bounce rate will increase, and ultimately you may end up losing your entire traffic.
Therefore, you should have no room for publishing content that has been duplicated to stay on the safe side. In this regard, you can use a free online plagiarism checker with percentage. It will let you know how much of the content has been replicated.
Fortunately, with advancements in technology, we now don’t have to go through the hassle of installing massive-sized software on our device to check the piracy in the content. There is plenty of plagiarism checker free available online that can assist you in finding any piracy in your content within a flash of an eye. Many of these plagiarism checker tools are paid, and some are unpaid as well. You can use any of them as per your requirements, but make sure of the tool’s efficiency before settling for it.
Opt for High-Quality Error Free Content
No one would ever want to read content that is full of errors or mistakes. If you get the content of poor quality published on your website, the user may get annoyed. Low-quality content brings your website on the verge of losing traffic and potential leads and sales. Therefore, you should always edit and proofread your content before processing it in the publishing pipeline. Most of the grammatical error detection tools come with plagiarism checkers as well.
Moreover, the editing and proofreading process has also become quite comfortable with the availability of grammar checking online tools. They let the users find mistakes and errors in the content from spelling mistakes to the sentence structure. You can use them to ensure that you have used proper punctuation. The tools also give out suggestions to replace the words according to the context of the sentence and passage.
If you think that you may need to learn some special skills to use an efficient plagiarism detector or grammatical mistake finder, then you are wrong. You can use these effective online tools without any hassle, and a few clicks on your device will enable you to execute the process.
Move Ahead to Provide Valuable Content
Users are always in search of content that has value for them. You would need to conduct deep research for providing the content that is supported by relevant facts and figures, and the user is gaining information about the subject that can help them a lot. Therefore, every piece of your content must be well-researched to convince the user that your website is the ultimate one-stop destination in providing accurate and valuable content. You should always run the textual content through a plagiarism checker to ensure that you are publishing produced content. It will not let you end up with any unexpected circumstances.
But what is valuable content? How can we determine the quality of content? Well, these are some valid questions here, and it is essential to understand these points. One of the most crucial components of great content is uniqueness. If the content has plagiarized content, or some of the material is duplicated, then we cannot consider it as high-quality content. People don’t like the content that is copied from other sources and may stop visiting your site if they find piracy in your content. So, it is suggested to check your content from a proficient online plagiarism checker before publishing it on the web.
Another key feature that a valuable content contains is a bunch of relevant images. As we all know, we live in the digital world, and the time span of liking or disliking something over the web has reduced a lot, so it becomes vital to use appropriate and appealing images in your content that can attract the people towards your content. Also, the immense popularity of Reverse Image Search has changed the strategies of generating high-quality content. All the leading content providers understood this new phenomenon and started creating the content according to it. So, if you want to stay in the race, then it is crucial for you to adopt this new change and add relevant images in your content.
Final Words
In the last analysis, usage of grammatical error detection tools and plagiarism checker utilities has become a compulsion for the website and blog owners. The tools will ensure that you publish content that is worthwhile and is as per the standards set out by search engines. If you are working on some kind of service providing a niche, you should also try to formulate your content so that you get a snippet in the search engine result page. It will let you generate more traffic to your website, which will, in return, turn out to produce good revenue.
The above-discussed information may help you understand the basic elements that must be examined to check the quality of content. Additionally, you may also have better information about the need for appropriate tools like Plagiarism checker to make sure the exclusiveness of your content. The efficient use of these online tools provides you with the opportunity to find any error in the material and prevents you from any unpleasant situation like a penalty from Google due to uploading plagiarized content.
So, use an efficient online plagiarism checker free from any part of the globe to detect piracy and make your content appealing and great within a few seconds.
Creator: Henny Kel – Digital Marketing Strategist & Brand Consultant at Designhill Photo by Kaleidico on Unsplash
Keeping customers can cause concern for customer-centric companies. For SaaS companies, in particular, the recurring revenue model means that every lost customer represents months of lost revenue. Reducing churn is critical to growing your business. Otherwise, you’ll spend more time replacing the revenue lost from churned customers than growing.
The top two leading causes of churn, according to Retently, are poor onboarding (23% of churn) and weak relationship building (16% of churn). Presenting quality webinars can address both of these causes, plus many more.
In this article, we walk through why and how you can develop a webinar strategy that builds relationships between you and your customers, promotes loyalty, and keeps customers around for life.
Improve Onboarding and Customer Education
Poor onboarding often leaves customers feeling lost. They don’t know what their next steps are, they don’t see the value in the product, and they usually end up giving up their fight to make sense of your product – resulting in churn. The effects of poor onboarding are far-reaching too. Customers who weren’t set up for success early never find their footing and can end up churning months later. Webinars can improve onboarding by providing an evergreen resource for new customers to refer to. Even if your webinar isn’t presented live, customers can be guided through setting up their new accounts and be given a virtual tour of your product. It’s a great starting point for building customer engagement too – after a webinar, connecting customers with their customer success manager or the customer support team can help launch a productive working relationship.
Webinars can also introduce new features to existing customers improving product adoption. By always giving your customers more value, you reduce the chance they will even consider walking out the door. Why leave when it keeps getting better?
Building Better Relationships
68% of customers have reported leaving a company because they didn’t feel the company cared about them. Building a close relationship with your customers provides more opportunities to show you care. Webinars can help bring people together.
How often do your customers actually talk with a member of your team? Sure, they might write an email, or exchange a few tweets, but face-to-face discussions are rare in the SaaS world. Webinars give your team a chance to get in front of the camera, show their personality and connect with customers in a new way.
Plus, webinars are a chance to give back to customers and your community with no expectation of purchase. Best practice webinars or professional development opportunities give value to your customers. This act of kindness is repaid through increased trust and long-term customer loyalty. If customers see you as a source of knowledge, they will be much more inclined to stay with your product for the long haul.
Creating a webinar strategy for churn reduction
Reducing churn with webinars requires a well-developed strategy and effective execution. You need to first decide which causes of churn you’re hoping to target, promote the content to the right audience, then create and deliver a thoughtful webinar. Follow the steps below to make sure you’re hitting all the right notes:
Identify causes of churn
While webinars can help with many aspects of customer loyalty, knowing what is causing customers to fail will help you be more targeted in your approach. There are many ways to determine why your customers are leaving, including:
Include a question in the cancellation flow asking why they are canceling, or if there was anything you could have done to keep them around.
Contact customers who have churned for post-cancellation interviews. This can be over phone or email. The response rates are typically low, but the information can still be valuable.
Look at customer usage data and the timing of when they churn. Is there a pattern to customers who churn? For example, are most cancellations occurring directly after the first bill is sent?
If you don’t know the cause of customer churn, it will be very difficult to address it, whether with webinars or any other techniques.
Define the purpose of your webinars
Once you know why some customers churn, you can start planning out your webinar series. Webinars are particularly effective in:
Building relationships between your customers and your company by putting a face in front of your brand and engaging customers in conversation
Educating customers about features they may not be using to their full advantage.
Providing value to customers beyond the product, like sharing industry best practices and helping them get better at their job.
Onboarding new customers to get them up and running more effectively.
Depending on the causes of customer churn in your business, the purpose of your webinar will vary. Try to be as specific as possible. If you’re starting with a series of three webinars designed to improve onboarding, identify exactly what customers should learn by the end of the webinar. By being specific you can be more targeted with your campaign and more effectively determine your impact on churn.
Promote to the target audience
By defining a purpose for your webinars, you can define the ideal audience. Rather than trying to appeal to everyone, segment your customers into personas that are trying to accomplish specific tasks. For example, many webinars are offered to help desk administrators and individual agents. By separating product-specific webinars from general best-practice webinars you’ll be able to segment these two groups so that you aren’t wasting anyone’s time delivering irrelevant content. While the existing customers might be interested in learning how to get more value from their help desk management system, it wouldn’t be relevant to the non-product users.
Promote your webinar to your defined target audience through email, social media, and in-product. Let your agents know about upcoming product webinars so they can share them with customers who are asking about specific features.
Remember, people need to actually attend the webinar in order for it to be effective – so don’t skimp on the promotion! Allow for at least two weeks of promotion before the day of the live webinar, so that you can build up a big attendance list.
Deliver webinar
You’ve made a plan and promoted it. Now it’s time to execute on your vision and share some knowledge with your customers.
Perform a test run with all presenters to make sure mics are working, slides are in order and everyone knows their role. A poorly organized webinar won’t build any trust with your customers and they likely won’t come back to another one.
Don’t be afraid to showcase your personality! By showing that there are real humans behind the brand (whether it’s a product manager, a support agent or your VP of marketing), you start building connections with customers.
Offer an opportunity for customers to ask questions, either through the webinar software you’re using or on social media. Follow-up with every single question, even if you don’t get to them live.
Record the webinar for anyone who couldn’t attend as well as future customers. By presenting the webinar once, you’ll gain a valuable resource for customers you can reuse and recycle.
Warning: webinars should not be self-promotional. If you lure customers in with the promise of learning and then start heavily pushing upsells, they will leave. The purpose of webinars is not to sell, it’s to educate.
Follow-up and measure success
After delivering your webinar, follow-up with everyone who attended to keep the conversation going. Deliver more resources so they can continue to learn on their own. Match them up with the customer support team if they have any further questions.
In order to see if your webinar strategy worked effectively, monitor the future actions of any attendees. Do they churn at a similar or lower rate than the average customer? Do they purchase more, or become more active users of the product? Measuring the return on investment of webinars can help you decide if you need to offer more or if they aren’t an effective strategy for your audience.
The warping is certainly the cool part here. Some fancy math literally transforms the path data to do the warping. But the UX detail work here is just as nice. Scrolling the page zooms in and out via a transform: scale() on the SVG wrapper (clever!). Likewise, holding the spacebar lets you pan around which is as simple as transform: translate() on another wrapper (smart!). To warp your own SVG files, you just drag-and-drop them on the page (easy!).
Tim Berners-Lee is fascinated with information. It has been his life’s work. For over four decades, he has sought to understand how it is mapped and stored and transmitted. How it passes from person to person. How the seeds of information become the roots of dramatic change. It is so fundamental to the work that he has done that when he wrote the proposal for what would eventually become the World Wide Web, he called it “Information Management, a Proposal.”
Information is the web’s core function. A series of bytes stream across the world and at the end of it is knowledge. The mechanism for this transfer — what we know as the web — was created by the intersection of two things. The first is the Internet, the technology that makes it all possible. The second is hypertext, the concept that grounds its use. They were brought together by Tim Berners-Lee. And when he was done he did something truly spectacular. He gave it away to everyone to use for free.
When Berners-Lee submitted “Information Management, a Proposal” to his superiors, they returned it with a comment on the top that read simply:
Vague, but exciting…
The web wasn’t a sure thing. Without the hindsight of today it looked far too simple to be effective. In other words, it was a hard sell. Berners-Lee was proficient at many things, but he was never a great salesman. He loved his idea for the web. But he had to convince everybody else to love it too.
Tim Berners-Lee has a mind that races. He has been known — based on interviews and public appearances — to jump from one idea to the next. He is almost always several steps ahead of what he is saying, which is often quite profound. Until recently, he only gave a rare interview here and there, and masked his greatest achievements with humility and a wry British wit.
What is immediately apparent is that Tim Berners-Lee is curious. Curious about everything. It has led him to explore some truly revolutionary ideas before they became truly revolutionary. But it also means that his focus is typically split. It makes it hard for him to hold on to things in his memory. “I’m certainly terrible at names and faces,” he once said in an interview. His original fascination with the elements for the web came from a very personal need to organize his own thoughts and connect them together, disparate and unconnected as they are. It is not at all unusual that when he reached for a metaphor for that organization, he came up with a web.
As a young boy, his curiosity was encouraged. His parents, Conway Berners-Lee and Mary Lee Woods, were mathematicians. They worked on the Ferranti Mark I, the world’s first commercially available computer, in the 1950s. They fondly speak of Berners-Lee as a child, taking things apart, experimenting with amateur engineering projects. There was nothing that he didn’t seek to understand further. Electronics — and computers specifically — were particularly enchanting.
Berners-Lee sometimes tells the story of a conversation he had with his with father as a young boy about the limitations of computers making associations between information that was not intrinsically linked. “The idea stayed with me that computers could be much more powerful,” Berners-Lee recalls, “if they could be programmed to link otherwise unconnected information. In an extreme view, the world can been seen as only connections.” He didn’t know it yet, but Berners-Lee had stumbled upon the idea of hypertext at a very early age. It would be several years before he would come back to it.
History is filled with attempts to organize knowledge. An oft-cited example is the Library of Alexandria, a fabled library of Ancient Greece that was thought to have had tens of thousands of meticulously organized texts.
At the turn of the century, Paul Otlet tried something similar in Belgium. His project was called the Répertoire Bibliographique Universel (Universal Bibliography). Otlet and a team of researchers created a library of over 15 million index cards, each with a discrete and small piece of information in topics ranging from science to geography. Otlet devised a sophisticated numbering system that allowed him to link one index card to another. He fielded requests from researchers around the world via mail or telegram, and Otlet’s researchers could follow a trail of linked index cards to find an answer. Once properly linked, information becomes infinitely more useful.
A sudden surge of scientific research in the wake of World War II prompted Vanneaver Bush to propose another idea. In his groundbreaking essay in The Atlantic in 1945 entitled “As We May Think,” Bush imagined a mechanical library called a Memex. Like Otlet’s Universal Bibliography, the Memex stored bits of information. But instead of index cards, everything was stored on compact microfilm. Through the process of what he called “associative indexing,” users of the Memex could follow trails of related information through an intricate web of links.
The list of attempts goes on. But it was Ted Neslon who finally gave the concept a name in 1968, two decades after Bush’s article in The Atlantic. He called it hypertext.
Hypertext is, essentially, linked text. Nelson observed that in the real world, we often give meaning to the connections between concepts; it helps us grasp their importance and remember them for later. The proximity of a Post-It to your computer, the orientation of ingredients in your refrigerator, the order of books on your bookshelf. Invisible though they may seem, each of these signifiers hold meaning, whether consciously or subconsciously, and they are only fully realized when taking a step back. Hypertext was a way to bring those same kinds of meaningful connections to the digital world.
Nelson’s primary contribution to hypertext is a number of influential theories and a decades-long project still in progress known as Xanadu. Much like the web, Xanadau uses the power of a network to create a global system of links and pages. However, Xanadu puts a far greater emphasis on the ability to trace text to its original author for monetization and attribution purposes. This distinction, known as transculsion, has been a near impossible technological problem to solve.
Nelson’s interest in hypertext stems from the same issue with memory and recall as Berners-Lee. He refers to it is as his hummingbird mind. Nelson finds it hard to hold on to associations he creates in the real world. Hypertext offers a way for him to map associations digitally, so that he can call on them later. Berners-Lee and Nelson met for the first time a couple of years after the web was invented. They exchanged ideas and philosophies, and Berners-Lee was able to thank Nelson for his influential thinking. At the end of the meeting, Berners-Lee asked if he could take a picture. Nelson, in turn, asked for a short video recording. Each was commemorating the moment they knew they would eventually forget. And each turned to technology for a solution.
By the mid-80s, on the wave of innovation in personal computing, there were several hypertext applications out in the wild. The hypertext community — a dedicated group of software engineers that believed in the promise of hypertext – created programs for researchers, academics, and even off-the-shelf personal computers. Every research lab worth their weight in salt had a hypertext project. Together they built entirely new paradigms into their software, processes and concepts that feel wonderfully familiar today but were completely outside the realm of possibilities just a few years earlier.
At Brown University, the very place where Ted Nelson was studying when he coined the term hypertext, Norman Meyrowitz, Nancy Garrett, and Karen Catlin were the first to breathe life into the hyperlink, which was introduced in their program Intermedia. At Symbolics, Janet Walker was toying with the idea of saving links for later, a kind of speed dial for the digital world – something she was calling a bookmark. At the University of Maryland, Ben Schneiderman sought to compile and link the world’s largest source of information with his Interactive Encyclopedia System.
Dame Wendy Hall, at the University of Southhampton, sought to extend the life of the link further in her own program, Microcosm. Each link made by the user was stored in a linkbase, a database apart from the main text specifically designed to store metadata about connections. In Microcosm, links could never die, never rot away. If their connection was severed they could point elsewhere since links weren’t directly tied to text. You could even write a bit of text alongside links, expanding a bit on why the link was important, or add to a document separate layers of links, one, for instance, a tailored set of carefully curated references for experts on a given topic, the other a more laid back set of links for the casual audience.
There were mailing lists and conferences and an entire community that was small, friendly, fiercely competitive and locked in an arms race to find the next big thing. It was impossible not to get swept up in the fervor. Hypertext enabled a new way to store actual, tangible knowledge; with every innovation the digital world became more intricate and expansive and all-encompassing.
Then came the heavy hitters. Under a shroud of mystery, researchers and programmers at the legendary Xerox PARC were building NoteCards. Apple caught wind of the idea and found it so compelling that they shipped their own hypertext application called Hypercard, bundled right into the Mac operating system. If you were a late Apple II user, you likely have fond memories of Hypercard, an interface that allowed you to create a card, and quickly link it to another. Cards could be anything, a recipe maybe, or the prototype of a latest project. And, one by one, you could link those cards up, visually and with no friction, until you had a digital reflection of your ideas.
Towards the end of the 80s, it was clear that hypertext had a bright future. In just a few short years, the software had advanced in leaps and bounds.
After a brief stint studying physics at The Queen’s College, Oxford, Tim Berners-Lee returned to his first love: computers. He eventually found a short-term, six-month contract at the particle physics lab Conseil Européen pour la Recherche Nucléaire (European Council for Nuclear Research), or simply, CERN.
CERN is responsible for a long line of particle physics breakthroughs. Most recently, they built the Large Hadron Collider, which led to the confirmation of the Higgs Boson particle, a.k.a. the “God particle.”
CERN doesn’t operate like most research labs. Its internal staff makes up only a small percentage of the people that use the lab. Any research team from around the world can come and use the CERN facilities, provided that they are able to prove their research fits within the stated goals of the institution. A majority of CERN occupants are from these research teams. CERN is a dynamic, sprawling campus of researchers, ferrying from location to location on bicycles or mine-carts, working on the secrets of the universe. Each team is expected to bring their own equipment and expertise. That includes computers.
Berners-Lee was hired to assist with software on an earlier version of the particle accelerator called the Proton Synchrotron. When he arrived, he was blown away by the amount of pure, unfiltered information that flowed through CERN. It was nearly impossible to keep track of it all and equally impossible to find what you were looking for. Berners-Lee wanted to capture that information and organize it.
His mind flashed back to that conversation with his father all those years ago. What if it were possible to create a computer program that allowed you to make random associations between bits of information? What if you could, in other words, link one thing to another? He began working on a software project on the side for himself. Years later, that would be the same way he built the web. He called this project ENQUIRE, named for a Victorian handbook he had read as a child.
Using a simple prompt, ENQUIRE users could create a block of info, something like Otlet’s index cards all those years ago. And just like the Universal Bibliography, ENQUIRE allowed you to link one block to another. Tools were bundled in to make it easier to zoom back and see the connections between the links. For Berners-Lee this filled a simple need: it replaced the part of his memory that made it impossible for him to remember names and faces with a digital tool.
Compared to the software being actively developed at the University of Southampton or at Xerox or Apple, ENQUIRE was unsophisticated. It lacked a visual interface, and its format was rudimentary. A program like Hypercard supported rich-media and advanced two-way connections. But ENQUIRE was only Berners-Lee’s first experiment with hypertext. He would drop the project when his contract was up at CERN.
Berners-Lee would go and work for himself for several years before returning to CERN. By the time he came back, there would be something much more interesting for him to experiment with. Just around the corner was the Internet.
Packet switching is the single most important invention in the history of the Internet. It is how messages are transmitted over a globally decentralized network. It was discovered almost simultaneously in the late-60s by two different computer scientists, Donald Davies and Paul Baran. Both were interested in the way in which it made networks resilient.
Traditional telecommunications at the time were managed by what is known as circuit switching. With circuit switching, a direct connection is open between the sender and receiver, and the message is sent in its entirety between the two. That connection needs to be persistent and each channel can only carry a single message at a time. That line stays open for the duration of a message and everything is run through a centralized switch.
If you’re searching for an example of circuit switching, you don’t have to look far. That’s how telephones work (or used to, at least). If you’ve ever seen an old film (or even a TV show like Mad Men) where an operator pulls a plug out of a wall and plugs it back in to connect a telephone call, that’s circuit switching (though that was all eventually automated). Circuit switching works because everything is sent over the wire all at once and through a centralized switch. That’s what the operators are connecting.
Packet switching works differently. Messages are divided into smaller bits, or packets, and sent over the wire a little at a time. They can be sent in any order because each packet has just enough information to know where in the order it belongs. Packets are sent through until the message is complete, and then re-assembled on the other side. There are a few advantages to a packet-switched network. Multiple messages can be sent at the same time over the same connection, split up into little packets. And crucially, the network doesn’t need centralization. Each node in the network can pass around packets to any other node without a central routing system. This made it ideal in a situation that requires extreme adaptability, like in the fallout of an atomic war, Paul Baran’s original reason for devising the concept.
When Davies began shopping around his idea for packet switching to the telecommunications industry, he was shown the door. “I went along to Siemens once and talked to them, and they actually used the words, they accused me of technical — they were really saying that I was being impertinent by suggesting anything like packet switching. I can’t remember the exact words, but it amounted to that, that I was challenging the whole of their authority.” Traditional telephone companies were not at all interested in packet switching. But ARPA was.
ARPA, later known as DARPA, was a research agency embedded in the United States Department of Defense. It was created in the throes of the Cold War — a reaction to the launch of the Sputnik satellite by Russia — but without a core focus. (It was created at the same time as NASA, so launching things into space was already taken.) To adapt to their situation, ARPA recruited research teams from colleges around the country. They acted as a coordinator and mediator between several active university research projects with a military focus.
ARPA’s organization had one surprising and crucial side effect. It was comprised mostly of professors and graduate students who were working at its partner universities. The general attitude was that as long as you could prove some sort of modest relation to a military application, you could pitch your project for funding. As a result, ARPA was filled with lots of ambitious and free-thinking individuals working inside of a buttoned-up government agency, with little oversight, coming up with the craziest and most world-changing ideas they could. “We expected that a professional crew would show up eventually to take over the problems we were dealing with,” recalls Bob Kahn, an ARPA programmer critical to the invention of the Internet. The “professionals” never showed up.
One of those professors was Leonard Kleinrock at UCLA. He was involved in the first stages of ARPANET, the network that would eventually become the Internet. His job was to help implement the most controversial part of the project, the still theoretical concept known as packet switching, which enabled a decentralized and efficient design for the ARPANET network. It is likely that the Internet would not have taken shape without it. Once packet switching was implemented, everything came together quickly. By the early 1980s, it was simply called the Internet. By the end of the 1980s, the Internet went commercial and global, including a node at CERN.
Once packet switching was implemented, everything came together quickly. By the early 1980s, it was simply called the Internet.
The first applications of the Internet are still in use today. FTP, used for transferring files over the network, was one of the first things built. Email is another one. It had been around for a couple of decades on a closed system already. When the Internet began to spread, email became networked and infinitely more useful.
Other projects were aimed at making the Internet more accessible. They had names like Archie, Gopher, and WAIS, and have largely been forgotten. They were united by a common goal of bringing some order to the chaos of a decentralized system. WAIS and Archie did so by indexing the documents put on the Internet to make them searchable and findable by users. Gopher did so with a structured, hierarchical system.
Kleinrock was there when the first message was ever sent over the Internet. He was supervising that part of the project, and even then, he knew what a revolutionary moment it was. However, he is quick to note that not everybody shared that feeling in the beginning. He recalls the sentiment held by the titans of the telecommunications industry like the Bell Telephone Company. “They said, ‘Little boy, go away,’ so we went away.” Most felt that the project would go nowhere, nothing more than a technological fad.
In other words, no one was paying much attention to what was going on and no one saw the Internet as much of a threat. So when that group of professors and graduate students tried to convince their higher-ups to let the whole thing be free — to let anyone implement the protocols of the Internet without a need for licenses or license fees — they didn’t get much pushback. The Internet slipped into public use and only the true technocratic dreamers of the late 20th century could have predicted what would happen next.
Berners-Lee returned to CERN in a fellowship position in 1984. It was four years after he had left. A lot had changed. CERN had developed their own network, known as CERNET, but by 1989, they arrived and hooked up to the new, internationally standard Internet. “In 1989, I thought,” he recalls, “look, it would be so much easier if everybody asking me questions all the time could just read my database, and it would be so much nicer if I could find out what these guys are doing by just jumping into a similar database of information for them.” Put another way, he wanted to share his own homepage, and get a link to everyone else’s.
What he needed was a way for researchers to share these “databases” without having to think much about how it all works. His way in with management was operating systems. CERN’s research teams all bring their own equipment, including computers, and there’s no way to guarantee they’re all running the same OS. Interoperability between operating systems is a difficult problem by design — generally speaking — the goal of an OS is to lock you in. Among its many other uses, a globally networked hypertext system like the web was a wonderful way for researchers to share notes between computers using different operating systems.
However, Berners-Lee had a bit of trouble explaining his idea. He’s never exactly been concise. By 1989, when he wrote “Information Management, a Proposal,” Berners-Lee already had worldwide ambitions. The document is thousands of words, filled with diagrams and charts. It jumps energetically from one idea to the next without fully explaining what’s just been said. Much of what would eventually become the web was included in the document, but it was just too big of an idea. It was met with a lukewarm response — that “Vague, but exciting” comment scrawled across the top.
A year later, in May of 1990, at the encouragement of his boss Mike Sendall (the author of that comment), Beners-Lee circulated the proposal again. This time it was enough to buy him a bit of time internally to work on it. He got lucky. Sendall understood his ambition and aptitude. He wouldn’t always get that kind of chance. The web needed to be marketed internally as an invaluable tool. CERN needed to need it. Taking complex ideas and boiling them down to their most salient, marketable points, however, was not Berners-Lee’s strength. For that, he was going to need a partner. He found one in Robert Cailliau.
Cailliau was a CERN veteran. By 1989, he’d worked there as a programmer for over 15 years. He’d embedded himself in the company culture, proving a useful resource helping teams organize their informational toolset and knowledge-sharing systems. He had helped several teams at CERN do exactly the kind of thing Berners-Lee was proposing, though at a smaller scale.
Temperamentally, Cailliau was about as different from Berners-Lee as you could get. He was hyper-organized and fastidious. He knew how to sell things internally, and he had made plenty of political inroads at CERN. What he shared with Berners-Lee was an almost insatiable curiosity. During his time as a nurse in the Belgian military, he got fidgety. “When there was slack at work, rather than sit in the infirmary twiddling my thumbs, I went and got myself some time on the computer there.” He ended up as a programmer in the military, working on war games and computerized models. He couldn’t help but look for the next big thing.
In the late 80s, Cailliau had a strong interest in hypertext. He was taking a look at Apple’s Hypercard as a potential internal documentation system at CERN when he caught wind of Berners-Lee’s proposal. He immediately recognized its potential.
Working alongside Berners-Lee, Cailliau pieced together a new proposal. Something more concise, more understandable, and more marketable. While Berners-Lee began putting together the technologies that would ultimately become the web, Cailliau began trying to sell the idea to interested parties inside of CERN.
The web, in all of its modern uses and ubiquity can be difficult to define as just one thing — we have the web on our refrigerators now. In the beginning, however, the web was made up of only a few essential features.
There was the web server, a computer wired to the Internet that can transmit documents and media (webpages) to other computers. Webpages are served via HTTP, a protocol designed by Berners-Lee in the earliest iterations of the web. HTTP is a layer on top of the Internet, and was designed to make things as simple, and resilient, as possible. HTTP is so simple that it forgets a request as soon as it has made it. It has no memory of the webpages its served in the past. The only thing HTTP is concerned with is the request it’s currently making. That makes it magnificently easy to use.
These webpages are sent to browsers, the software that you’re using to read this article. Browsers can read documents handed to them by server because they understand HTML, another early invention of Tim Berners-Lee. HTML is a markup language, it allows programmers to give meaning to their documents so that they can be understood. The “H” in HTML stands for Hypertext. Like HTTP, HTML — all of the building blocks programmers can use to structure a document — wasn’t all that complex, especially when compared to other hypertext applications at the time. HTML comes from a long line of other, similar markup languages, but Berners-Lee expanded it to include the link, in the form of an anchor tag. The tag is the most important piece of HTML because it serves the web’s greatest function: to link together information.
The hyperlink was made possible by the Universal Resource Identifier (URI) later renamed to the Uniform Resource Indicator after the IETF found the word “universal” a bit too substantial. But for Berners-Lee, that was exactly the point. “Its universality is essential: the fact that a hypertext link can point to anything, be it personal, local or global, be it draft or highly polished,” he wrote in his personal history of the web. Of all the original technologies that made up the web, Berners-Lee — and several others — have noted that the URL was the most important.
By Christmas of 1990, Tim Berners-Lee had all of that built. A full prototype of the web was ready to go.
Cailliau, meanwhile, had had a bit of success trying to sell the idea to his bosses. He had hoped that his revised proposal would give him a team and some time. Instead he got six months and a single staff member, intern Nicola Pellow. Pellow was new to CERN, on placement for her mathematics degree. But her work on the Line Mode Browser, which enabled people from around the world using any operating system to browse the web, proved a crucial element in the web’s early success. Berners-Lee’s work, combined with the Line Mode Browser, became the web’s first set of tools. It was ready to show to the world.
When the team at CERN submitted a paper on the World Wide Web to the San Antonio Hypertext Conference in 1991, it was soundly rejected. They went anyway, and set up a table with a computer to demo it to conference attendees. One attendee remarked:
They have chutzpah calling that the World Wide Web!
The highlight of the web is that it was not at all sophisticated. Its use of hypertext was elementary, allowing for only simplistic text based links. And without two-way links, pretty much a given in hypertext applications, links could go dead at any minute. There was no linkbase, or sophisticated metadata assigned to links. There was just the anchor tag. The protocols that ran on top of the Internet were similarly basic. HTTP only allowed for a handful of actions, and alternatives like Gopher or WAIS offered far more options for advanced connections through the Internet network.
It was hard to explain, difficult to demo, and had overly lofty ambition. It was created by a man who didn’t have much interest in marketing his ideas. Even the name was somewhat absurd. “WWW” is one of only a handful of acronyms that actually takes longer to say than the full “World Wide Web.”
We know how this story ends. The web won. It’s used by billions of people and runs through everything we do. It is among the most remarkable technological achievements of the 20th century.
It had a few advantages, of course. It was instantly global and widely accessible thanks to the Internet. And the URL — and its uniqueness — is one of the more clever concepts to come from networked computing.
But if you want to truly understand why the web succeeded we have to come back to information. One of Berners-Lee’s deepest held beliefs is that information is incredibly powerful, and that it deserves to be free. He believed that the Web could deliver on that promise. For it to do that, the web would need to spread.
Berners-Lee looked to his successors for inspiration: the Internet. The Internet succeeded, in part, because they gave it away to everyone. After considering several licensing options, he lobbied CERN to release the web unlicensed to the general public. CERN, an organization far more interested in particle physics breakthroughs than hypertext, agreed. In 1993, the web officially entered the public domain.
And that was the turning point. They didn’t know it then, but that was the moment the web succeeded. When Berners-Lee was able to make globally available information truly free.
I had the idea for it. I defined how it would work. But it was actually created by people.
That may sound like humility from one of the world’s great thinkers — and it is that a little — but it is also the truth. The web was Berners-Lee’s gift to the world. He gave it to us, and we made it what it was. He and his team fought hard at CERN to make that happen.
Berners-Lee knew that with the resources available to him he would never be able to spread the web sufficiently outside of the hallways of CERN. Instead, he packaged up all the code that was needed to build a browser into a library called libwww and posted it to a Usenet group. That was enough for some people to get interested in browsers. But before browsers would be useful, you needed something to browse.
Browser DevTools are indispensable for us front end developers. In this article, we’ll take a look at the Computed tab, a small corner of the DevTools panel that shows us big things, like how relative CSS values are resolved. We’ll also see how inheritance fits into the browser’s style computation process.
The “Computed” tab is generally located in the right panel of the DevTools interface, like it is shown here in Chrome.
The content in the Computed tab is important because it shows us the values that the browser is actually using on the rendered website. If an element isn’t styled how you think it should be, looking at its computed values can help you understand why.
If you’re more accustomed to using the Styles tab (called Rules in Firefox), you may wonder how it differs from the Computed tab. I mean, they both show styles that apply to an element. The answer? The Computed tab displays an alphabetized list of resolved styles that include what is declared in your stylesheet, those derived from inheritance, and the browser’s defaults.
The “Computed” tab takes a selected element (1) and displays a list of CSS properties (2) that have been rendered, allowing each one to be expanded (3) to reveal the cascade of inherited values alongside the actual computed value (4) that is currently in use.
The Styles tab, on the other hand, displays the exact rulesets of a selected element exactly as they were written. So while the Styles tab might show you something like .subhead {font-size: 75%}, the Computed tab will show you the actual font size, or what 70% currently resolves to. For example, the actual font size for the rendered text as shown above is 13.2px.
The “Styles” tab takes a selected element (1) and displays the ruleset (2) that is explicitly declared in the stylesheet, followed by other related rulesets that are included in the cascade (3), including those from other stylesheets (4). Notice how overridden values are crossed out, indicating that another property takes precedence.
Next, let’s briefly review the concepts of inheritance and the cascade, two things that are a huge part of how the computed values in the Computed tab are arrived at.
Crash course on inheritance and the cascade
CSS stands for Cascading Style Sheets, and that first word cascading is incredibly important to understand – the way that the cascade behaves is key to understanding CSS.
The cascade is notable because it’s the “C” in CSS. It’s the mechanism used for resolving conflicts that exist between the different sources of style declarations for a document.
For example, imagine a stylesheet that defines the width of a div twice:
div {
width: 65vw;
}
/* Somewhere, further down */
div {
width: 85vw;
}
In this specific example, the second width wins out since it is declared last. The first width could still win with !important but that’s technically breaking the cascade by brute force. The point here is that the cascade algorithm determines what styles apply to each element and prioritizes them in a predetermined order to settle on a value.
The cascade is applied for properties that are set explicitly, whether by the browser, the web developer, or the user. Inheritance comes into the picture when the output of the cascade is empty. When this happens, the computed value of a property on an element’s parent is pulled in as its own value for that property. For example, if you specify a color for an element, all child elements will inherit that color if you don’t specify theirs.
CodePen Embed Fallback
There are four key property values related to inheritance that we should get acquainted with before we plow ahead. We’ll be using these throughout the article.
initial
In an HTML document where the highest level of the DOM tree is the element, when we use the initial keyword on an element like this…
CodePen Embed Fallback
…the text color for that element is black, even though the body element is set to green. There’s the matter of the div selector having a higher specificity, however we’re interested in why initial translated to black.
In plain terms, this keyword sets the default value of a property as specified in its definition table (in the CSS specs). In this case, black happens to be the browser’s implementation of the initial color value.
I mention near the end of the article that you can learn whether or not a property is inherited by default by checking out its page on MDN. Well, you can also find the initial value for any property this way.
inherit
For non-inherited properties, this keyword forces inheritance. In the following example, the element has a solid red border. The border property isn’t inherited by default, but we can tell our div to inherit the same red border declared on the element by using the inherit keyword on its border property:
CodePen Embed Fallback
unset
unset will resolve to an inherited value if a property is inherited. Otherwise, the initial value is used. This basically means unset resets a property based on whether it is inherited or not. Here’s a demo that toggles unset to show its effect on elements with different levels of specificity.
CodePen Embed Fallback
revert
If no CSS properties are set on an element, then does it get any styles at all? You bet. It uses the browser’s default styles.
For example, the initial value for the display property for span elements is inline, but we can specify it as block in our stylesheet. Use the button in the following demo to toggle revert on both the span element’s display and color properties:
CodePen Embed Fallback
The span properly reverts to an inline element, but wait! Did you notice that the color of the span goes to a green color instead of the browser’s default black value? That’s because revertallows for inheritance. It will go as far back as the browser’s default to set the color, but since we’ve explicitly set a green color on the element, that’s what is inherited.
Finding computed values in DevTools
This is where we start talking about the computed values in DevTools. Just as with the default values of properties, the computed value of a CSS property is determined by that property’s definition table in the CSS specifications. Here’s what that looks like for the height property.
Say we use relative lengths in our CSS, like one of 10em or 70% or 5vw. Since these are “relative” to something – font-size or the viewport – they’ll need to get resolved to a pixel-absolute value. For example, an element with a 10% width may compute to 100px if the viewport is 1000px wide, but some other number altogether when the viewport width changes.
A button (1) is the current selected element in DevTools (2). The declared width of the button is 100% (3), which computes to 392px (4) when the viewport is in this condition.
These values are calculated whenever the DOM is modified in a process called computed styles calculation. This is what lets the browser know what styles to apply to each page element.
Style calculations happen in multiple steps involving several values. These are documented in the CSS Cascading and Inheritance Level 4 specification and they all impact the final value we see in the Computed tab. Let’s take a look at those next.
Values and how they’re processed
The values defined for the style calculation process include the declared value, the specified value, the cascaded value, the computed value, the used value, and the actual value. Who knew there were so many, right?
Declared values
A declared value is any property declaration applies to an element. A browser identifies these declarations based on a few criteria, including:
the declaration is in a stylesheet that applies to the current document
there was a matching selector in a style declaration
the style declaration contains valid syntax (i.e, valid property name and value)
Take the following HTML:
<main>
<p>It's not denial. I'm just selective about the reality I accept.</p>
</main>
Here are declared values that apply to the font-size of the text:
main {
font-size: 1.2em; /* this would apply if the paragraph element wasn't targeted specifically, and even then, as an inherited value, not "declared value" */
}
main > p {
font-size: 1.5em; /* declared value */
}
Cascaded values
The list of all declared values that apply to an element are prioritized based things like these to return a single value:
origin of the declaration (is it from the browser, developer, or another source?)
whether or not the declaration is marked ‘!important’
how specific a rule is (e.g, span {} vs section span {})
order of appearance (e.g, if multiple declarations apply, the last one will be used)
In other words, the cascaded value is the “winning” declaration. And if the cascade does not result in a winning declared value, well, then there is no cascaded value.
main > p {
font-size: 1.2em;
}
main > .product-description { /* the same paragraph targeted in the previous rule */
font-size: 1.2em; /* cascaded value based on both specificity and document order, ignoring all other considerations such as origin */
}
Specified values
As mentioned earlier, it is possible for the output of the cascade to be empty. However, a value still needs to be found by other means.
Now, let’s say we didn’t declare a value for a specific property on an element, but did for the parent. That’s something we often do intentionally because there’s no need to set the same value in multiple places. In this case, the inherited value for the parent is used. This is called the specified value.
In many cases, the cascaded value is also the specified value. However, it can also be an inherited value if there is no cascaded value and the property concerned is inherited, whether by default or using the inherit keyword. If the property is not inherited, then the specified value is the property’s initial value, which, as mentioned earlier, can also be set explicitly using the initial keyword.
In summary, the specified value is the value we intend to use on an element, with or without explicitly declaring it on that element. This is a little murky because the browser’s default can also become the specified value if nothing is declared in the stylesheet.
/* Browser default = 16px */
main > p {
/* no declared value for font-size for the paragraph element and all its ancestors */
}
Computed values
Earlier, we discussed, briefly, how relative values needed to be resolved to their pixel-absolute equivalent. This process, as already noted, is pre-determined. For example, property definition tables have a “Computed value” field that detail how specified values, in general, are resolved.
The specifications section of the MDN docs for the color property.
In the following example, we’re working with the em, a relative unit. Here, the final value used when rendering the element to which the property applies is not a fixed number as seen in our declared value, but something that needs to be calculated based on a few factors.
main {
font-size: 1.2em;
}
main > p {
font-size: 1.5em; /* declared value */
}
The font-size of the paragraph element is set to 1.5em, which is relative to the font-size value of the main element, 1.2em. If main is a direct child of the body element – and no additional font-size declarations are made above that, such as by using the :root selector – we can assume that the calculation for the paragraph’s font-size will follow this approximate course:
Open up DevTools and check out the computed font sizes in the Computed tab.
The declared font-size for the main element is 1.2em, which computes to 19.2px.The declared font-size for the paragraph element is 1.5em, which computes to 28.8px.
Let’s say we’re using rem units instead:
html {
font-size: 1.2em;
}
main {
font-size: 1.5rem;
}
div {
font-size: 1.7rem;
}
The computed value of a rem unit is based on the font-size of the root HTML element, so that means that the calculation changes a little bit. In this specific case, we’re using a relative unit on the HTML element as well, so the browser’s default font-size value is used to calculate the base font-size we’ll use to resolve all our rem values.
The value, 16px, for Browser_Default_FontSize is commonly used by browsers, but this is subject to variation. To see your current default, select the element in DevTools and check out the font-size that is shown for it. Note that if a value was set for the root element explicitly, just as in our example, you may have to toggle it off in the Rules tab. Next, toggle on the “Show all” or “Browser styles” (Firefox) checkbox in the Computed tab to see the default.
During inheritance, computed values are passed down to child elements from their parents. The computation process for this takes into account the four inheritance-controlling keywords we looked at earlier. In general, relative values become absolute (i.e. 1rem becomes 16px). This is also where relative URLs become absolute paths, and keywords such as bolder (value for the font-weight property) get resolved. You can see some more examples of this in action in the docs.
Used values
The used value is the final result after all calculations are done on the computed value. Here, all relative values are turned absolute. This used value is what will be applied (tentatively) in page layout. You might wonder why any further calculations have to happen. Wasn’t it all taken care of at the previous stage when specified values were processed to computed values?
Here’s the thing: some relative values will only be resolved to pixel-absolutes at this point. For example, a percentage-specified width might need page layout to get resolved. However, in many cases, the computed value winds up also being the used value.
…if a property does not apply to an element, it has no used value; so, for example, the flex property has no used value on elements that aren’t flex items.
Actual values
Sometimes, a browser is unable to apply the used value straightaway and needs to make adjustments. This adjusted value is called the actual value. Think of instances where a font size needs to be tweaked based on available fonts, or when the browser can only use integer values during rendering and need to approximate non-integer values.
Inheritance in browser style computations
To recap, inheritance controls what value is applied to an element for a property that isn’t set explicitly. For inherited properties, this value is taken from whatever is computed on the parent element, and for non-inherited properties, the initial value for that property is set (the used value when the keyword initial is specified).
We talked about the existence of a “computed value” earlier, but we really need to clarify something. We discussed computed values in the sense of one type of value that takes part in the style resolution process, but “computed value” is also a general term for values computed by the browser for page styling. You’ll typically understand which kind we mean by the surrounding context.
Only computed values are accessible to an inherited property. A pixel-absolute value such as 477px, a number such as 3, or a value such as left (e.g. text-align: left) is ready for the inheritance process. A percentage value like 85% is not. When we specify relative values for properties, a final (i.e. “used”) value has to be calculated. Percentage values or other relative values will be multiplied by a reference size (font-size, for instance) or value (e.g. the width of your device viewport). So, the final value for a property can be just what was declared or it might need further processing to be used.
You may or may not have already noticed, but the values shown in the Computed tab of the browser will not necessarily be the computed values we discussed earlier (as in computed vs. specified or used values). Rather, the values shown are the same as returned by the getComputedStyle() function. This function returns a value which, depending on the property, will either be the computed value or the used value.
Now, let’s see some examples.
Color inheritance
main {
color: blue;
}
/* The color will inherit anyway, but we can be explicit too: */
main > p {
color: inherit;
}
The value computed for the color property on the main element will be blue. As color is inherited by default, we really didn’t need color: inherit for the paragraph child element because it would wind up being blue anyway. But it helps illustrate the point.
Color values undergo their own resolution process to become used values.
Font size inheritance
main {
font-size: 1.2em;
}
main > p {
/* No styles specified */
}
As we saw earlier in the section on values and how they are processed, our relative value for font-size will compute to an absolute value and then be inherited by the paragraph element, even if we don’t explicitly declare it (again, font-size is inherited by default). If we had previously set styles via a global paragraph element selector, then the paragraph may gain some extra styles by virtue of the cascade. Any property values that may be inherited will be, and some properties for which the cascade and inheritance didn’t produce a value will be set to their initial value.
Percentage-specified font size inheritance
body {
font-size: 18px;
}
main {
font-size: 80%;
}
main > p {
/* No styles specified */
}
Similar to the previous example, the element’s font-size will be absolutized in preparation for inheritance and the paragraph will inherit a font-size that is 80% of the body’s 18px value, or 14.4px.
CodePen Embed Fallback
Forced inheritance and post-layout computation
Computed values generally resolve the specified value as much as possible without layout, but as mentioned earlier, some values can only be resolved post-layout, such as percentage-specified width values. Although width isn’t an inherited property, we can force inheritance for the purpose of illustrating pre-layout and post-layout style resolution.
CodePen Embed Fallback
This is a contrived example but what we’re doing is taking an element out of the page layout by setting its display property to none. We have two divs in our markup that inherit a width, 50%, from their parent element
. In the Computed tab in DevTools, the computed width for the first div is absolute, having been resolved to a pixel value (243.75px for me). On the other hand, the width of the second div that was taken out of the layout using display: none is still 50%.
We’ll imagine that the specified and computed value for the parent
element is 50% (pre-layout) and the used value is as shown under the Computed tab – that’s 487.5px for me, post-layout. This value is halved for inheritance by the child divs (50% of the containing block).
These values have to be computed whenever the width of the browser’s viewport changes. So, percentage-specified values become percentage-computed values, which become pixel-used values.
Properties that inherit by default
How do you know if a property inherits by default or not? For each CSS property in the MDN docs, there is a specifications section that provides some extra details that include whether or not the property is inherited. Here’s what that looks like for the color property:
The specifications section of the MDN docs for the color property.
Which properties are inherited by default and which aren’t is largely down to common sense.
Hopefully this gives you a solid idea of how browsers compute styles and how to reference them in DevTools. As you can see, there’s a lot that goes into a value behind the scenes. Having that context goes a long way in helping you troubleshoot your work as well as furthering your general understanding of the wonderful language we know as CSS.
So basically, if you haven’t heard already, one of Spotify’s biggest original podcast bets, The Michelle Obama Podcast, premiered on July 29th, 2020.
And who, you might ask yourself, had the amazing opportunity and honor to design for Mrs. Obama’s Podcast?
Well, it was none other than the Brooklyn-based creative production studio, And/Or.
According to an interview with And/Or, they stated that there were some difficulties in designing the branding and visuals for this podcast.
The reason being that they couldn’t listen to any of the episodes before the release, so they had to blindly design all of the visuals, and try to match the vibe they were looking for, just right.
And thankfully, they were able to capture Michelle’s personality and professionalism, while also having a bit of fun with the design process to bring some life and color to the visuals.
As And/Or said in their interview with It’s Nice That, “We started with concepts that drew Michelle’s life and history—illustrating important moments from her life over time in a more stoic tone because we didn’t have access to the podcast episodes yet. We developed those directions using context from the First Lady’s book, Becoming.”
The stoic tone that was presented to us in Michelle’s book, Becoming, was replaced with a more colorful, youthful, and fun look to it.
Because this podcast’s aim is to be light-hearted yet helpful and educational, Spotify was open to bright and happy designs, which And/Or was happy to create.
And what’s another one of the many amazing parts of this podcast, you might ask?
Well, let me tell you.
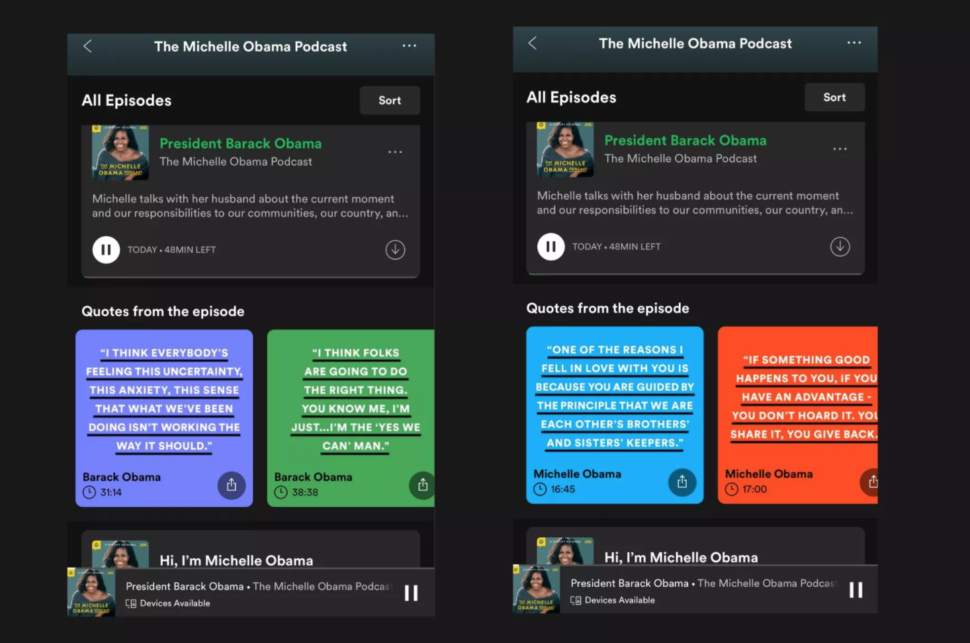
It comes with a new product feature: shareable quote cards.
When you begin to listen to the podcast, which is exclusively available to Spotify users(thank goodness, because that’s the only music streaming platform I use), you’ll be immediately presented with colorful cards with quotes on them that you will be able to share with others.
Of course, you’ll be able to share these quotes on any social media platform that you want, and not only will you be sharing powerful knowledge to all your followers and friends, but you’ll also be sharing beautifully designed quotes shared from Mrs. Obama herself.
“The headline here is Michelle Obama, and our mission was to help that come through, so we were conscious that the graphic should be a support, something that would immediately get to the point and get people excited, and not be too complicated, distracting or overwrought,” Creative director Kendra Eash from And/Or explained.
The overall goal was to amplify Obama’s personality in the podcast while [communicating] the intention of the podcast. Having an elegant typographic solution with a geometric typeface keeps the focus on those ideas. The colorful underline gives a “pop of color and energy to the animation.”
Artificial Intelligence is the use of computers or machines that have been created to work and react like humans. Some of the computers that have AI, are designed to include speech recognition, and learn user behaviours so they can predict activities or decisions before they happen.
AI creates a bridge to a new kind of interface, making work processes easier for businesses and customers alike.
Why is AI Important?
There are constant AI technological advances being made, so why not make the most of them and start integrating them into your toolset today? Read on to find out just why AI is important and how you can benefit from it in your work too.
Lower Costs
By integrating Artificial Intelligence into your toolset, you can stand to both save and earn more money. AI will leave you spending less time on various aspects of website management and development, freeing some of your time up and allowing you to finish websites faster. It will also leverage your set of skills and allow you to build greater sites that people will be willing to pay more money for.
Improve Customer Experience
Artificial Intelligence can be used to analyse data in much more depth than the human eye, so will greatly improve the customer experience. It will allow a more personalised and streamlined experience that users will be grateful for. By integrating AI into your toolset, you will soon learn about certain trends and patterns that AI picks up and utilise this with future sites you build, as well as being able to make suggestions to improve the customer journey on the site.
It’s The Future
With so many devices in our everyday lives tuning in to AI, it’s important websites are no different. Just look around many homes and you will likely see a device such as Amazon’s Alexa or Google Home. Phone’s have Siri or Bixby and many laptops have AI systems such as Cortana. As our technology continues to develop, websites need to do this too. Soon we will expect everything to be integrated and be able to control websites in a similar way to our AI devices with voice control and recognition.
How To Integrate AI Into Your Toolset
Chat Bots
One popular example of AI that is integrated into many different websites now, is the chat bot. A feature on a number of major sites, chat bots allow customers to ask and receive answers to questions without an employee having to take time out of their day to answer menial questions that they get asked all the time. The use of AI cuts out the middleman and recognises certain phrases and words to give the most relevant and comprehensive answer.
The first chatbots used to rely on simple, pre-programmed conversational pathways, but these had disappointing and often irrelevant results. More recently they use sophisticated natural language processing (NLP) systems which are a lot more complex and don’t follow just a scripted path, but allow for more meaningful conversations.
Sketch to Code
If you’ve just started in web design, or there are certain elements you are still learning about, AI can help with “sketch to code”. This clever piece of AI can transform a handwritten note, sketch or diagram into a valid HTML mark-up code that maintains itself. This can work from something as simple as a new design for a quote system, to something more complex.
Background Systems
AI can work in the background of a site in the run up to events and collect key aspects such as website analytics. Once this data is complete, the AI can take final instructions from you such as the content, theme and color preference and create a design from scratch that it thinks will perform the best due to the intelligence and knowledge it has been gathering in the background.
Voice Recognition
Back in 2012, the W3C Community introduced the Web Speech API specification with the aim of enabling speech recognition and synthesis in modern browsers. At present, Google Chrome is the only browser that has introduced this, however there is a HTML5 Speech Recognition API will allows JavaScript to have access to a browser’s audio stream and to convert it into text.
It’s important to get up to speed with voice recognition API’s as it’s predicted voice control will be huge in the future. If populating websites, think about how people speak and be sure to include some long-tail keywords that sound more natural. This will help those sites to rank when voice control is adopted more widely.
Adobe Sensei
Adobe Sensei is an AI and machine learning framework that is powering Adobe tools. It is a handy option to add to your toolkit to manage and work on your files.
If you are sourcing images for a website in Adobe Stock, there are over 100 million assets to sift through. Adobe Sensei uses AI and deep learning to understand what exact objects are within an image as well as deeper components such as the aesthetic quality, composition, color palette and even the emotional concept behind the images. This means it can quickly find the image most matched to your needs, saving you hours of time you would have spent sorting through to find the image you want.
Yossarian
Yossarian is a great tool that allows you to craft mood boards. With an aim to generate new ideas faster, it cites itself as “discovery with a twist.” Yossarian uses AI when creating mood boards to return “diverse and unexpected concepts” that share loose associations with what you have searched for, allowing you to be more creative. It will source different ideas and inspiration around what you are searching for, including many you might not have thought of associating with your initial search term.
Brandmark
If you create logos and design templates within your work, Brandmark logo maker is a great AI tool to add to your library. They cite themselves as the most advanced AI logo design tool on the market at the moment. Whether logo creation is something you currently offer, or something you are looking to do, this AI tool can make it easier.
Autodraw
Autodraw is another useful tool you can use for design jobs, where you draw a rough sketch and it will turn it into a neat graphic. This is a handy one to use in association with the concept of sketch to code above. It pairs the magic of machine learning with drawings to help you create professional looking graphics and visuals, quickly.
The main idea is simple: You write your main rule using CSS variables, and then use :nth-of-*() rules to set these variables to something different every N items. If you use enough variables, and choose your Ns for them to be prime numbers, you reach a good appearance of pseudo-randomness with relatively small Ns.
The update to the trick is that she doesn’t update the whole block of code for each of the selectors, it’s just one part of the clipping path that gets updated via a custom property.
Animation is one of the trickier things to get right with React. In this post, I’ll try to provide the introduction to react-spring I wish I had when I first started out, then dive into some interesting use cases. While react-spring isn’t the only animation library for React, it’s one of the more popular (and better) ones.
I’ll be using the newest version 9 which, as of this writing, is in release candidate status. If it’s not fully released by the time you read this, be sure to install it with react-spring@next. From on what I’ve seen and from what the lead maintainer has told me, the code is incredibly stable. The only issue I’ve seen is a slight bug when used with concurrent mode, which can be tracked in the GitHub repo.
react-spring redux
Before we get to some interesting application use cases, let’s take a whirlwind intro. We’ll cover springs, height animation, and then transitions. I’ll have a working demo at the end of this section, so don’t worry if things get a little confusing along the way.
springs
Let’s consider the canonical “Hello world” of animation: fading content in and out. Let’s stop for a moment and consider how we’d switch opacity on and off without any kind of animation. It’d look something like this:
export default function App() {
const [showing, setShowing] = useState(false);
return (
<div>
<div style={{ opacity: showing ? 1 : 0 }}>
This content will fade in and fade out
</div>
<button onClick={() => setShowing(val => !val)}>Toggle</button>
<hr />
</div>
);
}
Easy, but boring. How do we animate the changing opacity? Wouldn’t it be nice if we could declaratively set the opacity we want based on state, like we do above, except have those values animate smoothly? That’s what react-spring does. Think of react-spring as our middle-man that launders our changing style values, so it can produce the smooth transition between animating values we want. Like this:
We specify our initial style values with from, and we specify the current value in the to section, based on our current state. The return value, fadeStyles, contains the actual style values we apply to our content. There’s just one last thing we need…
You might think you could just do this:
<div style={fadeStyles}>
…and be done. But instead of using a regular div, we need to use a react-spring div that’s created from the animated export. That may sound confusing, but all it really means is this:
<animated.div style={fadeStyles}>
And that’s it.
animating height
Depending on what we’re animating, we may want the content to slide up and down, from a zero height to its full size, so the surrounding contents adjust and flow smoothly into place. You might wish that we could just copy the above, with height going from zero to auto, but alas, you can’t animate to auto height. That neither works with vanilla CSS, nor with react-spring. Instead, we need to know the actual height of our contents, and specify that in the to section of our spring.
We need to have the height of any arbitrary content on the fly so we can pass that value to react-spring. It turns out the web platform has something specifically designed for that: a ResizeObserver. And the support is actually pretty good! Since we’re using React, we’ll of course wrap that usage in a hook. Here’s what mine looks like:
export function useHeight({ on = true /* no value means on */ } = {} as any) {
const ref = useRef<any>();
const [height, set] = useState(0);
const heightRef = useRef(height);
const [ro] = useState(
() =>
new ResizeObserver(packet => {
if (ref.current && heightRef.current !== ref.current.offsetHeight) {
heightRef.current = ref.current.offsetHeight;
set(ref.current.offsetHeight);
}
})
);
useLayoutEffect(() => {
if (on && ref.current) {
set(ref.current.offsetHeight);
ro.observe(ref.current, {});
}
return () => ro.disconnect();
}, [on, ref.current]);
return [ref, height as any];
}
We can optionally provide an on value that switches measuring on and off (which will come in handy later). When on is true, we tell our ResizeObserver to observe out content. We return a ref that needs to be applied to whatever content we want measured, as well as the current height.
useHeight gives us a ref and a height value of the content we’re measuring, which we pass along to our spring. Then we apply the ref and apply the height styles.
<animated.div style={{ ...slideInStyles, overflow: "hidden" }}>
<div ref={heightRef}>
This content will fade in and fade out with sliding
</div>
</animated.div>
Oh, and don’t forget to add overflow: hidden to the container. That allows us to properly container our adjusting height values.
animating transitions
Lastly, let’s look at adding and removing animating items to and from the DOM. We already know how to animate changing values of an item that exists and is staying in the DOM, but to animate the adding, or removing of items, we need a new hook: useTransition.
If you’ve used react-spring before, this is one of the few places where version 9 has some big changes to its API. Let’s take a look.
As I alluded earlier, the return value, listTransitions, is a function. react-spring is tracking the list array, keeping tabs on the items which are added and removed. We call the listTransitions function, provide a callback accepting a single styles object and a single item, and react-spring will call it for each item in the list with the right styles, based on whether it’s newly added, newly removed, or just sitting in the list.
Note the keys section: This allows us to tell react-spring how to identify objects in the list. In this case, I decided to tell react-spring that an item’s index in the array uniquely defines that item. Normally this would be a terrible idea, but for now, it lets us see the feature in action. In the demo below, the “Add item” button adds an item to the end of the list when clicked, and the “Remove last item” button removes the most recently added item from the list. So, if you type in the input box then quickly hit the add button then the remove button, you’ll see the same item smoothly begin to enter, and then immediately, from whatever stage in the animation it’s at, begin to leave. Conversely, if you add an item, then quickly hit the remove button and the add button, the same item will begin to slide off, then abruptly stop in place, and slide right back to where it was.
Here’s that demo
Whew, that was a ton of words! Here’s a working demo, showing everything we just covered in action.
Did you notice how, when you slide down the content in the demo, it sort of bounces into place, like… a spring? That’s where the name comes from: react-spring interpolates our changing values using spring physics. It doesn’t simply chop the value changing into N equal deltas that it applies over N equal delays. Instead, it uses a more sophisticated algorithm that produces that spring-like effect, which will appear more natural.
The spring algorithm is fully configurable, and it comes with a number of presets you can take off the shelf — the demo above uses the stiff preset. See the docs for more info.
Note also how I’m animating values inside of translate3d values. As you can see, the syntax isn’t the most terse, and so react-spring provides some shortcuts. There’s documentaiton on this, but for the remainder of this post I’ll continue to use the full, non-shortcut syntax for the sake of keeping things as clear as possible.
I’ll close this section by calling attention to the fact that, when you slide the content up in the demo above, you’ll likely see the content underneath it get a little jumpy at the very end. This is a result of that same bouncing effect. It looks sharp when the content bounces down and into position, but less so when we’re sliding the content up. Stay tuned to see how we can switch it off. (Spoiler, it’s the clamp property).
A few things to consider with these sandboxes
Code Sandbox uses hot reloading. As you change the code, changes are usually reflected immediately. This is cool, but can wreck havoc on animations. If you start tinkering, and then see weird, ostensibly incorrect behavior, try refreshing the sandbox.
The other sandboxes in this post will make use of a modal. For reasons I haven’t quite been able to figure out, when the modal is open, you won’t be able to modify any code — the modal refuses to give up focus. So, be sure to close the modal before attempting any changes.
Now let’s build something real
Those are the basic building blocks of react-spring. Let’s use them to build something more interesting. You might think, given everything above, that react-spring is pretty simple to use. Unfortunately, in practice, it can be tricky to figure out some subtle things you need to get right. The rest of this post will dive into many of these details.
Prior blog posts I’ve written have been in some way related to my booklist side project. This one will be no different — it’s not an obsession, it’s just that that project happens to have a publicly-available GraphQL endpoint, and plenty of existing code that be can leveraged, making it an obvious target.
Let’s build a UI that allows you to open a modal and search for books. When the results come in, you can add them to a running list of selected books that display beneath the modal. When you’re done, you can close the modal and click a button to find books similar to the selection.
We’ll start with a functioning UI then animate the pieces step by step, including interactive demos along the way.
If you’re really eager to see what the final result will look like, or you’re already familiar with react-spring and want to see if I’m covering anything you don’t already know, here it is (it won’t win any design awards, I’m well aware). The rest of this post will cover the journey getting to that end state, step by step.
Animating our modal
Let’s start with our modal. Before we start adding any kind of data, let’s get our modal animating nicely. Here’s what a basic, un-animated modal looks like. I’m using Ryan Florence’s Reach UI (specifically the modal component), but the idea will be the same no matter what you use to build your modal. We’d like to get our backdrop to fade in, and also transition our modal content.
Since a modal is conditionally rendered based on some sort of “open” property, we’ll use the useTransition hook. I was already wrapping the Reach UI modal with my own modal component, and rendering either nothing, or the actual modal based on the isOpen property. We just need to go through the transition hook to get it animating.
There’s not too many surprises here. We want to fade things in and provide a slight vertical transition based on whether the modal is active or not. The odd piece is this:
I want to only use spring physics if the modal is opening. The reason for this — at least in my experience — is when you close the modal, the backdrop takes too long to completely vanish, which leaves the underlying UI un-interactive for too long. So, when the modal opens, it’ll nicely bounce into place with spring physics, and when closed, it’ll quickly vanish in 150ms.
And, of course, we’ll render our content via the transition function our hook returns. Notice that I’m plucking the opacity style off of the styles object to apply to the backdrop, and then applying all the animating styles to the actual modal content.
Let’s start with the use case I described above. If you’re following along with the demos, here’s a full demo of everything working, but with zero animation. Open the modal, and search for anything (feel free to just hit Enter in the empty textbox). You should hit my GraphQL endpoint, and get back search results from my own personal library.
The rest of this post will focus on adding animations to the UI, which will give us a chance to see a before and after, and (hopefully) observe how much nicer some subtle, well-placed animations can make a UI.
Animating the modal size
Let’s start with the modal itself. Open it and search for, say, “jefferson.” Notice how the modal abruptly becomes larger to accommodate the new content. Can we have the modal animate to larger (and smaller) sizes? Of course. Let’s dig out our trusty useHeight hook, and see what we can do.
Unfortunately, we can’t simply slap the height ref on a wrapper in our content, and then stick the height in a spring. If we did this, we’d see the modal slide into its initial size. We don’t want that; we want our fully formed modal to appear in the right size, and re-size fromthere.
What we want to do is wait for our modal content to be rendered in the DOM, then set our height ref, and switch on our useHeight hook, to start measuring. Oh, and we want our initial height to be set immediately, and not animate into place. It sounds like a lot, but it’s not as bad as it sounds.
We have some state for whether we’re measuring our modal’s height. This will be set to true when the modal is in the DOM. Then we call our useHeight hook with the on property, for whether we’re active. Lastly, some state to hold whether our UI is ready, and we can begin animating.
First things fist: how do we even know when our modal is actually rendered in the DOM? It turns out we can use a ref that lets us know. We’re used to doing <div ref={someRef} in React, but you can actually pass a function, which React will call with the DOM node after it’s rendered. Let’s define that function now.
That sets our height ref and switches on our useHeight hook. We’re almost done!
Now how do we get that initial animation to not be immediate? The useSpring hook has two new properties we’ll look at now. It has an immediate property which tells it to make states changes immediate instead of animating them. It also has an onRest callback which fires when a state change finishes.
Let’s leverage both of them. Here’s what the final hook looks like:
Once any height change is completed, we set the uiReady ref to true. So long as it’s false, we tell react-spring to make immediate changes. So, when our modal first mounts, contentHeight is zero (useHeight will return zero if there’s nothing to measure) and the spring is just chilling, doing nothing. When the modal switches to open and actual content is rendered, our activateRef ref is called, our useHeight will switch on, we’ll get an actual height value for our contents, our spring will set it “immediately,” and, finally, the onRest callback will trigger, and future changes will be animated. Phew!
I should point out that if, in some alternate use case we did immediately have a correct height upon the first render, we’d be able to simplify the above hook to just this:
Our hook would render initially with the correct height, and any changes to that value would be animated. But since our modal renders before it’s actually shown, we can’t avail ourselves to this simplification.
Keen readers might wonder what happens when you close the modal. Well, the content will un-render and the height hook will just stick with the last reported height, though still “observing” a DOM node that’s no longer in the DOM. If you’re worried about that, feel free to clean things up better than I have here, perhaps with something like this:
useLayoutEffect(() => {
if (!isOpen) {
setHeightOn(false);
}
}, [isOpen]);
That’ll cancel the ResizeObserver for that DOM node and fix the memory leak.
Next, let’s look at animating the changing of the results within the modal. If you run a few searches, you should see the results immediately swap in and out.
Take a look at the SearchBooksContent component in the searchBooks.js file. Right now, we have const booksObj = data?.allBooks; which plucks the appropriate result set off of the GraphQL response, and then later renders them.
As fresh results come back from our GraphQL endpoint, this object will change, so why not take advantage of that fact, and pass it to the useTransition hook from before, and get some transition animations defined.
Note the change from position: static to position: absolute. An outgoing result set with absolute positioning has no effect on its parent’s height, which is what we want. Our parent will size to the new contents and, of course, our modal will nicely animate to the new size based on the work we did above.
As before, we’ll use our transition function to render our content:
Now new result sets will fade in, while outgoing sets of results will fade (and slightly slide) out to give the user an extra cue that things have changed.
Of course, we also want to animate any messaging, such as when there’s no results, or when the user has selected everything in the result set. The code for that is pretty repetitive with everything else in here, and since this post is already getting long, I’ll leave the code in the demo.
Animating selected books (out)
Right now, selecting a book instantly and abruptly vanishes it from the list. Let’s apply our usual fade out while sliding it out to the right. And as the item is sliding out to the right (via transform), we probably want its height to animate to zero so the list can smoothly adjust to the exiting item, rather than have it slide out, leaving behind an the empty box, which then immediately disappears.
By now, you probably think this is easy. You’re expecting something like this:
This uses our trusted useHeight hook to measure our content, using the selected value to animate the item that’s leaving. We’re tracking the selected prop and animating to, or starting with, a height of 0 if it’s already selected, rather than simply removing the item and using a transition. This allows different result sets that have the same book to correctly decline to display it, if it’s selected.
But there’s a rub. If you select most of the books in a result set, there will be a kind of bouncy animation chain as you continue selecting. The book starts animating out of the list, and then the modal’s height itself starts trailing behind.
This looks goofy in my opinion, so let’s see what we can do about it.
We’ve already seen how we can use the immediate property to turn off all spring animations. We’ve also seen the onRest callback fire when an animation finishes, and I’m sure you won’t be surprised to learn there’s an onStart callback which does what you’d expect. Let’s use those pieces to allow the content inside our modal to “turn off” the modal’s height animation when the content itself is animating heights.
First, we’ll add some state to our modal that switches animation on and off.
Great. Now how do we get that modalSizingPacket down to our content, so whatever we’re rendering can actually switch off the modal’s animation, when needed? Context of course! Let’s create a piece of context.
Note the setTimeout at the very end. I’ve found it necessary to make sure the modal’s animation is truly shut off until everything’s settled.
I know that was a lot of code. If I moved too fast, be sure to check out the demo to see all this in action.
Animating selected books (in)
Let’s wrap this blog post up by animating the selected books that appear on the main screen, beneath the modal. Let’s have newly selected books fade in while sliding in from the left when selected, then slide out to the right while it’s height shrinks to zero when removed.
We’ll use a transition, but there already seems to be a problem because we need to account for each of the selected books needs to have its own, individual height. Previously, when we reached for useTransition, we’ve had a single from and to object that was applied to entering and exiting items.
Here, we’ll use an alternate form instead, allowing us to provide a function for the to object. It’s invoked with the actual animating item — a book object in this case — and we return the to object that contains the animating values. Additionally, we’ll keep track of a simple lookup object which maps each book’s ID to its height, and then tie that into our transition.
Note how we check that the height value has been updated with an actual value before calling it. That’s so we don’t prematurely set the value to zero before setting the correct height, which would cause our content to animate down, rather than sliding in fully-formed. Instead, no height will initially be set, so our content will default to height: auto. When our hook fires, the actual height will set. When an item is removed, the height will animate down to zero, as it fades and slides out.
Notice the update callback. It will adjust our content if any of the heights change. (You can force this in the demo by resizing the results pane after selecting a bunch of books.)
For a little icing on top of our cake, note how we’re conditionally setting the clamp property of our hook’s config. As content is animating in, we have clamp off, which produces a nice (at least in my opinion) bouncing effect. But when leaving, it animates down, but stays gone, without any of the jitteriness we saw before with clamping turned off.
Bonus: Simplifying the modal height animation while fixing a bug in the process
After finishing this post, I found a bug in the modal implementation where, if the modal height changes while it’s not shown, you’ll see the old, now incorrect height the next time you open the modal, followed by the modal animating to the correct height. To see what I mean, have a look at this update to the demo. You’ll notice new buttons to clear, or force results into the modal when it’s not visible. Open the modal, then close it, click the button to add results, and re-open it — you should see it awkwardly animate to the new, correct height.
Fixing this also allows us to simplify the code for the height animation from before. The problem is that our modal currently continues to render in the React component tree, even when not shown. The height hook is still “running,” only to be updated the next time the modal is shown, rendering the children. What if we moved the modal’s children to its own, dedicated component, and brought the height hook with it? That way, the hook and animation spring will only be render when the modal is shown, and can start with correct values. It’s less complicated than it seems. Right now our modal component has this:
This is a significant reduction in complexity compared to what we had before. We no longer have that activateRef function, and we no longer have the heightOn state that was set in activateRef. This component is only rendered by the modal if it’s being shown, which means we’re guaranteed to have content, so we can just add a regular ref to our div. Unfortunately, we do still need our uiReady state, since even now we don’t initially have our height on first render; that’s not available until the useHeight layout effect fires immediately after the first render finishes.
And, of course, this solves the bug from before. No matter what happens when the modal is closed, when it re-opens, this component will render anew, and our spring will start with a fresh value for uiReady.
If you’ve stuck with me all this way, thank you! I know this post was long, but I hope you found some value in it.
react-spring is an incredible tool for creating robust animations with React. It can be low-level at times, which can make it hard to figure out for non-trivial use cases. But it’s this low-level nature that makes it so flexible.
About a year ago, Automattic bought up Zero BS CRM. The thinking at the time was that it could be rebranded into the Jetpack suite and, well, that happened.
CRM meaning “Customer Relationship Management” if you’re like me and this is a little outside your sphere of everyday software. CRMs are big business though. When I lived in Silicon Valley, I would regularly drive by a very large building bearing the name of a CRM company that you’ve definitely heard of.
The name is a good one since CRMs are for helping you manage your customers. I have a brother-in-law who sells office furniture. He definitely uses a CRM. He gets leads for new clients, he helps figure out what they need, gets them quotes, and deals with billing them. It sounds straightforward, but it kinda isn’t. CRMs are complicated. Who better to bring you a good CRM than someone who brings you a good CMS?
The fact is that people are different and businesses are different, means that rather than forcing your business to behave like a CRM thinks it should, the CRM should flex to what you need. Jetpack CRM calls it a DIY CRM:
We let entrepreneurs pick and choose only what they need.
What appeals to me about Jetpack CRM is that you can leverage software that you already have and use. I swear the older I get the more cautious I become about adding major new software products to my life. There are always learning curves that are steeper than you want, gotchas you didn’t forsee, and maintenance you end up loathing. The idea of adding major new functionality under the WordPress roof feels much better to me. Everytime I do that with WordPress, I end up thinking it was the right move. I’ve done it now with both forums, newsletters, and eCommerce and each time was great.
I think it’s a smart move for Automattic. People should be able to do just about anything with their website, especially when it has the power of a login system, permission system, database, and all this infrastructure ready to go like any given WordPress site has. A CRM is a necessary thing for a lot of businesses and now Automattic has an answer to that.
Speaking of all the modularity of turning on and off features, you can also select a level that, essentially, specifies how much you want Jetpack CRM to take over your WordPress admin.
If running a CRM is the primary thing you’re doing with your WordPress site, Jetpack CRM can kinda take over and make the admin primarily that with the “CRM Only” setting. Or, just augment the admin and leave everything else as-is with the “Full” setting.
Like most things Jetpack these days, this is an ala-carte purchase if you need features beyond what the free plan offers. It’s not bundled with any other Jetpack stuff.
It’s also like WooCommerce in that there are a bunch of extensions for it that you only have to buy if you need them. For example, the $49 Gravity Forms extension allows you to build your lead forms with the Gravity Forms plugin, or it comes bundled in any of the paid plans. The $39 MailChimp plugin connects new leads to MailChimp lists.
“There’s a massive opportunity for CRM in the WordPress space,” said Stott. “A CRM is not like installing an SEO plugin on every website you own — generally you’d only have a single CRM for your business — but it’s the core of your business. The fact that 3,000+ users and counting are choosing WordPress to run their CRM is a great start.”
I’m a pretty heavy Jetpack user myself, using almost all it’s features.
Just to be clear, this isn’t some new feature of the core Jetpack plugin that’ll just show up on your site when you upgrade versions. It’s a totally separate product. In fact, the plugin folder you install to is called “zero-bs-crm,” the original name of the product.
I was able to install and play around with it right here on CSS-Tricks with no trouble at all. Being able to create invoices right here on the site is pretty appealing to me, so I’ll be playing with that some more.