Okay, this is extremely neat: Josh Comeau made this great site called Operator Lookup that explains how JavaScript operators work. There are some code examples to explain what they do as well, which is pretty handy.
My favorite bit of UI design here are the tags at the bottom of the search bar where you can select an operator to learn more about it because, as you hover, you can hear a tiny little clicking sound. Actual UI sounds! In a website!
Continuous Integration (CI) and Continuous Deployment (CD) are crucial development practices, especially for teams. Every project is prone to error, regardless of the size. But when there is a CI/CD process set up with well-written tests, those errors are a lot easier to find and fix.
In this article, let’s go through how to check test coverage, set up a CI/CD process that uses CircleCI and Coveralls, and deploys a Vue application to Heroku. Even if that exact cocktail of tooling isn’t your cup of tea, the concepts we cover will still be helpful for whatever is included in your setup. For example, Vue can be swapped with a different JavaScript framework and the basic principles are still relevant.
Here’s a bit of terminology before we jump right in:
Continuous integration: This is a practice where developers commit code early and often, putting the code through various test and build processes prior to merge or deployment.
Continuous deployment: This is the practice of keeping software deployable to production at all times.
Test Coverage: This is a measure used to describe the degree to which software is tested. A program with high coverage means a majority of the code is put through testing.
To make the most of this tutorial, you should have the following:
CircleCI account: CircleCI is a CI/CD platform that we’ll use for automated deployment (which includes testing and building our application before deployment).
GitHub account: We’ll store the project and its tests in a repo.
Heroku account: Heroku is a platform used for deploying and scaling applications. We’ll use it for deployment and hosting.
Coveralls account: Coveralls is a platform used to record and show code coverage.
NYC: This is a package that we will use to check for code coverage.
Next, we need to edit the scripts in package.json to check the test coverage. If we are trying to check the coverage while running unit tests, we would need to edit the test script:
This command assumes that we’re building the app with Vue, which includes a reference to cue-cli-service. The command will need to be changed to reflect the framework used on the project.
If we are trying to check the coverage separately, we need to add another line to the scripts:
Let’s go to our Heroku dashboard and register our app there. Heroku is what we’ll use to host it.
We’ll use CircleCI to automate our CI/CD process. Proceed to the CircleCI dashboard to set up our project.
We can navigate to our projects through the Projects tab in the CircleCI sidebar, where we should see the list of our projects in our GitHub organization. Click the “Set Up Project” button. That takes us to a new page where we’re asked if we want to use an existing config. We do indeed have our own configuration, so let’s select the “Use an existing config” option.
After that, we’re taken to the selected project’s pipeline. Great! We are done connecting our repository to CircleCI. Now, let’s add our environment variables to our CircleCI project.
To add variables, we need to navigate into the project settings.
The project settings has an Environment Variables tab in the sidebar. This is where we want to store our variables.
The Coveralls repository token is on the repository’s Coveralls account. First, we need to add the repo to Coveralls, which we do by selecting the GitHub repository from the list of available repositories.
Now that we’ve added the repo to Coveralls. we can get the repository token by clicking on the repo.
Integrating CircleCI
We’ve already connected Circle CI to our GitHub repository. That means CircleCI will be informed whenever a change or action occurs in the GitHub repository. What we want to do now is run through the steps to inform CircleCI of the operations we want it to run after it detects change to the repo.
In the root folder of our project locally, let’s create a folder named .circleci and, in it, a file called config.yml. This is where all of CircleCI’s operations will be.
Orbs are open source packages used to simplify the integration of software and packages across projects. In our code, we indicate orbs we are using for the CI/CD process. We referenced the node orb because we are making use of JavaScript. We reference heroku because we are using a Heroku workflow for automated deployment. And, finally, we reference the coveralls orb because we plan to send the coverage results to Coveralls.
The Heroku and Coverall orbs are external orbs. So, if we run the app through testing now, those will trigger an error. To get rid of the error, we need to navigate to the “Organization Settings” page in the CircleCI account.
Then, let’s navigate to the Security tab and allow uncertified orbs:
Workflows
workflows:
heroku_deploy:
jobs:
- build
- heroku/deploy-via-git: # Use the pre-configured job
requires:
- build
filters:
branches:
only: master
A workflow is used to define a collection of jobs and run them in order. This section of the code is responsible for the automated hosting. It tells CircleCI to build the project, then deploy. requires signifies that the heroku/deploy-via-git job requires the build to be complete — that means it will wait for the build to complete before deployment.
A job is a collection of steps. In this section of the code, we restore the dependencies that were installed during the previous builds through the restore_cache job.
After that, we install the uncached dependencies, then save them so they don’t need to be re-installed during the next build.
Then we’re telling CircleCI to run the tests we wrote for the project and check the test coverage of the project. Note that caching dependencies make subsequent builds faster because we store the dependencies hence removing the need to install those dependencies during the next build.
Uploading our code coverage to coveralls
- run: # run tests
name: test
command: npm run test:unit
- run: # run code coverage report
name: code-coverage
command: npm run coveralls
# - coveralls/upload
This is where the Coveralls magic happens because it’s where we are actually running our unit tests. Remember when we added the nyc command to the test:unit script in our package.json file? Thanks to that, unit tests now provide code coverage.
Unit tests also provide code coverage so we’ll those included in the coverage report. That’s why we’re calling that command here.
And last, the code runs the Coveralls script we added in package.json. This script sends our coverage report to coveralls.
You may have noticed that the coveralls/upload line is commented out. This was meant to be the finishing character of the process, but at the end became more of a blocker or a bug in developer terms. I commented it out as it may be another developer’s trump card.
Putting everything together
Behold our app, complete with continuous integration and deployment!
A successful build
Continuous integration and deployment helps in so many cases. A common example would be when the software is in a testing stage. In this stage, there are lots of commits happening for lots of corrections. The last thing I would want to do as a developer would be to manually run tests and manually deploy my application after every minor change made. Ughhh. I hate repetition!
I don’t know about you, but CI and CD are things I’ve been aware of for some time, but I always found ways to push them aside because they either sounded too hard or time-consuming. But now that you’ve seen how relatively little setup there is and the benefits that comes with them, hopefully you feel encouraged and ready to give them a shot on a project of your own.
As hyped futurist technology, the Internet of Things (IoT) has debuted. It has now become a reality both socially and technologically marvelous. This can be verified by the new IoT developments.
It is now used for artificial intelligence and data mining applications. These integrations help organizations enhance their operations, increase their profitability, and reduce overheads.
Moving forward in this article, we will be discussing the top trends of IoT that are going to rule the field of technology. We hope to get you up to date with IoT innovations with this list of the most emerging trends available today in IoT. This list will also help you in learning something new to exploit these patterns to extend your market if you’re in the business of eCommerce app development. So, let’s jump straight into the futuristic trends of IoT:
1. For Better Customer Service
One of the developments in the future of the Internet of Things is to boost the company’s customer experience through real-time access to data. IoT also supports various CRM applications, delivers user knowledge, and identifies client problems. Both IoT devices will potentially disclose these issues without the awareness of the consumer.
That is why many companies want to employ IoT developers in their business processes to incorporate this technology. You had to call the support staff earlier and write down the dilemma in-depth to understand and continue. The smart system concurrently transfers data directly to the customer service of the manufacturer. This saves a lot of time and the service provider can reach the core of the problem without any hassle.
2. For Smart Cities
The idea of intelligent cities has stormed the globe. IoT also encouraged the government’s willingness to prepare and address challenges on a much broader scale. Issues such as road delays are fixed every day, security problems are addressed more easily and efficiently. Smart cities ensure that the community residing in a particular region doesn’t face day-to-day issues.
3. Boon For Healthcare Industry
Health is an individual’s most valuable thing. The healthcare sector will be changed by IoT. Companies create devices that users wear 24 hours a day. For unlimited scans and checks, they won’t have to see the hospital. That would also contribute to a more balanced way of living.
4. Perfect Watcher For Security Concerns
Security is the most critical consideration for devices operated by IoT. With IoT tracking and fragmentation remote connectivity, there is a greater possibility that the device protection will be violated. In 2020, more secured frameworks will arise to solve the dynamic complexities of network security. A safe linked ecosystem with many smart devices will be built in the new year. This IoT pattern would overcome automated systems problems and reduce the risks associated with them.
5. For Blockchain
IoT devices are designed to support the existence of an entity or operating unit. This includes the continuous generation of personal data and the chances of hacker attacks are greater. The volume of data is also projected to increase exponentially, in line with the number of connections between devices. Therefore, blockchain’s distributed design can make accessible at all times loads of data with minimal safety threats when required.
6. For Better Retail Personalization
The consumer is also concentrated on other IoT-based retail software. During entering with your phones, the beacons will collect the involvement of some clients. Map applications will guide clients to the things they want. Without waiting in line, cashier-less shops will get busy without the customers outside in the line.
7. Improved Data Analytics
In the coming days, IoT with the aid of AI can get linked to the world and help in better data processing than a person. It will take critical decisions after examining various variables that bypass an individual’s mind. Ultimately, it is rising to change people’s lives.
8. Perfect Aid for 5G Technology
In 2020, 5G networks will continue to run in multiple sectors worldwide. In exchange, this would lead to an increase in the number of IoT users. The beacons of the Fourth Technological Revolution, which already begins in 2020, are considered 5G and, Internet of Things. Now is the time for them to accelerate the transition of technology together.
The 5th generation of mobile devices offers quicker and much more secure networking that enables businesses to render corresponding processes and production processes. IoT and 5G will develop a mobile and tablet system, wearable, medical, and automotive facilities, and enhanced equipment.
9. For Edge Computing
Everybody thinks that cloud computing is the future, but you’d be surprised by the fact that edge computing will replace cloud computing in the upcoming years. Rather than moving the IoT system data to the new cloud platform, developers send the data first to any local computers, present at the network edge.
The local computer is capable of filtering and measuring data before uploading it to the cloud to minimize network traffic. This edge computing approach thus helps with data management, server dependency reduction, and latency reduction.
10. For Sustainable Consumption
The consequences of climate change have already been anticipated by current times. It’s time to think of the right solution for washing water and air. IoT-powered systems can enable sustainable use of electricity. There are revolutionary water treatment facilities in several industrial industries to purify water to make it drinkable.
The Upshot
In one go, IoT is not implemented. It is a mechanism that increments the number of digital transitions that are virtually universal. In terms of consumer and technological problems, the 2020 developments aim to highlight both the future and the technologies that continue to transform our lives. The future is already startling. You will inevitably face a few obstacles.
Therefore, you need to have in-depth an awareness of the current developments and hurdles in IoT to adapt business operations effectively to the new capabilities. IoT is a rising trend in eCommerce app development. So, if you want to develop an eCommerce app, then you can always seek the help of the best eCommerce app development company.
The transitioning of power is fraught with difficulties. Different teams have different values, different experience, different expertise, different priorities, and that leads to different tooling, and different methodologies.
It’s tempting to think of web design as an end-to-end process, starting with research and concluding with metrics. The reality is that most designers and developers join projects part-way through an ongoing process.
That leaves us with a difficult choice: do we try and meet the client’s expectations with our own toolset, or adapt to the tools and processes that are already in place?
For anyone who’s taking over a web project from a different designer/developer/agency (D/D/A), here’s a practical guide to help you make a success of the transition.
Step 1: Find Out What Went Wrong
99.99% of the time, something broke down in the previous client-D/D/A relationship.
In my experience it’s almost never about money. Most clients are willing to pay above the basic market rate if they believe they’re receiving a good return on their investment. A client that tells you the previous D/D/A is simply too expensive is anticipating negotiating your fees.
happy clients don’t shop around
Occasionally you’ll find that a freelance designer has been headhunted by an agency, and is no longer available. Occasionally the company outgrows a D/D/A, moving into areas that the D/D/A doesn’t support. But these situations are rare, happy clients — even moderately content clients — don’t shop around. If they’re speaking to you, something motivated them to do so.
It is alarmingly common that a D/D/A simply goes AWOL. It’s most common at the lower end of the market where the sums of money involved are less likely to prompt a legal dispute. Frequently, an unreputable D/D/A will ghost a client in favour of a better, newer opportunity.
Sometimes the client hires a new manager, and the new manager ushers in revised expectations that the previous D/D/A can’t meet.
Most commonly, the previous D/D/A has dropped the ball one too many times — mistakes happen, and reasonable clients will tolerate them provided they are rectified promptly, but everyone has their limits.
Most clients will be more than happy to explain what went wrong in the previous relationship; it will inevitably be a one-sided explanation, but it will help you to understand the client’s expectations.
Be extremely wary of a client who doesn’t know what went wrong. Be even more wary of a client who talks about “upgrading” their outsourcing — they’re trying to flatter you. In these cases the client may well be hiding something — like their failure to pay invoices.
Remember: at some point the previous D/D/A was new, and excited about having a new client, was optimistic about the project, and it didn’t end well. The best way to not repeat mistakes is to learn from them, and to do that you need to know what they were.
Step 2: Carry Out a Comprehensive Audit
We’re often so eager to secure new work, that we rush to have the client sign on the dotted line, expecting to be able to tackle any problems later.
It is imperative that as a professional, you keep your promises. Before you make those promises, take your time to understand the project and related business. If a client is invested enough to sign a contract with you they won’t mind you doing due diligence first.
Is There Still a Relationship With the Previous Designer/Developer/Agency?
Clients rarely have a full picture of their project — they’re not web professionals, if they were they’d be building their own sites. Your best source of information is the previous D/D/A.
Before you contact the previous D/D/A check with your client; it’s possible they don’t know they’re being replaced yet. If your client is fine with it, then reach out.
When you speak to the previous D/D/A be sensitive to the fact that you’re taking money out of their pocket. Certainly the previous D/D/A may tell you where to go, they may ignore you altogether, but most will be pragmatic about handing over a project if only to ensure their final invoice to their now ex-client is paid promptly.
Every site has its idiosyncrasies, if you can establish a friendly rapport with the previous D/D/A then the transition will be considerably less bumpy.
Who Controls the Domain Name(s)?
In my opinion a company’s domain name(s) should always be held by the company; it’s such an essential business asset that it should be guarded as jealously as the company’s bank accounts.
Unfortunately there are businesses that outsource everything to do with the web. If the break with the previous D/D/A is acrimonious then securing the domain name could be problematic.
It’s not your job to secure the domain name — you have no leverage, the client does. It is your job to impress upon the client how mission-critical the domain name(s) is.
Who Controls the Hosting?
Hosting arrangements vary from project to project. It’s not uncommon, nor unreasonable, for the previous D/D/A to be hosting the client’s site on their own space. If that is the case, be prepared to migrate it quickly either to your own server, or a dedicated space.
If you’re migrating onto a new space pay particular attention to the email provision. Taking over a project usually means taking over a live project, and that usually means email accounts.
In any case, you need full access to the hosting space. You certainly need FTP access, you probably need SSH access.
In addition to hosting, check if your client’s site uses a CDN, and if it does, who has control of it.
Backend Source Code
Once you have FTP access to the hosting server you can probably grab all backend code from the server.
The benefit of grabbing the code from the server — as opposed to accepting files from the previous D/D/A — is that you can be absolutely certain you’re getting the current (working) code.
If the client has broken with the previous D/D/A because they were unable to deliver on a particular task, you do not want to be working with files that have been partially modified.
Fresh Installs
If you’re working with something like a CMS, it’s often a good idea to run a fresh install on your server, and then copy across any templates, plugins, and migrate the database.
Frontend Source Code
When it comes to acquiring source code, frontend code is far more problematic than backend.
frontend code is far more problematic than backend
If the previous D/D/A is even part-way competent then the CSS and JavaScript on the web space is minified. Minified CSS is not too problematic and can be unminified fairly easily, but you do not want to be unpicking a minified JavaScript file — I once had a project in which a developer had minified his own code in the same file with all of his dependencies, including both Vue and jQuery [yes, I know].
Dealing with frontend source code can take on an additional dimension if you discover that the previous D/D/A used techniques you don’t — using Less instead of Sass, or writing scripts in TypeScript.
Unminifying CSS & JavaScript
Unminifying (or beautifying, or prettifying) code is reasonably easy. There are tools online that will help, including Unminify, Online CSS Unminifier, FreeFormatter, JS Minify Unminify, and more. You’ll also find plenty of extensions for code editors including HTML-CSS-JS Prettify for Sublime Text, and Atom-Beautify for Atom. You’ll find that some editors have the functionality built in.
A word of warning: code beautification does not restore comments, and in the case of JavaScript, does not unobfuscate variable names. Beautifying code is no substitute for a copy of the original, unminified source code.
Emergency Measures
If unminifying the source code isn’t possible for any reason, or more likely, the unminified JavaScript still looks like minified code — albeit nicely formatted minified code — then your last resort is to import the code and override it where necessary.
The first thing to do in this case is to explain the situation to your client. Make sure they understand this is a temporary patch that you’ll iron-out as you rebuild parts of the project.
Then, copy and paste the old minified code into a fresh project setup. For CSS that probably means creating a legacy.scss file, including the old CSS, and importing it into your own Sass. For JavaScript, create a legacy.js file, add all the old JS, and import that.
This will result in a much bigger set of files than necessary, you may end up using !important in your style declarations [yuck], and you’ll trigger lots of Lighthouse warnings about surplus code.
However, in the likely event that your client has a long list of changes they wanted live yesterday, this dirty hack will give you a working site that you can then rebuild piece by piece over time.
Assets
Assets normally means images, and images can normally be grabbed via FTP.
Occasionally — although less occasionally now image files rarely contain text — you’ll need the source files to make changes to images.
Whether or not the client has them, or if the previous D/D/A will hand them over, depends largely on the agreement between the client and the previous D/D/A.
Most businesses are reasonably aware of the importance of brand assets, so you’ll probably find they at least have a copy of their logo; whether it’s an SVG or a JPG is another matter entirely. Impress upon them the importance of locating those files for you.
Third Party Code
It is rare to receive a project that doesn’t rely on third party code. That third party code is probably entwined in the custom source code, and unpicking it is a time-consuming job.
It is very likely the previous D/D/A used a library or framework, and given the increasing number of them, it’s even more likely that the library or framework they used is not the one you prefer.
Whether you choose to unpick the code and swap out the previous D/D/A’s dependencies for your own preferences (usually faster in the long term), or whether you choose to work with what you’re given (usually faster in the short term) is entirely up to you.
In my experience it’s no hardship to pick up another CSS library; switching from one JavaScript framework to another is a substantially bigger job involving not just syntax but core concepts.
Beware Build Environments
Everyone has their own way of doing things. Some D/D/As embrace build environments, some do not. Some build environments are simple to use, some are not. Some build environments are adaptable to your process, some are not.
Unlike adopting a library, or even a framework, adopting a new build process is rarely a good idea
Build environments are numerous — Gulp, Grunt, and Webpack are all popular — and D/D/As are almost as opinionated about them as they are about CMS.
In lieu of raw files, it’s not uncommon for the previous D/D/A to tell you to “just run such-and-such CLI” command, to match up your local environment to theirs. Unlike adopting a library, or even a framework, adopting a new build process is rarely a good idea because you’re relegating yourself from expert to novice at a time when you’ve yet to earn your new client’s trust.
Stand your ground. Their approach failed, that’s why you’ve been brought in. You do you.
Who is Licensed?
Any third part code that has been paid for is licensed. Always check who holds these licenses. As well as being legally required, valid licenses are normally required for updates, bug fixes, and in some cases support.
Common pitfalls include: font licenses (which may be licensed under the previous D/D/A’s Creative Cloud, Fontstand, Monotype, etc. account); stock image licenses (which may be licensed for use by the previous D/D/A alone); and plugins (which are frequently bulk-licensed to D/D/As in bundles).
It’s depressingly common to find clients using unlicensed assets. On more than one occasion I’ve had to explain to a client the potential consequences of using pirated fonts.
Fortunately it’s increasingly common for third party providers to attach a licence to a specified domain, which means you may be able to claim the licence on behalf of your client. Major suppliers like CMS and ecommerce solutions frequently have an option for the previous developer to release a licence and allow you to claim it.
In the case of licensing, if you’re unsure, do not be afraid to reach out to the third party provider and check with them if your client is licensed once they break ties with their previous D/D/A.
The only thing that sours a client relationship faster than telling them they need to buy a license they thought they’d already paid for, is telling them they’re being sued for copyright infringement.
Protect your client, and protect yourself, by making sure everything is licensed properly. If you can get something in writing to that effect from the previous D/D/A, do.
Who Has the Research and Analytics?
One of the major benefits of taking over a site, as opposed to building from scratch, is that you have a measurable set of site-specific data to guide your decision making.
This only applies if you have the data, so ask to be added to the client’s analytics account.
There’s a strong chance that the design research carried out by the previous D/D/A is considered an internal document, not a deliverable, by the previous D/D/A. Check with your client: if they paid for the research (is it specified on an invoice?) then they’re entitled to a copy.
We Have a Blog Too…
Clients have a tendency to use the term “website” as a catch-all term for everything digital.
When you take responsibility for a website, you’re almost always expected to take responsibility for any digital service the client uses. That means, newsletter services like Mailchimp, customer service accounts like Intercom, and 227,000 page WordPress blogs that they forgot to mention in the initial brief.
Repeat the whole of Step 2 for every additional app, micro-site, blog, and anything else the client has, unless you are expressly told by the client not to.
Step 3: The Point of No Return
Up until now, you haven’t asked the client to sign on the dotted line. This whole process is part of your due diligence.
By checking these things you can identify unforeseen problems, and potential costs. Are you tied to an obscure build process? Do you need to relicense the CMS? Do you need to recreate all of the site assets?
Some of these conversations are hard to have, but the time to have them is now
If there is any question of the project being more complex than anticipated, have an honest conversation with your client — they will appreciate your transparency, and they’ll appreciate being kept informed. Any client who doesn’t value a clear picture of what they’re paying you for, isn’t a client you want.
Some of these conversations are hard to have, but the time to have them is now, not three months down the line.
This is the point of no return. From this point on, any problems aren’t the previous D/D/A’s, they’re yours.
Change the Passwords
For every service you have, from the newsletter login, to the CMS login, to the FTP details, change the password. (Make sure you notify the client.)
Set Up a Staging Site
You’re going to need a staging site so your new client can preview the work you’ve done for them.
Set the staging site up immediately, before you’ve made any changes to the code. In doing so you’ll discover early on if there are files missing, or issues with the files you do have.
Successfully Transitioning a Project
When a client commissions a site from scratch they are filled with expectation. The fact that they are leaving their previous D/D/A and seeking you out demonstrates that their experience fell short of their hopes.
You now have a client with realistic — perhaps even pessimistic — expectations. You have a benchmark against which your work can be objectively measured.
When problems arise, as they invariably will, never try to blame the previous D/D/A; it was your job to assess the state of play before you started work. If there is an issue with legacy assets, you should have brought it to your client’s attention early on.
If you learn from the previous D/D/A’s mistakes, you won’t be handing the project on to someone else any time soon.
Every week users submit a lot of interesting stuff on our sister site Webdesigner News, highlighting great content from around the web that can be of interest to web designers.
The best way to keep track of all the great stories and news being posted is simply to check out the Webdesigner News site, however, in case you missed some here’s a quick and useful compilation of the most popular designer news that we curated from the past week.
Gmail’s New Logo is a Mess – This Amateur Designer Fixed it
GitHub Source Code Leak
What’s the Average Web Designer’s Salary? A Deep Dive into 2020
All the Resources You Need for Front End Development
Flat Illustrations – 100 Neat Illustrations for Websites and Apps
15 WordPress Plugins Every Content Creator Needs
9 Essential Elements of a Modern Website Design
30 Classic Ideas that Serve as Logo Design Inspirations in 2020
Color Contrast Mistakes that Weaken Button Hierarchy
How to Improve Conversions Using Color Psychology
20+ Free Design Resources for Developers
CSS Grid Layout Module Level 3
25 Striking Logo Color Schemes to Inspire your Branding
Cirrus V0.6 – A Component Centric CSS Framework for Fast Prototyping
What is the Best Digital Marketing Strategy?
What Should I Build? – Project Ideas for People Who are Learning Web Development
Introducing the 1st Design-to-Development Platform
Free Typography Logo Maker
The Caretaker – A Pure CSS Horror/Puzzle Game
Getting the WordPress Block Editor to Look like the Front End Design
Copying is the Way Design Works
Six Principles of System Design
Apple Silicon Mac Event Announced
4 Types of Sales Visuals that Increase Conversions
Chasing the Pixel-Perfect Dream
Want more? No problem! Keep track of top design news from around the web with Webdesigner News.
[On horizontal scrolling, like Netflix] This pattern is accessible, responsive and consistent across screen sizes. And it’s pretty easy to implement.
Too cold:
That’s a lot of pros for a pattern that in reality has some critical downsides.
Just right:
[On rows of content with “View All” links] This way, the content isn’t hidden; it’s easy to drill down into a category; data isn’t wasted; and an unconventional, labour intensive pattern is avoided.
One of the arguments against the Jamstack approach for building websites is that developing features gets complex and often requires a number of other services. Take commenting, for example. To set up commenting for a Jamstack site, you often need a third-party solution such as Disqus, Facebook, or even just a separate database service. That third-party solution usually means your comments live disconnected from their content.
When we use third-party systems, we have to live with the trade-offs of using someone else’s code. We get a plug-and-play solution, but at what cost? Ads displayed to our users? Unnecessary JavaScript that we can’t optimize? The fact that the comments content is owned by someone else? These are definitely things worth considering.
Monolithic services, like WordPress, have solved this by having everything housed under the same application. What if we could house our comments in the same database and CMS as our content, query it in the same way we query our content, and display it with the same framework on the front end?
It would make this particular Jamstack application feel much more cohesive, both for our developers and our editors.
Let’s make our own commenting engine
In this article, we’ll use Next.js and Sanity.io to create a commenting engine that meets those needs. One unified platform for content, editors, commenters, and developers.
Why Next.js?
Next.js is a meta-framework for React, built by the team at Vercel. It has built-in functionality for serverless functions, static site generation, and server-side rendering.
For our work, we’ll mostly be using its built-in “API routes” for serverless functions and its static site generation capabilities. The API routes will simplify the project considerably, but if you’re deploying to something like Netlify, these can be converted to serverless functions or we can use Netlify’s next-on-netlify package.
It’s this intersection of static, server-rendered, and serverless functions that makes Next.js a great solution for a project like this.
Why Sanity?
Sanity.io is a flexible platform for structured content. At its core, it is a data store that encourages developers to think about content as structured data. It often comes paired with an open-source CMS solution called the Sanity Studio.
We’ll be using Sanity to keep the author’s content together with any user-generated content, like comments. In the end, Sanity is a content platform with a strong API and a configurable CMS that allows for the customization we need to tie these things together.
Setting up Sanity and Next.js
We’re not going to start from scratch on this project. We’ll begin by using the simple blog starter created by Vercel to get working with a Next.js and Sanity integration. Since the Vercel starter repository has the front end and Sanity Studio separate, I’ve created a simplified repository that includes both.
The starter repo comes in two parts: the front end powered by Next.js, and Sanity Studio. Before we go any further, we need to get these running locally.
To get started, we need to set up our content and our CMS for Next to consume the data. First, we need to install the dependencies required for running the Studio and connecting to the Sanity API.
# Install the Sanity CLI globally
npm install -g @sanity/cli
# Move into the Studio directory and install the Studio's dependencies
cd studio
npm install
Once these finish installing, from within the /studio directory, we can set up a new project with the CLI.
# If you're not logged into Sanity via the CLI already
sanity login
# Run init to set up a new project (or connect an existing project)
sanity init
The init command asks us a few questions to set everything up. Because the Studio code already has some configuration values, the CLI will ask us if we want to reconfigure it. We do.
From there, it will ask us which project to connect to, or if we want to configure a new project.
We’ll configure a new project with a descriptive project name. It will ask us to name the “dataset” we’re creating. This defaults to “production” which is perfectly fine, but can be overridden with whatever name makes sense for your project.
The CLI will modify the file ~/studio/sanity.json with the project’s ID and dataset name. These values will be important later, so keep this file handy.
For now, we’re ready to run the Studio locally.
# From within /studio
npm run start
After the Studio compiles, it can be opened in the browser at http://localhost:3333.
At this point, it makes sense to go into the admin and create some test content. To make the front end work properly, we’ll need at least one blog post and one author, but additional content is always nice to get a feel for things. Note that the content will be synced in real-time to the data store even when you’re working from the Studio on localhost. It will become instantly available to query. Don’t forget to push publish so that the content is publicly available.
Once we have some content, it’s time to get our Next.js project running.
Getting set up with Next.js
Most things needed for Next.js are already set up in the repository. The main thing we need to do is connect our Sanity project to Next.js. To do this, there’s an example set of environment variables set in /blog-frontent/.env.local.example. Remove .example from that file and then we’ll modify the environment variables with the proper values.
We need an API token from our Sanity project. To create this value, let’s head over to the Sanity dashboard. In the dashboard, locate the current project and navigate to the Settings ? API area. From here, we can create new tokens to use in our project. In many projects, creating a read-only token is all we need. In our project, we’ll be posting data back to Sanity, so we’ll need to create a Read+Write token.
Adding a new read and write token in the Sanity dashboard
When clicking “Add New Token,” we receive a pop-up with the token value. Once it’s closed, we can’t retrieve the token again, so be sure to grab it!
This string goes in our .env.local file as the value for SANITY_API_TOKEN. Since we’re already logged into manage.sanity.io , we can also grab the project ID from the top of the project page and paste it as the value of NEXT_PUBLIC_SANITY_PROJECT_ID. The SANITY_PREVIEW_SECRET is important for when we want to run Next.js in “preview mode”, but for the purposes of this demo, we don’t need to fill that out.
We’re almost ready to run our Next front-end. While we still have our Sanity Dashboard open, we need to make one more change to our Settings ? API view. We need to allow our Next.js localhost server to make requests.
In the CORS Origins, we’ll add a new origin and populate it with the current localhost port: http://localhost:3000. We don’t need to be able to send authenticated requests, so we can leave this off When this goes live, we’ll need to add an additional Origin with the production URL to allow the live site to make requests as well.
Our blog is now ready to run locally!
# From inside /blog-frontend
npm run dev
After running the command above, we now have a blog up and running on our computer with data pulling from the Sanity API. We can visit http://localhost:3000 to view the site.
Creating the schema for comments
To add comments to our database with a view in our Studio, we need to set up our schema for the data.
To add our schema, we’ll add a new file in our /studio/schemas directory named comment.js. This JavaScript file will export an object that will contain the definition of the overall data structure. This will tell the Studio how to display the data, as well as structuring the data that we will return to our frontend.
In the case of a comment, we’ll want what might be considered the “defaults” of the commenting world. We’ll have a field for a user’s name, their email, and a text area for a comment string. Along with those basics, we’ll also need a way of attaching the comment to a specific post. In Sanity’s API, the field type is a “reference” to another type of data.
If we wanted our site to get spammed, we could end there, but it would probably be a good idea to add an approval process. We can do that by adding a boolean field to our comment that will control whether or not to display a comment on our site.
export default {
name: 'comment',
type: 'document',
title: 'Comment',
fields: [
{
name: 'name',
type: 'string',
},
{
title: 'Approved',
name: 'approved',
type: 'boolean',
description: "Comments won't show on the site without approval"
},
{
name: 'email',
type: 'string',
},
{
name: 'comment',
type: 'text',
},
{
name: 'post',
type: 'reference',
to: [
{type: 'post'}
]
}
],
}
After we add this document, we also need to add it to our /studio/schemas/schema.js file to register it as a new document type.
import createSchema from 'part:@sanity/base/schema-creator'
import schemaTypes from 'all:part:@sanity/base/schema-type'
import blockContent from './blockContent'
import category from './category'
import post from './post'
import author from './author'
import comment from './comment' // <- Import our new Schema
export default createSchema({
name: 'default',
types: schemaTypes.concat([
post,
author,
category,
comment, // <- Use our new Schema
blockContent
])
})
Once these changes are made, when we look into our Studio again, we’ll see a comment section in our main content list. We can even go in and add our first comment for testing (since we haven’t built any UI for it in the front end yet).
An astute developer will notice that, after adding the comment, the preview our comments list view is not very helpful. Now that we have data, we can provide a custom preview for that list view.
Adding a CMS preview for comments in the list view
After the fields array, we can specify a preview object. The preview object will tell Sanity’s list views what data to display and in what configuration. We’ll add a property and a method to this object. The select property is an object that we can use to gather data from our schema. In this case, we’ll take the comment’s name, comment, and post.title values. We pass these new variables into our prepare() method and use that to return a title and subtitle for use in list views.
The title will display large and the subtitle will be smaller and more faded. In this preview, we’ll make the title a string that contains the comment author’s name and the comment’s post, with a subtitle of the comment body itself. You can configure the previews to match your needs.
The data now exists, and our CMS preview is ready, but it’s not yet pulling into our site. We need to modify our data fetch to pull our comments onto each post.
Displaying each post’s comments
In this repository, we have a file dedicated to functions we can use to interact with Sanity’s API. The /blog-frontend/lib/api.js file has specific exported functions for the use cases of various routes in our site. We need to update the getPostAndMorePosts function in this file, which pulls the data for each post. It returns the proper data for posts associated with the current page’s slug, as well as a selection of new posts to display alongside it.
In this function, there are two queries: one to grab the data for the current post and one for the additional posts. The request we need to modify is the first request.
The filter – what set of data to find and send back *[_type == "post" && slug.current == $slug]
An optional pipeline component — a modification to the data returned by the component to its left | order(_updatedAt desc)
An optional projection — the specific data elements to return for the query. In our case, everything between the brackets ({}).
In this example, we have a variable list of fields that most of our queries need, as well as the body data for the blog post. Directly following the body, we want to pull all the comments associated with this post.
In order to do this, we create a named property on the object returned called 'comments' and then run a new query to return the comments that contain the reference to the current post context.
The filter matches all documents that meet the interior criteria of the square brackets ([]). In this case, we’ll find all documents of _type == "comment". We’ll then test if the current post’s _ref matches the comment’s _id. Finally, we check to see if the comment is approved == true.
Once we have that data, we select the data we want to return using an optional projection. Without the projection, we’d get all the data for each comment. Not important in this example, but a good habit to be in.
Sanity returns an array of data in the response. This can be helpful in many cases but, for us, we just need the first item in the array, so we’ll limit the response to just the zero position in the index.
Adding a Comment component to our post
Our individual posts are rendered using code found in the /blog-frontend/pages/posts/[slug].js file. The components in this file are already receiving the updated data in our API file. The main Post() function returns our layout. This is where we’ll add our new component.
Comments typically appear after the post’s content, so let’s add this immediately following the closing tag.
// ... The rest of the component
</article>
// The comments list component with comments being passed in
<Comments comments={post?.comments} />
We now need to create our component file. The component files in this project live in the /blog-frontend/components directory. We’ll follow the standard pattern for the components. The main functionality of this component is to take the array passed to it and create an unordered list with proper markup.
Since we already have a component, we can use that to format our date properly.
Back in our /blog-frontend/pages/posts/[slug].js file, we need to import this component at the top, and then we have a comment section displayed for posts that have comments.
import Comments from '../../components/comments'
We now have our manually-entered comment listed. That’s great, but not very interactive. Let’s add a form to the page to allow users to submit a comment to our dataset.
Adding a comment form to a blog post
For our comment form, why reinvent the wheel? We’re already in the React ecosystem with Next.js, so we might as well take advantage of it. We’ll use the react-hook-form package, but any form or form component will do.
First, we need to install our package.
npm install react-hook-form
While that installs, we can go ahead and set up our Form component. In the Post component, we can add a component right after our new component.
// ... Rest of the component
<Comments comments={post.comments} />
<Form _id={post._id} />
Note that we’re passing the current post _id value into our new component. This is how we’ll tie our comment to our post.
As we did with our comment component, we need to create a file for this component at /blog-frontend/components/form.js.
export default function Form ({_id}) {
// Sets up basic data state
const [formData, setFormData] = useState()
// Sets up our form states
const [isSubmitting, setIsSubmitting] = useState(false)
const [hasSubmitted, setHasSubmitted] = useState(false)
// Prepares the functions from react-hook-form
const { register, handleSubmit, watch, errors } = useForm()
// Function for handling the form submission
const onSubmit = async data => {
// ... Submit handler
}
if (isSubmitting) {
// Returns a "Submitting comment" state if being processed
return <h3>Submitting comment…</h3>
}
if (hasSubmitted) {
// Returns the data that the user submitted for them to preview after submission
return (
<>
<h3>Thanks for your comment!</h3>
<ul>
<li>
Name: {formData.name} <br />
Email: {formData.email} <br />
Comment: {formData.comment}
</li>
</ul>
</>
)
}
return (
// Sets up the Form markup
)
}
This code is primarily boilerplate for handling the various states of the form. The form itself will be the markup that we return.
// Sets up the Form markup
<form onSubmit={handleSubmit(onSubmit)} className="w-full max-w-lg" disabled>
<input ref={register} type="hidden" name="_id" value={_id} />
<label className="block mb-5">
<span className="text-gray-700">Name</span>
<input name="name" ref={register({required: true})} className="form-input mt-1 block w-full" placeholder="John Appleseed"/>
</label>
<label className="block mb-5">
<span className="text-gray-700">Email</span>
<input name="email" type="email" ref={register({required: true})} className="form-input mt-1 block w-full" placeholder="your@email.com"/>
</label>
<label className="block mb-5">
<span className="text-gray-700">Comment</span>
<textarea ref={register({required: true})} name="comment" className="form-textarea mt-1 block w-full" rows="8" placeholder="Enter some long form content."></textarea>
</label>
{/* errors will return when field validation fails */}
{errors.exampleRequired && <span>This field is required</span>}
<input type="submit" className="shadow bg-purple-500 hover:bg-purple-400 focus:shadow-outline focus:outline-none text-white font-bold py-2 px-4 rounded" />
</form>
In this markup, we’ve got a couple of special cases. First, our element has an onSubmit attribute that accepts the handleSubmit() hook. That hook provided by our package takes the name of the function to handle the submission of our form.
The very first input in our comment form is a hidden field that contains the _id of our post. Any required form field will use the ref attribute to register with react-hook-form’s validation. When our form is submitted we need to do something with the data submitted. That’s what our onSubmit() function is for.
// Function for handling the form submission
const onSubmit = async data => {
setIsSubmitting(true)
setFormData(data)
try {
await fetch('/api/createComment', {
method: 'POST',
body: JSON.stringify(data),
type: 'application/json'
})
setIsSubmitting(false)
setHasSubmitted(true)
} catch (err) {
setFormData(err)
}
}
This function has two primary goals:
Set state for the form through the process of submitting with the state we created earlier
Submit the data to a serverless function via a fetch() request. Next.js comes with fetch() built in, so we don’t need to install an extra package.
We can take the data submitted from the form — the data argument for our form handler — and submit that to a serverless function that we need to create.
We could post this directly to the Sanity API, but that requires an API key with write access and you should protect that with environment variables outside of your front-end. A serverless function lets you run this logic without exposing the secret token to your visitors.
Submitting the comment to Sanity with a Next.js API route
In order to protect our credentials, we’ll write our form handler as a serverless function. In Next.js, we can use “API routes” to create serverless function. These live alongside our page routes in the /blog-frontent/pages directory in the api directory. We can create a new file here called createComment.js.
To write to the Sanity API, we first need to set up a client that has write permissions. Earlier in this demo, we set up a read+write token and put it in /blog-frontent/.env.local. This environment variable is already in use in a client object from /blog-frontend/lib/sanity.js. There’s a read+write client set up with the name previewClient that uses the token to fetch unpublished changes for preview mode.
At the top of our createClient file, we can import that object for use in our serverless function. A Next.js API route needs to export its handler as a default function with request and response arguments. Inside our function, we’ll destructure our form data from the request object’s body and use that to create a new document.
Sanity’s JavaScript client has a create() method which accepts a data object. The data object should have a _type that matches the type of document we wish to create along with any data we wish to store. In our example, we’ll pass it the name, email, and comment.
We need to do a little extra work to turn our post’s _id into a reference to the post in Sanity. We’ll define the post property as a reference and give the_id as the _ref property on this object. After we submit it to the API, we can return either a success status or an error status depending on our response from Sanity.
// This Next.js template already is configured to write with this Sanity Client
import {previewClient} from '../../lib/sanity'
export default async function createComment(req, res) {
// Destructure the pieces of our request
const { _id, name, email, comment} = JSON.parse(req.body)
try {
// Use our Client to create a new document in Sanity with an object
await previewClient.create({
_type: 'comment',
post: {
_type: 'reference',
_ref: _id,
},
name,
email,
comment
})
} catch (err) {
console.error(err)
return res.status(500).json({message: `Couldn't submit comment`, err})
}
return res.status(200).json({ message: 'Comment submitted' })
}
Once this serverless function is in place, we can navigate to our blog post and submit a comment via the form. Since we have an approval process in place, after we submit a comment, we can view it in the Sanity Studio and choose to approve it, deny it, or leave it as pending.
Take the commenting engine further
This gets us the basic functionality of a commenting system and it lives directly with our content. There is a lot of potential when you control both sides of this flow. Here are a few ideas for taking this commenting engine further.
Create and send an email notification for a new message with SendGrid or other mail services.
Section the Sanity Studio API to show Approved, Unapproved, and Pending comments with Sanity’s Structure Builder.
We’ve certainly all heard the adage that a picture paints a thousand words. Turns out there is some science to this, as a now-classic and often-cited 1986 study found that the human brain processes images up to 60,000 times faster than it would text.
This number still stands, and we’ve since uncovered several other compelling facts about the many reasons why images support our marketing efforts. And one other way images can increase our marketing ROI that isn’t just being able to create highly engaging, memorable content?
Boosting SEO. Indeed, those original infographics, graphs, and charts you’re putting up with your blog posts can go much further than just breaking up long paragraphs of text or providing visual support for your data. They can boost your site traffic significantly, especially when paired with other SEO best practices.
In this post, we’re going to show you just how you can get started with your own image SEO campaigns using 7 of the best tips to really skyrocket your results. And after implementing these into your content marketing strategy, your site stands to benefit from higher traffic, more engaged readers, and increased leads and conversions overall.
Image SEO Best Practices to Use
When you combine traditional SEO tips for blog posts with image SEO, you increase your chances of ranking higher and higher in search engine results. Check out these essential 7 tips that will make your image SEO campaign a breeze.
Do your keyword research
Image SEO all starts with the right foundation, so it should come as no surprise that the first essential best practice is nailing down the right keywords you want to rank for. Do your due diligence and conduct some keyword research to get to know the best search terms to use, as well as secondary keywords that may give search engine crawlers more context about your image and content.
You’ll ideally want to choose keywords that are a balance of high search volume but with lower competition. After doing your research, choose one main keyword you want to rank for, and then list down 2 or 3 supporting keyword phrases.
Then keep this somewhere handy since you’ll be needing these throughout other steps.
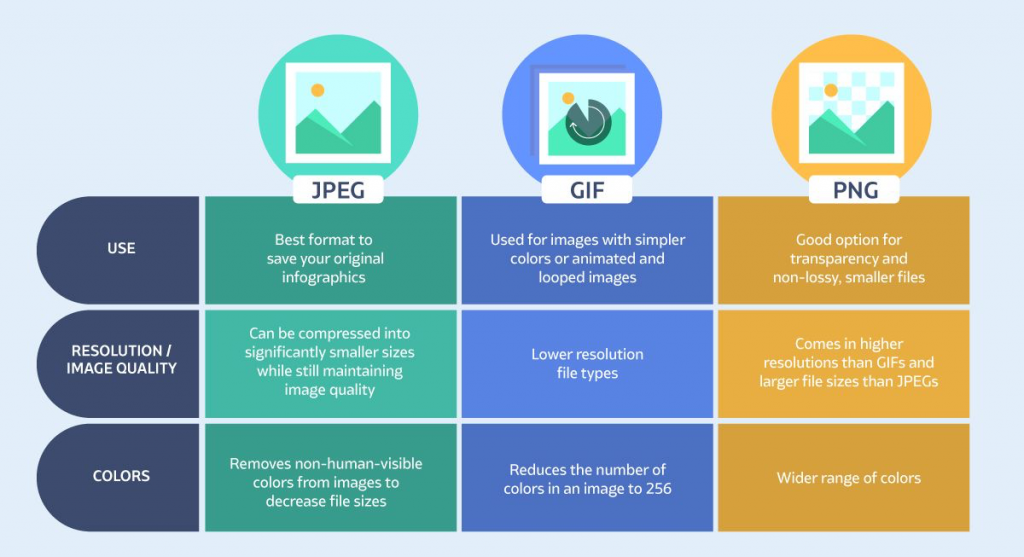
Use the right image format
If you’re new to image SEO, then it can be intimidating to have to understand what different image formats mean and why they matter. To make it as simple as possible, here’s what you absolutely need to know:
SVG. This file type is exclusively the best option for vector images. Vector images are usually shapes, icons, logos, and any flat images that you’ll want to keep high quality regardless of its size.
JPEG. These are good to use if you have generally more visual images, including stock photography or original infographics because of their smaller file size and compressibility.
GIF. You’ve probably seen tons of blogs now using GIFs to add notes of whimsy or personality into their blog posts. These work great with animated images or short video loops.
PNG. PNG is one of the best file types to use online since you can easily keep transparent backgrounds, display a wide range of colors and lossless image quality overall. Its most notable downside is the higher file size, but the quality of the images that it loads more than makes up for that fact.
Here’s an often-cited tip among SEO bloggers: compress your images. Larger images tend to take longer to load, and this can be a big snag that weighs down your overall SEO strategy.
Look at SEO as an all-encompassing strategy, where what seems like separate factors like images, keywords, or site speed actually work together to help boost your site rankings and thereby increase your traffic.
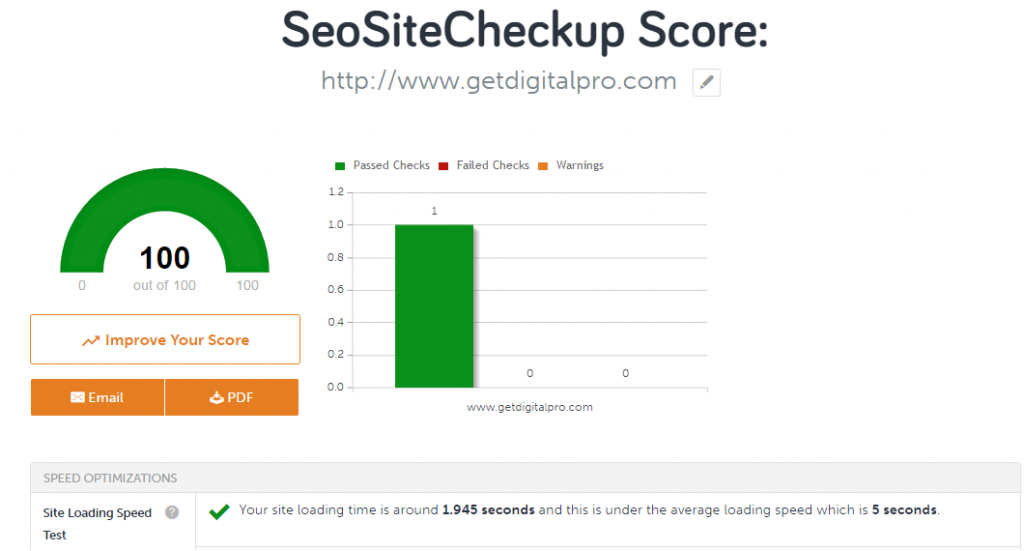
You can determine the health and speed of your site using popular SEO audit tools, like Seositecheckup.com. (Image source)
To search engines and their current algorithms that reward not only great content but also great website experiences, a slow-loading site is a signal that a user may not find the site valuable or worthwhile. In order to avoid search engine penalties for slow-loading sites, use tools like WP Smush, Tiny PNG, EWWW Image Optimizer, or image processors like Photoshop to adjust image sizes and resolution.
Original images with value works best
As much as possible, create original images over simply resorting to filling your site with stock photography. Doing the latter makes your site look like a generic site, while the former makes you interesting, engaging, and even increases perceived value in the eyes of blog readers.
This all plays into the bigger picture of recent SEO trends, where the E.A.T. concept — which stands for Expertise, Authority, Trust — is now a huge criteria for search rankings. By creating your own high-value images, including charts, infographics, or graphs, you’re doing just that.
And because Google now includes an Image search feature on its main site, by including a highly relevant and optimized image, you give your blog post and website a chance to be discovered organically when users toggle to the Image filter in their search query.
Infographics with comprehensive information presented in visually appealing ways, like this example taken from MyUKMailbox, not only help readers but even search engine crawlers to boost site rankings.
Optimize your alt text and description
Remember those keywords and keyword phrases you researched from the very first tip in this article? Here’s where that starts coming in.
It’s time to optimize your images using these keywords. One of the most important places to do just that is in the Alt Text section and description of your image.
Alt Text is the text that usually appears in the event a browser can’t load the image properly. Sometimes, you might hover over an image on a certain site, and see text hover where your cursor is; that too is sometimes the Alt Text attribute.
While it might not seem like the most crucial section to optimize, it’s important to note that even Google has confirmed that image Alt Text and tags go a long way for boosting site rankings.
Some content management systems like WordPress allow you to easily edit the Alt Text on images, but you can easily do this by adding a short Alt Tag using any standard HTML editor.
So if you had an infographic containing social media marketing statistics, your HTML might look like this:
You can do the same thing for your image description, this time sprinkling in your keywords as organically as possible. This helps provide context for web crawlers, and boosts your chances of ranking at the top of Image search query results.
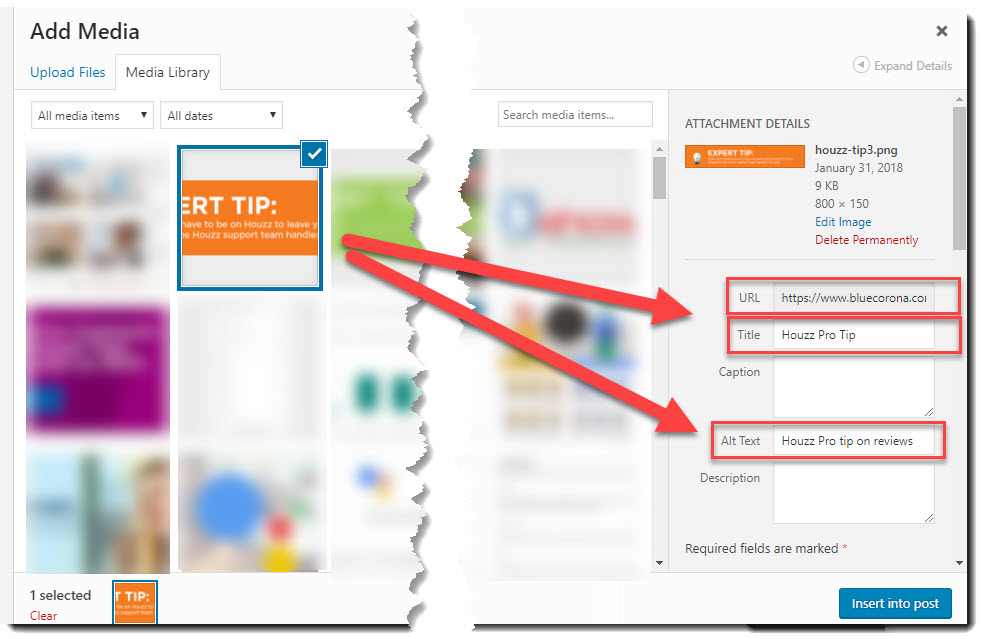
You can edit Alt Text and image descriptions straight from your WordPress Media Library. (Image source)
Make your images mobile-friendly
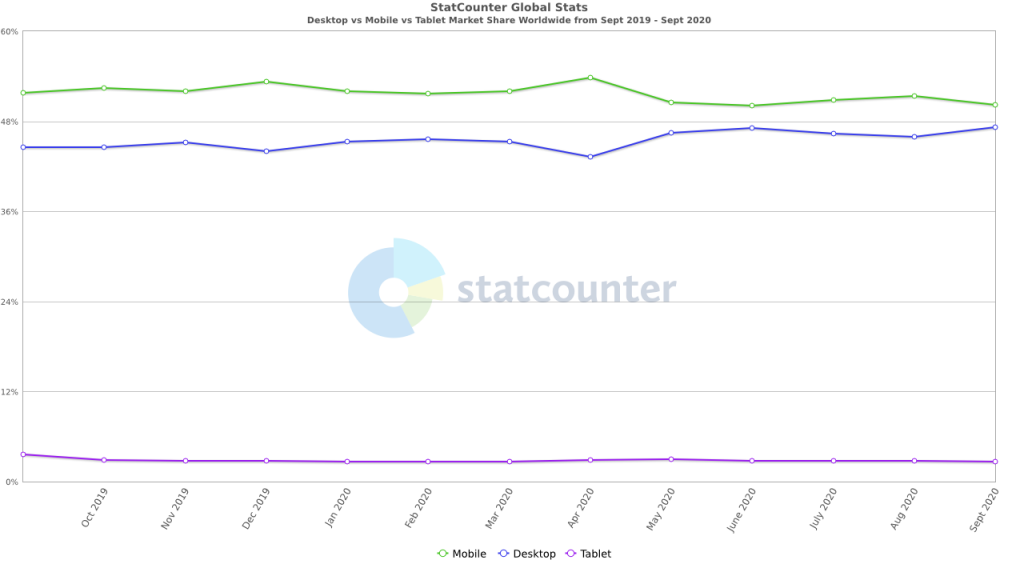
Since 2019, we’ve seen people’s search behaviors change — even more so as the world went digital given recent coronavirus measures. For instance, mobile search (50.21% as of September 2020) is now the most-used platform when conducting searches, overtaking desktop searches (47.17% as of September 2020) overall.
Because of this, make sure your images are optimized for mobile devices too. This simply means using responsive images, which scale up or down depending on the device in which they’re viewed. You may need to speak to your site developer to ensure that this is a staple command on your site, or if you use a theme, you can check with your theme’s creator if they’ve included this vital feature.
Last but not least, don’t underestimate the power of your image’s name. Your filename is often what informs the image URL, and we’re all too guilty of naming our images with random letters, numbers, or phrases at times.
Break the habit and practice responsible and accurate image naming. The reason this works is because search engines need all the help they can get when they’re trying to contextualize elements on your site. So if your infographic had the filename “infographic.jpg,” search engines will have a hard time identifying just what your image is about.
Name your images using your main keyword phrase, or whatever is most relevant. Use small caps and hyphens instead of spaces. This is a small change, but it can be a big boost in the long run.
Key Takeaways
Image SEO supports your overall SEO strategy, and by staying ahead of the competition and practicing these top tips, you can easily soar and dominate the rankings. Be sure to implement these simple image SEO tips and best practices, and soon you’ll see more traffic on your blog over time.
Domain Authority (DA) is a ranking metric that predicts how well a site will rank online. It goes by a scale of 1 to 100 — the closer you are to 100, the better your odds of ranking in search engine result pages (SERPs), thus giving you more clicks.
To see how your site currently ranks, visit Moz’s free Link Explorer to test your DA. Just type your website URL in the search bar and click “Analyze”. Just remember: don’t kick yourself if your DA is smaller than 30 to 50. If you follow these 9 tips today, you’ll most definitely see your DA score improve.
1. Domain Name Age
You know that old saying, right? Wisdom comes with age. Well, guess what? The same is true for your domain name. If your domain name doesn’t have an ‘old’ age, then it’ll rank lower, and users online might not see your site as legitimate.
But with an older domain name, not only will users see your site as more legitimate, but it’ll also have a much higher DA score than younger domain names. In other words, every time you change your domain, you might be doing more harm than good to it, since you’re actually knocking down the credibility you’ve built up over the years by starting from scratch.
Therefore, pick an easy-to-remember domain name that’s not only relevant to your niche, but it’s also something that you’re willing to keep for a very long time.
2. On-Page Optimization
Then, it’s time to optimize all the following on your pages:
Code;
Content;
Site structure;
Metatags;
Other on-page elements (H1, Title tags, Image alt tag, Site architecture, etc.).
Improving your DA with optimization can make your site be more search-engine-friendly.
3. Create Great Content
Want to attract high-quality links from multiple domains in your niche? Good news! More attraction to your site comes from creating high-quality content that appeals to your target audience. Otherwise, poor-quality content will only scare people away.
So, in providing the best content possible, that will definitely help you improve your DA score (and even give you many additional SEO benefits).
4. Internal Link Improvement
Why worry about earning external links when your internal links need the most attention? Yes, focusing too much on external links can make you lose sight of linking internally.
So, why internal links? These links help nudge visitors to what they’re trying to look for on your website. In that way, visitors are getting the best user experience, while you reap the rewards of having an increased DA score.
5. Link Profile Clean-Up
Having a clean link profile is essential, since it helps you obtain and maintain a great DA score. So, to clean up your link profile, you must remove the bad links from it.
These tools help you figure out any inappropriate or unwanted links.
After the link audit is complete, contact the website owners to have them either delete the link or add the “nofollow tag” (devalues the link). If this doesn’t work, use the Google Disavow tool to remove said links from your profile.
6. Know Your Niche
When running a site, it’s important for you to be the expert in what you have to offer online – and your DA is no exception to this. Becoming an authoritative figure in your niche allows you to gain the confidence of readers, while providing expert advice to the community.
If you have amazing content (i.e. guest blogs on industry-related forums) and clever ways to engage your target audience, then people will see you as an authority to your niche. This not only enhances your brand, but also increases your DA score.
7. Be Mobile-Friendly
Nowadays, people are on their phones, tablets, etc. Whatever device that they can use on the go, they’ll use. In other words, mobile isn’t just the way of the future – it’s happening right now, outpacing laptops since 2014. So, if your website isn’t mobile-friendly yet, then now is the time to fix that!
If your website hasn’t been optimized for mobile use yet, not only will it hurt your search rankings (since Google favors mobile-friendly sites), but you’ll also lose out on users visiting your site to begin with.
So, go to Google’s Mobile-Friendly Test, and then run a test for your domain. Afterwards, Google will give you a detailed report of how mobile-friendly your site is, and what you can do to improve it.
8. Improve Page Speed
Let’s face it: No one likes to wait for a webpage to load; they want quick results. So, if your site isn’t loading fast enough, then users will get frustrated and most likely go to another site. So, why not improve your page speed?
First, find the cause of your website running slower than it should. You can do this by running your website through Google’s PageSpeed Insights; it’ll analyze the speed of your site. And then, it will identify some effective ways for you to make your site faster and consequently improve your DA score.
9. Utilize Social Media
Finally, it’s important to increase your social signals, when it comes to gaining more authority with your domain. While search engines like Google won’t insist that sites make social signals a priority to increase their rankings, site runners must still take advantage of social media to do the following:
Promote their sites;
Promote their products and services;
Tell people about any events and contests.
As a result, sites are more likely to get likes, shares, and tweets through social media, versus going solo in search engines.
Conclusion
Domain authority is extremely important for your site. First, DA allows you to analyze how well your website does in the search space. Plus, it allows you to compare the performance of your website with that of your rival sites, thus showing you where you stand in search engine results.
So, why not get your site thriving today by improving and maintaining your DA score today? Your site will thank you for it!
localStorage can be an incredibly useful tool in creating experiences for applications, extensions, documentation, and a variety of use cases. I’ve personally used it in each! In cases where you’re storing something small for the user that doesn’t need to be kept permanently, localStorage is our friend. Let’s pair localStorage with Vue, which I personally find to be a great, and easy-to-read developer experience.
Simplified example
I recently taught a Frontend Masters course where we built an application from start to finish with Nuxt. I was looking for a way that we might be able to break down the way we were building it into smaller sections and check them off as we go, as we had a lot to cover. localStorage was a gsolition, as everyone was really tracking their own progress personally, and I didn’t necessarily need to store all of that information in something like AWS or Azure.
Here’s the final thing we’re building, which is a simple todo list:
CodePen Embed Fallback
Storing the data
We start by establishing the data we need for all the elements we might want to check, as well as an empty array for anything that will be checked by the user.
We’ll also output it to the page in the template tag:
<div id="app">
<fieldset>
<legend>
What we're building
</legend>
<div v-for="todo in todos" :key="todo">
<input
type="checkbox"
name="todo"
:id="todo"
:value="todo"
v-model="checked"
/>
<label :for="todo">{{ todo }}</label>
</div>
</fieldset>
</div>
Mounting and watching
Currently, we’re responding to the changes in the UI, but we’re not yet storing them anywhere. In order to store them, we need to tell localStorage, “hey, we’re interested in working with you.” Then we also need to hook into Vue’s reactivity to update those changes. Once the component is mounted, we’ll use the mounted hook to select checked items in the todo list then parse them into JSON so we can store the data in localStorage:
That’s actually all we need for this example. This just shows one small possible use case, but you can imagine how we could use localStorage for so many performant and personal experiences on the web!