The 7 Best Email Outreach Tools in 2020

The rumor that cold outreach is dead has been circulating the web for years now and yet cold email conversion rates continue to remain high with the average ROI being $38 to every $1 invested- that is a 3800% ROI.
Of course, the success of your outreach campaign depends on a multitude of factors whether that is a high open-rate or a good subject line. For example, did you know that A/B testing your subject line can increase your open rates by 49%?

According to Convince and Convert, 35% of email recipients open the email based on the subject line alone. Small yet significant changes such as a good subject line or following up at the right time can be what convinces someone to hit reply to one of your emails.
This is where having the right email outreach software comes in. You want a piece of software that will allow you to monitor the way your campaign is performing (with analytics) and allow you to make changes to the campaign to see better results.
This is very different compared to email marketing software and it is easy to get the two mixed up since a lot of online communities tend to recommend email marketing tools and outreach tools as if they are interchangeable. They are not.
Email marketing tools help you reach out to people who have subscribed to your email list via an opt-in form. This means that you have already built a relationship with them and are simply fostering that relationship.
Email outreach software, on the other hand, is software that you use to cold outreach to prospects for the first time. It includes features like analytics, reporting, A/B testing emails, and more to help you convert emails into leads.
7 Email Outreach Software Options Worth Considering:
These are some of my favorite email outreach tools for everyone from a freelancer who is trying to grow their passive income to a marketing team with ten people running things behind the scenes.
#1 Mailshake
I highly recommend Mailshake to anyone who is looking for a great outreach tool that can work seamlessly with other software you want to tie into your outreach process. You can tie your calls, emails, and social media outreach together under one platform which makes every campaign much easier.
Here is what a campaign creation process looks like from the inside-
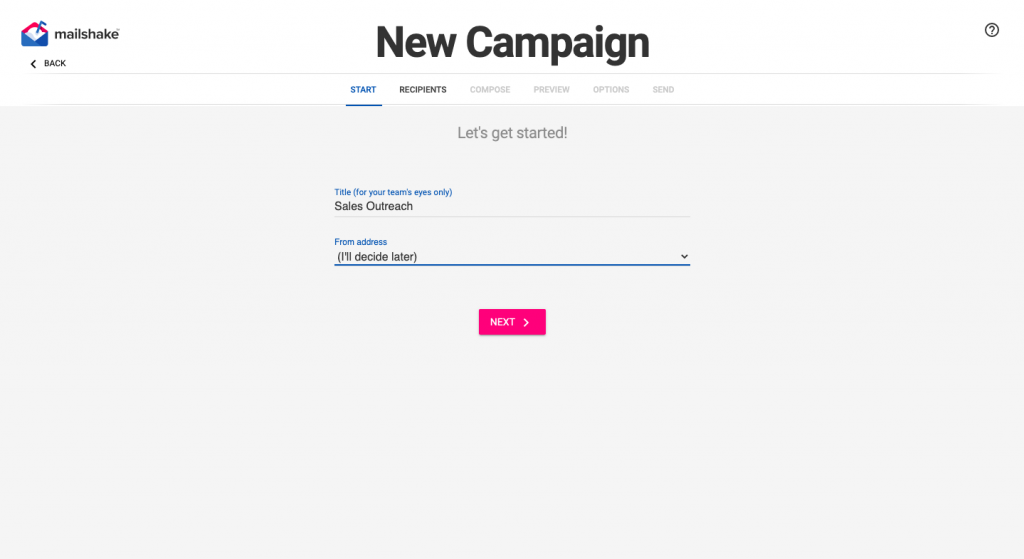
You decide what to call your campaign and what email address you want to send each email from. After that, you can create a list of recipients to reach out to by either adding a CSV file with their names and other contact information or using an existing list you have already uploaded. You can also manually add the email addresses.
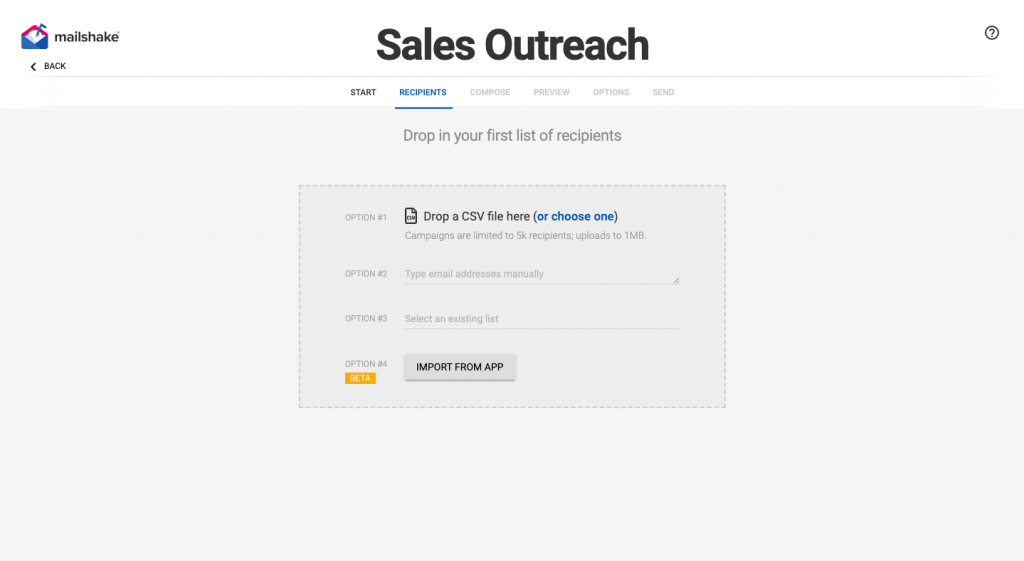
Now that you have got a list of people you want to reach out to you can begin creating your email. Mailshake has ways of making that much easier for you such as the ability to insert text replacements which means you can personalize an email template for every email you send out.
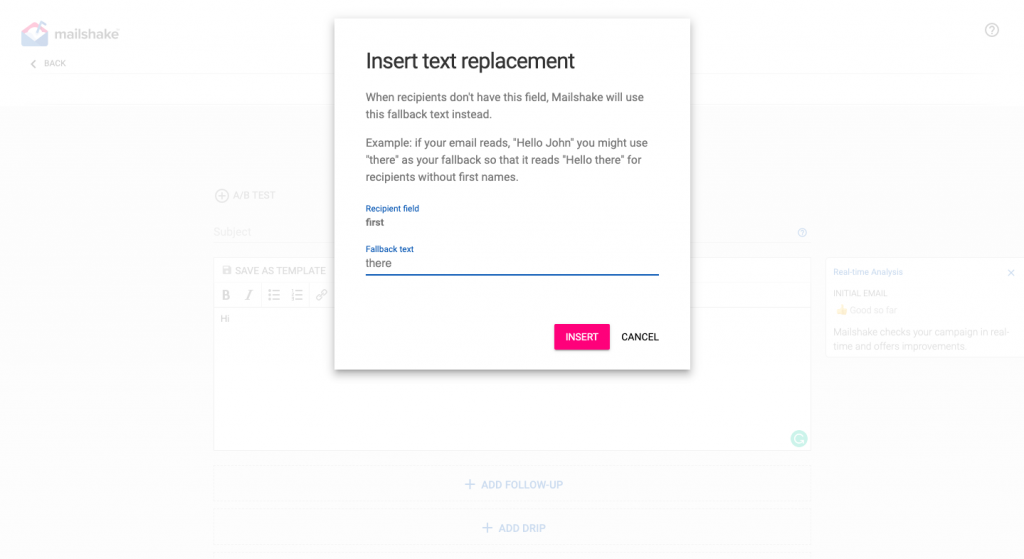
You can also add fallback texts such as ‘there’ if you do not have the name of the person to auto-add. Once you are done creating your initial outreach email, you can create follow-ups that will automatically send out a few days later based on your preferences (I personally see the best results spacing out each follow-up by 3-4 days).
Mailshake even allows you to track opens (how many times the person opened your email) and which links within your email they clicked. This helps you better understand what is interesting to your ideal customer.
Another feature I love is how clearly they show you when everything is going out through your sending calendar. Here is a look at mine-
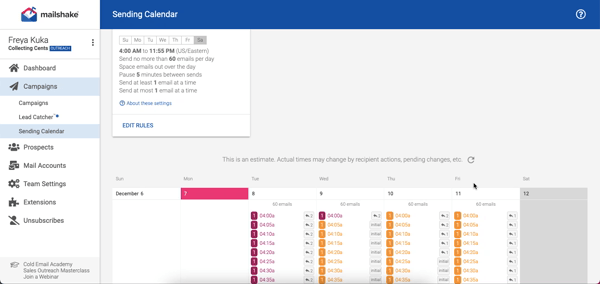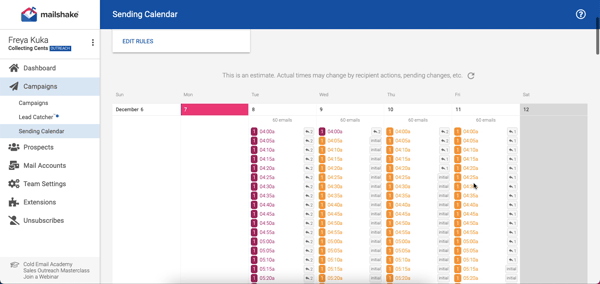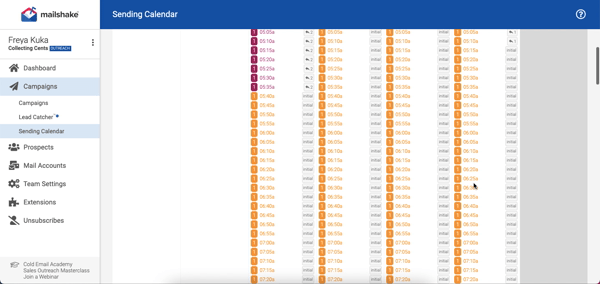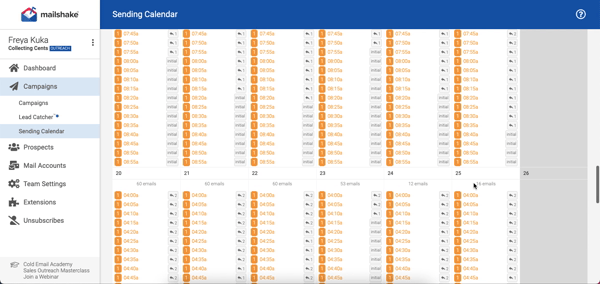
Essentially, Mailshake is a great tool to depend on if you are solely focused on email outreach and want the right tool to get you the best results. The pricing is pretty affordable and fair with the base package that focuses only on email outreach priced at $59 per month and the sales outreach package priced at $99 per month.
The sales outreach package is more suitable for marketing teams that include phone dialing and social selling as part of their outreach process.
#2 SalesHandy
Mailshake is great for me personally but I have had plenty of people ask me if I know of any options that are more affordable for absolute beginners or bloggers who want to scale their growth without spending $60 every single month.
Well, say hello to SalesHandy. A far more flexible pricing plan that starts at $9 for their regular plan and even a free plan for those in need of simply the bare essentials is what makes SalesHandy an option everyone can get behind.

However, this option does not come with the amount of personalization that Mailshake gives you. I also find Mailshake’s dashboard to give me better analytics and a better view of what is working and what isn’t.
For example, Mailshake allows me the ability to A/B test emails while SalesHandy does not.
#3 Prospect.io
Prospect dives a little deeper into email outreach while also diving a little deeper into your pockets. It is worth it for most marketing teams though- especially those teams that need to outreach at scale and can do with some extra help.
The key difference between Prospect and the tools we have covered so far is Prospect’s extra email finder feature. This feature essentially eliminates the need for email finder tools such as Hunter or FindThatLead that increase your overall monthly expenses in the long run.
So, indirectly you will save the extra money you spend on Prospect by eliminating the need to pay for an email finder tool like Hunter. Of course, some people may simply prefer using a separate tool for finding emails or may just prefer Hunter or FindThatLead’s algorithm. That comes down to preference.
It is also important to note that Prospect only gives customers 250 email finder credits in its essential plan ($89 per month) and 1,000 email finder credits in the Business plan ($149 per month). In comparison, Hunter gives you 500 searches for $49 per month (base plan) and FindThatLead gives you 5,000 for $49 per month (Growth Plan).
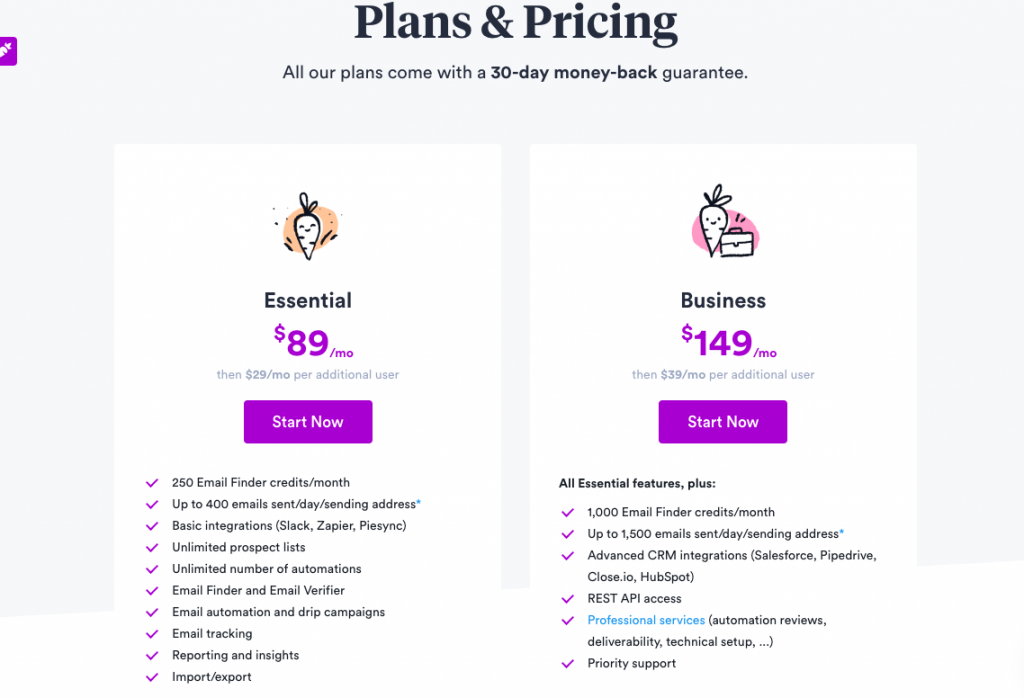
Apart from the email finder, their other features are pretty similar to competitor tools. They offer personalized emails, drip campaigns, automation, CRM integrations with companies like close.io and HubSpot, email tracking, and reporting among other features.
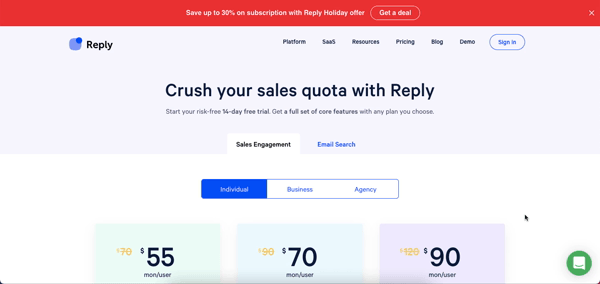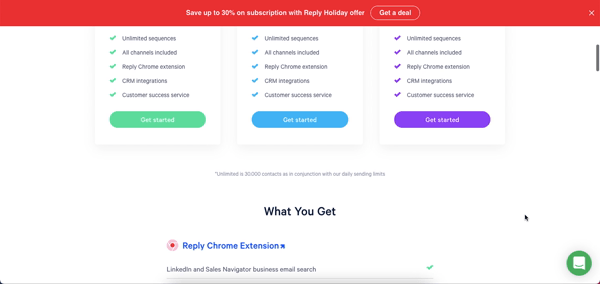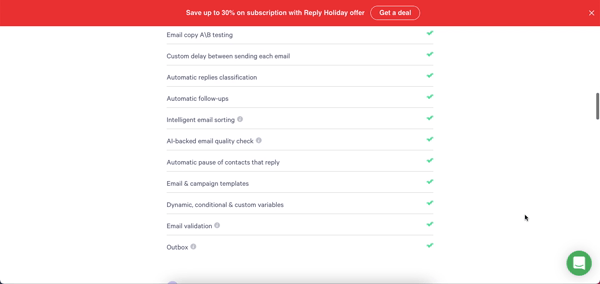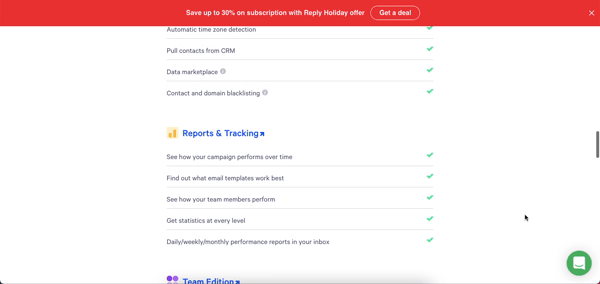
#4 Reply.io
Reply.io is more of an all-in-one outreach solution since it focuses on outreach via LinkedIn, calls, messages, WhatsApp, etc. alongside email outreach. Even their pricing plans are broken down by the number of people you can reach out to every month rather than channels of outreach.
So, if you are only interested in email outreach, this option does not make a whole lot of sense. When it comes to features, you can expect the basics- email tracking, adding follow-ups, scheduling campaigns, etc.
However, where reply.io shines is the additional features. Namely, email search and LinkedIn integration.
The integration with LinkedIn integration allows you to pull contact details from LinkedIn directly into the app. The email search feature is also pretty neat because we are normally stuck using a separate email finder tool. You can try the free plan with 200 credits and then choose to go for one of the paid plans if you like how it works.
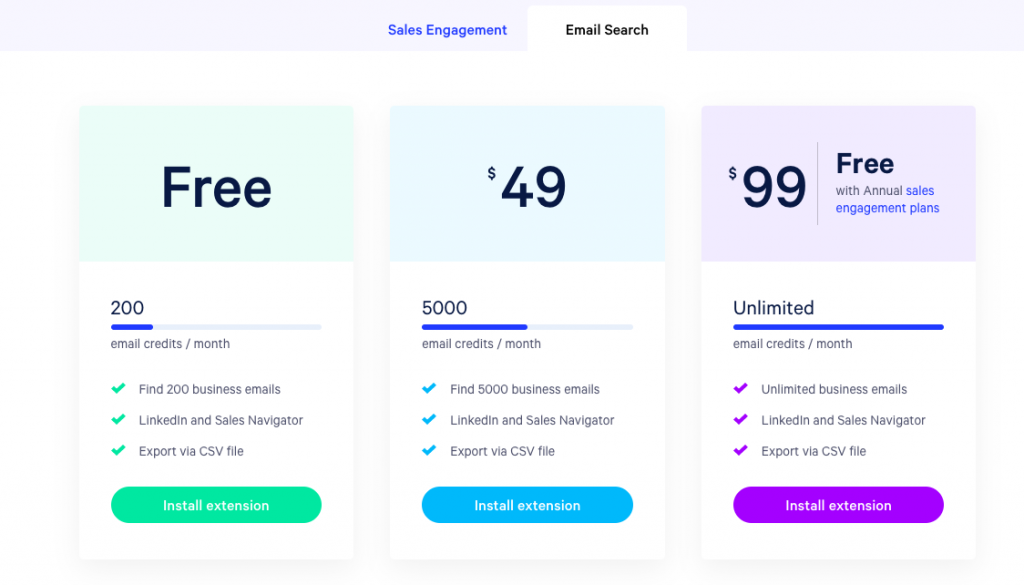
Lastly, pricing for the email outreach software starts at $70 per month per user and you can reach out to a 1000 contacts. After that, plans go up to $120 depending on how many contacts you want to reach.
#5 Snov.io
Snov.io is an often-overlooked email outreach assistant that deserves more attention. The pricing is great, it has every feature under the sun, and the dashboard is pretty visually appealing as well. They even have an email verify feature that helps you make sure the emails you are reaching out to are legit and won’t end up being undeliverable.
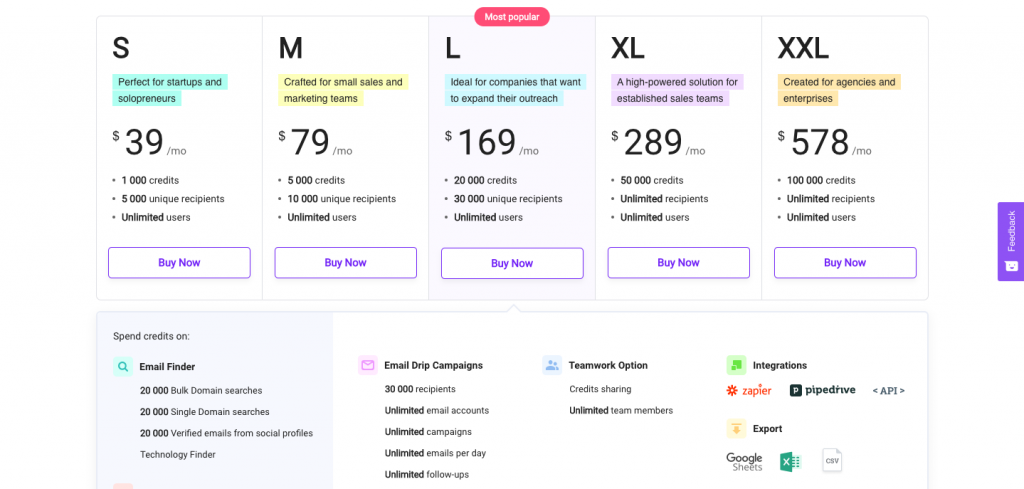
The email finder tool also comes with an additional chrome extension that you can use to find emails for every domain you visit. This is a simple, well-priced option for email outreach that includes everything you are going to need to nab some great leads.
#6 Outreach.io
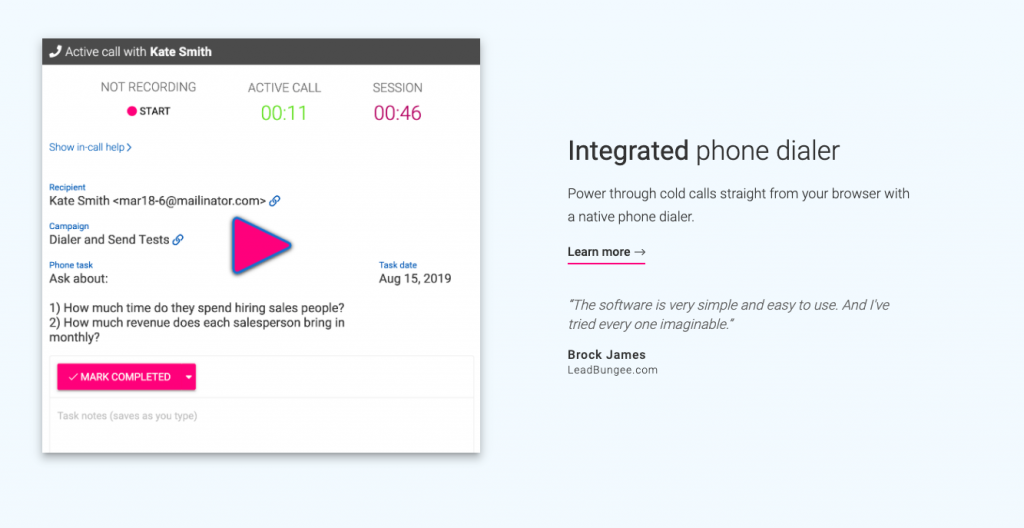
Outreach.io helps with more than just email outreach and is best suited for teams and sales management for companies. You have features like a phone dialer and the ability to sync up with your company’s CRM software. Once you track activity via email, social, or call; you can also set up online meetings through Outreach.
The last step of managing the opportunity or deal that comes through finding a new lead can also be done via the same software. All in all, this is a great solution for teams that are targeting a few contacts every month hoping to close some big-ticket deals.
#7 Autopilot
Autopilot is one of the most customizable outreach software options I can find. Some of the features Autopilot has that helps it stand out include-
- The ability to capture new leads from your website. This can be from a landing page or a blog post, for instance.
- Activity tracking allows you to see when customers have filled a form, visited a page, or opened one of the emails you sent out.
- The ‘outcome wheel’ allows you to change the next step of the outreach process for any individual client based on how they responded.
- A free 30-day trial lets you test out everything.
The ability to share your view with team members and work on responding to a client together makes this great for big companies.
What can email outreach be used for?
Now that you know what the market is offering you, let us talk about what an outreach email can be used for and what the end goal of an outreach campaign normally is.
Services or Products Provided By Your Team
A lot of outreach campaigns’ end goal is to get the responder to invest in a service or tool. Your service could be pretty much anything-
- A subscription service like Netflix
- Counseling services
- eCommerce products
- Training courses
- Freelance services of some kind (in this case you could lead your email readers towards your portfolio website so they can take a look at your work)
- Link building
- Keyword research, etc.
Forms or Surveys
If you are looking for more data on a subject, there is no better way to do it than to send out a simple form to the right people. The form can include a few easy to answer questions that will help you gain some valuable data on the subject.
You can use a free service like Jotform to create the survey you need.
An Auction
An outreach campaign can lead to an auction on your site wherein you are trying to sell something to the highest bidder (you can use a WordPress auction plugin to get this set up). This will allow you to reach out to interested parties before the auction starts and build up as much excitement as possible.
A Consultation
A big-ticket sale may need more customer management before you can ask for a sale. So, keeping this in mind, some outreach emails could simply lead to a consultation form as in the case of Brian White’s attorney practice.
This type of form can work for pretty much any consulting business from an attorney’s practice to a social media consulting company. The point is you are bringing your lead further down your sales funnel and the first step is outreach.
Things to keep in mind when crafting your email outreach template
It takes a whole lot of A/B testing to create an email outreach template that works and increases your conversion rates. It is a constant learning process and that can be exhausting which is why keeping a few basic tips in mind when creating your template can help you jump forward in the process.
Here are some things I would recommend-
- If you are reaching out to a company or blog, do not pretend like you have been a big fan of their work for ages. I personally roll my eyes whenever someone sends me an email saying they have followed my blog for ages because I know enough about my blog’s audience to know it isn’t people writing to me for favors. Do not mention you have used their service or read their work if you have not. People can normally tell that you haven’t.
- Consider greeting them enthusiastically. Even something as simple as an exclamation mark after the traditional ‘Hi ‘ could be helpful.
- Bolden any important bits of your email so people can skim through it.
- Personalize your email as much as you can. This could mean mentioning them by name or mentioning their company’s name within the email. No one likes replying to a forwarded message.
- Think about how you can help them instead of how they can help you. If you are asking someone if you can guest post on their website, let them know you are open to adding a quote of theirs in one of your future pieces.
- Lastly, sign off with a good email signature that lets people contact you easily if they need to. Here is mine-
Best,
Freya, personal finance blogger
Collecting Cents
You can also reach out to her on Twitter or Facebook.
Hopefully, these simple tips can help you craft your first outreach email so you can start seeing your efforts pay off sooner.
Wrapping it up
A lot of people tend to get into remote work of some sort thinking that is the end of outreach and human contact but that is simply not the case (sorry introverts!). You need to network, get to know people within your industry, and build relationships- even with people miles away.
If you want to do that at scale (which you should be doing), you cannot possibly expect to do it manually. A good outreach software will help you save time, connect with the right people, and give you enough information to show you what is working.
Photo by Austin Distel on Unsplash





































