Every week users submit a lot of interesting stuff on our sister site Webdesigner News, highlighting great content from around the web that can be of interest to web designers.
The best way to keep track of all the great stories and news being posted is simply to check out the Webdesigner News site, however, in case you missed some here’s a quick and useful compilation of the most popular designer news that we curated from the past week.
Low-code for Designers
The Scary Future of Instagram
Green UI/UX Trends: Designing with Sustainability In Mind
Whitehouse.gov Chooses WordPress, Again
Firefox Just Walked Away from a Key Piece of the Open Web
Escaping the Roadmap Trap
Iconduck – 100k Free Open Source Icons
Top Dying Programming Languages in 2021
Frugal Web Browser – A Design Experiment
Laws of UX V2.0
Pika Colour Picker
It’s Time We Say Goodbye to Pixel Units
The Holy Grail Layout with CSS Grid
Gleek – Free Online Diagramming Tool for Developers
The Styled-components Happy Path
A Google Designer Takes Us Inside Search’s Mobile Redesign
The Unreasonable Effectiveness of Simple HTML
Beau: No-code Customer Workflow Automation
Mona – Create a Beautiful Page to Sell your Skills
Why do You Need a UX Researcher on your Team?
Adee – Comprehensive Free Accessibility Testing Tool for Designers
Even the White House Logo Got a Makeover. See What Changed
Facet Image Editor
The Design Productivity Blueprint
How to Fix a Hacked WordPress Website
Want more? No problem! Keep track of top design news from around the web with Webdesigner News.
A clever use of CSS grid from Jay Freestone to accomplish a particular variation of the media object design pattern (where the image is centered with the title) without any magic numbers anything that isn’t flexible and resiliant.
The trick is to use an “extra” row above and below the title:
The image goes on the first three rows in the first column, and the content goes in the last three rows in the second column using named grid areas:
Read Jay’s post for a little more trickery required to make it entirely resilient.
I love the kind of post that zeroes in on the mental model behind CSS grid like this. It’s like… how can I slice up this design with arbitrary columns and rows, knowing that I can place things on arbitrary rectangular combinations of cells with any type of alignment, to best suit this design?
Nolan Lawson has a little emoji-picker-element that is awfully handy and incredibly easy to use. But considering you’d probably be using it within your own app, it should be style-able so it can incorporated nicely anywhere. How to allow that styling isn’t exactly obvious:
What wasn’t obvious to me, though, was how to allow users to style it. What if they wanted a different background color? What if they wanted the emoji to be bigger? What if they wanted a different font for the input field?
Nolan list four possibilities (I’ll rename them a bit in a way that helps me understand them).
CSS Custom Properties: Style things like background: var(--background, white);. Custom properties penetrate the Shadow DOM, so you’re essentially adding styling hooks.
Pre-built variations: You can add a class attribute to the custom elements, which are easy to access within CSS inside the Shadow DOM thanks to the pseudo selectors, like :host(.dark) { background: black; }.
Shadow parts: You add attributes to things you want to be style-able, like , then CSS from the outside can reach in like custom-component::part(foo) { }.
User forced: Despite the nothing in/nothing out vibe of the Shadow DOM, you can always reach the element.shadowRoot and inject a , so there is always a way to get styles in.
This is such a funky problem. I like the Shadow DOM because it’s the closest thing we have on the web platform to scoped styles which are definitely a good idea. But I don’t love any of those styling solutions. They all seem to force me into thinking about what kind of styling API I want to offer and document it, while not encouraging any particular consistency across components.
To me, the DOM already is a styling API. I like the scoped protection, but there should be an easy way to reach in there and style things if I want to. Seems like there should be a very simple CSS-only way to reach inside and still use the cascade and such. Maybe the dash-separated custom-element name is enough? my-custom-elemement li { }. Or maybe it’s more explicit, like @shadow my-custom-element li { }. I just think it should be easier. Constructable Stylesheets don’t seem like a step toward make it easier, either.
Last time I was thinking about styling web components, I was just trying to figure out how to it works in the first place, not considering how to expose styling options to consumers of the component.
Does this actually come up as a problem in day-to-day work? Sure does.
Heyyyy Web Component folks, I’m modernizing my old custom element (now built with lit-element and has better a11y and TimeJumping), but I left it as a PR because I have a few questions on how to best approach styling and customization. https://t.co/UecDytLUgF
I don’t see any particularly good options in that thread (yet) for the styling approach. If I was Dave, I’d be tempted to just do nothing. Offer minimal styling, and if people wanna style it, they can do it however they want from their copy of the component. Or they can “force” the styles in, meaning you have complete freedom.
How good is your knowledge of the history of design? Do you know which famous designer disliked computers? Or which designer compared their job to that of a host at a dinner party?
Kick back, relax, and take our quiz, featuring 24 memory-teasing quotes from some of the biggest names in design over the last century. How many can you get right?
High five to the Greensock gang for the ScrollTrigger release. The point of this new plugin is triggering animation when a page scrolls to certain positions, as well as when certain elements are in the viewport. Anything you’d want configurable about it, is. There’s been plenty of scroll-position libraries over the years, but Greensock has a knack for getting the APIs and performance just right — not to mention that because what you want is to trigger animations, now you’ve got Greensock at your fingertips making sure you’re in good hands. It’s tightly integrated with all the other animation possibilities of GSAP (e.g. animating a timeline based on scroll position).
They’ve got docs and a bunch of examples. I particularly like how they have a mistakes section with ways you can screw it up. Every project should do that.
CodePen is full of examples too, so I’ll take the opportunity to drop some here for your viewing pleasure. Note that while this is a paid plugin, you can play with it on CodePen for free (search for it).
CodePen Embed Fallback
CodePen Embed Fallback
CodePen Embed Fallback
CodePen Embed Fallback
CodePen Embed Fallback
If you’re worried about too much motion, that’s something that you can do responsibly through prefers-reduced-motion, which is available both as a CSS media query and in JavaScript.
I can’t stop thinking about this site. It looks like a pretty standard fare; a website with links to different pages. Nothing to write home about except that… the whole website is contained within a single HTML file.
What about clicking the navigation links, you ask? Each link merely shows and hides certain parts of the HTML.
<section id="home">
<!-- home content goes here -->
</section>
<section id="about">
<!-- about page goes here -->
</section>
Each
is hidden with CSS:
section { display: none; }
Each link in the main navigation points to an anchor on the page:
See that :target pseudo selector? That’s the magic! Sure, it’s been around for years, but this is a clever way to use it for sure. Most times, it’s used to highlight the anchor on the page once an anchor link to it has been clicked. That’s a handy way to help the user know where they’ve just jumped to.
CodePen Embed Fallback
Anyway, using :target like this is super smart stuff! It ends up looking like just a regular website when you click around:
Building a website in 2021? I’m guessing you’re going to take a component-driven approach. It’s all the chatter these days. React and Vue are everywhere (is Angular still a thing?), while other emerging frameworks continue to attempt a push into the spotlight.
Over the last decade or so we’ve seen an explosion of frameworks and tools that help us build sites systematically using components. Early frameworks like AngularJS helped shape the generic concept of web components. Web components are also reusable bits of HTML code that are written in JavaScript and made functional by the browser. They are client-side components.
But components, in a more generic sense, have actually been around much longer. In fact, they go back to the early days of the web. They just haven’t typically been called components, though they still function as such. Server components are also reusable bits of code, but are compiled into HTML before the browser sees them. They are server-side components, and they are still very much a thing today.
Even in a world in which all it seems like we hear is “React, React, React,” both types of components are still relevant and can help us build super awesome websites. Let’s explore how client and server components differ from one another. That will give us a clearer picture of where we came from. And then we’ll have the information we need to dream about the future.
Rendering
Perhaps the biggest difference between client-side and server-side components is what makes them what they are. That is the thing that is responsible for rendering them.
Server components are rendered by — you guessed it! — the server. They aren’t typically referred to as components. They’re often called partials, includes, snippets, or templates, depending on the framework in which they are used.
Server components can take two flavors. The first is the classic approach, which is to render components in real-time based on a request from the client. See here:
Server-side rendered components
The second flavor is the Jamstack approach. In this case, the entire site is compiled during a build a process, and static HTML is already available when requested by the client. See here:
Server components on a Jamstack site have already been compiled into HTML.
In both cases, the client (i.e. your browser) never sees the distinction between your components. It simply receives a bunch of HTML from the server.
Client components, on the other hand, are rendered by — you are two-for-two and on a ROLL! — the client. They are written in JavaScript and rendered by the client (your browser). Because the server is the server and it knows all, it can know about your client components, but whether it cares enough to do anything with them depends on the framework you’re using.
Like server components, there are also two flavors of client components. The first is the more official web component, which makes use of the shadow DOM. The shadow DOM helps with encapsulating styles and other functionality (we’ll talk more about this later). Frameworks like Polymer and Stencil make use of the shadow DOM.
The more popular frameworks, like React and Vue, represent the second flavor of component, which handles DOM manipulation and scoping on their own.
Interactivity
Because server components are just HTML when they are sent to the client, if they are to be interactive on the front end, the application must load JavaScript code separately.
Consider a countdown timer. Its presentation is determined by HTML and CSS (we‘ll come back to the CSS part). But if it is to do its thing (count), it also needs some JavaScript. That means not just bringing in that JavaScript, but also having a means by which the JavaScript can attach itself to the countdown’s HTML element(s), which must either be done manually or with (yet) another framework.
A component’s HTML and JavaScript are separated in SSR components.
Though this may feel unnecessarily tedious (especially if you’ve been around long enough to have been forced into this approach), there are benefits to it. It is a clear separation of concerns, where server-side code lives in one place, while the functionality lives in another. And it brings only the code it needs for the interactivity (theoretically), which can lessen the burden on the browser.
With client components, the markup and interactivity tend to be tightly coupled, often in the same file or directory. While this can quickly become a mess if you’re not diligent about staying organized, one major benefit to client components is that they already have access to the client. And because they are written in JavaScript, their functionality can ship right alongside their markup (and styles).
Client-side components are all wrapped up in JavaScript code.
Performance
In a one-to-one comparison, server-side components tend to perform better. When the page that a browser receives contains everything it needs for presentation, it’s going to be able to deliver that presentation to the user much quicker.
Technically all you need when rendering SSR components is a single request.
Because client-side components require JavaScript, the browser must download or process additional information (often in separate files) to be able to render the component.
Client component often require more code and requests.
That said, client-side components are often used within the context of a larger framework. React has Gatsby and Next, while Vue has Nuxt. These frameworks have mechanisms for creating a superior in-app experience. What I mean is that, while they may be slower to load the first page you visit on a site, they can then focus their energy on delivering subsequent views extremely fast — often faster than a server-side rendered site can deliver its content.
If you’re thinking, Yeah but whatabout pre-rendering and…
Yes, you’re right. We’ll get there. Also, no more spoilers, please. The rest of us are along for the ride.
Languages
Server components can be written in (almost) any server-side language. This enables you to write your templates in the same language as your application’s logic. For example, applications written with Ruby on Rails use ERB templating by default, which is a form of Ruby. Thus, Rails apps use the same language for the application itself as it does for its components.
The reason client components are written in JavaScript is because that’s the language browsers parse for interactivity on a website. However, JavaScript also has server-based runtimes, the most popular of which is Node.js. That means code for client components could be written in the same language as the application, as long as the application is written with Node (or similar).
Styling (CSS)
When it comes to styling components, server-side components run into the same trouble they face with JavaScript. The styles are typically detached from the components, and require a bit of extra effort to tie styles to the elements on the page.
However, there are frameworks like Tailwind CSS that are working to make this process less painful.
Many client-side component libraries come with CSS support (or at least a pattern for styling) right out of the box. That often means including the styles in the same file as the markup and logic, which can get messy. But typically, with a little effort, you can adjust that approach to your liking.
Welcome to the (hybrid) future
Neither type of component is the answer by itself. Server-side components require additional effort in styling and interactivity that feels unnecessary when we look at the offerings of client components. But then client components have a tendency to take away from performance on the front end. And because the success of a website often depends on user engagement, a lack of performance can hurt the end result and be enough not to want to use client components.
What does that mean for a future that demands both performance and a good developer experience? More than likely, a hybrid approach.
Components are going to have to be rendered on the server side. They just are. That‘s how we optimize performance, and good performance is going to continue to be an attribute of successful websites. But, now that we’ve seen the ease of front-end logic and interactivity using frameworks, again, like React and Vue, those frameworks are here to stay (at least for awhile).
So where are we going?
I think we’re going to see these components come together in three ways in the very near future.
1. Advancement of JavaScript framework frameworks
Remember when you thought up that spoiler about pre-rendering? Well, let’s talk about it now.
Frameworks like Gatsby, Next, and Nuxt act as front-end engines built on top of component frameworks, like React and Vue. They bring together tooling to build a comprehensive front-end experience using their preferred framework. One such feature is pre-rendering, which means these engines will introspect components and then write static HTML on the page while the site is being built. Then, when users view that page, it‘s actually already there. They don’t need JavaScript to view it.
However, JavaScript comes into play through a process called hydration. After the page loads and your user sees all the (static) content, that’s when JavaScript goes to work. It takes over the components to make them interactive. This provides the opportunity to build a client-side, component-based website with some of the benefits of the server, namely performance and SEO.
These tools have gotten super popular because of this approach, and I suspect we’ll see them continue to advance.
2. Baked-in client-side pre-rendering
That’s a lot of compound words.
What I‘ve been thinking about a lot the last couple years is: Why doesn’t React (or Vue) take on server-side rendering? They do, it’s just not super easy to understand or implement without another framework to help.
On one hand, I understand the single-responsibility principle, and that these component frameworks are just ways to build client-side components. But it felt like a huge miss to delegate server-side rendering to bigger, more complex tools like Gatsby and Next (among others).
I think we‘re going to see a lot more development while these traditionally client-side-focused tools solve for server-side rendering. I suspect that also means we‘ll hear a little more from Svelte in the future, which seems like it’s ahead of the game in this regard.
That may also lead to the development of more competitors to bulkier tools like Gatsby and Next. For example, look at what Netlify is doing with their website. It‘s an Eleventy project that pulls in Vue components and renders them for use on the server. What it’s missing is the hydration and interactivity piece. I expect that to come together in the very near future.
3. Server-side component interactivity
And still, we can‘t discount the continued use of server-side components. The one side effect of both of the other two advancements is that they’re still using JavaScript frameworks that can feel unnecessary when you only need just a little interactivity.
There must be a simpler way to add just a little JavaScript to make a server-side component that are written in a server-side language more interactive.
Solving that problem seems to be the approach from the folks at Basecamp, who just released Hotwire, which is a means to bring some of the gains of client components to the server, using (almost) any server-side language.
I don‘t know if that means we‘re going to see competition to Hotwire emerge right away. But I do think Hotwire is going to get some attention. And that might just bring folks back to working with full-stack monolithic frameworks like Rails. (Personally, I love that Rails hasn’t become obsolete in this JavaScript-focused world. The more competition we have, the better the web gets.)
Where do you think all this component business is going? Let’s talk about it.
In this article, we explain how to build an integrated and interactive data visualization layer into an application with Cumul.io. To do so, we’ve built a demo application that visualizes Spotify Playlist analytics! We use Cumul.io as our interactive dashboard as it makes integration super easy and provides functionality that allow interaction between the dashboard and applications (i.e. custom events). The app is a simple JavaScript web app with a Node.js server, although you can, if you want, achieve the same with Angular, React and React Native while using Cumul.io dashboards too.
Here, we build dashboards that display data from the The Kaggle Spotify Dataset 1921–2020, 160k+ Tracks and also data via the Spotify Web API when a user logs in. We’ve built dashboards as an insight into playlist and song characteristics. We’ve added some Cumul.io custom events that will allow any end user visiting these dashboards to select songs from a chart and add them to one of their own Spotify playlists. They can also select a song to display more info on them, and play them from within the application. The code for the full application is also publicly available in an open repository.
Here’s a sneak peak into what the end result for the full version looks like:
What are Cumul.io custom events and their capabilities?
Simply put, Cumul.io custom events are a way to trigger events from a dashboard, to be used in the application that the dashboard is integrated in. You can add custom events into selected charts in a dashboard, and have the application listen for these events.
Why? The cool thing about this tool is in how it allows you to reuse data from an analytics dashboard, a BI tool, within the application it’s built into. It gives you the freedom to define actions based on data, that can be triggered straight from within an integrated dashboard, while keeping the dashboard, analytics layer a completely separate entity to the application, that can be managed separately to it.
What they contain:Cumul.io custom events are attached to charts rather than dashboards as a whole. So the information an event has is limited to the information a chart has.
An event is simply put a JSON object. This object will contain fields such as the ID of the dashboard that triggered it, the name of the event and a number of other fields depending on the type of chart that the event was triggered from. For example, if the event was triggered from a scatter plot, you will receive the x-axis and y-axis values of the point it was triggered from. On the other hand, if it were triggered from a table, you would receive column values for example. See examples of what these events will look like from different charts:
// 'Add to Playlist' custom event from a row in a table
{
"type":"customEvent",
"dashboard":"xxxx",
"name":"xxxx",
"object":"xxxx",
"data":{
"language":"en",
"columns":[
{"id":"Ensueno","value":"Ensueno","label":"Name"},
{"id":"Vibrasphere","value":"Vibrasphere","label":"Artist"},
{"value":0.406,"formattedValue":"0.41","label":"Danceability"},
{"value":0.495,"formattedValue":"0.49","label":"Energy"},
{"value":180.05,"formattedValue":"180.05","label":"Tempo (bpm)"},
{"value":0.568,"formattedValue":"0.5680","label":"Accousticness"},
{"id":"2007-01-01T00:00:00.000Z","value":"2007","label":"Release Date (Yr)"},
],
"event":"add_to_playlist"
}
}
//'Song Info' custom event from a point in a scatter plot
{
"type":"customEvent",
"dashboard":"xxxx",
"name":"xxxx",
"object":"xxxx",
"data":{
"language":"en",
"x-axis":{"id":0.601,"value":"0.601","label":"Danceability"},
"y-axis":{"id":0.532,"value":"0.532","label":"Energy"},
"name":{"id":"xxxx","value":"xxx","label":"Name"},
"event":"song_info"
}
}
The possibilities with this functionality are virtually limitless. Granted, depending on what you want to do, you may have to write a couple more lines of code, but it is unarguably quite a powerful tool!
The dashboard
We won’t actually go through the dashboard creation process here and we’ll focus on the interactivity bit once it’s integrated into the application. The dashboards integrated in this walk through have already been created and have custom events enabled. You can, of course create your own ones and integrate those instead of the one we’ve pre-built (you can create an account with a free trial). But before, some background info on Cumul.io dashboards;
Cumul.io offers you a way to create dashboards from within the platform, or via its API. In either case, dashboards will be available within the platform, decoupled from the application you want to integrate it into, so can be maintained completely separately.
On your landing page you’ll see your dashboards and can create a new one:
You can open one and drag and drop any chart you want:
You can connect data which you can then drag and drop into those charts:
And, that data can be one of a number of things. Like a pre-existing database which you can connect to Cumul.io, a dataset from a data warehouse you use, a custom built plugin etc.
Enabling custom events
We have already enabled these custom events to the scatter plot and table in the dashboard used in this demo, which we will be integrating in the next section. If you want to go through this step, feel free to create your own dashboards too!
First thing you need to do will be to add custom events to a chart. To do this, first select a chart in your dashboard you’d like to add an event to. In the chart settings, select Interactivity and turn Custom Events on:
To add an event, click edit and define its Event Name and Label. Event Name is what your application will receive and Label is the one that will show up on your dashboard. In our case, we’ve added 2 events; ‘Add to Playlist’ and ‘Song Info’:
This is all the setup you need for your dashboard to trigger an event on a chart level. Before you leave the editor, you will need your dashboard ID to integrate the dashboard later. You can find this in the Settings tab of your dashboard. The rest of the work remains on application level. This will be where we define what we actually want to do once we receive any of these events.
Takeaway points
Events work on a chart level and will include information within the limits of the information on the chart
To add an event, go to the chart settings on the chart you want to add them to
Define name and label of event. And you’re done!
(Don’t forget to take note of the dashboard ID for integration)
Using custom events in your own platform
Now that you’ve added some events to the dashboard, the next step is to use them. The key point here is that, once you click an event in your dashboard, your application that integrates the dashboard receives an event. The Integration API provides a function to listen to these events, and then it’s up to you to define what you do with them. For more information on the API and code examples for your SDK, you can also check out the relevant developer docs.
For this section, we’re also providing an open GitHub repository (separate to the repository for the main application) that you can use as a starting project to add custom events to.
The cumulio-spotify-datatalks repository is structured so that you can checkout on the commit called skeleton to start from the beginning. All the following commits will represent a step we go through here. It’s a boiled down version of the full application, focusing on the main parts of the app that demonstrates Custom Events. I’ll be skipping some steps such as the Spotify API calls which are in src/spotify.js, so as to limit this tutorial to the theme of ‘adding and using custom events’.
Let’s have a look at what happens in our case. We had created two events; add_to_playlist and song_info. We want visitors of our dashboard to be able to add a song to their own playlist of choice in their own Spotify account. In order to do so, we take the following steps:
First, we need to add a dashboard to our application. Here we use the Cumul.io Spotify Playlist dashboard as the main dashboard and the Song Info dashboard as the drill through dashboard (meaning we create a new dashboard within the main one that pops up when we trigger an event). If you have checked out on the commit called skeleton and npm run start, the application should currently just open up an empty ‘Cumul.io Favorites’ tab, with a Login button at the top right. For instructions on how to locally run the project, go to the bottom of the article:
To integrate a dashboard, we will need to use the Cumulio.addDashboard() function. This function expects an object with dashboard options. Here’s what we do to add the dashboard:
In src/app.js, we create an object that stores the dashboard IDs for the main dashboard and the drill through dashboard that displays song info alongside a dashboardOptions object:
// create dashboards object with the dashboard ids and dashboardOptions object
// !!!change these IDs if you want to use your own dashboards!!!
const dashboards = {
playlist: 'f3555bce-a874-4924-8d08-136169855807',
songInfo: 'e92c869c-2a94-406f-b18f-d691fd627d34',
};
const dashboardOptions = {
dashboardId: dashboards.playlist,
container: '#dashboard-container',
loader: {
background: '#111b31',
spinnerColor: '#f44069',
spinnerBackground: '#0d1425',
fontColor: '#ffffff'
}
};
We create a loadDashboard() function that calls Cumulio.addDashboard(). This function optionally receives a container and modifies the dashboardOptions object before adding dashboard to the application.
// create a loadDashboard() function that expects a dashboard ID and container
const loadDashboard = (id, container) => {
dashboardOptions.dashboardId = id;
dashboardOptions.container = container || '#dashboard-container';
Cumulio.addDashboard(dashboardOptions);
};
Finally, we use this function to add our playlist dashboard when we load the Cumul.io Favorites tab:
At this point, we’ve integrated the playlist dashboard and when we click on a point in the Energy/Danceability by Song scatter plot, we get two options with the custom events we added earlier. However, we’re not doing anything with them yet.
Listen to incoming events
Now that we’ve integrated the dashboard, we can tell our app to do stuff when it receives an event. The two charts that have ‘Add to Playlist’ and ‘Song Info’ events here are:
First, we need to set up our code to listen to incoming events. To do so, we need to use the Cumulio.onCustomEvent() function. Here, we chose to wrap this function in a listenToEvents() function that can be called when we load the Cumul.io Favorites tab. We then use if statements to check what event we’ve received:
This is the point after which things are up to your needs and creativity. For example, you could simply print a line out to your console, or design your own behaviour around the data you receive from the event. Or, you could also use some of the helper functions we’ve created that will display a playlist selector to add a song to a playlist, and integrate the Song Info dashboard. This is how we did it;
Add song to playlist
Here, we will make use of the addToPlaylistSelector() function in src/ui.js. This function expects a Song Name and ID, and will display a window with all the available playlists of the logged in user. It will then post a Spotify API request to add the song to the selected playlist. As the Spotify Web API requires the ID of a song to be able to add it, we’ve created a derived Name & ID field to be used in the scatter plot.
An example event we receive on add_to_playlist will include the following for the scatter plot:
"name":{"id":"So Far To Go&id=3R8CATui5dGU42Ddbc2ixE","value":"So Far To Go&id=3R8CATui5dGU42Ddbc2ixE","label":"Name & ID"}
We extract the Name and ID of the song from the event via the getSong() function, then call the ui.addToPlaylistSelector() function:
/*********** LISTEN TO CUSTOM EVENTS AND ADD EXTRAS ************/
const getSong = (event) => {
let songName;
let songArtist;
let songId;
if (event.data.columns === undefined) {
songName = event.data.name.id.split('&id=')[0];
songId = event.data.name.id.split('&id=')[1];
}
else {
songName = event.data.columns[0].value;
songArtist = event.data.columns[1].value;
songId = event.data.columns[event.data.columns.length - 1].value;
}
return {id: songId, name: songName, artist: songArtist};
};
const listenToEvents = () => {
Cumulio.onCustomEvent(async (event) => {
const song = getSong(event);
console.log(JSON.stringify(event));
if (event.data.event === 'add_to_playlist'){
await ui.addToPlaylistSelector(song.name, song.id);
}
else if (event.data.event === 'song_info'){
//DO SOMETHING
}
});
};
Now, the ‘Add to Playlist’ event will display a window with the available playlists that a logged in user can add the song to:
Display more song info
The final thing we want to do is to make the ‘Song Info’ event display another dashboard when clicked. It will display further information on the selected song, and include an option to play the song. It’s also the step where we get into more some more complicated use cases of the API which may need some background knowledge. Specifically, we make use of Parameterizable Filters. The idea is to create a parameter on your dashboard, for which the value can be defined while creating an authorization token. We include the parameter as metadata while creating an authorization token.
For this step, we have created a songId parameter that is used in a filter on the Song Info dashboard:
Then, we create a getDashboardAuthorizationToken() function. This expects metadata which it then posts to the /authorization endpoint of our server in server/server.js:
const getDashboardAuthorizationToken = async (metadata) => {
try {
const body = {};
if (metadata && typeof metadata === 'object') {
Object.keys(metadata).forEach(key => {
body[key] = metadata[key];
});
}
/*
Make the call to the backend API, using the platform user access credentials in the header
to retrieve a dashboard authorization token for this user
*/
const response = await fetch('/authorization', {
method: 'post',
body: JSON.stringify(body),
headers: { 'Content-Type': 'application/json' }
});
// Fetch the JSON result with the Cumul.io Authorization key & token
const responseData = await response.json();
return responseData;
}
catch (e) {
return { error: 'Could not retrieve dashboard authorization token.' };
}
};
Finally, we use the load the songInfo dashboard when the song_info event is triggered. In order to do this, we create a new authorization token using the song ID:
And voilá! We are done! In this demo we used a lot of helper functions I haven’t gone through in detail, but you are free clone the demo repository and play around with them. You can even disregard them and build your own functionality around the custom events.
Conclusion
For any one intending to have a layer of data visualisation and analytics integrated into their application, Cumul.io provides a pretty easy way of achieving it as I’ve tried to demonstrate throughout this demo. The dashboards remain decoupled entities to the application that can then go on to be managed separately. This becomes quite an advantage if say you’re looking at integrated analytics within a business setting and you’d rather not have developers going back and fiddling with dashboards all the time.
Events you can trigger from dashboards and listen to in their host applications on the other hand allows you to define implementations based off of the information in those decoupled dashboards. This can be anything from playing a song in our case to triggering a specific email to be sent. The world is your oyster in this sense, you decide what to do with the data you have from your analytics layer. In other words, you get to reuse the data from your dashboards, it doesn’t have to just stay there in its dashboard and analytics world ?
Typography is one of the most important elements of any site, having a measurably large impact on brand and experience.
So fundamental is it that making wholesale changes to your typography — opting for a new font, changing the measure, increasing leading — is complex and fraught with potential time-sinks.
But there are some simple changes that you can make to your typography that won’t break your grid and can be achieved in 30 minutes or less. Here are eight of the easiest.
1. Increase Color Contrast
When laying out text, it’s common for designers to see text as a block within a visual design. A designer’s relationship to text is very different from a user’s; a designer positions text as a shape, a user reads it line by line. Consequently, designers tend to underestimate the amount of contrast text requires.
Light grey text is aesthetically beautiful but functionally useless. Text is meant to be read and needs to meet WCAG AA standards on desktop and WCAG AAA standards on mobile — or in any situation with many ambient light sources. The larger the text is, the more leeway you have.
Text should be thoroughly tested for contrast, but as a starting point, 18px text on a white background should never be lighter than #595959.
2. Tighten Heading Spacing
The vast majority of typefaces are designed for use as body text — large blocks of running text, multiple lines long. When the font was made, it was spaced for this use.
Unlike running text, headings tend to be short and are surrounded by more whitespace — especially above and below. Extra whitespace visually floods the negative space in the word shapes and forces letters apart.
To compensate, tighten the letter-spacing and word-spacing of headings by 1–5%.
3. Loosen Non-Word Spacing
When we read, our brain doesn’t spell out words letter by letter; it recognizes word shapes and even word groups’ shapes.
Most micro-typography is concerned with not disrupting those word shapes. However, there are times when you do want to prevent words from forming and allow individual characters.
Loosen the letter-spacing on any text intended to be read as a series of characters, such as serial numbers, tracking codes, and tabular data.
4. Use System Fonts for Inputs
Privacy is a big issue for users. Anything you can do as a designer to reassure users their data is safe will increase your site’s positive UX.
Style your HTML inputs to use system fonts — the default fonts set by the OS your user is accessing the site with. This creates a clear delineation between the brand data in the brand fonts and the user’s data in the user’s fonts.
Using system fonts in this way encourages the user to feel ownership of their data, builds trust, and increases conversions.
5. Mark Paragraphs Once
Paragraphs of text need a visual indication that they have begun. There are three ways in which this is normally conveyed: following a heading, with a vertical space before the paragraph, or indenting the first line.
Each paragraph should use one of these indicators and one only. Due to the nature of web content and the benefits headings have for quickly scan-reading content, for most sites, the best choice is a combination of following a heading and vertical spacing.
6. Use Genuine Styles
For various reasons ranging from the availability of fonts to aggressive optimization, it’s common for sites to fake alternative styles using CSS. Italics can be faked as obliques with a skew, bold weights can be faked by using the browser’s defaults, and small caps can be faked by setting text to uppercase and reducing the font-size.
These tricks do more harm than good, creating distorted word shapes that interrupt the natural flow of text.
If you cannot deploy genuine italic, bold, and small caps, then don’t fake them. Find alternative ways of creating emphasis, such as changing colors.
7. Use the Correct Quotes
Apostrophes, single, and double-quotes are specific characters. Most fonts provide a glyph for them that is distinct from the quick single or double-quote key on your keyboard.
These quote marks are most commonly referred to as “smart” quotes because word-processing apps usually have the option to be “smart” about which glyphs they use.
Using the correct quotes is one of the simplest ways to deliver a refined piece of text.
8. Hyphenate Text Properly
Hyphenation is the breaking of a word over two lines. It allows a less extreme ragged-right text, and it is vital on mobile devices where the available page width is relatively small compared with desktop.
The web has surprisingly poor support for correct hyphenation, but it is gradually improving, and it can be applied as a progressive enhancement.
CSS allows you to set hyphenation to none (no hyphens), auto (the browser inserts automatically), and manual (in which you specify where hyphens should appear using the soft hyphen character).
Typographically, a hyphen may be inserted in any word that is five characters or longer; there must be at least two characters preceding the hyphen and at least three following the hyphen.
You should never hyphenate three consecutive lines of text, but addressing this requires JavaScript. You can minimize this problem by increasing your measure.
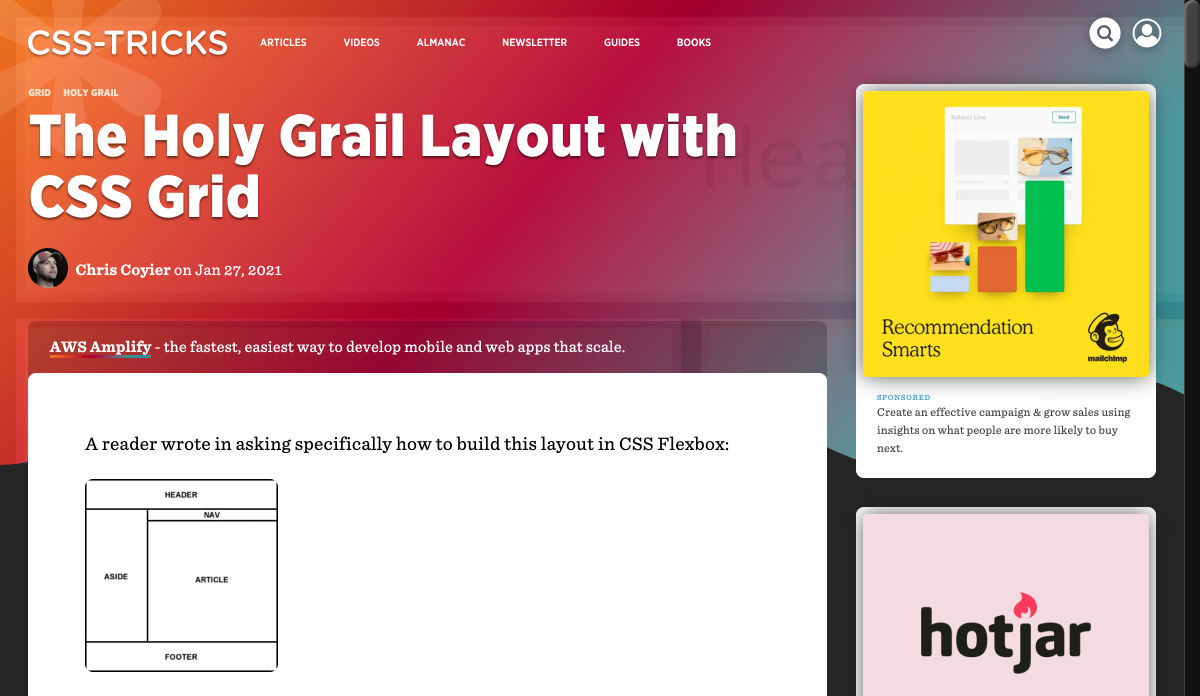
A reader wrote in asking specifically how to build this layout in CSS Flexbox:
My answer: That’s not really a layout for CSS Flexbox. You could pull it off if you had to, but you’d need some kind of conceit, like grouping the nav and article together in a parent element (if not more grouping). CSS Grid was born to describe this kind of layout and it will be far easier to work with, not to mention that the browser support for both is largely the same these days.
What do you mean by “Holy Grail”?
See, kids, layout on the web used to be so janky that the incredible simple diagram above was relatively difficult to pull off, particularly if you needed the “columns” there to match heights. I know, ridiculous, but that was the deal. We used super weird hacks to get it done (like huge negative margins paired with positive padding), which evolved over time to cleaner tricks (like background images that mimicked columns). Techniques that did manage to pull it off referred to it as the holy grail. (Just for extra clarity, usually, holy grail meant a three-column layout with content in the middle, but the main point was equal height columns).
CSS is much more robust now, so we can use it without resorting to hacks to do reasonable things, like accomplish this basic layout.
Here it is in CSS Grid
CodePen Embed Fallback
This grid is set up both with grid-template-columns and grid-template-rows. This way we can be really specific about where we want these major site sections to fall.
I slipped in some extra stuff
I had another question come my way the other day about doing 1px lines between grid areas. The trick there is as simple as the parent having a background color and using gap: 1px;, so I’ve done that in the demo above.
It’s likely that small screens move down to a single-column layout. I’ve done that at a media query above. Sometimes I use display: block; on the parent, turning off the grid, but here I’ve left grid on and reset the columns and rows. This way, we still get the gap, and we can shuffle things around if needed.
Another recent question I was asked about is the subtle “body border” effect you can see in the demo above. I did it about as simple as possible, with a smidge of padding between the body and the grid wrapper. I originally did it between the body and the HTML element, but for full-page grids, I think it’s smarter to use a wrapper div than use the body for the grid. That way, third-party things that inject stuff into the body won’t cause layout weirdness.