The Coronavirus changed upside down the world and the global economy. From having to wear masks and wash our hands all the time to seeing loved ones getting sick, things changed in an unprecedented way.
Entrepreneurs and small business owners are in a state of stress at this time of uncertainty. It seems like they cannot react to this crisis or don’t know how to do it.
During this pandemic, business owners should focus on performing an essential marketing plan to build a strong relationship with their audience. Although it is hard for many businesses to generate revenue, offering value to the customers and having a strong digital presence will significantly impact how a brand will perform in the future.
This post will guide you through some marketing techniques to help you stay ahead of the competition amid COVID.
Show How your Brand can Help
Customers will remember you by the kind of services you provide. Since customers can’t physically visit your store, you need to virtually create that customer experience and deliver value for your audience.
Brands should highlight how their products or services can benefit people during quarantine and make their lives easier.
Keep your focus on providing excellent customer service and value in these stressful times. For example, if you’re a food local business, give away coupons and special offers to medical workers and first responders for meals.
Creating a free online course is another excellent idea for your brand. A course in your niche that solves your customers’ pain points or an education-based material focuses on improving a skill, for example.
Giving away that content for free will make you a more prominent authority in your niche, and your audience will appreciate it.
As a result, when they are in the mood of purchasing something, you will probably be the first name on their mind.
Trust your Loyal Customer Base
Email can be your best friend during hard times. Leverage the power of your email list by creating a sequence of newsletters for your past customers. Many online email marketing providers have well-crafted templates that are ideal for businesses without experience and expertise in graphic design and email marketing.
Users who have already bought something from you must know that you are open for business. This list may address a loyal customer base and help them overcome fears and struggles during this period of uncertainty.
Don’t miss out on this marketing opportunity. The competition is low due to the pandemic. A few actionable moves can put your business ahead of the game and in front of the right customers.
Besides email marketing, social media can help you reach your target audience without spending many resources. Keep in mind that advertising is relatively cheap because of the Coronavirus. Take advantage of retargeting ads that can help you grow a loyal audience and build a better relationship with existing customers.
If you have the budget to push your brand out there using promotions, this is the best time.
Here are some of the benefits of retargeting ads:
Increase conversions
Increase brand awareness
Improve user engagement
This happens because you target users who are already active and have an interest in your brand. Highlighting your values and offering what they need will skyrocket your revenue and create a stronger customer base.
Keep in mind that during quarantine, it is all about creating a solid social media marketing plan and investing time into a lead generation strategy for your social media channels.
Think Again of your Marketing Budget
Public events and other product launches are not an option anymore. Businesses that were planning such actions should reconsider their advertising tactics.
Digital marketing can give your business a competitive advantage in the pandemic setting while simultaneously reducing the costs of organizing events that will not have a high return on investment.
Brands should focus on improving their foundation and make the appropriate changes to their marketing plan. Investing in online marketing can help them reach a broader audience and build better rapport.
Consumers are spending most of their time at home, which means that most of them will look for products and services they need through search engines and social media.
With that in mind, here are some marketing tips that can boost your brand awareness.
Create a blog section if you haven’t already and start sharing tips, tricks about news in your industry. Invest in an SEO campaign to help you rank higher than your competitors. Optimize the loading time of your website and make sure that it is mobile-friendly.
If you struggle to find a list of tools to improve your SEO, here is a list of the best ones.
Following these strategies will not only be beneficial just during the crisis but even when the pandemic is over. Implementing these essential marketing tactics will help your company reach its target audience and stay ahead of the competition.
Content Marketing via Social Media
Content is the key to every marketing campaign. However, during coronavirus, brands should rethink how they produce content to better suit this time.
Your brand must be a reliable source of information that shares compelling content so that the followers keep coming back to your pages. Whether it’s videos with COVID updates, infographics with safety tips, or other forms of content – continue creating posts that can educate your audience.
Along this challenging journey, make sure to measure your practices’ performance periodically to understand better what’s working. Knowing that you can better produce content that resonates with your target audience and improves the areas you need more work on.
Use the engagement metrics as your game-changers to pivot towards your most successful campaigns. Stick to them and start building the fundamentals of your next content marketing strategy.
The Takeaway
This pandemic indeed has the potential to turn down a lot of small companies. And it will. But your company doesn’t have to be one of them.
Use this time as an experimentation period for your brand to test out new kinds of content. Take advantage of the cheap promotional options and get your name out there. Optimize your website so that Google is more than happy to rank you higher than your competitors.
Take all these into consideration and trust me; this will be one of the most beneficial experiences for you and your company. Let me know which one of these strategies will you implement first in your next moves?
I just had to debug an issue with focusable elements in Firefox. Someone reported to me that when tabbing to a certain element within a CodePen embed, it shot the scroll position to the top of the page (WTF?!). So, I went to go debug the problem by tabbing through an example page in Firefox, and this is what I saw:
I didn’t even know what to make of that. It was like some elements you could tab to but not others? You can tab to s but not s? Uhhhhh, that doesn’t seem right that you can’t tab to links in Firefox?
After searching and asking around, it turns out it’s this preference at the OS level on macOS.
System Preferences > Keyboard > Shortcuts > User keyboard navigation to move focus between controls
If you have to turn that on, you also have to restart Firefox. Once you have, then you can tab to things you’d expect to be able to tab to, like links.
About that bug with the scrolling to the top of the page. See that “Skip Results Iframe” link that shows up when tabbing through the CodePen Embed? It only shows up when :focus-ed (as the point of it is to skip over the rather than being forced to tab through it). I “hid” it by doing a position: absolute; top: -9999px; left: -9999px thing (old muscle memory), then removing those values when in focus. For some reason, when tabbed to, Firefox would see those values and instantly jump the page up, even though the focus style moved it back into a normal place. Must have been some kind of race condition thing.
I also found it very silly that Firefox would do that to the parent page when that link was inside an iframe. I fixed it up using a more vetted accessible hiding technique.
With the recent climb of Bitcoin’s price over 20k $USD, and to it recently breaking 30k, I thought it’s worth taking a deep dive back into creating Ethereum applications. Ethereum, as you should know by now, is a public (meaning, open-to-everyone-without-restrictions) blockchain that functions as a distributed consensus and data processing network, with the data being in the canonical form of “transactions” (txns). However, the current capabilities of Ethereum let it store (constrained by gas fees) and process (constrained by block size or size of the parties participating in consensus) only so many txns and txns/sec. Now, since this is a “how to” article on building with Redwood and Fauna and not an article on “how does […],” I will not go further into the technical details about how Ethereum works, what constraints it has and does not have, et cetera. Instead, I will assume you, as the reader, already have some understanding about Ethereum and how to build on it or with it.
I realized that there will be some new people stumbling onto this post with no prior experience with Ethereum, and it would behoove me to point these viewers in some direction. Thankfully, as of the time of this rewriting, Ethereum recently revamped their Developers page with tons of resources and tutorials. I highly recommend newcomers to go through it!
Although, I will be providing relevant specific details as we go along so that anyone familiar with either building Ethereum apps, Redwood.js apps, or apps that rely on a Fauna, can easily follow the content in this tutorial. With that out of the way, let’s dive in!
Preliminaries
This project is a fork of the Emanator monorepo, a project that is well described by Patrick Gallagher, one of the creators of the app, in his blog post he made for his team’s Superfluid hackathon submission. While Patrick’s app used Heroku for their database, I will be showing how you can use Fauna with this same app!
Since this project is a fork, make sure to have downloaded the MetaMask browser extension before continuing.
Fauna
Fauna is a web-native GraphQL interface, with support for custom business logic and integration with the serverless ecosystem, enabling developers to simplify code and ship faster. The underlying globally-distributed storage and compute fabric is fast, consistent, and reliable, with a modern security infrastructure. Fauna is easy to get started with and offers a 100 percent serverless experience with nothing to manage.
Fauna also provides us with a High Availability solution with each server globally located containing a partition of our database, replicating our data asynchronously with each request with a copy of our database or the transaction made.
Some of the benefits to using Fauna can be summarized as:
Transactional
Multi-document
Geo-distributed
In short, Fauna frees the developer from worrying about single or multi-document solutions. Guarantees consistent data without burdening the developer on how to model their system to avoid consistency issues. To get a good overview of how Fauna does this see this blog post about the FaunaDB distributed transaction protocol.
There are a few other alternatives that one could choose instead of using Fauna such as:
Firebase
Cassandra
MongoDB
But these options don’t give us the ACID guarantees that Fauna does, compromising scaling. ACID stands for:
Atomic: all transactions are a single unit of truth, either they all pass or none. If we have multiple transactions in the same request then either both are good or neither are, one cannot fail and the other succeed.
Consistent: A transaction can only bring the database from one valid state to another, that is, any data written to the database must follow the rules set out by the database, this ensures that all transactions are legal.
Isolation: When a transaction is made or created, concurrent transactions leave the state of the database the same as they would be if each request was made sequentially.
Durability: Any transaction that is made and committed to the database is persisted in the database, regardless of down time of the system or failure.
Redwood.js
Since I’ve used Fauna several times, I can vouch for Fauna’s database first-hand, and of all the things I enjoy about it, what I love the most is how simple and easy it is to use! Not only that, but Fauna is also great and easy to pair with GraphQL and GraphQL tools like Apollo Client and Apollo Server!! However, we will not be using Apollo Client and Apollo Server directly. We’ll be using Redwood.js instead, a full-stack JavaScript/TypeScript (not production-ready) serverless framework which comes prepackaged with Apollo Client/Server!
Redwood.js is a newer framework to come out of the woodwork (lol) and was started by Tom Preston-Werner (one of the founders of GitHub). Even so, do be warned that this is an opinionated web-app framework, coming with a lot of the dev environment decisions already made for you. While some folk may not like this approach, it does offer us a faster way to build Ethereum apps, which is what this post is all about.
Superfluid
One of the challenges of working with Ethereum applications is block confirmations. The corollary to block confirmations is txn confirmations (i.e. data), and confirmations take time, which means time (usually minutes) that the user must wait until a computation they initiated (either directly via a UI or indirectly via another smart contract) is considered truthful or trustworthy. Superfluid is a protocol that aims to address this issue by introducing cashflows or txn streams to enable real-time financial applications; that is; apps where the user no longer needs to wait for txn confirmations and can immediately follow-up on the next set of computational actions.
Learn more about Superfluid by reading their documentation.
Emanator
Patrick’s team did something really cool and applied Superfluid’s streaming functionality to NFTs, allowing for a user to “mint a continuous supply of NFTs”. This stream of NFTs can then be sold via auctions. Another interesting part of the emanator app is that these NFTs are for creators, artists ??? , or musicians ? .
There are a lot more technical details about how this application works, like the use of a Superfluid Instant Distribution Agreement (IDA), revenue split per auction, auction process, and the smart contract itself; however, since this is a “how-to” and not a “how does […]” tutorial, I’ll leave you with a link to the README.md of the original Emanator `monorepo`, if you want to learn more.
Finally, let’s get to some code!
Setup
1. Download the repo from redwood-eth-with-fauna
Git clone the redwood-eth-with-fauna repo on your terminal, favorite text editor, or IDE. For greater cognitive ease, I’ll be using VSCode for this tutorial.
2. Install app dependencies and setup environment variables ?
To install this project’s dependencies after you’ve cloned the repo, just run:
yarn
…at the root of the directory. Then, we need to get our .env file from our .env.example file. To do that run:
cp .env.example .env
In your .env file, you still need to provide INFURA_ENDPOINT_KEY. Contrary to what you might initially think, this variable is actually your PROJECT ID of your Infura app.
If you don’t have an Infura account, you can create one for free! ? ?
An example view of the Infura dashboard for my redwood-eth-with-fauna app. Copy the PROJECT ID and paste it in your .env file as for INFURA_ENDPOINT_KEY
3. Update the GraphQL schema and run the database migration
In the schema file found by at:
api/prisma/schema.prisma
…we need to add a field to the Auction model. This is due to a bug in the code where this field is actually missing from the monorepo. So, we must add it to get our app working!
We are adding line 33, a contentHash field with the type `String` so that our Auctions can be added to our database and then shown to the user.
After that, we need to run a database migration using a Redwood.js command that will automatically update some of our project’s code. (How generous of the Redwood devs to abstract this responsibility from us; this command just works!) To do that, run:
yarn rw db save redwood-eth-with-fauna && yarn rw db up
You should see something like the following if this process was successful.
At this point, you could start the app by running
yarn rw dev
…and create, and then mint your first NFT! ? ?
Note: You may get the following error when minting a new NFT:
If you do, just refresh the page to see your new NFT on the right!
You can also click on the name of your new NFT to view it’s auction details like the one shown below:
You can also notice on your terminal that Redwood updates the API resolver when you navigate to this page.
That’s all for the setup! Unfortunately, I won’t be touching on how to use this part of the UI, but you’re welcome to visit Emanator’s monorepo to learn more.
Now, we want to add Fauna to our app.
Adding Fauna
Before we get to adding Fauna to our Redwood app, let’s make sure to power it down by pressing CTL+C (on macOS). Redwood handles hot reloading for us and will automatically re-render pages as we make edits which can get quite annoying while we make your adjustments. So, we’ll keep our app down for now until we’ve finished adding Fauna.
Next, we want to make sure we have a Fauna secret API key from a Fauna database that we create on Fauna’s dashboard (I will not walk through how to do that, but this helpful article does a good job of covering it!). Once you have copied your key secret, paste it into your .env file by replacing :
Make sure to leave the quotation marks in place!
Importing GraphQL Schema to Fauna
To import our GraphQL schema of our project to Fauna, we need to first schema stitch our 3 separate schemas together, a process we’ll do manually. Make a new file api/src/graphql/fauna-schema-to-import.gql. In this file, we will add the following:
type Query {
bids: [Bid!]!
auctions: [Auction!]!
auction(address: String!): Auction
web3Auction(address: String!): Web3Auction!
web3User(address: String!, auctionAddress: String!): Web3User!
}
# ------ Auction schema ------
type Auction {
id: Int!
owner: String!
address: String!
name: String!
winLength: Int!
description: String
contentHash: String
createdAt: String!
status: String!
highBid: Int!
generation: Int!
revenue: Int!
bids: [Bid]!
}
input CreateAuctionInput {
address: String!
name: String!
owner: String!
winLength: Int!
description: String!
contentHash: String!
status: String
highBid: Int
generation: Int
}
# Comment out to bypass Fauna `Import your GraphQL schema' error
# type Mutation {
# createAuction(input: CreateAuctionInput!): Auction
# }
# ------ Bids ------
type Bid {
id: Int!
amount: Int!
auction: Auction!
auctionAddress: String!
}
input CreateBidInput {
amount: Int!
auctionAddress: String!
}
input UpdateBidInput {
amount: Int
auctionAddress: String
}
# ------ Web3 ------
type Web3Auction {
address: String!
highBidder: String!
status: String!
highBid: Int!
currentGeneration: Int!
auctionBalance: Int!
endTime: String!
lastBidTime: String!
# Unfortunately, the Fauna GraphQL API does not support custom scalars.
# So, we'll this field from the app.
# pastAuctions: JSON!
revenue: Int!
}
type Web3User {
address: String!
auctionAddress: String!
superTokenBalance: String!
isSubscribed: Boolean!
}
Using this schema, we can now import it to our Fauna database.
Also, don’t forget to make the necessary changes to our 3 separate schema files api/src/graphql/auctions.sdl.js, api/src/graphql/bids.sdl.js, and api/src/graphql/web3.sdl.js to correspond to our new Fauna GraphQL schema!! This is important to maintain consistency between our app’s GraphQL schema and Fauna’s.
View Complete Project Diffs — Quick Start section
If you want to take a deep dive and learn the necessary changes required to get this project up and running, great! Head on to the next section!!
Otherwise, if you want to just get up and running quickly, this section is for you.
You can git checkout the `integrating-fauna` branch at the root directory of this project’s repo. To do that, run the following command:
git checkout integrating-fauna
Then, run yarn again, for a sanity check:
yarn
To start the app, you can then run:
yarn rw dev
Steps to add Fauna
Now for some more steps to get our project going!
1. Install faunadb and graphql-request
First, let’s install the Fauna JavaScript driver faunadb and the graphql-request. We will use both of these for our main modifications to our database scripts folder to add Fauna.
To install, run:
yarn workspace api add faunadb graphql-request
2. Edit api/src/lib/db.js and api/src/functions/graphql.js
Now, we will replace the PrismaClient instance in api/src/lib/db.js with our Fauna instance. You can delete everything in file and replace it with the following:
Then, we must make a small update to our api/src/functions/graphql.js file like so:
3. Create api/src/lib/fauna-client.js
In this simple file, we will instantiate our client-side instance of the Fauna database with two variables which we will be using in the next step. This file should end up looking like the following:
4. Update our first service under api/src/services/auctions/auctions.js
Here comes the hard part. In order to get our services running, we need to replace all Prisma related commands with commands using an instance of the Fauna client from our fauna-client.js we just created. This part doesn’t seem straightforward initially, but with some deep thought and thinking, all the necessary changes come down to understanding how Fauna’s FQL commands work.
FQL (Fauna Query Language) is Fauna’s native API for querying Fauna. Since FQL is expression-oriented, using it is as simple as chaining several functional commands. Thus, for the first changes in api/services/auctions/auctions.js, we’ll do the following:
To break this down a bit, first, we import the client variables and `db` instance from the proper project file paths. Then, we remove line 11, and replace it with lines 13 – 28 (you can ignore the comments for now, but if you really want to see the rest of these, you can check out the integrating-fauna branch from this project’s repo to see the complete diffs). Here, all we’re doing is using FQL to query the auctions Index of our Fauna Indexes to get all the auctions data from our Fauna database. You can test this out by running console.log(auctionsRaw).
From running that console.log(), we see that we need to do some object destructing to get the data we need to update what was previously line 18:
Since we dealing with an object, but we want an array, we’ll add the following in the next line after finishing the declaration of const auctionsRaw:
Now we can see that we’re getting the right data format.
Next, let’s update the call instance of `auctionsRaw` to our new auctionsDataObjects:
Here comes the most challenging part of updating this file. We want to update the simple return statement of both the auction and createAuction functions. Actually, the changes we make are actually quite similar. So, let’s make update our auction function like so:
Again, you can ignore the comments, as this comment is just to note the preference return command statement that was there prior to our changes.
All this query says is, “in the auction Collection, find one specific auction that has this address.”
This next step to complete this createAuctin function is admittedly quite hacky. While making this tutorial, I realized that Fauna’s GraphQL API unfortunately does not support custom scalars (you can read more about that under the Limitations section of their GraphQL documentation). This sadly meant that the GraphQL schema of Emanator’s monorepo would not work directly out of the box. In the end, this resulted in having to make many minor changes to get the app to properly run the creation of an auction. So, instead of walking in detail through this section, I will first show you the diff, then briefly summarize the purpose of the changes.
Looking at the green lines of 100 and 101, we can see that the functional commands we’re using here are not that much different; here, we’re just creating a new document in our Auction collection, instead of reading from the Indexes.
Turning back to the data fields of this createAuction function, we can see that we are given an input as argument, which actually refers to the UI input fields of the new NFT auction form on the Home page. Thus, input is an object of six fields, namely address, name, owner, winLength, description, and contentHash. However, the other four fields that are required to fulfill our GraphQL schema for an Auction type are still missing! Therefore, the other variables I created, id, dateTime, status, and highBid are variables I, more or less, hardcoded so that this function could complete successfully.
Lastly, we need to complete the export of the Auction constant. To do that, we’ll make use of the Fauna client once more to make the following changes:
And, we’re finally done with our first service ? , phew!
Completing GraphQL services
By now, you may be feeling a bit tired from these changes from updating the GraphQL services (I know I was while I was trying to learn the necessary changes to make!). So, to save you time getting this app to work, I’ll instead of walking through them entirely, I will share the git diffs again from the integrating-fauna branch that I have already working in the repo. After sharing them, I will summarize the changes that were made.
First file to update is api/src/services/bids/bids.js:
And, updating our last GraphQL service:
Finally, one final change in web/src/components/AuctionCell/AuctionCell.js:
So, back to Fauna not supporting custom scalars. Since Fauna doesn’t support custom scalars, we had to comment out the pastAuctions field from our web3.js service query (along with commenting it out from our GraphQL schemas).
The last change that was made in web/src/components/AuctionCell/AuctionCell.js is another hacky change to make the newly created NFT address domains (you can navigate to these when you click on the hyperlink of the NFT name, located on the right of the home page after you create a new NFT) clickable without throwing an error. ?
Conclusion
Finally, when you run:
yarn rw dev
…and you create a new token, you can now do so using Fauna!! ????
Final notes
There are two caveats. First, you will see this annoying error message appear above the create NFT form after you have created one and confirmed the transaction with MetaMask.
Unfortunately, I couldn’t find a solution for this besides refreshing the page. So, we will do this just like we did with our original Emanator monorepo version.
But when you do refresh the page, you should see your new shiny token displayed on the right! ?
And, this is with the NFT token data fetched from Fauna! ? ? ??
The second caveat is that the page for a new NFT is still not renderable due to the bug web/src/components/AuctionCell/AuctionCell.js.
This is another issue I couldn’t solve. However, this is where you, the community, can step in! This repo, redwood-eth-with-fauna is openly available on GitHub, along with the (currently) finalized integrating-fauna branch that has a working (as it currently does ?) version of the Emanator app. So, if you’re really interested in this app and would like to explore how to leverage this app further with Fauna, feel free to fork the project and explore or make changes! I can always be reached on GitHub and am always happy to help you! ?
That’s all for this tut, and I hope you enjoyed! Feel free to reach out with any questions on GitHub!
Serverless, GraphQL, and DynamoDB are a powerful combination for building websites. The first two are well-loved, but DynamoDB is often misunderstood or actively avoided. It’s often dismissed by folks who consider it only worth the effort “at scale.”
That was my assumption, too, and I tried to stick with a SQL database for my serverless apps. But after learning and using DynamoDB, I see the benefits of it for projects of any scale.
To show you what I mean, let’s build an API from start to finish — without any heavy Object Relational Mapper (ORM) or GraphQL framework to hide what is really going on. Maybe when we’re done you might consider giving DynamoDB a second look. I think it is worth the effort.
The main objections to DynamoDB and GraphQL
The main objection to DynamoDB is that it is hard to learn, but few people argue about its power. I agree the learning curve feels very steep. But SQL databases are not the best fit with serverless applications. Where do you stand up that SQL database? How do you manage connections to it? These things just don’t mesh with the serverless model very well. DynamoDB is serverless-friendly by design. You are trading the up-front pain of learning something hard to save yourself from future pain. Future pain that only grows if your application grows.
The case against using GraphQL with DynamoDB is a little more nuanced. GraphQL seems to fit well with relational databases partly because it is assumed by a lot of the documentation, tutorials, and examples. Alex Debrie is a DynamoDB expert who wrote The DynamoDB Book which is a great resource to deeply learn it. Even he recommends against using the two together, mostly because of the way that GraphQL resolvers are often written as sequential independent database calls that can result in excessive database reads.
Another potential problem is that DynamoDB works best when you know your access patterns beforehand. One of the strengths of GraphQL is that it can handle arbitrary queries more easily by design than REST. This is more of a problem with a public API where users can write arbitrary queries. In reality, GraphQL is often used for private APIs where you control both the client and the server. In this case, you know and can control the queries you run. With a GraphQL API it is possible to write queries that clobber any database without taking steps to avoid them.
A basic data model
For this example API, we will model an organization with teams, users, and certifications. The entity relational diagram is shown below. Each team has many users and each user can have many certifications.
Relational database model
Our end goal is to model this data in a DynamoDB table, but if we did model it in a SQL database, it would look like the following diagram:
To represent the many-to-many relationship of users to certifications, we add an intermediate table called “Credential.” The only unique attribute on this table is the expiration date. There would be other attributes for each of the tables, but we reduce it to just a name for each for simplicity.
Access patterns
The key to designing a data model for DynamoDB is to know your access patterns up front. In a relational database you start with normalized data and perform joins across the data to access it. DynamoDB does not have joins, so we build a data model that matches how we intend to access it. This is an iterative process. The goal is to identify the most frequent patterns to start. Most of these will directly map to a GraphQL query, but some may be only used internally to the back end to authenticate or check permissions, etc. An access pattern that is rarely used, like a check run once a week by an administrator, does not need to be designed. Something very inefficient (like a table scan) can handle these queries.
Most frequently accessed:
User by ID or name
Team by ID or name
Certification by ID or name
Frequently accessed:
All Users on a Team by Team ID
All Certifications for a given User
All Teams
All Certifications
Rarely accessed
All Certifications of users on a Team
All Users who have a Certification
All Users who have a Certification on a Team
DynamoDB single table design
DynamoDB does not have joins and you can only query based on the primary key or predefined indexes. There is no set schema for items imposed by the database, so many different types of items can be stored in a single table. In fact, the recommended best practice for your data schema is to store all items in a single table so that you can access related items together with a single query. Below is a single table model representing our data. To design this schema, you take the access patterns above and choose attributes for the keys and indexes that match.
The primary key here is a composite of the partition/hash key (pk) and the sort key (sk). To retrieve an item in DynamoDB, you must specify the partition key exactly and either a single value or a range of values for the sort key. This allows you to retrieve more than one item if they share a partition key. The indexes here are shown as gsi1pk, gsi1sk, etc. These generic attribute names are used for the indexes (i.e. gsi1pk) so that the same index can be used to access different types of items with different access pattern. With a composite key, the sort key cannot be empty, so we use “#” as a placeholder when the sort key is not needed.
Access pattern
Query conditions
Team, User, or Certification by ID
Primary Key, pk=”T#”+ID, sk=”#”
Team, User, or Certification by name
Index GSI 1, gsi1pk=type, gsi1sk=name
All Teams, Users, or Certifications
Index GSI 1, gsi1pk=type
All Users on a Team by ID
Index GSI 2, gsi2pk=”T#”+teamID
All Certifications for a User by ID
Primary Key, pk=”U#”+userID, sk=”C#”+certID
All Users with a Certification by ID
Index GSI 1, gsi1pk=”C#”+certID, gsi1sk=”U#”+userID
Database schema
We enforce the “database schema” in the application. The DynamoDB API is powerful, but also verbose and complicated. Many people jump directly to using an ORM to simplify it. Here, we will directly access the database using the helper functions below to create the schema for the Team item.
This forms the index and key values that are passed to the database API. The parse method takes an item from the database and translates it back to the application model.
GraphQL schema
type Team {
id: ID!
name: String
members: [User]
}
type User {
id: ID!
name: String
team: Team
credentials: [Credential]
}
type Certification {
id: ID!
name: String
}
type Credential {
id: ID!
user: User
certification: Certification
expiration: String
}
type Query {
team(id: ID!): Team
teamByName(name: String!): [Team]
user(id: ID!): User
userByName(name: String!): [User]
certification(id: ID!): Certification
certificationByName(name: String!): [Certification]
allTeams: [Team]
allCertifications: [Certification]
allUsers: [User]
}
Bridging the gap between GraphQL and DynamoDB with resolvers
Resolvers are where a GraphQL query is executed. You can get a long way in GraphQL without ever writing a resolver. But to build our API, we’ll need to write some. For each query in the GraphQL schema above there is a root resolver below (only the team resolvers are shown here). This root resolver returns either a promise or an object with part of the query results.
If the query returns a Team type as the result, then execution is passed down to the Team type resolver. That resolver has a function for each of the values in a Team. If there is no resolver for a given value (i.e. id), it will look to see if the root resolver already passed it down.
A query takes four arguments. The first, called root or parent, is an object passed down from the resolver above with any partial results. The second, called args, contains the arguments passed to the query. The third, called context, can contain anything the application needs to resolve the query. In this case, we add a reference for the database to the context. The final argument, called info, is not used here. It contains more details about the query (like an abstract syntax tree).
In the resolvers below, ctx.db.singletable is the reference to the DynamoDB table that contains all the data. The get and query methods directly execute against the database and the DB_MAP.TEAM.... translates the schema to the database using the helper functions we wrote earlier. The parse method translates the data back to the from needed for the GraphQL schema.
Now let’s follow the execution of the query below. First, the team root resolver reads the team by id and returns id and name. Then the Team type resolver reads all the members of that team. Then the User type resolver is called for each user to get all of their credentials and certifications. If there are five members on the team and each member has five credentials, that results in a total of seven reads for the database. You could argue that is too many. In a SQL database this might be reduced to four database calls. I would argue that the seven DynamoDB reads will be cheaper and faster than the four SQL reads in many cases. But this comes with a big dose of “it depends” on a lot of factors.
query { team( id:"t_01" ){
id
name
members{
id
name
credentials{
id
certification{
id
name
}
}
}
}}
Over-fetching and the N+1 problem
Optimizing a GraphQL API involves balancing a whole lot of tradeoffs that we won’t get into here. But two that weigh heavily in the decision of DynamoDB versus SQL are over-fetching and the N+1 problem. In many ways, these are opposite sides of the same coin. Over-fetching is when a resolver requests more data from the database than it needs to respond to the query. This often happens when you try to make one call to the database in the root resolver or a type resolver (e.g., members in the Team type resolver above) to get as much of the data as you can. If the query did not request the name attribute, it can be seen as wasted effort.
The N+1 problem is almost the opposite. If all the reads are pushed down to the lowest level resolver, then the team root resolver and the members resolver (for Team type) would make only a minimal or no request to the database. They would just pass the IDs down to the Team type and User type resolver. In this case, instead of members making one call to get all five members, it would push down to User to make five separate reads. This would result in potentially 36 or more separate reads for the query above. In practice, this does not happen because an optimized server would use something like the DataLoader library that acts as a middleware to intercept those 36 calls and batch them into probably only four calls to the database. These smaller atomic read requests are needed so that the DataLoader (or similar tool) can efficiently batch them into fewer reads.
So, to optimize a GraphQL API with SQL, it is usually best to have small resolvers at the lowest levels and use something like DataLoader to optimize them. But for a DynamoDB API it is better to have “smarter” resolvers higher up that better match the access patterns your single table database it written for. The over-fetching that results in this case is usually the lesser of the two evils.
This is where you realize the full payoff of using DynamoDB together with serverless GraphQL. I built this example with Architect. It is an open-source tool to build serverless apps on AWS without most of the headaches of directly using AWS. Once you clone the repo and run npm install, you can launch the app for local development (including a built-in local version of the database) with a single command. Not only that, you can also deploy it straight to production infrastructure (including DynamoDB) on AWS with a single command when you are ready.
Offering an enthralling eCommerce experience to B2B customers requires a lot of hard work. In 2020, B2B eCommerce businesses generated 6.7 trillion dollars in sales worldwide.
All those B2B companies who made billions must have something unique to offer to their B2B buyers.
Being a B2B marketer if you’re struggling with your eCommerce store, it won’t hurt to learn from experts to do it in the right way.
In this article, we’ll reveal some of the great examples of B2B eCommerce sites from which you should take inspiration from.
By looking at these examples, you’ll get a clearer picture of what actions you need to take to stay relevant and be ahead of your competitors to win B2B online sales.
Amazon Business
Amazon Business is one of the most popular players in the B2B eCommerce world. It’s been around for decades and all of us are pretty familiar with its online presence.
Amazon Business – the B2B business side of Amazon hits $10 billion sales only in 4 years. It’s certainly too high to believe but it’s real.
It incorporates all those tools and features that any B2B eCommerce business needs.
What makes Amazon Business so successful?
Easy to use. Amazon Business offers features including approval workflows, paying by invoice, Multi-user accounts, etc. There are plenty of benefits offered to buyers. They always try to bring innovation on the surface to improve the existing customer experience.
Noritex
The superstar of home decor, Noritex is a distributor, importer, and re-exporter who deals in all types of home decors, schools, religious, festivals, and textile items.
Nessim Btesh, the digital project manager of Noritex explained in a podcast throws light on his journey of taking his family business on a digital platform.
Nessiam stated his family, in the beginning, was skeptical about taking their family business on a digital platform because of security issues. He faced resistance from his family’s side and didn’t support him.
However, last year when pandemic broke out and businesses started to collapse, Nessim took the opportunity and took his business venture on the digital market.
They began their eCommerce journey with Shopify and later on they shifted to ShopifyPlus. However, this vendor-based eCommerce platform wasn’t working for them so they started looking for other options that can fulfill their business requirements.
Unfortunately, they couldn’t find any so decided to build one from scratch. Nortiex built a custom eCommerce platform. They grab all the necessary information from various resources to deliver a quality customer experience.
Their custom-built platform is another successful example that every B2B eCommerce website must follow.
Alibaba
The Chinese overwhelming force, Alibaba is not only one of the biggest B2C eCommerce companies but it’s one of the largest B2B companies across the globe. Currently, it is selling products in more than 40 different industries in 240 countries worldwide.
The key to its success is innovation. The process started from building a business ecosystem with not only Chinese manufacturers but with the global marketplace too.
Alibaba jumped on the eCommerce bandwagon in 1999 when the internet was barely used in China.
They build a system that can be scaled with business success. All the focuses on to fulfill customers’ needs.
Alibaba connects sellers and buyers on their platform and they earn from commissions and ads. Its success is not because of its website but how they treat their customers.
3DXTech
3DXTech is a well-known 3D printing company. They have designed their B2B eCommerce website in a unique invasive way. Generally, eCommerce sites prefer to use banners and popups to grab the attention of customers to increase sales conversion rates.
What they often overlook is these pop-ups and banners can be counterproductive and annoying. Well, that’s not the case with 3DXTech.
Their pop-ups are well-designed. They also provide free products to those visitors who provide them their email addresses. Moreover, the top banner on the website highlights products that are restocked.
They also offer rewards to customers on like and share on social media platforms or on giving reviews.
All they focus on is to clench the attention of customers and provide them what they’re looking for along with additional rewards and offers.
Chocomize
Chocomize is one of the most famous B2B companies that delivers customizable chocolate gifts to business owners who wish to promote their brand among their customers in a unique way.
The SEO experts working Chocomize are clever enough to increase their site’s Google rankings via on-page SEO tactics.
On visiting their awe-striking site, you’ll be amazed to see keywords like “custom chocolate square”, “custom chocolate coins”, or “custom corporate chocolate”. They customize and personalize their eCommerce Products and discount offers to enlighten their valuable customers.
They also focus on making the customer’s shopping journey better by offering discounts to those customers who place bulk orders. The “search by occasions” and “search by budget” options located on the menu bar are added to assist customers to find the right products within their budget.
Werner Electric
Werner Electric Supply has been doing business in this industry for decades. They do business in wholesale electrical products in the United States. They deal in hundreds of best quality electrical products which thousands of customers purchase every day.
Previously, Werner Electric customers used an online portal to place their orders. Placing orders via the online portal is pretty hectic since it was linked to their ERP. If customers want to place orders through their online portal they need to have some understanding of ERP.
To make this buying process easier, they have now completely digitized their customer’s operations. They took this step because they finally realized it was a difficult and time-consuming process.
With the help of a project partner, they worked together day and night to launch their B2B business on an eCommerce platform. They did an in-depth analysis of their customers, employers, business objectives and goals.
All they aimed to deliver a seamless ordering placing process to improve the customer experience.
By taking this aggressive approach, today Werner Electric is making billions and trillions by delivering quality customer experience.
Conclusion
We understand some of you might be skeptical about this idea of learning from other eCommerce websites. But we believe learning from these B2B giants will help you in finding flaws in your B2B eCommerce site so you can make it better to improve the conversion rate of your eCommerce website.
When creating a website, it’s vital to remember that not only does it need to work and look great on the device you are creating it on, but on all the other devices, it might be used on too.
Mobile and tablet optimization is important not only for the user journey but from an SEO point of view too, and badly created mobile sites just don’t cut it anymore.
With more and more devices entering the market, you need to check any website you create is compatible across the board. One bad experience and users are likely to leave and not come back again, which can be catastrophic for a business, particularly if it is just starting out.
It’s vital to check how a site looks and behaves when browsed differently from how you would use it. A common mistake is to assume users only browse websites on mobile devices in portrait mode; they don’t; landscape browsing is common, especially if the user is used to watching video.
Here are some of our top tools for testing websites on devices without the need for an entire device library:
1. Multi-Screen Test
WhatIsMyScreenResolution offers a great little tool to test how your site will look on different devices easily, and it costs absolutely nothing. You put the URL and choose between desktop, mobile, tablet, and television and then the orientation. Each device can also be broken down into different sizes and resolutions (or you can enter your own), making it easier than ever to test what a site will look like on different devices.
2. Responsinator
Responsinator is another great tool to test how a site looks on other devices without dipping into your wallet. Put your URL in the top bar, and it will instantly show you what it looks like on generic devices. This is a great, easy to use tool, and you can click through any links on your site to check the usability of multiple pages. This site is free, but if you want to “create your own” template, you need to sign up.
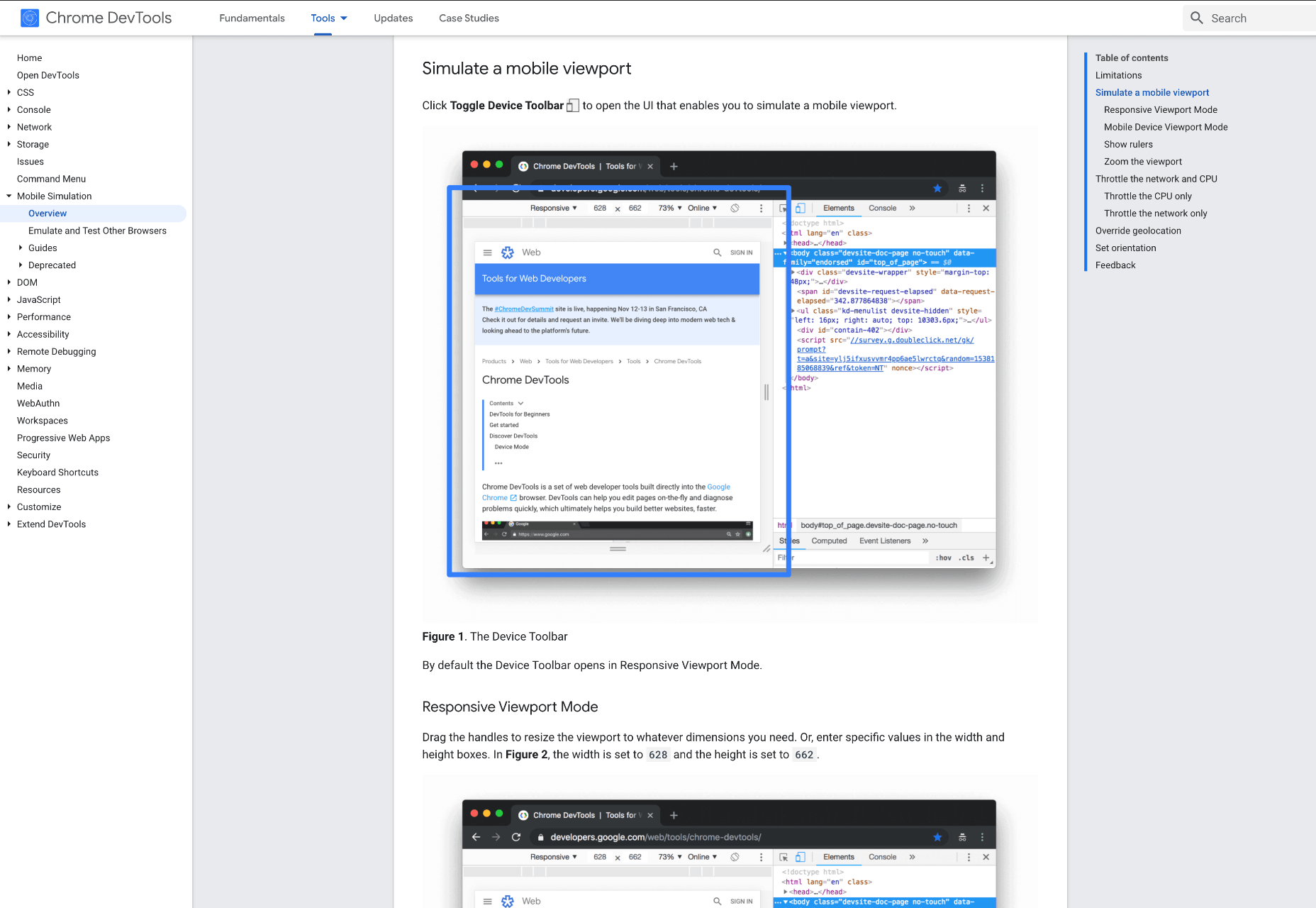
3. Google Dev Tools
Google Dev Tools is one of the most commonly used free tools. Add it to Chrome, and you can see how your site looks in a multitude of different screen sizes and resolutions. You can simulate touch inputs, device orientation, and geolocation to test how they work. It’s great to easily spot problems using their remote debugging tool to view, change, debug and profile a page’s code directly from your laptop or computer while viewing it on your mobile device.
4. Browser Stack
Browser Stack allows you to test your site on over 2,000 real devices and browsers, enabling you to see in real-time how your site looks. It is no hassle to set up, and it can be seamlessly integrated into your setup. As it tests on real browsers on real machines, you know the results are more reliable and accurate. It also enables you to debug in real-time using their pre-installed developer tools for ease of editing. The tests are all run securely on tamper-proof physical devices and are wiped clean of all data after each session, so you don’t need to worry about security being compromised.
5. TestComplete Mobile
TestComplete Mobile allows you to create and run UI tests across real mobile devices, virtual machines, and emulators. You can test both mobile device layouts and apps with script-free record and replay actions. This can help you to edit and fix any potential issues that may arise during the tests. Due to them being conducted on real devices, you know it is less likely to have errors in the system than a simulated device. This is free for 30 days then can get pricier, so make sure you take advantage of the trial and try the service before committing to it.
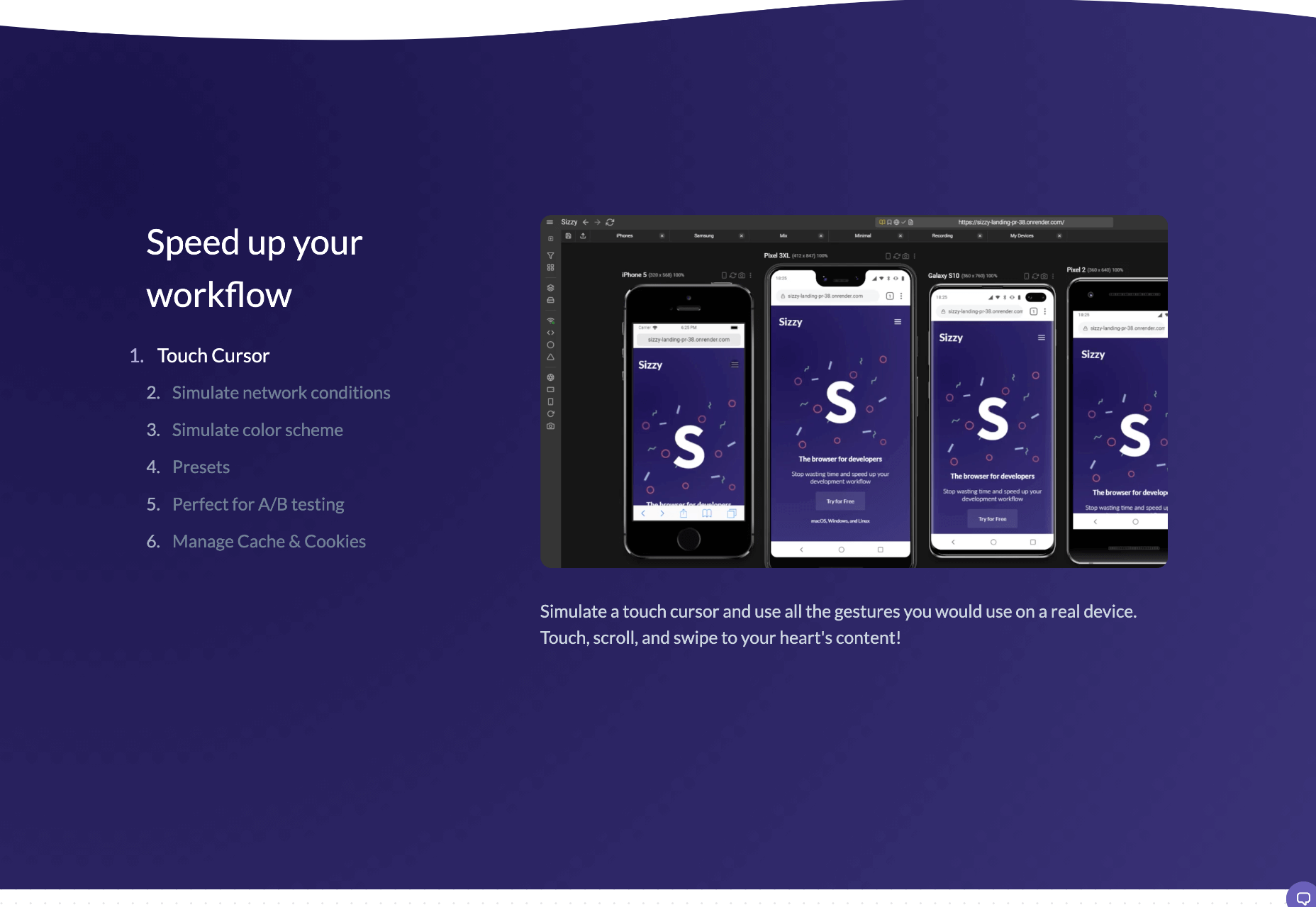
6. Sizzy
Sizzy is a great tool for checking sites, and it has a host of features to assist you. You can rotate the screen between portrait and landscape, filter by OS and device type, switch themes, and take screenshots. These little things mean it’s a super easy to use and convenient tool. It claims to simulate each device’s viewport and user agent, meaning the results are the same as what you would actually see on that phone/ tablet, etc. It can’t simulate different browser rendering engines however, so there’s a chance there might be some minor differences compared to the actual thing. Sizzy offers a free trial or has different price packages starting at $5 per month.
Apple devices are cool. But if you’ve ever switched to an Android device you know how much utility you’ve been missing out. We all have nightmares about “Syncing” our device with iTunes. Well, when there’s a problem, there are people who work on fixing that problem.
EaseUS MobiMover, as the name implies, is a tool that’s made to make the life of an Apple device user easier. Simply put, EaseUS MobiMover is a free file transfer software for transferring files between an iPhone and a PC or vice versa.
As mobile devices increasingly enter into our daily lives, they act as our cameras, wallets, music players, and even as business tools. Despite all of that, most iPhones have a limited storage capacity and we can easily lose our phones. With EaseUS you can easily transfer file between iPhone and Mac to quickly backup your files, photos, music, videos, and more.
EaseUS also allows you to easily transfer files between different phones. Let’s assume that you finally decided to upgrade your old iPhone with a new one, you’ll probably want all of your files on the new device as your phone is basically the passport of your daily life.
EaseUS is a fully-fledged iPhone file management platform and it’s main features include:
File transfer between an iPhone/iPad and a PC.
File transfer between two iPhones/iPads
iOS files backup and file restoration
Whatsapp chat & attachment back up.
Access to your iPhone/iPad files from a PC.
On top of all of the features and use cases listed before, EaseUS MobiMover also allows you to download videos and audio files from over 1,000 supported websites. This is one of the main problems with iPhones. You don’t have any option to download videos if you want to watch them offline other than relying on shady websites that both risk your device and reduce quality.
EaseUS allows you to download from sites such as YouTube, Twitter, Facebook, etc. You can even download your favorite audiobook to listen on the go. You can download these files directly to your phone or even download them to your PC.
We have tested EaseUS MobiMover so you don’t have to. Prior to hearing about it, we usually had to make room while we were outside (our cloud storage was already full). Setting it up is not that difficult and once you get the hang of it, it becomes quite convenient to use. We were able to back up our entire phone in quite a short time and we could clear space in our device through our PC easily.
All in all, EaseUS is a great tool for anyone who uses the iPhone extensively during their daily lives. Once you taste the peace of mind that comes when you know you can take as many photos or videos without worrying about opening up space and missing out on great memories.
With ES Modules, you can natively import other JavaScript. Like confetti, duh:
import confetti from 'https://cdn.skypack.dev/canvas-confetti';
confetti();
That import statement is just gonna run. There is a pattern to do it conditionally though. It’s like this:
(async () => {
if (condition) {
// await import("stuff.js");
// Like confetti! Which you have to import this special way because the web
const { default: confetti } = await import(
"https://cdn.skypack.dev/canvas-confetti@latest"
);
confetti();
}
})();
Why? Any sort of condition, I suppose. You could check the URL and only load certain things on certain pages. You could only be loading certain web components in certain conditions. I dunno. I’m sure you can think of a million things.
Hide the body (with JavaScript) right away with opacity: 0
Wait for all the JavaScript to execute
Unhide the body by transitioning it back to opacity: 1
Like this:
CodePen Embed Fallback
Louis demonstrates a callback method, as well as mentioning you could wait for window.load or a DOM Ready event. I suppose you could also just have the line that sets the className to visible as the very last line of script that runs like I did above.
Louis knows it’s not particularly en vogue:
I know nowadays we’re obsessed in this industry with gaining every millisecond in page performance. But in a couple of projects that I recently overhauled, I added a subtle and clean loading mechanism that I think makes the experience nicer, even if it does ultimately slightly delay the time that the user is able to start interacting with my page.
I think of stuff like font-display: swap; which is dedicated to rendering your text as absolutely fast as possible, FOUT be damned, rather than chiller options.
Marketing employs a wide range of design tactics to catch customer’s eyes, resonate, and leave a lasting impression.
A marketer’s goal is conversion and they use every means possible to make that happen. Did you know that an incredibly powerful conversion design aspect lies in the art of typography? From serif to sans serif fonts, kerning, and size variations, the way your words appear dramatically changes the power of your message.
Typography can propel a message forward and engage your audience. Maybe your type is hidden behind images pulling your audience in to decipher the full meaning. Or, perhaps you use a thick, bolded font to add weight to a certain element of a message. Transforming font is a creative power just as important as any other design aspect.
So whether you use free and public domain fonts or splurge on designing an explosive and powerful new design, keeping in mind the latest trends can help make sure you stand out.
The Word Counter team has just released their predictions for the typography design trends that will stand out in 2021. Check out this collection of 8 Typography Design Trends for 2021 that have seamlessly evolved traditional font styles into stunning modern types.