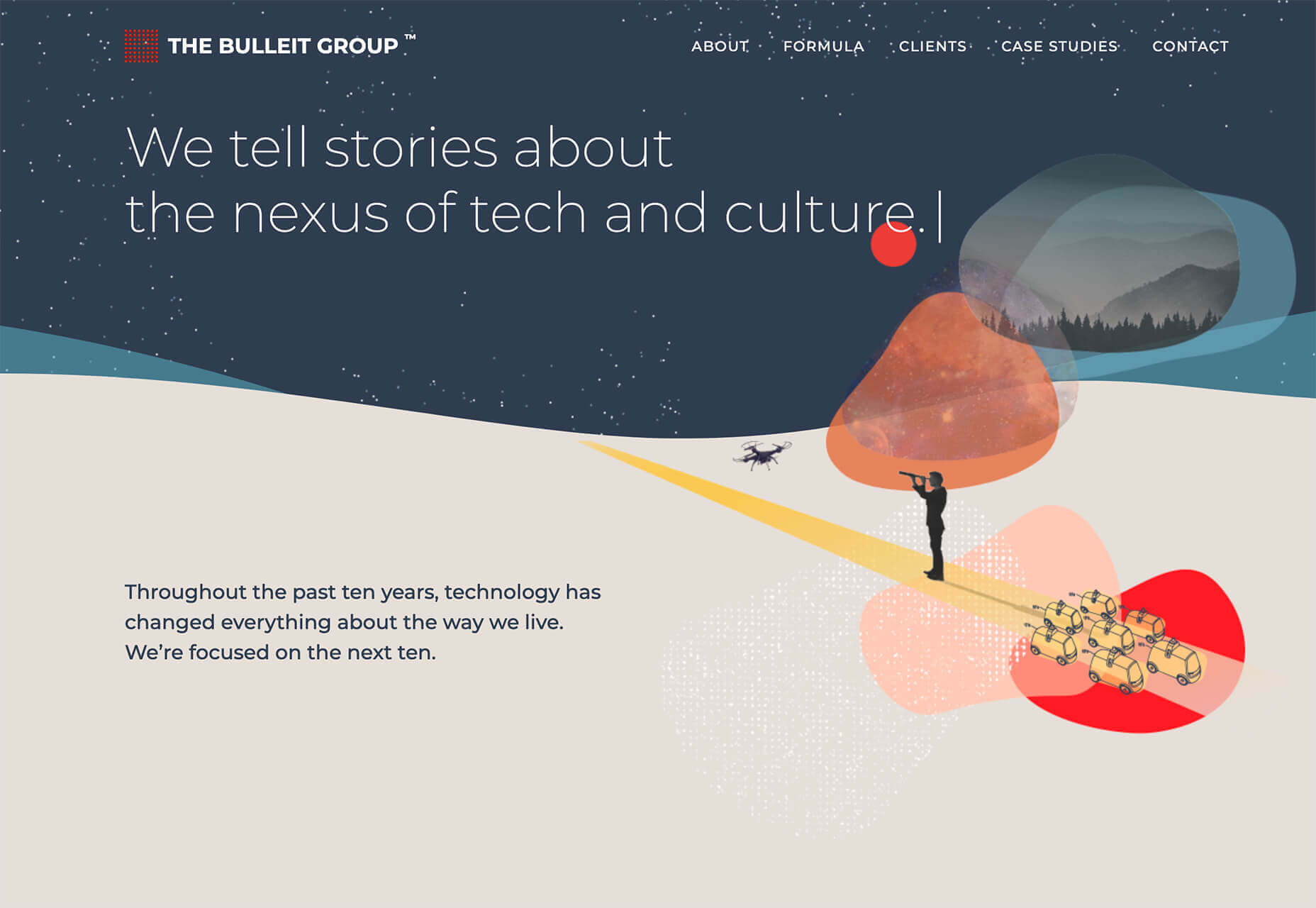
Every week users submit incredible stories to our sister-site Webdesigner News. Our colleagues sift through it, sorting the wheat from the chaff, and then post it for us to relish.
If you want to keep up with the latest news for web designers, the best way is to check out the Webdesigner News site. However, if you missed a day, here’s a useful compilation of the top curated stories from the past week. Enjoy!
Let’s explore the complexities of how CSS computes the width and height dimensions of elements. This is based on countless late-night hours debugging and fiddling with lots of combinations of CSS properties, reading though the specs, and trying to figure out why some things seem to behave one way or another.
But before jumping in, let’s cover some basics so we’re all on the same page.
The basics
You have an element, and you want it to be 640px wide and 360px tall. These are just arbitrary numbers that conform to 16:9 pixel ratio. You can set them explicitly like this:
.element {
width: 640px;
height: 360px;
}
Now, the design calls for some padding inside that element. So you modify the CSS:
What is the rendered width and height of the element now? I bet you can guess… it’s not 640×360px anymore! It’s actually 660×380px, because the padding adds 10px to each side (i.e. top, right, bottom and left), for an additional 20px on both the height and width.
This has to do with the box-sizing property: if it’s set to content-box (the default value), the rendered size of the element is the width and height plus the padding and border. That might mean that the rendered size is bigger than we intend which is funny because it might wind up that an element’s declared width and height values are completely different than what’s rendered.
That’s the power of The CSS Box Model. It calculates width and height like so:
What we just saw is how the dimensions for a block element are computed. Block elements include any element that naturally takes up the full width that’s available. So, by nature, it doesn’t matter how much content the element contains because its width is always 100%, that is, until we alter it. Think of elements like
But now we ought to look at inline elements because they behave differently when it comes to The Box Model and how their dimensions are computed. After that, we’ll look at the relationship between parent and child elements, and how they affect the width and height computations of each other.
The curious case of inline elements
As we just saw, the padding and border of any element are both included in the element’s computed width and height dimensions. Funny enough, there are cases where the width and height properties have no effect whatsoever. Such is the case when working with inline elements.
An inline element is an element that’s width and height are determined by the content it contains. Inline elements, such as a , will completely ignore the width and height as well the the left and right margin properties because, well, the content is what determines the dimensions. Here, sometimes a visual can help.
CodePen Embed Fallback
Just look at how nesting a block element inside of an inline element breaks the inline element’s shape simply because the block element is not defined by the amount of content it contains, but rather the amount of available space. You can really see that in action when we add a border to the inline element. Look how the inline element abruptly stops where the paragraph comes in, then continues after the paragraph.
CodePen Embed Fallback
The span sees the paragraph, which interrupts the inline flow of the span and essentially breaks out of it. Fascinating stuff!
But there’s more! Look how the inline element completely overlooks width and margin, even when those are declared right on it.
CodePen Embed Fallback
Crazy!
Parent and child elements
The parent-child relationship is a common pattern. A parent element is one that contains other elements nested inside it. And those nested elements are the parent element’s children.
<!-- The parent element -->
<div class="parent">
<!-- The children -->
<div class="child"></div>
<div class="another-child"></div>
<div class="twins">Whoa!</div>
</div>
The width and height of an element gets super interesting with parent and child elements. Let’s look at all the interesting quirks we get with this.
Relative units
Let’s start with relative units. A relative unit is computed by its context, or relation to other elements. Yeah, that’s sort of a convoluted definition. There are several different types of relative units, but let’s take percentages as an example. We can say that an element is 100% wide.
<div class="child">
<!-- nothing yet -->
</div>
.parent {
width: 100%;
}
Cool. If we plop that element onto an empty page, it will take up 100% of the available horizontal space. And what that 100% computes to depends on the width of the browser, right? 100% of a browser that’s 1,500 pixels is 1,500 pixels wide. 100% of a browser that’s 500 pixels is 500 pixels wide. That’s what we mean by a relative unit. The actual computed value is determined by the context in which it’s used.
So, the astute reader may already be thinking: Hey, so that’s sort of like a child element that’s set to a parent element’s width. And that would be correct. The width of the child at 100% will compute based on the actual width of the parent element that contains it.
Height works much the same way: it’s relative to the parent’s height. For example, two parent elements with different height dimensions but identical children result in children with different heights.
CodePen Embed Fallback
Padding and margin
The width and height of parent-child combinations get even more interesting when we look at other properties, such as padding and margin. Apparently, when we specify a percentage value for padding or margin, it is always relative to the width of the parent, even when dealing with vertical edges.
Some clever designers have taken advantage of it to create boxes of equal width and height, or boxes that keep a certain aspect ratio when the page resizes. This is particularly useful for video or image content, but can also be (ab)used in creative ways. Go ahead, type whatever you want into the editable element in this demo. The box maintains a proportional height and width, no matter how much (or little) content is added.
CodePen Embed Fallback
This technique for creating aspect ratio boxes is lovingly referred to as the “padding hack.” Chris has covered it extensively. But now that we have the aspect-ratio property gaining wide browser support, there’s less reason to reach for it.
display: inline and inline-block
Now that we’ve taken looks at how parent and child element dimensions are computed, we should check out two other interesting property values that affect an element’s width: min-content and max-content.
These properties tell the browser to look at the content of the element in order to determine its width. For instance, if we have the text: “hello CSS encyclopedia, nice to meet you!”, the browser would calculate the space that text would take up on the screen, and use it as the width.
The difference between min-content and max-content lies in how the browser does this calculation. For max-content, the browser pretends it has infinite space, and lays all the text in a single line while measuring its width.
For min-content, the browser pretends it has zero space, so it puts every word / child inline element in a different line. Let’s see this in action:
CodePen Embed Fallback
CodePen Embed Fallback
We actually saw max-content in action when we looked at the difference between block and inline elements. Inline elements, remember, are only as wide and tall as the content they contain. We can make most elements inline elements just by declaring display: inline; on it.
CodePen Embed Fallback
Cool. Another weapon we have is display: inline-block;. That creates an inline element, but enhanced with block-level computations in The Box Model. In other words, it’s an inline element that respects margin, width and height. The best of both worlds!
CodePen Embed Fallback
Cyclic percentage size
Did that last point make sense? Well, hopefully I won’t confuse you with this:
CodePen Embed Fallback
The child element in this example has a relative width of 33%. The parent element does not have a width declared on it. How the heck is the child’s computed width get calculated when there’s nothing relative to it?
To answer that, we have to look at how the browser calculates the size of the elements in this example. We haven’t defined a specific width for the parent element, so the browser uses the initial value for width , which is auto. And since the parent element’s display is set to inline-block, auto behaves like max-content. And max-content, as we saw, should mean the parent element is as wide as the content in it, which is everything inside the child element.
So, the browser looks at the element’s content (children) to determine its width. However, the width of the child also depends on the parent’s width! Gah, this is weird!
The CSS Box Sizing Module specification calls this cyclic percentage sizing. I’m not sure why it’s called that exactly, but it details the complex math the browser has to do to (1) determine the parent element’s width, and (2) reconcile that width to the relative width of the child.
The process is actually pretty cool once you get over the math stuff. The browser starts by calculating a temporary width for the child before its declared value is applied. The temporary width the browser uses for the child is auto which we saw behaves like max-content which, in turn, tells the browser that the child needs to be as wide as the content it contains. And right now, that’s not the declared 33% value.
That max-content value is what the browser uses to calculate the parent’s width. The parent, you see, needs to be at least as wide as the content that it contains, which is everything in the child at max-content. Once that resolves, the browser goes back to the child element and applies the 33% value that’s declared in the CSS.
This is how it looks:
There! Now we know how a child element can contribute to the computed value of its parent.
M&Ms: the min- and max- properties
Hey, so you’re probably aware that the following properties exist:
min-width
min-height
max-width
max-height
Well, those have a lot to do with an element’s width and height as well. They specify the limits an element’s size. It’s like saying, Hey, browser, make sure this element is never under this width/height or above this width/height.
So, even if we have declared an explicit width on an element, say 100%, we can still cap that value by giving it a max-width:
element {
width: 100%;
max-width: 800px;
}
This allows the browser to let the element take up as much space as it wants, up to 800 pixels. Let’s look what happens if we flip those values around and set the max-width to 100% and width to 800px:
element {
width: 800px;
max-width: 100%;
}
Hey look, it seems to result in the exact same behavior! The element takes up all the space it needs until it gets to 800 pixels.
CodePen Embed Fallback
Apparently, things start to get more complex as soon as we add a parent element into the mix. This is the same example as above, with one notable change: now each element is a child of an inline-block element. Suddenly, we see a striking difference between the two examples:
CodePen Embed Fallback
Why the difference? To understand, let’s consider how the browser calculates the width of the elements in this example.
We start with the parent element (.parent). It has a display property set to inline-block, and we didn’t specify a width value for it. Just like before, the browser looks at the size of its children to determine its width. Each box in this example is wrapped in the .parent element.
The first box (#container1) has a percentage width value of 100%. The width of the parent resolves to the width of the text within (the child’s max-content), limited by the value we specified by max-width, and that is used to calculate the width of the child as well.
The second box (#container2) has a set width of 800px, so its parent width is also 800px — just wide enough to fit its child. Then, the child’s max-width is resolved relative to the parent’s final width, that is 800px. So both the parent and the child are 800px wide in this case.
So, even though we initially saw the two boxes behave the same when we swapped width and max-width values, we now know that isn’t always true. In this case, introducing a parent element set to display: inline-block; threw it all off!
min(): Returns the minimum value of its arguments. The arguments can be given in different units, and we can even mix and match absolute and relative units, like min(800px, 100%).
max(): Returns the maximum value of its arguments. Just like min(), you can mix and match different units.
clamp(): A shorthand function for doing min and max at once: clamp(MIN, VAL, MAX) is resolved as max(MIN, min(VAL, MAX)). In other words, it will return VAL, unless it exceeds the boundaries defined by MIN and MAX, in which case it’ll return the corresponding boundary value.
Like this. Check out how we can effectively “re-write” the max-width example from above using a single CSS property:
That would set the width of the element to 800px, but make sure we don’t exceed the width of the parent (100%). Just like before, if we wrap the element with an inline-block parent, we can observe it behaving differently than the max-width variation:
CodePen Embed Fallback
The width of the children (800px) is the same. However, if you enlarge the screen (or use CodePen’s 0.5x button to zoom out), you will notice that the second parent is actually larger.
It boils down to how the browser calculates the parent’s width: we didn’t specify a width for the parent, and as child’s width value is using relative units, the browser ignores it while calculating the parent’s width and uses the max-content child of the child, dictated by the “very long … long” text.
Wrapping up
Phew! It’s crazy that something as seemingly simple as width and height actually have a lot going on. Sure, we can set explicit width and height values on an element, but the actual values that render often end up being something completely different.
That’s the beauty (and, frankly, the frustration) with CSS. It’s so carefully considered and accounts for so many edge cases. I mean, the concept of The Box Model itself is wonderfully complex and elegant at the same time. Where else can we explicitly declare something in code and have it interpreted in different ways? The width isn’t always the width.
And we haven’t even touched on some other contributing factors to an element’s dimensions. Modern layout techniques, like CSS Flexbox and Grid introduce axes and track lines that also determine the rendered size of an element.
In this week’s update, the CSS :not pseudo class can accept complex selectors, how to disable smooth scrolling when using “Find on page…” in Chrome, Safari’s support for there media attribute on elements, and the long-awaited debut of the path() function for the CSS clip-path property.
Let’s jump into the news…
The enhanced :not() pseudo-class enables new kinds of powerful selectors
After a years-long wait, the enhanced :not() pseudo-class has finally shipped in Chrome and Firefox, and is now supported in all major browser engines. This new version of :not() accepts complex selectors and even entire selector lists.
For example, you can now select all
elements that are not contained within an
element.
/* select all <p>s that are descendants of <article> */
article p {
}
/* NEW! */
/* select all <p>s that are not descendants of <article> */
p:not(article *) {
}
In another example, you may want to select the first list item that does not have the hidden attribute (or any other attribute, for that matter). The best selector for this task would be :nth-child(1 of :not([hidden])), but the of notation is still only supported in Safari. Luckily, this unsupported selector can now be re-written using only the enhanced :not() pseudo-class.
/* select all non-hidden elements that are not preceded by a non-hidden sibling (i.e., select the first non-hidden child */
:not([hidden]):not(:not([hidden]) ~ :not([hidden])) {
}
CodePen Embed Fallback
The HTTP Refresh header can be an accessibility issue
The HTTP Refresh header (and equivalent HTML tag) is a very old and widely supported non-standard feature that instructs the browser to automatically and periodically reload the page after a given amount of time.
<!-- refresh page after 60 seconds -->
<meta http-equiv="refresh" content="60">
According to Google’s data, the tag is used by a whopping 2.8% of page loads in Chrome (down from 4% a year ago). All these websites risk failing several success criteria of the Web Content Accessibility Guidelines (WCAG):
If the time interval is too short, and there is no way to turn auto-refresh off, people who are blind will not have enough time to make their screen readers read the page before the page refreshes unexpectedly and causes the screen reader to begin reading at the top.
However, WCAG does allow using the tag specifically with the value 0 to perform a client-side redirect in the case that the author does not control the server and hence cannot perform a proper HTTP redirect.
How to disable smooth scrolling for the “Find on page…” feature in Chrome
CSS scroll-behavior: smooth is supported in Chrome and Firefox. When this declaration is set on the element, the browser scrolls the page “in a smooth fashion.” This applies to navigations, the standard scrolling APIs (e.g., window.scrollTo({ top: 0 })), and scroll snapping operations (CSS Scroll Snap).
Unfortunately, Chrome erroneously keeps smooth scrolling enabled even when the user performs a text search on the page (“Find on page…” feature). Some people find this annoying. Until that is fixed, you can use Christian Schaefer’s clever CSS workaround that effectively disables smooth scrolling for the “Find on page…” feature only.
In the following demo, notice how clicking the links scrolls the page smoothly while searching for the words “top” and “bottom” scrolls the page instantly.
CodePen Embed Fallback
Safari still supports the media attribute on video sources
With the HTML element, it is possible to declare multiple video sources of different MIME types and encodings. This allows websites to use more modern and efficient video formats in supporting browsers, while providing a fallback for other browsers.
In the past, browsers also supported the media attribute on video sources. For example, a web page could load a higher-resolution video if the user’s viewport exceeded a certain size.
It is not appropriate for choosing between low resolution and high resolution because the environment can change (e.g., the user might fullscreen the video after it has begun loading and want high resolution). Also, bandwidth is not available in media queries, but even if it was, the user agent is in a better position to determine what is appropriate than the author.
Scott Jehl (Filament Group) argues that the removal of this feature was a mistake and that websites should be able to deliver responsive video sources using alone.
For every video we embed in HTML, we’re stuck with the choice of serving source files that are potentially too large or small for many users’ devices … or resorting to more complicated server-side or scripted or third-party solutions to deliver a correct size.
Scott has written a proposal for the reintroduction of media in video elements and is welcoming feedback.
The CSS clip-path: path() function ships in Chrome
It wasn’t mentioned in the latest “New in Chrome 88” article, but Chrome just shipped the path() function for the CSS clip-path property, which means that this feature is now supported in all three major browser engines (Safari, Firefox, and Chrome).
The path() function is defined in the CSS Shapes module, and it accepts an SVG path string. Chris calls this the ultimate syntax for the clip-path property because it can clip an element with “literally any shape.” For example, here’s a photo clipped with a heart shape:
International real estate broker Tranio‘s Executive Director Mikhail Bulanov explains how you can gain free online traction for your business by undertaking partner research, surveys, and analysis.
In just the last couple of years, our company Tranio has been featured over a thousand times by some of the largest media organisations in the world, including those that do not offer coverage in exchange for a fee.
While the general approach to getting cited in the media is the same, it is significantly more difficult to be featured by an international publication, where we face stiff competition from other PR contenders.
The main principle is to provide unique content that will capture the interest of the news publication’s readers.
Here are some of our key strategies:
1. Original analysis using open data
Using diverse sources of open data, your business can produce its own original analysis close to your area of focus.
At Tranio, for example, we can compare the number of pending development projects in Berlin with areas mentioned in search queries, to infer which locality Berlin residents would most want to buy an apartment in. We can then include comments from urban specialists and local real estate managers, and pitch this unique analytical piece to a leading German publication for coverage.
Using this strategy, we analyzed Spain’s land registry statistics and pitched an article about British nationals buying houses in Spain to The Independent, a popular UK-based news website.
An article in The Independent featuring our research.
2. Analysis of in-house statistics
Data collected in-house by your business can offer a wealth of analytical opportunities. Sales statistics, changes in demand trends, client profiles, etc., can provide an infinite source of unique information that media outlets will find valuable.
On the other hand, customer relationship management, or CRM, may sometimes offer very limited data points. In that case, it can be useful to conduct research using more populated data sets like Google data, which allows you to count and compare search queries.
In October 2020, we analyzed the number of search queries made by residents of a particular region about their preferred domestic and international holiday destinations. Not only was this analysis picked up by most major national media outlets in the region, but over 40 international publications – including Spanish, Latvian, and Bulgarian media – cited it as well.
Our statistics about Russian acquisitions in Germany published by Business Insider’s German edition.
3. Picture packages
Media outlets are always in search of images that can be attributed and used without facing the risk of copyright penalties.
To this end, any visual content generated by your business can be used to promote your brand in the media.
To illustrate, The Guardian referenced Tranio as many as eleven times in their article about unusual properties for sale.
Our pictures featured in The Guardian’s pictorial about homes with a view of the sunset.
4. Client surveys
When the COVID-19 first pandemic broke out and the real estate market came to a standstill, we conducted a survey asking our clients if they were willing to invest in international property remotely, and what they thought about changes in house prices.
Surveys like this can be conducted regularly, often by asking the same set of questions and comparing this year’s responses with the previous year. The results of such surveys can then be combined with your own expert commentary and pitched to the media.
5. Joint research with market giants
Surveys and analysis can also be conducted in partnership with established heavyweights in your field, who can provide both information and resources.
Tying up with a strong partner offers many benefits: it takes your brand position up a notch, and opens up new opportunities to distribute your content.
At Tranio, we like to collaborate with real estate exhibitions because this is where the main market players gather, giving us the opportunity to tap into their opinions. Such exhibitions do not take place very often, and nor do they have dedicated editorial and PR support, which can result in some logistical challenges. However, the event managers are always interested in publicity, which is where we step in.
We partner with exhibitions as follows: they carry out a survey and we draw on those survey results to conduct our research.
The same method can be used when collaborating with market players that offer professional services in your field, such as law firms, advisors, or banks. Such stakeholders generally have access to more data and resources than exhibitions, though this is not always the case. While they might be interested in a wider subject, a good strategy is to explore a narrow area within that topic and then generate publicity for your research together.
This is how we conducted joint research with MR&H, an exhibition for hotels and resorts investment in Europe. We conducted a survey of the hotel market using our own database, and the exhibition sent some mailouts using theirs. We then issued an analytical piece using the results of these surveys, which was also sent out to all our clients.
So, what did we gain? Despite being a small company in the context of the market, this collaboration resulted in our research material being distributed to all the largest market players. For example, senior management at Marriott International received an email citing our brand.
A joint initiative with a noteworthy partner also makes it easier to get published, as your partner’s brand recognition will immediately simplify interactions with any editorial publication.
Our collaborative research with MR&H mentioned by a Greek news website in an article about hotels investing in the Cyclades islands.
One major downside to working with large companies is that the project may move a bit slower than you would like. This is because big corporations have to get approvals, follow guidelines, cut through red tape, and communicate with their offices in various time zones.
For instance, we undertook a joint research effort with EY a year ago. For many of the reasons listed above, the overall production cycle took almost six months to complete. However, it was worth it in the end. EY sent three mailouts to contacts in their database, and we immediately had new clients asking us for advice and services. We were cited over 50 times for our collaboration with EY, including twice in Forbes, as well as publications like Lenta, The Bell, and other international media.
Establishing a strong rapport with large brands is key in this approach. Do not make the mistake of thinking that no one will respond to your requests because your business is too small. Even large and reputed companies are always happy to receive an additional promotion – especially if you do most of the work!
Summary:
Offer publications interesting and unique material.
Consult diverse sources of data like your CRM, or publicly available statistics. Remember that reporters are often willing to cite you in exchange for your research contribution.
Establish relationships with large brands in your field and propose to help them with publicity. Similar to reporters, large brands are open to interesting ideas and are willing to reciprocate by sharing their resources.
Mediator Component in React — Robin Wieruch’s article made me think just how un-opinionated React is and how architecturally on-your-own you are. It’s tough to find the right abstractions.
No One Ever Got Fired for Choosing React — Jake Lazaroff’s article is a good balance to the above. Sometimes you pick a library like React because it solves problems you’re likely to run into and lets you get to work.
A React “if component — I kinda like how JSX does conditional rendering, but hey, a lightweight abstraction like this might just float your boat.
State of the React Ecosystem in 2021 — Hooks are big. State management is all over the place, and state machines are growing in popularity. webpack is still the main bundler. Everyone is holding their breath about Suspense… so suspenseful.
Blitz.js — “The Fullstack React Framework” — interesting to see a framework built on top of another framework (Next.js).
Introducing Zero-Bundle-Size React Server Components — Feels like it will be a big deal, but will shine brightest when frameworks and hosts zero-in on offerings around it. I’m sure Vercel and Netlify are all ?.
The recent developments in telehealth have indicated important changes within the healthcare industry. New innovative solutions and technology emerge that shape the industry and take it to a new level.
What is Telehealth and Why Is It Gaining Popularity?
How Can Emerging Technologies Impact Telemedicine App Development?
How to Develop a Telemedicine App?
Key Features of Telehealth App
Requirements to Ensure HIPAA Compliance for Telehealth Video Conferencing.
What is Telehealth and Why is it Gaining Popularity?
Virtual has become a way of life. It doesn’t bypass the health care system. Thus, we have a new term to describe the use of technologies and innovative solutions to support long-distance clinical health care and health administration. And that is telehealth.
Telehealth is gaining traction over a couple of years. Why is it so?
Law
The legislative developments contribute to the expansion of telehealth. Most of the states, including the DC, have private parity laws that require the telehealth services to be covered and reimbursed at the same rate as face to face healthcare visits.
Efficiency
Telehealth can drive efficiency and cut costs on doctors’ visits. It’s a more convenient way both for the patients and the doctors.
Aging population
We witness an aging population and movement is an issue for a lot of people. It is much more convenient for the old aged to use their smartphones and tablets from their home for doctor consultations than to travel a long distance to a doctor’s place.
New technology
New technology is an answer. New smart devices are developed that suggest various handy solutions.
How Can Emerging Technologies Impact Telemedicine App Development?
We talked about emerging technologies. Let’s have a look at how they can impact telemedicine app development in 2021.
Artificial Intelligence
We know that we live in the age of Artificial Intelligence. AI is transforming healthcare in many ways. Today patients are diagnosed with less human intervention with the help of robots. We also see eldercare-assistive robots that can assist the elderly in various tasks.
IoT
We witness the expansion of IoT. Today, many devices can help patients to measure their blood pressure or pulse rates from home. Thus, there is no need for a visit to a doctor for the initial consultation.
Smart Devices
Smart sensors can collect data and analyze it using complex algorithms. This is done to monitor the state of health of those, particularly, living in remote areas. The data is then shared with healthcare professionals.
Blockchain
Blockchain is a chance for healthcare intuitions to store, transfer medical data securely and helps healthcare researchers to unlock genetic code.
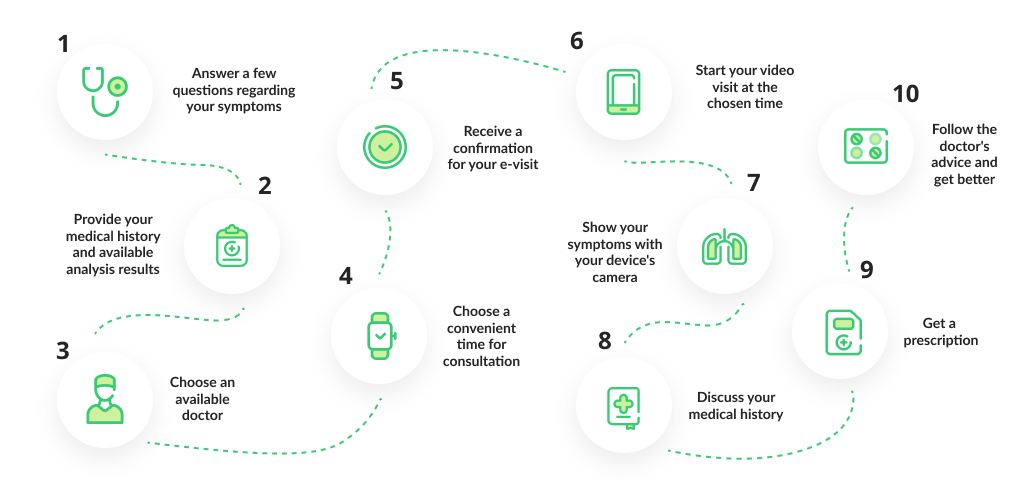
How to Develop a Telemedicine App?
Telemedicine app development in 2021 will not be much different in terms of procedures to follow. However, new technology will affect app development such as smart devices. Below are some basic steps to follow. Let’s go through each of them.
Before we do that, let’s have a look at the telehealth implementation process.
Here are the steps.
Discovery and Planning
This is a stage when the client and the app development company work closely. They perform market research, competitors’ analysis, discover main features and solutions to have advantages over similar products. You need to highlight what makes you different and develop a one-of-a-kind value proposition.
At this stage, the client and the app development company may decide on the cost of the project as well.
Prototyping and Design
After the client and the company come to an agreement on cost, features, and solutions, the actual work on the telemedicine project starts. After the layout is finalized, the designers work on the creation of the app’s user interface.
Testing
Before deploying your app, you need to test it on a small group of people. At this stage, you can solve bug issues and rebuild the app based on feedback. A good MVP is needed to collect and react to the feedback of potential clients.
Marketing
Finally, you need a good marketing strategy. Building the app is not the end of the job. You need to find the right audience. Efficient marketing enhances the app profitability.
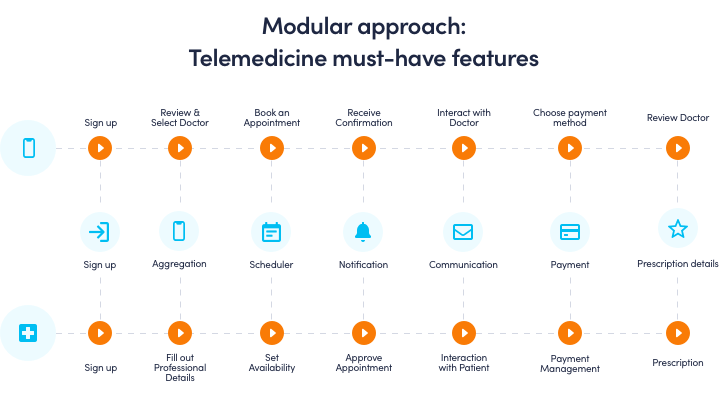
Key Features of Telehealth App
Encryption and Security Protocols
Confidentiality is the number one issue when it comes to medicine. The app company needs to develop security and encryption protocols.
HIPAA Compliance
HIPAA needs to be integrated into the app to secure electronic communication of healthcare transactions.
Video Conferencing
This feature is a key component of the app. The patient and the doctor should be able to interact through video conferencing as well as an easy messaging system.
Dashboard and analytics
Doctors should have a separate dashboard. Here they can make adjustments to the prescriptions and treatments. The appointments should be possible to manage online. The patients should be able to select an available slot from the doctor’s calendar.
Pharmacy databases
The app may be integrated with pharmacy databases so the patients can view the drug availability online.
Requirements to Ensure HIPAA Compliance for Telehealth Video Conferencing?
Personal health records are protected under the Health Insurance Portability and Accountability Act (HIPAA). Here are some requirements to consider to ensure HIPAA compliance.
Person or entity authentication
Strong authenticity is ensured through biometric information and matching passwords. It’s hard to cheat on biometric information like fingerprints or voice commands. Therefore, the app should ensure such options.
End-to-End Encryption
Does your video-conferencing software use encryption? This is important to eliminate unauthorized access. That is why end-to-end encryption is key for HIPAA compliance.
Routing
Does the video get routed through a server or is it connected to the patient’s device directly? This is another important question to answer. Your video conference must be directly connected to the patient’s device. This also ensures the quality of the connection.
BAAs
Business Associate Agreements (BAAs) are a part of the HIPAA compliance process. When you enter into such an agreement, all information is appropriately safeguarded.
Access Control
We talked about the impermissibility of unauthorized access. But what about their own employees? Do they have access to video conferencing and data? Only those with respective rights should have access to video conferencing according to HIPAA rules.
To ensure that, Role-based Access Control (RBAC) is applied. RBAC classifies users according to roles and privileges to control access in the video conferencing solution.
Wrapping up
In 2021, telemedicine apps will continue to grow. Traditional app development will continue to prevail. However, new smart devices, AI, IoT, and blockchain will determine the content of the apps as well as their format. The new emerging technologies will account for new possibilities and new niches to be included in the app development.
Today is the best time to invest in telehealth app development because the industry still has space for new players and the demand is growing.
How you present yourself as a designer, the core skills you nurture, the type of work you take on all contribute to a creative career you enjoy.
With various roles to choose from — and an exponentially greater number of job titles — how do you know what kind of design path suits your personality?
We’ve put together this fun quiz to help you identify your key personality traits, the skills you should work on in 2021, and the type of designer you are best suited to be.
Technology and innovations have transformed various organizations and manufacturers.
The need for IoT healthcare has all been exacerbated by an aging population, costly medical facilities, and inadequate healthcare facilities. Inexpensive and progressive health care isn’t a fuzzy fantasy but a truth for the future. The IoT offers a chance to change this industry radically.
Patients and healthcare professionals have been able to track critical health metrics in real-time with IoT-enabled devices, providing a customized treatment plan for diseases like diabetes and cardiovascular disease. This use of advanced technologies increases access to treatment, enhances the standard of care, and reduces treatment costs.
The study shows that the healthcare demand for IoT is expected to rise from 41 billion in 2017 to 265 billion by 2025. This rise will be primarily driven by growing initiatives by governments and policymakers in the healthcare sector. Among the most significant and crucial industries in the technological transition, we see the IoT for healthcare.
Let’s move forward and explore the most innovative ways IoT healthcare solutions are changing today’s age of healthcare. But first, here’s a brief info about IoT.
What is IoT, and what are the benefits of IoT in healthcare?
In easy sentences, the IoT could be represented as an interconnected device network. The IoT consists not of different entities but an entire integrated device system. These systems are capable of various sensors and processors, which allow data to be obtained and sent through the networks from the external environment. Without even any human-to-human or human-to-computer contact, this cycle begins.
In different types, IoT healthcare systems have been designed. You may see different kinds of heart rate, temperature, and blood sugar level devices on the marketplace. Medical equipment can gather valuable information and give additional information about symptoms and any defects of the human body to physicians; this helps to detect problems, and physicians are willing to offer medical support sooner. For the healthcare sector, such solutions are a genuine game-changer. There are numerous benefits of using IoT in the healthcare industry. Some of them are:
Benefits of IoT in the Healthcare Industry
Increasing healthcare technology renders this sector less reliant on individuals and, at the very same time, increasingly patient-oriented. The main benefits of the IoT from which healthcare organizations will benefit are:
Lesser cost.
Better drug management.
Reduces mistakes and wastage.
Enhances treatment outcomes.
Affordable and convenient.
Enhances data reporting, collections, and tracking.
Moving on, here are some exciting ways in which IoT solutions are transforming the healthcare industry.
Top IoT solutions that are revolutionizing the Healthcare Industry
1. Equipment Tracking Systems
For hospitals, patient and employee protection is a concern. Specific tools, namely MRIs, X-ray machines, CT scanners, and other appliances, are used by hospitals. It can become unsafe for staff and patients if this machinery is not tested regularly. The use of IoT solutions can avoid these kinds of issues. Monitoring systems for equipment will track performance problems and alert employees. Far before they eventually wind up risking medical devices’ protection, this device will find the issues.
Remote diagnostic tests, predictive analytics and maintenance, and regular performance updates are the positives of devices like this.
2. Smart Integrated Inhaler
Asthma is an illness that isn’t easily treatable, but it is manageable by using an inhaler. A patient may notice signs of an asthma attack half-hour or eight hours earlier. The IoT healthcare solutions could offer smart solutions here. A sensor-linked inhaler will warn the patient of a primary contributor (air pollution, air temperature) to avoid an asthma attack.
Offerings and Insights
Such mobile apps would make it much easier for a considerable time to fight against respiratory disease.
Precise current status monitoring will deter potential future threats.
Calculates the sensor data and recommends patients to take the appropriate steps.
Prevent additional hospital fees by early diagnosis.
3. Smart Contact Lenses
The eye is an incredible human organ. To maintain its functioning, tears place a thin coating over the eye. But tears may do more to keep it operating with the support of contact lenses centered on IoT. It is possible to determine signs of different diseases by integrating a detector and contact lens, which could be an excellent IoT in healthcare.
Offerings and Insights
IoT-based contact lenses may be used to measure tear glucose levels and help diagnose diabetes.
The adjustment in the shape of the eyeball, which is a sign of glaucoma, can be observed by a savvy contact lens.
Researchers are experimenting with a sensor-based contact lens to remedy presbyopia (a disorder caused by the loss of elasticity in the eye lens).
4. RFIDs
Radio Frequency Identification (RFID) tags or transmitters are discrete components that obtain, retain, and transfer data to nearby readers using close to zero radio waves. Inside the hospital community, RFID technology has potential uses. In the surgery room, RFID allows for more detailed inventory monitors for medication and pharmaceutical products, patient and personnel monitoring, and instrument monitoring. The use of RFID tags helps hospitals to standardize procedures that waste time and enhance connectivity.
5. Smart Hearing devices
IoT plays a wise role in healthcare, and the IoT-based hearing aid functionality is indeed popular. Nearly 466 million individuals have problems with significant hearing loss. The main aim of linking all internet-enabled devices is to make our lives convenient. A few of the attributes of IoT-based hearing aid systems are given below.
Offerings and insights
Users will simultaneously listen to multiple conversations.
With the use of a smoke sensor, it is easy to use it as a smoke detector.
The light can be turned on or off from remote locations by voice order.
6. Smart Robotic Surgery
With each day, the healthcare industry is becoming more dynamic, and with the change, analysts link devices through the internet. More specifically, doctors use IoT-driven robotic technology to perform surgical surgery. Within the patient’s body, the little automated unit will perform functions.
Offerings and Insights
It provides doctors with more power and accuracy to conduct the surgery.
It allows the procedure to be performed from a remote area, which could save several patients both in the hospitals and the conflict zone.
Operations such as heart valve repair, gynecologic surgical procedures, and more are now being done.
7. Remote Patient Monitoring
With IoT integration, remote patient monitoring will be feasible. Wearable devices with smart wearables can track the patient’s condition during the day and alert the doctors in case of emergency. Rather than hospitals or medical care centers, remote monitoring systems result in patients seeking treatment and screening in a personalized, remote location. It decreases the burden on healthcare staff who is struggling to deal with a rising volume of patients.
8. CGM (Continuous Glucose Meters)
A CGM is a remote monitoring device approved by the FDA that monitors day and night blood glucose levels. It can also help identify trends and patterns that provide a comprehensive understanding of a patient’s problem to their doctor. A sensor is attached to the rear of an individual’s armor under the skin of your abdomen. It emits data to a display that individuals can check on the device or in a mobile phone app. The data could help a person and their doctors make the right diabetes course of treatment.
In a nutshell
In several aspects, IoT is mostly about offering a better care experience for patients. Had nobody promising, the change would’ve been quick. It will take a concerted effort from all concerned and the patients; however, IoT would eventually change the healthcare landscape for the positive, indeed.
In the area and across the globe, the IoT healthcare sector is reconfiguring healthcare systems and services. IoT technology is built to better lives, but it is a perfect way to change lives.
Font-size: An Unexpectedly Complex CSS Property — From Manish Goregaokar in 2017. Of many oddities, I found the one where font: medium monospace renders at 13px where font: medium sans-serif renders at 16px particularly weird.
The good line-height — Since CSS supports unitless line-height, you probably shouldn’t be setting a hard number anyway.
Time to Say Goodbye to Google Fonts — Simon Wicki doesn’t mean don’t use them, they mean self-host them. Browsers are starting to isolate cache on a per-domain basis so that old argument that you buy speed because “users probably already have it cached” doesn’t hold up. I expected to hear about stuff like having more control over font loading, but this is just about the cache.
My Favorite Typefaces of 2020 — John Boardley’s picks for the past year. Have you seen these “color fonts”? They are so cool. Check out LiebeHeide, it looks like real pen-on-paper.
How to avoid layout shifts caused by web fonts — We’ve got CLS (Cumulative Layout Shift) now and it’s such an important performance metric that will soon start affecting SEO. And because we have CSS control over font loading via font-display, that means if we set things up such that font loading shifts the page, that’s bad. I like Simon Hearne’s suggestion that we tweak both our custom font and fallback font to match perfectly. I think perfect fallback fonts are one of the best CSS tricks.
How to pick a Typeface for User Interface and App Design? — Oliver Schöndorfer makes the case for “functional text” which is everything that isn’t body text (e.g. paragraphs of text) or display text (e.g. headers). “Clarity is key.”
The way routing works in JavaScript is usually that you specify which relative URL pattern you want for which component to render. So for /about you want the component to render. Let’s take a look at how to do this in Vue/Vue Router with lazy loading, and do it as cleanly as possible. I use this little tip all the time in my own work.
import Vue from 'vue'
import VueRouter from 'vue-router'
import Home from '../views/Home.vue'
import About from '../views/About.vue'
import Login from '../views/Login.vue'
Vue.use(VueRouter)
const routes = [
{ path: '/', name: 'Home', component: Home },
{ path: '/about', name: 'About', component: About },
{ path: '/login', name: 'Login', component: Login }
]
const router = new VueRouter({
routes
})
export default router
That will load the component at the / route, the component at the /about route, and the component at the /login route.
That doesn’t do a very good job of code splitting though, since all three of those components will be bundled together rather than loaded dynamically as needed.
Here’s another way to do the same, only with code splitting with dynamic import statements and webpack chunk names:
This is perfectly fine and doesn’t have any major downsides, other than being a bit verbose and repetitive. Since we’re awesome developers, let’s do a bit of abstraction to help, using an array that we’ll .map over.
Now we’ve reduced the use of the component key by using the route name as param in the import function.
But what happens if we want to set the chunk name?
As far as I know, you can’t have dynamic comments in JavaScript without some kind of build step. So, we are sacrificing comments (webpackChunkName) in favor of having to write less code in this case. It’s entirely up to you which you prefer.
Just kidding, let’s fix it.
As of webpack 2.6.0 , the placeholders [index] and [request] are supported, meaning we can set the name of the generated chunk like this:
Nice! Now we have all the power, plus dynamically loaded routes with named chunks. And it works with Vue 2 and Vue 3. You can check it out by running npm run build in the terminal:
See that? Now the components are chunked out… and the build did all the naming for us!
Buuuuut, we can still take this one step further by grouping the lazy loaded routes into named chunks rather than individual components. For example, we can create groups that group our most important components together and the rest in another “not so important” group. We merely update the webpack chunk name in place of the [request] placeholder we used earlier: