In recent years, the field of Content Creation and Representation on Digital platforms has seen a massive disruption. The widespread success of products like Quip, Google Docs and Dropbox Paper has shown how companies are racing to build the best experience for content creators in the enterprise domain and trying to find innovative ways of breaking the traditional moulds of how content is shared and consumed. Taking advantage of the massive outreach of social media platforms, there is a new wave of independent content creators using platforms like Medium to create content and share it with their audience.
As so many people from different professions and backgrounds try to create content on these products, it’s important that these products provide a performant and seamless experience of content creation and have teams of designers and engineers who develop some level of domain expertise over time in this space. With this article, we try to not only lay the foundation of building an editor but also give the readers a glimpse into how little nuggets of functionalities when brought together can create a great user experience for a content creator.
Understanding The Document Structure
Before we dive into building the editor, let’s look at how a document is structured for a Rich Text Editor and what are the different types of data structures involved.
Document Nodes
Document nodes are used to represent the contents of the document. The common types of nodes that a rich-text document could contain are paragraphs, headings, images, videos, code-blocks and pull-quotes. Some of these may contain other nodes as children inside them (e.g. Paragraph nodes contain text nodes inside them). Nodes also hold any properties specific to the object they represent that are needed to render those nodes inside the editor. (e.g. Image nodes contain an image src property, Code-blocks may contain a language property and so on).
There are largely two types of nodes that represent how they should be rendered –
- Block Nodes (analogous to HTML concept of Block-level elements) that are each rendered on a new line and occupy the available width. Block nodes could contain other block nodes or inline nodes inside them. An observation here is that the top-level nodes of a document would always be block nodes.
- Inline Nodes (analogous to HTML concept of Inline elements) that start rendering on the same line as the previous node. There are some differences in how inline elements are represented in different editing libraries. SlateJS allows for inline elements to be nodes themselves. DraftJS, another popular Rich Text Editing library, lets you use the concept of Entities to render inline elements. Links and Inline Images are examples of Inline nodes.
- Void Nodes — SlateJS also allows this third category of nodes that we will use later in this article to render media.
If you want to learn more about these categories, SlateJS’s documentation on Nodes is a good place to start.
Attributes
Similar to HTML’s concept of attributes, attributes in a Rich Text Document are used to represent non-content properties of a node or it’s children. For instance, a text node can have character-style attributes that tell us whether the text is bold/italic/underlined and so on. Although this article represents headings as nodes themselves, another way to represent them could be that nodes have paragraph-styles (paragraph & h1-h6) as attributes on them.
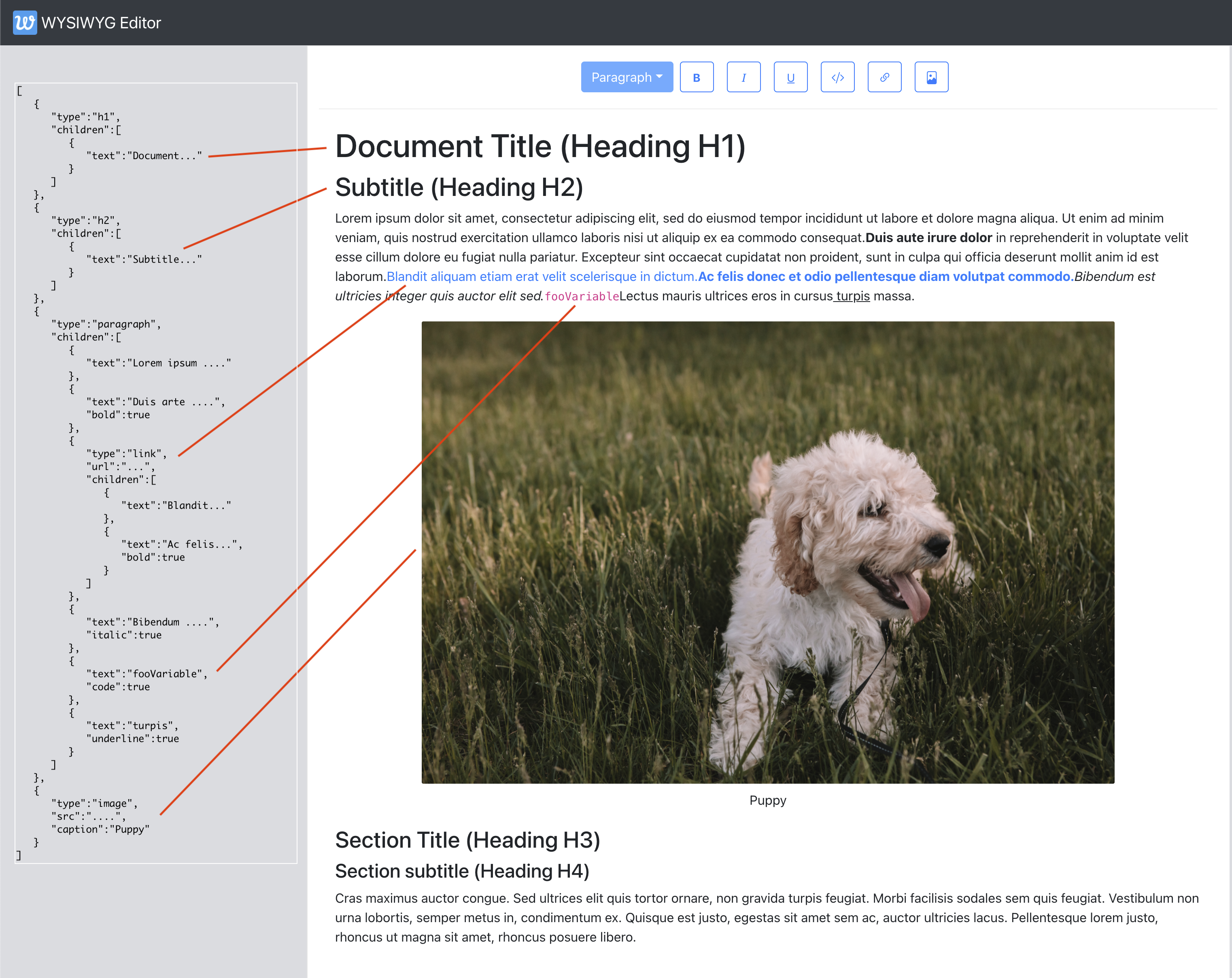
Below image gives an example of how a document’s structure (in JSON) is described at a more granular level using nodes and attributes highlighting some of the elements in the structure to the left.
Some of the things worth calling out here with the structure are:
- Text nodes are represented as
{text: 'text content'}
- Properties of the nodes are stored directly on the node (e.g.
url for links and caption for images)
- SlateJS-specific representation of text attributes breaks the text nodes to be their own nodes if the character style changes. Hence, the text ‘Duis aute irure dolor’ is a text node of it’s own with
bold: true set on it. Same is the case with the italic, underline and code style text in this document.
Locations And Selection
When building a rich text editor, it is crucial to have an understanding of how the most granular part of a document (say a character) can be represented with some sort of coordinates. This helps us navigate the document structure at runtime to understand where in the document hierarchy we are. Most importantly, location objects give us a way to represent user selection which is quite extensively used to tailor the user experience of the editor in real time. We will use selection to build our toolbar later in this article. Examples of these could be:
- Is the user’s cursor currently inside a link, maybe we should show them a menu to edit/remove the link?
- Has the user selected an image? Maybe we give them a menu to resize the image.
- If the user selects certain text and hits the DELETE button, we determine what user’s selected text was and remove that from the document.
SlateJS’s document on Location explains these data structures extensively but we go through them here quickly as we use these terms at different instances in the article and show an example in the diagram that follows.
- Path
Represented by an array of numbers, a path is the way to get to a node in the document. For instance, a path [2,3] represents the 3rd child node of the 2nd node in the document.
- Point
More granular location of content represented by path + offset. For instance, a point of {path: [2,3], offset: 14} represents the 14th character of the 3rd child node inside the 2nd node of the document.
- Range
A pair of points (called anchor and focus) that represent a range of text inside the document. This concept comes from Web’s Selection API where anchor is where user’s selection began and focus is where it ended. A collapsed range/selection denotes where anchor and focus points are the same (think of a blinking cursor in a text input for instance).
As an example let’s say that the user’s selection in our above document example is ipsum:
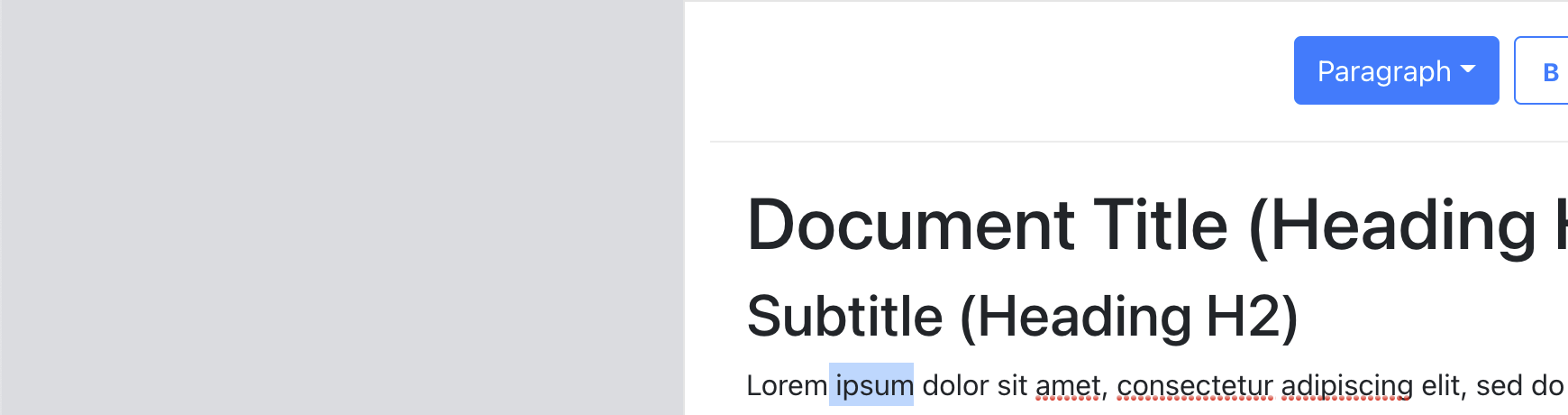
The user’s selection can be represented as:
{
anchor: {path: [2,0], offset: 5}, /0th text node inside the paragraph node which itself is index 2 in the document/
focus: {path: [2,0], offset: 11}, // space + 'ipsum'
}`
Setting Up The Editor
In this section, we are going to set up the application and get a basic rich-text editor going with SlateJS. The boilerplate application would be create-react-appreact-bootstrap
Create a folder called wysiwyg-editor and run the below command from inside the directory to set up the react app. We then run a yarn start command that should spin up the local web server (port defaulting to 3000) and show you a React welcome screen.
npx create-react-app .
yarn start
We then move on to add the SlateJS dependencies to the application.
yarn add slate slate-react
slate is SlateJS’s core package and slate-react includes the set of React components we will use to render Slate editors. SlateJS exposes some more packages organized by functionality one might consider adding to their editor.
We first create a utils folder that holds any utility modules we create in this application. We start with creating an ExampleDocument.js that returns a basic document structure that contains a paragraph with some text. This module looks like below:
const ExampleDocument = [
{
type: "paragraph",
children: [
{ text: "Hello World! This is my paragraph inside a sample document." },
],
},
];
export default ExampleDocument;
We now add a folder called components that will hold all our React components and do the following:
- Add our first React component
Editor.js to it. It only returns a div for now.
- Update the
App.js component to hold the document in its state which is initialized to our ExampleDocument above.
- Render the Editor inside the app and pass the document state and an
onChange handler down to the Editor so our document state is updated as the user updates it.
- We use React bootstrap’s Nav components to add a navigation bar to the application as well.
App.js component now looks like below:
import Editor from './components/Editor';
function App() {
const [document, updateDocument] = useState(ExampleDocument);
return (
<>
<Navbar bg="dark" variant="dark">
<Navbar.Brand href="#">
<img
alt=""
src="/app-icon.png"
width="30"
height="30"
className="d-inline-block align-top"
/>{" "}
WYSIWYG Editor
</Navbar.Brand>
</Navbar>
<div className="App">
<Editor document={document} onChange={updateDocument} />
</div>
</>
);
Inside the Editor component, we then instantiate the SlateJS editor and hold it inside a useMemo so that the object doesn’t change in between re-renders.
// dependencies imported as below.
import { withReact } from "slate-react";
import { createEditor } from "slate";
const editor = useMemo(() => withReact(createEditor()), []);
createEditor gives us the SlateJS editor instance which we use extensively through the application to access selections, run data transformations and so on. withReact is a SlateJS plugin that adds React and DOM behaviors to the editor object. SlateJS Plugins are Javascript functions that receive the editor object and attach some configuration to it. This allows web developers to add configurations to their SlateJS editor instance in a composable way.
We now import and render Slate exposes a bunch of React contexts we use to access in the application code. Editable is the component that renders the document hierarchy for editing. Overall, the Editor.js
import { Editable, Slate, withReact } from "slate-react";
import { createEditor } from "slate";
import { useMemo } from "react";
export default function Editor({ document, onChange }) {
const editor = useMemo(() => withReact(createEditor()), []);
return (
<Slate editor={editor} value={document} onChange={onChange}>
<Editable />
</Slate>
);
}
At this point, we have necessary React components added and the editor populated with an example document. Our Editor should be now set up allowing us to type in and change the content in real time — as in the screencast below.
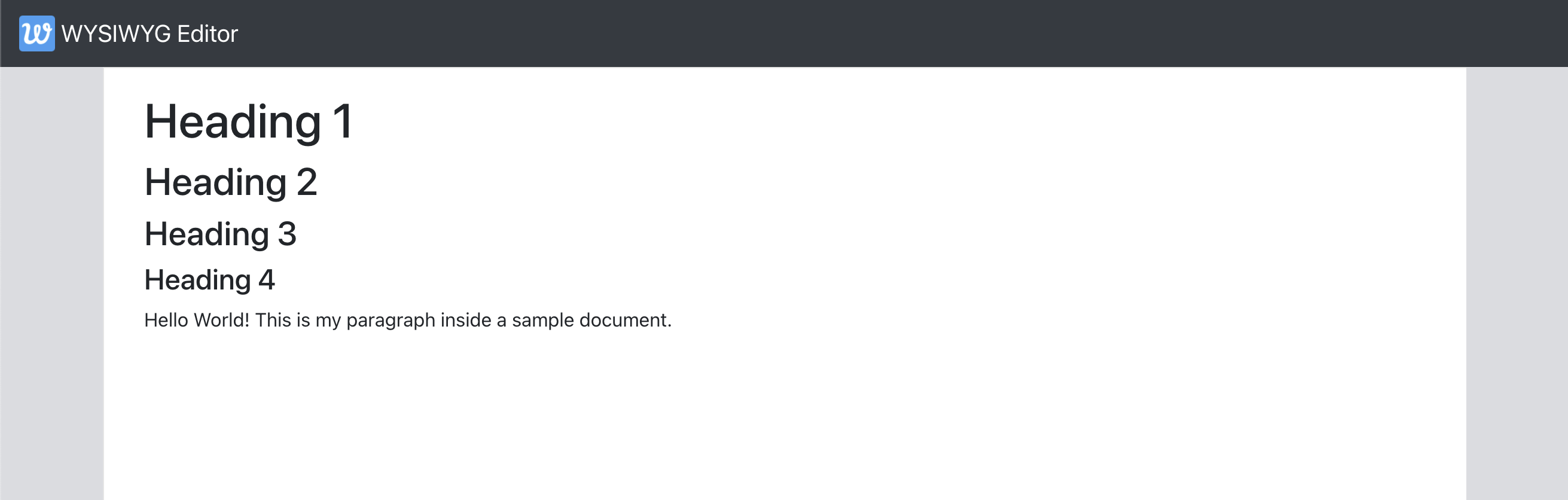
Character Styles
Similar to renderElement, SlateJS gives out a function prop called renderLeaf that can be used to customize rendering of the text nodes (Leaf referring to text nodes which are the leaves/lowest level nodes of the document tree). Following the example of renderElement, we write an implementation for renderLeaf.
export default function useEditorConfig(editor) {
return { renderElement, renderLeaf };
}
// ...
function renderLeaf({ attributes, children, leaf }) {
let el = <>{children}</>;
if (leaf.bold) {
el = <strong>{el}</strong>;
}
if (leaf.code) {
el = <code>{el}</code>;
}
if (leaf.italic) {
el = <em>{el}</em>;
}
if (leaf.underline) {
el = <u>{el}</u>;
}
return <span {...attributes}>{el}</span>;
}
An important observation of the above implementation is that it allows us to respect HTML semantics for character styles. Since renderLeaf gives us access to the text node leaf itself, we can customize the function to implement a more customized rendering. For instance, you might have a way to let users choose a highlightColor for text and check that leaf property here to attach the respective styles.
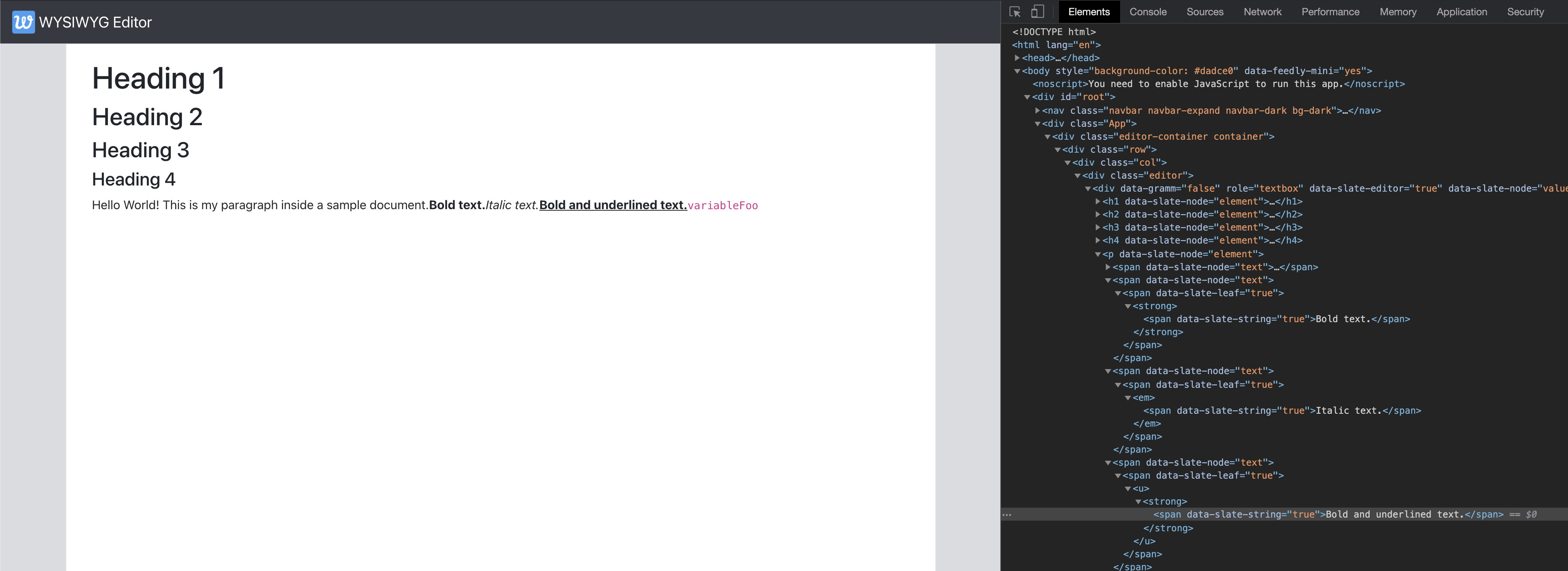
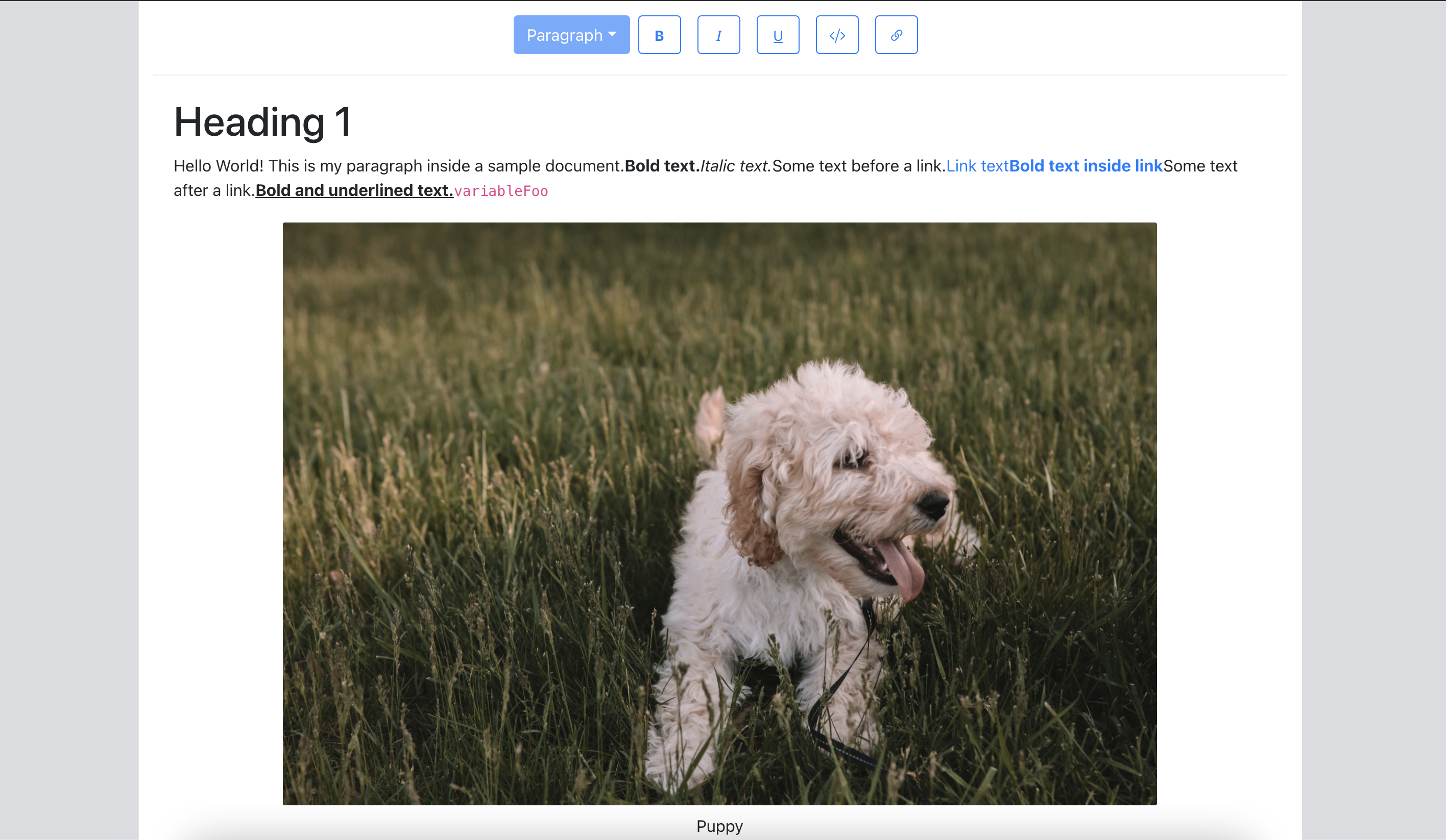
We now update the Editor component to use the above, the ExampleDocument to have a few text nodes in the paragraph with combinations of these styles and verify that they are rendered as expected in the Editor with the semantic tags we used.
# src/components/Editor.js
const { renderElement, renderLeaf } = useEditorConfig(editor);
return (
...
<Editable renderElement={renderElement} renderLeaf={renderLeaf} />
);
# src/utils/ExampleDocument.js
{
type: "paragraph",
children: [
{ text: "Hello World! This is my paragraph inside a sample document." },
{ text: "Bold text.", bold: true, code: true },
{ text: "Italic text.", italic: true },
{ text: "Bold and underlined text.", bold: true, underline: true },
{ text: "variableFoo", code: true },
],
},
Adding A Toolbar
Let’s begin by adding a new component Toolbar.js to which we add a few buttons for character styles and a dropdown for paragraph styles and we wire these up later in the section.
const PARAGRAPH_STYLES = ["h1", "h2", "h3", "h4", "paragraph", "multiple"];
const CHARACTER_STYLES = ["bold", "italic", "underline", "code"];
export default function Toolbar({ selection, previousSelection }) {
return (
<div className="toolbar">
{/* Dropdown for paragraph styles */}
<DropdownButton
className={"block-style-dropdown"}
disabled={false}
id="block-style"
title={getLabelForBlockStyle("paragraph")}
>
{PARAGRAPH_STYLES.map((blockType) => (
<Dropdown.Item eventKey={blockType} key={blockType}>
{getLabelForBlockStyle(blockType)}
</Dropdown.Item>
))}
</DropdownButton>
{/* Buttons for character styles */}
{CHARACTER_STYLES.map((style) => (
<ToolBarButton
key={style}
icon={<i className={`bi ${getIconForButton(style)}`} />}
isActive={false}
/>
))}
</div>
);
}
function ToolBarButton(props) {
const { icon, isActive, ...otherProps } = props;
return (
<Button
variant="outline-primary"
className="toolbar-btn"
active={isActive}
{...otherProps}
>
{icon}
</Button>
);
}
We abstract away the buttons to the ToolbarButton component that is a wrapper around the React Bootstrap Button component. We then render the toolbar above the Editable inside Editor component and verify that the toolbar shows up in the application.
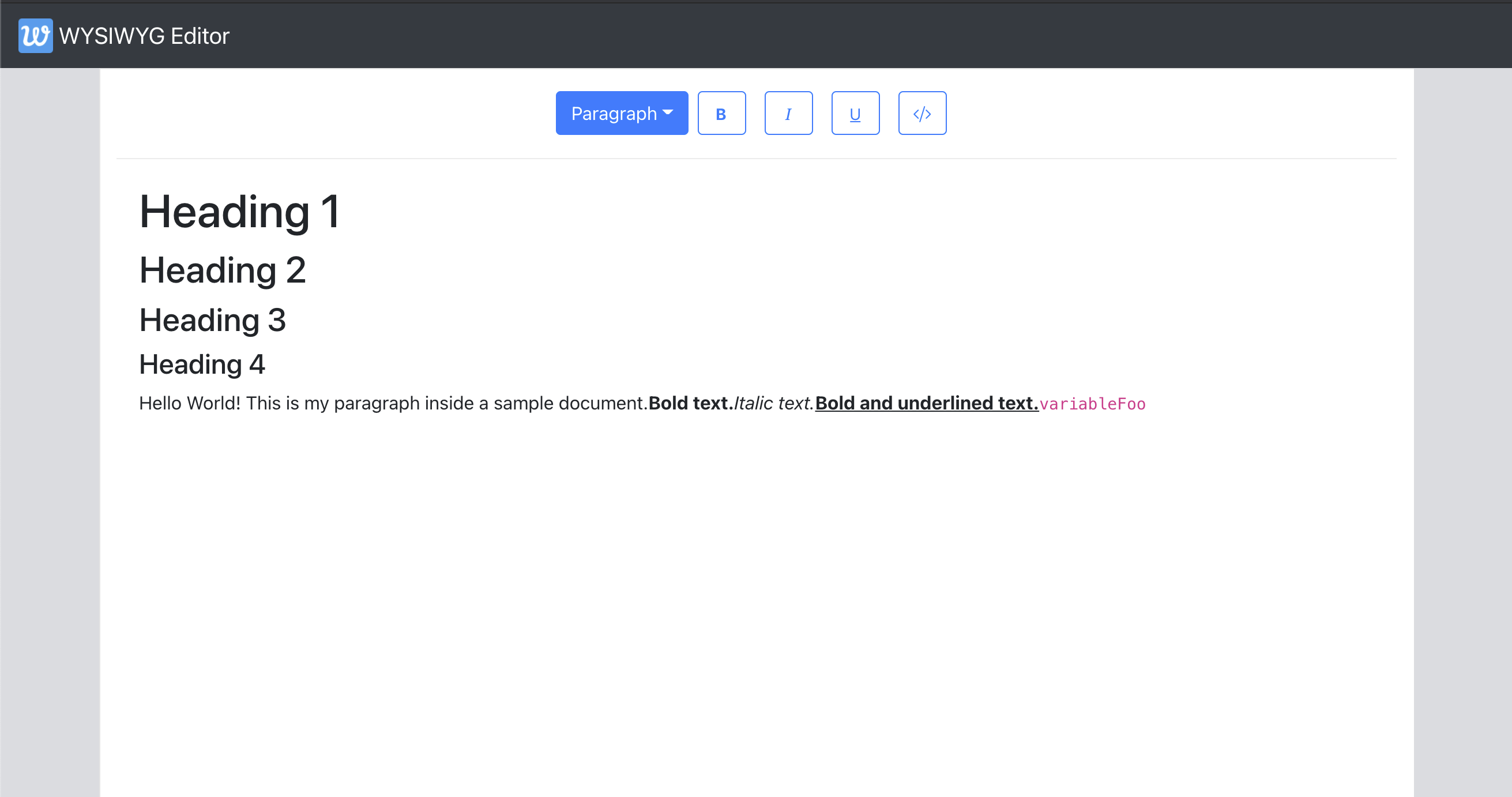
Here are the three key functionalities we need the toolbar to support:
- When the user’s cursor is in a certain spot in the document and they click one of the character style buttons, we need to toggle the style for the text they may type next.
- When the user selects a range of text and click one of the character style buttons, we need to toggle the style for that specific section.
- When the user selects a range of text, we want to update the paragraph-style dropdown to reflect the paragraph-type of the selection. If they do select a different value from the selection, we want to update the paragraph style of the entire selection to be what they selected.
Let’s look at how these functionalities work on the Editor before we start implementing them.
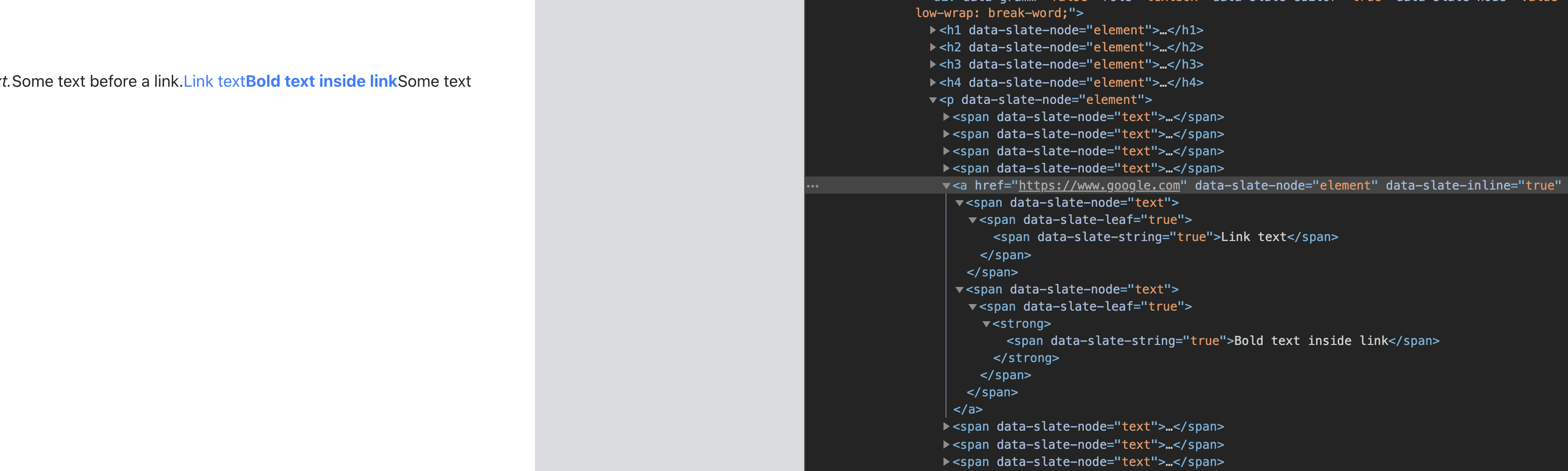
Adding A Link Button To The Toolbar
Let’s add a Link Button to the toolbar that enables the user to do the following:
- Selecting some text and clicking on the button converts that text into a link
- Having a blinking cursor (collapsed selection) and clicking the button inserts a new link there
- If the user’s selection is inside a link, clicking on the button should toggle the link — meaning convert the link back to text.
To build these functionalities, we need a way in the toolbar to know if the user’s selection is inside a link node. We add a util function that traverses the levels in upward direction from the user’s selection to find a link node if there is one, using Editor.above helper function from SlateJS.
# src/utils/EditorUtils.js
export function isLinkNodeAtSelection(editor, selection) {
if (selection == null) {
return false;
}
return (
Editor.above(editor, {
at: selection,
match: (n) => n.type === "link",
}) != null
);
}
Now, let’s add a button to the toolbar that is in active state if the user’s selection is inside a link node.
# src/components/Toolbar.js
return (
<div className="toolbar">
...
{/* Link Button */}
<ToolBarButton
isActive={isLinkNodeAtSelection(editor, editor.selection)}
label={<i className={`bi ${getIconForButton("link")}`} />}
/>
</div>
);

If we had to do this by ourselves, we’d have to figure out the range of selection and create three new nodes (text, link, text) that replace the original text node. SlateJS has a helper function called Transforms.wrapNodes that does exactly this — wrap nodes at a location into a new container node. We also have a helper available for the reverse of this process — Transforms.unwrapNodes which we use to remove links from selected text and merge that text back into the text nodes around it. With that, toggleLinkAtSelection has the below implementation to insert a new link at an expanded selection.
# src/utils/EditorUtils.js
export function toggleLinkAtSelection(editor) {
if (!isLinkNodeAtSelection(editor, editor.selection)) {
const isSelectionCollapsed =
Range.isCollapsed(editor.selection);
if (isSelectionCollapsed) {
Transforms.insertNodes(
editor,
{
type: "link",
url: '#',
children: [{ text: 'link' }],
},
{ at: editor.selection }
);
} else {
Transforms.wrapNodes(
editor,
{ type: "link", url: '#', children: [{ text: '' }] },
{ split: true, at: editor.selection }
);
}
} else {
Transforms.unwrapNodes(editor, {
match: (n) => Element.isElement(n) && n.type === "link",
});
}
}
If the selection is collapsed, we insert a new node there with Transform.insertNodes
# src/components/Toolbar.js
<ToolBarButton
...
isActive={isLinkNodeAtSelection(editor, editor.selection)}
onMouseDown={() => toggleLinkAtSelection(editor)}
/>

If the text ’ABCDE’ was the first text node of the first paragraph in the document, our point values would be —
cursorPoint = { path: [0,0], offset: 5}
startPointOfLastCharacter = { path: [0,0], offset: 4}
If the last character was a space, we know where it started — startPointOfLastCharacter.Let’s move to step-2 where we move backwards character-by-character until either we find another space or the start of the text node itself.
...
if (lastCharacter !== " ") {
return;
}
let end = startPointOfLastCharacter;
start = Editor.before(editor, end, {
unit: "character",
});
const startOfTextNode = Editor.point(editor, currentNodePath, {
edge: "start",
});
while (
Editor.string(editor, Editor.range(editor, start, end)) !== " " &&
!Point.isBefore(start, startOfTextNode)
) {
end = start;
start = Editor.before(editor, end, { unit: "character" });
}
const lastWordRange = Editor.range(editor, end, startPointOfLastCharacter);
const lastWord = Editor.string(editor, lastWordRange);
Here is a diagram that shows where these different points point to once we find the last word entered to be ABCDE.
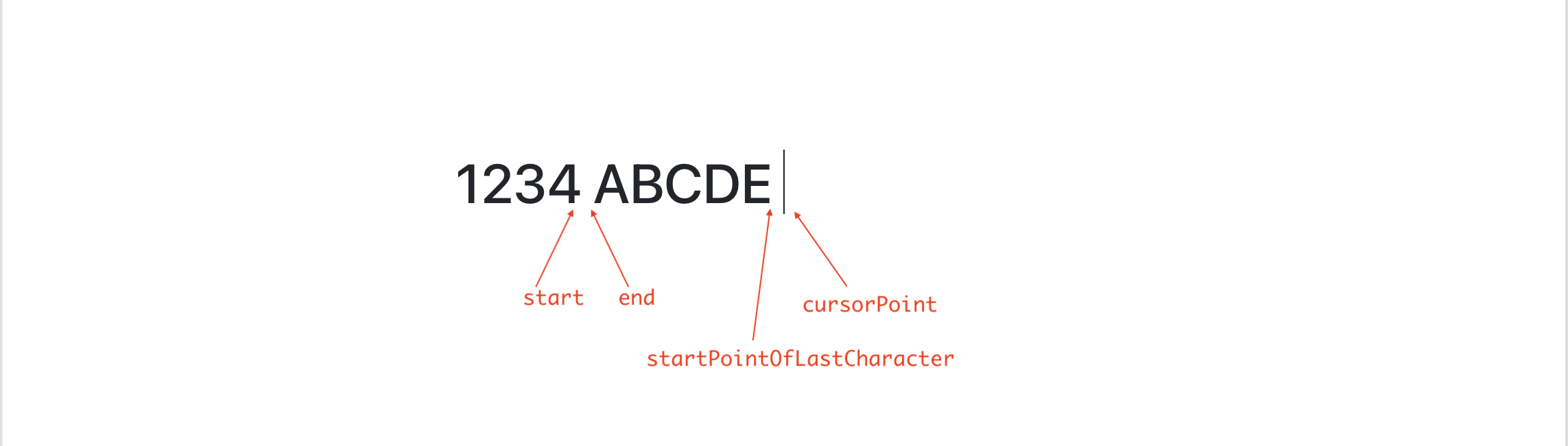
Note that start and end are the points before and after the space there. Similarly, startPointOfLastCharacter and cursorPoint are the points before and after the space user just inserted. Hence [end,startPointOfLastCharacter] gives us the last word inserted.
We log the value of lastWord to the console and verify the values as we type.
Now let’s focus on caption-editing. The way we want this to be a seamless experience for the user is that when they click on the caption, we show a text input where they can edit the caption. If they click outside the input or hit the RETURN key, we treat that as a confirmation to apply the caption. We then update the caption on the image node and switch the caption back to read mode. Let’s see it in action so we have an idea of what we’re building.
Let’s update our Image component to have a state for caption’s read-edit modes. We update the local caption state as the user updates it and when they click out (onBlur) or hit RETURN (onKeyDown), we apply the caption to the node and switch to read mode again.
const Image = ({ attributes, children, element }) => {
const [isEditingCaption, setEditingCaption] = useState(false);
const [caption, setCaption] = useState(element.caption);
...
const applyCaptionChange = useCallback(
(captionInput) => {
const imageNodeEntry = Editor.above(editor, {
match: (n) => n.type === "image",
});
if (imageNodeEntry == null) {
return;
}
if (captionInput != null) {
setCaption(captionInput);
}
Transforms.setNodes(
editor,
{ caption: captionInput },
{ at: imageNodeEntry[1] }
);
},
[editor, setCaption]
);
const onCaptionChange = useCallback(
(event) => {
setCaption(event.target.value);
},
[editor.selection, setCaption]
);
const onKeyDown = useCallback(
(event) => {
if (!isHotkey("enter", event)) {
return;
}
applyCaptionChange(event.target.value);
setEditingCaption(false);
},
[applyCaptionChange, setEditingCaption]
);
const onToggleCaptionEditMode = useCallback(
(event) => {
const wasEditing = isEditingCaption;
setEditingCaption(!isEditingCaption);
wasEditing && applyCaptionChange(caption);
},
[editor.selection, isEditingCaption, applyCaptionChange, caption]
);
return (
...
{isEditingCaption ? (
<Form.Control
autoFocus={true}
className={"image-caption-input"}
size="sm"
type="text"
defaultValue={element.caption}
onKeyDown={onKeyDown}
onChange={onCaptionChange}
onBlur={onToggleCaptionEditMode}
/>
) : (
<div
className={"image-caption-read-mode"}
onClick={onToggleCaptionEditMode}
>
{caption}
</div>
)}
</div>
...
With that, the caption editing functionality is complete. We now move to adding a way for users to upload images to the editor. Let’s add a toolbar button that lets users select and upload an image.
# src/components/Toolbar.js
const onImageSelected = useImageUploadHandler(editor, previousSelection);
return (
<div className="toolbar">
....
<ToolBarButton
isActive={false}
as={"label"}
htmlFor="image-upload"
label={
<>
<i className={`bi ${getIconForButton("image")}`} />
<input
type="file"
id="image-upload"
className="image-upload-input"
accept="image/png, image/jpeg"
onChange={onImageSelected}
/>
</>
}
/>
</div>
As we work with image uploads, the code could grow quite a bit so we move the image-upload handling to a hook useImageUploadHandler that gives out a callback attached to the file-input element. We’ll discuss shortly about why it needs the previousSelection state.
Before we implement useImageUploadHandler, we’ll set up the server to be able to upload an image to. We setup an Express server and install two other packages — cors and multer that handle file uploads for us.
yarn add express cors multer
We then add a src/server.js script that configures the Express server with cors and multer and exposes an endpoint /upload which we will upload the image to.
# src/server.js
const storage = multer.diskStorage({
destination: function (req, file, cb) {
cb(null, "./public/photos/");
},
filename: function (req, file, cb) {
cb(null, file.originalname);
},
});
var upload = multer({ storage: storage }).single("photo");
app.post("/upload", function (req, res) {
upload(req, res, function (err) {
if (err instanceof multer.MulterError) {
return res.status(500).json(err);
} else if (err) {
return res.status(500).json(err);
}
return res.status(200).send(req.file);
});
});
app.use(cors());
app.listen(port, () => console.log(`Listening on port ${port}`));
Now that we have the server setup, we can focus on handling the image upload. When the user uploads an image, it could be a few seconds before the image gets uploaded and we have a URL for it. However, we do what to give the user immediate feedback that the image upload is in progress so that they know the image is being inserted in the editor. Here are the steps we implement to make this behavior work –
- Once the user selects an image, we insert an image node at the user’s cursor position with a flag
isUploading set on it so we can show the user a loading state.
- We send the request to the server to upload the image.
- Once the request is complete and we have an image URL, we set that on the image and remove the loading state.
Let’s begin with the first step where we insert the image node. Now, the tricky part here is we run into the same issue with selection as with the link button in the toolbar. As soon as the user clicks on the Image button in the toolbar, the editor loses focus and the selection becomes null. If we try to insert an image, we don’t know where the user’s cursor was. Tracking previousSelection gives us that location and we use that to insert the node.
# src/hooks/useImageUploadHandler.js
import { v4 as uuidv4 } from "uuid";
export default function useImageUploadHandler(editor, previousSelection) {
return useCallback(
(event) => {
event.preventDefault();
const files = event.target.files;
if (files.length === 0) {
return;
}
const file = files[0];
const fileName = file.name;
const formData = new FormData();
formData.append("photo", file);
const id = uuidv4();
Transforms.insertNodes(
editor,
{
id,
type: "image",
caption: fileName,
url: null,
isUploading: true,
children: [{ text: "" }],
},
{ at: previousSelection, select: true }
);
},
[editor, previousSelection]
);
}
As we insert the new image node, we also assign it an identifier id using the uuid package. We’ll discuss in Step (3)’s implementation why we need that. We now update the image component to use the isUploading flag to show a loading state.
{!element.isUploading && element.url != null ? (
<img src={element.url} alt={caption} className={"image"} />
) : (
<div className={"image-upload-placeholder"}>
<Spinner animation="border" variant="dark" />
</div>
)}
That completes the implementation of step 1. Let’s verify that we are able to select an image to upload, see the image node getting inserted with a loading indicator where it was inserted in the document.
Moving to Step (2), we will use axois library to send a request to the server.
export default function useImageUploadHandler(editor, previousSelection) {
return useCallback((event) => {
....
Transforms.insertNodes(
…
{at: previousSelection, select: true}
);
axios
.post("/upload", formData, {
headers: {
"content-type": "multipart/form-data",
},
})
.then((response) => {
// update the image node.
})
.catch((error) => {
// Fire another Transform.setNodes to set an upload failed state on the image
});
}, [...]);
}
We verify that the image upload works and the image does show up in the public/photos folder of the app. Now that the image upload is complete, we move to Step (3) where we want to set the URL on the image in the resolve() function of the axios promise. We could update the image with Transforms.setNodes but we have a problem — we do not have the path to the newly inserted image node. Let’s see what our options are to get to that image —
- Can’t we use
editor.selection as the selection must be on the newly inserted image node? We cannot guarantee this since while the image was uploading, the user might have clicked somewhere else and the selection might have changed.
- How about using
previousSelection which we used to insert the image node in the first place? For the same reason we can’t use editor.selection, we can’t use previousSelection since it may have changed too.
- SlateJS has a History module that tracks all the changes happening to the document. We could use this module to search the history and find the last inserted image node. This also isn’t completely reliable if it took longer for the image to upload and the user inserted more images in different parts of the document before the first upload completed.
- Currently,
Transform.insertNodes’s API doesn’t return any information about the inserted nodes. If it could return the paths to the inserted nodes, we could use that to find the precise image node we should update.
Since none of the above approaches work, we apply an id to the inserted image node (in Step (1)) and use the same id again to locate it when the image upload is complete. With that, our code for Step (3) looks like below —
axios
.post("/upload", formData, {
headers: {
"content-type": "multipart/form-data",
},
})
.then((response) => {
const newImageEntry = Editor.nodes(editor, {
match: (n) => n.id === id,
});
if (newImageEntry == null) {
return;
}
Transforms.setNodes(
editor,
{ isUploading: false, url: `/photos/${fileName}` },
{ at: newImageEntry[1] }
);
})
.catch((error) => {
// Fire another Transform.setNodes to set an upload failure state
// on the image.
});
With the implementation of all three steps complete, we are ready to test the image upload end to end.
With that, we’ve wrapped up Images for our editor. Currently, we show a loading state of the same size irrespective of the image. This could be a jarring experience for the user if the loading state is replaced by a drastically smaller or bigger image when the upload completes. A good follow up to the upload experience is getting the image dimensions before the upload and showing a placeholder of that size so that transition is seamless. The hook we add above could be extended to support other media types like video or documents and render those types of nodes as well.
Conclusion
In this article, we have built a WYSIWYG Editor that has a basic set of functionalities and some micro user-experiences like link detection, in-place link editing and image caption editing that helped us go deeper with SlateJS and concepts of Rich Text Editing in general. If this problem space surrounding Rich Text Editing or Word Processing interests you, some of the cool problems to go after could be:
- Collaboration
- A richer text editing experience that supports text alignments, inline images, copy-paste, changing font and text colors etc.
- Importing from popular formats like Word documents and Markdown.
If you want to learn more SlateJS, here are some links that might be helpful.
- SlateJS Examples
A lot of examples that go beyond the basics and build functionalities that are usually found in Editors like Search & Highlight, Markdown Preview and Mentions.
- API Docs
Reference to a lot of helper functions exposed by SlateJS that one might want to keep handy when trying to perform complex queries/transformations on SlateJS objects.
Lastly, SlateJS’s Slack Channel is a very active community of web developers building Rich Text Editing applications using SlateJS and a great place to learn more about the library and get help if needed.