I’d like to tell you something not to do to make your website better. Don’t add anythird-party scriptsto your site.
That may sound extreme, but at one time it would’ve been common sense. On today’s modern web it sounds like advice from a tinfoil-hat-wearing conspiracy nut. But just because I’m paranoid doesn’t mean they’re not out to get your user’s data.
All I’m asking is that we treat third-party scripts like third-party cookies. They were a mistake.
Browsers are now beginning to block third-party cookies. Chrome is dragging its heels because the same company that makes the browser also runs an advertising business. But even they can’t resist the tide. Third-party cookies are used almost exclusively for tracking. That was never the plan.
In the beginning, there was no state on the web. A client requested a resource from a server. The server responded. Then they both promptly forgot about it. That made it hard to build shopping carts or log-ins. That’s why we got cookies.
In hindsight, cookies should’ve been limited to a same-origin policy from day one. That would’ve solved the problems of authentication and commerce without opening up a huge security hole that has been exploited to track people as they moved from one website to another. The web went from having no state to having too much.
Now that vulnerability is finally being closed. But only for cookies. I would love it if third-party JavaScript got the same treatment.
When you add any third-party file to your website—an image, a stylesheet, a font—it’s a potential vector for tracking. But third-party JavaScript files go one further. They can execute arbitrary code.
Just take a minute to consider the implications of that: any third-party script on your site is allowing someone else to execute code on your web pages. That’s astonishingly unsafe.
It gets better. One of the pieces of code that this invited intruder can execute is the ability to pull in other third-party scripts.
You might think there’s no harm in adding that one little analytics script. Or that one little Google Tag Manager snippet. It’s such a small piece of code, after all. But in doing that, you’ve handed over your keys to a stranger. And now they’re welcoming in all their shady acquaintances.
Request Map Generator is a great tool for visualizing the resources being loaded on any web page. Try pasting in the URL of an interesting article from a news outlet or magazine that someone sent you recently. Then marvel at the sheer size and number of third-party scripts that sneak in via one tiny script element on the original page.
That’s why I recommend that the one thing people can do to make their website better is to not add third-party scripts.
Easier said than done, right? Especially if you’re working on a site that currently relies on third-party tracking for its business model. But that exploitative business model won’t change unless people like us are willing to engage in a campaign of passive resistance.
I know, I know. If you refuse to add that third-party script, your boss will probably say, “Fine, I’ll get someone else to do it. Also, you’re fired.”
This tactic will only work if everyone agrees to do what’s right. We need to have one another’s backs. We need to support one another. The way people support one another in the workplace is through a union.
So I think I’d like to change my answer to the question that’s been posed.
The one thing people can do to make their website better is to unionize.
I saw Bartosz Ciechanowski’s “Curves and Surfaces” going around the other day and was like, oh hey, this is the same fella that did that other amazingly interactive blog post on the Internal Combustion Engine the other day. I feel like I pretty much get how engines work now because of that blog post. Then I thought I should see what other blog posts Bartosz has and, lo and behold, there are a dozen or so — and they are all super good. Like one on gears, color spaces, Earth and Sun, and mesh transforms.
If I was a person who hired people to design interactive science museums, I’d totally try to hire Bartosz to design one. I’m glad, though, that the web is the output of choice so far as the reach of the web is untouchable.
I wonder what the significance of the Patreon membership level numbers are? 3, 7, 19, 37, 71. Just random prime numbers? I threw in a few bucks. I’d increase my pledge if some of the bucks could go toward an improved accessibility situation. I think the sliders are largely unfocusable
situations so I imagine something better could be done there.
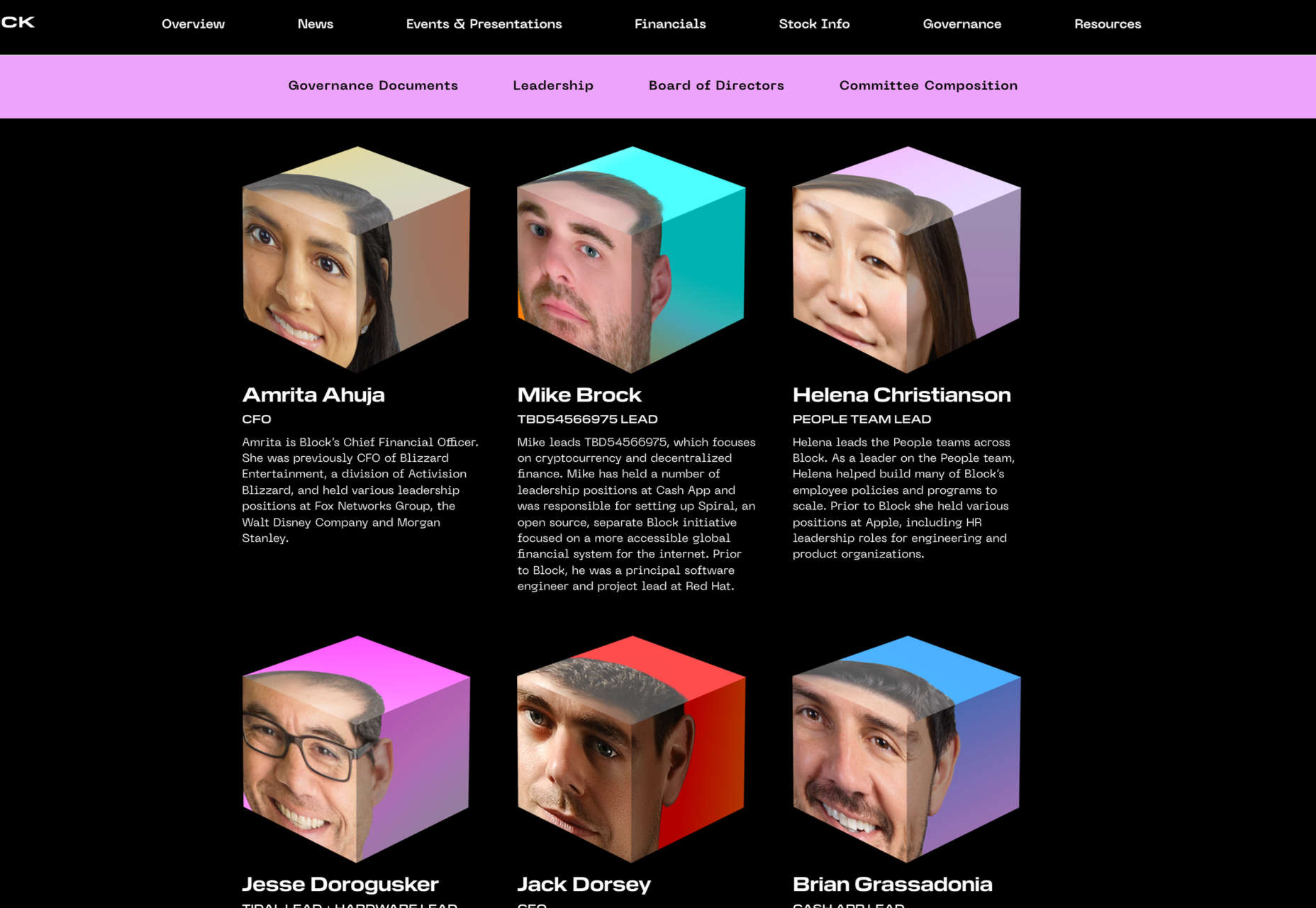
A few days ago, the big tech news was that Jack Dorsey was stepping down from his role as Twitter CEO to focus on Square, the payment processor he founded in 2009.
Two days later, it was announced that Square will now rebrand under the umbrella of Block. Like Meta and Alphabet, Block is a parent company — Square will remain Square, just as Facebook is still Facebook. The only actual product name change is that of Square Crypto will now be known as Spiral.
The move has reportedly been in the works for over a year. However, despite the marketing team’s best efforts to spread around the reference, it’s reasonably clear that Block is a reference to blockchain, the technology that powers cryptocurrency.
Dorsey has been a longtime advocate of cryptocurrency, particularly Bitcoin. With PayPal and Mastercard entering the crypto space, it was only a matter of time before Square’s focus was redirected away from legacy money.
The recent Meta rebrand was much scorned, but the new Block brand has been received with considerably more positivity. So what’s the difference?
Typically corporate rebrands, especially those in fintech, are detestable exercises in cowardice, where all trace of personality is driven out in favor of a nice safe sans-serif and a logomark as some form of tick or wave. Not so the Block branding, which feels like a cross between an Apple store and a hardcore night out in Berlin.
Yes, the logotype is sans-serif — it’s Pilat, to be precise. But the characters are pleasingly wide, and the overall shape of each is a rounded square. So much so that the ‘K’ feels a little out of place due to the rounded characteristics of the other letters. Most obviously of all, it’s uppercase, which in itself is nothing new, except that it breaks from the recent trend for lowercase. It’s incredibly refreshing to look at a brand that doesn’t mimic everything else in the space.
The logotype is crowned with a pleasantly brave mark; a morphing, twisting cube across the surface of which rainbows of gradients dance and play as it flips and spins. Interestingly, the logomark’s animated form is considered the primary version, with static versions only to be used when required.
The logo isn’t perfect — clearly, a design so dependent on color lends itself far better to dark mode than anything else — a good logo should be robust enough to work well in any context. However, I really like the design’s ambition to define itself, and the playfulness with which it does it.
A few years ago, there was this French book publisher. They specialize in technical books and published an author who wrote a book about CSS3, HTML5 and jQuery. The final version, however, a glaring typo on the cover where “HTML5” was displayed as “HTLM5.” Read that twice. Yes. “HTLM5.” (Note that it was also missing the capitalized “Q” in jQuery in one version.)
I don’t know how many people are involved in publishing and printing a book. I bet quite a few. Yet, it looked like none of the people involved saw the typo. It made it to the printer, after all.
And this kind of thing happens all the time on projects. One of my favorite French expressions is avoir la tête dans le guidon. A literal translation is “having your head in the handlebar.” (The English official version is having your nose in the grindstone.) It comes from cycling. When cyclists are trying to win a race, at some point, they end up with their nose so close to the handlebar that nothing else around them matters. They are hyper focused on the road ahead. They can’t see anything else around anymore.
And this is exactly what happens to us quite often on projects. We and our teams are so focused at some point on shipping the site (or printing the book) that we get blindfolded and fail to see little (or big) details anymore. This is how you ship a book about “HTLM5” and a website with navigation issues and dead ends in user flows, or features no one needs.
Gaining an external view with user testing
If you want to avoid these sorts of things, you need an external view of your site, product or service. And the best way to gain that view is to test it with people who are not on the team. We call this usability or user testing. I have to confess that I’m biased here since part of my job is to perform user testing on websites. So, I have to say that, ideally, you want to test with your target audience — the people who actually use your website, product, or service. But, if (and this is a big if) you can’t find any users, at least have a first round of tests with people who did not work directly on the project.
You also want to test with people with different impairments to make sure the end result is as accessible as possible.
When should I start testing my project?
In a perfect world, you test as soon and as often as possible. Testing prototypes built in design tools before starting development is cheaper. If the concept doesn’t work, at least you did not invest three months of development into an ineffective feature.
You can also test HTML/CSS/JavaScript prototypes with fake data built for the tests — or test once the feature or website is developed. This does mean, though, that any changes are more complex and expensive.
Define what you want to test
The first step is to define what specific tasks or activities you want to test. Usually, you want a set of different actions with a user goal at the end. For example:
an account creation process
a whole checkout process
a search process from the homepage to the final blog post, etc.
List the tasks and activities the user needs to accomplish in the form of questions. We call this a creating a test script. You can find an example here from 18F.
Be careful not to bias users. This is the tricky part. For example, if you want to test an account creation flow and the button says “Sign up,” then avoid asking your test users to “sign up” because the first thing they will do is search for a button with the same verb on the screen. You could ask them to “create an account” instead and gain better insights.
Example of a protype build in Axure and a test script
Then prepare the prototype you want to test. As mentioned before, it can range from mockups with a click-through prototype to a fully-developed prototype with real data. It’s totally up to you and how far you are in the project. Just make sure it works (technically, I mean).
Recruit participants
You know who your users are on most of your projects. The question is: how can you reach out to them? There’s plenty of ways. You might go through support or salespeople with lists of possible participants. If it’s a broad target audience, you could recruit testers right where they are. Working on an e-commerce website that sells plants? Why not try visiting actual physical shops, online communities for gardeners, community gardens, Facebook groups, etc.
You can use social media to recruit participants as long as you recruit the right people who are prospective users of the site. This is why UX professionals use screeners. A screener is a set of questions you while recruiting (and when starting the test), to make sure you are working with someone who is in the target audience.
Note that participants are usually compensated for their time. It can be gift cards, maybe getting of your product, some really nice chocolate — something that encourages people to spend time with you in a way that thanks them.
If you struggle recruiting and have a budget, you can use professional user research recruitment websites like userinterviews.com or testingtime.com.
Schedule, set up, prepare
Once you successfully recruit participants for testing, schedule a meeting with them, including the testing date, time, and place. The test can be remote or face to face. I won’t detail the logistics here, but at some point, you will need help to set up an actual room or a virtual space for the testing. If it’s a physical room, make sure it’s calm and accessible for your users. If it’s remote, make sure the tools are accessible and people can install them if needed on their computers.
Schedule some emails in advance to remind participants the day before the test, just in case.
Last but not least: do a dry run of your test using people from your team. This helps avoid typos in the scripts and prototypes. You want to make sure the prototype works properly, that there are no technical issues, etc. You want to avoid anything that could bias the test.
Facilitate the test
You need two testers to conduct a usability test. One person facilitates. The other takes care of the logistics and notes.
Start the recording, but only if they give you permission to do so, of course. Explain that you are testing the site, not them, and that there are no right or wrong answers. Encourage them to think out loud, and to tell you exactly what they do, see, and think.
Put them at ease by starting with a few soft questions to get them to talk. Then follow your script.
The most important thing: don’t help users accomplish the tasks. I know, this is hard. We don’t like to see people struggle. But if you help them, you will bias the results. Of course, if they struggle for five minutes and you need them to accomplish the task to go to the next one, you can unlock them. Mark that particular task as “failed.”
Once testing is finished, thank the test user for their time and offer them the compensation (or tell them how to get compensated if it was a remote test).
Get the recording, upload it somewhere in the cloud so there is a backup. Same for your notes. Trust me on that, there’s nothing worse than losing some data because the computer crashed.
Analyze and document the results
After the test, I usually like to put together a quick “first draft” of the analysis for a given participant because the testing is still fresh in my mind.
Some people do this in shared documents or Excel sheets. My favorite method is using the actual screens that were used for testing in a Miro board. And I put digital sticky notes on them with the test’s main findings. I use different colors for different types of feedback, like a user comment, feature request, usability issue, etc.
When multiple users give the same feedback or experience the same issue, I add a small dot on the note. This way, I have a visual summary of everything that happened during all the tests.
And then? Learn, iterate, improve.
We don’t test for the fun of testing. We test to improve things. So, the next step is to learn from those tests. What worked well? What can be improved? How might we improve? Of course, you might not have the time and budget to improve everything at once. My advice is to prioritize and iterate. Fix the biggest issues first. “Big” is a relative term, of course, and that depends on your project or KPIs. It could mean “most users have this issue.” Or it could mean, “if this doesn’t get fixed, we will lose users and revenue.” This is when it becomes again, a team sport.
In conclusion
I hope I’ve convinced you to test your site soon and often. This was just a small introduction to the world of testing with real users. I simplified a lot in here to give you an idea of what goes into user testing. Proper professional usability testing is more complex, especially on large projects. While I always favor hiring someone dedicated to user research and testing, I also understand that it might be complicated for smaller projects.
If you want to go further, I recommend checking out the following resources:
Just Enough Research by Erika Hall — There is an entire chapter on interviews with great advice
“User testing” by Ida Aalen — Great information on testing with a limited budget.
“Qualitative Usability Testing: Study Guide” by Kate Moran — This is a collection of links to Nielson Norman Group articles and videos to about planning, conducting, and analyzing qualitative user testing.
Websites change. Healthy codebases are constantly being updated. Legacy code dies when it eventually goes down with the ship. Recognizing that my code is transient allows me to be more practical about my code and what guides my decision-making as I author it.
Your code is transient.
I like to think that code changes stem from one of two causes: code decay or website relevance.
Code decay
The code we write follows specifications from authorities like web browsers or frameworks. It can also be based on requirements from a business or organization the website is for. All of these rules change as our websites and their contexts evolve. I think of this as code decay. Maybe an HTML spec is adopted by browsers allowing our markup to become more semantic, or perhaps we’re using a framework and want to upgrade to the latest major version. Maybe a business needs to change payment providers, or perhaps there’s a new security requirement we need to adopt. Our code frequently needs to be maintained in order to keep up and, at times, keep working. Occasionally, we can get by without changing it for long periods of time, but there is always a point at which old code needs either to be changed or disposed of.
Website relevance
Let’s face it, our website is not as cool as it used to be. Maybe this is because the design has grown old, or perhaps what it does is less important to people than it was before. Maybe there’s a new requirement and feature that needs to be added, or perhaps we’re just tired of staring at it. Redesign! Rebrand! Iterate! It is unreasonable to expect most websites to stay relevant without changing their content or code significantly over time. We should expect our code to do the same and change over time—especially on the front end.
Accepting change
The reality of change seems like a fairly obvious thing to acknowledge, however, I find it to be a helpful reminder as someone who has a tendency to go off coding as if I am building The Great Pyramid of Giza. Coding is often much more like setting up camp, not knowing if we will be staying for a few days or a year. I try to start with the assumption that it will be brief, and settle in over time. Consider picking up some overpriced water at the store before we dig an entire well. So often I find myself in a frenzied relocation days after pitching my tent. I do not need to look much further back than a few months to find code I have written that already needs to change. It doesn’t need to change because I didn’t do it good enough the first time—it’s just time to change it! How should this influence the way we code or think about our code? Here are a few thoughts I have adopted recently.
1) Write transient code.
Knowing that my code may change in the near future allows me to focus on its current purpose and ensuring its footprint is isolated. It has freed me to focus on the code in front of me and not be distracted by the possible future timelines of the code I am writing. This is particularly applicable for large portions of small projects. For large projects, you can apply this principle to pieces of your codebase. If you have used a component in a library for an entire year, often its requirements have changed over time. Removing the cruft of the past can help give it purpose for the immediate future. I often find writing a replacement component to be quicker than updating an old one, and the result to be easier to use and understand. Where applicable, I try to replace instead of rehabilitate. When I create something new, I prioritize the present, trusting that I will give myself space to solve future problems later on. Future problems are often best solved in the future because you tend to have more facts and fewer assumptions the closer you are to the problem.
2) When possible, avoid dependencies.
More and more I am drawn towards built-in browser functionality and have a high bar when justifying the use of frameworks. At certain scales dependencies are unavoidable and frequently more efficient in collaborative environments. When I do use them, I try to isolate or wrap their functionality so that it is easier to untangle later on if I need to. If you can justify the effort of writing your own code, you become more familiar with web specifications and learn just how robust they are on their own. You also end up with something that can be easier to maintain long-term because it is closest to the core evolutionary path of the web. There is no dependency upgrade between your code and ever-evolving browser functionality.
3) Let the code die.
While this is only an acceptable outcome for situations that don’t require change for important reasons, like usability, this is my favorite thing to do when it makes sense. Let things get old. Don’t intend on updating them. Creative projects and demos are a great case for this. By letting old projects die, I am acknowledging that their value was very much tied to the moment of time they existed within. Not everything needs to be around forever (spoiler, nothing we make will be around forever). If something is important and you want to preserve it, capture its meaningfulness through screen recordings and documentation, and then move on. This has allowed me to proceed to the next the thing more freely.
Moving forward
For me, the most meditative and rejuvenating thing I can do as someone who writes code is to reflect on the fact that the code I write is transient. So often this space can be highly combative when we talk about tooling, best practices, and the new hot thing. A spirit of urgency to adopt the “best” approach applies immense amounts of pressure as we plan out projects. We speak in absolutes with an air of permanence and often overlook just how dated our opinions are going to sound in the near future. The stakes are ultimately never as high as they feel when you are making decisions about tooling.
I prefer to be in a place where I am continually recognizing that the code I write is temporary, that technology is growing faster than I can individually match pace, and that I will never need to have expertise in all things. It is here that I find comfort in knowing the best code I write is in front of me and that the best website I can make right now is the next one.
Videos appeal to humans in a way no other form of the content does. A video includes motion, music, still images, text, speech, and a few other elements, all of which combine to deliver engagement like never before.
According to research, users spend 88% more time on a website with videos, and video content receives 1200% more shares than images or text. This is corroborated by the trend we see on key social media platforms, with businesses on these platforms now preferring video content over still images.
When streaming videos on one’s website or app, hosting a video on a platform like YouTube might not be a viable option. This is especially true if you want to present a native-looking user experience and control it, or you do not want to share revenues with a third party.
In such cases, cloud providers like AWS become the go-to choice for hosting and streaming videos.
Streaming optimized videos from S3 — current methods and drawbacks
A typical setup includes hosting the videos on AWS S3, the most popular cloud object storage around, and then directly streaming them on the users’ device.
For an even better video load time, you can use AWS CloudFront CDN with your S3 bucket.
Typical video streaming setup with AWS S3 and CloudFront CDN without any video optimizations
However, given that the original videos are often massive in size and that neither S3 nor CloudFront have built-in video optimization capabilities, this is far from ideal.
Therefore, the video streaming is slow and results in unnecessary waste of bandwidth, lower average video playback time, and lower user retention and revenues.
To solve this, we need to optimize videos for different devices, network speeds, and our website or app layout before streaming from the S3 storage.
While you could use a solution like AWS Elemental MediaConvert for all kinds of transcoding and optimizations, such solutions often have a steep learning curve and often become very complex to manage. For example:
You need to understand how to set up these tools with your existing workflow and storage, understand job creation in these tools, and manage job queues and job completion notifications in your workflow.
To create MediaConvert jobs, you would have to understand different streaming protocols, encoding, formats, resolution, codecs, etc., for video streaming and map them to your requirements to build the right jobs.
AWS MediaConvert is not an on-the-fly video conversion tool in itself. You need to pair it with other AWS services to make it work in real-time, making the setup even more complex and expensive. If you do not opt for on-the-fly video conversion, you need to configure MediaConvert’s jobs correctly from the go. Any new requirement will require the job to be changed and re-run on all videos to generate a new encoding or format. With an ever-changing video streaming landscape coupled with new device sizes, this can be a severe limitation if you have a lot of videos coming in regularly.
< Description: Typical setup with on-the-fly video conversion with AWS MediaConvert involving multiple components. (Source: AWS)
With videos becoming the choice of media online, it should be easier to stream videos from your S3 storage so that you can focus on delivering a better user experience and the core business rather than understanding the intricacies of video streaming.
This is where ImageKit comes in.
ImageKit is a complete media management and delivery platform with a Video API that allows you to stream videos stored in AWS S3 and optimize and transform them in real-time with just a few minutes of setup.
That’s right. You will be able to deliver videos perfected for every device without learning about the complications of video streaming and without spending hours configuring a tool.
ImageKit + AWS S3 video streaming setup with on-the-fly video optimizations
Let’s look at how you can use ImageKit for streaming videos from your S3 bucket.
S3 video streaming with ImageKit
To be able to stream videos from in our S3 bucket with ImageKit, we would need to do two things:
Allow ImageKit to read the objects in the S3 bucket
Access the video in the S3 bucket via their ImageKit URLs
Let’s look at these two steps in detail.
1. Connecting your bucket with ImageKit for access
ImageKit can pull assets from all popular storage and servers, including private and public S3 buckets. Access to a private S3 bucket is done using a pair of read-only keys that you create in your AWS account. You can read more about adding the S3 bucket origin in detail here.
If your bucket or the video objects inside it are public, you can add it as a web folder type origin. To do this, you would need to use the S3 bucket’s domain name as the base URL for this origin.
Also, ensure that you map the S3 bucket to a URL endpoint in the ImageKit dashboard.
That’s it! You have now connected your S3 bucket with ImageKit.
Bonus: ImageKit also provides an integrated Media Library, file storage built on AWS S3, with easy-to-use UI and APIs for advanced media management and search. If you do not have an S3 bucket or want a better solution to organize your video content, you can host your videos in ImageKit’s Media Library as well.
2. Video Streaming from S3 using ImageKit URLs
With your S3 bucket now attached to ImageKit, you can now access any video file in your bucket via ImageKit.
For example, we have the video sample.mp4 in our test bucket at the key videos/woman-walking.mp4. We can access it with ImageKit using the following URL:
And because ImageKit comes integrated with AWS CloudFront CDN, your videos will get delivered in milliseconds to your users, thereby improving the overall streaming experience.
Using video optimizations and transformations with S3 streaming
We have seen how to stream videos from S3 using ImageKit on our apps. However, as mentioned earlier in the article, we need to optimize videos for different devices, website layout, and other conditions.
ImageKit helps us there as well. It can optimize and scale your videos or encode them to different formats in real-time. In addition, ImageKit makes most of the necessary optimizations automatically, using the best defaults, or exposes the functionalities as easy-to-use URL parameters that work in real-time.
So, unlike the other tools like AWS MediaConvert, there is minimal learning you need to do. And you definitely won’t have to learn the nuances of video streaming and encoding.
Let’s look at the video optimizations and transformations ImageKit is capable of, apart from direct streaming of videos from S3.
1. Automatic conversion to best format while streaming
ImageKit automatically identifies the video formats supported in browsers and combines them with the original video information to encode it to the best possible output format.
The video format optimization is done in real-time when you request your S3 video via ImageKit and results in a smaller video size sent to the user.
To enable this automatic format conversion, you have to enable the corresponding setting in your ImageKit dashboard. No complex setup, no configurations needed.
For example, after enabling the above setting, an MP4 video gets delivered in WebM format in Chrome and MP4 in Safari.
Same video delivered in WebM format in Chrome browser
2. Automatic compression of videos while streaming
Modern cameras capture videos that can easily run into a few 100MBs, if not GBs. It is not ideal to deliver such large video files to your users. It will take them ages to stream the video, results in a poor user experience, and impact your business.
Therefore, we need to compress the video to deliver it quickly to our users. However, we need to do so while maintaining the visual quality of the video.
That is again something ImageKit does for you automatically.
You can turn on the corresponding setting from the ImageKit dashboard and set the default compression level for your videos. By default, this value would be 50, which strikes a good balance between output size and visual quality.
Turning on automatic quality optimization in the dashboard
Because of the compression, though the following video has the same format as its original video, it is lighter by almost 15% at 12.6MB compared to the original video at 14.6MB.
Using real-time video compression for slow network users
As explained with examples later in this article, ImageKit allows you to transform videos in real-time. One of the real-time URL transformations possible in ImageKit is to modify the compression level.
This transformation allows us to override the default compression level selected in the dashboard.
The video below, for example, is compressed to a quality level of 30 and is almost 70% smaller than the video we encoded using the default quality level of 50 set in the dashboard.
This real-time compression-level transformation allows us to adapt our videos to users on slow networks.
For example, if someone is experiencing poor network conditions, you can stream a more compressed, lighter video to them.
3. Scaling S3 videos in real-time while streaming
Imagine you want to load a video on your page and have only a 200px width available for your content. The resolution of the original video you have, almost always, would be a lot higher than this size. Loading anything significantly larger than the size you require is a waste of bandwidth and offers no benefit to the user.
With ImageKit, you can scale the video to any size in real-time before streaming it on the device. Just like its real-time image transformation API, you can add a width or height parameter to the URL, and you will get a video with the required dimensions in real-time.
For example, we have scaled down our video to a width of 200px using the URL given below.
4. Adapting videos to different placeholders and creating vertical videos
We often shoot videos in landscape mode, i.e., the video’s width is greater than its height. However, you would often require a portrait or vertical video where the height is greater than the video’s width.
A very common use case would be converting your landscape video to a vertical one like an Instagram story.
ImageKit makes it super simple with its real-time video transformations. You can add the width and height parameters to the video URL and get the output video in the requested size.
ImageKit streams the video in the most suitable format and at the right compression level for all the transformations above. The video is delivered via its integrated AWS CloudFront CDN for a fast load time.
For the demo video used in this article, we started with a 14.6MB original video, but after all the optimizations and scaling it down, we were able to bring down the size to 1.8MB in the last example of the vertical video.
Signup with ImageKit for S3 video streaming for free
ImageKit offers a Forever Free plan that includes video delivery as well as processing. On this plan, you would be able to optimize and transform over 15 minutes of fresh video content every month and then deliver it to thousands of users without paying a single penny or even providing your credit card. This is perfect for a small business or your side project where you can connect your S3 bucket to ImageKit and start streaming optimized videos immediately.
Sign up now for ImageKit to start streaming optimized videos from S3 for free.
I think if you’re a DevOps person in any capacity, the utility of Docker is very clear. Your things run in containers that are identical everywhere. Assuming Docker is working/running, the code will execute in a reliably consistent way whether that is Docker running on some developer’s computer, or a sky computer. The (massive) appeal there is that bugs will happen consistently. “Production-only” bugs become a thing of the past. There are other benefits, too, like shipping a dev environment to a team of developers that is entirely consistent, even across platforms, rather than battling with individual developers computers.
So… great? Use it all the time for everything? The stopper there is that it’s complicated, and web dev is already friggin complicated and it often just feels like too much. Andrew Welch, however, makes the case that you don’t have to learn Docker super deeply in order to use it:
Docker is a devops tool that some people find intimidating because there is much to learn in order to build things with it. And while that’s true, it’s actually quite simple to start using Docker for some very practical and useful things, by leveraging what other people have created.
Fair point. I don’t deeply understand most of the technology I use, but I can still use it.
While I run Docker all day for CodePen’s fancy dev environment, that’s what my use is limited to. I don’t reach for it like Andrew does for everything. But I can see how it might feel liberating having all that isolation between projects. One of my favorite of points that Andrew makes is:
Switching to a new computer is easy. You don’t have to spend hours meticulously reconfiguring your shiny new MacBook Pro with all the interconnected tools & packages you need.
I find myself bopping around between computers fairly often for various odd reasons, and being able to make the switch with minimal fussing around is appealing.
In nature, no two things are ever the same. Life is imperfect, unpredictable, and beautiful. We can walk through the same forest every day and see differently colored leaves. We can look up at the clouds every minute and watch a whole new formation. The physical world is transient and ever-changing. What if our designs were a little more like this?
Often, we spend hours, weeks, even months carefully crafting our websites/applications, sculpting every last pixel until they are just right. Then, we set them free into the world — a perfectly formed, yet static snapshot of something that once was a living, evolving thing.
There is (of course!) nothing wrong with this way of working. But what if we let go of the idea that there can be only one final version of a design? What if our interfaces were free to take more than one form?
I could write forever about this stuff, but I think it’s best to show you what I mean. Naturally, here’s a Pen:
CodePen Embed Fallback
Try clicking the “Regenerate” button above. Notice how the interface changes just a little every time? By parameterizing aspects of a design, then randomizing those parameters, we can create near-infinite variations of a single idea. For those familiar with generative art — art made using a system that includes an element of autonomy — this is likely a familiar concept.
For makers (particularly perfectionists like me!), this approach to design can be incredibly liberating.
For the folk who use the things we make, it creates an experience that is truly individual. In randomizing carefully chosen aspects of our interfaces, they become ephemeral, and to me, this is kind of magical. No two people will ever see the same version of our work.
The web can be a cold, sterile place. By embracing the unpredictable, we can add a joyful, organic touch to our creations — to me, this is the essence of generative UI design, and I would love if you gave it a try! SVG, Canvas, and CSS/Paint API are all excellent mediums for generative work, so pick the one that is most familiar and experiment.
Just remember: apply carefully, and always be mindful of accessibility/UX. Magically evolving designs are great, but only if they are great for everyone.
What is one thing people can do to make their website better?
Exactly what you want to build!
Ask yourself:
What drew you to development in the beginning?
Is there an experimental API that you’ve been wanting to try out?
What could you spend all night hacking away at, just for the fun of it?
Your personal site is a statement of who you are and what you want to do. If you showcase your favorite type of work, you’ll get more requests for similar projects or jobs — feeding back into a virtuous cycle of doing more of what you love.
Like stage performances, you can tell when love and excitement went into creating a website. One of my favorite examples is Cassie Evans’ website. She added so many fun flourishes (including an adorable SVG self-portrait). The joy baked into her work has (at least partially) led to her current role, bestowing animation superpowers at GreenSock!
So, go forth, and create a trailing mouse cursor. Or a confetti component! A real-time drawing pad, or some hardware to show the current state of your coffee machine. Really, anything that gets you excited to build!
As a UX designer, you get to work on creative, rewarding, even life-changing projects. It’s an industry with flexible working and countless opportunities. All this, and you get paid well too.
It doesn’t matter if you’re not a creative prodigy, or a tech grandmaster; you can learn to become a UX designer with the right mindset, a few tools you pick up along the way, and some committed learning.
By the time you’ve finished reading this post, you’ll be well on your way to designing your new career.
You can do this, let’s get started…
What is a Career in UX like?
Every career is different, but generally speaking, a UX designer works on making a user’s interaction with a product or service (normally websites) as intuitive as possible.
Just as a golf architect designs the layout of a golf course to flow through greens, tees, and holes, with buggy paths for access, and the odd bunker to add a challenge; so a UX designer creates the optimum experience for a site. A golf architect doesn’t need to reinvent the game of golf, and neither does a UX designer need to reinvent websites.
A golf architect will not design a course with a 360-degree sand bunker surrounding a tee (well, they might, but they really really shouldn’t), or a hole too small for a golf ball. In the same way as a UX designer, you’re not going to design an ecommerce site with a cart in the bottom left, a non-existent search feature, or hidden pricing.
The best thing about being a UX designer is that you don’t need to spend years in formal education to get qualified. The flipside is that if you want to be a great UX designer, it’s not a walk in the park.
Every designer is different, but some of the main traits of successful UX designers are: an enjoyment of problem-solving; good listening skills; curiosity; open-mindedness; attention to detail; creativity; communication skills; process-driven; and adaptability.
UX design is a practical skill. It’s all well and good knowing the theory, but without practice putting the theory into action no one will give you a chance to prove what you can do. So how do you get practical experience? You get certified, and there are three popular options: online, in-person training, or self-taught.
A good UX syllabus will include portfolio-building projects, tool mastery, networking opportunities, and even 1-2-1 mentorship. As well as learning the fundamentals of UX, you’ll cover user research and strategy, analysis, UI design, and more.
Option A: Online Course
Online courses tend to be much easier on the bank balance, as well as being flexible, which means you can fit them around your current job. You can work at your own pace, and in many cases choose modules that interest you, once you’ve completed the basic introduction.
Whatever option you choose, it is a good idea to get as broad a perspective as possible, so consider following more than one course — perhaps mix and match a paid course with a free one.
Option B: In-Person Training
This could be a university course, or a local boot camp where you physically sit in with an instructor and classmates.
This is more expensive, but it provides benefits that nothing else does. Firstly, you’ll have classmates you can bounce ideas off, collaborate with, keep motivated, inspired, and accountable. You can also get real-time, intensive coaching and advice from someone who’s been there, done that, bought the T-shirt (and redesigned it so it fits better).
Seach local boot camps and workshops, check out workshops at local conferences, and ask your local college what courses they offer.
Option C: Self-Taught
Being self-taught is the cheapest of all options. Work at your own pace, where, and when you want to. Watch YouTube videos, read blogs, garner information anywhere you can find it.
This option involves a lot of stumbling around in the dark. The biggest challenge is that you don’t know what it is that you don’t know. For this reason, it can pay to follow the syllabus of a local college course, even if you’re not enrolled and don’t attend lectures.
In reality, all education is self-taught to an extent, even the most prescribed courses need self-motivation.
Recruiters and hiring managers will seek your technical ability and your experience using popular tools from user research, to wireframing, to prototyping. When you get your first job in UX, the tools you use will be determined by your project manager, so it’s a good idea to have a passing familiarity with the most popular. These will include Maze, Userzoom, Sketch, XD, Figma, Marvel, and Hotjar.
If you’re following a guided course you should get an introduction to at least a couple of important tools. Once you understand one, you can probably pick the others up quite quickly… because, after all… they should be intuitive.
You do not need to know how to code, but understanding the roles, and restrictions of HTML, CSS, and JavaScript is very beneficial. When you get your first UX job, you’ll need to be able to talk about how technologies fit into the plan.
Building a UX Portfolio
Your portfolio is your résumé. The golden ticket. The silver bullet. Amassing a content-rich portfolio is paramount. You don’t need a real-world job to build your portfolio, and you should already have content to add from your course.
You need to demonstrate knowledge of UX tools and processes (what future employers will look for). Case studies that incorporate research, problem-solving, strategy, imagination, and (if possible) results are the best way to do this.
There are a variety of ways of building a portfolio, but the best is taking a real website, and redesigning it. Don’t worry if your first few projects aren’t the best; as long as you demonstrate improvement and growth, that counts for something.
You can showcase your portfolio on sites such as Behance, Dribbble, or preferably create your website.
Landing Your First Job in UX
Start combing the job boards to see which companies are looking for UX designers. There’s a global shortage of qualified UX designers, so if you can’t find anything you’re looking in the wrong place! Make sure your whole network, from your Mom’s hairdresser to the barista at your favorite coffee place know that you’re looking; you never know where a good lead will come from.
Some companies are looking for UX skills as part of other roles. Others are looking for full-time UXers.
Don’t be disheartened if “Junior UX Designer” positions require 2 years of experience; HR just throws this in as a pre-filter. If you think you can do the job, apply anyway, if your portfolio’s good you might get an interview regardless, and if you get an interview they think you’re worth taking the time to meet.
If you don’t get the job, don’t be downhearted. Remember: every time someone else gets a job, that’s one less person you’re competing with for the next job.
Quick Prep on Some Common UX Interview Questions:
What’s your interpretation of a UX Designer?
What has inspired you to become a UX Designer?
How do you take constructive feedback and non-constructive feedback?
Who, or what companies, do you look up to in this industry, and why?
What’s your process with a new project?
Good Luck!
So, now you know what it takes to get into the field, it’s time to start applying yourself to this newfound and richly rewarding career. As the great writer Anton Chekov said, “Knowledge is of no value unless you put it into practice.” So get out there and practice, practice, practice. Add and add and add to your portfolio.
To become a UX Designer, enroll in a great course, build your portfolio, network, apply for roles, and always be learning. Always be open to new ideas and suggestions. There’s a lot of leg work, but the juice will be worth the squeeze.