Static First: Pre-Generated JAMstack Sites with Serverless Rendering as a Fallback
You might be seeing the term JAMstack popping up more and more frequently. I’ve been a fan of it as an approach for some time.
One of the principles of JAMstack is that of pre-rendering. In other words, it generates your site into a collection of static assets in advance, so that it can be served to your visitors with maximum speed and minimum overhead from a CDN or other optimized static hosting environment.
But if we are going to pre-generate our sites ahead of time, how do we make them feel dynamic? How do we build sites that need to change often? How do we work with things like user generated content?
As it happens, this can be a great use case for serverless functions. JAMstack and serverless are the best of friends. They complement each other wonderfully.
In this article, we’ll look at a pattern of using serverless functions as a fallback for pre-generated pages in a site that is comprised almost entirely of user generated content. We’ll use a technique of optimistic URL routing where the 404 page is a serverless function to add serverless rendering on the fly.
Buzzwordy? Perhaps. Effective? Most certainly!
You can go and have a play with the demo site to help you imagine this use case. But only if you promise to come back.
Is that you? You came back? Great. Let’s dig in.
The idea behind this little example site is that it lets you create a nice, happy message and virtual pick-me-up to send to a friend. You can write a message, customize a lollipop (or a popsicle, for my American friends) and get a URL to share with your intended recipient. And just like that, you’ve brightened up their day. What’s not to love?
Traditionally, we’d build this site using some server-side scripting to handle the form submissions, add new lollies (our user generated content) to a database and generate a unique URL. Then we’d use some more server-side logic to parse requests for these pages, query the database to get the data needed to populate a page view, render it with a suitable template, and return it to the user.
That all seems logical.
But how much will it cost to scale?
Technical architects and tech leads often get this question when scoping a project. They need to plan, pay for, and provision enough horsepower in case of success.
This virtual lollipop site is no mere trinket. This thing is going to make me a gazillionaire due to all the positive messages we all want to send each other! Traffic levels are going to spike as the word gets out. I had better have a good strategy of ensuring that the servers can handle the hefty load. I might add some caching layers, some load balancers, and I’ll design my database and database servers to be able to share the load without groaning from the demand to make and serve all these lollies.
Except… I don’t know how to do that stuff.
And I don’t know how much it would cost to add that infrastructure and keep it all humming. It’s complicated.
This is why I love to simplify my hosting by pre-rendering as much as I can.
Serving static pages is significantly simpler and cheaper than serving pages dynamically from a web server which needs to perform some logic to generate views on demand for every visitor.
Since we are working with lots of user generated content, it still makes sense to use a database, but I’m not going to manage that myself. Instead, I’ll choose one of the many database options available as a service. And I’ll talk to it via its APIs.
I might choose Firebase, or MongoDB, or any number of others. Chris compiled a few of these on an excellent site about serverless resources which is well worth exploring.
In this case, I selected Fauna to use as my data store. Fauna has a nice API for stashing and querying data. It is a no-SQL flavored data store and gives me just what I need.
Critically, Fauna have made an entire business out of providing database services. They have the deep domain knowledge that I’ll never have. By using a database-as-a-service provider, I just inherited an expert data service team for my project, complete with high availability infrastructure, capacity and compliance peace of mind, skilled support engineers, and rich documentation.
Such are the advantages of using a third-party service like this rather than rolling your own.
Architecture TL;DR
I often find myself doodling the logical flow of things when I’m working on a proof of concept. Here’s my doodle for this site:
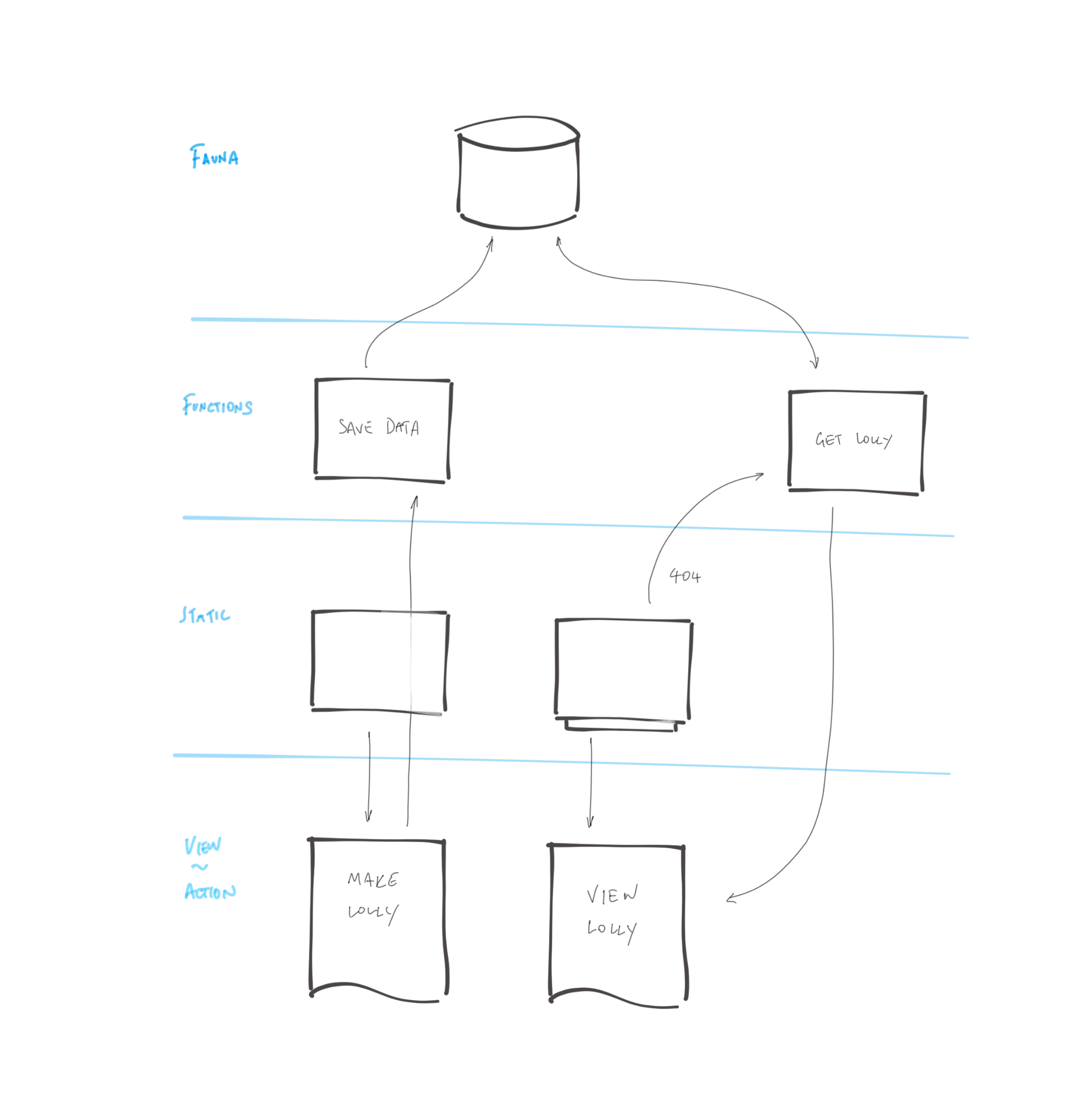
And a little explanation:
- A user creates a new lollipop by completing a regular old HTML form.
- The new content is saved in a database, and its submission triggers a new site generation and deployment.
- Once the site deployment is complete, the new lollipop will be available on a unique URL. It will be a static page served very rapidly from the CDN with no dependency on a database query or a server.
- Until the site generation is complete, any new lollipops will not be available as static pages. Unsuccessful requests for lollipop pages fall back to a page which dynamically generates the lollipop page by querying the database API on the fly.
This kind of approach, which first assumes static/pre-generated assets, only then falling back to a dynamic render when a static view is not available was usefully described by Markus Schork of Unilever as “Static First” which I rather like.
In a little more detail
You could just dive into the code for this site, which is open source and available for you to explore, or we could talk some more.
You want to dig in a little further, and explore the implementation of this example? OK, I’ll explain in some more details:
- Getting data from the database to generate each page
- Posting data to a database API with a serverless function
- Triggering a full site re-generation
- Rendering on demand when pages are yet to be generated
Generating pages from a database
In a moment, we’ll talk about how we post data into the database, but first, let’s assume that there are some entries in the database already. We are going to want to generate a site which includes a page for each and every one of those.
Static site generators are great at this. They chomp through data, apply it to templates, and output HTML files ready to be served. We could use any generator for this example. I chose Eleventy due to it’s relative simplicity and the speed of its site generation.
To feed Eleventy some data, we have a number of options. One is to give it some JavaScript which returns structured data. This is perfect for querying a database API.
Our Eleventy data file will look something like this:
// Set up a connection with the Fauna database.
// Use an environment variable to authenticate
// and get access to the database.
const faunadb = require('faunadb');
const q = faunadb.query;
const client = new faunadb.Client({
secret: process.env.FAUNADB_SERVER_SECRET
});
module.exports = () => {
return new Promise((resolve, reject) => {
// get the most recent 100,000 entries (for the sake of our example)
client.query(
q.Paginate(q.Match(q.Ref("indexes/all_lollies")),{size:100000})
).then((response) => {
// get all data for each entry
const lollies = response.data;
const getAllDataQuery = lollies.map((ref) => {
return q.Get(ref);
});
return client.query(getAllDataQuery).then((ret) => {
// send the data back to Eleventy for use in the site build
resolve(ret);
});
}).catch((error) => {
console.log("error", error);
reject(error);
});
})
}I named this file lollies.js which will make all the data it returns available to Eleventy in a collection called lollies.
We can now use that data in our templates. If you’d like to see the code which takes that and generates a page for each item, you can see it in the code repository.
Submitting and storing data without a server
When we create a new lolly page we need to capture user content in the database so that it can be used to populate a page at a given URL in the future. For this, we are using a traditional HTML form which posts data to a suitable form handler.
The form looks something like this (or see the full code in the repo):
<form name="new-lolly" action="/new" method="POST">
<!-- Default "flavors": 3 bands of colors with color pickers -->
<input type="color" id="flavourTop" name="flavourTop" value="#d52358" />
<input type="color" id="flavourMiddle" name="flavourMiddle" value="#e95946" />
<input type="color" id="flavourBottom" name="flavourBottom" value="#deaa43" />
<!-- Message fields -->
<label for="recipientName">To</label>
<input type="text" id="recipientName" name="recipientName" />
<label for="message">Say something nice</label>
<textarea name="message" id="message" cols="30" rows="10"></textarea>
<label for="sendersName">From</label>
<input type="text" id="sendersName" name="sendersName" />
<!-- A descriptive submit button -->
<input type="submit" value="Freeze this lolly and get a link">
</form>We have no web servers in our hosting scenario, so we will need to devise somewhere to handle the HTTP posts being submitted from this form. This is a perfect use case for a serverless function. I’m using Netlify Functions for this. You could use AWS Lambda, Google Cloud, or Azure Functions if you prefer, but I like the simplicity of the workflow with Netlify Functions, and the fact that this will keep my serverless API and my UI all together in one code repository.
It is good practice to avoid leaking back-end implementation details into your front-end. A clear separation helps to keep things more portable and tidy. Take a look at the action attribute of the form element above. It posts data to a path on my site called /new which doesn’t really hint at what service this will be talking to.
We can use redirects to route that to any service we like. I’ll send it to a serverless function which I’ll be provisioning as part of this project, but it could easily be customized to send the data elsewhere if we wished. Netlify gives us a simple and highly optimized redirects engine which directs our traffic out at the CDN level, so users are very quickly routed to the correct place.
The redirect rule below (which lives in my project’s netlify.toml file) will proxy requests to /new through to a serverless function hosted by Netlify Functions called newLolly.js.
# resolve the "new" URL to a function
[[redirects]]
from = "/new"
to = "/.netlify/functions/newLolly"
status = 200Let’s look at that serverless function which:
- stores the new data in the database,
- creates a new URL for the new page and
- redirects the user to the newly created page so that they can see the result.
First, we’ll require the various utilities we’ll need to parse the form data, connect to the Fauna database and create readably short unique IDs for new lollies.
const faunadb = require('faunadb'); // For accessing FaunaDB
const shortid = require('shortid'); // Generate short unique URLs
const querystring = require('querystring'); // Help us parse the form data
// First we set up a new connection with our database.
// An environment variable helps us connect securely
// to the correct database.
const q = faunadb.query
const client = new faunadb.Client({
secret: process.env.FAUNADB_SERVER_SECRET
})Now we’ll add some code to the handle requests to the serverless function. The handler function will parse the request to get the data we need from the form submission, then generate a unique ID for the new lolly, and then create it as a new record in the database.
// Handle requests to our serverless function
exports.handler = (event, context, callback) => {
// get the form data
const data = querystring.parse(event.body);
// add a unique path id. And make a note of it - we'll send the user to it later
const uniquePath = shortid.generate();
data.lollyPath = uniquePath;
// assemble the data ready to send to our database
const lolly = {
data: data
};
// Create the lolly entry in the fauna db
client.query(q.Create(q.Ref('classes/lollies'), lolly))
.then((response) => {
// Success! Redirect the user to the unique URL for this new lolly page
return callback(null, {
statusCode: 302,
headers: {
Location: `/lolly/${uniquePath}`,
}
});
}).catch((error) => {
console.log('error', error);
// Error! Return the error with statusCode 400
return callback(null, {
statusCode: 400,
body: JSON.stringify(error)
});
});
}Let’s check our progress. We have a way to create new lolly pages in the database. And we’ve got an automated build which generates a page for every one of our lollies.
To ensure that there is a complete set of pre-generated pages for every lolly, we should trigger a rebuild whenever a new one is successfully added to the database. That is delightfully simple to do. Our build is already automated thanks to our static site generator. We just need a way to trigger it. With Netlify, we can define as many build hooks as we like. They are webhooks which will rebuild and deploy our site of they receive an HTTP POST request. Here’s the one I created in the site’s admin console in Netlify:
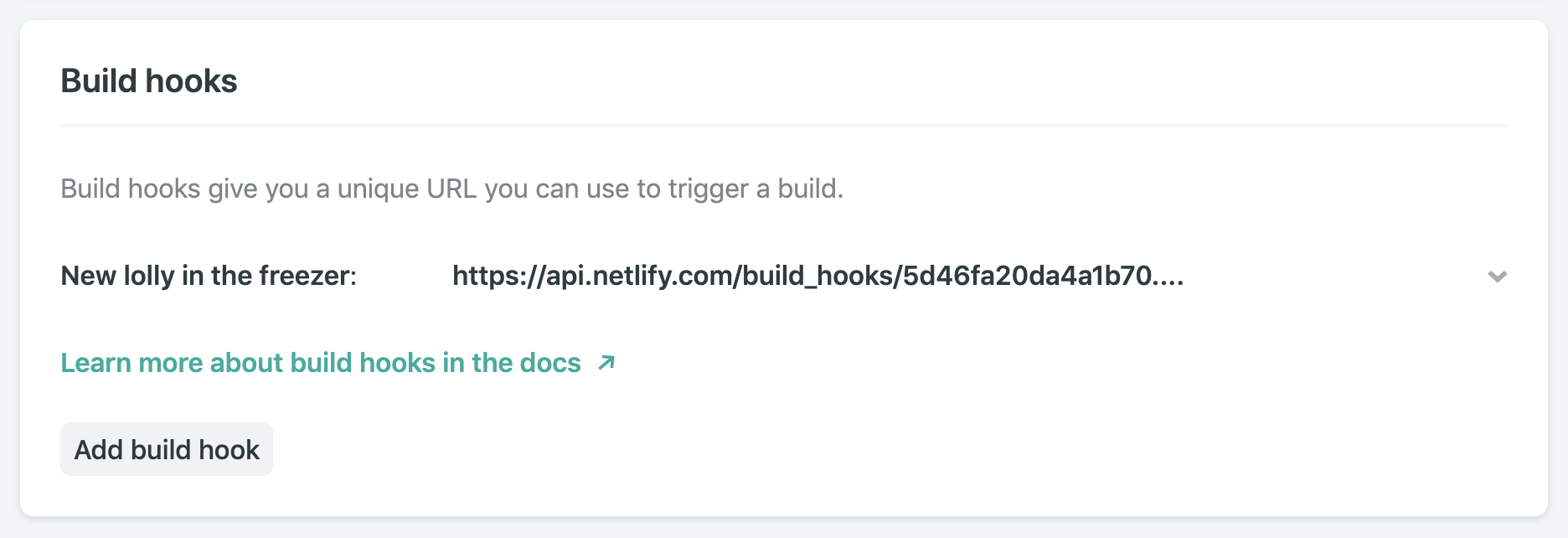
To regenerate the site, including a page for each lolly recorded in the database, we can make an HTTP POST request to this build hook as soon as we have saved our new data to the database.
This is the code to do that:
const axios = require('axios'); // Simplify making HTTP POST requests
// Trigger a new build to freeze this lolly forever
axios.post('https://api.netlify.com/build_hooks/5d46fa20da4a1b70XXXXXXXXX')
.then(function (response) {
// Report back in the serverless function's logs
console.log(response);
})
.catch(function (error) {
// Describe any errors in the serverless function's logs
console.log(error);
});You can see it in context, added to the success handler for the database insertion in the full code.
This is all great if we are happy to wait for the build and deployment to complete before we share the URL of our new lolly with its intended recipient. But we are not a patient lot, and when we get that nice new URL for the lolly we just created, we’ll want to share it right away.
Sadly, if we hit that URL before the site has finished regenerating to include the new page, we’ll get a 404. But happily, we can use that 404 to our advantage.
Optimistic URL routing and serverless fallbacks
With custom 404 routing, we can choose to send every failed request for a lolly page to a page which will can look for the lolly data directly in the database. We could do that in with client-side JavaScript if we wanted, but even better would be to generate a ready-to-view page dynamically from a serverless function.
Here’s how:
Firstly, we need to tell all those hopeful requests for a lolly page that come back empty to go instead to our serverless function. We do that with another rule in our Netlify redirects configuration:
# unfound lollies should proxy to the API directly
[[redirects]]
from = "/lolly/*"
to = "/.netlify/functions/showLolly?id=:splat"
status = 302This rule will only be applied if the request for a lolly page did not find a static page ready to be served. It creates a temporary redirect (HTTP 302) to our serverless function, which looks something like this:
const faunadb = require('faunadb'); // For accessing FaunaDB
const pageTemplate = require('./lollyTemplate.js'); // A JS template litereal
// setup and auth the Fauna DB client
const q = faunadb.query;
const client = new faunadb.Client({
secret: process.env.FAUNADB_SERVER_SECRET
});
exports.handler = (event, context, callback) => {
// get the lolly ID from the request
const path = event.queryStringParameters.id.replace("/", "");
// find the lolly data in the DB
client.query(
q.Get(q.Match(q.Index("lolly_by_path"), path))
).then((response) => {
// if found return a view
return callback(null, {
statusCode: 200,
body: pageTemplate(response.data)
});
}).catch((error) => {
// not found or an error, send the sad user to the generic error page
console.log('Error:', error);
return callback(null, {
body: JSON.stringify(error),
statusCode: 301,
headers: {
Location: `/melted/index.html`,
}
});
});
}If a request for any other page (not within the /lolly/ path of the site) should 404, we won’t send that request to our serverless function to check for a lolly. We can just send the user directly to a 404 page. Our netlify.toml config lets us define as many level of 404 routing as we’d like, by adding fallback rules further down in the file. The first successful match in the file will be honored.
# unfound lollies should proxy to the API directly
[[redirects]]
from = "/lolly/*"
to = "/.netlify/functions/showLolly?id=:splat"
status = 302
# Real 404s can just go directly here:
[[redirects]]
from = "/*"
to = "/melted/index.html"
status = 404And we’re done! We’ve now got a site which is static first, and which will try to render content on the fly with a serverless function if a URL has not yet been generated as a static file.
Pretty snappy!
Supporting larger scale
Our technique of triggering a build to regenerate the lollipop pages every single time a new entry is created might not be optimal forever. While it’s true that the automation of the build means it is trivial to redeploy the site, we might want to start throttling and optimizing things when we start to get very popular. (Which can only be a matter of time, right?)
That’s fine. Here are a couple of things to consider when we have very many pages to create, and more frequent additions to the database:
- Instead of triggering a rebuild for each new entry, we could rebuild the site as a scheduled job. Perhaps this could happen once an hour or once a day.
- If building once per day, we might decide to only generate the pages for new lollies submitted in the last day, and cache the pages generated each day for future use. This kind of logic in the build would help us support massive numbers of lolly pages without the build getting prohibitively long. But I’ll not go into intra-build caching here. If you are curious, you could ask about it over in the Netlify Community forum.
By combining both static, pre-generated assets, with serverless fallbacks which give dynamic rendering, we can satisfy a surprisingly broad set of use cases — all while avoiding the need to provision and maintain lots of dynamic infrastructure.
What other use cases might you be able to satisfy with this “static first” approach?
The post Static First: Pre-Generated JAMstack Sites with Serverless Rendering as a Fallback appeared first on CSS-Tricks.
