I often hear that native mobile app accessibility is more challenging than web accessibility. Teams don’t know where to start, where to find guidance on mobile accessibility, or how to prevent mobile-specific accessibility barriers.
As someone who works for a company with an active community of mobile assistive technology users, I get to learn about the challenges from the user’s perspective. In fact, I recently ran a survey with our community about their experiences with mobile accessibility, and I’d like to share what I learned with you.
If you only remember one thing from this article, make it this:
Half of assistive technology users said that accessibility barriers have a significant impact on their day-to-day well-being.
Accessibility goes beyond making products user-friendly. It can impact the quality of life for people with disabilities.
Types Of Mobile Assistive Technology
I typically group assistive technologies into three categories:
Screen readers: software that converts information on a screen to speech or braille.
Screen magnifiers: software or system settings to magnify the screen, increase contrast, and otherwise modify the content to make it easier to see.
Alternative navigation: software and/or hardware that replaces an input device such as a keyboard, mouse, or touchscreen.
Across all categories of assistive technology, 81% of the people I surveyed change the accessibility settings on their smartphone and/or tablet. Examples of accessibility settings include the following:
Increasing the font size;
Turning on captions;
Extending the tap duration;
Inverting colours.
There are smartphone settings such as dark mode that benefit people with disabilities even though they aren’t considered accessibility settings.
Now, let’s dive into the specifics of each assistive technology category and learn more about the user preferences that shape their digital experiences.
Screen Reader Users
Both iPhone and Android smartphones come with a screen reader installed. On iPhone, the screen reader is VoiceOver, and on Android, it is TalkBack. Both screen readers allow users to explore by touching and dragging their fingers to hear content under their fingers read out loud or to swipe forwards and backward through all elements on the screen in a linear fashion. Both screen readers also let users navigate by headings or other types of elements.
The mobile screen reader users I surveyed tend to have several devices that work together to cover all their accessibility needs, and they support businesses that prioritize mobile accessibility.
Nearly half of screen reader users also own a smartwatch.
Half use an external keyboard with their smartphone, and a third use a braille display.
Almost all factor the accessibility of apps and mobile sites into deciding which businesses to support.
That last point is really important! Accessibility truly inspires purchasing decisions and brand loyalty.
Screen Magnification Users
In addition to magnification, Android smartphones also have a variety of vision-related accessibility features that allow users to change screen colours and text sizes. The iPhone Magnifier app lets users apply colour filters, adjust brightness or contrast, and detect people or doors nearby.
My survey showed that screen magnification users had the highest percentage of tablet ownership, with 77% owning both a smartphone and a tablet. Alternative navigation users followed closely, with 62% owning a tablet, but only 42% of the screen reader users I surveyed own a tablet.
Screen magnification users are less likely to investigate the accessibility of paid apps before purchasing (63%) compared to screen reader and alternative navigation users (89% and 91%, respectively). I suspect this is because device magnification, contrast, and colour inversion settings may allow users to work around some design choices that make an app inaccessible.
Alternative Navigation Users
Switch Access (Android) and Switch Control (iOS) let users interact with their devices using one or more switches instead of the touchscreen. There are a variety of things you can use as a switch: an external device, keyboard, sounds, or the smartphone camera or buttons.
Item scan allows users to highlight items one by one and select an item in focus by activating the switch. Point and scan moves a horizontal line down from the top of the screen. When this line is over the desired element, the user selects their switch to stop it. A vertical line then moves from the left of the screen. When this line is also over the element, the user stops it with their switch. The user can then select the element in the cross hairs of the two lines. In addition to these two methods, users can also customize buttons to perform gestures such as swipe down or swipe left.
Android and iPhone devices can be controlled through Voice Access and Voice Control. Both allow users to speak commands to interact with their smartphone instead of using the touchscreen. The command “Say names” can expose labels that aren’t obvious. The command “Show numbers” allows users to say “tap two” to select the element labeled with the number 2. “Show grid” is a command often used as a last resort to select an element. This approach overlays a grid across their screen area and allows users to select the grid square where the element is in focus.
Alternative navigation users were least likely to own a smartwatch (26%) out of all three assistive technology categories, according to my survey. All the alternative navigation users that own a smartwatch, except for one, use it for health tracking. 24% use an external switch device with their smartphone.
Most Common Mobile Accessibility Barriers
Now that you know about some of the assistive technologies available on Android and iPhone devices, we can explore some specific challenges commonly encountered by users when navigating websites and native apps on their smartphones.
I’ll outline an inclusive development process that can help you discover barriers that are specific to your own app. If you need general tips on what to avoid right now, here are common mobile accessibility issues that assistive technology users encounter. To get this list, I asked the community to select up to three of their most challenging accessibility barriers on mobile.
Unlabelled Buttons Or Links
Unlabelled buttons and links are the number one challenge reported by assistive technology users. Screen reader users are impacted the most by unlabelled elements, but also people who use voice commands to interact with their smartphone.
Small Buttons Or Links
Buttons and links that are too small to tap with a finger or require great precision to select using switch functions are a challenge for anyone with mobility issues. Tiny buttons and links are also hard to see for anyone with low vision.
Gesture Interactions
Gestures like swipe to delete, tap and drag, and anything more complex than a simple tap or double tap can cause problems for many users. Gestures can be difficult to discover, and if you’re not a power mobile user, you may never figure them out. Your best bet is to include a button to perform the same action that a gesture can perform. Custom actions can expose more options, but only to assistive technology users and not to people with disabilities that may not use assistive technology, for example, cognitive disabilities.
Elements Blocking Parts Of The Screen
A chat button that is always hovering and may cover parts of the content. A sticky header or footer that takes up a big portion of the screen when the user zooms in or magnifies their screen. These screen blockers can make it very difficult or impossible for some users to view content.
Missing Error Messages
Keeping a submit button inactive until a form is correctly filled out is often used as an alternative to providing error messages. That approach can be a challenge for assistive technology users in particular, but also anyone with a cognitive disability or who isn’t tech-savvy. Sometimes, error messages exist, but they aren’t announced to screen reader users.
Resizing Text And Pinch And Zoom
When an app doesn’t respect the font size increases set by a user through accessibility settings, people who need larger text must find alternative ways to read content. Some websites disable pinch and zoom — a feature that is not just useful for enlarging text but is often used to see images better.
Other Mobile Accessibility Barriers
The accessibility barriers that weren’t mentioned as often but still represent significant challenges for assistive technology users include:
Low contrast If the contrast between text and background is low, it makes it harder for folks with low vision to read. Customizing contrast settings can make content more legible for a broader range of people.
No dark mode For some people, black text on a white background can be painful to the eyes or trigger migraines.
Fixed orientation Not being able to rotate from portrait to landscape can impact people who have their device in a fixed position on a wheelchair or people with low vision who use landscape mode to make text and images appear larger.
Missing captions No captions on videos were also cited as a barrier. This is one that I relate to personally, as I rely on captions myself because of my hearing disability.
I knew I couldn’t capture all of the mobile accessibility barriers in my list of choices, so I gave the survey respondents a free text field to enter their own. Here’s what they said:
Screen reader users encounter unlabelled images or labels that don’t make sense. AI-based image recognition technology can help but often can’t provide the same context that a designer would. Screen reader users also run into apps that unexpectedly move their screen reader’s focus, changing their location on the screen and causing confusion.
Voice Control users find apps and sites that aren’t responsive to their voice commands. They have to try alternate commands to activate interactive elements, sometimes slowing them down significantly.
Complex navigation, such as large, dynamic lists or menus that expand and collapse automatically, can be challenging to use with assistive technologies. There aren’t often workarounds to interacting with navigation, so this can influence whether a user will abandon an app or website.
Inclusive Design Approaches For Mobile
It’s important to avoid getting overwhelmed and not doing anything at all because mobile accessibility seems hard. Instead, focus on fixing the most critical issues first, then release, celebrate, and repeat the process.
Ideally, you’ll want to change your processes to avoid creating more accessibility issues in the future. Here’s a high-level process for inclusive app development:
Do research with users to understand how their assistive technology works and what challenges they have with your existing app.
Create designs for accessibility features such as font scaling and state and focus indicators.
Revise designs and get feedback from users that can be applied in development.
Annotate design files for accessibility based on user feedback and best practices.
Create a new build and use automated testing tools to find barriers.
Do manual QA testing on the new build using your phone’s accessibility settings.
Release a private build and test with users again before the production release.
Conclusion
Fixing and, more importantly, avoiding mobile accessibility barriers can be easier if you understand how assistive technologies work and the common challenges users encounter on mobile devices. Remember the key takeaway from the beginning of this article: half of the people surveyed felt accessibility barriers had a significant impact on their well-being. With that in mind, I encourage you not to let a lack of understanding of technical accessibility compliance hold you back from building inclusive apps and mobile-friendly websites.
When you look at accessibility from the lens of usability for everyone and learn from assistive technology users, you take a step towards empowering everyone to independently interact with your products and services, playing your part in building a more equitable Internet.
The marketing plan in hospitals and medical centers needs to be great if they are to grow and do their best in this rapidly changing world of healthcare. Healthcare has special needs unlike other areas, which calls for unique marketing procedures.
Nevertheless, the healthcare industry would reap significantly from appropriate marketing techniques. With approximately 88% of the population seeking medical information online, the internet emerges as a powerful tool for healthcare practices to engage with patients and stakeholders. In other words, one needs a suitable plan that will allow them to reach many individuals through the web besides ensuring smooth running at hospitals and clinics
However, before prominent names in the healthcare industry can adopt these strategies, there is a need to delve into one basic question: What is specifically meant by marketing strategies in healthcare systems?
In this blog entry, we are going to untangle intricacies together with opportunities lurking in healthcare marketing, as well as take a look at how organizations are using innovative ways to communicate with audiences, enhance access to care, and drive meaningful results.
Why Is Healthcare Marketing Important?
Healthcare marketing has undergone significant transformation, evolving into a valuable asset for medical practices. Today, marketing plays a pivotal role in aiding healthcare professionals to effectively create, communicate, and deliver value to their intended audience. They contribute to sustainable growth in patient numbers, fostering loyalty among clientele. Unlike in the past, contemporary marketers prioritize understanding their clientele over simply pushing products or services. Their focal point lies in nurturing enduring relationships rather than mere one-time transactions, aiming to foster high levels of customer satisfaction to encourage repeat patronage. This significantly reduces patient attrition and drives positive changes in financial demographics.
This is despite the fact that the United States spends around $4.5 trillion each year on health care services, which represents 18 percent of its GDP. This led to an increase in interactions by providing clear communication channels as well as trust building.
A properly designed marketing plan promotes relationships through which connections are strengthened and loyalty enhanced. In addition, healthcare marketing helps to distinguish between competing practices, hence playing a role in the success of thriving healthcare facilities.
The Evolving Landscape Of Healthcare Marketing – What Has Changed In 2024?
The last decade has witnessed many changes in healthcare marketing trends that immensely influenced its landscape. These trends include:
Transition from Mass Marketing to a Targeted Approach
Shift from Image Marketing to Service Marketing
Move from Uniformity to Personalization
Transition from Episode Care to Long-Term Relationships
Adoption of Market Intelligence over Neglecting Market Trends
Shift from Low-Tech to High-Tech Solutions
These forces have driven considerable changes in healthcare marketing, which has had to adapt itself to the emerging demands and preferences of healthcare providers and patients. Subsequently, this shift caused crucial misgivings about how the firms’ marketers should approach the industry.
Conversely, it is now more focused on personalized care that addresses individual patient needs and preferences. As such, various traditional marketing means are currently being reassessed as they give way to new strategies that focus on making patients feel engaged with information about their health and satisfied.
Furthermore, technology-driven approaches and data analytics have gained popularity amongst marketers who use them for directing their campaigns. Such platforms like social media, mobile apps as well as telehealth solutions are some of the things that healthcare organizations are using today in order to reach out to a large number of patients thereby making their treatment processes more effective.
10 Compelling Reasons Why Marketing Strategies Are Vital in Healthcare Systems
As the healthcare landscape continues to evolve, it becomes increasingly apparent that strategic marketing approaches are a “must-have” rather than a “nice-to-have.”
Here are the top 10 reasons healthcare systems need a marketing strategy to pave their way in this brave new world.
Enhanced Patient Engagement and Satisfaction
Patient engagement isn’t easy these days, but it’s worth it. Marketing approach in healthcare systems means more meaningful interaction and engagement. Healthcare systems can tailor messages and services to their patients, meeting their unique needs and preferences. The result? A more personal and efficient relationship that means an exceptional experience for the patient all around
Access to quality care
Marketing especially when it comes to awareness around healthcare services and resources is paramount to improving access to care, particularly for underserved populations. It ensures that patients know about the care and services available and has them seek that care when they need it.
Financial Visibility
Marketing is crucial for contacting patients and helping them coordinate care between specialties.If, however, efforts to contact patients are not successful, marketing that attracts patients and drives revenue is essential to the financial viability of healthcare systems. By driving patient volume, and, indeed, retention, marketing strategies prove to be a critical component to the health and sustainability of a healthcare organization.
Improved Patient Retention
It is extremely important to have successful marketing strategies in reaching out to patients, as this helps empower and educate them. This not only encourages their commitment to healthcare but also supports them throughout their entire medical experience. Through continuous and consistent communication, along with a focus on treating patients as valued customers, healthcare providers can establish a strong bond with their patients. This approach cultivates loyalty and trust, essential elements in building enduring relationships.
Enhanced Reach
One of the most significant impacts of marketing strategies in healthcare systems is the heightened awareness of health issues. Utilizing accurate data, endorsing treatments, and promoting national healthcare schemes are all crucial elements of medical campaigns.
Research conducted in 2023 revealed that approximately 7% or approximately 25.3 million Americans of all ages did not have health insurance. This marks a decrease from 8.0% or around 26.4 million individuals during the same period in 2022. However, effective healthcare marketing has played a vital role in making individuals more aware of company insurance and other medical schemes, thereby expanding prospects for access to healthcare services
Building Trust and Credibility
Trust is fundamental in healthcare, and effective marketing strategies help build trust and credibility among patients. This can be done by delivering transparent and accurate information, healthcare systems can establish themselves as trustworthy sources of care, leading to increased patient confidence and loyalty.
Promoting Public Health Initiatives
Marketing strategies have their contributions not only to institutions but also to the public. As a case in point, they may be employed to instill healthy behaviors in patients and to make them go after preventive care, thereby decreasing the incidence rates and severity of chronic diseases. This plays very well in increasing the population’s health outcomes.
PromotesLeadership In The Healthcare Market
Effective marketing strategies are the cornerstone of Promoting leadership in the healthcare market. You can consistently produce high-quality content, such as whitepapers, research studies, and educational materials, and position yourselves as thought leaders in your areas of expertise. This will not only enhance credibility but also attract attention and respect within the industry.
Building Strong Relationships with The Community
Strategic healthcare marketing extends beyond mere service promotion; it nurtures a professional reputation and nurtures a positive community perception.
Central to healthcare systems is the cultivation of patient trust and adherence to community standards. Moreover, contributing positively to the community’s well-being serves as a cornerstone in enhancing an organization’s standing. By employing effective marketing strategies, medical practitioners can foster loyalty within the community, attracting patients from neighboring areas and beyond.
Increased Referrals
An increase in referrals is a direct outcome of effective healthcare marketing strategies. By employing targeted campaigns, healthcare organizations expand their community presence, encouraging satisfied patients to endorse their services.
Strategic marketing initiatives, such as referral programs and patient testimonials, motivate existing patients to promote the healthcare provider. Additionally, upholding a stellar reputation through outstanding patient care and regular communication further drives word-of-mouth referrals.
In summary, marketing strategies facilitate a steady stream of referrals, ultimately contributing to the growth and success of healthcare organizations.
Summing Up
In healthcare, trust is an understated substructure, and marketing strategies are pivotal to its fostering. At first consideration, marketing strategies may appear solely concerned with advertising. However, when executed effectively, these strategies not only build a hospital’s reputation and culture but also raise the profile of a brand – ultimately impacting patient volume and changing lives for the better. An effective marketing strategy attracts clinical customers connects them with hospital systems, and brings authenticity to the industry. And for good reason: Almost 94% of patients say they carefully evaluate healthcare facilities based on their reputation.
At the end of the day, an effective marketing strategy achieves a positive return on patients, which means that the only true way to exceed patient expectations is with the quality of clinical services offered.
A website is like a need of an hour for all businesses, regardless of their product or services, to survive and thrive in this digital landscape. WordPress is one such platform that businesses worldwide have considered for building websites for more than two decades.
So, if you have decided to go with a leading content management system worldwide, it is the most effective choice. However, to ensure you are able to get the desired website for your business, you need the right partner by your side. By partner, we mean the right WordPress website development company.
However, with the increasing number of WordPress development companies globally, it becomes really challenging to choose the right one.
To simplify your task, we have researched and curated the top tips for choosing the right WordPress website development company.
So, let’s start.
Access Your Needs Well
The first and foremost thing for choosing the right WordPress development service provider is knowing your needs well. Therefore, you should give enough time to review, clarify, and evaluate all the things about your project.
By clarifying all the things in advance, you can ensure that the company you select can meet your specific requirements. Here are some of the questions you should answer to choose the right WordPress development company.
Consider what your website aims to achieve: Is it an e-commerce platform, an informational blog, a portfolio, or a social network?
Obtain all the essential information about the project.
Make a proper strategy for the project.
Check your competitors and see what they are offering.
Schedule a meeting and discuss all the requirements of your project with your team.
By answering all of these questions, you can know your project needs well.
Define Your Project Brief
After knowing your requirements well, your next step will be to make detailed documentation.
Here is a list of things you should consider for the project brief:
Project Scope: Initiate by defining the scope of your project. This includes the specific features and functionalities you envision for your website. Whether a simple blog or a complex e-commerce site, a clear project scope can set the tone for successful execution.
This lets developers understand and complete your tasks in the desired timeline.
Aesthetics and User Experience: Next, consider the aesthetics and user experience. Do you have a specific design in mind? How do you want your users to interact with your website? These decisions contribute significantly to the overall appeal and effectiveness of your site.
Consumer Journey: It’s also essential to outline the consumer journey on your website.
It includes answering the following questions:
How will users navigate your site?
What actions do you want them to take?
Understanding this can help create a website that guides users seamlessly through the conversion funnel.
Developers can understand the consumer journey, and build the website accordingly.
Brand Messaging: Your website is a reflection of your brand vision and mission. Therefore, it’s crucial to ensure that your brand messaging is clear and consistent across the site. It comprises your brand voice, colors, and the overall feel of your site.
Scalability: Last but not least thing is scalability. If you plan to expand your services or products in the future, your website should be able to accommodate this growth. A scalable website is about handling increased traffic and being flexible enough to incorporate new features and functionalities as needed.
Remember, a well-defined project brief not only guides the development process but also helps you choose a company that can effectively bring your vision to life.
Check Customer Reviews and Testimonials
Evaluating customer reviews and testimonials is akin to looking through a window into the company’s reliability and quality of service. These firsthand accounts provide invaluable insights into the experiences of previous clients, highlighting the company’s strengths and areas for improvement.
Apart from this, reviews on platforms like Clutch, Google, and Yelp along with testimonials on the company’s website can reveal much about their professionalism, responsiveness, and ability to deliver projects on time, and within budget.
Focus on how the company responds to negative feedback, which indicates their commitment to customer satisfaction and quality.
It would help if you kept in mind that a company that believes in making positive relationships with the client will treat your project with the attention and respect it deserves.
Remember, a company proficient in fostering positive relationships with its clients will more likely treat your project with the attention and respect it deserves.
Review Portfolio and Case Studies
Going deeper into the company’s portfolio and case studies is essential for assessing capability and expertise in WordPress development.
A company with a diverse and robust portfolio presents you with various projects the company has undertaken. Along with that, it even demonstrates their ability to cater to different industries and client needs.
Check if the project has worked with any projects with the same scope and complexity as yours. It gives you confidence to trust the company.
Case studies offer a deeper insight into the company’s process, from conceptualization to execution. They highlight the challenges faced and the solutions implemented, offering a glimpse into the company’s problem-solving capabilities.
A WordPress development company showcases detailed case studies, is transparent about its methods, and is proud of its outcomes, two qualities that are invaluable in a development partner.
Conduct Thorough Interviews
Conducting thorough interviews with potential WordPress development companies is the most crucial step in this process. It allows you to gauge the technical expertise, communication skills, and cultural fit of the team you’ll be working with.
Prepare a list of questions that cover their approach to project management, their experience with similar projects, and how they handle deadlines and unexpected challenges.
With the help of this interview, you will get an idea about various things about the WordPress service provider, such as the total number of projects they have worked on, development method, choice of hosting provider, and any additional skills they can bring to the table, and more.
In short, these interviews reveal a lot about the company’s commitment to understanding, and fulfilling your project’s unique needs. Please pay attention to how well they listen and respond to your questions. A company genuinely interested in your project will ask insightful questions in return, aiming to deeply understand your objectives, and how they can help achieve them.
Technical Skills & Expertise
Before choosing any WordPress development agency, you should check that their experts have knowledge of the latest trends and technologies running in the WordPress world.
To test whether the experts have the knowledge of the same or not, you can ask questions related to WordPress tools, technologies, plugins, features, and more. Besides this, also check that they have knowledge of different WordPress areas, such as CSS, PHP, WordPress API, JavaScript, etc.
By analyzing all of these things about the WordPress development company, you know whether the company stays updated with the latest things in the WordPress world.
Budget and Pricing
When choosing a WordPress agency, budget and pricing are two of the most critical financial constraints you should focus on before investing. Check that the company is operating on the hourly or fixed price model. Also, ensure that the pricing structure is transparent, with no hidden fees down the line. Budget is crucial, but you should not focus on that thing.
The reason is that the cheapest option might not provide you with the desired quality of service. On the contrary, highly-priced services can’t always guarantee the best results. Strike a balance between your budget and the value provided by the development company.
Obtain quotes from multiple WordPress development service providers, compare their offerings, and choose the one that offers the best service in your budget. In the end, investing in a reputable company might incur a higher initial cost, but it pays off with a professionally crafted website that aligns with your goals and objectives.
After Sales Support & Maintenance
Your website is a living entity in the digital world, and it requires ongoing care. The real journey begins after your site goes live. This is where after-sales support and maintenance come into play.
Therefore, before you choose any WordPress development company, you should ensure that the company offers ongoing support for updates and bug fixes. One best practice here is to go for a company that provides maintenance packages customized to your needs, such as regular backups, security updates, and troubleshooting assistance.
Also, check if the company offers multiple channels of communication in case of emergencies or inquiries. In addition, please inquire about the company’s policy on software updates, and how they handle compatibility issues with plugins or themes.
Investing in a company prioritizing post-development support ensures your website remains secure, up-to-date, and functional in the long term, safeguarding your online presence and user experience.
Conclusion
Ultimately, choosing the right WordPress website development company might be challenging at first. However, by focusing on all the tips we have shared in this blog, such as the budget and pricing, client testimonials and reviews, after-sales support, and maintenance, you can choose a partner that works according to your visions and goals.
Please note that a website doesn’t become successful immediately after its launch; it needs to evolve over time to get the desired results. So, shortlist the best WordPress development service providers, and choose the one that helps you establish an online presence and move forward quickly in the digital landscape.
It’s a New Year, but one thing hasn’t changed. The number of web design resources and tools just keeps on increasing. That’s a good thing. But it does make it that much more difficult to find a theme, plugin, or resource you really have a need for if you are to stay abreast of or leapfrog the competition.
We are in a position to make your search easier. Much easier in fact. We reviewed and tested web design tools & resources we believe many users, designers, and developers have a genuine need for. The types we believe to be essential, and that you will see in our final list of 15 are:
website builders for building landing pages and multiple-page websites quickly, easily, and without any need for coding.
WordPress plugins that can incorporate potentially game-changing functionalities, that are challenging to design, into websites.
WordPress themes for building complex and high-conversion rate websites and online stores.
Vector illustrations that can give a website a whimsical or entertaining aspect.
font identifiers to identify and provide access information to a “must have” font or fonts.
A majority of the web design resources and tools in the following list have a free or trial version:
What are a few of the important attributes these Excellent Web Design Tools & Resources for Designers and Agencies share?
They look premium. There is something about a top tool or resource that makes you wish you had acquired it a long time ago, e.g., how enjoyable it is to use.
They are intuitive. From signing up, to downloading, using, cancelling, and anything in between, everything needed is placed precisely where it should be.
They add real value. They facilitate getting more and higher paid assignments by helping you deliver web design projects faster, making your final deliverables more attractive, or both.
15 best web design Tools & Resources for Designers and Agencies
To help you in your research, we’ve included top features, customer average grade on non-biased platforms such as Trustpilot, Capterra or WordPress.org, and client feedback.
Brizy is the best website builder for Agencies, Designers, and anyone else in need of a White Label solution.
Brizy’s top feature is without a doubt its 100% customizable White Label solution that allows its users to add their own branding, including the builder name, builder logo, domain URL, support link, about link, and project subdomain.
Brizy Builder’s library of demo/template/prebuilt websites is also highly popular with its users. Soulful and Cuisine is one of the 5 most downloaded pre-built websites. It is attractive and inspirational, and while it provides an ideal foundation for a restaurant or bistro, the layout can be used for other service-oriented website types as well.
There’s more to like as well. New users quickly become aware of Brizy’s intuitiveness, and their ability to edit any type of content in place. Many competing builders force their users to create their content in a disjointed sidebar. That’s not the case with Brizy.
Customer Average Grade: 4.6/5 on Trustpilot
Client Feedback: “I am amazed by my experience with Brizy. The tool is easy to use, and the support is one of the best I have ever experienced. Fast replies and my contact really went the extra mile in helping me solve my problem. I can only recommend Brizy to everyone who’s looking to build their own website”!
The Best Free Scheduling Online Software Solution for Business Owners.
Flexibility is always important when selecting a theme or plugin. The top feature of this software solution is the ability to operate in a wide range of languages because of its powerful Multilingual Notifications System.
This user favorite:
facilitates the effective management of appointments and events using email, SMS and/or WhatsApp messages.
keeps users informed about the status of appointments or events.
offers custom notifications that enable users to tailor alerts for specific services or events.
The library of prebuilt websites also plays a significant role in making working with Trafft a pleasant experience. The Career Mastery Coaching prebuilt website illustrates what an effective event booking system might look like.
Key features users notice once they start using Trafft include easy backend and frontend interface navigation and the power the customization options bring to the table.
Web developers and digital design agencies can be expected to be more than pleased to discover that Trafft offers a White Label option.
Customer Average Grade: 5 stars on Capterra
Client Feedback: “ I love that Trafft has so much included – and that you can customize literally everything, including the email & SMS notification wording (which is a big deal for me since I like communications to be in my brand voice).”
Support Materials: Trafft’s ticketing system. Support manual, YouTube videos, social media, and email.
wpDataTables offers an ideal solution for businesses and individuals who need to create tables and charts.
The wpDataTable plugin’s top feature, its Multiple Database Connections capability, represents a data management breakthrough by empowering every table to become a data hub that can pull information from different databases or servers.
By simplifying data management tasks, wpDataTables allows its users to create custom, responsive, easily editable tables and charts with ease. A bookseller could probably put this Responsive Catalog Table with Books to good use.
Features new wpDataTables users will discover include:
an abundance of useful functionality wrapped in an intuitive package.
the ability to adroitly manage complicated data structures.
wpDataTables also supports separate connections for working with specialized database systems and features chart engines for displaying data for marketing, financial, and environmental uses.
Customer Average Grade: 4.5/5 pm WprdPress.org
Client Feedback: “WpDataTables is an excellent WordPress Plugin. What you are able to accomplish with this plugin is nothing short of amazing. Their support is even better! Highly, highly recommend using this product and supporting this company.
I have tried different utilities for creating charts out of a series of CSV files I use for weather data, but it has been a hassle until I discovered wpDataTables which does exactly what I need. Very user friendly and versatile. And it also understands that there are other standards for date, decimal, and time apart from the Americas.”
Support Materials: Support manual, the Facebook community, and YouTube videos
Uncode is the #1 WordPress and WooCommerce theme for creatives, professional designers, and agencies looking for an ideal solution for any project.
While Uncode’s ensemble of website building tools and options would seem to more than justify its popularity, most of its users say the demo library is its #1 feature. The demos not only exhibit exceptional attention to detail but have proven to be excellent sources of inspiration as well.
Uncode’s classic Web Experiences is one of the 5 most downloaded demos. Just imagine what you could do with it.
New users are impressed with the value inherent in Uncode’s demos and wireframes, the level of customization, and the top-notch customer support.
Uncode’s principal users are:
Agencies and Freelancers, because of the multitude of options that cover the needs of every customer or client.
Shop creators, who can easily make effective use of Uncode’s advanced WooCommerce features.
Customer Average Grade: 4.89/5
Client Feedback: “I have used Uncode on 6+ websites now, and it’s absolutely my go-to theme! The features, quality, and customer support are outstanding. The developers do an incredible job of keeping the theme up to date and stable, constantly implementing new features and optimizing the theme. A solid product with great documentation and responsive support team. Kudos!”
Support Materials: Support manual, Facebook groups, YouTube videos
LayerSlider, the top-rated WordPress slider plugin, empowers web designers to effortlessly enhance websites and make them truly shine.
LayerSlider’s scroll effect has emerged as its top feature. You can find it prominently displayed in the recent batch of full-size hero scene and whole website templates. Scroll through the Flavor Factory pre-built web page and see how easy it can be to use LayerSlider to help capture and engage visitors.
LayerSlider easily accommodates a range of uses, from creating simple sliders or slideshows to sprucing up your site with captivating animated content.
Newer users appreciate:
LayerSlider’s customizable interface that suggests the plugin was created specifically for their use only.
easy access to millions of stock photos and videos plus other integrated online services.
the Project Editor that ensures that what you need is right where you need it.
LayerSlider also really shines when there is a need to create content for marketing purposes. Marketers are impressed with the mind-blowing effects that can be incorporated into their popups and banners.
Client Feedback:“A fantastic slider plugin with regular updates to make sure compatibility is never a problem. Keep up the amazing work!”
Support Materials: Product manual, In-editor help, support tickets, and email.
Amelia is the best WordPress plugin for Agencies and Businesses in need of a streamlined booking solution.
The automated notifications system is Amelia’s top feature. Users could tell you how easy it was to categorize and position appointments as pending, approved, cancelled, rejected, or rescheduled. Special notices such as upcoming events or birthday congratulations can also be forwarded via the notifications system to assist clients and enhance their loyalty.
Amelia offers a number of templates that can be customized to help businesses grow. Yoga Studio is a notable example of how a template can be put to use to advertise a business.
Those new to Amelia could tell you about:
the ease of navigation they discovered, the innovativeness exhibited in the backend and frontend interfaces, and its functionality and user-friendly design.
the value its transparent pricing policy offers.
the extent of the customization options.
The Amelia plugin offers an ideal booking solution for service-oriented businesses including those specializing in ticket sales and/or events. Programming agencies and developers could also profit from having Amelia in their design toolkits.
Customer Average Grade: 4.8 on Capterra
Client Feedback: “Great plugin, I have tested similar, but Amelia seems to be the best for my site, I have many customers through the site, and everybody is satisfied with this appointment system. Sometimes there are a few bugs but quickly corrected through regular updates. Globally very good notation.”
Support Materials: YouTube videos, Discord Group, and Support Manual
The most powerful and accurate free font identifier.
This tool’s top feature is its accuracy. WhatFontis users have a 90%+ chance of finding whatever free or licensed font they want identified.
No other system can claim that accuracy, and most of them charge a fee for whatever service they provide. It is worth noting that the ability of WhatFontis to identify a given font correctly can be compromised if the quality of the submitted image is subpar, and that is what accounts for some of the roughly 10% of missed identifications.
WhatFontis can do what it does best in part because of its database of 990K+ free and commercial fonts. This is nearly 5 times as many fonts as that attributed to the nearest competitor.
Whether the goal is to identify a specific font sent by a client, or simply because it is attractive, a customer wants to know what it is and where to find it. A search can be conducted for a font regardless of its publisher, producer, or foundry.
The process is as easy as can be.
Upload a clean font image.
In response, an AI-powered search engine identifies the font and as many as 60 close neighbors.
Links are provided that show where a free font can be downloaded or where a commercial font can be purchased.
Note: Cursive font letters must be separated before being submitted.
Client Feedback: “I came across this website courtesy Google search, used their services successfully; and today I find out it’s on product hunt! If you are ‘driven’ by the need to discover what font ‘that person/ company’ uses, then this should be your go-to solution site. For most of us it would be a once in a blue moon need, except for the professionals.”
Slider Revolution is the best WordPress plugin for Designers, Web Developers and anyone seeking a way to create jaw-dropping animated sliders.
This plugin’s top feature is the ability it gives to its users to visually create stunning animated effects for WordPress.
The Slider Revolution plugin is not limited to creating sliders. It can be used to:
create stunning home pages that immediately engage its visitors.
create portfolios that will be viewed a second, or third, time because of the method of presentation.
design eye-catching sections anywhere on a website.
A stroll through Slider Revolution’s library of 250+ templates may be all that’s necessary if you need a little inspiration to get started. These templates have been 100% optimized for different screen configurations and feature special effects you won’t see on most websites. The Woodworking Website template for example, makes clever use of the hover effect to highlight both text and images. The layout itself can be used for a wide variety of website types or niches.
The Slider Revolution plugin is tailor made for individual web designers and developers, web shops, and small agencies.
Customer Average Grade: 4.6/5 on Trustpilot
Client Feedback: “I absolutely love the Slider Revolution. It does wonders for my projects. I am super excited about all of the templates that are ready for use. Their support has been incredible”.
The best resource for designers who are looking for top quality illustrations with terrific attention to detail.
Getillustrations’ top feature is three things in one; 21,500+ vector illustrations, free updates for one year, and new illustrations added every week. In other words, once you get started, good things keep coming your way!
You will have 40+ nicely arranged categories to select from. Most categories have several hundred illustrations, a few have more than 1,000.
These illustrations appeal to clients ranging from students and businesses to designers and developers. You’ll find pencil and basic ink illustrations, several 3D illustration categories, and fitness, logistics, and ecology illustrations to name but a few, and since they are exclusive to Getillustrations you will have an edge over those using other stock illustration resources.
You can purchase illustrations by the pack if you choose to. The Motion Illustrations pack is one of the larger ones with 1,090 vector web illustrations at latest count .These Motion illustrations feature a diverse range of themes, each of which makes a statement.
Client Feedback:“I really like the different styles available in this library. I used it to illustrate some of my blog posts. Since you get vector files, you can also recolor them to have them match your brand and product identity!”
Support Materials: Vector stock illustrations in .Ai .Figma .PNG and .SVG
The best tool for creating and downloading full page websites using prompt commands only.
The Mobirise AI website builder is a revolutionary tool that uses intelligent algorithms to generate beautiful websites. Its top feature enables its user to generate a website using a single prompt.
The super-intuitive single prompt interface makes Mobirise AI an ideal choice for anyone looking for a simplistic yet efficient design approach.
Describe in detail what your site is all about, and this AI website builder will take your data and through the use of intelligent algorithms auto-generate a basic layout.
Once that is accomplished you can use prompts to customize style, colors, fonts, etc., and edit pre-generated content to suit your needs.
When you have the beautiful, optimized for Google and mobile devices website you want you can launch it with a single prompt.
Note: Even though Mobirise AI does much of the work, you retain full ownership of your website.
Client Feedback: “The AI website builder was astonishingly intuitive. What I appreciated the most was the seamless drag-and-drop interface which allowed me to position elements anywhere on my site. The AI’s design recommendations saved me hours of second-guessing my layout choices. Not to mention, the automatic SEO feature was a godsend–it optimized my site without me having to learn the complex ins and outs.”
Support Materials: Support Manual, User Forum, YouTube Videos
XStore is the best WooCommerce theme for anyone looking to quickly build a high-converting online store.
XStore is obviously tailored for use by shop owners and prospective shop owners who seek an online presence. While the selection of ready-made stores (pre-built websites) has always been highly popular, the recently introduced selection of Sales Booster features has emerged as the top favorite.
New users soon come to appreciate the Builders Panel and the intuitive XStore Control Panel, both of which give them the store-building and customization flexibility needed to create the custom store they envision.
They also like the solid start XStore’s pre-built websites make possible. The layout of the Marseille prebuilt website is an excellent example of why it’s possible for a novice to get a store up in running in a few hours.
XStore doesn’t stop there. Its users have instant access to the powerful family of Single Product, Checkout, Cart, Archive Products, and 404 Page Builders; all favorites of shop owners.
Customer Average Grade: 4.87/5
Client Feedback:“I love this theme! There’s a wider learning curve to go through before getting a hang of the features, but the overall versatility and aesthetic factor is excellent.”
Blocksy is the best free WordPress theme for building attractive, lightweight websites in 2024.
There doesn’t appear to be much about Blocksy that its users don’t love. Consequently, when it comes to identifying this premium WooCommerce WordPress theme’s top feature, there’ s a 4-way tie.
Blocksy’s footer and header builders are super-user friendly.
Gutenberg support ensures top performance.
Developers love the advanced hooks and display conditions.
Everyone appreciates seamless WooCommerce integration together with its associated features.
And on top of it all, Blocksy is free!
Several of the things new users quickly recognize is that Blocksy:
uses the latest web technologies.
provides exceptional performance.
integrates easily with the most popular plugins.
Cosmetic is a beautiful, meticulously crafted starter site with a pleasant design that lets products take center stage. While centered on beauty products, its layout can be used for a wide variety of website niches. Cosmetic is one of the 5 most commonly used starter sites.
Customer Average Grade: 5/5 on WordPress.org
Client Feedback: “Blocksy is fast and light, responsive and beautiful. Blocksy has nothing superfluous and has everything you need. I love Blocksy, and Blocksy loves me.”
Support Materials: A readily accessible Documentation Section, Support Manual, YouTube videos. Facebook Group
Total is the best WordPress theme for web designers and developers seeking the flexibility required to design from-scratch.
Total’s top feature is its seemingly unlimited flexibility. Its assortment of design tools and options makes it a Swiss Army knife of website design and is one reason its name is so appropriate. A well-deserved reputation for amazing support also tends to set Total apart.
Not long after becoming acquainted with Total, its users could tell you about a number of things they discovered and like including the fact that:
Total has settings for everything, tons of page building options, a font manager, custom post types, and more.
Total is speed optimized.
Total provides dynamic templates for posts and archives.
Total’s pre-built website collection is another favorite. Synergy’s minimalistic design lends itself to a wide range of uses and is one of the 5 most widely used pre-built websites.
Total is tailored for beginners, developers, and DIYers. Advanced designers like Total as well, and for all intents and purposes, anyone else will too.
Customer Average Grade: 4.86/5
Client Feedback:“I have been using Total for several years now for several (10+) websites. Out of the box it’s already a great theme and very well documented. Some websites required specific functionality and so far, there was nothing I couldn’t provide. If I can’t figure it out myself, support is always willing to help. I don’t need another theme anymore.”
Essential Grid is the best WordPress Gallery Plugin for businesses who want to capture visitors’ attention with breathtaking galleries.
Essential Grid is the best WordPress Gallery Plugin for anyone who wants to create a unique, attention-getting gallery.
Essential Grid’s library of 50+ unique grid skins is its top feature and is what this WordPress gallery plugin is all about. Why these skins are such a favorite is easy to see. Most web designers and developers would not want to have to take the time to create a gallery from scratch and the grid skins offer an excellent alternative approach.
In addition to making it easier to create a gallery layout you want, it’s also possible you’ll come across a grid skin layout you haven’t even thought possible and can’t wait to put into use. The YouTube Playlist layout for example shows how the hover effect can transform a seemingly run-of-the-mill gallery into a real attention getter.
Essential Grid’s users will tell you how much of a time saver this plugin can be, and how effective it is at helping them organize their content streams.
Customer Average Grade: 4.7/5 on Trustpilot
Client Feedback:“I have to say that the level of support I received is definitely one of the best I have ever experienced. Big thumbs up!”
Support Materials: Support manual and YouTube videos
WoodMart is the best WooCommerce theme for niche ecommerce design.
Just a glance at the WoodMart website is enough to grab your attention. Woodmart’s top feature, super-realism, pops right out at you. The custom layouts for shop, cart, and checkout pages are so well done that it’s easy to forget where you are and start window shopping.
There is plenty more to about WoodMart too, for example:
A multiplicity of available design options.
Easy customization to fit the brand.
The time-saving Theme Settings Search and Theme Settings Performance Optimization features.
Widely used “Frequently Bought Together”, “Dynamic Discounts”, and social integrations options.
WoodMart also has a White Label option.
Finding the most popular demos isn’t easy since most of them enjoy lots of usage. WoodMart Organic Baby Clothes is one of the 5 most downloaded demos.
Customer Average Grade: 4.93/5
Client Feedback:“This theme is perfect. It has all the options you can imagine and tooltips to help you understand what you are about to change. It’s fast out of the box and makes a great use of Elementor. Great responsive design.”
Support Materials: Support Manual and YouTube Videos
Do you see one or more web design resources and tools you would like to add to your toolkit? It would certainly be easier than having to sift through hundreds on your own. That is why we did the vetting process for you. You still will want to preview those that interest you and try them out if possible. The free ones are of course for the taking.
What will you be looking for? These 15 excellent web design tools & resources have several characteristics in common. Characteristics that are necessary to be considered as “best-in-class”. Those characteristics are as follows.
Plugins, themes, and resources are easy to install or set up and are user friendly.
They give your website an edge in terms of design, functionality, or visitor appeal; or all three.
Customer support is friendly, fast, and competent.
They allow you to test the product for free. Or give you enough information to ensure that won’t end up feeling like the product you purchased is markedly different from the one you saw advertised.
Check out any or all of the 15 best web design tools and resources you believe you could put to good use. Test them out if you can and either add them to your toolkit or write them off.
Are you done? Not really. Since there are many new web design tools & resources coming into the marketplace every day, some of which might offer greater opportunities, your search will never really end.
Whether it’s boosting your organic search visibility or collecting data for targeted email marketing campaigns, a great quiz can do wonders for your website. In this guide, we’re going to reveal ten WordPress quiz plugins you need to know about.
In the fast-paced, technology-driven 21st century, our lives are intricately woven with digital threads, relying on technology for everything from ordering food to managing finances. With staffing solutions of tomorrow and a projected global IT sector revenue of USD 1,570.00 billion by 2027, the demand for IT professionals has skyrocketed.
However, this growth faces a significant hurdle – the scarcity of skilled IT professionals, threatening to result in a loss of $8.5 trillion by 2030 in the U.S. alone.
Companies use innovative staffing solutions, like IT staff augmentation, to bridge the skills gap in response to this challenge. This blog delves into the power and power of IT augmentation companies, exploring the benefits of staff augmentation services, types, business advantages, challenges, and the future of IT augmentation landscape.
What is Staff Augmentation?
IT staff augmentation is a hiring practice involving external talent to complement a company’s existing staff, enabling them to fill skill gaps without needing full-time hires. The skills gap dilemma poses a significant economic impact, making IT staff augmentation a strategic solution.
The concept of IT Staff Augmentation includes:
Enhancing Capabilities through External Expertise
IT staff augmentation is aimed at elevating the capabilities of an organization by selectively incorporating external expertise.
Tackling Skill Gaps with Precision
IT Staff Augmentation surgically addresses future workforce solutions, skill gaps within an organization. Rather than committing to the overheads and permanence of full-time hires, top IT staff augmentation companies can bring in external professionals with specialized skills.
IT staff augmentation is not merely a reactive response to skill shortages; it’s a proactive strategy that positions companies to thrive amid industry evolution.
Why Consider IT Staff Augmentation?
Necessity of Technology
In an era where the success of organizations is linked to technology, leveraging IT capabilities is not just an option but a necessity. However, only some companies possess the in-house resources or expertise to navigate the complexities of their IT needs effectively. This is where future of IT staff augmentation services emerges as a compelling solution.
Navigating the Digital Landscape
With the business landscape becoming increasingly digitized, organizations must harness technology for enhanced efficiency, heightened productivity, and sustained profitability. IT staff augmentation becomes the strategic ally for those lacking an extensive internal IT infrastructure.
Efficient Management of IT Needs
Managing IT in-house can be a resource-intensive challenge for many companies, especially smaller ones. IT staff augmentation allows organizations to bridge this gap efficiently by bringing in external professionals with the precise skills needed without the commitment of full-time hires.
Global Access to IT Talent
The scope of IT staff augmentation extends beyond geographical boundaries, offering organizations a passport to a global network of IT resources. This global access becomes instrumental in securing the right expertise for specific projects, bringing in a diverse pool of talent that may not be readily available locally.
Tapping into a Diverse Talent Pool
Every project has unique demands, and sourcing the right talent locally might limit the options available. IT staff augmentation breaks down these barriers by providing worldwide access to a diverse talent pool. Companies can cherry-pick professionals with specialized skills that perfectly align with their project requirements.
Overcoming Local Talent Constraints
Certain regions may experience shortages in specific IT skills, creating challenges for organizations with localized teams. IT staff augmentation is a remedy by allowing companies to transcend these local talent constraints and tap into a broader, more varied talent landscape.
Flexibility in Talent Acquisition
Whether a company is situated in a bustling tech hub or a region with limited IT expertise, IT staff augmentation ensures flexibility in talent acquisition. Organizations can scale their IT teams based on project needs, drawing on global talent without being bound by geographical limitations.
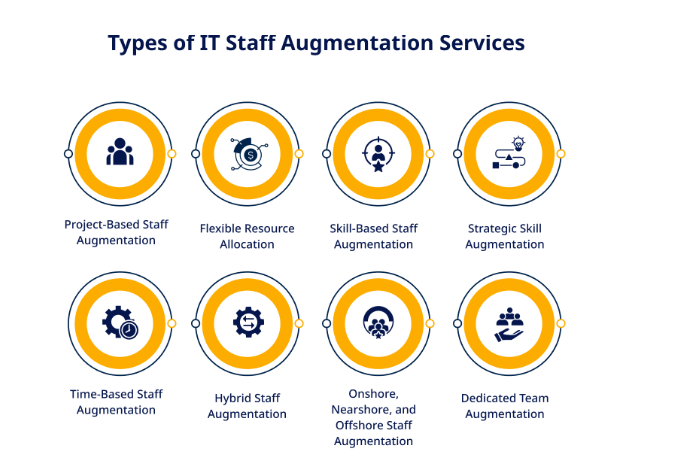
Types of IT Staff Augmentation Services
In the dynamic landscape of IT staff augmentation, various service models cater to diverse business needs.
Project-Based Staff Augmentation
Whether developing a new software application or implementing a technological overhaul, project-based staff augmentation provides targeted expertise without a long-term commitment.
Flexible Resource Allocation
Companies can scale their team up or down based on project requirements. It’s a cost-effective approach, as resources are allocated precisely when needed.
Skill-Based Staff Augmentation
For organizations facing skill gaps, skill-based staff augmentation is the remedy. This approach involves hiring temporary professionals with specific skill sets for successful execution.
Strategic Skill Augmentation
Rather than committing to full-time hires for skills needed on a project-by-project basis, skill-based augmentation strategically augments the team when specific expertise is essential.
Time-Based Staff Augmentation
When projects require additional resources for a predetermined timeframe, time-based staff augmentation comes into play. Companies can enlist third-party developers or engineers for the duration necessary to meet project milestones or deadlines.
Hybrid Staff Augmentation
It allows the combining of two or more approaches, creating a customized solution. Whether blending project-based and skill-based models or incorporating time-based augmentation as needed, this hybrid approach adapts to the unique requirements of each project.
Onshore, Nearshore, and Offshore Staff Augmentation
Onshore staff augmentation involves hiring from the same country, ensuring high levels of communication. Nearshore involves neighboring countries with similar time zones, while offshore entails working with professionals from different countries, offering cost-efficient solutions.
Dedicated Team Augmentation
This model ensures undivided attention and specialized expertise. The dedicated team works exclusively for the organization, offering high commitment and alignment with business goals.
Exploring these types of IT staff augmentation services empowers organizations to strategically leverage external talent, addressing specific project needs, skill gaps, or resource demands. Each model brings its advantages, allowing companies to tailor their approach based on the intricacies of their projects and overall business objectives.
Business Benefits of IT Staff Augmentation
Access to Top IT Talent
IT staff augmentation opens the doors to a vast pool of highly skilled and seasoned professionals. This influx of expertise is pivotal for ensuring the success of projects, bringing in specialized knowledge and experience that might be lacking in-house.
Cost Savings and Flexibility
Embracing IT staff augmentation translates to smart resource allocation. Companies sidestep the expenses of recruiting, training, and retaining full-time employees. The ability to scale teams based on project needs ensures a cost-effective and efficient approach.
Faster Time to Market
The synergy of top-notch IT talent and the adaptability to scale teams swiftly accelerate project timelines. This agility is instrumental in hastening the delivery of products or services to the market, giving businesses a competitive edge.
Reduced Risks
Mitigating risks associated with permanent hires, IT staff augmentation allows companies to test the waters. They can evaluate external professionals before making long-term commitments, ensuring a strategic and low-risk approach to talent acquisition.
Potential Challenges of IT Staffing Augmentation
Communication Difficulties
Collaborating with outsourced IT staff brings challenges in communication. Addressing cultural differences, language barriers, and time zone variations becomes crucial for fostering effective collaboration.
Lack of Control
Entrusting projects to external vendors through IT staff augmentation means relinquishing a degree of control. For companies, especially those dealing with sensitive data, finding the right balance between oversight and outsourcing becomes paramount.
Quality of Work
Not all IT outsourcing service companies uphold the same standards. Choosing a reputable provider is critical to ensuring consistent and high-quality work. Thorough vetting and due diligence are essential steps in safeguarding project outcomes.
Data Security Risks
Security concerns loom large in staff augmentation. Opting for a partner with robust security measures is non-negotiable. Safeguarding sensitive information becomes a shared responsibility, and companies must prioritize data security in their selection process.
IT Staffing Augmentation vs. Other Staffing Solutions
Comparison with Managed Services:
IT staff augmentation puts the reins of IT operations firmly in your hands. You retain full control over your IT functions, dictating the course of action.
In-House Recruitment vs. Staff Augmentation
In-house recruitment fosters team alignment with your company culture. However, this approach can be both expensive and time-consuming.
On the flip side, staff augmentation offers flexibility without the hassle and expense of hiring and training new employees, providing a more agile solution.
Staff Augmentation vs. Outsourcing
Outsourcing specific IT tasks to external companies means relinquishing control over the process.
Staff augmentation maintains flexibility and cost-effectiveness, especially for short-term projects. The choice hinges on the level of control you desire over your project.
Staff Augmentation vs. Independent Contractors
Staff augmentation provides a structured framework for accessing top skills. This managed approach ensures reliable project delivery, a stark contrast to freelancers who may offer skills but lack the structured support that staff augmentation brings.
Steps in the IT Staff Augmentation Process
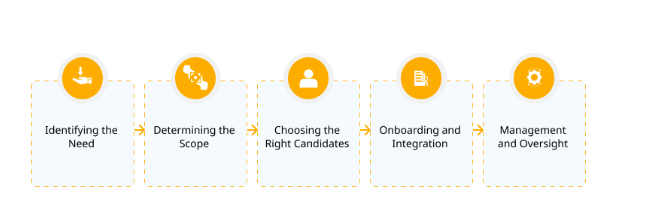
Here are the steps of the IT Staff Augmentation Process:
Identifying the Need
Recognizing shortages in skills, expertise, or upcoming projects prompts the need for external resources.
Determining the Scope
Defining project roles, responsibilities, duration, and specific skills required for successful augmentation.
Choosing the Right Candidates
Rigorously screening candidates through referrals, recruitment agencies, and job postings to ensure the necessary skills and experience.
Onboarding and Integration
Facilitating the integration of external staff into the existing team, providing access to tools, resources, and team introductions.
Management and Oversight
Continuously managing and overseeing external professionals, ensuring alignment with expectations and project requirements.
When to Choose IT Staff Augmentation Services
Addressing Skill Gaps – When specific projects require skills not present in the in-house team.
Seasonal Spikes in Workload – To meet demands during workload spikes without needing permanent hires.
Mitigating Project Risks – To provide additional resources and manage risks associated with project timelines.
Meeting Tight Project Deadlines – For quick team scaling to meet tight project deadlines.
Scaling IT Teams Based on Business Needs – To retain flexibility and adapt to changing business requirements.
The Future of IT Augmentation
Prospects on the Horizon
The future of IT staff augmentation looks bright, with the market projected to reach a substantial USD 147.2 billion by 2028. This anticipated growth underscores the increasing significance of IT staffing solutions.
Driving Forces
The escalating adoption of transformative technologies fuels the surge in demand for IT staff augmentation services. Cloud computing, big data, artificial intelligence (AI), and the Internet of Things (IoT) collectively drive the need for specialized IT talents, propelling the growth of IT staffing firms.
Remote Work’s Influence
The COVID-19 pandemic and the widespread embrace of remote work have ushered in a new era of global hiring practices. The geographical barriers to talent acquisition have dissolved, contributing significantly to the expansion of IT staffing firms.
As technology continues its relentless evolution, the demand for skilled IT professionals will persist, and IT staff augmentation is poised to play an instrumental role in meeting this demand. Embracing these trends ensures that businesses stay ahead in harnessing the power of the future of IT augmentation for their evolving needs.
Conclusion
The power, potential, and future of IT augmentation services lie in their ability to bridge skill gaps seamlessly, offer global access to IT talent, and provide flexible solutions tailored to diverse business needs. From project-based and skill-based augmentation to onshore, nearshore, and offshore models, the versatility of IT staff augmentation empowers organizations to optimize resource utilization and enhance efficiency.
While challenges like communication difficulties and data security risks exist, a strategic approach, rigorous candidate selection, and partnering with reputable providers mitigate these concerns.
As businesses face the future with uncertainty, embracing the trends of IT staff augmentation ensures they stay at the forefront, harnessing their capabilities for evolving needs and propelling success in the digital era.
In the ever-evolving realm of hotel management, the role of metasearch engines has become pivotal in shaping a hotel’s online presence. To empower hoteliers with the right tools for success, we embark on an in-depth exploration of the top ten metasearch software for hotels solutions. This comparative analysis delves into the distinctive features, nuanced pricing structures, and user insights that set each platform apart.
1. HotelRunner: Navigating the Metasearch Landscape with Ease
Features:
HotelRunner positions itself as a comprehensive solution with seamless integration, dynamic pricing, and real-time analytics. The platform provides hoteliers with the tools to navigate the metasearch landscape effectively.
Pricing:
Adopting a subscription-based model, HotelRunner tailors its pricing to the unique needs and size of each hotel.
User Reviews:
Hoteliers commend HotelRunner for its intuitive interface and robust analytics, allowing for a deeper understanding of metasearch performance.
With its user-friendly approach and real-time insights, HotelRunner is the go-to choice for those seeking a dynamic metasearch management solution.
2. Koddi: Empowering Hotels through Advanced Optimization
Features:
Koddi stands out with advanced bidding and budget optimization tools, coupled with multi-channel distribution and comprehensive reporting. The platform empowers hotels with tools for precise campaign management.
Pricing:
Koddi’s pricing model is customized based on the specific requirements of each hotel.
User Reviews:
Users highlight Koddi’s efficiency in bid management, resulting in a notable improvement in return on investment (ROI).
For hotels aiming for precise campaign control and optimized budgets, Koddi emerges as a powerful ally in the metasearch arena.
3. Fornova: The AI-Powered Path to Metasearch Excellence
Features:
Fornova takes a leap into the future with AI-powered optimization, competitor benchmarking, and integration with major online travel agencies. The platform equips hotels with the intelligence to make strategic decisions.
Pricing:
Fornova adopts a tailored pricing approach, ensuring that each hotel pays for the features that align with its unique requirements.
User Reviews:
Fornova receives acclaim for its data-driven approach and adaptability to ever-changing market conditions.
For those seeking cutting-edge AI solutions and market insights, Fornova stands as a beacon of innovation in metasearch management.
4. Triptease: Direct Bookings and Personalized Communication
Features:
Triptease distinguishes itself with direct booking tools, price intelligence, and a guest messaging platform. The platform emphasizes direct bookings and personalized communication.
Pricing:
Triptease adopts a transparent pricing structure based on the room count of the hotel.
User Reviews:
Triptease users appreciate the platform’s emphasis on direct bookings and its effective communication tools.
Triptease emerges as the choice for hotels aiming to strengthen direct bookings and establish personalized connections with guests.
5. RateGain: Navigating the Pricing Labyrinth with Precision
Features:
RateGain offers comprehensive rate intelligence, channel management, and in-depth analytics. The platform empowers hotels with the tools for strategic decision-making.
Pricing:
RateGain’s pricing is tailored to the unique requirements of each hotel.
User Reviews:
Hoteliers applaud RateGain for its robust features and its role in streamlining metasearch strategies.
RateGain proves to be an invaluable asset for hotels navigating the complex landscape of pricing optimization and distribution.
6. Bookassist: Elevating Direct Bookings and Online Reputation
Features:
Bookassist integrates a direct booking engine with metasearch platforms, mobile-friendly solutions, and reputation management tools. The platform focuses on enhancing user experience and maximizing direct bookings.
Pricing:
Bookassist adopts a transparent pricing approach, considering the room count and specific needs of the hotel.
User Reviews:
Users commend Bookassist for its user-friendly interface and positive impact on direct bookings.
With its emphasis on user experience and direct bookings, Bookassist emerges as a holistic solution for metasearch management.
7. Travel Tripper: Intelligent Pricing and Seamless Integration
Features:
Travel Tripper employs intelligent pricing algorithms, seamless metasearch integration, and website optimization tools. The platform equips hotels with comprehensive tools for enhanced user experience and optimal rate management.
Pricing:
Travel Tripper customizes its pricing based on the specific needs and size of each hotel.
User Reviews:
Hoteliers appreciate Travel Tripper’s holistic approach to metasearch management and its positive impact on direct booking optimization.
For hotels seeking a comprehensive suite of tools for metasearch management, Travel Tripper stands out as a reliable partner.
8. MyHotelShop: Simplicity and Effectiveness in Metasearch Campaigns
Features:
MyHotelShop boasts automated bidding and budget management, competitor benchmarking, and a user-friendly dashboard for real-time monitoring. The platform simplifies metasearch campaigns without compromising effectiveness.
Pricing:
MyHotelShop offers subscription-based pricing tailored to the size and needs of the hotel.
User Reviews:
Users praise MyHotelShop for its simplicity and efficiency in managing metasearch campaigns.
MyHotelShop emerges as the choice for those who seek a straightforward yet powerful solution for metasearch campaign management.
9. Fastbooking: A Multi-Channel Approach to Distribution
Features:
Fastbooking adopts a multi-channel distribution approach, dynamic pricing tools, and performance analytics. The platform provides hotels with comprehensive tools for data-driven decision-making.
Pricing:
Fastbooking customizes its pricing based on the size and requirements of each hotel.
User Reviews:
Hoteliers value Fastbooking for its comprehensive suite of tools and the positive impact on metasearch performance.
For hotels aiming for a multi-channel approach to distribution and data-driven decision-making, Fastbooking emerges as a reliable choice.
10. Mirai: User-Friendly Interface for Enhanced Direct Bookings
Features:
Mirai integrates a direct booking engine with metasearch channels, rate intelligence, and mobile-friendly solutions. The platform prioritizes a user-friendly interface to maximize direct bookings.
Pricing:
Mirai adopts transparent pricing based on the room count and specific needs of the hotel.
User Reviews:
Users appreciate Mirai for its user-friendly interface and positive impact on direct bookings.
Mirai stands as a testament to the importance of user experience in metasearch management, providing a seamless interface for enhanced direct bookings.
Conclusion: Navigating the Metasearch Landscape
In conclusion, the world of metasearch management offers a diverse array of solutions, each catering to unique needs within the hospitality industry. Hoteliers must carefully consider their priorities, whether it be direct bookings, pricing optimization, or comprehensive analytics, to select the platform that aligns with their goals.
As the hospitality landscape continues to evolve, the right metasearch management software can be the key to unlocking success. By understanding the distinct offerings of each platform, hoteliers can make informed decisions that pave the way for increased visibility, enhanced guest experiences, and ultimately, a thriving bottom line in the competitive world of hospitality.
Are you a seller and want to sell your products faster and smarter than others? During the process, you might face several challenges while promoting and delivering your products or services to customers.
No wonder selling goods and services is challenging for everyone in today’s competitive market. You have to face various difficulties that include evolving buyer expectations, a changing economic environment, and heavy competition.
So, to get ahead of your competitors and overcome these obstacles, you have to sell your products faster and smarter, which will lead you to increase your sales and revenues.
In this guide, we will briefly explain to you how to sell your product or service faster and smarter.
Tips on How to Sell Your Product or Service Faster and Smarter
Every entrepreneur should know that you have to be one step ahead of your competitors to increase your sales. You have to study the market, examine the products, apply the best marketing strategy, and follow the latest market trends.
Besides this, here are ten key points that will help you to reach your ideal customers and boost your sales.
1. Know Your Ideal Customer
Ideal customers are those people who love and enjoy your products or services and share that enthusiasm with the people they know.
For that reason, it’s important to know about your ideal customers and understand them, who they are, and what they are exactly looking for. It includes understanding the characteristics of your buyers who are most likely to be interested in buying your products or services.
Furthermore, you have to communicate personally with those who have used your products to get their feedback. You can get a Vanity phone number for your business, it helps to improve customer service and experience. Moreover, customers can easily memorize it and reach out to you.
2. Utilizing the Sales Funnel Model
The Sales Funnel Model is a representation of the customer’s journey, from prospecting to purchase.
When you utilize this method, it helps you organize your approach to sales and find weak spots in your sales methods.
Even more, it also tests out possible improvements and better assists with customers.
Overall, the point of using this method is to reach your business target audience and move them through a series of steps, which eventually results in them becoming your customers.
3. Master the Art of Storytelling
Everyone loves stories, and a good story conveys a good message to people. Storytelling is a powerful tool in the digital era that can increase your product’s value in the world of sales.
Initially, you have to select your target audience to craft a better and more compelling story to create it effectively.
Following that, you can create an emotional connection with your prospects and inspire them to become loyal customers.
After mastering it, you can transform your sales presentation from exhausting to an engaging and compelling experience that resonates with your buyers.
4. Leverage Powerful Content Marketing
Every business owner should be aware of the power of content marketing in this digital world, especially if you’re selling online.
This is a powerful tool that can drive your business forward in the digital presence.
Businesses need to create excellent content about their products or services after understanding customers’ desires. It boosts your brand visibility to more people.
Also, buyers will get to know more about your products or services closely with the content. Hence, make sure to explain how your products solve the customer’s problem and what the main features are that make you better than others in your content.
5. Utilize Social Media Ads
Millions of users are active on social media platforms like Facebook, Twitter, and Instagram on a daily basis.
So, it’s easier to promote your products or services using social media ads. You just have to select the target audience that you want to sell your products and place ads on those platforms after paying some cost.
It is a very simple and effective way to communicate with your prospects and improve your brand value.
The biggest advantage of doing social media ads is you can even select a specific geographic area.
6. Motivate Employees
Employees play a vital role in growing the company and creating good brand value among buyers.
So, keeping the employees motivated increases the work value. It depends on the level of dedication and commitment that the employee gives during the working day.
Thus, a company should focus on developing a positive work culture to encourage creativity and innovation.
You have to promote teamwork and collaboration to set clear goals. Remember, motivated employees always give more than an employer expects from them at work.
7. Invest in Email Marketing
People mainly prefer email over other media for communication. Even more, this is the platform where you’ll reach your mobile users the most.
A billion users use email, which makes email marketing a powerful tool for a company who are looking for effective advertising strategies to engage with its loyal customers.
A company can inform its prospects about its latest discounts, deals, new products, and much more through email.
Additionally, you can make customers aware of the product’s features and their advantages by sending personal mail to them.
8. Monitor Trends
You always have to follow the latest market trends to know what customers are exactly looking for.
These days, it’s easy to track it using a trend discovery tool that provides a database of trending topics. Furthermore, netizens follow the trend started by the influencers; therefore, you can also track them on social media.
By looking at market trends, businesses can make decisions based on facts. It helps you to understand where the market is heading. Nowadays businesses have started using phone system for sales teams to simplify communication. It will help you to increase productivity. Even more, it helps you to reduce the risk of going down in the market.
9. Presenting a product benefit
Product benefits are often the main point of selling. In this technique, when you gain knowledge about the customer’s desire, then you can tell how your product will fit their needs.
10. Offer a free trial or demonstration
Offering a free trial or demonstration helps customers determine if the product is helpful or satisfies their needs or not for them. For instance, when buyers purchase an Apple Vision Pro, they will first try it and buy if the product meets their requirements.
Why is it Important to Have Effective Selling Strategies?
Whether you have a small or big business, everyone has to follow selling strategies that are effective to increase sales.
This strategy helps you to build a mutually beneficial relationship with customers. It also allows the company to focus on its target customers and communicate with them in relevant ways.
Even more, effective selling strategies improve team performance to achieve effective targets, higher conversion rates, and increased customer retention rates.
Some other important of having an effective selling strategy include:
Enhance Customer Service
An effective sales strategy helps you to interact better with customers and allows you to understand their needs more closely.
Furthermore, it allows you to be more attentive to customer inquiries and respond instantly to improve customer experience.
Boost Sales Efficiency
An excellent sales strategy optimized resources and prioritized the most profitable areas.
A company can decide which marketing channels bring the best results by analyzing the customer data to adjust the approach for more efficient sales operations for a better return on investment.
Increase More Revenue
A perfect sales strategy helps you to boost higher conversion rates and generate more revenue. But you have to target the right markets using the resources effectively to increase profits.
Conclusion
Overall, whether you have a small or big business, everyone has to follow the sales technique to boost their sales and increase their annual growth rate.
You always need to follow the market trends to know what your prospects are really looking for in products and services. Businesses can apply the above eight key points to sell their goods or services faster than others.
Frequently Asked Questions (FAQs)
What are the 4 basic selling techniques?
The four basic selling techniques are as follows:
Transactional selling
Solution selling
Consultative selling
Provocative selling
What are the 5 steps to sell?
Here are the five steps to follow to sell your products:
Identify your target customer
Find out about buyers’ desire
Provide a solution or present value proposals
Close Sales
Complete the sale and follow up with thank you notes
What is a method of selling?
A method of selling is the method used by a salesperson or sales team that helps to sell products or services more effectively. There are various methods of selling, such as SPIN selling, Inbound selling, Solution selling, and many more.
Accessibility has become a fundamental element in contemporary design. It greatly contributes to the establishment of an inclusive digital sphere. With the continuous progression of technology, designers are recognizing the importance of guaranteeing the usability of websites. They make them suitable for individuals with diverse abilities or disabilities. This evolution encompasses principles such as responsive design and the incorporation of assistive technologies. We’ll discover some strategies that will push the digital sphere toward a universal future. Learn how you can make your networks a space for everyone.
The Significance of Inclusive Design
Inclusive design has its own philosophy centered on developing products and environments accessible and usable by people with different backgrounds. Whether applied to interface design, physical spaces, or product development, the emphasis is on inclusivity. It should exceed the mere accommodation of specific groups. It aims to provide an equitable experience for everyone. Here’s a closer look at why inclusive design is a fundamental aspect of responsible and ethical practices.
Diverse User Base
Our world is diverse, reflecting the varied tapestry of its population. Inclusive design embraces this diversity. It guarantees that all the products and services suit the needs of a broad spectrum of people. By taking into account an array of abilities, disabilities, cultural backgrounds, languages, and preferences, designers can develop solutions that connect with a wider audience.
Enhanced User Experience
It contributes to an improved user experience for everyone. For instance, text alternatives for images can be extremely useful. They benefit those with visual impairments and provide clarity in different contexts. These might include poor internet connectivity or when images fail to load.
Market Expansion
By prioritizing inclusivity in design you can broaden market reach and unlock new avenues for expansion. Companies that adopt this approach can get into previously unexplored markets and gain new clients. Additionally, the promotion of inclusivity sparks innovation. It inspires designers to think outside the box and develop solutions that cater to a diverse spectrum of needs.
Cultivating Sympathy
This strategy promotes understanding and empathy. It cultivates a sense of belonging and shared experiences for users. Interaction with inclusive products or spaces creates a sense of stronger connection. It can really help break down barriers and develop a more compassionate society.
Responsive Design for All Devices
Now, the array of devices used to access the internet is pretty wide. Most users anticipate a seamless and uniform experience across all their gadgets. Responsive design stands out as a top-notch strategy to fulfill this expectation. It ensures that webpages adjust to different screen sizes and meet the needs of different user groups. Below, we gathered some other pros it offers.
Flexibility
The primary goal of this approach is to create websites that are fluid and flexible. They should be capable of adjusting their layout and content. The content has to be clear, easy to navigate, and visually engaging on both a desktop monitor and a compact smartphone screen.
Cost-Efficiency
Previously, developers had to generate distinct site versions for different devices. However, the current approach is much faster and simpler. It involves a unified codebase capable of adjusting to diverse screen dimensions. This not only reduces development time and costs but also simplifies maintenance. Updates can be applied universally without the need for specific modifications.
Better SEO Performance
Search engines prioritize mobile-friendly pages in their rankings. Google, for instance, uses mobile-first indexing. This means it primarily considers the mobile version for indexing and ranking. This strategy confirms that your platform remains competitive in search engine results across all gadgets. When delving into adtech software development, ensuring mobile responsiveness is not just a matter of SEO but also a crucial aspect of delivering a seamless and effective user experience for your audience on various devices.
Consistent Branding and Messaging
Maintaining a uniform brand image is essential for all companies and organizations. Responsive design ensures that branding elements, messaging, and overall aesthetics remain consistent across appliances. This cohesiveness contributes to brand recognition and reinforces a unified identity.
Color Accessibility
Color has the influential ability to evoke emotions and express information effectively. Yet, in our pursuit of visually captivating designs, it’s vital to analyze the impact of color selections on accessibility. It should go beyond mere aesthetics. Make sure that individuals with visual impairments or color blindness can fully understand the content.
Approximately 1 in 12 men and 1 in 200 women experience some form of color blindness. When you design with accessibility in mind, it lets you transfer information properly to people with vision deficiencies. Try utilizing combinations that maintain sufficient contrast and choose distinct hues that improve the readability.
Web Content Accessibility Guidelines provide a set of standards for creating unrestricted materials. Contrast is a specific criterion outlined in these guidelines. It allows you to confirm that text and interactive elements are easily distinguishable. Adhering to WCAG not only supports inclusivity but also helps designers meet legal and regulatory requirements.
There are a few considerations regarding this approach you should take into account:
Ensure high contrast ratios;
Avoid color as the sole indicator;
Provide accessible palettes;
Supply alternative cues;
Test with accessibility tools.
Voice User Interface
Voice commands are another component of a more accessible virtual experience. They make it easier for those with mobility issues or disabilities to interact with interfaces. Also, they open the door to a more inclusive global audience by breaking down language barriers. People can interact with webpages and applications using their voice. It doesn’t depend on their proficiency in typing or reading in a particular language.
Their hands-free nature provides a great alternative for individuals who may have limited dexterity or prefer a hands-free browsing experience. Plus, this type of interface can become a lifesaver for someone with visual impairments. It supplies spoken feedback and allows users to navigate the page with the help of voice commands. This creates a sense of autonomy, as they don’t have to rely on someone else to comprehend the content.
Another great point is its contribution to a more natural and engaging background. People can interact with digital interfaces in a conversational manner. It creates a sense of a more intuitive and human-like exchange. This can lead to longer sessions, boosted user satisfaction, and a deeper connection with the platform.
Accessible Forms and Input Fields
Forms are a ubiquitous element of web design. To ensure a truly inclusive online background, designers must prioritize accessibility in the arrangement of forms and input fields.
Use a form builder that allows you to provide clear and concise labels for each field. Ensure that they are associated with their respective input fields programmatically. This helps screen reader users understand the purpose of each one of them. Establish a logical tab order to confirm that people can go through the form in a sequential and intuitive manner. A logical tab order is especially important for those who rely on keyboard navigation.
Don’t forget to implement descriptive and timely error messages. Clearly communicate any mistakes in a way that is both visually and programmatically perceivable. Utilize appropriate input types (e.g., email, phone, date) to trigger the correct keyboard on mobile devices and provide context.
Let people customize input assistance features, such as autocorrect and autocomplete, according to their preferences. It allows them to make this process more personalized and efficient. Always try to maintain proper contrast between text and background to aid users with low eyesight or vision deficiencies. Additionally, use visual cues, such as asterisks, to indicate required fields clearly.
Alt Texts and Descriptive Media
Alt texts, or alternative texts, provide a textual description of images. By incorporating these descriptions, designers ensure that individuals with eyesight limitations can access and understand the information. To make them functional, be concise and deliver context that mirrors the purpose of the image. Avoid generic phrases and instead focus on conveying the message or function of the picture.
For videos and podcasts, provide transcripts that detail the spoken materials. This caters to people who may have difficulty perceiving visual or auditory information. Also, extend accessibility to interactive elements by providing descriptive information. For example, make sure that buttons, links, and form fields are labeled appropriately. Choose visuals that enhance, rather than hinder, accessibility. When possible, use universal symbols and create materials that are easily comprehensible.
Conclusion
Technology continues to develop and designers are realizing the necessity of crafting virtual environments that meet the needs of diverse users. The web design trends, like color accessibility, Voice User Interface integration, and many others, make the internet more welcoming and user-friendly for everyone. By embracing these practices designers break down barriers and cultivate a more empathic and inclusive space. As these tendencies continue to evolve, the future holds the promise of a more universally accessible and equitable online experience. Make these points a priority and you’ll receive an opportunity to supply your services to a wider audience.