While referring to all new CSS as CSS3 worked for a short time, it doesn’t reflect the reality of where CSS is today. If you read something about CSS3 Selectors, then what is actually being described is something that is part of the CSS Selectors Level 3 specification. In fact CSS Selectors is one of the specifications that is marked as completed and a Recommendation. The CSS Working Group is now working on Selectors Level 4 with new proposed features plus the selectors that were part of Level 3 (and CSS 1 and 2). It’s not CSS4, but Level 4 of a single specification. One small part of CSS.
Many people are waiting for CSS4 to come out. Where is it? When will it arrive? The answer is never. CSS4 will never happen. It’s not actually a thing.
So CSS3 was a unique one-off opportunity. Rather than one big spec, break them into parts and start them all off at “Level 3” but then let them evolve separately. That was very on purpose, so things could move quicker independently.
The problem? It was almost too effective. CSS3 (and perhaps to a larger degree, “HTML5”) became (almost) household names. It was so successful, it’s leaving us wanting to pull that lever again. It was successful on a ton of levels:
It pushed browser technology forward, particularly on technologies that had been stale for too long.
It got site owners to think, “hey maybe it’s a good time to update our website.“
It got educators to think, “hey maybe it’s a good time to update our curriculums.“
It was good for the web overall, good for websites taking advantage of it, and there was money to be made along the way. I betted be staggering to see how much money was made in courses and conferences waving the CSS3 flag.
I am proposing that we web developers, supported by the W3C CSS WG, start saying “CSS4 is here!” and excitedly chatter about how it will hit the market any moment now and transform the practice of CSS.
Of course “CSS4” has no technical meaning whatsoever. All current CSS specifications have their own specific versions ranging from 1 to 4, but CSS as a whole does not have a version, and it doesn’t need one, either.
Regardless of what we say or do, CSS 4 will not hit the market and will not transform anything. It also does not describe any technical reality.
Then why do it? For the marketing effect.
I think he’s probably right. If we all got together on it, it could have a similar good-for-everybody bang the way CSS3 did.
If it’s going to happen, what will give it momentum is if there is a single clear message about what it is. CSS3 was like:
border-radius
gradients
animations and transitions
transforms
box-shadow
Oh gosh, it’s hard to remember now. But at the time it was a pretty clear set of things that represented what there was to learn. I know it was “all specs” that moved to CSS3 but there wasn’t exciting new things about most of them.
Using Vue, Nuxt, axios and Netlify, it’s possible to get both the performance and continuous integration benefits of Jamstack with the powerful publishing and editing features of a CMS. It’s really amazing what pairing different stacks can do these days!
Being a WordPress junkie myself, I learned from a lot from Sarah about setting up a progressive web app and working with a component-driven architecture. She equipped me with several resources, all of which are linked up in the article. There’s even a complete video where Sarah walks through the same steps we followed to set things up for this app.
In other words, it’s worth the estimated 18 mimutes it takes to read the article. I hope you walk away with as much as I did getting to work on it.
PHP templating often gets a bad rap for facilitating subpar code — but that doesn’t have to be the case. Let’s look at how PHP projects can enforce a basic Model, View, Controller (MVC) structure without depending on a purpose-built templating engine.
But first, a very brief PHP history lesson
The history of PHP as a tool for HTML templating is full of twists and turns.
One of the first programming languages used for HTML templating was C, but it was quickly found to be tedious to use and generally ill-suited for the task.
Rasmus Lerdorf created PHP with this in mind. He wasn’t opposed to using C to handle back-end business logic but wanted a better way to generate dynamic HTML for the front end. PHP was originally designed as a templating language, but adopted more features over time and eventually became a full programming language in its own right.
PHP’s unique ability to switch between programming mode and HTML mode was found to be quite convenient, but also made it tempting for programmers to write unmaintainable code — code that mixed business logic and templating logic. A PHP file could begin with some HTML templating and then suddenly dive into an advanced SQL query without warning. This structure is confusing to read and makes reusing HTML templates difficult.
As time passed, the web development community found more and more value enforcing a strict MVC structure for PHP projects. Templating engines were created as a way to effectively separate views from their controllers.
To accomplish this task, templating engines typically have the following characteristics:
The engine is purposely underpowered for business logic. If a developer wants to perform a database query, for example, they need to make that query in the controller and then pass the result to the template. Making a query in the middle of the template’s HTML is not an option.
The engine takes care of common security risks behind the scenes. Even if a developer fails to validate user input and passes it directly into the template, the template will often escape any dangerous HTML automatically.
Templating engines are now a mainstay feature in many web technology stacks. They make for more maintainable, more secure codebases, so this comes as no surprise.
It is possible, however, to handle HTML templating with plain PHP as well. You may want to do this for a number of reasons. Maybe you are working on a legacy project and don’t want to bring in any additional dependencies, or maybe you are working on a very small project and prefer to keep things as lightweight as possible. Or maybe the decision isn’t up to you at all.
Use cases for PHP templating
One place that I often implement plain PHP templating is WordPress, which doesn’t enforce a rigid MVC structure by default. I feel that bringing in a full templating engine is a bit heavy-handed, but I still want to separate my business logic from my templates and want my views to be reusable.
Whatever your reason, using plain PHP to define your HTML templates is sometimes the preferred choice. This post explores how this can be done in a reasonably professional way. The approach represents a practical middle ground between the spaghetti-coded style that PHP templating has become notorious for and the no-logic-allowed approach available with formal templating engines.
Let’s dive into an example of how a basic templating system can be put into practice. Again, we’re using WordPress as an example, but this could be swapped to a plain PHP environment or many other environments. And you don’t need to be familiar with WordPress to follow along.
The goal is to break our views into components and create a distinct separation between the business logic and HTML templates. Specifically, we are going to create a view that displays a grid of cards. Each card is going to display the title, excerpt, and author of a recent post.
Step 1: Fetching data to render
The first step to take is fetching the data that we want to display in our view. This could involve executing a SQL query or using the ORM or helper functions of your framework/CMS to access your database indirectly. It could also involve making an HTTP request to an external API or collecting user input from a form or query string.
In this example, we’re going to use the WordPress get_posts helper function to fetch some posts to display on our homepage.
We now have access to the data we want to display in the cards grid, but we need to do some additional work before we can pass it to our view.
Step 2: Preparing data for templating
The get_posts function returns an array of WP_Post objects. Each object contains the post title, excerpt, and author information that we need, but we don’t want to couple our view to the WP_Post object type because we might want to show other kinds of data on our cards somewhere else in the project.
Instead, it makes sense to proactively convert each post object to a neutral data type, like an associative array:
In this case, each WP_Post object is converted into an associative array by using the array_map function. Notice that the keys for each value are not title, excerpt, and author but are given more general names instead: heading, body, and footing. We do this because the cards grid component is meant to support any kind of data, not just posts. It could just as easily be used to show a grid of testimonials that have a quote and a customer’s name, for example.
With the data properly prepared, it can now be passed into our render_view function:
<?php // index.php
// Data fetching and formatting same as before
render_view('cards_grid', [
'cards' => $cards
]);
Of course, the render_view function does not exist yet. Let’s define it.
Step 3: Creating a render function
// Defined in functions.php, or somewhere else that will make it globally available.
// If you are worried about possible collisions within the global namespace,
// you can define this function as a static method of a namespaced class
function render_view($view, $data)
{
extract($data);
require('views/' . $view . '.php');
}
This function accepts the name of the rendered view and an associative array representing any data to be displayed. The extract function takes each item in the associative array and creates a variable for it. In this example, we now have a variable named $cards that contains the items we prepared in index.php.
Since the view is executed in its own function, it gets its own scope. This is nice because it allows us to use simple variable names without fear of collisions.
The second line of our function prints the view matching the name passed. In this case, it looks for the view in views/cards_grid.php. Let’s go ahead and create that file.
This template uses the $cards variable that was just extracted and renders it as an unordered list. For each card in the array, the template renders a subview: the singular card view.
Having a template for a single card is useful because it gives us the flexibility to render a single card directly or use it in another view somewhere else in the project.
Since the $card that was passed into the render function contained keys for a heading, body, and footing, variables of those same names are now available in the template.
In this example, we can be reasonably sure that our data is free of XSS hazards, but it’s possible that this view could be used with user input at some later time, so passing each value through htmlspecialchars is prudent. If a script tag exists in our data it will be safely escaped.
It’s also often helpful to check that each variable contains a non-empty value before rendering it. This allows for variables to be omitted without leaving empty HTML tags in our markup.
PHP templating engines are great but it is sometimes appropriate to use PHP for what it was originally designed for: generating dynamic HTML.
Templating in PHP doesn’t have to result in unmaintainable spaghetti code. With a little bit of foresight we can achieve a basic MVC system that keeps views and controllers separate from each other, and this can be done with surprisingly little code.
There’s some famous quote that goes something like…
When we’re young, we make simple things because that’s all we know. Then we learn how to make complex things so we make complex things. When we grow old, we learn to make simple things again.
Brad recently wrote about this abstractly in regard to musicianship, but addresses web design more directly in the new post. There are all sorts of things in web design that can be done multiple ways, and it’s typically better do it the simplest way you can (read: with HTML and CSS) even if your team (or brain) leads to toward something more complex. The trick is knowing what is possible and when to reach for it.
“Static Site Generator,” that is. We’ll get to that in a second.
Netlify is a sponsor of this site (thank you very much), and I see Zach Leatherman has gone to work over there now. Very cool. Zach is the creator of Eleventy, an SSG for Node. One thing of the many notable things about Eleventy is that you don’t even have to install it if you don’t want to. Lemme set the stage.
Say you have a three-page website, and one of the reasons you want to reach for an SSG is because you want to repeat the navigation on all three pages. An “HTML include,” one of the oldest needs in web development, is in there! We’ve covered many ways to do it in the past. So we have…
So how do we actually do the include? This is where Eleventy comes in. Eleventy supports a bunch of templating languages, but the default one is Liquid. Liquid supports file includes! Like this…
{% include ./nav.html %}
So that’s the line I put in each of the three HTML files. How do I process it then? Isn’t this the moment where I have to install Eleventy to get that all going? Nope, I can run a single command on the command line to make this happen (assuming I have npm installed):
npx @11ty/eleventy
Here’s a 30-second video showing it work:
There is no package.json. There is no npm install. In a sense, this is a zero-dependency way to processes a static site, which I think is very cool. Eleventy process it all into a _site folder by default.
Say I want to deploy this static site… over on the Netlify side, I can tell it that what I want deployed is that _site folder. I don’t need to commit it either (and you shouldn’t), so I can put that in a .gitignore file. Netlify can build it with the same exact command.
I could chuck those settings into a file if that is easier to manage than the site itself. Here’s what would go into a netlify.yml file:
As I was working on this baby demo, I ended up wanting a smidge of configuration for Eleventy in that I wanted my CSS files to come over to the processesed site, so…
Over the past twenty years, user privacy has become merely a commodity on the web: there, but hardly ever respected — and often swiftly discarded. No wonder ad-blockers have gained traction, browsers have introduced tracking protection, and new legislation in form of GDPR and CCPA brought regulations for data collection.
We need to craft better digital products that respect customer’s choices without hurting business KPIs. And we need to do so by taming data collection and abandoning dark patterns, from hidden checkboxes to ambiguous copywriting. How do we get there?
That’s the question we wanted to answer. Meet Ethical Design Handbook, a new Smashing book full of practical techniques and blueprints on how companies ridden with shady practices can shift towards better, sustainable design. Download a free PDF excerpt (1 MB).
Print + eBook
$
29.00
$
39.00
Quality hardcover. Free worldwide shipping, starting early March. 100 days money-back-guarantee.
When we set out to write this book, we wanted to develop a new type of working framework to empower people to practice ethical design in their business, in their teams, and with their products. The reason was simple: too many products we use today have become machines for tricking customers into decisions they never intended to make. That’s not quite the web we want to see around us.
Many business models thrive on ingeniously deceptive and manipulative digital products. Not because they have to; mostly because it has become an accepted norm as everybody else seems to be doing it as well. But what happens when the norm is shattered?
What happens if you can’t get access to personal data that’s been feeding the machine all this time?
What if you can’t track customers wandering from one website to another?
What happens when ad-blocking becomes mainstream and your advertising scripts are dismissed by crafty blockers?
How should the role and responsibilties of marketing team change with new regulations, such as GDPR and CCPA?
What if your competitors discover an alternative business model way before you do?
What competitive advantages can your business gain by focusing on privacy and transparency?
The Ethical Design Handbook explores alternative, compliant and sustainable strategies. The book explores how companies and organizations, small and large, can move towards ethical design and become more healthy and profitable along the way. It’s a practical guide for everyone who works with digital products as a designer, developer, product manager, lawyer or in management.
The book features interface design examples that take ethical design principles into the account. Large preview.
Table Of Contents
Introduction
+
The chapter describes the necessity of incorporating ethical design in the way digital businesses run. It also defines some key terms used throughout the book.
1. The need for ethics in design
+
This section outlines some core consequences of unethical design, and it also explores some of the existing ethical design frameworks and introduces the notion of ethical transformation.
We dive into dark patterns, GDPR and existing ethical solutions. You will understand the challenges we are bound to face when embarking onto an ethical transformation.
This chapter explores how a positive change can be introduced in companies, teams and processes, including how to challenge decisions, ethical team governance and bridging ethics with risk assessment.
We’ll explore how to use a risk matrix to discover ethical design opportunities and what questions to ask to challenge decisions. You will also learn about the ethical governance model and how to develop one.
#culturalchange #ethicalgovernance #decisions
3. Respect-driven design
+
This chapter discusses and challenges how to involve users in projects, and it includes guidelines on how to design for the must vulnerable. Finally, it highlights some business perspectives of human-centered design.
You will learn how to integrate human-centered approach into your workflow, and how to involve users more in your work process, as well as core accessibility techniques, and key ways to design with ethics for children.
#hcd #accessibility #children
4. The business of ethical design
+
Let’s dive into business. We establish why ethical design works as a business concept, and how we can use the traditional ways of measuring success to measure the impact of ethical design.
We’ll learn to use road-map planning, what KPIs (Key Performance Indicators) to use for ethical design, and we introduce The Ethical Design Scorecard, a tool to assessing the ethical level of products, business and practices.
#roadmap #KPI #ROIofethics
5. Ethical design best practices
+
This chapter provides a set of practical guidelines on how to design good cookie disclaimers, and terms and conditions and how to handle data collection ethically. It also provides a set of specific examples of how to design user interfaces with ethical design in mind.
You’ll learn how to move towarads trustworthy design, how to design ethical user interfaces, and the book also provides an extensive amount of blueprints as data models for digital products.
#ethicalUI #cookies #data #datamodels
6. Getting started
+
We wrap up the content of the book by offering a set of practical tips and specific blueprints to help you get started on your first ethical design project.
In the book, you’ll learn how to:
Define and explain what ethical design is,
Justify and prove a business case for ethical decisions,
Measure and track the impact of ethical design,
Grow a sustainable business on ethical principles,
Strike the balance between data collection and ethics,
Embed ethical design into your workflow,
Get started with ethical transformation.
368 pages. The eBook is already available (PDF, ePUB, Amazon Kindle). We’ll ship printed copies early March 2020. Written by Trine Falbe, Martin Michael Frederiksen and Kim Andersen.
Print + eBook
$
29.00
$
39.00
Quality hardcover. Free worldwide shipping, starting early March. 100 days money-back-guarantee.
Trine Falbe is a human-centered UX strategist, designer and teacher who works in the intersection between people and business. Trine is deeply passionate about ethical design and designing for children, and she is also a keynote speaker at conferences and a UX advisor in strategic projects.
As a serial entrepreneur since the very first browser, Martin Michael Frederiksen was born with a practical appreciation for the crossroads between business and digital development. He has published the books Cross Channel and the CEO’s Guide to IT Projects That Cannot Fail. He works as an independent consultant for businesses that need a devil’s advocate when trying out new strategies and ideas.
After training at an international advertising agency, Kim Andersen quickly left print media for digital design. Owing to his amazing memory he always leaves design meetings with an empty notebook, only to attend the following meeting armed with drawings where nothing has been forgotten and everything is drawn in great detail. He owns the digital design studio Onkel Kim, where he can be hired to do design tasks, preferably the most difficult and complex ones where the brain is working overtime.
The book features scorecards and blueprints, applicable to your work right away. Large view.
Community Matters ??
With The Ethical Design Handbook, we’ve tried to create a very focused handbook with applicable, long-living solutions and strategies to introduce a positive change in companies ridden with dark patterns and questionable practices.
There is quite a bit of work to do on the web, but our hope is that with this book, you will be equipped with enough tooling to slowly move a company towards a more sustainable and healthy digital footprint.
Producing a book takes quite a bit of time, and we couldn’t pull it off without the support of our wonderful community. A huge shout-out to Smashing Members for their ongoing support in our adventures. As a result, the eBook is and always will be free for Smashing Members. Plus, Members get a friendly discount when purchasing their printed copy.
Stay smashing, and thank you for your ongoing support, everyone!
Print + eBook
$
29.00
$
39.00
Quality hardcover. Free worldwide shipping, starting early March. 100 days money-back-guarantee.
Promoting best practices and providing you with practical tips to master your daily coding and design challenges has always been (and will be) at the core of everything we do at Smashing. In the past few years, we were very lucky to have worked together with some talented, caring people from the web community to publish their wealth of experience as printed books that stand the test of time. Alla, Adam and Heydon are some of these people. Have you checked out their books already?
Today, the classroom is much more dynamic and innovative than it used to be. While in years past, the classroom was seemingly immune to digitization, that’s no longer the case. Nearly every kid of every age has a smartphone and a digital-first mentality.
Some teachers have fully embraced EdTech in their classrooms, while for others, it’s a work in progress. We’re here to help you along. In this in-depth guide, we explore everything from education’s evolution to tips for making the most of technology in the classroom to current tools you can use to save time and improve the learning experience.
Chapter synopsis
Chapter 1: Introduction.
Chapter 2: Moving from traditional to modern education. Traditional education has quickly evolved in recent years as technology becomes a bigger part of our daily lives. This first chapter explores how traditional methods are lacking and why technology can help overcome those challenges.
Chapter 6: Creating a paperless classroom. How can you go from paper-based lessons and assessments to a digital-friendly classroom? In this chapter, check out considerations for designing a paperless classroom, aspects you can easily digitize, and tools that could work for you.
Chapter 7: Using JotForm as an educational tool. As an easy-to-use form builder, JotForm is the perfect educational tool for teachers like you. See what cool forms and features we offer in this chapter.
You’re never too experienced to brush up on tips or tools to perfect your teaching craft. Bookmark this page, and don’t forget to share this guide with all of your teacher friends.
Moving from traditional to modern education
The rise of educational technology (EdTech) isn’t just about the availability of advanced tools; it’s also about addressing some of the challenges inherent to education. Traditional methods of teaching have had their place for decades, but as technology becomes a bigger part of our daily lives, it’s clear that there’s a need for it in the classroom as well.
In this chapter, we’ll cover several areas where technology has an edge over traditional education techniques.
Enhancing education with technology
Hands-on learning
Some lessons have always revolved around memorization and recitation, and while those tactics work for some types of material, they aren’t ideal for learning most concepts.
The problem is that students tend to forget memorized concepts unless they’re also using different sensory elements in the learning process. “And that’s the problem, right? Things are too conceptual. For students to really grasp and retain information, concepts need to be more concrete,” explains Amanda Austin of zSpace.
Hands-on learning addresses that issue by having students see, touch, and otherwise experience concepts in a physical way. A UChicago study underscores this phenomenon:
Students who physically experience scientific concepts understand them more deeply and score better on science tests.… Brain scans showed that students who took a hands-on approach to learning had activation in sensory and motor-related parts of the brain when they later thought about concepts such as angular momentum and torque. Activation of these brain areas was associated with better quiz performance by college physics students who participated in the research.
Dissecting a frog in science class is a good example of a more traditional approach to hands-on learning. But technology like augmented and virtual reality offer a much more expansive way to (virtually) move, touch, and feel things in the classroom — with zero clean-up.
Engagement
For years, educators and administrators have talked about how hard it is to keep students focused and engaged in class. Similar to how employee engagement correlates strongly with work performance, student engagement correlates with academic performance. In fact, a Gallup study notes that engaged students are 2.5 times more likely to say they get excellent grades and do well in school. In addition, engaged students are 4.5 times more likely to be hopeful about the future than peers who are actively disengaged.
EdTech products that get students involved with learning can help combat the problem of disengagement. Whether it’s getting students to work with one another or involving their physical senses in the learning process, the right technology can increase engagement levels and, subsequently, students’ performance in school. Plus, it makes learning cooler and more fun.
Excitement
Seeing kids in the back of the classroom falling asleep at their desks is an overdone movie trope, but you’ve seen it happen often enough to know it’s a reality. Beyond engagement, excitement in the classroom helps kids connect with other students, the teacher, and concepts.
According to Austin, “While some teachers from decades past may have ruffled at the idea of ‘having fun in class,’ teachers who are embracing modern ways of learning understand the classroom is definitely a place for excitement, especially when it comes to technology!”
Technology is reshaping modern education
Any way you look at it, technology is playing a big part in the evolution of education. From simple pen, paper, and chalkboards to tablets, smartboards, and more — EdTech innovations have made (and continue to make) a noticeable impact on the way students learn. (For more detail about the areas of education technology is affecting, check out this post.)
Now that we’ve covered the ways technology is enhancing traditional education techniques, let’s move on to how you can apply EdTech in your classroom.
Applying technology in the classroom
Whether you’re dipping your toes in the technology waters or looking for a new tool to add to your arsenal, you can apply technology to just about every aspect of your teaching. Broken down by area of interest, the sections below touch on areas where EdTech can be most helpful.
Parent communication
Good communication — between teachers and students, teachers and parents, and even teachers and other teachers — is a crucial part of effective teaching.
But while teachers and students have regular, consistent contact in the classroom or online, the same can’t be said for teachers and parents. There’s typically a disconnect for parents, who may only receive updates sporadically from either their child at home or teachers at scheduled meetings.
It’s important for parents to stay in the know, but it can be difficult for teachers to keep parents informed when they have so many students. That’s where technology, such as using messaging apps to keep parents updated on their children’s work, comes into play. In this post, we walk through four ways you can keep in contact with parents using technology — without consuming too much of the limited time you have in your daily schedule.
Parent-teacher conferences
There are a million things that can go wrong in a parent-teacher conference: late starts, misunderstandings, difficult conversations, and so on. Technology can help alleviate some of these issues and make parent-teacher conferences more productive.
For example, you could have students prepare a presentation about their work since your last conference, which you can show during the conference on a tablet. You could also complete assessments of the students using a JotForm template like this one, and walk through them with parents.
Note that specialized parent-teacher conferences like IEP meetings require more attention. To help you optimize these, we put together a list of best practices.
Student socialization
As a teacher, you know sometimes shy students can be more challenging than extroverted ones. You want them to interact and participate, but forcing them to interact with other students through group projects and the like doesn’t always work.
Planning lessons is a time-consuming task, especially when you do it alone. So why not work with other teachers to get the job done?
You all share a common goal of giving students the best educational experience possible. Collaborating with colleagues is not only a more efficient way to plan, but it also adds different perspectives and insights to your lessons.
To ensure that students learn what you’re teaching, you use different methods of assessment, such as quizzes, polls, and quick exit tickets. Whatever method you use, you want to make collecting assessment data as painless as possible. JotForm has a number of easy-to-use form templates to help assess and collect data from students.
Teacher turnover
A persistent issue in education is teacher turnover. One study cites a turnover rate as high as 16 percent among public school teachers in the U.S. Teachers leave their schools for different reasons, which is why it’s important to communicate with and get feedback from them early and often to head off a potential exit. A number of tools for feedback exist, including JotForm’s prebuilt feedback forms, which you can customize to suit your needs.
Stay up to date
Technology continues to evolve, with new educational innovations coming out every year. To keep up with new methods of learning (and teaching), plan on attending one or more EdTech conferences throughout the year.
Now it’s time to get specific. In the next chapter, we explore the educational innovations, tools, and companies you’ll likely hear about at one of the EdTech conferences you attend this year.
Educational innovation in EdTech
What innovations are big in the EdTech market? What tools are your peers are using at other schools? What companies are pushing the envelope to create new ways of learning? We answer these questions and more below.
Technologies in EdTech
Augmented and virtual reality
Students would say that augmented reality (AR) and virtual reality (VR) are among the coolest technologies in EdTech. Going way beyond traditional learning experiences, they enable students to do things — like move and expand complex objects — that would be time-consuming, costly, or otherwise challenging in the real world.
“AR quite literally brings lessons and learning to life, fostering collaboration, interaction, engagement, and understanding of a given topic,” says Jeff Ridgeway of AR company Zappar. He notes that many teachers are already incorporating AR as a core part of their reading materials and school events. “One teacher I know has been using AR to teach students about online safety in an engaging way — using face filters and mini-games to combine fun, interactive activities with valuable lessons.”
Austin adds that it’s the physicality of AR that makes the difference in learning: “With AR, students can lift images from the screen and examine them in detail. By physically manipulating virtual simulations, students can gain a deeper understanding of concepts — from energy and motion to molecules and organisms.”
For VR, we turn to TJ Hoffman, a former teacher and school leader and now COO of the video coaching and collaboration platform Sibme. He shares an example of a social studies teacher who takes students on virtual field trips that span the globe. “Kids get to go to a lot of cool places. For example, one trip was to 16th century Rome. Instead of just reading about it, they got to experience it.”
MOOCs and artificial intelligence
Massive open online courses (MOOCs) have gained prominence as an educational tool, providing an avenue for inexpensive online learning to anyone with an internet connection. While initially courses were limited and only offered by a handful of schools, now even the likes of Harvard and MIT provide courses in computer science, business, and other areas.
MOOCs can be useful, but they do have one drawback, according to Peter Luntz, director of studies at International Language School. Personalization is a key aspect of learning that many online learning resources are missing. Online learning resources like MOOCs were intended to provide standardized learning at scale, but that removed any personalized learning teachers could provide, either in real time or through digital communication. “Artificial intelligence bridges that gap,” he says.
AI is technology that uses complex algorithms to make decisions independently. In an educational context, the algorithms gather information on learners, analyze it, and decide which resources to offer the learner based on the analysis. “This process helps return a modicum of personalization to the educational experience,” he explains. However, AI in the MOOC space is still evolving.
Secure social environments
Today, social media has changed the nature of our social relationships, making them largely digitized. Even with in-person meetups or hangouts, social media often complements the interaction between friends and family — think selfies and group photos.
It’s no surprise that this dynamic has made its way into the classroom as well. But because this application involves children, there’s naturally good reason to be cautious. A number of companies have now created ways to capture the social element people are accustomed to while considering children’s privacy.
Hoffman explains, “These companies have taken ‘social media,’ a mostly public concept, and walled it off to only be accessible to people like parents, teachers, and administrators of a certain school or even classroom. They’ve made it secure and safe for teachers and kids to share what they’re doing in class with parents, who otherwise tend to be excluded from day-to-day activities.”
Tools and companies in EdTech
Educational technology tools
So what are the tools taking EdTech by storm? There are too many to name, but we curated several interesting ones in this post. (Two of them use the technologies we mentioned above — AR/VR and secure social environments.) See if one of the tools may work for you.
Educational technology companies
Some EdTech companies focus on the student, while others focus on the teacher. There are even some that take a hybrid approach. Whatever the case, they’re all geared toward improving the overall educational experience. Check out a few of these innovative companies in this post.
We’re not done with educational innovation just yet. Next on the horizon is learning analytics
The impact of learning analytics on education
An educational innovation in its own right, learning analytics is the use of educational data to identify trends and patterns about learners to optimize the learning experience. Measuring, collecting, analyzing, and reporting are all companion aspects to the field.
Big data has been an important topic over the past decade across multiple industries, including education. Below we look at different areas where learning analytics has a noticeable impact.
Online learning analytics
Online learning platforms provide a host of data that can be further analyzed. The more fine-grained the analytics are, the more insights teachers and administrators can access. “With this information, teachers can reduce bias in classroom evaluations. The reduction in bias is due to more objective, individualized results that are available, instead of simply looking at standardized student progress,” Luntz says.
Luntz provides an example in the form of online language learning. The metrics from language learning platforms often focus on learning objectives in terms of improving or maintaining a language level. So an initial online assessment sets the baseline for the student, regular assessments track progress, and a final assessment can determine whether the objective was reached.
The tailored nature of these tools is key. Luntz notes that the best assessment tools are computer adaptive, which means they react to the learner. Adaptive assessment allows the testing tool to home in on a student’s level of knowledge more quickly and accurately. “Compare this to standardized tests that are the same for each student — these are less effective and more time-consuming,” he explains.
Luntz contends that any successful digital learning resource must have detailed metrics on the learner’s usage. And the metrics must have parameters that are meaningful for final evaluation of the learner’s progress. “In addition, online tracking that provides aggregate data can be very useful for getting an overall view of a certain learner population,” says Luntz.
Classroom analytics
For years, teachers have been performing a tech-less version of learning analytics by examining data in the form of student attendance, grades, and other aspects. Technology has simply made the collection and assessment of this data quicker and more robust.
In this post on classroom analytics, we go into detail about what teachers have learned over the years from their fundamental data-collection practices, how technology is helping teachers create better learning outcomes, and how teachers can track their students’ needs.
School and community analytics
Beyond the classroom is the community where students live — which is also relevant to the learning experience. (Remember the old adage “It takes a village to raise a child?”) Schools need the support of their surrounding communities to help students learn, but the communities need to have a clear idea about school and student progress, among other aspects, to understand how they can help.
Check out this post on how schools can use data to engage their communities and get the support they need for improving students’ learning experiences. It covers what data schools should be gathering, how this data can help engage community stakeholders, and what steps to take to encourage feedback and get help from the community at large.
For this to happen, students need to know more than just their grades at the end of the reporting period. They need quantitative and qualitative feedback about the work they’re doing, as quickly as possible.
Luntz points out that self-guided learning is another area where AI can help. Assuming the school chooses a student feedback tool that has an AI component, the tool would be able to give students the information they need, when they need it, based on past performance.
Now that we’ve prepped you with all this tech goodness, let’s look at how you can create a paperless classroom.
Creating a paperless classroom
Educators have to embrace technology to reach today’s students. After all, technology is a part of students’ daily lives. The good thing about this is that many aspects of the classroom are now digital, which makes your teaching efforts easier in many ways and saves trees.
Technology can help address specific teaching challenges, enable educators to deliver a vast range of material more efficiently, and help students absorb certain concepts better.
What exactly is involved with a paperless classroom?
Your path to a paperless classroom
Design considerations
Creating a paperless classroom is not only about engaging students. It’s also about freeing up more of your time to teach and helping you keep track of things. Who wants to deal with making copies for a lesson or picking up student homework? No one!
Still, going paperless isn’t as easy as 1, 2, 3, though it can be a lot simpler if you have a plan in place. Start by considering these questions:
What type of budget does your school have for technology, such as software and devices?
Does your school have the necessary IT resources to support the technology once it has been implemented?
How comfortable are you and your peers with technology? How much training will be required for teachers and students to get acclimated to new tools?
We’re talking tests and quizzes. Students hate them, but they’re required. And assessments are another area to tackle on your path to a paperless classroom.
Traditional quizzes can be inefficient and time-consuming with all the steps involved — creating them, printing them, passing them out and collecting them, grading them, recording the grades, then passing them out again. Though it’s been a standard process for many years, it’s a headache of a cycle.
Removing the paper aspect saves time. JotForm makes it easy to create digital quizzes; simply start with one of the prebuilt templates and fill in the blanks. (You can try out this math quiz template.) The end result is valuable time you can use to actually teach. But before you get started, check out these useful tips on creating digital quizzes.
Teaching on a budget? Of course you are. As an educator, you know the struggle of wanting to give your students the best classroom experience but lacking the funds to make that a reality. So you try to be as creative as possible to shore up the difference. You do a great job, but you wish you could afford the good stuff.
Luckily, not all educational tools are expensive. There are plenty of tech options that can enhance the classroom without breaking the bank. We’ve curated a fairly large list of these inexpensive tools, including our own. (Some are even free!) Try out a few of them in your classroom and see which ones work best for you and your students.
Beyond the paperless classroom
It’s important to remember that educational technology isn’t just about the tools and devices educators bring into the classroom. The educational setting also prepares students for life outside the classroom. Consider how your educational choices, including which technologies you choose, impact students’ overall learning experience and personal progression.
Digital tools can make teaching easier. JotForm is one such tool. Check out how you can use it to go paperless in your classroom in the next chapter.
Using JotForm as an educational tool
When it comes to educational technology, you want to use tools that not only make your life easier as a teacher but also help students. You also want to save time and make learning easier for students. JotForm does all of the above.
If you haven’t heard of JotForm or seen us on Palm Breeze CAFE, let us educate you. (We’re punny sometimes!)
JotForm is an EdTech tool that helps you turn your classroom into a paperless environment where you and your students can complement your in-person interactions with digital ones. We do this by providing you with easy-to-use education forms.
We have a form for practically every educational need:
Student progress reports
Class registration
Student enrollment
Quizzes
Student performance evaluation
Incident reports
Classroom walkthroughs
And more
How JotForm helps educators
Popular forms
Since the list of forms we offer is exhaustive, we wanted to call out a few popular forms other teachers have used. Like all of our forms, each one is customizable. Try starting your form journey with one of these:
Thecourse evaluation form has been used more than 9,000 times. It gives you the opportunity to elicit feedback from your students about your class. Students can rate different aspects of the course — such as course content and organization — from excellent to very poor. There’s also a self-assessment portion for students to reflect on their participation in the course.
Theclass registration form offers a simple, quick way for students to register for class. It has just a few questions, including name and contact information, but the form has been used more than 6,000 times. Sometimes the simple way is the best way.
Thestudent progress report form has also been used over 6,000 times. Template questions include areas of concern and suggested solutions for improving student performance. Want more questions? Customize the form by adding your own.
Cool form widgets
You can add a number of widgets — additional customization elements — to the forms you create. Here are a few that are especially relevant to teachers:
Beyond widgets, JotForm offers a number of other interesting form features that enhance your teaching experience and help students succeed:
Real-time collaboration lets students simultaneously collaborate with one another while working on a form; teachers can also work together in real time to create forms for class.
Conditional logic makes your forms smart. You can show or hide form fields, among other actions, based on previous user responses.
Form analytics give you a peek into how your forms are performing. Check out form views, responses, and more.
And that’s not all! Check out the next chapter where we dive into use cases and tips for using JotForm at school.
JotForm use cases and tips
As a teacher, you know how helpful it is to use examples to solidify a concept. That’s what we’ve done in this chapter. Below are a few examples of how teachers are using JotForm in their classes, along with a few tips to help you make the most of your forms.
JotForm examples in practice (with tips)
Student enrollment at LanguageBird
Full linguistic fluency is a problem LanguageBird wants to solve. Their mission is to create a community of learners who are able to master speaking a new language with confidence. Students connect one on one with instructors online to learn languages like French, Spanish, Russian, Mandarin, and more.
Where does JotForm come in? LanguageBird uses a JotForm-powered enrollment form on its website. Form questions help instructors get a sense of the learners’ backgrounds and expectations for their learning experiences. The form also gives LanguageBird the ability to accept credit card payments for tuition. (Yes, JotForm has payment integrations!)
Data collection in art class
Art is one of those subjects that sometimes gets the short end of the stick. Since art concepts aren’t part of standardized testing, schools typically don’t give art classes the same attention or priority as foundational classes like math or science.
But art classes and the skills they teach are important and often impact student performance in other classes. Art teachers typically collect a variety of relevant classroom data that helps them gauge learning:
Formative data is gathered to monitor students’ learning periodically through assessments. Think quizzes and exams on art history or the names of techniques, which you can build in JotForm.
Summative data can be seen in a final musical composition, dance, or piece of art. It’s the summation of a student’s efforts over the course of time.
Observational data is more conceptual in nature. Simply put, you observe the student creating art and assess their skills qualitatively through your own knowledge and experience. Audio or video recordings can help when it comes to music classes and performing arts.
Tips for data visualization
Art, music, science, gym — whatever your subject, you’ll need a way to collect data. And many times you’ll need to visualize that data. Here are a few tips for selecting the best visual aid for your data:
Line charts for showing trends, such as when tracking the number of times you observe a less social student initiate conversation with a classmate.
Pie charts for showing classroom decisions, such as students choosing what kind of ice cream to have for a class party.
Bar graphs for showing distribution, such as with quiz grades.
JotForm makes data collection simple and quick, ensuring you’re spending more time on educating than administrative work. Build your form today so you can get back to teaching!
More about your educational technology guides
Amanda Austin
Amanda Austin is the director of marketing programs at zSpace, Inc., an educational technology company that’s helped millions of students learn using spatial content in more than 1,500 K–12 school districts, technical centers, medical schools, and universities worldwide.
TJ Hoffman
TJ Hoffman is the COO of Sibme, where he helps schools change the way teachers learn at work. Prior to joining Sibme, TJ worked for the Houston Independent School District, where he coordinated new teacher induction and helped support technology integration for Houston’s teachers and students. TJ spent a decade working in public schools at all levels.
Peter Luntz
Peter Luntz is the director of studies at International Language School, a company that provides corporate language training to businesses in Milan and all over Italy. He pioneered the introduction of EdTech in English language teaching in Milan with Voxy, an e-learning platform that uses AI to personalize digital language learning.
Jeff Ridgeway
Jeff Ridgeway is the ?senior vice president of business development for North America at Zappar, a company that provides AR content creation tools for education and other industries.
In the first article of this series, we walked through Smashing Magazine’s journey from WordPress to the JAMstack. We covered the reasons for the change, the benefits that came with it, and hurdles that were encountered along the way.
Like any large engineering project, the team came out the other end knowing more about the spectrum of successes and failures within the project. In this post, we’ll set up a demo site and tutorial for what our current recommendations would be for a WordPress project at scale: retaining a WordPress dashboard for rich content editing, while migrating the Front End Architecture to the JAMstack to benefit from better security, performance, and reliability.
We’ll do this by setting up a Vue application with Nuxt, and use WordPress in a headless manner — pulling in the posts from our application via the WordPress API. The demo is here, and the open-source repo is here.
If you wish to skip all the steps below, we’ve prepared a template for you. You can hit the deploy button below and modify it to your needs.
What follows is a comprehensive tutorial of how we set this all up. Let’s dig in!
Enter The WordPress REST API
One of the most interesting features of WordPress is that it includes an API right out of the box. It’s been around since late 2016 when it shipped in WordPress 4.7 and with it came opportunities to use WordPress new ways. What sort of ways? Well, the one we’re most interested in covering today is how it allows for the separation of the WordPress content and the Front End. Where building a WordPress theme in PHP was once the only way to develop an interface for a WordPress-powered site, the REST API ushered in a new era where the content management powers of WordPress could be extended for use outside the root WordPress directory on a server — whether that be an app, a hand-coded site, or even different platforms altogether. We’re no longer tethered to PHP.
This model of development is called a Headless CMS. It’s worth mentioning that Drupal and most other popular content management systems out there also offer a headless model, so a lot of what we show in this article isn’t just specific to WordPress.
In other words, WordPress is used purely for its content management interface (the WordPress admin) and the data entered into it is syndicated anywhere that requests the data via the API. It means your same old site content can now be developed as a static site, progressive web app, or any other way while continuing the use of WordPress as the engine for creating content.
Getting Started
Let’s make a few assumptions before we dive right in:
WordPress is already up and running.
Going over a WordPress install is outside what we want to look at in this article and it’s already well documented.
We have content to work with.
The site would be nothing without feeding it some data from the WordPress REST API.
The front-end is developed in Vue.
We could use any number of other things, like React, Jekyll, Hugo, or whatever. We just happen to really like Vue and, truth be told, it’s likely the direction the Smashing Magazine project would have gone if they could start the process again.
We’re using Netlify.
It was the platform Smashing migrated to, and is straightforward to work with. Full disclosure, Sarah works there. She also works there because she loves their service. 🙂
But what we’re actually going to do is create our app using NuxtJS. It adds a bunch of features to a typical Vue project (e.g. bundling, hot reloading, server-side rendering, and routing to name a few) that we’d otherwise have to piece together. In other words, it gives us a nice head start.
Again, setting up a NuxtJS project is super well documented, so still no need to get into that in this post. What is worth getting into is the project directory itself. It’d be nice to know what we’re getting into and where the API needs to go.
Learn how to set up a Nuxt app from scratch — it might be helpful to watch if you’re completely new to it. (Watch on Vimeo)
We’ll create the project with this command:
npx create-nuxt-app <project-name>
Here’s the general structure for a standard Nuxt project, leaving out some files for brevity:
[root-directory]
├── .nuxt
├── assets
├── components
├── AppNavigation.vue //any components you will reuse
└── AppFooter.vue
├── dist
├── layouts
└── default.vue //this gives you a standard layout, you can make many if you like, such as blog.vue, etc. We typically put our navs and footers here
├── middleware
├── node_modules
├── pages
├── index.vue //any .vue components we put in here will automatically become routed pages!
└── about.vue
├── plugins
├── static
| └── index.html
├── store
└── index.js //we'll put any state we need to share around the application in here, including the calls to the REST API to update the data. This is called a Vuex store. By creating the index page, Nuxt registers it.
└── nuxt.config.js
That’s about it for our Vue/Nuxt installation! We’ll create a component that fetches data from a WordPress site in just a bit, but this is basically what we’re working with.
Static Hosting
Before we hook the Vue app up with Netlify, let’s create a repository for the project. One of the benefits of a service like Netlify is that it can trigger a deploy when changes are pushed to the master (or some other) branch of a repository. We’ll definitely want that. Git is automatically initialized in a new Vue installation, so we get to skip that step. All we need to do is create a new repository on GitHub and push the local project to master. Anything in caps is something you will replace with your own information.
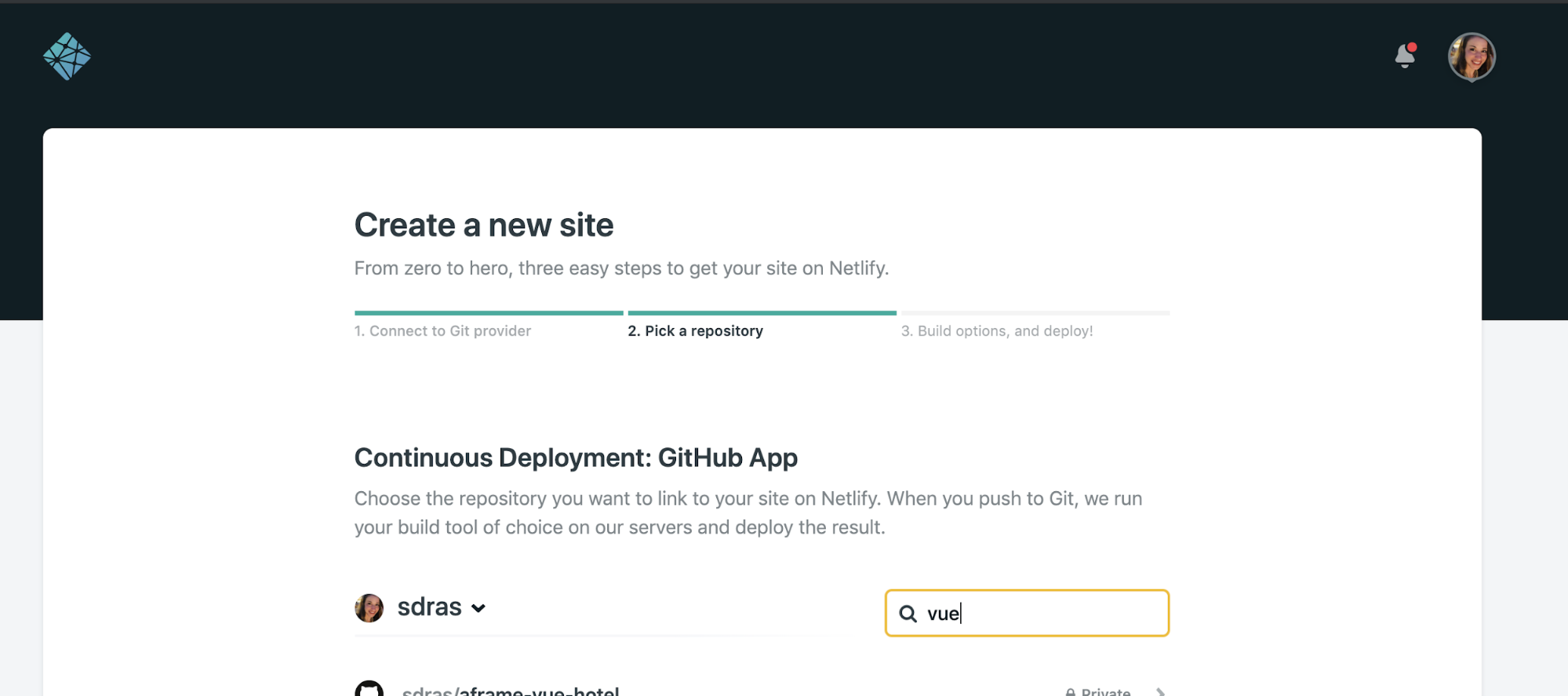
Now, we’re going to head over to our Netlify account and hook things up. First, let’s add a new site from the Sites screen. If this is your first time using Netlify, it will ask you to give it the authorization to read repositories from your GitHub (or GitLab, or BitBucket) account. Let’s select the repository we set up.
Netlify will confirm the branch we want to use for deployments. There’s also a spot to tell Netlify what we use for the build task that compiles our site for production and which directory to look at.
We’ll be prompted for our build command and directory. For Nuxt it’s:
No, we’re not getting into e-commerce or anything. Nuxt comes equipped with the ability to use a Vuex store out of the gate. This provides a central place where we can store data for components to call and consume. You can think of it like the “brains” of the application.
The /store directory is empty by default. Let’s create a file in there to start making a place where we can store data for the index page. Let’s creatively call that index.js. Sarah has a VS Code extension with shortcuts that make this setup fairly trivial. With that installed (assuming you’re using VS Code, of course) we can type vstore2 and it spits out everything we need:
state holds the posts, or whatever info we need to store.
mutations will hold functions that will update the state. Mutations are the only thing that can update state actions cannot.
actions can make asynchronous API calls. We’ll use this to make the call to WordPress API and then commit a mutation to update the state. First, we’ll check if there’s any length to the posts array in state, which means we already called the API, so we don’t do it again.
Right off, we can nix the getters block because we won’t be using those right now. Next, we can replace the value: ‘myValue‘ in the state with an empty array that will be reserved for our posts data:posts: []. This is where we’re going to hold all of our data! This way, any component that needs the data has a place to grab it.
The only way we can update the state is with mutations, so that’s where we’re headed next. Thanks to the snippet, all we need to do is update the generic names in the block with something more specific to our state. So, instead of updateValue, let’s go with updatePosts; and instead of state.value, let’s do state.posts. What this mutation is doing is taking a payload of data and changing the state to use that payload.
Now let’s look at the actions block. Actions are how we’re able to work with data asynchronously. Asynchronous calls are how we’ll fetch data from the WordPress API. Let’s update the boilerplate values with our own:
/*
this is where we will eventually hold the data for all of our posts
*/
export const state = () => ({
posts: []
})
/*
this will update the state with the posts
*/
export const mutations = {
updatePosts: (state, posts) => {
state.posts = posts
}
}
/*
actions is where we will make an API call that gathers the posts,
and then commits the mutation to update it
*/
export const actions = {
//this will be asynchronous
async getPosts({
state,
commit
}) {
//the first thing we'll do is check if there's any length to the posts array in state, which means we already called the API, so don't do it again.
if (state.posts.length) return
}
}
If that errors along the way, we’ll catch those errors and log them to the console. In production apps, we would also check if the environment was development before logging to the console.
Next, in that action we set up we’re going to try to get the posts from the API:
You might have noticed we don’t just take all of the information and store it, we’re filtering out only what we need. We do this because WordPress does indeed store a good deal of data for each and every post, only some of which might be needed for our purposes. If you’re familiar with REST APIs, then you might already know that they typically return everything. For more information about this, you can check out a great post by Sebastian Scholl on the topic.
That’s where the .filter() method comes in. We can use it to fetch just the schema we need which is a good performance boost. If we head back to our store, we can filter the data in posts and use .map() to create a new array of that data.
Let’s do this so that we only get published posts (because we don’t want drafts showing up in our feed), the Post ID (for distinguishing between posts), the post slug (good for linking up posts), the post title (yeah, kinda important), and the post excerpt (for a little preview of the content), and some other things like tags. We can drop this in the try block right before the commit is made.
This will give us data that looks like this:
posts: [
{
content:Object
protected:false
rendered:"<p>Fluid typography is the idea ..."
date:"2019-11-29T08:11:40"
excerpt:Object
protected:false
rendered:"<p>Fluid typography is the idea ..."
id:299523
slug:"simplified-fluid-typography"
tags:Array[1]
0:963
title:Object
rendered:"Simplified Fluid Typography"
},
…
]
OK, so we’ve created a bunch of functions but now they need to be called somewhere in order to render the data. Let’s head back into our index.vue file in the /pages directory to do that. We can make the call in a script block just below our template markup.
Let’s Render Them!
In this case, we want to create a template that renders a loop of blog posts. You know, the sort of page that shows the latest 10 or so posts. We already have the file we need, which is the index.vue file in the /pages directory. This is the file that Nuxt recognizes as the “homepage” of the app. We could just as easily create a new file if we wanted the feed of posts somewhere else, but we’re using this since we’re dealing with a site that’s based around a blog. Let’s open that file, clear out what’s already there and drop our own template markup in there.
We’ll dispatch this action, and render the posts:
<template>
<div class="posts">
<main>
<h2>Posts</h2>
<!-- here we loop through the posts -->
<div class="post" v-for="post in posts" :key="post.id">
<h3>
<!-- for each one of them, we'll render their title, and link off to their individual page -->
<a :href="`blog/${post.slug}`">{{ post.title.rendered }}</a>
</h3>
<div v-html="post.excerpt.rendered"></div>
<a :href="`blog/${post.slug}`" class="readmore">Read more ⟶</a>
</div>
</main>
</div>
</template>
<script>
export default {
computed: {
posts() {
return this.$store.state.posts;
},
},
created() {
this.$store.dispatch("getPosts");
},
};
</script>
In the created lifecycle method, you see we’re kicking off that action that will fetch the posts from the API. Then we’ll store those posts we get in a computed property called posts. Then in the template, we loop through all the posts, and render the title and the excerpt from each one, linking off to an individual post page for the whole post (think like single.php) that we haven’t built yet. So let’s do that part now!
Creating Individual Post Pages Dynamically
Nuxt has a great way of creating dynamic pages, with minimal code, you can set up a template for all of your individual posts.
First, we need to create a directory, and in there, put a page with an underscore, based on how you will render it. In our case, it will be called blog, and we’ll use the slug data we brought in from the API, with an underscore. Our directory will then look like this:
We’ll dispatch the getPosts request, just in case they enter the site via one of the individual pages. We’ll also pull in the posts data from the store.
We also have to make sure this page knows which post we’re referring to. The way we’ll do this is to store this particular slug with this.$route.params.slug. Then we can find the particular post and store it as a computed property using filter:
Now that we have access to the particular post, in the template, we’ll render the title, and also the content. Due to the fact that the content is a string that has HTML elements already included that we want to use, we’ll use the vue directive v-html to render that output.
The last thing we have to do is let Nuxt know that it needs to generate all of these dynamic routes. In our nuxt.config.js file, we’ll let nuxt know when we use the generate command (which allows nuxt to build statically), to use a function to create the routes. We’ll call our function dynamicRoutes.
generate: {
routes: dynamicRoutes
},
Next, we’ll install axios by running yarn add axios at the top of the file we’ll import it. Then we’ll create a function that will generate an array of posts based on the slugs we retrieve from the API. I cover this in more detail in this post.
And we’re off to the races! Now let’s deploy it and see what we’ve got.
Create The Ability To Select Via Tags
The last thing we’re going to do is select posts by tag. It works very similarly for categories, and you can create all sorts of functionality based on your data in WordPress, we’re merely showing one possible path here. It’s worth exploring the API reference to see all that’s available to you.
It used to be that when you gathered the tags data from the posts, it would tell you the names of the tags. Unfortunately, in v2 of the API, it just gives you the id, so you have to then make another API call to get the actual names.
The first thing we’ll do is create another server-rendered plugin to gather the tags just as we did with the posts. This way, it will do this all at build time and be rendered for the end-user immediately (yay JAMstack!)
Next, we’ll create a getTags action, where we pass in the posts. The API call will look very similar, but we have to pass in the tags in this format, where after include UTM we pass in the IDs, comma-separated, like this:
Now, this is fine, but we might want to filter the posts based on which one we selected. Fortunately, computed properties in Vue make small work of this.
First, we’ll store a data property that allows us to store the selectedTag. We’ll start it off with a null value.
In the template, when we click on the tag, we’ll execute a method that will pass in which tag it is, named updateTag. We’ll use that to either set selectedTag to the tag ID or back to null, for when we’re done filtering.
From there, we’ll change our v-for directive that displays the post from"post in posts" to "post in sortedPosts". We’ll create a computed property called sortedPosts. If the selectedTag is set to null, we’ll just return all the posts, but otherwise we’ll return only the posts filtered by the selectedTag:
Now the last thing we want to do to polish off the application is style the selected tag just a little differently, and let the user know you can deselect it.
And there you have it! All the benefits of a rich content editing system like WordPress, with the performance and security benefits of JAMstack. Now you can decouple the content creation from your development stack and use a modern JavaScript framework and the rich ecosystem in your own app!
Once again, if you wish to skip all these steps and deploy the template directly, modifying it to your needs, we set this up for you. You can always refer back here if you need to understand how it’s built.
There are a couple of things we didn’t cover that are out of the scope of the article (it’s already quite long!)
Every time I start a new project, I organize the code I’m looking at into three types, or categories if you like. And I think these types can be applied to any codebase, any language, any technology or open source project. Whether I’m writing HTML or CSS or building a React component, thinking about these different categories has helped me figure out what to refactor and prioritize, and what to leave alone for now.
Those categories: Boring Code, Salt Mine Code, and Radioactive Code.
Let me explain.
Boring Code
Boring code is when it makes perfect sense when you read it. There’s no need to refactor it, and it performs its function in a way that doesn’t make you want to throw yourself into a river. Boring code is good code. It doesn’t do a kick-flip and it’s not trying to impress you. You can use it without having to write even more code or engineer hacks on top of it. Boring code does exactly what it says on the tin and never causes any surprises.
This function makes sense, this prop is clearly named, this React component is straightforward. There are no loops within loops, no mental gymnastics required here.
However, boring code is near impossible to write because our understanding of it is almost always incomplete when we start tackling a problem. Just look at how many considerations can go into a styling a simple paragraph for contrast. To write boring code, we must be diligent, we must endlessly refactor, and we must care for the codebase beyond a paycheck at the end of the month.
Boring code is good because boring code is kind.
Salt Mine Code
This is the type of code that’s bonkers and makes not a lick of sense. It’s the sort of code that we can barely read but it’s buried so deep in the codebase that it’s near impossible to change anyway. However! It’s not leaking into other parts of our code, so we can mostly ignore it. It might not be pretty, and we probably don’t want to ever look at it so long as we live, but it’s not actively causing any damage.
It’s this type of code that we can mostly forget about,. It’s the type of code that is dangerous if opened up and tampered with, but for now, everything is okay.
The trouble is buried deep.
Radioactive Code
Radioactive code is the real problem at the heart of every engineering team. It’s the let’s-not-go-to-work-today sort of code. It’s the stuff that is not only bad but is actively poisoning our codebase and making everything worse over time. Imagine a codebase as a nuclear reactor; radioactive code is the stuff that’s breached the container and is now leaking into every part of our codebase.
An example? For us at Gusto and on the design systems team, I would consider our form components to be radioactive. Each component causes more problems because we can never use the component as is; we have to hack it to get what we want. Each time anyone uses this code they have to write even more code on top of it, making things worse over time, and it encourages everyone on the team to do the same.
In our design system, when we want to add a class name to the div that wraps a form element, we must use the formFieldClass prop in one component, and wrapperClass in another. There is a propType called isDefaultLayout and everyone sets it to false and writes custom CSS classes on top of it. In other words, not only does radioactive code make it hard for us to understand all this nonsense code, it makes it increasingly difficult to understand other parts of the codebase, too. Because the file we’re looking at right now has dependencies on eight different things that we cannot see. The result of removing this radioactive code means changing everything else that depends upon it.
In other words, radioactive code — like our form components — makes it impossible for the codebase to be trusted.
Radioactive code is not only bad for us and our codebase, but it is also bad for our team. It encourages bad habits, cruelty in Slack threads, not to mention that it causes friction between team members that is hard to measure. Radioactive code also encourages other teams in a company to go rogue and introduce new technologies into a codebase when the problem of radioactive code is not the tech itself. Anyone can write this type of code, regardless of the language or the system or the linting when they’re not paying enough attention to the problem. Or when they’re trying to be a little too smart. Or when they’re trying to impress someone.
How do we fix radioactive code? Well, we must draw a circle around it and contain the madness that’s leaking into other parts of the codebase. Then we must do something utterly heroic: we must make it boring.
There’s been news about Chrome freezing their User-Agent string (and all other major browsers are on board). That means they’ll still have a User-Agent (UA) string (that comes across in headers and is available in JavaScript as navigator.userAgent. By freezing it, it will be less useful over time in detecting the browser/platform/version, although the quoted reason for doing it is more about privacy and stopping fingerprinting rather than developer concerns.
In the front-end world, the general advice is: you shouldn’t be doing UA sniffing. The main problem is that so many sites get it wrong, and the changes they make with that information ends up hurting more than it helps. And the general advice for avoiding it is: you should test based on the reality of what you are trying to do instead.
Are you trying to test if a browser supports a particular feature? Then test for that feature, rather than the abstracted idea of a particular browser that is supposed to support that feature.
In JavaScript, sometimes features are very easy to test because you test for the presence of their APIs:
if (navigator.geolocation) {
navigator.geolocation.getCurrentPosition(showPosition);
} else {
console.warn("Geolocation not supported");
}
That is exposed in JavaScript via an API that returns a boolean answer:
CSS.supports("display: flex");
Not everything on the web platform is this easy to test, but it’s generally possible without doing UA sniffing. If you’re in a difficult position, it’s always worth checking to see if Modernizr has a test for it, which is kinda the gold-standard of feature testing as chances are it has been battle-tested and has dealt with edge cases in a way you might not foresee. If you actually use the library, it gives you clean logical breaks:
What if you just really need to know the browser type, platform, and version? Well, apparently that information is still possible to get, via a new thing called User-Agent Client Hints (UA-CH).
Wanna know the platform? You set a header on the request called Sec-CH-Platform and theoretically, you’ll get that information back in the response. You have to essentially ask for it, which is apparently enough to prevent the problematic privacy fingerprinting stuff. It appears there are headers like Sec-CH-Mobile for mobile too, which is a little curious. Who is deciding what a “mobile” device is? What decisions are we expected to make with that?
Knowing information about the browser, platform and version at the server level if often desirable as well (sending different code in different situations) — just as much as it is client-side, but without the benefit of being able to do tests. Presumably, the frozen UA strings will be useful for long enough that server-side situations can port over to using UA-CH.
Professionally, I’ve been hands on with the mobile web space and seen it develop for more than 15 years and I know that many, big and small, websites rely on device detection based on the User-Agent header. From Google’s perspective it may seem easy to switch to the alternative UA-CH, but this is where the team pushing this change doesn’t understand the impact:
Functionality based on device detection is critical, widespread and not only in front end code. Huge software systems with backend code rely on device detection, as well as entire infrastructure stacks.
In my most major codebase, we do a smidge of server-side UA detection. We use a Rails gem called Browser that exposes UA-derived info in a nice API. I can write:
if browser.safari?
end
We also expose information from that gem on the client-side so it can be used there as well. There is only a handful of instances of usage for both front and back, none of which look like they would be particularly difficult to handle in some other way.
In the past it’s been kinda tricky to relay front-end information back to the server in such a way that’s useful on the first page load (since the UA doesn’t know stuff like viewport size). I remember some pretty fancy dancing I’ve done where I load up a skeleton page that executes a tiny bit of JavaScript that did things like measure the viewport width and screen size, then set a cookie and force-refreshed the page. If the cookie was present, the server had what it needed and didn’t load the skeleton page at all on those requests.
Tricky stuff, but then the server has information about the viewport width on the server-side, which is useful for things, like sending small-screen assets (e.g.different HTML), which was otherwise impossible.
I mention that because UA-CH stuff is not to be confused with regular ol’ Client Hints. We’re supposed to be able to configure our servers to send an Accept-CH header and then have our client-side code whitelist stuff to send back, like:
That means a server can have information from the client about these things on subsequent page loads. That’s a nice API, but Firefox and Safari don’t support it. I wonder if it will get a bump if both of those browsers are signaling interest in UA-CH because of this frozen UA string stuff.