Why You Should Consider Graphs For Your Next GraphQL Project
This article is a sponsored by Neo4j
The explosion of GraphQL over the past few years has introduced many front-end developers to the concepts of data modeling and storage, turning front-end developers into full-stack developers.
GraphQL provides developers working on a simple contract with a database, guaranteeing consistency and predictability of the data returned while also managing persistence and data fetching. The developer trusts the API to store and retrieve the data most efficiently.
But convenience comes at a cost. One day, your side project hits the front page of Hacker News, and a sudden influx of users grinds your database to a halt. Sometimes, the remedy is as simple as using the right underlying database for the loads.
In this article, I will look at the Graph behind GraphQL and demonstrate why Neo4j is the best fit for your next project.
The Graph In GraphQL
GraphQL itself is a database-agnostic query language. Many database companies and startups now offer libraries that convert a GraphQL query or mutation into a query language that works with the underlying data store, whether that be SQL for relational databases, Cypher for graph databases, or any number of proprietary query languages.
Graphs provide a natural way to represent data, where Nodes (or vertices) that represent entities or things are connected together by Relationships (or edges). Depending on the underlying data storage in your GraphQL library of choice, a certain amount of gymnastics may be involved. Suddenly, unnatural tables with strange names are created, or data is duplicated to improve query response times, introducing technical debt along the way.
This is where Neo4j comes in. Neo4j is a native Graph Database. Graph Databases are in a category all of their own, and for a good reason.
Graph databases treat the connections between data as first-class citizens, storing relationships so that highly connected datasets can be queried in real-time.
An Example: Movie Recommendations
Say we’re sick of scrolling through an endless list of thumbnails on our favorite streaming platform looking for something to watch. We decided to build a new website where users can register, provide movie ratings, and in return, receive movie recommendations based on users who have similar ratings.
In our GraphQL schema, we define types that represent movie information. Users provide movie ratings, each with a score between 1 and 5. Movies can have one or more actors and one or more directors. Movies are also tagged with one or more genres.
Note: Luckily, this Recommendations dataset already exists as a free Neo4j Sandbox. Neo4j Sandbox instances are free of charge, initially run for three days, and can be extended up to 10 days.
type User {
userId: ID!
name: string
email: string
ratings: [Rating]
}
type Rating {
user: User!
movie: Movie!
rating: Int
createdAt: Date
}
type Movie {
movieId: ID!
title: String
released: Date
actors: [Role]
directors: [Person]
}
type Role {
person: Person!
movie: Movie!
roles: [String]
}
type Person {
personId: ID!
name: String!
born: Date!
roles: [Role]
directed: [Movie]
}
Let’s take a look at how this data will be stored in a relational database, a document store, and a graph and see where we might hit a problem when trying to generate recommendations.
In A Relational Database
Relational databases provide a structured method of data storage where data is organized into tables. Tables conform to strict rules known as a database schema, where each row contains a set number of columns, each with a set data type. Where a value may not exist, nullable columns can be used.
The underlying database schema provides a perfect base to map GraphQL Type Definitions. Each field within a type description will map one-to-one with a column. Those Type Definitions can be quickly translated into an SQL query (SQL stands for Structured Query Language) to insert or retrieve data.
A JOIN is constructed at read-time for nested types, joining two tables using foreign keys to find the corresponding records in a database. Here comes the first potential problem.
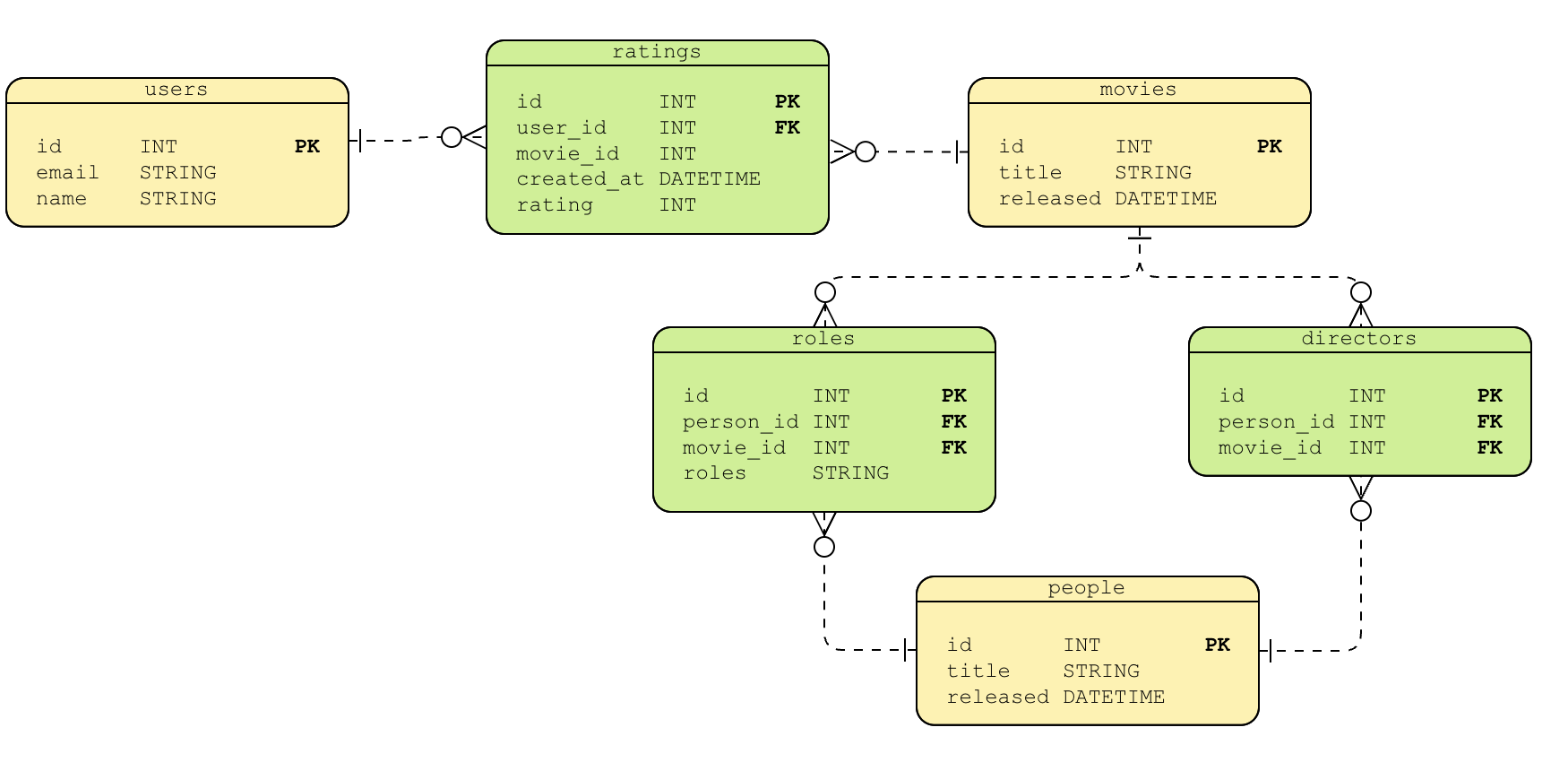
Let’s look at an Entity Relationship Diagram (ERD) that describes how the data may be stored in a relational database.
The tables highlighted in yellow represent the main entities in the data model: users, people, and movies. The tables highlighted in green represent the JOIN tables required to facilitate the many-to-many relationships between the entities.
There are two potential pitfalls here. First, let’s talk about naming. The example above is fairly straightforward, but say we have a many-to-many relationship in our data model between Products and Orders — an order may contain one or more products, and a product may appear in many orders. What do we call that table? order_products, order_line? This feels unnatural, and instantly you are adding tribal knowledge to the database, making it harder for others to understand.
When you use that table to find an actor for a particular movie, you start to hit the O(n) problem.
JOINs & The O(n) Problem
GraphQL is designed to be a flexible query language that allows you to retrieve an infinite level of nested values. The more nested items retrieved, the more joins are queried. Therefore the longer the query takes. Furthermore, the more data added to the database, the larger the underlying indexes become and the longer the query will take to return a result.
This is known as the Big O notation or O(n) notation — the number of computational resources required to compute the JOINs is relative to the size of the input data. The more data added to the database, the more data needs to be processed, and the slower the database will become.
Many relational databases support subqueries or window functions, but these must still be constructed in memory at query time, which can be an expensive operation.
This problem can be partially resolved by database tuning, partitioning, or denormalizing data to improve response times, at which point you’ll need to become a database expert.
In A Document Store
Document stores, such as MongoDB or CouchDB, differ from Relational databases in that they are designed to store unstructured or semi-structured data. Data is organized into collections, each of which consists of many documents. Each document in a collection represents a single record, which can have its own unique set of key-value pairs. This approach is more flexible than relational databases, but as the data is schema-less, you must be careful to enforce consistency through your application layer.
You would most likely create collections to store users, movies, and people.
Data Duplication for Query Performance
Document Stores can also fall foul of the O(n) problem. NoSQL databases, in general, are all designed to provide various their own solutions to the problems of read and write performance.
A common approach to solve the O(n) problem is to duplicate data across collections to speed up query responses. For example, the movies collection may store directors as an array of string values.
{
"_id": ObjectId("63da26bc2e002491266b6205"),
"title": "Toy Story",
"released": "1996-03-22",
"directors": ["Tom Lasseter"]
}
This is perfect if you only want to display the data within a UI. But if we need to ask more complex questions, for example, how many movies has Tom Lasseter directed? — things start to get complicated. Do we loop through every movie record and check the directors array for a name? What if two directors share the same name?
If you want to query across collections, you would usually store a reference to the unique ID of the record in the corresponding collection. Take the user example below: the ratings for that user can be stored as an array against the user document, making it easy to access. Each rating contains a reference (in this case, a MongoDB DBRef to reference the ObjectId of the document in the movies collection).
{
"_id": ObjectId("63da267a89f7381acf7ab183"),
"email": "john.doe@example.com",
"name": "John Doe",
"ratings": [
{
"movie": {
"$ref": "movies",
"$id": ObjectId("63da2681680f57e194eb3199"),
"$db": "neoflix"
},
"rating": 5
},
{
"movie": {
"$ref": "movies",
"$id": ObjectId("63da26b613fe29cf79d92e2f"),
"$db": "neoflix"
},
"rating": 3
},
]
}
Document stores support pipelines or map-reduce functions that allow you to compute the JOIN at read time. But these can become unwieldy quickly and hard to reason about, and take time to compute. These read-time JOINs also fall victim to the O(n) problem. Each reference must be looked up in an index to find the corresponding record, which must also be decoded. The larger the collection, the larger the index and the longer each lookup may take. Multiply that time and complexity by the number of nested items, and all of a sudden, we’ve got a slow and complicated pipeline or map/reduce function.
To avoid this complexity, you could also store some of the required properties for the movie, for example, the movie title, in the rating object.
You may also store the movie title as a key in the rating to balance out the ease of readability and data duplication. But now we also have to make difficult decisions on what data to duplicate to speed up. If the use case changes in any way, a mountain of work is required to fit the new use case. What if we want to query from movie to rating?
You may also want to fan out your writes, duplicating data across collections to speed up the read-time performance, but that also comes with its own maintenance headaches and a whole load of potential for technical debt.
The Case for Graphs
Now, let’s look at this data as a graph. The data structure of Nodes and Relationships fits this problem well. Rather than creating JOIN tables to handle many-to-many relationships or storing duplicated data for reference, the verbs in the use case are stored as relationships:
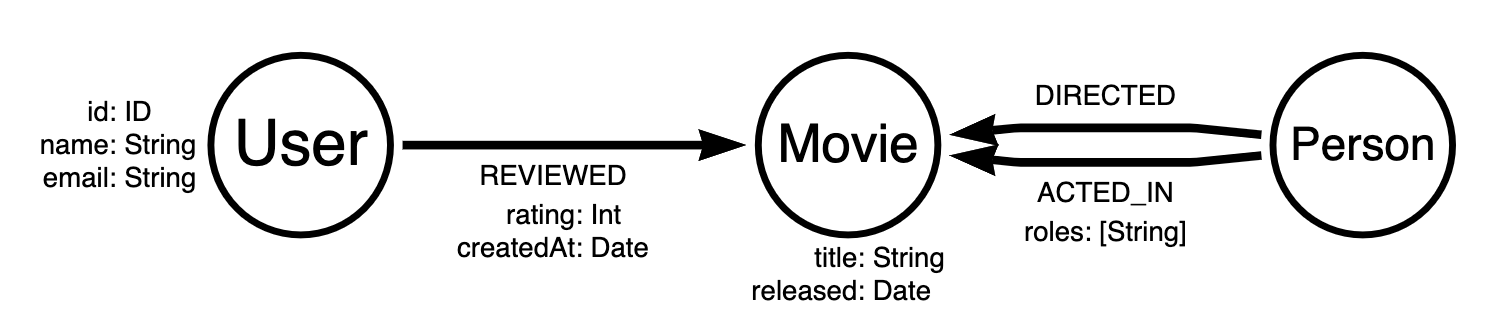
More Natural Modeling
The data model above is easier to understand and reason about. At a quick glance, you can see that a User may have one or more REVIEWED relationships pointing to a Movie node. Nodes and relationships can both contain properties stored as key-value pairs. We can use this to store the rating and createdAt properties of the review directly on the relationship.
Constant Query Times
Remember how I mentioned earlier that relationships are treated as first-class citizens? When a relationship is created in Neo4j, a pointer is appended to the node at each end of the relationship, ensuring that every node is aware of every relationship going out from or coming into it.
This enables the query engine to quickly lookup relationships without relying on an index. This ensures that query response times remain constant to the amount of the graph touched during the query rather than the data size overall.
Querying a Neo4j graph is also different from relational databases and document stores. Neo4j uses a proprietary language called Cypher. Cypher is similar in structure to SQL, but instead of starting with a SELECT statement and using JOINs to combine data, a Cypher statement begins with a MATCH clause, which defines a pattern of data to return.
Neo4j will then parse the query, examine the database schema and use database statistics to determine the most efficient way to traverse the pattern. Regardless of the way the pattern is written, the query will be executed in the same way.
Let’s look at the SQL and Cypher statements required to retrieve the data side by side. Both queries will find the names of actors from the movie The Matrix.
| SQL | Cypher |
|---|---|
| SELECT p.name, p.born, r.roles, m.title FROM people p INNER JOIN roles r on p.id = r.person_id INNER JOIN movies m on r.movie_id = m.id WHERE m.title = ‘The Matrix’ |
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie) WHERE m.title = ‘The Matrix’ RETURN p.name, p.born, r.roles |
In a Cypher statement, you use an ASCII-art style syntax to draw the pattern you would like to read from the graph. Nodes are surrounded by parentheses ( , and relationships are drawn using dashes and an arrow to represent the direction. This declarative approach differs from a Pipeline in MongoDB, where you must express exactly how the data should be retrieved.( and ) )
This is only a trivial example, but the more complex the use case becomes, the more a Cypher statement comes into its own. I have shown Cypher statements to business owners, architects, and even C-level executives, who have all quickly understood what the statement is doing, which cannot be said for an SQL statement and certainly cannot be said for a pipeline.
Suddenly the barrier to data engineering doesn’t seem so high.
Conclusion
My mantra has always been to use the best tool for the job, particularly when it comes to databases. You may feel that my opinion is a little biased, as I am literally paid to have this opinion. But since first installing Neo4j around a decade ago, I’ve started to see the value of connections everywhere.
A simple network of nodes and relationships is surprisingly powerful when storing data. Graph databases allow you to avoid much additional work to model your use case to work with a database and naturally handle performance and scale.
If you would like to learn more about Neo4j, you can check Neo4j GraphAcademy, where we have constructed Beginners courses that will give you the confidence to import and query data in Neo4j, and the Developer courses teach you will show you how to connect to Neo4j using one of the five official drivers: Java, JavaScript, Python, .NET, and Go.
You can create an AuraDB Free instance pre-populated with data, which will hold 200k nodes and 400k relationships, and it’s free for as long as you need.
So, if you are working with a complex, highly connected dataset or would like to futureproof your project against complicated database migrations and refactoring in the future, why not put the Graph into GraphQL?
